
aRTIC GAN: A Recursive Text-Image-Conditioned GAN

 ,
, 

Abstract
:1. Introduction
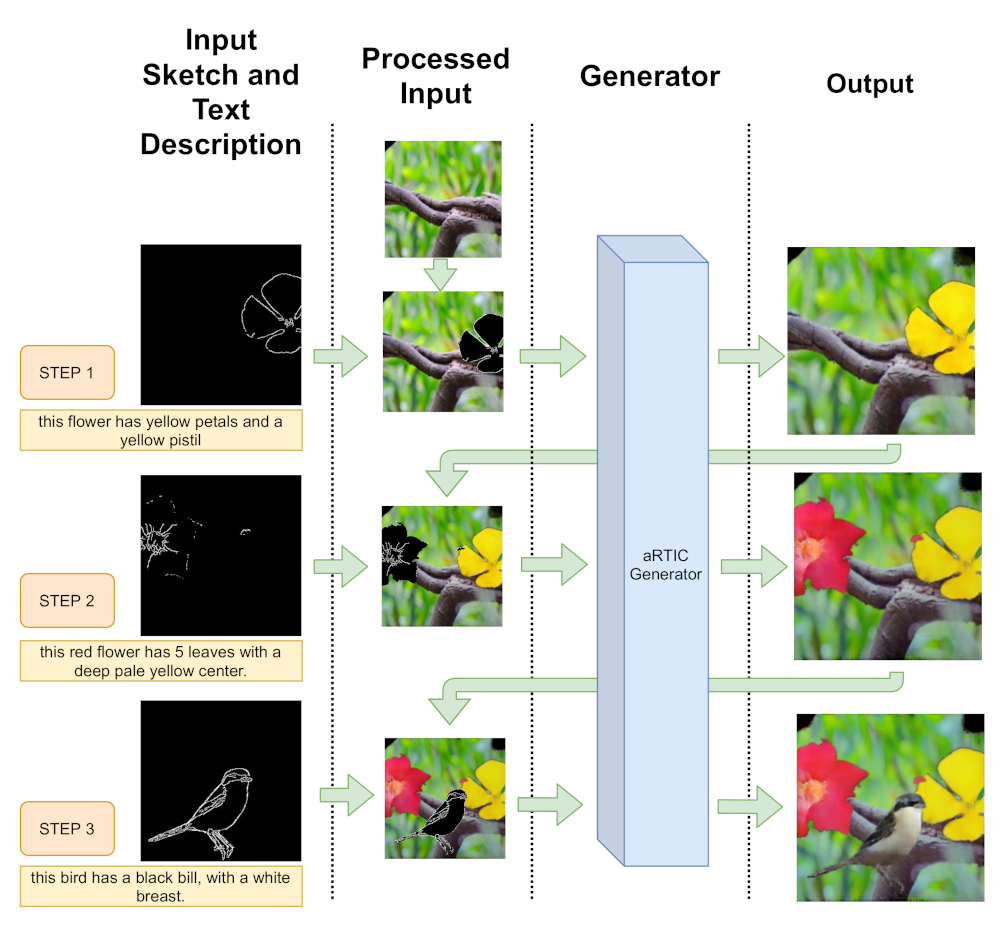
- (i)
- aRTIC GAN exploits two specifically designed refinement blocks (Section 3.2) to deal with image artifacts and fine detail enforcement as opposed to the multi-stage generation approaches. This structure aims to achieve a small parameter count, much lower than the aforesaid counterparts, while still obtaining high-quality performance.
- (ii)
- In order to use a unique discriminator for single-stage generation, our discriminator produces different outputs at the same time. This design allows us to simultaneously analyze text consistency and image quality at several levels without weighing down excessively the overall complexity. The model and the novel losses are described, respectively, in Section 3.3 and Section 3.4.
- (iii)
- The use of sketches and text descriptions improves performance while reducing the Mode Collapsing effects, since each constraint influences and dampens the variation suppression problem caused by the other input. As an additional effect, the generator appears to better discern elements from multiple domains and to generate them accordingly, boosting even more the all-round realism quality and the detail enhancement (Section 5.3).
2. Related Works
3. Method
3.1. Text Mask Generator
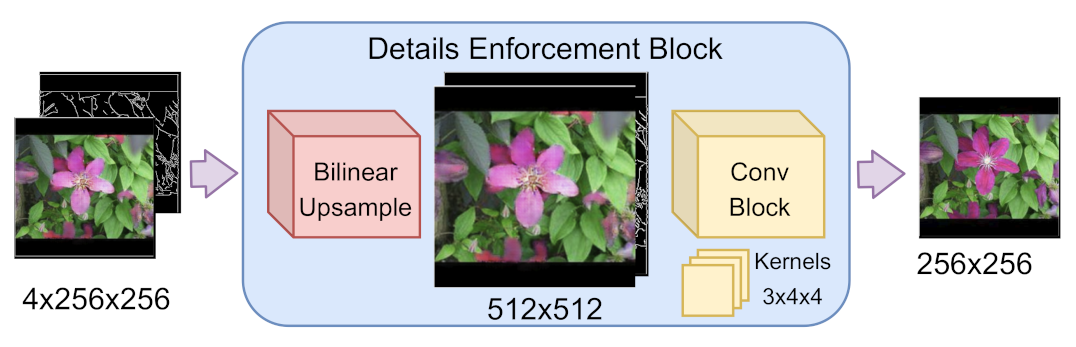
3.2. Refinement Blocks
3.3. Loss Functions
3.4. aRTIC GAN Architecture
4. Implementation Details
4.1. Datasets
4.2. Input Preparation
4.2.1. Background Generation
4.2.2. Sketch Mask and Input Generation
4.2.3. Sketch Generation
4.2.4. Char CNN-RNN Text Embedding
4.3. Network Setup
4.4. Training Procedures
| Algorithm 1: Independent steps learning |
| Input: Inpainted sketch, text embedding and GT image |
| Output: Generated image and weights update step |
| 1 Generator Call over the inpainted sketch and text embedding |
| 2 Discriminator Call over the generator output and the GT |
| 3 Generator Losses: Binary, Patch and Double L1 |
| 4 Discriminator Losses: Binary, Patch and Text Reconstruction |
| 5 Gradient Computation |
| 6 Weights Update; |
| Algorithm 2: Random consecutive steps training |
 |
5. Experiments and Results
5.1. Metrics
5.2. aRTIC GAN Evaluation
5.3. Comparison with the State of the Art on Single Domain
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Advances in Neural Information Processing Systems. Available online: https://papers.nips.cc/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 22 May 2012).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. 2010; Volume 2. Available online: http://yann.lecun.com/exdb/mnist (accessed on 1 January 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Kim, J.H.; Kitaev, N.; Chen, X.; Rohrbach, M.; Zhang, B.T.; Tian, Y.; Batra, D.; Parikh, D. CoDraw: Collaborative drawing as a testbed for grounded goal-driven communication. arXiv 2017, arXiv:1712.05558. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Park, H.; Yoo, Y.; Kwak, N. Mc-gan: Multi-conditional generative adversarial network for image synthesis. arXiv 2018, arXiv:1805.01123. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 217–225. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Bhubaneswar, India, 16–19 December 2008. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Bejiga, M.B.; Melgani, F. Gan-based domain adaptation for object classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1264–1267. [Google Scholar]
- Jin, X.; Chen, Z.; Lin, J.; Zhou, W.; Chen, J.; Shan, C. Ai-gan: Signal de-interference via asynchronous interactive generative adversarial network. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 228–233. [Google Scholar]
- Chen, Q.; Koltun, V. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1511–1520. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive Learning for Unpaired Image-to-Image Translation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 319–345. [Google Scholar]
- Li, X.; Zhang, S.; Hu, J.; Cao, L.; Hong, X.; Mao, X.; Huang, F.; Wu, Y.; Ji, R. Image-to-image translation via hierarchical style disentanglement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8639–8648. [Google Scholar]
- Gokay, D.; Simsar, E.; Atici, E.; Ahmetoglu, A.; Yuksel, A.E.; Yanardag, P. Graph2Pix: A Graph-Based Image to Image Translation Framework. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2001–2010. [Google Scholar]
- Artbreeder. Available online: https://www.artbreeder.com/ (accessed on 1 April 2022).
- Dai, L.; Tang, J. iFlowGAN: An invertible flow-based generative adversarial network for unsupervised image-to-image translation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 3062849. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Hong, S.; Yang, D.; Choi, J.; Lee, H. Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, M.; Lang, C.; Liang, L.; Feng, S.; Wang, T.; Gao, Y. End-to-End Text-to-Image Synthesis with Spatial Constrains. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–19. [Google Scholar] [CrossRef]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. MirrorGAN: Learning Text-To-Image Generation by Redescription. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tao, M.; Tang, H.; Wu, S.; Sebe, N.; Jing, X.Y.; Wu, F.; Bao, B. DF-GAN: Deep Fusion Generative Adversarial Networks for Text-to-Image Synthesis. arXiv 2020, arXiv:2008.05865. [Google Scholar]
- Li, B.; Qi, X.; Torr, P.; Lukasiewicz, T. Lightweight generative adversarial networks for text-guided image manipulation. Adv. Neural Inf. Process. Syst. 2020, 33, 22020–22031. [Google Scholar]
- Gatys, L.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 26 June–1 July 2016; pp. 10501–10510. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Madaan, A.; Setlur, A.; Parekh, T.; Poczos, B.; Neubig, G.; Yang, Y.; Salakhutdinov, R.; Black, A.W.; Prabhumoye, S. Politeness transfer: A tag and generate approach. arXiv 2020, arXiv:2004.14257. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Zeng, J.; Ma, X.; Zhou, K. CAAE++: Improved CAAE for age progression/regression. IEEE Access 2018, 6, 66715–66722. [Google Scholar] [CrossRef]
- Liu, S.; Sun, Y.; Zhu, D.; Bao, R.; Wang, W.; Shu, X.; Yan, S. Face aging with contextual generative adversarial nets. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 82–90. [Google Scholar]
- Zhai, Z.; Zhai, J. Identity-preserving conditional generative adversarial network. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–5. [Google Scholar]
- Sun, Y.; Tang, J.; Shu, X.; Sun, Z.; Tistarelli, M. Facial age synthesis with label distribution-guided generative adversarial network. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2679–2691. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, J.; Yao, Y.; Sun, Y.; Rao, H.; Shu, X. CAN-GAN: Conditioned-attention normalized GAN for face age synthesis. Pattern Recognit. Lett. 2020, 138, 520–526. [Google Scholar] [CrossRef]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. ArtFlow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 862–871. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6649–6658. [Google Scholar]
- Lin, T.; Ma, Z.; Li, F.; He, D.; Li, X.; Ding, E.; Wang, N.; Li, J.; Gao, X. Drafting and revision: Laplacian pyramid network for fast high-quality artistic style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5141–5150. [Google Scholar]
- Duan, B.; Wang, W.; Tang, H.; Latapie, H.; Yan, Y. Cascade attention guided residue learning gan for cross-modal translation. arXiv 2019, arXiv:1907.01826. [Google Scholar]
- Sun, W.; Wu, T. Learning layout and style reconfigurable gans for controllable image synthesis. arXiv 2020, arXiv:2003.11571. [Google Scholar] [CrossRef]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H. Manigan: Text-guided image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7880–7889. [Google Scholar]
- Kenan, E.; Sun, Y.; Lim, J.H. Learning Cross-Modal Representations for Language-Based Image Manipulation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Online, 25–28 October 2020; pp. 1601–1605. [Google Scholar] [CrossRef]
- Sylvain, T.; Zhang, P.; Bengio, Y.; Hjelm, R.D.; Sharma, S. Object-centric image generation from layouts. arXiv 2020, arXiv:2003.07449. [Google Scholar]
- Turkoglu, M.O.; Thong, W.; Spreeuwers, L.; Kicanaoglu, B. A layer-based sequential framework for scene generation with gans. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8901–8908. [Google Scholar]
- El-Nouby, A.; Sharma, S.; Schulz, H.; Hjelm, D.; Asri, L.E.; Kahou, S.E.; Bengio, Y.; Taylor, G.W. Tell, draw, and repeat: Generating and modifying images based on continual linguistic instruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10304–10312. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Sugawara, Y.; Shiota, S.; Kiya, H. Checkerboard artifacts free convolutional neural networks. APSIPA Trans. Signal Inf. Process. 2019, 8, e9. [Google Scholar] [CrossRef] [Green Version]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer Science & Business Media: Berlin, Heidelberg, Germany, 2012. [Google Scholar]
- Butterworth, S. On the theory of filter amplifiers. Wirel. Eng. 1930, 7, 536–541. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2017; pp. 2794–2802. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing Through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local Nash equilibrium. In Proceedings of theAdvances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Borji, A. Pros and cons of gan evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Learn, imagine and create: Text-to-image generation from prior knowledge. Adv. Neural Inf. Process. Syst. 2019, 32, 887–897. [Google Scholar]
- Tan, H.; Liu, X.; Li, X.; Zhang, Y.; Yin, B. Semantics-enhanced adversarial nets for text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10501–10510. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance | CUB-200 | Flowers 102 | Multi-Domain |
|---|---|---|---|
| IS | 5.54 ± 0.33 | 4.28 ± 0.31 | 7.15 ± 0.34 |
| SSIM | 0.86 | 0.71 | 0.80 |
| 0.04 | 0.045 | 0.042 |
| Distance | CUB-200 | Flowers 102 | CUB-Flowers |
|---|---|---|---|
| SSIM | 0.072 ± 0.192 | 0.057 ± 0.121 | 0.062 ± 0.053 |
| CS | 0.27 ± 0.178 | 0.64 ± 0.092 | −0.04 ± 0.034 |
| Model | Multi-Domain IS |
|---|---|
| aRTIC GAN | 7.20 ± 0.29 |
| BG-Augmentation | 6.28 ± 0.18 |
| Architecture | CUB-200 (IS) | Flowers 102 (IS) | CUB-200 (FID) |
|---|---|---|---|
| Pix2Pix [7] | 2.76 ± 0.13 | 2.62 ± 0.023 | - |
| GAWWN [12] | 3.62 ± 0.07 | - | 67.22 |
| AttnGAN+CL [9] | 4.42 ± 0.05 | - | 16.34 |
| StackGAN [5] | 3.70 ± 0.04 | 3.20 ± 0.01 | 51.89 |
| StackGAN V2 [6] | 4.04 ± 0.05 | 3.26 ± 0.01 | 15.30 |
| MirrorGAN [33] | 4.56 | - | 34.71 |
| LeicaGAN [71] | 4.62 ± 0.06 | 3.92 ± 0.02 | - |
| LeicaGAN* [71] | 5.69 ± 0.06 | 3.80 ± 0.01 | - |
| DM-GAN [32] | 4.75 | - | 16.09 |
| SEGAN [72] | 4.67 ± 0.04 | - | 18.167 |
| DF-GAN [34] | 5.10 | - | 14.81 |
| aRTIC GAN | 5.54 ± 0.33 | 4.28 ± 0.31 | 14.17 |
| Mode | Parameters | Inception Score |
|---|---|---|
| Fully connected | 116.086.915 | 6.56 ± 0.24 |
| FC 16 × 16 + upsample | 49.174.983 | 6.96 ± 0.23 |
| FC 32 × 32 + upsample | 49.962.166 | 7.20 ± 0.29 |
| FC 64 × 64 + upsample | 53.110.949 | 6.96 ± 0.22 |
| Removed Comp. | FID |
|---|---|
| aRTIC GAN | 14.17 |
| TMG (Section 3.1) | 22.83 |
| AGB (Section 3.2) | 48.42 |
| DEB (Section 3.2) | 39.71 |
| AGB + DEB | 83.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alati, E.; Caracciolo, C.A.; Costa, M.; Sanzari , M.; Russo, P.; Amerini, I. aRTIC GAN: A Recursive Text-Image-Conditioned GAN. Electronics 2022, 11, 1737. https://doi.org/10.3390/electronics11111737
Alati E, Caracciolo CA, Costa M, Sanzari M, Russo P, Amerini I. aRTIC GAN: A Recursive Text-Image-Conditioned GAN. Electronics. 2022; 11(11):1737. https://doi.org/10.3390/electronics11111737
Chicago/Turabian StyleAlati, Edoardo, Carlo Alberto Caracciolo, Marco Costa, Marta Sanzari , Paolo Russo, and Irene Amerini. 2022. "aRTIC GAN: A Recursive Text-Image-Conditioned GAN" Electronics 11, no. 11: 1737. https://doi.org/10.3390/electronics11111737
APA StyleAlati, E., Caracciolo, C. A., Costa, M., Sanzari , M., Russo, P., & Amerini, I. (2022). aRTIC GAN: A Recursive Text-Image-Conditioned GAN. Electronics, 11(11), 1737. https://doi.org/10.3390/electronics11111737