3.1. CycleGAN-IC and CycleGAN-IC2
CycleGAN-IC and CycleGAN-IC2 are based on and share the same generators and discriminators with CycleGAN-VC and CycleGAN-VC2. Suppose we want to convert a source into a target and we have acoustic feature sequences and belonging to audio source X and target Y. Q is the feature dimension and and are the length of the source and target sequences, respectively. The data distribution is denoted as and . The objective is to learn mapping , which is a non-parallel conversion from to .
In CycleGAN-IC, the adversarial losses, cycle-consistency loss, and identity-mapping loss are defined as in Equations (1)–(4). Equations (1) and (2) are adversarial losses, which aim to make
(
x) close to
y, and
(
y) close to
x.
In Equation (1), the discriminator aims not to be deceived by maximizing the loss, and aims to generate indistinguishable audio by minimizing the loss. On the other hand, in Equation (2), the discriminator aims not to be deceived by maximizing the loss, and aims to generate indistinguishable audio by minimizing the loss.
Equation (3) is the cycle-consistency loss
, where
is the forward generator and
is the inverse generator. The purpose of cycle-consistency loss is to measure the difference between the input audio and the audio after forward-inverse or inverse-forward, and to further regularize the mapping.
Equation (4) is the identity-mapping loss
of
and
.
The identity-mapping loss is the sum of the difference between and plus the difference between and . It encourages the generator to preserve the composition between the input and output.
The full objective loss of CycleGAN-IC is shown in Equation (5) as follows.
In Equation (5), the full loss of CycleGAN-IC,
, is the overall sum of adversarial loss, cycle-consistency loss, and identity-mapping loss. The weighting of cycle-consistency loss
and identity-mapping loss
are controlled by
and
, respectively. CycleGAN-IC uses adversarial loss once in each cycle, which is called one-step adversarial loss. The optimum solution of the mapping
X to
Y and
Y to
X equals
On the other hand, CycleGAN-IC2 uses adversarial losses twice in each cycle, which are two-step adversarial losses and are defined as in Equations (7) and (8).
and
are additional discriminators.
Finally, the full objective loss of CycleGAN-IC2 is shown in Equation (9) as follows.
In conventional CycleGAN-VC and CycleGAN-VC2, = 10 and = 5. When the training steps reach 10,000, changes to 0. Since singing/humming to instrument is different to human voice conversion, and the cycle-consistency loss aims to encourage and to find (x, y) pairs with the same contextual information, if the weighting of cycle-consistency loss is increased, the generator may fail to preserve the composition between the input and output. Therefore, unlike the original design of CycleGAN-VC and CycleGAN-VC2, which adopts larger weights of cycle-consistency loss, the weights of cycle-consistency loss in CycleGAN-IC and CycleGAN-IC2 are lower than the weights of identity loss, so that the identity loss is more important in the process of loss convergence, and the composition and timbre of the instrument can be preserved in the human voice to instrument conversion. In this research, we use = 1 and = 5 in CycleGAN-IC and CycleGAN-IC2, and the value of does not change during the training.
RNN is generally used in sequential signals such as speech. However, it is computationally demanding. Considering singing, humming, or instrument sounds are also sequential, gated CNNs containing activation function—gated linear units (GLUs)—are also used in CycleGAN-IC and CycleGAN-IC2. Assume
is the output of the
l-th layer;
,
are learned convolutional model parameters;
,
are learned biases.
where
is the element-wise product and
is the sigmoid function. The element-wise product, also called Hadamard product, of
matrices
A and
B is defined as
, for
. Sigmoid function is formulated as
.
3.2. Dual Conversion Model
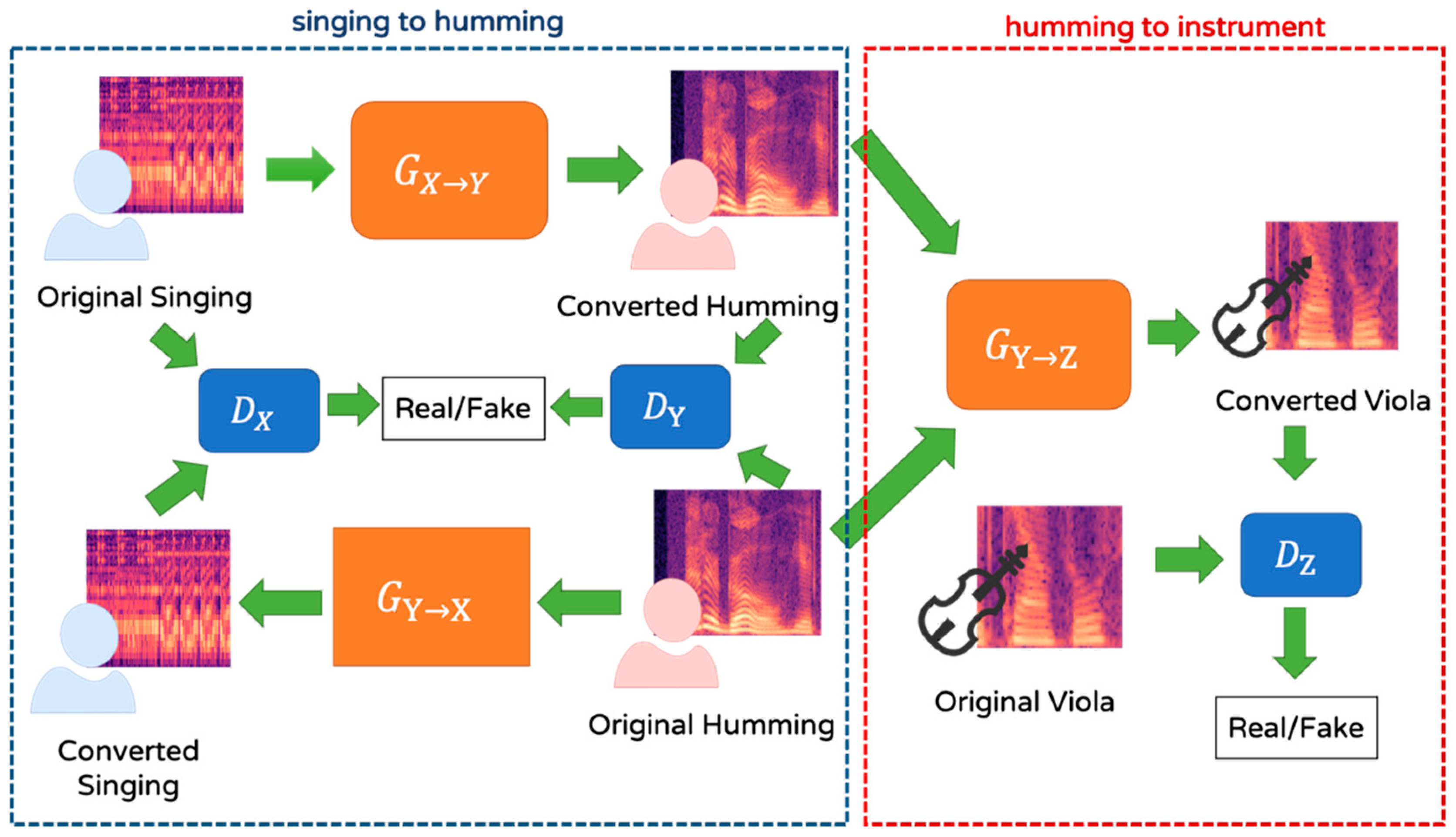
Since singing contains lyrics besides melody, it is very different from the sound of the viola, which makes the converted audio in singing to instrument conversion remain the feature of singing and unable to resemble the instrument sound. To fix the problem, a dual conversion model, CycleGAN-ICd, is proposed. The dual conversion model is as shown in
Figure 1. We propose converting human singing into human humming first and then converting it into musical instrument. Since humming does not contain lyrics, it is more similar to the instrument sound. The dual conversion makes the converted quality better than direct conversion from singing to instrument.
In addition to the generators
and
, and discriminators
and
in CycleGAN-IC2, CycleGAN-ICd adds one generator
and one discriminator
. The architecture of the generators and discriminators of CycleGAN-ICd is the same as CycleGAN-IC2. As shown in the left part of
Figure 1, we will first convert singing to humming. The full objective loss is as Equation (9). The weighting of cycle-consistency loss
and identity-mapping loss
are controlled by
and
, respectively. In this research, we used
= 1,
= 5. The value of
remains unchanged during the training. After the singing to humming is finished, humming to instrument is processed. As shown in the right part of
Figure 1, both the original and converted humming are input to the generator
to create a converted viola to fool the discriminator
. Two additional adversarial losses,
and
relating to original and converted humming, and identity-mapping loss
are added as in Equations (11)–(13). The full objective loss of the humming to instrument conversion in the dual model is the sum of
,
, and
.
3.3. Theoretical Analysis of Convergence and Complexity
Game theory is the study of the predicted and actual strategic behavior of rational agents in the game and building the mathematical models for finding the optimal strategies. Each player aims to maximize his utility by choosing the action maximizing the payoff. The action of a player is picked regarding other players’ actions. Among the game types, zero-sum games, such as poker, Go, and chess, grab a lot of attention. Zero-sum games are games in which decisions by players cannot change the sum of the players’ utilities. Actually, the total benefit of all the players equals zero all the time, for each kind of strategy. In games, how to deal with finding optimal equilibrium from multiple equilibria and avoiding undesirable equilibrium is a critical issue in game theory.
For GAN-based technology such as the proposed methods, the generator and the discriminator are two players playing against each other in a repetitive zero-sum game. The generator model is parameterized by , and the discriminator is parameterized by . In this study, deep neural networks are used for the generator model G and discriminator model D. The cost functions of the proposed CycleGAN-IC, CycleGAN-IC2, and CycleGAN-ICd are listed in Equations (5) and (9), and the sum of Equations (11)–(13).
The alternating gradient updates procedure (AGD) is generally used to reach an equilibrium in GAN-based problems. Convergence can happen based on the assumption that one player, the discriminator, is playing optimally at each step, such as in Wasserstein GAN [
32], which can continuously estimate the Earth-Mover (EM) distance (or Wasserstein-1) by optimizing the discriminator. The EM distance is defined as
is the set of all joint distributions . Real distribution and transformed distribution are the marginals. EM distance is continuous and differential, so the Wasserstein GAN critic can be trained to optimality. However, the assumption is strong and unrealistic. Wasserstein GAN becomes unstable at times.
Convergence can also be analyzed by studying GAN training dynamics as a repeated game in which both the players are utilizing no-regret algorithms [
33]. From game theory, it yields a proof for the asymptotic convergence for convex-concave case as follows. Sion’s minimax theorem [
33] states that if
,
, and they are compact and convex, and the function
is convex and concave in the first and second, then
and an equilibrium exists. Sion’s minimax theorem can be proven [
34] by Helly’s theorem, which is a statement in combinatorial geometry on the intersections of convex sets, and the KKM theorem of Knaster, Kuratowski, and Mazurkiewicz, which is a result in mathematical fixed-point theory. Therefore, if the generator and discriminator parameters are compact and convex, and the cost function is convex and concave in the first and second, there exists an equilibrium according to Sion’s minimax theorem. The procedure of getting such an equilibrium can be achieved in game theory if both players update their parameters by no-regret algorithms. The definition of no-regret algorithm is as follows [
33]. Given convex loss function sequences
,
, …:
, to select a sequence
’s, which depends only on the previous
, …
, if
, the selection algorithm is no regret, where
However, the convergence does not hold for the practical non-convex case, which is the general case for deep learning. In practice, the generator and discriminator are deep neural networks, and the cost function is not necessarily convex-concave. In non-convex games, AGD can keep cycling or converge to local equilibrium. Local regret [
35] is introduced, which shows that the game converges to local equilibrium in a non-convex case if a smoothed variant of online gradient descent (OGD) and mild assumptions are used.
-local regret of an online algorithm by fixing some
is defined as follows.
where
is window size;
is iteration;
is total round; and
is a convex set. From [
35], for any
, 1
, and
, a distribution
on 0-smooth, 1-bounded cost functions on
exists, such that for any online algorithm,
Hence, in online learning, time smoothing truly captures non-convex optimization. The convergence of the proposed methods will further be shown through observing the convergence curve in the experiment in
Section 4.
The computational complexities of CycleGAN-IC and CycleGAN-IC2 are the same as CycleGAN-VC and CycleGAN-VC2 because CycleGAN-IC and CycleGAN-IC2 share the same architecture of the generators and discriminators with CycleGAN-VC and CycleGAN-VC2. The computational complexity of CycleGAN-ICd is 1.5 times that of CycleGAN-IC2 because CycleGAN-ICd has three generators and three discriminators and shares the same architecture of the generators and discriminators with CycleGAN-IC2, while CycleGAN-IC2 has two generators and two discriminators. FLOPs (floating-point operations) [
36] of the generators and discriminators are used for computational complexity analysis.
For each convolutional kernel, FLOPs equal
,
,
,
, and
are height, width, the number of channels, kernel width, and the number of output channels, respectively. The parameters of the generator and discriminator architectures are presented in
Table 1. For detailed operations in the tables, please refer to [
10].







{kind=link}
{kind=link}
{kind=link}
{kind=link}