
Hybrid Memristor–CMOS Implementation of Combinational Logic Based on X-MRL †

 ,
,  , , and
, , and
Abstract
1. Introduction
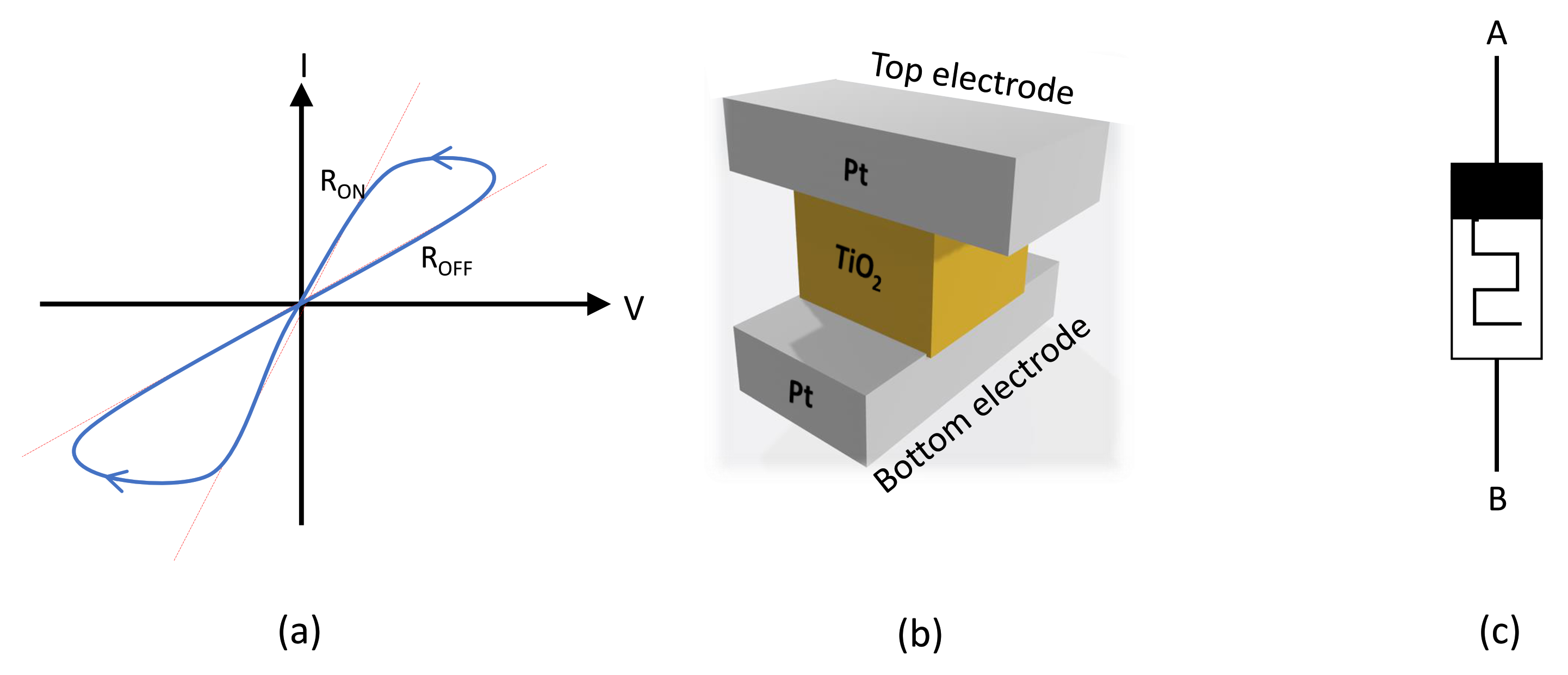
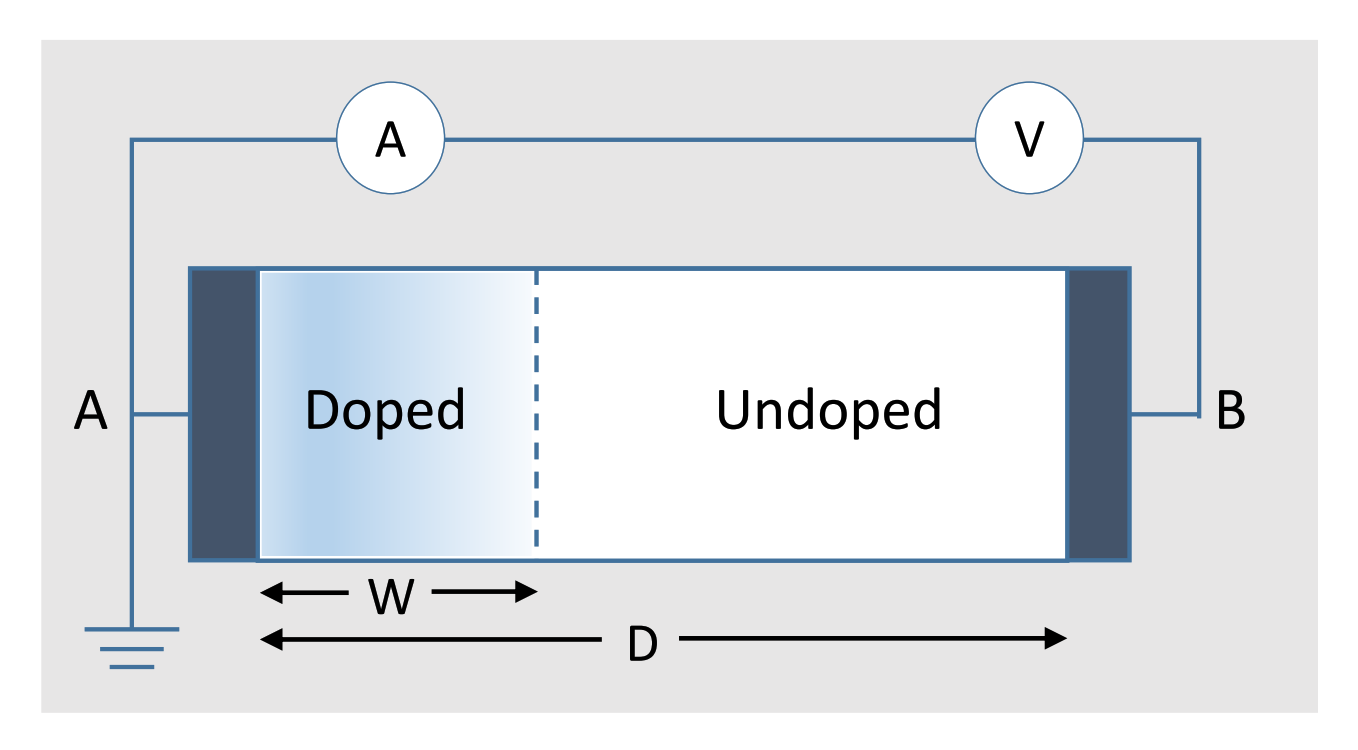
2. Memristor Behavior and Modeling
3. Memristor-Based Logic Design Styles
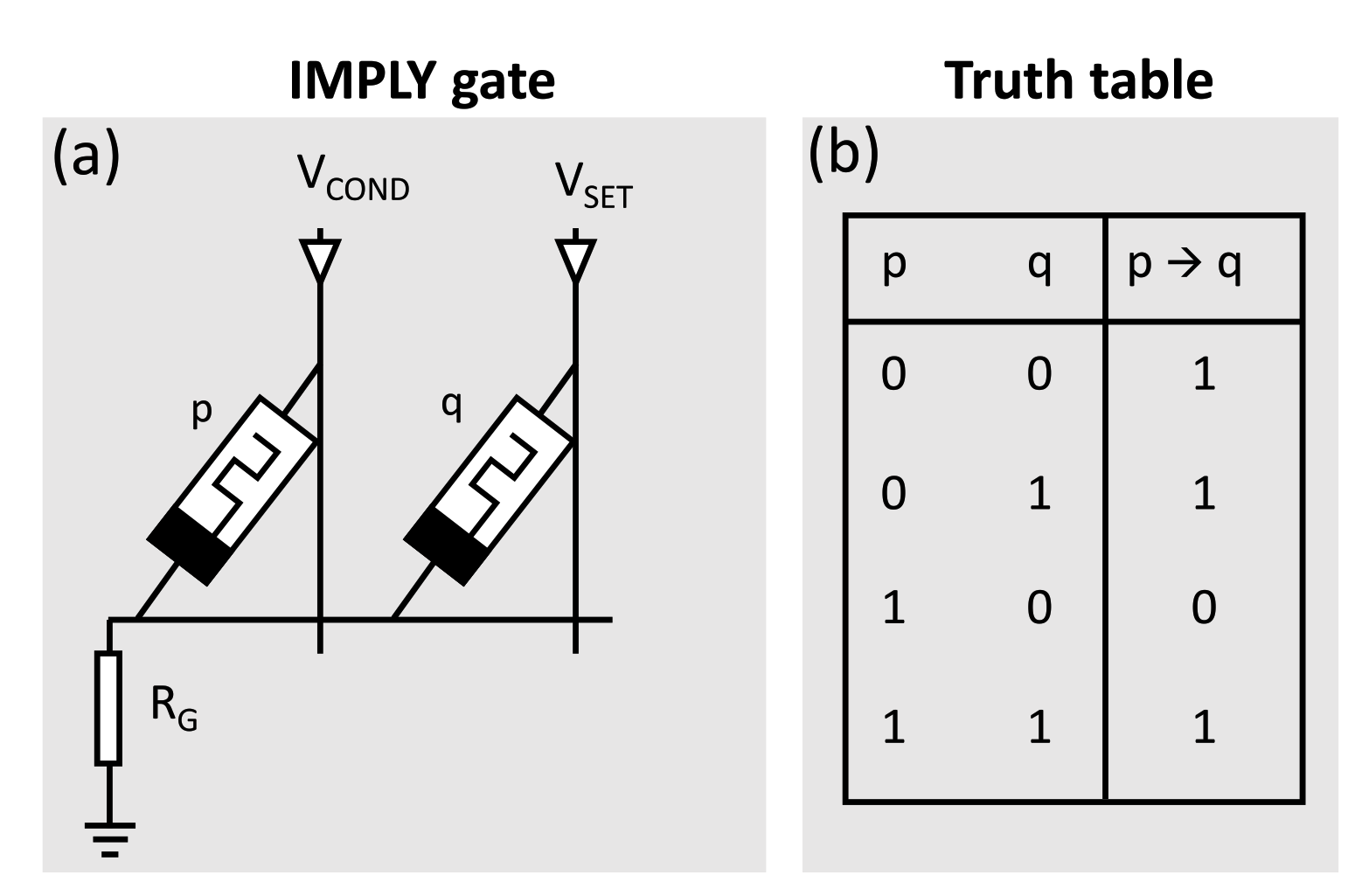
3.1. Material Implication IMPLY Gates
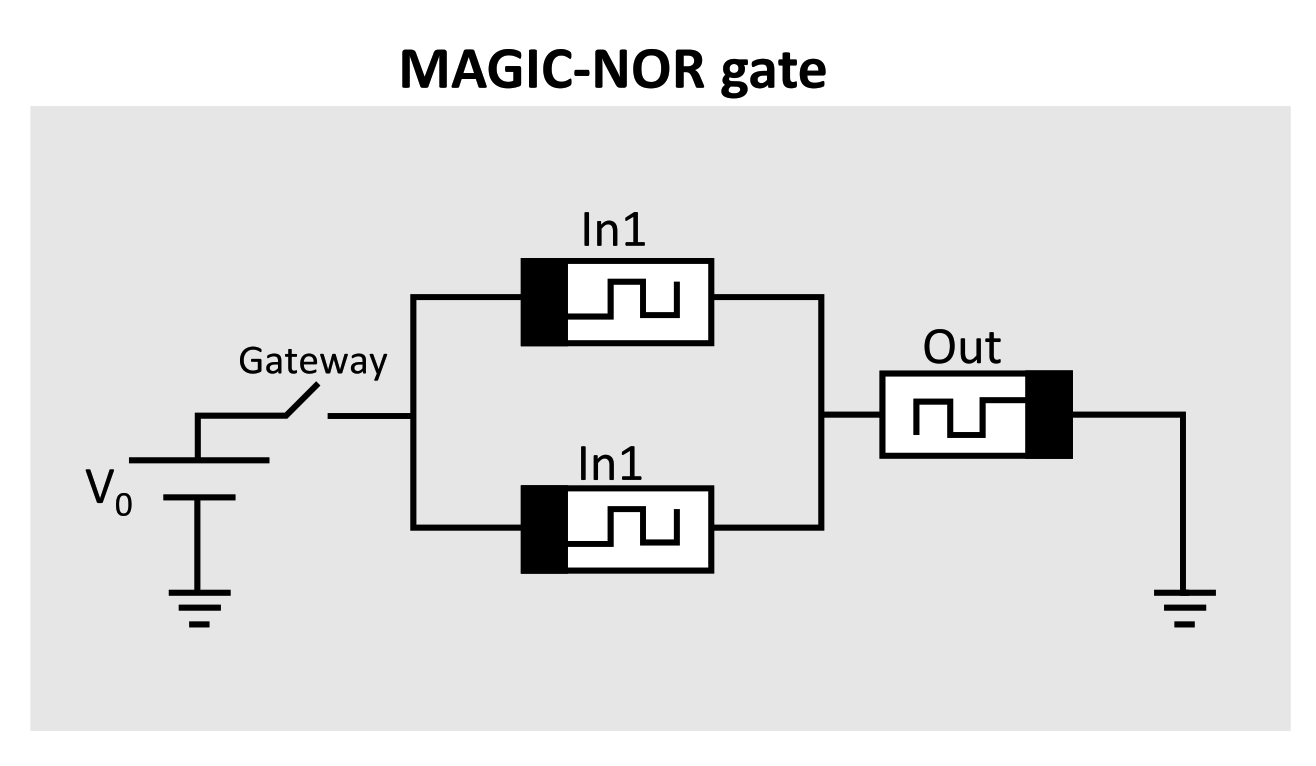
3.2. Memristor Aided Logic (MAGIC)
3.3. Memristor Ratioed Logic (MRL)
4. Proposed X-MRL Design for Logic Computation
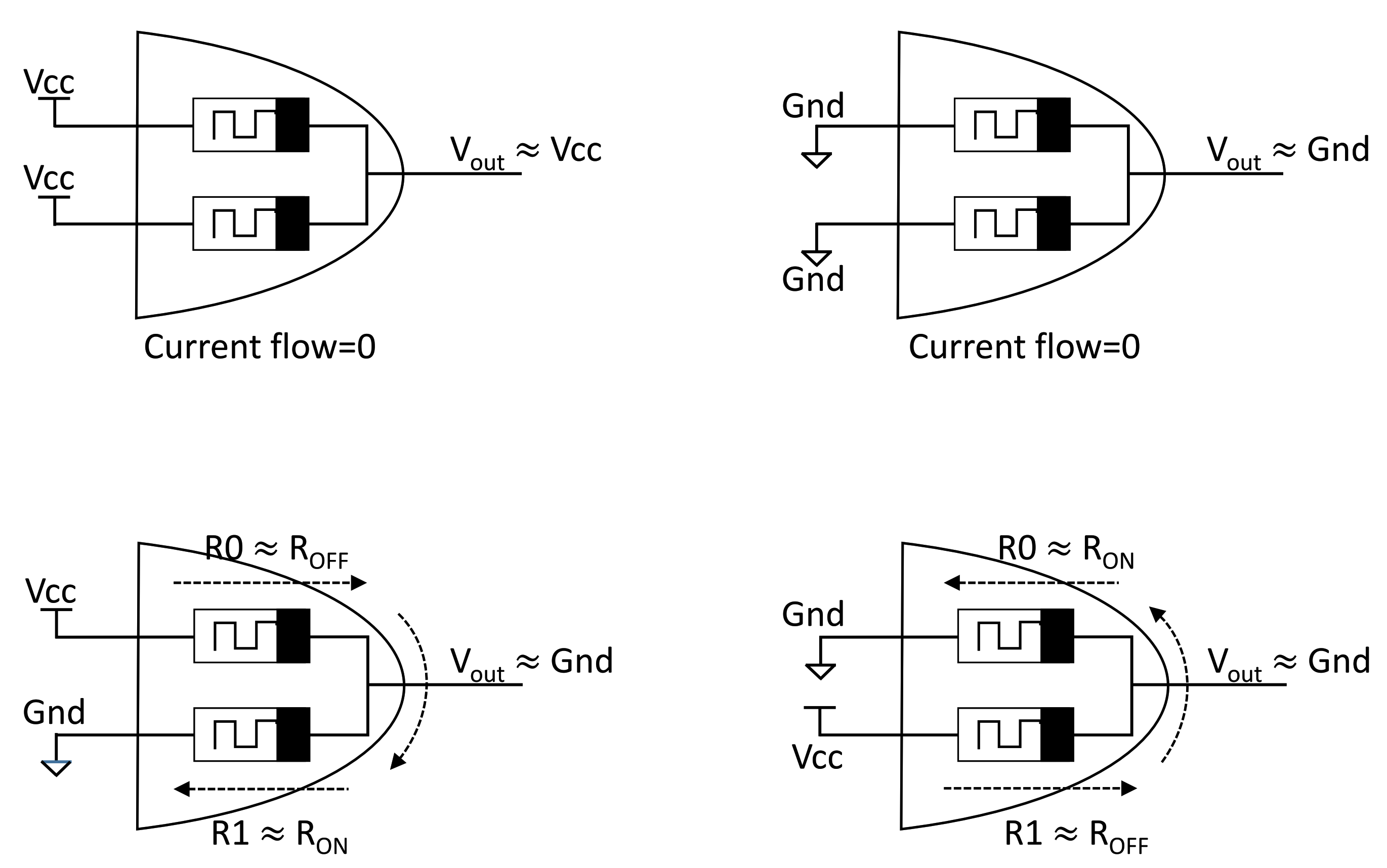
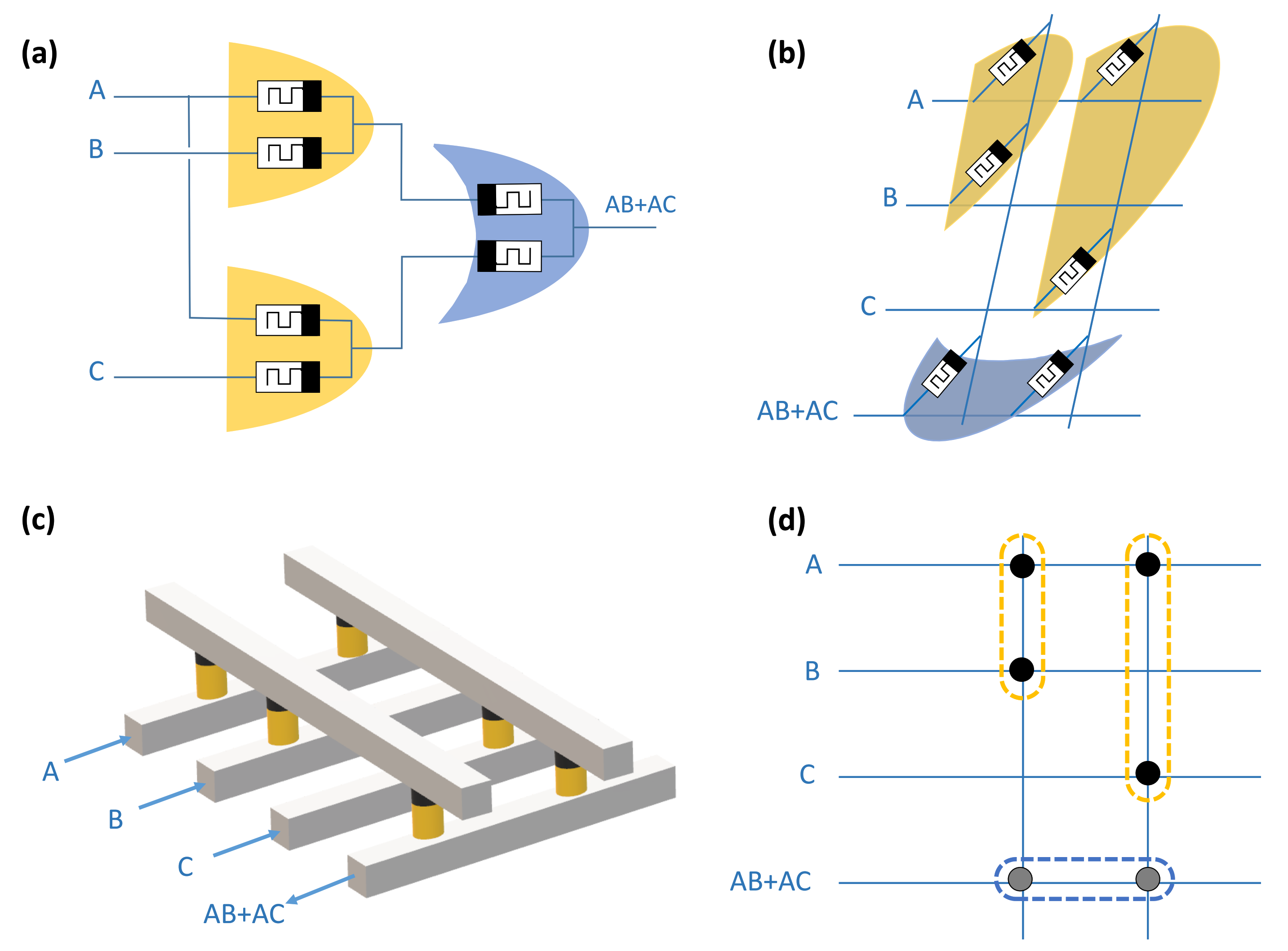
4.1. X-MRL Structure
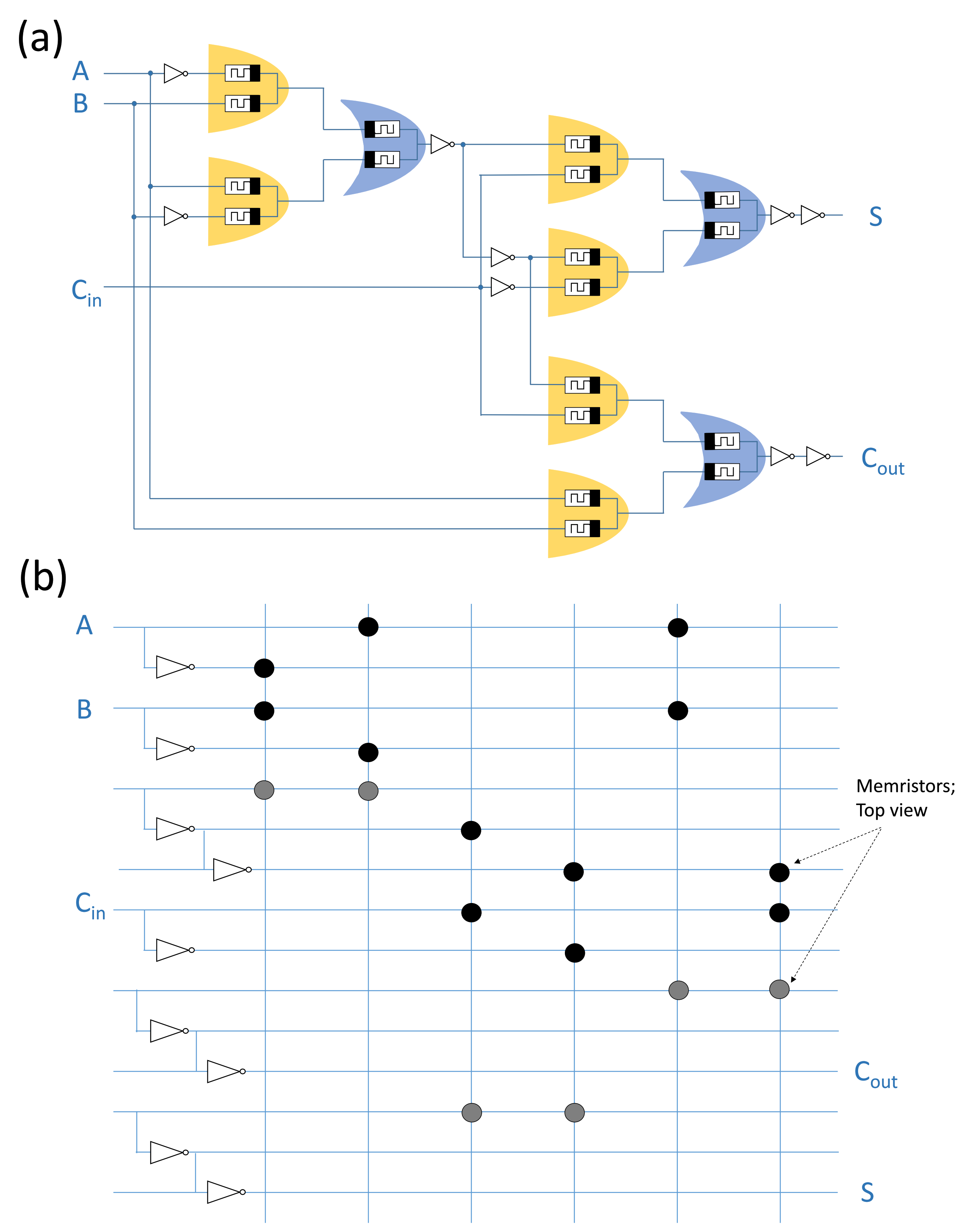
4.2. X-MRL Full Adder
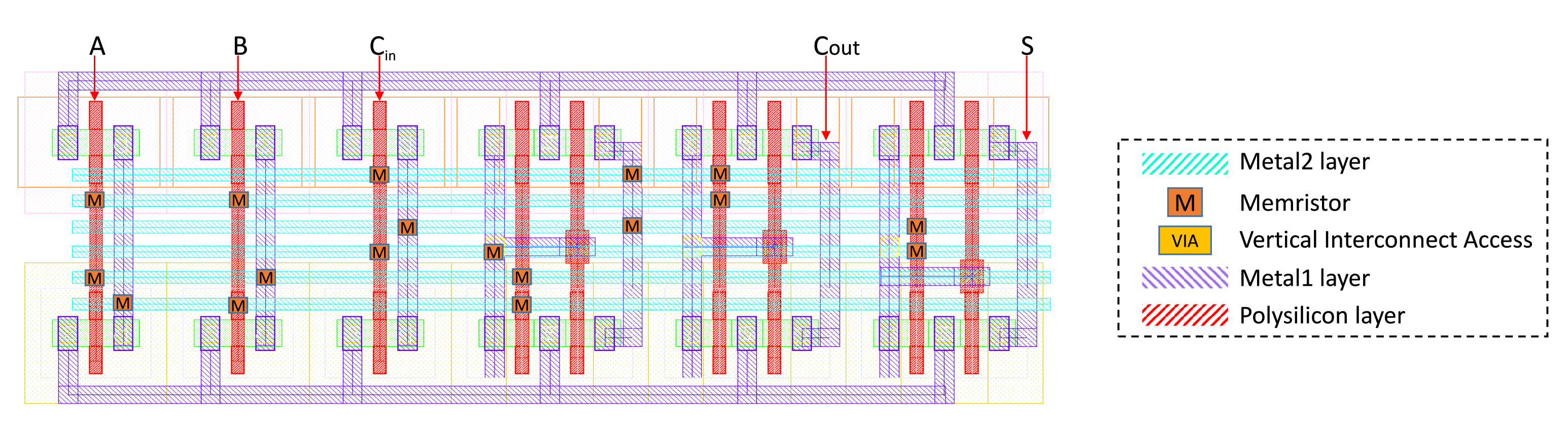
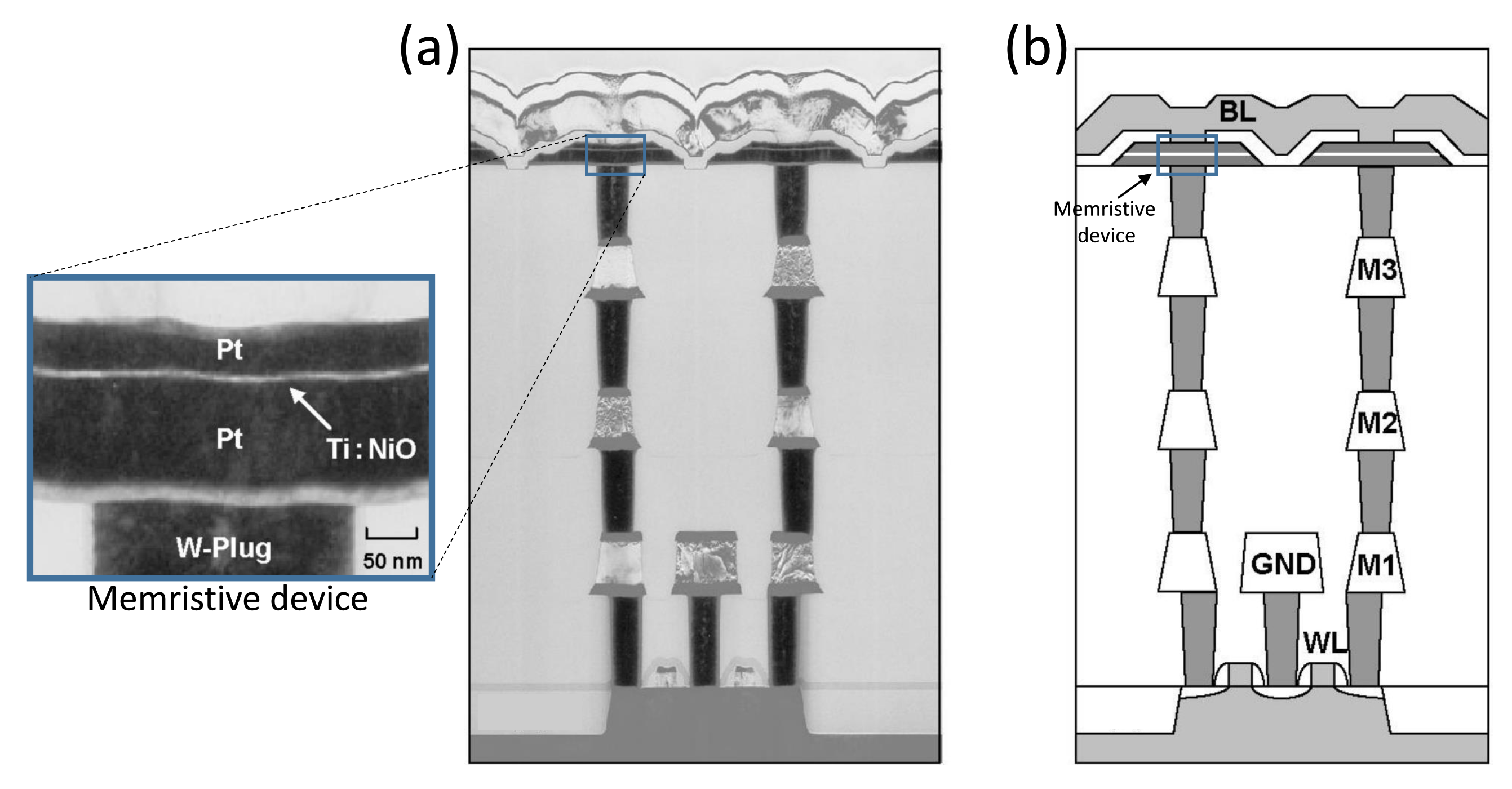
4.3. Layout
5. Simulation and Performance Analysis
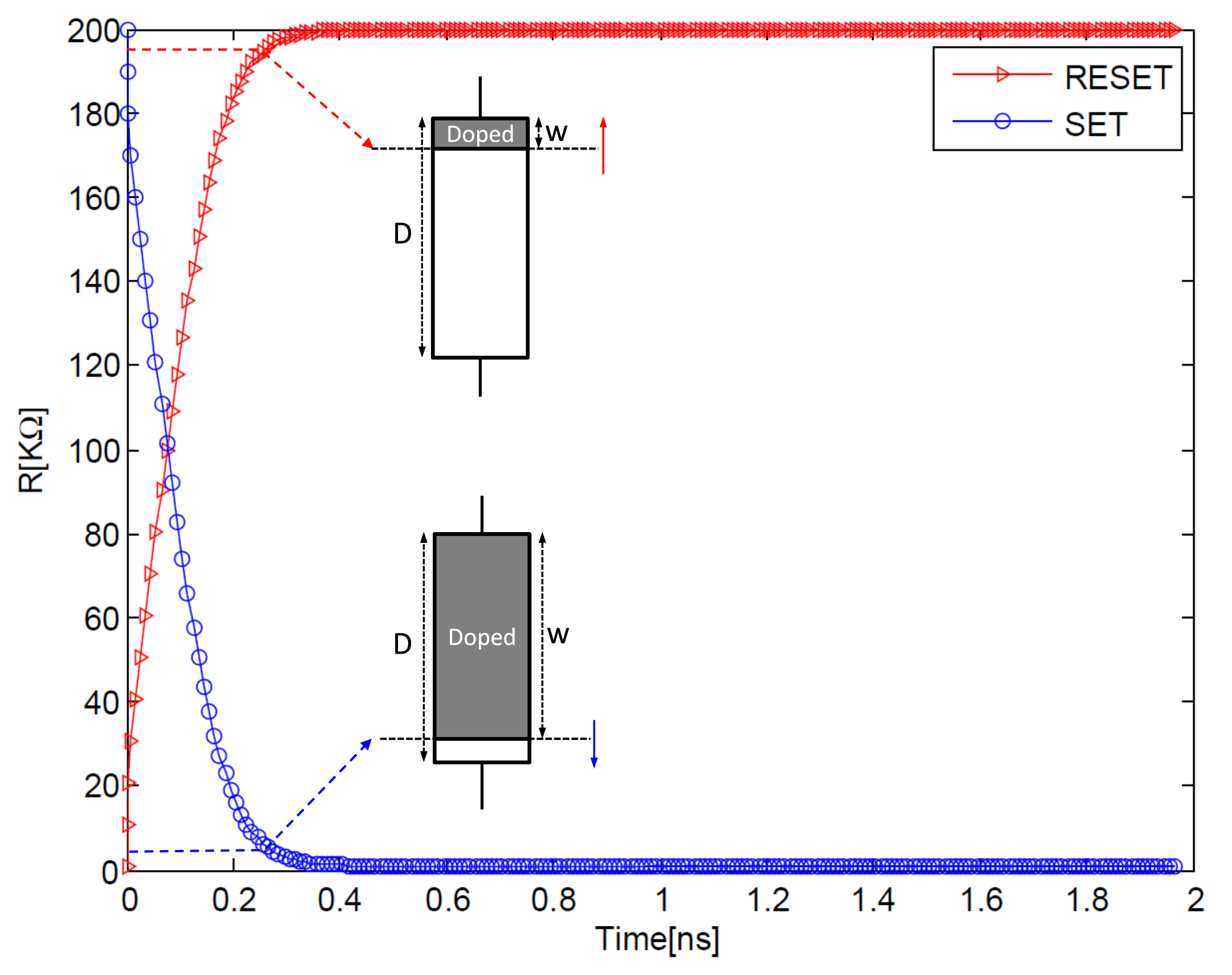
5.1. Memristor Model Fitting
5.2. Performance Analysis
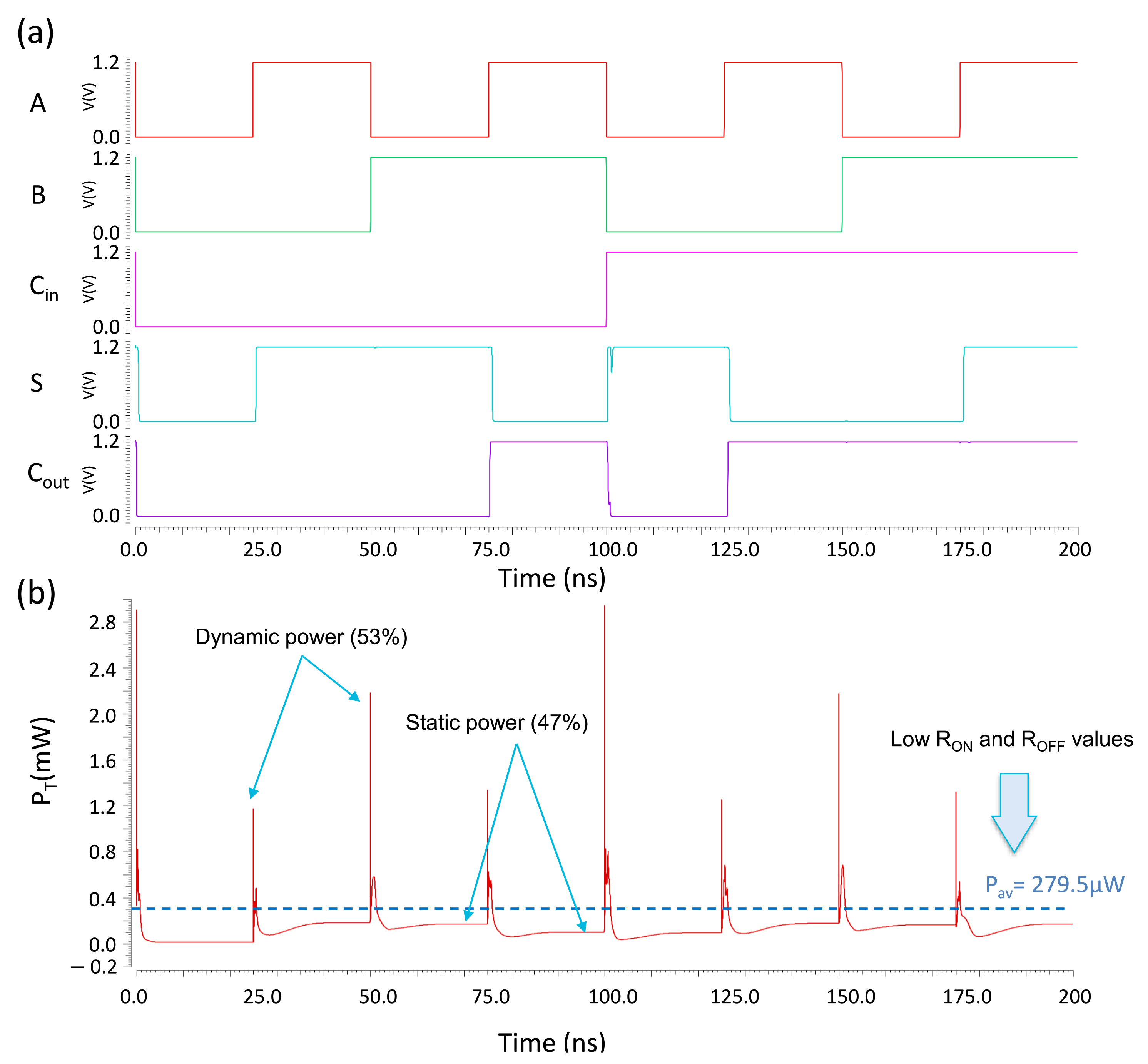
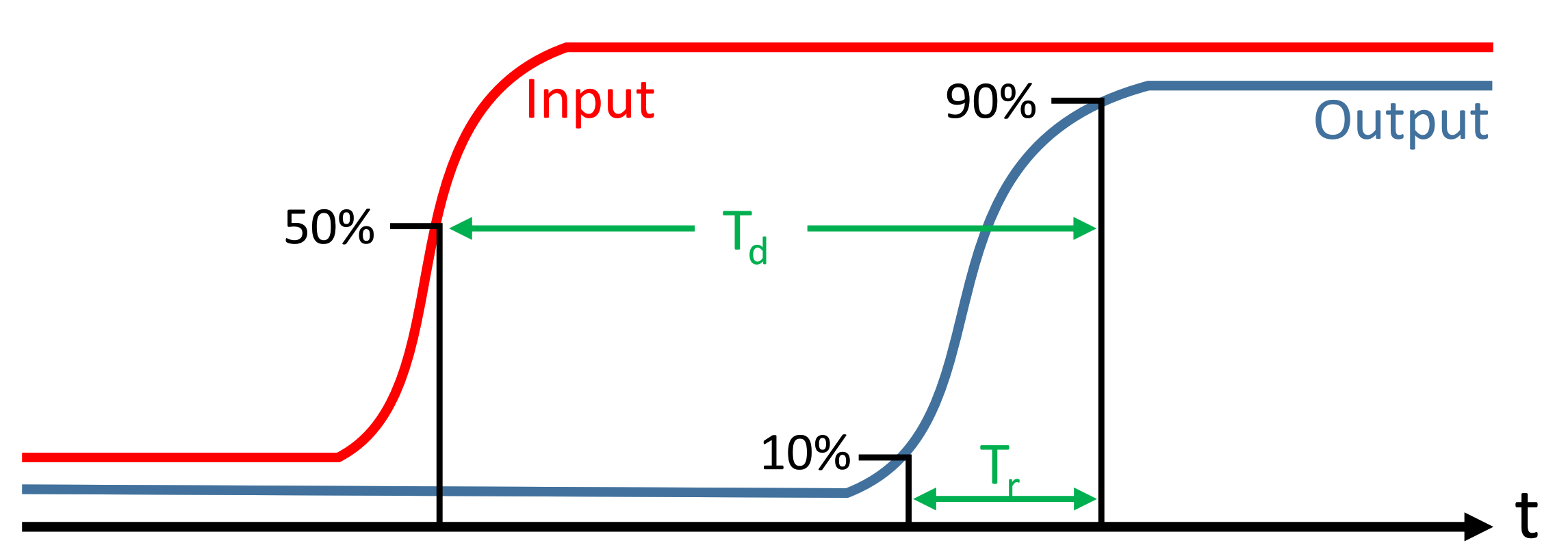
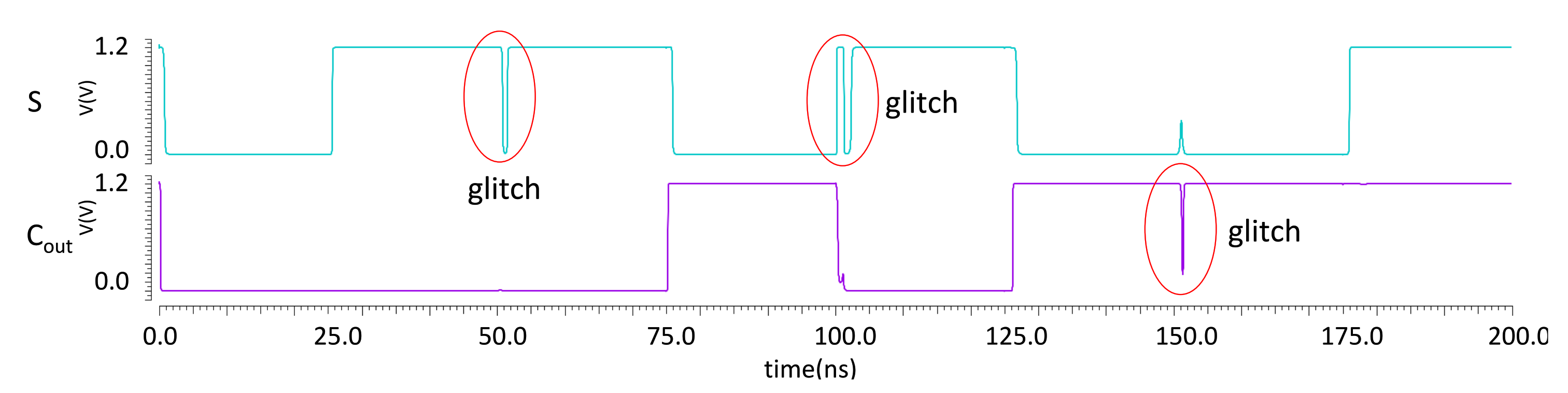
5.2.1. Timing Analysis
5.2.2. Energy Consumption
5.2.3. Utilized Area
6. Comparison
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chua, L. Memristor-The missing circuit element. IEEE Trans. Circuit Theory 1971, 18, 507–519. [Google Scholar] [CrossRef]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The missing memristor found. Nature 2008, 453, 80–83. [Google Scholar] [CrossRef] [PubMed]
- Mladenov, V. Analysis of memory matrices with HfO2 memristors in a PSpice environment. Electronics 2019, 8, 383. [Google Scholar] [CrossRef]
- Hamdioui, S.; Du Nguyen, H.A.; Taouil, M.; Sebastian, A.; Le Gallo, M.; Pande, S.; Schaafsma, S.; Catthoor, F.; Das, S.; Redondo, F.G.; et al. Applications of computation-in-memory architectures based on memristive devices. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 486–491. [Google Scholar]
- Kvatinsky, S.; Belousov, D.; Liman, S.; Satat, G.; Wald, N.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. MAGIC—Memristor-aided logic. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 895–899. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Satat, G.; Wald, N.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. Memristor-based material implication (IMPLY) logic: Design principles and methodologies. IEEE Trans. VLSI Syst. 2014, 22, 2054–2066. [Google Scholar] [CrossRef]
- Reuben, J.; Ben-Hur, R.; Wald, N.; Talati, N.; Ali, A.H.; Gaillardon, P.E.; Kvatinsky, S. Memristive logic: A framework for evaluation and comparison. In Proceedings of the 27th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), Thessaloniki, Greece, 25–27 September 2017. [Google Scholar]
- Kvatinsky, S.; Wald, N.; Satat, G.; Kolodny, A.; Weiser, U.C.; Friedman, E.G. MRL—Memristor ratioed logic. In Proceedings of the International Workshop on Cellular Nanoscale Networks and their Applications, Turin, Italy, 29–31 August 2012. [Google Scholar]
- Liu, B.; Wang, Y.; You, Z.; Han, Y.; Li, X. A signal degradation reduction method for memristor ratioed logic (MRL) gates. IEICE Electron. Express 2015, 12, 20150062. [Google Scholar] [CrossRef]
- Chowdhury, J.; Das, K.; Rout, K. Implementation Of 24T Memristor Based Adder Architecture With Improved Performance. Int. J. Electr. Electron. Data Commun. 2015, 3, 91–94. [Google Scholar]
- Cho, K.; Lee, S.J.; Eshraghian, K. Memristor-CMOS logic and digital computational components. Microelectron. J. 2015, 46, 214–220. [Google Scholar] [CrossRef]
- Ali, K.A.; Rizk, M.; Baghdadi, A.; Diguet, J.P.; Jomaah, J. MRL Crossbar-Based Full Adder Design. In Proceedings of the 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Genoa, Italy, 27–29 November 2019; pp. 674–677. [Google Scholar]
- Pickett, M.D.; Strukov, D.B.; Borghetti, J.L.; Yang, J.J.; Snider, G.S.; Stewart, D.R.; Williams, R.S. Switching dynamics in titanium dioxide memristive devices. J. Appl. Phys. 2009, 106, 074508. [Google Scholar] [CrossRef]
- Yang, J.J.; Pickett, M.D.; Li, X.; Ohlberg, D.A.; Stewart, D.R.; Williams, R.S. Memristive switching mechanism for metal/oxide/metal nanodevices. Nat. Nanotechnol. 2008, 3, 429–433. [Google Scholar] [CrossRef]
- Lehtonen, E.; Laiho, M. CNN using memristors for neighborhood connections. In Proceedings of the International Workshop on Cellular Nanoscale Networks and their Applications (CNNA), Berkeley, CA, USA, 3–5 February 2010. [Google Scholar]
- Simmons, J.G. Generalized Formula for the Electric Tunnel Effect between Similar Electrodes Separated by a Thin Insulating Film. J. Appl. Phys. 1963, 34. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. TEAM: Threshold adaptive memristor model. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 60, 211–221. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Ramadan, M.; Friedman, E.G.; Kolodny, A. VTEAM: A general model for voltage-controlled memristors. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 786–790. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Kolodny, A.; Weiser, U.C.; Friedman, E.G. Memristor-based IMPLY logic design procedure. In Proceedings of the IEEE International Conference on Computer Design (ICCD), Amherst, MA, USA, 9–12 October 2011. [Google Scholar]
- Bickerstaff, K.; Swartzlander, E.E. Memristor-based arithmetic. In Proceedings of the Conference Record of the Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010. [Google Scholar]
- Rahman, K.C.; Hammerstrom, D.; Li, Y.; Castagnaro, H.; Perkowski, M.A. Methodology and design of a massively parallel memristive stateful IMPLY logic-based reconfigurable architecture. IEEE Trans. Nanotechnol. 2016, 15, 675–686. [Google Scholar] [CrossRef]
- Hur, R.B.; Kvatinsky, S. Memristive memory processing unit (MPU) controller for in-memory processing. In Proceedings of the IEEE International Conference on the Science of Electrical Engineering (ICSEE), Eilat, Israel, 16–18 November 2016. [Google Scholar]
- Talati, N.; Gupta, S.; Mane, P.; Kvatinsky, S. Logic design within memristive memories using memristor-aided loGIC (MAGIC). IEEE Trans. Nanotechnol. 2016, 15, 635–650. [Google Scholar] [CrossRef]
- Gharpinde, R.; Thangkhiew, P.L.; Datta, K.; Sengupta, I. A Scalable In-Memory Logic Synthesis Approach Using Memristor Crossbar. IEEE Trans. VLSI Syst. 2018, 26, 355–366. [Google Scholar] [CrossRef]
- Teimoori, M.; Ahmadi, A.; Alirezaee, S.; Ahmadi, M. A novel hybrid CMOS-memristor logic circuit using Memristor Ratioed Logic. In Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, BC, Canada, 15–18 May 2016. [Google Scholar]
- Williams, R.S. Finding the missing memristor. Keynote Talk at UC San Diego CNS Winter, California, 2010. [Google Scholar]
- Xia, Q.; Robinett, W.; Cumbie, M.W.; Banerjee, N.; Cardinali, T.J.; Yang, J.J.; Wu, W.; Li, X.; Tong, W.M.; Strukov, D.B.; et al. Memristor- CMOS hybrid integrated circuits for reconfigurable logic. Nano Lett. 2009, 9, 3640–3645. [Google Scholar] [CrossRef]
- Yang, J.J.; Strukov, D.B.; Stewart, D.R. Memristive devices for computing. Nat. Nanotechnol. 2013, 8, 13–24. [Google Scholar] [CrossRef]
- Tsunoda, K.; Kinoshita, K.; Noshiro, H.; Yamazaki, Y.; Iizuka, T.; Ito, Y.; Takahashi, A.; Okano, A.; Sato, Y.; Fukano, T.; et al. Low power and high speed switching of Ti-doped NiO ReRAM under the unipolar voltage source of less than 3V. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 10–12 December 2007. [Google Scholar]
- Kwon, D.H.; Kim, K.M.; Jang, J.H.; Jeon, J.M.; Lee, M.H.; Kim, G.H.; Li, X.S.; Park, G.S.; Lee, B.; Han, S.; et al. Atomic structure of conducting nanofilaments in TiO 2 resistive switching memory. Nat. Nanotechnol. 2010, 5, 148–153. [Google Scholar] [CrossRef]
- Wang, Z.; Joshi, S.; Savel’ev, S.E.; Jiang, H.; Midya, R.; Lin, P.; Hu, M.; Ge, N.; Strachan, J.P.; Li, Z.; et al. Memristors with diffusive dynamics as synaptic emulators for neuromorphic computing. Nat. Mater. 2017, 16, 101–108. [Google Scholar] [CrossRef]
- Guan, X.; Yu, S.; Wong, H.S.P. A SPICE compact model of metal oxide resistive switching memory with variations. IEEE Electron Device Lett. 2012, 33, 1405–1407. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Deng, E.; Klein, J.O.; Naviner, L.A.; Zhao, W. Compact model of magnetic tunnel junction with stochastic spin transfer torque switching for reliability analyses. Microelectron. Reliab. 2014, 54, 1774–1778. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, H.; Naviner, L.A.; Zhang, Y.; Klein, J.O. Compact thermal modeling of spin transfer torque magnetic tunnel junction. Microelectron. Reliab. 2015, 55, 1649–1653. [Google Scholar] [CrossRef]
- Lee, H.; Chen, Y.; Chen, P.; Gu, P.; Hsu, Y.; Wang, S.; Liu, W.; Tsai, C.; Sheu, S.; Chiang, P.; et al. Evidence and solution of over-RESET problem for HfOx based resistive memory with Sub-ns switching speed and high endurance. In Proceedings of the IEEE International Electron Devices Meeting, San Francisco, CA, USA, 2 March 2010. [Google Scholar]
- Chanthbouala, A.; Garcia, V.; Cherifi, R.O.; Bouzehouane, K.; Fusil, S.; Moya, X.; Xavier, S.; Yamada, H.; Deranlot, C.; Mathur, N.D.; et al. A ferroelectric memristor. Nat. Mater. 2012, 11, 860–864. [Google Scholar] [CrossRef]
- Kang, J.; Huang, P.; Gao, B.; Li, H.; Chen, Z.; Zhao, Y.; Liu, C.; Liu, L.; Liu, X. Design and application of oxide-based resistive switching devices for novel computing architectures. IEEE J. Electron Devices Soc. 2016, 4, 307–313. [Google Scholar] [CrossRef]
- Baek, I.; Lee, M.; Seo, S.; Lee, M.; Seo, D.; Suh, D.S.; Park, J.; Park, S.; Kim, H.; Yoo, I.; et al. Highly scalable nonvolatile resistive memory using simple binary oxide driven by asymmetric unipolar voltage pulses. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 13–15 December 2004. [Google Scholar]
- Diokh, T.; Le-Roux, E.; Jeannot, S.; Gros-Jean, M.; Candelier, P.; Nodin, J.; Jousseaume, V.; Perniola, L.; Grampeix, H.; Cabout, T.; et al. Investigation of the impact of the oxide thickness and RESET conditions on disturb in HfO2-RRAM integrated in a 65 nm CMOS technology. In Proceedings of the IEEE International Reliability Physics Symposium (IRPS), Monterey, CA, USA, 14–18 April 2013. [Google Scholar]
- Lee, H.; Chen, P.; Wu, T.; Chen, Y.; Wang, C.; Tzeng, P.; Lin, C.; Chen, F.; Lien, C.; Tsai, M.J. Low power and high speed bipolar switching with a thin reactive Ti buffer layer in robust HfO2 based RRAM. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 15–17 December 2008. [Google Scholar]
- Biolek, Z.; Biolek, D.; Biolkova, V. SPICE Model of Memristor with Nonlinear Dopant Drift. Radioengineering 2009, 18, 210–214. [Google Scholar]
- Mandal, S.; Sinha, J.; Chakraborty, A. Design of Memristor—CMOS based logic gates and logic circuits. In Proceedings of the 2nd International Conference on Innovations in Electronics, Signal Processing and Communication (IESC), Shillong, India, 1–2 March 2019; pp. 215–220. [Google Scholar]
- Thangkhiew, P.L.; Gharpinde, R.; Chowdhary, P.V.; Datta, K.; Sengupta, I. Area efficient implementation of ripple carry adder using memristor crossbar arrays. In Proceedings of the International Design & Test Symposium (IDT), Hammamet, Tunisia, 18–20 December 2016. [Google Scholar]
- Thangkhiew, P.; Gharpinde, R.; Yadav, D.N.; Datta, K.; Sengupta, I. Efficient implementation of adder circuits in memristive crossbar array. In Proceedings of the IEEE Region 10 Conference (TENCON), Penang, Malaysia, 5–8 November 2017. [Google Scholar]
- Teimoory, M.; Amirsoleimani, A.; Shamsi, J.; Ahmadi, A.; Alirezaee, S.; Ahmadi, M. Optimized implementation of memristor-based full adder by material implication logic. In Proceedings of the IEEE International Conference on Electronics, Circuits and Systems (ICECS), Marseille, France, 7–10 December 2014. [Google Scholar]
- TaheriNejad, N.; Delaroche, T.; Radakovits, D.; Mirabbasi, S. A semi-serial topology for compact and fast IMPLY-based memristive full adders. In Proceedings of the 17th IEEE International New Circuits and Systems Conference (NEWCAS), Munich, Germany, 23–26 June 2019; pp. 1–4. [Google Scholar]
- Rohani, S.G.; Taherinejad, N.; Radakovits, D. A Semiparallel Full-Adder in IMPLY Logic. IEEE Trans. Very Large Scale Integr. Syst. 2019, 28, 297–301. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material | (ohm) | (ohm) | Switching Speed | Voltage Range | Reference | |
|---|---|---|---|---|---|---|
| - | - | >300 | 1 ns | −1.5 V to +1.5 V | [28] | |
| FTJ | >200 | 10 ns | −5.6 V to +4.2 V | [36] | ||
| HfO | <1 ns | <1.5 V | [37] | |||
| <10 k | >100 k | >100 | 300 ps | <1.4 V | [35] | |
| TMO | - | 100 k | - | 10 ns to 100 ns | 3 V | [38] |
| HfO | 100 | - | −1.5 V to +1 V | [39] | ||
| TiN///TiN | 1 k | >1 M | >1000 | 5 ns | −1.5 V to +1.5 V | [40] |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| p | 2 | ||
| 3 | |||
| D | nm | 3 | |
| m/s | V | ||
| m/s | V | ||
| nm | nm |
| Reference | Memristors | CMOS Transistors | Energy | Steps | Step Delay | Energy.Delay |
|---|---|---|---|---|---|---|
| (This work) | 18 | 18 | pJ | 1 | ns | pJ.ns |
| MRL [9] | 16 | 12 | - | 1 | - | - |
| MRL [42] | 18 | 8 | pJ | 1 | ns | pJ.ns |
| MAGIC [43] | 9 | Peripheral drivers | pJ | 35 | ns | pJ.ns |
| MAGIC (Optimized no. of steps) [23] | 10 | Peripheral drivers | pJ | 13 | ns | pJ.ns |
| MAGIC (Area optimized) [23] | 5 | Peripheral drivers | pJ | 15 | ns | pJ.ns |
| MAGIC [44] | 15 | Peripheral drivers | pJ | 13 | ns | pJ.ns |
| MAGIC (Naive mapping) [24] | 15 | Peripheral drivers | pJ | 12 | ns | pJ.ns |
| MAGIC (Compact mapping)[24] | 24 | Peripheral drivers | pJ | 16 | ns | pJ.ns |
| IMPLY [45] | 6 | Peripheral drivers | - | 23 | ns | - |
| IMPLY (Semi-serial) [46] | 8 | Peripheral drivers | - | 12 | s | - |
| IMPLY (Semi-parallel) [47] | 5 | Peripheral drivers | - | 17 | s | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, K.A.; Rizk, M.; Baghdadi, A.; Diguet, J.-P.; Jomaah, J. Hybrid Memristor–CMOS Implementation of Combinational Logic Based on X-MRL. Electronics 2021, 10, 1018. https://doi.org/10.3390/electronics10091018
Ali KA, Rizk M, Baghdadi A, Diguet J-P, Jomaah J. Hybrid Memristor–CMOS Implementation of Combinational Logic Based on X-MRL. Electronics. 2021; 10(9):1018. https://doi.org/10.3390/electronics10091018
Chicago/Turabian StyleAli, Khaled Alhaj, Mostafa Rizk, Amer Baghdadi, Jean-Philippe Diguet, and Jalal Jomaah. 2021. "Hybrid Memristor–CMOS Implementation of Combinational Logic Based on X-MRL" Electronics 10, no. 9: 1018. https://doi.org/10.3390/electronics10091018
APA StyleAli, K. A., Rizk, M., Baghdadi, A., Diguet, J.-P., & Jomaah, J. (2021). Hybrid Memristor–CMOS Implementation of Combinational Logic Based on X-MRL. Electronics, 10(9), 1018. https://doi.org/10.3390/electronics10091018