
Entity Factor: A Balanced Method for Table Filling in Joint Entity and Relation Extraction


Abstract
:1. Introduction
2. Related Work
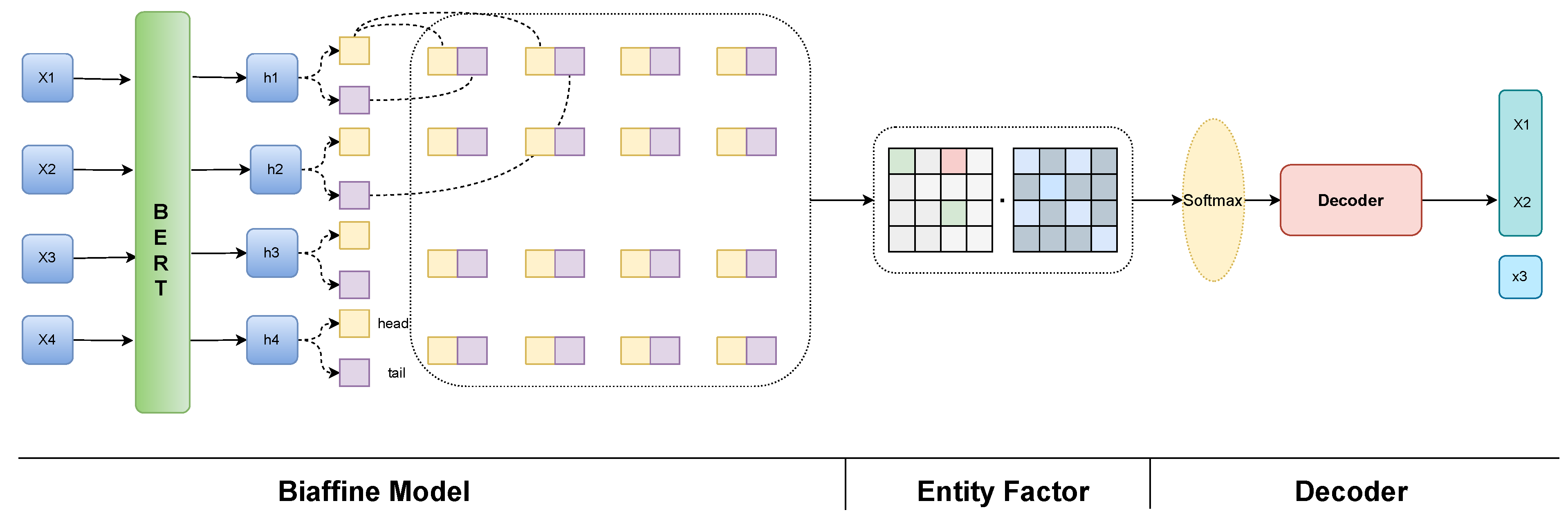
3. Methodology
3.1. Problem Definition
3.2. Encoder
3.3. Decoder
| Algorithm 1: Encoder |
|
| Algorithm 2: Decoder |
|
4. Experiment and Results
4.1. Dataset
4.2. Evaluation
4.3. Implementation Details
4.4. Performance Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sang, E.F.T.K. Introduction to the CoNLL-2002 shared task: Language-independent named entity recognition. In Proceedings of the International Conference on Computational Linguistics Association for Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 142–147. [Google Scholar]
- Bunescu, R.; Mooney, R. A shortest path dependency kernel for relation extraction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing (EMNLP), Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 724–731. [Google Scholar]
- Florian, R.; Jing, H.; Kambhatla, N.; Zitouni, I. Factorizing complex models: A case study in mention detection. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–18 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 551–560. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 402–412. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using LSTMs on sequences and tree structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1105–1116. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 917–928. [Google Scholar]
- Wadden, D.; Wennberg, U.; Luan, Y.; Hajishirzi, H. Entity, relation, and event extraction with contextualized span representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5788–5793. [Google Scholar]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A unified label space for entity relation extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Bangkok, Thailand, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 220–231. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1774–1784. [Google Scholar]
- Miwa, M.; Sasaki, Y. Modeling joint entity and relation extraction with table representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1858–1869. [Google Scholar]
- Wang, J.; Lu, W. Two are better than one: Joint entity and relation extraction with tablesequence encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 19–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 1706–1721. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proceedings of the International Conference on Machine Learning (ICML), Nashville, TN, USA, 8–12 July 1997; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 179–186. [Google Scholar]
- Wallace, B.C.; Small, K.; Brodley, C.E.; Trikalinos, T.A. Class imbalance, redux. In Proceedings of the 11th IEEE International Conference on Data Mining—ICDM 2011, Vancouver, BC, Canada, 11–14 December 2011; pp. 754–763. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for deep face recognition with long-tail data. arXiv 2018, arXiv:1803.09014. [Google Scholar]
- Fawcett, T.; Provost, F. Combining data mining and machine learning for effective user profiling. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Portland, OR, USA, 2–4 August 1996; ACM: New York, NY, USA, 1996; pp. 8–13. [Google Scholar]
- Collell, G.; Prelec, D.; Patil, K.R. Reviving threshold-moving: A simple plug-in bagging ensemble for binary and multiclass imbalanced data. arXiv 2016, arXiv:1606.08698. [Google Scholar]
- Kim, B.; Kim, J. Adjusting decision boundary for class imbalanced learning. IEEE Access 2019, 8, 81674–81685. [Google Scholar] [CrossRef]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. In Proceedings of the Eighth International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Morik, K.; Brockhausen, P.; Joachims, T. Combining statistical learning with a knowledge-based approach—A case study in intensive care monitoring. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML), San Francisco, CA, USA, 27–30 June 1999; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; pp. 268–277, ISBN 1-55860-612-2. [Google Scholar]
- Zhang, X.; Fang, Z.; Wen, Y.; Li, Z.; Qiao, Y. Range loss for deep face recognition with long-tailed training data. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Cambridge, MA, USA, 22–29 October 2017; pp. 5419–5428. [Google Scholar]
- Tan, J.; Wang, C.; Li, B.; Li, Q.; Ouyang, W.; Yin, C.; Yan, J. Equalization Loss for Long-Tailed Object Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11659–11668. [Google Scholar]
- Menon, A.K.; Jayasumana, S.; Rawat, A.S.; Jain, H.; Veit, A.; Kumar, S. Long-tail learning via logit adjustment. arXiv 2020, arXiv:2007.07314. [Google Scholar]
- Dozat, T.; Manning, C.D. Deep biaffine attention for neural dependency parsing. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France,, 24–26 April 2017. [Google Scholar]
- Roth, D.; Yih, W.-T. A Linear Programming Formulation for Global Inference in Natural Language Tasks. In Proceedings of the CoNLL 2004 at HLT-NAACL 2004, Boston, MA, USA, 2–7 May 2004; ACL: Stroudsburg, PA, USA, 2004; pp. 1–8. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 3219–3232. [Google Scholar]
- Taillé, B.; Guigue, V.; Scoutheeten, G.; Gallinari, P. Let’s stop incorrect comparisons in end-to-end relation extraction! In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3689–3701. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 7–11 November 2021; pp. 50–61. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #sents | #ents(#types) | #rels(#types) |
|---|---|---|---|
| ConLL04 | 1441 | 5349(4) | 2048(5) |
| SciERC | 2687 | 8094(6) | 5463(7) |
| Dataset | Model | Encoder | Entity | Relation | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |||
| CoNLL04 | PURE [29] | BERT | - | - | 88.1 | - | - | 68.4 |
| UNIRE [9] | BERT | 87.6 | 88.5 | 88.1 | 68.3 | 71.1 | 69.7 | |
| Logit-Adjust [23] | BERT | 86.9 | 88.2 | 87.6 | 69.7 | 68.7 | 69.2 | |
| ours | BERT | 87.7 | 89.1 | 88.0 | 69.8 | 72.7 | 71.2 | |
| SciERC | PURE [29] | SciBERT | - | - | 68.2 | - | - | 36.7 |
| UNIRE [9] | SciBERT | 67.1 | 70.6 | 68.8 | 34.8 | 34.1 | 34.4 | |
| Logit-Adjust [23] | SciBERT | 65.6 | 70.8 | 68.1 | 34.1 | 43.0 | 38.0 | |
| ours | SciBERT | 67.1 | 72.4 | 69.6 | 39.7 | 39.3 | 39.5 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Tao, M.; Zhou, C. Entity Factor: A Balanced Method for Table Filling in Joint Entity and Relation Extraction. Electronics 2023, 12, 121. https://doi.org/10.3390/electronics12010121
Liu Z, Tao M, Zhou C. Entity Factor: A Balanced Method for Table Filling in Joint Entity and Relation Extraction. Electronics. 2023; 12(1):121. https://doi.org/10.3390/electronics12010121
Chicago/Turabian StyleLiu, Zhifeng, Mingcheng Tao, and Conghua Zhou. 2023. "Entity Factor: A Balanced Method for Table Filling in Joint Entity and Relation Extraction" Electronics 12, no. 1: 121. https://doi.org/10.3390/electronics12010121
APA StyleLiu, Z., Tao, M., & Zhou, C. (2023). Entity Factor: A Balanced Method for Table Filling in Joint Entity and Relation Extraction. Electronics, 12(1), 121. https://doi.org/10.3390/electronics12010121