
Design Space Exploration on High-Order QAM Demodulation Circuits: Algorithms, Arithmetic and Approximation Techniques †


Abstract
:1. Introduction
- The analysis and assessment of the effects of tunable approximation methods on high-order QAM demodulation, achieving improved hardware efficiency with limited accuracy loss, which is the first one performed in the literature to the best of our knowledge.
- The assessment of various trade-offs (i.e., accuracy–hardware, accuracy–throughput, and accuracy–power) among different demodulation algorithms.
2. Related Work
2.1. Telecommunication Functions on FPGAs
2.2. Circuit Approximation Techniques
3. Design of Approximate QAM Demodulation Circuits
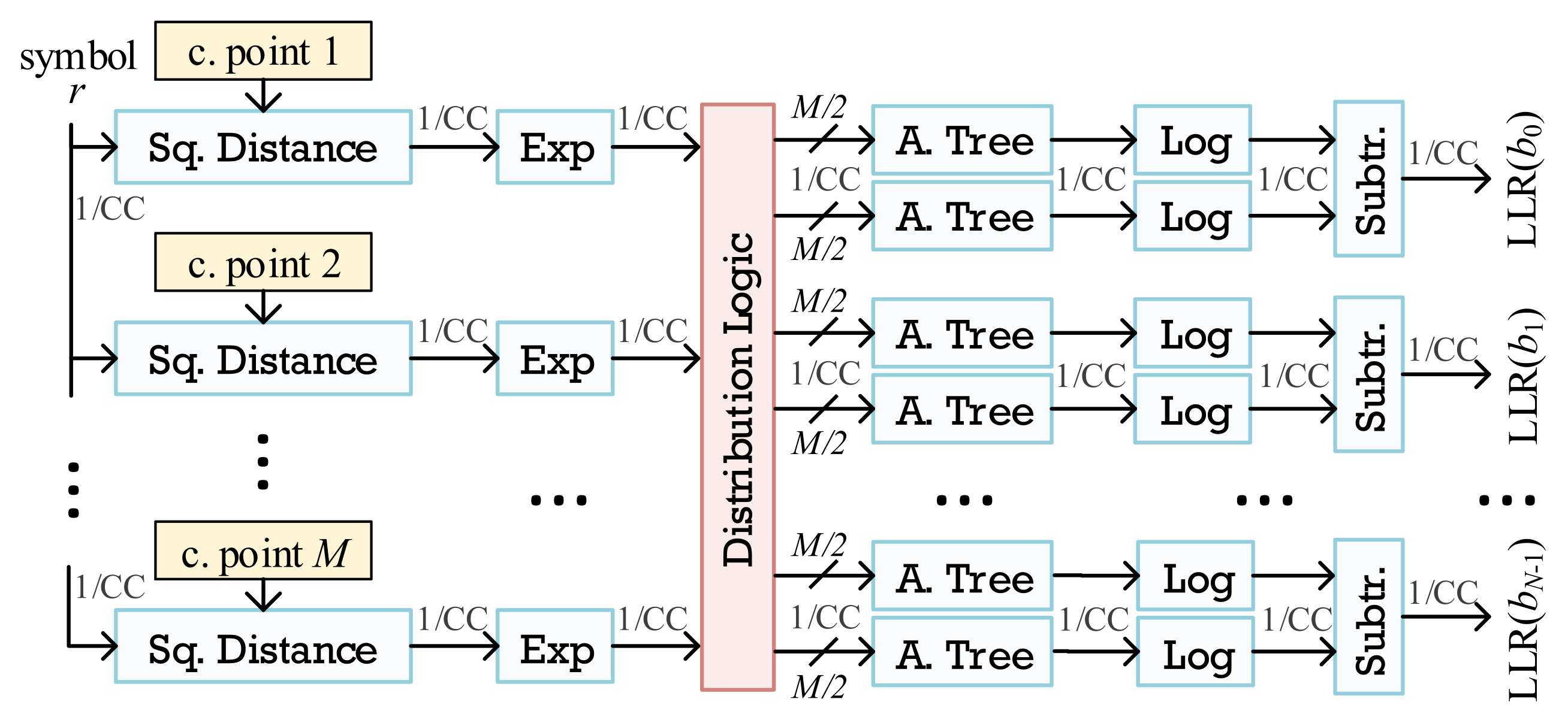
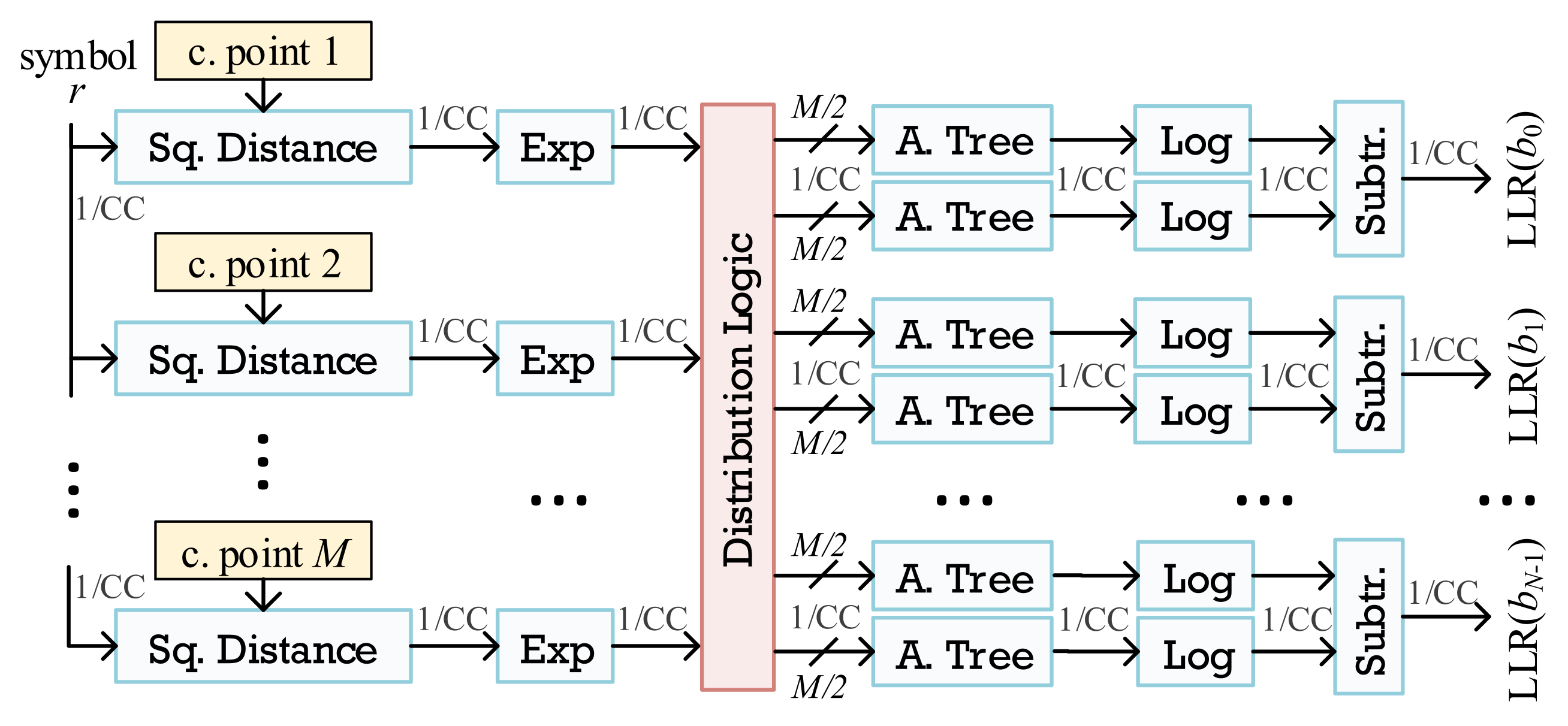
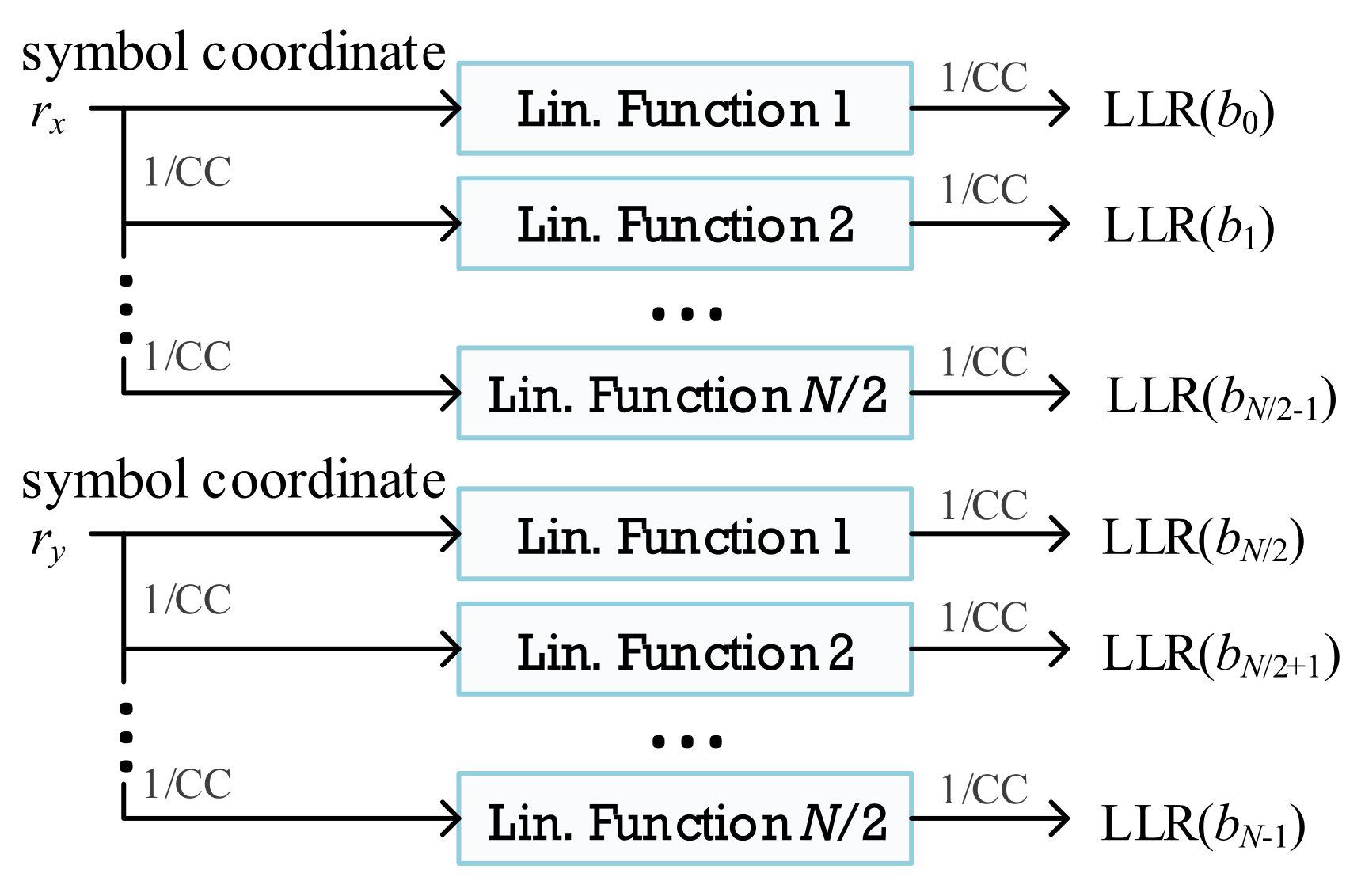
3.1. Exact LLR Architecture
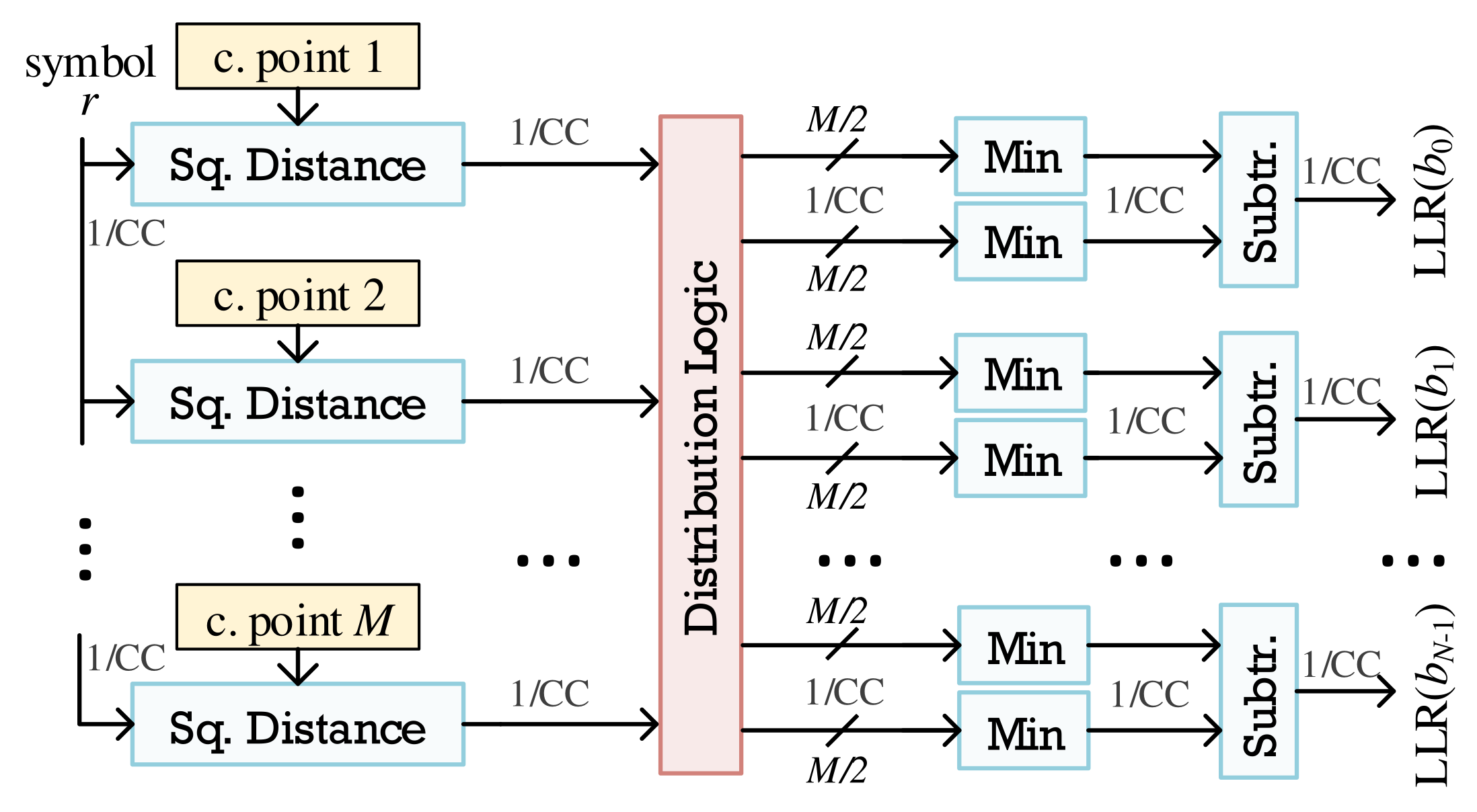
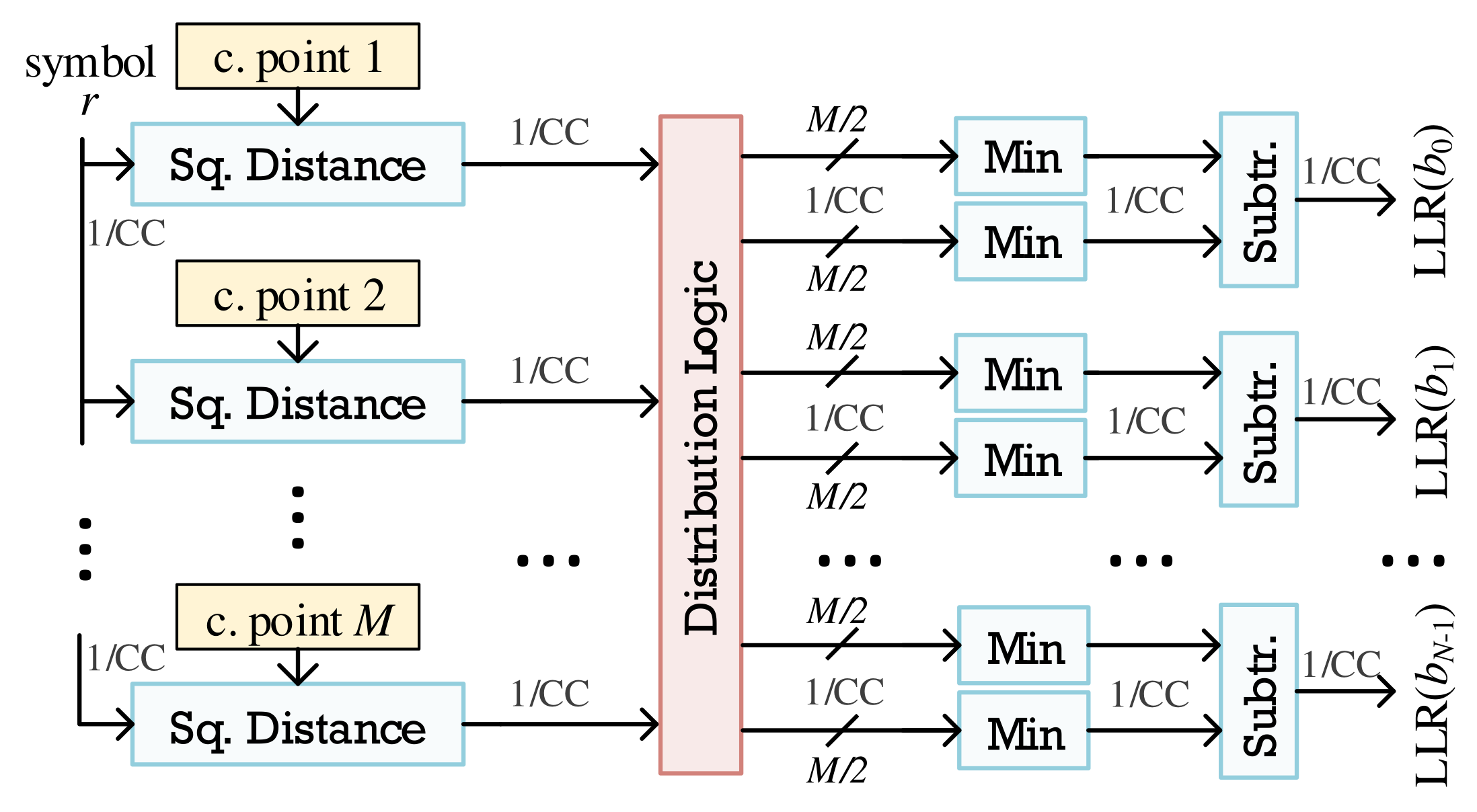
3.2. Approximate LLR Architecture
3.3. Piecewise LLR Architecture
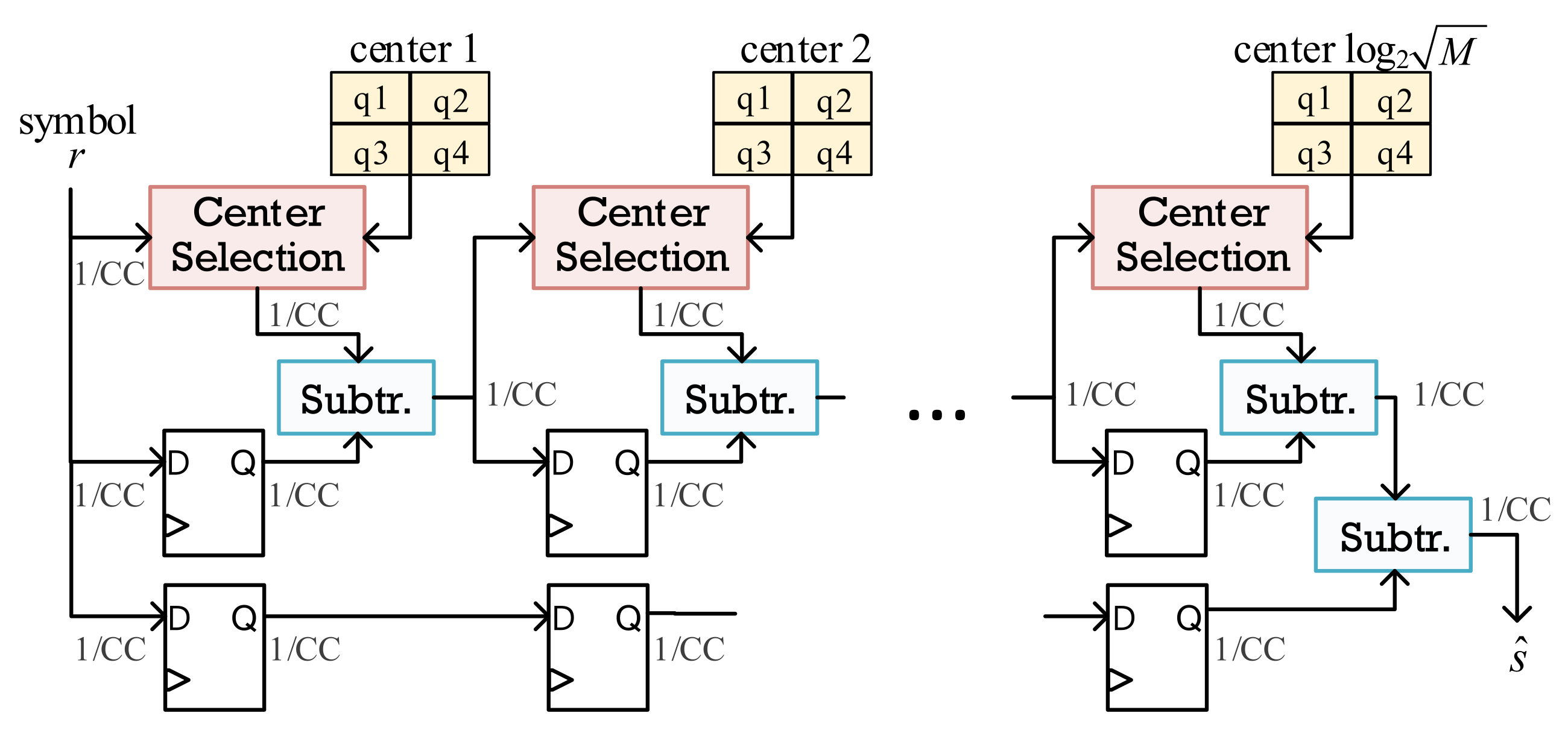
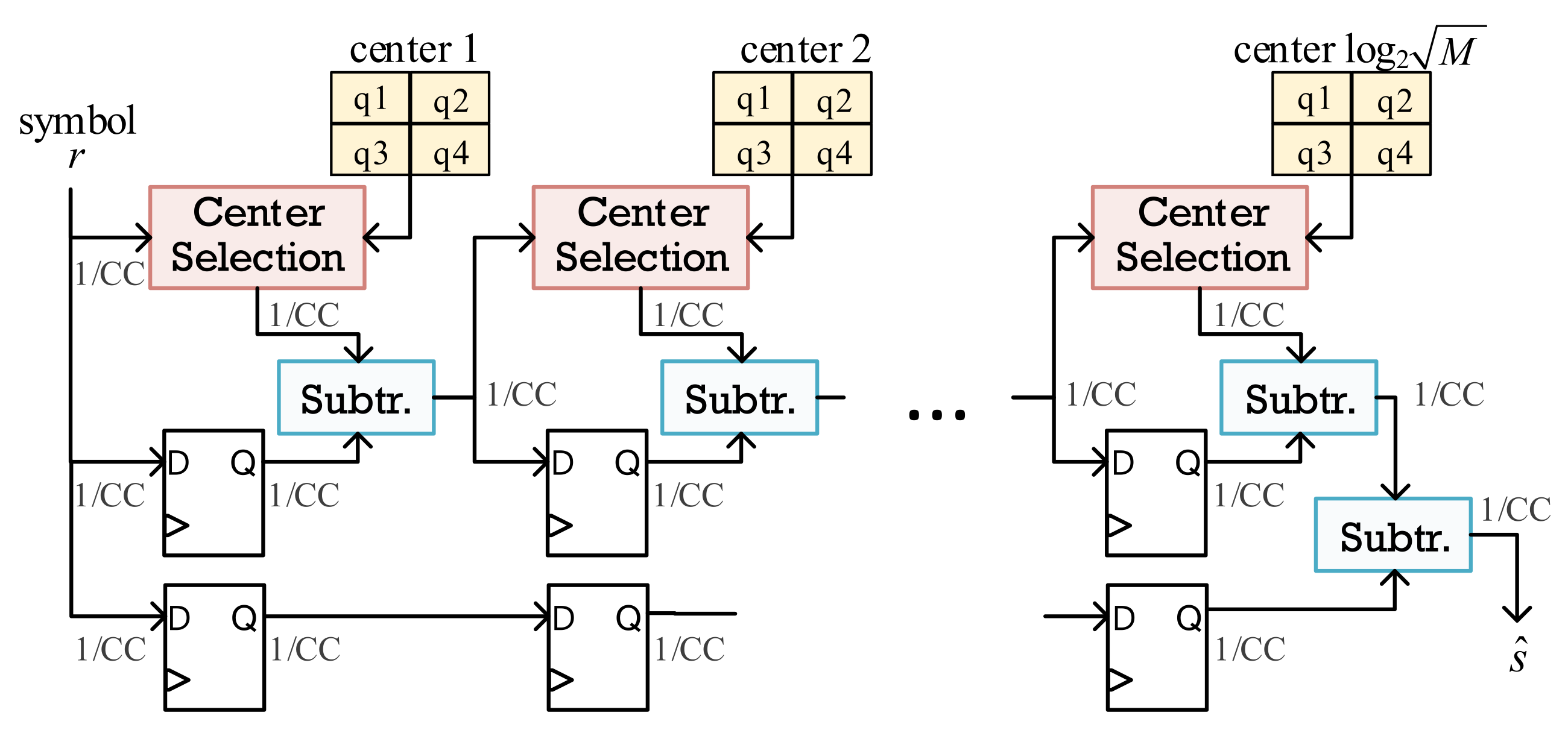
3.4. Approximate ML Architecture
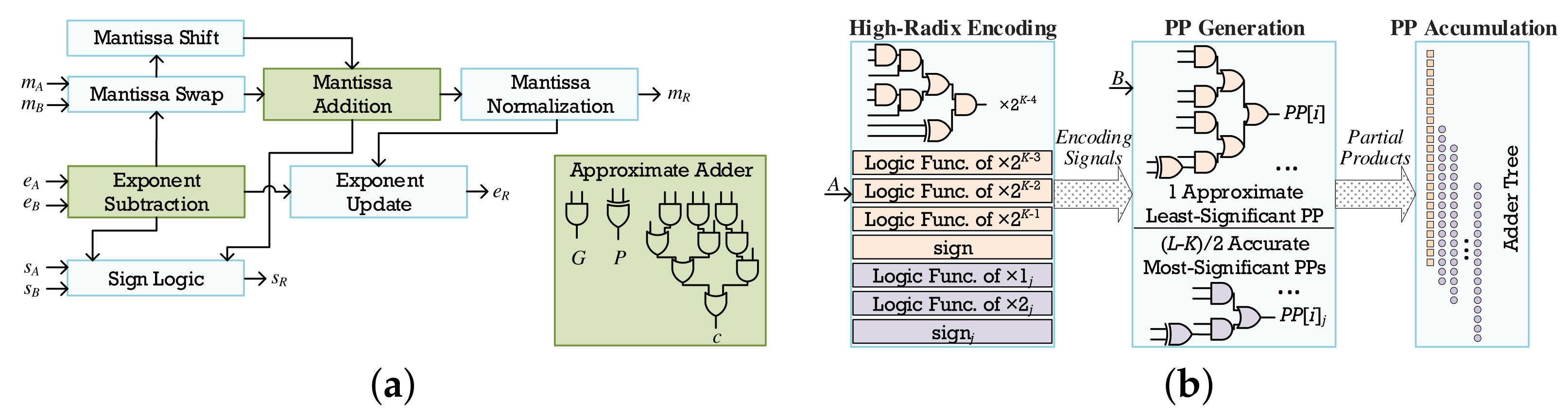
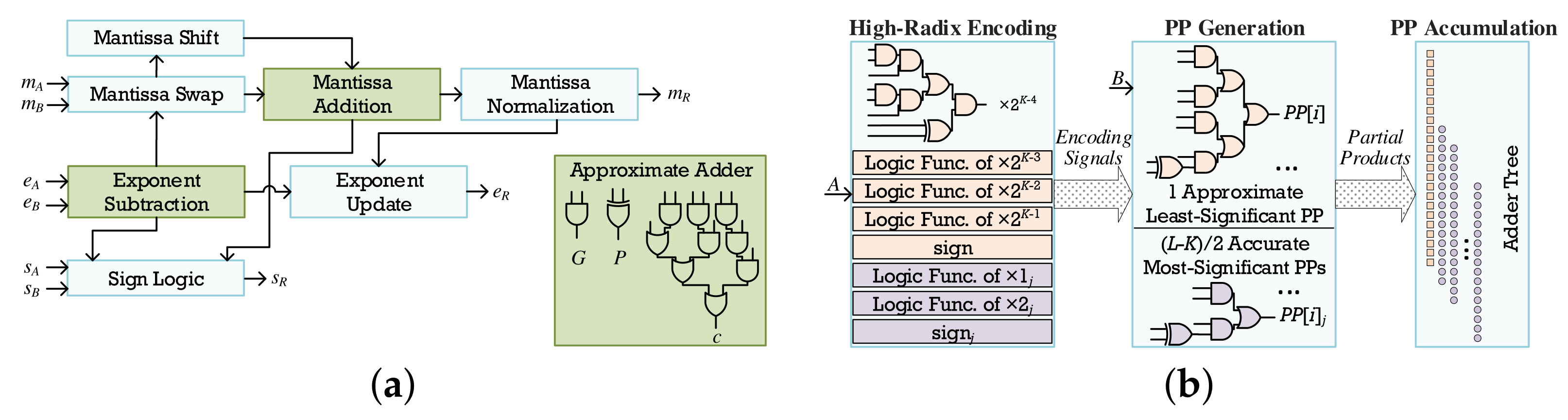
3.5. Arithmetic Approximation Techniques
3.5.1. Floating-Point Approximations
3.5.2. Fixed-Point Approximations
4. Experimental Evaluation
4.1. Experimental Setup
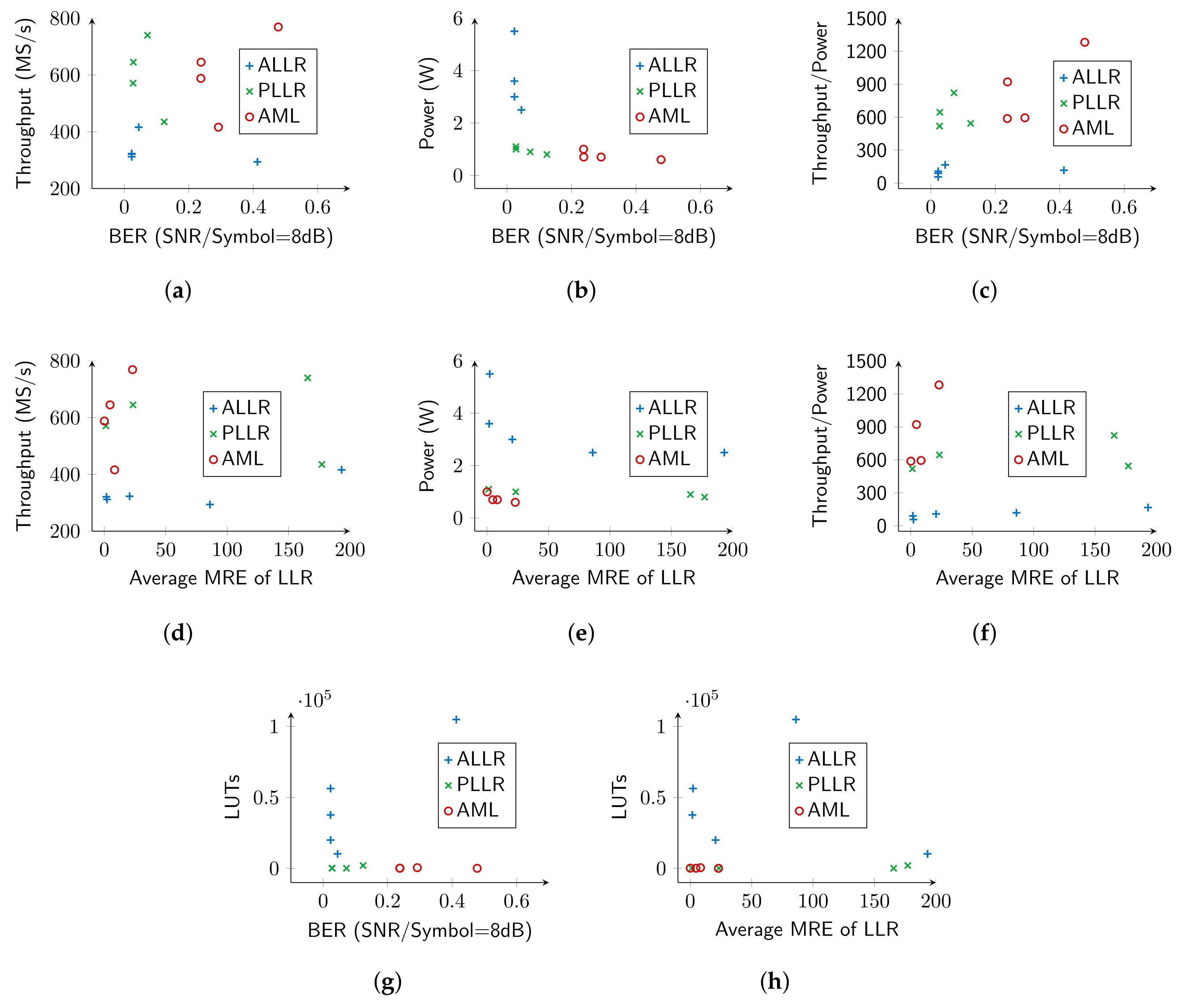
4.2. Exploration Results
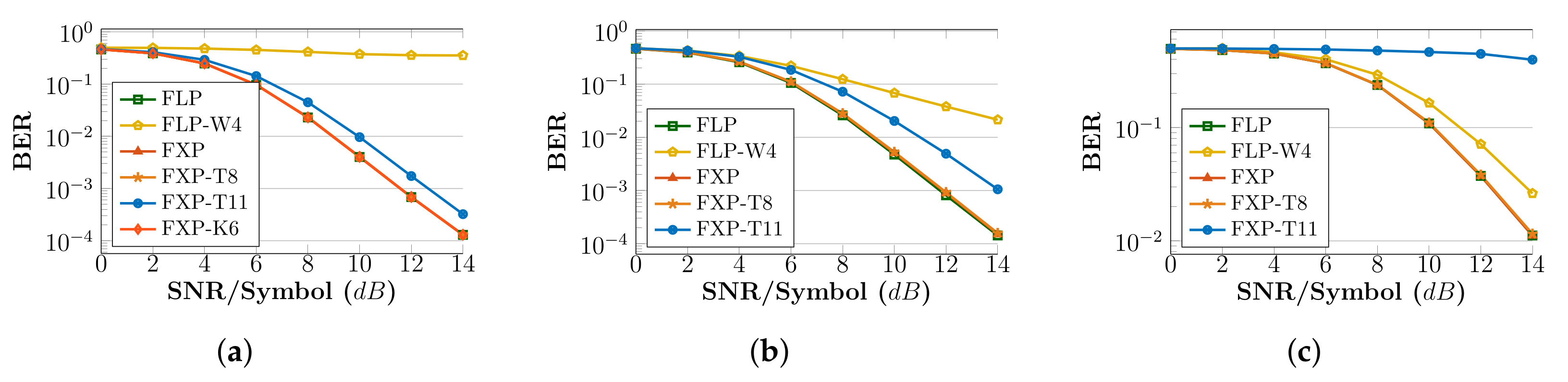
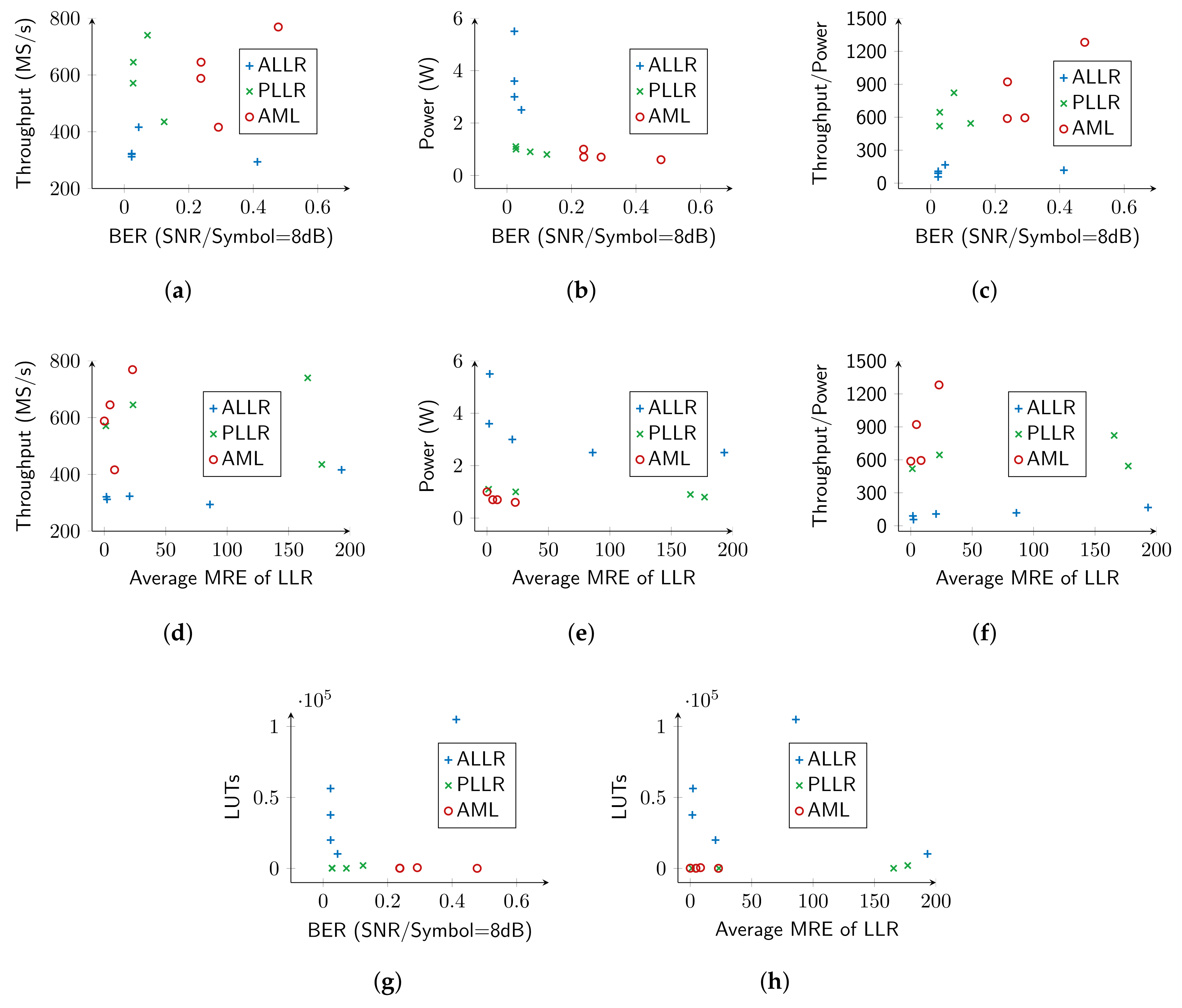
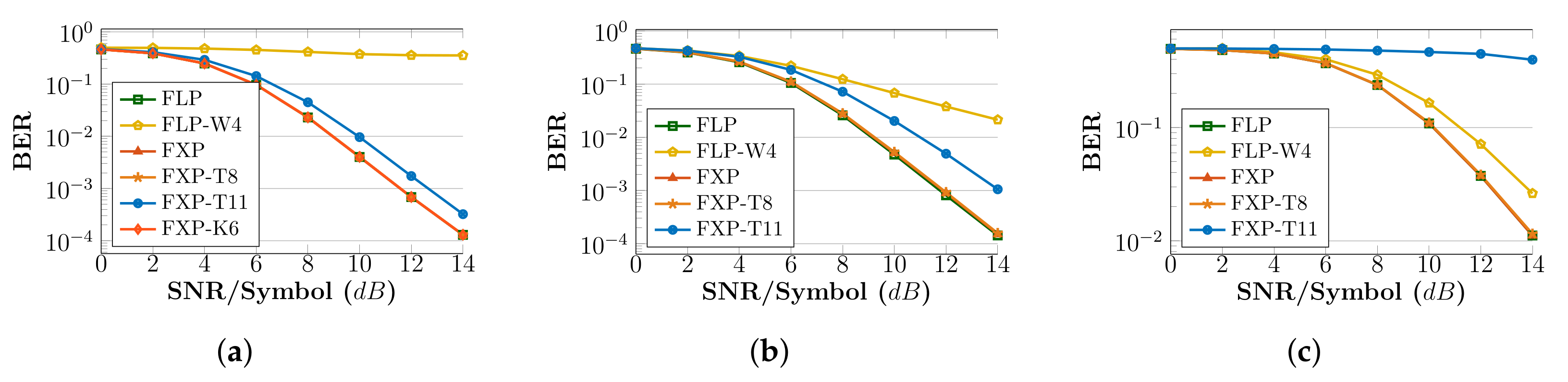
- ALLR circuits: The FLP-W4 implementation provides a negligible reduction of only in LUTs and only increase in frequency compared to FLP. On the other hand, the fixed-point ALLR circuits deliver increased gains. The accurate FXP circuit gains in resources and has higher frequency, while FXP-T8 and FXP-T11 have and reduction in LUTS, and reduction in DFFs, and and increase in frequency, respectively. FXP-K6 reduces its utilization by in LUTs, in DFFs and operates faster. If we seek BER performance in-line with FLP, circuits with moderate truncation (FXP-T8) or approximate multipliers (FXP-K6) can be used. Additionally, considering the MRE metric, FXP-T8 is worse than FXP-K6 ( vs ).
- PLLR circuits: FLP-W4 offers only reduction in LUTs, but gains in frequency compared to the FLP circuit. Regarding fixed-point circuits, we observe , , reduction in LUTs, , , reduction in DFFs and , , higher operating frequencies for the accurate FXP, approximate FXP-T8 and FXP-T11 circuits, respectively. As SNR increases (Figure 6b), the BER performance of FLP-W4 and FXP-T11 deviates significantly from FLP; thus, a fixed-point architecture with moderate truncation can be adopted.
- AML circuits: FLP-W4 achieves LUT reduction and frequency increase compared with the accurate FLP circuit. For the fixed-point circuits, we observe LUT reduction, DFF reduction either we have accurate circuits (FXP) or approximate ones (FXP-T8, FXP-T11). Regarding frequency, an increase by for the accurate FXP, for the FXP-T8 and almost for the FXP-T11 is seen. However, we note that AML provides the worst BER performance among all algorithms and arithmetic, and thus, its deployment on a real-world system may be limited. Incorporating the BER results (Figure 6c), a fixed-point with moderate truncation (T8) circuit is preferable, as it follows the BER curve of FLP.
4.3. Pareto Trade-Off Analysis: Hardware Resources vs. Accuracy
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Andrews, J.G.; Buzzi, S.; Choi, W.; Hanly, S.V.; Lozano, A.; Soong, A.C.K.; Zhang, J.C. What Will 5G Be? IEEE J. Sel. Areas Commun. 2014, 32, 1065–1082. [Google Scholar] [CrossRef]
- Kuon, I.; Tessier, R.; Rose, J. FPGA Architecture: Survey and Challenges; Now Publishers: Hanover, MA, USA, 2008; pp. 135–253. [Google Scholar] [CrossRef]
- Lentaris, G.; Maragos, K.; Stratakos, I.; Papadopoulos, L.; Papanikolaou, O.; Soudris, D.; Lourakis, M.; Zabulis, X.; Gonzalez-Arjona, D.; Furano, G. High-performance embedded computing in space: Evaluation of platforms for vision-based navigation. J. Aerosp. Inf. Syst. 2018, 15, 178–192. [Google Scholar] [CrossRef]
- Leon, V.; Stamoulias, I.; Lentaris, G.; Soudris, D.; Gonzalez-Arjona, D.; Domingo, R.; Codinachs, D.M.; Conway, I. Development and Testing on the European Space-Grade BRAVE FPGAs: Evaluation of NG-Large Using High-Performance DSP Benchmarks. IEEE Access 2021, 9, 131877–131892. [Google Scholar] [CrossRef]
- Pham, T.H.; Fahmy, S.A.; McLoughlin, I.V. An End-to-End Multi-Standard OFDM Transceiver Architecture Using FPGA Partial Reconfiguration. IEEE Access 2017, 5, 21002–21015. [Google Scholar] [CrossRef]
- Ferreira, M.L.; Ferreira, J.C. Reconfigurable NC-OFDM processor for 5G communications. In Proceedings of the 2015 IEEE 13th International Conference on Embedded and Ubiquitous Computing, Porto, Portugal, 21–23 October 2015; pp. 199–204. [Google Scholar]
- Ferreira, M.L.; Barahimi, A.; Ferreira, J.C. Reconfigurable FPGA-based FFT processor for cognitive radio applications. In Proceedings of the International Symposium on Applied Reconfigurable Computing, Mangaratiba, Brazil, 22–24 March 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 223–232. [Google Scholar]
- Deng, R.; He, J.; Chen, M.; Chen, L. SFO compensation by pilot-aided channel estimation for real-time DDO-OFDM system. Opt. Commun. 2015, 355, 172–176. [Google Scholar] [CrossRef]
- Rommel, S.; Grivas, E.; Cimoli, B.; Dodane, D.; Morales, A.; Pikasis, E.; Bourderionnet, J.; Feugnet, G.; Carvalho, J.B.; Katsikis, M.; et al. Real-time high-bandwidth mm-wave 5G NR signal transmission with analog radio-over-fiber fronthaul over multi-core fiber. Eurasip J. Wirel. Commun. Netw. 2021, 2021, 43. [Google Scholar] [CrossRef]
- Jiang, H.; Han, J.; Qiao, F.; Lombardi, F. Approximate Radix-8 Booth Multipliers for Low-Power and High-Performance Operation. IEEE Trans. Comput. 2016, 65, 2638–2644. [Google Scholar] [CrossRef]
- Liu, W.; Qian, L.; Wang, C.; Jiang, H.; Han, J.; Lombardi, F. Design of Approximate Radix-4 Booth Multipliers for Error-Tolerant Computing. IEEE Trans. Comput. 2017, 66, 1435–1441. [Google Scholar] [CrossRef]
- Mrazek, V.; Hrbacek, R.; Vasicek, Z.; Sekanina, L. EvoApprox8b: Library of Approximate Adders and Multipliers for Circuit Design and Benchmarking of Approximation Methods. In Proceedings of the Design, Automation and Test in Europe Conference (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 258–261. [Google Scholar] [CrossRef]
- Leon, V.; Asimakopoulos, K.; Xydis, S.; Soudris, D.; Pekmestzi, K. Cooperative Arithmetic-Aware Approximation Techniques for Energy-Efficient Multipliers. In Proceedings of the Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; p. 160. [Google Scholar] [CrossRef]
- Leon, V.; Zervakis, G.; Soudris, D.; Pekmestzi, K. Approximate Hybrid High Radix Encoding for Energy-Efficient Inexact Multipliers. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 421–430. [Google Scholar] [CrossRef]
- Leon, V.; Zervakis, G.; Xydis, S.; Soudris, D.; Pekmestzi, K. Walking through the Energy-Error Pareto Frontier of Approximate Multipliers. IEEE Micro 2018, 38, 40–49. [Google Scholar] [CrossRef]
- Leon, V.; Paparouni, T.; Petrongonas, E.; Soudris, D.; Pekmestzi, K. Improving Power of DSP and CNN Hardware Accelerators Using Approximate Floating-Point Multipliers. ACM Trans. Embed. Comput. Syst. 2021, 20, 1–21. [Google Scholar] [CrossRef]
- Kahng, A.B.; Kang, S. Accuracy-configurable Adder for Approximate Arithmetic Designs. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 3–7 June 2012; pp. 820–825. [Google Scholar] [CrossRef] [Green Version]
- Shafique, M.; Ahmad, W.; Hafiz, R.; Henkel, J. A low latency generic accuracy configurable adder. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 7–11 June 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Omidi, R.; Sharifzadeh, S. Design of low power approximate floating-point adders. Int. J. Circuit Theory Appl. 2020, 49, 1–11. [Google Scholar] [CrossRef]
- Leon, V.; Pekmestzi, K.; Soudris, D. Exploiting the Potential of Approximate Arithmetic in DSP & AI Hardware Accelerators. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Mrazek, V.; Hrbacek, R.; Vasicek, Z.; Sekanina, L. ALWANN: Automatic Layer-Wise Approximation of Deep Neural Network Accelerators without Retraining. In Proceedings of the International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Leon, V.; Stratakos, I.; Armeniakos, G.; Lentaris, G.; Soudris, D. ApproxQAM: High-Order QAM Demodulation Circuits with Approximate Arithmetic. In Proceedings of the 2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 5–7 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Lentaris, G.; Chatzitsompanis, G.; Leon, V.; Pekmestzi, K.; Soudris, D. Combining Arithmetic Approximation Techniques for Improved CNN Circuit Design. In Proceedings of the IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 23–25 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Ragavan, R.; Barrois, B.; Killian, C.; Sentieys, O. Pushing the limits of voltage over-scaling for error-resilient applications. In Proceedings of the Design, Automation and Test in Europe (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 476–481. [Google Scholar] [CrossRef] [Green Version]
- Jiao, X.; Jiang, Y.; Rahimi, A.; Gupta, R.K. SLoT: A supervised learning model to predict dynamic timing errors of functional units. In Proceedings of the Design, Automation and Test in Europe (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1183–1188. [Google Scholar] [CrossRef]
- Hamkins, J. Performance of low-density parity-check coded modulation. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 6–13 March 2010; pp. 1–14. [Google Scholar] [CrossRef]
- Tasissa, A. Functional Approximation and the Remez Algorithm; Report 2013. Available online: https://sites.tufts.edu/atasissa/files/2019/09/remez.pdf (accessed on 19 December 2021).
- Tosato, F.; Bisaglia, P. Simplified soft-output demapper for binary interleaved COFDM with application to HIPERLAN/2. In Proceedings of the IEEE International Conference on Communications, New York, NY, USA, 28 April–2 May 2002; pp. 664–668. [Google Scholar] [CrossRef]
- Yoon, E. Maximum Likelihood Detection with a Closed-Form Solution for the Square QAM Constellation. IEEE Commun. Lett. 2017, 21, 829–832. [Google Scholar] [CrossRef]
- Leon, V.; Xydis, S.; Soudris, D.; Pekmestzi, K. Energy-Efficient VLSI Implementation of Multipliers with Double LSB Operands. IET Circuits Devices Syst. 2019, 13, 816–821. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approximate LLR (ALLR) | Piecewise LLR (PLLR) | Approximate ML (AML) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FLP | FLP-W4 | FXP | FXP-T8 | FXP-T11 | FXP-K6 | FLP | FLP-W4 | FXP | FXP-T8 | FXP-T11 | FLP | FLP-W4 | FXP | FXP-T8 | FXP-T11 | |
| LUT | 106,097 | 104,881 | 56,278 | 19,957 | 10,210 | 37,653 | 2060 | 2020 | 160 | 76 | 59 | 3848 | 3504 | 139 | 91 | 44 |
| DFF | 42,432 | 42,432 | 21,596 | 10,684 | 9316 | 51,572 | 886 | 886 | 215 | 126 | 96 | 1204 | 1204 | 44 | 28 | 18 |
| MHz1 | 286 | 294 | 312 | 323 | 416 | 321 | 333 | 435 | 571 | 645 | 740 | 385 | 416 | 588 | 645 | 769 |
| W2 | 5.0 | 4.9 | 5.5 | 3.0 | 2.5 | 3.6 | 0.8 | 0.8 | 1.1 | 1.0 | 0.9 | 0.6 | 0.7 | 1.0 | 0.7 | 0.6 |
| MHz/W3 | 114.4 | 117.6 | 56.7 | 107.7 | 166.4 | 89.2 | 416.3 | 543.8 | 519.1 | 645.0 | 822.2 | 641.7 | 594.3 | 588.0 | 921.4 | 1281.7 |
| avg. MRE | – | 86.00 | 2.22 | 20.59 | 193.14 | 1.74 | – | 177.05 | 1.28 | 23.35 | 165.55 | – | 8.36 | 0.02 | 4.65 | 22.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stratakos, I.; Leon, V.; Armeniakos, G.; Lentaris, G.; Soudris, D. Design Space Exploration on High-Order QAM Demodulation Circuits: Algorithms, Arithmetic and Approximation Techniques. Electronics 2022, 11, 39. https://doi.org/10.3390/electronics11010039
Stratakos I, Leon V, Armeniakos G, Lentaris G, Soudris D. Design Space Exploration on High-Order QAM Demodulation Circuits: Algorithms, Arithmetic and Approximation Techniques. Electronics. 2022; 11(1):39. https://doi.org/10.3390/electronics11010039
Chicago/Turabian StyleStratakos, Ioannis, Vasileios Leon, Giorgos Armeniakos, George Lentaris, and Dimitrios Soudris. 2022. "Design Space Exploration on High-Order QAM Demodulation Circuits: Algorithms, Arithmetic and Approximation Techniques" Electronics 11, no. 1: 39. https://doi.org/10.3390/electronics11010039
APA StyleStratakos, I., Leon, V., Armeniakos, G., Lentaris, G., & Soudris, D. (2022). Design Space Exploration on High-Order QAM Demodulation Circuits: Algorithms, Arithmetic and Approximation Techniques. Electronics, 11(1), 39. https://doi.org/10.3390/electronics11010039