
Area-Time Efficient Two-Dimensional Reconfigurable Integer DCT Architecture for HEVC

 ,
,
Abstract
1. Introduction
- A hardware-oriented algorithm for integer DCT computation for HEVC is proposed.
- Three different flexible hardware architectures for the integer DCT are proposed, each with advantages in terms of area, delay, or power.
- A novel 2D integer DCT architecture having double the throughput and less latency (without increasing the size of the transposition buffer) is proposed.
- A novel low-cost pipeline strategy is proposed to reduce the critical path of the proposed 1D integer DCT.
- Comparisons with existing methods are provided in terms of various metrics such as gate counts, maximum usable frequency, throughput, latency, etc.
2. Key Features of Integer DCT for HEVC
3. Proposed Reconfigurable Architectures for 1D Integer DCT
3.1. Proposed 1D DCT Architecture-1
3.2. Proposed 1D DCT Architecture-2
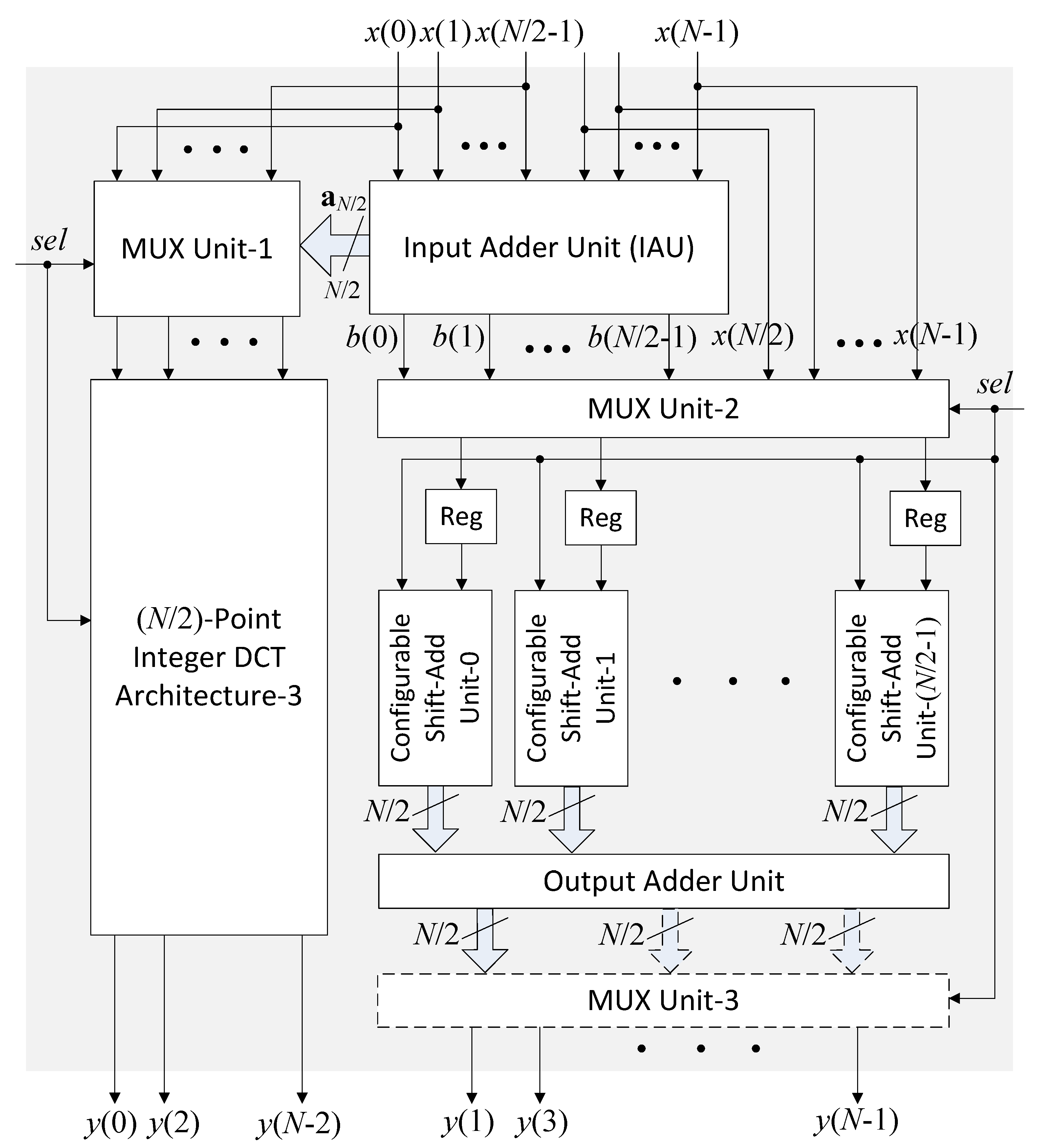
3.3. Proposed 1D DCT Architecture-3
4. High-Throughput 2D Integer DCT Architecture
5. Implementation Results
6. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Liu, S.; Deng, G.; Rahardja, S. Hardware Efficient Integer Discrete Cosine Transform for Efficient Image/Video Compression. IEEE Access 2019, 7, 152635–152645. [Google Scholar] [CrossRef]
- Ahmed, N.; Natarajan, T.; Rao, K. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- JCTVC-G495, CE10: Core Transform Design for HEVC: Proposal for Current HEVC Transform. Available online: http://phenix.it-sudparis.eu/jct/doc_end_user/current_document.php?id=3752 (accessed on 4 March 2021).
- Bross, B.; Han, W.; Ohm, J.; Sullivan, G.; Wang, Y.; Wiegand, T. High Efficiency Video Coding HEVC Text Specification Draft 10, JCTVC-L1003. Available online: http://phenix.int-evry.fr/jct/doc_end_user/documents/8_San%20Jose/wg11/JCTVC-H1003-v22.zip (accessed on 4 March 2021).
- Singhadia, A.; Bante, P.; Chakrabarti, I. A Novel Algorithmic Approach for Efficient Realization of 2D-DCT Architecture for HEVC. IEEE Trans. Consum. Electron. 2019, 65, 264–273. [Google Scholar] [CrossRef]
- Zhao, W.; Onoye, T.; Song, T. High-Performance Multiplierless Transform Architecture for HEVC. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 1668–1671. [Google Scholar]
- Zhu, J.; Liu, Z.; Wang, D. Fully Pipelined DCT/IDCT/Hadamard Unified Transform Architecture for HEVC Codec. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 677–680. [Google Scholar]
- Ahmed, A.; Shahid, M.U.; ur Rehman, A. N-point DCT VLSI architecture for emerging HEVC standard. VLSI Des. 2012, 2012, 752024. [Google Scholar] [CrossRef]
- Park, J.S.; Nam, W.J.; Han, S.M.; Lee, S. 2D large inverse transform (16×16, 32×32) for HEVC (High Efficiency Video Coding). J. Semicond. Technol. Sci. 2012, 12, 203–211. [Google Scholar] [CrossRef]
- Budagavi, M.; Sze, V. Unified forward + inverse transform architecture for HEVC. In Proceedings of the IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 209–212. [Google Scholar]
- Sun, H.; Zhou, D.; Zhu, J.; Kimura, S.; Goto, S. An area-efficient 4/8/16/32-point inverse DCT architecture for UHDTV HEVC decoder. In Proceedings of the IEEE International Conference on Visual Communications and Image Processing, Valletta, Malta, 7–10 December 2014; pp. 197–200. [Google Scholar]
- Meher, P.K.; Park, S.Y.; Mohanty, B.K.; Lim, K.S.; Yeo, C. Efficient Integer DCT Architectures for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 168–178. [Google Scholar] [CrossRef]
- Park, S.Y.; Meher, P.K. Flexible integer DCT architectures for HEVC. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 1376–1379. [Google Scholar]
- Shen, S.; Shen, W.; Fan, Y.; Zeng, X. A unified 4/8/16/32-point integer IDCT architecture for multiple video coding standards. In Proceedings of the IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 788–793. [Google Scholar]
- Software/Hardware Generation of DSP Algorithms. Available online: http://www.spiral.net/ (accessed on 4 March 2021).
- Potkonjak, M.; Srivastava, M.B.; Chandrakasan, A.P. Multiple constant multiplications: Efficient and versatile framework and algorithms for exploring common subexpression elimination. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1996, 15, 151–165. [Google Scholar] [CrossRef]
- Macleod, M.D.; Dempster, A.G. Common subexpression elimination algorithm for low-cost multiplierless implementation of matrix multipliers. Electron. Lett. 2004, 40, 651–652. [Google Scholar] [CrossRef]
- Boullis, N.; Tisserand, A. Some optimizations of hardware multiplication by constant matrices. IEEE Trans. Comput. 2005, 54, 1271–1282. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computation of in the matrix-vector-product unit (MVPU) for 8-point DCT computation |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; |
| Computation of in the MVPU for 16-point DCT computation |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; |
| ; ; ; ; |
| ; ; ; |
| ; ; ; |
| ; ; |
| ; ; |
| Computation of in the MVPU for 32-point DCT computation |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; ; |
| ; ; ; ; ; ; ; |
| ; ; ; ; ; ; |
| ; ; ; ; ; |
| ; ; ; ; ; |
| ; ; ; ; ; |
| ; ; ; |
| ; ; ; |
| ; ; ; |
| ; ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| ; ; |
| N | IAU | MVPU | -DCT | Total | |||
|---|---|---|---|---|---|---|---|
| [12] | Figure 1 | [12] | Figure 1 | [12] | Figure 1 | ||
| 4 | 4 | 10 | 14 | ||||
| 8 | 8 | 28 | 33 | 14 | 50 | 55 | |
| 16 | 16 | 120 | 112 | 50 | 55 | 186 | 183 |
| 32 | 32 | 464 | 367 | 186 | 183 | 682 | 582 |
| Design | Tech. (nm) | Gates (K) | MUF (MHz) | Samples/ Cycle | TPT (GSPS) | Latency | Power (mW) | EPS (mW × ns) | TSG (KSPSPG) |
|---|---|---|---|---|---|---|---|---|---|
| Zhao et al. [6] | 45 | 205 | 333 | 32 | * | 38 | − | − | * |
| Zhu et al. [7] | 90 | 412 | 311 | * | * | ||||
| Meher et al. [12] | 90 | 463 | 310 | 32 | 32 | ||||
| Sun et al. [11] | 90 | 155 | 312 | 4 | − | − | − | ||
| Park et al. [13] | 90 | 402 | 336 | * | * | ||||
| Architecture-1 | 90 | 310 | 400 | * | * | ||||
| Architecture-2 | 90 | 423 | 400 | 32 | |||||
| Architecture-3 | 90 | 367 | 380 | 32 | |||||
| Architecture- | 90 | 453 | 400 | * | * | ||||
| Architecture- | 90 | 662 | 400 | 64 | |||||
| Architecture- | 90 | 561 | 380 | 64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meher, P.K.; Lam, S.-K.; Srikanthan, T.; Kim, D.H.; Park, S.Y. Area-Time Efficient Two-Dimensional Reconfigurable Integer DCT Architecture for HEVC. Electronics 2021, 10, 603. https://doi.org/10.3390/electronics10050603
Meher PK, Lam S-K, Srikanthan T, Kim DH, Park SY. Area-Time Efficient Two-Dimensional Reconfigurable Integer DCT Architecture for HEVC. Electronics. 2021; 10(5):603. https://doi.org/10.3390/electronics10050603
Chicago/Turabian StyleMeher, Pramod Kumar, Siew-Kei Lam, Thambipillai Srikanthan, Dong Hwan Kim, and Sang Yoon Park. 2021. "Area-Time Efficient Two-Dimensional Reconfigurable Integer DCT Architecture for HEVC" Electronics 10, no. 5: 603. https://doi.org/10.3390/electronics10050603
APA StyleMeher, P. K., Lam, S.-K., Srikanthan, T., Kim, D. H., & Park, S. Y. (2021). Area-Time Efficient Two-Dimensional Reconfigurable Integer DCT Architecture for HEVC. Electronics, 10(5), 603. https://doi.org/10.3390/electronics10050603