
Research on Medical Text Classification Based on Improved Capsule Network


Abstract
:1. Introduction
- 1.
- We proposed an improved Capsule network model based on features of Chinese medical text classification. The unique network structure and powerful capability of feature extraction of the Capsule network enable us to extract the features of complex medical texts;
- 2.
- Combined with the initial processing of medical text by the Long Short-Term Memory (LSTMs) network, the Capsule network has better performance, with at least 4% improvement in F1 values compared to other baseline models.
2. Related Work
2.1. Text Classification
2.2. Capsule Network
3. Model
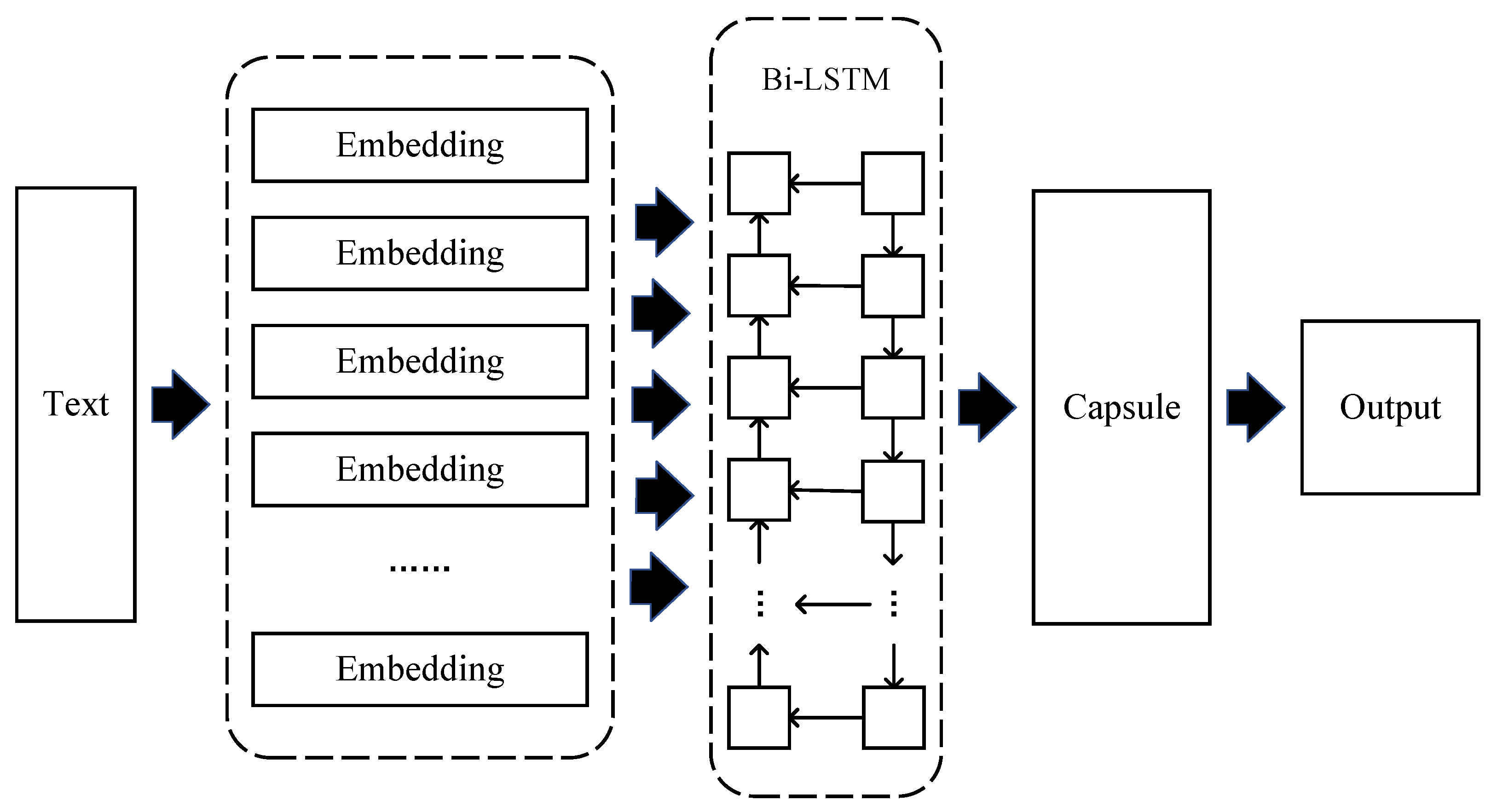
3.1. Model Structure
3.2. Capsule Network Structure
4. Experiments
4.1. Dataset
4.2. Evaluation Criteria and Parameter
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jasmir, J.; Nurmaini, S.; Malik, R.F.; Tutuko, B. Bigram feature extraction and conditional random fields model to improve text classification clinical trial document. Telkomnika 2021, 19, 886–892. [Google Scholar] [CrossRef]
- Hao, T.; Rusanov, A.; Boland, M.R.; Weng, C. Clustering clinical trials with similar eligibility criteria features. J. Biomed. Inform. 2014, 52, 112–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thadani, S.R.; Weng, C.; Bigger, J.T.; Ennever, J.F.; Wajngurt, D. Electronic screening improves efficiency in clinical trial recruitment. J. Am. Med. Inform. Assoc. 2009, 16, 869–873. [Google Scholar] [CrossRef] [PubMed]
- Gulden, C.; Kirchner, M.; Schüttler, C.; Hinderer, M.; Kampf, M.; Prokosch, H.U.; Toddenroth, D. Extractive summarization of clinical trial descriptions. Int. J. Med. Inform. 2019, 129, 114–121. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Toti, G.; Morley, K.I.; Ibrahim, Z.M.; Folarin, A.; Jackson, R.; Kartoglu, I.; Agrawal, A.; Stringer, C.; Gale, D.; et al. SemEHR: A general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research. J. Am. Med. Inform. Assoc. 2018, 25, 530–537. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Mousa, A.; Schuller, B. Contextual bidirectional long short-term memory recurrent neural network language models: A generative approach to sentiment analysis. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, T.; Zhu, S.; Ogihara, M. Using discriminant analysis for multi-class classification: An experimental investigation. Knowl. Inf. Syst. 2006, 10, 453–472. [Google Scholar] [CrossRef]
- Huang, C.C.; Lu, Z. Community challenges in biomedical text mining over 10 years: Success, failure and the future. Brief. Bioinform. 2016, 17, 132–144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Burns, G.A.; Li, X.; Peng, N. Building deep learning models for evidence classification from the open access biomedical literature. Database 2019, 2019, baz034. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amin, S.; Uddin, M.I.; Hassan, S.; Khan, A.; Nasser, N.; Alharbi, A.; Alyami, H. Recurrent neural networks with TF-IDF embedding technique for detection and classification in tweets of dengue disease. IEEE Access 2020, 8, 131522–131533. [Google Scholar] [CrossRef]
- Li, Q.; Li, Y.K.; Xia, S.Y.; Kang, Y. An Improved Medical Text Classification Model: LS-GRU. J. Northeast. Univ. Nat. Sci. 2020, 41, 938. [Google Scholar]
- Zhao, W.; Ye, J.; Yang, M.; Lei, Z.; Zhang, S.; Zhao, Z. Investigating capsule networks with dynamic routing for text classification. arXiv 2018, arXiv:1804.00538. [Google Scholar]
- Srivastava, S.; Khurana, P.; Tewari, V. Identifying aggression and toxicity in comments using capsule network. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 98–105. [Google Scholar]
- Yang, M.; Zhao, W.; Chen, L.; Qu, Q.; Zhao, Z.; Shen, Y. Investigating the transferring capability of capsule networks for text classification. Neural Netw. 2019, 118, 247–261. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, C.; Liu, J.; Ma, X. Improving text classification with weighted word embeddings via a multi-channel TextCNN model. Neurocomputing 2019, 363, 366–374. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Sachin, S.; Tripathi, A.; Mahajan, N.; Aggarwal, S.; Nagrath, P. Sentiment analysis using gated recurrent neural networks. SN Comput. Sci. 2020, 1, 74. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Input | Input (in English) | Category |
|---|---|---|---|
| S1 | 全麻手术患者 | Patients undergoing general anesthesia. | Therapy or Surgery |
| S2 | 过去4周内服用催眠或镇静药、精神类药物 | Use of hypnotic or sedative drugs, or psychotropic drugs within the past 4 weeks. | Pharmaceutical Substance or Drug |
| S3 | 血糖< 2.7 mmol/L | Blood glucose < 2.7 mmol/L | Laboratory Examinations |
| Category | Count (Ratio) | Min Length | Max Length | Average Length |
|---|---|---|---|---|
| Disease | 5127 (22.33%) | 3 | 213 | 23.90 |
| Multiple | 4556 (19.84%) | 7 | 342 | 42.09 |
| Therapy or Surgery | 1504 (6.55%) | 5 | 159 | 21.67 |
| Consent | 1319 (5.74%) | 4 | 112 | 19.10 |
| Diagnostic | 1233 (5.37%) | 7 | 194 | 29.54 |
| Laboratory Examinations | 1142 (4.97%) | 5 | 174 | 33.36 |
| Pregnancy-related Activity | 1026 (4.47%) | 7 | 186 | 20.52 |
| Age | 917 (3.99%) | 5 | 67 | 13.27 |
| Pharmaceutical Substance or Drug | 877 (3.82%) | 6 | 238 | 31.32 |
| Risk Assessment | 708 (3.08%) | 8 | 195 | 23.66 |
| Allergy Intolerance | 668 (2.91%) | 4 | 76 | 21.28 |
| Enrollment in other studies | 514 (2.24%) | 9 | 58 | 22.48 |
| Researcher Decision | 464 (2.02%) | 12 | 225 | 27.35 |
| Compliance with Protocol | 370 (1.61%) | 5 | 67 | 19.35 |
| Organ or Tissue Status | 358 (1.56%) | 6 | 100 | 17.18 |
| Sign | 286 (1.25%) | 4 | 65 | 19.86 |
| Addictive Behavior | 272 (1.18%) | 3 | 133 | 23.94 |
| Capacity | 168 (0.73%) | 6 | 303 | 21.48 |
| Life Expectancy | 166 (0.72%) | 9 | 30 | 15 |
| Symptom | 154 (0.67%) | 5 | 144 | 23.39 |
| Neoplasm Status | 131 (0.57%) | 6 | 69 | 22.48 |
| Device | 129 (0.56%) | 7 | 71 | 21.35 |
| Special Patient Characteristic | 104 (0.45%) | 4 | 43 | 15.28 |
| Non-Neoplasm Disease Stage | 103 (0.45%) | 6 | 57 | 20.81 |
| Data Accessible | 71 (0.31%) | 8 | 169 | 23.15 |
| Encounter | 66 (0.29%) | 8 | 61 | 21.33 |
| Diet | 61 (0.27%) | 11 | 111 | 37.07 |
| Smoking Status | 54 (0.24%) | 6 | 123 | 27.93 |
| Literacy | 52 (0.23%) | 8 | 37 | 20.75 |
| Oral related | 51 (0.22%) | 4 | 78 | 23.75 |
| Healthy | 39 (0.17%) | 6 | 77 | 22.05 |
| Address | 31 (0.14%) | 9 | 35 | 17.10 |
| Blood Donation | 31 (0.14%) | 10 | 56 | 30.00 |
| Gender | 30 (0.13%) | 4 | 32 | 9.7 |
| Receptor Status | 28 (0.12%) | 9 | 56 | 23.68 |
| Nursing | 22 (0.10%) | 12 | 39 | 18.36 |
| Exercise | 21 (0.09%) | 10 | 60 | 26.48 |
| Education | 19 (0.08%) | 11 | 37 | 16.79 |
| Disabilities | 17 (0.07%) | 8 | 58 | 24.41 |
| Sexual related | 17 (0.07%) | 6 | 57 | 30.71 |
| Alcohol Consumer | 17 (0.07%) | 17 | 104 | 56.65 |
| Bedtime | 14 (0.06%) | 5 | 53 | 20.29 |
| Ethical Audit | 12 (0.05%) | 10 | 21 | 14.5 |
| Ethnicity | 13 (0.06%) | 5 | 15 | 8.70 |
| Model | Sources of Difference | SS (Sum of Squared Deviations) | df (Degrees of Freedom) | MS (Mean Square) | F (Effect Term/Error Term) | p-Value | F Crit |
|---|---|---|---|---|---|---|---|
| Capsule + GRU | Between groups | 0.05109 | 3 | 0.01703 | 63.79289 | 1.76 × 10 | 2.86626 |
| Inside the group | 0.00961 | 36 | 0.00026 | - | - | - | |
| Capsule + LSTM | Between groups | 0.07403 | 3 | 0.02467 | 96.17230 | 2.99 × 10 | 2.86626 |
| Inside the group | 0.00923 | 36 | 0.00025 | - | - | - |
| Size | Precision | Recall | F1 |
|---|---|---|---|
| 128 | 80.46% | 70.55% | 73.51% |
| 246 | 78.58% | 70.64% | 73.36% |
| 512 | 73.24% | 67.91% | 68.93% |
| 1024 | 76.95% | 69.29% | 71.42% |
| Learning Rate | Precision | Recall | F1 |
|---|---|---|---|
| 0.0001 | 81.31% | 69.14% | 73.04% |
| 0.00033 | 77.57% | 67.48% | 70.83% |
| 0.001 | 80.46% | 70.55% | 73.51% |
| 0.003 | 57.86% | 52.65% | 53.96% |
| Category | GRU | LSTM | CNN | Capsule+GRU | Capsule+LSTM |
|---|---|---|---|---|---|
| Multiple | 68.00% | 68.82% | 68.75% | 67.89% | 68.92% |
| Ethnicity | 66.67% | 66.67% | 57.14% | 100.00% | 100.00% |
| Gender | 78.26% | 85.71% | 94.74% | 82.35% | 85.71% |
| Bedtime | 28.57% | 12.50% | 55.33% | 55.33% | 30.77% |
| Blood Donation | 71.43% | 87.50% | 80.00% | 87.50% | 80.00% |
| Diagnostic | 73.87% | 75.62% | 74.63% | 75.46% | 74.91% |
| Address | 73.68% | 60.87% | 60.00% | 63.16% | 77.78% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Yuan, Q.; Lv, P.; Zhang, M.; Lv, L. Research on Medical Text Classification Based on Improved Capsule Network. Electronics 2022, 11, 2229. https://doi.org/10.3390/electronics11142229
Zhang Q, Yuan Q, Lv P, Zhang M, Lv L. Research on Medical Text Classification Based on Improved Capsule Network. Electronics. 2022; 11(14):2229. https://doi.org/10.3390/electronics11142229
Chicago/Turabian StyleZhang, Qinghui, Qihao Yuan, Pengtao Lv, Mengya Zhang, and Lei Lv. 2022. "Research on Medical Text Classification Based on Improved Capsule Network" Electronics 11, no. 14: 2229. https://doi.org/10.3390/electronics11142229
APA StyleZhang, Q., Yuan, Q., Lv, P., Zhang, M., & Lv, L. (2022). Research on Medical Text Classification Based on Improved Capsule Network. Electronics, 11(14), 2229. https://doi.org/10.3390/electronics11142229