4.2. Selection of the Training Dataset
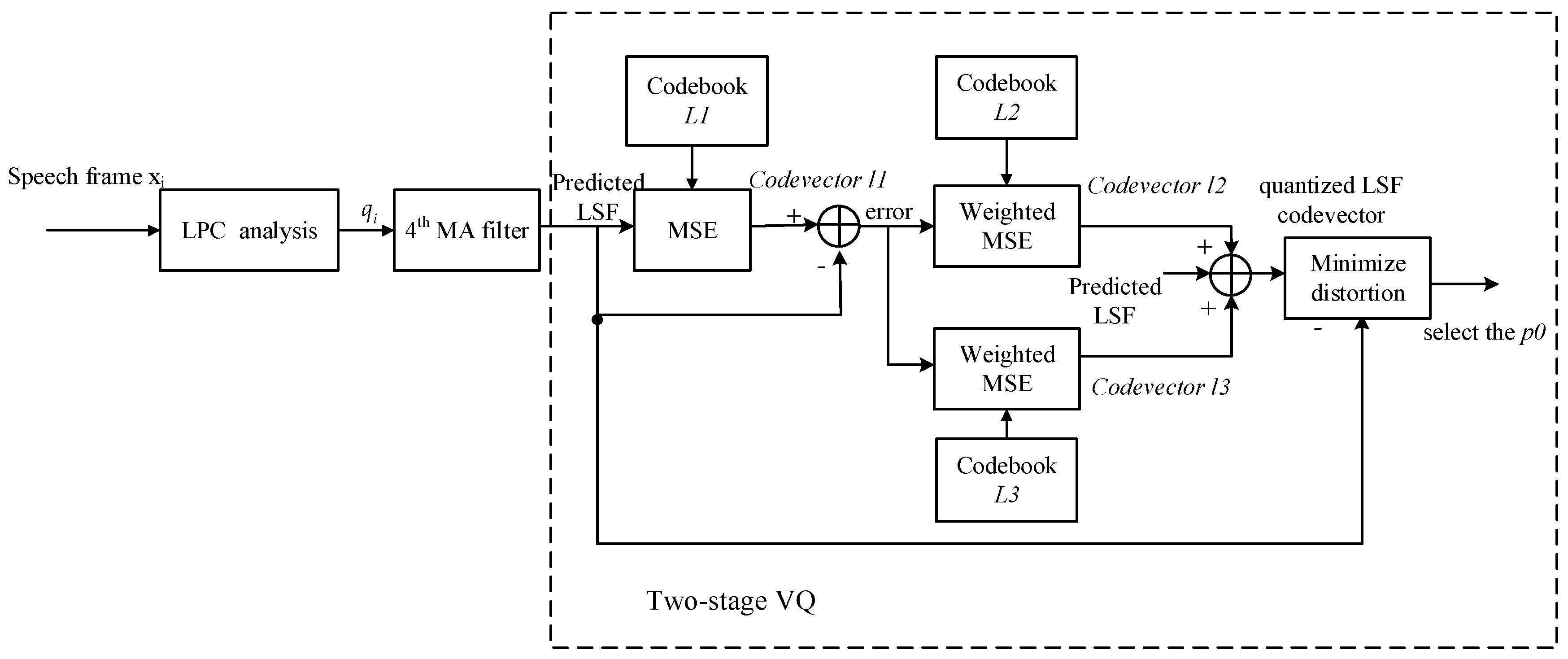
As introduced in
Section 3, the proposed method included a training procedure and an encoding procedure. The training procedure provided a squared-error look-up table for the encoding procedure. The selection of the training speech dataset directly affected the application scope of the squared-error look-up table. Further, it affected the computation loads and quantization accuracy of the subsequent encoding process. Therefore, we discuss the influence of the selection of the training dataset on the application scope of the squared-error look-up table.
The Aurora Test-A set included 1001 clean files and 1001 noisy speech files that were used to train and test the robustness of the proposed algorithm. Here we will compare the performance of the proposed method with three experimental environments. To evaluate the quantization accuracy of the proposed algorithm, a parameter defined as error rate (ER) was proposed, symbolized as . The average search times are symbolized as ASN, and the reduction of the ASN is presented as a computational saving (CS) and symbolized as , given to evaluate the reduction of the computational load. The following three experimental results were all obtained with the value .
For the first experimental conditions, the 1001 clean files, which included 350,866 speech frames, were all selected as the training set, then a squared-error look-up table which is symbolized as table A was obtained after the training procedure. Then, table A was employed in the encoding process. The testing datasets were clean files and noisy speech files, respectively. When there were 500 clean files, which included 174,630 speech frames used as the testing dataset, the experimental results show that there were 1412 uncorrected quantized frames, thus ER = 0.81%, and ASN = 18.82. When there were 201 speech files with noise, which included 70,170 frames used as a testing dataset, the experimental results show that there were 2579 uncorrected quantized frames, thus t ER = 3.7% and ASN = 18.9.
For the second experimental conditions, the training dataset included 500 clean speech files and 500 speech files with noise, which included 348,724 frames. Then, when the training dataset was used as a testing dataset, the experimental results show there were 1062 uncorrected quantized frames, thus and ASN = 18.8. When the other 201 clean speech files, which included 70,170 frames used as testing data, the experimental result shows that there were 2038 uncorrected quantized frames, thus and ASN = 19.3. When the other 201 speech files with noise, which included 70,170 frames used as a testing set, the experimental results show that there were 1975 uncorrected quantized frames, thus and ASN = 18.9.
For the third experimental conditions, the training dataset included 1001 clean files and 1001 speech files with noise, which included 701,508 frames. When there were 201 clean speech files used as a testing set, the experimental results show that there were 556 uncorrected quantized frames, thus and ASN = 20. When there were 201 speech files with noise, which included 70,170 frames used as a testing set, the experimental results show that there were 605 uncorrected quantized frames, thus and ASN = 19.9.
Details of the above three experiments and the corresponding experimental results can be found in
Table 3. Even under the worst training conditions, 1, where the training set was clean speech and the testing set was speech files with noise, the experimental results show that
and ASN = 18.9. Under the best training conditions, 3, the experimental results show that
and ASN = 20. Comparing the results of these three conditions, the
ER value ranges from 0.7% to 3.7%, and the ASN value ranges from 18.82 to 20. It can be concluded that when the training set was large enough, the selection of the training set had no significant influence on the encoding process. The robustness of the prebuilt squared-error look-up table was good. The variation ranges of
ER and ASN were within acceptable limits.
4.3. Performance of the Proposed Method
Here we choose experiment 1 to illustrate the performance of the proposed method. The generation of the squared-error look-up table is a very important process of the proposed algorithm. Thus, we extracted some intermediate experimental data as examples to illustrate the created procedure.
Figure 3 illustrates the design procedure of the squared-error look-up table of the proposed algorithm. It shows that the generation of the squared-error look-up table can reduce the number of candidate code words significantly and reduce the search range.
The computational load and the quantization accuracy are compared for the proposed algorithm with TIE [
18], ITIE [
21], and BSS-ITIE [
28] approaches. With the
performance of the full search algorithm as the benchmark,
Table 4 gives the comparison of
ER, ASN, and
CS
for the proposed algorithm with TIE [
18], ITIE [
21], and BSS-ITIE [
28] approaches. The experimental results show that the proposed algorithm provided
CS of up to 92% when
and when
, it still reduced the computational load by 85%. Compared to the TIE and ITIE methods, the proposed method provided
CS of up to 76% and 63% with almost the same quantization accuracy.
To further evaluate the reduction of computational load, the comparison of the average number of basic operations, including addition, multiplication, and comparison, is shown in
Table 5 and is illustrated as a bar graph in
Figure 4. The multiplication operation was the dominant computation, with the highest computational complexity. The reduction in the number of multiplications is the load reduction (LR), symbolized as
, where MulN is the number of multiplications. The proposed algorithm provided
LR up to 90% in the full search algorithm, with almost the same quantization accuracy.
Table 6 and
Figure 5 give the comparison results with the BSS-ITIE [
28] as the benchmark. When
, the ASN of the BSS-ITIE algorithm was 18.47 with
. In comparison, the ASN of the proposed algorithm was 18.82 with
, and
. This indicates the proposed algorithm can obtain a better speech quality than the BSS-ITIE algorithm with great reduction of the number of multiplications. On the other hand, when
, the ASN of the proposed algorithm was 13.10 with
. When
, the ASN of the proposed algorithm was 12.33 with
. This indicates the proposed algorithm provided
of about 29–33%, and
LR up to 67–69%, over the BSS-ITIE algorithm with almost the same
.
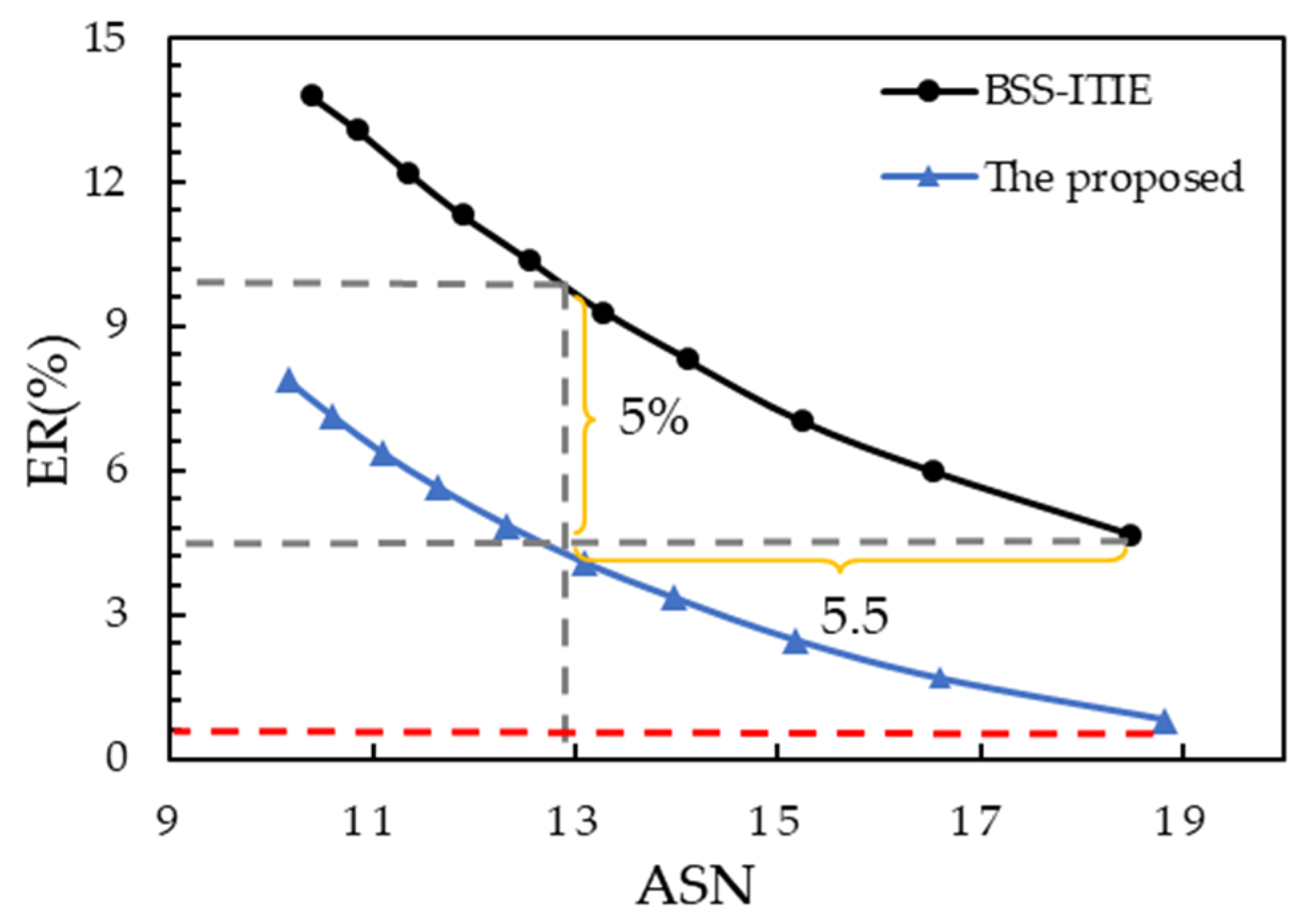
Figure 6 shows that when ASN was about equal to 19, the
of the proposed method was equal to 0.81%, while with the BSS-ITIE it was equal to 4.66%. For instance, when ASN was approximately equal to 13, the
of the proposed method was lower than that of the BSS-ITIE method by about 5%. When
was approximately equal to 4%, the ASN of the proposed method was about 5.5 lower than that of the BSS-ITIE method. Thus, the proposed algorithm had a significantly better performance than the BSS-ITIE method.
In addition, to better measure the quantization error, the average vector quantization error (AVQR) was defined as the absolute error value between the quantized code word and the best-matched code word. The
AVQR was computed by Equation (16).
where
was the quantized code word, and
was the best-matched code word with the input vector which was searched by the full search algorithm.
L was the total number of input speech frames. The
AVQR value of the BSS-ITIE [
22] and the proposed algorithm were computed, while the
TQA ranged from 0.90 to 0.99, respectively.
Table 7 shows the
AVQR comparison between the BSS-ITIE [
22] method and the proposed method. The experimental results show that all the
AVQR values of the proposed method were lower than 0.1, and the
AVQR value of the BSS-ITIE method ranged from 0.0695 to 0.2324. Further, the max value of
AVQR for the proposed method was 0.0974 when
TQA = 0.90, which is about equal to the
AVQR value of the BSS-ITIE method when
TQA = 0.98. Thus, the experimental results show that the proposed method can obtain a much lower quantization error than the BSS-ITIE method.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}