
Learning to Co-Embed Queries and Documents


Abstract
:1. Introduction
- We propose Gaussian Embedding model for Ranking, GERank, to co-embed queries and documents into the same semantic space so as to alleviate the mismatch problem between queries and documents.
- To the best of our knowledge, our GERank algorithm is the first attempt to incorporate embedding techniques into L2R algorithms with constraints.
- To further enhance the performance of document retrieval, GERank learns to infer both the embeddings and their covariances of queries and documents such that their similarities can be effectively measured.
- We provide the experimental evidence of the effectiveness of our model. Our model can outperform the state-of-the-art L2R models on two LETOR datasets and one TREC dataset.
2. Related Work
2.1. Learning to Rank
2.2. Representation Learning
3. Notations and Problem Formulation
4. Learning to Co-Embed Queries and Documents
4.1. Dissimilarity Metric
4.2. Constraints
4.3. Co-Embedding Queries and Documents
| Algorithm 1: Training in GERank. |
 |
5. Experimental Setup
5.1. Research Questions
- In terms of the performance of GERank:
- RQ1
- How does our GERank perform in the task of document retrieval?
- RQ2
- Can our GERank outperform traditional pairwise-based L2R methods?
- RQ3
- Can we make the advantages of our GERank L2R model explainable?
- RQ4
- How does the embedding size affect the retrieval performance of our GERank model?
- RQ5
- How does the size of the hidden layer affect the retrieval performance of our GERank model?
5.2. Datasets
- NP2004: The NP2004 dataset is originally collected for the task of named-page finding in TREC2004 [68]. It contains a query set with 75 queries and 73,834 query–document pairs with ratings of 0 and 1 corresponding to “non-relevant” and “relevant” relationships between the queries and the documents, respectively. In the NP2004 dataset, each query–document pair is represented by 64 features, including the BM25 scores, Inverse Document Frequency (IDF) scores, PageRank scores, etc. These features are categorized into three classes, i.e., those depending only on the query, only on the document and on both of the query and the document, respectively. Specifically, five features in each query–document pair are only depended on query, which are constructed by the IDF of query term in body, anchor, title, URL and whole document.
- OHSUMED: The OHSUMED dataset is obtained by Qin et al. [22] from the OHSUMED corpus [69]. It contains a query set with 106 queries and 16,140 query–document pairs with three types of ratings, i.e., 0, 1, and 2, corresponding to “non-relevant”, “partially relevant” and “definitely relevant” relationships between the queries and the documents, respectively. As for OHSUMED, each query–document pair can be represented by 45 features, including the language model features, BM25 scores, and the others. These features are categorized into two classes, i.e., those depending only on the query, and on both the query and the document. There are 9 query-depend features in each query–document pair, and the details of these features can be found in [22].
- Robust04: This TREC dataset consists of documents from the Financial Times Limited, the Congressional Record of the 103rd Congress, the Federal Register, the Foreign Broadcast Information Service, and the Los Angeles Times, and has been widely used in a variety of TREC tasks, including TREC ad hoc collections 6–8, TRECs 8–9 question answering track, and the TREC Robust track. We apply the BERT model to extract 100-dimensional features for each document and also 100-dimensional query-depend features.
5.3. Baselines
- LR maps a feature vector to a retrieval score by a linear function. Given a training query, relevance score of each document is used to train the model. The model aims at enforcing the relevance score of more relevant documents to be greater than that of a less relevant document.
- Ranking SVM [16,17] transforms L2R to a binary classification problem. It considers the partial ordering of the documents and solves the binary classification problem using a Support Vector Machine. SVM-light, a public tool (The SVM-light program is available from the web site http://www.cs.cornell.edu/people/tj/svm_light/svm_rank.html, accessed on 10 August 2022), is used in the experiment. The ranking function is linear.
- RankBoost [18] adopts the Adaboost algorithm for the classification over document pairs given the queries. The distribution in RankBoost is defined over document pairs. For each iteration, RankBoost trains a weak document ranking model. These weak models are combined to obtain the final retrieval model. The weights of document pairs are changed by decreasing the weights of correctly ranked pairs. We follow Qin et al. [22] to define each weak ranker on the basis of a single feature.
- FRank [35] is a pairwise ranking algorithm with a fidelity loss function. The fidelity was originally used in quantum physics to measure the difference between two probabilistic states of a quantum. In our experiments, as a baseline, it is used to measure the difference between the target probability and the modeled probability.
- SciBERT [70] is a representation learning mechanism that integrates structural relations with semantic information to enrich the document embeddings for document retrieval. It involves training a document representation model that encodes the corpus structure along with the content semantics into the learned document embeddings in a metric learning setting. It makes similar documents close in the representation space while dissimilar documents separated. It accepts similar and dissimilar document pairs as input, one each for content semantics and corpus structure.
- ListNet [19] is based on probability distribution on permutations. The main work of ListNet is to map the relevance of query–document pairs to a real-value score. For a document list, the Luce model used by definition a permutation probability distribution based on score and another based on the ground truth labels. The loss function of the model is the cross enthalpy between two distributions.
- AdaRank-MAP and AdaRank-NDCG [33] are built based on the Adaboost algorithm. They aim to repeatedly construct weak rankers on the basis of re-weighted training queries and finally linearly combine the weak rankers to make ranking predictions. The difference is that AdaRank-MAP uses MAP to measure the effectiveness of a weak ranker, while AdaRank-NDCG utilizes NDCG to optimize the model.
- SVM [34] utilizes the framework of structured SVM to optimize the evaluation measure, i.e., MAP. The main idea of SVM is to use Support Vector Machines to solve the ranking problem.
5.4. Evaluation Metrics
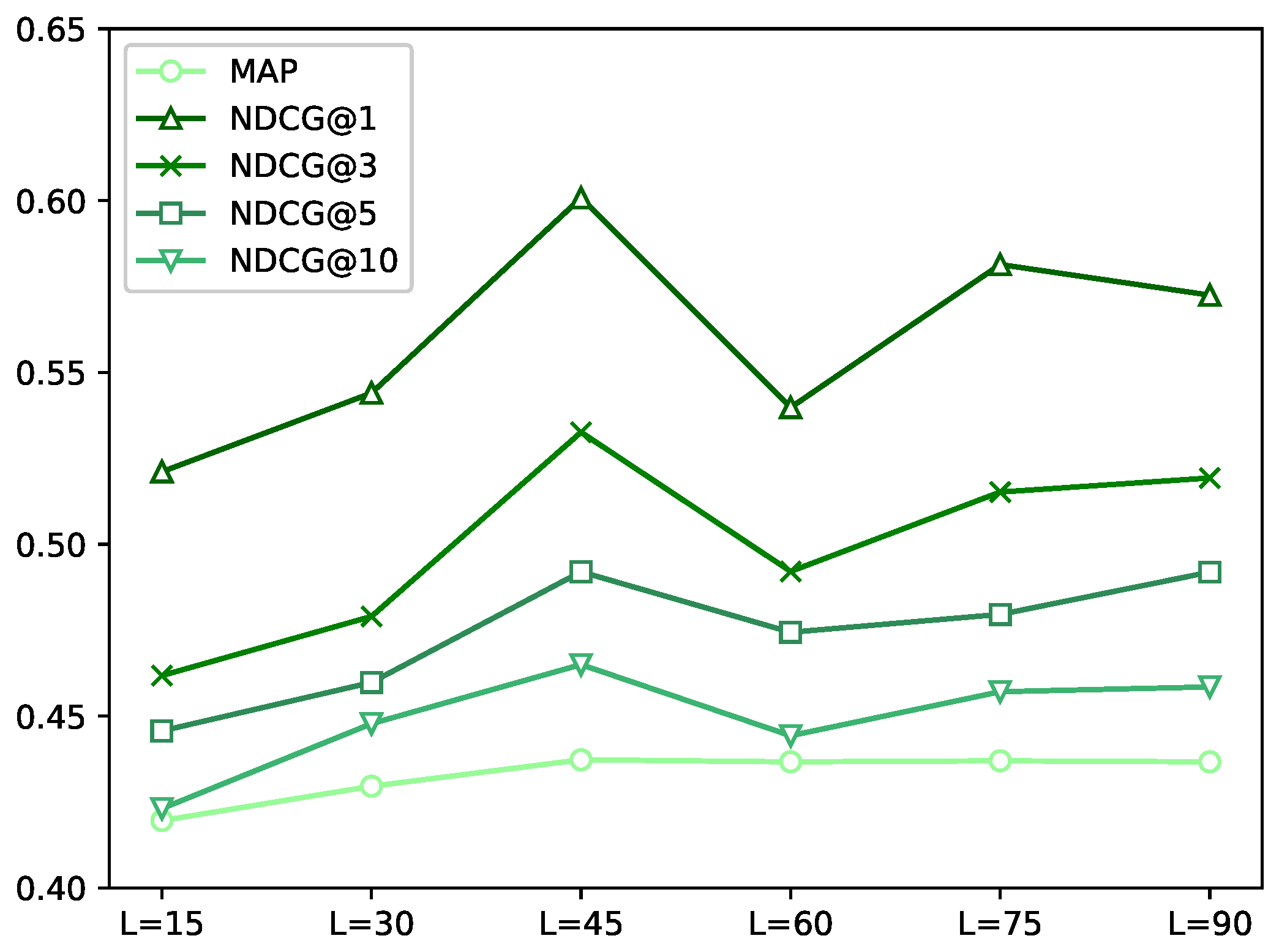
- NDCG: NDCG is a measure of ranking quality that is computed based on the discounted cumulative gain. The discounted cumulative gain (DCG) [23] at a particular rank threshold k is defined aswhere is the judgment (, , , , etc.) at rank j in set . The ideally ordered set contains all documents rated for the given query sorted descending by the judgment value. Then, the normalized discounted cumulative gain (NDCG) [23] at a particular rank threshold k is defined asNDCG discounts the contribution of a document to the overall score as its rank increases. NDCG value at rank threshold k when the set is clear from the context is often written as .
- MAP: The mean average precision (MAP) [24] of a test query set is the mean of the average precision (AP) values of all queries in the query set. The average precision of a ranked result set in response to a given query is defined as:where j is the position of the document (in our case, group), denotes the relevance of the document (in our case, group) in position j, and . Typically, a binary value for is used by setting it to 1 if the document (group) in position j has a human judgment of or better and 0 otherwise.
- Precision:Precision at k [24] only considers the total number of relevant documents ranked within the top k positions and can be simply computed aswhere “relevant documents” are those that have human judgments of Fair or better.
5.5. Experimental Settings
6. Results
6.1. Overall Retrieval Performance
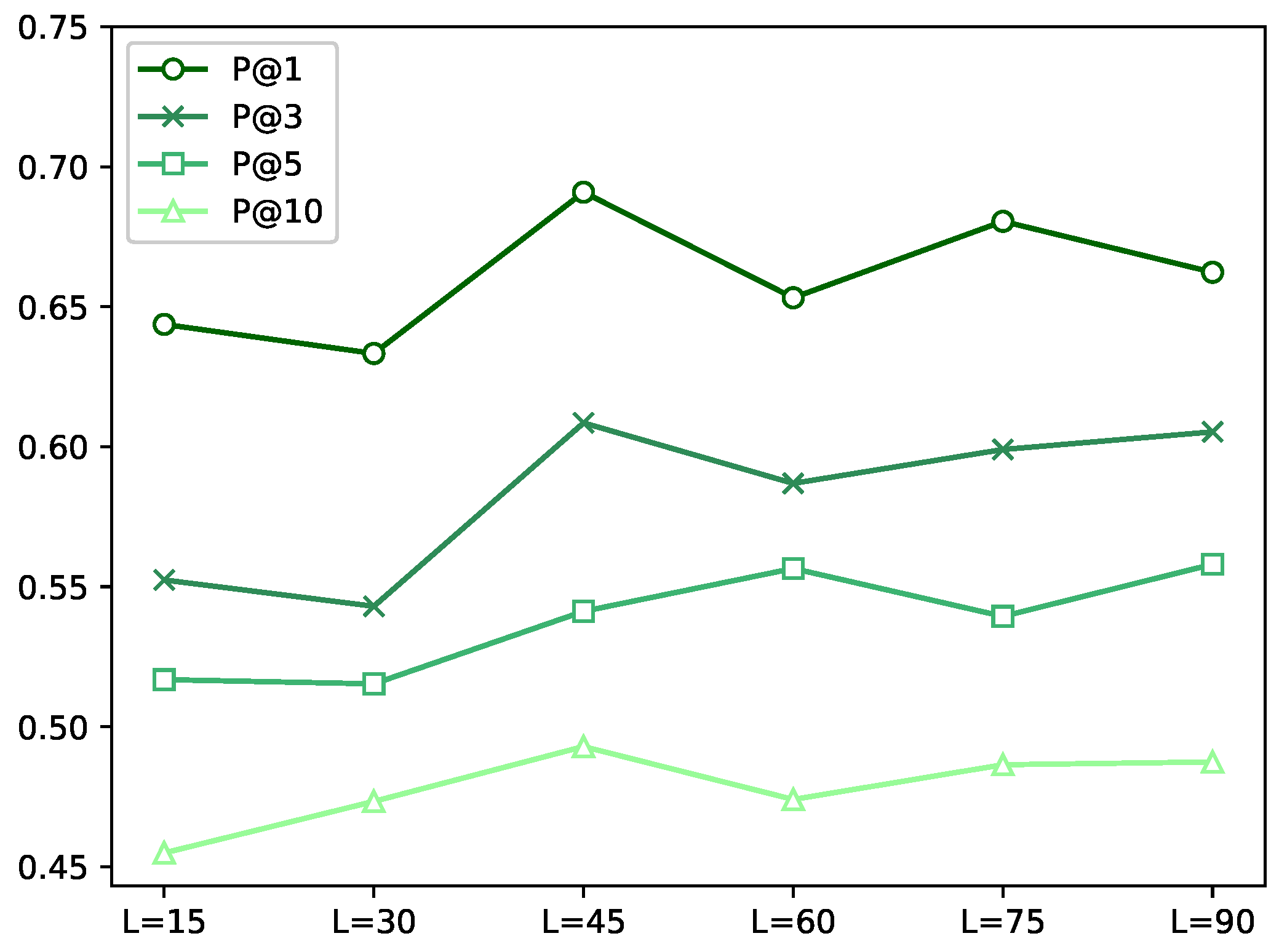
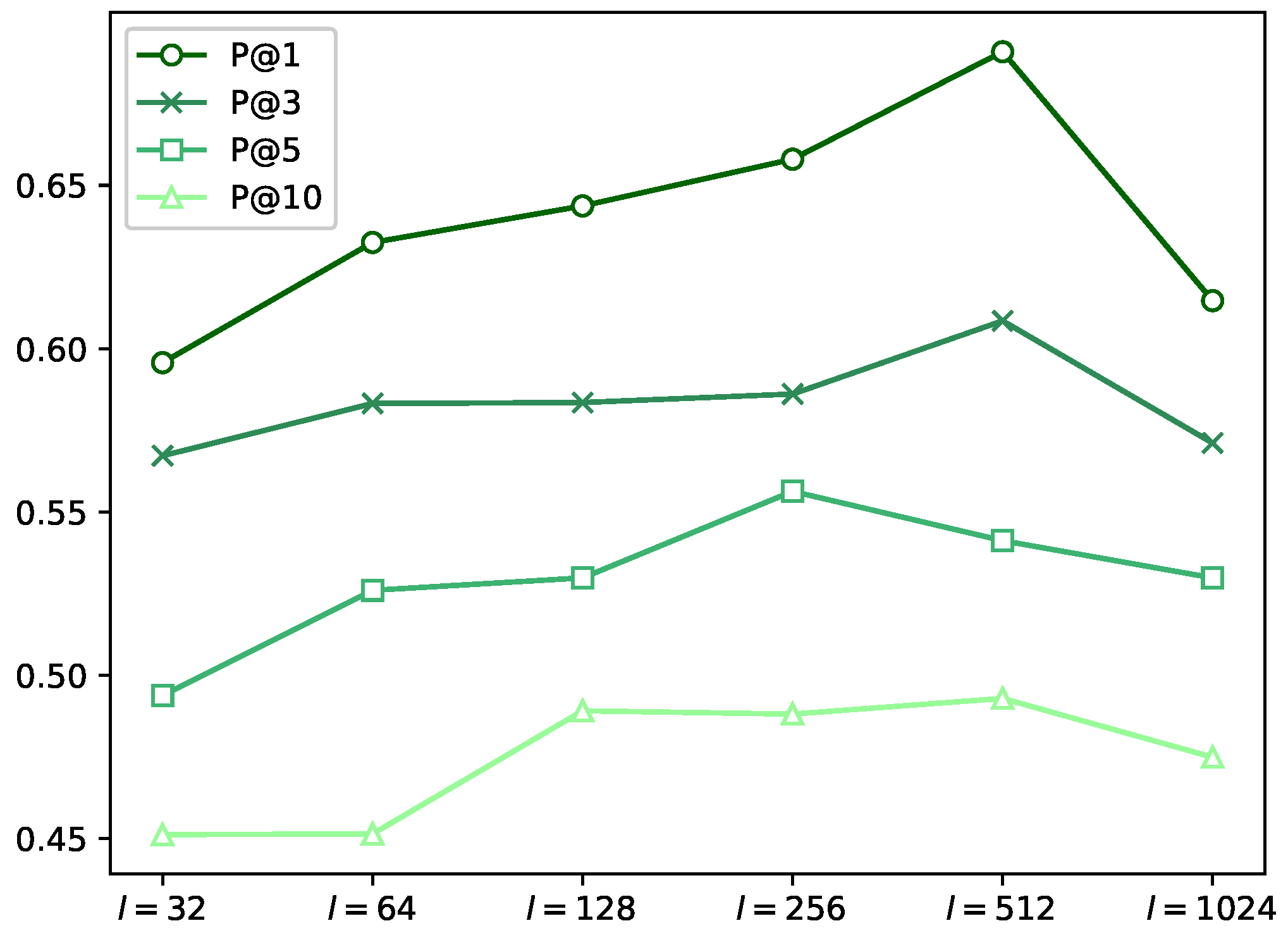
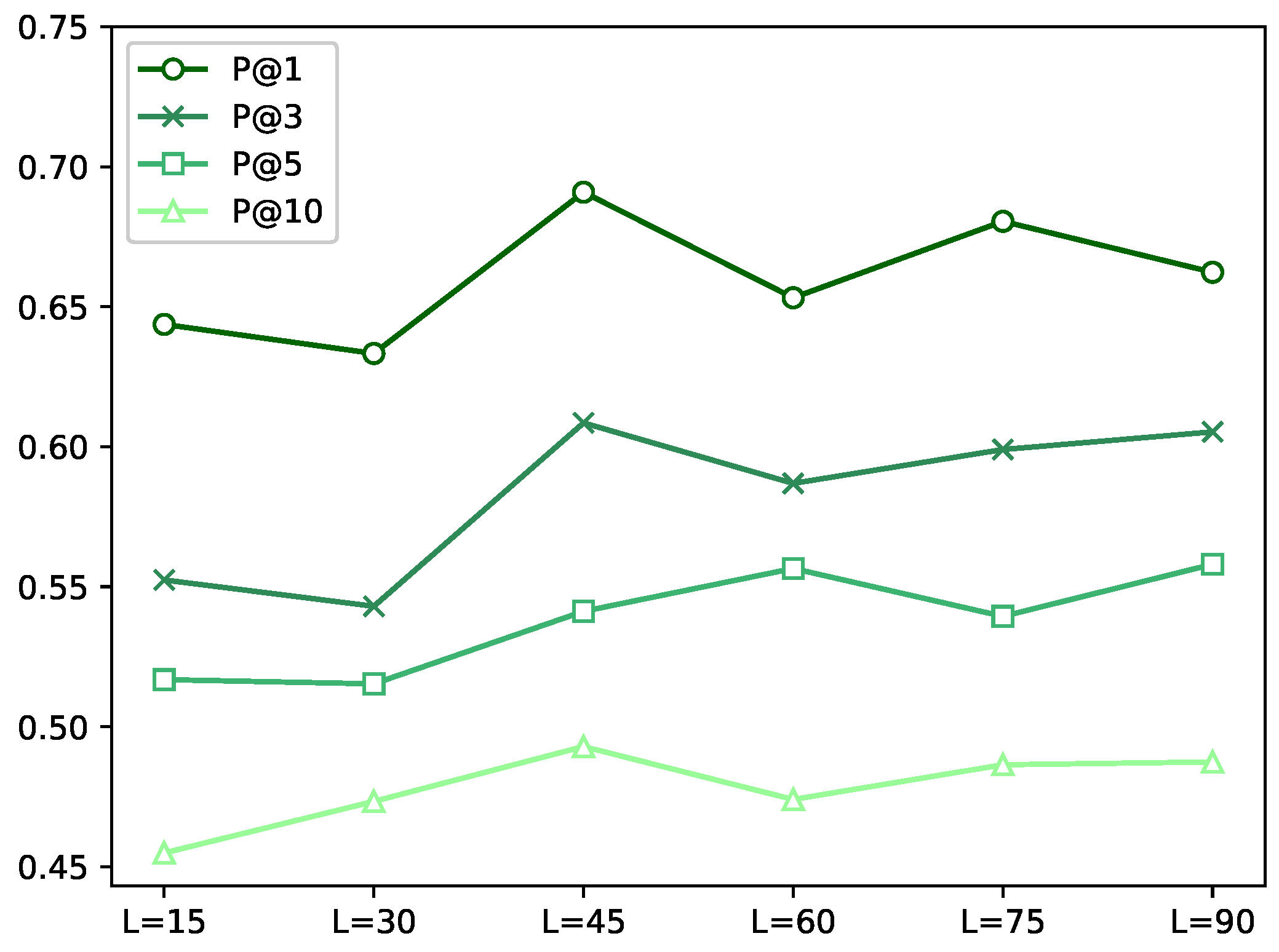
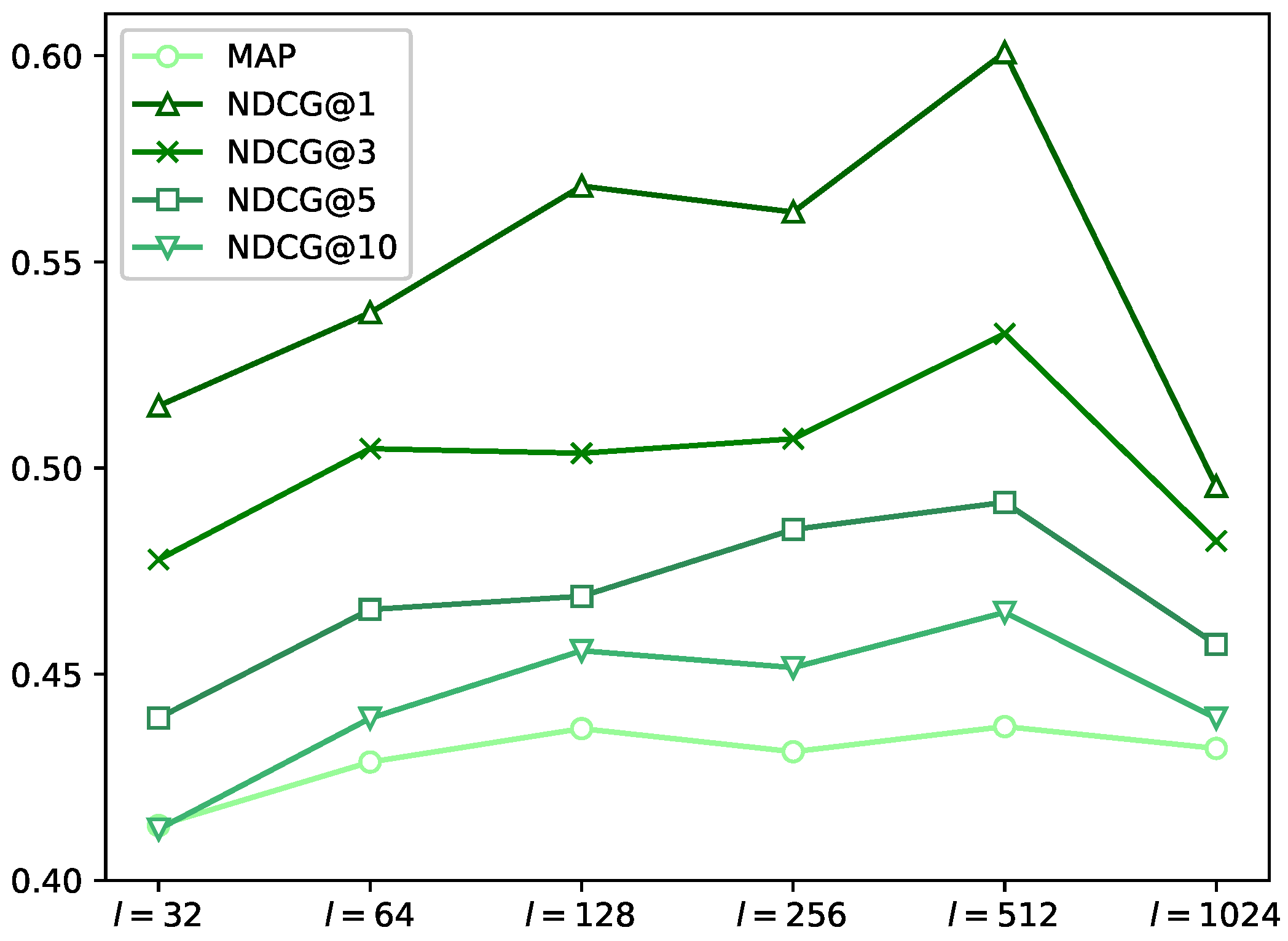
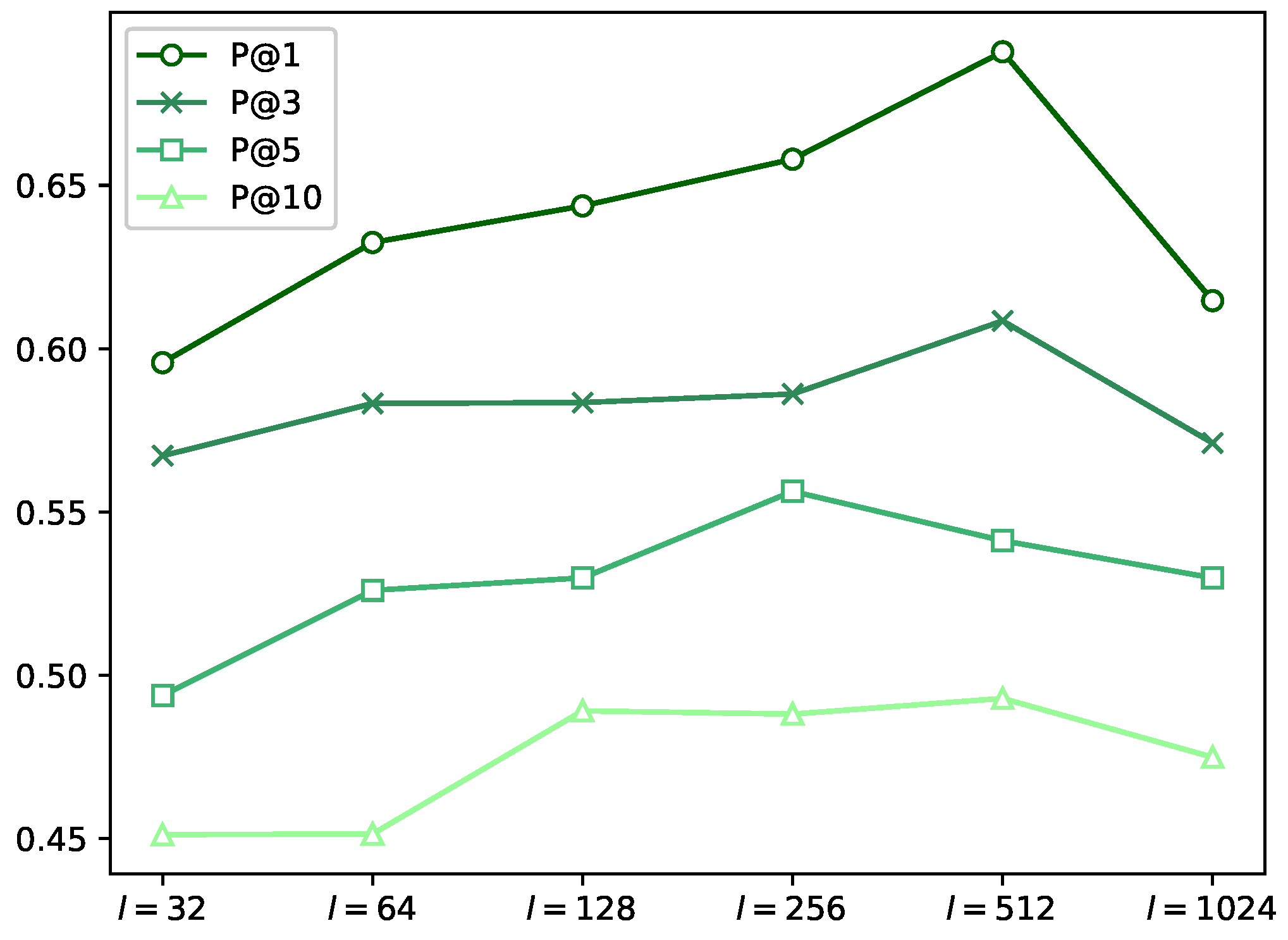
6.2. Impact of Embedding Dimension
6.3. Effect of Hidden Layer
7. Conclusions
- (a)
- We plan to infer embeddings and the covariances of queries and documents via other embedding techniques such as variational auto-encoders [71].
- (b)
- We plan to apply GERank to other information retrieval applications such as: given a question, rank answers that are relevant to the question in question-answering communities, where users’ interaction historical information in the communities can be utilized to boost the retrieval performance.
- (c)
- We intend to integrate our GERank into listwise L2R approaches, as listwise approaches have shown their better performance compared to that produced by the pairwise L2R approaches on the testing datasets.
- (d)
- We also intend to improve big data law for a number of information retrieval applications such as document retrieval.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. KL Divergence between Two Multivariate Gaussian Distributions
Appendix B. Proof of Algorithm Convergence
Appendix C. Supplement to the Measure and Loss Function
References
- Yue, S.; Larson, M.; Hanjalic, A. Listwise learning to rank with matrix factorization for collaborative filtering. In Proceedings of the ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010. [Google Scholar]
- Yue, S.; Karatzoglou, A.; Baltrunas, L.; Larson, M.; Oliver, N.; Hanjalic, A. CLiMF: Learning to maximize reciprocal rank with collaborative less-is-more filtering. In Proceedings of the ACM Recommender Systems, Dublin, Ireland, 9–13 September 2012. [Google Scholar]
- Koren, Y.; Rendle, S.; Bell, R. Advances in collaborative filtering. Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2022; pp. 91–142. [Google Scholar]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural collaborative filtering vs. matrix factorization revisited. In Proceedings of the Fourteenth ACM Conference on Recommender Systems, Virtual, 22–26 September 2020; pp. 240–248. [Google Scholar]
- Xu, D.; Ruan, C.; Korpeoglu, E.; Kumar, S.; Achan, K. Rethinking neural vs. matrix-factorization collaborative filtering: The theoretical perspectives. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 11514–11524. [Google Scholar]
- Cao, Y.; Xu, J.; Liu, T.Y.; Li, H.; Huang, Y.; Hon, H.W. Adapting Ranking SVM to Document Retrieval. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 186–193. [Google Scholar]
- Hofstätter, S.; Zamani, H.; Mitra, B.; Craswell, N.; Hanbury, A. Local self-attention over long text for efficient document retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 30–25 July 2020; pp. 2021–2024. [Google Scholar]
- Abolghasemi, A.; Verberne, S.; Azzopardi, L. Improving BERT-based query-by-document retrieval with multi-task optimization. In Proceedings of the European Conference on Information Retrieval, Stavanger, Norway, 10–14 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–12. [Google Scholar]
- Tagami, Y.; Ono, S.; Yamamoto, K.; Tsukamoto, K.; Tajima, A. CTR Prediction for Contextual Advertising: Learning-to-rank Approach. In Proceedings of the Seventh International Workshop on Data Mining for Online Advertising, Chicago, IL, USA, 11 August 2013; pp. 4:1–4:8. [Google Scholar]
- Ciaramita, M.; Murdock, V.; Plachouras, V. Online Learning from Click Data for Sponsored Search. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 227–236. [Google Scholar]
- Gharibshah, Z.; Zhu, X. User response prediction in online advertising. ACM Comput. Surv. CSUR 2021, 54, 1–43. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics (ACL ’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Robertson, S.; Zaragoza, H.; Taylor, M. Simple BM25 extension to multiple weighted fields. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 42–49. [Google Scholar]
- Herbrich, R.; Graepel, T.; Obermayer, K. Support Vector Learning for Ordinal Regression; IET: London, UK, 1999. [Google Scholar]
- Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 133–142. [Google Scholar]
- Freund, Y.; Iyer, R.; Schapire, R.E.; Singer, Y. An efficient boosting algorithm for combining preferences. J. Mach. Learn. Res. 2003, 4, 933–969. [Google Scholar]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to rank: From pairwise approach to listwise approach. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 129–136. [Google Scholar]
- Trabelsi, M.; Chen, Z.; Davison, B.D.; Heflin, J. Neural ranking models for document retrieval. Inf. Retr. J. 2021, 24, 400–444. [Google Scholar] [CrossRef]
- Datta, S.; Ganguly, D.; Greene, D.; Mitra, M. Deep-qpp: A pairwise interaction-based deep learning model for supervised query performance prediction. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual, 21–25 February 2022; pp. 201–209. [Google Scholar]
- Qin, T.; Liu, T.Y.; Xu, J.; Li, H. LETOR: A benchmark collection for research on learning to rank for information retrieval. Inf. Retr. 2010, 13, 346–374. [Google Scholar] [CrossRef]
- Clarke, C.L.; Kolla, M.; Cormack, G.V.; Vechtomova, O.; Ashkan, A.; Büttcher, S.; MacKinnon, I. Novelty and diversity in information retrieval evaluation. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 659–666. [Google Scholar]
- Manning, C.; Raghavan, P.; Schütze, H. Introduction to information retrieval. Nat. Lang. Eng. 2010, 16, 100–103. [Google Scholar]
- Li, H. Learning to rank for information retrieval and natural language processing. In Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2014; Volume 7, pp. 1–121. [Google Scholar]
- Liang, S. Unsupervised Semantic Generative Adversarial Networks for Expert Retrieval. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–14 May 2019; pp. 1039–1050. [Google Scholar]
- Van Gysel, C.; de Rijke, M.; Worring, M. Unsupervised, efficient and semantic expertise retrieval. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2016; pp. 1069–1079. [Google Scholar]
- Tay, Y.; Phan, M.C.; Tuan, L.A.; Hui, S.C. Learning to rank question answer pairs with holographic dual LSTM architecture. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 695–704. [Google Scholar]
- Zehlike, M.; Yang, K.; Stoyanovich, J. Fairness in Ranking, Part II: Learning-to-Rank and Recommender Systems. ACM Comput. Surv. CSUR 2022. [Google Scholar] [CrossRef]
- Kveton, B.; Meshi, O.; Zoghi, M.; Qin, Z. On the Value of Prior in Online Learning to Rank. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Virtual, 28–30 March 2022; pp. 6880–6892. [Google Scholar]
- Cossock, D.; Zhang, T. Statistical analysis of Bayes optimal subset ranking. IEEE Trans. Inf. Theory 2008, 54, 5140–5154. [Google Scholar] [CrossRef]
- Li, P.; Wu, Q.; Burges, C.J. Mcrank: Learning to rank using multiple classification and gradient boosting. In Proceedings of the Advances in Neural Information Processing Systems, Whistler, BC, Canada, 12 December 2008; pp. 897–904. [Google Scholar]
- Xu, J.; Li, H. Adarank: A boosting algorithm for information retrieval. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Yue, Y.; Finley, T.; Radlinski, F.; Joachims, T. A support vector method for optimizing average precision. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 271–278. [Google Scholar]
- Tsai, M.F.; Liu, T.Y.; Qin, T.; Chen, H.H.; Ma, W.Y. FRank: A ranking method with fidelity loss. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 383–390. [Google Scholar]
- Severyn, A.; Moschitti, A. Learning to rank short text pairs with convolutional deep neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 373–382. [Google Scholar]
- Wang, B.; Klabjan, D. An attention-based deep net for learning to rank. arXiv 2017, arXiv:1702.06106. [Google Scholar]
- Song, B. Deep Neural Network for Learning to Rank Query-Text Pairs. arXiv 2018, arXiv:1802.08988. [Google Scholar]
- Ai, Q.; Bi, K.; Guo, J.; Croft, W.B. Learning a deep listwise context model for ranking refinement. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 135–144. [Google Scholar]
- Zhao, X.; Li, X.; Zhang, Z. Multimedia retrieval via deep learning to rank. IEEE Signal Process. Lett. 2015, 22, 1487–1491. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning semantic representations using convolutional neural networks for web search. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 373–374. [Google Scholar]
- Tang, S.; Meng, Z.; Liang, S. Dynamic Co-Embedding Model for Temporal Attributed Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Fang, J.; Liang, S.; Meng, Z.; Zhang, Q. Gaussian process with graph convolutional kernel for relational learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 353–363. [Google Scholar]
- Liang, S.; Zhang, X.; Ren, Z.; Kanoulas, E. Dynamic embeddings for user profiling in twitter. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1764–1773. [Google Scholar]
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to generate a good word embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- Zamani, H.; Croft, W.B. Relevance-based word embedding. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 505–514. [Google Scholar]
- Shen, D.; Wang, G.; Wang, W.; Min, M.R.; Su, Q.; Zhang, Y.; Li, C.; Henao, R.; Carin, L. Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms. arXiv 2018, arXiv:1805.09843. [Google Scholar]
- Chen, G.; Fang, J.; Meng, Z.; Zhang, Q.; Liang, S. Multi-Relational Graph Representation Learning with Bayesian Gaussian Process Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 5530–5538. [Google Scholar]
- Fang, J.; Liang, S.; Meng, Z.; De Rijke, M. Hyperspherical Variational Co-embedding for Attributed Networks. ACM Trans. Inf. Syst. TOIS 2021, 40, 1–36. [Google Scholar] [CrossRef]
- Fang, J.; Zhang, Q.; Meng, Z.; Liang, S. Structure-Aware Random Fourier Kernel for Graphs. Adv. Neural Inf. Process. Syst. 2021, 34, 17681–17694. [Google Scholar]
- Liao, S.; Liang, S.; Meng, Z.; Zhang, Q. Learning dynamic embeddings for temporal knowledge graphs. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual, 8–12 March 2021; pp. 535–543. [Google Scholar]
- Vilnis, L.; McCallum, A. Word representations via gaussian embedding. arXiv 2014, arXiv:1412.6623. [Google Scholar]
- He, S.; Liu, K.; Ji, G.; Zhao, J. Learning to represent knowledge graphs with gaussian embedding. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 623–632. [Google Scholar]
- Ren, Z.; Jin, H.; Lin, Z.; Fang, C.; Yuille, A. Joint image-text representation by gaussian visual-semantic embedding. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 207–211. [Google Scholar]
- Bojchevski, A.; Günnemann, S. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv 2017, arXiv:1707.03815. [Google Scholar]
- Wang, M.; Smith, N.A.; Mitamura, T. What is the Jeopardy model? A quasi-synchronous grammar for QA. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 23–30 June 2007; pp. 22–32. [Google Scholar]
- Dos Santos, L.; Piwowarski, B.; Gallinari, P. Multilabel classification on heterogeneous graphs with gaussian embeddings. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 606–622. [Google Scholar]
- Pan, Y.; Liang, S.; Ren, J.; Meng, Z.; Zhang, Q. Personalized, sequential, attentive, metric-aware product search. ACM Trans. Inf. Syst. TOIS 2021, 40, 1–29. [Google Scholar] [CrossRef]
- Liang, S.; Luo, Y.; Meng, Z. Profiling users for question answering communities via flow-based constrained co-embedding model. ACM Trans. Inf. Syst. TOIS 2021, 40, 1–38. [Google Scholar] [CrossRef]
- LeCun, Y.; Chopra, S.; Hadsell, R.; Ranzato, M.; Huang, F. A tutorial on energy-based learning. In Predicting Structured Data; MIT Press: Cambridge, MA, USA, 2006; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, X.; He, B.; Sun, L. Groupwise query performance prediction with bert. In Proceedings of the European Conference on Information Retrieval, Stavanger, Norway, 10–14 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 64–74. [Google Scholar]
- Fröbe, M.; Akiki, C.; Potthast, M.; Hagen, M. How Train-Test Leakage Affects Zero-shot Retrieval. arXiv 2022, arXiv:2206.14759. [Google Scholar]
- Jung, E.; Choi, J.; Rhee, W. Semi-Siamese Bi-encoder Neural Ranking Model Using Lightweight Fine-Tuning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 502–511. [Google Scholar]
- Dai, Z.; Callan, J. Deeper text understanding for IR with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 985–988. [Google Scholar]
- Craswell, N.; Hawking, D. Overview of the TREC 2004 Web Track; NIST Special Publications (SP): Gaithersburg, MD, USA, 2004. [Google Scholar]
- Hersh, W.; Buckley, C.; Leone, T.; Hickam, D. OHSUMED: An interactive retrieval evaluation and new large test collection for research. In Proceedings of the SIGIR’94, Dublin, Ireland, 3–6 July 1994; Springer: London, UK, 1994; pp. 192–201. [Google Scholar]
- Raman, N.; Shah, S.; Veloso, M. Structure and Semantics Preserving Document Representations. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 780–790. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Gloss |
|---|---|
| Document corpus | |
| Set of queries | |
| Relevant documents to the queries | |
| Set of relevant documents to the query q | |
| M | Number of queries |
| L | Dimension of embedding space |
| Number of relevant document for a given ith query | |
| Relevance degree of for a given query | |
| Triplet set of query and two relevant documents | |
| ith query in , | |
| jth document for a given ith query, | |
| Gaussian distribution of ith query | |
| Gaussian distribution of document , | |
| Mean of query in Gaussian distribution | |
| Mean of document in Gaussian distribution | |
| Covariance of ith query in Gaussian distribution | |
| Covariance of document in Gaussian distribution | |
| Dissimilarity measure between query and document | |
| KL divergence between and | |
| Document pair in which is ranked lower than to query |
| Datasets | #Queries | #Documents | #Features | #Query-Depend Features | #Relevances |
|---|---|---|---|---|---|
| NP2004 | 75 | 73,834 | 64 | 5 | 2 |
| OHSUMED | 106 | 16,140 | 45 | 9 | 3 |
| Robust04 | 249 | 556,077 | 100 | 100 | 2 |
| Approach | Model | P@1 | P@3 | P@5 | P@10 | MAP |
|---|---|---|---|---|---|---|
| Pointwise | LR | 0.3733 | 0.2000 | 0.1440 | 0.0820 | 0.5142 |
| Listwise | ListNet | 0.5333 | 0.2667 | 0.1787 | 0.0940 | 0.6720 |
| AdaRank-MAP | 0.4800 | 0.2444 | 0.1627 | 0.0880 | 0.6220 | |
| AdaRank-NDCG | 0.5067 | 0.2489 | 0.1653 | 0.0900 | 0.6269 | |
| SVM | 0.5200 | 0.2667 | 0.1787 | 0.0960 | 0.6620 | |
| Pairwise | Ranking SVM | 0.5067 | 0.2622 | 0.1787 | 0.0930 | 0.6588 |
| RankBoost | 0.4267 | 0.2311 | 0.1520 | 0.0880 | 0.5640 | |
| SciBERT | 0.4326 | 0.2324 | 0.1554 | 0.0892 | 0.5721 | |
| FRank | 0.4800 | 0.2356 | 0.1600 | 0.0930 | 0.6008 | |
| GERank | 0.2489 | 0.1653 | 0.0893 |
| Approach | Model | NDCG@1 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| Pointwise | LR | 0.3733 | 0.5554 | 0.6135 | 0.6530 |
| Listwise | ListNet | 0.5333 | 0.7587 | 0.7965 | 0.8120 |
| AdaRank-MAP | 0.4800 | 0.6979 | 0.7310 | 0.7490 | |
| AdaRank-NDCG | 0.5067 | 0.6722 | 0.7122 | 0.7380 | |
| SVM | 0.5200 | 0.7489 | 0.7869 | 0.8079 | |
| Pairwise | Ranking SVM | 0.5067 | 0.7503 | 0.7957 | 0.8060 |
| RankBoost | 0.4267 | 0.6274 | 0.6512 | 0.6914 | |
| SciBERT | 0.4374 | 0.6352 | 0.6678 | 0.7021 | |
| FRank | 0.4800 | 0.6431 | 0.6870 | 0.7290 | |
| GERank | 0.6620 | 0.6914 | 0.7095 |
| Approach | Model | P@1 | P@3 | P@5 | P@10 | MAP |
|---|---|---|---|---|---|---|
| Pointwise | LR | 0.5965 | 0.5768 | 0.5337 | 0.4660 | 0.4220 |
| Listwise | ListNet | 0.6524 | 0.6016 | 0.5502 | 0.4970 | 0.4457 |
| AdaRank-MAP | 0.6338 | 0.5895 | 0.5674 | 0.4970 | 0.4487 | |
| AdaRank-NDCG | 0.6719 | 0.5984 | 0.5767 | 0.5080 | 0.4498 | |
| SVM | 0.6433 | 0.5802 | 0.5523 | 0.4910 | 0.4453 | |
| Pairwise | Ranking SVM | 0.5974 | 0.5427 | 0.5319 | 0.4860 | 0.4334 |
| RankBoost | 0.5576 | 0.5609 | 0.5447 | 0.4966 | 0.4411 | |
| SciBERT | 0.5682 | 0.5478 | 0.5305 | 0.4872 | 0.4331 | |
| FRank | 0.6429 | 0.5925 | 0.5638 | 0.5010 | 0.4439 | |
| GERank | 0.5412 | 0.4929 | 0.4373 |
| Approach | Model | NDCG@1 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| Pointwise | LR | 0.4456 | 0.4426 | 0.4278 | 0.4110 |
| Listwise | ListNet | 0.5326 | 0.4732 | 0.4432 | 0.4410 |
| AdaRank-MAP | 0.5388 | 0.4682 | 0.4613 | 0.4420 | |
| AdaRank-NDCG | 0.5330 | 0.4790 | 0.4673 | 0.4490 | |
| SVM | 0.5229 | 0.4663 | 0.4516 | 0.4319 | |
| Pairwise | Ranking SVM | 0.4958 | 0.4207 | 0.4164 | 0.4140 |
| RankBoost | 0.4632 | 0.4555 | 0.4494 | 0.4302 | |
| SciBERT | 0.4589 | 0.4472 | 0.4210 | 0.4243 | |
| FRank | 0.5300 | 0.4812 | 0.4588 | 0.4430 | |
| GERank |
| Approach | Model | P@1 | P@3 | P@5 | P@10 | MAP |
|---|---|---|---|---|---|---|
| Pointwise | LR | 0.5212 | 0.4814 | 0.4242 | 0.4317 | 0.3415 |
| Listwise | ListNet | 0.5356 | 0.5238 | 0.4913 | 0.4320 | 0.3421 |
| AdaRank-MAP | 0.5440 | 0.5215 | 0.4871 | 0.4313 | 0.3433 | |
| AdaRank-NDCG | 0.5455 | 0.5232 | 0.4751 | 0.4237 | 0.3413 | |
| SVM | 0.5345 | 0.5173 | 0.4828 | 0.4332 | 0.3421 | |
| Pairwise | Ranking SVM | 0.5870 | 0.5721 | 0.5235 | 0.4856 | 0.3761 |
| RankBoost | 0.5742 | 0.5627 | 0.5043 | 0.4722 | 0.3755 | |
| SciBERT | 0.5548 | 0.5474 | 0.4925 | 0.4656 | 0.3722 | |
| FRank | 0.5932 | 0.5871 | 0.5525 | 0.4926 | 0.3814 | |
| GERank | 0.4901 |
| Approach | Model | NDCG@1 | NDCG@3 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|---|
| Pointwise | LR | 0.5212 | 0.5521 | 0.6220 | 0.7322 |
| Listwise | ListNet | 0.5356 | 0.5544 | 0.6213 | 0.7251 |
| AdaRank-MAP | 0.5440 | 0.5647 | 0.6321 | 0.7421 | |
| AdaRank-NDCG | 0.5455 | 0.5678 | 0.6402 | 0.7452 | |
| SVM | 0.5345 | 0.5427 | 0.6398 | 0.7423 | |
| Pairwise | Ranking SVM | 0.5870 | 0.6327 | 0.6872 | 0.7824 |
| RankBoost | 0.5742 | 0.6247 | 0.6745 | 0.7743 | |
| SciBERT | 0.5548 | 0.6122 | 0.6554 | 0.7532 | |
| FRank | 0.5932 | 0.6472 | 0.6923 | 0.7951 | |
| GERank |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Lu, B.; Tian, L.; Liang, S. Learning to Co-Embed Queries and Documents. Electronics 2022, 11, 3694. https://doi.org/10.3390/electronics11223694
Wu Y, Lu B, Tian L, Liang S. Learning to Co-Embed Queries and Documents. Electronics. 2022; 11(22):3694. https://doi.org/10.3390/electronics11223694
Chicago/Turabian StyleWu, Yuehong, Bowen Lu, Lin Tian, and Shangsong Liang. 2022. "Learning to Co-Embed Queries and Documents" Electronics 11, no. 22: 3694. https://doi.org/10.3390/electronics11223694
APA StyleWu, Y., Lu, B., Tian, L., & Liang, S. (2022). Learning to Co-Embed Queries and Documents. Electronics, 11(22), 3694. https://doi.org/10.3390/electronics11223694