
A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields


Abstract

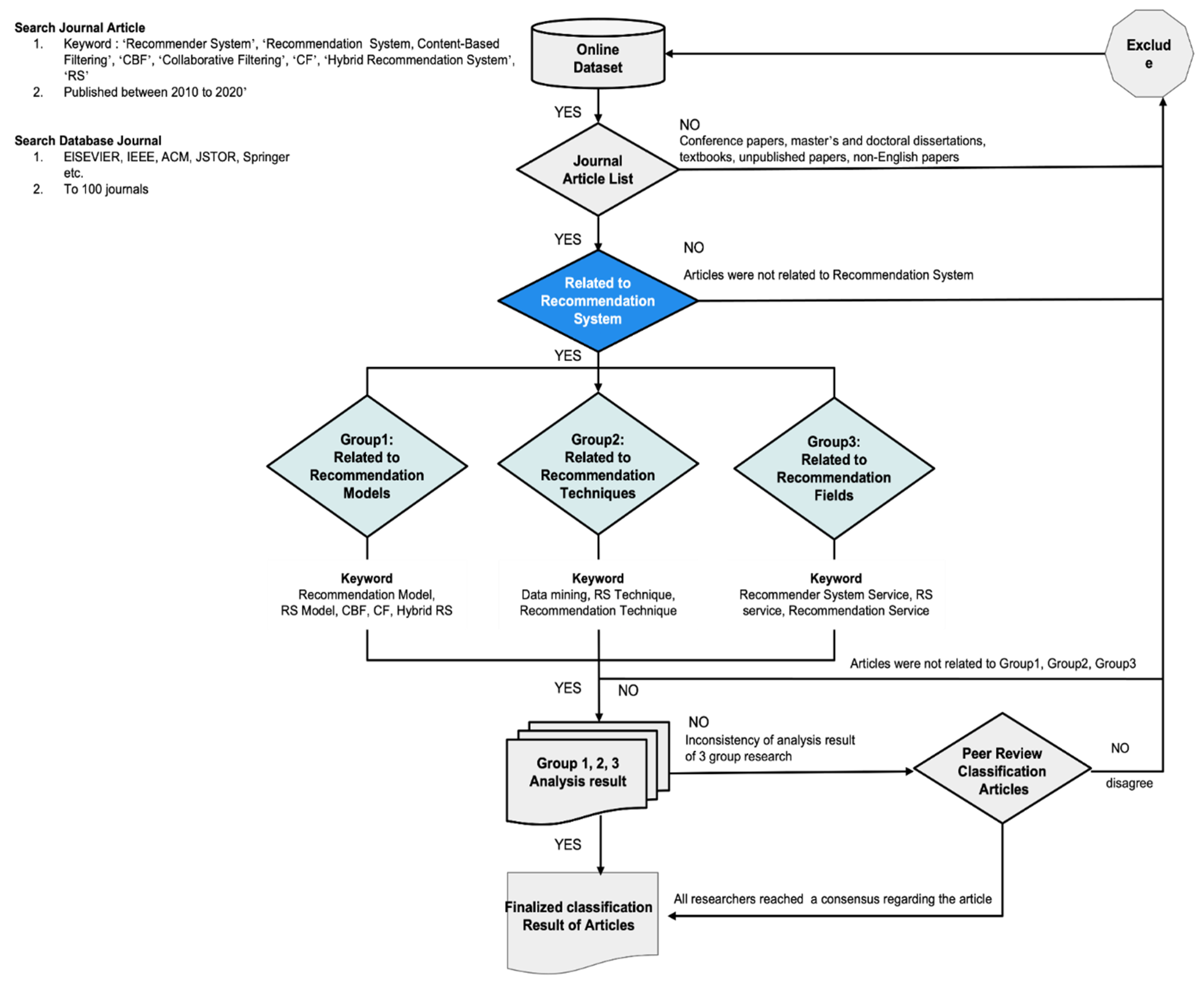
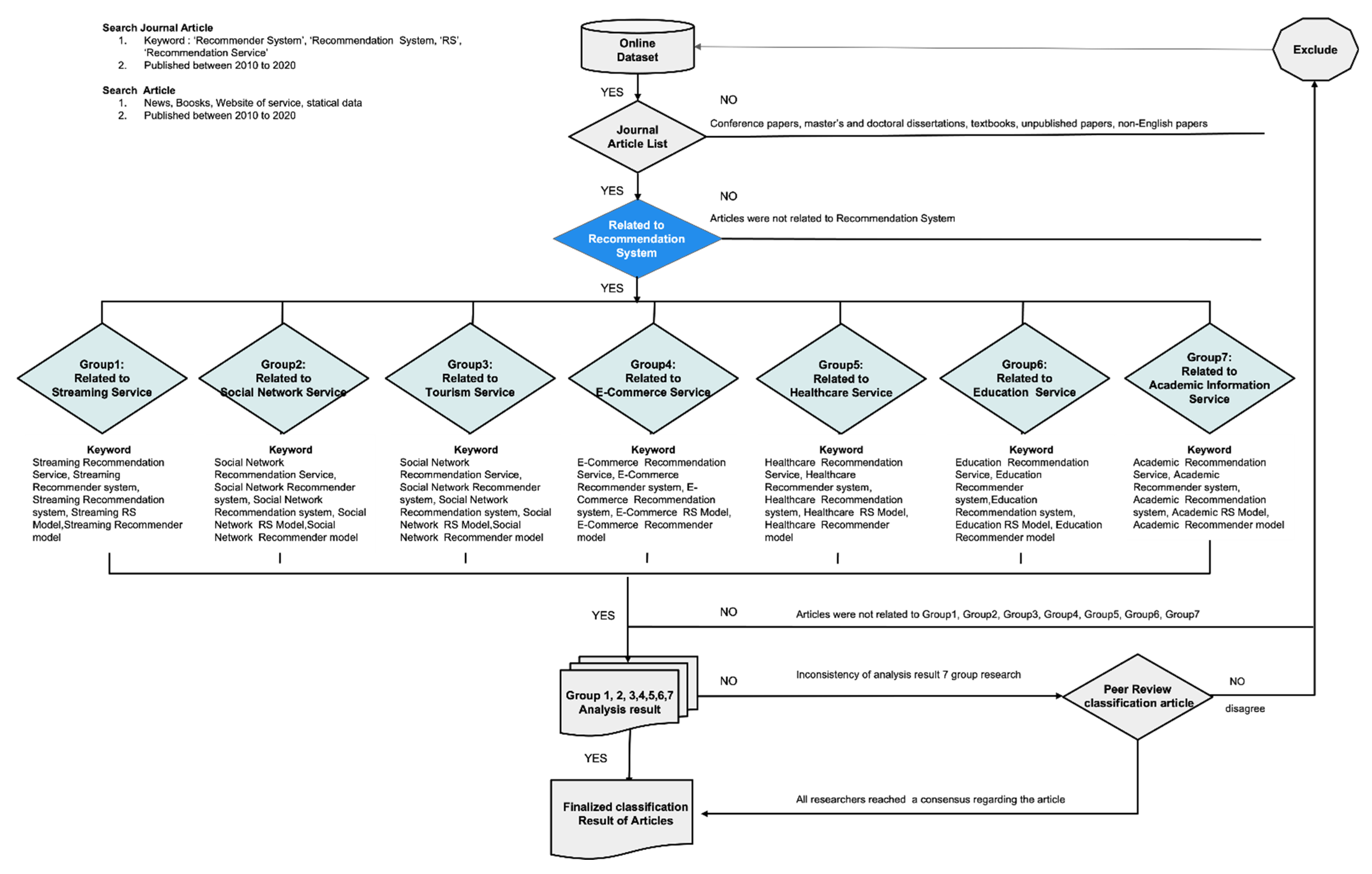
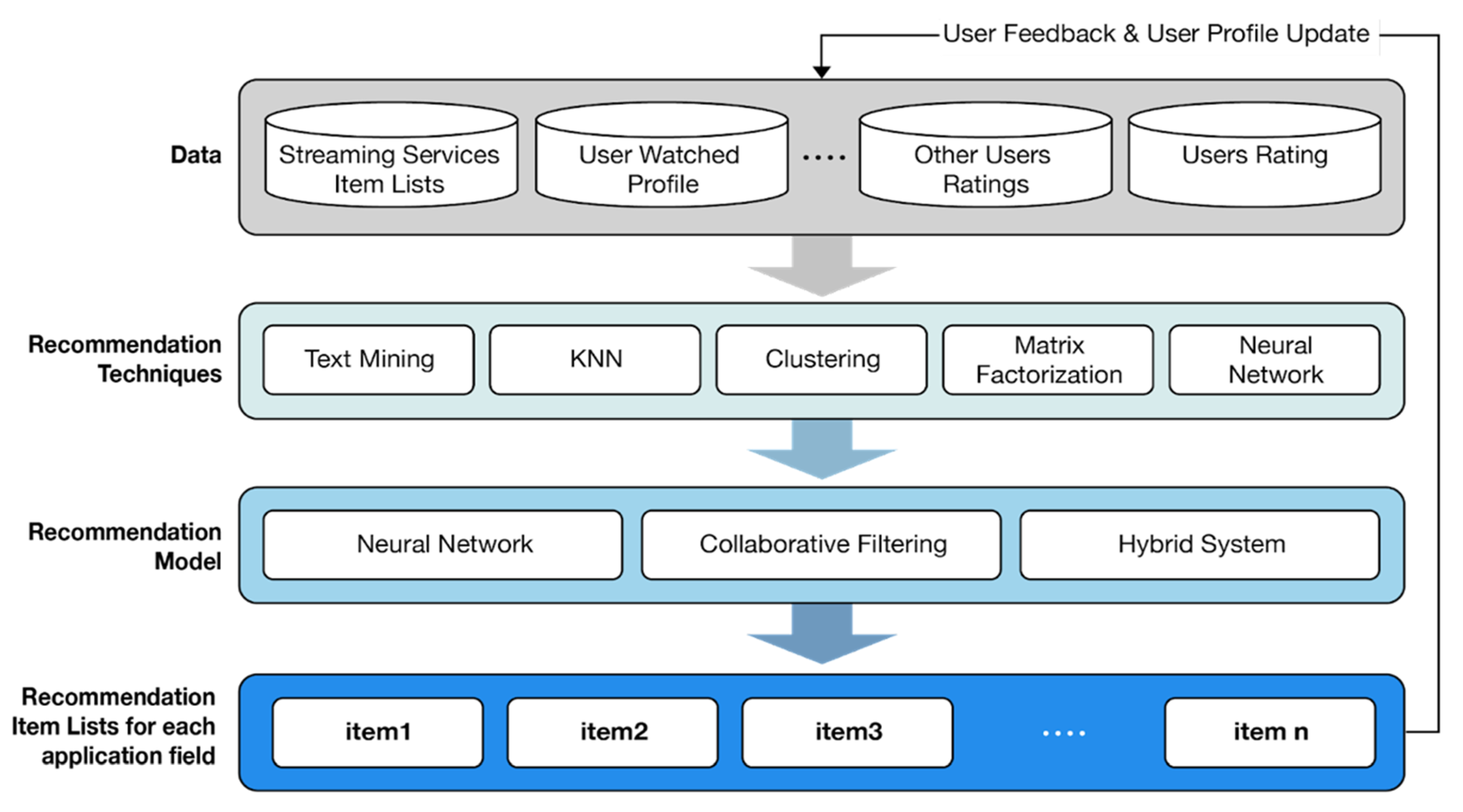
1. Introduction
2. Literature Surveys
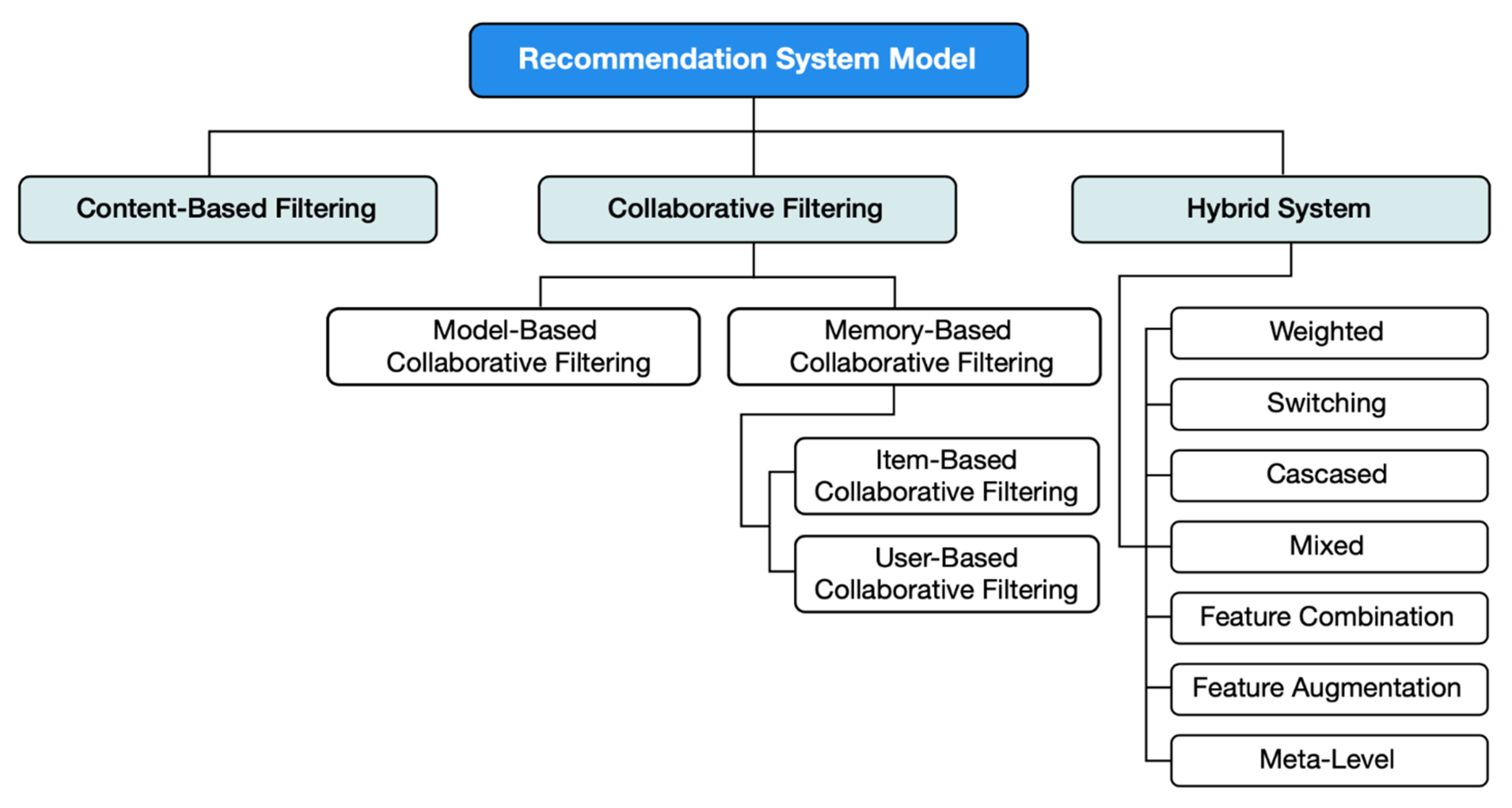
2.1. Recommendation Models
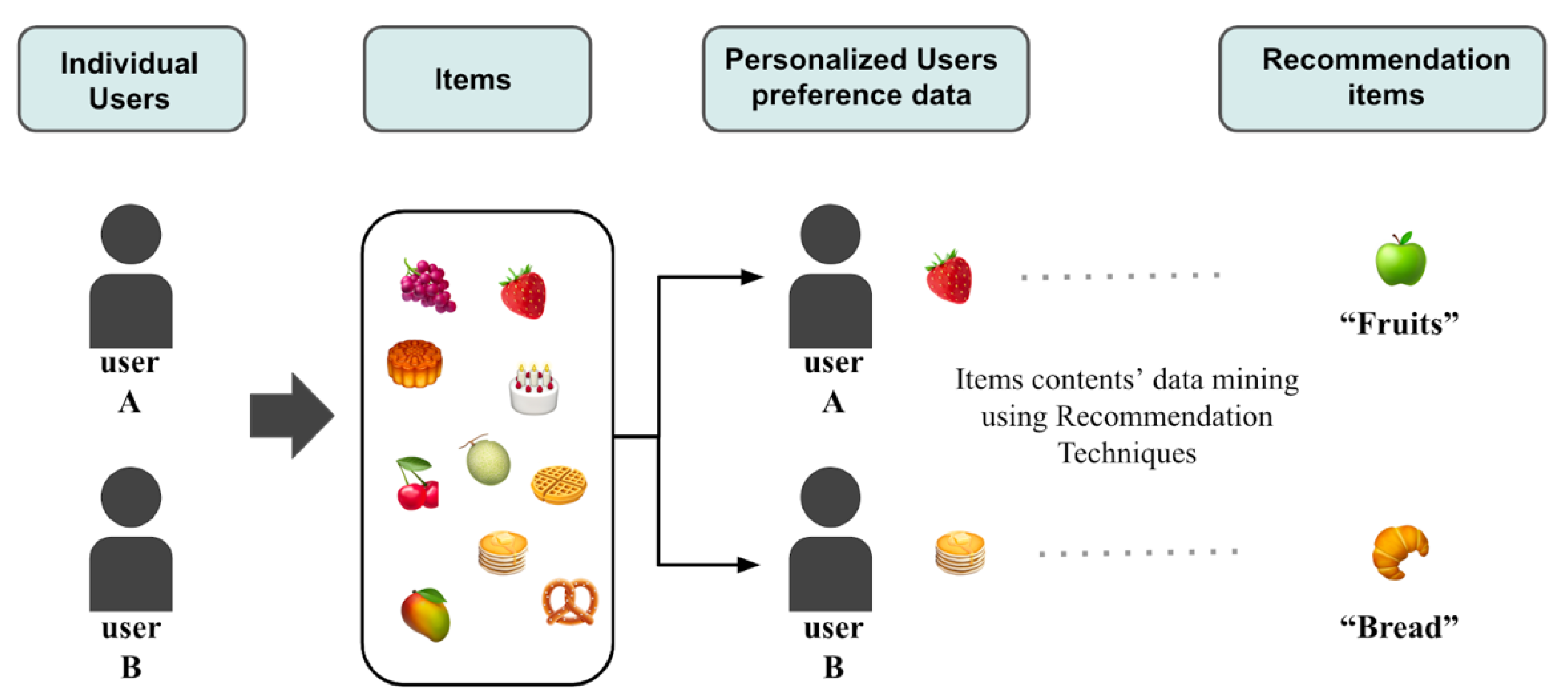
2.1.1. Content-Based Filtering
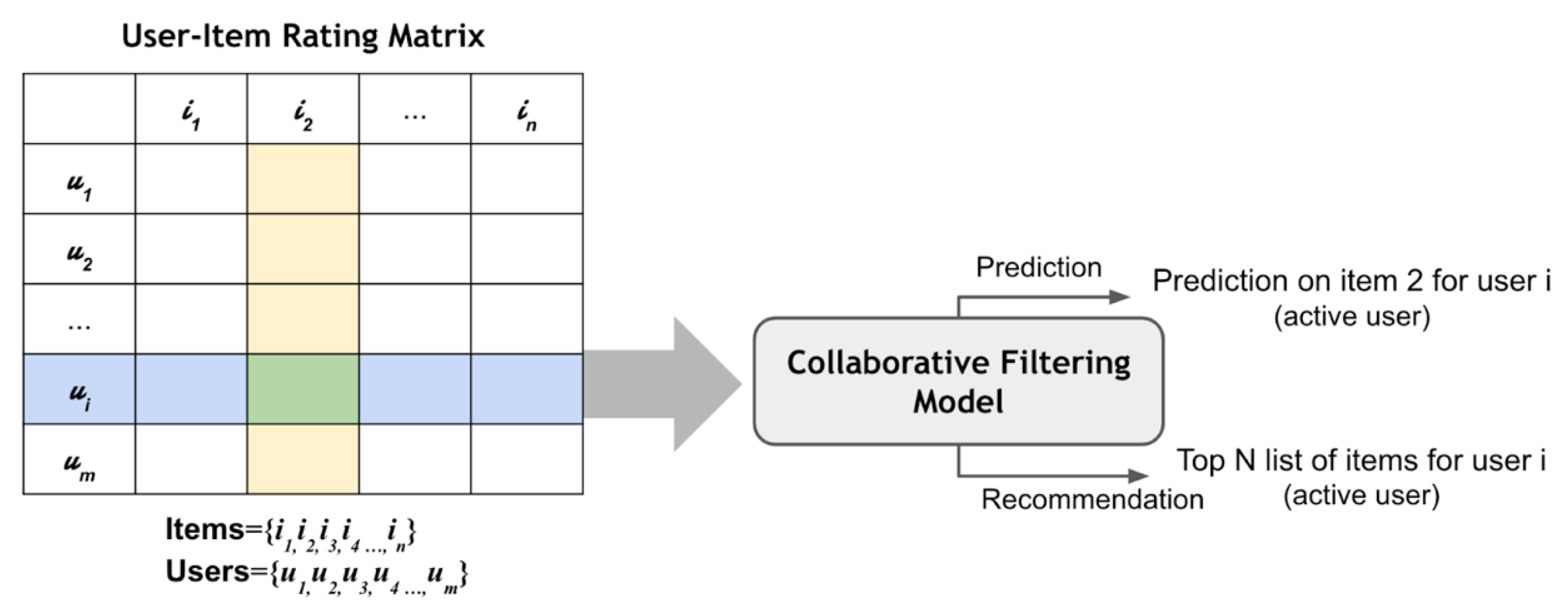
2.1.2. Collaborative Filtering
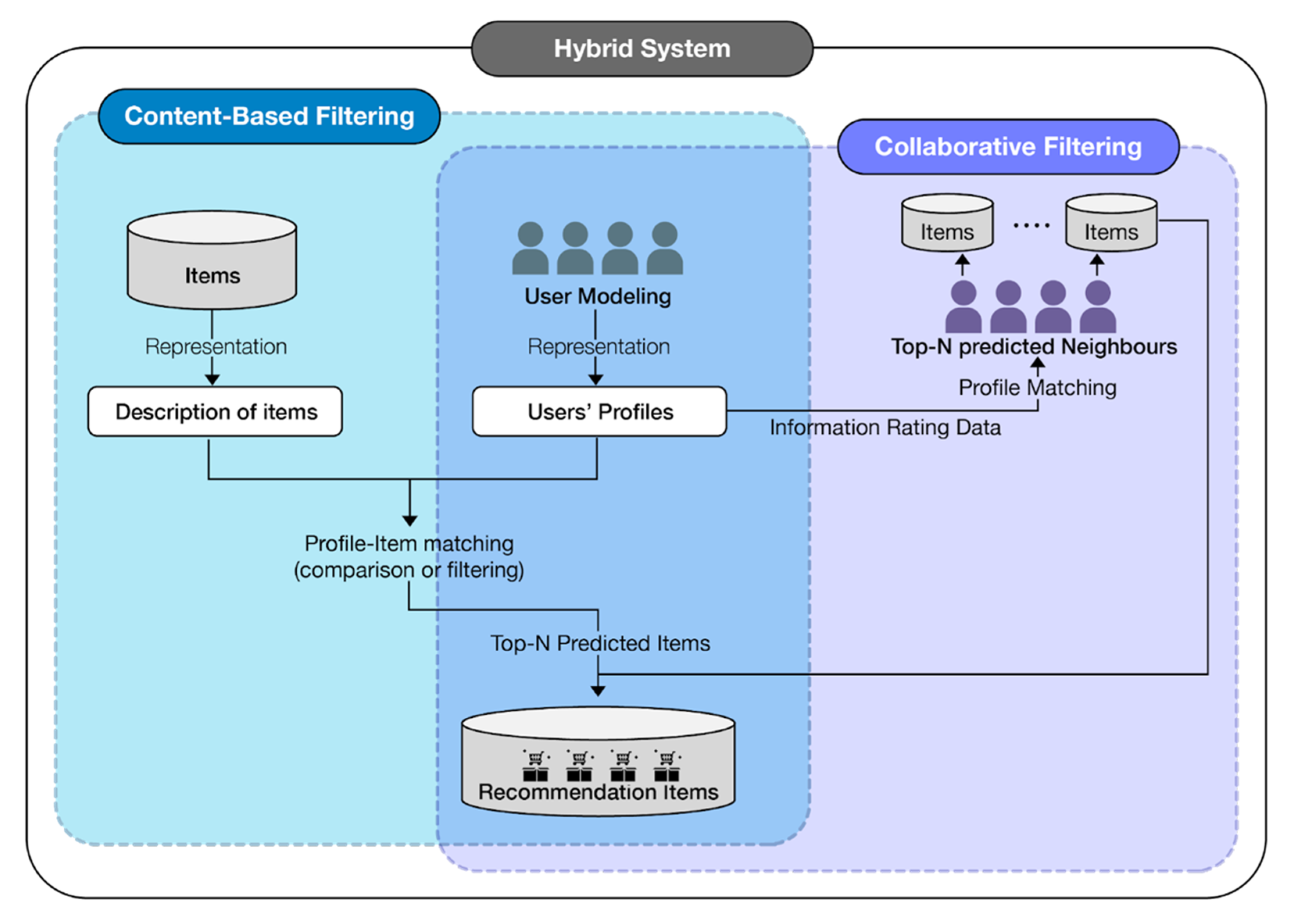
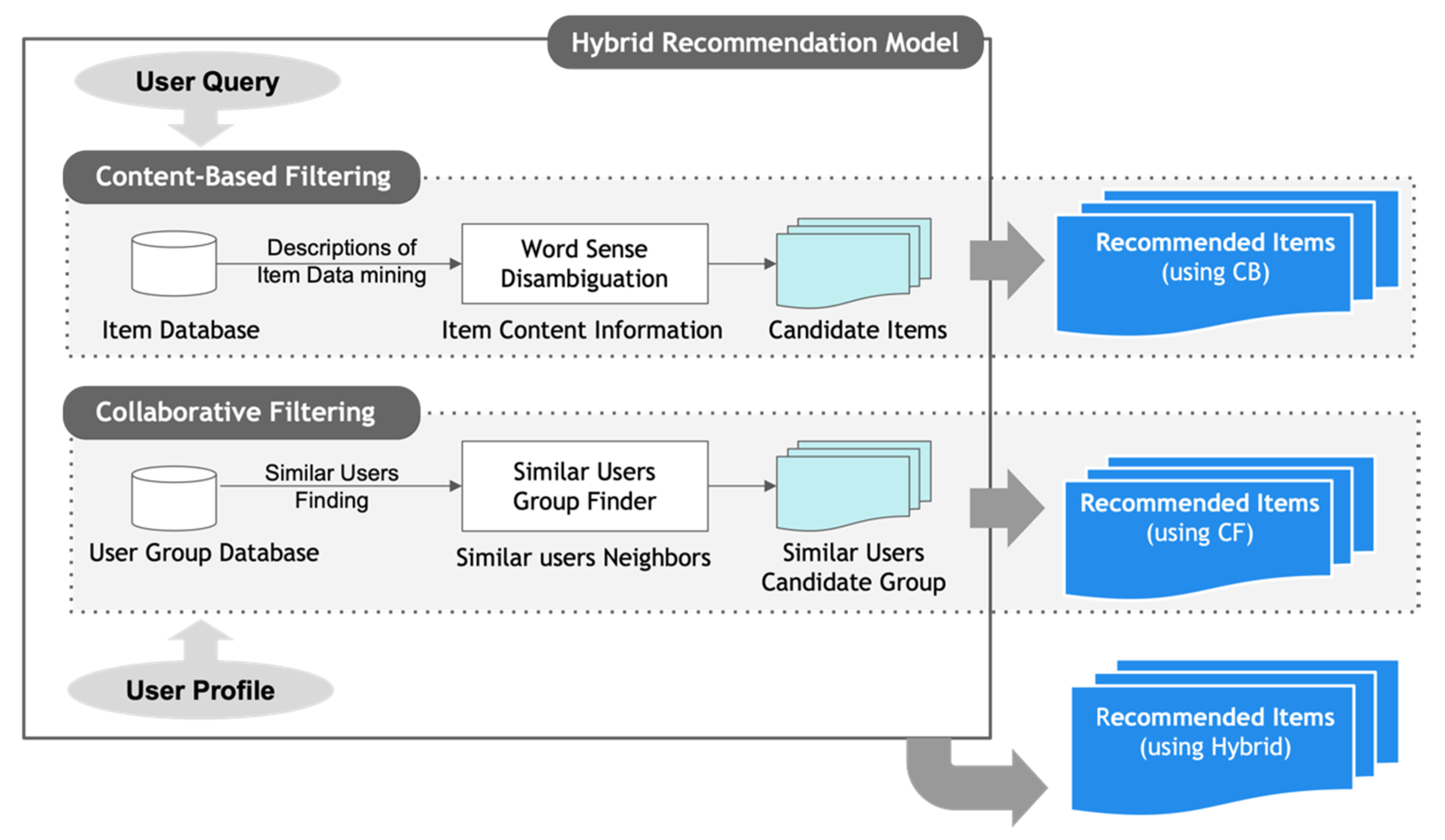
2.1.3. Hybrid System
2.1.4. Qualitative Evaluation Metrics of Recommendation Systems
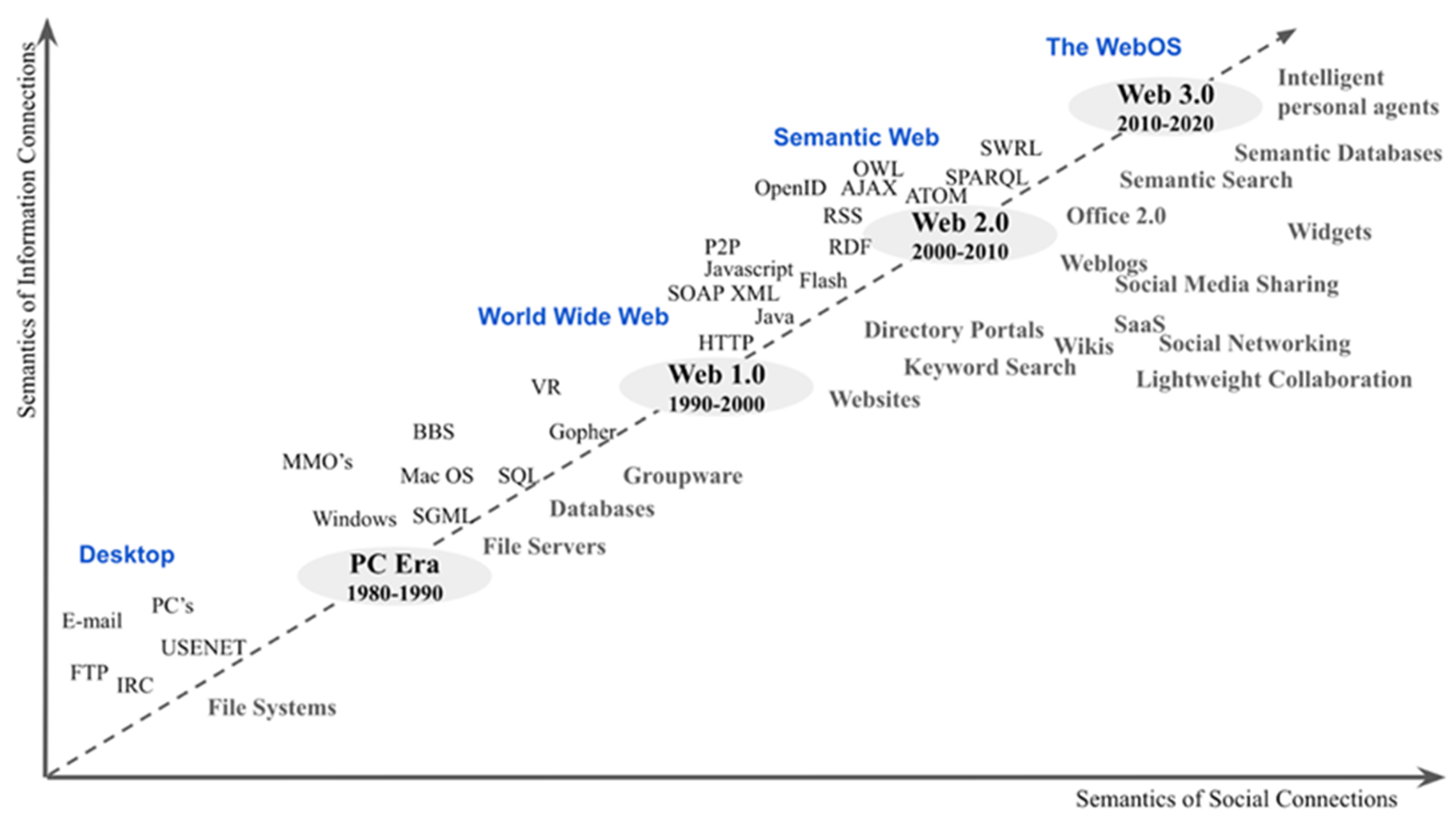
2.1.5. Research Trend of Recommendation Models
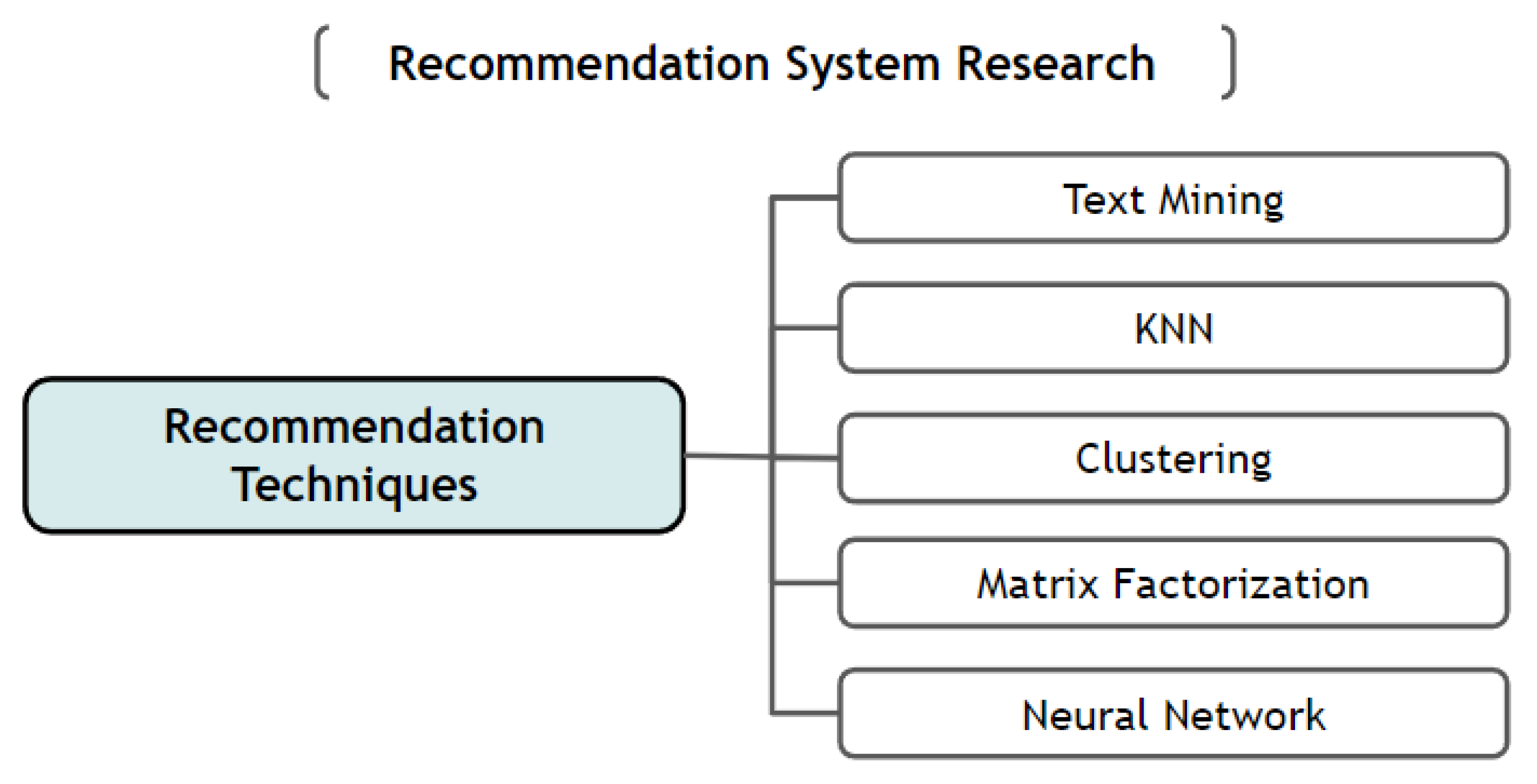
2.2. Recommendation Techniques
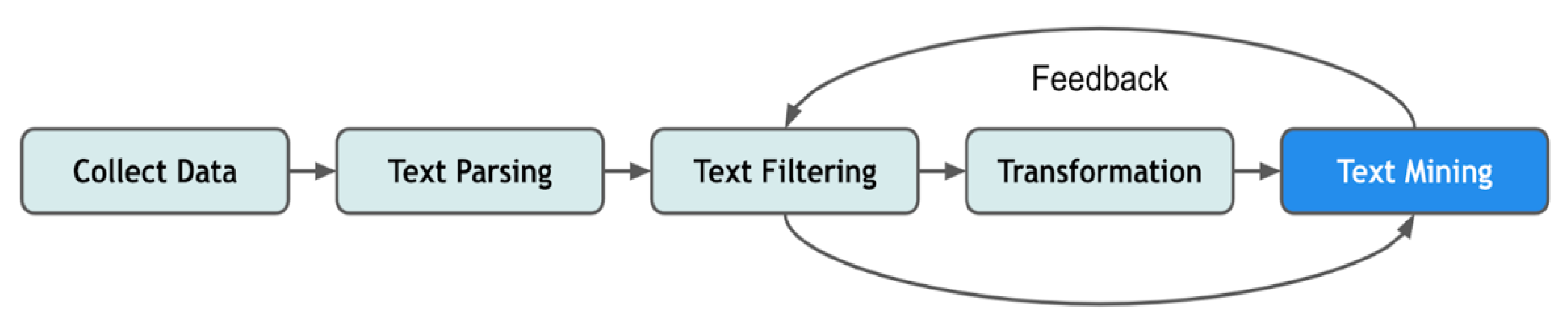
2.2.1. Text Mining
2.2.2. KNN (K-Nearest Neighbor)
2.2.3. Clustering
2.2.4. Matrix Factorization
2.2.5. Neural Network
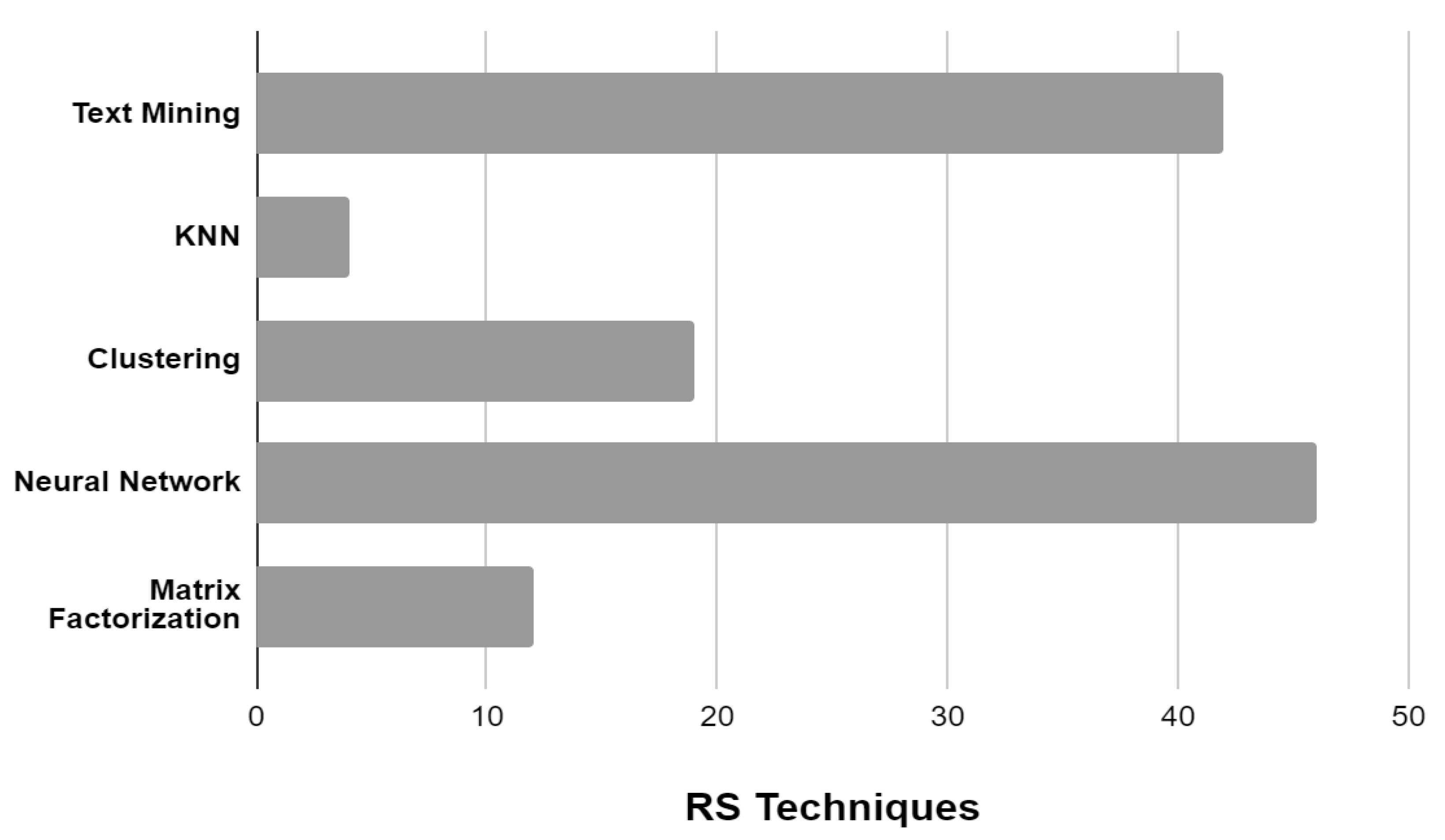
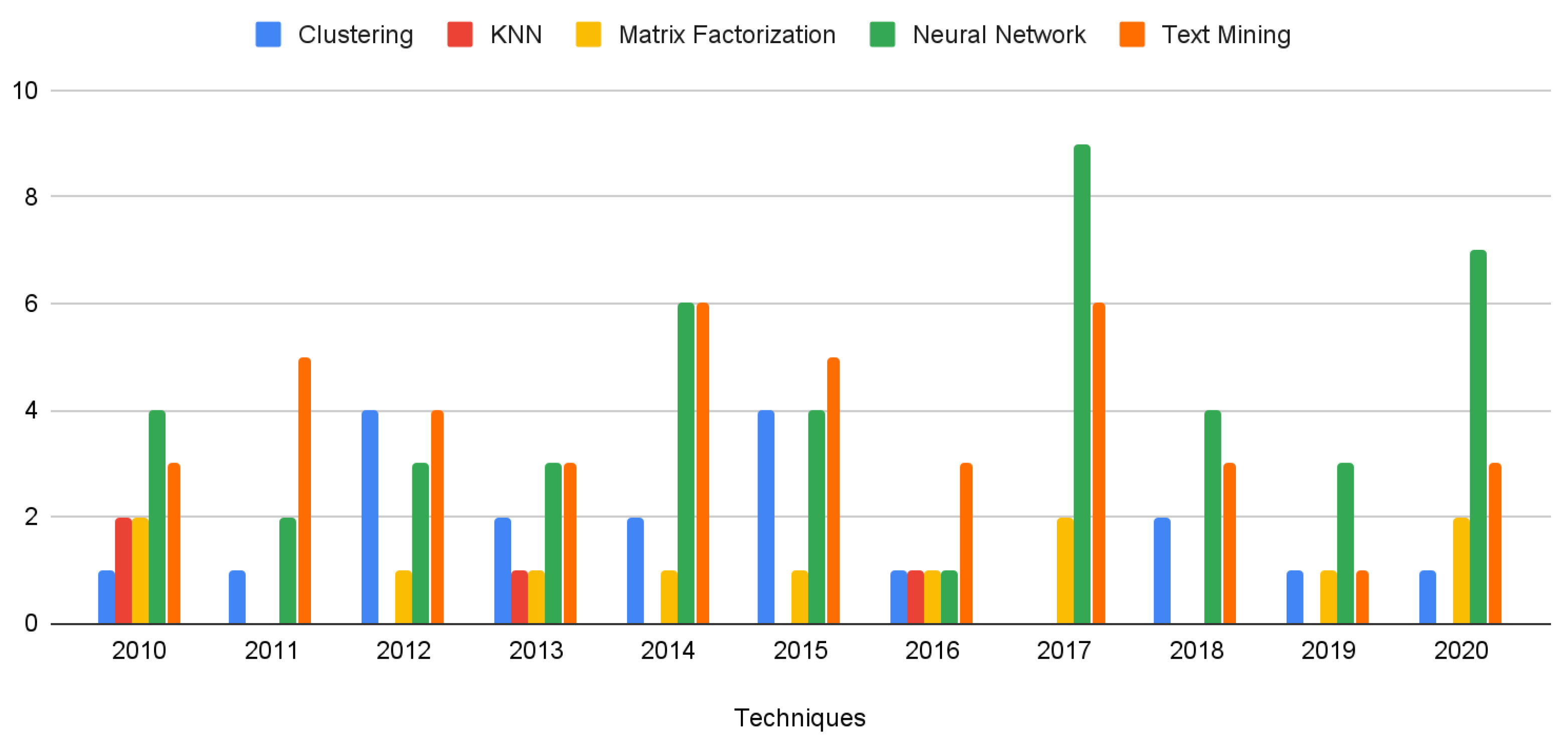
2.2.6. Research Trends of Recommendation System Techniques
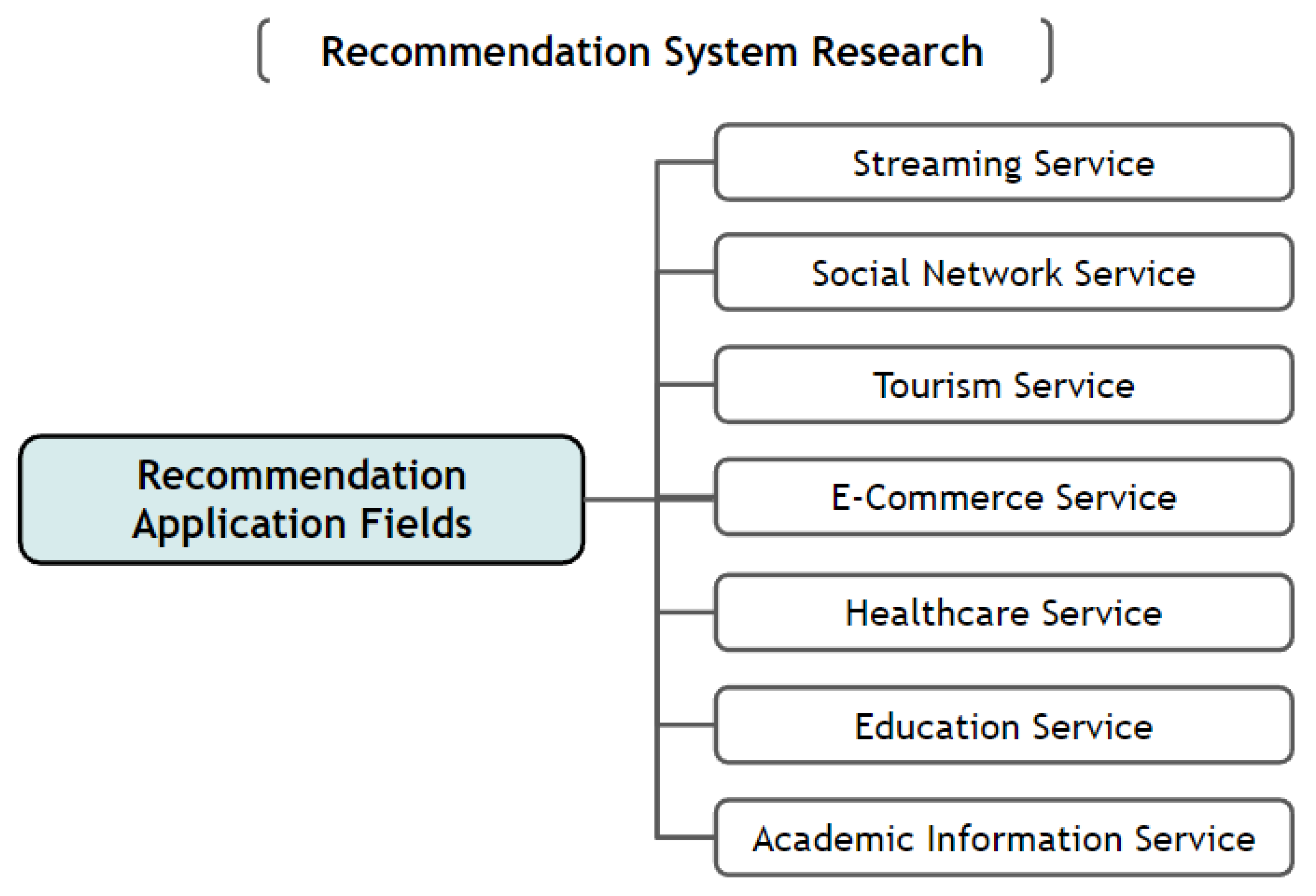
2.3. Application Fields
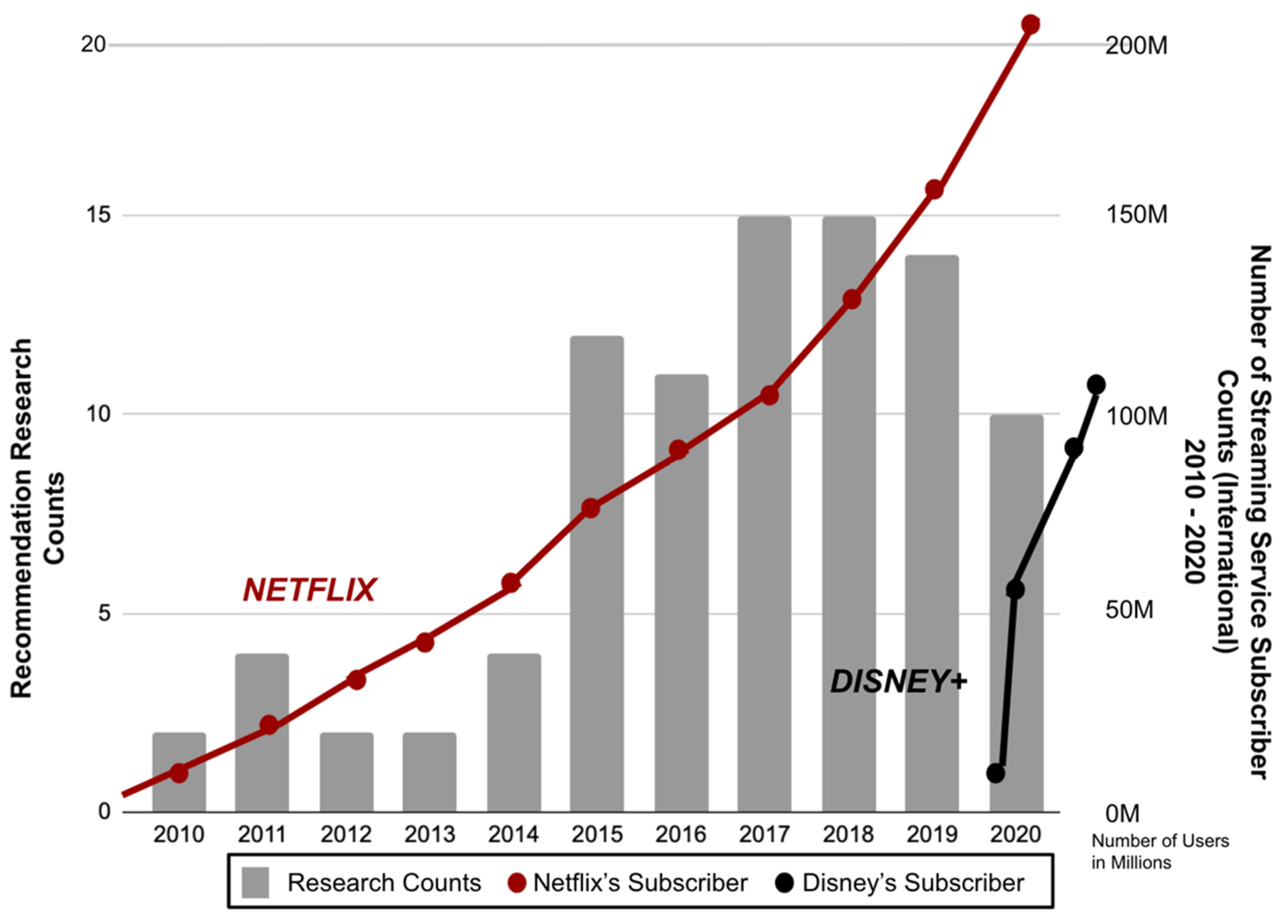
2.3.1. Streaming Service
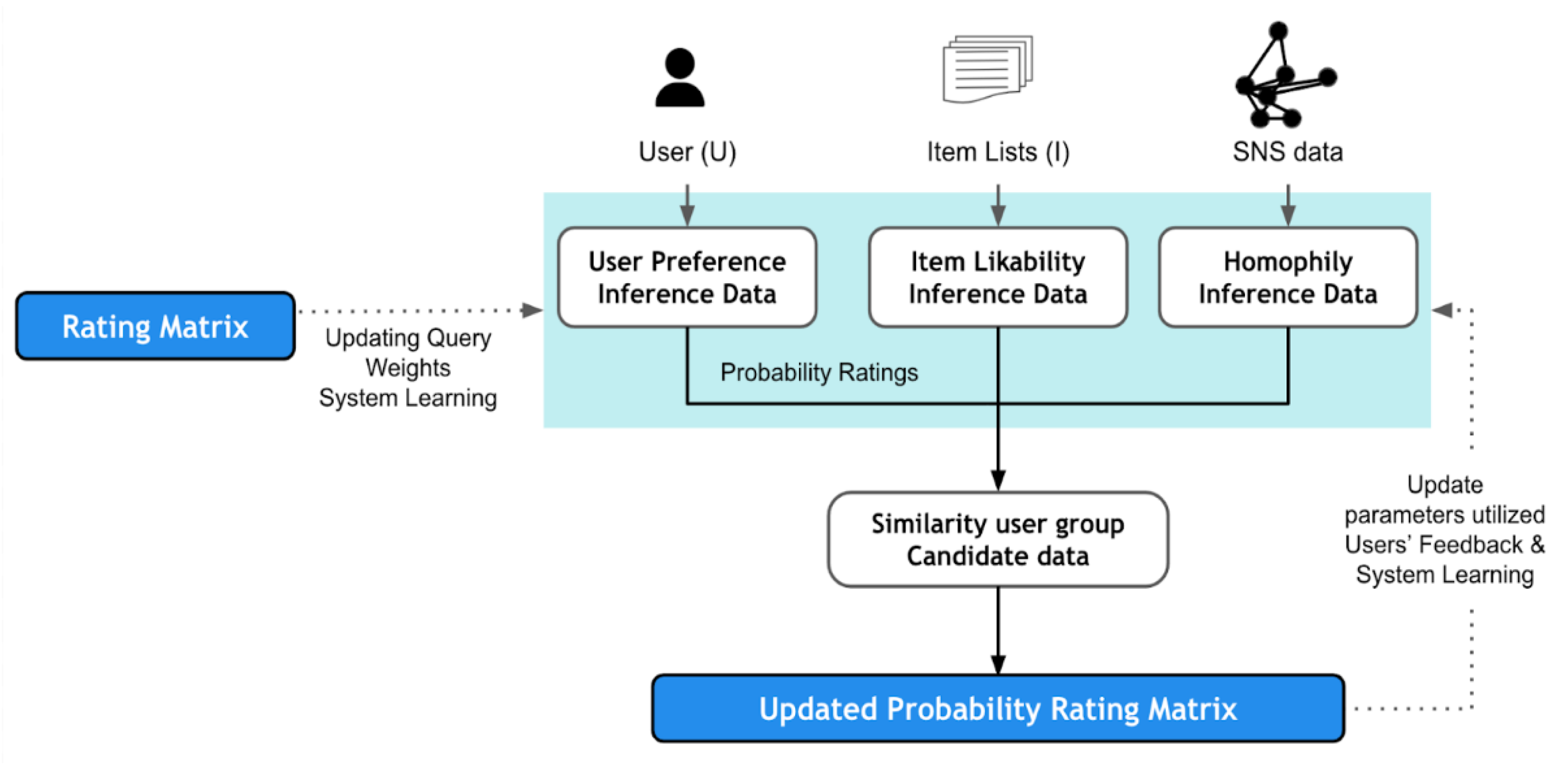
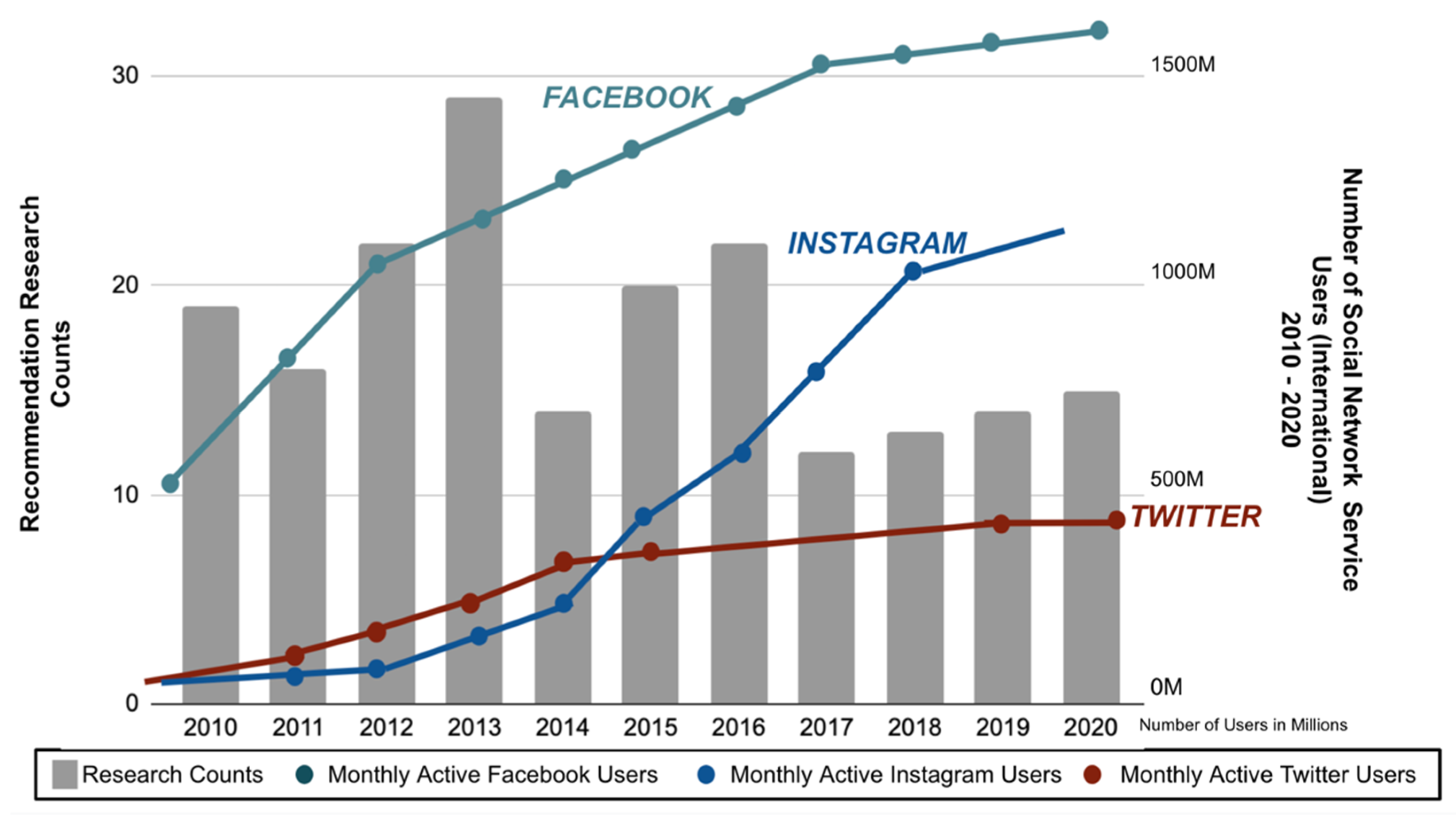
2.3.2. Social Network Service
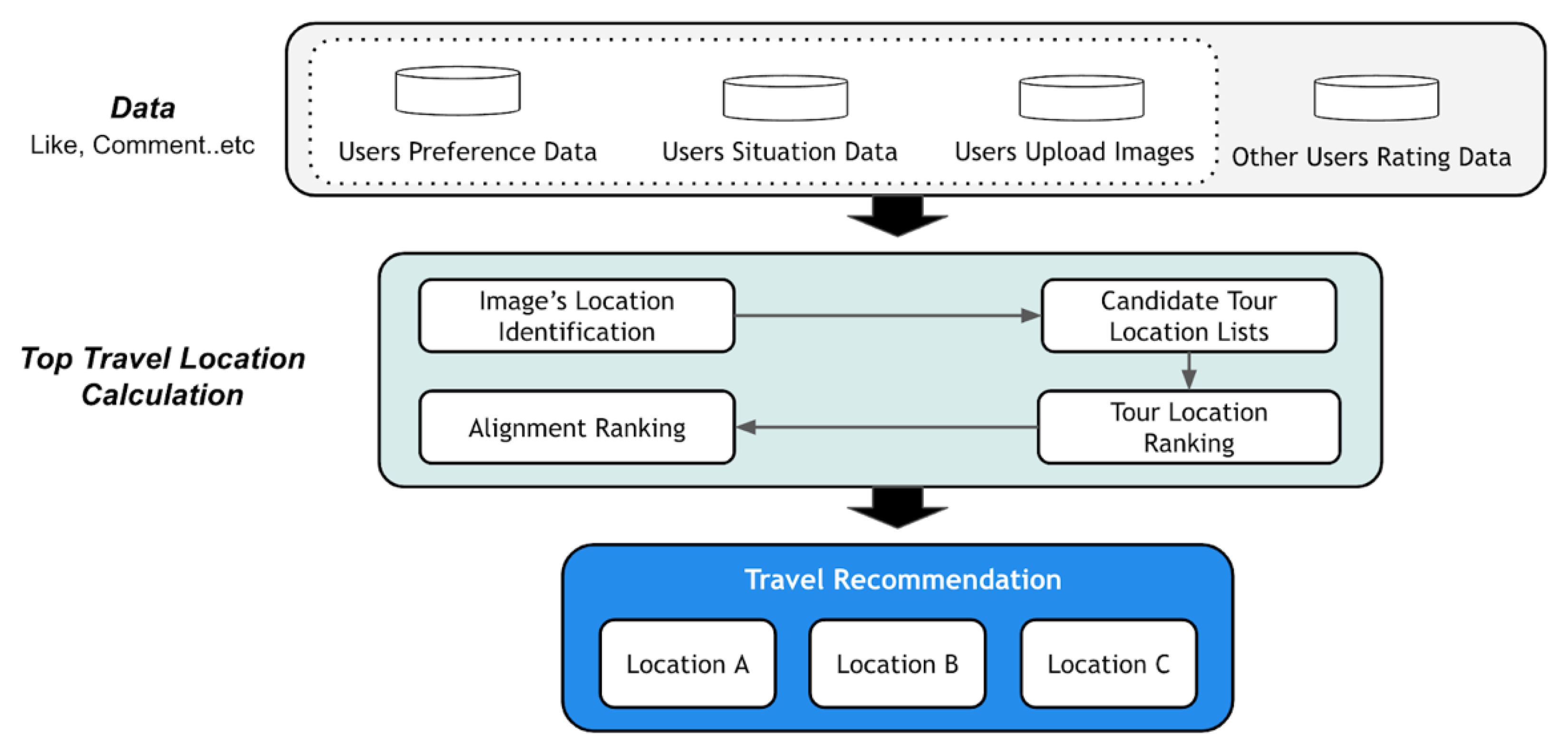
2.3.3. Tourism Service
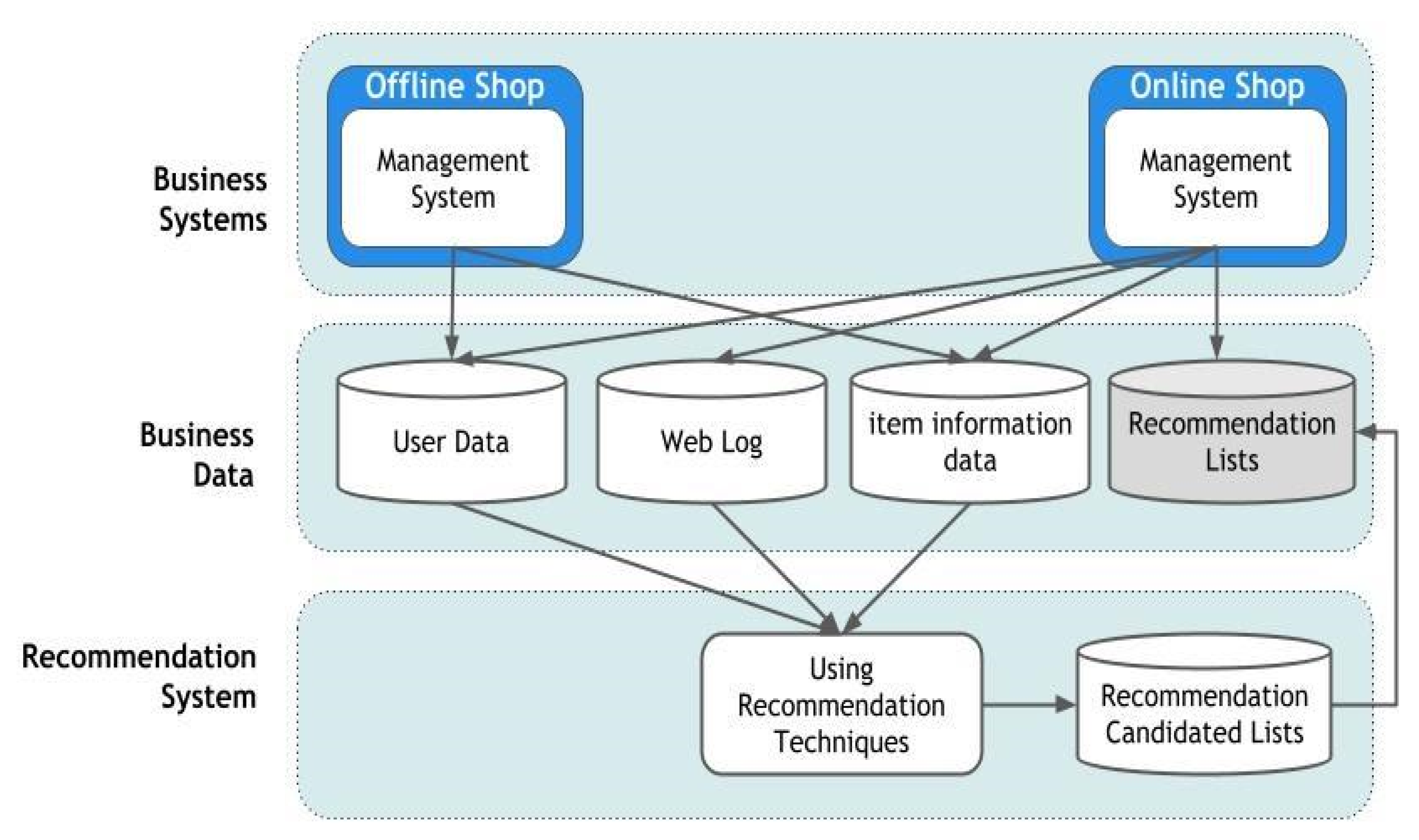
2.3.4. E-Commerce Service
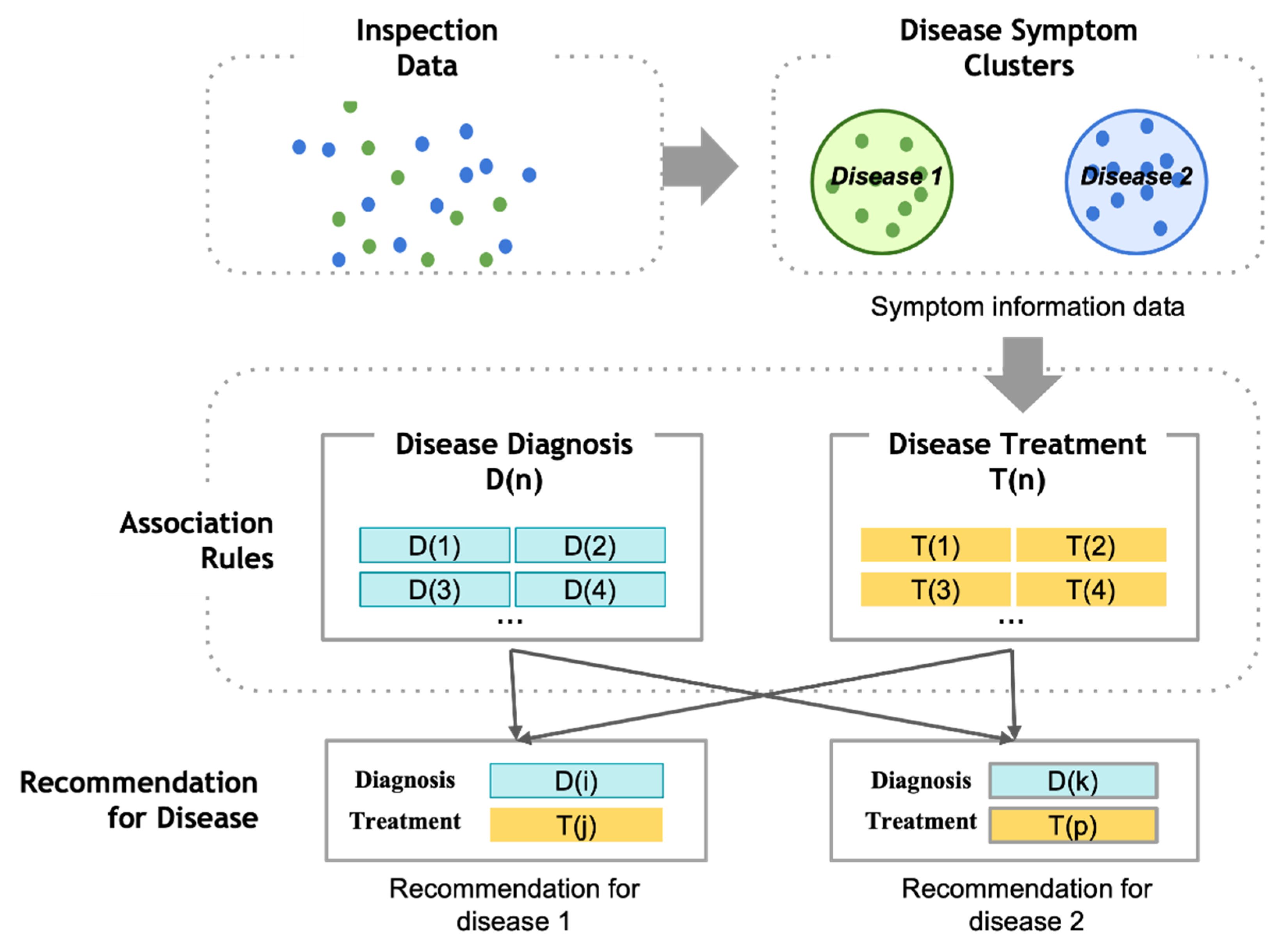
2.3.5. Healthcare Service
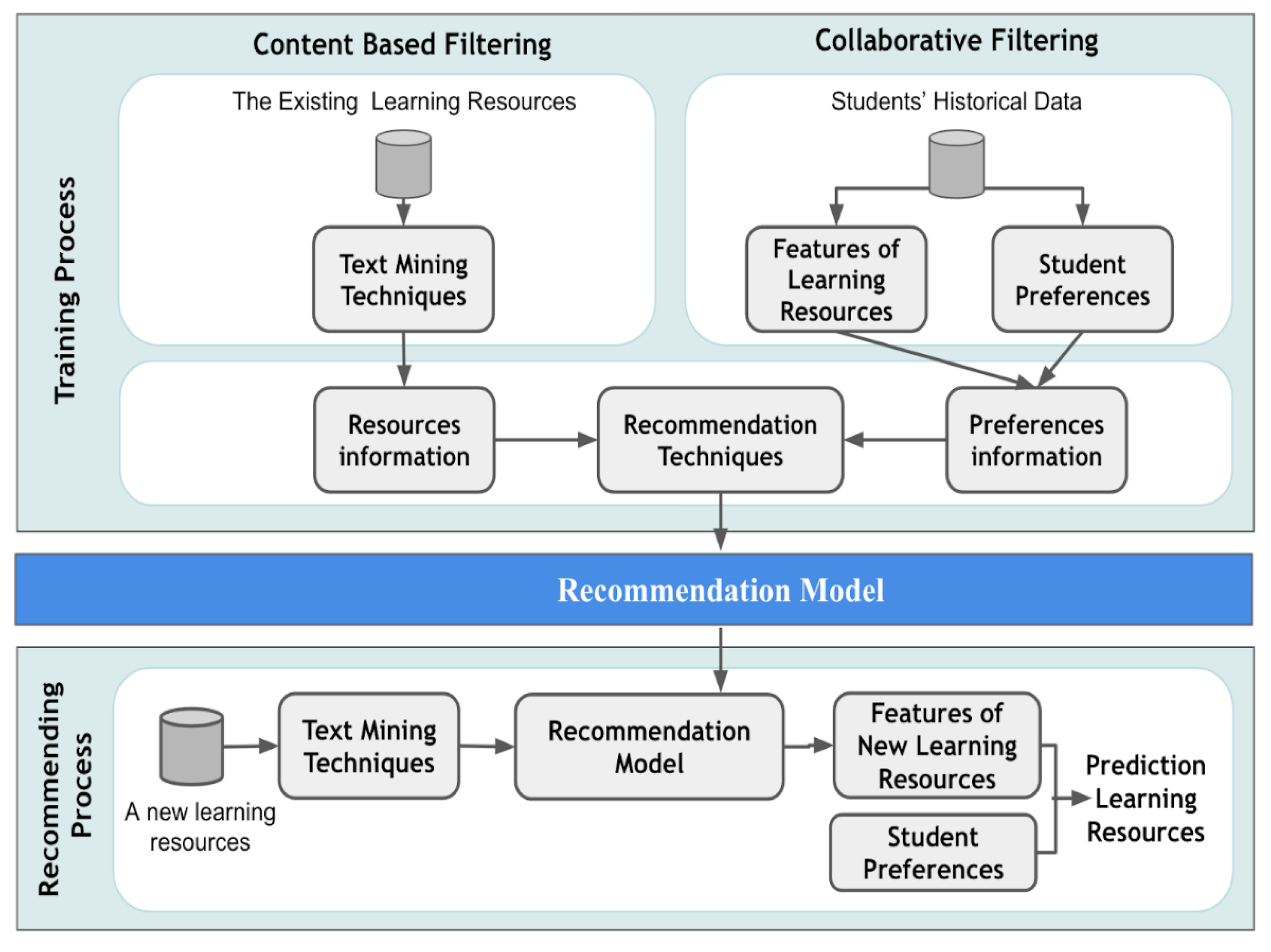
2.3.6. Education Service
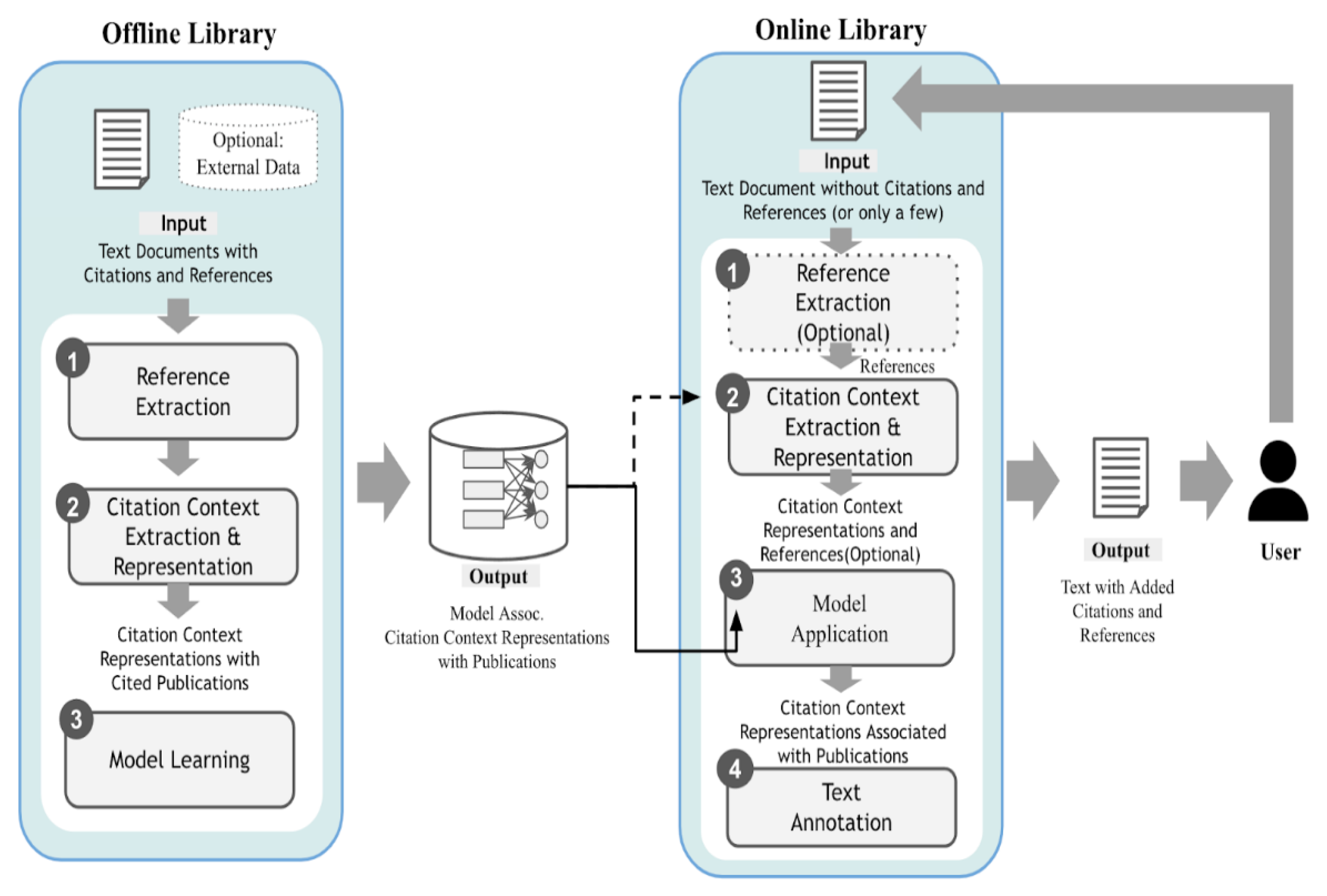
2.3.7. Academic Information Service
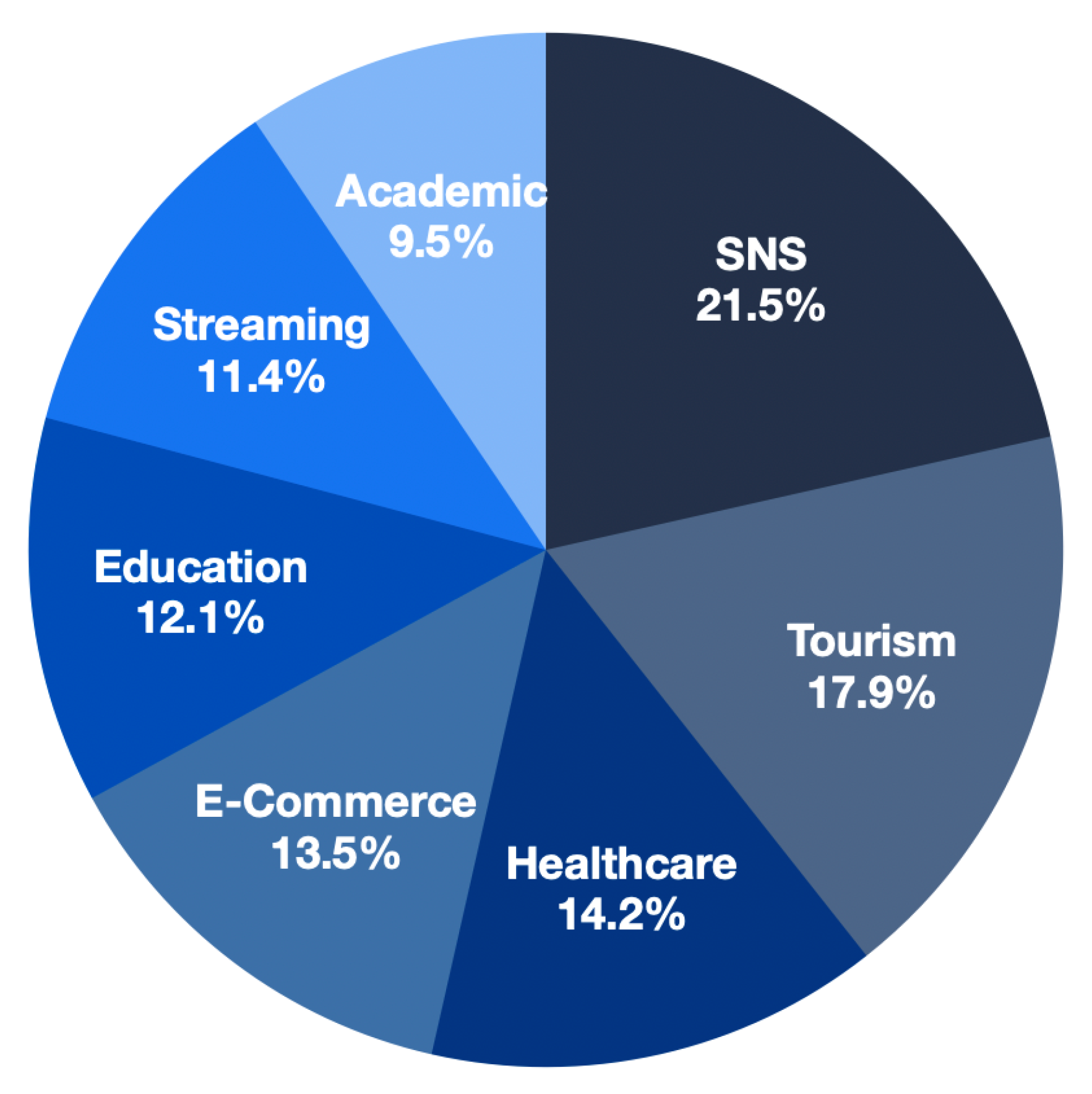
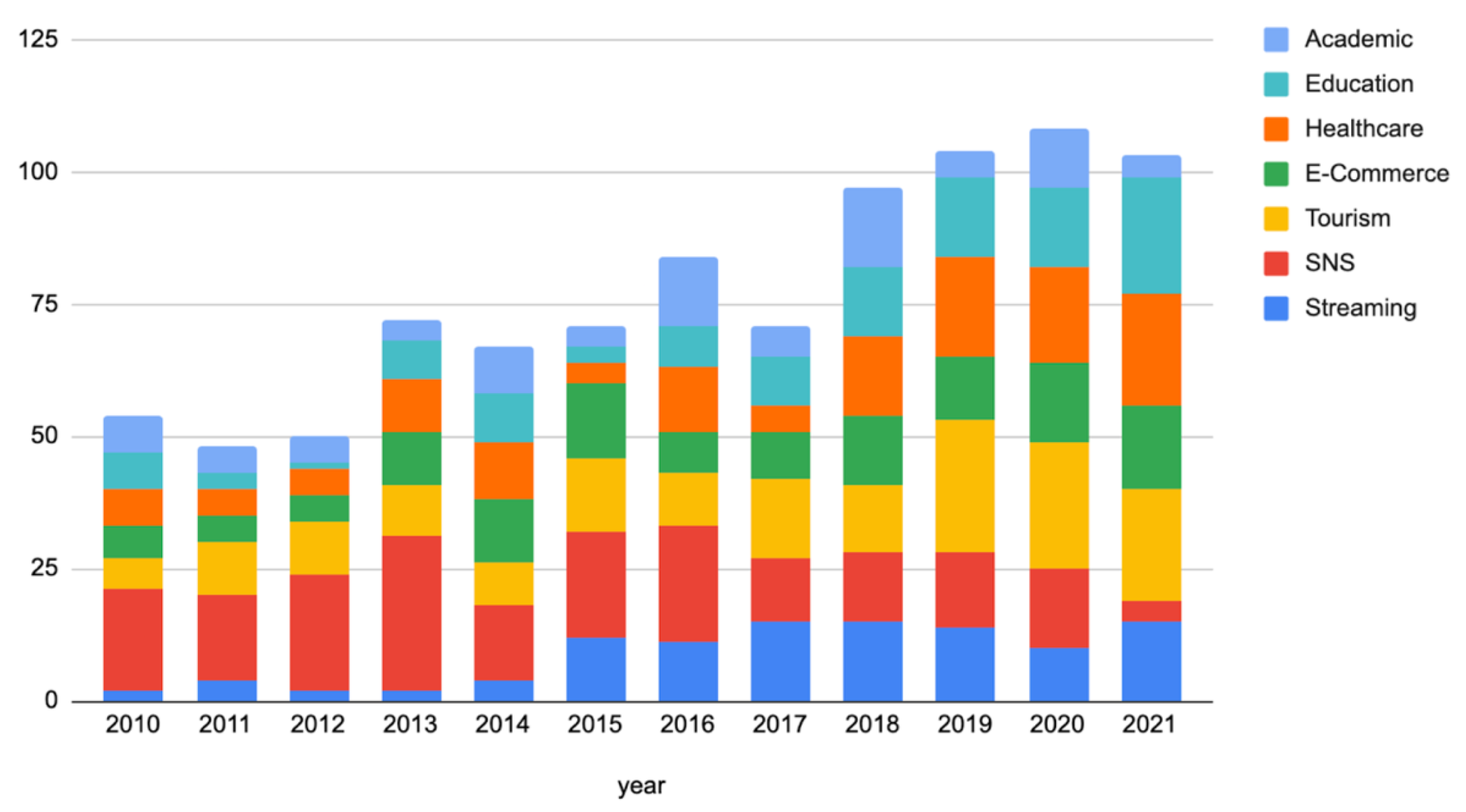
2.4. Recommendation System Research Trend
2.4.1. Streaming Service and Research Trend
2.4.2. Social Network Service and Research Trends
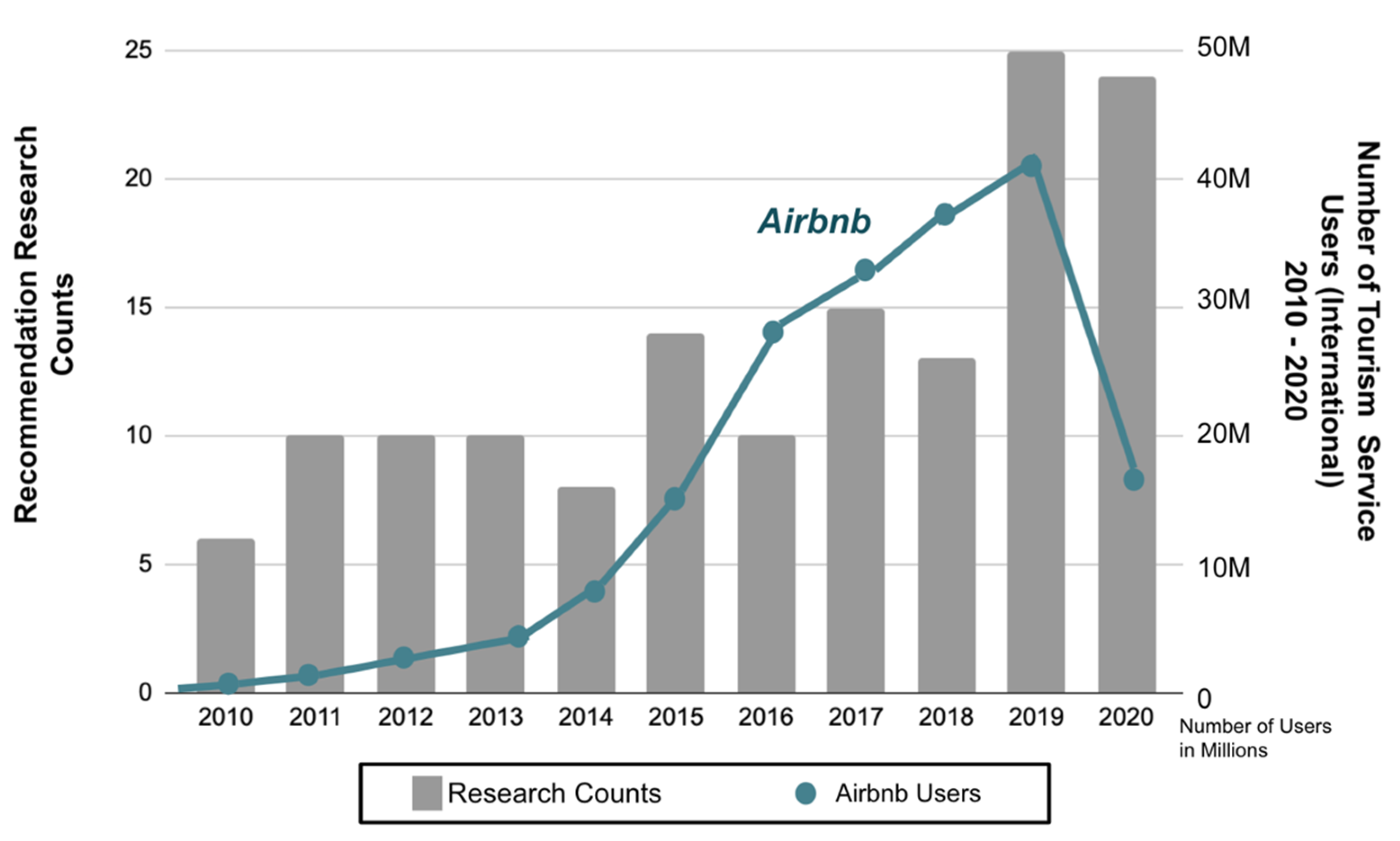
2.4.3. Tourism Service and Research Trend
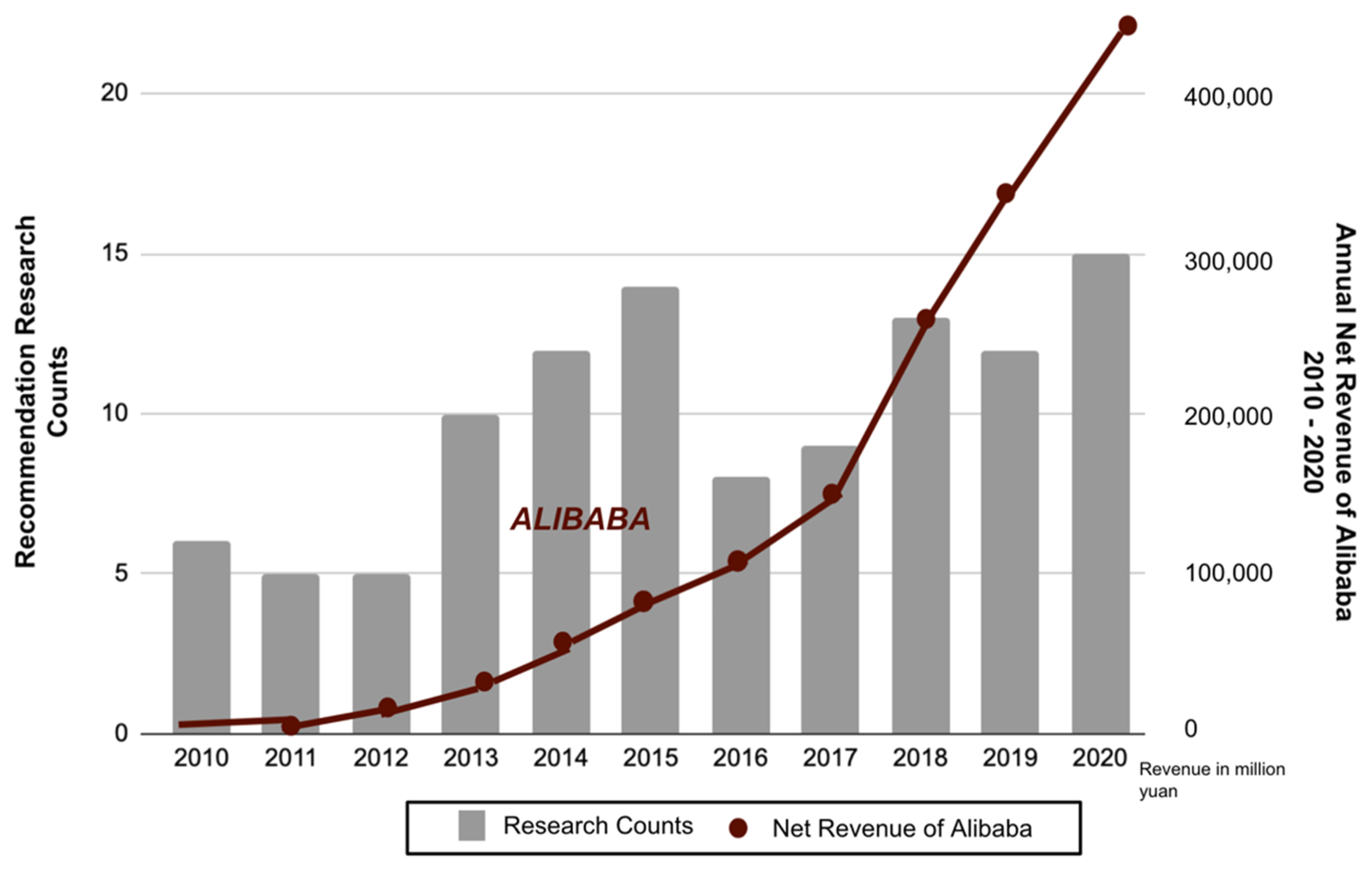
2.4.4. E-Commerce Service and Research Trends
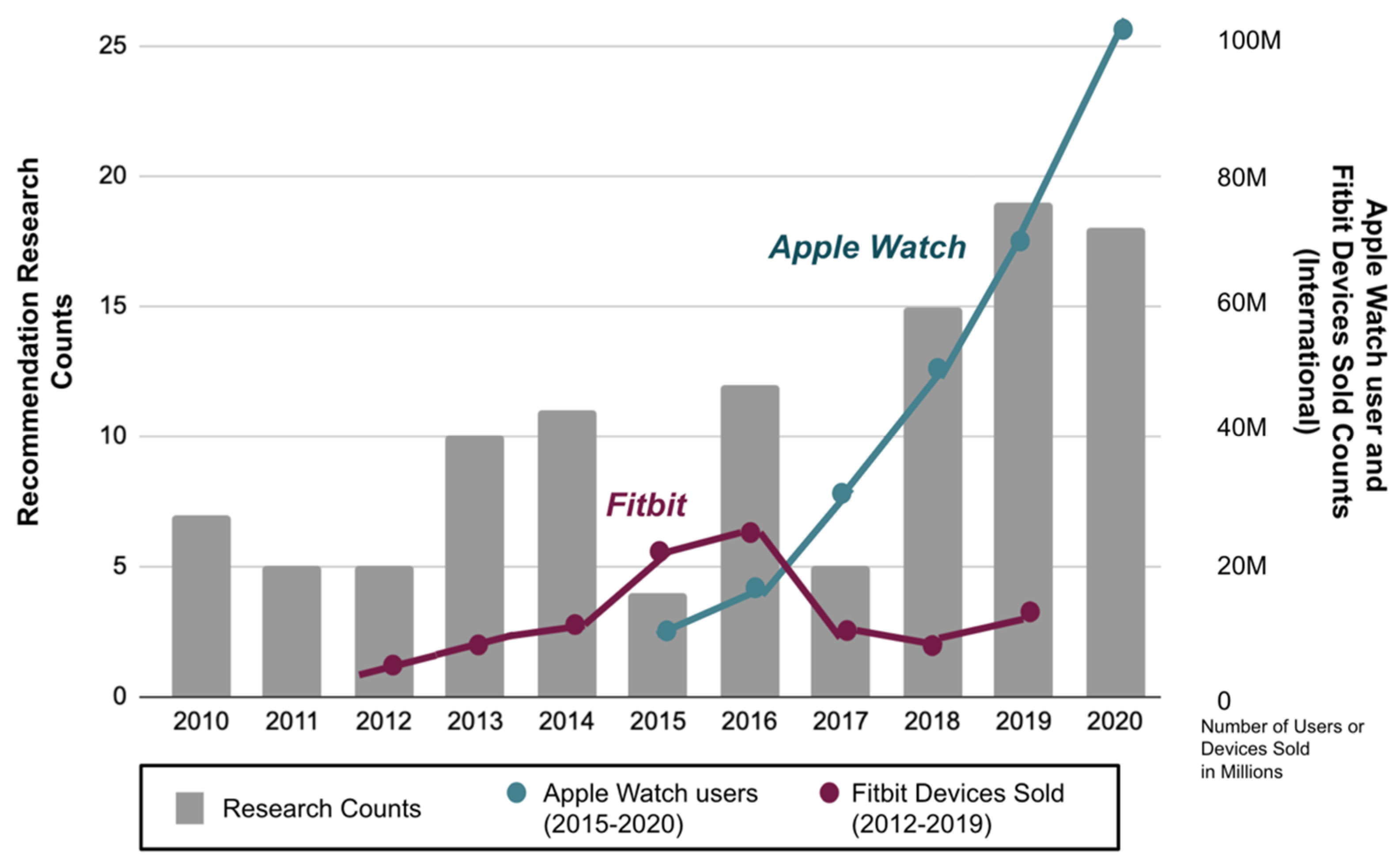
2.4.5. Healthcare Service and Research Trends
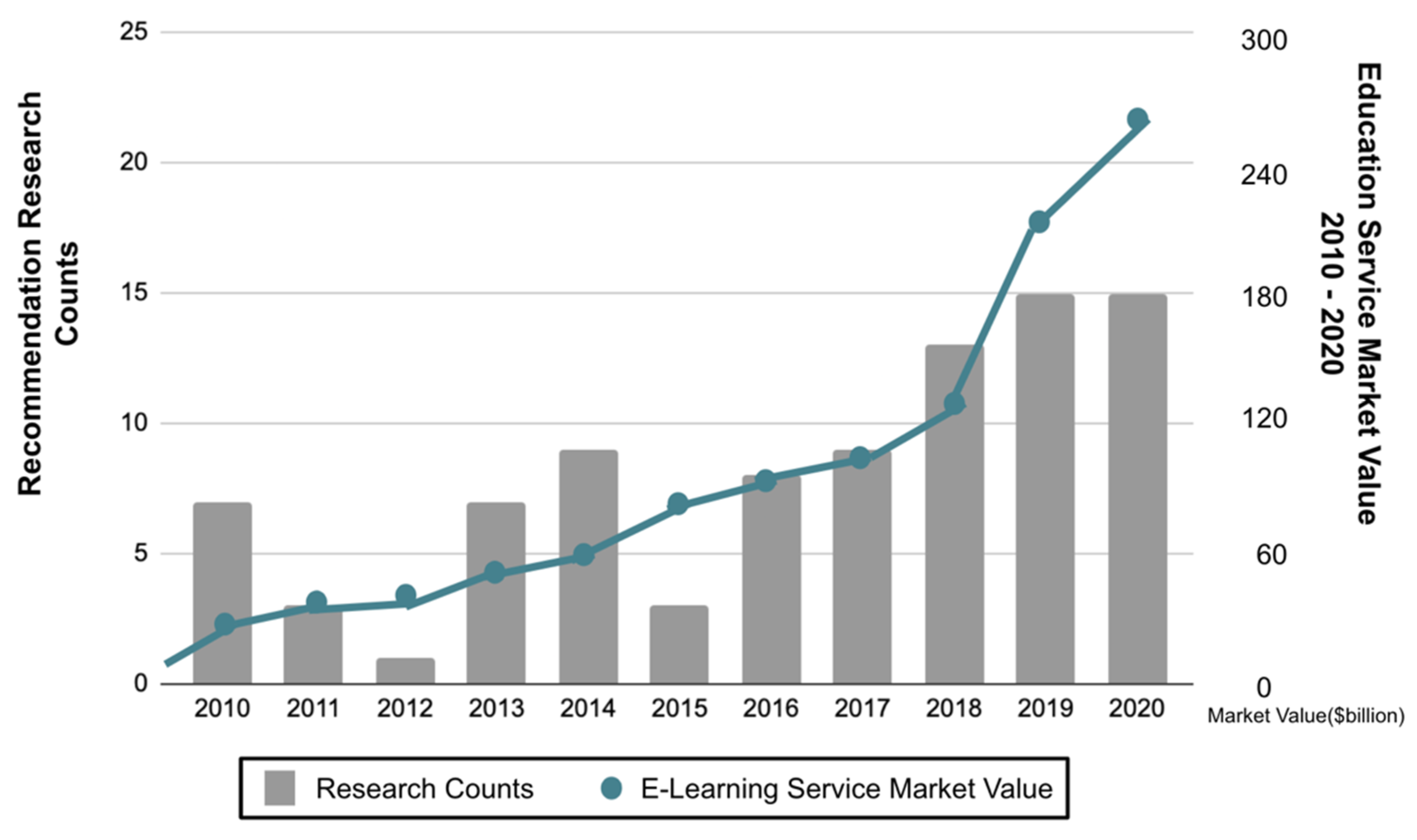
2.4.6. Education Service and Research Trends
2.4.7. Summary of Research Trends
3. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Beheshti, A.; Yakhchi, S.; Mousaeirad, S.; Ghafari, S.M.; Goluguri, S.R.; Edrisi, M.A. Towards Cognitive Recommender Systems. Algorithms 2020, 13, 176. [Google Scholar] [CrossRef]
- Abbasi-Moud, Z.; Vahdat-Nejad, H.; Sadri, J. Tourism Recommendation System Based on Semantic Clustering and Sentiment Analysis. Expert Syst. Appl. 2021, 167, 114324. [Google Scholar] [CrossRef]
- Liu, F.; Lee, H.J. Use of Social Network Information to Enhance Collaborative Filtering Performance. Expert Syst. Appl. 2010, 37, 4772–4778. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social Collaborative Filtering by Trust. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1633–1647. [Google Scholar] [CrossRef] [PubMed]
- Amato, F.; Moscato, V.; Picariello, A.; Piccialli, F. SOS: A Multimedia Recommender System for Online Social Networks. Future Gener. Comput. Syst. 2019, 93, 914–923. [Google Scholar] [CrossRef]
- Capdevila, J.; Arias, M.; Arratia, A. GeoSRS: A Hybrid Social Recommender System for Geolocated Data. Inf. Syst. 2016, 57, 111–128. [Google Scholar] [CrossRef][Green Version]
- Tarus, J.K.; Niu, Z.; Yousif, A. A Hybrid Knowledge-Based Recommender System for e-Learning Based on Ontology and Sequential Pattern Mining. Future Gener. Comput. Syst. 2017, 72, 37–48. [Google Scholar] [CrossRef]
- Choi, S.-M.; Ko, S.-K.; Han, Y.-S. A Movie Recommendation Algorithm Based on Genre Correlations. Expert Syst. Appl. 2012, 39, 8079–8085. [Google Scholar] [CrossRef]
- Walek, B.; Fojtik, V. A Hybrid Recommender System for Recommending Relevant Movies Using an Expert System. Expert Syst. Appl. 2020, 158, 113452. [Google Scholar] [CrossRef]
- Pan, Y.; He, F.; Yu, H. Learning Social Representations with Deep Autoencoder for Recommender System. World Wide Web 2020, 23, 2259–2279. [Google Scholar] [CrossRef]
- Aivazoglou, M.; Roussos, A.O.; Margaris, D.; Vassilakis, C.; Ioannidis, S.; Polakis, J.; Spiliotopoulos, D. A Fine-Grained Social Network Recommender System. Soc. Netw. Anal. Min. 2020, 10, 8. [Google Scholar] [CrossRef]
- García-Sánchez, F.; Colomo-Palacios, R.; Valencia-García, R. A Social-Semantic Recommender System for Advertisements. Inf. Process. Manag. 2020, 57, 102153. [Google Scholar] [CrossRef]
- Bollen, D.; Knijnenburg, B.P.; Willemsen, M.C.; Graus, M. Understanding Choice Overload in Recommender Systems. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 63–70. [Google Scholar]
- Im, I.; Hars, A. Does a One-Size Recommendation System Fit All? The Effectiveness of Collaborative Filtering Based Recommendation Systems across Different Domains and Search Modes. ACM Trans. Inf. Syst. 2007, 26, 4. [Google Scholar] [CrossRef]
- Wu, M.-L.; Chang, C.-H.; Liu, R.-Z. Integrating Content-Based Filtering with Collaborative Filtering Using Co-Clustering with Augmented Matrices. Expert Syst. Appl. 2014, 41, 2754–2761. [Google Scholar] [CrossRef]
- Van Meteren, R.; Van Someren, M. Using content-based filtering for recommendation. In Proceedings of the Machine Learning in the New Information Age MLnet/ECML2000 Workshop, Barcelona, Spain, 30 May 2000; pp. 47–56. [Google Scholar]
- Iyengar, S.S.; Lepper, M.R. When Choice Is Demotivating: Can One Desire Too Much of a Good Thing? J. Personal. Soc. Psychol. 2000, 79, 995–1006. [Google Scholar] [CrossRef]
- Loeb, S.; Terry, D. Information Filtering. Commun. ACM 1992, 35, 26–28. [Google Scholar] [CrossRef]
- Cantador, I.; Fernández, M.; Vallet, D.; Castells, P.; Picault, J.; Ribière, M. A Multi-Purpose Ontology-Based Approach for Personalised Content Filtering and Retrieval. In Advances in Semantic Media Adaptation and Personalization; Wallace, M., Angelides, M.C., Mylonas, P., Eds.; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; Volume 93, pp. 25–51. ISBN 978-3-540-76359-8. [Google Scholar]
- Salter, J.; Antonopoulos, N. CinemaScreen Recommender Agent: Combining Collaborative and Content-Based Filtering. IEEE Intell. Syst. 2006, 21, 35–41. [Google Scholar] [CrossRef]
- Iwahama, K.; Hijikata, Y.; Nishida, S. Content-Based Filtering System for Music Data. In Proceedings of the 2004 International Symposium on Applications and the Internet Workshops. 2004 Workshops, Tokyo, Japan, 26–30 January 2004; 2004; pp. 480–487. [Google Scholar]
- Weihong, H.; Yi, C. An E-Commerce Recommender System Based on Content-Based Filtering. Wuhan Univ. J. Nat. Sci. 2006, 11, 1091–1096. [Google Scholar] [CrossRef]
- Ghauth, K.I.; Abdullah, N.A. Learning Materials Recommendation Using Good Learners’ Ratings and Content-Based Filtering. Educ. Technol. Res. Dev. 2010, 58, 711–727. [Google Scholar] [CrossRef]
- Di Noia, T.; Mirizzi, R.; Ostuni, V.; Romito, D.; Zanker, M. Linked open data to support content-based recommender systems. In Proceedings of the 8th International Conference on Semantic Systems, Graz, Austria, 5–7 September 2012; pp. 1–8. [Google Scholar]
- Kompan, M.; Bieliková, M. Content-Based News Recommendation. In E-Commerce and Web Technologies; Buccafurri, F., Semeraro, G., Eds.; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2010; Volume 61, pp. 61–72. ISBN 978-3-642-15207-8. [Google Scholar]
- Son, J.; Kim, S.B. Content-Based Filtering for Recommendation Systems Using Multiattribute Networks. Expert Syst. Appl. 2017, 89, 404–412. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using Collaborative Filtering to Weave an Information Tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186. [Google Scholar]
- Park, S.-H.; Han, S.P. Empirical Analysis of the Impact of Product Diversity on Long-Term Performance of Recommender Systems. In Proceedings of the 14th Annual International Conference on Electronic Commerce—ICEC ’12, Singapore, 7–8 August 2012; pp. 280–281. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 77–118. [Google Scholar]
- Nilashi, M.; Ibrahim, O.; Bagherifard, K. A Recommender System Based on Collaborative Filtering Using Ontology and Dimensionality Reduction Techniques. Expert Syst. Appl. 2018, 92, 507–520. [Google Scholar] [CrossRef]
- Ansari, A.; Essegaier, S.; Kohli, R. Internet Recommendation Systems. J. Mark. Res. 2000, 37, 363–375. [Google Scholar] [CrossRef]
- Papagelis, M.; Plexousakis, D.; Kutsuras, T. Alleviating the Sparsity Problem of Collaborative Filtering Using Trust Inferences. In Trust Management; Herrmann, P., Issarny, V., Shiu, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3477, pp. 224–239. ISBN 978-3-540-26042-4. [Google Scholar]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative Filtering and Deep Learning Based Recommendation System for Cold Start Items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef]
- Gras, B.; Brun, A.; Boyer, A. Identifying Grey Sheep Users in Collaborative Filtering: A Distribution-Based Technique. In Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization, Halifax, NS, Canada, 13–16 July 2016; pp. 17–26. [Google Scholar]
- Barragáns-Martínez, A.B.; Costa-Montenegro, E.; Burguillo, J.C.; Rey-López, M.; Mikic-Fonte, F.A.; Peleteiro, A. A Hybrid Content-Based and Item-Based Collaborative Filtering Approach to Recommend TV Programs Enhanced with Singular Value Decomposition. Inf. Sci. 2010, 180, 4290–4311. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A New User Similarity Model to Improve the Accuracy of Collaborative Filtering. Knowl.-Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, M.; Hanjalic, A. Collaborative Filtering beyond the User-Item Matrix: A Survey of the State of the Art and Future Challenges. ACM Comput. Surv. 2014, 47, 1–45. [Google Scholar] [CrossRef]
- Kim, H.-N.; Ji, A.-T.; Ha, I.; Jo, G.-S. Collaborative Filtering Based on Collaborative Tagging for Enhancing the Quality of Recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Bobadilla, J.; Hernando, A.; Ortega, F.; Gutiérrez, A. Collaborative Filtering Based on Significances. Inf. Sci. 2012, 185, 1–17. [Google Scholar] [CrossRef]
- Koohi, H.; Kiani, K. User Based Collaborative Filtering Using Fuzzy C-Means. Measurement 2016, 91, 134–139. [Google Scholar] [CrossRef]
- Choi, K.; Suh, Y. A New Similarity Function for Selecting Neighbors for Each Target Item in Collaborative Filtering. Knowl.-Based Syst. 2013, 37, 146–153. [Google Scholar] [CrossRef]
- Basilico, J.; Hofmann, T. Unifying Collaborative and Content-Based Filtering. In Proceedings of the Twenty-First International Conference on Machine Learning—ICML ’04, Banff, AB, Canada, 4–8 July 2004; 2004; p. 9. [Google Scholar]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Kim, Y.M.; Choi, S. Scalable Variational Bayesian Matrix Factorization with Side Information. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; pp. 493–502. [Google Scholar]
- Strub, F.; Gaudel, R.; Mary, J. Hybrid Recommender System Based on Autoencoders. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 11–16. [Google Scholar]
- Zhao, H.; Yao, Q.; Song, Y.; Kwok, J.T.; Lee, D.L. Side Information Fusion for Recommender Systems over Heterogeneous Information Network. ACM Trans. Knowl. Discov. Data 2021, 15, 1–32. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Bag, S.; Kumar, S.; Awasthi, A.; Tiwari, M.K. A Noise Correction-Based Approach to Support a Recommender System in a Highly Sparse Rating Environment. Decis. Support Syst. 2019, 118, 46–57. [Google Scholar] [CrossRef]
- Khelloufi, A.; Ning, H.; Dhelim, S.; Qiu, T.; Ma, J.; Huang, R.; Atzori, L. A Social-Relationships-Based Service Recommendation System for SIoT Devices. IEEE Internet Things J. 2021, 8, 1859–1870. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, J.; Yan, C.; Wu, X.; Chen, F. Research on the Matthews Correlation Coefficients Metrics of Personalized Recommendation Algorithm Evaluation. Int. J. Hybrid Inf. Technol. 2015, 8, 163–172. [Google Scholar] [CrossRef]
- Krichene, W.; Rendle, S. On Sampled Metrics for Item Recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23 August 2020; pp. 1748–1757. [Google Scholar]
- Hsu, F.-M.; Lin, Y.-T.; Ho, T.-K. Design and Implementation of an Intelligent Recommendation System for Tourist Attractions: The Integration of EBM Model, Bayesian Network and Google Maps. Expert Syst. Appl. 2012, 39, 3257–3264. [Google Scholar] [CrossRef]
- Parra, D.; Sahebi, S. Recommender Systems: Sources of Knowledge and Evaluation Metrics. In Advanced Techniques in Web Intelligence-2; Velásquez, J.D., Palade, V., Jain, L.C., Eds.; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; Volume 452, pp. 149–175. ISBN 978-3-642-33325-5. [Google Scholar]
- Kawasaki, M.; Hasuike, T. A Recommendation System by Collaborative Filtering Including Information and Characteristics on Users and Items. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Hendler, J. Web 3.0 emerging. Computer 2009, 42, 111–113. [Google Scholar] [CrossRef]
- Di Noia, T.; Mirizzi, R.; Ostuni, V.C.; Romito, D. Exploiting the Web of Data in Model-Based Recommender Systems. In Proceedings of the Sixth ACM Conference on Recommender Systems—RecSys ’12, New York, NY, USA, 9–13 September 2012; p. 253. [Google Scholar]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the Cold Start Problem in Recommender Systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Gündüz, S.; Özsu, M.T. A web page prediction model based on click-stream tree representation of user behavior. In Proceedings of the 9th ACM International Conference on Knowledge Discovery and Data Mining (KDD), Washington, DC, USA, 24–27 August 2003; pp. 535–540. [Google Scholar]
- Gómez-Pérez, A.; Corcho, O. Ontology languages for the Semantic Web. IEEE Intell. Syst. 2002, 17, 54–60. [Google Scholar] [CrossRef]
- Yu, Eunji; Kim, Jung-Cheol; Lee, Choon Yeul; Kim, Namgyu Using Ontologies for Semantic Text Mining. J. Inf. Syst. 2012, 21, 137–161. [CrossRef]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Abowd, G.D.; Dey, A.K.; Brown, P.J.; Davies, N.; Smith, M.; Steggles, P. Towards a Better Understanding of Context and Context-Awareness. In Handheld and Ubiquitous Computing; Gellersen, H.-W., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1707, pp. 304–307. ISBN 978-3-540-66550-2. [Google Scholar]
- Zadeh, L.A. The Concept of a Linguistic Variable and Its Application to Approximate Reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Porcel, C.; Herrera-Viedma, E. Dealing with Incomplete Information in a Fuzzy Linguistic Recommender System to Disseminate Information in University Digital Libraries. Knowl.-Based Syst. 2010, 23, 32–39. [Google Scholar] [CrossRef]
- Trstenjak, B.; Mikac, S.; Donko, D. KNN with TF-IDF Based Framework for Text Categorization. Procedia Eng. 2014, 69, 1356–1364. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE.; Meersman, R., Tari, Z., Schmidt, D.C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2888, pp. 986–996. ISBN 978-3-540-20498-5. [Google Scholar]
- Jannach, D.; Lerche, L.; Kamehkhosh, I.; Jugovac, M. What Recommenders Recommend: An Analysis of Recommendation Biases and Possible Countermeasures. User Model User-Adap. Inter. 2015, 25, 427–491. [Google Scholar] [CrossRef]
- Shepitsen, A.; Gemmell, J.; Mobasher, B.; Burke, R. Personalized Recommendation in Social Tagging Systems Using Hierarchical Clustering. In Proceedings of the 2008 ACM Conference on Recommender Systems—RecSys ’08, Lausanne, Switzerland, 23–25 October 2008; p. 259. [Google Scholar]
- Bilge, A.; Polat, H. A Comparison of Clustering-Based Privacy-Preserving Collaborative Filtering Schemes. Appl. Soft Comput. 2013, 13, 2478–2489. [Google Scholar] [CrossRef]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; Society for Industrial and Applied Mathematics: Philadelphia, VA, USA, 2007. [Google Scholar]
- Gong, S. A Collaborative Filtering Recommendation Algorithm Based on User Clustering and Item Clustering. J. Softw. 2010, 5, 745–752. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems; IEEE: Piscatawy, NJ, USA, 2008; pp. 1257–1264. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. SoRec: Social Recommendation Using Probabilistic Matrix Factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Mining—CIKM ’08, Napa Valley, CA, USA, 26–30 October 2008; p. 931. [Google Scholar]
- Kim, Y.; Shim, K. TWILITE: A Recommendation System for Twitter Using a Probabilistic Model Based on Latent Dirichlet Allocation. Inf. Syst. 2014, 42, 59–77. [Google Scholar] [CrossRef]
- Zhang, Y. GroRec: A Group-Centric Intelligent Recommender System Integrating Social, Mobile and Big Data Technologies. IEEE Trans. Serv. Comput. 2016, 9, 786–795. [Google Scholar] [CrossRef]
- Seo, Y.-S.; Huh, J.-H. GUI-Based Software Modularization through Module Clustering in Edge Computing Based IoT Environments. J. Ambient Intell. Human. Comput. 2019, pp. 1–15. Available online: https://link.springer.com/article/10.1007%2Fs12652-019-01455-3 (accessed on 6 September 2019).
- Van den Oord, A.; Dieleman, S.; Schrauwen, B. Deep Content-Based Music Recommendation. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 15–19 December 2013; pp. 2643–2651. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.-Y. Collaborative Deep Learning for Recommender Systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1235–1244. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee; pp. 173–182. [Google Scholar]
- Gomez-Uribe, C.A.; Hunt, N. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Trans. Manage. Inf. Syst. 2016, 6, 1–19. [Google Scholar] [CrossRef]
- Koren, Y. Factor in the Neighbors: Scalable and Accurate Collaborative Filtering. ACM Trans. Knowl. Discov. Data 2010, 4, 1–24. [Google Scholar] [CrossRef]
- Bell, R.M.; Koren, Y. Lessons from the Netflix Prize Challenge. SIGKDD Explor. Newsl. 2007, 9, 75–79. [Google Scholar] [CrossRef]
- McFee, B.; Barrington, L.; Lanckriet, G. Learning Content Similarity for Music Recommendation. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2207–2218. [Google Scholar] [CrossRef]
- Odić, A.; Tkalčič, M.; Tasič, J.F.; Košir, A. Predicting and Detecting the Relevant Contextual Information in a Movie-Recommender System. Interact. Comput. 2013, 25, 74–90. [Google Scholar] [CrossRef][Green Version]
- Wang, X.; Wang, Y. Improving Content-Based and Hybrid Music Recommendation Using Deep Learning. In Proceedings of the 22nd ACM International Conference on Multimedia, rlando, FL, USA, 3–7 November 2014; pp. 627–636. [Google Scholar]
- Bogdanov, D.; Haro, M.; Fuhrmann, F.; Xambó, A.; Gómez, E.; Herrera, P. Semantic Audio Content-Based Music Recommendation and Visualization Based on User Preference Examples. Inf. Process. Manag. 2013, 49, 13–33. [Google Scholar] [CrossRef]
- Colombo-Mendoza, L.O.; Valencia-García, R.; Rodríguez-González, A.; Alor-Hernández, G.; Samper-Zapater, J.J. RecomMetz: A Context-Aware Knowledge-Based Mobile Recommender System for Movie Showtimes. Expert Syst. Appl. 2015, 42, 1202–1222. [Google Scholar] [CrossRef]
- Vall, A.; Dorfer, M.; Eghbal-zadeh, H.; Schedl, M.; Burjorjee, K.; Widmer, G. Feature-Combination Hybrid Recommender Systems for Automated Music Playlist Continuation. User Model User-Adap. Inter. 2019, 29, 527–572. [Google Scholar] [CrossRef]
- Huh, J.-H.; Otgonchimeg, S.; Seo, K. Advanced Metering Infrastructure Design and Test Bed Experiment Using Intelligent Agents: Focusing on the PLC Network Base Technology for Smart Grid System. J. Supercomput. 2016, 72, 1862–1877. [Google Scholar] [CrossRef]
- Lee, S.; Jeong, H.; Ko, H. Classical Music Specific Mood Automatic Recognition Model Proposal. Electronics 2021, 10, 2489. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, X.; Feng, N.; Wang, Z. An Improved Collaborative Movie Recommendation System Using Computational Intelligence. J. Vis. Lang. Comput. 2014, 25, 667–675. [Google Scholar] [CrossRef]
- Sánchez-Moreno, D.; Gil González, A.B.; Muñoz Vicente, M.D.; López Batista, V.F.; Moreno García, M.N. A Collaborative Filtering Method for Music Recommendation Using Playing Coefficients for Artists and Users. Expert Syst. Appl. 2016, 66, 234–244. [Google Scholar] [CrossRef]
- He, J.; Chu, W.W. A Social Network-Based Recommender System (SNRS). In Data Mining for Social Network Data; Memon, N., Xu, J.J., Hicks, D.L., Chen, H., Eds.; Annals of Information Systems; Springer: Boston, MA, USA, 2010; Volume 12, pp. 47–74. ISBN 978-1-4419-6286-7. [Google Scholar]
- Tsur, O.; Rappoport, A. What’s in a Hashtag? Content Based Prediction of the Spread of Ideas in Microblogging Communities. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining—WSDM ’12, New York, NY, USA, 8–12 February 2012; p. 643. [Google Scholar]
- Wang, Z.; Sun, L.; Zhu, W.; Yang, S.; Li, H.; Wu, D. Joint Social and Content Recommendation for User-Generated Videos in Online Social Network. IEEE Trans. Multimed. 2013, 15, 698–709. [Google Scholar] [CrossRef]
- Kazienko, P.; Musial, K.; Kajdanowicz, T. Multidimensional Social Network in the Social Recommender System. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 746–759. [Google Scholar] [CrossRef]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L.; Braziunas, D. Low-rank linear cold-start recommendation from social data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, Menlo Park, CA, USA, 4–9 February 2017; pp. 1502–1508. [Google Scholar]
- Davoodi, E.; Kianmehr, K.; Afsharchi, M. A Semantic Social Network-Based Expert Recommender System. Appl. Intell. 2013, 39, 1–13. [Google Scholar] [CrossRef]
- Kesorn, K.; Juraphanthong, W.; Salaiwarakul, A. Personalized Attraction Recommendation System for Tourists Through Check-In Data. IEEE Access 2017, 5, 26703–26721. [Google Scholar] [CrossRef]
- Sun, Y.; Fan, H.; Bakillah, M.; Zipf, A. Road-Based Travel Recommendation Using Geo-Tagged Images. Comput. Environ. Urban Syst. 2015, 53, 110–122. [Google Scholar] [CrossRef]
- Smirnov, A.V.; Kashevnik, A.M.; Ponomarev, A. Context-Based Infomobility System for Cultural Heritage Recommendation: Tourist Assistant—TAIS. Pers. Ubiquit. Comput. 2017, 21, 297–311. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chung, S.-H. A Personalized Route Recommendation Service for Theme Parks Using RFID Information and Tourist Behavior. Decis. Support Syst. 2012, 52, 514–527. [Google Scholar] [CrossRef]
- Ruotsalo, T.; Haav, K.; Stoyanov, A.; Roche, S.; Fani, E.; Deliai, R.; Mäkelä, E.; Kauppinen, T.; Hyvönen, E. SMARTMUSEUM: A Mobile Recommender System for the Web of Data. J. Web Semant. 2013, 20, 50–67. [Google Scholar] [CrossRef]
- Al-Hassan, M.; Lu, H.; Lu, J. A Semantic Enhanced Hybrid Recommendation Approach: A Case Study of e-Government Tourism Service Recommendation System. Decis. Support Syst. 2015, 72, 97–109. [Google Scholar] [CrossRef]
- Nilashi, M.; bin Ibrahim, O.; Ithnin, N.; Sarmin, N.H. A Multi-Criteria Collaborative Filtering Recommender System for the Tourism Domain Using Expectation Maximization (EM) and PCA–ANFIS. Electron. Commer. Res. Appl. 2015, 14, 542–562. [Google Scholar] [CrossRef]
- Logesh, R.; Subramaniyaswamy, V. Exploring Hybrid Recommender Systems for Personalized Travel Applications. In Cognitive Informatics and Soft Computing; Mallick, P.K., Balas, V.E., Bhoi, A.K., Zobaa, A.F., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2019; Volume 768, pp. 535–544. ISBN 9789811306167. [Google Scholar]
- Colomo-Palacios, R.; García-Peñalvo, F.J.; Stantchev, V.; Misra, S. Towards a Social and Context-Aware Mobile Recommendation System for Tourism. Pervasive Mob. Comput. 2017, 38, 505–515. [Google Scholar] [CrossRef]
- Galhotra, B.; Dewan, A. Impact of COVID-19 on Digital Platforms and Change in E-Commerce Shopping Trends. In Proceedings of the 2020 Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Coimbatore, India, 7–9 October 2020; pp. 861–866. [Google Scholar]
- Zhang, X.; Liu, H.; Chen, X.; Zhong, J.; Wang, D. A Novel Hybrid Deep Recommendation System to Differentiate User’s Preference and Item’s Attractiveness. Inf. Sci. 2020, 519, 306–316. [Google Scholar] [CrossRef]
- Lu, Y.; Zhao, L.; Wang, B. From Virtual Community Members to C2C E-Commerce Buyers: Trust in Virtual Communities and Its Effect on Consumers’ Purchase Intention. Electron. Commer. Res. Appl. 2010, 9, 346–360. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T.; Hussain, O.; Wilbik, A. Fuzzy Approach to Purchase Intent Modeling Based on User Tracking For E-Commerce Recommenders. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 July 2021; pp. 1–8. [Google Scholar]
- Jiang, L.; Cheng, Y.; Yang, L.; Li, J.; Yan, H.; Wang, X. A trust-based collaborative filtering algorithm for E-commerce recommendation system. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3023–3034. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the Tenth International Conference on World Wide Web—WWW ’01, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Hwangbo, H.; Kim, Y.S.; Cha, K.J. Recommendation System Development for Fashion Retail E-Commerce. Electron. Commer. Res. Appl. 2018, 28, 94–101. [Google Scholar] [CrossRef]
- Ho, S.Y.; Bodoff, D.; Tam, K.Y. Timing of Adaptive Web Personalization and Its Effects on Online Consumer Behavior. Inf. Syst. Res. 2011, 22, 660–679. [Google Scholar] [CrossRef]
- Guo, Y.; Yin, C.; Li, M.; Ren, X.; Liu, P. Mobile E-Commerce Recommendation System Based on Multi-Source Information Fusion for Sustainable e-Business. Sustainability 2018, 10, 147. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T. Deep Learning-Enhanced Framework for Performance Evaluation of a Recommending Interface with Varied Recommendation Position and Intensity Based on Eye-Tracking Equipment Data Processing. Electronics 2020, 9, 266. [Google Scholar] [CrossRef]
- Castro-Schez, J.J.; Miguel, R.; Vallejo, D.; López-López, L.M. A Highly Adaptive Recommender System Based on Fuzzy Logic for B2C E-Commerce Portals. Expert Syst. Appl. 2011, 38, 2441–2454. [Google Scholar] [CrossRef]
- Tröster, G. The Agenda of Wearable Healthcare. Yearb. Med. Inf. 2005, 14, 125–138. [Google Scholar] [CrossRef]
- Apple. Use Emergency SOS on Your Apple Watch. 2021. Available online: https://support.apple.com/en-us/HT206983 (accessed on 27 April 2021).
- Mishra, T.; Wang, M.; Metwally, A.A.; Bogu, G.K.; Brooks, A.W.; Bahmani, A.; Alavi, A.; Celli, A.; Higgs, E.; Dagan-Rosenfeld, O.; et al. Pre-Symptomatic Detection of COVID-19 from Smartwatch Data. Nat. Biomed. Eng. 2020, 4, 1208–1220. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.W.; Zhang, Z.B.; Wu, T.H.; Zhang, Y. A Wearable Mobihealth Care System Supporting Real-Time Diagnosis and Alarm. Med. Bio. Eng. Comput. 2007, 45, 877–885. [Google Scholar] [CrossRef] [PubMed]
- Raghupathi, W.; Raghupathi, V. Big Data Analytics in Healthcare: Promise and Potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Rehman, A.; Naz, S.; Razzak, I. Leveraging Big Data Analytics in Healthcare Enhancement: Trends, Challenges and Opportunities. Multimed. Syst. 2021, 1, 1–33. [Google Scholar] [CrossRef]
- Duan, L.; Street, W.N.; Xu, E. Healthcare Information Systems: Data Mining Methods in the Creation of a Clinical Recommender System. Enterp. Inf. Syst. 2011, 5, 169–181. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Rong, H.; Bilal, K.; Yang, N.; Li, K. A Disease Diagnosis and Treatment Recommendation System Based on Big Data Mining and Cloud Computing. Inf. Sci. 2018, 435, 124–149. [Google Scholar] [CrossRef]
- Thong, N.T.; Son, L.H. HIFCF: An Effective Hybrid Model between Picture Fuzzy Clustering and Intuitionistic Fuzzy Recommender Systems for Medical Diagnosis. Expert Syst. Appl. 2015, 42, 3682–3701. [Google Scholar] [CrossRef]
- Ko, H.; Huh, J.-H. Electronic Solutions for Artificial Intelligence Healthcare. Electronics 2021, 10, 2421. [Google Scholar] [CrossRef]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Bashir, A.K.; Noor, F. Realizing an Efficient IoMT-Assisted Patient Diet Recommendation System Through Machine Learning Model. IEEE Access 2020, 8, 28462–28474. [Google Scholar] [CrossRef]
- Yang, L.; Hsieh, C.-K.; Yang, H.; Pollak, J.P.; Dell, N.; Belongie, S.; Cole, C.; Estrin, D. Yum-Me: A Personalized Nutrient-Based Meal Recommender System. ACM Trans. Inf. Syst. 2017, 36, 1–31. [Google Scholar] [CrossRef]
- Sezgin, E.; Ozkan, S. A systematic literature review on Health Recommender Systems. In Proceedings of the 2013 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2013. [Google Scholar] [CrossRef]
- Sanchez Bocanegra, C.L.; Sevillano Ramos, J.L.; Rizo, C.; Civit, A.; Fernandez-Luque, L. HealthRecSys: A Semantic Content-Based Recommender System to Complement Health Videos. BMC Med. Inf. Decis. Mak. 2017, 17, 63. [Google Scholar] [CrossRef]
- Wiesner, M.; Pfeifer, D. Health Recommender Systems: Concepts, Requirements, Technical Basics and Challenges. IJERPH 2014, 11, 2580–2607. [Google Scholar] [CrossRef] [PubMed]
- Abbas, K.; Afaq, M.; Ahmed Khan, T.; Song, W.-C. A Blockchain and Machine Learning-Based Drug Supply Chain Management and Recommendation System for Smart Pharmaceutical Industry. Electronics 2020, 9, 852. [Google Scholar] [CrossRef]
- Chen, R.-C.; Huang, Y.-H.; Bau, C.-T.; Chen, S.-M. A Recommendation System Based on Domain Ontology and SWRL for Anti-Diabetic Drugs Selection. Expert Syst. Appl. 2012, 39, 3995–4006. [Google Scholar] [CrossRef]
- Tikhomirov, V.; Dneprovskaya, N.; Yankovskaya, E. Three Dimensions of Smart Education. In Smart Education and Smart e-Learning; Uskov, V.L., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer International Publishing: Cham, Switzerland, 2015; Volume 41, pp. 47–56. ISBN 978-3-319-19874-3. [Google Scholar]
- Lin, J.; Pu, H.; Li, Y.; Lian, J. Intelligent Recommendation System for Course Selection in Smart Education. Procedia Comput. Sci. 2018, 129, 449–453. [Google Scholar] [CrossRef]
- Zhu, Z.-T.; Yu, M.-H.; Riezebos, P. A Research Framework of Smart Education. Smart Learn. Environ. 2016, 3, 4. [Google Scholar] [CrossRef]
- Wan, S.; Niu, Z. An E-Learning Recommendation Approach Based on the Self-Organization of Learning Resource. Knowl.-Based Syst. 2018, 160, 71–87. [Google Scholar] [CrossRef]
- Shu, J.; Shen, X.; Liu, H.; Yi, B.; Zhang, Z. A Content-Based Recommendation Algorithm for Learning Resources. Multimed. Syst. 2018, 24, 163–173. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Liu, J.; Ying, Z. Recommendation System for Adaptive Learning. Appl. Psychol. Meas. 2018, 42, 24–41. [Google Scholar] [CrossRef]
- Klašnja-Milićević, A.; Vesin, B.; Ivanović, M.; Budimac, Z. E-Learning Personalization Based on Hybrid Recommendation Strategy and Learning Style Identification. Comput. Educ. 2011, 56, 885–899. [Google Scholar] [CrossRef]
- Dwivedi, P.; Bharadwaj, K.K. E-Learning Recommender System for a Group of Learners Based on the Unified Learner Profile Approach. Expert Syst. 2015, 32, 264–276. [Google Scholar] [CrossRef]
- Wu, D.; Lu, J.; Zhang, G. A Fuzzy Tree Matching-Based Personalized E-Learning Recommender System. IEEE Trans. Fuzzy Syst. 2015, 23, 2412–2426. [Google Scholar] [CrossRef]
- Obeid, C.; Lahoud, I.; El Khoury, H.; Champin, P.-A. Ontology-Based Recommender System in Higher Education. In Proceedings of the Companion Proceedings of The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1031–1034. [Google Scholar]
- Gulzar, Z.; Leema, A.A.; Deepak, G. PCRS: Personalized Course Recommender System Based on Hybrid Approach. Procedia Comput. Sci. 2018, 125, 518–524. [Google Scholar] [CrossRef]
- Esteban, A.; Zafra, A.; Romero, C. Helping University Students to Choose Elective Courses by Using a Hybrid Multi-Criteria Recommendation System with Genetic Optimization. Knowl.-Based Syst. 2020, 194, 105385. [Google Scholar] [CrossRef]
- Serrano-Guerrero, J.; Herrera-Viedma, E.; Olivas, J.A.; Cerezo, A.; Romero, F.P. A Google Wave-Based Fuzzy Recommender System to Disseminate Information in University Digital Libraries 2.0. Inf. Sci. 2011, 181, 1503–1516. [Google Scholar] [CrossRef]
- Tejeda-Lorente, Á.; Porcel, C.; Peis, E.; Sanz, R.; Herrera-Viedma, E. A Quality Based Recommender System to Disseminate Information in a University Digital Library. Inf. Sci. 2014, 261, 52–69. [Google Scholar] [CrossRef]
- He, Q.; Pei, J.; Kifer, D.; Mitra, P.; Giles, L. Context-aware citation recommendation. In Proceedings of the 19th International Conference on World Wide Web—WWW ’10, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar] [CrossRef]
- Wang, D.; Liang, Y.; Xu, D.; Feng, X.; Guan, R. A Content-Based Recommender System for Computer Science Publications. Knowl.-Based Syst. 2018, 157, 1–9. [Google Scholar] [CrossRef]
- Park, N.; Roman, R.; Lee, S.; Chung, J.E. User Acceptance of a Digital Library System in Developing Countries: An Application of the Technology Acceptance Model. Int. J. Inf. Manag. 2009, 29, 196–209. [Google Scholar] [CrossRef]
- Jeong, H. An Investigation of User Perceptions and Behavioral Intentions towards the E-Library. Libr. Collect. Acquis. Tech. Serv. 2011, 35, 45–60. [Google Scholar] [CrossRef]
- Achakulvisut, T.; Acuna, D.E.; Ruangrong, T.; Kording, K. Science Concierge: A Fast Content-Based Recommendation System for Scientific Publications. PLoS ONE 2016, 11, e0158423. [Google Scholar] [CrossRef]
- Färber, M.; Jatowt, A. Citation Recommendation: Approaches and Datasets. Int. J. Digit. Libr. 2020, 21, 375–405. [Google Scholar] [CrossRef]
- Brian, D. Netflix Subscriber and Growth Statistics: How Many People Watch Netflix in 2021? Available online: https://backlinko.com/netflix-users (accessed on 25 February 2021).
- Statista. Disney+’s Number of Subscribers Worldwide from 1st Quarter 2020 to 2nd Quarter 2021. Available online: https://www.statista.com/statistics/1095372/disney-plus-number-of-subscribers-us/ (accessed on 19 August 2021).
- BBC News. Netflix Launches UK Film and TV Streaming Service. Available online: https://web.archive.org/web/20120109175608/http://www.bbc.co.uk/news/technology-16467432 (accessed on 9 January 2012).
- PR Newswire. Netflix Launches in Sweden, Denmark, Norway and Finland. Available online: https://web.archive.org/web/20141127211314/http://www.prnewswire.com/news-releases/netflix-launches-in-sweden-denmark-norway-and-finland-174749581.html (accessed on 27 November 2014).
- Variety. Netflix’s ‘House of Cards’ Falls Prey to Piracy. Available online: https://variety.com/2013/digital/news/pirates-swarm-netflixs-house-of-cards-1200333171/ (accessed on 4 April 2013).
- Gupta, G.; Singharia, K. Consumption of OTT Media Streaming in COVID-19 Lockdown: Insights from PLS Analysis. Vision 2021, 25, 36–46. [Google Scholar] [CrossRef]
- Ryan; Meg; Anousha. Shaken Studios. Empty Theaters. What Hollywood Lost during the Pandemic. Available online: https://www.latimes.com/entertainment-arts/business/story/2020-12-09/everything-hollywood-lost-during-the-pandemic (accessed on 9 December 2020).
- Insider Intelligence. Top OTT VOD Streaming Services in 2021 by Viewer Count and Growth. Available online: https://www.insiderintelligence.com/insights/ott-vod-video-streaming-services/ (accessed on 21 July 2021).
- Statista. Facebook Keeps on Growing. Available online: https://www.statista.com/chart/10047/facebooks-monthly-active-users/ (accessed on 4 February 2021).
- Prabhakaran. 50+ Instagram Stats Everyone Must Know in 2020. Available online: https://www.connectivasystems.com/instagram-stats-2020/ (accessed on 1 April 2020).
- Statista. Number of Monthly Active Twitter Users Worldwide from 1st Quarter 2010 to 1st Quarter 2019. Available online: https://www.statista.com/statistics/282087/number-of-monthly-active-twitter-users/ (accessed on 31 December 2021).
- Hughes, D.J.; Rowe, M.; Batey, M.; Lee, A. A Tale of Two Sites: Twitter vs. Facebook and the Personality Predictors of Social Media Usage. Comput. Hum. Behav. 2012, 28, 561–569. [Google Scholar] [CrossRef]
- Highfield, T.; Leaver, T. A Methodology for Mapping Instagram Hashtags. First Monday 2014, 20, 1–11. [Google Scholar] [CrossRef]
- Sarah, F. The Inside Story of How Facebook Acquired Instagram. Available online: https://onezero.medium.com/the-inside-story-of-how-facebook-acquired-instagram-318f244f1283 (accessed on 5 August 2020).
- Dave, S. Chart of the Day: Instagram Is Now Bigger Than Twitter. Available online: https://www.businessinsider.com.au/chart-of-the-day-instagram-is-now-bigger-than-twitter-2014-12 (accessed on 11 December 2014).
- Li, S.; Takahashi, S.; Yamada, K.; Takagi, M.; Sasaki, J. Analysis of SNS Photo Data Taken by Foreign Tourists to Japan and a Proposed Adaptive Tourism Recommendation System. In Proceedings of the 2017 International Conference on Progress in Informatics and Computing (PIC), Nanjing, China, 15–17 December 2017; pp. 323–327. [Google Scholar]
- Chao, L.; Jian, Y.; Xiang, L.; Hui, C.J. A Social Network System Oriented Hybrid Recommendation Model. In Proceedings of the 2012 2nd International Conference on Computer Science and Network Technology, Changchun, China, 29–31 December 2012; pp. 901–906. [Google Scholar]
- Jeong, O.-R. SNS-Based Recommendation Mechanisms for Social Media. Multimed Tools Appl 2015, 74, 2433–2447. [Google Scholar] [CrossRef]
- Statista. New Year’s Peak Illustrates Airbnb’s Growing Stature. Available online: https://lb-aps-frontend.statista.com/chart/20386/guests-staying-at-airbnb-appartments-on-new-years-eve/ (accessed on 2 January 2020).
- Siegler, M.G. Airbnb Cozies Up to Facebook to Help You Feel More at Home When Away from Home. Available online: https://techcrunch.com/2011/05/09/airbnb-social-connections/ (accessed on 10 May 2011).
- Kontogianni, A.; Alepis, E. Smart Tourism: State of the Art and Literature Review for the Last Six Years. Array 2020, 6, 100020. [Google Scholar] [CrossRef]
- Balasaraswathi, M.; Srinivasan, K.; Udayakumar, L.; Sivasakthiselvan, S.; Sumithra, M.G. Big Data Analytic of Contexts and Cascading Tourism for Smart City. Mater. Today Proc. 2020, S2214785320377129. [Google Scholar] [CrossRef]
- Yoo, C.W.; Goo, J.; Huang, C.D.; Nam, K.; Woo, M. Improving Travel Decision Support Satisfaction with Smart Tourism Technologies: A Framework of Tourist Elaboration Likelihood and Self-Efficacy. Technol. Forecast. Soc. Chang. 2017, 123, 330–341. [Google Scholar] [CrossRef]
- Tribe, J.; Mkono, M. Not Such Smart Tourism? The Concept of e-Lienation. Ann. Tour. Res. 2017, 66, 105–115. [Google Scholar] [CrossRef]
- Kim, I.-S.; Jeong, C.-S.; Jung, T.-W.; Kang, J.-K.; Jung, K.-D. AR Tourism Recommendation System Based on Character-Based Tourism Preference Using Big Data. Int. J. Internet Broadcasting Commun. 2021, 13, 61–68. [Google Scholar] [CrossRef]
- Statista. Net Revenue of Amazon from 1st Quarter 2007 to 1st Quarter 2021. Available online: https://www.statista.com/statistics/273963/quarterly-revenue-of-amazoncom/ (accessed on 19 July 2021).
- Statista. Annual Revenue of Alibaba Group from Financial Year 2011 to 2021. Available online: https://www.statista.com/statistics/225614/net-revenue-of-alibaba/ (accessed on 15 September 2021).
- Linden, G.; Smith, B.; York, J. Amazon.Com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two Decades of Recommender Systems at Amazon.Com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Wang, J.; Huang, P.; Zhao, H.; Zhang, Z.; Zhao, B.; Lee, D.L. Billion-Scale Commodity Embedding for E-Commerce Recommendation in Alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 839–848. [Google Scholar]
- Chen, Q.; Zhao, H.; Li, W.; Huang, P.; Ou, W. Behavior Sequence Transformer for E-Commerce Recommendation in Alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, Alaska, 5 August 2019; pp. 1–4. [Google Scholar]
- Statista. Apple Watch Installed Base Worldwide from 2015 to 2020. Available online: https://www.statista.com/statistics/1221051/apple-watch-users-worldwide/ (accessed on 17 March 2021).
- Statista. Fitbit’s Community Grows Amid Stalling Device Sales. Available online: https://www.statista.com/chart/13083/worldwide-fitbit-shipments/ (accessed on 4 August 2020).
- Dino, G. Huffpost. Fitbit Recalls Fitbit Force after Complaints of Severe Rashes. Available online: https://www.huffpost.com/entry/fitbit-force-recall_n_4832771 (accessed on 21 February 2014).
- Mallory, H. Apple Study Finds Watch Can Detect More Types of Irregular Heartbeats. Available online: https://www.mobihealthnews.com/news/apple-study-finds-watch-can-detect-more-types-irregular-heartbeats (accessed on 29 September 2021).
- Statista. Global Apple Watch shipments from 2017 to 2019. Available online: https://www.statista.com/statistics/526005/global-apple-watch-shipments-forecast/ (accessed on 31 December 2021).
- Zoë, B. Apple Topped the Swiss in Holiday Watch Shipments. Available online: https://www.businessinsider.com/apple-watch-sells-more-than-swiss-watches-charts-2018-2 (accessed on 13 February 2018).
- Elearningfeeds. eLearning Statistics and Trends: 2020. Available online: https://elearningfeeds.com/elearning-statistics-and-trends-2020/ (accessed on 14 December 2020).
- Miran, P.; Sunil, J.; Seungin, K. A Study on Application and Prospect with Prevalence Tablet PC -An Approach of Humanities, Science and Design. J. Korea Des. Knowl. 2011, 18, 84–93. Available online: http://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE01772204 (accessed on 30 June 2011).
- Jisu, K.; Ko, H. Comparison of the Convolutional Neural Network models with an art dataset. In Proceedings of the 17th International Conference on Multimedia Information Technology and Applications (MITA 2021), Seogwipo, Korea, 5–7 July 2021; pp. 117–120. [Google Scholar]
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hybrid Method | Description |
|---|---|
| Weighted Hybridization | A method in which the weight is gradually adjusted according to the degree to which the user’s evaluation of an item coincides with the evaluation predicted by the recommendation system. |
| Switching Hybridization | A method of changing the recommendation model used depending on the situation. |
| Cascaded Hybridization | After using one of the recommendation system models to create a candidate set with a similar taste to the user, the method combinesthe previously used recommendation system model with another model to sort the candidate set in the order of items most suited to the user’s taste. |
| Mixed Hybridization | When many recommendations are made at the same time, Content-Based Filtering can recommend items based on the description of the items without user evaluation, but there is a start-up problem in that it cannot recommend new items with insufficient information. In order to solve this problem, the Mixed Hybridization method recommends items to the user by integrating the user’s past history data that is collected when the recommendation system service is started. |
| Feature- Combination | A collaborative filtering model is used for featured data and example data for items, and a Content-Based Filtering model is used for augmented data. |
| Feature- Augmentation | A Hybrid method in which one Recommendation System Model is used to classify an item’s preference score or item, and the generated information is integrated into the next Recommendation System Model. |
| Meta-Level | A method of using the entire model of one recommendation system as the input data in the model of another recommendation system. Since the user’s taste is compressed and expressed using Meta-Level, it is easier to operate the Collaborative Mechanism than when raw rating data are used as single-input data. |
| Preference | Recommended | Not Recommended |
|---|---|---|
| User-preferred item | True Positives (TP) | True Negatives (TN) |
| User-non-preferred item | False Positives (FP) | False Negatives (FN) |
| Evaluation Metrics | Equation | Definition |
|---|---|---|
| Precision | Precision = TP/TP + FP | The ratio of items that match the user’s taste among all items recommended to the user. |
| Recall | Recall = TP/TP + FN | The ratio of items that match the user’s taste among all items recommended to the user. |
| Accuracy | Accuracy = TP + TN/TP + FN + FP + TN | The ratio of successful referrals to total referrals. |
| F-Measure | F-Measure = 2 × (Precision × Recall)/(Precision + Recall) | Harmonic mean value of Precision and Recall. |
| ROC curve | Ratio of TP Rate (= TP/TP + FN) and FP Rate (= FP/FP + TN) | A graph showing the relationship between FPR and TPR. A visual description of the ratio of the performance results of Precision and Recall. |
| AUC | Area under the ROC curve | AUC measures the probability that a random relevant item is ranked higher than a random irrelevant item |
| Web 1.0 | Web 2.0 | Web 3.0 | |
|---|---|---|---|
| Communication | Broadcast | Interactive | Engaged/Invested |
| Information | Static/Read-only | Dynamic | Portable/Personal |
| Focus | Organization | Community | Individual |
| Personal | Home Pages | Blogs/ SNS | Life Streams |
| Interaction | Web Forms | Web Applications | Smart Applications |
| Search | Directories | Keywords/Tags | Context/Relevance |
| Metrics | Page Views | Cost Per Click | User Engagement |
| Research | Britannica Online | Wikipedia | The Semantic Web |
| Streaming Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
| Video | CF | Clustering | [95] |
| Matrix Factorization | [85] | ||
| Hybrid System | Text Mining | [8,91] | |
| Matrix Factorization | [9,36,88] | ||
| Music | CB | Text Mining | [90] |
| Neural Network | [81] | ||
| CF | KNN | [96] | |
| Hybrid System | Matrix Factorization | [87,92] | |
| Neural Network | [89] |
| SNS Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
|
SNS Followers or Item Recommendation | CF | Text Mining | [100] |
| KNN | [3] | ||
| Matrix Factorization | [4,78] | ||
| Hybrid System | Text Mining | [6] | |
| Clustering | [5] | ||
|
Information Recommendation Using SNS Data | CB | Text Mining | [18,98] |
| Matrix Factorization | [101] | ||
| Neural Network | [11] | ||
| CF | Text Mining | [97] | |
| Matrix Factorization | [10,79] | ||
| Neural Network | [10] | ||
| Hybrid System | Text Mining | [12] | |
| Clustering | [102] |
| Tourism Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
|
Tourist Attractions or Tourist Information Recommendation | CB | Clustering | [107] |
| CF | Text Mining | [108] | |
| Clustering | [109] | ||
| Matrix Factorization | [109] | ||
| Hybrid System | Text Mining | [103,110,111] | |
| Clustering | [2] | ||
|
Tourist Route or Transportation Recommendation | CB | Clustering | [103,106] |
| CF | Text Mining | [105] |
| E-Commerce Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
| Web | CF | Text Mining | [122] |
| Clustering | [72] | ||
| [118] | |||
| Hybrid System | Neural Network | [113] | |
| Mobile | Hybrid System | Neural Network | [120] |
| Healthcare Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
|
Medical Treatment or Diet Recommendation | CB | Text Mining | [129,139] |
| Clustering | [130] | ||
| Neural Network | [134] | ||
| CF | Clustering | [131] | |
| Hybrid System | Neural Network | [133] | |
|
Health Information Recommendation Using E-Health | CB | Text Mining | [136,137] |
| Neural Network | [138] |
| Education Service | RS Model | RS Techniques | Literature Sources |
|---|---|---|---|
|
E-Learning and Customized Learning Recommendation | CB | Text Mining | [145] |
| Neural Network | [144]] | ||
| CF | Text Mining | [147] | |
| Hybrid System | Text Mining | [7,148] | |
| Clustering | [143,146] | ||
|
Education Course Recommendation | Hybrid System | Text Mining | [149,151] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, H.; Lee, S.; Park, Y.; Choi, A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics 2022, 11, 141. https://doi.org/10.3390/electronics11010141
Ko H, Lee S, Park Y, Choi A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics. 2022; 11(1):141. https://doi.org/10.3390/electronics11010141
Chicago/Turabian StyleKo, Hyeyoung, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. "A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields" Electronics 11, no. 1: 141. https://doi.org/10.3390/electronics11010141
APA StyleKo, H., Lee, S., Park, Y., & Choi, A. (2022). A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics, 11(1), 141. https://doi.org/10.3390/electronics11010141