Abstract
In compressed sensing (CS), one seeks to down-sample some high-dimensional signals and recover them accurately by exploiting the sparsity of the signals. However, the traditional sparsity assumption cannot be directly satisfied in most practical applications. Fortunately, many signals-of-interest do at least exhibit a low-complexity representation with respect to a certain transformation. Particularly, total variation (TV) minimization is a notable example when the transformation operator is a difference matrix. Presently, many theoretical properties of total variation have not been completely explored, e.g., how to estimate the precise location of phase transitions and their rigorous understanding is still in its infancy. So far, the performance and robustness of the existing algorithm for phase transition prediction of TV model are not satisfactory. In this paper, we design a new approximate message passing algorithm to solve the above problems, called total variation vector approximate message passing (TV-VAMP) algorithm. To be specific, we first consider the problem from the Bayesian perspective, and formulate it as an optimization problem. Then, the vector factor graph for the TV model is constructed based on the formulized problem. Finally, the TV-VAMP algorithm is derived according to the idea of probabilistic inference in machine learning. Compared with the existing algorithm, our algorithm can be applied to a wider range of measurements distributions, including the non-zero-mean Gaussian distribution measurements matrix and ill-conditioned measurements matrix. Furthermore, in experiments with various settings, including different measurement distribution matrices, signal gradient sparsity, and measurement times, the proposed algorithm can almost reach the target mean squared error (−60 dB) with fewer iterations and better fit the empirical phase transition curve.
1. Introduction
Compressed sensing concerns the problem of recovering a high-dimensional signal from a small number of linear observations , which has received increasing attention over the past few years [1,2]. In recent years, compressed sensing has been applied to multifarious areas such as radar analysis, medical imaging, distributed signal processing, and data quantization, to name a few; see [3] for an overview. Similar to compressed sensing, the total variation model also belongs to the signal recovery model based on prior distribution. Since the TV model was proposed by Rudin [4], it has been applied in many fields due to its characteristics, such as image denoising [5] and compressed video sensing [6]. Especially, it plays a significant role in image restoration to recover signals from degraded measurements, such as denoising [7,8,9,10], compressed sensing [2,11], and deconvolution [12,13,14]. However, lots of theoretical properties of total variation regularization problems have not been explored [15], e.g., how to estimate the precise location of phase transitions is still an open problem [16,17].
Recent studies have shown that phase transitions occur in lots of stochastic convex optimization problems in mathematical signal processing and computational statistics [18,19]. In the case of random measurements, numerical results have observed that phase transitions emerge in total variation regularization problems. Concretely, when the number of the measurements exceeds a threshold, this procedure can precisely reconstruct signal with high probability. When the number of the measurements is below the threshold, this procedure fails with high probability. This phenomenon is called phase transition [20]. Notably, the reason for studying phase transitions is to determine the minimum number of observations at which the original signal can be accurately recovered, which is meaningful in practical application.
Many related studies try to determine the location of this phase transition based on different proof strategies. For example, ref. [21] introduced the concept of -RIP and has shown that measurements are sufficient to guarantee success, where and denotes the TV operator. This bound on the sample rate naturally extends the classical guarantee for sparse recovery towards TV regularization. Another line of works [22,23,24] relied on Gaussian processing theory and demonstrated the phase transition occurs around , where denotes the tangent cone introduced by at point and represents the Gaussian width of the sphere part of this tangent cone. In contrast to [24], ref. [25] used tools from conical integral geometry and shown that the phase transition is located at . Here denotes the statistical dimension of the same cone, which was proved to be almost equivalent to the squared Gaussian width; however, how to accurately estimate the Gaussian width or statistical dimension turns out to be a quite challenge problem. Several works have provided upper or lower bounds on these two geometric quantities. For example, ref. [26] established an upper bound on the Gaussian width when is a frame or TV operator. Ref. [27] improved this bound by using more careful approximations in the proofs. In a recent work [17], the authors obtained accurate estimation of when the Gram matrix is almost diagonal. On the other hand, ref. [16] provided a numerically sharp lower bound for the statistical dimension when is TV operator; however, the results of above methods are only an approximation of the phase transition curve given from the perspective of the Gaussian process, and cannot fit the empirical phase transition accurately. In addition, they cannot give a specific solution to the problem.
Approximate message passing (AMP) algorithm is a kind of probability inference algorithm based on probability graph model in machine learning [28], which has been proved to be effective in reconstructing sparse signals from linear inverse problems [29,30,31]. It is worth noting that AMP algorithm is a general term for a class of probability inference algorithms, not a specific algorithm. Recently, some works study the phase transitions of total variation regularization problems under the approximate message passing (AMP) framework. Ref. [32] proposed a total variation approximate message passing (TVAMP) algorithm, attempted to solve the above problems and explore the phase transition of these problems at the same time; however, the TVAMP algorithm is limited to zero-mean Gaussian (or sub-Gaussian) measurements, and could not fit the empirical phase transition well.
In this paper, we follow a different strategy and provide a new iterative algorithm, total variation vector approximate message passing (TV-VAMP), to solve total variation regularization problems and estimate the phase transitions of these problems. The TVAMP algorithm in [32] is selected for comparison because it is an AMP-like approach as our algorithm, and provides a specific solution to total variation regularization problems. Numerical experiments verify that the proposed algorithm shows great advantage in many aspects. The main contributions made in our work are as follows:
- A new total variation vector approximate message passing algorithm (TV-VAMP) is designed to solve total variation regularization problems and estimate the phase transitions of these problems.
- Compared with the TVAMP algorithm, the proposed algorithm has better performance in convergence and phase transition prediction, when the measurements distribution is zero-mean Gaussian distribution.
- The proposed algorithm can be applied to a wider range of measurements distributions, including non-zero-mean measurements distribution and ill-conditioned measurements distribution, and has stronger robustness to the measurement matrix. In addition, TV-VAMP algorithm can still maintain excellent performance in the above scenarios.
The rest of this paper is organized as follows. In the next section, total variation regularization problems are expressed in the form of a mathematical formula. The specific derivation of the TV-VAMP algorithm for total variation model is discussed in Section 3. In Section 4, we make several numerical experiments and comparisons. Ultimately, Section 5 summarizes the entire work.
Before the discussion, the mathematical symbols in this paper are explained. Boldface letters in upper case and lower case denote matrices and column vectors, respectively. Scalars are signed with lowercase letters. Apart from that, the following mathematical symbols, parameters and operators are used:
- : the trace of a matrix;
- : the set of real numbers;
- : Euclidean norm or -norm;
- : absolute-value norm or -norm;
- ∂: differential operator;
- : variable y is proportional to x;
- : inverse of matrix ;
- : transpose of matrix ;
- : inner product of vector and vector ;
- : the mean of the element-wise sums of the vector ;
- : a square diagonal matrix with the elements of vector on the main diagonal;
- : the expectation of under the distribution;
- : the variance of under the distribution;
- : simplified notation for exponential function;
- : variable x follows a Gaussian distribution with mean and variance ;
- : subject to.
2. Problem Formulations
The total variation model considers the problem of reconstructing a high-dimensional signal from a little collection of observations
where is a measurements matrix with and represents the observation noise. The goal is to recover unknown signal from observation . Traditional compressed sensing usually assumes that is sparse (or nearly sparse), which is often not satisfied in practice. A increasing number of applications concern the case that is sparse with respect to some transformations [15,21,33,34]. As a typical example, total variation model aims to solve this kind of recovery problem when the transformation operator is a difference matrix. The key idea is to analyze signal with a collection of vectors , i.e.,
where
denotes the TV operator (difference matrix). One may expect the transformed signal to be sparse (or nearly sparse); a natural method to recover the signal is the -analysis minimization:
where reflects the noise level in terms of -norm. Consequently, total variation regularization problems can be formulized as problem (3).
3. Total Variation Vector Approximate Message Passing Algorithm
In this section, we discuss our algorithm in detail. First of all, we introduce the vector factor graph and state the vector message-passing rules. Then, we construct the vector factor graph for TV model based on problem (3). Finally, we give the specific derivation of our TV-VAMP algorithm for total variation regularization problems.
3.1. Introduction of Vector Factor Graph
A factor graph is a bipartite graph that shows the decomposition of a function. In probability theory, factor graphs are used to represent the factorization of probability distribution functions, which can be efficiently computed by belief propagation algorithm [35,36,37]. The factor graph consists of variable nodes and factor nodes, where the factor nodes are functions of the variable nodes, representing the relationship between the variables [38,39]. Variable nodes and factor nodes are connected to each other through messages. It is worth mentioning that the message and the belief (mentioned below) are both probability distributions of variables. As a matter of fact, message passing is equivalent to computing the marginal probabilities of a variable. In the factor graph, the probability distribution of the high-dimensional signal is iteratively calculated through the process of message passing. A vector factor graph is a special kind of factor graph whose variable nodes are vectors.
In a vector factor graph, the message passing between variables follows certain rules, which are called vector message passing rules [40]. There are three rules for vector messaging, as shown in Figure 1. We present them here for the sake of discussion.
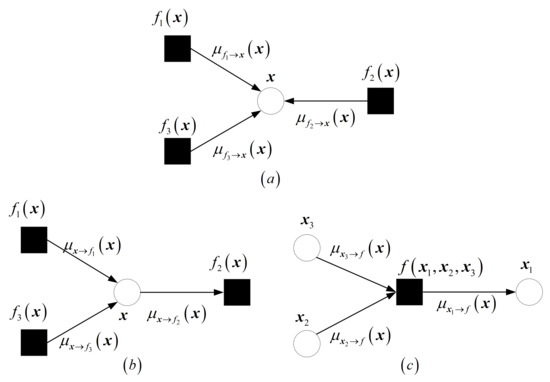
Figure 1.
The figure illustrates vector message-passing rules. The circles represent variable nodes and the squares represent factor nodes. denotes the message from the factor node f to the variable node and denotes the message from the variable node to the factor node f. (a) shows the rule of calculating approximate beliefs. (b) shows the rule of calculating variable-to-factor messages. (c) shows the rule of calculating factor-to-variable messages.
- (1)
- Approximate beliefs: The approximate belief on variable node is , where and are the mean and average variance of the corresponding sum product belief . Illustration given by Figure 1a.
- (2)
- Variable-to-factor messages: The message from a variable node to a connected factor node is , i.e., the ratio of the most latest approximate belief to the most recent message from to . Illustration given by Figure 1b.
- (3)
- Factor-to-variable messages: The message from a factor node f to a connected variable node is See Figure 1c for an illustration.
3.2. Construction of Vector Factor Graph for TV Model
In Section 2, we obtain that total variation regularization problems can be formulized as problem (3). In this subsection, we consider the problem from a Bayesian perspective and further build relevant vector factor graph. Given a regularization parameter , the solution of problem (3) can be expressed as
In accordance with maximum a posteriori probability (MAP) estimate, we give the following posterior distribution of
and assume noise precision . In fact, our estimate value is exactly the optimal value that maximizes the distribution in Equation (5). Subsequently, we introduce a new variable , giving an equivalent factorization
where is the Dirac delta distribution. In term of the joint distribution , we could easily obtain the corresponding vector factor graph for total variation model, which is shown in Figure 2.
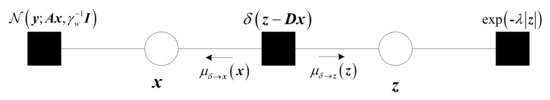
Figure 2.
The figure shows the factor graph of Vector AMP for total variation regularization problems. The circles represent variable nodes and the squares represent factor nodes. and denote the messages from the factor node to the variable nodes and . There are mutual messages between any two adjacent nodes in the graph. We omit some messages that are not drawn.
Consequently, the solution of problem (3) is equivalent to finding that maximizes the distribution in Equation (6). In the next subsection, we give the derivation of on the basis of the vector message-passing rules and vector factor graph for total variation model. Specifically, we first find the approximate distribution of , then calculate the expectation of the distribution, which is the estimation of the real signal. Notably, the above steps are calculated iteratively through the message-passing process in Figure 2.
3.3. Derivation of TV-VAMP Algorithm
In this section, we present the detailed derivation of TV-VAMP algorithm. First of all, we assume that the messages from factor node to variable nodes and are Gaussian distributions,
After that, we initialize the message passing with
Throughout the derivation, k denotes the TV-VAMP iteration. The following steps are then repeated for . The concrete derivation of algorithm follows the steps below.
Step 1: Calculate approximate belief . Applying vector message passing rule 1 to the variable in Figure 2, we have
where
Accordingly, the mean and average variance of the estimated value of variable in step k can be obtained for
which yields
Step 2: Update parameters and . Applying vector message passing rule 2 to the variable in Figure 2, we have
where
and
Applying vector message passing rule 3 to the message in Figure 2, we have
Step 3: Calculate approximate belief . Applying vector message passing rule 1 to the variable in Figure 2, we have
Unfortunately, we cannot obtain the mean and average variance of the estimated value of variable for the distribution . Therefore, we consider instead a different distribution here
and take the limit , thus making the entire mass of the distribution concentrate around its mode. Then, according to the Laplace approximate method [41], we can easily obtain
where is soft thresholding function
Therefore, we obtain
Here we consider the reason why the approximation (Equation (25)) holds from a different perspective. If we treat and as the prior and likelihood functions, then the distribution is the corresponding posterior distribution. Therefore, the mean of can be regarded as the Bayesian solution of the problem:
Similarly, the mean of is the maximum a posteriori probability (MAP) solution of this problem. Specifically, when we take the limit , the entire mass of the distribution concentrate around the value making the posterior distribution maximum, which is in line with the maximum a posteriori estimation. Consequently, we can consider the above process as utilizing the MAP solution to approximate the Bayesian solution of the same problem.
Step 4: Update parameters and . Applying vector message passing rule 2 to the variable in Figure 2, we have
where
Applying vector message passing rule 3 to the message in Figure 2, we have
The above steps are then repeated with . Due to the parameters And are mutually expressed, so we can unify the parameters And . To be specific, we define
Furthermore, we have
and
Subsequently, the approximate mean and average variance of the estimated value of the distribution in Equations (25) and (26) can be expressed as
and
Finally, combining Equations (39), (40) with (13), (17), (35), and (36), we could obtain Algorithm 1. The output of our algorithm is , which is the solution to problem (3), i.e., the estimated value of the true signal. Additionally, the other quantities in the algorithm are intermediate parameters.
| Algorithm 1 TV-VAMP Algorithm |
|
4. Simulation Results
In this section, we present several numerical experiments to compare the TV-VAMP algorithm with the TVAMP algorithm from [32]. We concern three different measurements matrices in this section:
- Zero-mean Gaussian distribution measurements matrix.
- Non-zero-mean Gaussian distribution measurements matrix.
- Ill-conditioned measurements matrix.
Furthermore, we discuss two types of simulation results for each measurements matrix:
- Normalized mean squared error (NMSE) convergence over iterations.
- Phase transitions.
Before the description, experimental settings are stated.
4.1. Experimental Settings
All these simulation results are averaged over 50 trials using the Monte Carlo method. At each Monte Carlo trial, we reconstruct unknown signal from measurements , where is gradient sparse, noise and noise precision . Moreover, we consider that the transformation operator is a difference matrix in all experiments. For the TVAMP algorithm and TV-VAMP algorithm, we set the maximum iteration step to 500, and regularization parameter .
4.1.1. Experimental Settings for NMSE Convergence over Iterations Experiment
The experiment settings for NMSE convergence over iterations experiment are as follows: signal feature dimension , m denotes the number of measurements times and s denotes signal gradient sparsity. We observe NMSE over iterations for four different scenarios of :
- (a)
- ,
- (b)
- ,
- (c)
- ,
- (d)
- , .
4.1.2. Experimental Settings for Phase Transition Experiment
The experiment settings for phase transition experiment are as follows: signal feature dimension , the measurements number m and gradient sparsity s changes from 5 to n with step 5. We declare success if the solution to problem (3) satisfies
where denotes the true value and denotes the estimated value.
4.2. Zero-Mean Gaussian Distribution Measurements Matrix A
In the first experiment, realizations of are constructed by drawing an i.i.d. matrix and . We have two tasks here.
4.2.1. NMSE Convergence over Iterations
First of all, we compare the convergence over iterations of TVAMP algorithm with TV-VAMP algorithm. The experimental results are shown in Figure 3.
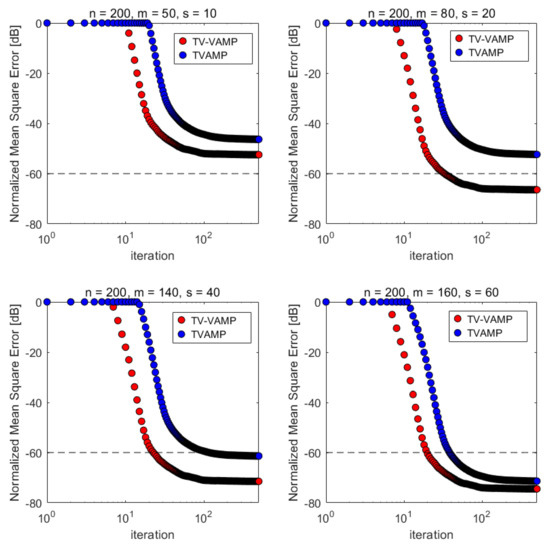
Figure 3.
Normalized mean squared error (NMSE) convergence over iterations when is a zero-mean Gaussian distribution measurements matrix. Each curve is the average of 50 Monte Carlo samples.
Table 1 reports the results of the TVAMP algorithm and TV-VAMP algorithm when is a zero-mean Gaussian distribution measurements matrix. We give the number of iteration steps required for both algorithms to reach the target MSE (−60 dB of NMSE) in all cases. In four different experimental settings, our TV-VAMP algorithm can converge to the target MSE in the latter three cases, while TVAMP algorithm can only converge to the target MSE in the latter two cases. Additionally, we need fewer iteration steps and can converge to a smaller NMSE. Overall, our algorithm performs better in terms of convergence performance in this scenario.

Table 1.
Average number of iterations to achieve NMSE = −60 dB for zero-mean Gaussian distribution measurements matrix.
According to Table 1, we find that TVAMP and TV-VAMP algorithms cannot converge to the target MSE (−60 dB of NMSE) under some experimental settings. We believe that it is caused by insufficient measurement times. Notably, this is the purpose of our study of phase transition, which is discussed in the following section. We can determine the minimum number of measurements at which the real signal can be reconstructed according to the phase transition curve, which is of great significance in practical applications.
4.2.2. Phase Transition
In this subsection, we utilize TVAMP algorithm and TV-VAMP algorithm to predict the phase transition of total variation regularization problems. The purpose of studying phase transitions is to evaluate how the measurements number m varies with gradient sparsity s. Moreover, we can determine the minimum number of observations at which the original signal can be reconstructed.
In order to obtain the empirical phase transition, we use CVX [42] to solve the convex problem (3), which is a Matlab software for disciplined convex programming. Similarly, the empirical phase transition is averaged over 50 trials using the Monte Carlo method. The phase transition diagrams of CVX, TVAMP algorithm, and TV-VAMP algorithm, are shown in Figure 4.
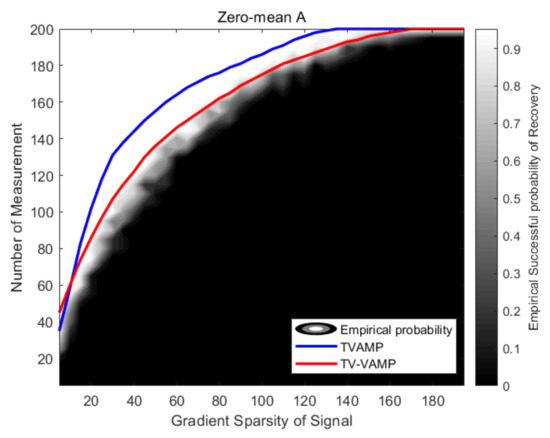
Figure 4.
The figure shows phase transitions of CVX, TVAMP algorithm, and TV-VAMP algorithm when is a zero-mean Gaussian distribution measurements matrix and .
The brightness of figure in each pair shows the empirical probability of success (black = 0% and white = 100%) in Figure 4. For the TVAMP algorithm and TV-VAMP algorithm, the phase transition curves are connection of experimental points having 0.5 success rate of the signal recovery. The upper part of the curve can reconstruct the original signal, while the part below the curve cannot. Compared with TVAMP algorithm, we can see that the phase transition curve obtained by TV-VAMP algorithm can better fit the empirical phase transition.
4.3. Non-Zero-Mean Gaussian Distribution Measurements Matrix A
In the second experiment, realizations of are constructed by drawing an i.i.d. matrix and . In a similar way, we have two different experiments here.
4.3.1. NMSE Convergence over Iterations
Firstly, the convergence of two different algorithms is compared. Our numerical experiment results are shown in Figure 5.
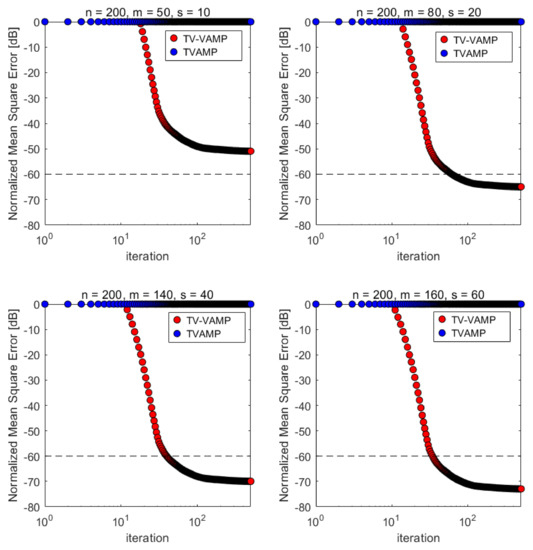
Figure 5.
Normalized mean squared error (NMSE) convergence over iterations in the case of and . Each curve is the average of 50 Monte Carlo samples.
Additionally, the results of two different algorithms are listed in Table 2 when is a non-zero-mean Gaussian distribution measurements matrix and the mean of the distribution . Homogeneously, we give the number of iteration steps required to reach the target MSE (−60 dB of NMSE). Specifically, our TV-VAMP algorithm can converge to the target MSE in the latter three cases, while TVAMP algorithm all fails, which confirms the effectiveness of TV-VAMP algorithm.
Table 2.
Average number of iterations to achieve NMSE = −60 dB for non-zero-mean Gaussian distribution measurements matrix.
4.3.2. Phase Transition
In this subsection, since the TVAMP algorithm does not converge, we only compare the phase transition of TV-VAMP algorithm with the empirical phase transition. Equally, we use CVX [42] to obtain the empirical phase transition, and the experiment settings are the same as Section 4.2.2. The simulation results are shown in Figure 6. Conspicuously, the phase transition curve of TV-VAMP algorithm is still sufficiently close to the empirical phase transition when is a non-zero-mean Gaussian distribution measurements matrix.
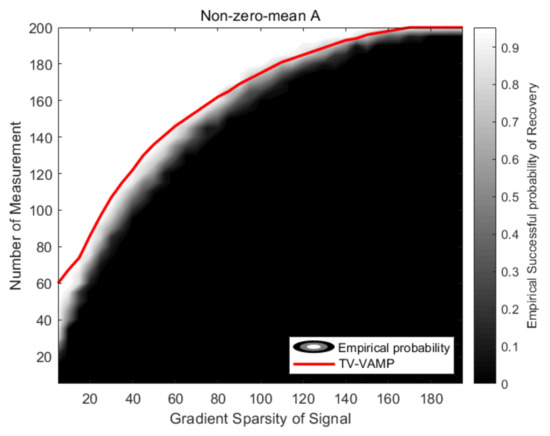
Figure 6.
The figure shows phase transitions of CVX and TV-VAMP algorithm in the case of and .
4.4. Ill-Conditioned Measurements Matrix A
In the third experiment, we explore algorithm robustness to the condition number of . In this case, realizations of are constructed from singular value decomposition (SVD) , where and are randomly sampled from the set of orthogonal matrices, and is constructed by singular values of . We consider zero-mean measurements, i.e., , and set , where is the condition number of , which is the ratio of the largest singular value to the smallest singular value of .
4.4.1. NMSE Convergence over Iterations
First of all, we compare the convergence over iterations of two different algorithms. Figure 7 and Table 3 shows the results of two different algorithms when is ill-conditioned. Similarly, Table 3 reports the number of iteration steps required to reach the target MSE (−60 dB of NMSE). In four different experimental settings, our TV-VAMP algorithm can converge to the target MSE in the latter two scenarios, while the TVAMP algorithm is divergent in all experiments, which demonstrates the robustness of our algorithm. We believe that the reason why the NMSE of the TV-VAMP algorithm can not converge to −60 dB in the first two scenarios is that the number of measurements times are not enough.
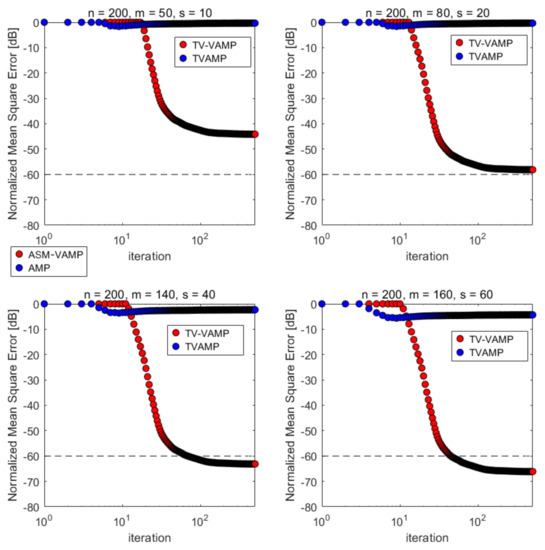
Figure 7.
Normalized mean squared error (NMSE) convergence over iterations in the case of and . Each curve is the average of 50 Monte Carlo samples.
Table 3.
Average number of iterations to achieve NMSE = −60 dB for ill-conditioned measurements matrix.
4.4.2. Phase Transition
As before, we investigate the phase transition of TV-VAMP algorithm when the measurements matrix has an ill-conditioned number. Similarly, the empirical phase transition is calculated by CVX [42], and the experiment settings are the same as Section 4.2.2. Figure 8 confirms that the phase transition curve of TV-VAMP algorithm is still relatively accurate. In addition, it can be seen from the phase transition diagram in Figure 8 that when the gradient sparsity of the signal , at least the number of measurements times is required to recover the original signal ( = −60 dB), while the number of measurements in the experiment is less than that. This is the reason why the NMSE of the TV-VAMP algorithm cannot converge in the first two cases in Table 3. Notably, the above is the purpose of our study of phase transition. We can determine the minimum number of observations at which the original signal can be reconstructed according to the phase transition curve, which is of great significance in practical applications.
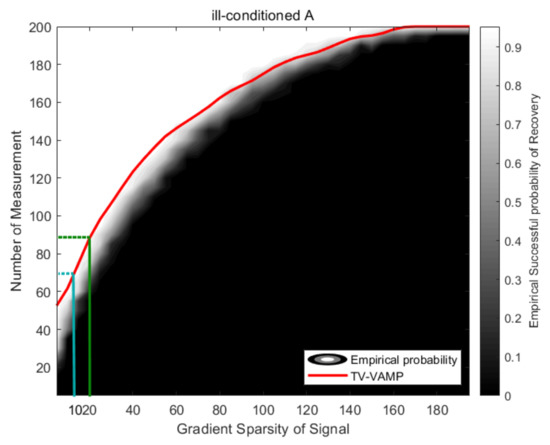
Figure 8.
The figure shows phase transitions of CVX and TV-VAMP algorithm in the case of and .
In the process of signal recovery, the measurement matrix plays an important role. The above numerical experiments show that the proposed TV-VAMP algorithm can be applied to a wider range of measurement matrices, especially when the measurement matrix is ill-conditioned, as it can still accurately recover the original signal, which verifies that our algorithm is robust to the measurement matrix.
5. Conclusions and Future Work
In this paper, we design a new iterative algorithm, called total variation vector approximate message passing (TV-VAMP), to solve total variation regularization problems and estimate the phase transitions of these problems. According to numerical simulations, we verify that the proposed algorithm is more robust than the TVAMP algorithm [32]. Specifically, our algorithm is suitable for a wider range of measurements distributions, including non-zero-mean Gaussian distribution measurements matrix and ill-conditioned measurements matrix. Furthermore, the experimental results confirm that our algorithm can better fit the empirical phase transition. Particularly, we can determine the minimum number of observations at which the real signal can be precisely recovered, which is meaningful in practical application; however, there is still a gap between the phase transition curve obtained by our algorithm and the empirical phase transition. The existence of the gap is caused by approximation steps in the derivation of TV-VAMP algorithm.
We believe that the gap could be improved if we can optimize the approximation steps in this paper. To be specific, we are going to find a more appropriate approximation to the mean and average variance of the distribution in Equation (23). Apart from that, it is necessary to note that, according to the existing references [29,30], state evolution can accurately predict the phase transition of the corresponding model, which is a simple scalar iterative scheme that can track dynamics of approximate message passing algorithm. Therefore, we prepare to deduce the state evolution of the total variation model and further infer the corresponding optimal TV-VAMP algorithm on the basis of state evolution.
Author Contributions
Conceptualization, X.C. and H.L.; methodology, X.C.; software, X.C.; validation, X.C.; formal analysis, X.C.; investigation, X.C.; resources, X.C.; data curation, X.C.; writing—original draft preparation, X.C.; writing—review and editing, X.C.; visualization, X.C.; supervision, H.L.; project administration, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Kutyniok, G. Compressed Sensing: Theory and Applications; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Wu, Q.; Li, Y.; Lin, Y. The application of nonlocal total variation in image denoising for mobile transmission. Multimed. Tools Appl. 2017, 76, 17179–17191. [Google Scholar] [CrossRef]
- Hosseini, M.S.; Plataniotis, K.N. High-accuracy total variation with application to compressed video sensing. IEEE Trans. Image Process. 2014, 23, 3869–3884. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.; Esedoglu, S.; Park, F.; Yip, A. Total variation image restoration: Overview and recent developments. In Handbook of Mathematical Models in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 17–31. [Google Scholar]
- Chan, T.; Marquina, A.; Mulet, P. High-order total variation-based image restoration. SIAM J. Sci. Comput. 2000, 22, 503–516. [Google Scholar] [CrossRef]
- Bredies, K.; Kunisch, K.; Pock, T. Total generalized variation. SIAM J. Imaging Sci. 2010, 3, 492–526. [Google Scholar] [CrossRef]
- Benning, M.; Brune, C.; Burger, M.; Müller, J. Higher-order TV methods—Enhancement via Bregman iteration. J. Sci. Comput. 2013, 54, 269–310. [Google Scholar] [CrossRef]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2010, 20, 681–695. [Google Scholar] [CrossRef]
- Figueiredo, M.A.; Bioucas-Dias, J.M. Restoration of Poissonian images using alternating direction optimization. IEEE Trans. Image Process. 2010, 19, 3133–3145. [Google Scholar] [CrossRef]
- Almeida, M.S.; Figueiredo, M. Deconvolving images with unknown boundaries using the alternating direction method of multipliers. IEEE Trans. Image Process. 2013, 22, 3074–3086. [Google Scholar] [CrossRef]
- Matakos, A.; Ramani, S.; Fessler, J.A. Accelerated edge-preserving image restoration without boundary artifacts. IEEE Trans. Image Process. 2013, 22, 2019–2029. [Google Scholar] [CrossRef]
- Kabanava, M.; Rauhut, H. Analysis ℓ1-recovery with Frames and Gaussian Measurements. Acta. Appl. Math. 2015, 140, 173–195. [Google Scholar] [CrossRef]
- Daei, S.; Haddadi, F.; Amini, A. Living Near the Edge: A Lower-Bound on the Phase Transition of Total Variation Minimization. IEEE Trans. Inf. Theory 2020, 66, 3261–3267. [Google Scholar] [CrossRef]
- Genzel, M.; Kutyniok, G.; März, M. ℓ1-Analysis minimization and generalized (co-)sparsity: When does recovery succeed? Appl. Comput. Harmon. Anal. 2021, 52, 82–140. [Google Scholar] [CrossRef]
- Chandrasekaran, V.; Sanghavi, S.; Parrilo, P.A.; Willsky, A.S. Rank-sparsity incoherence for matrix decomposition. SIAM J. Optim. 2011, 21, 572–596. [Google Scholar] [CrossRef]
- Donoho, D.L.; Gavish, M.; Montanari, A. The phase transition of matrix recovery from Gaussian measurements matches the minimax MSE of matrix denoising. Proc. Natl. Acad. Sci. USA 2013, 110, 8405–8410. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef]
- Candès, E.J.; Eldar, Y.C.; Needell, D.; Randall, P. Compressed sensing with coherent and redundant dictionaries. Appl. Comput. Harmon. Anal. 2011, 31, 59–73. [Google Scholar] [CrossRef]
- Rudelson, M.; Vershynin, R. On sparse reconstruction from Fourier and Gaussian measurements. Comm. Pure Appl. Math. 2008, 61, 1025–1045. [Google Scholar] [CrossRef]
- Stojnic, M. Various thresholds for ℓ1-optimization in compressed sensing. arXiv 2009, arXiv:0907.3666. [Google Scholar]
- Chandrasekaran, V.; Recht, B.; Parrilo, P.A.; Willsky, A.S. The Convex Geometry of Linear Inverse Problems. Found. Comput. Math. 2012, 12, 805–849. [Google Scholar] [CrossRef]
- Amelunxen, D.; Lotz, M.; McCoy, M.B.; Tropp, J.A. Living on the edge: Phase transitions in convex programs with random data. Inf. Inference J. IMA 2014, 3, 224–294. [Google Scholar] [CrossRef]
- Kabanava, M.; Rauhut, H.; Zhang, H. Robust analysis ℓ1-recovery from Gaussian measurements and total variation minimization. Eur. J. Appl. Math. 2014, 26, 917–929. [Google Scholar] [CrossRef]
- Daei, S.; Haddadi, F.; Amini, A. Sample Complexity of Total Variation Minimization. IEEE Signal Process. Lett. 2018, 25, 1151–1155. [Google Scholar] [CrossRef]
- Feng, O.Y.; Venkataramanan, R.; Rush, C.; Samworth, R.J. A unifying tutorial on Approximate Message Passing. Found. Trends Mach. Learn. 2022, 15, 335–536. [Google Scholar] [CrossRef]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing. Proc. Nat. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef]
- Bayati, M.; Montanari, A. The Dynamics of Message Passing on Dense Graphs, with Applications to Compressed Sensing. IEEE Trans. Inf. Theory 2011, 57, 764–785. [Google Scholar] [CrossRef]
- Ma, Y.; Rush, C.; Baron, D. Analysis of Approximate Message Passing With Non-Separable Denoisers and Markov Random Field Priors. IEEE Trans. Inf. Theory 2019, 65, 7367–7389. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.; Montanari, A. Accurate Prediction of Phase Transitions in Compressed Sensing via a Connection to Minimax Denoising. IEEE Trans. Inf. Theory 2013, 59, 3396–3433. [Google Scholar] [CrossRef]
- Liu, Y.; Mi, T.; Li, S. Compressed Sensing With General Frames via Optimal-Dual-Based ℓ1-Analysis. IEEE Trans. Inf. Theory 2012, 58, 4201–4214. [Google Scholar] [CrossRef]
- Nam, S.; Davies, M.; Elad, M.; Gribonval, R. The cosparse analysis model and algorithms. Appl. Comput. Harmon. Anal. 2013, 34, 30–56. [Google Scholar] [CrossRef]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical models, exponential families, and variational inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef]
- Loeliger, H.A. An introduction to factor graphs. IEEE Signal Process. Mag. 2004, 21, 28–41. [Google Scholar] [CrossRef]
- Frey, B.J.; Kschischang, F.R.; Loeliger, H.A.; Wiberg, N. Factor graphs and algorithms. In Proceedings of the Annual Allerton Conference on Communication Control and Computing, Monticello, IL, USA, 1 October 1997; Volume 35, pp. 666–680. [Google Scholar]
- Rangan, S.; Schniter, P.; Fletcher, A.K. Vector Approximate Message Passing. IEEE Trans. Inf. Theory 2019, 65, 6664–6684. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. 2014. Available online: https://web.stanford.edu/~boyd/papers/pdf/disc_cvx_prog.pdf (accessed on 12 August 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).