




A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model
 ,
, 
Abstract
:1. Introduction
2. Literature Review
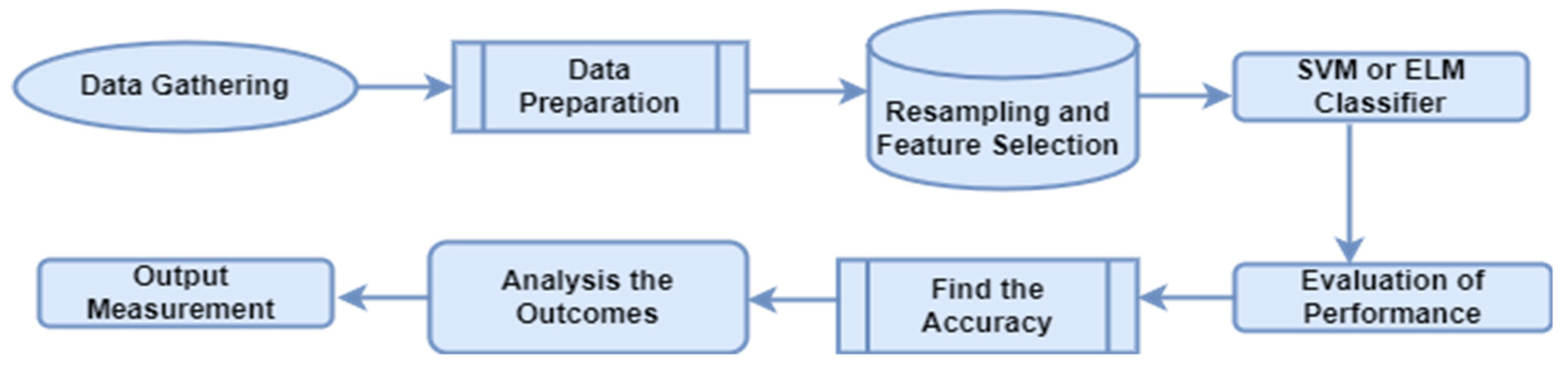
3. Proposed Methodology
- Data Gathering.
- Data Preparation.
- Resampling and Feature Selection Methodology.
- Training the SVM classifier.
- Training the ELM classifier.
- Proposed Model and Algorithms for calculating the accuracy and time.
- Results and analysis.
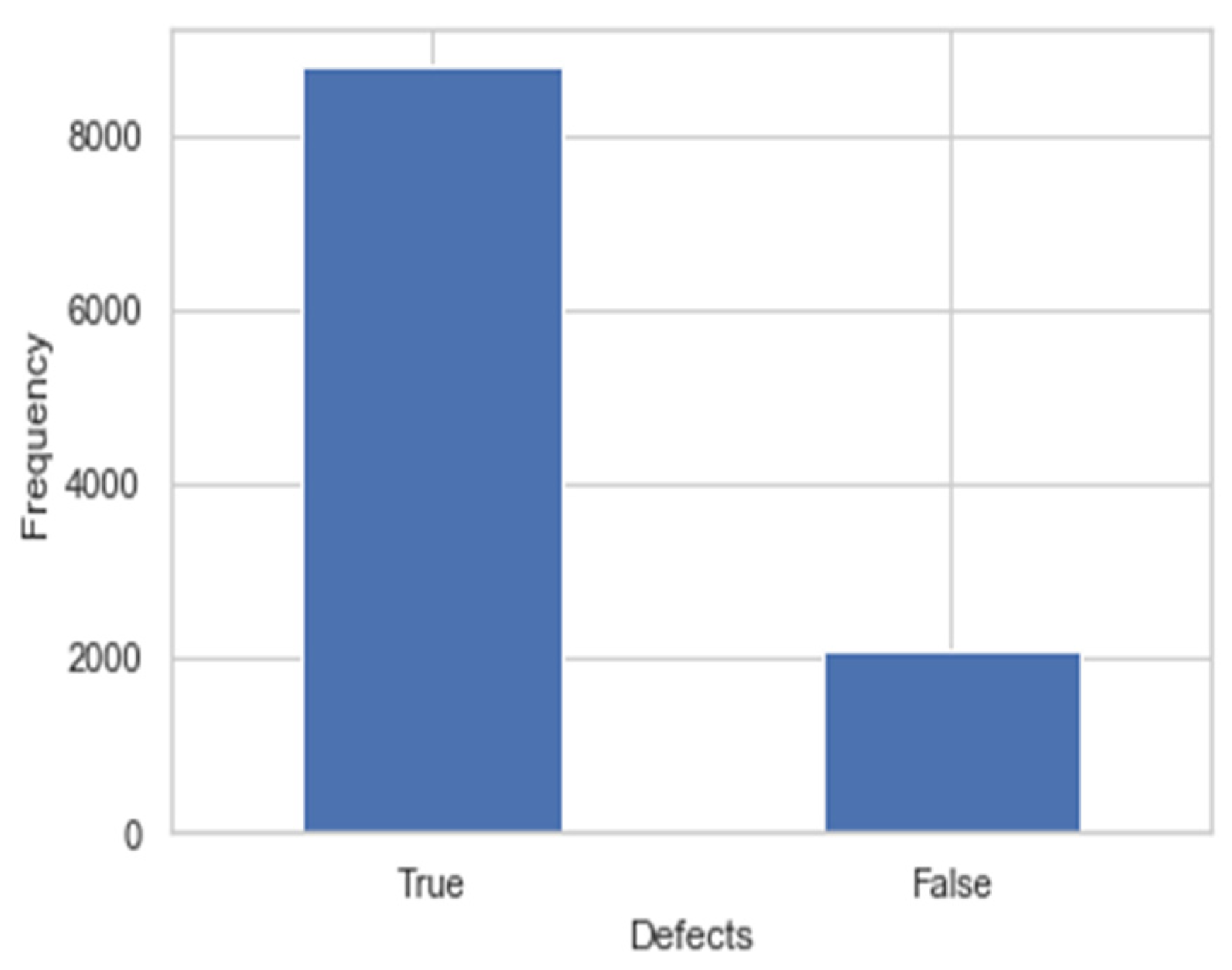
3.1. Data Gathering
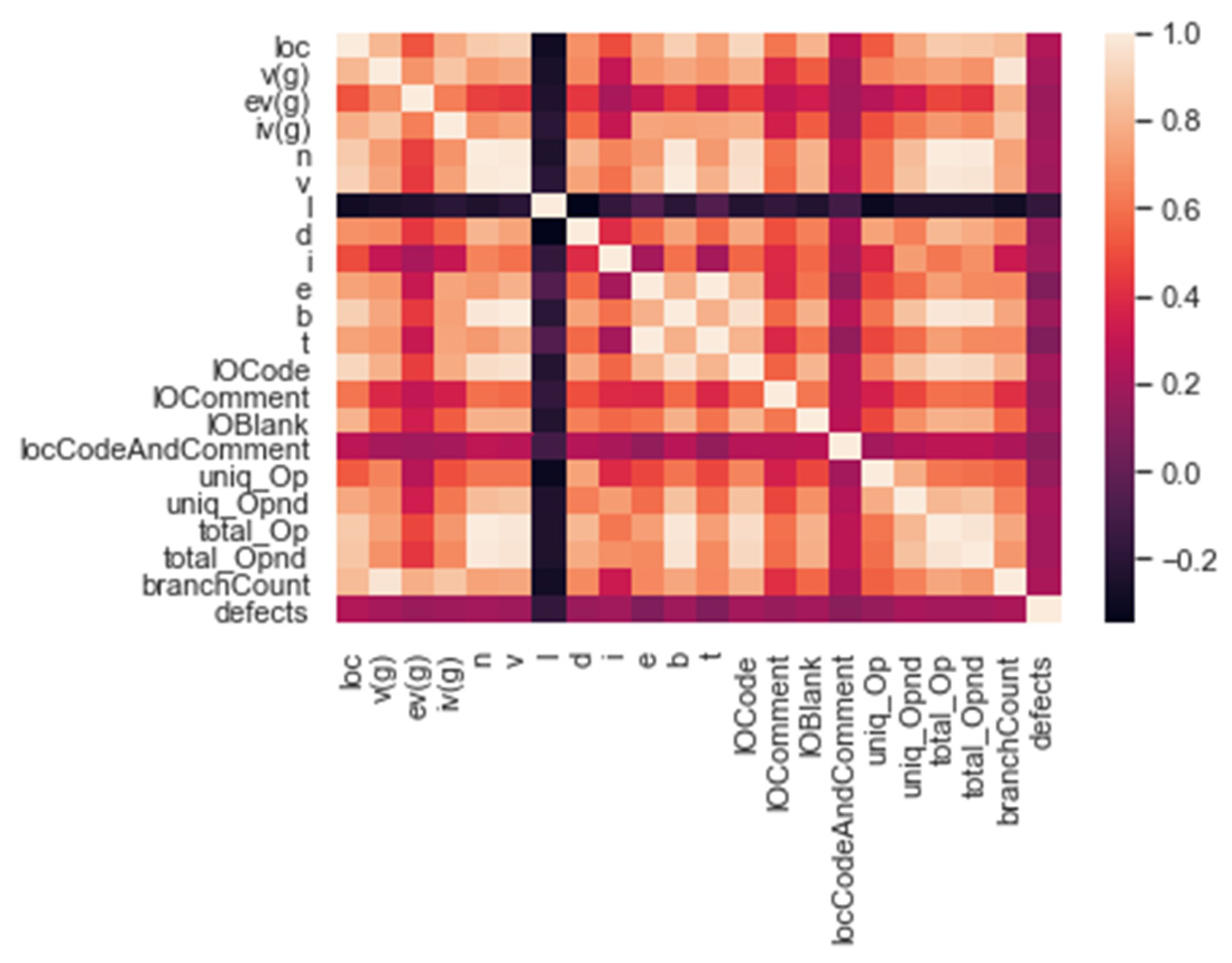
3.2. Data Preparation
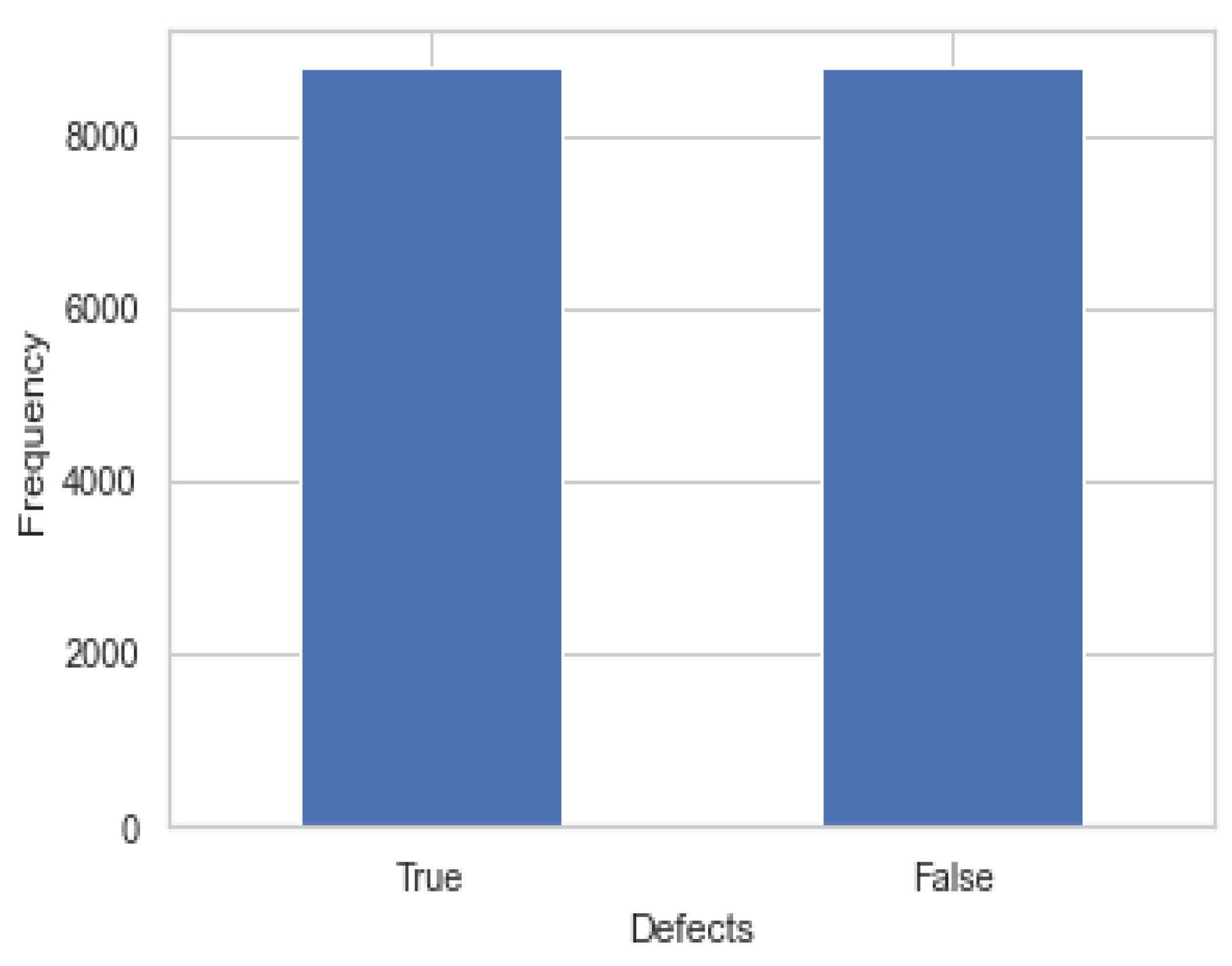
3.3. Resampling and Feature Selection Methodology
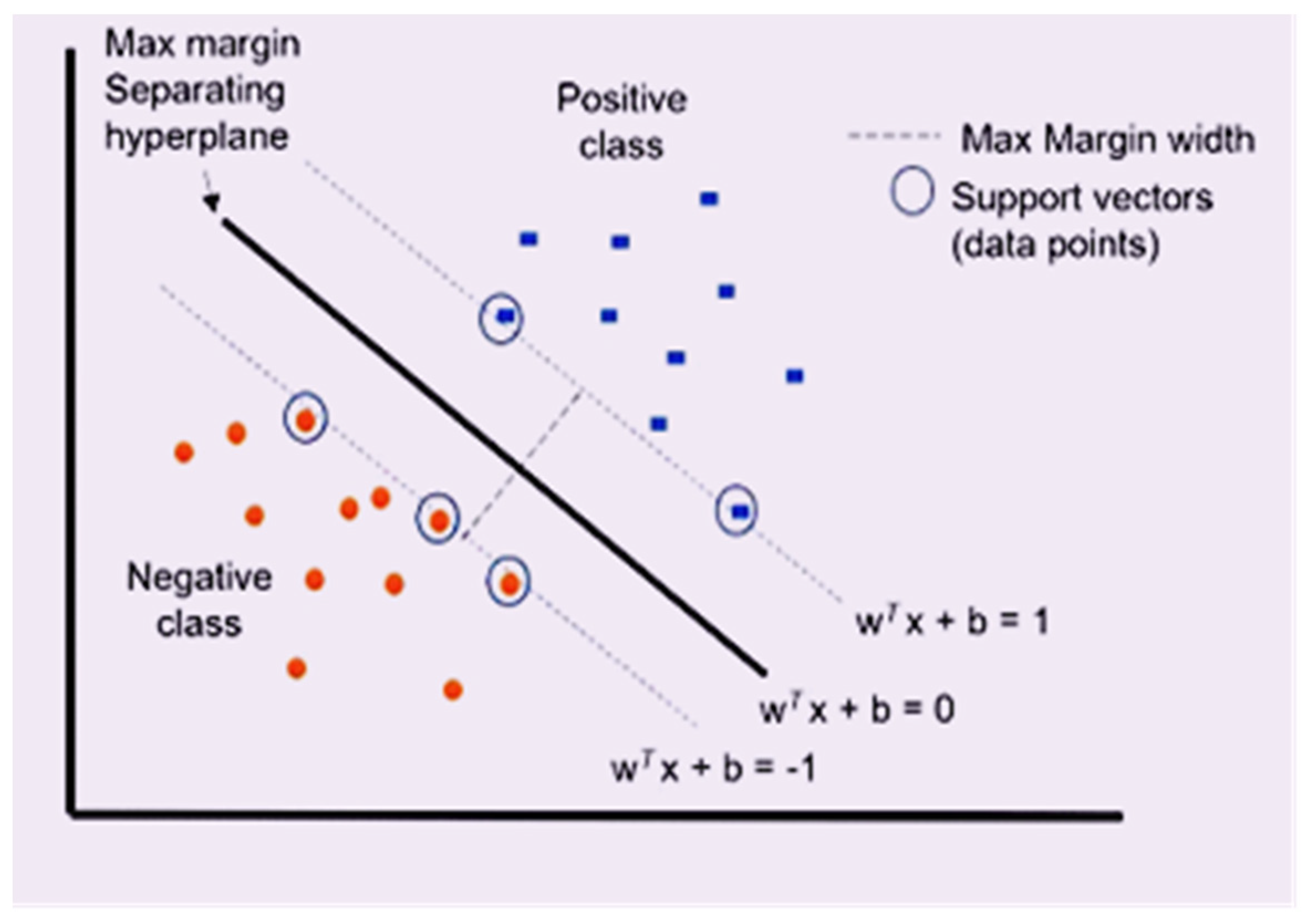
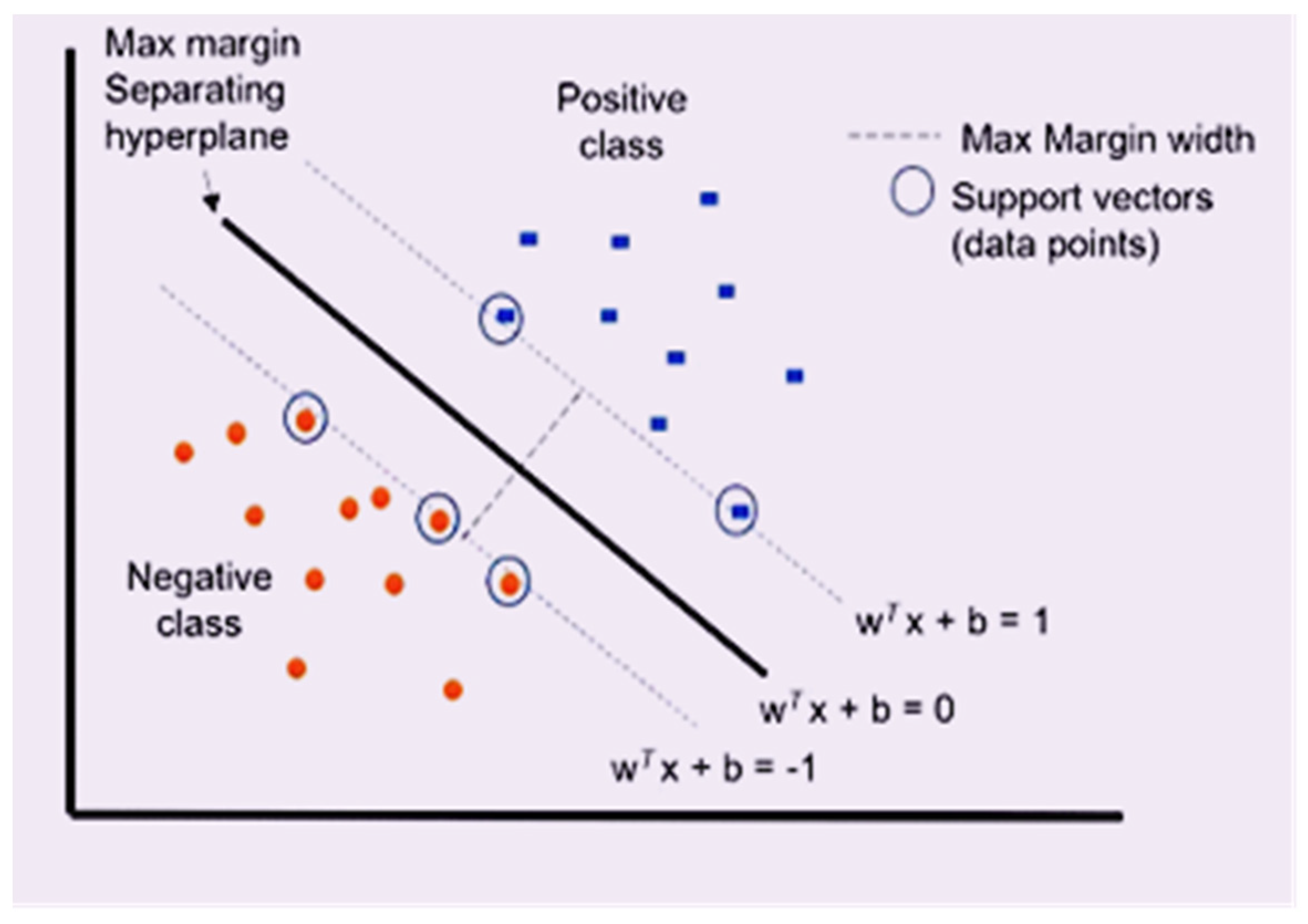
3.4. Training the SVM Classifier
- Linear f(X) = wT × X + b
- Polynomial f(X1, X2) = (a + X1T × X2) b
- Gaussian RBF f(X1, X2) = exp (−γ || X1 − X2 ||) 2
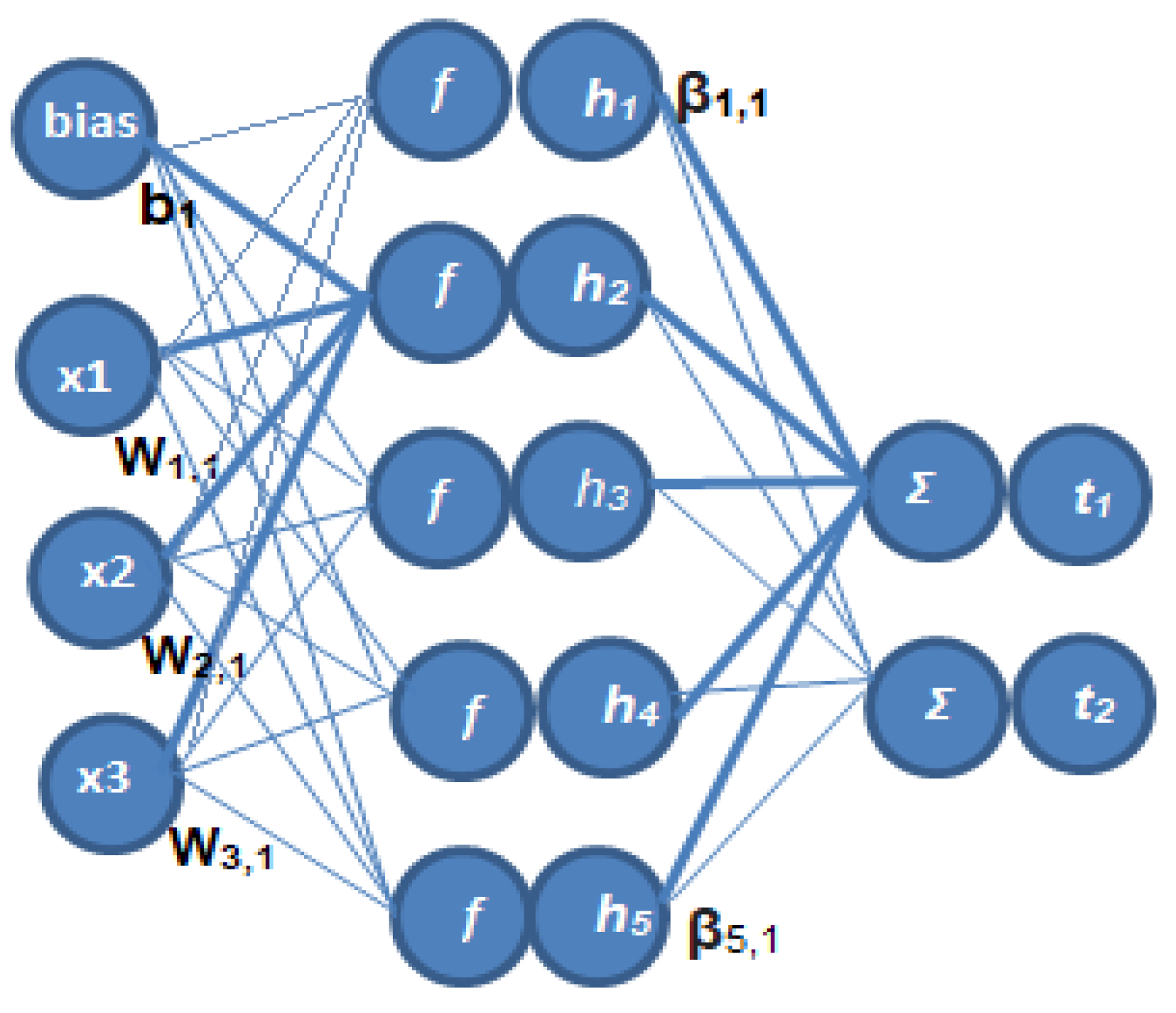
3.5. Training the ELM Classifier
3.6. Proposed Model and Algorithm for Calculating the Accuracy and Time
| Algorithm 1 Calculating the accuracy and time |
| Input: NASA Dataset Output: To improve precision and reliability Step-1 Begin Step-2 Import NASA’s data. Step-3 NASA dataset pre-processing features Step-4 Implement the Resampling MethodStep-4 Implement the Method of Feature Selection Step-5 Then, for hyper-parameter analysis, we used SVM or ELM classifiers on our Dataset with various functions. Step-6 Our model then concentrates on Hyper-plane. Step-7 Calculate the accuracy and time. Step-8 End |
3.7. Testing and Calculation of Accuracy
4. Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L.; Ah Chung, T.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Osindero, S.; The, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann machines. In Proceedings of the International Conference Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2009; pp. 448–455. [Google Scholar]
- Huang, G.B.; Lee, H.; Learned-Miller, E. Learning hierarchical representations for face verification with convolutional deep belief networks. In Proceedings of the IEEE International Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2518–2525. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Hybrid deep learning for face verification. In Proceedings of the IEEE International Conference Computer Vision, University of Science and Technology of China 2013, Sydney, Australia, 1–8 December 2013; p. 262 L. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE International Computer Vision and Pattern Recognition, Menlo Park, CA, USA, 23–28 June 2014. [Google Scholar]
- Zhou, E.; Cao, Z.; Yin, Q. Naïve-deep face recognition: Touching the limit of LFW benchmark or not? arXiv 2015, arXiv:1501.04690. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Huang, G.; Zhu, Q.; Siew, C. Extremelearningmachine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.; Chen, L.; Siew, C. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar]
- Haykin, S.O. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice-Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Funahashi, K.; Funahashi, K.I. On the approximate realization of continuous mappings by neural networks. Neural Netw. 1989, 2, 183–192. [Google Scholar] [CrossRef]
- Shanthini, A. Effect of ensemble methods for software fault prediction at various metrics level. In International Journal of Applied Information Systems (IJAIS); Foundation of Computer Science FCS: New York, NY, USA, 2013. [Google Scholar]
- Xia, X.; Lo, D.; McIntosh, S.; Shihab, E.; Hassan, A.E. Cross-Project Build Co-Change Pre-Diction. In Proceedings of the IEEE 22nd International Conference on Software Analysis, Evolution and Reengineering (SANER), Gold Coast, Australia, 9–12 December 2015; pp. 311–320. [Google Scholar]
- Yang, F.-J. An Implementation of Naive Bayes Classifier. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 301–306. [Google Scholar] [CrossRef]
- Elish, K.O.; Elish, M.O. Predicting defect-prone software modules using support vector machines. J. Syst. Softw. 2008, 81, 649–660. [Google Scholar] [CrossRef]
- Yan, Z.; Chen, X.; Guo, P. Software defect prediction using fuzzy support vector regression. Adv. Neural Netw. 2010, 6064, 17–24. [Google Scholar]
- Jing, X.; W, F.; Dong, X.; Qi, F.; Xu, B. Heterogeneous cross-company defect prediction by unified metric representation and CCA-based transfer learning. In Proceedings of the 10th Joint Meeting on Foundations of Software Engineering (FSE), ACM, Bergamo, Italy, 30 August–4 September 2015; pp. 496–507. [Google Scholar]
- Goel, A.L. A Guidebook for Software Reliability Assessment; Rep. RADCTR-83-176; Syracuse University: New York, NY, USA, 1983. [Google Scholar]
- Knab, P.; Pinzger, M.; Bernstein, A. Predicting defect densities in source code files with decision tree learners. In Proceedings of the 3rd International Workshop on Mining Software Repositories (MSR), ACM, Shanghai, China, 22–23 May 2006; pp. 119–125. [Google Scholar]
- Thwin, M.M.T.; Quah, T.-S. Application of neural networks for software quality prediction using object-oriented metrics. J. Syst. Softw. 2005, 76, 147–156. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Allen, E.B.; Hudepohl, J.P.; Aud, S.J. Application of neural networks to software quality modeling of a very large telecommunications system. IEEE Trans. Neural Netw. 1997, 8, 902–909. [Google Scholar] [CrossRef] [PubMed]
- Neumann, D.E. An enhanced neural network technique for software risk analysis. IEEE Trans. Soft. Eng. 2002, 28, 904–912. [Google Scholar] [CrossRef]
- Panichella, A.; Oliveto, R.; de Lucia, A. Cross-project defect prediction models: L’union fait la force. In Proceedings of the IEEE 21st Software Evolution Week-IEEE Conference on Software Maintenance, Reengineering and Reverse Engineering (CSM- R-WCRE), Antwerp, Belgium, 3–6 February 2014; pp. 164–173. [Google Scholar]
- Boetticher, G.; Menzies, T.; Ostrand, T. PROMISE Repository of Empirical Software Engineering Data; West Virginia University, Department of Computer Science: Morgantown, WV, USA, 2007. [Google Scholar]
- Leo, M.; Sharma, S.; Maddulety, K. Machine learning in banking risk management: A literature review. Risks 2019, 7, 29. [Google Scholar] [CrossRef]
- Boughaci, D.; Alkhawaldeh, A.A. Appropriate machine learning techniques for credit scoring and bankruptcy prediction in banking and finance: A comparative study. Risk Decis Anal. 2020, 8, 15–24. [Google Scholar] [CrossRef]
- Kou, G.; Chao, X.; Peng, Y.; Alsaadi, F.E.; Herrera-Viedma, E. Machine learning methods for systemic risk analysis in financial sectors. Technol. Econ. Dev. Econ. 2019, 25, 716–742. [Google Scholar] [CrossRef]
- Beam, A.L.; Kohane, I.S. Big data and machine learning in health care. JAMA 2018, 319, 1317–1318. [Google Scholar] [CrossRef]
- Char, D.S.; Shah, N.H.; Magnus, D. Implementing machine learning in health care Addressing ethical challenges. N. Engl. J. Med. 2018, 378, 981. [Google Scholar] [CrossRef]
- Panch, T.; Szolovits, P.; Atun, R. Artificial intelligence, machine learning, and health systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef] [PubMed]
- Stone, P.; Veloso, M. Multiagent systems: A survey from a machine learning perspective. Auton Robots 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Mosavi, A.; Varkonyi, A. Learning in robotics. Int. J. Comput. Appl. 2017, 157, 8–11. [Google Scholar] [CrossRef]
- Polydoros, A.S.; Nalpantidis, L. Survey of model-based reinforcement learning: Applications on robotics. J. Intell. Robot. Syst. 2017, 86, 153–173. [Google Scholar] [CrossRef]
- Bhavsar, P.; Safro, I.; Bouaynaya, N.; Polikar, R.; Dera, D. Machine learning in transportation data analytics. In Data Analytics for Intelligent Transportation Systems; Elsevier: Amsterdam, The Netherlands, 2017; pp. 283–307. [Google Scholar]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef]
- Ermagun, A.; Levinson, D. Spatiotemporal traffic forecasting: Review and proposed directions. Transp. Rev. 2018, 38, 786–814. [Google Scholar] [CrossRef]
- Ballestar, M.T.; Grau-Carles, P.; Sainz, J. Predicting customer quality in e-commerce social networks: A machine learning approach. Rev. Manag. Sci. 2019, 13, 589–603. [Google Scholar] [CrossRef]
- Rath, M. Machine Learning and Its Use in E-Commerce and E-Business. In Handbook of Research on Applications and Implementations of Machine Learning Techniques; IGI Global; Birla Global University: Odisha, India, 2020; pp. 111–127. [Google Scholar]
- Kohavi, R.; John, G.H. Wrapper for Feature Subset Selection; Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1997; pp. 273–324. [Google Scholar]
- Shivaji, S.; Whitehead, E.J.; Akella, R.; Kim, S. Reducing features to improve code change-based bug prediction. IEEE Trans. Softw. Eng. 2013, 39, 552–569. [Google Scholar] [CrossRef]
- Blum, A.L.; Rivest, R.L. Training a 3-node neural networks is NP-complete. Neural Netw. 1992, 5, 117–127. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Kluwer Academic Publishers: Boston, MA, USA, 1998. [Google Scholar]
- Song, Q.; Jia, Z.; Shepperd, M.; Ying, S.; Liu, J. A general software defect-proneness prediction framework. IEEE Trans. Softw. Eng. 2011, 37, 356–370. [Google Scholar] [CrossRef]
- Shivaji, S.; Whitehead, J.E.J.; Akella, R.; Kim, S. Reducing features to improve bug prediction. In Proceedings of the 24th International Conference on Automated Software Engineering (ASE), Auckland, New Zealand, 16–20 November 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 600–604. [Google Scholar]
- Elmurngi, E.; Gherbi, A. An empirical study on detecting fake reviews using machine learning techniques. In Proceedings of the IEEE 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; pp. 107–114. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis, Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Gao, K.; Khoshgoftaar, T.M.; Wang, H.; Seiya, N. Choosing software metrics for defect prediction: An investigation on feature selection techniques. Softw. Pract. Exp. 2011, 41, 579–606. [Google Scholar] [CrossRef]
- Chen, X.; Shen, Y.; Cui, Z.; Ju, X. Applying feature selection to software defect prediction using multi-objective optimization. In Proceedings of the IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; pp. 54–59. [Google Scholar]
- Catal, C.; Diri, B. Investigating the effect of dataset size, metrics sets, and feature selection techniques on software fault prediction problem. Inf. Sci. 2009, 179, 1040–1058. [Google Scholar] [CrossRef]
- Vandecruys, O.; Martens, D.; Baesens, B.; Mues, C.; Backer, M.D.; Haesen, R. Mining software repositories for comprehensible software fault prediction models. J. Syst. Softw. 2008, 81, 823–839. [Google Scholar] [CrossRef]
- Czibula, G.; Marian, Z.; Czibula, I.G. Software defect prediction using relational association rule mining. Inf. Sci. 2014, 260–278. [Google Scholar] [CrossRef]
- Mahaweerawat, A.; Sophatsathit, P.; Lursinsap, C.; Musilek, P. MASP-An enhanced model of fault type identification in object-oriented software engineering. J. Adv. Comput. Intell. Intell. Inform. 2006, 10, 312–322. [Google Scholar] [CrossRef]
- Gondra, I. Applying machine learning to software fault-proneness prediction. J. Syst. Softw. 2008, 81, 186–195. [Google Scholar] [CrossRef]
- Menzies, T.; Greenwald, J.; Frank, A. Data mining static code attributes to learn defect predictors. IEEE Trans. Softw. Eng. 2007, 33, 2–13. [Google Scholar] [CrossRef]
- Van Heeswijk, M.; Miche, Y.; Lindh-Knuutila, T.; Hilbers, P.A.; Honkela, T.; Oja, E.; Lendasse, A. Adaptive ensemble models of extreme learning machines for time series prediction. Lect. Notes Comput. Sci. 2009, 5769, 305–314. [Google Scholar]
- Rong, H.-J.; Ong, Y.-S.; Tan, A.-H.; Zhu, Z. A fast pruned extreme earning machine for classification problem. Neurocomputing 2008, 72, 359–366. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature Selection for Classification; Intelligent Data Analysis; Elsevier: Amsterdam, The Netherlands, 1997; pp. 131–156. [Google Scholar]
- Rath, S.K.; Sahu, M.; Das, S.P.; Mohapatra, S.K. Hybrid Software Reliability Prediction Model Using Feature Selection and Support Vector Classifier. In Proceedings of the 2022 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 9–11 March 2022; pp. 1–4. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
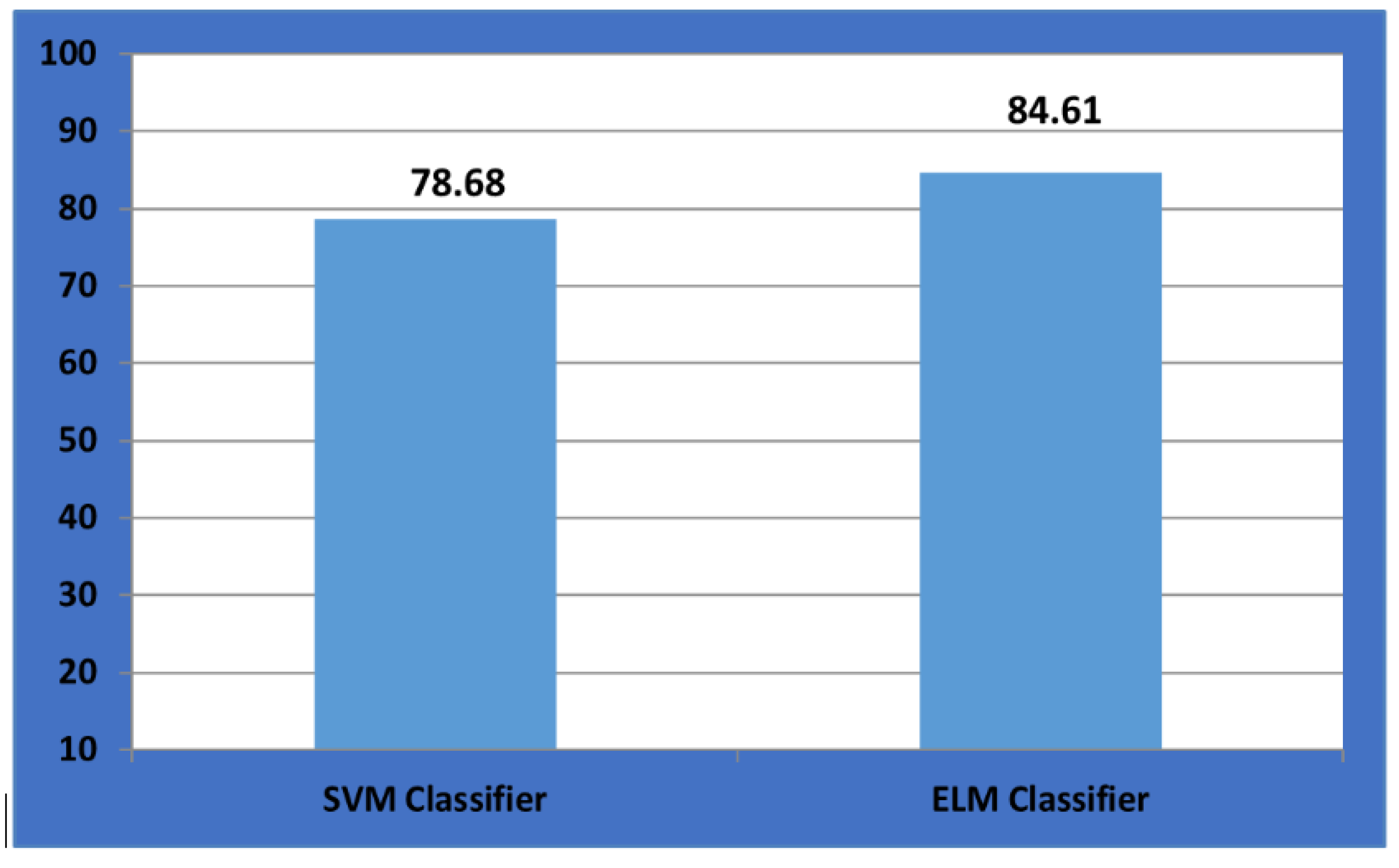
| Input | Accuracy Calculated Using SVM Classifier | Accuracy Calculated Using ELM Classifier | Time Required For Execution of SVM Classifier | Time Required for Execution of ELM Classifier |
|---|---|---|---|---|
| NASA dataset | 0.7868965517241 | 0.84617241379310 | 2.8329972743988037 s | 0.6670020008087158 s |
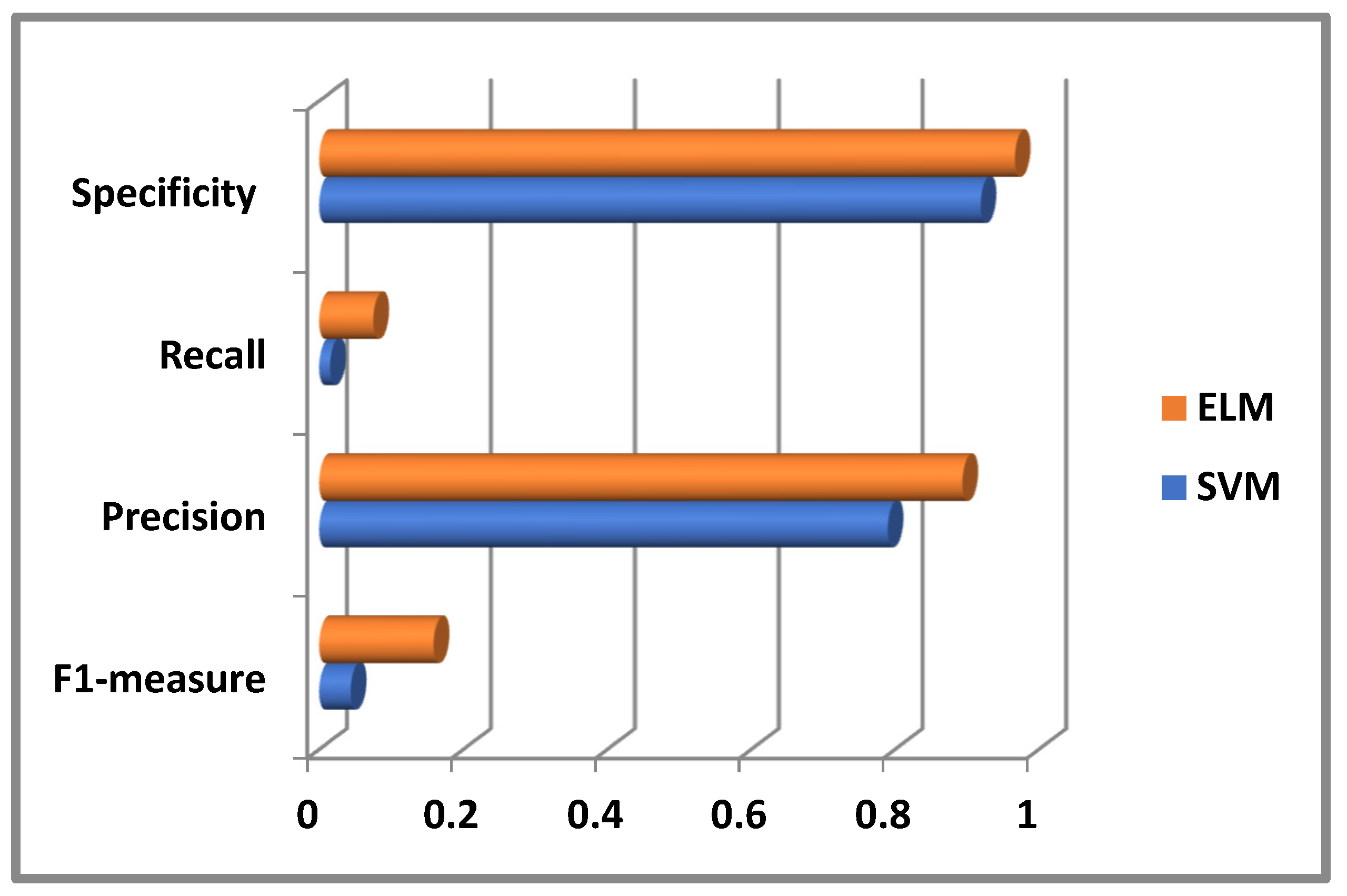
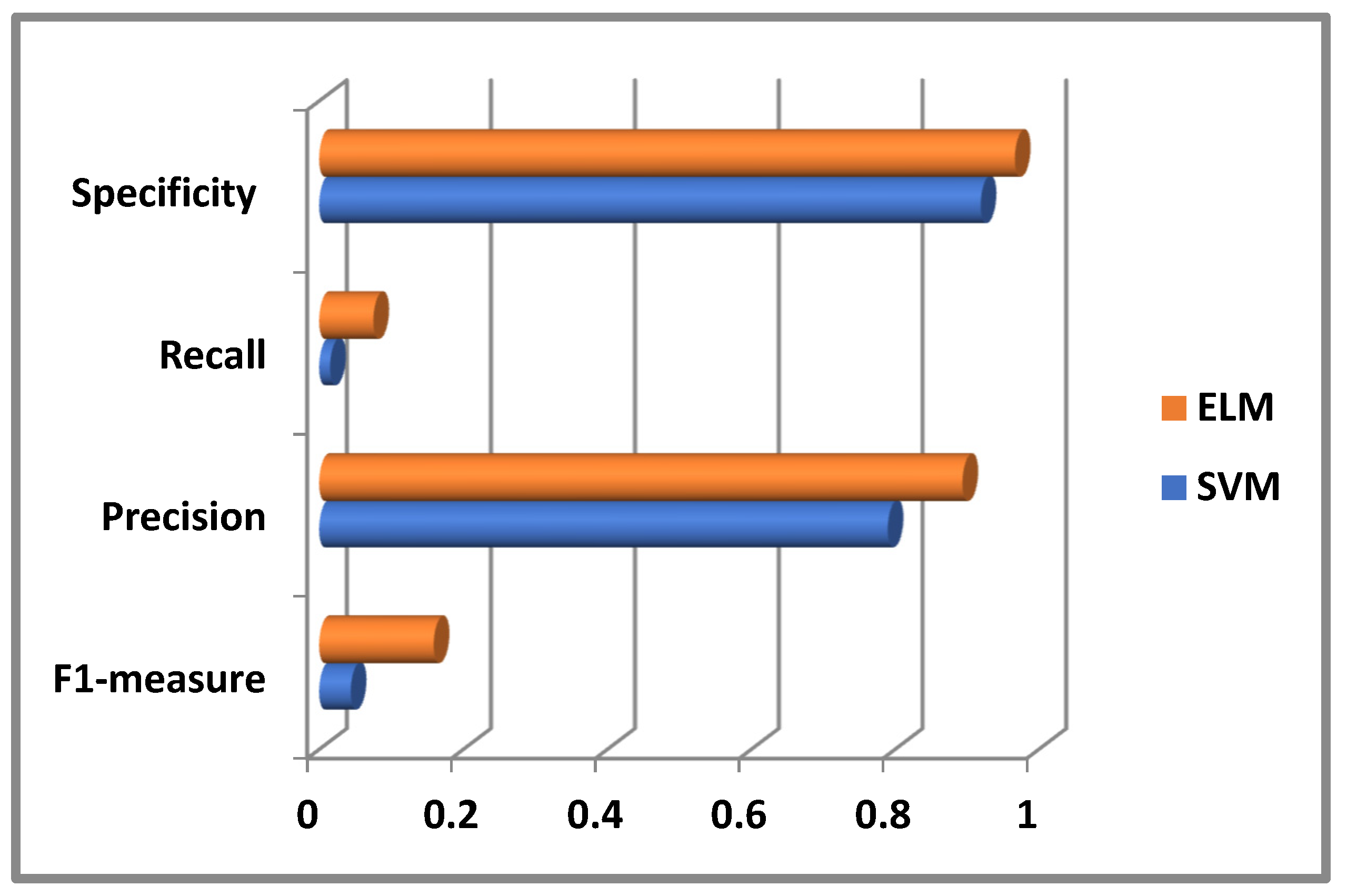
| Input | F1-Measure Calculated Using SVM Classifier | Precision Calculated Using SVM Classifier | Recall Calculated Using SVM Classifier | Specificity Calculated Using SVM Classifier |
|---|---|---|---|---|
| NASA dataset | 0.043638 | 0.79 | 0.015163 | 0.919331 |
| Input | F1-Measure Calculated Using ELM Classifier | Precision Calculated Using ELM Classifier | Recall Calculated Using ELM Classifier | Specificity Calculated Using ELM Classifier |
|---|---|---|---|---|
| NASA dataset | 0.158019 | 0.894939 | 0.075128 | 0.966846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rath, S.K.; Sahu, M.; Das, S.P.; Bisoy, S.K.; Sain, M. A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model. Electronics 2022, 11, 2707. https://doi.org/10.3390/electronics11172707
Rath SK, Sahu M, Das SP, Bisoy SK, Sain M. A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model. Electronics. 2022; 11(17):2707. https://doi.org/10.3390/electronics11172707
Chicago/Turabian StyleRath, Suneel Kumar, Madhusmita Sahu, Shom Prasad Das, Sukant Kishoro Bisoy, and Mangal Sain. 2022. "A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model" Electronics 11, no. 17: 2707. https://doi.org/10.3390/electronics11172707
APA StyleRath, S. K., Sahu, M., Das, S. P., Bisoy, S. K., & Sain, M. (2022). A Comparative Analysis of SVM and ELM Classification on Software Reliability Prediction Model. Electronics, 11(17), 2707. https://doi.org/10.3390/electronics11172707