
Classification of Left and Right Coronary Arteries in Coronary Angiographies Using Deep Learning

 , , , , , , , and
, , , , , , , and
Abstract
:1. Introduction
2. Materials and Methods
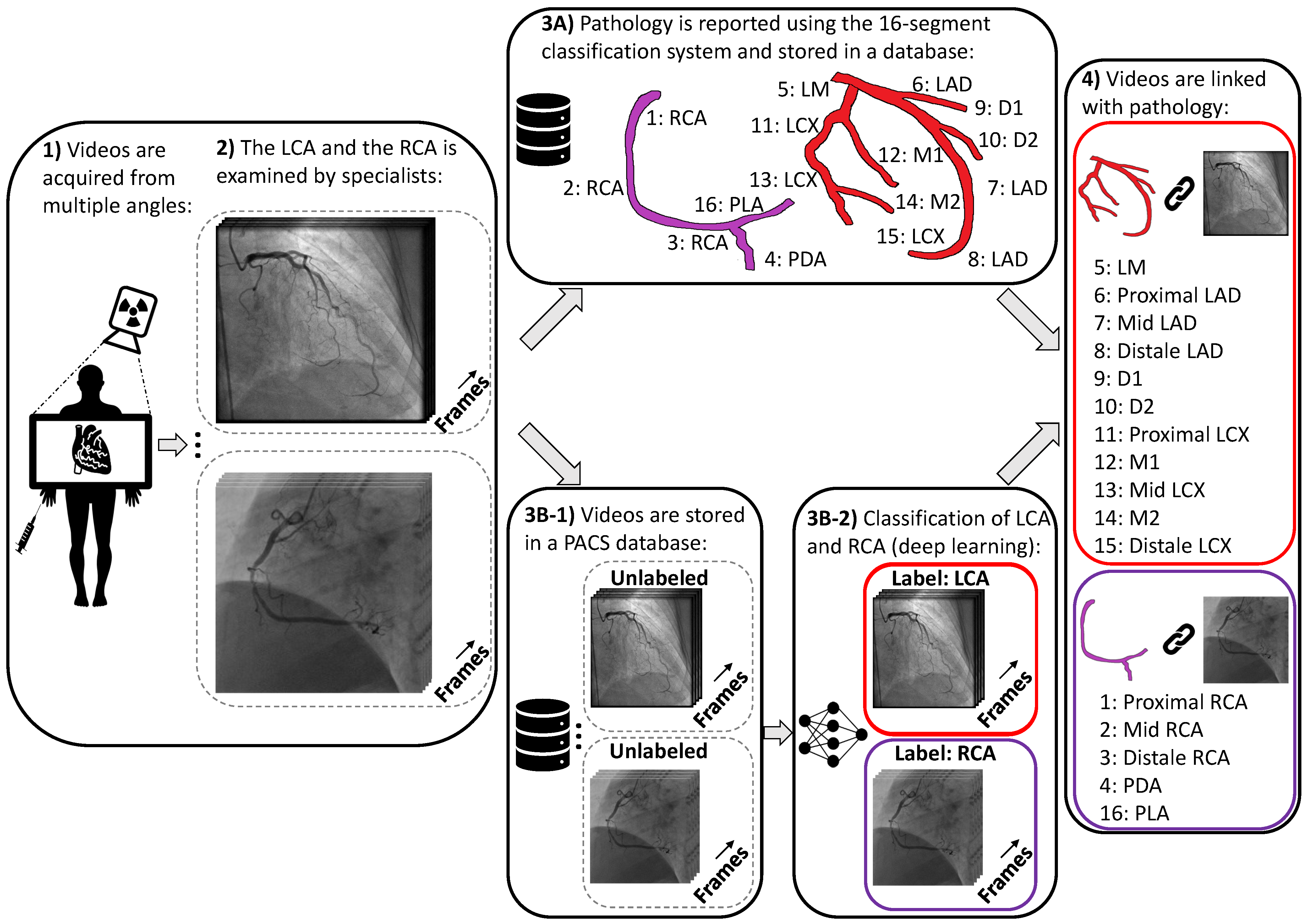
2.1. Data Collection and Data Curation
2.2. Methods
2.2.1. Baseline
2.2.2. R(2+1)D
2.2.3. X3D
2.2.4. MVIT
2.2.5. Preprocessing and Data Augmentations
2.2.6. Implementation Details
3. Results
3.1. Performance Using Meta Data
3.2. Model and Input Size Comparison
3.3. Effect of Data Size
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shah, N.S.; Molsberry, R.; Rana, J.S.; Sidney, S.; Capewell, S.; O’Flaherty, M.; Carnethon, M.; Lloyd-Jones, D.M.; Khan, S.S. Heterogeneous trends in burden of heart disease mortality by subtypes in the United States, 1999–2018: Observational analysis of vital statistics. BMJ 2020, 370, m2688. [Google Scholar] [CrossRef] [PubMed]
- Mozaffarian, D.; Benjamin, E.J.; Go, A.S.; Arnett, D.K.; Blaha, M.J.; Cushman, M.; De Ferranti, S.; Després, J.P.; Fullerton, H.J.; Howard, V.J.; et al. Heart disease and stroke statistics—2015 update: A report from the American Heart Association. Circulation 2015, 131, e29–e322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McDonagh, T.A.; Metra, M.; Adamo, M.; Gardner, R.S.; Baumbach, A.; Böhm, M.; Burri, H.; Butler, J.; Čelutkienė, J.; Chioncel, O.; et al. 2021 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure: Developed by the Task Force for the diagnosis and treatment of acute and chronic heart failure of the European Society of Cardiology (ESC) With the special contribution of the Heart Failure Association (HFA) of the ESC. Eur. Heart J. 2021, 42, 3599–3726. [Google Scholar] [PubMed]
- Leape, L.L.; Park, R.E.; Bashore, T.M.; Harrison, J.K.; Davidson, C.J.; Brook, R.H. Effect of variability in the interpretation of coronary angiograms on the appropriateness of use of coronary revascularization procedures. Am. Heart J. 2000, 139, 106–113. [Google Scholar] [CrossRef]
- Zir, L.M.; Miller, S.W.; Dinsmore, R.E.; Gilbert, J.; Harthorne, J. Interobserver variability in coronary angiography. Circulation 1976, 53, 627–632. [Google Scholar] [CrossRef] [PubMed]
- Marcus, M.L.; Skorton, D.J.; Johnson, M.R.; Collins, S.M.; Harrison, D.G.; Kerber, R.E. Visual estimates of percent diameter coronary stenosis: “A battered gold standard”. J. Am. Coll. Cardiol. 1988, 11, 882–885. [Google Scholar] [CrossRef] [Green Version]
- Raphael, M.; Donaldson, R. A “significant” stenosis: Thirty years on. Lancet 1989, 333, 207–209. [Google Scholar] [CrossRef]
- Grundeken, M.J.; Ishibashi, Y.; Genereux, P.; LaSalle, L.; Iqbal, J.; Wykrzykowska, J.J.; Morel, M.A.; Tijssen, J.G.; De Winter, R.J.; Girasis, C.; et al. Inter–Core Lab Variability in Analyzing Quantitative Coronary Angiography for Bifurcation Lesions: A Post-Hoc Analysis of a Randomized Trial. JACC Cardiovasc. Interv. 2015, 8, 305–314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neumann, F.J.; Sousa-Uva, M.; Ahlsson, A.; Alfonso, F.; Banning, A.P.; Benedetto, U.; Byrne, R.A.; Collet, J.P.; Falk, V.; Head, S.J.; et al. 2018 ESC/EACTS Guidelines on myocardial revascularization. Eur. Heart J. 2019, 40, 87–165. [Google Scholar] [CrossRef] [PubMed]
- Austen, W.G.; Edwards, J.E.; Frye, R.L.; Gensini, G.; Gott, V.L.; Griffith, L.S.; McGoon, D.C.; Murphy, M.; Roe, B.B. A reporting system on patients evaluated for coronary artery disease. Report of the Ad Hoc Committee for Grading of Coronary Artery Disease, Council on Cardiovascular Surgery, American Heart Association. Circulation 1975, 51, 5–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sianos, G.; Morel, M.A.; Kappetein, A.P.; Morice, M.C.; Colombo, A.; Dawkins, K.; van den Brand, M.; Van Dyck, N.; Russell, M.E.; Mohr, F.W.; et al. The SYNTAX Score: An angiographic tool grading the complexity of coronary artery disease. EuroIntervention 2005, 1, 219–227. [Google Scholar] [PubMed]
- Parikh, N.I.; Honeycutt, E.F.; Roe, M.T.; Neely, M.; Rosenthal, E.J.; Mittleman, M.A.; Carrozza, J.P., Jr.; Ho, K.K. Left and codominant coronary artery circulations are associated with higher in-hospital mortality among patients undergoing percutaneous coronary intervention for acute coronary syndromes: Report From the National Cardiovascular Database Cath Percutaneous Coronary Intervention (CathPCI) Registry. Circ. Cardiovasc. Qual. Outcomes 2012, 5, 775–782. [Google Scholar] [PubMed] [Green Version]
- Yang, S.; Kweon, J.; Roh, J.H.; Lee, J.H.; Kang, H.; Park, L.J.; Kim, D.J.; Yang, H.; Hur, J.; Kang, D.Y.; et al. Deep learning segmentation of major vessels in X-ray coronary angiography. Sci. Rep. 2019, 9, 16897. [Google Scholar] [CrossRef] [PubMed]
- Iyer, K.; Najarian, C.P.; Fattah, A.A.; Arthurs, C.J.; Soroushmehr, S.; Subban, V.; Sankardas, M.A.; Nadakuditi, R.R.; Nallamothu, B.K.; Figueroa, C.A. Angionet: A convolutional neural network for vessel segmentation in X-ray angiography. Sci. Rep. 2021, 11, 18066. [Google Scholar] [CrossRef] [PubMed]
- Nasr-Esfahani, E.; Karimi, N.; Jafari, M.H.; Soroushmehr, S.M.R.; Samavi, S.; Nallamothu, B.; Najarian, K. Segmentation of vessels in angiograms using convolutional neural networks. Biomed. Signal Process. Control 2018, 40, 240–251. [Google Scholar] [CrossRef]
- Zai, S.; Abbas, A. An Effective Enhancement and Segmentation of Coronary Arteries in 2D Angiograms. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), Kuala Lumpur, Malaysia, 11–12 July 2018; pp. 1–4. [Google Scholar]
- Avram, R.; Olgin, J.; Wan, A.; Ahmed, Z.; Verreault-Julien, L.; Abreau, S.; Wan, D.; Gonzalez, J.E.; So, D.; Soni, K.; et al. CATHAI: Fully automated coronary angiography interpretation and stenosis detection using a deep learning-based algorithmic pipeline. J. Am. Coll. Cardiol. 2021, 77, 3244. [Google Scholar] [CrossRef]
- Moon, J.H.; Cha, W.C.; Chung, M.J.; Lee, K.S.; Cho, B.H.; Choi, J.H. Automatic stenosis recognition from coronary angiography using convolutional neural networks. Comput. Methods Programs Biomed. 2021, 198, 105819. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Feichtenhofer, C. X3D: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6824–6835. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6047–6056. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]


{kind=link}
{kind=link}
| Model Type | CNN | Transformer | Parameters | Inference Throughput (Videos/Second) |
|---|---|---|---|---|
| R(2+1)D-18 | ✓ | 33.3 million | 31.79 | |
| X3D-S | ✓ | 3.76 million | 19.78 | |
| MVIT32-3 | ✓ | 36.6 million | 21.06 |
| Model Type | Data Type | Parameters | F1 Score |
|---|---|---|---|
| Logistic regression | Meta data | 5 | 0.75 |
| Support Vector Machine | Meta data | 2543 | 0.84 |
| MLP (50 hidden units) | Meta data | 352 | 0.88 |
| MLP (500 hidden units) | Meta data | 3502 | 0.89 |
| X3D-S (CNN) | Videos | 3.76 millions | 0.99 |
| Spatial Size: 130 × 130 | Spatial Size: 224 × 224 | |||||
|---|---|---|---|---|---|---|
| Models | Augmentation Types | Temporal Size: 16 | Temporal Size: 32 | Temporal Size: 64 | Temporal Size: 16 | Temporal Size: 32 |
| R(2+1)D-18 | w/o augs | 0.993 | 0.982 | 0.994 | 0.988 | 0.982 |
| w/translation | 0.988 | 0.98 | 0.988 | 0.996 | 0.994 | |
| w/rotation | 0.988 | 0.994 | 0.997 | 0.997 | 0.987 | |
| w/scaling temporal | 0.99 | 0.997 | 0.996 | 0.994 | 0.993 | |
| w/scaling spatial | 0.994 | 0.988 | 0.988 | 0.987 | 0.988 | |
| w/all augs | 0.99 | 0.993 | 0.988 | 0.99 | 0.99 | |
| X3D-s | w/o augs | 0.994 | 0.994 | 0.994 | 0.996 | 0.994 |
| w/translation | 0.986 | 0.994 | 0.988 | 0.988 | 0.994 | |
| w/rotation | 0.99 | 0.99 | 0.99 | 0.991 | 0.988 | |
| w/scaling temporal | 0.988 | 0.988 | 0.988 | 0.996 | 0.994 | |
| w/scaling spatial | 0.985 | 0.996 | 0.988 | 0.986 | 0.984 | |
| w/all augs | 0.99 | 0.99 | 0.996 | 0.994 | 0.993 | |
| MVIT-B (16 × 4, 32 × 3) | w/o augs | N/A | N/A | N/A | 0.996 | 0.993 |
| w/translation | N/A | N/A | N/A | 0.988 | 0.993 | |
| w/rotation | N/A | N/A | N/A | 0.993 | 0.993 | |
| w/scaling temporal | N/A | N/A | N/A | 0.988 | 0.996 | |
| w/scaling spatial | N/A | N/A | N/A | 0.994 | 0.996 | |
| w/all augs | N/A | N/A | N/A | 0.985 | 0.993 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eschen, C.K.; Banasik, K.; Christensen, A.H.; Chmura, P.J.; Pedersen, F.; Køber, L.; Engstrøm, T.; Dahl, A.B.; Brunak, S.; Bundgaard, H. Classification of Left and Right Coronary Arteries in Coronary Angiographies Using Deep Learning. Electronics 2022, 11, 2087. https://doi.org/10.3390/electronics11132087
Eschen CK, Banasik K, Christensen AH, Chmura PJ, Pedersen F, Køber L, Engstrøm T, Dahl AB, Brunak S, Bundgaard H. Classification of Left and Right Coronary Arteries in Coronary Angiographies Using Deep Learning. Electronics. 2022; 11(13):2087. https://doi.org/10.3390/electronics11132087
Chicago/Turabian StyleEschen, Christian Kim, Karina Banasik, Alex Hørby Christensen, Piotr Jaroslaw Chmura, Frants Pedersen, Lars Køber, Thomas Engstrøm, Anders Bjorholm Dahl, Søren Brunak, and Henning Bundgaard. 2022. "Classification of Left and Right Coronary Arteries in Coronary Angiographies Using Deep Learning" Electronics 11, no. 13: 2087. https://doi.org/10.3390/electronics11132087
APA StyleEschen, C. K., Banasik, K., Christensen, A. H., Chmura, P. J., Pedersen, F., Køber, L., Engstrøm, T., Dahl, A. B., Brunak, S., & Bundgaard, H. (2022). Classification of Left and Right Coronary Arteries in Coronary Angiographies Using Deep Learning. Electronics, 11(13), 2087. https://doi.org/10.3390/electronics11132087