Abstract
Fundus image is an image that captures the back of the eye (retina), which plays an important role in the detection of a disease, including diabetic retinopathy (DR). It is the most common complication in diabetics that remains an important cause of visual impairment, especially in the young and economically active age group. In patients with DR, early diagnosis can effectively help prevent the risk of vision loss. DR screening was performed by an ophthalmologist by analysing the lesions on the fundus image. However, the increasing prevalence of DR is not proportional to the availability of ophthalmologists who can read fundus images. It can lead to delayed prevention and management of DR. Therefore, there is a need for an automated diagnostic system as it can help ophthalmologists increase the efficiency of the diagnostic process. This paper provides a deep learning approach with the concatenate model for fundus image classification with three classes: no DR, non-proliferative diabetic retinopathy (NPDR), and proliferative diabetic retinopathy (PDR). The model architecture used is DenseNet121 and Inception-ResNetV2. The feature extraction results from the two models are combined and classified using the multilayer perceptron (MLP) method. The method that we propose gives an improvement compared to a single model with the results of accuracy, and average precision and recall of 91% and 90% for the F1-score, respectively. This experiment demonstrates that our proposed deep-learning approach is effective for the automatic DR classification using fundus photo data.
1. Introduction
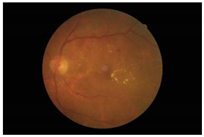
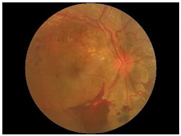
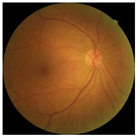
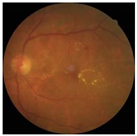
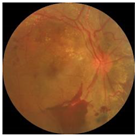
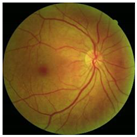
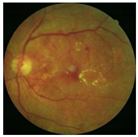
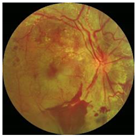
Diabetes is characterised by hyperglycaemia and impaired carbohydrate, lipid, and protein metabolism related with absolute or relative insulin activity or secretion [1]. The estimated worldwide prevalence of diabetes in 2019 was 9.3% (463 million people), and in 2045 is expected to continue to increase to 10.9% (700 million people) [2]. Hyperglycaemia that is not well controlled can lead to complications of diabetes, such as nephropathy, retinopathy, neuropathy, and cardiovascular disease [3]. The most common complication is diabetic retinopathy (DR), a significant cause of visual impairment, especially in the younger and economically active age group. It usually occurs due to the appearance of a series of lesions on the retina characterised by changes in capillary microaneurysms (MAs), capillary degeneration, vascular permeability, and abnormal production of blood vessels [3]. More than 4 million people experience sight loss due to DR, of which 3.3 million have moderate-to-severe visual impairment and the rest are blind [4]. There are two main classes of DR, namely, non-proliferative diabetic retinopathy (NPDR) and proliferative diabetic retinopathy (PDR) [5]. NPDR has lesions, such as the appearance of MAs, haemorrhages (HMs), and hard exudates (EXs) on the retina. Meanwhile, PDR is the more advanced stage of DR characterised by neovascularisation or abnormal blood vessel development [5,6]. Figure 1 presents the fundus images.
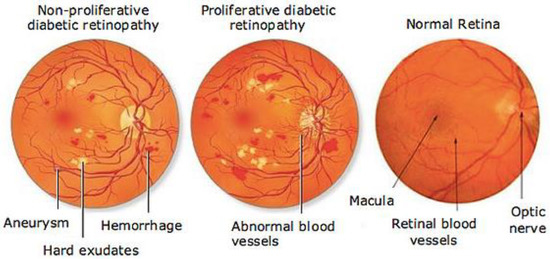
Figure 1.
Fundus images.
Regular eye examination in patients with diabetes is the only way to determine the severity of DR [7]. A trained practitioner such as an ophthalmologist or retina specialist should perform retinal screening to determine the presence of DR and its classification. DR detection is accomplished by using a fundus camera to take photos of the back of the eye. It requires a digital camera specially designed to take pictures of the eye. An illustration is presented in Figure 2. The fundus image is usually sent to a central facility to be analysed by the retinal specialist. Therefore, limited resources of ophthalmologists can hinder the prevention and management of DR.
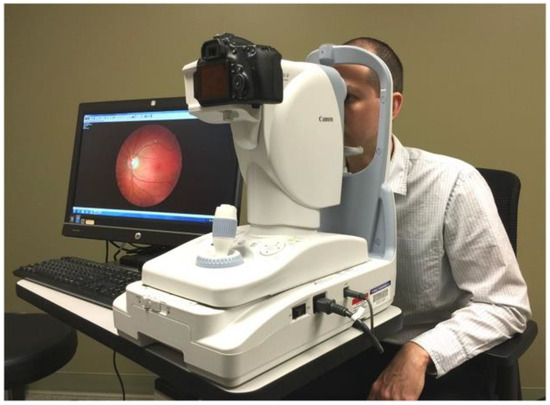
Figure 2.
DR screening using fundus camera [8].
The latest advances in machine learning, particularly concerning deep learning, are helping to classify and identify patterns in medical images, including fundus images. The multidisciplinary collaboration between medical science and mathematics in computer-assisted disease detection enables original research based on the suitability of data in the field [9]. Thus, researchers and clinicians are beginning to be interested in this collaboration, given the limited number of ophthalmologists interpreting fundus images.
Numerous researchers have started to develop machine learning and deep learning methods, to assist health workers in analysing fundus images. Sarwinda, et al. [10] achieved 85% accuracy by proposing feature extraction using a gradient-oriented histogram algorithm and DR classification using machine learning methods such as random forest and support vector machine (SVM). Salma, et al. [11] focused on applying deep learning, namely, the GoogLeNet architecture, as feature extraction, and a classifier with an accuracy of 88%. Patel and Chaware [12] achieved an accuracy of 91% by implementing deep learning development, namely, the transfer learning method with fine-tuned MobileNetV2.
The studies conducted by the aforementioned authors used publicly available fundus image datasets, such as DiaretDB1, EyePACS, Messidor, eOphtha, HRF, IDRID, STARE, and Kaggle. The use of these datasets has resulted in excellent accuracy. In this paper, the dataset used is relatively new and was collected by [13]. Based on the review article [14], no paper uses the dataset other than the source paper for the dataset itself. In addition, the novelty in this research lies in the method. Usually, in classifying DR diseases, many researchers only use a single method such as a machine learning classifier or a single CNN model [10,11,12]. This study applied two CNN models, namely DenseNet121 and Inception-ResNetV2, as feature extractors. The goal is that the fundus image can be studied from a different point of view from each model to produce better model learning performance. The result of feature extraction from the two models is a feature vector that is then combined with the concatenation technique, entering the classification stage using multilayer perceptron (MLP).
2. Materials and Methods
In building a model for classifying the severity of DR on fundus images, we carried out several stages as presented in Figure 3. First, we collected a publicly available fundus image dataset. Furthermore, the pre-processing techniques were performed on the dataset to enable easy use of the model in image recognition. We leveraged the DenseNet121 and Inception-ResNetV2 architectural models to extract image features. DenseNet121 is a depth-based CNN architecture, whereas Inception-ResNetV2 is a multipath-based CNN [15]. The uniqueness of each architecture can help the model in receiving more comprehensive feature learning information. The features obtained from each architecture are combined and forwarded to the classification stage using the MLP method. This method is the most widely used neural network structure, with the main use cases being classification, recognition, prediction, and forecasting [16].
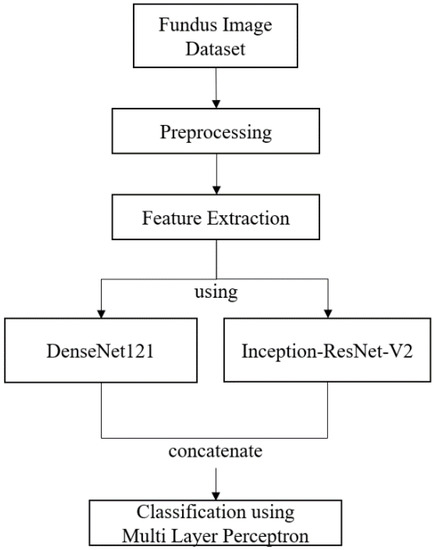
Figure 3.
The design of the proposed method.
2.1. Fundus Image Dataset
Fundus image is a retinal imaging that can capture the anatomical structure of the ball on the back of the eye [17,18]. Many crucial biomarkers can be visible on fundus images, inclusive of an optic disc; optic cup; blood vessels; macula; fovea; and DR-related lesions, including MAs, HMs, and EXs [18]. Fundus photography is most frequently used for disease documentation and clinical studies, especially DR.
In this study, we used the Dataset for Diabetic Retinopathy (DDR) dataset [13], one of the fundus image datasets that became available to the public in 2019. This relatively new dataset contains 13,673 fundus images from 9598 patients collected from several hospitals in China in 2016–2018. DDR fundus images were collected from several different camera types using single-view and captured using the same technique. It consists of six categories, such as normal (6266 data), mild NPDR (630 data), moderate NPDR (4477 data), severe NPDR (236 data), PDR (913 data), and the undegradable images with poor quality (1151 data). It should be noted that classes are very unbalanced in the DDR datasets. The classification of unbalanced classes is challenging due to the highly skewed distribution of classes and the unequal costs of misclassification. Li, Gao, Wang, Guo, Liu, and Kang [13] state that lesions on the fundus image of mild NPDR are difficult to identify, and some severe NPDR classes are also easily misclassified as moderate NPDR. Therefore, we balanced this dataset by re-sampling using only three classes: normal, NPDR (mild, moderate, and severe classes were combined into one class), and PDR. Then, each class contains 913 data points, adjusting the amount of data in the PDR class with the distribution of training, validation, and testing data as described in Table 1. A sample of the DDR dataset is presented in Figure 4. It can be seen that there are no DR lesions on the normal retina. Retinal signs of NPDR can be observed in the presence of lesions, such as exudates, MAs, and HAs. Meanwhile, new blood vessels form in the retina affected by PDR (advanced DR cases).

Table 1.
DDR dataset composition.
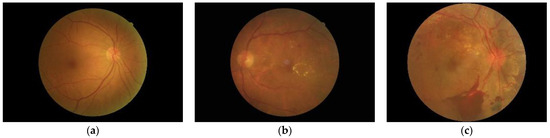
Figure 4.
Example of DDR dataset: (a) normal; (b) NPDR; (c) PDR.
2.2. Preprocessing
The DDR fundus image dataset is a colour fundus image containing red, green, and blue components or commonly known as the RGB channel. We divided a fundus image into three channels, as can be seen from Figure 5. Blood vessels are visible in the red channel. However, these channels usually contain too much noise or are saturated, as most features transmit signals in the red channel. Contrarily, low contrast and insufficient information occur in the blue channel. At the same time, the green channel in the colour fundus image provides the best results on the blood vessels contrast. Hence, we applied contrast uniformity with the contrast limited adaptive histogram equalisation technique (CLAHE) [19] on the green channel so that the information on that channel can be maximised; this will enable the model to better recognise DR lesions in the image [20]. Next, each fundus image of the retina was cropped so that the black border did not stand out too much on the fundus image. Finally, the images were resized to 224 × 224 pixels to fit the model built. The crop and resize steps are carried out with the OpenCV library in Python, which is commonly used for image processing.
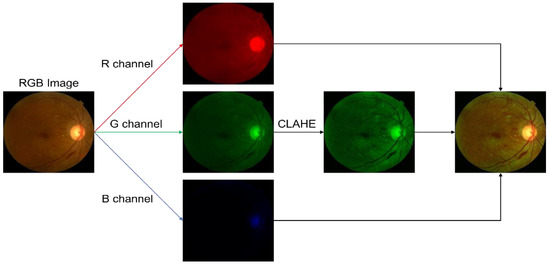
Figure 5.
Pre-processing technique.
2.3. Deep Feature Vector
2.3.1. Convolutional Neural Network
In image classification tasks, CNN has been shown to give impressive results [21]. CNN is split into two stages, namely, feature extraction and classification. Figure 6 shows that the feature extraction section has several layers of convolutional followed by pooling layers. Meanwhile, in the classification part, there is a fully connected layer.
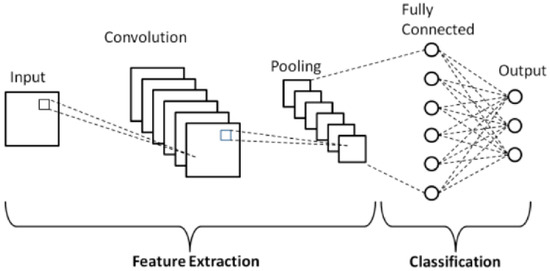
Figure 6.
DenseNet121 architecture [22].
The convolutional layer contains the computation between the input image and the kernel filter with the convolution operation. It can extract various features of an image, such as textures, edges, and objects [23]. The mathematical formula for convolution is defined by Equation (1), where denotes the pre-activation output of layer , the activation of layer ; , the convolution operator; and , the weights.
The pooling layer is helpful for simplifying information from the output convolutional layer, but it retains essential information. It has several operations, including global average pooling, max pooling, L2-norm pooling, and others. The max pooling and average pooling operations are expressed in Equations (2) and (3), respectively, where is the filter size [24].
The output of the feature extraction section is called a feature map, where the shape is still a multidimensional array. Therefore, the shape of the feature map must be converted into a vector so that it can be used as an input in the classification stage.
2.3.2. DenseNet121
CNN is a neural network that has shown excellent performance. Its powerful ability to learn the data representation is demonstrated through the feature extraction stage (hidden layers). This study uses dense convolutional network (DenseNet, also known as DenseNet-121), which has 121 layers, as the model architecture.
DenseNet is a CNN architecture proposed by Huang, et al. [25]. The concept of this architecture is to connect each layer to all subsequent layers. The feature map of all previous layers is received by the -th layer. The result of the -th layer is defined in Equation (4), where are concatenation operations (combined feature maps) at layers , and is a composite function of operations, including pooling, convolution, batch normalisation, and activation function. Concatenation operations are shortcut connections on DenseNet. Generally, DenseNet consists of convolutional layers, dense blocks, and transition layers, as shown in Figure 7. Because of its dense network, this network architecture is called the DenseNet. The operation on the dense block follows Equation (4). The transition layer is utilised for dimensional adjustments or down sampling between dense blocks. In Figure 7, there are also pooling layers that follow Equations (2) and (3) discussed previously.
2.3.3. Inception-ResNetV2
The Inception-ResNetV2 architecture, which combines the inception structure and residual network connection (ResNet), was created by Szegedy, et al. [26]. The inception model is famous for its multipronged architecture. They have a set of filters (1 × 1, 3 × 3, 5 × 5, etc.) coupled to the circuit in each branch. The split–transform–merge architecture of the initial module was observed as a strong representation capability in its dense layer [27]. Residual connection models can eliminate degradation problems during deep structures and provide specific features, such as texture, size, colour, and location [28]. The initial module combines multiple convolutions, pooling layers, and all feature maps combined into a single vector in the Results section. Modules typically have filter sizes of 5 × 5, 3 × 3, and 1 × 1 to extract general and local features from the input data. ResNet is famous for its shortcut links, which effectively encapsulate features from one layer to the next. It empowers features and ultimately achieves increased accuracy. The Inception-ResNetV2 architecture is presented in Figure 8.
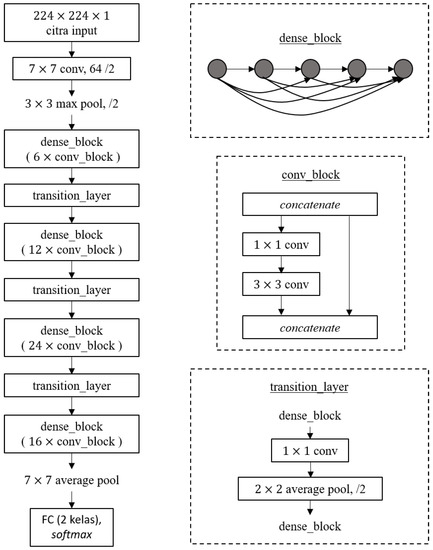
Figure 7.
DenseNet121 architecture [29].
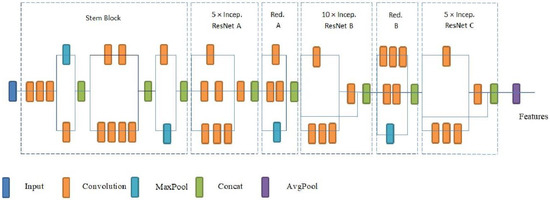
Figure 8.
Inception-ResNetV2 architecture [30].
2.4. Classification
The DenseNet and Inception-ResNetV2 neural networks are generally used for feature extraction and classification of input data with the help of the global average pooling layer and softmax layers. In this study, for each of the two networks, features extracted from the average output of the pooling layer are taken and given to the classifier for classification. In this final project, the output of DenseNet produces 1024 features and Inception-ResNetV2 produces 1536 features. The features of both models are combined with the concatenate method. Combined features get 2560 features. Furthermore, these features become inputs for processing in the classification stage. The concatenate formula of the two CNN feature extraction results is defined by Equation (5), and the illustration is presented in Figure 9.
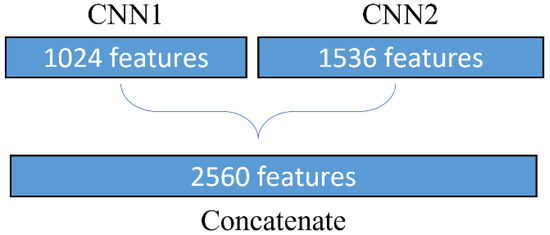
Figure 9.
Illustration of concatenating features.
Multilayer Perceptron (MLP)
We applied the MLP-based concatenate method in the classification stage as presented in Figure 10, which studied the features generated from two CNN models, DenseNet121 and Inception-ResNetV2. Combining the features of these two different models allows the classifier to better recognize the lesion pattern on the fundus image.
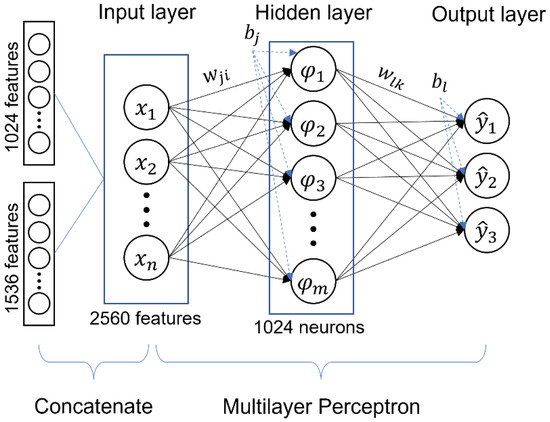
Figure 10.
Architecture of our classifier.
MLP is well known in a variety of areas, such as image recognition, speech recognition, and machine translation software. It is the most common topology of artificial neural networks, where perceptron is fully connected at each layer. MLP has an input layer, leastwise one hidden layer and an output layer that uses backpropagation for learning [31]. This deep learning framework can differentiate between linearly separable and non-separable data. Whenever the data is linearly separated, all neurons can have a linear activation function that maps linearly from input to output. For data that cannot be separated linearly, the algorithm will use a nonlinear activation function, such as a logistic or sigmoid function [32]. The output of this network is the final predicted value.
The calculations for each neuron in the output and hidden layers are presented in Equations (6) and (7), with bias vector , weights , and activation functions and . The parameters to learn are bias and weights. The output of this network is the final predicted value. In this work, we set a hidden layer with 1024 neurons in the MLP technique. The number of neurons is suggested by [33,34].
2.5. Experimental Setup
2.5.1. System Specifications
We used Google Colaboratory, Python 3 programming language and TensorFlow library to simulate the model. The following are the system specifications:
- RAM: 13 GB
- Memory: 32 GB
- GPU: Nvidia Tesla K80 with 16 GB memory, CUDA version 11.2
- -
- Number of sockets: one (available slots for physical processors)
- -
- Number of cores each processor has: one core(s) per socket
- -
- Number of threads each core has: two thread(s) per core
2.5.2. Evaluation Metrics
Classification performance measures are calculated based on a confusion matrix or truth table. It contains several terms, including true positive (TP), false positive (FP), false negative (FN), and true negative (TN) [35]. In the multiclass case, the confusion matrix is presented in Figure 11. Metric values such as precision, recall, F1-score, and accuracy for a generic class as the reference focus are defined by Equations (8)–(11) [36].

Figure 11.
An example of confusion matrix: (a) focusing on class ‘A’; (b) focusing on class ‘B’; (c) focusing on class ‘C’.
2.5.3. Hyperparameter Tuning
Neural networks are proven to be powerful for studying complex connections between their inputs and outputs automatically [37]. However, a number of these connections may be due to sampling noise, so they may persist throughout the training but may not be present in the actual test data. It can cause overfitting issues and might so decrease the predictive performance of deep learning models [37]. Hence, we followed a process of tuning the hyperparameters to derive the general performance of our proposed model. The methodology used to select the best hyperparameters is as follows: First, categorical cross-entropy was chosen as a loss function for our multiclass classification problem. Equation (12) can be used to calculate the loss, where denotes the real value and is the predicted value.
Then, Adam’s algorithm (adaptive moment estimation) [38] was then used throughout the training stage to optimise with 30 epochs. The mathematical notations for Adam are defined in Equations (13)–(16), where denotes the initial learning rate; , gradient at time along ; , exponential average of gradient along ; , exponential average of squares of gradient along ; and , hyperparameters.
At this stage, we set the initial learning rate to 0.001. If the loss value increases in an epoch, then the learning rate will be divided by 10. The dropout rate is set to 0.5 to avoid overfitting throughout the model training [39]. Then, we record the best model weights based on minimum loss of validation. Finally, these weights are used to predict the class on the test dataset. We used convolutional filters, pooling filters, steps, and padding with the defaults mentioned in the original DenseNet121, Inception-ResNetV2, and MLP architectures [25,26,31].
3. Results
3.1. Preprocessing Implementation
The model development process was carried out as the research flow described previously. First, we applied fundus image pre-processing to the DDR dataset we had previously collected. Table 2 presents an example of the pre-processing results from the original image.
Table 2.
Examples of pre-processing implementations.
3.2. Evaluation of DenseNet121 and Inception-ResNetV2
The fundus image that passed the pre-processing stage was then ready to enter the model training process, which consists of two sections, namely, feature extraction and classification. We used the concatenation model of two CNN architectures, namely, DenseNet121 and Inception-ResNetV2 in the feature extraction stage. The training and validation curves of the DenseNet121 model throughout the training phase are plotted in Figure 12a, whereas the curve for the Inception-ResNetV2 model is presented in Figure 12b. The accuracy and loss of the training process show that the training processes of both the models have converged so that previously unseen data can be tested.
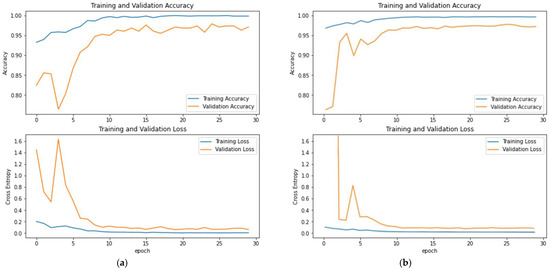
Figure 12.
The training and validation curves of (a) the DenseNet121 and (b) the Inception-ResNetV2.
The confusion matrix and performance of the DenseNet121 model test with the test dataset are presented in Table 3 and Table 4. The accuracy obtained was 89.3%, with precision, recall, and F1-score of about 89%. In the Inception-ResNetV2 model, the test results with the test dataset are presented in Table 5 and Table 6, with an accuracy of 88.8%. Similar to the DenseNet121 model, the precision, recall and F1-score of Inception-ResNetV2 obtained was 89%.
Table 3.
The confusion matrix of DenseNet121.
Table 4.
Performance metrics of DenseNet121.
Table 5.
The confusion matrix of Inception-ResNetV2.
Table 6.
Performance metrics of Inception-ResNetV2.
We proposed to combine the results of feature extraction of the DenseNet121 and Inception-ResNetV2 architectural models using MLP as a classifier of the severity of DR in the fundus images. The results of model testing show improved performance of the combined model, as presented in Table 7 and Table 8. Meanwhile, Table 9 shows a comparison of the performance results of the single model and the proposed model.
Table 7.
The confusion matrix of proposed method.
Table 8.
Performance metrics of proposed method.
Table 9.
The comparison of the performance results of the single model with the proposed model.
4. Discussion
The effectiveness of this method can be compared with those of various previous studies that performed fundus image classification tasks with three classes, namely, normal, NPDR, and PDR as described in Table 10. In 2012, Venkatesan, et al. [40] used a combination of datasets, such as DIARETDB0, DIARETDB1, STARE, and Messidor. They achieved an accuracy of 87.61% by applying the Gabor technique and semantic of neighbourhood colour moment features at the feature extraction stage, which then classified the features using SVM. Five years later, Sayed, et al. [41] compared two machine learning methods that achieved an accuracy of 80% for the probabilistic neural network (PNN) and 90% for the SVM method. Similar to [40,41], Hortinela, et al. [42] recently used the SVM method at the classification stage, but the feature extraction method used was different, using the principal component analysis (PCA). The accuracy they achieved was 86.67%. Chaudhary and Ramya [43] extracted the fundus image features using the grey-level co-occurrence matrix (GLCM) method with 85% accuracy for the fuzzy classifier and 90% for the CNN classifier. Chowdhury and Meem [44] applied one of the deep learning methods, namely a single CNN with InceptionV3 architecture. They achieved an accuracy of 60.3%. On the other hand, Queentinela and Triyani [45] tried several CNN architectures such as AlexNet, GoogleNet, and SqueezeNet. The accuracy obtained from each architecture was 64.4%, 66.7%, and 75.6%, respectively.
Table 10.
The comparison of model performance using three classes (no DR, NPDR, and PDR) with other studies.
The method we propose in this study, namely, the concatenate model of two CNN models (DenseNet121 and Inception-ResNetV2), outperformed those of previous studies, with an accuracy of 91%. In the future, this model should be improved and evaluated on image datasets of much better quality and quantity to recognise the five severity levels of DR, thus resulting in a better research [46].
5. Conclusions
This study presents a deep learning technique using the concatenate model for DR fundus image classification using a relatively new dataset, DDR. The main purpose of this paper is to classify fundus images effectively into three classes: no DR, NPDR, and PDR. The dataset is processed first at the data pre-processing stage to produce an image that the model more easily recognises. We found that it would be better to use a combination of features from the feature extraction results of two single models. For this purpose, we used the concatenate model of the DenseNet121 and Inception-ResNetV2 architectures, which are well tuned and relatively robust. This proposed approach exhibits competitive performance on the DR fundus image classification. However, the dataset we collected contained only three classes with a balanced number of images. Future indications for this work are an expansion of our dataset and inclusion of classification images of NPDR, such as mild, moderate, and severe classes, for more complex classification problems. In addition, some robust classifiers can be discussed to improve accuracy in future research, which can refer to [47,48,49].
Author Contributions
Conceptualization, R.H.P., P.A., A.B., A.A.V. and A.R.Y.; methodology, R.H.P., A.B. and P.A.; software, R.H.P.; validation, A.B., A.A.V., A.R.Y. and W.M.; project administrator, A.B. and P.A.; clinical analysis, A.A.V. and A.R.Y.; writing—original draft, R.H.P.; writing—review and editing, R.H.P., P.A. and A.A.V.; supervision, A.B., A.A.V., A.R.Y. and W.M.; funding acquisition, W.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by PDUPT 2021 with contract number NKB-183/UN2.RST/HKP.05.00/2021 from RISTEK/BRIN (Directorate General of Higher Education in Indonesia).
Institutional Review Board Statement
Ethical review and approval were waived for this study, due to aims to develop better research in the field of computer science in the future.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The dataset analysed in this study is publicly available and can be found here: https://github.com/nkicsl/DDR-dataset (accessed on 3 September 2021).
Acknowledgments
To members of the Laboratory of Bioinformatics and Advanced Computing (BACL), Department of Mathematics, Data Science Center (DSC), Department of Ophthalmology, Department of Biology, University of Indonesia, Cipto Mangunkusumo National General Hospital, and Directorate General of Higher Education, the authors are grateful for your support.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses or interpretation of data; in the writing of the manuscript; and in the decision to publish the results.
References
- Sperling, M.A.; Tamborlane, W.V.; Battelino, T.; Weinzimer, S.A.; Phillip, M. CHAPTER 19—Diabetes mellitus. In Pediatric Endocrinology, 4th ed.; Sperling, M.A., Ed.; W.B. Saunders: Philadelphia, PA, USA, 2014; pp. 846–900.e841. [Google Scholar]
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ohiagu, F.O.; Chikezie, P.C.; Chikezie, C.M. Pathophysiology of diabetes mellitus complications: Metabolic events and control. Biomed. Res. Ther. 2021, 8, 4243–4257. [Google Scholar] [CrossRef]
- Adelson, J.; Rupert, R.A.B.; Briant, P.S.; Flaxman, S.; Taylor, H.; Jonas, J.B. Causes of Blindness and Vision Impairment in 2020 and Trends over 30 Years: Evaluating the Prevalence of Avoidable Blindness in Relation to “VISION 2020: The Right to Sight”. Available online: https://www.iapb.org/learn/vision-atlas/causes-of-vision-loss/ (accessed on 30 September 2021).
- Wang, W.; Lo, A.C.Y. Diabetic Retinopathy: Pathophysiology and Treatments. Int. J. Mol. Sci. 2018, 19, 1816. [Google Scholar] [CrossRef] [Green Version]
- Wong, T.; Aiello, L.; Ferris, F.; Gupta, N.; Kawasaki, R.; Lansingh, V. Updated 2017 ICO Guidelines for Diabetic Eye Care. Available online: http://www.icoph.org/downloads/ICOGuidelinesforDiabeticEyeCare.pdf (accessed on 30 September 2021).
- International Diabetes Feredation and The Fred Hollows Foundation. Diabetes Eye Health: A Guide for Health Care Professionals; International Diabetes Feredation and The Fred Hollows Foundation: Brussels, Belgium, 2015. [Google Scholar]
- Mackay, D.D.; Bruce, B.B. Non-mydriatic fundus photography: A practical review for the neurologist. Pract. Neurol. 2016, 16, 343–351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anki, P.; Bustamam, A.; Buyung, R.A. Looking for the link between the causes of the COVID-19 disease using the multi-model application. Commun. Math. Biol. Neurosci. 2021, 2021, 75. [Google Scholar]
- Sarwinda, D.; Siswantining, T.; Bustamam, A. Classification of diabetic retinopathy stages using histogram of oriented gradients and shallow learning. In Proceedings of the 2018 International conference on computer, control, informatics and its applications (IC3INA), Tangerang, Indonesia, 1–2 November 2018; pp. 83–87. [Google Scholar]
- Salma, A.; Bustamam, A.; Sarwinda, D. Diabetic Retinopathy Detection Using GoogleNet Architecture of Convolutional Neural Network Through Fundus Images. Nusant. Sci. Technol. Proc. 2021, 1–6. Available online: https://nstproceeding.com/index.php/nuscientech/article/view/299 (accessed on 7 October 2021).
- Patel, R.; Chaware, A. Transfer Learning with Fine-Tuned MobileNetV2 for Diabetic Retinopathy. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–4. [Google Scholar]
- Li, T.; Gao, Y.; Wang, K.; Guo, S.; Liu, H.; Kang, H. Diagnostic assessment of deep learning algorithms for diabetic retinopathy screening. Inf. Sci. 2019, 501, 511–522. [Google Scholar] [CrossRef]
- Lakshminarayanan, V.; Kheradfallah, H.; Sarkar, A.; Jothi Balaji, J. Automated Detection and Diagnosis of Diabetic Retinopathy: A Comprehensive Survey. J. Imag. 2021, 7, 165. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Abirami, S.; Chitra, P. Chapter Fourteen—Energy-efficient edge based real-time healthcare support system. In Advances in Computers; Raj, P., Evangeline, P., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 117, pp. 339–368. [Google Scholar]
- Besenczi, R.; Tóth, J.; Hajdu, A. A review on automatic analysis techniques for color fundus photographs. Comput. Struct. Biotechnol. J. 2016, 14, 371–384. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, T.; Bo, W.; Hu, C.; Kang, H.; Liu, H.; Wang, K.; Fu, H. Applications of deep learning in fundus images: A review. Med. Image Anal. 2021, 69, 101971. [Google Scholar] [CrossRef]
- Patil, S.B.; Patil, B. Retinal fundus image enhancement using adaptive CLAHE methods. J. Seybold Rep. ISSN NO 2020, 1533, 9211. [Google Scholar]
- Hammod, E. Automatic early diagnosis of diabetic retinopathy using retina fundus images enas hamood al-saadi-automatic early diagnosis of diabetic retinopathy using retina fundus images. Eur. Acad. Res. 2014, 2, 11397–11418. Available online: https://www.researchgate.net/publication/269761931_Automatic_Early_Diagnosis_of_Diabetic_Retinopathy_Using_Retina_Fundus_Images_Enas_Hamood_Al-Saadi-Automatic_Early_Diagnosis_of_Diabetic_Retinopathy_Using_Retina_Fundus_Images (accessed on 14 October 2021).
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Phung, V.H.; Rhee, E.J. A deep learning approach for classification of cloud image patches on small datasets. J. Inf. Commun. Converg. Eng. 2018, 16, 173–178. [Google Scholar]
- Yang, B.; Guo, H.; Cao, E.; Aggarwal, S.; Kumar, N.; Chelliah, P.R. Design of cyber-physical-social systems with forensic-awareness based on deep learning. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2020; Volume 120, pp. 39–79. [Google Scholar]
- Mishkin, D.; Sergievskiy, N.; Matas, J. Systematic evaluation of convolution neural network advances on the imagenet. Comput. Vis. Image Underst. 2017, 161, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Bustamam, A.; Sarwinda, D.; Paradisa, R.H.; Victor, A.A.; Yudantha, A.R.; Siswantining, T. Evaluation of convolutional neural network variants for diagnosis of diabetic retinopathy. Commun. Math. Biol. Neurosci. 2021, 2021, 42. [Google Scholar]
- Thomas, A.; Harikrishnan, P.M.; Ponnusamy, P.; Gopi, V.P. Moving Vehicle Candidate Recognition and Classification Using Inception-ResNet-v2. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 467–472. [Google Scholar]
- Zubair, M.; Kim, J.; Yoon, C. An automated ECG beat classification system using convolutional neural networks. In Proceedings of the 2016 6th International Conference on IT Convergence and Security (ICITCS), Prague, Czech Republic, 26 September 2016; pp. 1–5. [Google Scholar]
- Lee, S.J.; Yun, J.P.; Choi, H.; Kwon, W.; Koo, G.; Kim, S.W. Weakly supervised learning with convolutional neural networks for power line localization. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 1–27 December 2017; pp. 1–8. [Google Scholar]
- Layouss, N.G.A. A Critical Examination of Deep Learningapproaches to Automated Speech Recognition. 2014. Available online: https://www.semanticscholar.org/paper/A-critical-examination-of-deep-learningapproaches-Layouss/9dab70e007d7e443b32e4277c60e220e2785c82f (accessed on 14 October 2021).
- Yu, D.; Deng, L. Efficient and effective algorithms for training single-hidden-layer neural networks. Pattern Recognit. Lett. 2012, 33, 554–558. [Google Scholar] [CrossRef]
- Kotu, V.; Deshpande, B. Chapter 8—Model Evaluation. In Data Science, 2nd ed.; Kotu, V., Deshpande, B., Eds.; Morgan Kaufmann: Burlington, MA, USA, 2019; pp. 263–279. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Venkatesan, R.; Chandakkar, P.; Li, B.; Li, H.K. Classification of diabetic retinopathy images using multi-class multiple-instance learning based on color correlogram features. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 1462–1465. [Google Scholar]
- Sayed, S.; Inamdar, V.; Kapre, S. Detection of Diabetic Retinopathy Using Image Processing and Machine Learning. 2017 IJIRSET 2017. Available online: https://www.semanticscholar.org/paper/Detection-of-Diabetic-Retinopathy-using-Image-and-Sayed-Inamdar/910e15c06f270fe65b2e283ef32e5e020f579807 (accessed on 15 October 2021).
- Hortinela, C.C.; Balbin, J.R.; Magwili, G.V.; Lencioco, K.O.; Manalo, J.C.M.; Publico, P.M. Determination of Non-Proliferative and Proliferative Diabetic Retinopathy through Fundoscopy Using Principal Component Analysis. In Proceedings of the 2020 IEEE 12th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 3–7 December 2020; pp. 1–6. [Google Scholar]
- Chaudhary, S.; Ramya, H. Detection of Diabetic Retinopathy using Machine Learning Algorithm. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology (INOCON), Bangluru, India, 6–8 November 2020; pp. 1–5. [Google Scholar]
- Chowdhury, M.M.H.; Meem, N.T.A. A Machine Learning Approach to Detect Diabetic Retinopathy Using Convolutional Neural Network. In International Joint Conference on Computational Intelligence; Springer: Singapore, 2020; pp. 255–264. [Google Scholar] [CrossRef]
- Queentinela, V.A.; Triyani, Y. Klasifikasi penyakit diabetic retinopathy pada citra fundus berbasis deep learning. ABEC Indones. 2021, 9, 1007–1018. [Google Scholar]
- Anki, P.; Bustamam, A. Measuring the accuracy of LSTM and BiLSTM models in the application of artificial intelligence by applying chatbot programme. Indones. J. Electr. Eng. Comput. Sci. 2021, 23, 197–205. [Google Scholar] [CrossRef]
- Xia, S.; Chen, B.; Wang, G.; Zheng, Y.; Gao, X.; Giem, E.; Chen, Z. mCRF and mRD: Two classification methods based on a novel multiclass label noise filtering learning framework. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Xia, S.; Zheng, S.; Wang, G.; Gao, X.; Wang, B. Granular ball sampling for noisy label classification or imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst 2021, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Liu, T.; Gong, M.; Zhang, K.; Batmanghelich, K.; Tao, D. Transfer learning with label noise. arXiv 2017, arXiv:1707.09724. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).