
An Effective Orchestration for Fingerprint Presentation Attack Detection



Abstract
:1. Introduction
2. Related Work
2.1. Feature-Based Approach
2.2. CNN-Based Approach
2.3. Fusion Approach
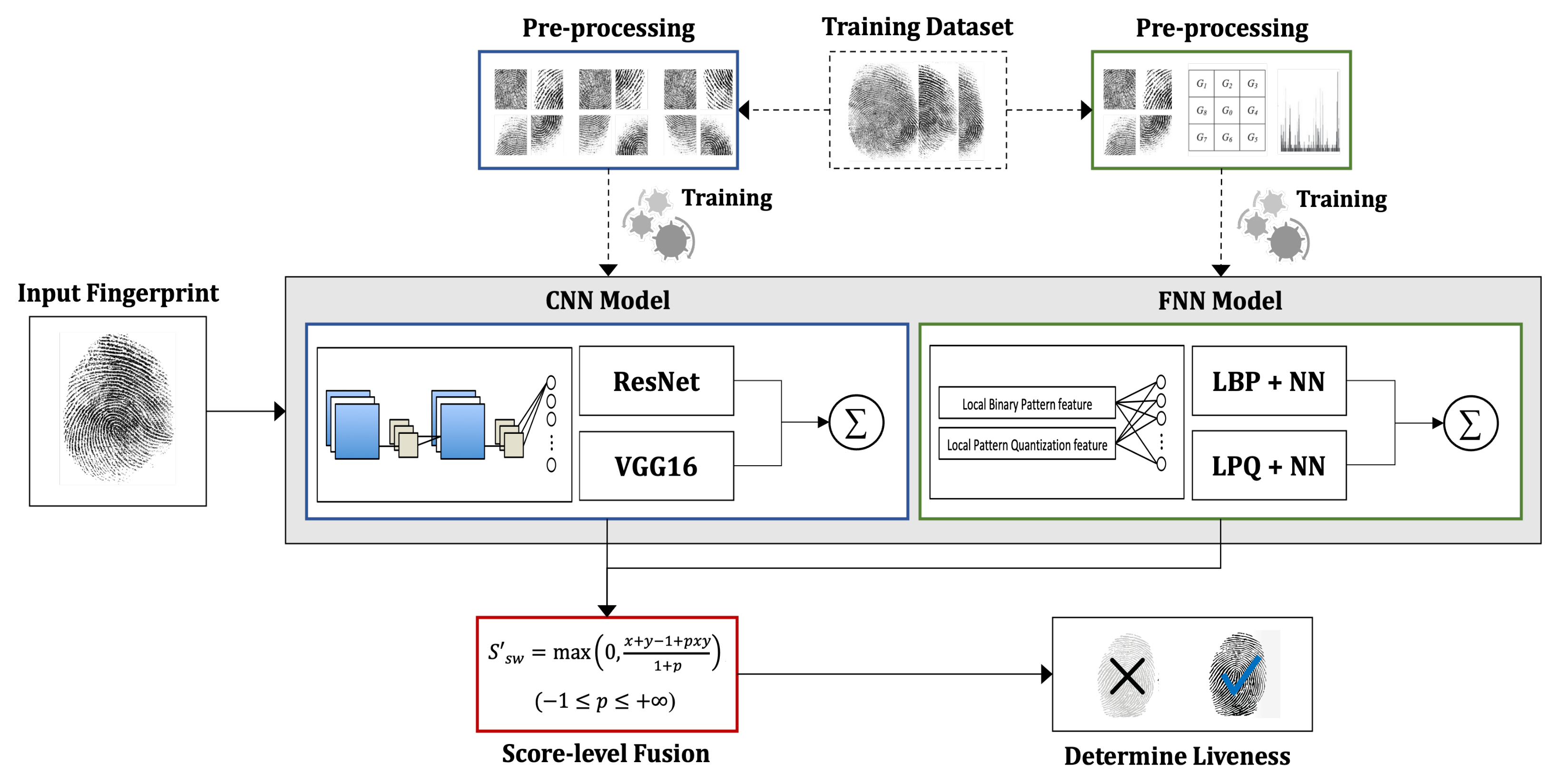
3. Proposed Method
3.1. Data Augmentation
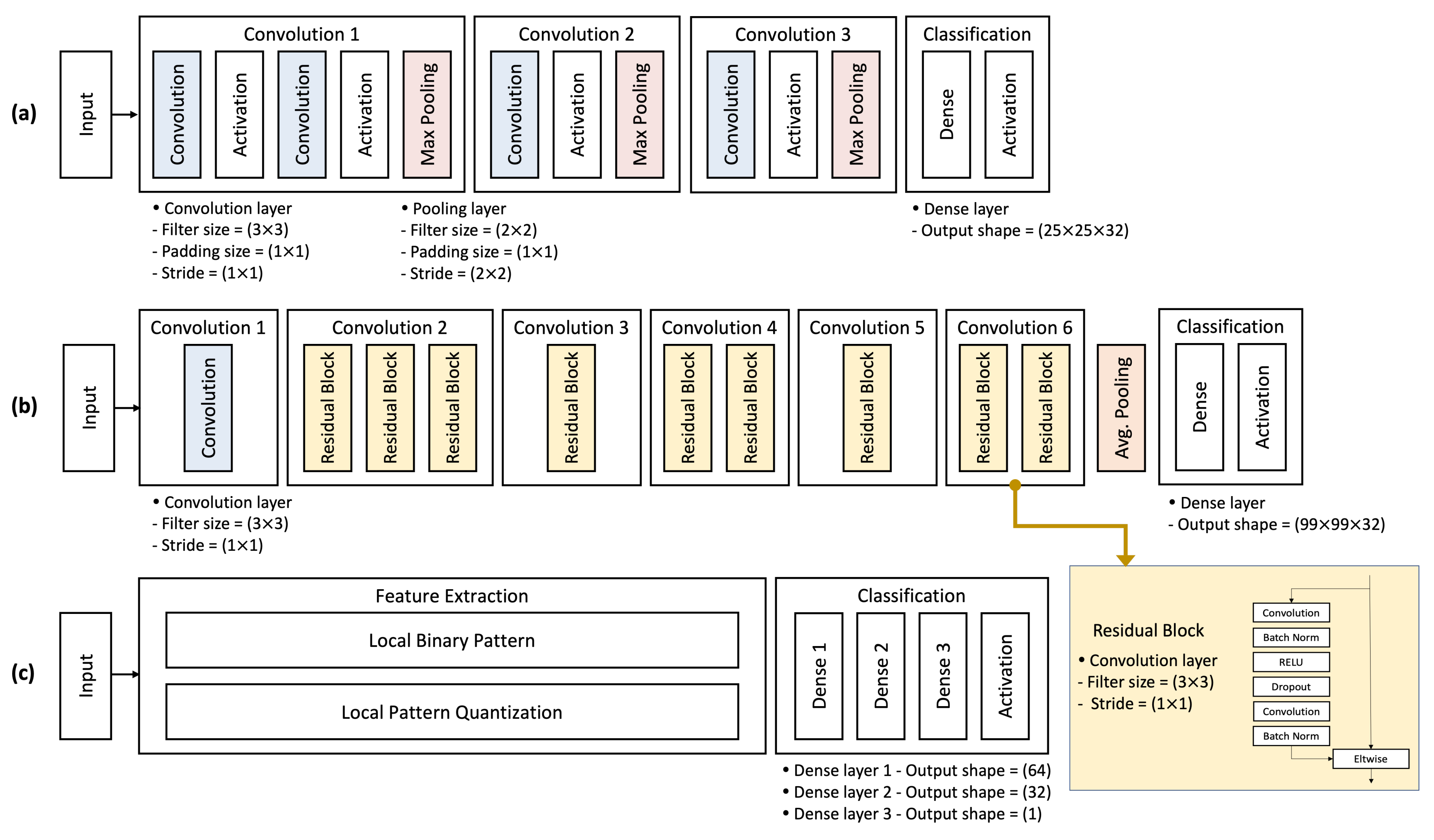
3.2. CNN-Based Model
3.3. Feature-Based Model
3.4. A Score-Level Fusion for PAD
3.5. Liveness Determination
4. Evaluation
- RQ1. How well does our orchestration method perform compared to existing fusion methods? (in terms of accuracy and generalization performance)
- RQ2. How well does our method perform compared to existing PAD methods? (in terms of accuracy and generalization performance)
- RQ3. How well does our CNN and FNN architecture perform compared to others? (in terms of accuracy and processing time)
- RQ4. How well does our data augmentation improve overall performance? (in terms of accuracy and generalization performance)
4.1. Experimental Setup
4.2. Experimental Result
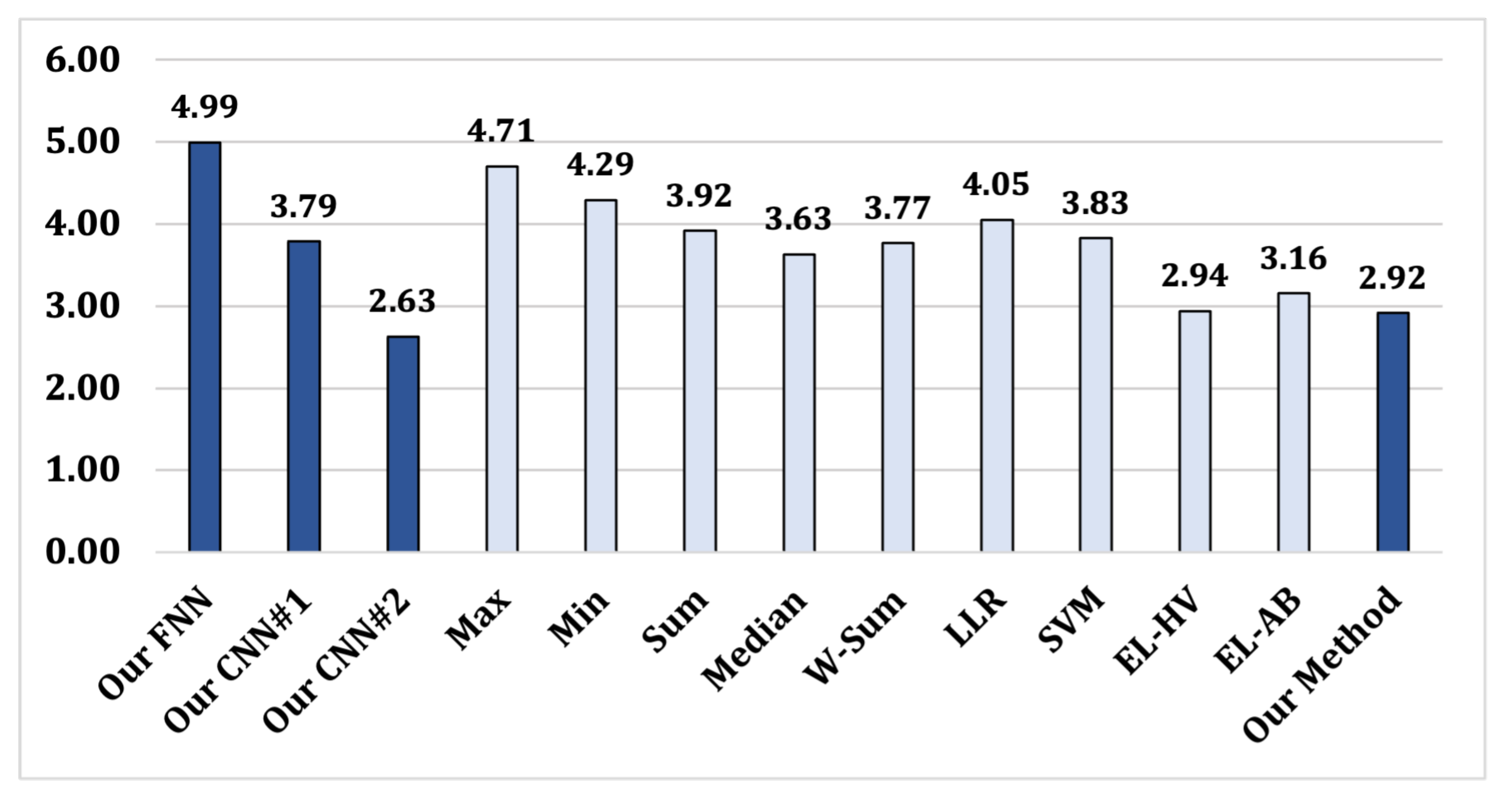
4.2.1. Results for RQ1
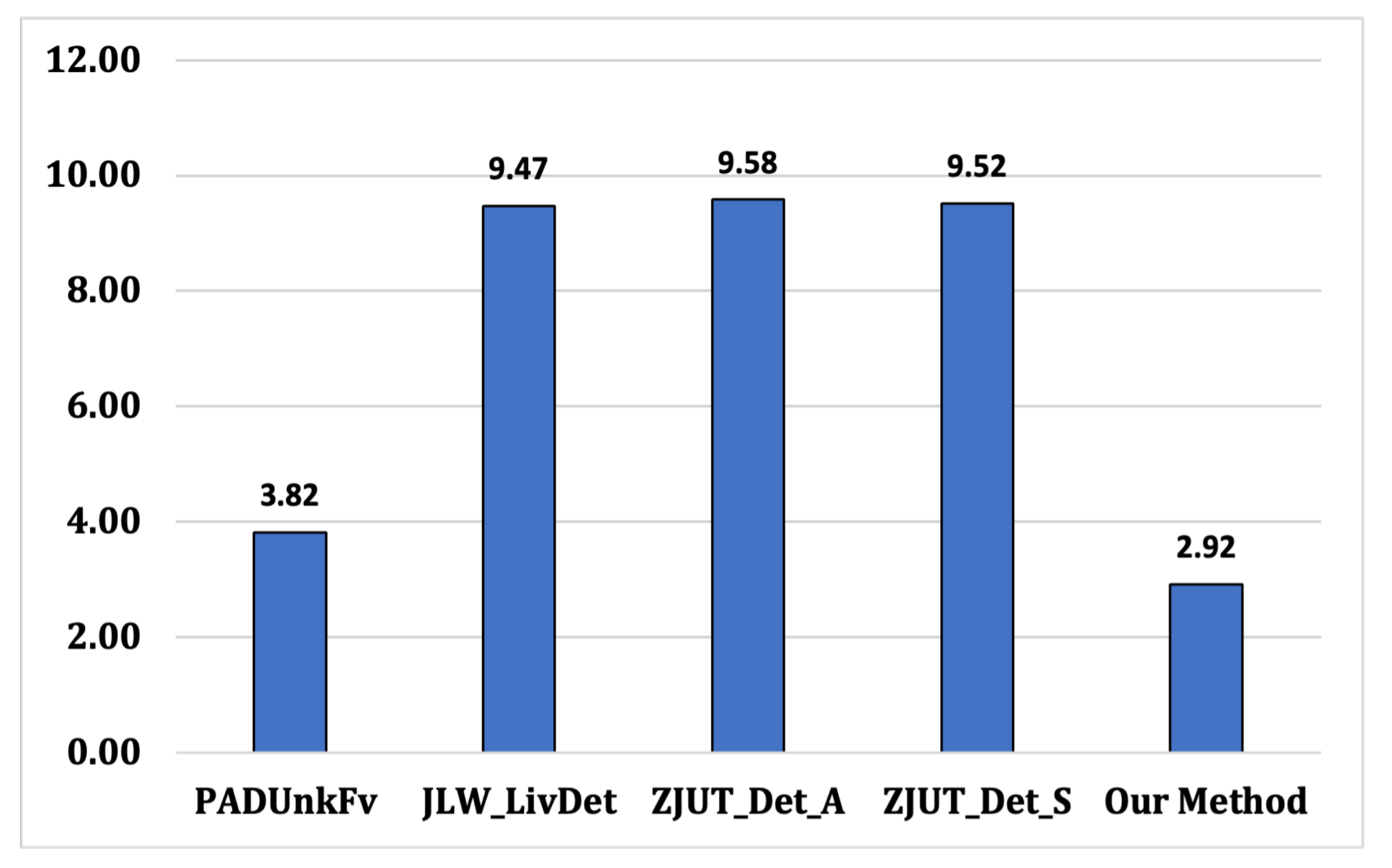
4.2.2. Results for RQ2
4.2.3. Results for RQ3
4.2.4. Results for RQ4
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Markets and Markets. Fingerprint Sensor Market by Type, Technology, Application, and Geography–Global Forecast to 2023. 2018. Available online: https://www.researchandmarkets.com/reports/4542299/ (accessed on 9 October 2020).
- Lee, Y.K.; Jeong, J. Securing biometric authentication system using blockchain. ICT Express 2021, 7, 322–326. [Google Scholar] [CrossRef]
- Adhikari, S. Galaxy S10’s Ultrasonic Fingerprint Sensor Fooled by a 3D-Printed Fingerprint. 2019. Available online: https://www.sammobile.com/ (accessed on 9 October 2020).
- Abhyankar, A.; Schuckers, S.A.C. Fingerprint Liveness Detection Using Local Ridge Frequencies and Multiresolution Texture Analysis Techniques. In Proceedings of the International Conference on Image Processing (ICIP), Atlanta, GA, USA, 8–11 October 2006; pp. 321–324. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Poggi, G.; Sansone, C.; Verdoliva, L. Local Contrast Phase Descriptor for Fingerprint Liveness Detection. Pattern Recognit. 2015, 48, 1050–1058. [Google Scholar] [CrossRef]
- Coli, P.; Marcialis, G.L.; Roli, F. Power spectrum-based fingerprint vitality detection. In Proceedings of the IEEE Workshop on Automatic Identification Advanced Technologies (AutoID), Alghero, Italy, 7–8 June 2007; pp. 169–173. [Google Scholar] [CrossRef]
- Marasco, E.; Sansone, C. Combining perspiration-and morphology-based static features for fingerprint liveness detection. Pattern Recognit. Lett. 2012, 33, 1148–1156. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Poggi, G.; Sansone, C.; Verdoliva, L. An Investigation of Local Descriptors for Biometric Spoofing Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 849–863. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Poggi, G.; Sansone, C.; Verdoliva, L. Fingerprint liveness detection based on weber local image descriptor. In Proceedings of the IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications (BIOMS), Napoli, Italy, 9 September 2013; pp. 46–50. [Google Scholar]
- Ghiani, L.; Marcialis, G.L.; Roli, F. Experimental results on the feature-level fusion of multiple fingerprint liveness detection algorithms. In Proceedings of the Multimedia and Security Workshop (MM & Sec) 2012, Coventry, UK, 6–7 September 2012; pp. 157–164. [Google Scholar] [CrossRef]
- Gottschlich, C. Convolution comparison pattern: An efficient local image descriptor for fingerprint liveness detection. PLoS ONE 2016, 11, e0148552. [Google Scholar] [CrossRef] [PubMed]
- Kembhavi, A.; Siddiquie, B.; Miezianko, R.; McCloskey, S.; Davis, L.S. Incremental Multiple Kernel Learning for object recognition. In Proceedings of the IEEE 12th International Conference on Computer Vision, (ICCV) 2009, Kyoto, Japan, 27 September–4 October 2009; pp. 638–645. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, S.; Hussain, T.; Muhammad, K.; Sangaiah, A.K.; Castiglione, A.; Esposito, C.; Baik, S.W. CNN-based anti-spoofing two-tier multi-factor authentication system. Pattern Recognit. Lett. 2019, 126, 123–131. [Google Scholar] [CrossRef]
- Nogueira, R.F.; de Alencar Lotufo, R.; Machado, R.C. Fingerprint liveness detection using convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1206–1213. [Google Scholar] [CrossRef]
- Hanmandlu, M.; Grover, J.; Gureja, A.; Gupta, H.M. Score level fusion of multimodal biometrics using triangular norms. Pattern Recognit. Lett. 2011, 32, 1843–1850. [Google Scholar] [CrossRef]
- Jeon, W.S.; Rhee, S.Y. Fingerprint pattern classification using convolution neural network. Int. J. Fuzzy Log. Intell. Syst. 2017, 17, 170–176. [Google Scholar] [CrossRef]
- Ghiani, L.; Hadid, A.; Marcialis, G.L.; Roli, F. Fingerprint Liveness Detection using Binarized Statistical Image Features. In Proceedings of the IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS) 2013, Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Mezai, L.; Hachouf, F. Score-level fusion of face and voice using particle swarm optimization and belief functions. IEEE Trans. Hum. Mach. Syst. 2015, 45, 761–772. [Google Scholar] [CrossRef]
- Kabir, W.; Ahmad, M.O.; Swamy, M.N.S. A new anchored normalization technique for score-level fusion in multimodal biometrie systems. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS) 2016, Montréal, QC, Canada, 22–25 May 2016; pp. 93–96. [Google Scholar] [CrossRef]
- Menotti, D.; Chiachia, G.; Pinto, A.; Schwartz, W.R.; Pedrini, H.; Falcao, A.X.; Rocha, A. Deep representations for iris, face, and fingerprint spoofing detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 864–879. [Google Scholar] [CrossRef]
- Orrù, G.; Casula, R.; Tuveri, P.; Bazzoni, C.; Dessalvi, G.; Micheletto, M.; Ghiani, L.; Marcialis, G.L. LivDet in Action-Fingerprint Liveness Detection Competition 2019. In Proceedings of the International Conference on Biometrics (ICB) 2019, Crete, Greece, 4–7 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Ojansivu, V.; Heikkilä, J. Blur Insensitive Texture Classification Using Local Phase Quantization. In Proceedings of the Image and Signal Processing-3rd International Conference (ICISP) 2008, Cherbourg-Octeville, France, 1–3 July 2008; Volume 5099, pp. 236–243. [Google Scholar] [CrossRef]
- Husseis, A.; Liu-Jimenez, J.; Sanchez-Reillo, R. Fingerprint presentation attack detection utilizing spatio-temporal features. Sensors 2021, 21, 2059. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics, (ICACCI) 2017, Udupi, India, 13–16 September 2017; pp. 1222–1228. [Google Scholar] [CrossRef]
- Ravi, V.; Chaganti, R.; Alazab, M. Recurrent deep learning-based feature fusion ensemble meta-classifier approach for intelligent network intrusion detection system. Comput. Electr. Eng. 2022, 102, 108156. [Google Scholar] [CrossRef]
- Chaganti, R.; Ravi, V.; Pham, T.D. Deep Learning based Cross Architecture Internet of Things malware Detection and Classification. Comput. Secur. 2022, 120, 102779. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Viswanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Nogueira, R.F.; de Alencar Lotufo, R.; Machado, R.C. Evaluating software-based fingerprint liveness detection using convolutional networks and local binary patterns. In Proceedings of the IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications (BIOMS) 2014, Rome, Italy, 17 October 2014; pp. 22–29. [Google Scholar]
- Marasco, E.; Wild, P.; Cukic, B. Robust and interoperable fingerprint spoof detection via convolutional neural networks. In Proceedings of the IEEE Symposium on Technologies for Homeland Security (HST) 2016, Waltham, MA, USA, 10–11 May 2016; pp. 1–6. [Google Scholar]
- Park, E.; Kim, W.; Li, Q.; Kim, J.; Kim, H. Fingerprint Liveness Detection Using CNN Features of Random Sample Patches. In Proceedings of the 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 321–328. [Google Scholar] [CrossRef]
- Wang, C.; Li, K.; Wu, Z.; Zhao, Q. A DCNN Based Fingerprint Liveness Detection Algorithm with Voting Strategy. In Proceedings of the Biometric Recognition-10th Chinese Conference (CCBR) 2015, Tianjin, China, 13–15 November 2015; Volume 9428, pp. 241–249. [Google Scholar] [CrossRef]
- Xu, Z.; Li, S.; Deng, W. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition (ACPR) 2015, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 141–145. [Google Scholar] [CrossRef]
- Jia, X.; Yang, X.; Cao, K.; Zang, Y.; Zhang, N.; Dai, R.; Zhu, X.; Tian, J. Multi-scale local binary pattern with filters for spoof fingerprint detection. Inf. Sci. 2014, 268, 91–102. [Google Scholar] [CrossRef]
- Nikam, S.B.; Agarwal, S. Local binary pattern and wavelet-based spoof fingerprint detection. Int. J. Biom. 2008, 1, 141–159. [Google Scholar] [CrossRef]
- Fuster-Garcia, E.; Bresó, A.; Martínez-Miranda, J.; Rosell-Ferrer, J.; Matheson, C.; García-Gómez, J.M. Fusing actigraphy signals for outpatient monitoring. Inf. Fusion 2015, 23, 69–80. [Google Scholar] [CrossRef]
- Paul, P.P.; Gavrilova, M.L.; Alhajj, R. Decision fusion for multimodal biometrics using social network analysis. IEEE Trans. Syst. Man, Cybern. Syst. 2014, 44, 1522–1533. [Google Scholar] [CrossRef]
- Nagar, A.; Nandakumar, K.; Jain, A.K. Multibiometric cryptosystems based on feature-level fusion. IEEE Trans. Inf. Forensics Secur. 2011, 7, 255–268. [Google Scholar] [CrossRef]
- Li, W.; Zhang, D.; Zhang, L.; Lu, G.; Yan, J. 3-D palmprint recognition with joint line and orientation features. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 41, 274–279. [Google Scholar] [CrossRef]
- Jeng, R.H.; Chen, W.S. Two feature-level fusion methods with feature scaling and hashing for multimodal biometrics. IETE Tech. Rev. 2017, 34, 91–101. [Google Scholar] [CrossRef]
- Alshehri, H.; Hussain, M.; Aboalsamh, H.A.; Al Zuair, M.A. Cross-sensor fingerprint matching method based on orientation, gradient, and Gabor-HoG descriptors with score level fusion. IEEE Access 2018, 6, 28951–28968. [Google Scholar] [CrossRef]
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint spoof buster: Use of minutiae-centered patches. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2190–2202. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar]
- Gomez-Barrero, M.; Kolberg, J.; Busch, C. Multi-Modal Fingerprint Presentation Attack Detection: Analysing the Surface and the Inside. In Proceedings of the International Conference on Biometrics (ICB) 2019, Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Ross, A.A.; Nandakumar, K.; Jain, A.K. Handbook of Multibiometrics, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Peng, J.; Abd El-Latif, A.A.; Li, Q.; Niu, X. Multimodal biometric authentication based on score level fusion of finger biometrics. Optik 2014, 125, 6891–6897. [Google Scholar] [CrossRef]
- Gottwald, S. Local and relativized local finiteness in t-norm based structures. Inf. Sci. 2013, 228, 26–36. [Google Scholar] [CrossRef]
- Weber, S. A general concept of fuzzy connectives, negations and implications based on t-norms and t-conorms. Fuzzy Sets Syst. 1983, 11, 115–134. [Google Scholar] [CrossRef]
- Hanmandlu, M.; Grover, J.; Madasu, V.K.; Vasirkala, S. Score level fusion of hand based biometrics using t-norms. In Proceedings of the IEEE International Conference on Technologies for Homeland Security (HST) 2010, Waltham, MA, USA, 8–10 November 2010; pp. 70–76. [Google Scholar]
- Keras. Keras: The Python Deep Learning API. 2020. Available online: https://keras.io (accessed on 9 October 2020).
- Developers, G. Keeping Your App Responsive|Android Developers. 2015. Available online: https://developer.android.com/training/articles/perf-anr.html (accessed on 16 August 2016).
- Casula, R.; Micheletto, M.; Orrù, G.; Delussu, R.; Concas, S.; Panzino, A.; Marcialis, G.L. LivDet 2021 Fingerprint Liveness Detection Competition–Into the unknown. In Proceedings of the International IEEE Joint Conference on Biometrics (IJCB) 2021, Shenzhen, China, 4–7 August 2021; pp. 1–6. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train (Original) | Train (Augmented) | Test | |||
|---|---|---|---|---|---|---|
| Live | Fake | Live | Fake | Live | Fake | |
| Green Bit | 1000 | 1200 | 12,000 | 14,400 | 1020 | 1224 |
| Digital Persona | 1000 | 1000 | 12,000 | 12,000 | 1019 | 1224 |
| Orcanthus | 1000 | 1200 | 12,000 | 14,400 | 990 | 1088 |
| Method | Green Bit | Digital Persona | Orchantus | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | ||
| Our FNN | 0.77 | 1.41 | 98.91 | 5.53 | 8.32 | 93.08 | 4.80 | 0.75 | 97.23 | 96.40 |
| Our CNN#1 | 0.30 | 0.93 | 99.39 | 3.41 | 6.61 | 94.99 | 3.21 | 0.48 | 98.16 | 97.51 |
| Our CNN#2 | 0.31 | 0.93 | 99.38 | 3.53 | 4.61 | 95.93 | 3.99 | 0.54 | 97.74 | 97.68 |
| Max | 0.65 | 1.11 | 99.12 | 5.11 | 7.66 | 93.62 | 4.31 | 0.65 | 97.52 | 96.75 |
| Min | 0.64 | 1.01 | 99.18 | 4.94 | 7.01 | 94.03 | 4.42 | 0.66 | 97.46 | 96.89 |
| Sum | 0.44 | 1.01 | 99.28 | 4.93 | 6.21 | 94.43 | 4.52 | 0.65 | 97.42 | 97.04 |
| Median | 0.49 | 1.01 | 99.25 | 4.36 | 6.22 | 94.71 | 4.48 | 0.65 | 97.44 | 97.13 |
| W-Sum | 0.27 | 0.94 | 99.40 | 4.35 | 6.01 | 94.82 | 3.92 | 0.53 | 97.78 | 97.33 |
| LLR | 0.65 | 1.59 | 98.88 | 4.73 | 7.91 | 93.68 | 4.46 | 1.18 | 97.18 | 96.58 |
| SVM | 0.62 | 3.43 | 97.98 | 6.45 | 7.99 | 92.78 | 4.37 | 5.71 | 94.96 | 95.24 |
| EL-HV | 0.39 | 1.17 | 99.22 | 3.24 | 5.94 | 95.41 | 3.76 | 0.64 | 97.80 | 97.48 |
| EL-AB | 0.58 | 0.62 | 99.40 | 3.46 | 5.88 | 95.33 | 3.42 | 0.62 | 97.98 | 97.57 |
| Our Method | 0.36 | 0.83 | 99.41 | 3.42 | 4.36 | 96.11 | 2.23 | 0.48 | 98.65 | 98.05 |
| Method | Green Bit | Digital Persona | Orchantus | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | ||
| PADUnkFv | 3.24 | 1.55 | 97.68 | 4.8 | 7.67 | 93.63 | 3.64 | 2.02 | 97.21 | 96.17 |
| JLW_LivDet | 0.39 | 1.14 | 99.2 | 7.75 | 13.96 | 88.86 | 4.75 | 0.55 | 97.45 | 95.17 |
| ZJUT_Det_A | 0.39 | 1.14 | 99.2 | 7.75 | 14.15 | 88.77 | 4.65 | 0.55 | 97.5 | 95.16 |
| ZJUT_Det_S | 0.39 | 1.14 | 99.2 | 7.75 | 14.06 | 88.81 | 4.75 | 0.55 | 97.45 | 95.15 |
| Our Method | 0.36 | 0.83 | 99.41 | 3.42 | 4.36 | 96.11 | 2.23 | 0.48 | 98.65 | 98.05 |
| Architecture | Green Bit | Digital Persona | Orchantus | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | Ferrlive | Ferrfake | ACC | ||
| LBP+SVM | 2.24 | 2.07 | 97.85 | 6.74 | 16.25 | 88.51 | 5.11 | 1.03 | 96.93 | 94.43 |
| LPQ+SVM | 5.11 | 1.45 | 96.72 | 7.22 | 18.03 | 87.38 | 6.93 | 1.25 | 95.91 | 93.34 |
| LBP+LPQ+SVM | 5.09 | 1.38 | 96.77 | 7.09 | 16.25 | 88.33 | 6.65 | 1.04 | 96.16 | 93.75 |
| LBP+NN | 0.67 | 1.63 | 98.85 | 5.61 | 8.12 | 93.14 | 5.24 | 1.02 | 96.87 | 96.29 |
| LPQ+NN | 0.88 | 1.29 | 98.92 | 5.53 | 9.44 | 92.52 | 4.93 | 0.99 | 97.04 | 96.16 |
| Our FNN | 0.77 | 1.41 | 98.91 | 5.53 | 8.32 | 93.08 | 4.80 | 0.75 | 97.23 | 96.40 |
| ResNet-34 | 0.42 | 1.25 | 99.17 | 3.91 | 4.57 | 95.76 | 3.93 | 0.73 | 97.67 | 97.53 |
| Slim-ResNet | 0.59 | 1.25 | 99.08 | 4.16 | 5.11 | 95.37 | 4.05 | 0.89 | 97.53 | 97.33 |
| VGG-16 | 0.51 | 1.2 | 99.15 | 5.77 | 4.38 | 94.93 | 4.15 | 0.53 | 97.66 | 97.24 |
| VGG-19 | 0.39 | 1.11 | 99.25 | 4.03 | 4.31 | 95.83 | 4 | 0.53 | 97.74 | 97.61 |
| Our CNN#1 | 0.30 | 0.93 | 99.39 | 3.41 | 6.61 | 94.99 | 3.21 | 0.48 | 98.16 | 97.51 |
| Our CNN#2 | 0.31 | 0.93 | 99.38 | 3.53 | 4.61 | 95.93 | 3.99 | 0.54 | 97.74 | 97.68 |
| FNN Architecture | Processing Time | CNN Architecture | Processing Time |
|---|---|---|---|
| LBP+SVM | 8 ms | ResNet-34 | 151 ms |
| LPQ+SVM | 8 ms | Slim-ResNet | 92 ms |
| LBP+LPQ+SVM | 9 ms | VGG-16 | 81 ms |
| LBP+NN | 11 ms | VGG-19 | 105 ms |
| LPQ+NN | 11 ms | Our CNN#1 | 24 ms |
| Our FNN | 12 ms | Our CNN#2 | 49 ms |
| Type | Green Bit | Digital Persona | Orchantus | Difference |
|---|---|---|---|---|
| ACC | ACC | ACC | ||
| Augmented | 99.41 | 96.11 | 98.65 | 2.92 |
| Non-Augmented | 94.38 | 82.99 | 92.34 | 10.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.K.; Jeong, J.; Kang, D. An Effective Orchestration for Fingerprint Presentation Attack Detection. Electronics 2022, 11, 2515. https://doi.org/10.3390/electronics11162515
Lee YK, Jeong J, Kang D. An Effective Orchestration for Fingerprint Presentation Attack Detection. Electronics. 2022; 11(16):2515. https://doi.org/10.3390/electronics11162515
Chicago/Turabian StyleLee, Youn Kyu, Jongwook Jeong, and Dongwoo Kang. 2022. "An Effective Orchestration for Fingerprint Presentation Attack Detection" Electronics 11, no. 16: 2515. https://doi.org/10.3390/electronics11162515
APA StyleLee, Y. K., Jeong, J., & Kang, D. (2022). An Effective Orchestration for Fingerprint Presentation Attack Detection. Electronics, 11(16), 2515. https://doi.org/10.3390/electronics11162515