1. Introduction
Countries all over the world are accelerating the development of unmanned combat aerial vehicles (UCAVs) as artificial intelligence technology advances [
1]. AlphaDogfight, a DARPA-sponsored proximity autonomous intelligent air warfare project in the United States, exemplifies the most recent application of artificial intelligence in the field of autonomous air combat [
2]. However, the current level of intelligence is insufficient to meet the actual needs, so UCAV autonomous air warfare has been studied as an important issue [
3,
4].
According to the OODA ring [
5], decision making is the central component of UCAV autonomous air combat, serving as the “brain” of the UCAV [
6]. Current close air combat maneuver decision methods are classified into three types [
7]: game theory-based maneuver decision methods, artificial intelligence-based maneuver decision methods, and optimization theory-based methods.
The game theory-based maneuver decision method mainly employs game theory for air combat maneuver decisions, and it consists mainly of the differential countermeasure method and the influence diagram method. The differential countermeasure method is used to solve bilateral extreme value problems by converting offensive and defensive countermeasures. In Ref. [
8], Lee et al. used a game-theoretic-based minmax algorithm to select the optimal maneuver command by constructing a score matrix, and the simulation results showed that it could make fast decisions; discrete maneuvers are used in the library text, which may result in the maneuvers obtained from the decision not being the globally optimal maneuver strategy. The influence diagram method uses expert knowledge from air combat games and is a decision model with a directed acyclic graph representation. Virtanen et al. [
9] describe a multi-stage influence diagram game that simulates maneuvering decisions in one-to-one air combat and determines and achieves a Nash equilibrium of the dynamic game at each decision segment, but the influence diagram approach is complex and difficult to satisfy in real time.
Artificial intelligence-based maneuvering decision methods mainly include rule-based expert system methods and deep neural network-based reinforcement learning methods, etc. The rule-based expert system approach is an expert system library built according to IF-THEN rules, and the corresponding maneuvers are performed when the rules are met. Fu Li et al. [
10] combined expert systems with rolling time-domain optimization, and used a rolling time-domain optimal control model when the expert system failed, which can make decisions quickly and effectively, but it is difficult to improve the rule base establishment of the expert system. Unlike expert systems, deep neural network-based reinforcement learning methods do not require air combat samples and enable autonomous air combat maneuvering decisions through self-learning and self-updating. Yang et al. [
11] established a maneuver decision model based on Deep Q Network (DQN) and achieved autonomous maneuver decisions against enemy close range after phased training, but the reinforcement learning method has long training time and the effect is difficult to guarantee. Jiseon et al. [
12] use reinforcement learning on multi-UAV target tracking. Their improved algorithm has the potential to be applied to the multi-UAV air combat problem.
Optimization theory-based methods primarily convert maneuver decision problems into single-objective or multi-objective optimization problems and solve them using heuristic optimization algorithms. Ruan et al. [
13] used the Transfer Learning Pigeon-Inspired Optimization (TLPIO) algorithm to search for optimal hybrid strategies and verify the search accuracy of the algorithm using a test function, but the paper does not compare the algorithm with other heuristics on the maneuver decision problem. It does not show the advantage of the algorithm for the maneuvering decision problem. Yang et al. [
14] designed an autonomous evasive maneuver decision method for over-the-horizon air combat, considering both longer off-target distance, less energy consumption, and longer maneuver duration, and transformed the evasive maneuver problem into a multi-objective optimization problem. A hierarchical multi-objective evolutionary algorithm (HMOEA) has been designed to find the approximate Pareto optimal solution of the problem. Simulation results showed that it can meet the needs of the different evasive tactics of UCAV. However, this method can only be used for escape, not for attack. Li et al. [
15] proposed a multi-UCAV over-the-horizon cooperative occupancy maneuver decision method, which uses weapon strike zones and air combat geometry to establish dominance functions for posture evaluation. The multi-UCAV maneuver decision problem was transformed into a mixed integer nonlinear programming (MINLP) problem and was solved using an improved discrete particle swarm optimization (DPSO) algorithm. There is also no comparison of the effectiveness of different algorithms on the maneuvering decision problem in the paper.
By categorizing the existing researchs,
Table 1 was obtained. According to the findings of the preceding research, it is difficult to find an analytical solution to achieve Nash equilibrium in the real air combat environment using the maneuvering decision method based on game theory, and the high computational complexity makes meeting the real-time requirements difficult. The air combat rules are tough to complete using the artificial intelligence-based maneuvering method, and the effect of using reinforcement learning requires a significant amount of training time. The maneuvering decision method based on optimization theory typically establishes the situation function and solves the control variables by the method of situation finding, which easily falls into the local optimum. Additionally, the decision dimension is low when solved using a heuristic algorithm, making it difficult to realize its advantages.
Additionally, none of the studies mentioned above used the enemy aircraft’s predicted trajectory to guide their maneuvering decisions or took into account how they would situate themselves over a longer period of time. When establishing the objective function, the next moment’s posture advantage of our aircraft is considered, and the UCAV can only maintain the posture advantage from time to time, which is easily deceived by the enemy tactics.
There are various control methods currently available for UAVs, which have been developed to meet the needs of trajectory tracking [
27] and geographic boundary avoidance [
28]. However, for the air combat environment, open-loop system control methods such as model predictive control are still used as the classical control methods [
29].
Therefore, this paper adopts a model predictive control framework that combines trajectory prediction of enemy aircraft with the average of the relative situations of our aircraft and enemy aircraft at multiple future moments as the objective function. Multiple steps are taken in one decision, and the first step is used as the input for the next moment, thus completing the maneuver decision and realizing the utilization of enemy aircraft trajectory prediction data and the consideration of the long-term situation. Compared with the existing work, this paper is able to break through the problem that optimization algorithms for maneuvering decision problems tend to fall into local optimality and uses the MPC framework to incorporate trajectory prediction into maneuvering decisions. It aims to obtain air combat victory faster. Most importantly, the paper compares the different algorithms used for maneuvering decisions. The innovation and main work of this paper are shown below:
- (1)
For long-time domain time series data prediction, Bi-LSTM network rolling recursive prediction theory is introduced, which solves the short time domain for the trajectory prediction issue.
- (2)
A model predictive control theory is presented, which combines a target prediction trajectory with several steps in a single decision, using the control variable from the first control sequence as the control variable for the next instant. Future dynamics are incorporated into the objective function using this method.
- (3)
The LSHADE-TSO algorithm replaces the traditional model predictive control solver, sequential quadratic programming, which solves the problem of complex nonlinear models easily falling into local optimum.
- (4)
Based on a modification of the LSAHDE algorithm, the LSHADE-TSO algorithm is proposed, and the search accuracy is validated using the CEC2014 test functions.
- (5)
The superiority of the maneuvering decision method proposed in this paper is demonstrated by an experimental analysis of air combat countermeasures, and the decision duration is examined to demonstrate that it can meet real-time demand.
The rest of the paper is organized as follows. Multi-step trajectory prediction based on a Bi-LSTM network is described in
Section 2.
Section 3 describes the UCAV maneuvering decision model in the MPC framework; it combines the trajectory prediction and MPC framework for maneuvering decisions. The close air combat situation function is also presented in
Section 3. In
Section 4, the LSHADE-TSO algorithm is proposed and tested by CEC2014 test functions.
Section 5 demonstrates simulation results for the comparison of different maneuvering decision methods and algorithms.
Section 6 summarizes the simulation results and the work in this paper.
4. LSHADE-TSO
4.1. Brief Review of LSHADE and TSO
- (1)
LSHADE
In addition, since 2005, many variants of DE have managed to obtain a position among the top three algorithms in the CEC competitions in successive years, except for 2013, when DE obtained the 4th rank. LSHADE was the champion in the 2014 Evolutionary Computing Conference competition [
37]. The basic steps of LSHADE are given below.
Step 1: An initial population, P0, is created as follows:
where
is the
ith individual,
j represents the
jth dimension, and
NP is the initial population number.
Step 2: The algorithm parameters crossover rate,
CR, and scaling factor,
F, are set.
In case a value for
CRi outside of [0, 1] is generated, it is replaced by the limit value (0 or 1) closest to the generated value. When
Fi > 1, Fi is truncated to 1, and when
Fi ≤ 0, Equation (2) is repeatedly applied to try to generate a valid value. These manners are according to the procedure for [
38].
Step 3: According to current-to-pbest/1 mutation strategy, a mutant vector,
, is created as follows:
where
xi,g represents the
ith target vector of the
gth generation,
Fi is the scaling factor of the
ith target vector,
is a random
p target vector with the best fitness value, and
r1 and
r2 are random indexes selected from the current population and a combination of the current population and an external archive, respectively.
Step 4: The trial vector,
, is obtained through replacing some components of the target vector,
, with the corresponding mutant vector,
.
The randi (1, D) generate a random integer between 0 and D. is the crossover factor that decides the proportion of replaced components in .
Step 5: Selection operation: according to the greedy strategy, the individual of next generation is selected by comparing the trail vector,
, and the target vector,
, in DE. The selection method is as follows:
Step 6: According to linear population size reducing (LPSR) [
37], the population size is updated by evaluation number.
- (2)
TSO
The LSHADE algorithm uses a single mutation strategy, which leads to the algorithm falling into local optimum. In this regard, the two foraging search strategies in tuna swarm optimization (TSO) [
39] are introduced into the mutation operation of LSHADE. The two mutation strategies account for a certain percentage of the population to improve population diversity and avoid local optimum.
Tuna Swarm Optimization is one of the latest proposed swarm-based global optimization algorithms. Its main inspiration comes from two cooperative foraging behaviors of tuna swarm in the ocean: spiral foraging and parabolic foraging. Its global exploration ability is better than the exploitation ability.
(1) Spiral foraging
The heuristic algorithm usually performs a global search of the range in the initial stage of the search to determine the main area of the optimal position, and then performs an exact local search afterwards. Therefore, as the number of iterations increases, the target of spiral foraging of TSO gradually changes from random individuals to optimal individuals, and its probability increases with the amount of iterations. In summary, the final mathematical model of the spiral foraging strategy is shown below:
(2) Parabolic foraging
To prevent prey from escaping, in addition to forming a spiral line to feed, the swarm of tuna also forms a parabolic line to feed. While forming a parabolic formation with the prey as the reference point, the group of tuna also conducts a search for prey around itself, both of which are carried out with a 50% probability at the same time. The mathematical model is shown below:
where
TF is a random value of −1 or 1.
Tuna swarms forage cooperatively with the two foraging methods mentioned above, and each individual randomly chooses one strategy to execute.
4.2. Description of LSHADE-TSO
On the basis of LSHADE, this paper proposes a novel algorithm, called LSHADE-TSO. It competes the variant strategies in LSHADE with TSO predation strategies through an adaptive competition mechanism, thus expanding the search range. Meanwhile, strategies such as cross-factor ranking and top 60% r1 selection are applied to LSHADE to enhance its convergence ability.
- (1)
Adaptive competition mechanism
For the variants of LSHADE, the search process is prone to fall into the local optimum trap due to the single variant strategy. In this regard, this paper proposes an adaptive competition mechanism, by competing with spiral foraging and parabolic foraging in TSO through current-to-pbest in LSHADE; population diversity is expanded, thus avoiding getting trapped in a local optimum. After generating the variance vector, the test vector is generated by the crossover operation in Equation (22). Each individual
x in
P will generate offspring individual
u using either LSHADE or TSO. The choice of these two strategies is achieved through the probability variable
P.
P is randomly selected from the memory sequence
MP. Thus, more individuals will be gradually assigned to the better performing algorithms. The memory sequence,
MP, is updated in the following way:
where c is the learning rate and
is the improvement rate for each algorithm.
is the summation of differences between old and new fitness values for each individual belonging to Algorithm 1.
where
f is the fitness function,
x is the old individual,
u is the offspring individual, and
n is the number of individuals belonging to Algorithm 1.
- (2)
Crossover rate sorting mechanism
In order to establish the relationship between
CR and the individual fitness values, the
CR sorting mechanism [
40] is introduced. Firstly, the
CR values are generated by Gaussian distribution and are then sorted in ascending order. This is shown as follows:
By sorting the CR values, the individuals with better fitness are given a smaller CR, so their next generation can retain more parts of the parent individuals. Meanwhile, the poor individuals will be given a larger CR, and a larger proportion of components will be replaced by the mutated individuals. This helps to improve the exploration efficiency.
- (3)
Top α r1 selection
In LSHADE-RSP [
41], a ranking-based approach was proposed for the selection of
r1 and
r2. In the JADE algorithm, the selection of the
r1 individual is random. To improve the convergence efficiency of the algorithm, the top α
r1 selection strategy is used. The selection of the
r1 is shown as follows:
where
is the number of candidates for the selection of
r1, and
rand is a random value selected in [0, 1]. The individuals with better fitness values will have a greater probability of being selected. In this way, it is easier to form a difference vector that evolves towards the current optimal individual and accelerates convergence.
| Algorithm 1: LSHADE-TSO algorithm pseudo-code. |
| Initialise population |
|
| for g = 1 to gmax do |
| for i = 1:NP |
| , |
| end |
|
|
| for i = 1:NP |
| if rand<P |
| Generate |
|
|
| else |
| if rand<0.5 |
| generate According to Equation (26) |
| else |
| generate According to Equation (27) |
| end |
| end |
| if |
|
|
| else |
|
|
| end |
| , |
| if |
|
|
| else |
|
|
| end |
| end |
| Update , MP, and NP |
| Update archive size by removing worst solutions |
| Update population size by removing worst solutions |
| end |
4.3. Algorithm Performance Verification
In this subsection, we verify the performance of LSHADE-TSO using the CEC2014 single-objective optimization test set presented at the 2014 IEEE Conference on Evolutionary Computation (2014 IEEE CEC). This paper compares LSHADE-TSO with SPS-LSHADE-EIG [
42], LSAHDE, CPI-JADE [
43], TSO, and MPA. LSHADE was the winner of the CEC 2014 competition. SPS-LSHADE-EIG was the second winner of the CEC 2015 competition. CPI-JADE was proposed in 2016. TSO and MPA were recently proposed in 2021.
The CEC2014 test set contains 30 test functions, which can be divided into four types according to their different characteristics: F1–F3 for single-peaked functions, F4–F16 for multi-peaked functions, F17–F22 for mixed functions, and F23–F30 for combined functions; the definitions and optimal values of these functions can be found in the literature. The maximum number of evaluations (Maximum Function Evaluations, FEsmax) was set to D × 10,000, where D denotes the dimension of the problem. This section uses the CEC2014 30D function for testing, so FEsmax is equal to 300,000. The environment for simulation experiments was an AMD R7 4800 U (1.80 GHz) processor and 16 GB RAM, and the program was run on the MATLAB 2016b platform. Each algorithm was solved 51 times for each test function, and the mean and standard deviation were recorded.
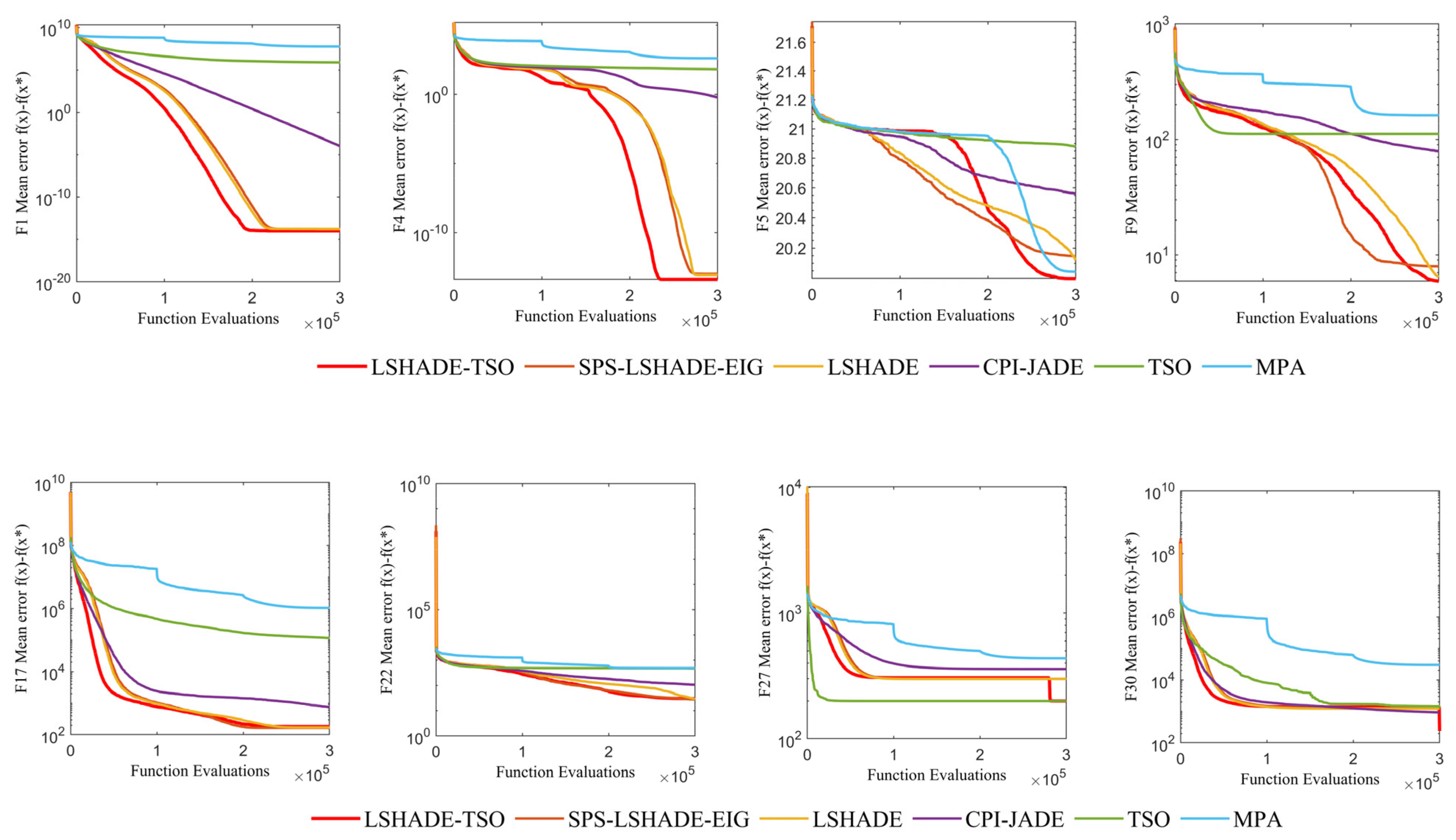
In this paper, some of the four types of test functions are selected to demonstrate the convergence performance of the LSHADE-TSO algorithm. In
Figure 5, f(x*) is the minimum value of the test function. It is clear shown in
Figure 5 that the LSHADE-TSO algorithm converges faster and with greater accuracy in these test functions.
Table 2 shows the ranking table of the algorithms obtained from Friedman’s test. There is no doubt that LSHADE-TSO is ranked first.
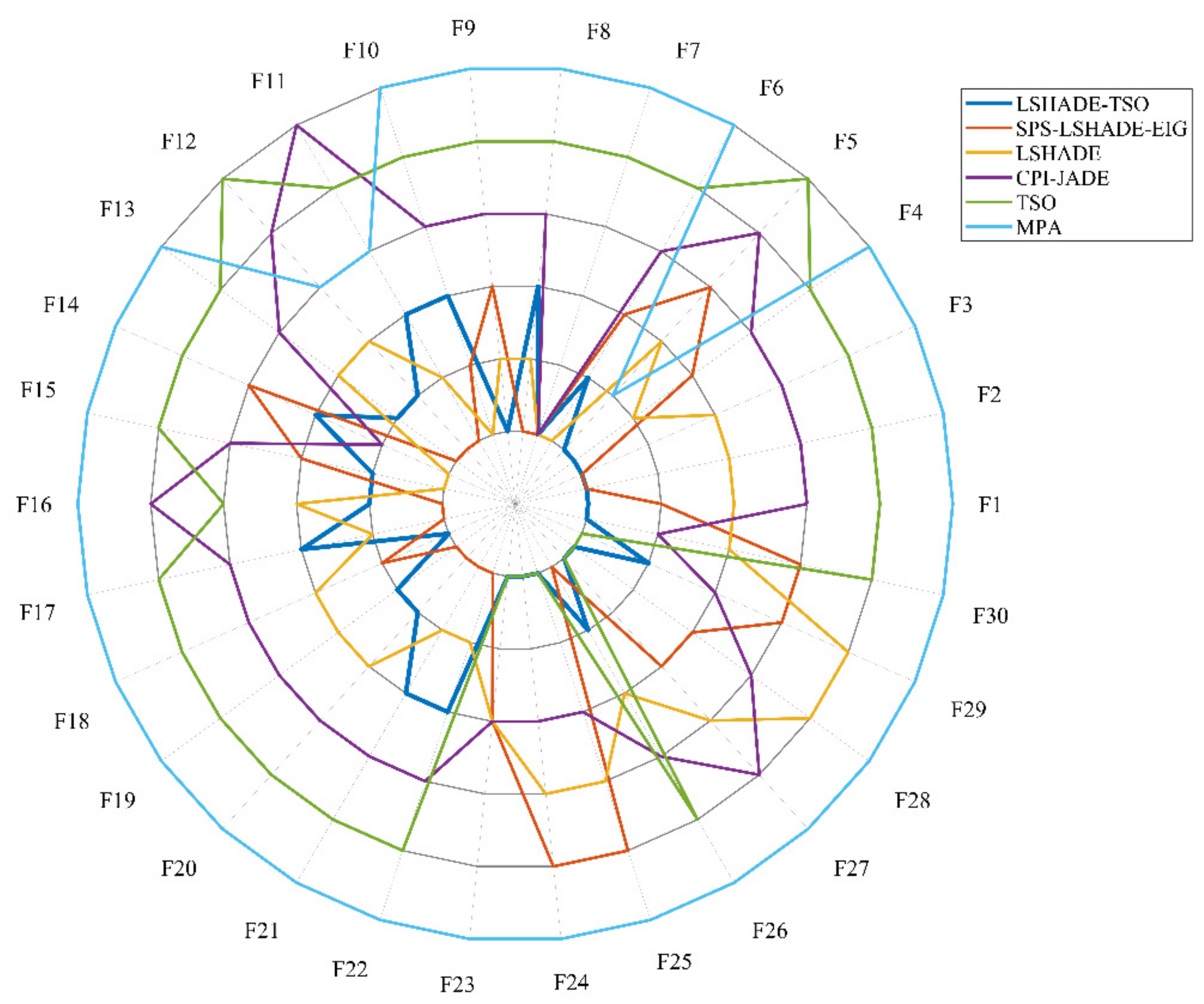
The algorithm ranking radar chart of the six algorithms is shown in
Figure 6, and it can be seen that the LSHADE-TSO algorithm is ranked in the top two in most of the tested functions, with a few ranked third.
5. Simulation Experiments and Analysis
The aerodynamic parameters are the same for both red and blue, and the control variable limit range for both sides is
,
. Both the UCAV and enemy initial control variables are
. The simulation time per step is set to 1 s (second). Both the enemy and the UCAV use the same vehicle platform, the initial distance between the two aircraft is 14.142 km, and the same type of infrared close-range air-to-air combat missile is mounted.
is set as 60°. The missile attack zone is solved using the method in the literature [
44], and the air battle is set to end when the target remains for 5 s in the missile non-escapable zone. When the altitude is lower than 1000 m, it is determined that the air combat zone is exceeded, the simulation ends, and the winner is determined. This air combat simulation has been performed in many papers [
24,
36]; only the initial states and situation functions differ.
The initial state settings for the UCAV and enemy aircraft are shown in
Table 3.
5.1. LSHADE-TSO-MPC Maneuver Decision against Trial Maneuver Decision
The trial maneuver decision method is a more advanced maneuver decision method that has been proposed in recent years, which is characterized by rapid decision making, and its main method is to divide the control variable gradient so as to form a variety of optional control variable schemes, from which a maneuver trial is conducted to select a control volume scheme with the largest situation value. In this paper, the three control variables change range is divided into 11 gradients, thus forming 11 × 11 × 11 = 1331 medium maneuver schemes, whose gradient change values are set as follows:
The simulation results are shown below.
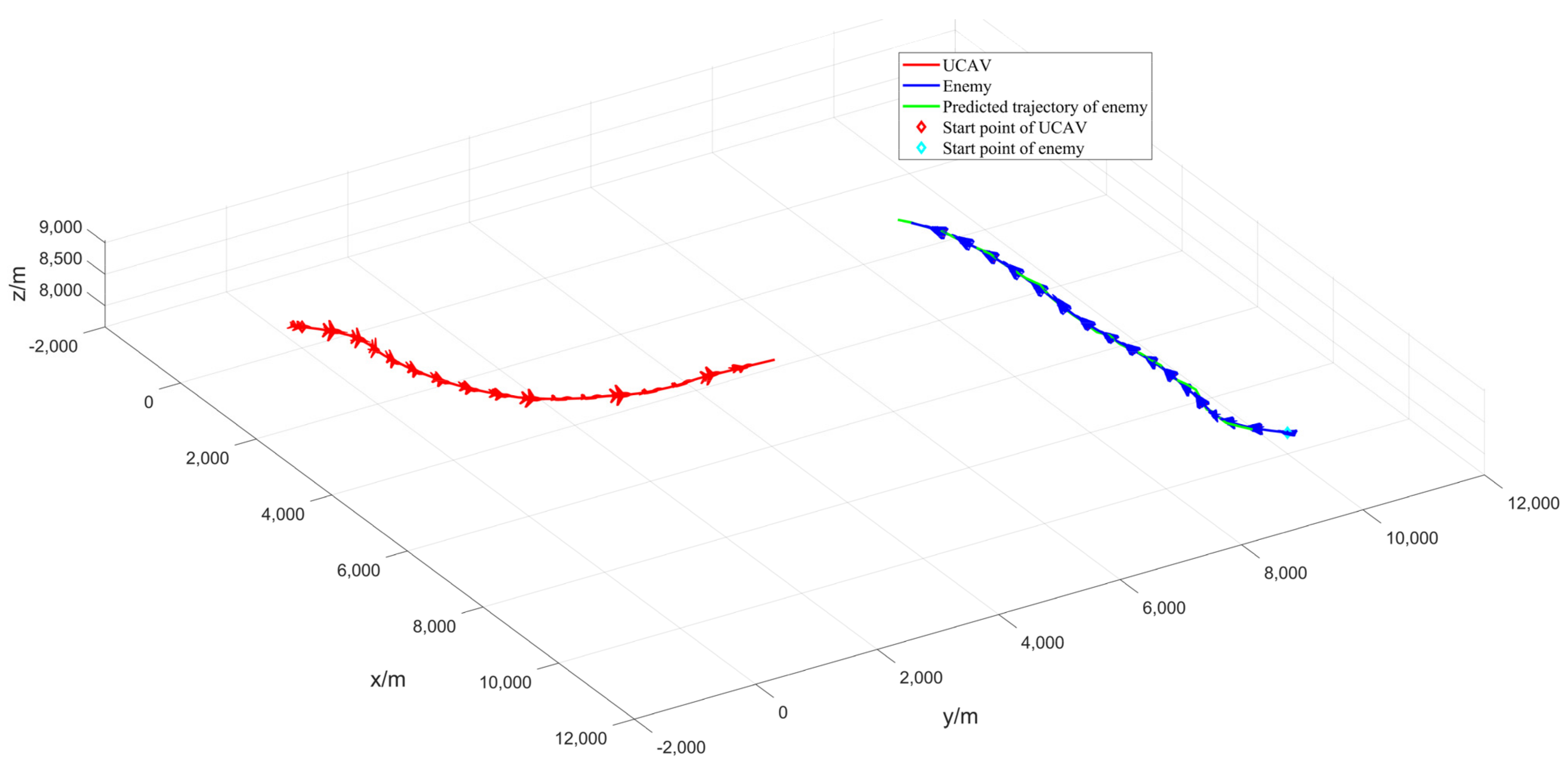
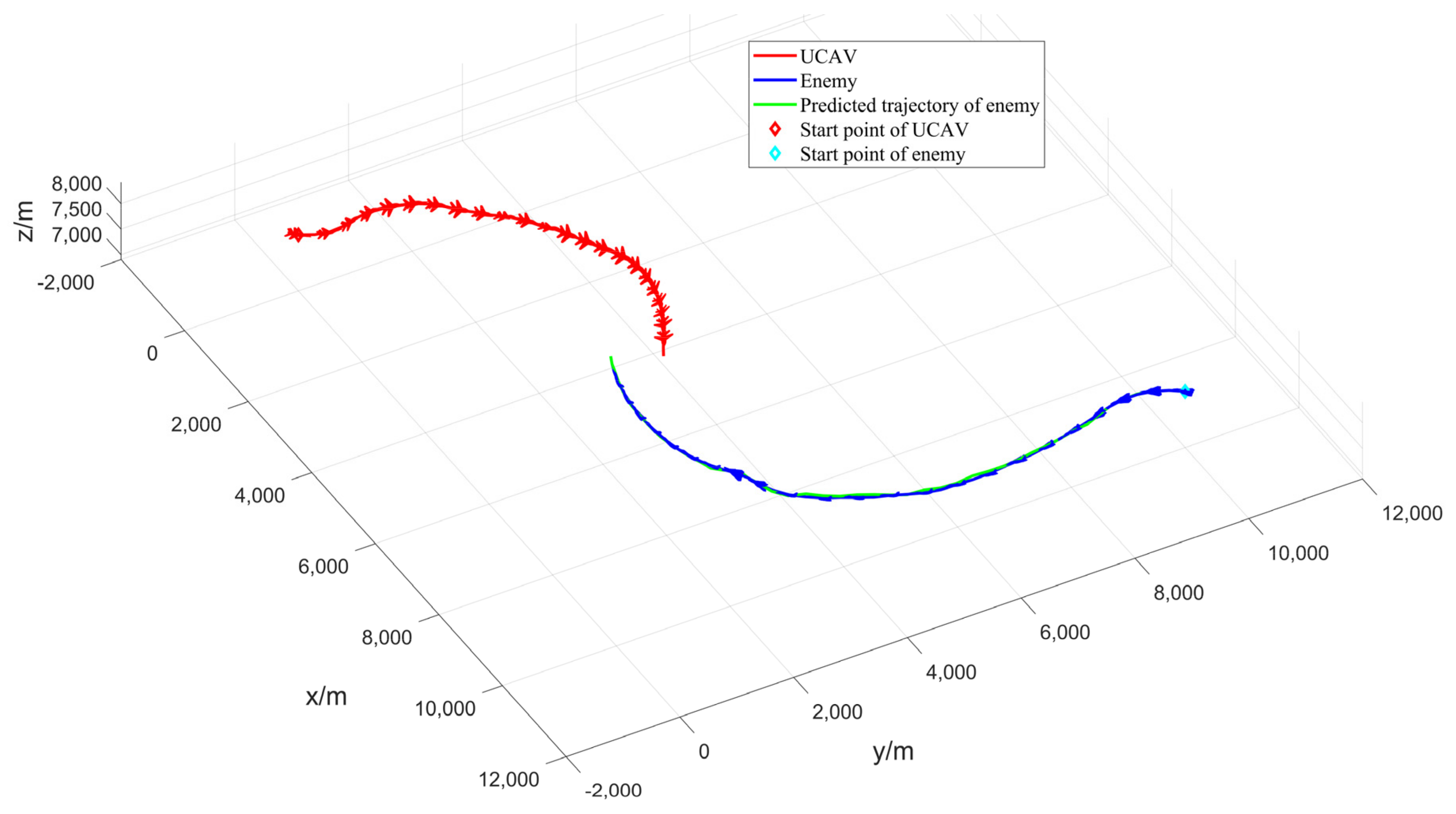
Figure 7 depicts the 3D trajectory of the UCAV and the enemy, as well as the predicted trajectory of the enemy. After 34 s, the enemy aircraft is in our aircraft’s missile inescapable zone for 5 s continuously within 29–34 s, and our aircraft finally wins the air battle.
Figure 7 shows that both the enemy aircraft and our aircraft performed similar maneuvers, first a right turn followed by a left turn, because our aircraft and the enemy aircraft used the same attitude function. However, our aircraft uses the enemy aircraft’s online prediction information via the MPC framework to ultimately win the air combat.
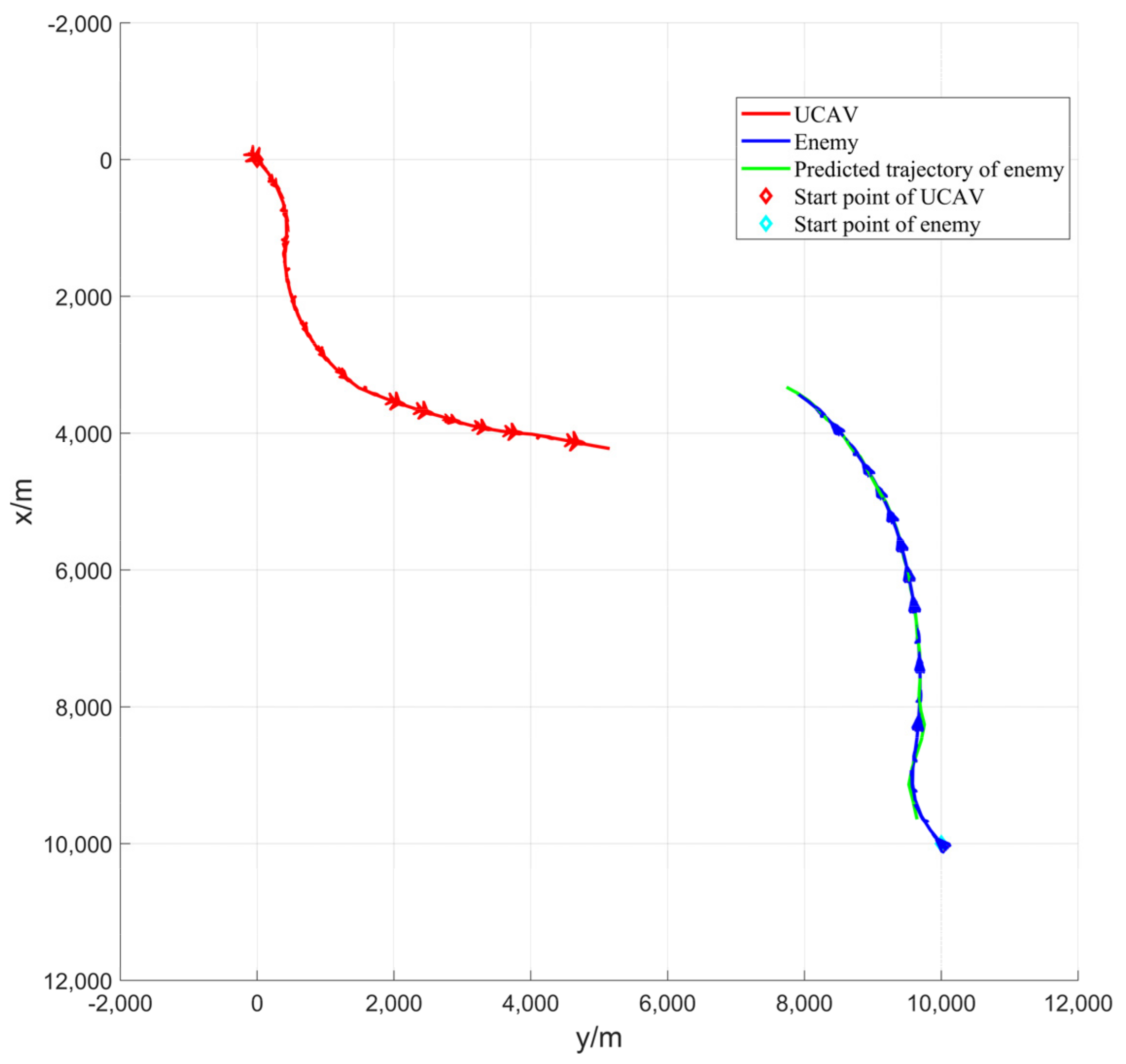
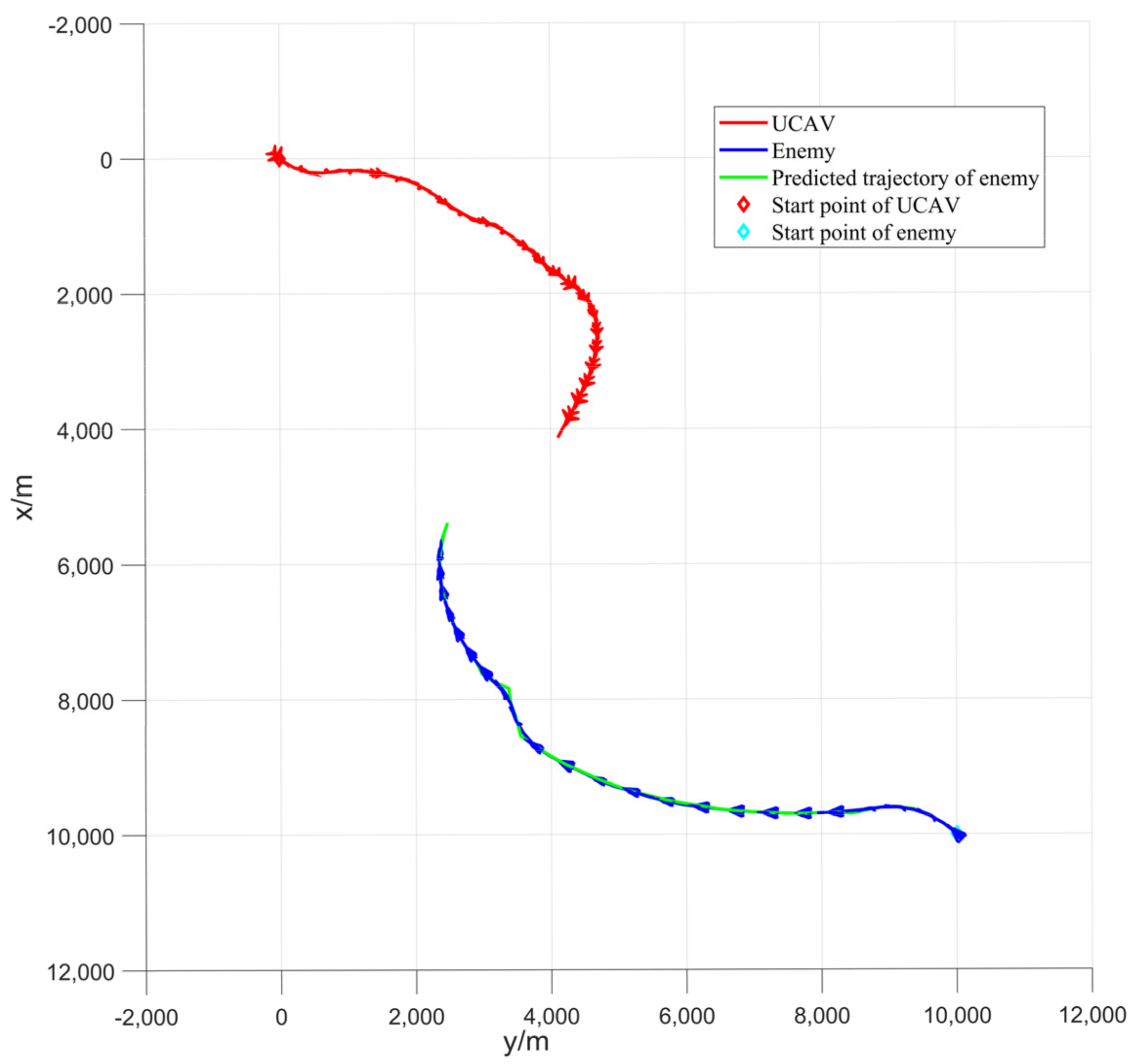
Figure 8 shows that the accuracy of predicting the trajectory of enemy aircraft decreases when they perform large maneuvers, such as some fluctuations in enemy aircraft predicted trajectory during right turns. In
Figure 8, the predicted trajectory for the enemy aircraft is 3 s, and the length of one MPC control framework decision is also 3 s.
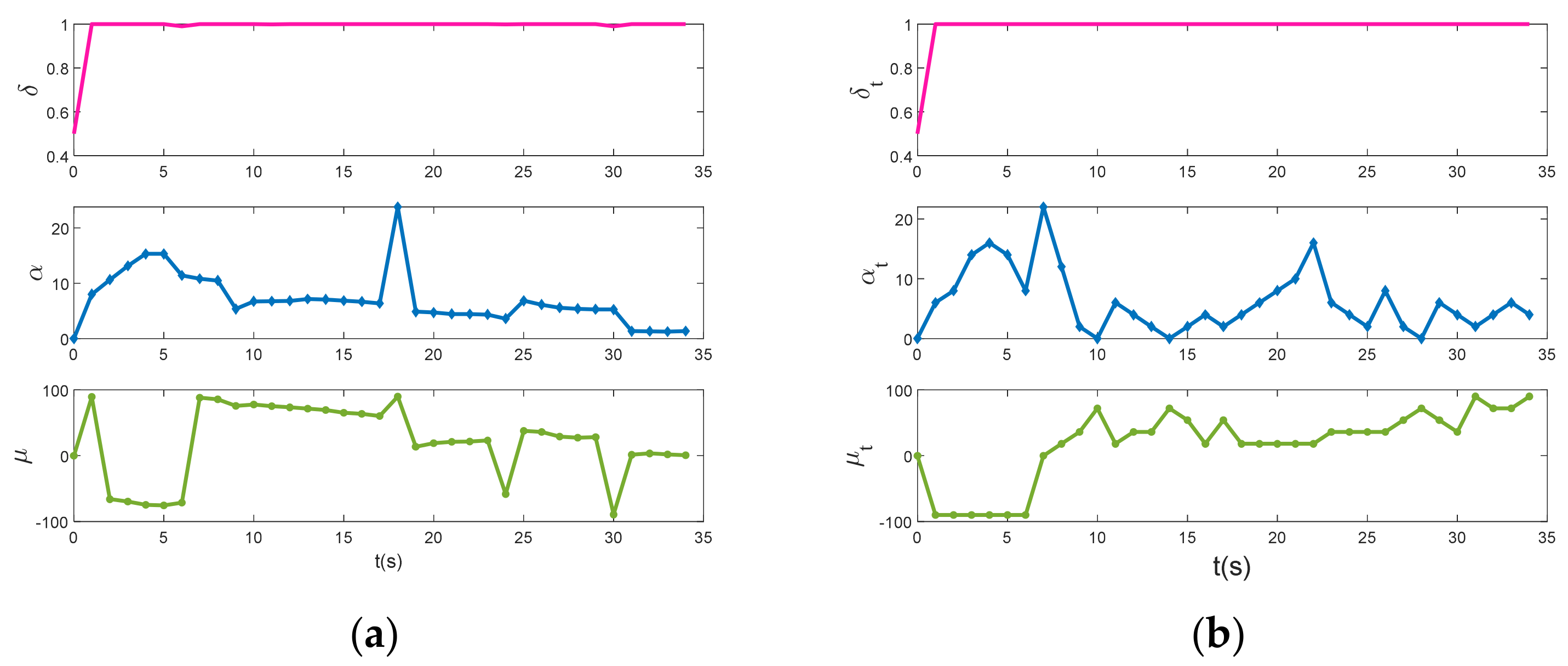
The graph above depicts the UCAV and enemy maneuver decision factor curves.
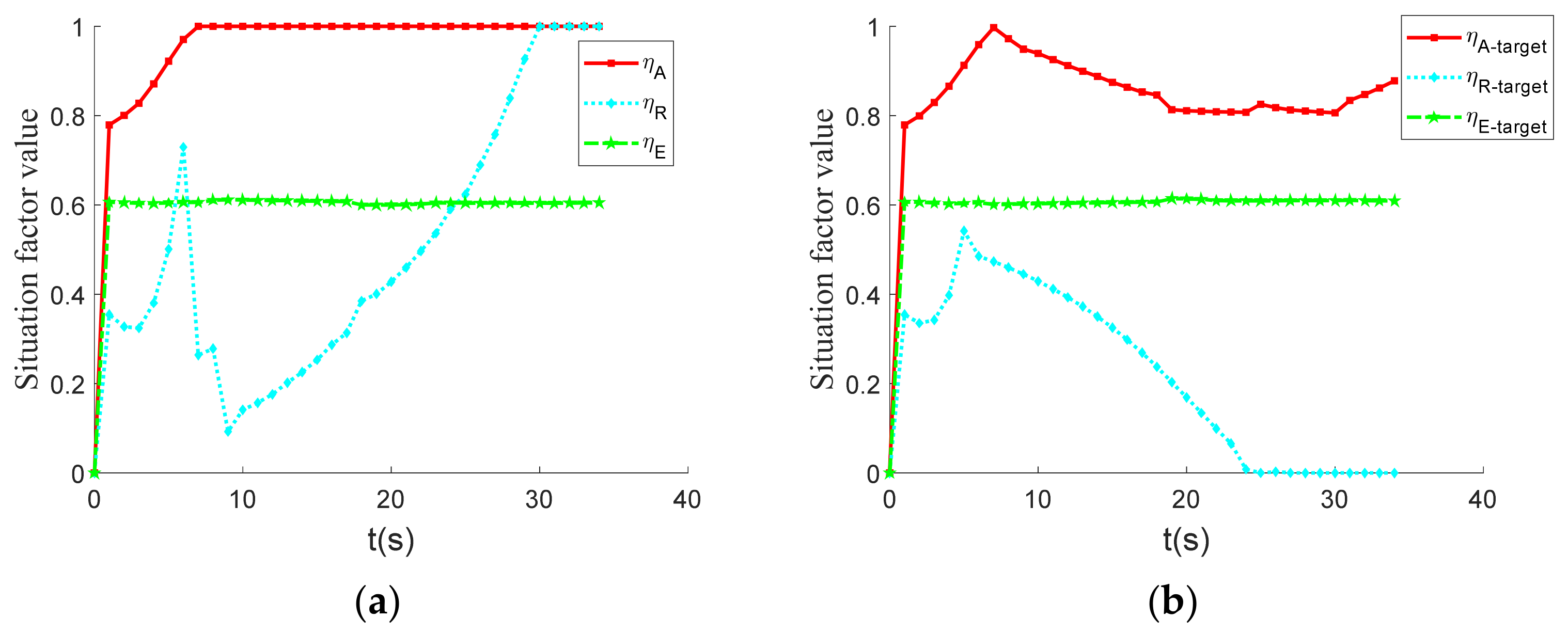
Figure 9 shows that the angular situation factor value of our aircraft remains at 1 after rising in the initial stage, while the angular situation factor value of the enemy aircraft rises in the initial stage and gradually decreases. Because the enemy and our aircraft start at the same speed and altitude and perform similar maneuvers, their energy situation factor curves are similar. Our aircraft’s posture factor curve value continued to rise after a brief drop and eventually remained at 1, whereas the enemy aircraft’s distance posture factor value dropped to 0 in the final stage. The main reason for this is that the enemy is in the UCAV’s missile inescapable zone, and because the distance posture factor is coupled with the angular posture factor, the distance posture factor curves of the two aircraft differ significantly.
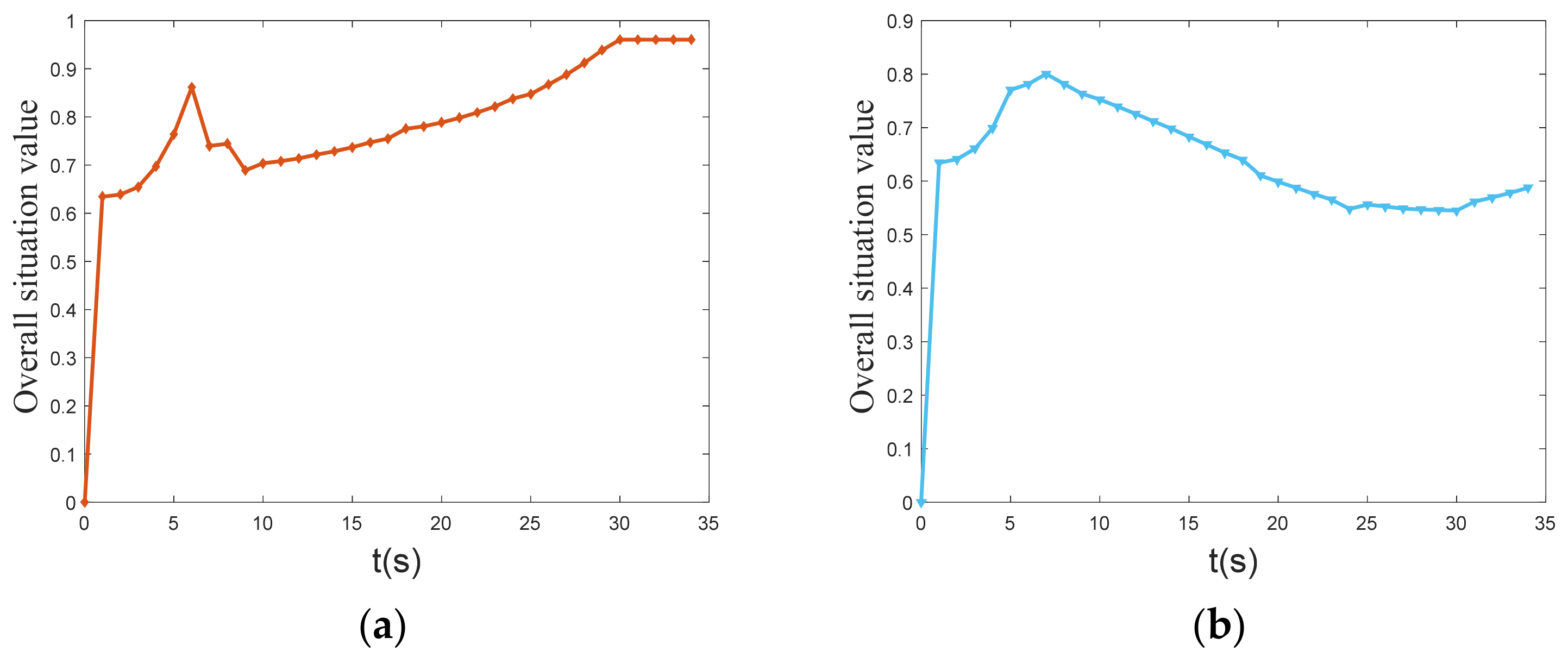
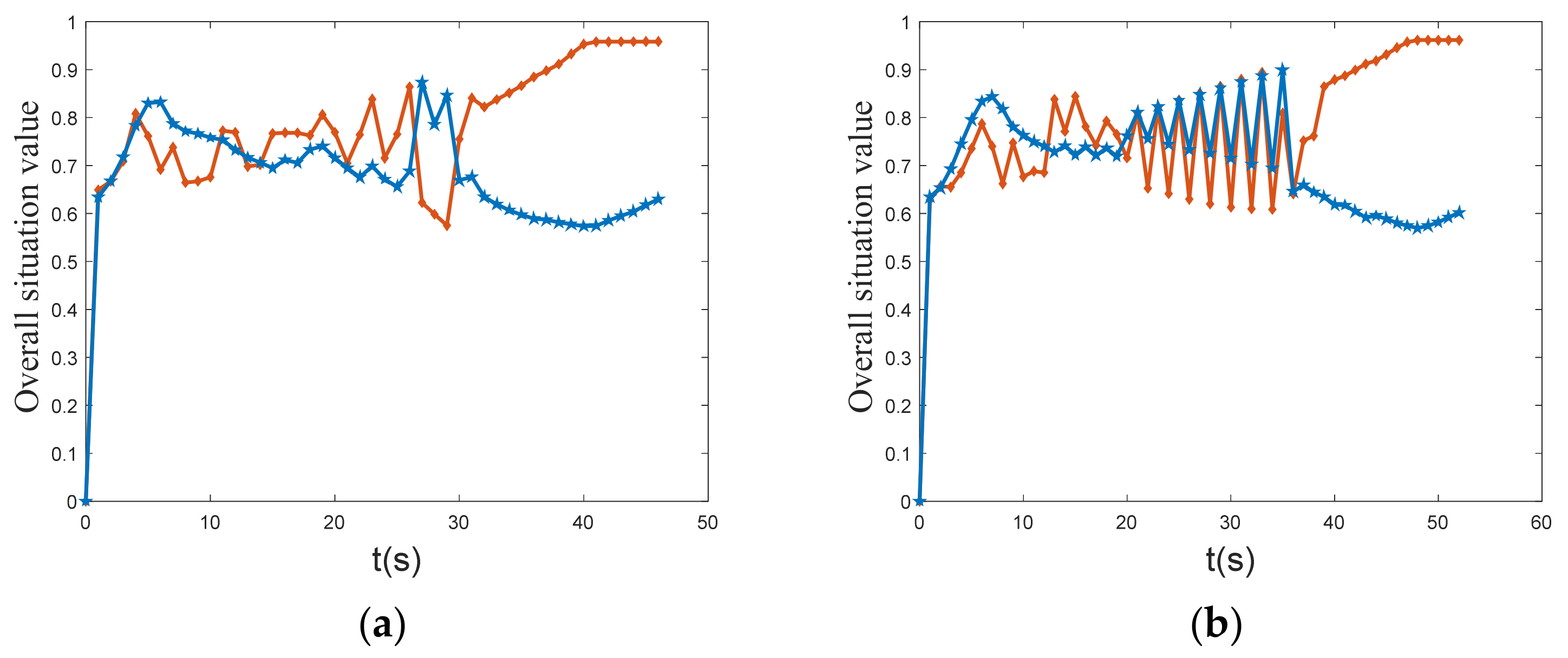
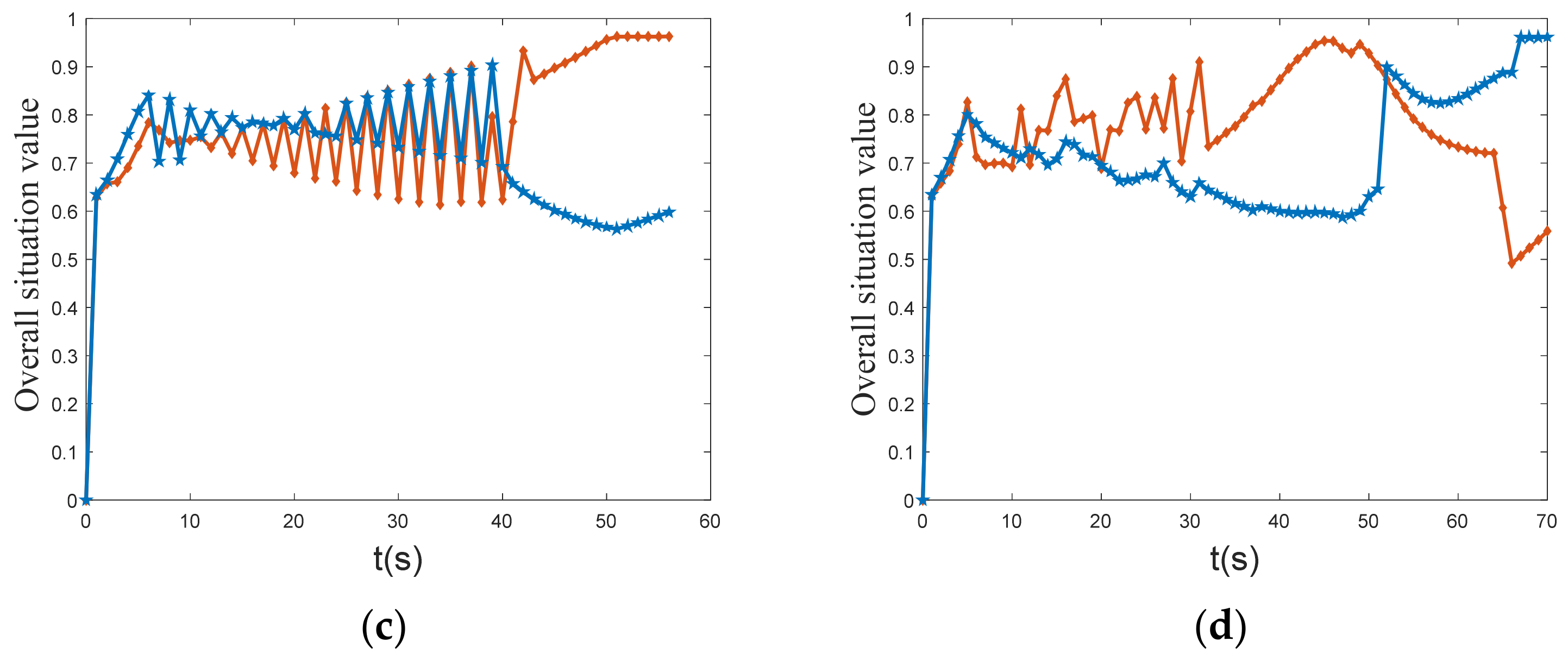
Figure 10 shows the overall situation value curves of UCAV and enemy. At the initial moment, the situation values of UCAV and enemy are the same, but after 34 s of maneuvering, the situation value of the UCAV reaches approximately 0.96, while the enemy’s situation value drops to approximately 0.56, and finally the UCAV wins the air battle. The overall situation value of the UCAV is greater than that of the enemy when the UCAV and the enemy use the same situation function, which shows that the maneuver decision method of the UCAV has a significant advantage over the enemy.
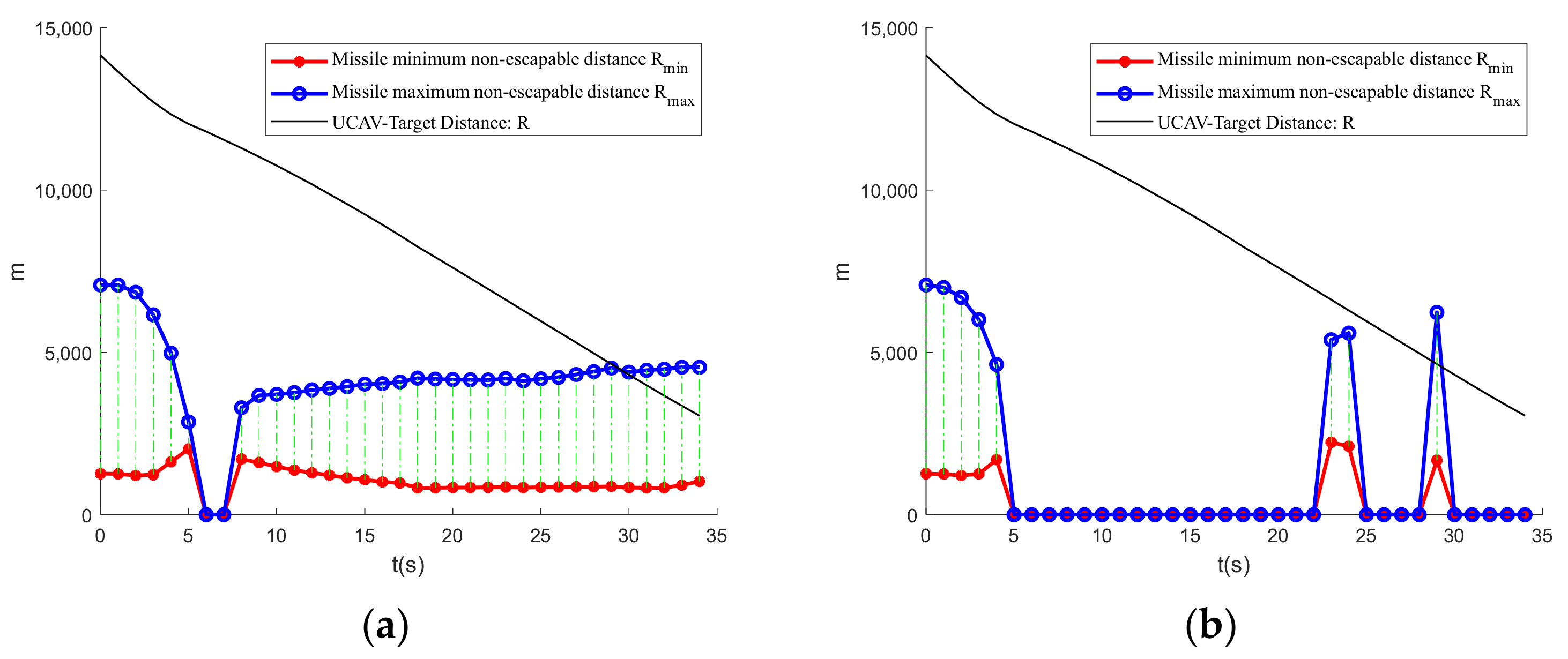
Figure 11 depicts the UCAV-enemy relative distance and missile inescapable distance curves. From 29–34 s, the enemy is in the UCAV’s missile inescapable zone for 5 s in a row, indicating that the UCAV has won the air battle. However, the enemy’s missile launchable distance is 0 because the enemy’s advance angle is greater than the missile’s maximum off-axis launch angle, preventing the missile from being launched and resulting in a 0 launchable distance.
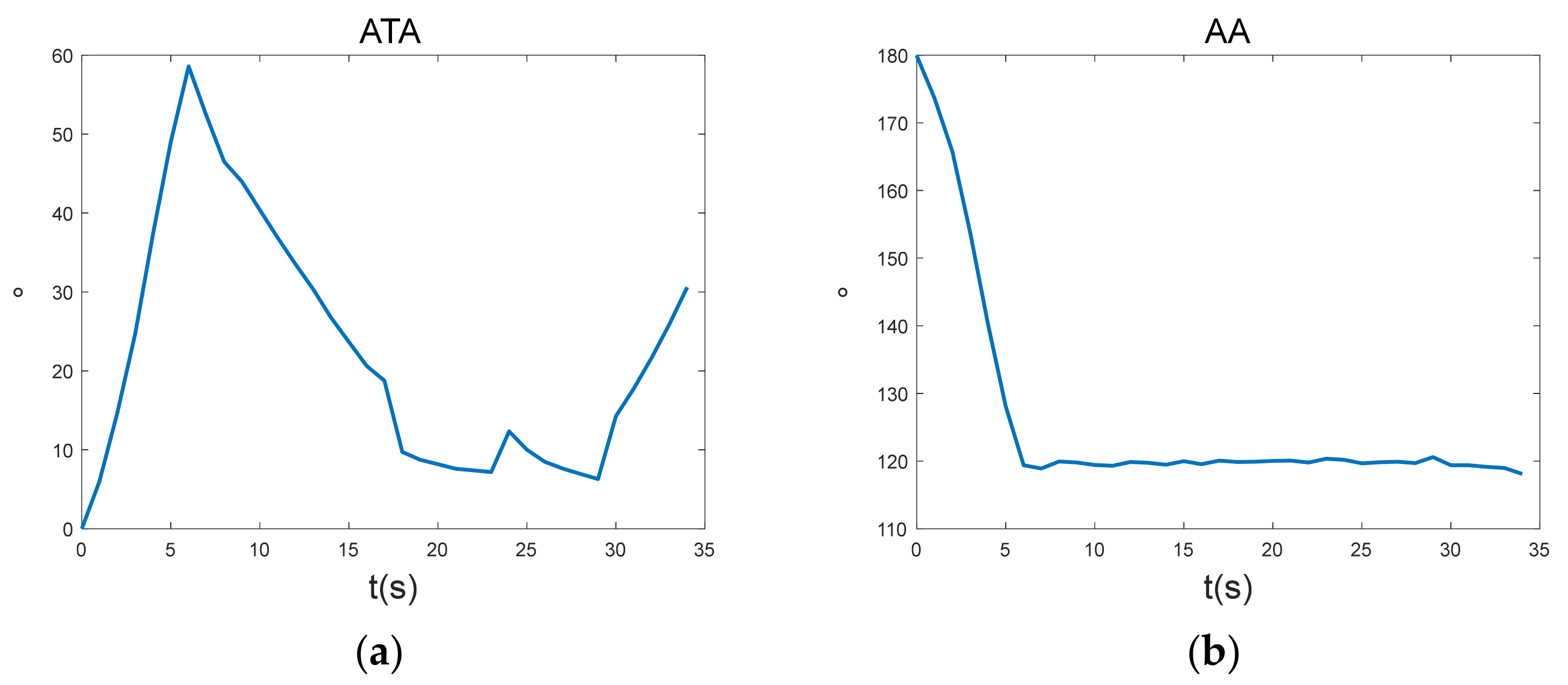
Figure 12 shows that the advance angle of the UCAV is less than 60 degrees most of the time, indicating that the enemy is within the maximum off-axis firing angle of our missile most of the time, whereas the enemy’s advance angle is continuously less than 120 degrees from the eighths, indicating that the UCAV is continuously outside the maximum off-axis firing angle of the enemy’s missile.
Figure 13 shows the control variables curves of the UCAV and the enemy. The three lines from top to bottom represent the throttle, angle of approach and roll angle respectively. It can be seen that the control volume of the enemy aircraft is strictly on the gradient of the control volume range division, but our aircraft does not have this constraint in the control volume range. The control volume is a continuous variable, and the optimal control volume after discretizing it is likely to be in the gradient interval, which is why it is difficult for the trial maneuver decision method to beat the optimization algorithm decision method.
5.2. LSHADE-TSO-MPC Maneuver Decision against LSHADE-TSO Maneuver Decision
As shown in
Figure 14, the three-dimensional trajectory of the UCAV and the enemy and the predicted trajectory of the enemy lasted for 46 s. Within 41–46 s, the enemy is in the inescapable missile zone of the UCAV for 5 s. Finally, the UCAV wins the air battle. As shown in
Figure 14, both the UCAV and the enemy perform a left turn maneuver, but the UCAV performs a larger left turn and then a quick right turn. However, the UCAV makes a large left turn and then a quick right turn, whereas the enemy aircraft makes a small left turn followed by a near level flight and then a right turn, giving the UCAV the first opportunity to win the air battle.
Figure 15 shows the top view, from which we can see that the error between the predicted trajectory and the actual trajectory increases when the enemy performs a large overload maneuver with a prediction length of 3 s, which is reflected in
Figure 15 as the distance between the green curve and the blue curve increases, showing a “burr” shape. In
Figure 15, the predicted trajectory of the enemy aircraft is 3 s, and the length of one decision of the MPC framework is also 3 s.
Figure 16 depicts the UCAV and enemy maneuver decision factor curves.
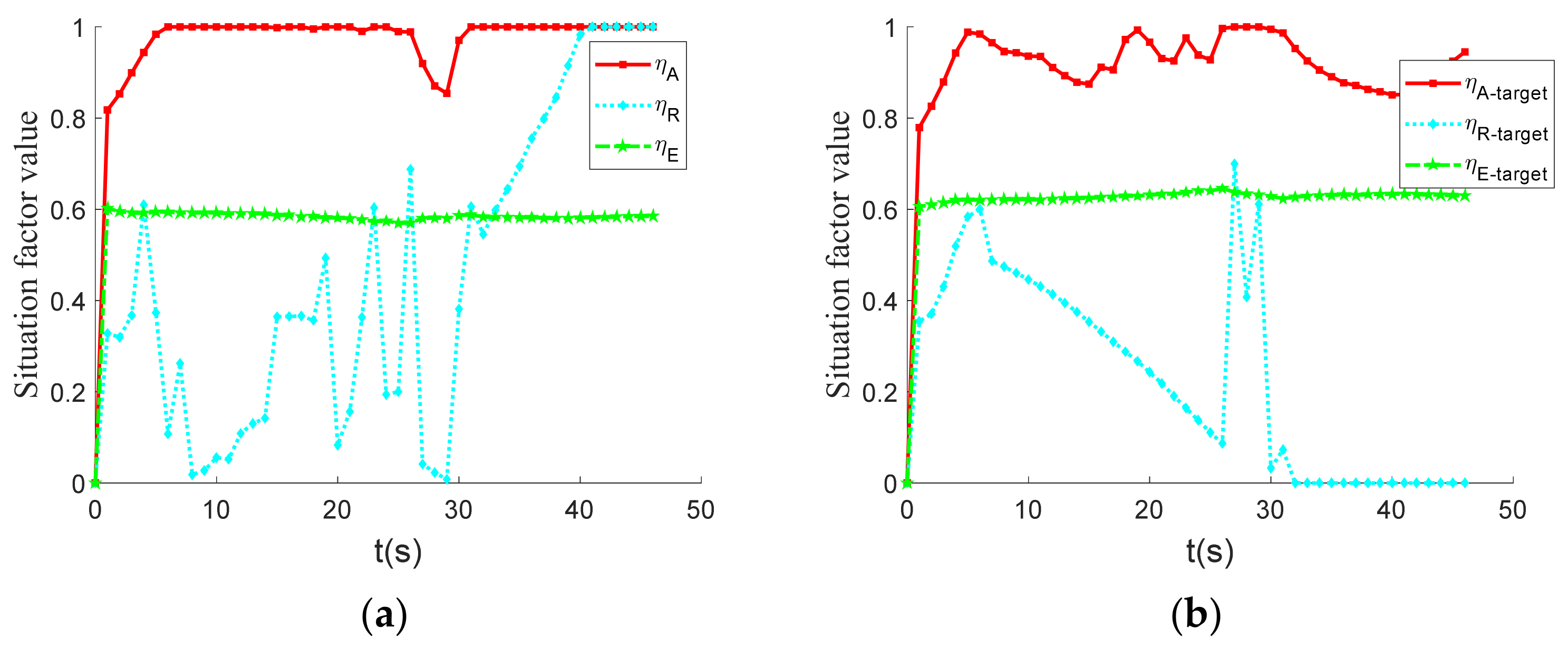
Figure 16 shows that the UCAV’s overall angular situation factor curve fluctuates from increasing to decreasing, then increasing again, and finally remaining at 1. The angular situation factor curve of the enemy aircraft undergoes a process from increasing and staying at 1 and then decreasing and then increasing again, but finally does not reach 1. The energy situation factor curves of the enemy and UCAV are similar and fluctuate in a very small range around 0.6. The distance situation factor of the UCAV factor fluctuates throughout the 0–30 s, but it increases rapidly after 32 s and eventually reaches 1. The distance situation factor value of the enemy aircraft decreases rapidly at 29 s and eventually drops to 0.
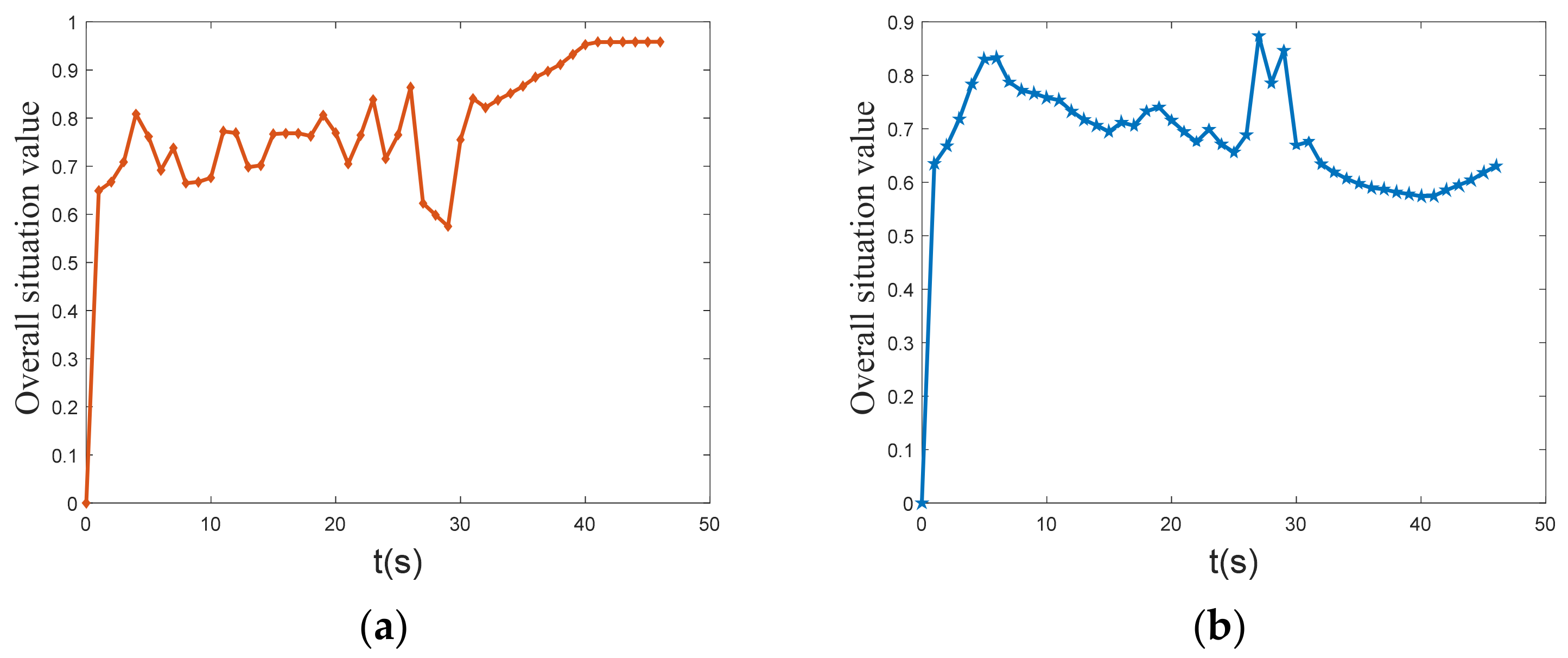
Figure 17 depicts the curve of UCAV and enemy overall situation value. The graph shows that the initial value of the overall situation of UCAV and enemy is similar. In the middle stage, the overall situation value of the enemy is clearly higher than that of the UCAV, but after 30 s, the overall situation value of UCAV increases rapidly, while the overall situation value of the enemy aircraft decreases. Finally, the overall situation value of the UCAV is stable at approximately 0.96, and the overall situation value of the enemy is stable at approximately 0.62. The UCAV’s situation value is significantly greater than the enemy’s, and it eventually wins the air combat.
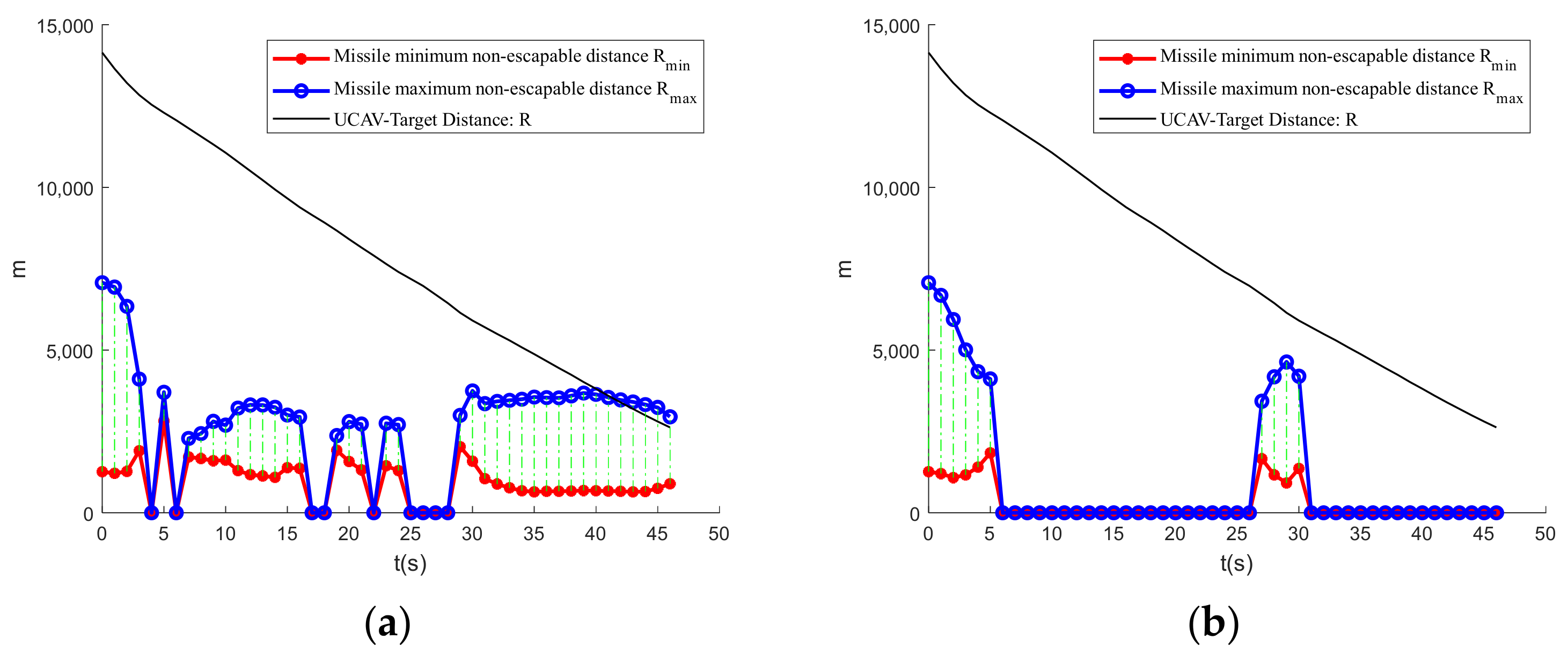
Figure 18 depicts the UCAV’s and the enemy’s missile inescapable distance, as well as the two aircraft’s distance curve. In the 27–30 s time period, the enemy’s advance angle is less than the maximum missile off-axis launch angle, and the UCAV is within the enemy’s maximum missile off-axis launch angle. However, because the two aircraft are so far apart at this point, the UCAV does not enter the enemy’s missile-proof zone. The UCAV then maneuvers to successfully lasso the enemy into the missile inescapable zone and finally wins the air battle. From the missile launchable distance curve, the UCAV sacrificed some situational advantage when both sides were far away to gain a situational advantage when they were closer, which reflects the foresight of the LSHADE-TSO-MPC machine-dynamic decision method, which was able to consider the situational advantage at a longer distance, which has advantages over the optimization algorithm decision method.
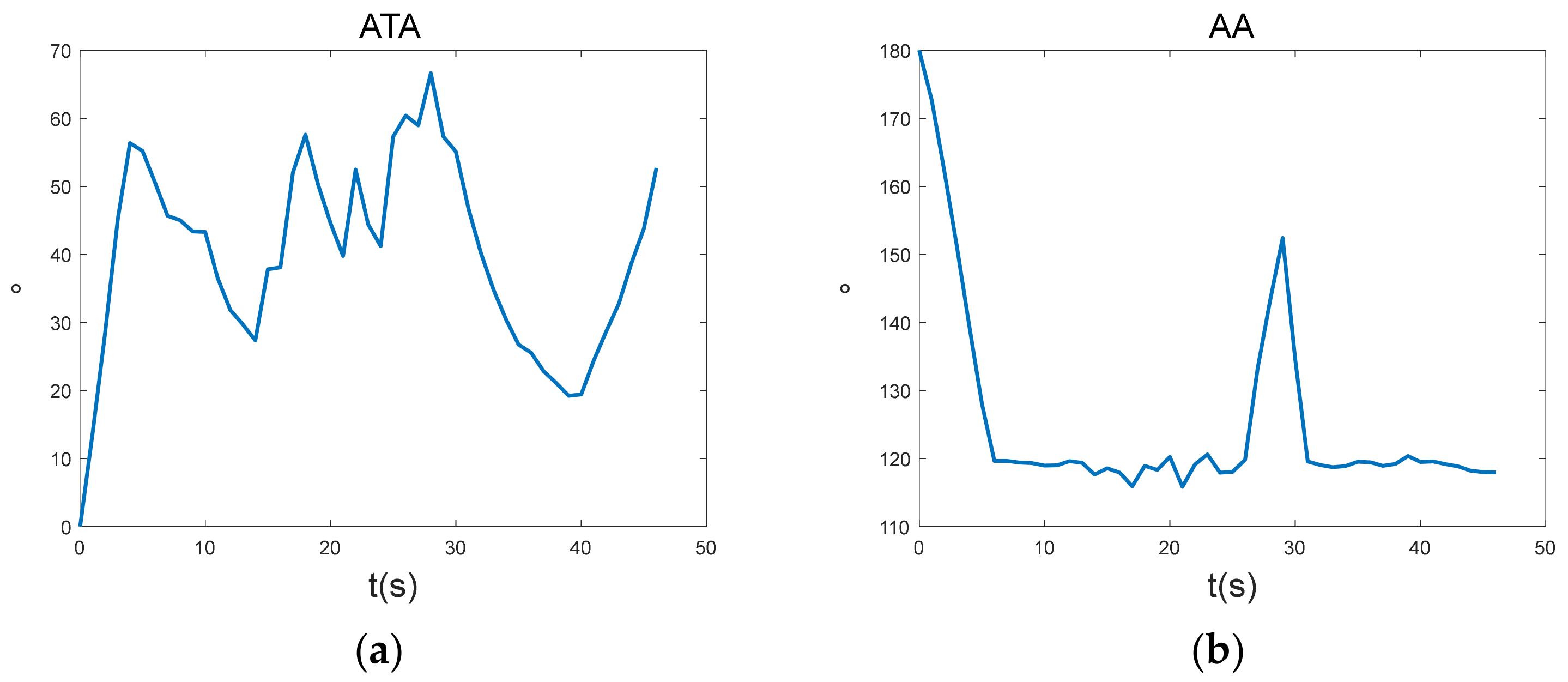
Figure 19 shows the change curves of the advance angle between our aircraft and the enemy aircraft. Because the maximum off-axis launch angle of the missile is 60 degrees, the ATA of our aircraft fluctuates by approximately 60 degrees within 5–28 s, while the AA fluctuates by approximately 120 degrees. However, after 28 s, the ATA drops, while the AA fluctuates still around 120 degrees, and finally our aircraft achieves the air combat victory condition.
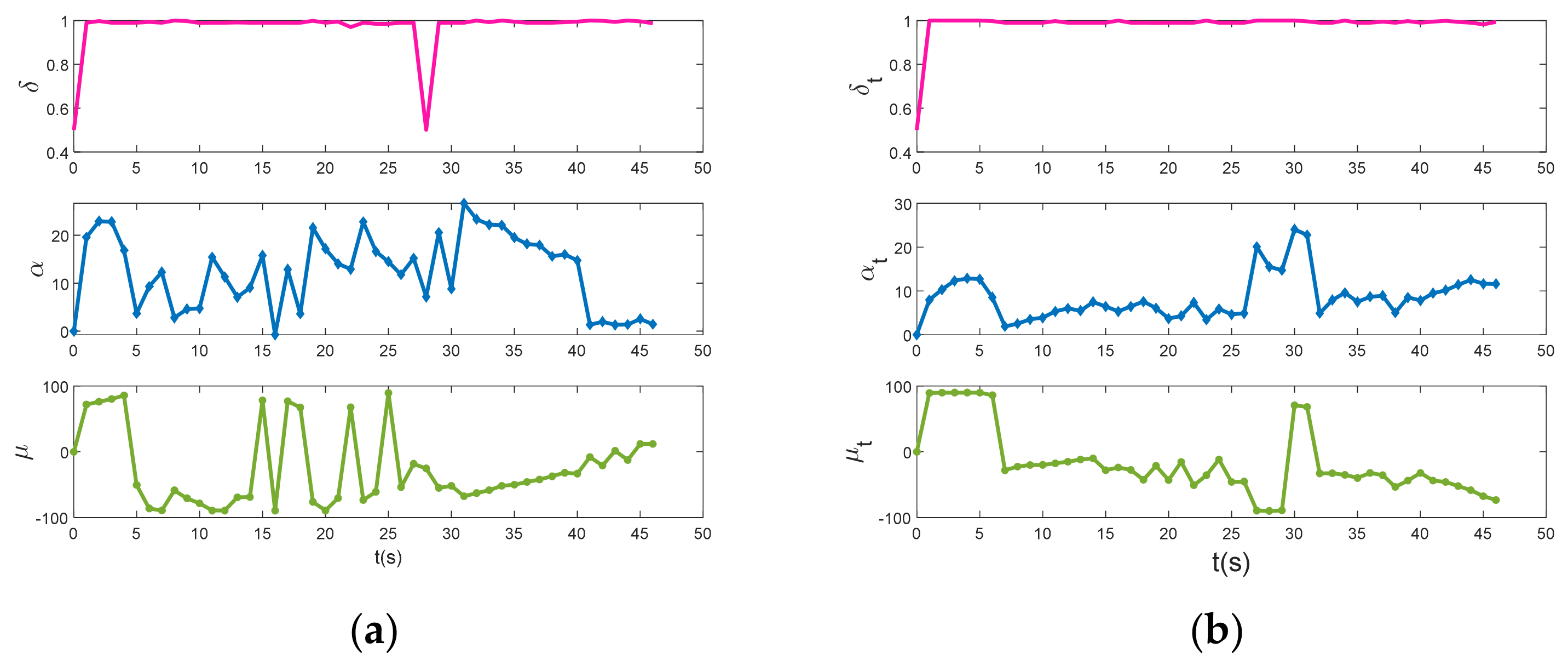
The three lines in
Figure 20 from top to bottom represent the throttle, angle of approach and roll angle respectively. The curves of UCAV and enemy control variables shown in
Figure 20 show that the change of angle of attack of the UCAV is more drastic than the enemy aircraft, and the throttle is not always in the maximum position, indicating that the UCAV can consider the relationship between speed and situation comprehensively, rather than just pursuing at maximum throttle and maximum speed.
5.3. Comparative Analysis of Different Algorithms Combined with MPC Framework
In the previous subsection we compared the LSHADE-TSO-MPC maneuver decision with the trial maneuver decision and LSHADE-TSO maneuver decision, and both achieved air combat victories, but we did not compare LSHADE-TSO-MPC with the rest of the optimization algorithms combined with the MPC framework. Therefore, this section confronts the maneuver decision methods of different optimization algorithms combined with the MPC framework with the LSHADE-TSO maneuver decision method. The simulation results are used to verify the performance of LSHADE-TSO-MPC compared to the rest of the optimization algorithms combined with the MPC framework.
The following methods are compared in this paper: LSHADE-MPC, TSO-MPC, and MPA-MPC for performance comparison, with a maximum of 50 iterations and a population size of 100, and the rest of each for comparison. The algorithm parameters are set as shown in
Table 4. The adversary employs the LSHADE-TSO maneuver decision, and the situation curves of both sides are obtained as shown in
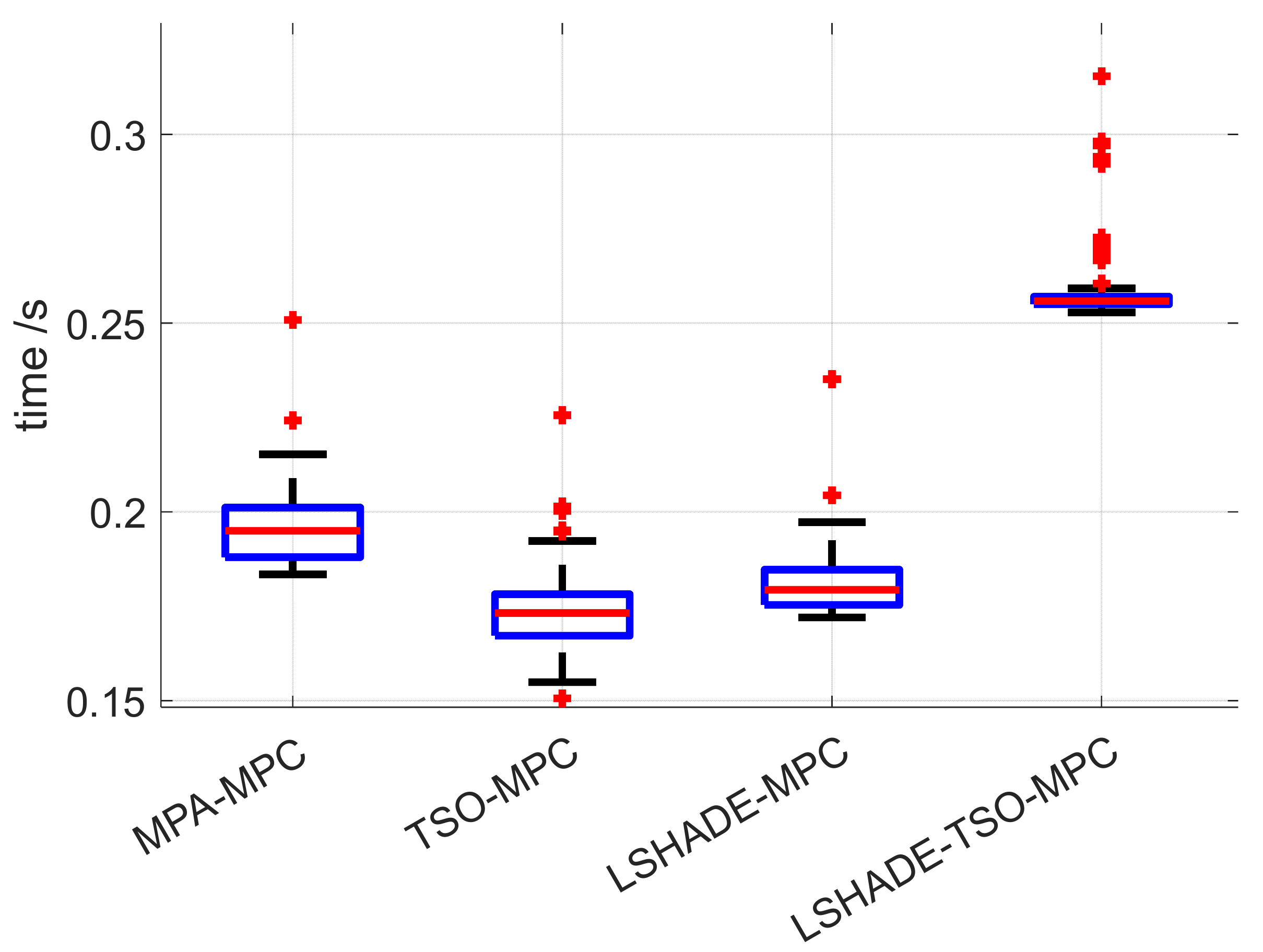
Figure 21. The time used for each maneuver decision method step are shown in
Figure 22.
In PSO, C1 is the individual learning factor of the particle, C2 is the social learning factor of the particle, and is the inertia factor. In GA, Pc is the crossover probability and Pm is the variation probability.
The overall situation value curves of both sides are obtained by combining LSHADE-MPC, TSO-MPC, and MPA-MPC with the LSHADE-TSO maneuvering decision, as shown in
Figure 21. The results of the confrontation are presented in
Table 5. LSHADE-MPC achieved air combat victory in 52 s. GA-MPC achieved air combat victory in 56 s. At 70 s, the MPA-MPC was defeated by the enemy aircraft. LSHADE-TSO-MPC achieved air combat victory in 46 s. It is clear that the proposed LSHADE-TSO-MPC has some advantages over other optimization algorithms combined with the MPC framework, such as improved search and convergence capabilities.
Figure 22 shows the comparison of the decision time used for the LSHADE-MPC, MPA-MPC, TSO-MPC, and LSHADE-TSO-MPC maneuver decision methods, where the average decision time of LSHADE-MPC is 0.1793 s, the average decision time of MPA-MPC is 0.1949 s, the average decision time of TSO-MPC is 0.1731 s, and the average decision time of LSHADE-TSO-MPC is 0.2557 s. From the results, the LSHADE-TSO-MPC has a longer decision time compared to the optimization algorithms in the literature [
36], mainly due to the amount of control in deciding multiple steps in one decision, but it is acceptable compared to the 1 s decision cycle and can meet the real-time requirements.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}