
Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution


Abstract
:1. Introduction
- (1)
- The focus of this paper is devoted to improving the extraction of spatio-temporal features of skeletal sequences while considering the different importance levels of individual skeletal joints and their connections in different behaviors; here, a learnable parameter matrix is added to enhance the capability of the model with respect to spatial feature extraction of skeletal data.
- (2)
- A temporally gated unit is added to the feature extraction process in the temporal dimension in order to alleviate the influence of non-critical frames on feature extraction, filter out redundant temporal information, improve the inference speed of the model, and reduce computational burden.
- (3)
- Two attention mechanisms, namely, a channel attention mechanism based on an SE module and a frame attention mechanism, are introduced in order to learn the correlations between channels and to filter out the information of critical frames, respectively.
- (4)
- Through extensive comparison and ablation experiments, a six-layer GCN structure is proposed for spatial feature extraction, reducing the size and complexity of the model and adding residual connections to avoid model performance degradation. Extensive experiments on the NTU RGB+D 60 [19], NTU RGB+D 120 [20], and Kinetics Skeleton [21] datasets show the good performance of our proposed model.
2. Related Work
2.1. GCN-Based Skeleton Action Recognition
2.2. Temporal Gated Unit and SE Module
2.3. Attention Mechanism
3. Approach
3.1. Graph Convolutional Network
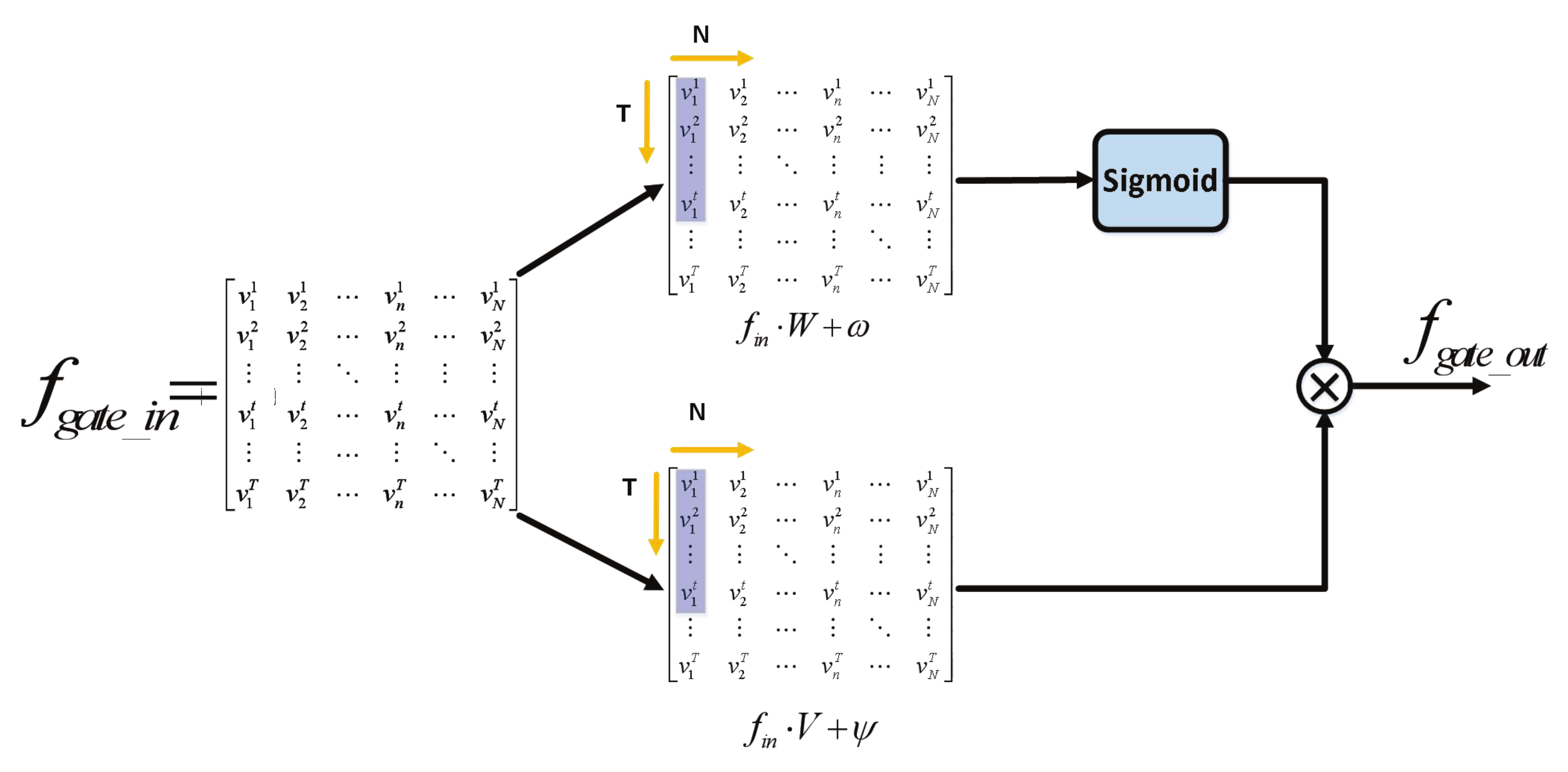
3.2. Temporal Gated Unit (TGU) and Temporal Convolutional Network (TCN)
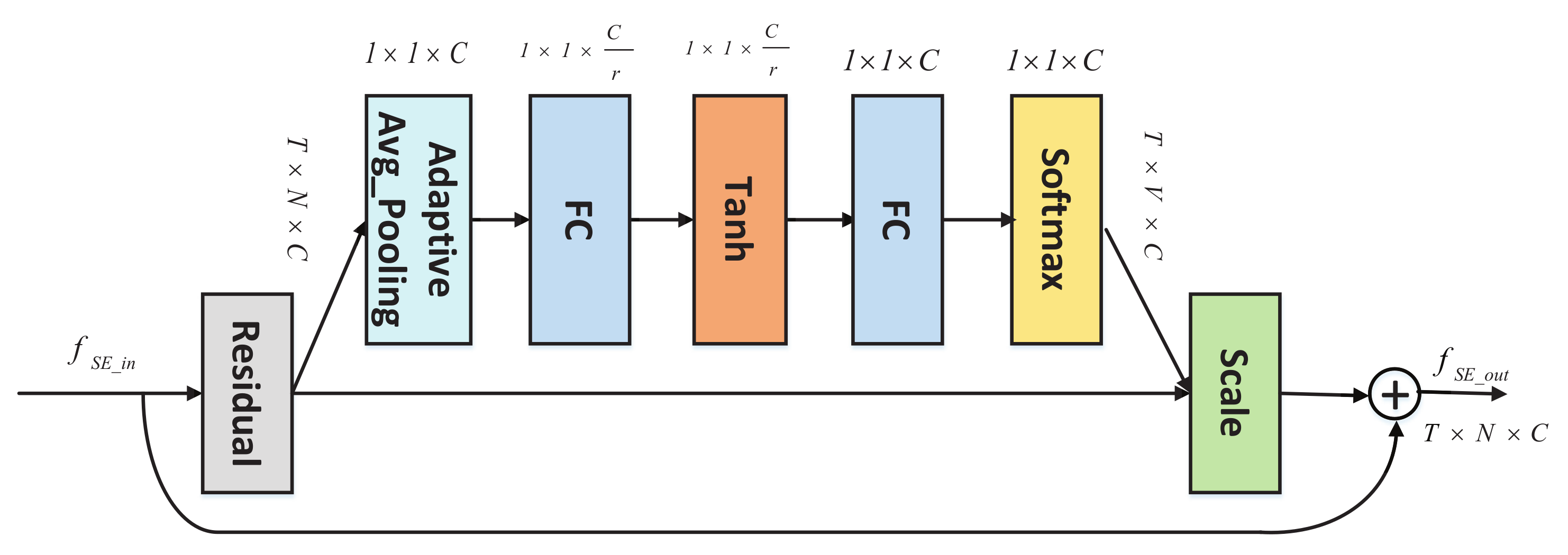
3.3. SE Block
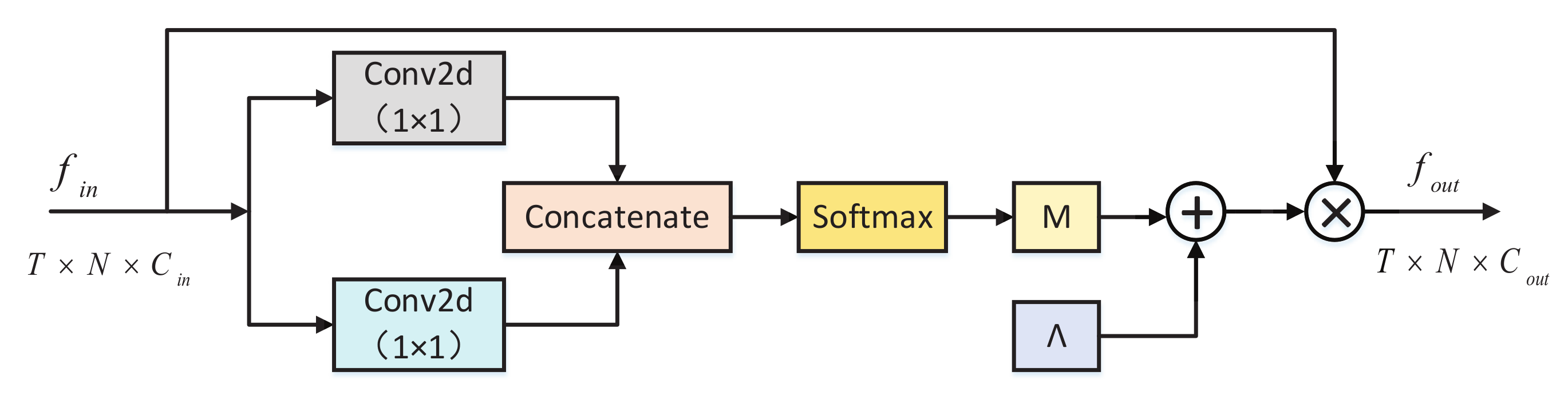
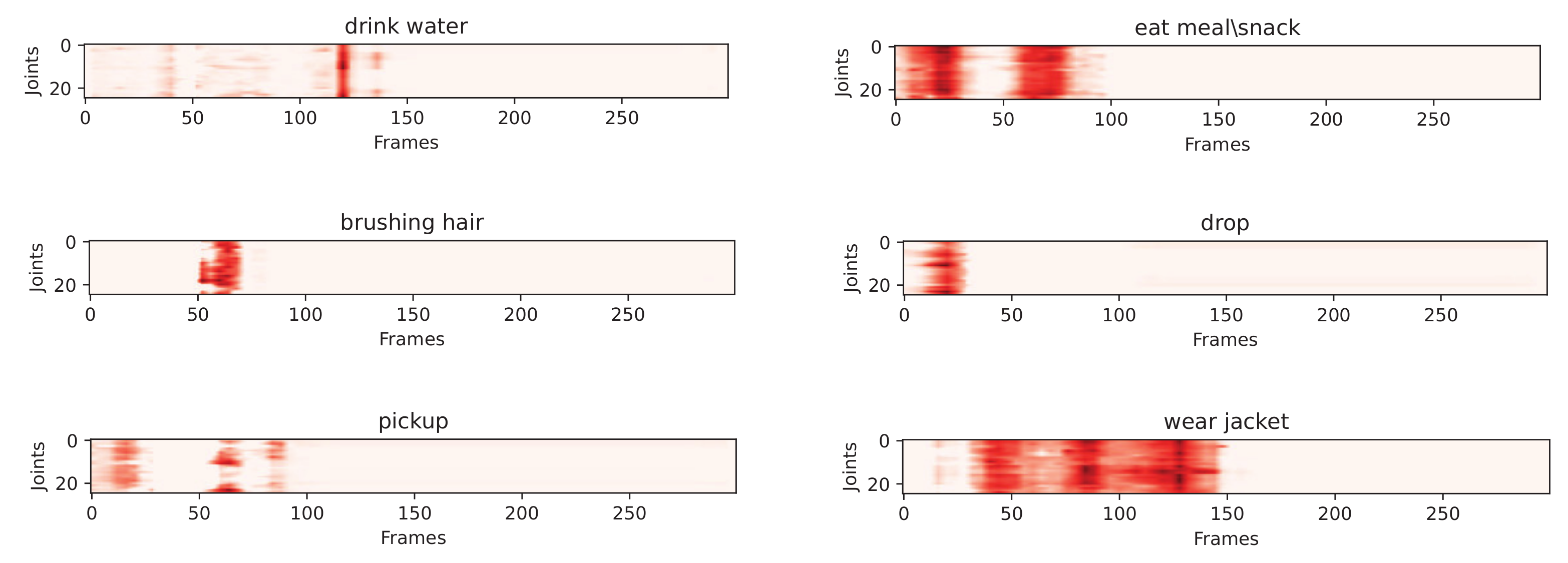
3.4. Attention Block
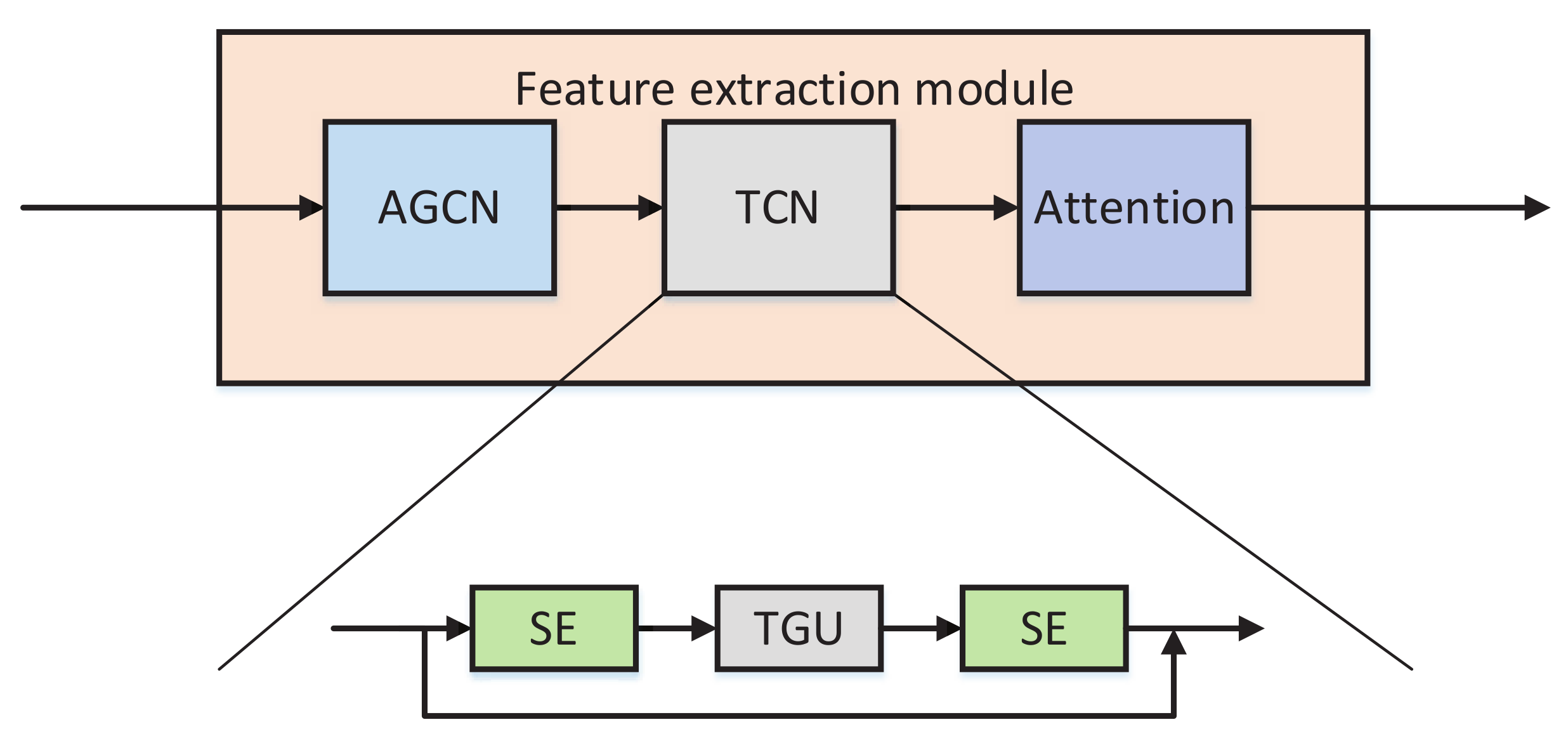
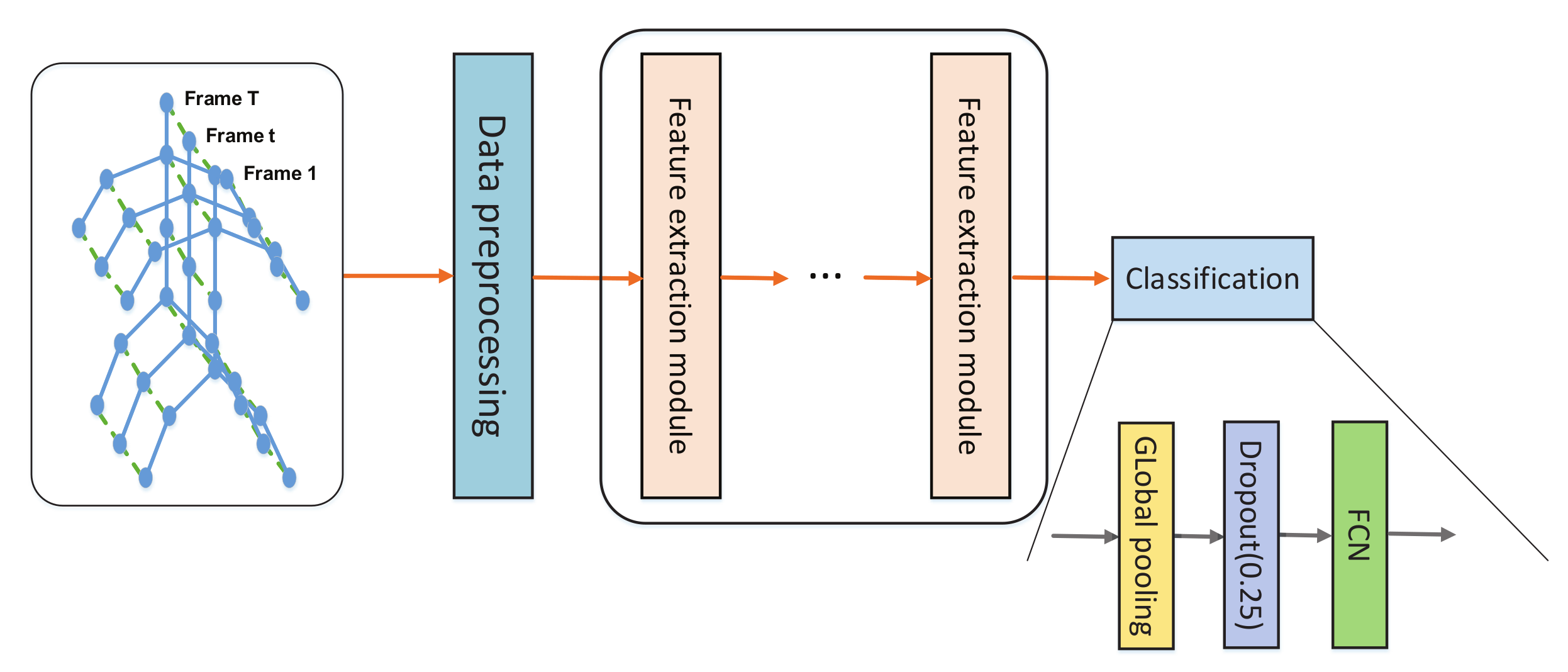
3.5. Overall Network Structure
4. Experiments
4.1. Datasets
4.2. Experiment Settings
4.3. Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GCN | Graph convolutional network |
| ST-GCN | Spatio-temporal graph convolutional network |
| TCN | Temporal convolutional neural network |
| DD-Net | Double-feature and double-motion network |
| LSTM | Long short-term memory |
| Bi-RNNs | Bidirectional RNN |
| AGCN | Adaptive graph convolutional network |
| AS-GCN | Action-structural graph convolutional network |
| PB-GCN | Part-based graph convolutional network |
| SE | Squeeze-and-excitation |
| 2s-AGCN | Two-stream adaptive graph convolutional network |
| GFT | Graph Fourier transform |
| AGC-LSTM | Attention-enhanced graph convolutional LSTM |
| GAT | Graph-aware transformer |
| TGU | Temporal gated unit |
| TCN | Temporal convolutional network |
| GLU | Gated linear units |
| FC | Fully connected |
| FCN | Fully connected network |
| SGD | Stochastic gradient descent |
References
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. Assoc. Comput. Mach. 2011, 43, 1–43. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3590–3598. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Multiview-based 3-D action recognition using deep networks. IEEE Trans. Hum.-Mach. Syst. 2018, 49, 95–104. [Google Scholar] [CrossRef]
- Fan, Y.; Yang, W.; Sakriani, S.; Satoshi, N. Make skeleton-based action recognition model smaller, faster and better. Assoc. Comput. Mach. 2019, 31, 1–6. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3D action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Cao, C.; Lan, C.; Zhang, Y.; Zeng, W.; Lu, H.; Zhang, Y. Skeleton-based action recognition with gated convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3247–3257. [Google Scholar] [CrossRef]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multiscale deep CNN. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604.
- Song, S.; Lan, C.; Xing, J.; Zeng, W.P.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4263–4270. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2136–2145. [Google Scholar]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently recurrent neural network (IndRNN): Building a longer and deeper RNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5457–5466. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Venice, Italy, 22–29 October 2017; pp. 7444–7452. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, Faster and More Explainable: A Graph Convolutional Baseline for Skeleton-Based Action Recognition; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1625–1633. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef] [PubMed]
- Thakkar, K.C.; Narayanan, P.J. Part-based Graph Convolutional Network for Action Recognition. arXiv 2018, arXiv:1809.04983. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+ D: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human pose estimation via deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. arXiv 2017, arXiv:1611.08050. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Duvenaud, D.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional networks on graphs for learning molecular fingerprints. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2224–2232. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. In Proceedings of the International Conference on Learning Representations (ICLR2014), CBLS, Banff, AB, Canada, 14–16 April 2014; pp. 1–14. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2014–2023. [Google Scholar]
- Ye, F.; Pu, S.; Zhong, Q.; Li, C.; Xie, D.; Tang, H. Dynamic gcn: Context-Enriched Topology Learning for Skeleton-Based Action Recognition; Association for Computing Machinery: New York, NY, USA, 2020; pp. 55–63. [Google Scholar]
- Chen, S.; Xu, K.; Mi, Z.; Jiang, X.; Sun, T. Dual-domain graph convolutional networks for skeleton-based action recognition. Mach. Learn. 2022, 111, 2381–2406. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1227–1236. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J. Human action recognition: Pose-based attention draws focus to hands. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 604–613. [Google Scholar]
- Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.; Cheng, J.; Lu, H. Decoupling gcn with dropgraph module for skeleton-based action recognition. Comput. Vis. 2020, 12369, 536–553. [Google Scholar]
- Zhang, J.; Xie, W.; Wang, C.; Tu, R.; Tu, Z. Graph-aware transformer for skeleton-based action recognition. Vis. Comput. 2022. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal LSTM with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–833. [Google Scholar]
- Song, Y.; Zhang, Z.; Wang, L. Richly activated graph convolutional network for action recognition with incomplete skeletons. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Huang, L.; Huang, Y.; Ouyang, W.; Wang, L. Part-level graph convolutional network for skeleton-based action recognition. AAAI Conf. Artif. Intell. 2020, 34, 11045–11052. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. Pattern Recognit. 2021, 12663, 694–701. [Google Scholar]
- Fu, Z.; Liu, F.; Zhang, J.; Wang, H.; Yang, C.; Xu, Q.; Qi, J.; Fu, X.; Zhou, A. SAGN: Semantic adaptive graph network for skeleton-based human action recognition. In Proceedings of the International Conference on Multimedia Retrieval, New York, NY, USA, 21–24 August 2021; pp. 110–117. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Inference Speed | Param. | X-Sub | X-View |
|---|---|---|---|---|
| ST-LSTM [38] | - | - | 69.20% | 77.70% |
| Clips+CNN+MTN [7] | - | - | 79.60% | 84.80% |
| 3scale ResNet152 [9] | - | - | 85.00% | 92.30% |
| ST-GCN [14] | 42.91 | 3.10 M | 81.50% | 88.30% |
| RA-GCN [39] | 18.72 | 6.21 M | 85.90% | 93.50% |
| 2s-AGCN [15] | 22.31 | 9.94 M | 88.50% | 95.10% |
| PL-GCN [40] | - | 20.70 M | 89.20% | 90.50% |
| ST-TR [41] | - | - | 89.90% | 96.10% |
| SAGN [42] | - | 1.83 M | 89.20% | 94.20% |
| DD-GCN [31] | - | - | 88.90% | 95.80% |
| GAT [35] | - | 5.86 M | 89.00% | 95.20% |
| Proposed Method | 86.23 | 1.40 M | 89.63% | 94.91% |
| Method | Inference Speed | Param. | X-Sub120 | X-Set120 |
|---|---|---|---|---|
| ST-LSTM [38] | - | - | 55.00% | 57.90% |
| ST-GCN [14] | 42.91 | 3.10 M | 70.70% | 73.20% |
| RA-GCN [39] | 18.72 | 6.21 M | 82.50% | 84.20% |
| 2s-AGCN [15] | 22.31 | 9.94 M | 82.50% | 84.20% |
| ST-TR [41] | - | - | 81.90% | 84.10% |
| SAGN [42] | - | 1.83 M | 82.10% | 83.80% |
| DD-GCN [31] | - | - | 84.90% | 86.00% |
| GAT [35] | - | 5.86 M | 84.00% | 86.10% |
| Proposed Method | 86.23 | 1.40 M | 84.59% | 85.64% |
| Method | Top-1 | Top-5 |
|---|---|---|
| ST-GCN [14] | 30.70% | 52.80% |
| 2s-AGCN [15] | 36.10% | 58.70% |
| ST-TR [40] | 36.11% | 58.70% |
| DD-GCN [30] | 36.10% | 59.50% |
| GAT [35] | 35.90% | 58.90% |
| Proposed Method | 33.96% | 57.49% |
| Method | Param. | Accuracy | F-1 | ||
|---|---|---|---|---|---|
| Without A and B | 1.24 M | 89.33% | 0.9090 | 0.9375 | 0.9230 |
| Without A and C | 1.01 M | 88.69% | 0.9129 | 0.9258 | 0.9193 |
| Without B and C | 0.88 M | 88.58% | 0.8923 | 0.9145 | 0.9143 |
| A, B and C | 1.40 M | 89.63% | 0.9579 | 0.9479 | 0.9529 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Deng, H.; Wang, K. Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution. Electronics 2022, 11, 2973. https://doi.org/10.3390/electronics11182973
Zhu Q, Deng H, Wang K. Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution. Electronics. 2022; 11(18):2973. https://doi.org/10.3390/electronics11182973
Chicago/Turabian StyleZhu, Qilin, Hongmin Deng, and Kaixuan Wang. 2022. "Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution" Electronics 11, no. 18: 2973. https://doi.org/10.3390/electronics11182973
APA StyleZhu, Q., Deng, H., & Wang, K. (2022). Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution. Electronics, 11(18), 2973. https://doi.org/10.3390/electronics11182973