1. Introduction
With the development of computer vision techniques and intelligent grids, the scale of high-voltage transmission lines is increasing. Regular inspection of transmission lines is becoming an important task to ensure the safety and reliable operation of power systems. Specifically, insulators are an indispensable, essential piece of equipment in transmission lines, which play an important role in electrical insulation and mechanical support [
1,
2]. However, insulators are usually outdoors and subjected to harsh weather conditions. Insulator failure is likely to threaten the safety of the power system, resulting in large-scale blackouts and huge economic losses. Consequently, insulator detection based on computer vision is of great practical significance [
3]. Over the past few years, the development of Unmanned Aerial Vehicle (UAV) and sensor techniques [
4,
5] has led to their exploitation as effective tools for transmission line inspection. Insulator detection by UAVs has become one of the primary research directions for intelligent grid systems [
6]. Some scholars have engaged in research on insulator detection from aerial images, and many remarkable results have been achieved through image processing. Current methods for insulator detection can be divided into three categories: (1) traditional image processing methods, (2) machine learning methods, and (3) deep learning methods.
Based on traditional image processing methods, segmentation and feature extraction of aerial images have been explored as a way to recognize insulators within complex backgrounds. Generally, the features of insulators in aerial images include texture [
7] shape [
8] color [
9], gradient [
10], and edge [
11], among others. Thus, edge detection, morphology, scale-invariant features [
12], and wavelet transformations [
13,
14] are usually employed to extract features and separate insulators from complicated backgrounds. Mathematical models have been established to detect insulators, as well. However, aerial images often include diverse background interference, as shown in
Figure 1.
Specifically, in the work of Wang et al. [
15], color, shape, and texture features were combined to detect insulators in aerial images. Firstly, the parallel line features were adopted as prior knowledge in order to obtain a region of interest (ROI) for insulators. Secondly, the local binary pattern (LBP) was presented to extend candidate regions of insulators. Finally, the LBP and hue saturation value (HSV) histograms were employed to match insulators with the prior knowledge model. This method effectively reduced the impact of complex backgrounds on insulator detection. However, it required complicated computation and feature extraction. The method also struggled to deal with many kinds of complex scenes. Iruansi et al. [
16] proposed an active counter model for segmenting and extracting insulators from ROI regions. Experimental results demonstrated that active contour models were more efficient and flexible than threshold segmentation and gradient algorithms. However, relevant features of insulators are changeable—due to different shooting angles and distances—which reduced the accuracy of insulator detection. In the work of [
17], a method of orientation angle detection based on binary shape and prior knowledge was proposed to distinguish insulators from complex backgrounds. Multiple insulators could be detected in complex aerial images with different angles. However, the method required all possible angles of the insulators to be set in advance, and did not work well if the shape of insulator was unknown. Commonly, the color of insulators is quite different from their background interference, and the color histogram is considered an effective method to describe color features. In [
18], hue saturation intensity (HIS) color space was adopted to segment glass insulators in aerial images based on a threshold segmentation algorithm. However, it struggled to segment insulators from complex backgrounds by the use of only one threshold. To solve this problem, Zhai et al. [
19] proposed an insulator detection method based on the color and spatial morphology features in aerial images. Firstly, color models of insulators were constructed by setting corresponding thresholds for the red-gree-blue (RGB) color space. Secondly, ROIs for insulators were extracted by color and spatial features. Finally, mathematical morphologies were adopted to detect insulators. This method exhibited better robustness and real-time performance compared with other existing methods. However, it did not work well in complex scenes containing various types of background interference. Based on observation of traditional image processing methods, they rely on a variety of feature extraction algorithms and are quite sensitive to background interference. Meanwhile, in the actual detection environment, aerial images captured by UAV usually suffer from different shooting angles, shooting distances, and luminous conditions. Thus, it is impossible to design a model for detecting multiple insulators simultaneously.
Based on machine learning methods, Ada-Boost and Support Vector Machines (SVM) [
20] are the most commonly used feature classifier algorithms for insulator detection. In [
21], deep convolution feature maps were presented to detect insulators in infrared images, and the classification algorithm of SVM was adopted to achieve that goal. However, this method was easily affected by background interference in aerial images. In [
22], background suppression was used to remove the redundant information before extracting insulators from cluttered backgrounds. However, it was difficult to train an SVM classifier with a single feature (which could not effectively detect insulators from complex scenes). In the work of [
23], insulators in aerial images were accurately detected through the superposition of weak classifiers. The accuracy of their insulator segmentation and detection was improved to a certain extent, but it did not work well when the insulator was covered by a large area or suffered from complex background interference. To solve this problem, a structural model of insulators and the optimal entropy method of threshold segmentation were proposed in [
24] for insulator detection. Firstly, the software of Sketch-Up was adopted to generate insulator simulation images. Next, an insulator training set was constructed. Then, the mathematical morphology algorithm was employed to segment insulators from complex backgrounds. Finally, the Ada-Boost classifier was introduced to detect insulators in aerial images amid cluttered backgrounds. However, the samples of insulators available for training were limited, resulting in the classifier algorithm being difficult to apply on a large scale. Compared with traditional image processing methods, the machine learning methods rely less on specific features in aerial images. However, the algorithms are complicated and require a large amount of calculation.
With recent advances in artificial intelligence and deep learning, many researchers have applied deep learning architectures to object detection, and these techniques have been variously applied [
25,
26,
27,
28]. Deep learning architectures make full use of convolution neural networks (CNNs) to automatically learn the depth feature of images layer-by-layer, and optimize the network model parameters by training large-scale data to improve detection accuracy. Recently, with the rapidly development of deep learning theories, more and more researchers have paid attention to deep CNNs, which show a strong advantage in feature extraction. Moreover, large-scale public datasets, high performance hardware processing systems, and deep CNNs have promoted object detection algorithms to a new level. The object detection algorithms based on deep CNNs are divided into single-stage models and two-stage models. Specifically, the single-stage models include single shot multibox detector (SSD) [
29] and YOLO [
30,
31]. Regions with convolutional neural network (R-CNN) [
32], fast R-CNN [
33], and faster R-CNN [
34] are two-stage models. The two-stage models exhibit high detection accuracy, but they are difficult to train and do not currently meet requirements for real-time application. Single-stage models can achieve real-time detection with some loss of accuracy compared to two-stage models. Because of this, they are more feasible for real-world application [
35]. Meanwhile, the networks of YOLOv2 and YOLOv3—which are single-stage models—have been widely used for object detection [
36,
37,
38,
39,
40,
41]. Consequently, existing single-stage models can be adapted to detect insulators by transferring learning strategies. To improve the robustness and accuracy of insulator detection, multilevel perception methods were presented in [
42]. The SSD model was adopted to train insulator detection models on multilevel training sets. Experimental results demonstrated that the proposed method met the requirement of off-line analysis for insulator detection. However, the samples used for training were limited, and the processing speed of a single image needed to be improved. In the work of [
43], the YOLOv2 network was applied to transmission lines, inspecting systems for insulator detection. To solve the problem of lacking samples, several augmentation techniques were employed to avoid overfitting. It was demonstrated in the experimental results that the YOLOv2 network achieved a good detection performance (average prediction accuracy: 88%, average prediction time: 0.04 s). The YOLOv3 network was adopted as a deep-learning model for insulator locating in [
44]. Experimental results validated the YOLOv3 model, which performed well on insulator detection. To detect remote sensing targets from complex backgrounds, Xu et al. [
45] proposed a multiscale method based on improved YOLOv3 for remote sensing target detection. Experimental results demonstrated that the mean average precision of the proposed method was 10% higher than that of the original YOLOv3.
In summary, traditional image processing methods often rely on a certain feature. The applicability of the final algorithm needs to be further improved if image segmentation is insufficient. Machine learning is more complicated and difficult to implement, compared with deep learning methods. It can thus be concluded that using YOLO models can achieve insulator detection and potentially meet the requirements of actual real-world application. Nevertheless, there are still many difficulties in realizing this potentiality, e.g., different-sized insulators and the complex, ever-changing backgrounds of aerial images. As a feed-forward neural network, DenseNet makes better use of the extracted features, achieving feature reuse and preventing feature loss. Inspired by the work of [
45], on the basis of YOLOv3 and DenseNet, this work proposed a network (YOLOv3-dense) to detect insulators in aerial images with complex backgrounds. To enhance feature propagation and reuse, Dense-Blocks are adopted to replace some residual units with lower resolution. To obtain different scales of insulator feature information, a structure of multiscale feature fusion was proposed for the YOLOv3-dense network. To improve the abundance of semantic information in upper and lower layers, multilevel feature mapping modules were employed to YOLO headers.
The rest of this study is organized as follows: (1)
Section 1 reports the existing works of insulator detection. (2)
Section 2 introduces the framework of YOLOv3. (3)
Section 3 details the proposed network of YOLOv3-dense. (4)
Section 4 gives experimental results and analysis. (5)
Section 5 presents the conclusion of this study.
2. The Network of YOLOv3
YOLO is an end-to-end object detection algorithm based on deep CNNs, transforming object detection into a regression problem—which remarkably enhances the speed of object detection. Specifically, the input image is divided into S × S grids; the grid is responsible for detecting an object if the center of the object’s ground truth falls within its boundaries. Then, the object is predicted by a bounding box on each grid without a proposal region. The final coordinates of the bounding box and category probabilities are generated through regression algorithms. This is the reason why the detection speed of the YOLO algorithm is faster than two-stage models.
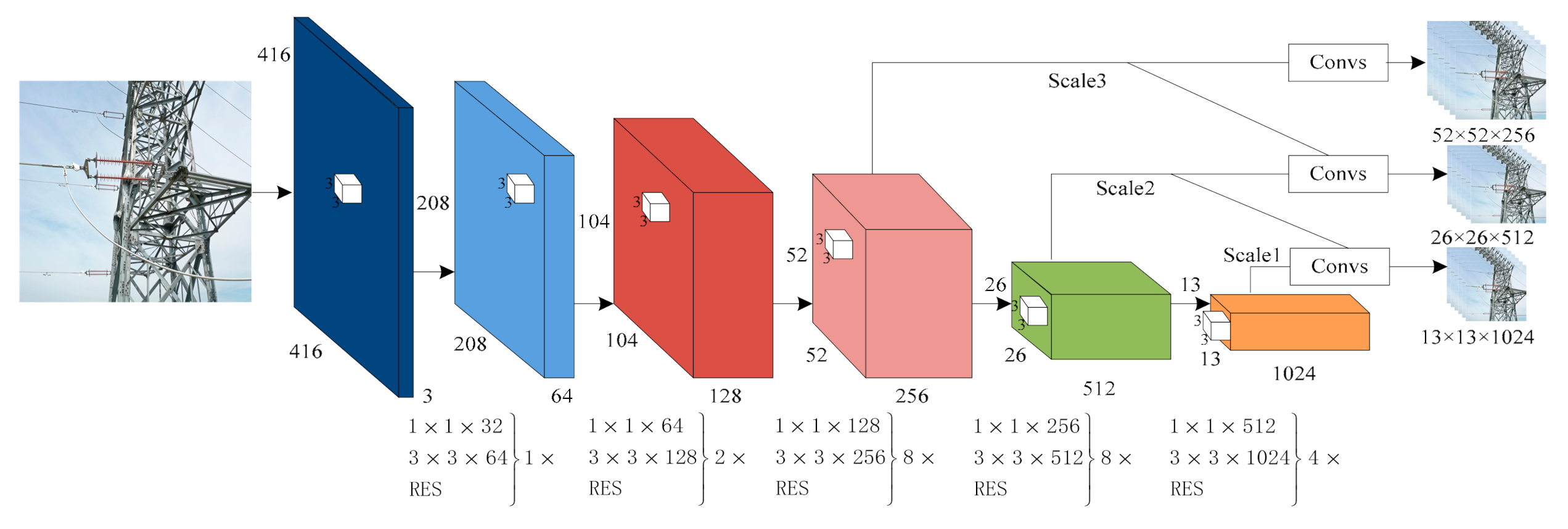
An object detection algorithm for YOLOv3 was proposed by Joseph Redmon in 2019. It evolved from YOLO and YOLOv2. The backbone of the YOLOv3 network is Darknet-53, which is a combination of the Darknet-19 and Res-net modules. The structure of the YOLOv3 network is shown in
Figure 2. Specifically, Darknet-53 and multiscale fusion are adapted to the feature extraction network of YOLOv3. The width and height of images are cropped to a multiple of 32, and sized to 416 × 416 for normalization. Then, the cropped and resized image is sent to the Darknet-53 network for feature extraction and three different feature maps (sized 13 × 13, 26 × 26, and 52 × 52) are obtained. To better learn the features in the image, 26 × 26 feature maps are fused with 52 × 52 feature maps via upsampling. Using the same method, the 13 × 13 feature maps are fused with the 26 × 26 ones. Detection accuracy can be improved through multiscale fusion of the deep and shallow features. Finally, the detection results of the YOLOv3 network are predicted by three different scales, (scale 1, scale 2, and scale 3 are used to predict large objects, medium objects, and small objects, respectively).
The feature extraction network of YOLOv3 is shown in
Table 1: five Res-net modules are adapted to the feature extraction network. Each Res-net module is composed of a Residual unit (which is mainly made up of 1 × 1 and 3 × 3 convolutional kernels) and a shortcut connection. There are 23 Residual units (1×, 2×, 8×, 8×, 4×, respectively) in the Darknet-53 network. It is possible for the output of the former layer to skip several layers (as the input of the later layers) by introducing Res-net modules.
3. Materials and Methods
Deep learning theory is an important part of computer vision, which has become a research hot spot in object detection technology. The traditional object detection algorithms have been gradually replaced by deep learning-based ones. More and more, deep learning algorithms have been adapted to object detection, and better results have been obtained.
With the deepening of the network, YOLOv3 failed to make full use of multilayer features, which led to the loss of insulator information in the transmission process. It was thus difficult to detect insulators accurately amid complex background interference. In order to enhance feature propagation and reuse, this paper proposes the YOLOv3-dense network, based on the YOLOv3 network. The entire structure of the YOLOv3-dense network is shown in
Figure 3. It is composed of a feature extraction network, a feature pyramid network (FPN), feature mapping modules, and a detection network. To improve feature propagation and reuse of the feature extraction network, Dense-Blocks were adapted to replace some of the Residual units with lower resolutions. To obtain different scales of insulator feature information, a structure of multiscale feature fusion was proposed for the YOLOv3-dense network. To obtain abundant semantic information on upper and lower layers, multilevel feature mapping modules were employed for YOLO headers.
3.1. The Feature Extraction Network
During the training of the neural network, the feature maps were compressed by convolution and downsampling. The transmission of image feature maps can be weakened gradually with the deepening of network layers, resulting in the loss of feature information transmission. To solve this problem, the DenseNet [
46,
47,
48] was introduced to reuse those features and prevent their loss, leading to improvements in network performance. In addition, the parameters of the training network could be reduced effectively and low-level features could be retained as long as possible. Consequently, the reuse and fusion of the multilevel features of the network can be further realized by the use of DenseNet. The structure of Dense-Blocks is shown in
Figure 4. It can be seen that the input of H1 is X0, the input of H2 is X0, and X1, …, and the input of Ht is X0, X1, …, and X(t−1). This means that in the network, each layer’s input comes from the output of all the previous layers. The expression of Dense-Blocks is defined as follows:
[X0, X1, …, X(t − 1)] are the spliced feature maps of layers X0, X1, …, and X(t − 1). H1, H2, …, and Ht are the spliced functions for feature maps. The function Hi (i = 1, 2, 3, 4) is composed of batch normalization (BN), rectified linear units (ReLU), and convolutional (Conv), commonly BN-ReLU-Conv (1 × 1) and BN-ReLU-Conv (3 × 3), which are employed in transfer function.
To improve feature propagation and facilitate reuse of the feature extraction network, Dense-Blocks were adopted to replace some Residual units with lower resolution. Three Dense-Blocks were adopted to the YOLOv3-dense network; the structure of Dense-Blk1, Dense-Blk2, and Dense-Blk3 are shown in
Figure 4. Specifically, in the network architecture of Dense-Blk1 (
Figure 4a), the output of the first layer X0 was 52 × 52 × 128. The output of the second layer X1 was 52 × 52 × 32 after BN-ReLU-Conv (1 × 1 × 32) and BN-ReLU-Conv (3 × 3 × 32) operations by function H1. The feature layers X0 and X1 were spliced into [X0, X1] (52 × 52 × 160) as the input of function H2. Moreover, the function H2 employed BN-ReLU-Conv (1 × 1 × 32) and BN-ReLU-Conv (3 × 3 × 32) operations on the feature maps [X0, X1], and the output of the third layer X2 (52 × 52 × 32) was obtained. The feature layers X0, X1, and X2 were spliced into [X0, X1, X2] (52 × 52 × 192) as the input of function H3. The function H3 employed BN-ReLU-Conv (1 × 1 × 32) and BN-ReLU-Conv (3 × 3 × 32) operations on the feature maps [X0, X1, X2], and the output of the forth layer X3 (52 × 52 × 32) was obtained. The feature layers X0, X1, X2, and X3 were spliced into [X0, X1, X2, X3] (52 × 52 × 224) as the input of function H4. Finally, the function H4 employed BN-ReLU-Conv (1 × 1 × 32) and BN-ReLU-Conv (3 × 3 × 32) operations on the feature maps [X0, X1, X2, X3], and the output of the fifth layer X4 (52 × 52 × 32) was obtained. The feature layers X0, X1, X2, X3, and X4 were spliced into [X0, X1, X2, X3, X4] (52 × 52 × 256) as the input of Res-net modules (52 × 52). Similarly, in the network architecture of Dense-Blk2 (
Figure 4b), the output of first layer X0 was 26 × 26 × 256, and the output of layer X1, X2, X3, and X4 was 26 × 26 × 64. The transfer functions of H1, H2, H3, and H4 were BN-ReLU-Conv (1 × 1 × 64) and BN-ReLU-Conv (3 × 3 × 64), and the spliced feature maps of [X0, X1], [X0, X1, X2], [X0, X1, X2, X3], [X0, X1, X2, X3, X4] were 26 × 26 × 320, 26 × 26 × 384, 26 × 26 × 450, and 26 × 26 × 512, respectively. The final feature maps 26 × 26 × 512 were used as the input of Res-net modules (26 × 26). In the network architecture of Dense-Blk3 (
Figure 4c), the output of the first layer X0 was 13 × 13 × 512, and the output of layer X1, X2, X3, and X4 was 13 × 13 × 128. The transfer functions of H1, H2, H3, and H4 were BN-ReLU-Conv (1 × 1 × 128) and BN-ReLU-Conv (3 × 3 × 128), and the spliced feature maps of [X0, X1], [X0, X1, X2], [X0, X1, X2, X3], [X0, X1, X2, X3, X4] were 13 × 13 × 640, 13 × 13 × 768, 13 × 13 × 896, and 13 × 13 × 1024, respectively. The final feature maps 13 × 13 × 1024 were used as the input of Res-net modules (13 × 13).
Dense-Blocks were adopted to the proposed network (YOLOv3-dense). The shallow-level features were able to be transmitted more swiftly and easily to high-level features via convolution layers, and multilayer feature reuse and fusion could then be realized. On the other hand, the information and gradient transfer efficiency of the whole network could be improved, which would be beneficial to the fusion of upsampling and shallow features for object detection.
The feature extraction network of YOLOv3-dense is shown in
Table 2, which can be divided into six sections, as follows: (1) One convolutional layer was employed in the first section, and the size of the convolution kernel was 3 × 3 × 32. The output feature maps 416 × 416 × 32 were obtained after the convolution operation. (2) One Residual layer and three convolutional layers were employed in the second section, and the sizes of convolution kernels were 3 × 3/2 × 64, 1 × 1 × 32, and 3 × 3 × 64, respectively. The output feature maps 208 × 208 × 64 were obtained after the convolution operation. (3) Two Residual layers and five convolutional layers were employed in the third section, and the sizes of convolution kernels were 3 × 3/2 × 128, 1 × 1 × 64, and 3 × 3 × 128, respectively. The output feature maps 104 × 104 × 128 was obtained after the convolution operation. (4) 18 convolutional layers, 4 Residual layers, and 4 Dense layers were employed in the fourth section, and the sizes of convolution kernels were 3 × 3/2 × 256, 1 × 1 × 128, 1 × 1 × 32, 3 × 3 × 32, and 3 × 3 × 256, respectively. The output feature maps 52 × 52 × 256 were obtained after the convolution operation. (5) 17 convolutional layers, 4 Residual layers, and 4 Dense layers were employed in the fifth section, and the sizes of the convolution kernels were 3 × 3/2 × 256, 1 × 1 × 64, 3 × 3 × 64, 1 × 1 × 256, and 3 × 3 × 512, respectively. The output feature maps 26 × 26 × 512 were obtained after the convolution operation. (6) 17 convolutional layers, 4 Residual layers, and 4 Dense layers were employed in the sixth section, and the sizes of the convolution kernels were 3 × 3/2 × 512, 1 × 1 × 128, 3 × 3 × 128, 1 × 1 × 512, and 3 × 3 × 1024, respectively. The output feature maps 13 × 13 × 1024 were obtained after the convolution operation.
3.2. The Structure of Feature Pyramid Network
In YOLOv3-dense, the input size for aerial images was 416 × 416. The sizes of extracted feature maps for insulator detection were 52 × 52, 26 × 26, and 13 × 13, respectively. Note that the detail and location information of shallow-level feature layers is generally abundant; however, with the gradual deepening of feature layers, detail information decreased, while semantic information increased. Owing to different filming angles and filming distances, insulators exhibit different sizes in aerial images. It is difficult to recognize insulators using only high-level semantic information, because shallow-level feature maps may be ignored, leading to the loss of many details (e.g., the shape, color, and texture, etc. of the insulators). Inspired by the works [
49,
50,
51], in order to obtain different scales of insulator feature information, a structure of multiscale feature fusion was proposed in this work, as shown in
Figure 3. High-level feature maps were fused with shallow-level feature maps, and multiresolution feature maps were obtained for insulator prediction.
The structure of multi-scale feature fusion in this work was as follows: first, three-scale effective feature maps (52 × 52 × 256), (26 × 26 × 512), and (13 × 13 × 1024) were extracted by the network of YOLOv3-dense and recorded as large feature layer (LFL0), medium feature layer (MFL0), and small feature layer (SFL0), respectively. Secondly, the small feature layer (SFL0) was upsampled and then fused with the medium feature laayer (MFL0) to obtain a 26 × 26 medium feature layer (MFL1). That medium feature layer (MFL1) was upsampled and then fused with the large feature layer (LFL0) to obtain a 52 × 52 large feature layer (LFL1). That resultant large feature layer (LFL1) employed a feature mapping module to obtain another large feature layer (LFL2) for scale 52 × 52 prediction. Finally, the LFL2 was downsampled and then fused with the dense feature layer (DFL1) from the output of DenseBlk2 to obtain a 26 × 26 medium feature layer (MFL2). MFL2 employed a feature mapping module to obtain a medium feature layer (MFL3) for scale 26 × 26 prediction. Meanwhile, MFL3 was downspampled and then fused with dense feature layer 2 (DFL2) from the output of DenseBlk3 to obtain a 13 × 13 small feature layer (SFL1). SFL1 employed a feature mapping module to obtain small feature layer 2 (SFL2) for scale 13 × 13 prediction.
In this work, the final feature layers of three different scales (LFL2, MFL3, and SFL2) were obtained from the proposed structure of FPN. Through the feature fusion operation, the final feature layer for prediction had more semantic information and higher resolution, which made it more effective in predicting insulators of different scales. The detection accuracy of different size insulators could be improved by FPN.
3.3. The Feature Mapping Module
In the network of YOLOv3, five convolutional layers were employed in previous YOLO headers. To avoid gradient vanishing and enhance the semantic information of upper and lower layers, feature mapping modules were adopted to replace the five convolutional layers. Each feature mapping module contained two Residual units. The structures of feature mapping modules are shown in
Table 3. The convolution operations 1×1 and 3×3 can obtain information about different receptive domains in aerial images, and the results of these convolution operations can be aggregated to obtain abundant semantic information. Multiscale feature mapping modules provide different receptive domains and abundant semantic information, which can be beneficial to insulator detection in aerial images with complex backgrounds.
5. Conclusions
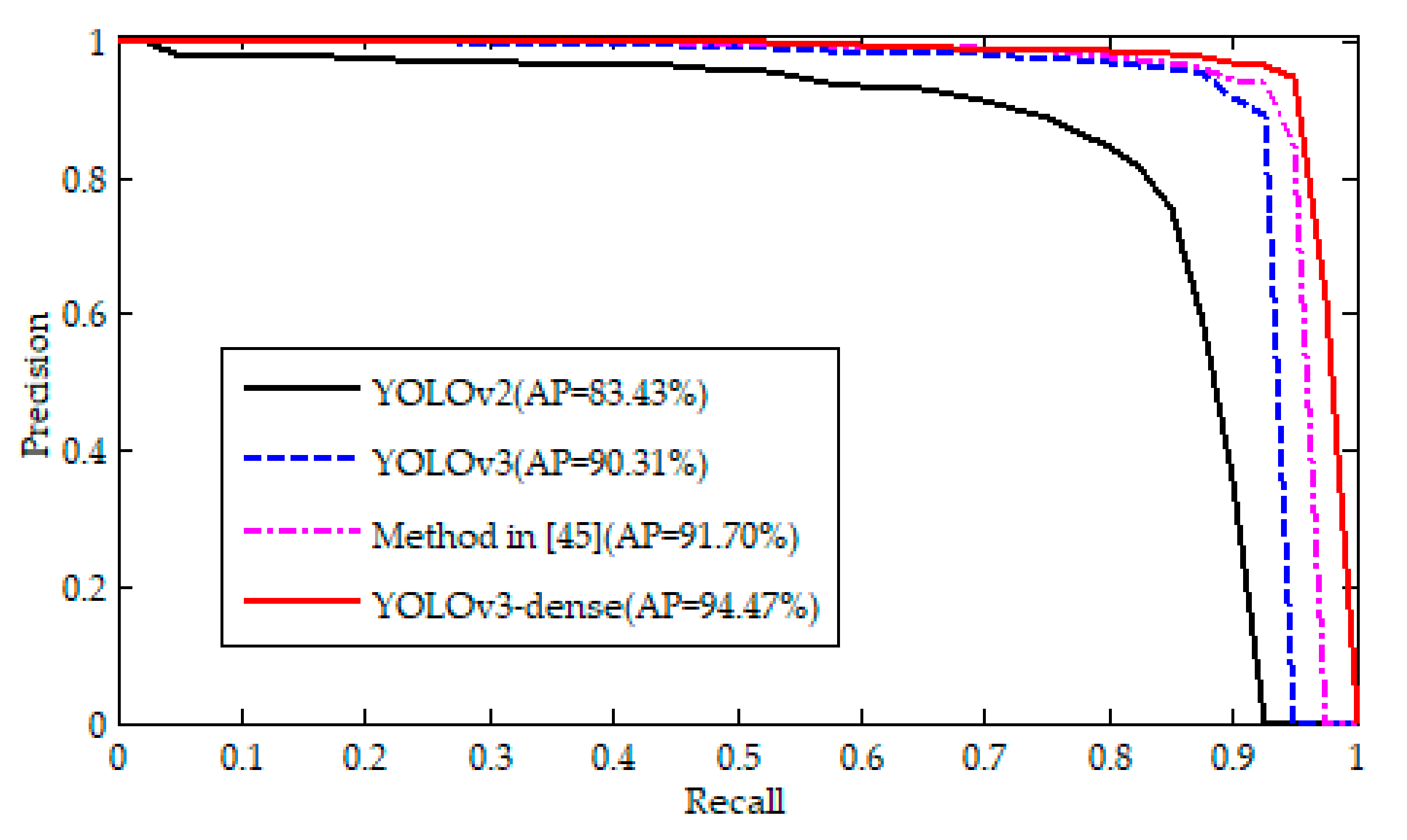
In this study, a modified network (YOLOv3-dense) was proposed for the detection of different-sized insulators in aerial images with complex backgrounds. A novel insulator dataset was constructed, which contained composite insulator images captured by UAV in common aerial scenes. The modified network YOLOv3-dense combined YOLOv3 with Dense-Blocks to optimize the feature extraction network. To enhance the accuracy and robustness of different-sized insulator detection, a structure of FPN was proposed as an addition to the YOLOv3-dense network. Multilevel feature mapping modules were adapted to the YOLOv3-dense network to obtain abundant semantic information of the upper and lower layers. The networks of YOLOv3-dense, the method in [
45], YOLOv3, and YOLOv2 were trained and tested on the constructed dataset. Experimental results demonstrated that the AP value of the YOLOv3-dense was 2.8%, 4%, and 11% higher than that of the method in [
45], YOLOv3 and YOLOv2, respectively. In addition, the precision values of the networks YOLOv3-dense, the method in [
45], YOLOv3, and YOLOv2 were 94%, 94%, 90%, and 87%, respectively—and the recall values were 96%, 90%, 91%, and 83%, respectively. The results confirmed that the proposed network is superior to the method in [
45], YOLOv3 and YOLOv2. Although the running time of the proposed network (8.5 ms) is slightly higher than that of YOLOv3 (8 ms), the proposed network can still be used to detect insulators in real-time. Consequently, the proposed network achieved good performance in different-sized insulator detection amid diverse background interference.
For a future study, the proposed model will be used for UAV-based real-time inspection of transmission lines.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}