In this work, the control problem of a mobile robot is solved by the application of the Reinforcement Learning approach. In general, the target of Reinforcement Learning is to find the optimal policy for the given environment. Learning is carried out based on rewards returned by the environment. The target of the RL algorithm is to find the optimal policy or at least its close approximation. In order to build the environment, firstly, the model of the two-wheeled robot is defined with two sets of inputs consisting of the yaw angular velocity, the forward velocity, and the angular velocities of the right and left wheel. Next, the environment that describes the control problem is proposed. We analyze different rewards to obtain the best final results.
2.1. The Mobile Robot Environment
The kinematics of a differentially driven robot with two wheels has been well studied in the literature [
11,
18,
23,
24]. In our work, we consider the following model:
where
is the state of the robot which consists of the orientation
and the position
,
. The robot parameters are defined as:
where
r is the radius of the wheel and
b is the tread of the wheel.
In this work, we consider two kinds of input,
U and
:
where
and
are the angular velocities of the right and left wheel,
and
are the yaw angular velocity and the forward velocity of the mobile robot, respectively. The control signals
and
are linked by the invertible matrix
J. Therefore, it is possible to calculate
based on
and the other way around. However, in simulations, we show that from the point of view of the Reinforcement Learning algorithms the choice of input will give different results.
The above model is presented in the continuous-time domain, which is typical for the kinematic representation of mobile robots [
11,
18,
23,
24]. To implement the model in the environment, it is converted by the Euler forward method to the discrete representation:
where
denotes
(and similarly for other signals) and
is the time step.
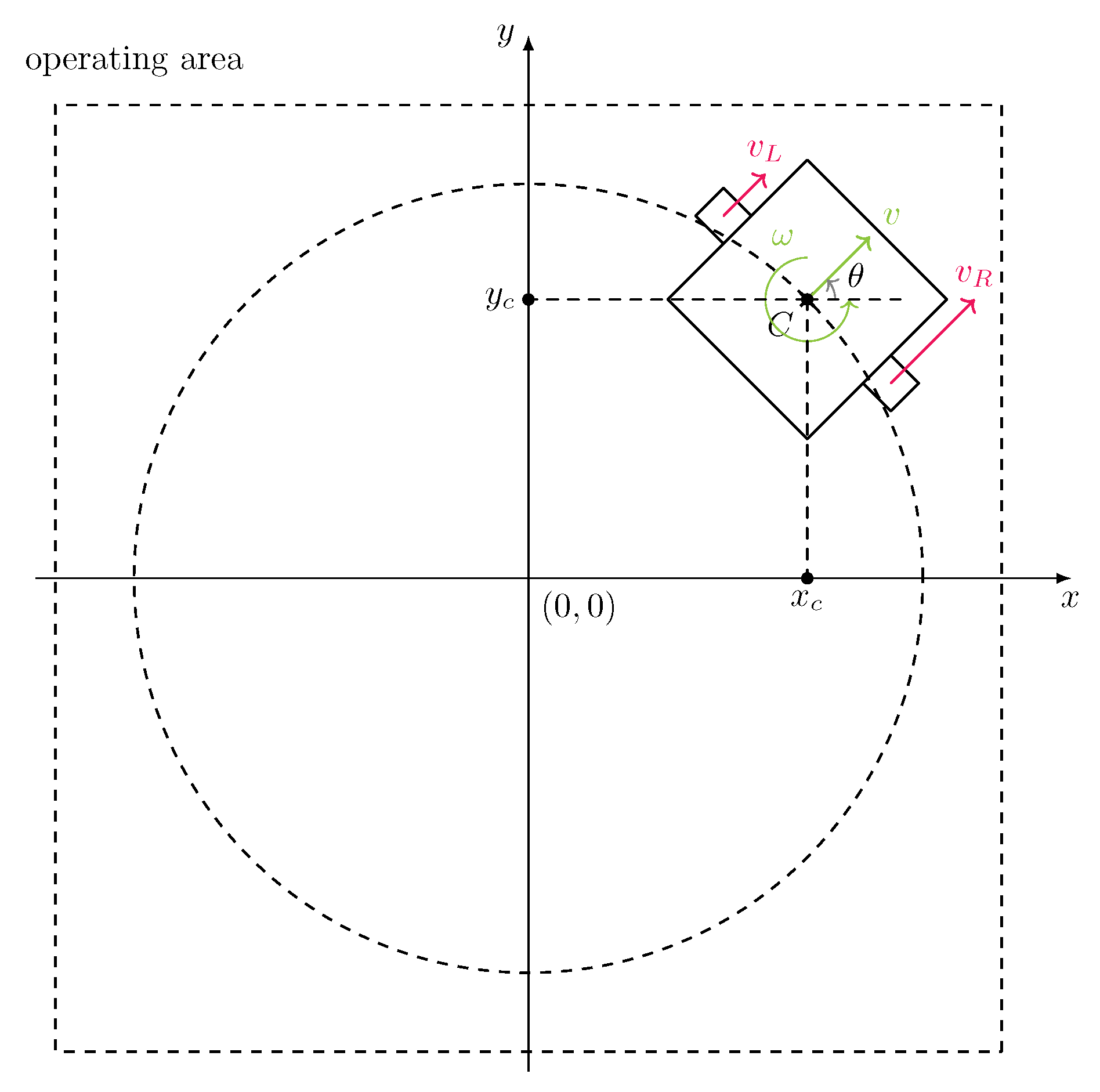
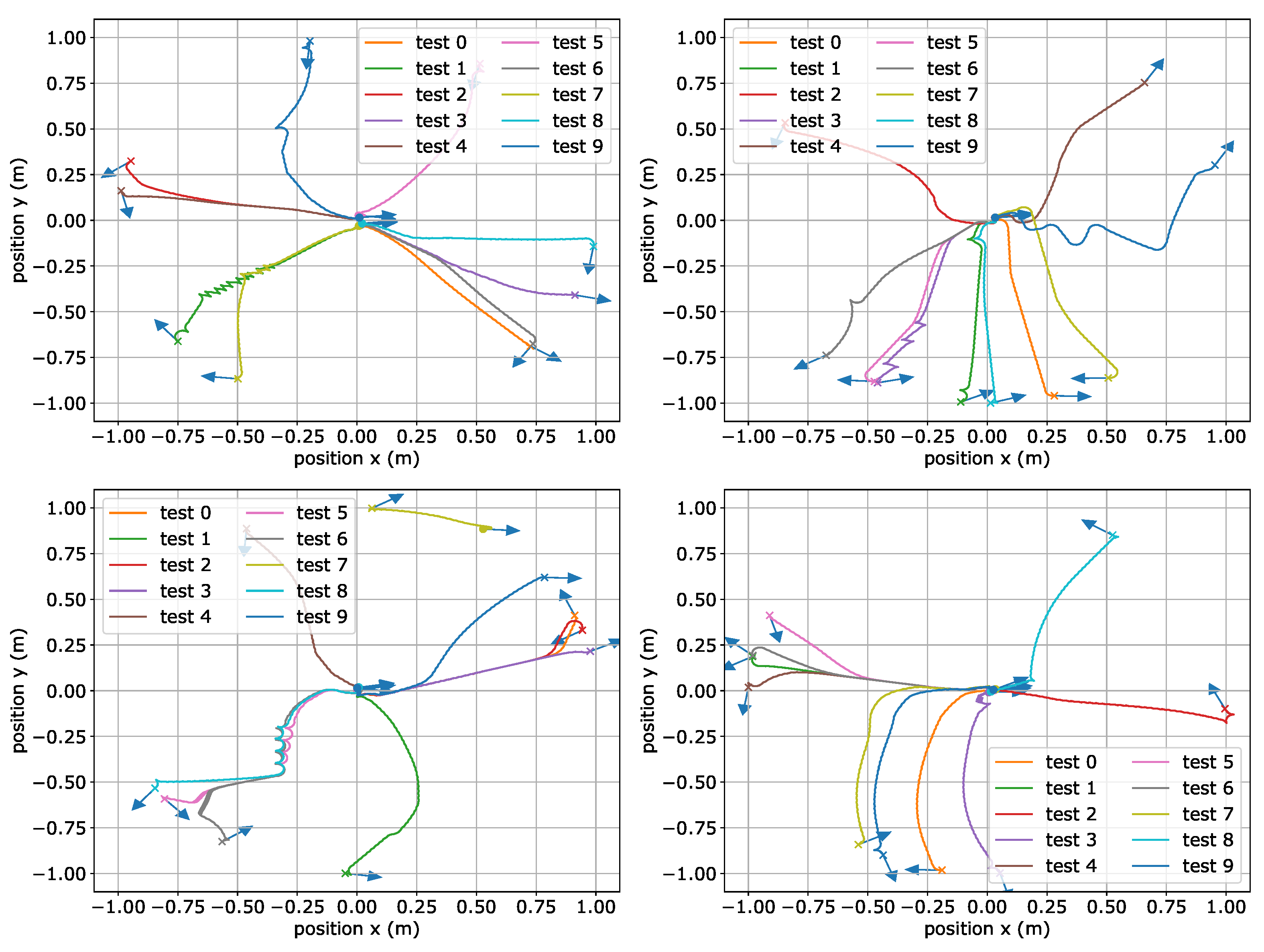
The goal of the work is to drive the robot from the initial state
to goal state
. The initial position of the mobile robot
is randomly chosen in the circle with radius 1 around the point
. The orientation
is also randomly chosen from the range
to
, so from a practical point of view it does not have limitations. The mobile robot with the state and input variables is presented in
Figure 1. The figure also shows possible initial positions. It is worth pointing out that the initial orientation is not constrained, so that the mobile robot can be directed inside or outside the circle.
The crucial part of the Reinforcement Learning approach is the definition of the environment. In our work, the environment is directly incorporated from the discrete model of the mobile robot Equation (
4). Therefore, the environment state is
and the action is
or
.
To complete the environment, the reward must be designed. We define the auxiliary sets and variables to simplify the description of the reward function. The region in which the robot can move is defined as:
where
and
are the maximum positions around the robot. The orientation is not limited, but it is kept in the range
,
by
signal normalization. The normalization does not influence the possibility of robot rotation, which can be performed without limit.
We also define the distance to
as:
and the norm of orientation:
The reward is defined in various ways to show its strong influence on the learning process:
where
is a definition of the cost related to goal achievement and
is a common term for all costs related to escaping the operating area. The cost
is given by:
where
is a boundary of
. Furthermore, if
reaches the limits of
the episode is terminated.
At some cost
, the additional cost will be added, which partially describes success. It is given by:
and is
(so the reward is 100) inside the region
that is defined around the goal position:
The symbols and are the thresholds for distance and orientation. The target of this cost is to promote being close to the goal position.
Now, we propose the set of costs that can be considered to solve the problem of mobile robot control. The general idea of the cost is based on the literature [
4,
11]; however, it is also fit to the presented problem. Its objective is to drive the robot from initial state to goal state. Some of the cost only takes into account position but some also take the orientation. The first cost is given by
and the goal part is defined similarly to the Lyapunov function. It takes into account the orientation and position with the same weights. The second cost is defined as the weighted part of the distance and the squared orientation:
Compared with cost
, the influence of orientation is decreased. The next cost is the weighted part of absolute orientation and position:
Its intention is to significantly reduce the absolute position error rather than the orientation. However, in the case of small position error, orientation also becomes important. The following cost function:
only takes the position into account, and the thresholds only depend on the distance. The next cost is defined as:
and only the position is taken into account. In addition, a decrease in distance error is promoted, which is different from all previous costs. In the region around the goal position, the additional reward is given. A similar approach with incremental reward is given in the work [
11]. The following cost:
is similar to the previous one (
16). However, the increase in distance gives a constant penalty when the decrease in distance gives a reward. The cost with varying weights is defined as
to first decrease the position error, then the orientation error. It is also an extension of the cost Equation (
13). At the last but not the least cost, we define three thresholds:
If the distance is above the threshold , then the cost is proportional to the decrease in the distance and the orientation error. If the distance is below the threshold then two levels of cost are assigned, respectively, to orientation.
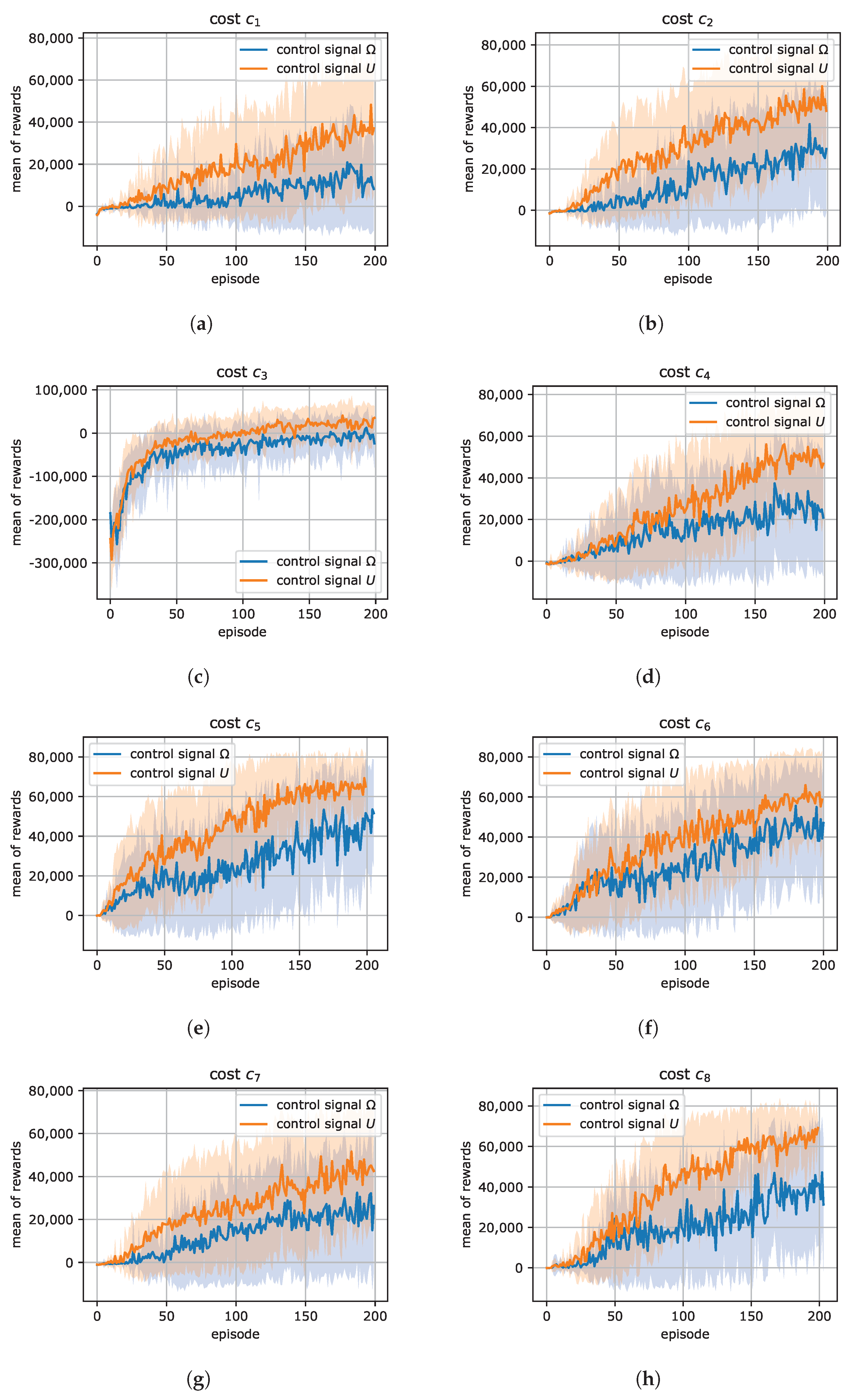
In summary, we defined 8 different costs in which the goal position is taken into account. In
Table 1, we present information about attributes for each cost function. The costs
,
,
and
,
depend on the orientation of the goal, while the costs
,
,
only take position into account. The costs
,
and
depend on the current and the previous state, while others only the current state. Our intention is to check different types of errors and their influence on the learning process and final results.
2.2. The Learning Algorithm
The environment with the mobile robot has continuous input and state. This is one of the crucial aspects of choosing the Reinforcement Learning algorithm. Therefore, we solve the problem by applying the Deep Deterministic Policy Gradient algorithm, which allows to have continuous action space and state space. The DDPG algorithm represents the actor–critic algorithm, which uses approximations by neural networks. The actor decides about the current action based on the policy , which depends on the current state. The critic is described by an action-value function Q. In this work, both the functions Q and are approximated by Deep Neural Network with multiple layers.
In general, the target of Reinforcement Learning and, therefore, the DDPG algorithm, is to find the optimal policy that chooses the action
based on the distribution
. The learning process is based on the Deterministic Policy Gradient described in the work [
8,
17]. According to the work [
7,
8], the important parts of Deep Reinforcement Learning are the replay buffer and target networks.
In our work, the action is a control signal (
or
U) set to mobile robot. We consider two problems where, first, the action is
and secondly the action is
, both defined in Equation (
4). The optimal policy
decides the action based on the current state
. In this work, the environment state
is based on the mobile robot model described in the previous section and is equal to
.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}