
An Assessment of Deep Learning Models and Word Embeddings for Toxicity Detection within Online Textual Comments




Abstract
1. Introduction
- We analyzed four deep learning models based on Dense, Convolutional Neural Network (CNN), and Long-Short Term Memory (LSTM) layers to detect various levels of toxicity within online textual comments.
- We provide a comparison between deep learning models against common baselines that are used within classification tasks of textual resources.
- We release contextual word embeddings resource trained on a dataset, including toxic comments.
- We also release mimicked word embeddings of tokens that are missing in the pre-trained Google Word2Vec (https://code.google.com/archive/p/word2vec/, accessed on 11 February 2021) word embeddings.
2. Related Work
3. Problem Formulation
4. The Proposed Approach
4.1. Preprocessing
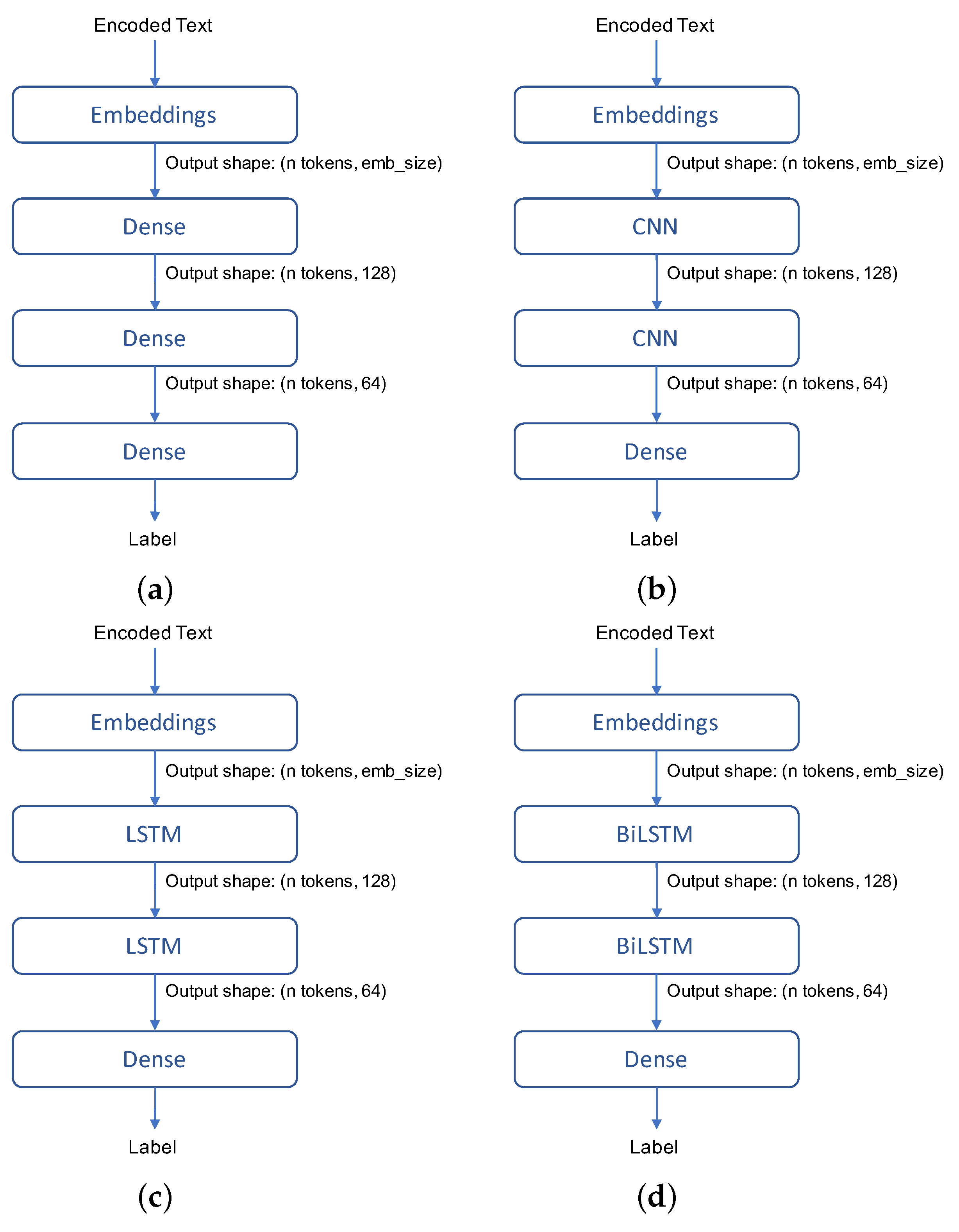
4.2. Deep Learning Models
4.2.1. Dense Model
4.2.2. CNN Model
4.2.3. LSTM Model
4.2.4. Bidirectional LSTM
4.3. Word Embeddings Representations
4.3.1. Word2Vec
- Pre-trained. Pre-trained word embeddings that are released by Google and available online (https://code.google.com/archive/p/word2vec/, accessed on 11 February 2021). They are trained on the Google news dataset and they contain more than one billion words. However, their use can be limited by words that could be misspelled (e.g., words with orthographic errors) or domain-dependent words within the input data. These words are commonly referred to as Out Of Vocabulary (OOV) words.
- Domain-trained. Domain-trained word embeddings are trained on the original unbalanced dataset (we merged the training and the test set) provided by the Kaggle challenge. The reader notices that we computed the domain-trained embeddings on the new training sets only (at each iteration of the 10-fold cross-validation procedure) of our evaluation strategy. Training the embeddings on the domain data solves the problem of OOV words, because, for each word, it is possible to associate a vector. However, words that are not frequent within our data might have a vector that does not fully and correctly represent words’ semantics. The Skip-gram Word2Vec algorithm available within the gensim (https://radimrehurek.com/gensim/, accessed on 11 February 2021) library is used. The model is trained using 20 epochs.
- Mimicked. Mimicked word embeddings are embeddings of OOV words that are not present within the original model used to represent the text data, but they are inferred by exploiting syntactic similarities of words that are in the originally considered vocabulary. More in details, we used the algorithm that was proposed by [44], which is based on an RNN and works at character level. Words within an original vector model representation are firstly encoded by sequences of characters, and characters are associated with new vector representations. Subsequently, by using a BiLSTM network, an OOV word w is associated to a new word embedding e. To create word embeddings for the OOV words, we used the default input dataset, the hyperparameters mentioned in [44], and the pre-trained Word2Vec Google embeddings.
4.3.2. BERT
4.3.3. Word Embeddings Preparation
5. Experimental Study
5.1. The Dataset
5.2. Baselines
- Decision Tree (DT). The Decision Tree algorithm builds a model by learning decision rules that when applied to the input features can correctly predict the target class. The model has a root node that represents the whole set of input data. This node is subsequently split into its children by applying a given rule. The process is then recursively applied to its children as long as there are nodes that can be split.
- Random Forest (RF). This method adopts more DTs applied on different samples of the input data and uses a majority voting strategy to predict the output classes. The strength of this algorithm is that each DT is individually trained; therefore, overfitting and errors due to biases are limited. We adopted a classifier that made use of 100 DTs estimators.
- Multi-Layer Perceptron (MLP). This is a neural network that is composed of a single layer of nodes. We used a layer with 100 nodes in our experiment.
5.3. Results and Discussion
5.4. Comparison with the Kaggle Challenge
5.4.1. Baseline Comparison
5.4.2. Dense-Based Model
5.4.3. CNN-Based Model
5.4.4. LSTM-Based Model
5.4.5. BiLSTM-Based Model
5.4.6. Overall Evaluation of the Deep Learning Models
5.4.7. Overall Evaluation of Word Embeddings
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AUC | Area under the curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long-Short Term Memory |
| CBOW | Continuous Bag-Of-Words |
| CNN | Convolutional Neural Network |
| DT | Decision Tree |
| ELMO | Embeddings from Language Models |
| GPU | Graphics Processing Unit |
| GRU | Gated Recurrent Unit |
| kNN | k-Nearest Neighbors |
| LR | Logistic Regression |
| LSTM | Long-Short Term Memory |
| MLP | Multi-Layer Perceptron |
| NB | Naive Bayes |
| NLP | Natural Language Processing |
| OOV | Out Of Vocabulary |
| RF | Random Forest |
| ROC | Receiver Operating Characteristic |
| RNN | Recurrent Neural Network |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| SVM | Support Vector Machine |
References
- Saeed, H.H.; Shahzad, K.; Kamiran, F. Overlapping Toxic Sentiment Classification Using Deep Neural Architectures. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1361–1366. [Google Scholar]
- Hosseini, H.; Kannan, S.; Zhang, B.; Poovendran, R. Deceiving google’s perspective api built for detecting toxic comments. arXiv 2017, arXiv:1702.08138. [Google Scholar]
- Srivastava, S.; Khurana, P.; Tewari, V. Identifying aggression and toxicity in comments using capsule network. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 98–105. [Google Scholar]
- Dessì, D.; Dragoni, M.; Fenu, G.; Marras, M.; Recupero, D.R. Evaluating neural word embeddings created from online course reviews for sentiment analysis. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 2124–2127. [Google Scholar]
- Dridi, A.; Atzeni, M.; Recupero, D.R. FineNews: Fine-grained semantic sentiment analysis on financial microblogs and news. Int. J. Mach. Learn. Cybern. 2019, 10, 2199–2207. [Google Scholar] [CrossRef]
- Consoli, S.; Dessì, D.; Fenu, G.; Marras, M. Deep Attention-based Model for Helpfulness Prediction of Healthcare Online Reviews. In Proceedings of the First Workshop on Smart Personal Health Interfaces Co-Located with 25th International Conference on Intelligent User Interfaces (SmartPhil@IUI 2020), Cagliari, Italy, 17 March 2020; pp. 33–49. [Google Scholar]
- Carta, S.; Corriga, A.; Mulas, R.; Recupero, D.R.; Saia, R. A Supervised Multi-class Multi-label Word Embeddings Approach for Toxic Comment Classification. In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Vienna, Austria, 17–19 September 2019; pp. 17–19. [Google Scholar]
- Schouten, K.; Frasincar, F. Survey on aspect-level sentiment analysis. IEEE Trans. Knowl. Data Eng. 2015, 28, 813–830. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wu, Z.; Helaoui, R.; Kumar, V.; Recupero, D.R.; Riboni, D. Towards Detecting Need for Empathetic Response in Motivational Interviewing. In Proceedings of the Companion Publication of the 2020 International Conference on Multimodal Interaction, ICMI Companion 2020, Virtual Event, Utrecht, The Netherlands, 25–29 October 2020; 2020; pp. 497–502. [Google Scholar] [CrossRef]
- Dragoni, M.; Petrucci, G. A neural word embeddings approach for multi-domain sentiment analysis. IEEE Trans. Affect. Comput. 2017, 8, 457–470. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Reforgiato Recupero, D.; Cambria, E. ESWC 14 challenge on Concept-Level Sentiment Analysis. Commun. Comput. Inf. Sci. 2014, 475, 3–20. [Google Scholar]
- Recupero, D.R.; Dragoni, M.; Presutti, V. ESWC 15 Challenge on Concept-Level Sentiment Analysis. Semantic Web Evaluation Challenges. In Proceedings of the Second SemWebEval Challenge at ESWC 2015, Portorož, Slovenia, 31 May–4 June 2015; pp. 211–222. [Google Scholar] [CrossRef]
- Recupero, D.R.; Consoli, S.; Gangemi, A.; Nuzzolese, A.G.; Spampinato, D. A Semantic Web Based Core Engine to Efficiently Perform Sentiment Analysis. In The Semantic Web: ESWC 2014 Satellite Events; Presutti, V., Blomqvist, E., Troncy, R., Sack, H., Papadakis, I., Tordai, A., Eds.; Springer: Cham, The Netherlands, 2014; pp. 245–248. [Google Scholar]
- Dragoni, M.; Reforgiato Recupero, D. Challenge on fine-grained sentiment analysis within ESWC2016. Commun. Comput. Inf. Sci. 2016, 641, 79–94. [Google Scholar]
- Reforgiato Recupero, D.; Cambria, E.; Di Rosa, E. Semantic sentiment analysis challenge at ESWC2017. Commun. Comput. Inf. Sci. 2017, 769, 109–123. [Google Scholar]
- Kumar, V.; Recupero, D.R.; Riboni, D.; Helaoui, R. Ensembling Classical Machine Learning and Deep Learning Approaches for Morbidity Identification From Clinical Notes. IEEE Access 2021, 9, 7107–7126. [Google Scholar] [CrossRef]
- Dridi, A.; Recupero, D.R. Leveraging semantics for sentiment polarity detection in social media. Int. J. Mach. Learn. Cybern. 2019, 10, 2045–2055. [Google Scholar] [CrossRef]
- Recupero, D.R.; Alam, M.; Buscaldi, D.; Grezka, A.; Tavazoee, F. Frame-Based Detection of Figurative Language in Tweets. IEEE Comput. Intell. Mag. 2019, 14, 77–88. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Atzeni, M.; Recupero, D.R. Multi-domain sentiment analysis with mimicked and polarized word embeddings for human-robot interaction. Future Gener. Comput. Syst. 2020, 110, 984–999. [Google Scholar] [CrossRef]
- Yin, H.; Gai, K. An empirical study on preprocessing high-dimensional class-imbalanced data for classification. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, Lisbon, Portugal, 17–21 September 2015; pp. 1314–1319. [Google Scholar]
- Momtazi, S. Fine-grained German Sentiment Analysis on Social Media. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC 2012), Istanbul, Turkey, 23–25 May 2012; 2012; pp. 1215–1220. [Google Scholar]
- Rothfels, J.; Tibshirani, J. Unsupervised Sentiment Classication of English Movie Reviews Using Automatic Selection of Positive and Negative Sentiment Items; Technical Report; Stanford University: Stanford, CA, USA, 2010. [Google Scholar]
- Cheng, K.; Li, J.; Tang, J.; Liu, H. Unsupervised sentiment analysis with signed social networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Reyes, A.; Rosso, P.; Buscaldi, D. From humor recognition to irony detection: The figurative language of social media. Data Knowl. Eng. 2012, 74, 1–12. [Google Scholar] [CrossRef]
- Hamdan, H.; Bellot, P.; Bechet, F. Lsislif: Crf and logistic regression for opinion target extraction and sentiment polarity analysis. In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 753–758. [Google Scholar]
- Dragoni, M.; da Costa Pereira, C.; Tettamanzi, A.G.; Villata, S. Combining argumentation and aspect-based opinion mining: The smack system. AI Commun. 2018, 31, 75–95. [Google Scholar] [CrossRef]
- Pavlopoulos, J.; Sorensen, J.; Dixon, L.; Thain, N.; Androutsopoulos, I. Toxicity Detection: Does Context Really Matter? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4296–4305. [Google Scholar] [CrossRef]
- Saif, H.; He, Y.; Alani, H. Semantic Sentiment Analysis of Twitter. In Proceedings of the 11th International Conference on The Semantic Web (ISWC12), Boston, MA, USA, 11–15 November 2012; pp. 508–524. [Google Scholar]
- Brassard-Gourdeau, E.; Khoury, R. Subversive toxicity detection using sentiment information. In Proceedings of the Third Workshop on Abusive Language, Florence, Italy, 1 August 2019; pp. 1–10. [Google Scholar]
- Gangemi, A.; Presutti, V.; Recupero, D.R. Frame-Based Detection of Opinion Holders and Topics: A Model and a Tool. IEEE Comp. Int. Mag. 2014, 9, 20–30. [Google Scholar] [CrossRef]
- Recupero, D.R.; Presutti, V.; Consoli, S.; Gangemi, A.; Nuzzolese, A.G. Sentilo: Frame-Based Sentiment Analysis. Cogn. Comput. 2015, 7, 211–225. [Google Scholar] [CrossRef]
- Wright, A.; Shaikh, O.; Park, H.; Epperson, W.; Ahmed, M.; Pinel, S.; Yang, D.; Chau, D.H. RECAST: Interactive Auditing of Automatic Toxicity Detection Models. In Proceedings of the Chinese CHI 2020: The Eighth International Workshop of Chinese CHI, Honolulu, HI, USA, 25–30 April 2020; pp. 80–82. [Google Scholar] [CrossRef]
- Han, X.; Tsvetkov, Y. Fortifying Toxic Speech Detectors Against Veiled Toxicity. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 7732–7739. [Google Scholar] [CrossRef]
- Morzhov, S. Avoiding Unintended Bias in Toxicity Classification with Neural Networks. In Proceedings of the 2020 26th Conference of Open Innovations Association (FRUCT), Yaroslavl, Russia, 20–24 April 2020; pp. 314–320. [Google Scholar] [CrossRef]
- Dessì, D.; Fenu, G.; Marras, M.; Recupero, D.R. COCO: Semantic-Enriched Collection of Online Courses at Scale with Experimental Use Cases. In Proceedings of the World Conference on Information Systems and Technologies, Naples, Italy, 27–29 March 2018; pp. 1386–1396. [Google Scholar]
- Georgakopoulos, S.V.; Tasoulis, S.K.; Vrahatis, A.G.; Plagianakos, V.P. Convolutional neural networks for toxic comment classification. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; p. 35. [Google Scholar]
- Martens, M.; Shen, S.; Iosup, A.; Kuipers, F. Toxicity Detection in Multiplayer Online Games. In Proceedings of the 14th International Workshop on Network and Systems Support for Games (NetGames), Zagreb, Croatia, 3–4 December 2015. [Google Scholar] [CrossRef]
- Pinter, Y.; Guthrie, R.; Eisenstein, J. Mimicking word embeddings using subword rnns. arXiv 2017, arXiv:1707.06961. [Google Scholar]
- Si, Y.; Wang, J.; Xu, H.; Roberts, K. Enhancing Clinical Concept Extraction with Contextual Embedding. arXiv 2019, arXiv:1902.08691. [Google Scholar] [CrossRef]
- Reimers, N.; Schiller, B.; Beck, T.; Daxenberger, J.; Stab, C.; Gurevych, I. Classification and Clustering of Arguments with Contextualized Word Embeddings. arXiv 2019, arXiv:1906.09821. [Google Scholar]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333. [Google Scholar] [CrossRef]
- Dessì, D.; Fenu, G.; Marras, M.; Recupero, D.R. Bridging learning analytics and Cognitive Computing for Big Data classification in micro-learning video collections. Comput. Hum. Behav. 2019, 92, 468–477. [Google Scholar] [CrossRef]
- Dessì, D.; Recupero, D.R.; Fenu, G.; Consoli, S. A recommender system of medical reports leveraging cognitive computing and frame semantics. In Machine Learning Paradigms; Springer: Berlin, Germany, 2019; pp. 7–30. [Google Scholar]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and Word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics Cognitive Computing (ICCI*CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning (ICML ’06), Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL, North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]


{kind=link}
| Toxicity Class | Number of Comments | Percentage | Balanced Dataset Size |
|---|---|---|---|
| No toxic | 201,081 | 89.95% | - |
| toxic | 21,384 | 9.57% | 42,768 |
| severe toxic | 1962 | 0.88% | 3924 |
| obscene | 12,140 | 5.43% | 24,280 |
| threat | 689 | 0.31% | 1378 |
| insult | 11,304 | 5.06% | 22,608 |
| identity hate | 2117 | 0.95% | 4234 |
| Learning Model | Feature | Toxic | Severe Toxic | Obscene | Threat | Identity Hate | Insult | Average |
|---|---|---|---|---|---|---|---|---|
| Deep Model Dense | pre-trained | 0.921 | 0.968 | 0.936 | 0.977 | 0.944 | 0.933 | 0.947 |
| domain-trained | 0.915 | 0.959 | 0.928 | 0.968 | 0.934 | 0.924 | 0.938 | |
| mimicked | 0.922 | 0.969 | 0.938 | 0.981 | 0.941 | 0.931 | 0.947 | |
| bert | 0.898 | 0.964 | 0.904 | 0.945 | 0.924 | 0.906 | 0.924 | |
| Deep Model CNN | pre-trained | 0.905 | 0.964 | 0.924 | 0.969 | 0.934 | 0.915 | 0.935 |
| domain-trained | 0.895 | 0.950 | 0.857 | 0.957 | 0.909 | 0.903 | 0.912 | |
| mimicked | 0.906 | 0.961 | 0.923 | 0.974 | 0.935 | 0.914 | 0.936 | |
| bert | 0.881 | 0.952 | 0.894 | 0.909 | 0.892 | 0.895 | 0.904 | |
| Deep Model LSTM | pre-trained | 0.970 | 0.982 | 0.980 | 0.983 | 0.968 | 0.976 | 0.977 |
| domain-trained | 0.963 | 0.980 | 0.977 | 0.983 | 0.968 | 0.970 | 0.974 | |
| mimicked | 0.971 | 0.983 | 0.977 | 0.985 | 0.970 | 0.977 | 0.977 | |
| bert | 0.930 | 0.974 | 0.940 | 0.956 | 0.950 | 0.940 | 0.948 | |
| Deep Model Bidirectional LSTM | pre-trained | 0.969 | 0.981 | 0.973 | 0.984 | 0.967 | 0.975 | 0.975 |
| domain-trained | 0.963 | 0.980 | 0.977 | 0.984 | 0.964 | 0.970 | 0.973 | |
| mimicked | 0.969 | 0.963 | 0.980 | 0.988 | 0.970 | 0.976 | 0.974 | |
| bert | 0.930 | 0.970 | 0.939 | 0.951 | 0.947 | 0.941 | 0.946 |
| Learning Model | Feature | Toxic | Severe Toxic | Obscene | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| p | r | f | p | r | f | p | r | f | ||
| Decision Trees Random Forests MLP | tf-idf | 0.859 | 0.855 | 0.857 | 0.847 | 0.947 | 0.894 | 0.926 | 0.929 | 0.928 |
| tf-idf | 0.860 | 0.856 | 0.858 | 0.888 | 0.940 | 0.913 | 0.945 | 0.834 | 0.913 | |
| tf-idf | 0.849 | 0.857 | 0.853 | 0.913 | 0.918 | 0.915 | 0.884 | 0.895 | 0.889 | |
| Deep Model Dense | pre-trained | 0.863 | 0.856 | 0.858 | 0.923 | 0.910 | 0.916 | 0.886 | 0.867 | 0.876 |
| domain-trained | 0.855 | 0.848 | 0.851 | 0.893 | 0.910 | 0.899 | 0.874 | 0.863 | 0.867 | |
| mimicked | 0.868 | 0.844 | 0.855 | 0.926 | 0.914 | 0.919 | 0.880 | 0.877 | 0.878 | |
| bert | 0.828 | 0.817 | 0.822 | 0.912 | 0.917 | 0.913 | 0.844 | 0.821 | 0.832 | |
| Deep Model CNN | pre-trained | 0.848 | 0.849 | 0.848 | 0.910 | 0.911 | 0.909 | 0.863 | 0.861 | 0.861 |
| domain-trained | 0.846 | 0.841 | 0.842 | 0.903 | 0.875 | 0.888 | 0.858 | 0.849 | 0.853 | |
| mimicked | 0.836 | 0.865 | 0.850 | 0.886 | 0.919 | 0.901 | 0.856 | 0.870 | 0.862 | |
| bert | 0.801 | 0.812 | 0.805 | 0.899 | 0.911 | 0.904 | 0.819 | 0.832 | 0.825 | |
| Deep Model LSTM | pre-trained | 0.914 | 0.915 | 0.914 | 0.944 | 0.962 | 0.953 | 0.927 | 0.949 | 0.938 |
| domain-trained | 0.903 | 0.916 | 0.909 | 0.947 | 0.948 | 0.947 | 0.929 | 0.944 | 0.936 | |
| mimicked | 0.895 | 0.938 | 0.916 | 0.941 | 0.966 | 0.953 | 0.928 | 0.938 | 0.932 | |
| bert | 0.866 | 0.851 | 0.858 | 0.927 | 0.932 | 0.929 | 0.889 | 0.861 | 0.875 | |
| Deep Model Bidirectional LSTM | pre-trained | 0.906 | 0.923 | 0.914 | 0.936 | 0.959 | 0.947 | 0.963 | 0.854 | 0.905 |
| domain-trained | 0.905 | 0.915 | 0.910 | 0.948 | 0.962 | 0.955 | 0.941 | 0.933 | 0.937 | |
| mimicked | 0.910 | 0.921 | 0.915 | 0.939 | 0.963 | 0.951 | 0.929 | 0.945 | 0.937 | |
| bert | 0.875 | 0.841 | 0.856 | 0.933 | 0.941 | 0.937 | 0.892 | 0.852 | 0.871 | |
| Learning Model | Feature | Threat | Identity Hate | Insult | ||||||
| p | r | f | p | r | f | p | r | f | ||
| Decision Trees Random Forests MLP | tf-idf | 0.917 | 0.891 | 0.903 | 0.819 | 0.927 | 0.869 | 0.887 | 0.891 | 0.889 |
| tf-idf | 0.954 | 0.897 | 0.924 | 0.847 | 0.911 | 0.877 | 0.929 | 0.851 | 0.888 | |
| tf-idf | 0.914 | 0.916 | 0.913 | 0.889 | 0.897 | 0.893 | 0.871 | 0.880 | 0.876 | |
| Deep Model Dense | pre-trained | 0.934 | 0.930 | 0.931 | 0.897 | 0.865 | 0.879 | 0.872 | 0.865 | 0.869 |
| domain-trained | 0.913 | 0.918 | 0.914 | 0.858 | 0.877 | 0.866 | 0.876 | 0.846 | 0.860 | |
| mimicked | 0.933 | 0.932 | 0.931 | 0.881 | 0.882 | 0.880 | 0.873 | 0.857 | 0.863 | |
| bert | 0.867 | 0.891 | 0.877 | 0.874 | 0.865 | 0.855 | 0.841 | 0.827 | 0.834 | |
| Deep Model CNN | pre-trained | 0.932 | 0.870 | 0.891 | 0.872 | 0.863 | 0.867 | 0.842 | 0.862 | 0.851 |
| domain-trained | 0.898 | 0.899 | 0.898 | 0.823 | 0.868 | 0.842 | 0.874 | 0.816 | 0.843 | |
| mimicked | 0.927 | 0.918 | 0.922 | 0.860 | 0.879 | 0.869 | 0.847 | 0.849 | 0.847 | |
| bert | 0.842 | 0.872 | 0.849 | 0.824 | 0.842 | 0.832 | 0.831 | 0.821 | 0.826 | |
| Deep Model LSTM | pre-trained | 0.932 | 0.967 | 0.948 | 0.907 | 0.909 | 0.906 | 0.918 | 0.939 | 0.928 |
| domain-trained | 0.949 | 0.951 | 0.950 | 0.913 | 0.925 | 0.918 | 0.919 | 0.930 | 0.924 | |
| mimicked | 0.953 | 0.962 | 0.957 | 0.887 | 0.946 | 0.914 | 0.916 | 0.948 | 0.931 | |
| bert | 0.916 | 0.899 | 0.907 | 0.880 | 0.895 | 0.886 | 0.874 | 0.870 | 0.872 | |
| Deep Model Bidirectional LSTM | pre-trained | 0.946 | 0.961 | 0.952 | 0.905 | 0.921 | 0.912 | 0.918 | 0.931 | 0.924 |
| domain-trained | 0.949 | 0.949 | 0.949 | 0.904 | 0.935 | 0.919 | 0.918 | 0.938 | 0.927 | |
| mimicked | 0.941 | 0.944 | 0.940 | 0.902 | 0.934 | 0.916 | 0.920 | 0.935 | 0.927 | |
| bert | 0.913 | 0.900 | 0.905 | 0.900 | 0.857 | 0.874 | 0.889 | 0.866 | 0.877 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dessì, D.; Recupero, D.R.; Sack, H. An Assessment of Deep Learning Models and Word Embeddings for Toxicity Detection within Online Textual Comments. Electronics 2021, 10, 779. https://doi.org/10.3390/electronics10070779
Dessì D, Recupero DR, Sack H. An Assessment of Deep Learning Models and Word Embeddings for Toxicity Detection within Online Textual Comments. Electronics. 2021; 10(7):779. https://doi.org/10.3390/electronics10070779
Chicago/Turabian StyleDessì, Danilo, Diego Reforgiato Recupero, and Harald Sack. 2021. "An Assessment of Deep Learning Models and Word Embeddings for Toxicity Detection within Online Textual Comments" Electronics 10, no. 7: 779. https://doi.org/10.3390/electronics10070779
APA StyleDessì, D., Recupero, D. R., & Sack, H. (2021). An Assessment of Deep Learning Models and Word Embeddings for Toxicity Detection within Online Textual Comments. Electronics, 10(7), 779. https://doi.org/10.3390/electronics10070779