Since the length of the original word of the ARIA block cipher is 8-bit, the implementation of ARIA is efficient for the 8-bit architecture as described in [
2]. However, the 8-bit word-based ARIA architecture is not efficient for 16-bit cases. For this reason, optimizations for 16-bit architecture should be considered. For the case of 32-bit, the developer of ARIA block cipher suggested techniques to combine substitute and diffusion layers. This approach efficiently performs the computation with
look-up table access, which is the optimal method for the 32-bit architecture.
We implemented the ARIA for both MSP430 and ARM Cortex-M3 microcontrollers. For the case of MSP430 microcontrollers, two 8-bit wise operations are combined to construct the 16-bit word for the efficient diffusion layer. The 8-bit wise memory access is efficiently handled for the substitution layer. For the case of ARM Cortex-M3 microcontrollers, the previous look-up table based access is further optimized by considering the 3-stage pipe-lining of the 32-bit ARM Cortex-M3 microcontroller. Particularly, instructions are re-scheduled to avoid pipeline stalls. Byte wise rotation operations are also efficiently implemented with ARM native instruction sets.
3.1. Optimized ARIA Implementation on 16-Bit MSP430
The MSP430 microcontroller has twelve 16-bit registers for general purposes. In
Table 3, the general purpose register utilization for ARIA encryption on 16-bit MSP430 microcontrollers is presented. In particular, general purpose registers are used for different purposes, such as plaintext pointer, round key pointer, plaintext, loop counter, and temporal variable.
Diffusion Layer: The diffusion layer executes consecutive XOR operations with 8-bit words in a certain order. Some XOR operations of diffusion layer are repeated several times (
T value of Algorithm 1). These repeated parts can be computed once. Then, these results can be used several times through the caching to reduce the number of computations. Detailed descriptions for sequential diffusion layer are presented in Algorithm 1. In Steps 1, 6, 11, and 16, some parts of XOR operations are pre-computed. Then, these results are used several times in following steps (2–5, 7–10, 12–15, and 17–20). However, the target microcontroller only supports 16-bit word size and instructions. The straight-forward implementation of 8-bit wise pre-computation technique (i.e., Algorithm 1) is inefficient for the 16-bit MSP430 microcontroller, because only half of register is utilized during the computation.
| Algorithm 1 Sequential diffusion layer of ARIA block cipher for 8-bit AVR [1]. |
| Input: 128-bit input (i[0–15]) | 10: |
| Output: 128-bit output (o[0–15]) | 11: |
| 1: | 12: |
| 2: | 13: |
| 3: | 14: |
| 4: | 15: |
| 5: | 16: |
| 6: | 17: |
| 7: | 18: |
| 8: | 19: |
| 9: | 20: |
In Algorithm 2, the implementation of a 2-way diffusion layer to utilize the 16-bit word for the 16-bit MSP430 microcontroller is presented. Unlike the straight-forward implementation, two 8-bit words are concatenated to form a 16-bit word (i.e., size of MSP430 microcontroller) and a 16-bit wise XOR operation is performed at once. Similar to the previous approach, the 16-bit wise pre-computation () is performed and the result is utilized by several times in other steps. Compared with the previous approach, the approach halves the number of required number of XOR operations and general purpose registers.
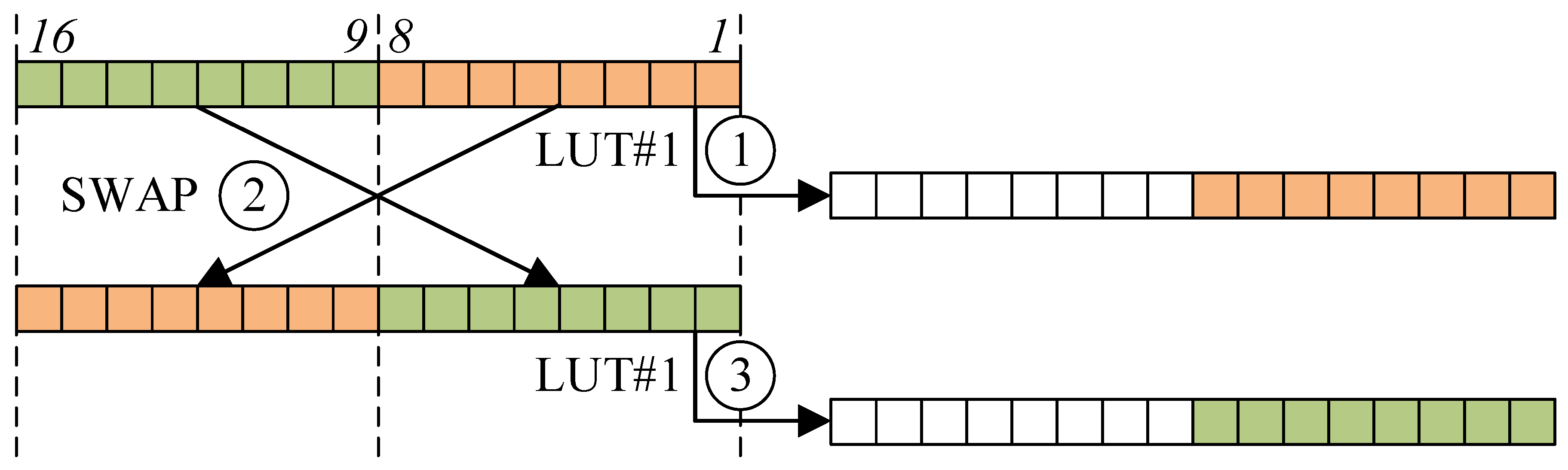
Substitution Layer: The substitution layer can be implemented with the
look-up table access (i.e., memory access). The 16-bit MSP430 microcontroller supports both word-wise and byte-wise memory access (
.B). Since the look-up table is 8-bit wise, we utilized byte-wise memory access. In particular, the 16-bit result is accessed twice by 8-bit wise. Detailed procedures for substitution layer on the 16-bit MSP430 microcontroller are given in
Figure 1 and described as follows:
The lower part of the general purpose register (1–8) is used for index of look-up table access. To extract the lower part (8-bit) from the word of the target architecture (16-bit), MOV.B instruction is utilized.
The higher part of the general purpose register (9–16) is used for index of look-up table access. To extract the higher part (8-bit) from the word (16-bit), the higher part and lower part are swapped (SWPB) and utilized. Then, the lower part is moved with the MOV.B instruction.
| Algorithm 2 The 2-way diffusion layer of ARIA block cipher for the 16-bit MSP430 microcontroller. |
| Input: 128-bit input (i[0–15]) |
| Output: 128-bit output (o[0–15]) |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
Optimization of Counter Mode of Operation for 16-bit Architecture: The counter mode of operation can be skipped through pre-computation with constant variables [
2]. Previous works have been devoted to improve the performance of counter mode through the pre-computation [
2,
20,
21,
22,
23,
24]. The input of counter mode of operation consists of counter (32-bit) and constant nonce (96-bit). One substitution and one diffusion, and two add-round-key operations for the 96-bit constant nonce part can be pre-computed. Only the remaining part for the 32-bit counter is computed online. The optimized ARIA–CTR implementation was presented by [
2].
In Algorithm 3, the 2-way diffusion layer after the pre-computation is given. In Steps 1–2, computations on counter value are performed. In Steps 3–5, 3 XOR operations are performed with
in 2-way. In Steps 6, the 16-bit word is swapped in byte-wise. Then, 4 XOR operations are performed with
. In Steps 11–13, 3 XOR operations are performed with
in the 2-way parallel way. In Step 14, the 16-bit word is swapped in byte-wise. Then, 4 XOR operations are performed with
.
| Algorithm 3 The 2-way diffusion layer of ARIA block cipher for CTR mode on the 16-bit MSP430 microcontroller. |
| Input: 128-bit pre-computed (p[0–15]), 32-bit counter (c[0–3]) |
| Output: 128-bit output (o[0–15]) |
| // computation with counter value |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| // byte-wise swap operation |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: |
| // byte-wise swap operation |
| 14: |
| 15: |
| 16: |
| 17: |
| 18: |
3.2. Optimized ARIA Block Cipher on Cortex-M3
ARM Cortex-M3 microcontrollers have 14 32-bit general purpose registers. In
Table 4, the register utilization for ARIA encryption on target microcontrollers is presented. Plaintext pointer, round key pointer, look-up table pointer, temporal variables, and plaintext are allocated in registers.
Diffusion and Substitution Layers: In [
1], the
look-up table-based round implementation was presented. The look-up table combines both diffusion and substitution layers for the 32-bit architecture. The diffusion layer
A is constructed in the form of
where
For simplifying above notations, the following notations are used.
When
S is the substitution layer, the round without key addition is performed as follows:
is performed by using look-up tables, where M is a block diagonal matrix. As described above, the efficient implementation of each matrix (, P, ) is important. The optimal implementation is highly related with compact memory access on the target microcontroller. In this paper, we presented the pipelined LUT access method.
Optimization of
matrix: The
table look-up is performed with the 8-bit wise offset. Since the word size of the ARM Cortex-M3 processor is 32-bit long, four 8-bit wise look-up accesses are required for full 32-bit computations. Detailed descriptions are presented in
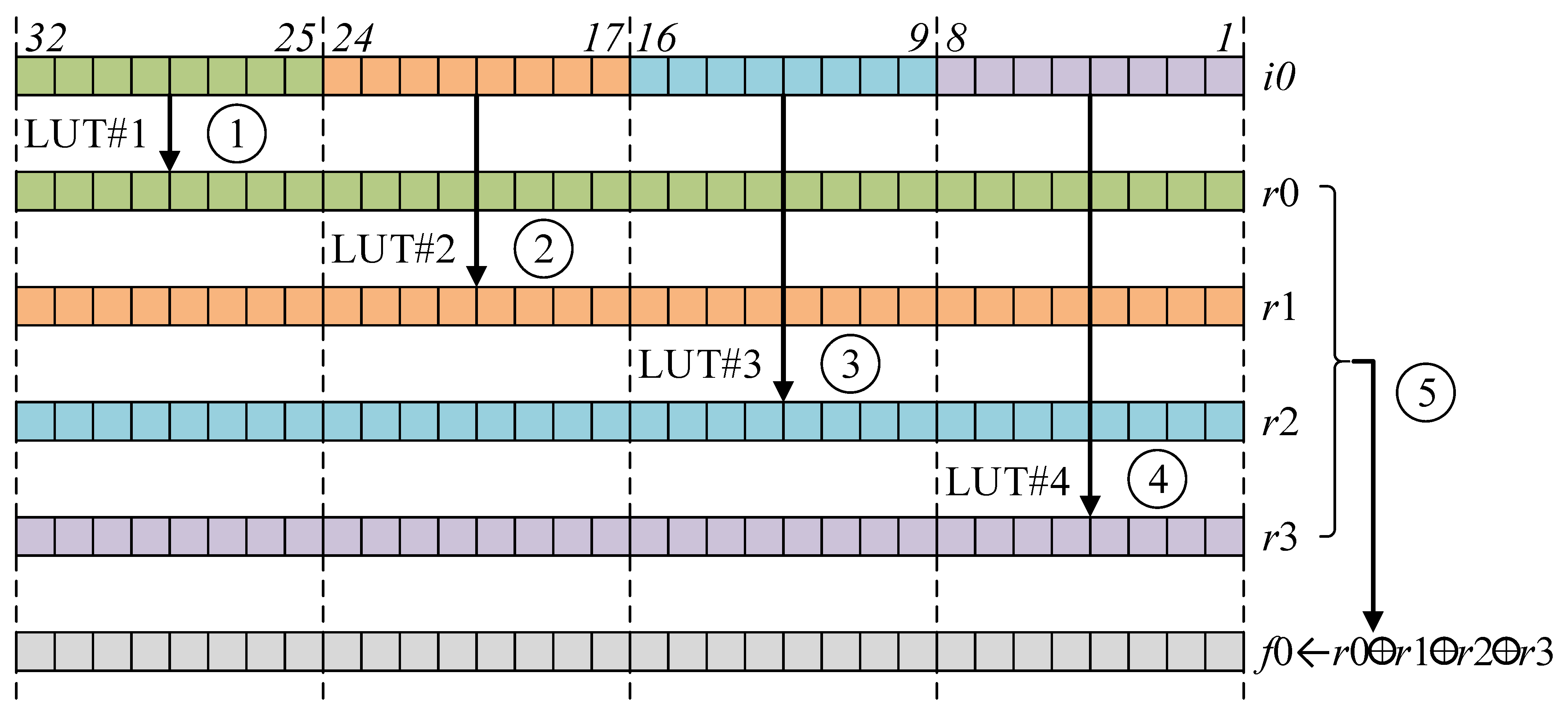
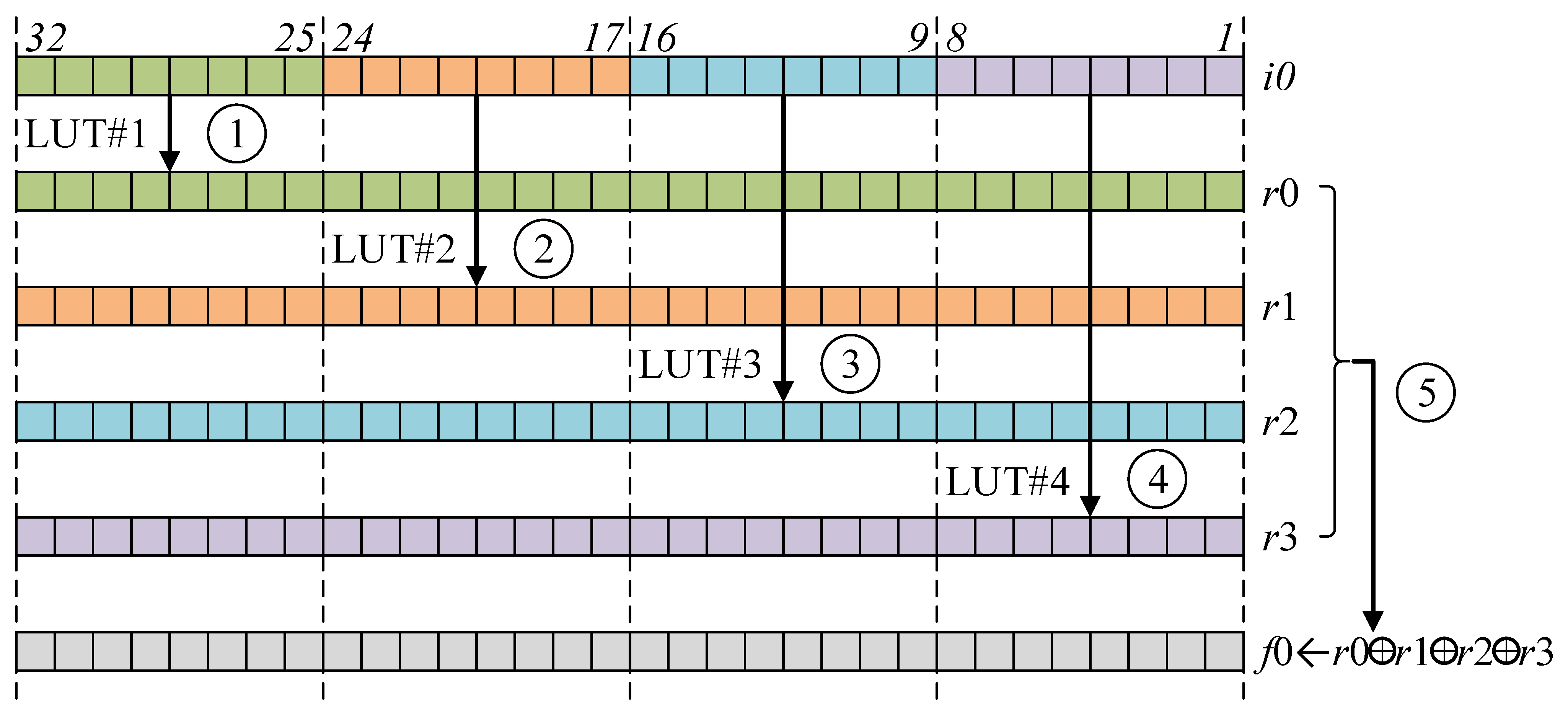
Figure 2. To extract the 8-bit value out of 32-bit, barrel-shifter, rotation, and masking operations are performed. The sequential pre-computed table-based approach performs four pre-computed table accesses, consecutively. However, the read-and-write dependency between source and destination addresses leads to pipeline stalls in this approach and pipeline stalls introduce the timing delay.
To resolve this performance penalty, the pipelined LUT access for layer is proposed in Algorithm 4. The dependency between source and destination addresses is removed by re-alignment of instruction sets. The operation consists of three steps. In Steps 1–6, the offset setting for memory address pointer is performed. This step generates four 8-bit offsets from 32-bit word for four memory address pointers. In Steps 7–10, four memory accesses are performed with four base address pointers, consecutively. In Steps 11–13, results of LUTs are accumulated together. Finally, the result (Y0) is returned in Step 14.
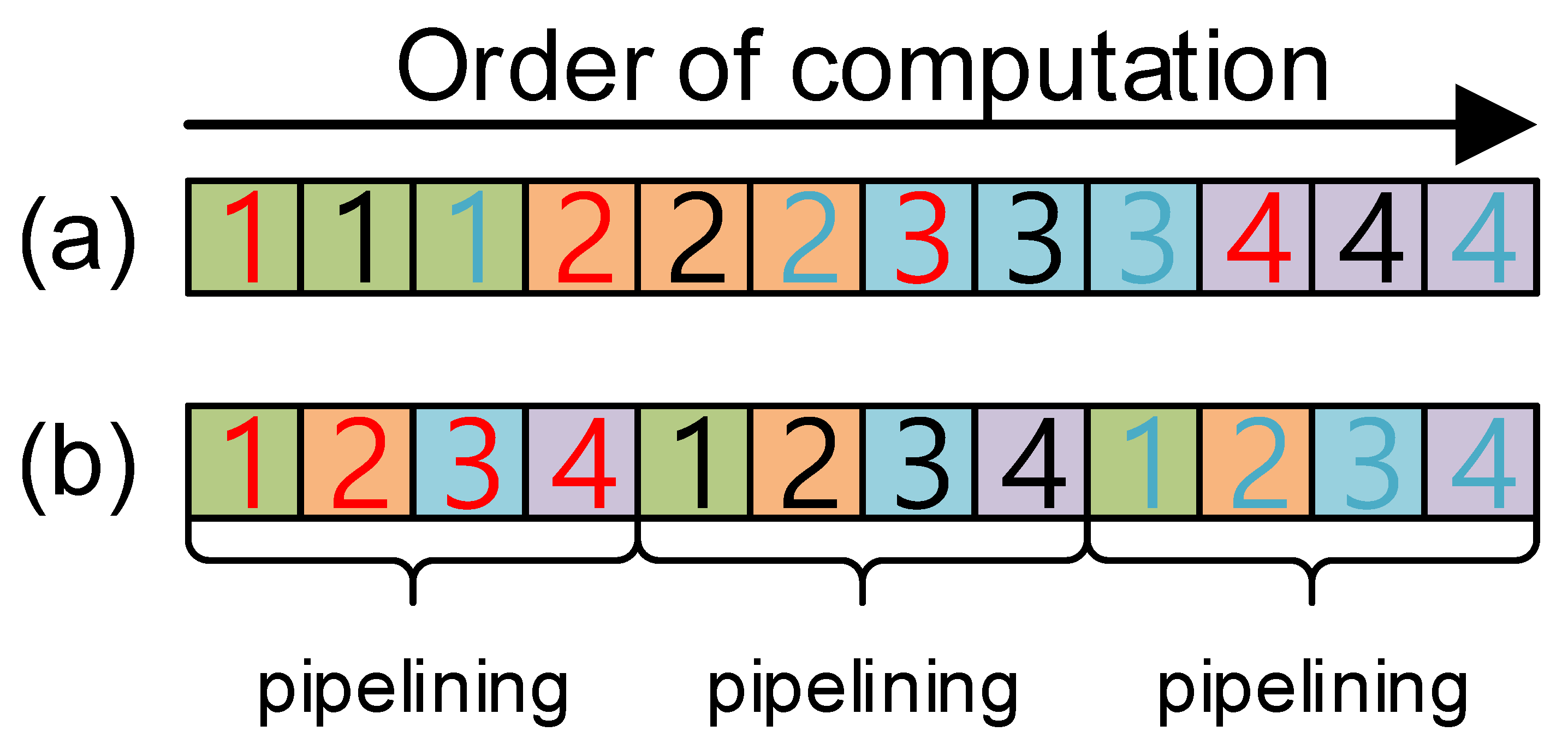
In
Figure 3, the comparison of computation order between previous and proposed methods is presented. The previous method does not take advantage of pipelining features, while the proposed method achieved the pipelining feature by re-ordering operations. The proposed approach ensures low latency by avoiding the pipeline stall.
| Algorithm 4 Pipelined LUT access for layer of ARIA block cipher on the ARM Cortex-M3 microcontroller. |
| Input: LUT input X0, LUT memory addresses (P0, P1, P2, and P3) |
| Output: LUT result Y0 |
| // offset setting for address pointer |
| 1: LSR Y0, X0, #24 | {25–32-th bits} |
| 2: AND TMP0, X0, #0XFF0000 | {17–24-th bits} |
| 3: ADD TMP0, P1, TMP0, LSR #14 |
| 4: AND TMP1, X0, #0XFF00 | {9–16-th bits} |
| 5: ADD TMP1, P2, TMP1, LSR #6 |
| 6: AND X0, X0, #0XFF | {1–8-th bits} |
| // memory access |
| 7: LDR Y0, [P0, Y0, LSL #2] | {LUT#1 access} |
| 8: LDR TMP0, [TMP0] | {LUT#2 access} |
| 9: LDR TMP1, [TMP1] | {LUT#3 access} |
| 10: LDR X0, [P3, X0, LSL #2] | {LUT#4 access} |
| //result accumulation |
| 11: EOR Y0, Y0, TMP0 | {} |
| 12: EOR Y0, Y0, TMP1 | {} |
| 13: EOR Y0, Y0, X0 | {} |
| 14: return Y0 |
Optimization of
matrix: The implementation of
layer consists of 6 XOR operations. Descriptions are presented in Algorithm 5. The
matrix is performed twice in each round.
| Algorithm 5 layer of ARIA block cipher on ARM Cortex-M3. |
| Input: Intermediate result (T0, T1, T2, T3) | 3: EOR T0, T0, T1 |
| Output: Result (T0, T1, T2, T3) | 4: EOR T3, T3, T1 |
| 1: EOR T1, T1, T2 | 5: EOR T2, T2, T0 |
| 2: EOR T2, T2, T3 | 6: EOR T1, T1, T2 |
Optimization of
P matrix: The
P layer performs three byte-wise rotation operations. These rotation operations are efficiently performed with dedicated instructions of target ARM processor. Detailed descriptions of
P layer of ARIA block cipher on the ARM Cortex-M3 microcontroller are shown in Algorithm 6.
| Algorithm 6P layer of ARIA block cipher on the ARM Cortex-M3 microcontroller. |
| Input: Intermediate result (T1, T2, T3) |
| Output: Result (X1, X2, X3) |
| 1: REV16 X1, T1 | {reverse byte order in each halfword independently} |
| 2: ROR X2, T2, #16 | {right rotate by 16-bit} |
| 3: REV X3, T3 | {reverse byte order in a word} |
Optimization of Counter Mode of Operation for 32-bit Architecture: Previous optimization methods for counter mode of operation are not available in the ARM Cortex-M3 microcontroller [
2], since 32-bit ARM Cortex-M3 implementation employed the LUT method while the previous approach utilized the 8-bit S-box-based implementation. For that reason, the CTR technique is re-designed for the LUT-based implementation. First,
layer is optimized. Only the 32-bit counter part is calculated online for this layer. Second,
layer is also optimized. Only the computation with 32-bit counter part is computed. The detailed
layer is given in Algorithm 7. Only three XOR operations are performed.
| Algorithm 7 Optimized layer of ARIA block cipher for counter mode of operation on ARM Cortex-M3. |
| Input: Intermediate result (T1, T2, T3) | 2: EOR T3, T3, T1 |
| Output: Result (T1, T2, T3) | 3: EOR T1, T1, T2 |
| 1: EOR T2, T2, T3 | |


 ,
, 


{kind=link}
{kind=link}
{kind=link}