1. Introduction
Language modeling with binary one-hot word encoding is higher dimensional and sparse with no semantic information. As a result, the word analogy is missing; e.g., the distance between word vectors represents only the difference in alphabetic ordering. However, point vector representation of words in the embedding space like word2vec [
1] and GloVe [
2,
3] contain semantic information. Representing a dense low-dimensional fixed-length document vector is much more expensive and complicated. Moreover, it is challenging to infer unseen documents during the test process. The simplest method to get document embedding is the weighted averaging of word embeddings in the document [
4]. Document Vector through Corruption (Doc2VecC) [
5] is a significant study that shows how a simple weighted averaging technique combined with a simple noise-eliminating procedure can be effective. However, Doc2VecC did not cover the underlying themes of the document. Sparse Composite Document Vector (SCDV) [
6] addresses this limitation by using word embeddings and the Gaussian mixture clustering to generate the document vector, which also overcomes the shortcomings of the hard-clustering approach [
7]. SCDV shows significant improvement in the downstream natural language processing (NLP) tasks, including document classification. However, SCDV inherits noisy tails from the Gaussian mixture clustering that is not appropriate for the document containing multiple sentences [
8]. Another vital issue ignored by most document representation methods is ignoring potential terms in the corpus, which is essential for understanding deep semantic insight of the documents.
It is hard to encode the richness of semantic insights for short-length documents where word co-occurrence information is limited [
9]. Therefore, many works suggest importing semantic information from external sources [
10,
11,
12]. However, accessing information from external sources (e.g., Wikipedia) may cause irrelevant noise corresponding to the current short text corpus.
In this context, we aim to develop corpus statistics-based semantically enriched vectorial representation of the noisy long and sparse short texts for the multi-class document classification performance with the objectives of solving the following research questions:
How to efficiently model noisy long and sparse short texts for the classification performance?
How to efficiently encode the semantically enriched vectorial representation of documents using available corpus statistics to enhance classification performance?
Is it possible to model efficient sparse short-length documents utilizing available corpus statistics instead of depending on external knowledge sources?
How can we utilize potential words in the document for deep thematic insights?
Sparse Composite Document Vector with Multi-Sense Embeddings (SCDV-MS) [
13] forces discarding the outliers from the clustering output to eliminate long-tail noises in the SCDV, which applies a hard threshold that may hinder the thematic representation of documents. Moreover, representing proper expressive documents depends upon modeling the underlying semantic topics in the correct form [
14], which requires capturing deep semantics insights buried in words, expressions, and string patterns [
15]. Hence, for the noisy long texts, we proposed
Weighted Sparse Document Vector (WSDV) that embodies important words emphasizing capability using
Pomegranate General Mixture model [
16], and a soft threshold-based noise reduction technique.
It is challenging to capture semantics insights in document modeling with sparse short texts. The probability distribution of words captures better semantics than the point embedding approach (e.g., word2vec) [
17] as it generalizes deterministic point embeddings of the terms using the mean vector, and the covariance matrix holds uncertainty of the estimations. Hence, instead of depending on external knowledge sources, we proposed corpus statistics empowered
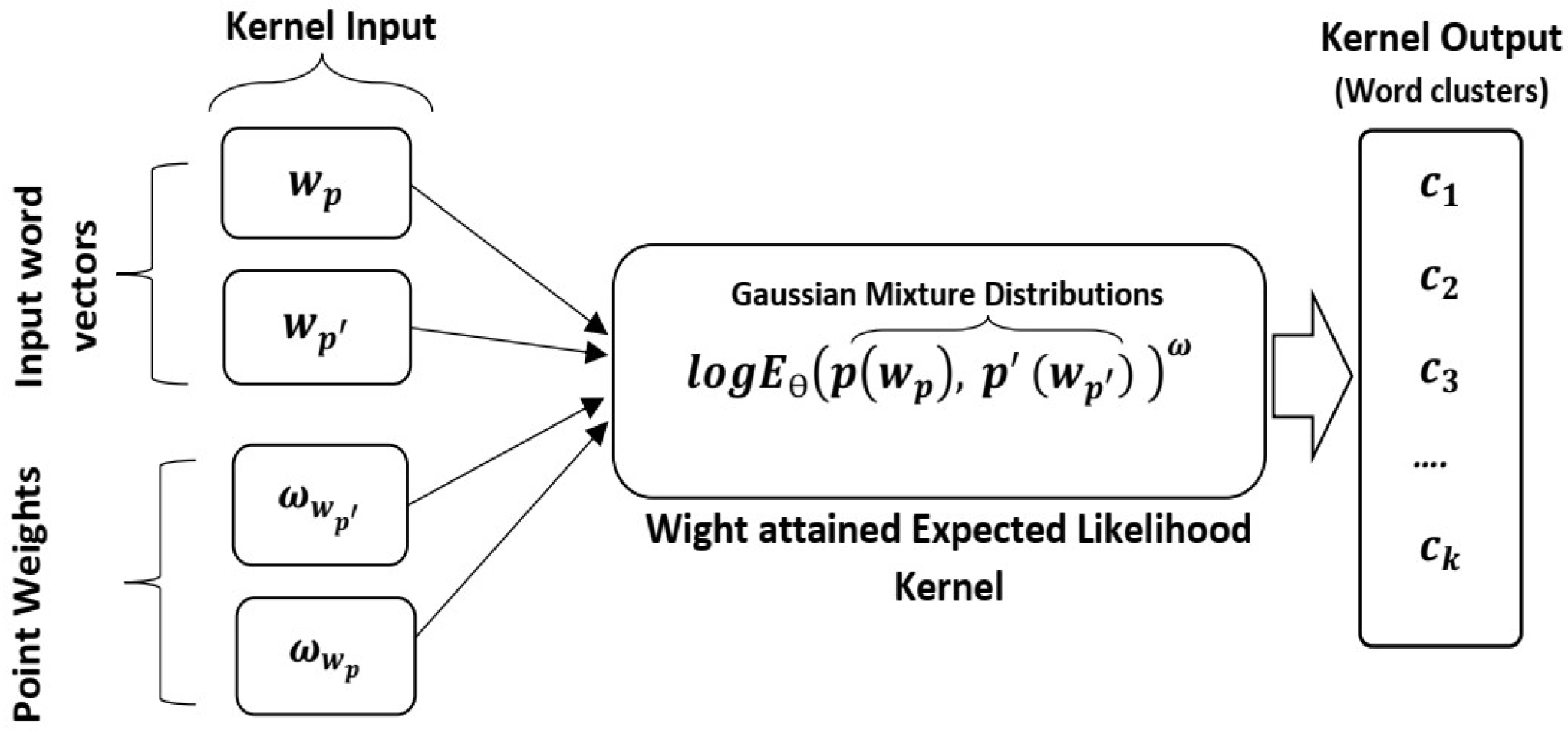
Weighted Compact Document Vector (WCDV), which emphasizes potential terms while performing probability word distribution using the weighted energy function. In WCDV, we employ the
Multimodal word Distributions [
18] that learns distributions of words using the Expected Likelihood Kernel [
19], which computes the inner product between distributions of words to get the affinity of word pairs. However, every word in a document does not hold the same importance; some are used more frequently than others, indicating their importance in the corpus. It is required to emphasize the frequently used words, especially when word co-occurrence information is limited (e.g., microblogging, product review, etc.). Therefore, to preserve the word frequency importance, we proposed
Weight attained Expected Likelihood Kernel which considers term frequency-based point weights while measuring the partial log energy between distributions in the
Multimodal word Distributions [
18].
The organization of the remaining parts of the paper is as follows.
Section 2 contains discussions about related works.
Section 3 explains the methodologies used in the proposed approaches.
Section 4 represents the functionality of the proposed approaches.
Section 5 carries out the analysis of the experiments and obtained results. Finally,
Section 6 concludes the article.
2. Literature Review
Word embeddings models ignore side information (e.g., document labels) while learning embeddings from enormous document corpora. To improve word representation and text classification accuracy, Linear, Y. et al. [
20] proposed to use document labels as the global context both in the local neural network model and the global matrix factorization framework. Obayes, H.K. et al. [
21] combined GloVe and bidirectional long short-term memory (BiLSTM) recurrent neural network for better sentiment classification, which causes expensive computation and no guidance for documents containing multiple sentences. Yang, Z. et al. [
22] proposed Hierarchical attention networks (HAN) for document classification, which maintain a hierarchical structure of word to sentence (building sentence from words) and sentence to document (aggregating sentences to a document representation). Zhang, Z. et al. [
23] proved that the TFIDF algorithm with the combination of Naive Bayes has significance in the text classification task compared to many complex models.
Recently, transformers-based models [
24,
25] became more prevalent in downstream Natural Language Processing (NLP) tasks (e.g., document classification). Wang, B. andlinebreak Kuo, C-C.J. [
26] proposed SBERTWK for sentence embedding, which trains on both word and sentence level objectives but no guidance for representing a document that contains multiple sentences. However, the transformer-based model requires enormous computational resources. Sanh, V. et al. [
27] introduced a distilled version of BERT called DistilBERT, which is smaller, faster, cheaper, and lighter than other transformers-based models.
Mapping sentences to a fixed-length embedding vector using Universal Sentence Encoder (USE) based method [
28] also got success in the downstream Natural Language Processing (NLP) task. The sentence analysis method made by combining Universal Language Model Fine-tuning (ULMFiT) with the Support Vector Machine (SVM) [
29] is capable of performing document classification using a small amount of data but has higher computational complexity.
Yet, K.S. et al. [
30] proposed document embedding along with their uncertainty called the Bayesian subspace multinomial model (Bayesian SMM) to capture better semantics. It is a generative log-linear model that learns to represent documents in the form of the Gaussian distributions and encodes uncertainty in the covariance matrix but holds only a single mode of words. Therefore, encoded uncertainty might diffuse spontaneously; the mean vector can be pulled in one direction and represents one particular meaning by leaving others not representing [
31]. Different senses of a word lie in the linear superposition of standard word embeddings [
32] and the Gaussian mixture model holds multiple modes to represent distinct meanings of words.
For the long texts classification, we proposed WCDV, which represents documents with uncertainty estimations in the distribution of words using Gaussian Mixtures distributions for short-length document classification. We proposed WSDV using the Pomegranate General Mixture model for the long texts classification. Both WSDV and WCDV accommodate polysemous terms and train on the labeled documents corpus for better classification performance.
Noisy topics are outliers prone, thus less coherent and less expressive. Newman, D. [
33] regularized the LDA-based topic model where only the higher frequency terms allow into the word dependencies sparse covariance matrix. This model executes two prime steps. Firstly, measuring the point weight of each word in the vocabulary, and secondly, putting a threshold point to eliminate lower weighted words from the covariance matrix. Mittal, M. et al. [
34] introduced automated K-means clustering, where they applied a threshold point to decide whether or not to create a new cluster for the objects. This approach prohibits outlier tendency by accommodating lower probability objects into a new cluster. Gupta, V. et al. [
13] introduced SCDV-MS, which removes noise by applying a hard threshold on the fuzzy word cluster assignments, which proved better classification performance and lower space and time complexity than SCDV [
6].
In contrast, the proposed WSDV contains more natural noise removal techniques using a soft threshold and more efficient sparse vectorial representation for the long text (e.g., removing first principle components).
To capture better corpus semantics, Sia, S. et al. [
35] introduced weighted data clustering on pre-trained word embeddings, where they also proved the effectiveness of re-ranking the top words in a cluster for better representative topics. Similarly, Gebru, I.D. et al. [
36] proposed a Gaussian mixture-based weighted data clustering method called WD-GMM that demonstrates how the point weight of datum affects the covariance matrix and leads to better clustering. Inspired by them, we proposed WSDV, which extends the clustering process on the weighted data for the multi-class document classification performance.
Short texts are sparse due to limited word co-occurrence, which requires special treatment to capture hidden semantic information [
37,
38]. Pretrained word embedding over large external corpora is a common remedy for dealing short length documents. Zuo, Y. et al. [
39] proposed a word embedding-enhanced Pseudo-document-based Topic Model (WE-PTM) to leverage pre-trained word embeddings that is essential for alleviating data sparsity. Instead of incorporating external knowledge sources, Zhang, P. and He, Z. [
40] proposed an ensemble approach by exploiting both word embeddings and latent topics in sentence-level sentiment analysis for sentence polarity detection.
Therefore, for semantically enriched short-length document representation, instead of importing information from external knowledge sources, we employ
Multimodal word Distributions [
18] to capture uncertainty in the distribution of word embeddings for the vectorial representation of documents.
The contextual analysis-based model emphasizes potential terms that capture better semantics insights and boost classification performance [
41]. Xu, J. et al. [
42] proposed a convolutional neural network-based model, which incorporates context-relevant concepts into text representation for uplifting short text classification performance, but it requires expensive computational capacity.
In WCDV, we use the weighted energy function to emphasize potential terms in the short texts corpus.
Weighted Kernel Density Estimation (WKDE) [
43,
44] based on point weights has proved effective. For the semantic similarity measuring task, constant weighting assumption-based semantic similarity [
45] measure between two concepts/words holds better performance for the semantic representation of the concept/words but holds the same weighting relevance. Later, it found that the weight propagation mechanism [
46,
47] for augmenting input with semantic information achieves desired performance and removes the same weighting curse for concepts/words. Recently, Liu J. et el. [
48] introduced a weighted kernel mechanism for the weighted k-means multi-view clustering, where they redefined the objective by assigning weights to the cluster level instead of global weighting for each view and outperforming the existing objective.
Inspired by their work, we proposed a novel word frequency concerned energy function called
Weight attained Expected Likelihood Kernel for computing affinity between word pairs. To capture better segments in the WCDV, we modify the objective of the
Multimodal word Distributions [
18] by applying the newly proposed energy function and employ the modified
Multimodal word Distributions for the topic distribution of words in WCDV.
5. Experimental Results and Discussion
To evaluate the proposed approaches on several publicly available datasets, we perform the experiments using Intel® Core™ i5-7500 CPU@3.40 GHz., 8GiB RAM machine with Ubuntu 16.04.7 LTS operating system.
To evaluate WSDV, we perform document classification on three publicly available datasets (long text): 20Newsgroup (almost balanced), R8 (imbalanced), and AgNews (balanced).
To evaluate WCDV, we perform document classification on two publicly available short-text datasets: SearchSnippets (balanced) and Twitter (imbalanced).
Table 1 represents the statistics of the datasets mentioned above. All datasets come with train and test subsets (by default). We use the Python NLTK (Natural language toolkit) library to remove punctuations, digits, and stopwords. We also remove extra spaces from the datasets as part of data preprocessing.
5.1. Document Classification (Long Text)
We compare the classification results of the WSDV with a study was done by Wagh, V. et al. [
73], as their experiments range from simple NaiveBayes to complex BERT approaches intending to compare the classification performance of machine learning algorithms under the same set of long document datasets. To avoid training complexity (e.g., computational environment, parameter settings of different models) of the baselines, we prefer to use the obtained results by Wagh, V. et al. [
73] as the standard for all three (long text) datasets mentioned above.
To train WSDV, we set
= 7 in Equation (
5). For other hyper parameters settings, we follow similar settings as SCDV [
6], such as word embedding dimension to 200, document vector sparsity threshold to 0.04, minimum word count to 20, window size to 10, and downsampling to 10
.
For the classification, we set the number of topics to 20 (ground truth) for 20Newsgroup, 8 (ground truth) for R8, and 4 (ground truth) for AgNews.
Table 2 illustrates classification accuracy compared with the proposed WSDV and the baselines [
73] using different datasets (long-text), where bold indicates the best results in the table. From
Table 2 we see, WSDV obtaines superior scores in terms of accuracy—about 97.83% accuracy using AgNews, about 86.05% accuracy using 20Newsgrup and about 98.76% accuracy using R8 datasets.
WSDV is closely related to SCDV and SCDV-MS. For the efficiency assessment of the proposed WSDV, we compare the time and space complexity, sparsity analysis, and the obtained F1 scores using the 20Newsgroup corpus. For the fair assessment, we use SCDV-MS with word2vec instead of the Doc2vecC version in the comparison, as both other (WSDV and SCDV) models use SkipGram negative sampling (SGNS). We use an unlabeled 20Newsgroup corpus and set the number of topics to 20.
Table 3 represents class-wise F1 scores obtained by WSDV, SCDV, and SCDV-MS (word2vec), where bold indicates the best results in the table. For the experiments in this section, we use the default parameters settings for SCDV and SCDV-MS.
Table 4 illustrates an empirical study of the time and space complexities of WSDV, SCDV, and SCDV-MS (word2vec). WSDV deals with weighted data clustering, where every data point is associated with a unique point weight. Weighted data clustering takes a little extra time for the clustering process of WSDV (22.36 s). However, it carries faster (0.54 s) prediction characteristics inherited from the
Pomegranate General Mixture model [
16] that acquires less memory space (66.9 kb). When comparing WSDV (multi-sense) with SCDV-MS (word2vec), again WSDV (multi-sense) takes a higher clustering time (104.6 s) but faster (0.96 s) prediction time than SCDV-MS (word2vec) and takes less memory space (102.1 kb).
Table 5 demonstrates sparsity level in the word-topic
vector and document
vector. WSDV applies a threshold to remove outliers (similar to SCDV-MS), which leads to higher sparsity (94.85%) in the word-topic
vector. When comparing WSDV (multi-sense) with SCDV-MS (word2vec), WSDV has an additional document vector sparsity mechanism (similar to SCDV) and achieves higher (65.50%) sparsity in the final document representation than SCDV-MS (word2vec).
Table 6 exhibits the effects of weighted data clustering and re-ranking the top words for topical representation of WSDV over SCDV.
Topic1 related to sports where WSDV represents a better topic (with the PMI score −372.469) than SCDV (with the PMI score −373.966). After re-ranking the top words, WSDV improves topic quality with a PMI score of −181.043.
Topic2 related to IT, it is interesting to see that both the SCDV (PMI score −403.195) and the WSDV (PMI score −404.763) represent similar top 10 words. After re-ranking,
WSDV surpasses both scores by obtaining an improved PMI score of −230.419.
Topic3 related to vehicles, though
WSDV shows a better PMI score (−380.499) than the SCDV (−394.077), SCDV seems to represent more relevant words than WSDV. Again after re-ranking, WSDV shows more relevant words (with the PMI score −210.754).
Table 6 also proves the necessity of clustering on weighted data for exuberant document representation.
From the discussion above, we see the efficiency of the WSDV in the multi-class document classification tasks over SCDV and other baselines.
5.2. Short Text Classification
Yi, F. et al. proposed a regularized non-negative matrix factorization topic model (TRNMF) [
12] for short text. TRNMF utilized pre-trained distributional vector representation of words using an external corpus and employed a clustering mechanism under document-to-topic distribution. One of our research objectives was to model efficient sparse short-length documents utilizing available corpus statistics instead of depending on external knowledge sources. Therefore, for a fair assessment of the classification performance of the proposed WCDV using the same (SearchSnippet and Twitter) datasets and to avoid train complexity of the baselines, we consider the obtained short text classification scores in the study done by Yi, F. et al. [
12] as standard for the baselines.
To train WCDV, we follow the same parameters settings as
Multimodal word Distributions [
18], such as embedding size to 50, window size to 5, batch size to 256, train epoch to 10, variance scale to 0.05, and choose spherical covariance matrix. To compare short text classification accuracy with baselines, in WCDV, we set the number of topics to 8 (ground truth) and 4 (ground truth) for the SearchSnippets and the Twitter dataset correspondingly.
Table 7 illustrates classification accuracy obtained by baselines [
12] and the proposed WCDV using SearchSnippets and Twitter datasets, where WCDV shows superior scores, about 72.7% accuracy using SearchSnippets, and about 89.4% accuracy using Twitter datasets.
Short texts tend to have a small number of themes. Besides performing the classification accuracy under the ground truth (
Table 7), similar to Yi, F. et al. [
12], we also perform short text classification under the number of topics to 10 (ten) for both (SearchSnippets and Twitter) datasets to explore F1 scores obtained by the proposed WCDV. The F1 score is a statistical explanation of the classification performance; higher F1 scores indicate better classification performance.
Figure 5 exhibits the obtain F1 scores. TRNMF has the best (55.1%) F1 score compared to other benchmark methods (BTM 24.2%, WNTM 50.8%, LF-DMM 18.9%, GPU-DMM 34.3%, PTM 16.6%) using the SearchSnippet dataset, where WCDV surpass all the baselines (including TRNMF) by obtaining 60.7% F1 score.
Similarly, WCDV shows outstanding performance over the baselines [
12] using the Twitter dataset, where WCDV obtains the highest F1 score of 90.1 %, which surpass the best baseline model TRNMF (80.4%) by the margin of 9.7% improvement.
For all classification experiments using WCDV, we set the minimum word count to 10 for the SearchSnipts dataset and 5 for the Twitter dataset. The
Multimodal word Distributions [
18] has proved effective in the polysemous word representation. To evaluate the efficiency of the newly proposed objective (Equation (
19)), we compare nearest neighbors (cosine similarity) between the Gaussian mixtures (components
) mean vectors for the base
(Equation (
15)) and the new
(Equation (
19)) objectives.
For this experiment, we use the Text8 dataset and set the number of topics to 2, the embedding dimensions to 50, the context window size to 10, the learning rate to 0.05, batch size to 128, the number of epochs to 10, use adagard as the optimizer, and choose spherical covariance model with variance scale 0.05. For both objectives, we use Tensorflow 1.5.0.
Table 8 contains three words corresponding to two components (namely 0 and 1) of the mixtures of Gaussian. The notation
w:
i denotes the
ith mixture component of the word
w.
Words Rock and Bank represent the right theme corresponding to each mixture component for both objectives. However, the new objective works in more detail than the base objective . Bank0 represents a specific area of a place. Words for in the table pose this characteristic, which is not true for words represented by , specifically, in word mostar:1 is the name of a person, which is irrelevant. Bank1 represents a theme related to finance, where for words are relevant. For eu:1, sector:1 and eurozone:1 do not directly hold financial sense. However, for the word Apple we found inconsistency for the base objective , where Apple1 and Apple0 represent the same theme. In the case of Apple0, the nearest neighbor words pies:0, oyster:0, and fermented:0 are neither related to the computer technology nor the fruit; those may relate to the food theme, but other neighboring words represent the computer-related sense. However, the new objective represents the fruit (particularly apple; food, and drinks processed from apple; quince:0 is a fruit related to apple.) theme for Apple1 and the computer technology theme for Apple0 properly.
From the overall analysis, we see the new objective performs better than the base objective in terms of the similarity measure of the polysemous words. It proves the efficiency of the Weight attained Expected Likelihood Kernel as a novel energy function.
5.3. Discussion
This research focused on utilizing available corpus statistics to enhance document classification performance, where we proposed Weighted Sparse Document Vector (WSDV) for the long text and Weighted Compact Document Vector (WCDV) for the short text.
SCDV [
6] and SCDV-MS [
13] have achieved enormous performance by addressing the challenges in the document (long text) modeling. However, we proposed further escalation in the document classification by introducing WSDV. Designing WSDV includes emphasizing potential terms of the document in the corpus (using weighted data clustering), noise elimination (soft threshold noise removal) from the noisy long tail clusters, and utilizing corpus statistics in different steps of the vectorial representation of documents. Experiments in
Section 5.1 demonstrate that WSDV significantly outperforms SCDV and SCDV-MS in document modeling (long text). Moreover, WSDV efficiently handles balanced (AgNews) and imbalanced (R8) corpus for the classification task (according to
Table 2). Therefore, WSDV is an excellent addition to the existing state-of-the-art long text classification approaches.
Most state-of-the-art short text models suggest acquiring knowledge from external rich knowledge sources to tackle data sparseness. However, depending on the external knowledge sources is not reliable (e.g., data unavailability, missing URLs, etc.). Sometimes it may increase unusual noise in the current corpus or cause higher costs. Therefore, we proposed
Weighted Compact Document Vector (WCDV). WCDV utilizes corpus statistics in different steps of the vectorial representation of short-length documents. Experiments reveal that WCDV efficiently deals with sparse short texts without depending on external knowledge sources with balanced (SearchSnippets) and imbalanced (Twitter) datasets (according to
Table 7, and
Figure 5). Moreover, we have introduced a novel energy function to capture the affinity of the distributions, which emphasizes the potential terms by assigning corresponding point weights to them. Experiment in
Section 5.2 demonstrate that the proposed
Weight attained Expected Likelihood Kernel is an excellent addition to the similarity kernel and performs better than its counterpart.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}