
Development of a Hairstyle Conversion System Based on Mask R-CNN


Abstract
:1. Introduction
- We created a new dataset that divided the hair and face based on facial image data.
- We extracted hair and facial features more effectively using the pyramidal attention network (PAN), which effectively extracts context from the pyramidal scale for more accurate segmentation.
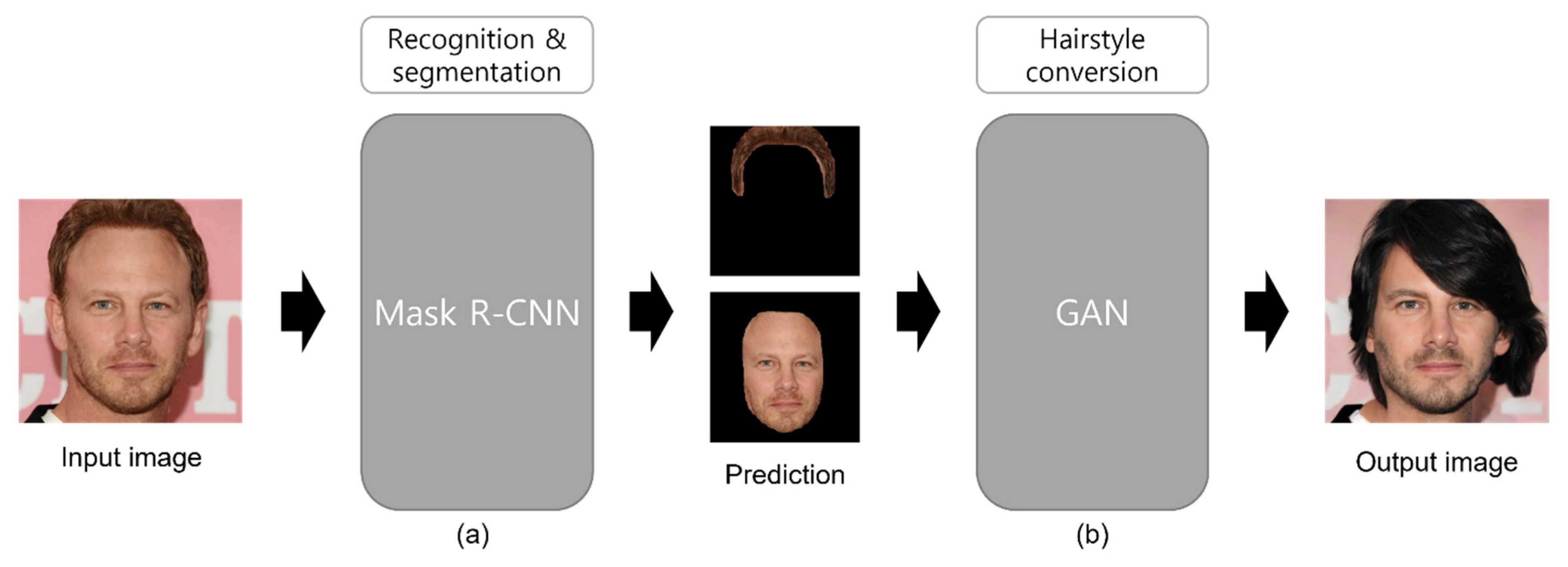
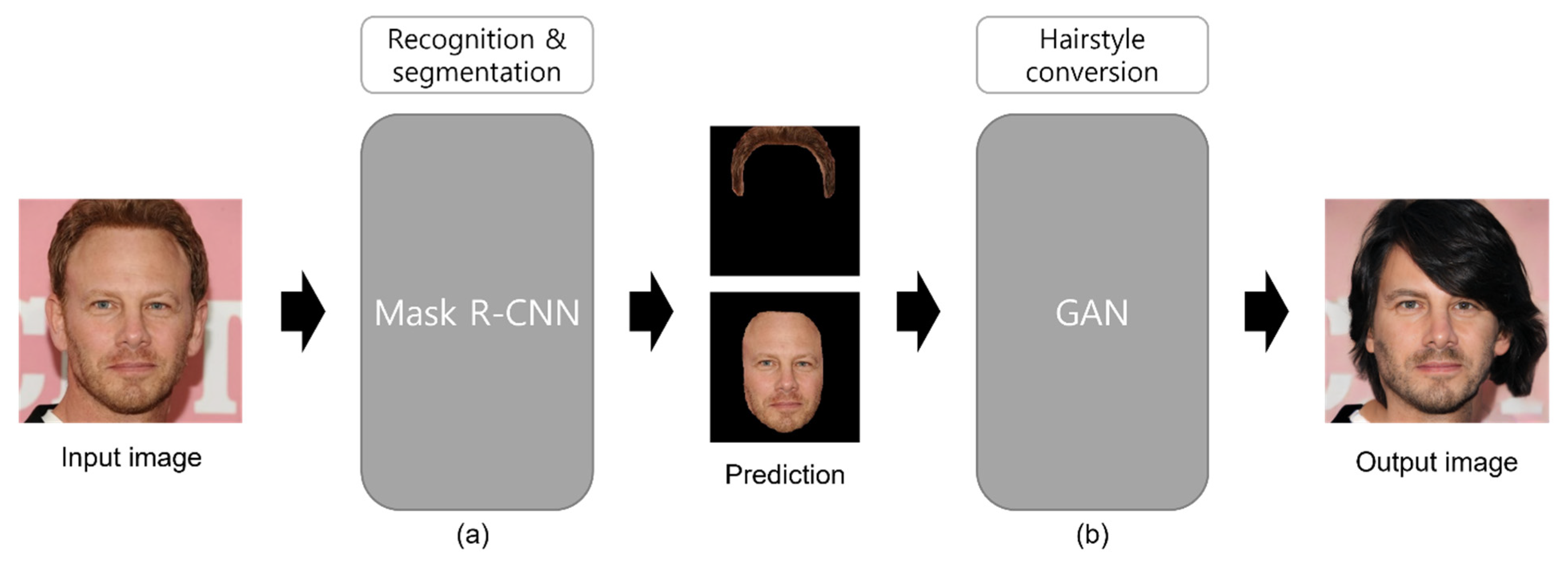
- We propose the hairstyle conversion network (HSC-Net), which is a network model that combines the Mask R-CNN with PAN and GAN, to provide hairstyle conversion.
2. Related Work
3. Method
3.1. HSC-Net
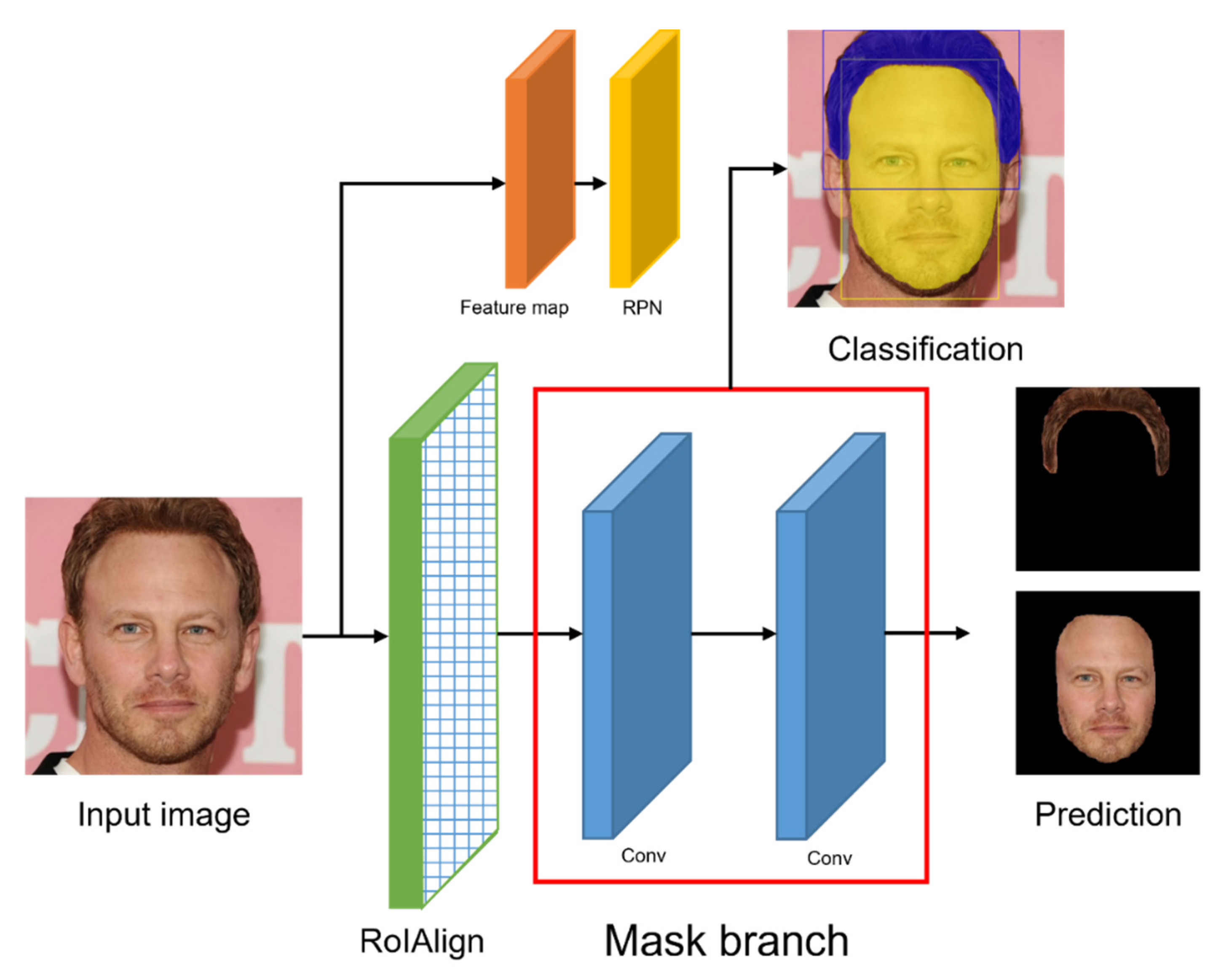
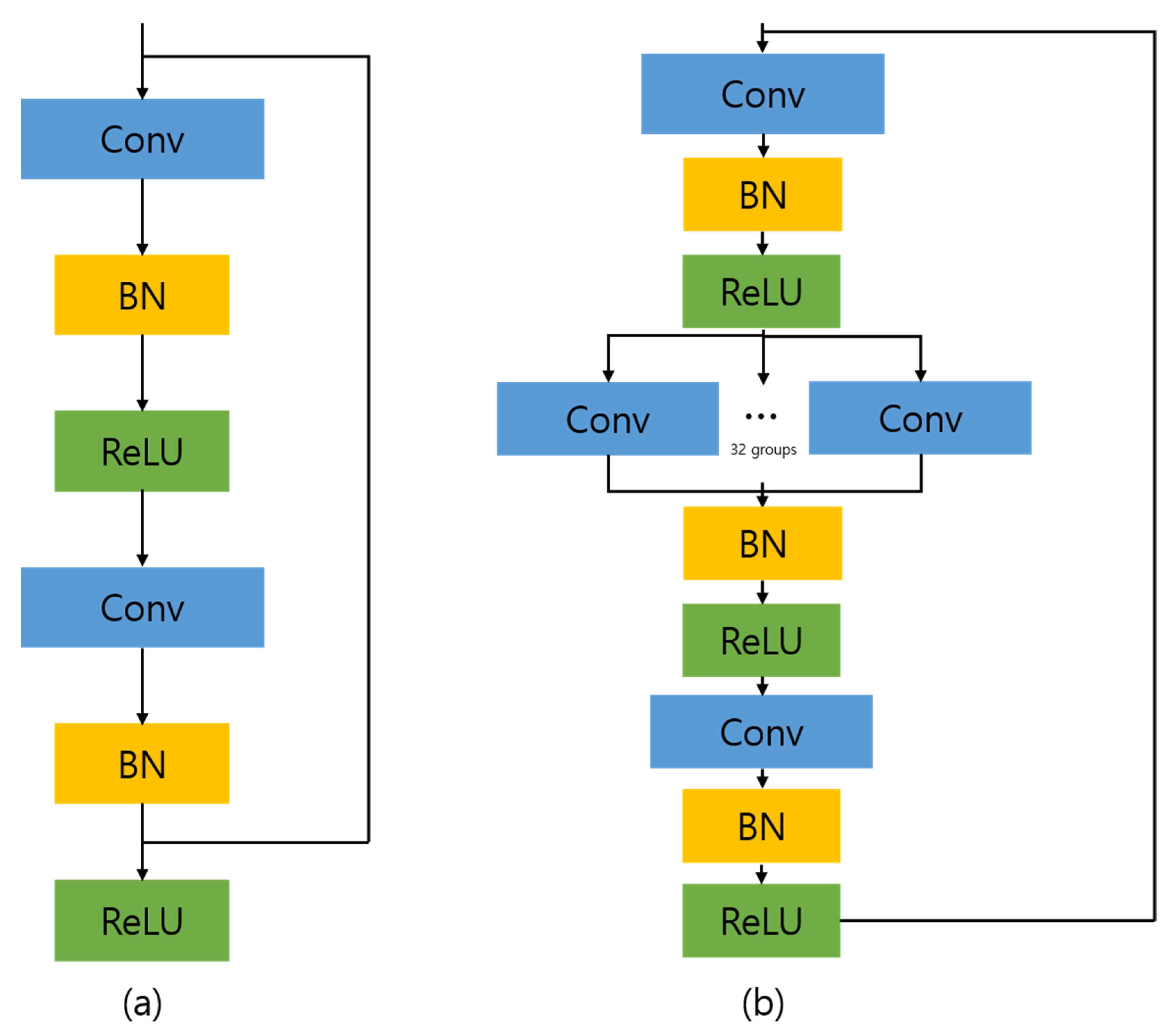
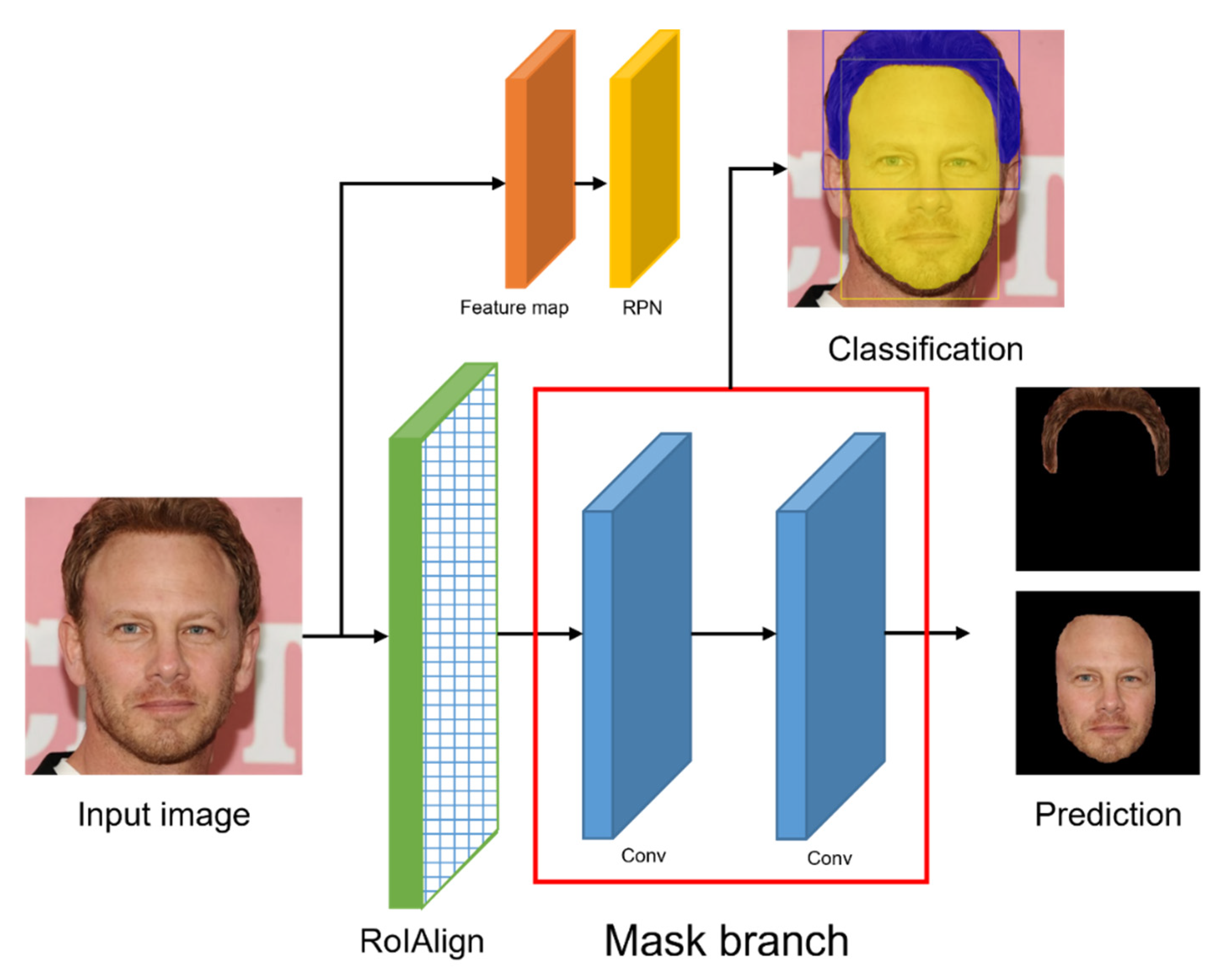
3.2. Mask R-CNN
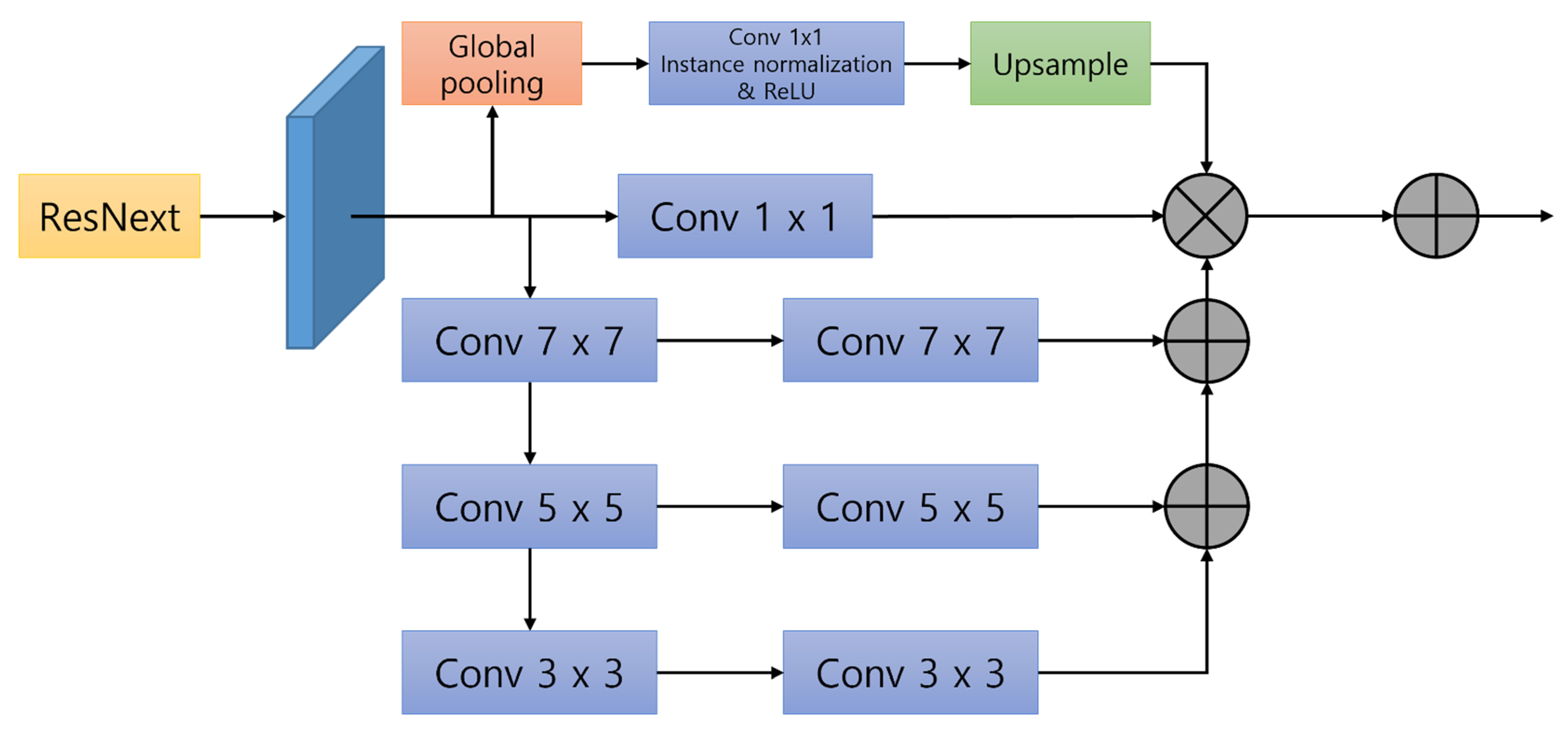
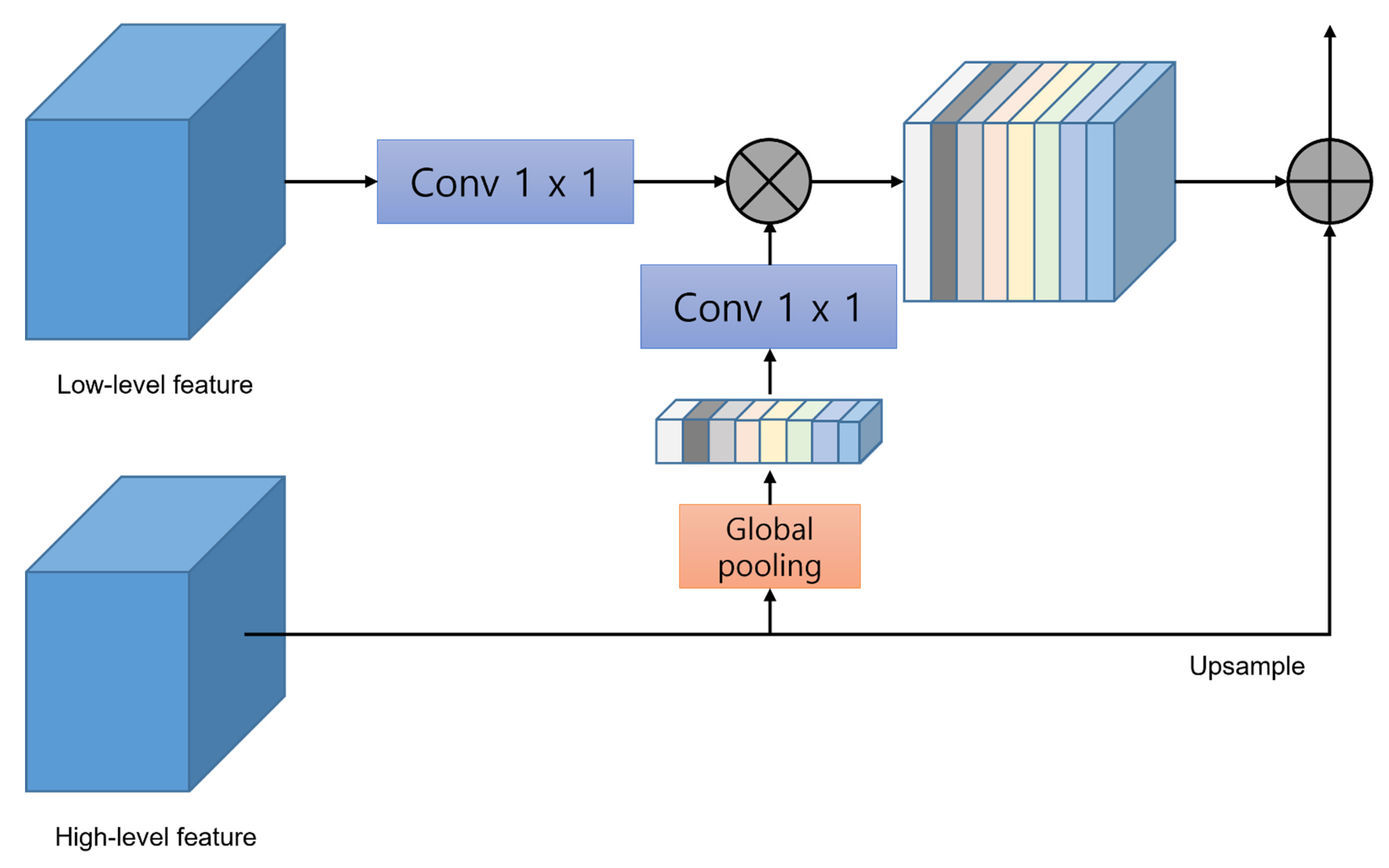
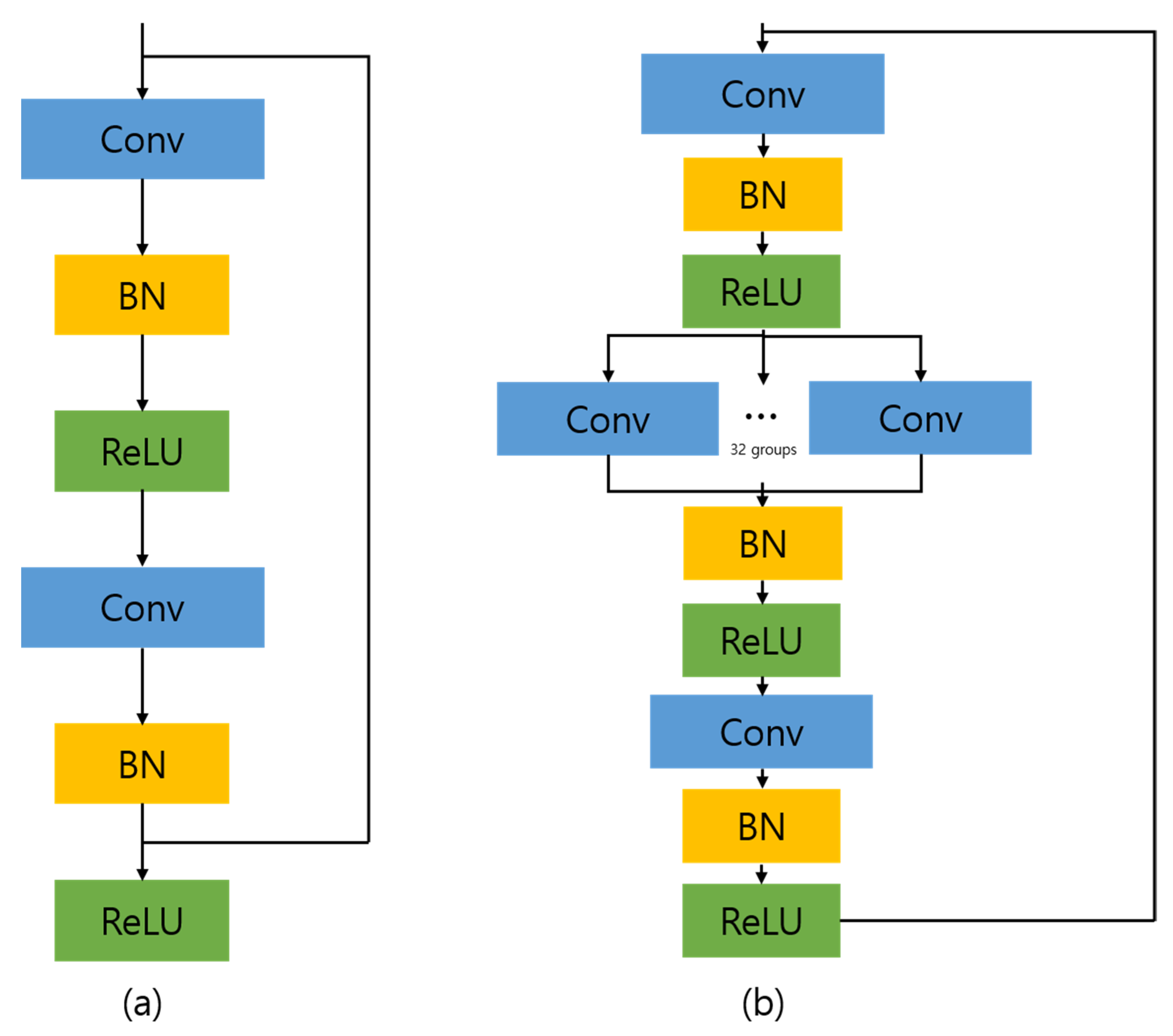
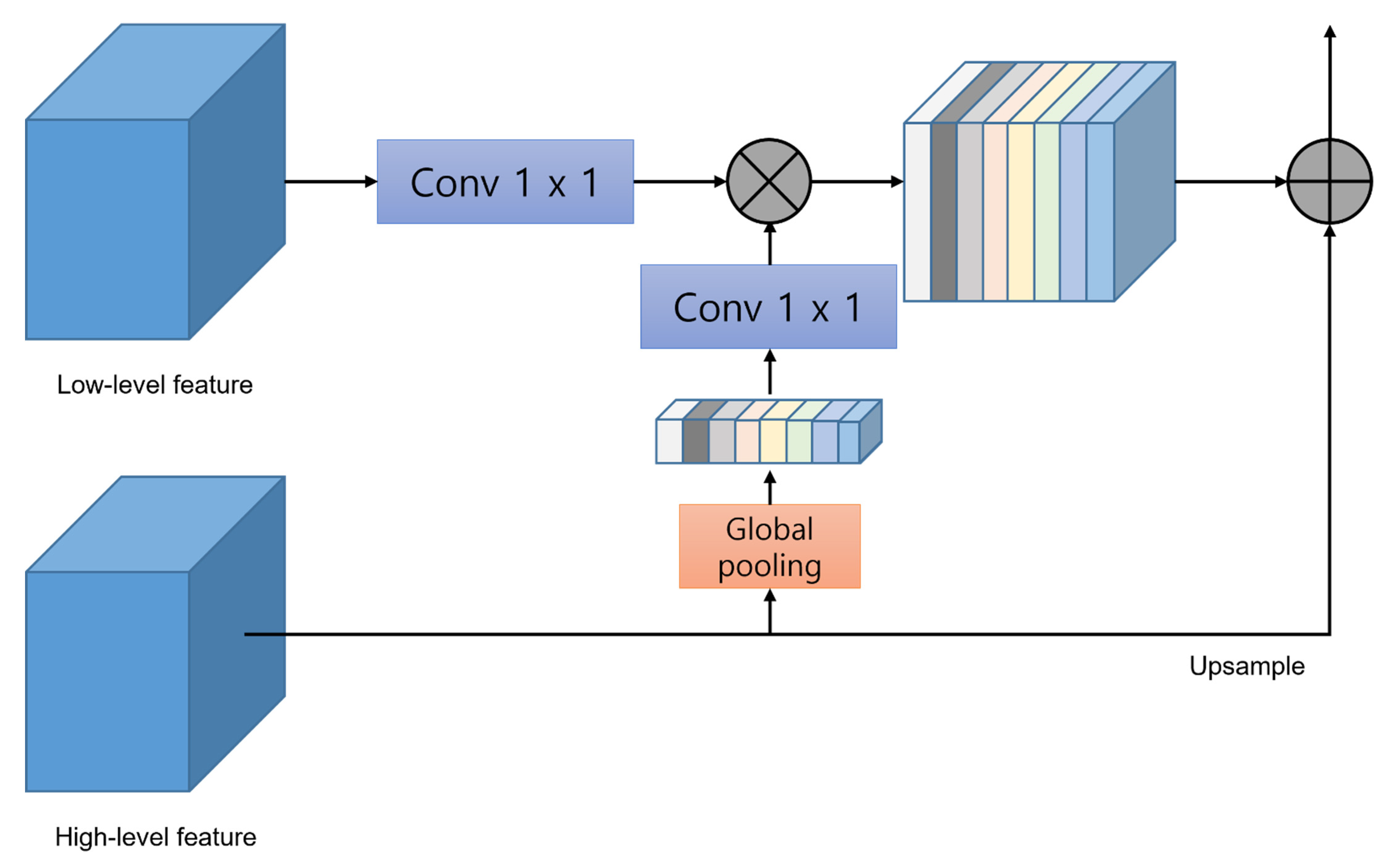
PAN
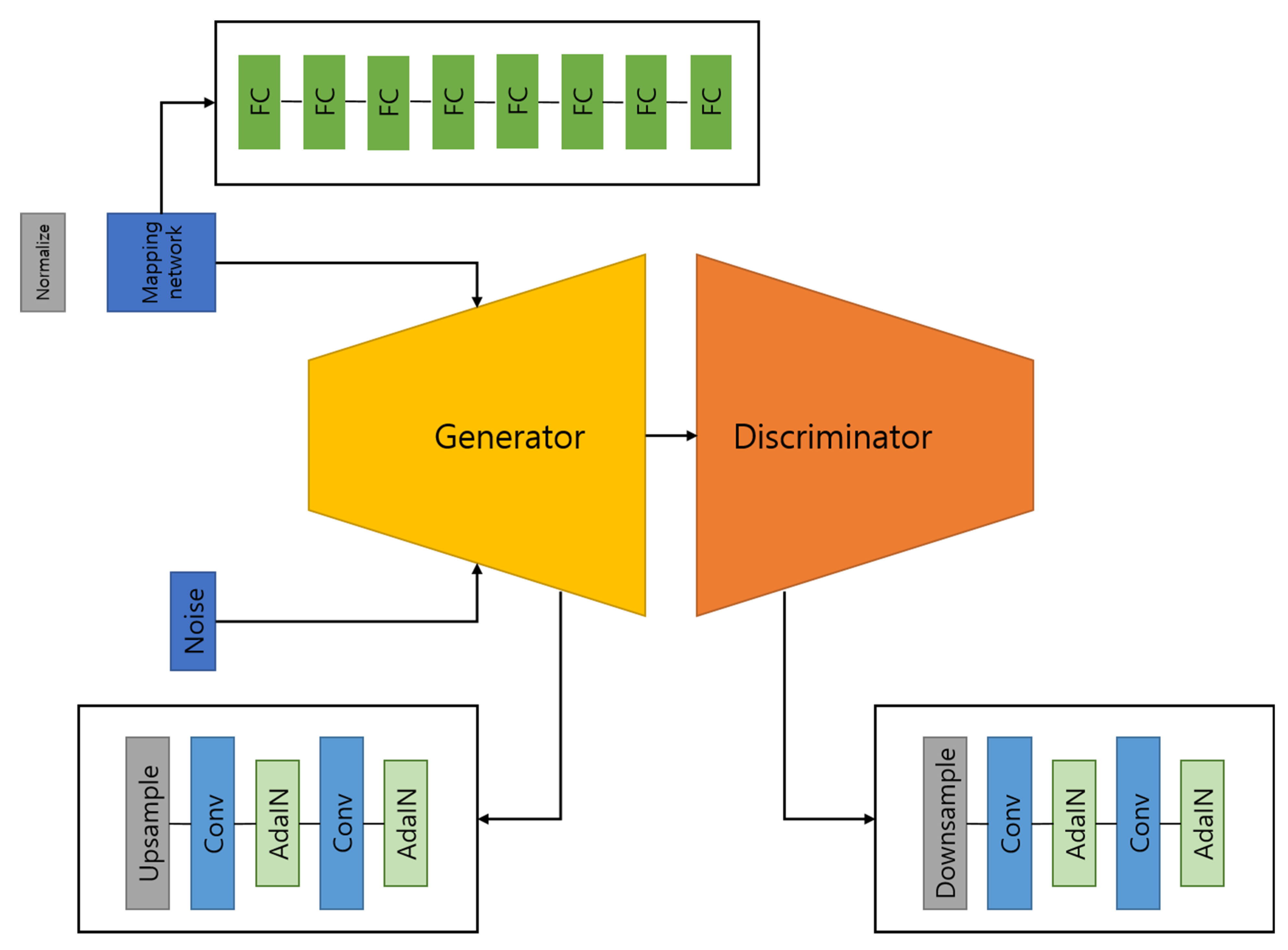
3.3. GAN
4. Results
4.1. Implementation Details
Datasets
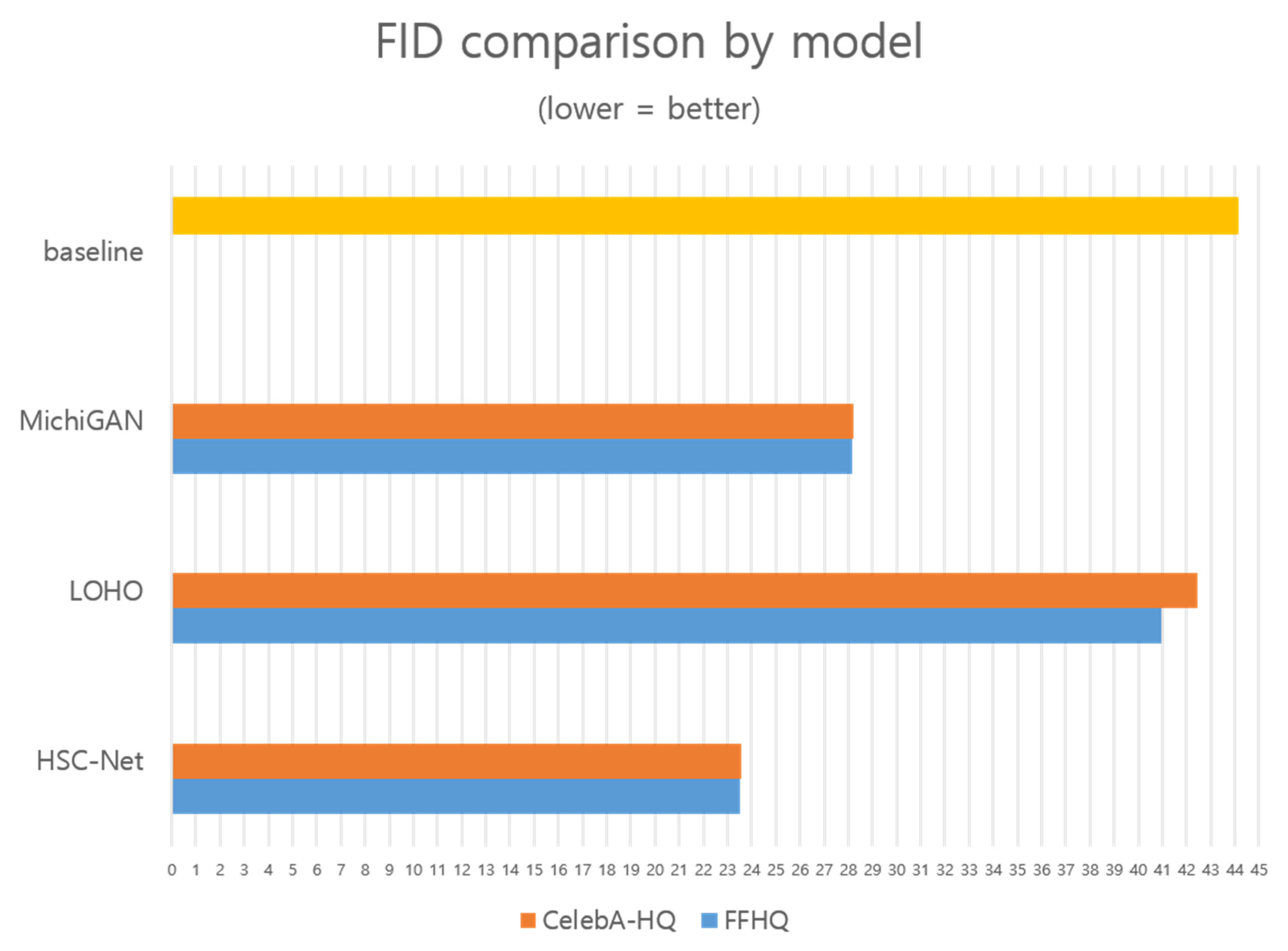
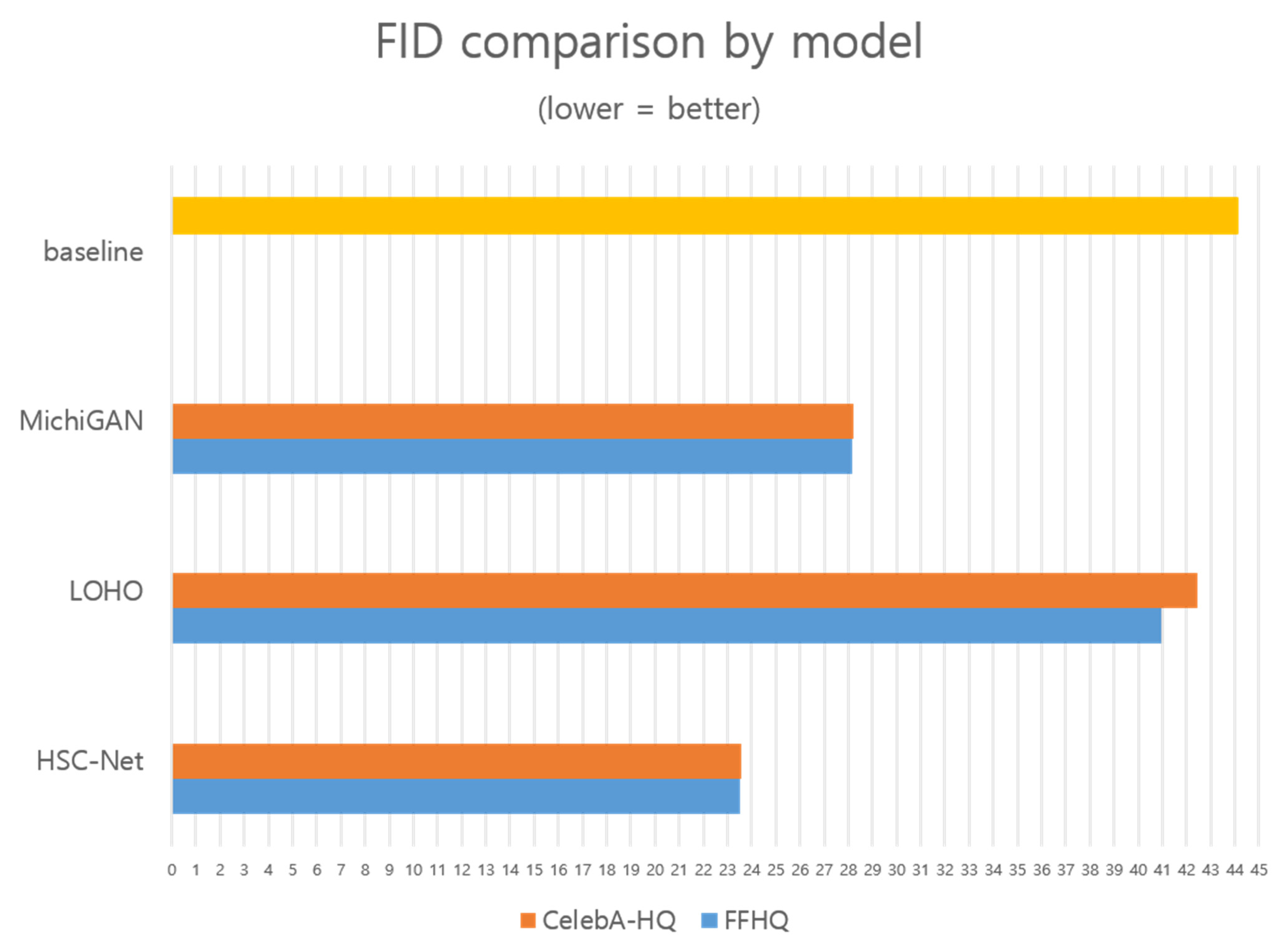
4.2. Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Meaning |
| CNN | convolutional neural networks |
| GAN | generative adversarial networks |
| PAN | pyramidal attention networks |
| HSC-Net | hairstyle conversion network |
| LOHO | latent optimization of hairstyles via orthogonalization |
| FAN | feature attention network |
| RoI | region of interest |
| FPA | feature pyramid attention |
| GAU | global attention upsample |
| ReLU | rectified linear unit |
| MichiGAN | multi input conditioned hair image GAN |
| AdaIN | adaptive instance normalization |
| Conv | convolution layer |
| CelebA-HQ | CelebFaces attributes-HQ |
| LPIPS | learned perceptual image patch similarity |
| FID | Fréchet inception distance |
| PSNR | peak signal-to-noise ratio |
| SSIM | structural similarity index map |
| FFHQ | Flicker-Faces-HQ |
References
- Sunhem, W.; Pasupa, K.; Jansiripitikul, P. Hairstyle recommendation system for women. In Proceedings of the 2016 Fifth ICT International Student Project Conference (ICT-ISPC), Nakhon Pathom, Thailand, 27–28 May 2016; IEEE: New York, NY, USA, 2016; pp. 166–169. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Vuola, A.O.; Akram, S.U.; Kannala, J. Mask-RCNN and U-net ensembled for nuclei segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: New York, NY, USA, 2019; pp. 208–212. [Google Scholar]
- Zhang, Q.; Chang, X.; Bian, S.B. Vehicle-damage-detection segmentation algorithm based on improved mask RCNN. IEEE Access 2020, 8, 6997–7004. [Google Scholar] [CrossRef]
- Liang, S.; Qi, F.; Ding, Y.; Cao, R.; Yang, Q.; Yan, W. Mask R-CNN based segmentation method for satellite imagery of photovoltaics generation systems. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; IEEE: New York, NY, USA, 2020; pp. 5343–5348. [Google Scholar]
- Liu, M.-Y.; Tuzel, O. Coupled generative adversarial networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5 December 2016; pp. 469–477. [Google Scholar]
- Tariq, S.; Lee, S.; Kim, H.; Shin, Y.; Woo, S.S. Detecting both machine and human created fake face images in the wild. In Proceedings of the 2nd International Workshop on Multimedia Privacy and Security, Toronto, ON, Canada, 15 October 2018; pp. 81–87. [Google Scholar]
- Yang, T.; Ren, P.; Xie, X.; Zhang, L. GAN prior embedded network for blind face restoration in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 672–681. [Google Scholar]
- Saha, R.; Duke, B.; Shkurti, F.; Taylor, G.W.; Aarabi, P. Loho: Latent optimization of hairstyles via orthogonalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1984–1993. [Google Scholar]
- Gong, K.; Gao, Y.; Liang, X.; Shen, X.; Wang, M.; Lin, L. Graphonomy: Universal human parsing via graph transfer learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7450–7459. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Huang, Z.; Zhong, Z.; Sun, L.; Huo, Q. Mask R-CNN with pyramid attention network for scene text detection. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; IEEE: New York, NY, USA, 2019; pp. 764–772. [Google Scholar]
- Zhang, X.; An, G.; Liu, Y. Mask R-CNN with feature pyramid attention for instance segmentation. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; IEEE: New York, NY, USA, 2018; pp. 1194–1197. [Google Scholar]
- Almahairi, A.; Rajeshwar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 195–204. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8160–8168. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Tan, Z.; Chai, M.; Chen, D.; Liao, J.; Chu, Q.; Yuan, L.; Tulyakov, S.; Yu, N. Michigan: Multi-input-conditioned hair image generation for portrait editing. arXiv 2020, arXiv:2010.16417. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017. pp. 6629–6640.
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: New York, NY, USA, 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: New York, NY, USA, 2003; pp. 1398–1402. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Size | Attention |
|---|---|---|
| Conv 1 | 112 × 112 | 7 × 7, 64, stride 2 |
| Conv 2 | 56 × 56 | 3 × 3 max pool, stride 2 |
| Conv 3 | 28 × 28 | |
| Conv 4 | 14 × 14 | |
| Conv5 | 7 × 7 | |
| Global average pool | 1 × 1 | softmax |
| Model | LPIPS↓ | FID↓ | PSNR↑ | SSIM↑ |
|---|---|---|---|---|
| Baseline | 0.20 | 44.10 | 24.12 | 0.85 |
| MichiGAN | 0.13 | 28.23 | 28.15 | 0.89 |
| LOHO | 0.19 | 42.45 | 24.49 | 0.85 |
| HSC-Net (ours) | 0.09 | 23.55 | 29.79 | 0.91 |
| Model | CelebA-HQ | FFHQ | ||||||
|---|---|---|---|---|---|---|---|---|
| LPIPS↓ | FID↓ | PSNR↑ | SSIM↑ | LPIPS↓ | FID↓ | PSNR↑ | SSIM↑ | |
| MichiGAN | 0.13 | 28.23 | 28.15 | 0.89 | 0.12 | 28.17 | 28.30 | 0.90 |
| LOHO | 0.19 | 42.45 | 24.49 | 0.85 | 0.17 | 40.97 | 25.02 | 0.88 |
| HSC-Net (ours) | 0.09 | 23.55 | 29.79 | 0.91 | 0.09 | 23.52 | 29.94 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, S.-G.; Man, Q.; Cho, Y.-I. Development of a Hairstyle Conversion System Based on Mask R-CNN. Electronics 2022, 11, 1887. https://doi.org/10.3390/electronics11121887
Jang S-G, Man Q, Cho Y-I. Development of a Hairstyle Conversion System Based on Mask R-CNN. Electronics. 2022; 11(12):1887. https://doi.org/10.3390/electronics11121887
Chicago/Turabian StyleJang, Seong-Geun, Qiaoyue Man, and Young-Im Cho. 2022. "Development of a Hairstyle Conversion System Based on Mask R-CNN" Electronics 11, no. 12: 1887. https://doi.org/10.3390/electronics11121887
APA StyleJang, S.-G., Man, Q., & Cho, Y.-I. (2022). Development of a Hairstyle Conversion System Based on Mask R-CNN. Electronics, 11(12), 1887. https://doi.org/10.3390/electronics11121887