
Phase Transition of Total Variation Based on Approximate Message Passing Algorithm


Abstract
:1. Introduction
- A new total variation vector approximate message passing algorithm (TV-VAMP) is designed to solve total variation regularization problems and estimate the phase transitions of these problems.
- Compared with the TVAMP algorithm, the proposed algorithm has better performance in convergence and phase transition prediction, when the measurements distribution is zero-mean Gaussian distribution.
- The proposed algorithm can be applied to a wider range of measurements distributions, including non-zero-mean measurements distribution and ill-conditioned measurements distribution, and has stronger robustness to the measurement matrix. In addition, TV-VAMP algorithm can still maintain excellent performance in the above scenarios.
- : the trace of a matrix;
- : the set of real numbers;
- : Euclidean norm or -norm;
- : absolute-value norm or -norm;
- ∂: differential operator;
- : variable y is proportional to x;
- : inverse of matrix ;
- : transpose of matrix ;
- : inner product of vector and vector ;
- : the mean of the element-wise sums of the vector ;
- : a square diagonal matrix with the elements of vector on the main diagonal;
- : the expectation of under the distribution;
- : the variance of under the distribution;
- : simplified notation for exponential function;
- : variable x follows a Gaussian distribution with mean and variance ;
- : subject to.
2. Problem Formulations
3. Total Variation Vector Approximate Message Passing Algorithm
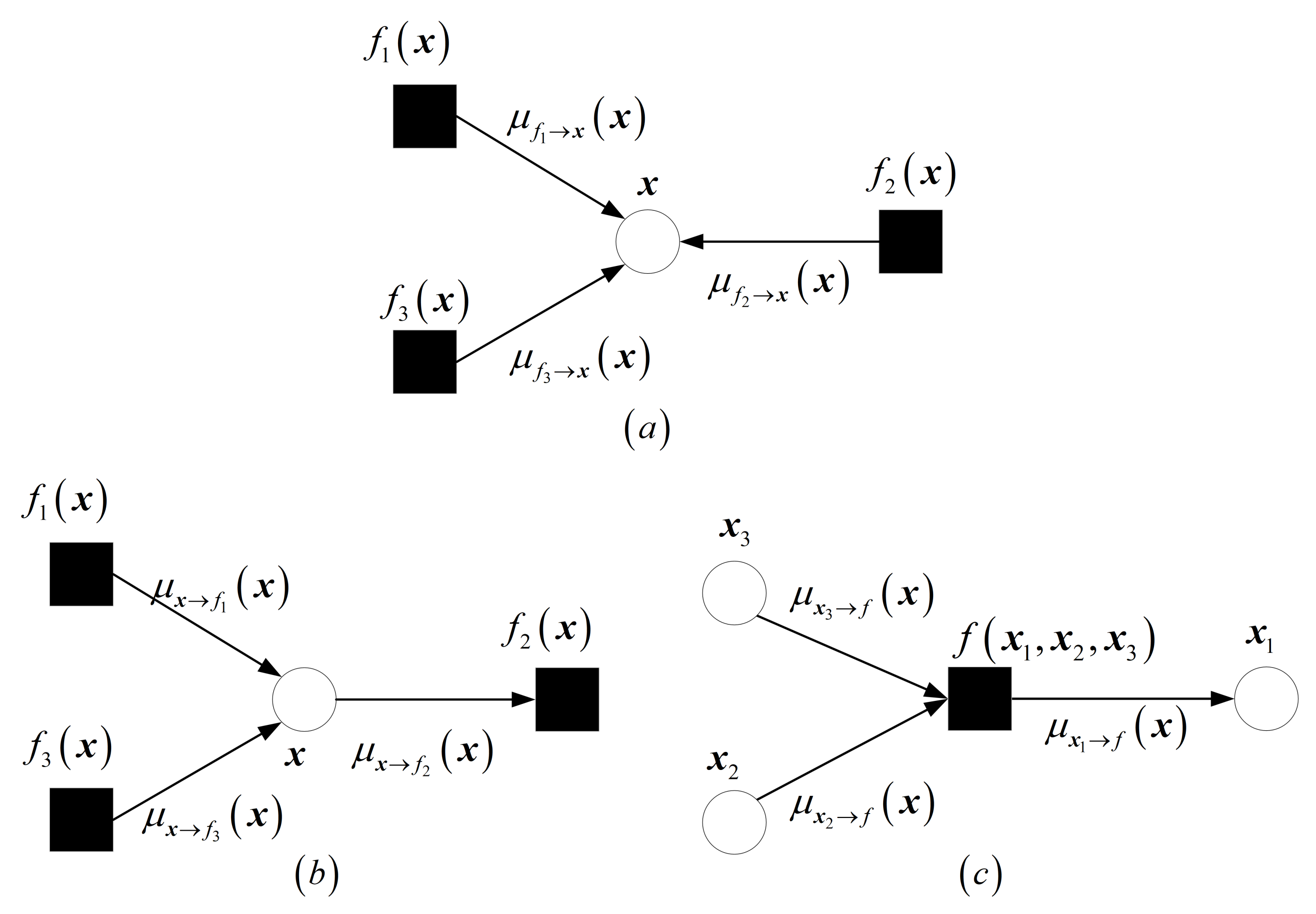
3.1. Introduction of Vector Factor Graph
- (1)
- Approximate beliefs: The approximate belief on variable node is , where and are the mean and average variance of the corresponding sum product belief . Illustration given by Figure 1a.
- (2)
- Variable-to-factor messages: The message from a variable node to a connected factor node is , i.e., the ratio of the most latest approximate belief to the most recent message from to . Illustration given by Figure 1b.
- (3)
- Factor-to-variable messages: The message from a factor node f to a connected variable node is See Figure 1c for an illustration.
3.2. Construction of Vector Factor Graph for TV Model
3.3. Derivation of TV-VAMP Algorithm
| Algorithm 1 TV-VAMP Algorithm |
|
4. Simulation Results
- Zero-mean Gaussian distribution measurements matrix.
- Non-zero-mean Gaussian distribution measurements matrix.
- Ill-conditioned measurements matrix.
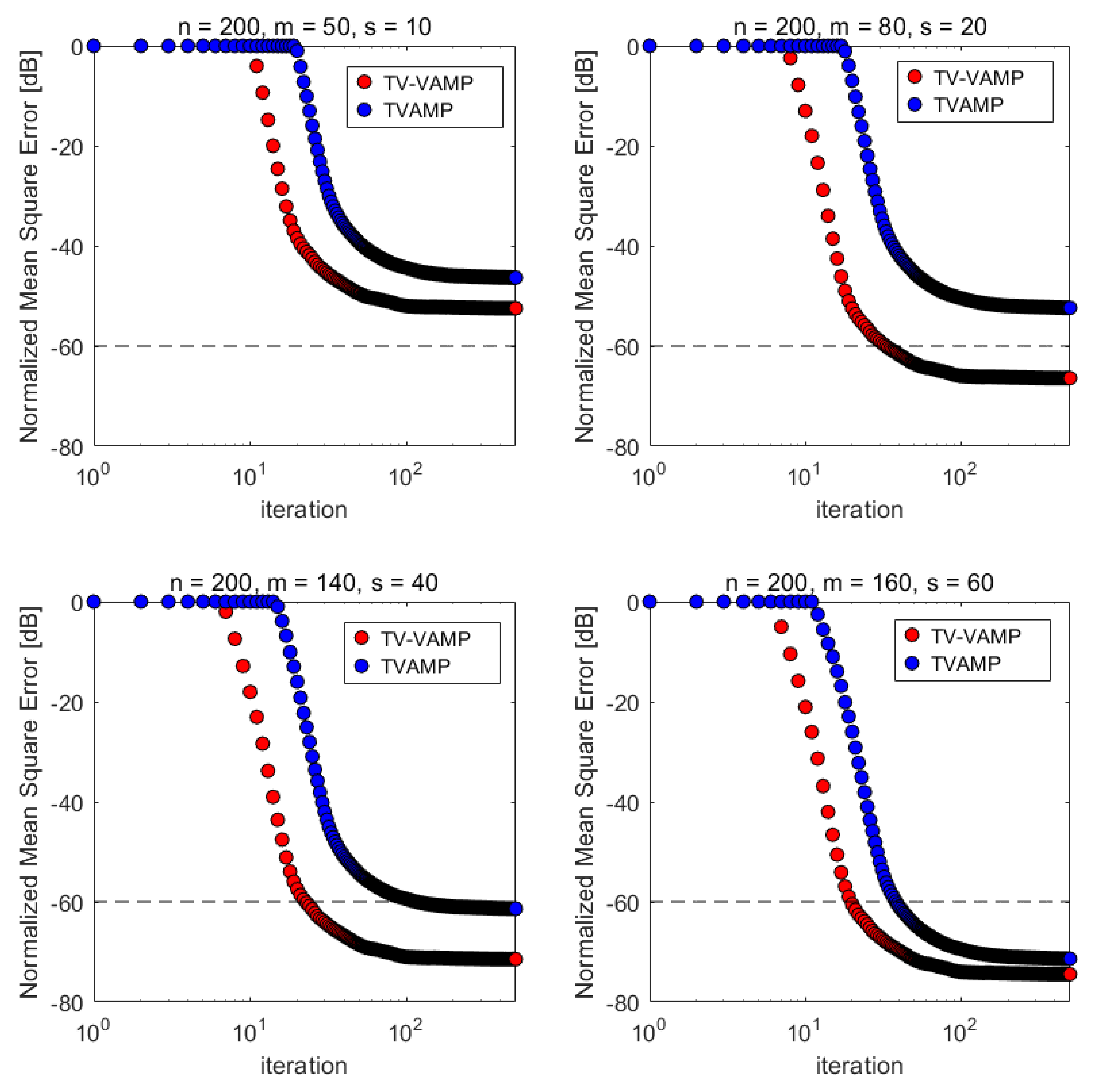
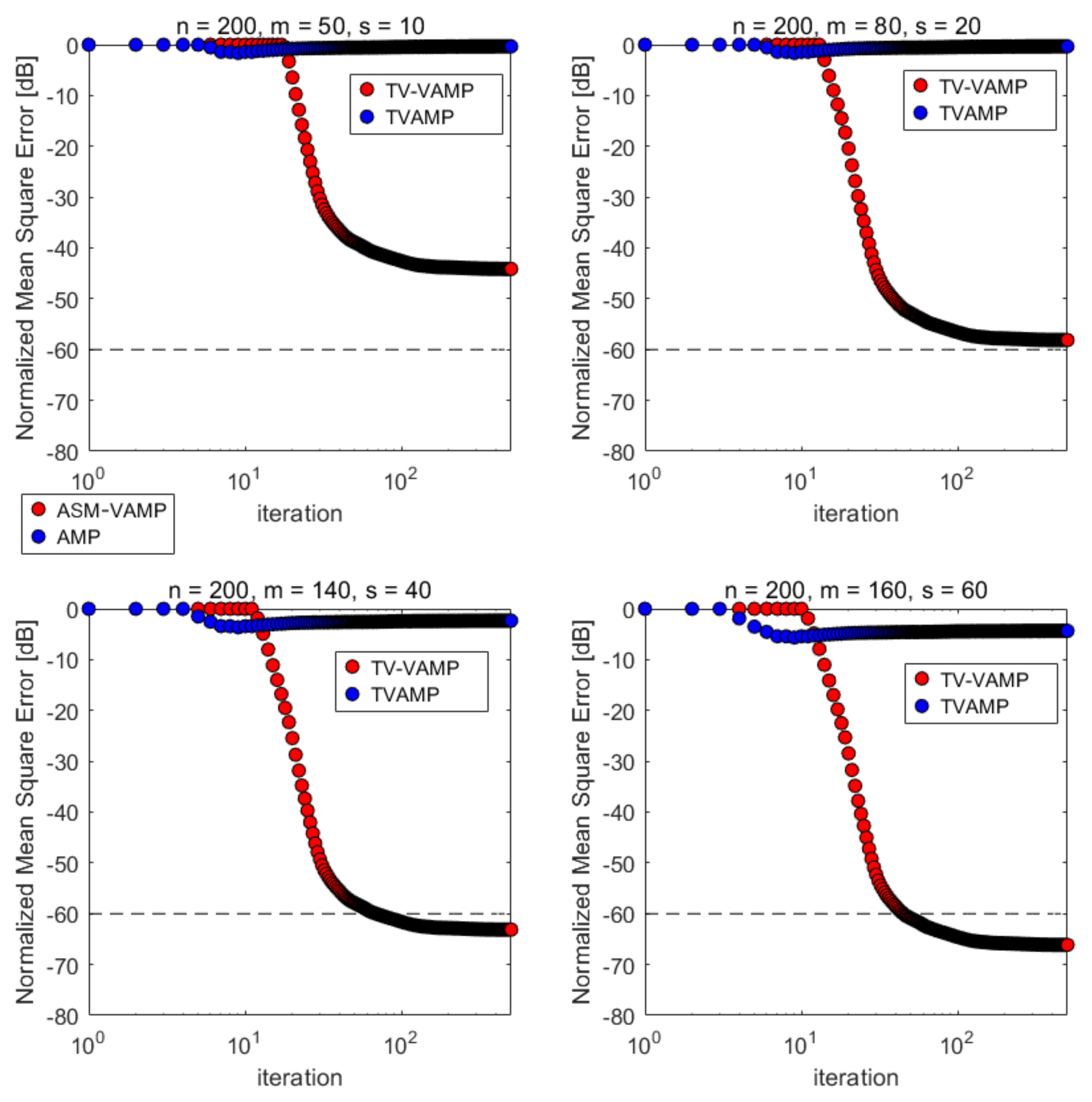
- Normalized mean squared error (NMSE) convergence over iterations.
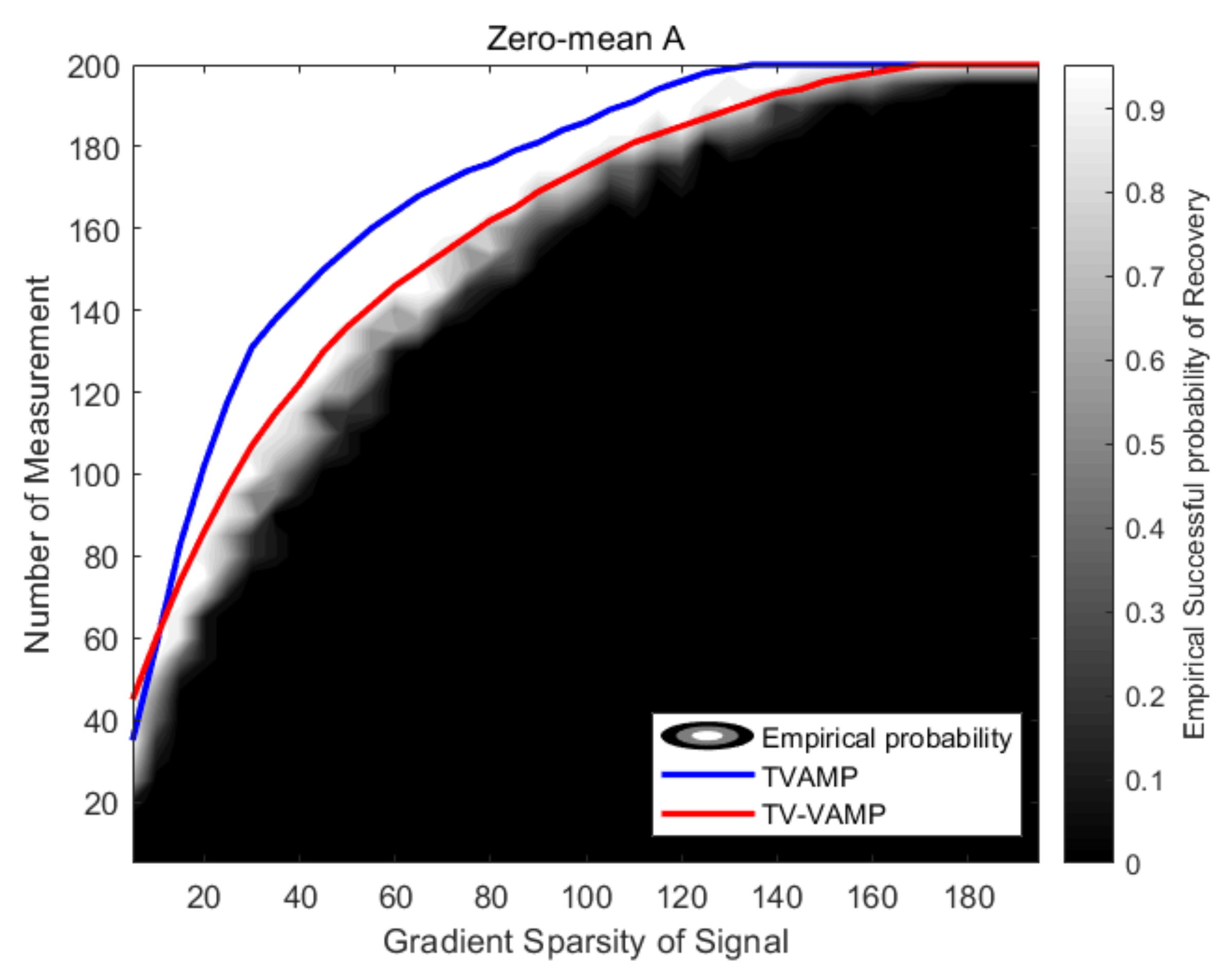
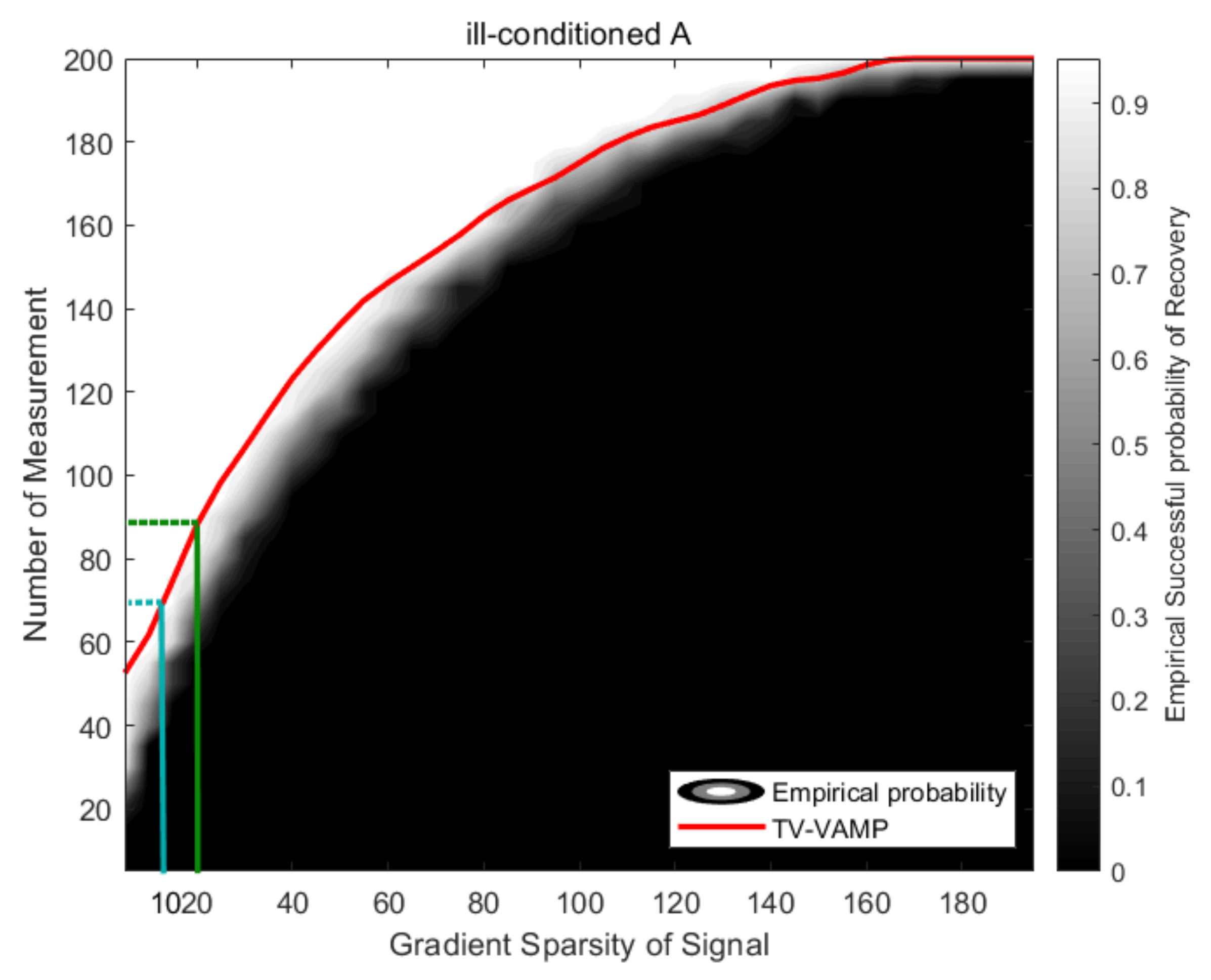
- Phase transitions.
4.1. Experimental Settings
4.1.1. Experimental Settings for NMSE Convergence over Iterations Experiment
- (a)
- ,
- (b)
- ,
- (c)
- ,
- (d)
- , .
4.1.2. Experimental Settings for Phase Transition Experiment
4.2. Zero-Mean Gaussian Distribution Measurements Matrix A
4.2.1. NMSE Convergence over Iterations
4.2.2. Phase Transition
4.3. Non-Zero-Mean Gaussian Distribution Measurements Matrix A
4.3.1. NMSE Convergence over Iterations
4.3.2. Phase Transition
4.4. Ill-Conditioned Measurements Matrix A
4.4.1. NMSE Convergence over Iterations
4.4.2. Phase Transition
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Kutyniok, G. Compressed Sensing: Theory and Applications; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Wu, Q.; Li, Y.; Lin, Y. The application of nonlocal total variation in image denoising for mobile transmission. Multimed. Tools Appl. 2017, 76, 17179–17191. [Google Scholar] [CrossRef]
- Hosseini, M.S.; Plataniotis, K.N. High-accuracy total variation with application to compressed video sensing. IEEE Trans. Image Process. 2014, 23, 3869–3884. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.; Esedoglu, S.; Park, F.; Yip, A. Total variation image restoration: Overview and recent developments. In Handbook of Mathematical Models in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 17–31. [Google Scholar]
- Chan, T.; Marquina, A.; Mulet, P. High-order total variation-based image restoration. SIAM J. Sci. Comput. 2000, 22, 503–516. [Google Scholar] [CrossRef]
- Bredies, K.; Kunisch, K.; Pock, T. Total generalized variation. SIAM J. Imaging Sci. 2010, 3, 492–526. [Google Scholar] [CrossRef]
- Benning, M.; Brune, C.; Burger, M.; Müller, J. Higher-order TV methods—Enhancement via Bregman iteration. J. Sci. Comput. 2013, 54, 269–310. [Google Scholar] [CrossRef]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2010, 20, 681–695. [Google Scholar] [CrossRef]
- Figueiredo, M.A.; Bioucas-Dias, J.M. Restoration of Poissonian images using alternating direction optimization. IEEE Trans. Image Process. 2010, 19, 3133–3145. [Google Scholar] [CrossRef]
- Almeida, M.S.; Figueiredo, M. Deconvolving images with unknown boundaries using the alternating direction method of multipliers. IEEE Trans. Image Process. 2013, 22, 3074–3086. [Google Scholar] [CrossRef]
- Matakos, A.; Ramani, S.; Fessler, J.A. Accelerated edge-preserving image restoration without boundary artifacts. IEEE Trans. Image Process. 2013, 22, 2019–2029. [Google Scholar] [CrossRef]
- Kabanava, M.; Rauhut, H. Analysis ℓ1-recovery with Frames and Gaussian Measurements. Acta. Appl. Math. 2015, 140, 173–195. [Google Scholar] [CrossRef]
- Daei, S.; Haddadi, F.; Amini, A. Living Near the Edge: A Lower-Bound on the Phase Transition of Total Variation Minimization. IEEE Trans. Inf. Theory 2020, 66, 3261–3267. [Google Scholar] [CrossRef]
- Genzel, M.; Kutyniok, G.; März, M. ℓ1-Analysis minimization and generalized (co-)sparsity: When does recovery succeed? Appl. Comput. Harmon. Anal. 2021, 52, 82–140. [Google Scholar] [CrossRef]
- Chandrasekaran, V.; Sanghavi, S.; Parrilo, P.A.; Willsky, A.S. Rank-sparsity incoherence for matrix decomposition. SIAM J. Optim. 2011, 21, 572–596. [Google Scholar] [CrossRef]
- Donoho, D.L.; Gavish, M.; Montanari, A. The phase transition of matrix recovery from Gaussian measurements matches the minimax MSE of matrix denoising. Proc. Natl. Acad. Sci. USA 2013, 110, 8405–8410. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef]
- Candès, E.J.; Eldar, Y.C.; Needell, D.; Randall, P. Compressed sensing with coherent and redundant dictionaries. Appl. Comput. Harmon. Anal. 2011, 31, 59–73. [Google Scholar] [CrossRef]
- Rudelson, M.; Vershynin, R. On sparse reconstruction from Fourier and Gaussian measurements. Comm. Pure Appl. Math. 2008, 61, 1025–1045. [Google Scholar] [CrossRef]
- Stojnic, M. Various thresholds for ℓ1-optimization in compressed sensing. arXiv 2009, arXiv:0907.3666. [Google Scholar]
- Chandrasekaran, V.; Recht, B.; Parrilo, P.A.; Willsky, A.S. The Convex Geometry of Linear Inverse Problems. Found. Comput. Math. 2012, 12, 805–849. [Google Scholar] [CrossRef]
- Amelunxen, D.; Lotz, M.; McCoy, M.B.; Tropp, J.A. Living on the edge: Phase transitions in convex programs with random data. Inf. Inference J. IMA 2014, 3, 224–294. [Google Scholar] [CrossRef]
- Kabanava, M.; Rauhut, H.; Zhang, H. Robust analysis ℓ1-recovery from Gaussian measurements and total variation minimization. Eur. J. Appl. Math. 2014, 26, 917–929. [Google Scholar] [CrossRef]
- Daei, S.; Haddadi, F.; Amini, A. Sample Complexity of Total Variation Minimization. IEEE Signal Process. Lett. 2018, 25, 1151–1155. [Google Scholar] [CrossRef]
- Feng, O.Y.; Venkataramanan, R.; Rush, C.; Samworth, R.J. A unifying tutorial on Approximate Message Passing. Found. Trends Mach. Learn. 2022, 15, 335–536. [Google Scholar] [CrossRef]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing. Proc. Nat. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef]
- Bayati, M.; Montanari, A. The Dynamics of Message Passing on Dense Graphs, with Applications to Compressed Sensing. IEEE Trans. Inf. Theory 2011, 57, 764–785. [Google Scholar] [CrossRef]
- Ma, Y.; Rush, C.; Baron, D. Analysis of Approximate Message Passing With Non-Separable Denoisers and Markov Random Field Priors. IEEE Trans. Inf. Theory 2019, 65, 7367–7389. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.; Montanari, A. Accurate Prediction of Phase Transitions in Compressed Sensing via a Connection to Minimax Denoising. IEEE Trans. Inf. Theory 2013, 59, 3396–3433. [Google Scholar] [CrossRef]
- Liu, Y.; Mi, T.; Li, S. Compressed Sensing With General Frames via Optimal-Dual-Based ℓ1-Analysis. IEEE Trans. Inf. Theory 2012, 58, 4201–4214. [Google Scholar] [CrossRef]
- Nam, S.; Davies, M.; Elad, M.; Gribonval, R. The cosparse analysis model and algorithms. Appl. Comput. Harmon. Anal. 2013, 34, 30–56. [Google Scholar] [CrossRef]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical models, exponential families, and variational inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Loeliger, H.A. An introduction to factor graphs. IEEE Signal Process. Mag. 2004, 21, 28–41. [Google Scholar] [CrossRef]
- Frey, B.J.; Kschischang, F.R.; Loeliger, H.A.; Wiberg, N. Factor graphs and algorithms. In Proceedings of the Annual Allerton Conference on Communication Control and Computing, Monticello, IL, USA, 1 October 1997; Volume 35, pp. 666–680. [Google Scholar]
- Rangan, S.; Schniter, P.; Fletcher, A.K. Vector Approximate Message Passing. IEEE Trans. Inf. Theory 2019, 65, 6664–6684. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. 2014. Available online: https://web.stanford.edu/~boyd/papers/pdf/disc_cvx_prog.pdf (accessed on 12 August 2022).
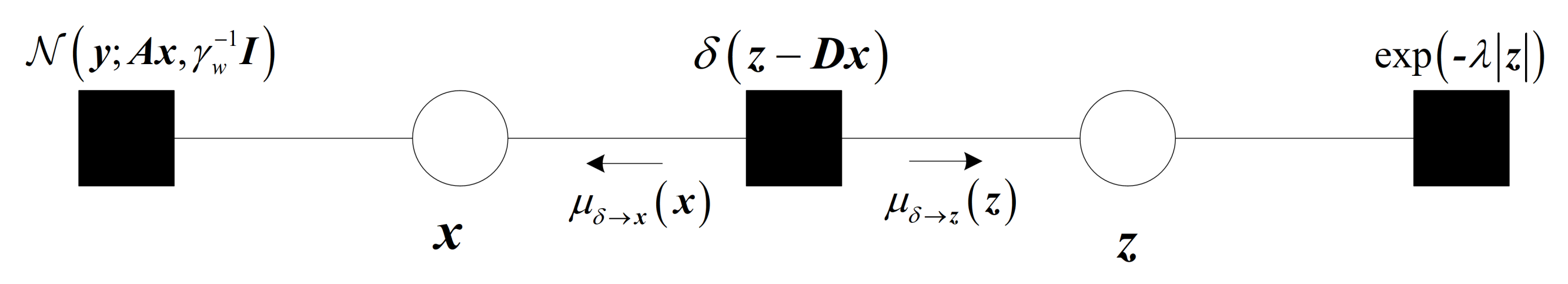



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | ||||
|---|---|---|---|---|
| TVAMP | ∞ | ∞ | 112 | 36 |
| TV-VAMP | ∞ | 32 | 23 | 21 |
| Cases | ||||
|---|---|---|---|---|
| TVAMP | ∞ | ∞ | ∞ | ∞ |
| TV-VAMP | ∞ | 58 | 35 | 32 |
| Cases | ||||
|---|---|---|---|---|
| TVAMP | ∞ | ∞ | ∞ | ∞ |
| TV-VAMP | ∞ | ∞ | 60 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Lei, H. Phase Transition of Total Variation Based on Approximate Message Passing Algorithm. Electronics 2022, 11, 2578. https://doi.org/10.3390/electronics11162578
Cheng X, Lei H. Phase Transition of Total Variation Based on Approximate Message Passing Algorithm. Electronics. 2022; 11(16):2578. https://doi.org/10.3390/electronics11162578
Chicago/Turabian StyleCheng, Xiang, and Hong Lei. 2022. "Phase Transition of Total Variation Based on Approximate Message Passing Algorithm" Electronics 11, no. 16: 2578. https://doi.org/10.3390/electronics11162578
APA StyleCheng, X., & Lei, H. (2022). Phase Transition of Total Variation Based on Approximate Message Passing Algorithm. Electronics, 11(16), 2578. https://doi.org/10.3390/electronics11162578