1. Introduction
In recent years, the decision problem of close-range air combat has become a hot topic. Close-range air combat is a game process involving a target; it is characterized by high-level dynamics and intense confrontation [
1,
2]. Fighters make maneuver decisions according to rapidly changing information in air combat situations. Since an air combat environment often contains complex factors such as uncertainty and incompleteness, it poses severe challenges for air combat decision making. Moreover, fighters are always in high-speed motion and lots of players are involved in the game. A lack of a definite pattern or method for soldiers, as well as incomplete combat rules, will lead to explosive growth in the game solution space. The purpose of air combat maneuver decisions is to obtain an optimal air combat situation, i.e., to threaten the target fighter and carry out effective attacks, to get rid of the lock of a target fighter and get out of danger. Therefore, every maneuver will directly affect the development of the process.
Despite the numerous achievements in air combat maneuver decision-making in a battlefield environment, few studies have focused on uncertain battlefield environment information. Addressing the decision problem of air combat maneuvers under the condition of certain battlefield environmental information, Dr. Luo and Dr. Meng [
3] used a multi-state transition Markov network to construct a maneuvering decision network, which met the real-time requirements of air combat decision-making but did not use network parameters for learning. An iterative algorithm for online integral strategy combining approximate dynamic programming and a zero-sum game was proposed in [
4]. An algorithm combining game theory and a deep reinforcement learning algorithm to study the maneuvering decision problem of close-range air combat were proposed in [
5,
6]. The above models are mainly game methods applying the strategies of two or more sides, which can be categorized as matrix games and differential games. Their main characteristics are to factor an opponent’s strategy into the analysis, and to emphasize the antagonism between two or more sides. In addition, there are methods that consider unilateral optimization, focusing on the optimization of their own strategies, as opposed to predicting and analyzing opponents’ strategies; these mainly include intelligent methods, guidance laws, and expert systems methods, etc. An evolutionary expert system tree method to study air combat decision-making is proposed in [
7]; it solves the problem associated with the inability of traditional expert system methods to cope with unexpected situations. The method described in [
8] uses the deep reinforcement learning method to solve the air combat maneuver decision-making problem. Prof. Du [
9] proposed a maneuvering decision model that combines multi-objective optimization and reinforcement learning. Dr. Xu [
10] combined the characteristics of a missile attack zone and the basic flight maneuver (BFM) method to study the 1vs1 autonomous air combat decision-making problem. An air combat maneuver method based on BFM was also introduced in [
11].
It is usually difficult for both sides to obtain accurate information about each other on the battlefield. Therefore, it is necessary not only to study the problem of deterministic information-based air combat games, but also to solve the problems of incomplete information in air combat. Aiming at the problems of uncertain battlefield information, Chen Xia and Liu Min [
12] studied an offensive and defensive setting involving unmanned aerial vehicle (UAV) air combat. They also modeled the payoff function and combined it with particle swarm optimization (PSO), proposing the Nash equilibrium solution method under uncertain information conditions. The authors of [
13] established an intuitive fuzzy game model for UAV air combat maneuvering, and proposed a nonlinear programming method for solving Nash equilibrium which addresses the problems of UAV air combat maneuvering decision-making under uncertain environments. The authors of [
14] attempted to solve the Nash equilibrium of non-cooperative games under an uncertain battlefield information environment, and analyzed the influence of different combat factors on the outcomes of air-to-air confrontations. An information supplement method based on Bayesian theory and an information reduction method based on rough and light set theory were adopted to process uncertain air combat information. These processes improved the efficiency of autonomous decision-making in air combat [
15]. Additionally, a belief state based on MCTS was proposed by Dr. Xu to tackle their use in problems with imperfect information [
16].
Motived by the above discussion, in our paper, a close-range air combat decision process under uncertain interval information conditions is modeled as a two-layer game decision-making solution. Additionally, a double game tree distributed Monte Carlo search algorithm is proposed to determine the optimal game strategy scheme. Both parties establish a game tree to make synchronous decisions. Due to the nature of the applied multi-fighter, multi-round, continuous air combat game, there are a large number of players, and the air combat has no fixed strategies, i.e., the combat styles are complex and diverse. As a result, the maneuvering decision-making solution space dramatically increases in complexity. Traditional maneuvering decision-making methods are difficult to simulate and are unable to comprehensively predict situations in air combat games. It is therefore necessary to find a more efficient solution. The MCTS algorithm introduces the idea of reinforcement learning based on trial sampling, and simulates and evaluates the air combat process through the iterative process of the algorithm, which is equivalent to filtering and optimizing the policy search space. This approach is suitable for solving problems with huge decision spaces. Therefore, the algorithm can grasp and predict air combat game situations more and more accurately in a continuous simulation game process, and as such, can accurately grasp and predict trends in the enemy’s strategy as much as possible. As a result, it can determine the best maneuvering strategy scheme in current and future situations.
2. Modeling of Two-Layer Game Maneuver Decision Problem
Because of limited intelligence information and the influence of electromagnetic interference on the battlefield, sensors may be restricted in their ability to identify targets or to determine the maximum detection range of radar and the ranges of certain weapons. As such, partial information is likely to be obtained only within a certain range. Therefore, it is necessary to study the uncertain information air combat game strategy algorithm for incomplete information. In order to improve the nature of maneuver decision-making, the analysis and processing of uncertain information is critical.
Multi-fighter air combat maneuver decision-making needs to solve the problems of who the combat target is, how to fly, and how to maneuver, which actually involve target allocation, coordinated tactics, and an action selection strategy. Based on the accurate modeling of air combat games and the determination of a fighter’s intentions, this paper simulates operational decision-making thinking according to the idea of simplifying complex problems and divides maneuver decisions into two levels: target allocation and action selection. Target allocation decisions are made on the first level and air combat maneuvering decisions on the second, after identifying a target. Target allocation decision-making mainly determines the target allocation strategy in one-to-one or many-to-one situations, and solves the problem of who the combat target is and with whom to coordinate the operation. Action selection involves choosing a suitable maneuver strategy based on the target allocation plan, serving mainly to solve the problems of how to fly and maneuver. The cooperative nature of the target allocation decision-making layer mainly determines the cooperative allocation scheme according to the performance threat index and intention threat index of the whole system and the cooperative effect generated by the game payoffs of each fighter in the system. The cooperative tactics of the action selection decision-making layer are mainly determined by the cooperative performance threat index of opponent fighters and the game payoff value of the maneuver decision-making.
First, a dominant function model should be established to assess the situation and the effect of multi-fighter coordination, as well as to make multi-fighter air combat target allocation and maneuver decisions. Many factors affect air combat situations. The process described in this paper makes air combat target allocation decisions based on angle and distance factors, the performance threat and combat intention threat indexes, as well as changes of the total threat index due to multi-fighter cooperation.
2.1. First Layer Target Allocation Decision Model
2.1.1. The Performance Dominant Function
The fighter performance dominant function needs to comprehensively consider factors such as maneuverability, detection ability, firepower, and electronic countermeasures ability. Suppose the maximum detection range of the radar of the
i-th fighter of N is
, its maximum range of attack is
, and its electronic countermeasure capability coefficient is
. At the same time, suppose the maximum detection range of the radar of the
j-th fighter of M is
, its maximum range of attack is
, and its electronic countermeasure capability coefficient is
. Since the fighter can perform various maneuvers quickly, it can be assumed that the radar on the fighter is omnidirectional and the fire attack angle is 360 degrees.
is the air combat performance advantage index of the
i-th fighter of N and
is the air combat performance advantage index of the
j-th fighter of M.
and
are calculated in the same way. Based on [
17], the performance dominance function of fighter
is established as follows:
2.1.2. The Angular Dominant Function
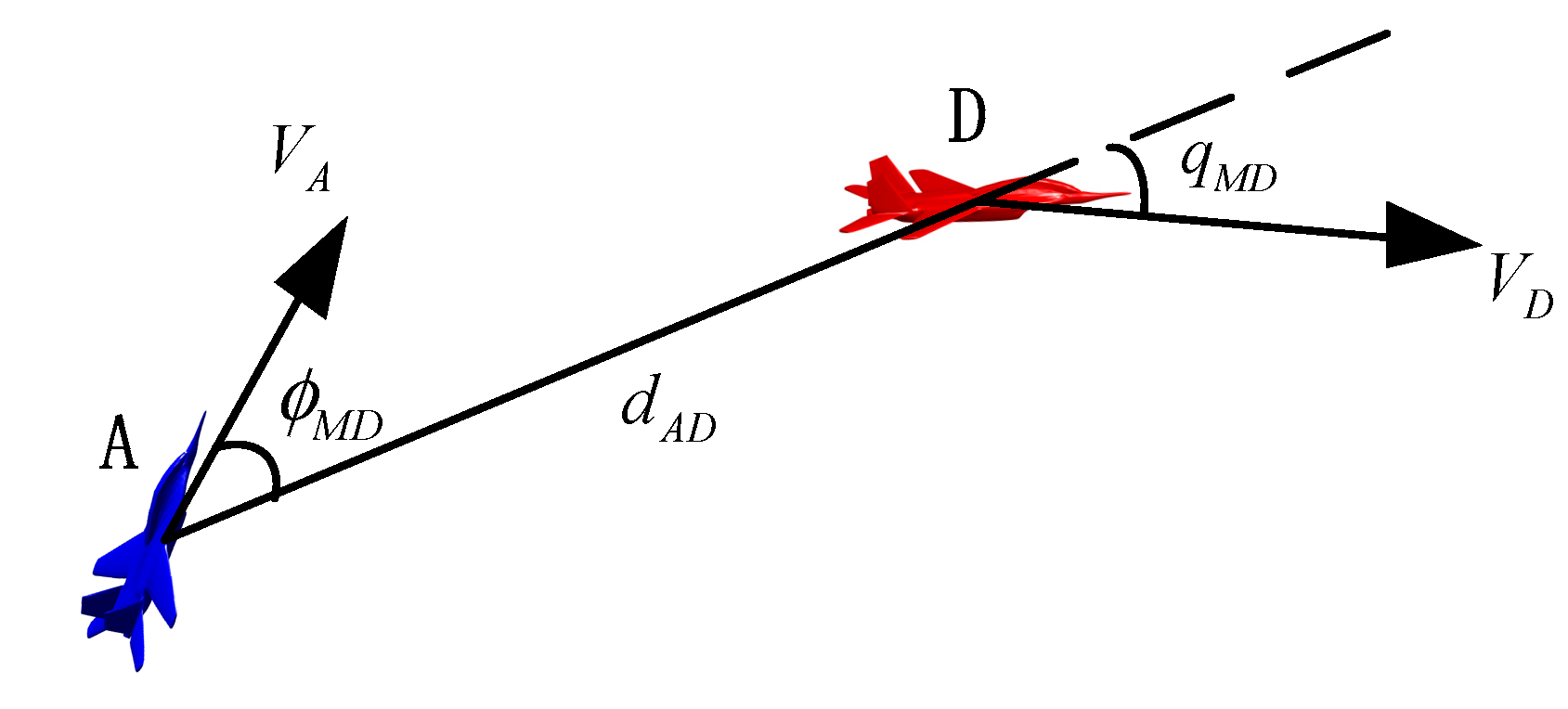
The influence of the angle between two fighters on an attack situation is called the angular dominant function. Suppose A is an attack fighter and D is the target fighter (
Figure 1). The target line
is defined as the line between A and D.
is the angle between the velocity vector of A and the target line.
is the angle between the velocity vector of D and the target line. Then, the value of angular dominant function may be defined as follows:
2.1.3. The Distance Dominant Function
The influence of the distance between two fighters on an attack situation is called the distance dominant function. The distance dominant function represents the distance advantage of the two fighters and the influence of the distance after an air combat decision.
is the distance between the
i-th fighter of N and the
j-th fighter of M. Generally, the maximum detection range of radar is larger than the range of missiles. Suppose that the distance advantages are 0 and 1 for the cases of outside the radar detection range and inside the missile range, respectively. When the distance is between the maximum detection range of the radar and the range of the missile, the distance advantage value increases with the decrease of the distance between the two fighters. The value of the distance dominant function may be calculated as follows:
2.1.4. The Performance Threat Index Dominant Function
When multiple fighters cooperate in air combat, the synergistic effect is reflected in that the total threat index of one side decreases while that of the other side increases. Therefore, after the targets have been allocated, the performance threat index dominant function of the
i-th fighter of N relative to the
j-th fighter of M may be calculated as follows:
when the distance between the two fighters is larger than the maximum detection range of the opponent’s radar, the threat index is 0. The parameter
is the threat index;
suggests that the threat index decreases with an increase of distance. The threat index dominant function
of the
j-th fighter of M relative to the
i-th fighter of N is calculated analogously.
2.1.5. The Combat Intention Threat Value
In an air combat environment, both sides will take a series of combat actions to achieve their combat intentions. Combat actions are achieved through a series of maneuvers, and the execution of such maneuvers will lead to changes in the fighter status [
18]. Therefore, the achievement of combat intention is ultimately manifested as the changes of combat status parameters, while different combat intentions correspond to different change rules of status parameters. In this paper, intention space in close air combat is defined as four types of combat intention strategies
, where cover includes reconnaissance, jamming, maneuvering cover, and feint, and penetration includes low- and high-altitude penetration. According to [
19,
20,
21], the mapping relationship between a fighter’s combat intention and the characteristic status parameters can be obtained.
Table 1,
Table 2 and
Table 3 list the corresponding relationship between the fighter’s characteristic status information regarding altitude, course angle, maneuver type and combat intention. The intention threat value as showed in
Table 4.
2.1.6. The Combat Intention Threat Index Dominant Function
To estimate the threat index of the combat intentions of both sides, the enemy’s combat intentions should be identified first. According to the estimated threat index of combat intention and the influence of combat intention on combat effectiveness, game countermeasure strategies are adopted to achieve the optimal combat effectiveness. In air combat, the enemy usually hides their true combat intentions as far as possible, which leads to the concealment of the status information obtained by the opponent at a given moment. Moreover, the target fighters’ combat intentions are implemented through a series of combat actions and maneuvers. The real intention is usually hidden in the dynamic and time-changing status information, so the combat intention should be identified from the target status fighter’s information from several consecutive moments. According to the method described in [
22], we can extract a fighter’s characteristic information from time series and dynamically changing air combat situation data. On this basis, we can map the relationship between combat intention and the characteristic status parameters. Then, we can use the Long Short Term Memory (LSTM) neural network to learn the fighter’s time series characteristics and identify the target fighter’s combat intention. After determining the enemy’s combat intention, the threat index of the
i-th fighter of N relative to the
j-th fighter of M is estimated using the following formula. The threat index,
, of the
j-th fighter of M relative to the
i-th fighter of N is calculated analogously.
2.1.7. The Total Threat Index of Multi-Fighter Coordination
The change in the collaborative total threat index is due to the influence of multi-fighter coordinated air combat on the combat situation. The total threat index of multi-fighter coordination mainly manifests in changes in the global performance threat index and combat intention threat index after multi-fighter coordination. Both the total performance and the total intention threat index of the whole system should consider the threat of each combat unit to the each of the opponent’s combat units. These reflect the overall synergistic threat effect and performance of both sides. Therefore, when multiple fighters cooperate in air combat, the total performance threat index and the total intention threat index of both sides may be respectively calculated by the following equations.
The cooperative performance threat index of N and the cooperative performance threat index of M are calculated using Equations (7) and (8):
Similarly, the cooperative intention threat index of N and the cooperative intention threat index of M are calculated as follows:
2.1.8. The Target Allocation Decision Function
In the first layer, the decisions of target allocation and combat intention are completed. In the target allocation decision stage, it is assumed that the following constraints are met: a fighter from N should attack at least one fighter from M, and only one fighter from M can be attacked in a discrete short interval. Four factors are considered to make the target allocation decision. Firstly, the performance and threat factors of the opponent’s fighters, such as their maneuverability, electronic countermeasure capability, and detection and firepower capabilities, are assessed. Secondly, the positional factors of the opponent’s fighters, i.e., the angle and distance are considered. Thirdly, the threat factors of the combat intentions of both sides are considered after determining the opponent’s combat intentions. Fourth, the effect factors of the threat index are updated based on multi-fighter collaboration. Since height dominance can be derived from the distance and angle, it is not considered in this paper. Speed is considered in the basic maneuver library, and the decision to either accelerate or decelerate is made. Taking an N fighter as an example, the comprehensive dominant function of the i-th N fighter relative to the j-th M fighter is constructed as , , and . These values represent the angle dominant function, distance dominant function, combat intention threat value, and the performance dominant function of the i-th N fighter relative to the j-th M fighter in the current situation. These are all normalized values.
In conclusion, the total dominant function of multi-fighter cooperative air combat in the target allocation scheme can be established. These four factors, as well as the influence of the collaborative performance threat index and collaborative intention threat index of the system globally are mainly comprehensively in the target allocation stage. The optimal payoff of collaborative target allocation is determined on this basis. Therefore, the total payoff functions of N and M, respectively, can be calculated as follows:
where
,
,
,
are weight coefficients and
.
Both sides in the air combat game always try to maximize their respective payoff functions. Therefore, the target allocation decision function selects the scheme with the optimal total dominant function value from many options, i.e., or .
2.2. The Second Layer Maneuver Decision Model
2.2.1. Basic Maneuver Library
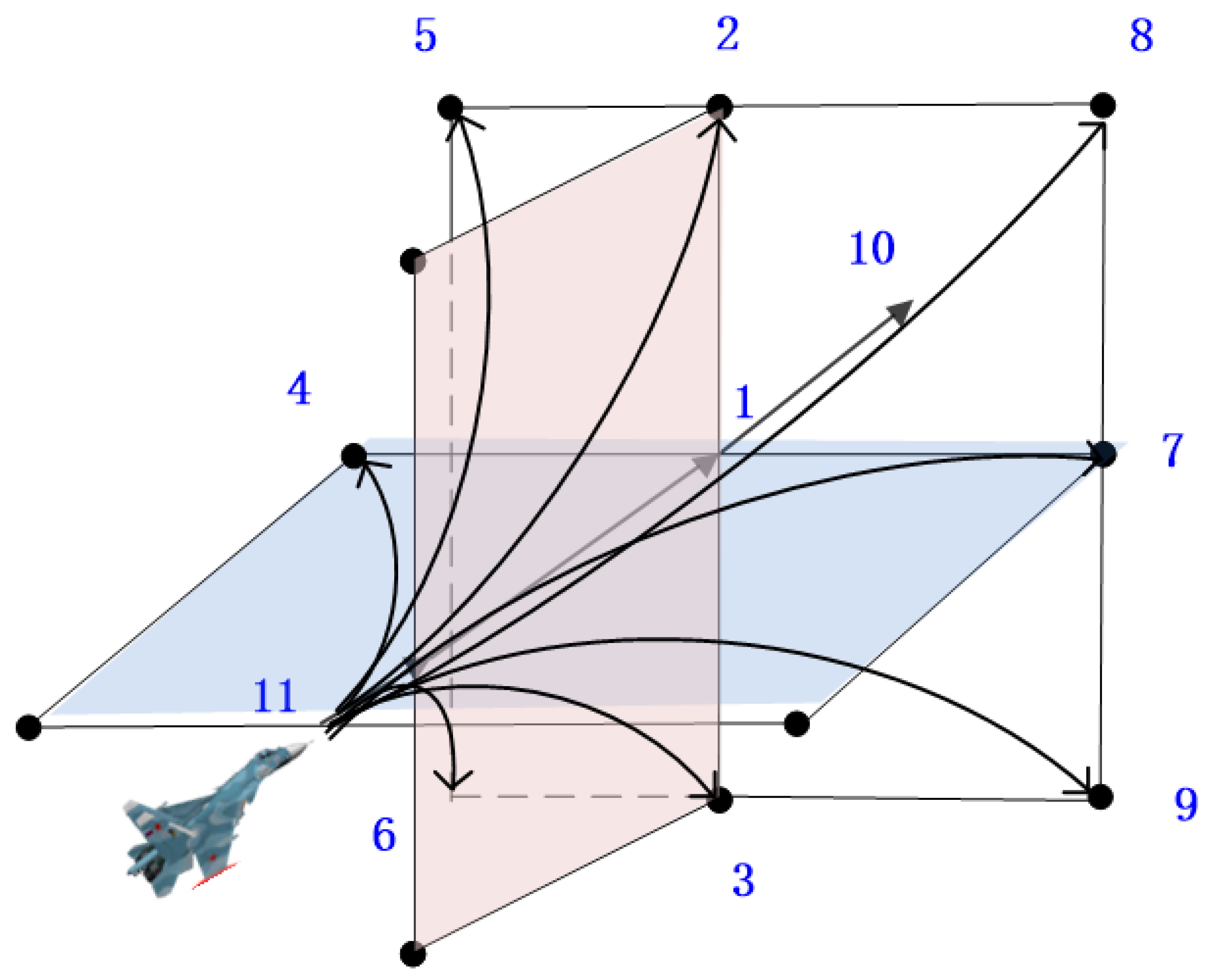
If an air combat game is considered as a game of chess in a three-dimensional space, then the game strategies can be considered to be based upon the various positions on the chessboard and the choice of different game strategies, which will result in different payoffs. According to [
1], the maneuvers of a fighter in three-dimensional space can be divided into 11 categories. As shown in
Figure 2, these maneuvers include: 1. direct flight without any maneuver, 2. Climbing, 3. Diving, 4. Turning left, 5. Climbing to the left, 6. Diving to the left, 7. Turning right, 8. Climbing to the right, 9. Diving to the right, 10. Accelerating, and 11. Decelerating. The inclination angle can reach −60°, 0°, and 60°, corresponding to climbing, flying without any maneuver, and diving, respectively, and the roll angle can reach −30°, 0°, and 30°, corresponding to turning left, flying without any maneuver, and turning right, respectively. The basic maneuver library can combine most tactical maneuvers in air combat, and different combinations of sequences correspond to different tactical maneuvers [
1,
9].
In the existing literature, the relationship between the current maneuver and the next one is often ignored. For example, if a fighter chooses to dive to the left, after performing this action, only maneuvers 3 and 4 should be possible in the next maneuver decision, because the fighter cannot, e.g., turn or dive to the right in the next decision-making cycle. Therefore, for close-range air combat decision-making, the decision result of the current maneuver affects the range of possible maneuvers in the next decision cycle. Accordingly, this paper establishes a constraint relationship between the current maneuver decision and the next maneuver decision library, as shown in
Table 5, in order to prevent the algorithm from searching for the maneuvers that are difficult or impractical.
2.2.2. The Maneuver Decision Function
In the second layer, air combat maneuver decisions are made. Decisions regarding air combat maneuvers consider three factors: the first is the distance factor between the opposing fighters; the second is the angle factor of the two fighters; and the third is the performance threat effect factor of multi-fighter cooperation.
where
and
are the payoffs of a maneuver decision,
,
are weight coefficients;
.
,
,
,
,
,
are different from the decision process of target allocation. At this point in the process, they are the angle dominant function, distance dominant function and performance dominant function at the next moment situation. These values are all normalized.
3. Interval Number Correlation Methods
3.1. The Operational Rules of Interval Numbers
is called an interval number [
23,
24], if
, where
R is a set of real numbers,
is the lower limit value of
, and
is the upper limit value of
.
If and are two interval numbers, then their operational rules are defined as follows:
(1) Addition
(2) Subtraction
,
and , .
(3) Multiplication
, and , where is a positive real number.
(4) Division
, where
(5) Logarithm
, where
In the first layer game decision, N has mn kinds of allocation schemes and m side has nm kinds of allocation schemes. According to the operation rules of interval numbers, due to the uncertainty of the information interval, each value obtained by the payoff function is an interval number. Therefore, the payoff value of the game can be written as: and .
Similarly, in the second layer game decision, the payoff value can be written as: and .
3.2. The Solving Game Method Based on the Possibility Degree
According to [
25], two interval numbers
and
can be compared by the possibility degree. Namely, the definition of the possibility degree that
is superior to
is regarded as
:
Accordingly, the definition of the possibility degree that
is superior to
is regarded as:
Using Equations (15) and (16), we can obtain the possibility degree matrix using and comparing every two interval numbers as follow: .
is the payoff value of the h-th scheme and is the possibility degree value of , , . When , represents no comparison. The value indicates the level of . If , is definitely better than . Conversely, if , is definitely better than . Thus, the matrix is a complementary judgment matrix.
By comparing all the strategy combination schemes, namely, comparing the interval numbers of the payoff in pairs, we can obtain the possibility degree matrix. Then, by employing the improved chaotic particle swarm algorithm and sorting the strategy combination schemes, we can obtain the optimal scheme.
4. The Solving Algorithm Based on Two-Layer Game Decision-Making and Distributed MCTS
4.1. Distributed Monte Carlo Search Algorithm Based on Double Game Trees
Both sides establish their own game trees in the air combat game process. The whole process is described as a path from the root to the leaf of a multi-way game tree because the game process chooses a target fighter and a maneuver strategy for both sides. After the target allocation of the first layer decision, the target of each fighter is determined. This is equivalent to pre-pruning the game tree. Therefore, in the second layer decision-making, we consider the maneuvering decision under the condition that the target fighter has been determined. Compared with a one-time decision, the game strategy search space is greatly reduced, and the searching efficiency is improved.
The MCTS algorithm is used for game strategy selection. The algorithm can maintain a balance between exploitation and exploration, i.e., it aims to ensure the best rewards from past decisions and to obtain greater rewards in the future. It can master and predict game strategies more and more accurately in the current and future situations. The MCTS algorithm is a method by which to establish a search tree to find the best decision based on the decision space of sampling in a specific field. In summary, the air combat situation is mainly determined by the distance and angle between the two fighters. It includes four steps: selection, expansion, simulation, and back-propagation [
26]. In order to search the air combat game node, in this paper, the MCTS frame adopted a modified Upper Confidence Bound (UCB) algorithm.
Step 1: Selection. Suppose the root node is the attacking side. The UCB value is calculated by Equation (17). The node with the maximum UCB value will be selected as the subsequent node.
where
is a normalized value of the average payoff of fighter
in the past, i.e.,
,
is the total number of times which a game strategy is selected, and
is the number of times which the
game strategy was selected. The regulatory factor is C; it is used to adjust the balance between the return value and the unexplored node.
Step 2: Expansion. If the MCTS algorithm does not reach the termination condition for the maximum number of iterations or leaf nodes, then it can continue to select the game strategy is a downward process. If the MCTS algorithm reaches the leaf node, then it needs to expand the game strategy as a new node; as a result, the new game strategy will be added to the Monte Carlo tree.
Step 3: Simulation. Since the new node has not yet been visited, the times of visits and the times of wins are both 0. A simulation is then carried out on the node according to the default random strategy.
Step 4: Back-propagation. Suppose side N or side M wins. Then, the times of visits and of wins of every node on the simulation path will both be updated to 1, that is, 1 will be added to those values on all the father nodes.
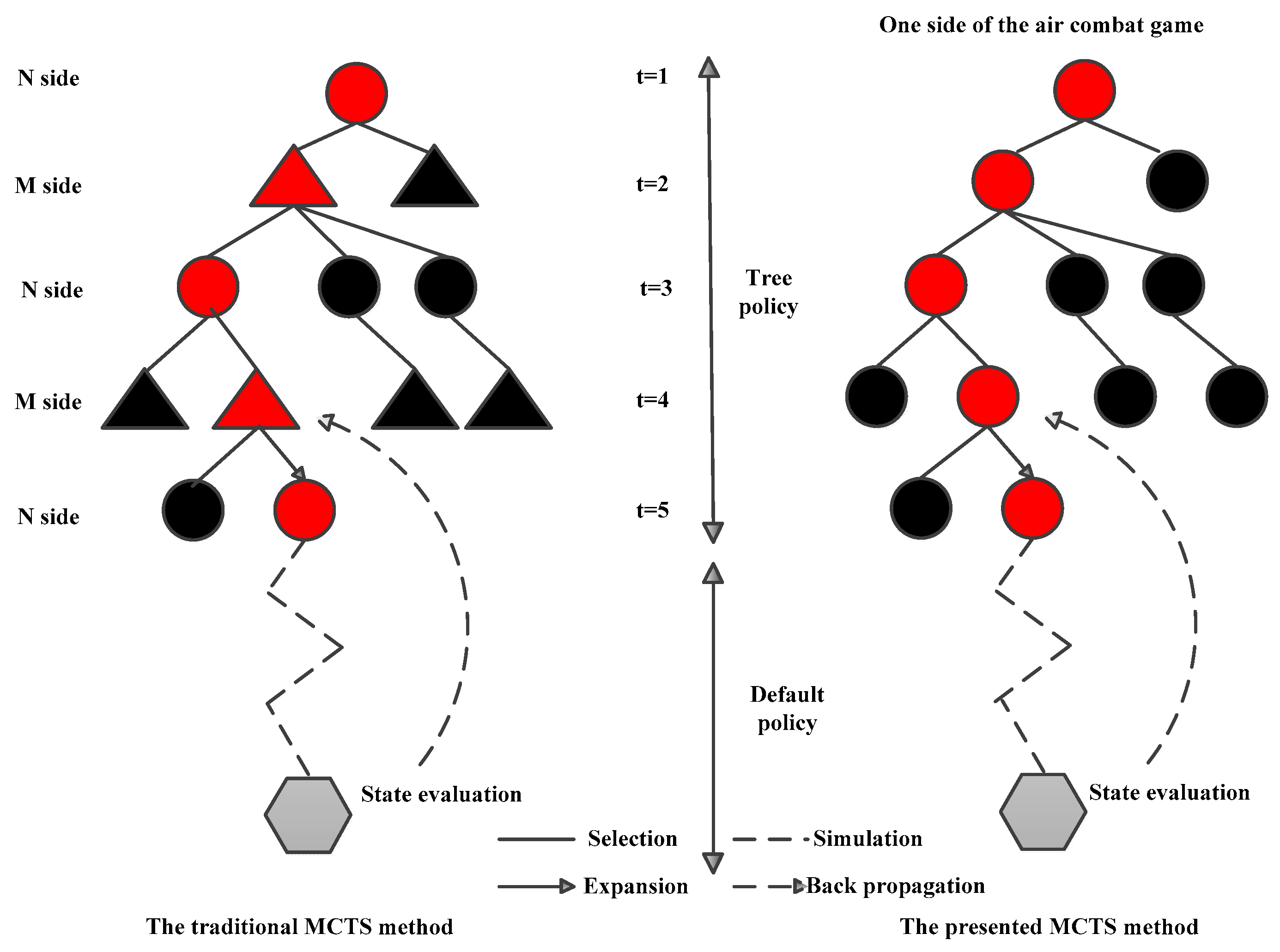
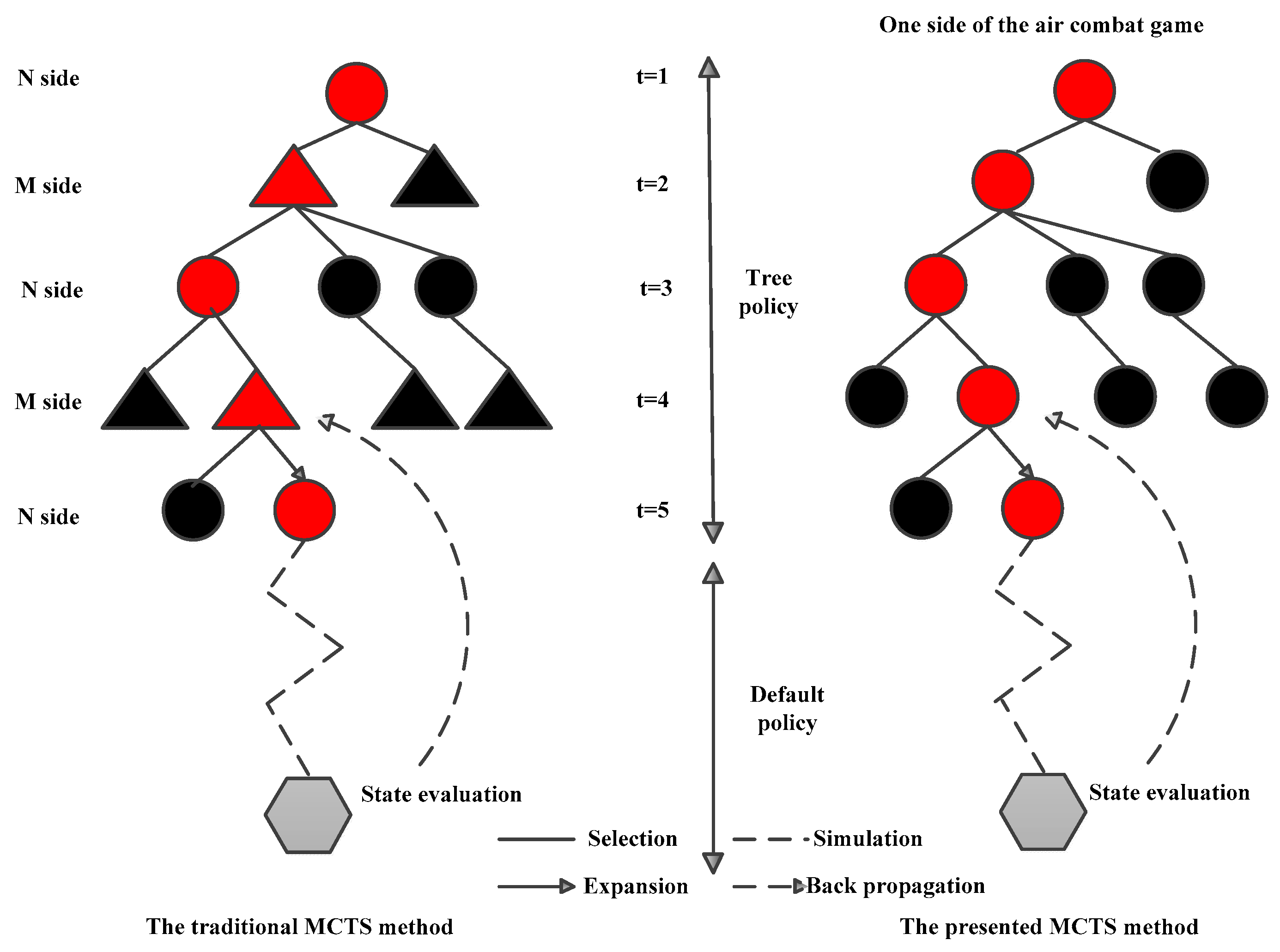
In the traditional Monte Carlo search method, both sides of the game play sequential games on the same game tree and make decisions in turn [
16,
26]. In this way, both sides will make game decisions in chronological order. For example, when
t = 1, the decision is made by N, but when
t = 2, the decision is made by M; subsequently, when
t = 3, the decision is made by N, and so on. Thus, the game is a repetitive process, as shown on the left of
Figure 3. In sequential game decision-making, the player who makes the strategy choice and takes the action first usually occupies an advantageous position. The other player must choose its own strategy on the basis of the opponent’s action strategy. The most important characteristic of the air combat game, in contrast to a game of chess, is that both sides make decisions simultaneously under the current game situation environment.
Due to the different mission characteristics and the high real-time requirements of the air combat game, it is not suitable to directly use a traditional Monte Carlo tree search. In the multi-fighter and multi-round continuous air combat game, not only the coordination of multi-fighter combat, but also the influence of the historical game strategies of both sides should be taken into account, and the decisions of both sides should be made at the same time rather than in turn in order to avoid problems such as lagging decision information. Therefore, a distributed double game tree Monte Carlo search algorithm was designed in this paper for maneuvering decisions; this represents a novel MCTS method. As shown on the right of
Figure 3, both sides establish a game tree. At
t = 1,
t = 2, …,
t =
n, both sides make synchronous decisions in their respective game trees at every moment, and there is no need to wait for the opponent to make a decision before taking turns. Meanwhile, the dominant value and decision function are calculated according to the real-time updated situation information. In this way, the battlefield situation can be perceived in real time, the opponent’s strategies can be applied when making decisions, and the optimal game strategy scheme can be obtained.
4.2. The Algorithm Flow
(1) Initialization: set the values of the parameters
(2) Repeat
(3) Determine the current nodes of the game trees and identify the opponent’s intentions according the situation information;
(4) Calculate the various target allocation schemes, or , at the current moment;
(5) The first layer of game decision: select the optimal scheme, i.e., or ;
(6) Calculate all possible maneuver decision schemes, or , at the next moment;
(7) The second layer of game decision: select the maneuver decision scheme using the UCB algorithm and MCTS;
(8) Update the situation information of the game decision trees of both sides;
(9) t = t + 1;
(10) Repeat until the maximum number of iterations, or , has been reached.
5. Experiment and Results
A 2vs2 air combat was simulated in three-dimensional space in this experiment. The initialization in the simulation was as follows. The initial coordinates of the N and M fighters were (1000, 500, 6100), (1500, 800, 4000) and (5000, 1000, 3200), (4500, 1500, 6500), respectively. The initial yaw angle, track inclination angle and roll angle were (1, 0, 20), (1, 0, 0), (1, 0, 0) and (1, 0, −15), respectively. The of N were [12, 16] and [17, 20], and the of M were [10, 15] and [17, 21]. The of N were [500, 800] and [800, 1000], and the of M were [600, 800] and [700, 1000]. The of N were [0.5, 0.8] and [0.6, 0.9], and the of M were [0.7, 0.9] and [0.6, 0.9]. k = −1/400 and C = 0.1. , , , were set as 0.2, 0.3, 0.3 and 0.2, and and were set as 0.6 and 0.4. The termination condition of the algorithm was set as follows: reaching the maximum number of decision iterations (21), or the difference between the two payoff function values reaching the threshold value of 0.9.
The simulation results are shown in
Figure 4,
Figure 5,
Figure 6 and
Figure 7 and
Table 6. In this simulation, it was assumed that the basic maneuver libraries of both sides were the same, and the same decision algorithm was adopted. In
Figure 5,
Figure 6 and
Figure 7, the average values of the interval results were used for plotting.
Table 6 lists the maneuver decisions for all fighters.
Figure 4 shows the air combat flight trajectories of the four fighters.
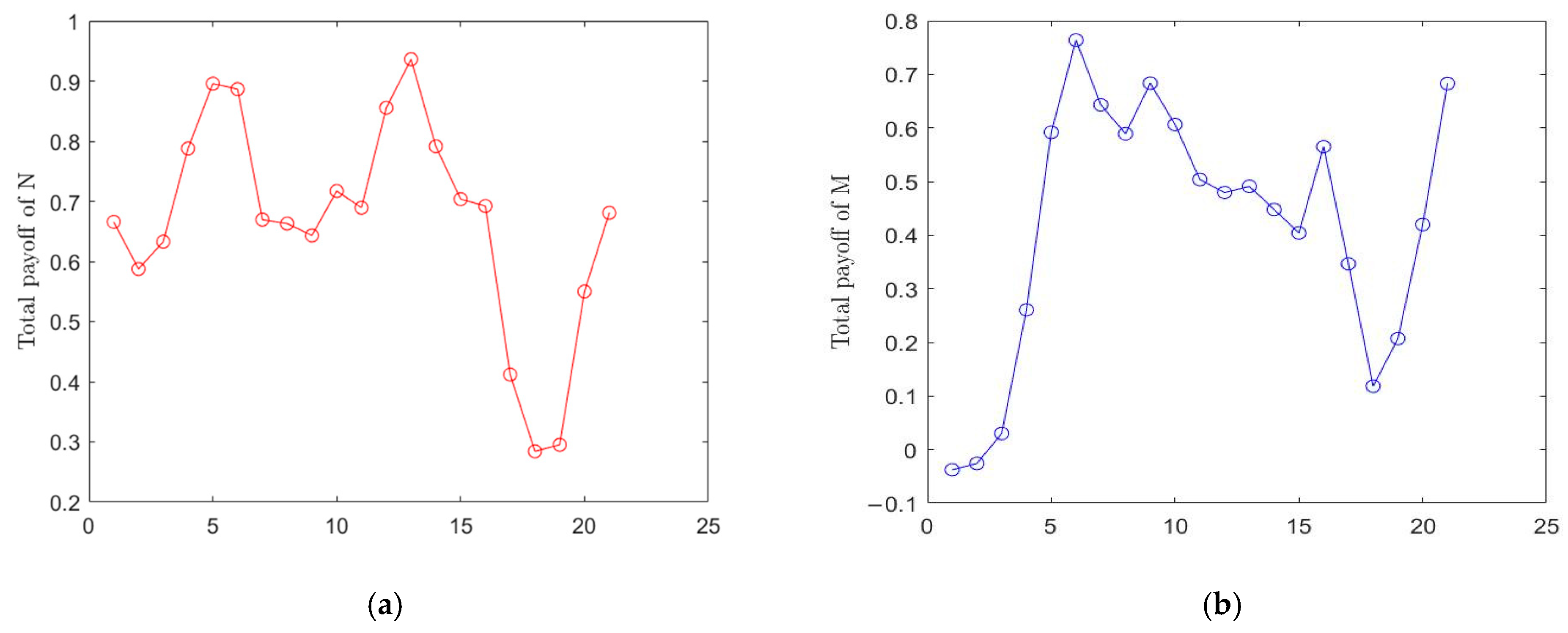
Figure 4a,b present the three- and two-dimensional plane projection graphs of the flight trajectories, respectively. Each curve represents the combat flight trajectory of a fighter according to our algorithm. The total payoff function change curves of N and M, corresponding to the decision in the first layer game, are shown in
Figure 5.
Figure 5a presents the total payoff function of decisions taken by N, and
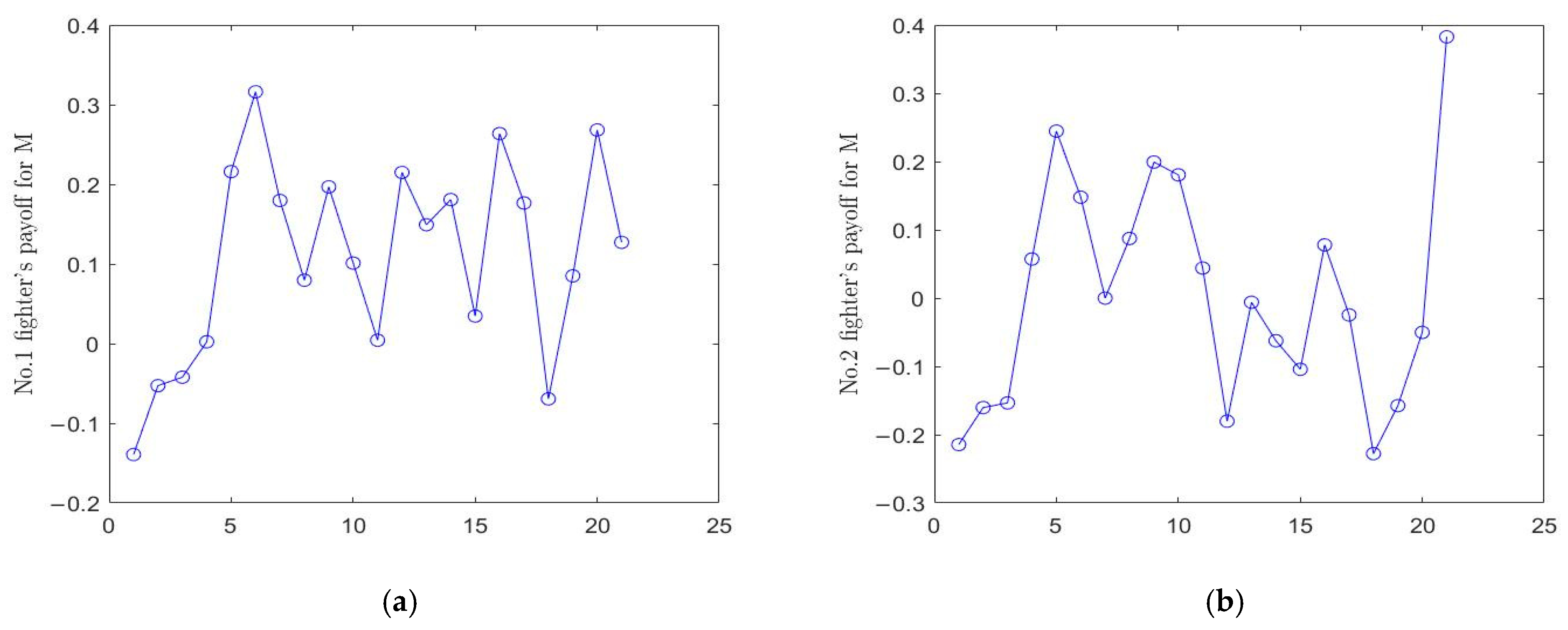
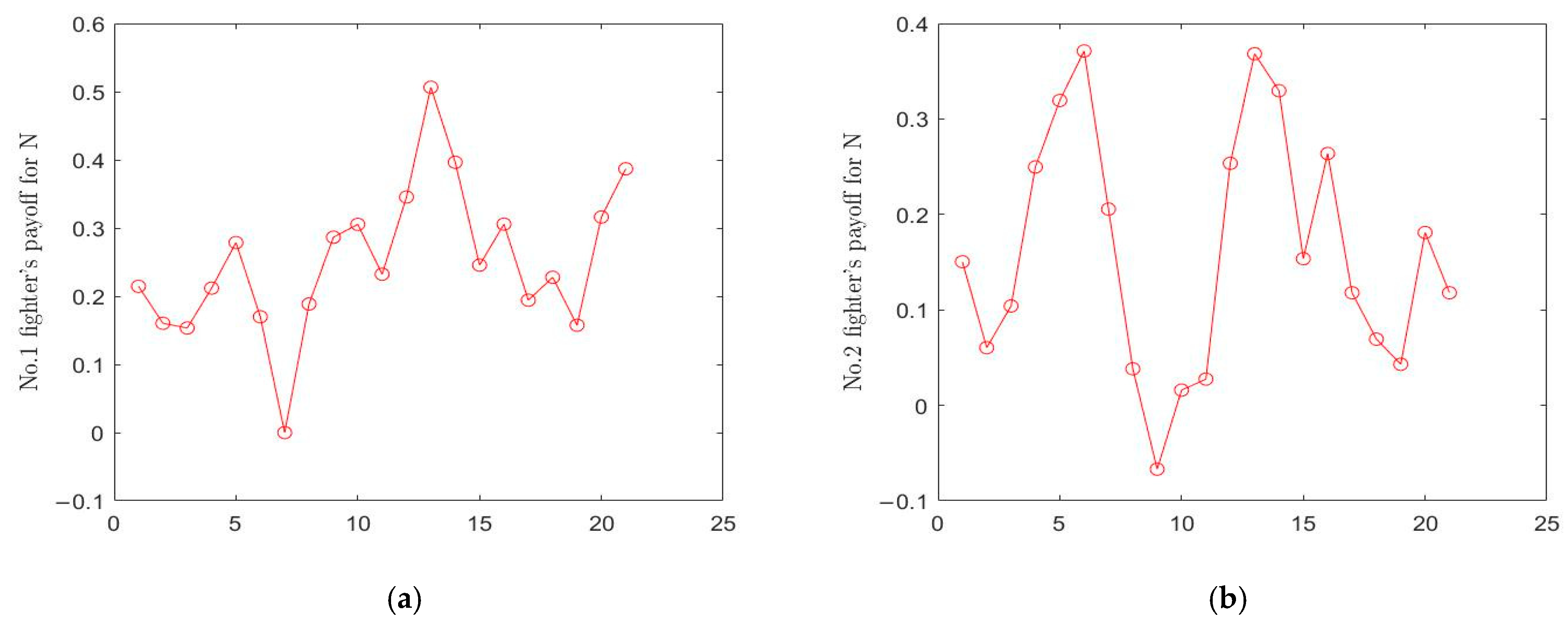
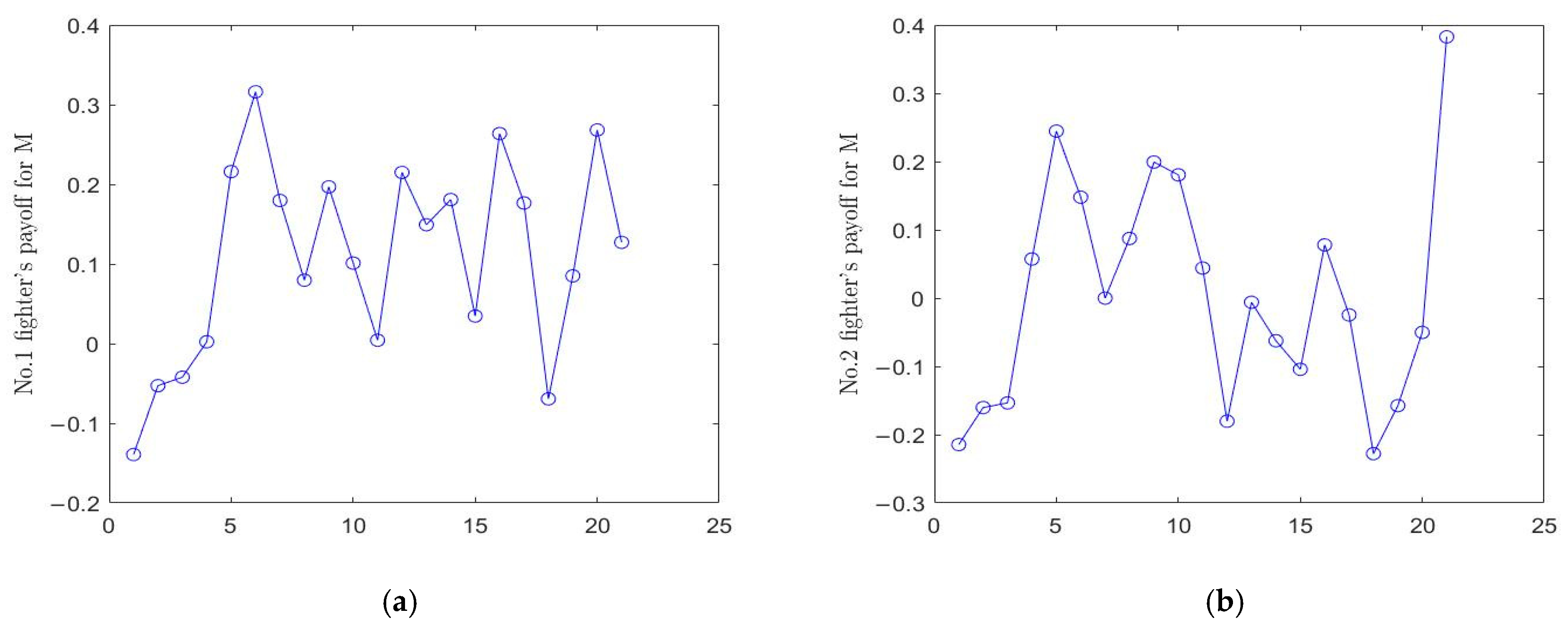
Figure 5b those of M. The payoff function change curves of the four fighters corresponding to the decisions in the second layer game are shown in
Figure 6 and
Figure 7.
Figure 6a,b presents the changes of payoff function of fighters 1 and 2 of N in the whole decision-making process, respectively, while
Figure 7a,b presents those of fighters 1 and 2 of M.
From the experimental results, it can be seen that the algorithm proposed in this paper is effective. Under the condition that the fighter performance on both sides is closely matched, combat fighters can correctly identify the combat intention and movement state of the opponent, forecast the trajectory of the opponent’s fighter and accurately predict the battlefield situation, and quickly make the optimal decision. It can be seen from
Figure 4a,b that the two sides struggle due to continuous target allocation and maneuvering decisions, and the flight trajectories show a highly staggered pattern. It is obvious that the situation changes rapidly and becomes complicated. For example, the target allocation of the No. 1 fighter of N changed at
t = 11, while the target allocation of the other fighters remained unchanged. From
Figure 5a,b, it can be seen that the total payoff values of both sides and the payoff values of each fighter fluctuated constantly, indicating that the situation changed frequently for both sides, and that there were situations in which an advantage turned into disadvantage, or vice versa. This conforms to actual combat situations. As can be seen from the results, when
t = 1, the initial total payoff values of N and M were 0.6659 and −0.0375, respectively, at the target allocation stage; the payoff values of fighters 1 and 2 of N were 0.2145 and 0.1504, respectively; and the payoff values of fighters 1 and 2 of M were −0.1392 and −0.2145 respectively. However, when
t = 21, the total payoff values of N and M were 0.6809 and 0.6829, respectively, at the target allocation stage; the payoff values of fighters 1 and 2 of N were 0.3869 and 0.1179, respectively; and the payoff values of fighters 1 and 2 of M were 0.1272 and 0.3827, respectively. It can be concluded that M was at a disadvantage in the initial situation, but by the end, both sides were basically balanced. The strategy space for air combat games is very large, and it is impossible for the opponent to adopt the optimal solution every time. Even if the opponent uses the MCTS method to determine the optimal solution, if the best decision-making time is achieved and the right decision-making solution is used, it is possible to turn defeat into victory.
In order to verify the performance of the algorithm, we performed four groups of comparative experiments. In the four groups, N adopted the algorithm designed in this paper, while M adopted four different algorithms, namely, the algorithm described in this paper, the traditional MCTS algorithm, the angle and distance optimal algorithm, and the distance optimal algorithm. All four algorithms need to meet the maneuver constraints in
Table 5 when making decisions. According to the design idea of the algorithm proposed in this paper, the traditional MCTS algorithm will select and decide the optimal combat strategy for M from the first layer decision-making schemes at time
t (e.g., Equation (12)) and combine the second layer decision-making schemes at time
t + 1 (e.g., Equation (14)). However, in the decision-making process, the traditional MCTS algorithm does not make two-layer decisions, but rather, makes several decisions simultaneously. The third group attempts to optimize the angle and distance to make decisions. That is, according to Equations (3) and (4), the maneuvering strategy with the maximum benefit is selected as the combat strategy for M based on the optimization of angle and distance at time
t and angle and distance at time
t + 1. The fourth group applies the optimal distance to make decisions. That is, the maneuvering strategy with the maximum benefit is selected as the combat strategy of M based on the comprehensive optimization of distance at time
t and time
t + 1.
In the algorithm proposed in this paper, the difference in the first layer decision payoff between the two sides is noted as
, while the difference in the second layer decision payoff is noted as
. The four groups of experiments were carried out 20 times each, and the
and
values of the four groups of experiments were compared. The results are shown in
Table 7 and
Table 8. As can be seen from the experimental results, when
> 0 and
> 0, the N side has a better payoff. Conversely, when
< 0 and
< 0, N has a poor payoff and is at a disadvantage. When
= 0 and
= 0, both sides have the same payoff and the air combat situation is balanced. In the experiments, M used four different algorithms for air combat, while the N algorithm remained unchanged. When the probability of
> 0 and the probability of
> 0 are greater, it was difficult for M to gain an advantage, and the benefits that M side were smaller. Otherwise, the air combat countermeasure performance of the algorithm was better. Similarly, when the probability of
< 0 and the probability of
< 0 were greater, it was likely that M would gain an advantage. The experimental statistical results showed that among the four algorithms, the distance optimal algorithm model was the simplest but the air combat performance was the worst. Compared with the other three algorithms, the algorithm proposed in this paper had the best air combat performance and air combat effect; the performance of the angle and distance optimal algorithm was close to that of the traditional MCTS algorithm, but the performance of the latter was slightly better than that of the angle and distance optimal algorithm.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}