
Attributation Analysis of Reinforcement Learning-Based Highway Driver


Abstract
1. Introduction
1.1. Motivation
1.2. Contribution
2. Related Work
2.1. RL in AV
2.2. Explainable RL
3. Preliminaries
3.1. Reinforcement Learning Agents
3.2. Integrated Gradients
4. Description of Experiment
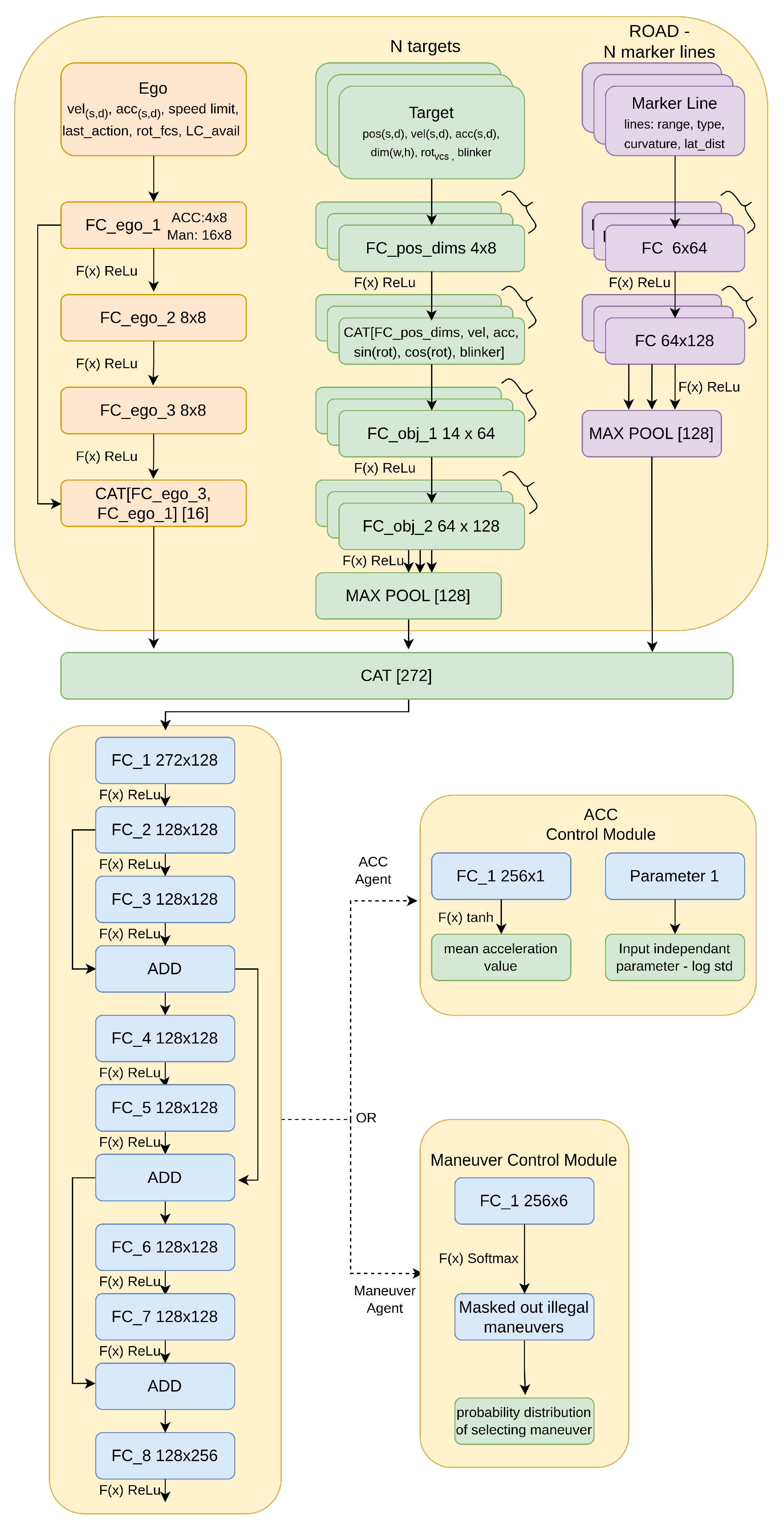
4.1. Neural Networks
4.2. Reward Functions
- Speed limit execution —calculated as a ratio of ego velocity and speed limit; forces agent to maximize speed limit.
- Squared acceleration —the squared value of acceleration; negative reward promotes smooth ride.
- Jerk absolute —the value of absolute jerk; also promotes comfort driving experience.
- Safety violation —a negative reward for being too close to other vehicles. Distance is calculated based on Responsibility-Sensitive Safety assumptions [9].
- Terminal state —a reward for causing a collision or speeding too much.
- Speed limit execution cube calculated as a ratio of ego velocity and speed limit—forces agent to maximize speed limit, encourages to overtake slower cars.
- Negative acceleration Squared —a reward for braking events, incentives for smooth driving.
- Sequence maneuver execution —a reward for inconsistency in selecting maneuvers, this term has non-zero value when agent selects different action then selected before. It reduces action flickering problem.
- Collision —a negative reward for causing collision.
- Right lane available —non-zero when the right lane is available and the agent can change to it. It promotes gentleness on road by releasing the left lane for faster vehicles.
- Being overtaken by right —this reward is non-zero when the agent is slower than vehicles in the right lane. The agent should change the lane to the right to allow faster vehicles to drive on the left.
- Overtaking right —this term rewards agents for overtaking other cars while driving on the left lane.
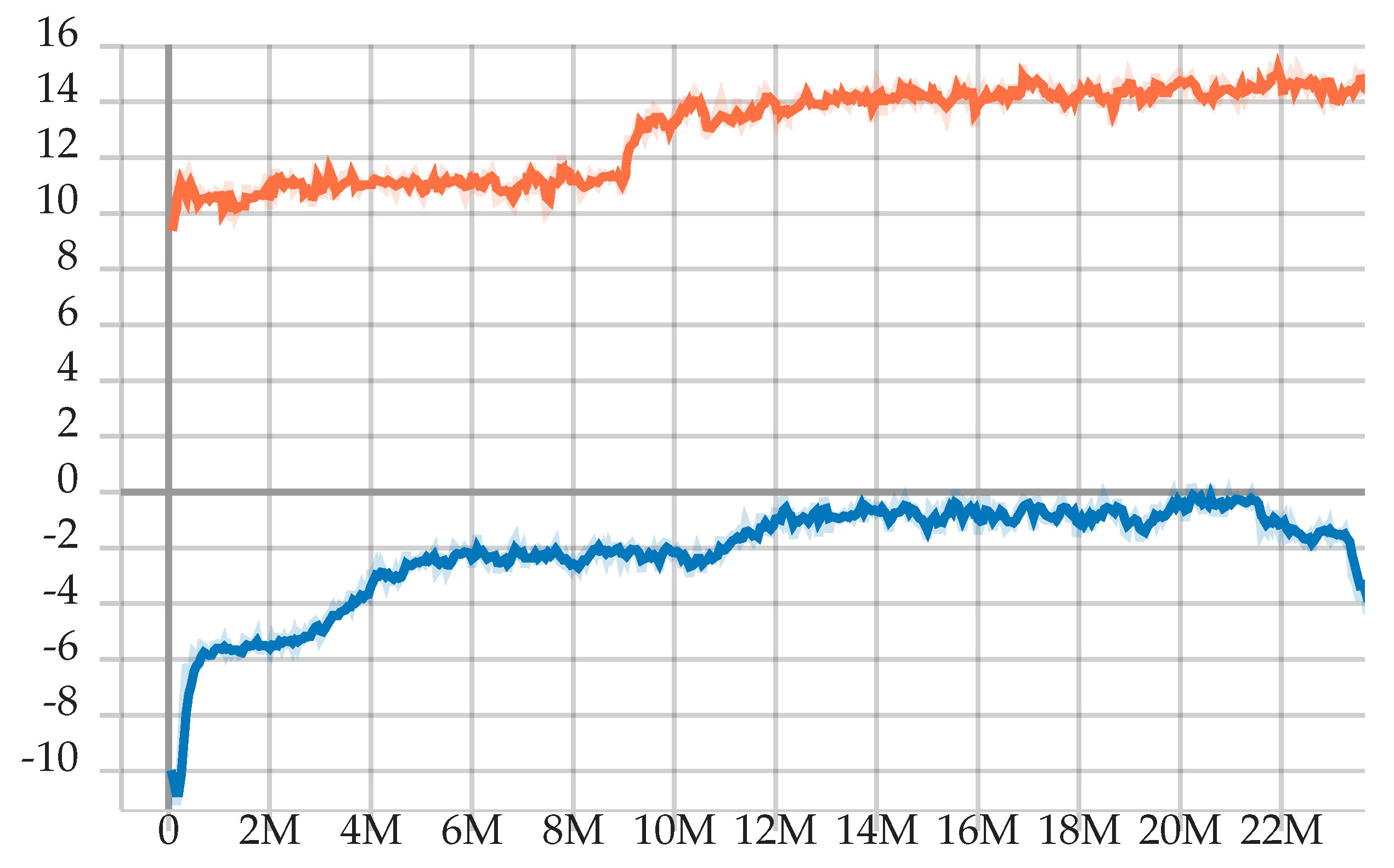
4.3. Agent Training
4.4. Collecting Neural Activations
4.5. Statistical Analysis
4.5.1. ANOVA and t-Tests
4.5.2. Correlation Tests
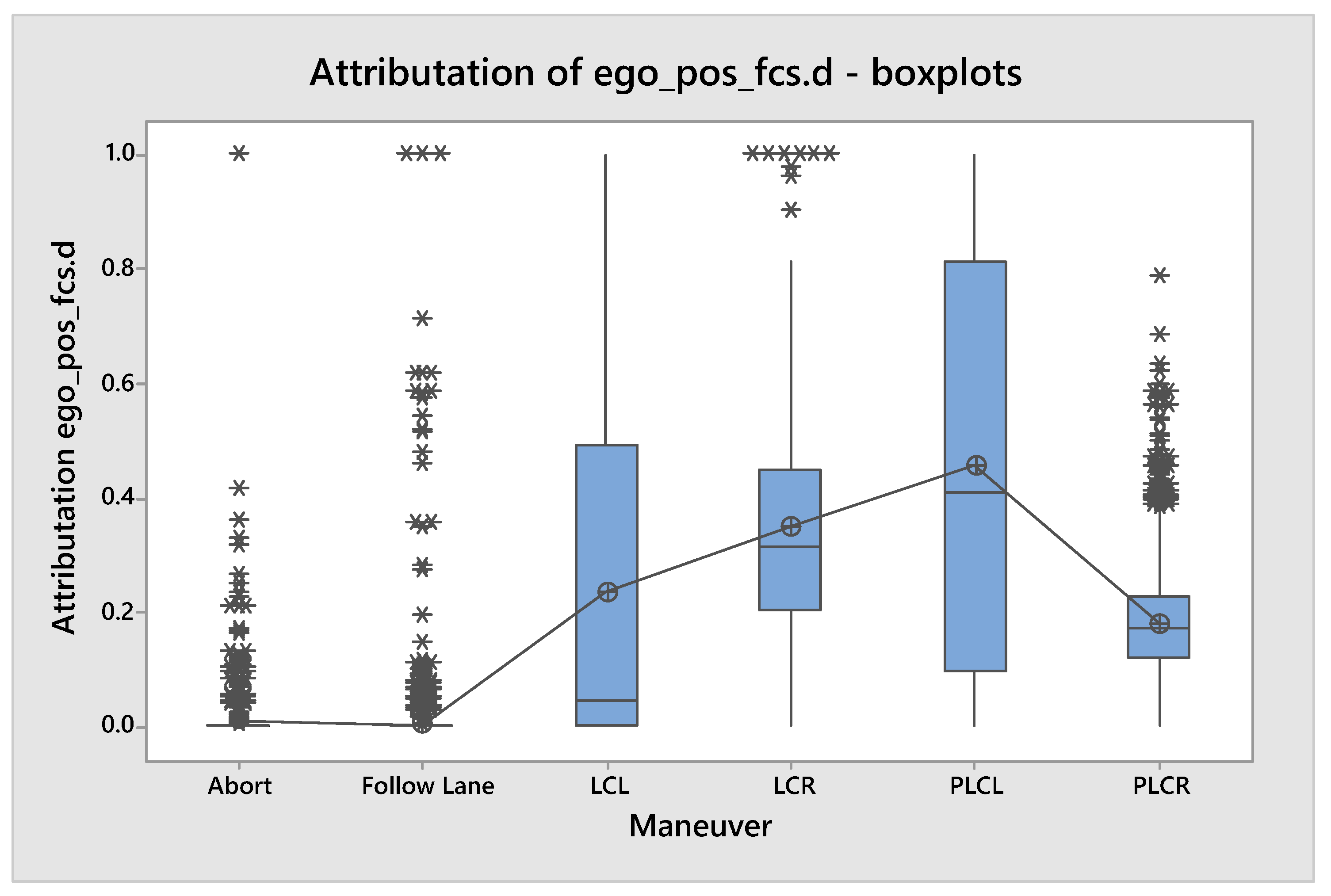
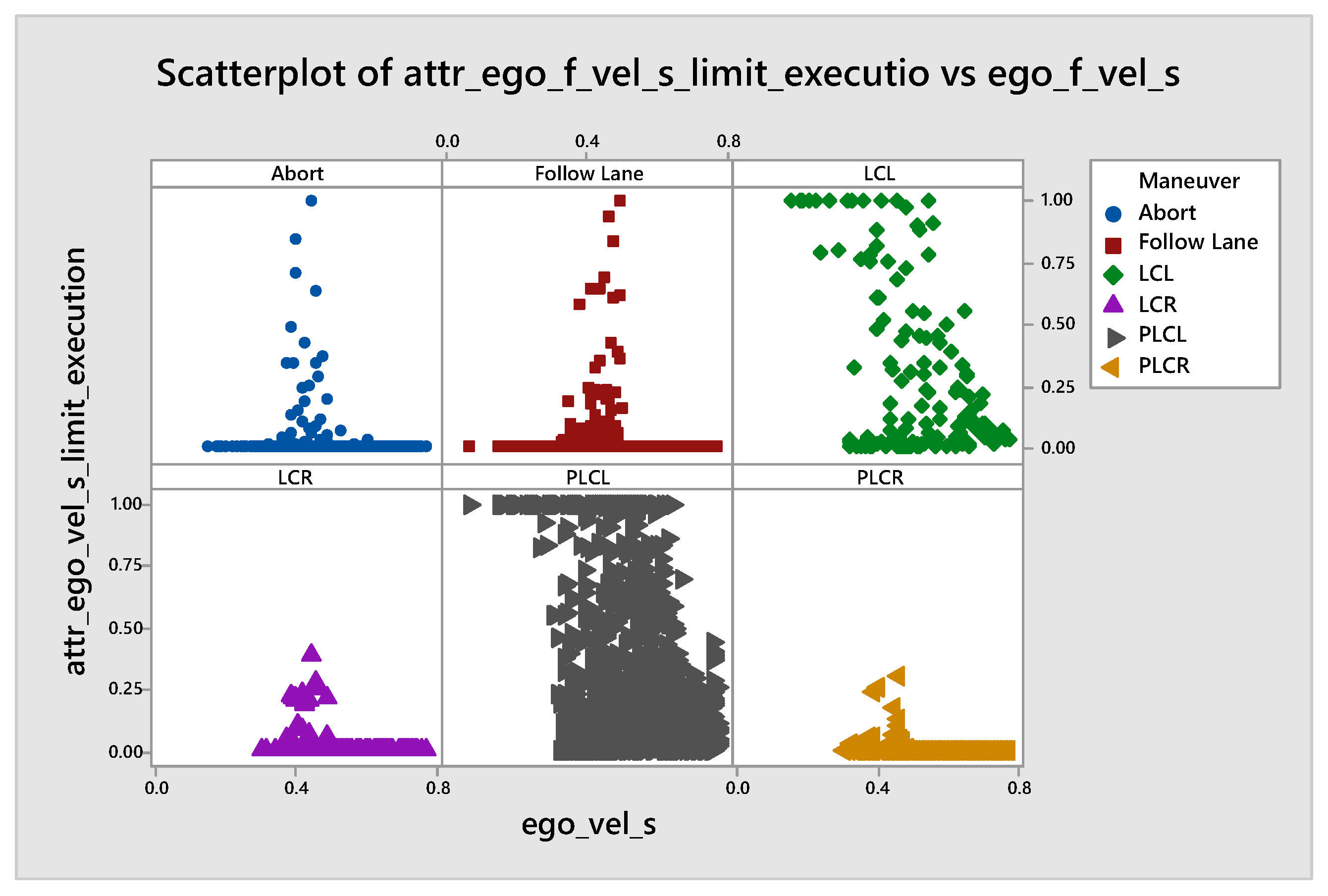
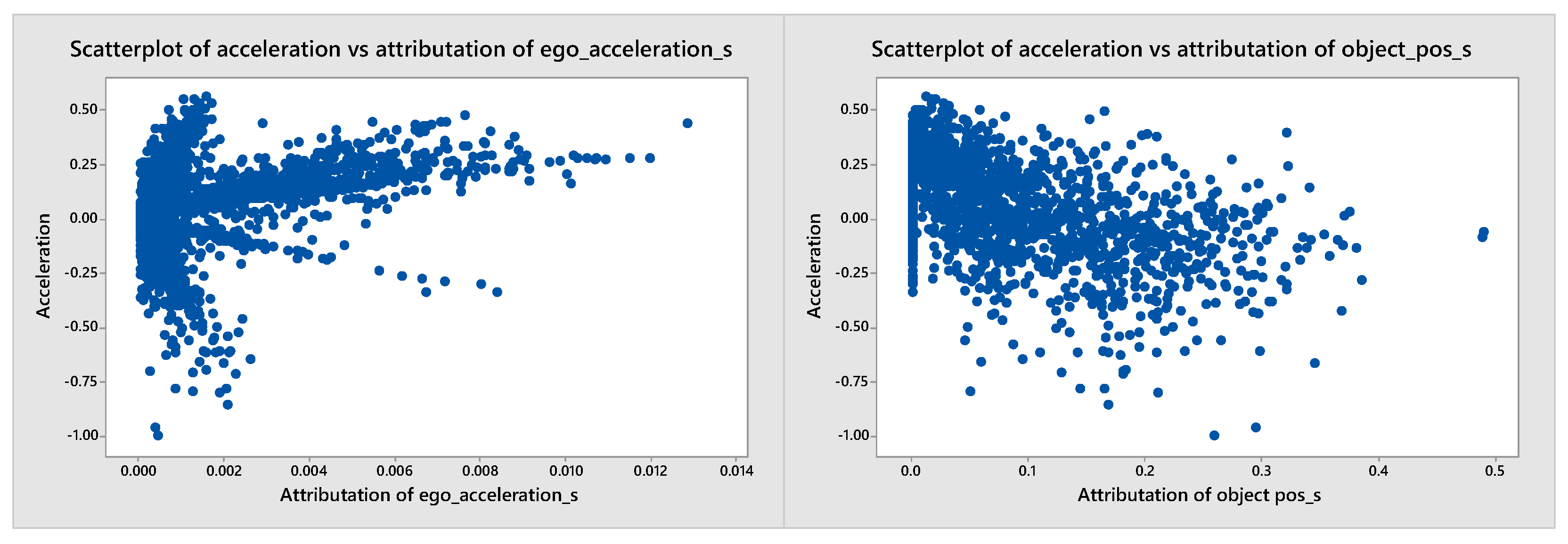
5. Results
6. Application
7. Discussion
8. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- MacKay, D.J.C. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 7, pp. 5109–5118. [Google Scholar]
- Freedman, D.; Pisani, R.; Purves, R. Statistics (International Student Edition), 4th ed.; Pisani, R.P., Ed.; WW Norton & Company: New York, NY, USA, 2007. [Google Scholar]
- Zar, J.H. Spearman rank correlation. In Encyclopedia of Biostatistics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Wang, P.; Chan, C.; de La Fortelle, A. A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers. arXiv 2018, arXiv:1804.07871. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Orłowski, M.; Wrona, T.; Pankiewicz, N.; Turlej, W. Safe and Goal-Based Highway Maneuver Planning with Reinforcement Learning. In Proceedings of the Advanced, Contemporary Control, Łódź, Poland, 25 June 2020; Bartoszewicz, A., Kabziński, J., Kacprzyk, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1261–1274. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. On a Formal Model of Safe and Scalable Self-driving Cars. arXiv 2017, arXiv:1708.06374. [Google Scholar]
- Isele, D.; Cosgun, A.; Subramanian, K.; Fujimura, K. Navigating Intersections with Autonomous Vehicles using Deep Reinforcement Learning. arXiv 2017, arXiv:1705.01196. [Google Scholar]
- Keselman, A.; Ten, S.; Ghazali, A.; Jubeh, M. Reinforcement Learning with A* and a Deep Heuristic. arXiv 2018, arXiv:1811.07745. [Google Scholar]
- Aradi, S. Survey of Deep Reinforcement Learning for Motion Planning of Autonomous Vehicles. arXiv 2020, arXiv:2001.11231. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.K.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. arXiv 2020, arXiv:2002.00444. [Google Scholar] [CrossRef]
- Angerschmid, A.; Zhou, J.; Theuermann, K.; Chen, F.; Holzinger, A. Fairness and Explanation in AI-Informed Decision Making. Mach. Learn. Knowl. Extr. 2022, 4, 556–579. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Allen, P.G.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 4768–4777. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 7, pp. 4844–4866. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Dhamdhere, K.; Yan, Q.; Sundararajan, M. How Important Is a Neuron? In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Leino, K.; Sen, S.; Datta, A.; Fredrikson, M.; Li, L. Influence-Directed Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE International Test Conference (ITC), Phoenix, AZ, USA, 29 October–1 November 2018. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2016, 128, 336–359. [Google Scholar] [CrossRef]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- van Seijen, H.; Fatemi, M.; Romoff, J.; Laroche, R.; Barnes, T.; Tsang, J. Hybrid Reward Architecture for Reinforcement Learning. arXiv 2017, arXiv:1706.04208. [Google Scholar]
- Kawano, H. Hierarchical sub-task decomposition for reinforcement learning of multi-robot delivery mission. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 828–835. [Google Scholar] [CrossRef]
- Juozapaitis, Z.; Koul, A.; Fern, A.; Erwig, M.; Doshi-Velez, F. Explainable Reinforcement Learning via Reward Decomposition. In Proceedings of the International Joint Conference on Artificial Intelligence. A Workshop on Explainable Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Raffin, A.; Hill, A.; Traoré, R.; Lesort, T.; Rodríguez, N.D.; Filliat, D. S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning. arXiv 2018, arXiv:1809.09369. [Google Scholar]
- Mundhenk, T.N.; Chen, B.Y.; Friedland, G. Efficient Saliency Maps for Explainable AI. arXiv 2019, arXiv:1911.11293. [Google Scholar]
- Yeom, S.; Seegerer, P.; Lapuschkin, S.; Wiedemann, S.; Müller, K.; Samek, W. Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning. arXiv 2019, arXiv:1912.08881. [Google Scholar] [CrossRef]
- Sequeira, P.; Gervasio, M. Interestingness Elements for Explainable Reinforcement Learning: Understanding Agents’ Capabilities and Limitations. Artif. Intell. 2019, 288, 103367. [Google Scholar] [CrossRef]
- Traffic AI—Simteract. 2018. Available online: https://simteract.com/pl/projects/traffic-ai-pl/ (accessed on 12 September 2022).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Goldberg, K.; Gonzalez, J.; Jordan, M.; Stoica, I. RLlib: Abstractions for Distributed Reinforcement Learning. In Proceedings of the Machine Learning Research; Dy, J., Krause, A., Eds.; JMLR: Cambridge, MA, USA, 2018; Volume 80, pp. 3053–3062. [Google Scholar]
- Kokhlikyan, N.; Miglani, V.; Martin, M.; Wang, E.; Alsallakh, B.; Reynolds, J.; Melnikov, A.; Kliushkina, N.; Araya, C.; Yan, S.; et al. Captum: A unified and generic model interpretability library for PyTorch. arXiv 2020, arXiv:2009.07896. [Google Scholar]
- Minitab, LLC—Version 18. Available online: https://www.minitab.com (accessed on 12 September 2022).
- Liu, H. Comparing Welch’s ANOVA, a Kruskal-Wallis Test, and Traditional ANOVA in Case of Heterogeneity of Variance; Virginia Commonwealth University: Richmond, VA, USA, 2015. [Google Scholar]
- Sauder, D.C.; DeMars, C.E. An Updated Recommendation for Multiple Comparisons. Adv. Methods Pract. Psychol. Sci. 2019, 2, 26–44. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameter | Mean | St. Dev | Min | Median | Max |
|---|---|---|---|---|---|
| ego_f_pos_fcs.d | −1.03 | 0.10 | −2.06 | −1.03 | 0.04 |
| real_ego_f_pos_fcs.d | −0.054 | 0.20 | −2.12 | −0.06 | 2.09 |
| ego_f_vel_s | 0.52 | 0.13 | 0.06 | 0.50 | 0.77 |
| real_ego_f_vel_s | 25.92 | 6.29 | 2.85 | 25.11 | 38.63 |
| ego_f_vel_s_limit_execution | 0.97 | 0.07 | 0.17 | 1.00 | 1.48 |
| ego_f_vel_d | 0.00 | 0.09 | −1.00 | −0.00 | 1.00 |
| real_ego_f_vel_d | 0.00 | 0.36 | −4.00 | −0.00 | 4.00 |
| ego_f_acc_s | 0.00 | 0.04 | −0.60 | 0.00 | 0.45 |
| real_ego_f_acc_s | 0.01 | 0.38 | −6.00 | 0.00 | 4.50 |
| ego_f_acc_d | 0.00 | 0.01 | −0.19 | 0.00 | 0.25 |
| real_ego_f_acc_d | 0.00 | 0.01 | −0.38 | 0.00 | 0.50 |
| ego_f_rot_fcs | −0.00 | 0.00 | −0.05 | −0.00 | 0.05 |
| Training Parameter | Maneuver | ACC |
|---|---|---|
| gamma | 0.9985 | 0.998 |
| lambda | 0.95 | 0.95 |
| batch size | 1024 | 50,000 |
| mini batch size | 512 | 20,000 |
| steps | 38 M | 30 M |
| best checkpoint step | 22 M | 20 M |
| grad_clip | 3.0 | 3.0 |
| lr | 4.5 × 10−5 | 0.0001 |
| num_gpu | 1 | 1 |
| sgd_iter | 3 | 3 |
| workers | 80 | 80 |
| Mutual Information | |
|---|---|
| Feature | MI |
| ego_acc_s | 1.658 |
| ego_last_action_acc | 1.074 |
| attr_obs_acc_s | 0.621 |
| attr_ego_last_action_acc | 0.350 |
| attr_ego_vel_s | 0.273 |
| road_att_lat_dist | 0.272 |
| attr_ego_vel_s_limit_exec | 0.248 |
| road_att_closes_in | 0.244 |
| obj_att_pos_s | 0.196 |
| obj_att_pos_d | 0.159 |
| PEARSON | ||||||
|---|---|---|---|---|---|---|
| ego | Follow Lane | PLCL | PLCR | LCL | LCR | Abort |
| pos_fcs.d | 0.064 | −0.026 | −0.186 | −0.157 | −0.122 | −0.21 |
| vel_s | −0.05 | 0.063 | −0.116 | −0.124 | −0.408 | −0.305 |
| vel_s_limi | 0.204 | −0.895 | 0.182 | 0.166 | −0.916 | 0.786 |
| vel_d | −0.014 | 0.056 | 0.07 | 0.17 | −0.042 | −0.137 |
| acc_s | −0.024 | −0.025 | −0.082 | −0.054 | −0.062 | −0.39 |
| acc_d | 0.008 | 0.173 | −0.031 | 0.023 | 0.011 | −0.254 |
| rot_fcs | −0.017 | 0.06 | 0.093 | −0.121 | −0.146 | −0.105 |
| Spearman Rho | ||||||
|---|---|---|---|---|---|---|
| ego | Follow Lane | PLCL | PLCR | B | LCR | Abort |
| pos_fcs.d | 0.135 | 0.121 | −0.078 | 0.108 | −0.165 | 0.039 |
| vel_s | −0.688 | −0.657 | 0.557 | −0.472 | −0.061 | −0.28 |
| vel_s_limi | 0.877 | 0.858 | −0.938 | 0.646 | −0.978 | 0.52 |
| vel_d | 0.016 | 0.035 | 0.011 | 0.006 | −0.156 | 0.095 |
| acc_s | −0.636 | −0.642 | 0.49 | −0.493 | −0.267 | −0.099 |
| acc_d | 0.02 | 0.023 | −0.009 | 0.014 | 0.068 | −0.143 |
| rot_fcs | 0.031 | 0.054 | −0.001 | 0.017 | −0.171 | 0.094 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pankiewicz, N.; Kowalczyk, P. Attributation Analysis of Reinforcement Learning-Based Highway Driver. Electronics 2022, 11, 3599. https://doi.org/10.3390/electronics11213599
Pankiewicz N, Kowalczyk P. Attributation Analysis of Reinforcement Learning-Based Highway Driver. Electronics. 2022; 11(21):3599. https://doi.org/10.3390/electronics11213599
Chicago/Turabian StylePankiewicz, Nikodem, and Paweł Kowalczyk. 2022. "Attributation Analysis of Reinforcement Learning-Based Highway Driver" Electronics 11, no. 21: 3599. https://doi.org/10.3390/electronics11213599
APA StylePankiewicz, N., & Kowalczyk, P. (2022). Attributation Analysis of Reinforcement Learning-Based Highway Driver. Electronics, 11(21), 3599. https://doi.org/10.3390/electronics11213599