
Transformer-Based Distillation Hash Learning for Image Retrieval


Abstract
:1. Introduction
2. Related Works
3. Method
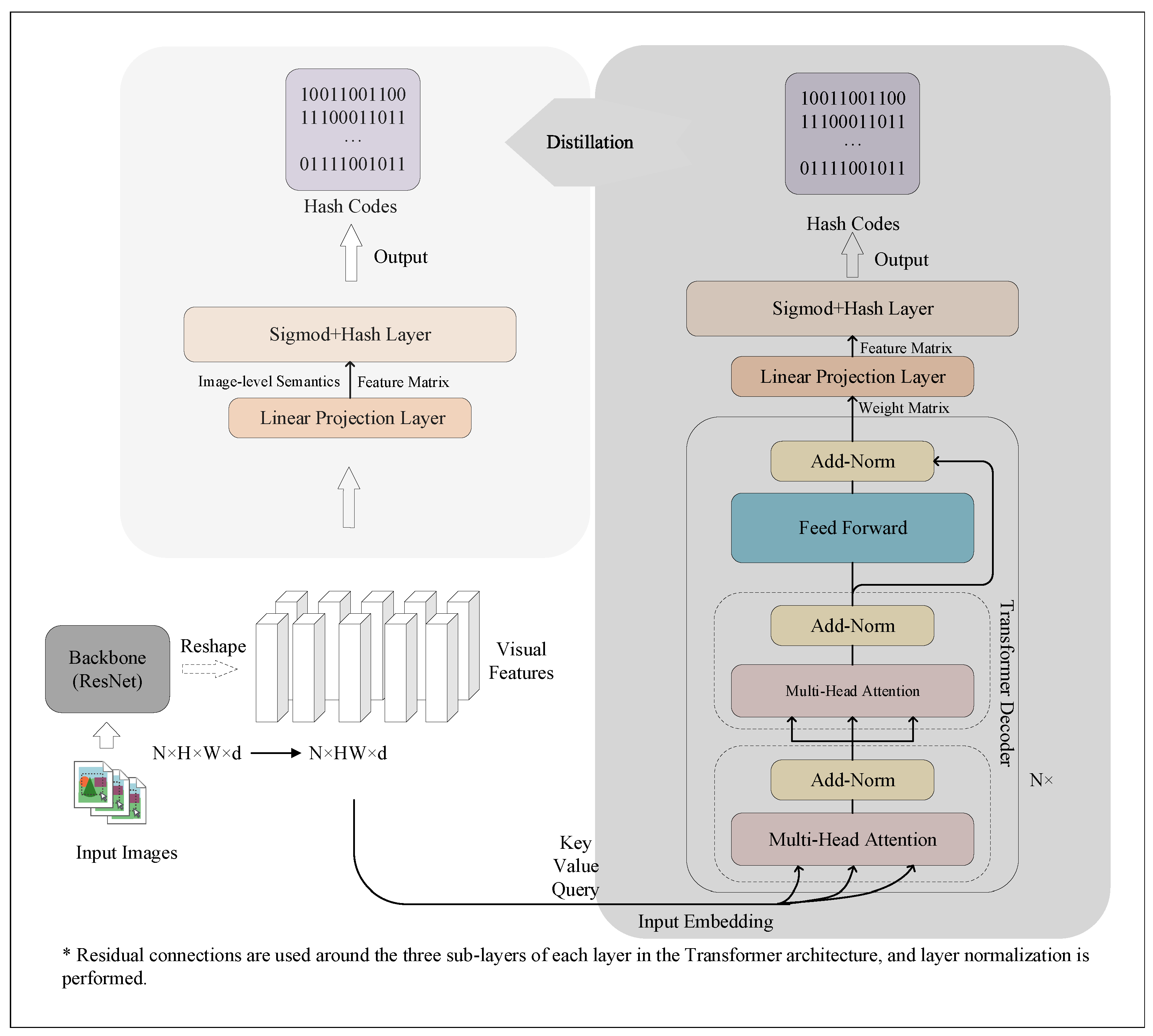
3.1. Model Overview
3.2. CNN-Based Backbone
3.3. Transformer Teacher Module and Student Module
3.4. Training
4. Experiment and Analysis
4.1. Datasets and Metrics
4.2. Training
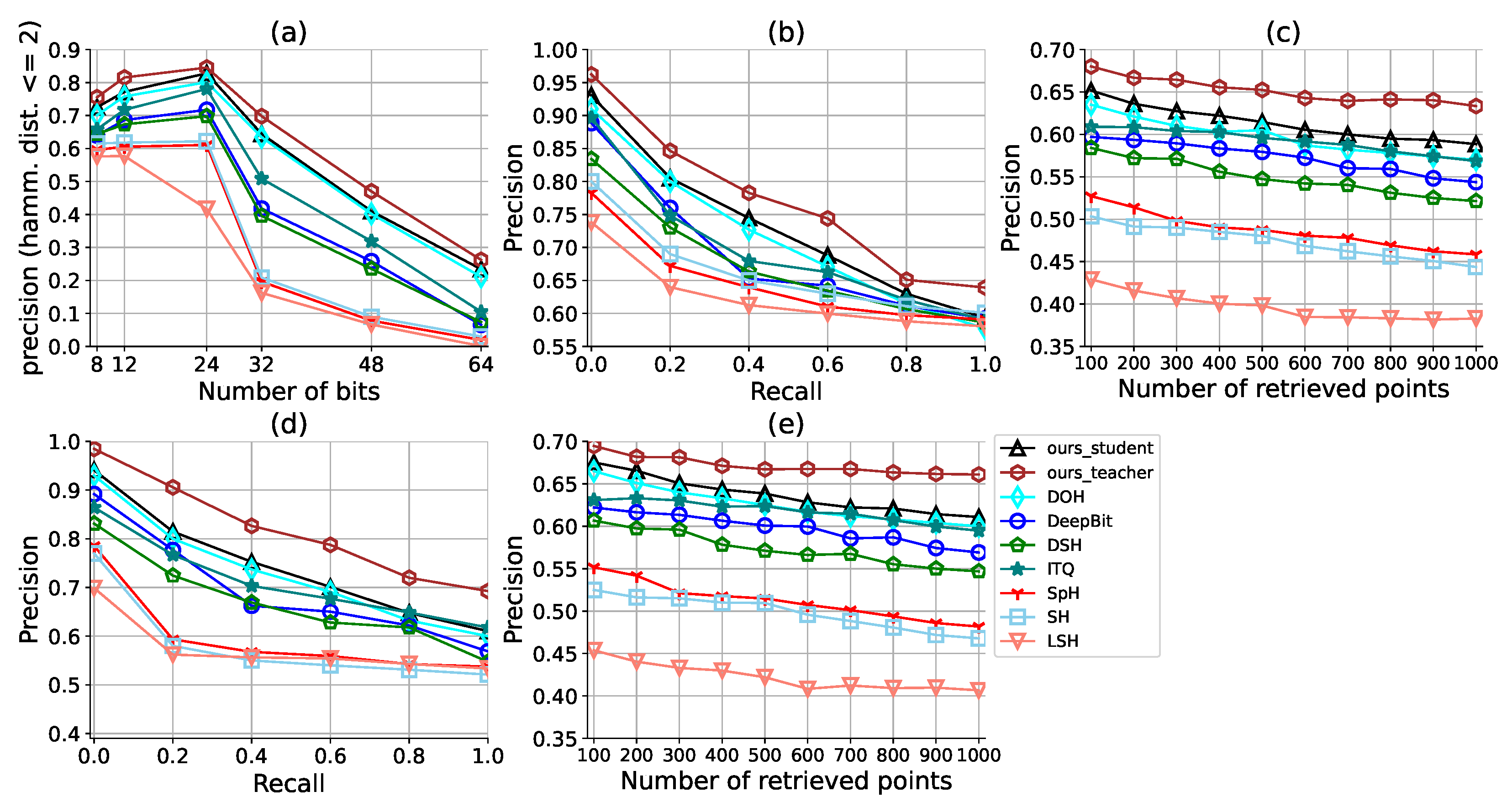
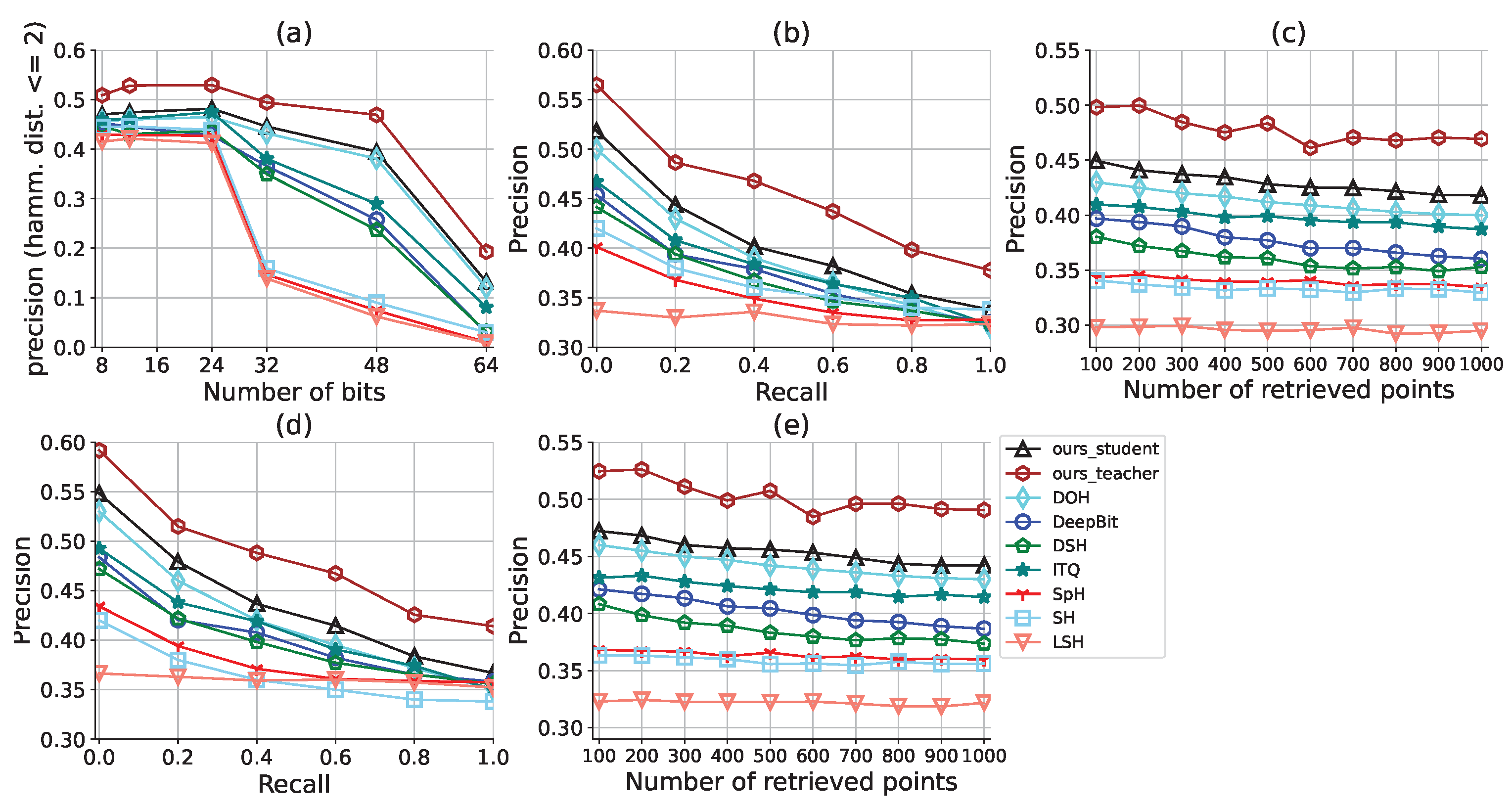
4.3. Analysis of the Lifting Effect of Transformer and Distillation
4.4. Comparison to the State of the Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Birjandi, M.; Mohanna, F. 24 MODIFIED KEYWORD BASED RETRIEVAL ON FABRIC IMAGES. Quantum J. Eng. Sci. Technol. 2020, 1, 1–14. [Google Scholar]
- Rout, N.K.; Atulkar, M.; Ahirwal, M.K. A review on content-based image retrieval system: Present trends and future challenges. Int. J. Comput. Vis. Robot. 2021, 11, 461–485. [Google Scholar] [CrossRef]
- Peng, T.Q.; Li, F. Image retrieval based on deep convolutional neural networks and binary hashing learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1742–1746. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Ribeiro, M.T.; Wu, T.; Guestrin, C.; Singh, S. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4902–4912. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. In ACM Computing Surveys (CSUR); Association for Computing Machinery (ACM): New York, NY, USA, 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- El-Nouby, A.; Neverova, N.; Laptev, I.; Jégou, H. Training vision transformers for image retrieval. arXiv 2021, arXiv:2102.05644. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gionis, A.; Indyk, P.; Motwani, R. Similarity search in high dimensions via hashing. In Proceedings of the International Conference on Very Large Data Bases, Scotland, UK, 7–10 September 1999; pp. 518–529. [Google Scholar]
- Jain, P.; Kulis, B.; Grauman, K. Fast image search for learned metrics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Liu, W.; Wang, J.; Ji, R.; Jiang, Y.G.; Chang, S.F. Supervised hashing with kernels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2074–2081. [Google Scholar]
- Yang, H.F.; Lin, K.; Chen, C.S. Supervised learning of semantics-preserving hash via deep convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 437–451. [Google Scholar] [CrossRef]
- Zhao, W.; Luo, H.; Peng, J.; Fan, J. Spatial pyramid deep hashing for large-scale image retrieval. Neurocomputing 2017, 243, 166–173. [Google Scholar] [CrossRef]
- Zhao, W.; Guan, Z.; Luo, H.; Peng, J.; Fan, J. Deep Multiple Instance Hashing for Fast Multi-Object Image Search. IEEE Trans. Image Process. 2021, 30, 7995–8007. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chugh, H.; Gupta, S.; Garg, M.; Gupta, D.; Mohamed, H.G.; Noya, I.D.; Singh, A.; Goyal, N. An Image Retrieval Framework Design Analysis Using Saliency Structure and Color Difference Histogram. Sustainability 2022, 14, 10357. [Google Scholar] [CrossRef]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef]
- Kaur, P.; Harnal, S.; Tiwari, R.; Alharithi, F.S.; Almulihi, A.H.; Noya, I.D.; Goyal, N. A hybrid convolutional neural network model for diagnosis of COVID-19 using chest X-ray images. Int. J. Environ. Res. Public Health 2021, 18, 12191. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Ullman, S. High-Level Vision: Object Recognition and Visual Cognition; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai J F, D.D. Deformable transformers for end-to-end object detection. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Max-deeplab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5463–5474. [Google Scholar]
- Lu, X.; Zhao, T.; Lee, K. VisualSparta: An Embarrassingly Simple Approach to Large-scale Text-to-Image Search with Weighted Bag-of-words. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; pp. 5020–5029. [Google Scholar]
- Henkel, C. Efficient large-scale image retrieval with deep feature orthogonality and Hybrid-Swin-Transformers. arXiv 2021, arXiv:2110.03786. [Google Scholar]
- Yang, M.; He, D.; Fan, M.; Shi, B.; Xue, X.; Li, F.; Ding, E.; Huang, J. Dolg: Single-stage image retrieval with deep orthogonal fusion of local and global features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11772–11781. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12009–12019. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5191–5198. [Google Scholar]
- Tian, J.; Xu, X.; Shen, F.; Yang, Y.; Shen, H.T. TVT: Three-Way Vision Transformer through Multi-Modal Hypersphere Learning for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, February 22–1 March 2022; Volume 36, pp. 2370–2378. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Thomee, B.; Lew, M.S. New Trends and Ideas in Visual Concept Detection: The MIR Flickr Retrieval Evaluation Initiative. In Proceedings of the ACM International Conference on Multimedia Information Retrieval, Philadelphia, PA, USA, 29–31 March 2010; pp. 527–536. [Google Scholar]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. NUS-WIDE: A real-world web image database from National University of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini Island, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Charikar, M.S. Similarity estimation techniques from rounding algorithms. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 380–388. [Google Scholar]
- Wang, J.; Kumar, S.; Chang, S.F. Semi-Supervised Hashing for Large-Scale Search. IEEE Trans. Pattern. Anal. Mach. Intell. 2012, 34, 2393–2406. [Google Scholar] [CrossRef] [PubMed]
- Sun, A.; Bhowmick, S.S. Quantifying tag representativeness of visual content of social images. In Proceedings of the ACM International Conference on Multimedia, Firenze, Italy, 25 October 2010; pp. 471–480. [Google Scholar]
- Liong, V.E.; Lu, J.; Wang, G.; Moulin, P.; Zhou, J. Deep hashing for compact binary codes learning. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lin, K.; Lu, J.; Chen, C.S.; Zhou, J. Learning Compact Binary Descriptors with Unsupervised Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jin, Z.; Li, C.; Lin, Y.; Cai, D. Density Sensitive Hashing. IEEE Trans. Cybern. 2017, 44, 1362–1371. [Google Scholar] [CrossRef]
- Do, T.T.; Doan, A.D.; Cheung, N.M. Learning to Hash with Binary Deep Neural Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Shen, Y.; Liu, L.; Shao, L. Unsupervised binary representation learning with deep variational networks. Int. J. Comput. Vis. 2019, 127, 1614–1628. [Google Scholar] [CrossRef]
- Xie, F.; Zhao, W.; Guan, Z.; Wang, H.; Duan, Q. Deep objectness hashing using large weakly tagged photos. Neurocomputing 2022, 502, 186–195. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Train Data | Length | MAP | Time |
|---|---|---|---|---|
| Teacher | MIRFlickr-25K | 24 | 0.7582 | 2.11 s |
| 48 | 0.7435 | 2.18 s | ||
| Student | 24 | 0.7112 | 0.19 s | |
| 48 | 0.7088 | 0.21 s | ||
| Teacher | NUS-WIDE | 24 | 0.6932 | 2.11 s |
| 48 | 0.6882 | 2.18 s | ||
| Student | 24 | 0.6473 | 0.19 s | |
| 48 | 0.6482 | 0.21 s |
| Model | Teacher | Train Data | Length | MAP |
|---|---|---|---|---|
| Student | None | MIRFlickr-25K | 24 | 0.6678 |
| Transformer | 24 | 0.7112 | ||
| None | 48 | 0.6561 | ||
| Transformer | 48 | 0.7088 | ||
| Student | None | NUS-WIDE | 24 | 0.5321 |
| Transformer | 24 | 0.6473 | ||
| None | 48 | 0.5396 | ||
| Transformer | 48 | 0.6482 |
| Methods | MIR Flickr-25K | NUS-WIDE | ||||||
|---|---|---|---|---|---|---|---|---|
| Length | 12 | 24 | 32 | 48 | 12 | 24 | 32 | 48 |
| LSH [42] | 0.5763 | 0.6065 | 0.5966 | 0.6263 | 0.3523 | 0.4096 | 0.4186 | 0.4555 |
| SH [15] | 0.6621 | 0.6433 | 0.6296 | 0.6225 | 0.5652 | 0.5061 | 0.4866 | 0.4546 |
| SpH [44] | 0.5982 | 0.5832 | 0.5831 | 0.582 | 0.4656 | 0.4662 | 0.4473 | 0.4481 |
| ITQ [16] | 0.6932 | 0.7082 | 0.6686 | 0.6991 | 0.6332 | 0.6255 | 0.5922 | 0.6481 |
| PCAH [43] | 0.6444 | 0.6321 | 0.6377 | 0.6534 | 0.5775 | 0.5052 | 0.4921 | 0.4924 |
| DSH [47] | 0.6962 | 0.7076 | 0.6851 | 0.6612 | 0.5944 | 0.5987 | 0.5725 | 0.5795 |
| DH [45] | 0.6021 | 0.6176 | 0.6144 | 0.6174 | 0.4745 | 0.4631 | 0.4625 | 0.4755 |
| DeepBit [46] | 0.5887 | 0.6033 | 0.6092 | 0.6091 | 0.5465 | 0.5551 | 0.5626 | 0.5612 |
| BDNN [48] | 0.6654 | 0.6692 | 0.6678 | 0.6695 | 0.5932 | 0.5922 | 0.5912 | 0.6098 |
| DVB [49] | - | - | - | - | - | - | 0.562 | - |
| DOH [50] | - | - | 0.6728 | 0.6712 | - | - | 0.6145 | 0.6251 |
| Ours—student | 0.7046 | 0.7112 | 0.7092 | 0.7088 | 0.6361 | 0.6473 | 0.6526 | 0.6482 |
| Ours—teacher | 0.7471 | 0.7582 | 0.7485 | 0.7435 | 0.6818 | 0.6932 | 0.6925 | 0.6882 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, Y.; Wang, C.; Yuan, W.; Qian, X.; Yang, W.; Zhao, W. Transformer-Based Distillation Hash Learning for Image Retrieval. Electronics 2022, 11, 2810. https://doi.org/10.3390/electronics11182810
Lv Y, Wang C, Yuan W, Qian X, Yang W, Zhao W. Transformer-Based Distillation Hash Learning for Image Retrieval. Electronics. 2022; 11(18):2810. https://doi.org/10.3390/electronics11182810
Chicago/Turabian StyleLv, Yuanhai, Chongyan Wang, Wanteng Yuan, Xiaohao Qian, Wujun Yang, and Wanqing Zhao. 2022. "Transformer-Based Distillation Hash Learning for Image Retrieval" Electronics 11, no. 18: 2810. https://doi.org/10.3390/electronics11182810
APA StyleLv, Y., Wang, C., Yuan, W., Qian, X., Yang, W., & Zhao, W. (2022). Transformer-Based Distillation Hash Learning for Image Retrieval. Electronics, 11(18), 2810. https://doi.org/10.3390/electronics11182810