
Performance Improvement of Image-Reconstruction-Based Defense against Adversarial Attack



Abstract
:1. Introduction
2. Related Work
2.1. Evasion Attack
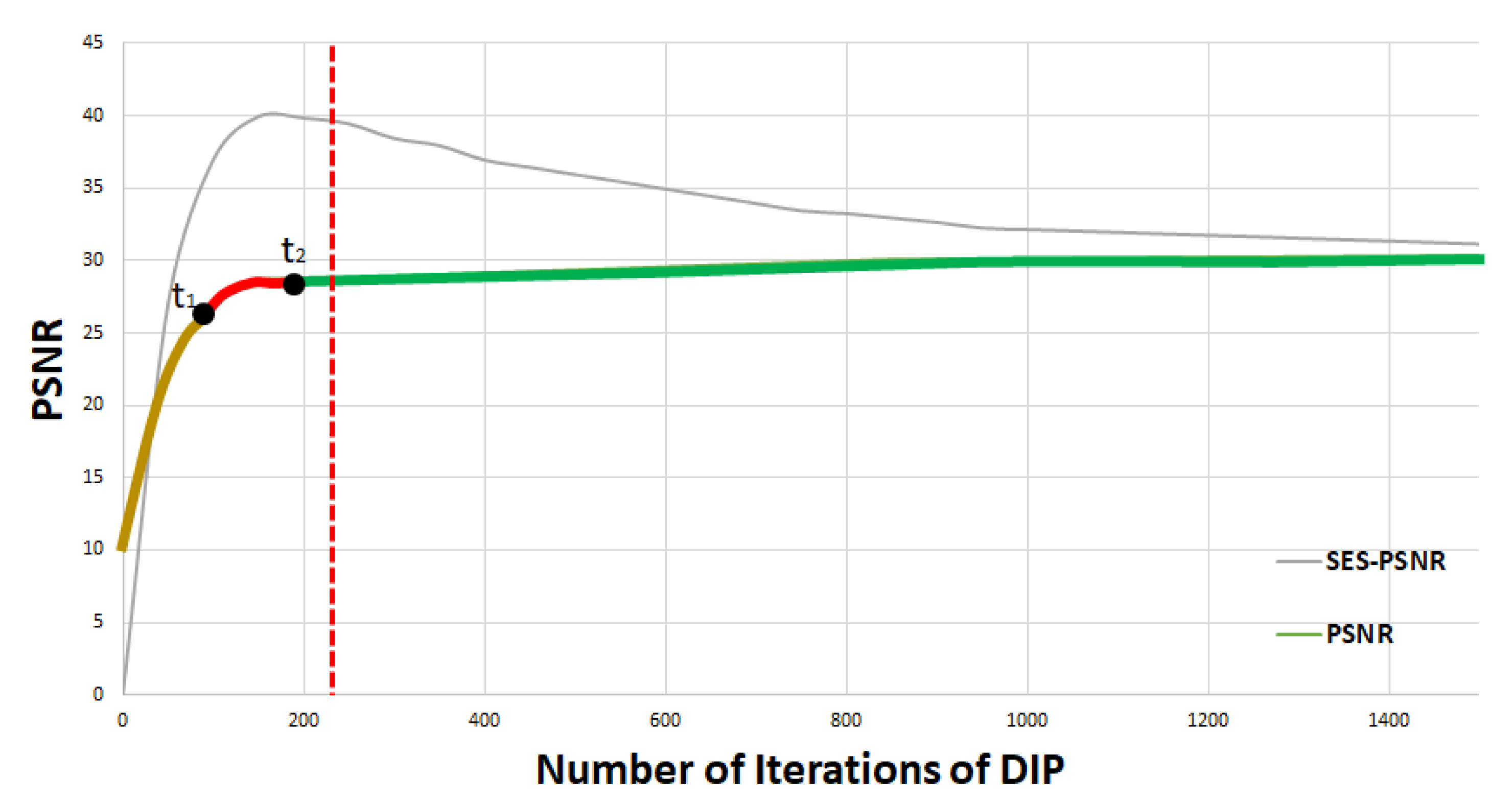
2.2. Deep Image Prior (DIP)
3. Proposed Method
3.1. Searching for Ground-Truth Label Using Low-Pass Filter (LPF)
3.2. Different Parameters for DIPDepend
- Mode 1: , ;
- Mode 2: , ;
- Mode 3: , ;
- Mode 4: , .
3.3. Algorithm of Proposed Method
| Algorithm 1 Prediction of the original label. |
|
- Mode 1: , ,
- Mode 2: , ,
- Mode 3: , , and
- Mode 4: , .
| Algorithm 2 Inference with adaptive and . |
|
4. Evaluation
4.1. Experimental Settings
4.2. Results on the Accuracy and Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Luo, X. Fuzzy Control Method for Synchronous Acquisition of High Resolution Image based on Machine Learning. Int. J. Circuits Syst. Signal Process. 2022, 16, 363–373. [Google Scholar] [CrossRef]
- Shylashree, N.; Anil Naik, M.; Sridhar, V. Design and Implementation of Image Edge Detection Algorithm on FPGA. Int. J. Circuits Syst. Signal Process. 2022, 16, 628–636. [Google Scholar] [CrossRef]
- Chowdhary, K. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 603–649. [Google Scholar]
- Bojarski, M.; Testa, D.D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:abs/1604.07316. [Google Scholar]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Caridade, C.M.R.; Roseiro, L. Automatic Segmentation of Skin Regions in Thermographic Images: An Experimental Study. WSEAS Trans. Signal Process. 2021, 17, 57–64. [Google Scholar]
- Vetova, S. A Comparative Study of Image Classification Models using NN and Similarity Distance. WSEAS Trans. Int. J. Electr. Eng. Comput. Sci. 2021, 3, 109–113. [Google Scholar]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial attacks and defences: A survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Goel, A.; Agarwal, A.; Vatsa, M.; Singh, R.; Ratha, N.K. DNDNet: Reconfiguring CNN for adversarial robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 22–23. [Google Scholar]
- Ye, S.; Xu, K.; Liu, S.; Cheng, H.; Lambrechts, J.H.; Zhang, H.; Zhou, A.; Ma, K.; Wang, Y.; Lin, X. Adversarial robustness vs. model compression, or both? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2019; pp. 111–120. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Dai, T.; Feng, Y.; Wu, D.; Chen, B.; Lu, J.; Jiang, Y.; Xia, S.T. DIPDefend: Deep Image Prior Driven Defense against Adversarial Examples. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1404–1412. [Google Scholar]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial examples are not bugs, they are features. arXiv 2019, arXiv:1905.02175. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Selesnick, I.W.; Graber, H.L.; Pfeil, D.S.; Barbour, R.L. Simultaneous Low-Pass Filtering and Total Variation Denoising. IEEE Trans. Signal Process. 2014, 62, 1109–1124. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Components | Feature |
|---|---|
| Robust Features | Characteristics that can be distinguished by human Low-Frequency E.g., tails of animals, ears of animals, etc. |
| Non-Robust Features | Characteristics that human cannot be distinguished well High-Frequency E.g., hair whorl of animals, etc. |
| Kernel Size | No LPF | 3 | 5 | 7 | 9 | 11 | 13 |
|---|---|---|---|---|---|---|---|
| Accuracy (%) | 17.4 | 55.2 | 57.8 | 55.2 | 47.8 | 38.8 | 33.0 |
| Kernel Size | No LPF | 3 | 5 | 7 | 9 | 11 | 13 |
|---|---|---|---|---|---|---|---|
| Accuracy (%) | 3.0 | 34.4 | 47.4 | 48.2 | 42.4 | 35.4 | 32.2 |
| Kernel Size | No LPF | 3 | 5 | 7 | 9 | 11 | 13 |
|---|---|---|---|---|---|---|---|
| Accuracy (%) | 2.4 | 20.6 | 35.6 | 38.6 | 36.2 | 32 | 27.8 |
| Attack | No Attack | |||
|---|---|---|---|---|
| Ratio (%) | 32 | 32.4 | 25.6 | 18.2 |
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) |
|---|---|---|---|---|
| Accuracy (%) | 13.0 | 38.6 | 49.2 | 65.4 |
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) |
|---|---|---|---|---|
| Accuracy (%) | 13.4 | 38.0 | 48.2 | 61.8 |
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) |
|---|---|---|---|---|
| Accuracy (%) | 13.4 | 34.4 | 45.8 | 52.2 |
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) |
|---|---|---|---|---|
| Number of DIP iterations | 250 | 583 | 923 | 2514 |
| 2 | 8 | 16 | |
|---|---|---|---|
| Accuracy(%) | 69.2 | 66.4 | 61.8 |
| 0 (No Attack) | 2 | 8 | 16 | |
|---|---|---|---|---|
| Accuracy (%) | 72.2 | 17.4 | 3.0 | 2.4 |
| DIPDefend | Proposed Method | ||||
|---|---|---|---|---|---|
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) | |
| Accuracy (%) | 13.0 | 38.6 | 49.2 | 65.4 | 62.6 |
| Execution Time (s) | 24.30 | 56.52 | 89.49 | 244.0 | 143.2 |
| DIPDefend | Proposed Method | ||||
|---|---|---|---|---|---|
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) | |
| Accuracy (%) | 13.4 | 38 | 48.2 | 61.8 | 60 |
| Execution Time (s) | 24.26 | 56.40 | 89.41 | 243.6 | 135.1 |
| DIPDefend | Proposed Method | ||||
|---|---|---|---|---|---|
| (, ) | (0.01, 0.01) | (0.01, 0.001) | (0.001, 0.01) | (0.001, 0.001) | |
| Accuracy (%) | 13.4 | 34.4 | 45.8 | 52.2 | 51.8 |
| Execution Time (s) | 24.15 | 56.33 | 89.13 | 242.0 | 145.6 |
| 2 | 8 | 16 | ||||
|---|---|---|---|---|---|---|
| Defense Method | DIPDefend | Proposed Method | DIPDefend | Proposed Method | DIPDefend | Proposed Method |
| Accuracy (%) | 65.4 | 62.6 | 61.8 | 60 | 52.2 | 51.8 |
| Accuracy drop (%) | 2.8 | 1.8 | 0.4 | |||
| Execution time (s) | 244.0 | 143.2 | 243.6 | 135.1 | 242.0 | 145.6 |
| Exec. improvement (%) | 41.3 | 44.5 | 39.8 | |||
| Defense Method | DIPDefend | Proposed Method |
|---|---|---|
| Accuracy (%) | 66.0 | 62.1 |
| Accuracy drop (%) | 3.9 | |
| Execution time (s) | 243.8 | 158.8 |
| Exec. improvement (%) | 34.9 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Yang, H. Performance Improvement of Image-Reconstruction-Based Defense against Adversarial Attack. Electronics 2022, 11, 2372. https://doi.org/10.3390/electronics11152372
Lee J, Yang H. Performance Improvement of Image-Reconstruction-Based Defense against Adversarial Attack. Electronics. 2022; 11(15):2372. https://doi.org/10.3390/electronics11152372
Chicago/Turabian StyleLee, Jungeun, and Hoeseok Yang. 2022. "Performance Improvement of Image-Reconstruction-Based Defense against Adversarial Attack" Electronics 11, no. 15: 2372. https://doi.org/10.3390/electronics11152372
APA StyleLee, J., & Yang, H. (2022). Performance Improvement of Image-Reconstruction-Based Defense against Adversarial Attack. Electronics, 11(15), 2372. https://doi.org/10.3390/electronics11152372