
Real-Time Sentiment Analysis for Polish Dialog Systems Using MT as Pivot


Abstract
:1. Introduction
2. Experimental Environment and the Current State of Knowledge
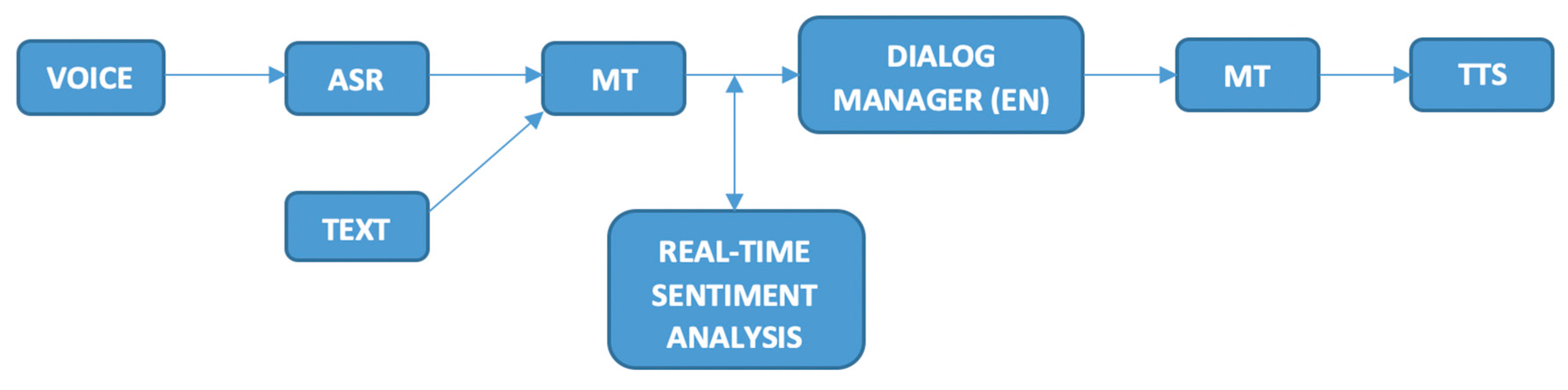
2.1. Testing Environment
2.2. Sentiment Analysis Techniques Used
3. Experiments
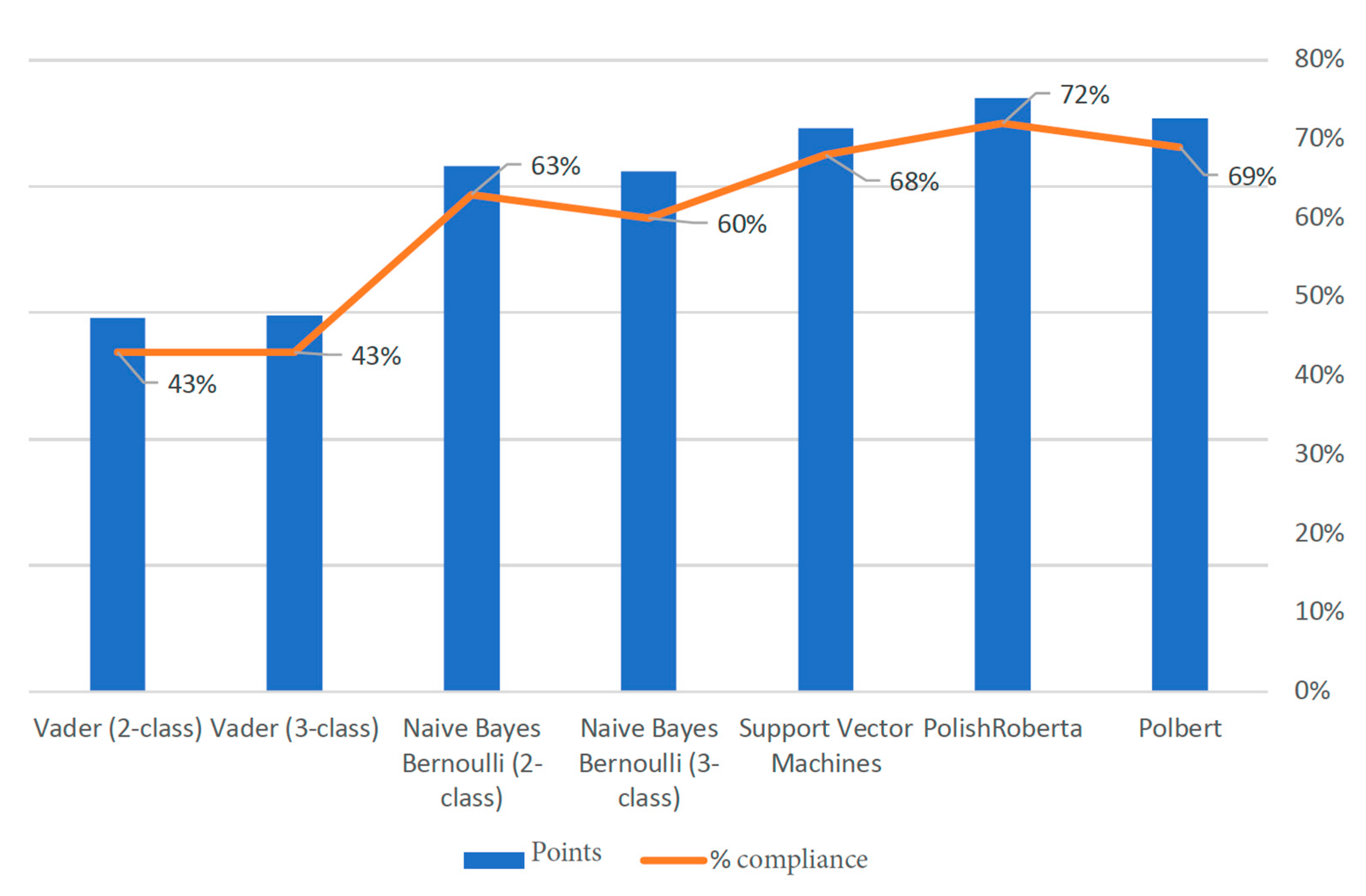
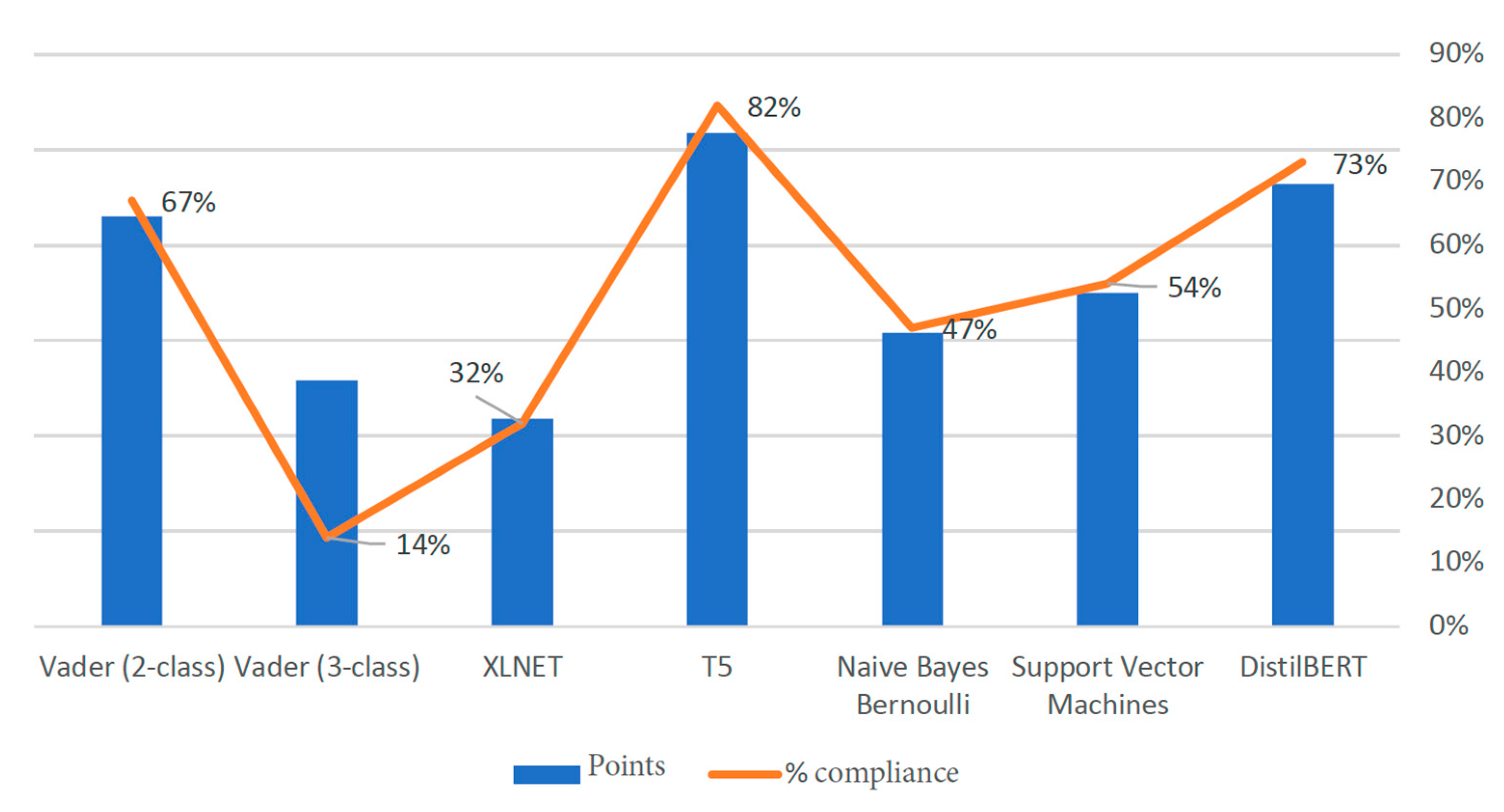
3.1. Pretrained English Models
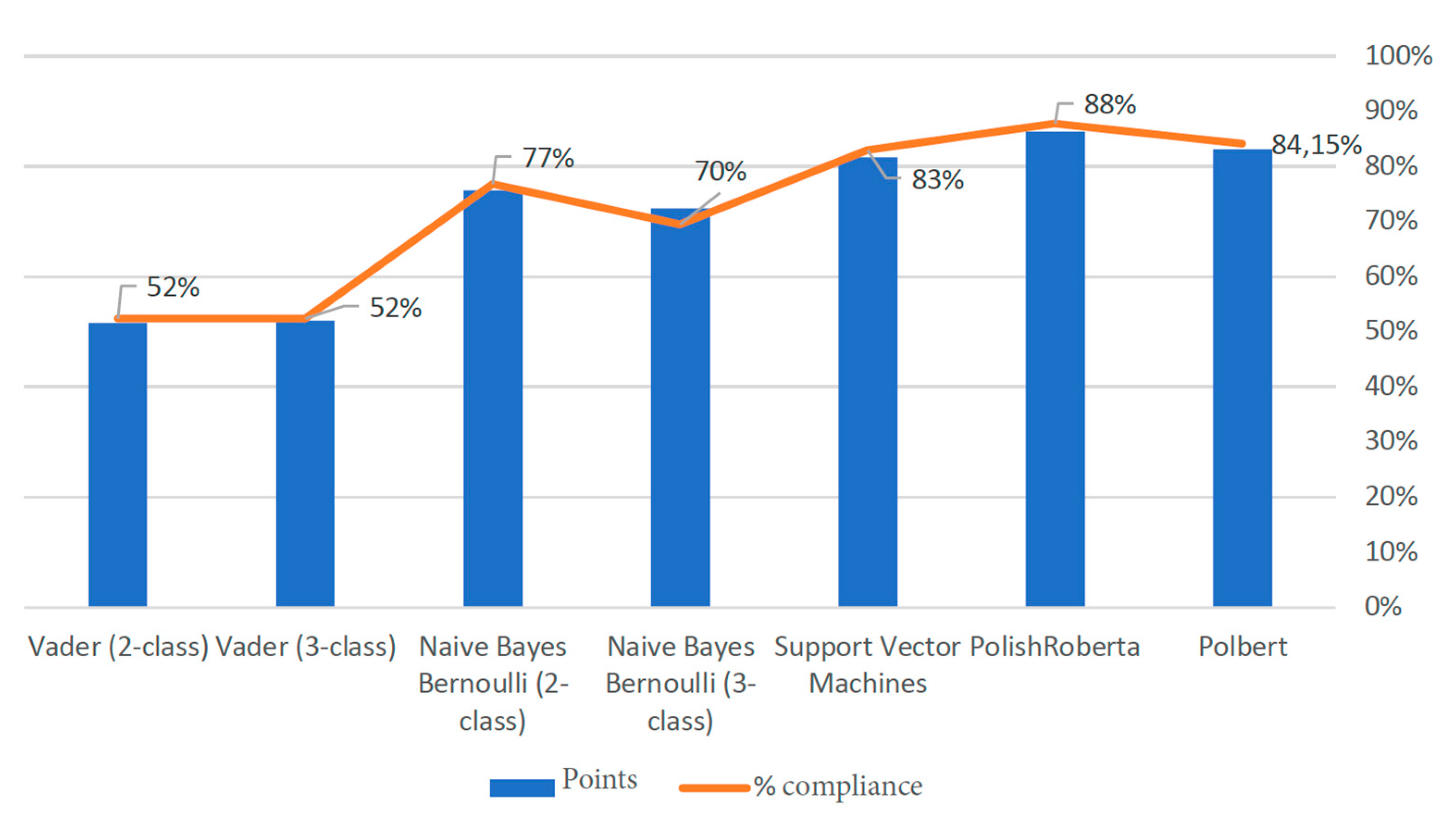
3.2. Comparative Experiments for Polish-Language Models
3.3. Possible Optimization of Models
3.4. Results of Polish Models
4. Manual Evaluation
5. Conclusions and Discussion
Funding
Conflicts of Interest
References
- Ahmed, A.; Ali, N.; Aziz, S.; Abd-alrazaq, A.A.; Hassan, A.; Khalifa, M.; Elhusein, B.; Ahmed, M.; Ahmed, M.A.S.; Househ, M. A review of mobile chatbot apps for anxiety and depression and their self-care features. Comput. Methods Programs Biomed. Update 2021, 1, 100012. [Google Scholar] [CrossRef]
- Cahn, J. CHATBOT: Architecture, Design, & Development. Senior Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2017. Available online: https://d1wqtxts1xzle7.cloudfront.net/57035006/CHATBOT_thesis_final-with-cover-page-v2.pdf?Expires=1627527612&Signature=Z-xxlmjFf3kt7YLdYI8CCqQD884mEVa4yN7qScUdor7lr6Vc3s65krgFhlE9Ox0h~NN~OExeu7GwNsa1OQMaOwbK6u8i9G~VDRst5YAyvig6GATS4G5hUYfFfPN5mbIBLsmDRboJdoQPAjiPv~KmzLjoIHshIQ2YcaXigSq6zDZvOUcOQaYfKSkQAu1OHll5QHzmycKFgUfhbzaJNnLqrAVc~LUL6UXLWl8KttZbotKyFO8PDQKMj6jSTcxQW8tYKxZ73tyCH~BzV8dpxfIkd-RljxkB6Adxp-XrM1w7Tz~2a6NflJrHsg4WFh4RZ9ub421VeSRy~PO-Z-IshsqxjQ__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA (accessed on 28 May 2021).
- Xu, A.; Liu, Z.; Guo, Y.; Sinha, V.; Akkiraju, R. A new chatbot for customer service on social media. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3506–3510. [Google Scholar]
- Csaky, R. Deep learning based chatbot models. arXiv 2019, arXiv:1908.08835. [Google Scholar]
- Linchpin, T. 25 Chatbot Stats and Trends Shaping Businesses in 2021. Available online: https://linchpinseo.com/chatbot-statistics-trends/ (accessed on 28 May 2021).
- Singh, S.; Thakur, H.K. Survey of Various AI Chatbots Based on Technology Used. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 1074–1079. [Google Scholar]
- Nosotti, E. Building a Multi-Language Chatbot with Automated Translations. Available online: https://medium.com/rockedscience/building-a-multi-language-chatbot-with-automated-translations-e2acd053bc5c (accessed on 29 May 2021).
- Hu, W.; Le, R.; Liu, B.; Ma, J.; Zhao, D.; Yan, R. Translation vs. Dialogue: A Comparative Analysis of Sequence-to-Sequence Modeling. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 4111–4122. [Google Scholar]
- Soloveva, A. SO at SemEval-2020 task 7: DeepPavlov logistic regression with BERT embeddings vs. SVR at funniness evaluation. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 1055–1059. [Google Scholar]
- Rana, M. Eaglebot: A Chatbot Based Multi-Tier Question Answering System For Retrieving Answers From Heterogeneous Sources Using BERT. Master’s Thesis, Georgia Southern University, Statesboro, GA, USA, 2019; pp. 431–437. [Google Scholar]
- Germann, U.; Barbu, E.; Bentivogli, L.; Bertoldi, N.; Bogoychev, N.; Buck, C.; van der Meer, J. Modern MT: A new open-source machine translation platform for the translation industry. Baltic J. Mod. Comput. 2016, 4, 397. [Google Scholar]
- Tiedemann, J. Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC’2012), Istanbul, Turkey, 23–25 May 2012; pp. 2214–2218. [Google Scholar]
- Guglani, J.; Mishra, A.N. Continuous Punjabi speech recognition model based on Kaldi ASR toolkit. Int. J. Speech Technol. 2018, 21, 211–216. [Google Scholar] [CrossRef]
- Draxler, C.; van den Heuvel, H.; van Hessen, A.; Calamai, S.; Corti, L. A CLARIN Transcription Portal for Interview Data. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 13–15 May 2020; pp. 3353–3359. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Favre, B.; Cheung, K.; Kazemian, S.; Lee, A.; Liu, Y.; Munteanu, C.; Zeller, F. Automatic human utility evaluation of ASR systems: Does WER really predict performance? In Proceedings of the INTERSPEECH 2013 14thAnnual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 3463–3467. [Google Scholar]
- Borg, A.; Boldt, M. Using VADER sentiment and SVM for predicting customer response sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 216–225. [Google Scholar]
- Zhang, Y.; Vogel, S.; Waibel, A. Interpreting bleu/nist scores: How much improvement do we need to have a better system? In Proceedings of the LREC, Lisbon, Portugal, 26–28 May 2004. [Google Scholar]
- Tymann, K.; Lutz, M.; Palsbröker, P.; Gips, C. GerVADER-A German Adaptation of the VADER Sentiment Analysis Tool for Social Media Texts. In Proceedings of the LWDA, Berlin, German, 30 September–2 October 2019; pp. 178–189. [Google Scholar]
- Shelar, A.; Huang, C.Y. Sentiment analysis of twitter data. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 1301–1302. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Almatarneh, S.; Gamallo, P.; Pena, F.J.R. CiTIUS-COLE at semeval-2019 task 5: Combining linguistic features to identify hate speech against immigrants and women on multilingual tweets. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 387–390. [Google Scholar]
- Singh, G.; Kumar, B.; Gaur, L.; Tyagi, A. Comparison between multinomial and Bernoulli naïve Bayes for text classification. In Proceedings of the 2019 International Conference on Automation, Computational and Technology Management (ICACTM), London, UK, 24–26 April 2019; pp. 593–596. [Google Scholar]
- Scikit-Learn: Machine Learning in Python. Available online: http://scikit-learn.org/stable/index.html (accessed on 28 May 2021).
- Sentiment140. Available online: http://help.sentiment140.com/for-students (accessed on 28 May 2021).
- Clarin SI Repository. Available online: https://www.clarin.si/repository/xmlui/ (accessed on 28 May 2021).
- Tweepy—An Easy-to-Use Python Library for Accessing the Twitter API. Available online: https://www.tweepy.org/ (accessed on 28 May 2021).
- Sajjad, H.; Dalvi, F.; Durrani, N.; Nakov, P. On the Effect of Dropping Layers of Pre-Trained Transformer Models. 2020. Available online: https://arxiv.org/pdf/2004.03844.pdf (accessed on 28 May 2021).
- Rankings on NLP. Available online: https://paperswithcode.com/task/sentiment-analysis/latest (accessed on 28 May 2021).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Pipalia, K.; Bhadja, R.; Shukla, M. Comparative Analysis of Different Transformer Based Architectures Used in Sentiment Analysis. In Proceedings of the 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 4–5 December 2020; pp. 411–415. [Google Scholar]
- Banerjee, S.; Jayapal, A.; Thavareesan, S. NUIG-Shubhanker@ Dravidian-CodeMix-FIRE2020: Sentiment Analysis of Code-Mixed Dravidian text using XLNet. arXiv 2020, arXiv:2010.07773. [Google Scholar]
- Transformers—Natural Language Processing for Jax, PyTorch and TensorFlow. Available online: https://github.com/huggingface/transformers (accessed on 28 May 2021).
- Subramanian, V. Deep Learning with PyTorch: A Practical Approach to Building Neural Network Models Using PyTorch; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Donadi, M. A System for Sentiment Analysis of Online-Media with TensorFlow. Ph.D. Thesis, Hochschule Für Angewandte Wissenschaften Hamburg, Hamburg, Germany, 2018. [Google Scholar]
- Sharma, M. Polarity Detection in a Cross-Lingual Sentiment Analysis using spaCy. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 490–496. [Google Scholar]
- Microsoft/Onnxruntime: Onnx Runtime: Cross-Platform, High Performance Scoring Engine for mL Models. Available online: https://github.com/microsoft/onnxruntime (accessed on 28 May 2021).
- Štrimaitis, R.; Stefanovič, P.; Ramanauskaitė, S.; Slotkienė, A. Financial Context News Sentiment Analysis for the Lithuanian Language. Appl. Sci. 2021, 11, 4443. [Google Scholar] [CrossRef]
- Straka, M.; Náplava, J.; Straková, J.; Samuel, D. RobeCzech: Czech RoBERTa, a monolingual contextualized language representation model. arXiv 2021, arXiv:2105.11314. [Google Scholar]
- Intellica, A.I. Available online: https://intellica-ai.medium.com/aspect-based-sentiment-analysis-everything-you-wanted-to-know-1be41572e238 (accessed on 28 May 2021).
- Altun, L. A Corpus Based Study: Analysis of the Positive Reviews of Amazon. com Users. Adv. Lang. Lit. Stud. 2019, 10, 123–128. [Google Scholar] [CrossRef]
- Yun-tao, Z.; Ling, G.; Yong-cheng, W. An improved TF-IDF approach for text classification. J. Zhejiang Univ. Sci. A 2005, 6, 49–55. [Google Scholar]
- Kallimani, J.S. Machine Learning Based Predictive Action on Categorical Non-Sequential Data. Recent Adv. Comput. Sci. Commun. (Former. Recent Pat. Comput. Sci.) 2020, 13, 1020–1030. [Google Scholar]
- Wang, R.; Li, J. Bayes test of precision, recall, and f1 measure for comparison of two natural language processing models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4135–4145. [Google Scholar]
- Wang, B.; Shang, L.; Lioma, C.; Jiang, X.; Yang, H.; Liu, Q.; Simonsen, J.G. On position embeddings in bert. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021; Volume 2, pp. 12–13. [Google Scholar]
- Sajjad, H.; Dalvi, F.; Durrani, N.; Nakov, P. Poor Man’s BERT: Smaller and Faster Transformer Models. arXiv 2020, arXiv:2004.03844. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Amazon Video Games. Available online: http://jmcauley.ucsd.edu/data/amazon/ (accessed on 28 May 2021).
- T5: Text-To-Text Transfer Transformer. Available online: https://github.com/google-research/text-to-text-transfer-transformer#dataset-preparation (accessed on 28 May 2021).
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Polish RoBERTa. Available online: https://github.com/sdadas/polish-roberta (accessed on 28 May 2021).
- Kłeczek, D. Polbert: Attacking Polish NLP Tasks with Transformers. In Proceedings of the PolEval 2020 Workshop, Warszawa, Poland, 26 October 2020; pp. 79–88. [Google Scholar]
- Zumel, P.; Garcia, O.; Cobos, J.A.; Uceda, J. Tight magnetic coupling in multiphase interleaved converters based on simple transformers. In Proceedings of the Twentieth Annual IEEE Applied Power Electronics Conference and Exposition, 2005 APEC, Busan, Korea, 18–19 November 2005; pp. 385–391. [Google Scholar]
- Twitter Sentiment for 15 European Languages. Available online: https://www.clarin.si/repository/xmlui/handle/11356/1054 (accessed on 28 May 2021).
- Kocoń, J.; Miłkowski, P.; Zaśko-Zielińska, M. Multi-level sentiment analysis of PolEmo 2.0: Extended corpus of multi-domain consumer reviews. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 980–991. [Google Scholar]
- AllegroReviews Dataset. Available online: https://github.com/allegro/klejbenchmark-allegroreviews (accessed on 28 May 2021).
- Boughorbel, S.; Jarray, F.; El-Anbari, M. Optimal classifier for imbalanced data using Matthews Correlation Coefficient metric. PLoS ONE 2017, 12, e0177678. [Google Scholar] [CrossRef] [PubMed]
- Gorbachev, Y.; Fedorov, M.; Slavutin, I.; Tugarev, A.; Fatekhov, M.; Tarkan, Y. Openvino deep learning workbench: Comprehensive analysis and tuning of neural networks inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Jin, T.; Bercea, G.T.; Le, T.D.; Chen, T.; Su, G.; Imai, H.; Eichenberger, A.E. Compiling ONNX Neural Network Models Using MLIR. arXiv 2020, arXiv:2008.08272. [Google Scholar]
- Ren, H.; Manivannan, N.; Lee, G.C.; Yu, S.; Sha, P.; Conti, T.; D’Souza, N. Improving OCT B-scan of interest inference performance using TensorRT based neural network optimization. Investig. Ophthalmol. Vis. Sci. 2020, 61, 1635. [Google Scholar]
- Shanmugamani, R. Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using Tensorflow and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Optimization Practice of Deep Learning Inference Deployment on Intel® Processors. Available online: https://software.intel.com/content/www/us/en/develop/articles/optimization-practice-of-deep-learning-inference-deployment-on-intel-processors.html (accessed on 28 May 2021).
- Onan, A.; Korukoğlu, S.; Bulut, H. A hybrid ensemble pruning approach based on consensus clustering and multi-objective evolutionary algorithm for sentiment classification. Inf. Process. Manag. 2017, 53, 814–833. [Google Scholar] [CrossRef]
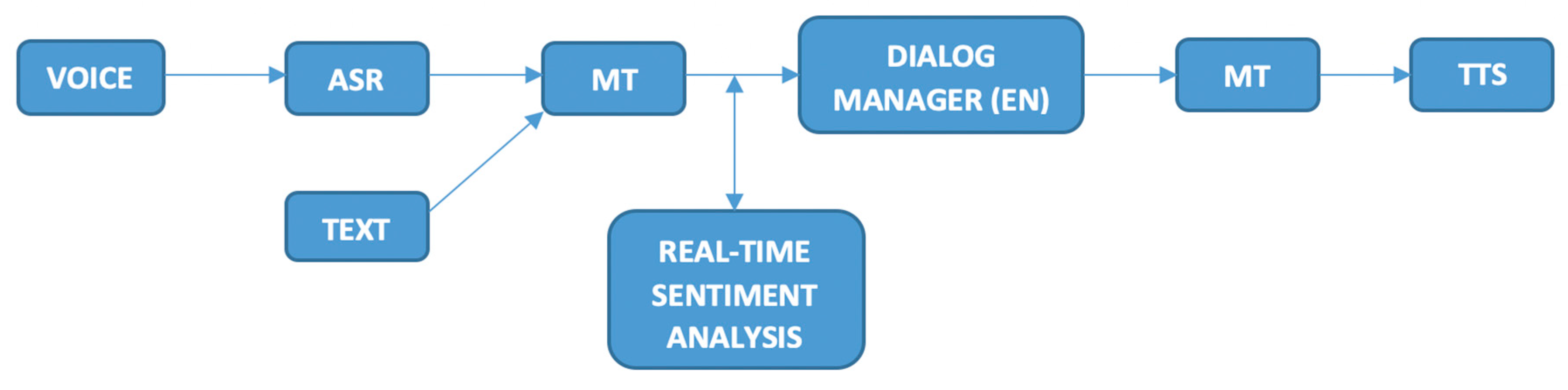

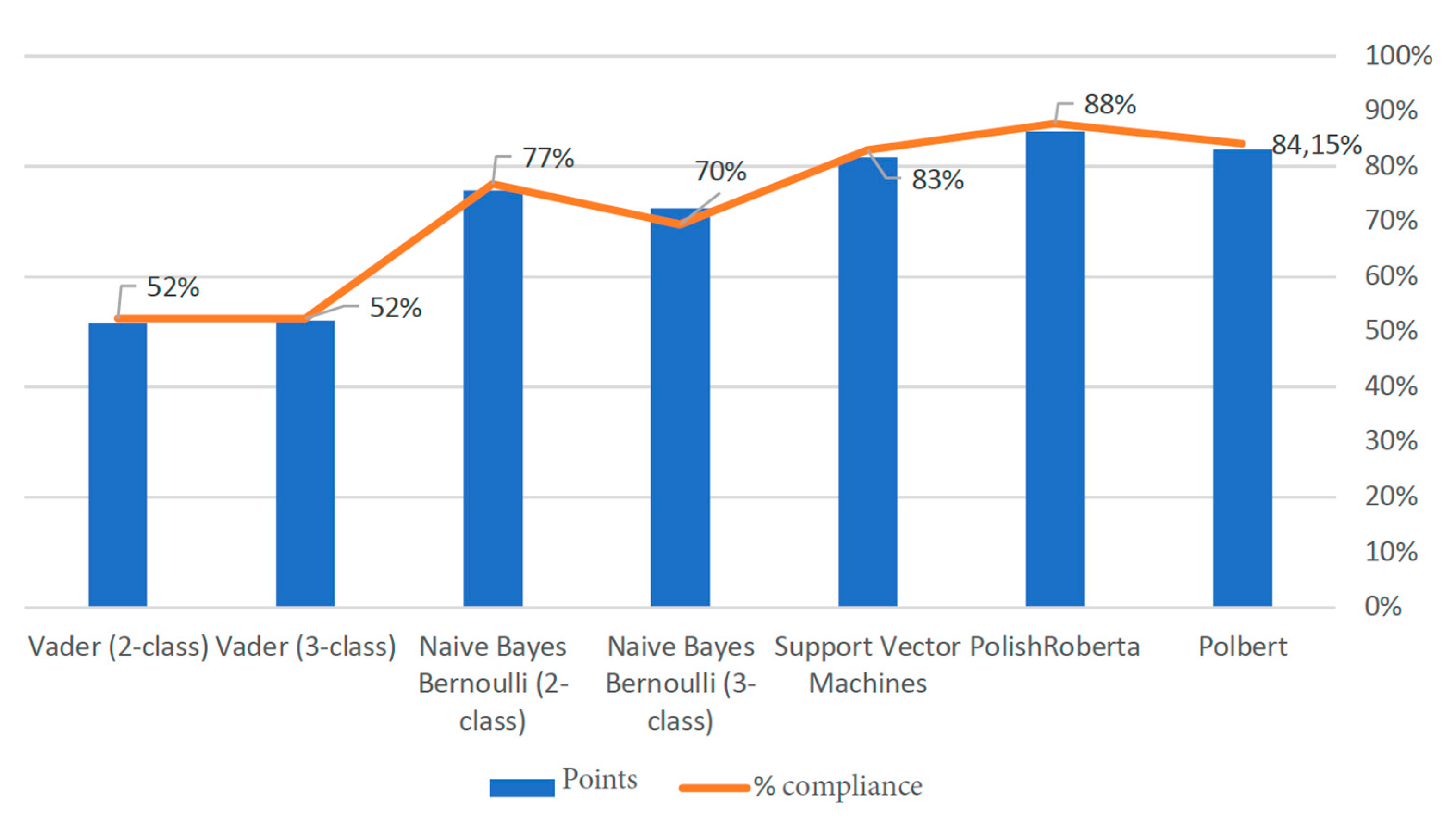
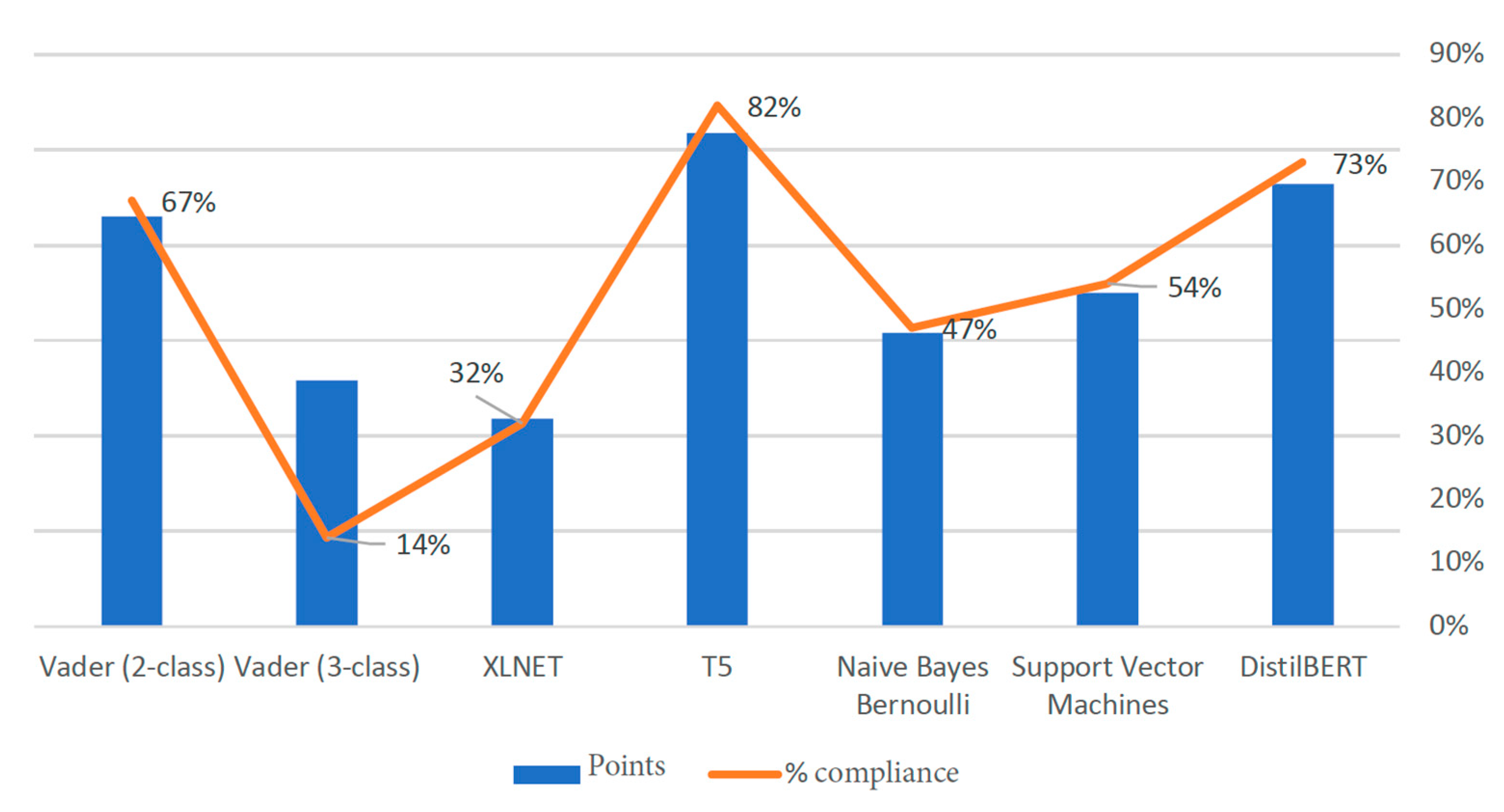
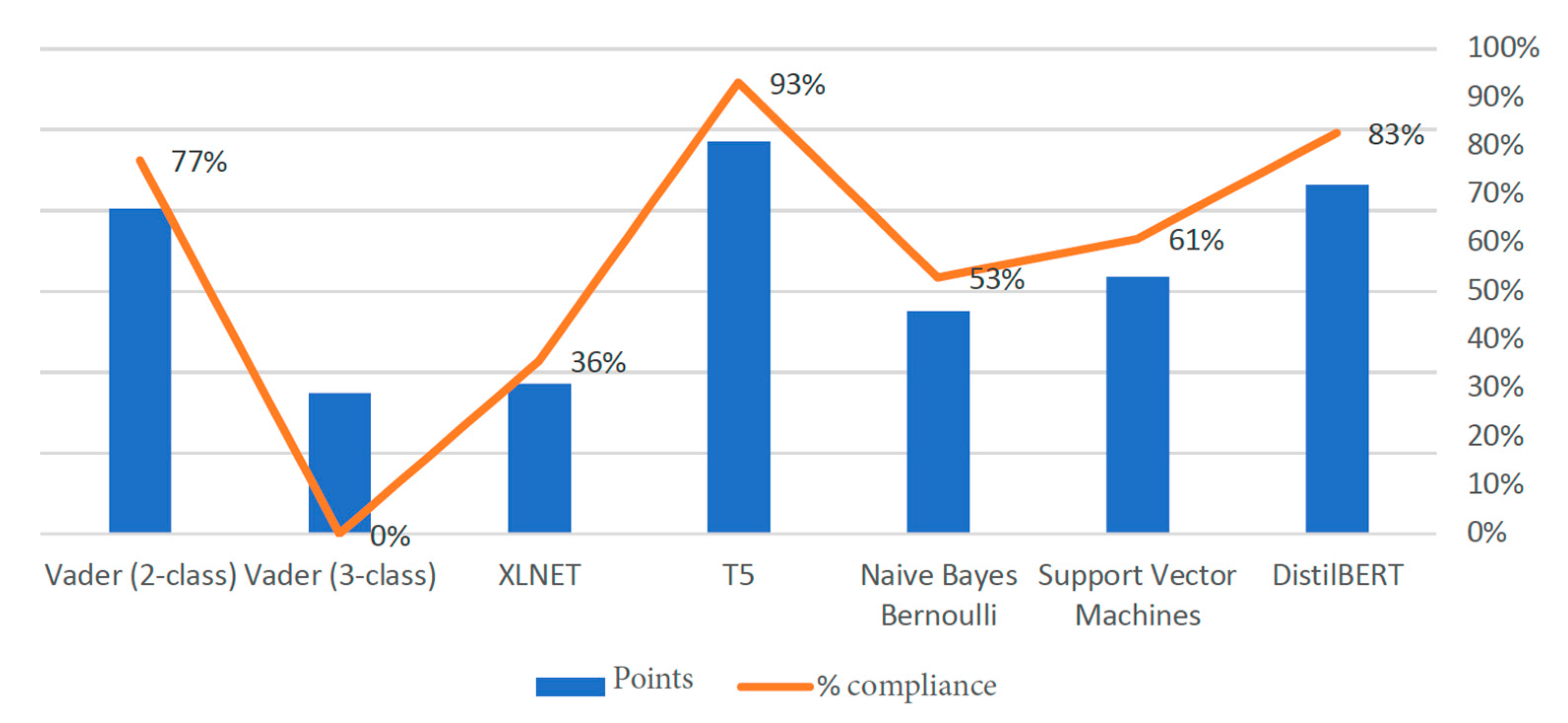

{kind=link}
{kind=link}
{kind=link}
{kind=link}
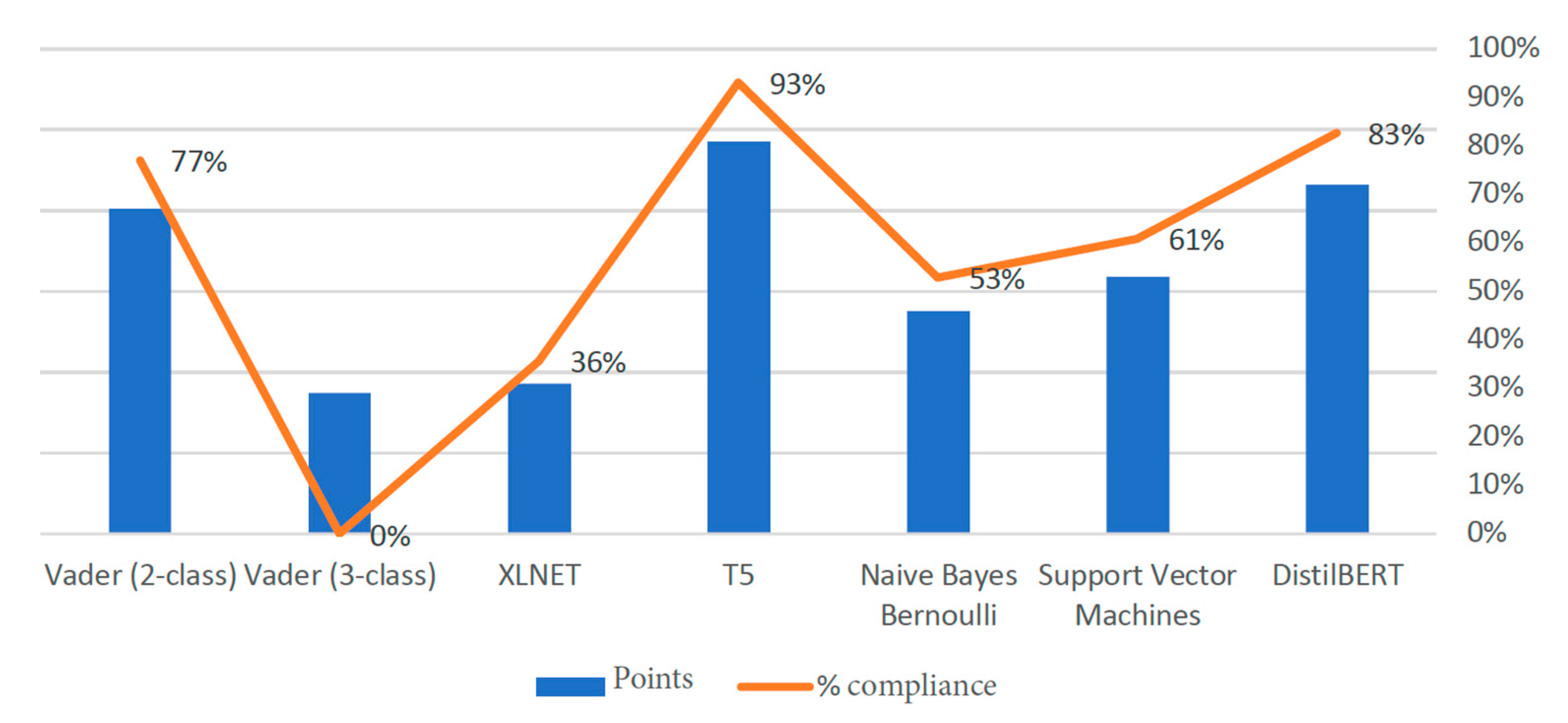{kind=link}
| LinearSVC | Precision | Recall | F1 Score |
|---|---|---|---|
| Word Embedding | 0.885928 | 0.914875 | 0.900169 |
| TF–IDF | 0.914081 | 0.987962 | 0.949587 |
| Naive Bayes Bernoulli | |||
| Word Embedding | 0.965066 | 0.376812 | 0.541999 |
| TF–IDF | 0.906364 | 0.849957 | 0.877255 |
| XLNET | T5 | DistilBERT | Naive Bayes Bernoulli | LinearSVC | Vader |
|---|---|---|---|---|---|
| 31.09% | 79.99% | 84.73% | 65.78% | 75.69% | 84.70% |
| Clarin | PolElmo 2.0 | Allegro Reviews | Result | |
|---|---|---|---|---|
| Polish RoBERTa | - | - | - | acc = 0.5751 eval_loss = 0.6870 f1 = 0.0839 mcc = −0.0172 |
| Polish RoBERTa | x | - | - | acc = 0.7790 eval_loss = 0.5570 f1 = 0.8060 mcc = 0.5510 |
| Polish RoBERTa | - | x | - | acc = 0.8625 eval_loss = 0.3680 f1 = 0.8358 mcc = 0.7177 |
| Polish RoBERTa | - | - | x | acc = 0.7936 eval_loss = 0.5181 f1 = 0.8849 mcc = 0.0 |
| Polish RoBERTa | x | x | - | acc = 0.8930 eval_loss = 0.3228 f1 = 0.8685 mcc = 0.7786 |
| Polish RoBERTa | - | x | x | acc = 0.5864 eval_loss = 0.6782 f1 = 0.0 mcc = 0.0 |
| PolBERT | - | - | - | acc = 0.5965 eval_loss = 0.6772 f1 = 0.7038 mcc = 0.1110 |
| PolBERT | - | x | - | acc = 0.8804 eval_loss = 0.3225 f1 = 0.8538 mcc = 0.7528 |
| PolBERT | x | - | - | acc = 0.7961 eval_loss = 0.4759 f1 = 0.8366 mcc = 0.5718 |
| PolBERT | x | x | - | acc = 0.7913 eval_loss = 0.6397 f1 = 0.8255 mcc = 0.5660 |
| Model | AVG CPU% | MAX CPU% | AVG MEM | MAX MEM | Inference Time | Accuracy% |
|---|---|---|---|---|---|---|
| LinearSVC_PL | 385.9 | 1057.9 | 162.3 MB | 315.4 MB | 0.001117994379997 | 98.77 |
| PolishRoberta | 1548.81 | 4276.68 | 2.5 GB | 4.3 GB | 2.8007734849453 | 93.07 |
| Polbert | 1123.87 | 4107.96 | 4.2 GB | 6.7 GB | 2.48969090027809 | 92.97 |
| NaiveBayes_2_CLS_PL | 161.33 | 1141.81 | 309.3 MB | 322.1 MB | 0.012122882723808 | 89.38 |
| NaiveBayes_3_CLS_PL | 146.47 | 1028.85 | 314.4 MB | 325.3 MB | 0.014599187135696 | 88.31 |
| LinearSVC_EN | 99.95 | 100.22 | 1.1 GB | 1.3 GB | 0.003802319741249 | 87.27 |
| NaiveBayes_2_CLS_EN | 109.67 | 1045.76 | 1.3 GB | 1.4 GB | 0.072344211030006 | 83.29 |
| T5 | 3936.15 | 4604.82 | 3.0 GB | 3.0 GB | 0.640251659822464 | 75.36 |
| DistilBERT | 3498.85 | 4106.75 | 2.6 GB | 3.0 GB | 0.356072693634033 | 70.88 |
| Vader_2_CLS_EN | 100.02 | 100.69 | 1.1 GB | 1.2 GB | 0.009924677634239 | 65.87 |
| Vader_3_CLS_EN | 564.29 | 1028.49 | 610.2 MB | 1.1 GB | 8.09271097183228E-05 | 60.38 |
| Vader_PERCENTAGE_EN | 582.74 | 1065.38 | 607.8 MB | 1.1 GB | 8.22359085083008E-05 | 58.13 |
| XLNET | 3850.74 | 4490.56 | 3.0 GB | 3.3 GB | 0.501096723675728 | 44.04 |
| Model | AVG CPU% | MAX CPU% | AVG MEM | MAX MEM | Inference Time | Accuracy% |
|---|---|---|---|---|---|---|
| Polbert | 1032.09 | 4081.53 | 4.4 GB | 6.8 GB | 2.57093233888149 | 92.95 |
| PolishRoberta | 1542.35 | 4358.97 | 2.6 GB | 4.7 GB | 2.87089015738964 | 92.5 |
| LinearSVC_PL | 268.9 | 644.87 | 162.8 MB | 301.6 MB | 0.001157759809494 | 90.58 |
| NaiveBayes_2_CLS_PL | 125.06 | 525.94 | 299.6 MB | 307.8 MB | 0.01218701300621 | 84.05 |
| NaiveBayes_3_CLS_PL | 125.84 | 644.87 | 295.1 MB | 309.5 MB | 0.014857436347008 | 77.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wołk, K. Real-Time Sentiment Analysis for Polish Dialog Systems Using MT as Pivot. Electronics 2021, 10, 1813. https://doi.org/10.3390/electronics10151813
Wołk K. Real-Time Sentiment Analysis for Polish Dialog Systems Using MT as Pivot. Electronics. 2021; 10(15):1813. https://doi.org/10.3390/electronics10151813
Chicago/Turabian StyleWołk, Krzysztof. 2021. "Real-Time Sentiment Analysis for Polish Dialog Systems Using MT as Pivot" Electronics 10, no. 15: 1813. https://doi.org/10.3390/electronics10151813
APA StyleWołk, K. (2021). Real-Time Sentiment Analysis for Polish Dialog Systems Using MT as Pivot. Electronics, 10(15), 1813. https://doi.org/10.3390/electronics10151813