
A GPU Scheduling Framework to Accelerate Hyper-Parameter Optimization in Deep Learning Clusters

 , ,
, , 
Abstract
1. Introduction
- Parallelization of hyper-parameter optimization process: Hermes parallelizes hyper-parameter optimization by time-sharing between containers running DL jobs. The container preemption is implemented using the model checkpointing feature supported by TensorFlow [13].
- Convergence-aware scheduling policy: Hermes accelerates hyper-parameter optimization by prioritizing jobs based on the convergence speed. This sharply contrasts to the Gandiva’s approach [7] since not all tasks are trained equally, but important tasks are selected and accelerated.
- No prior knowledge and modification of user code: In contrast to previous works, Hermes does not need prior knowledge about the jobs such as job completion time (JCT) distribution. Moreover, it does not try to predict the JCT of the jobs. Moreover, Hermes does not require modification to the user code and all modifications are transparent to the users.
- Real implementation: We have implemented Hermes over Kubernetes [6], one of the most popular open-source platforms for container orchestration.
2. Background and Motivation
2.1. Training of Deep Learning Models
2.1.1. Overview of Deep Learning Training
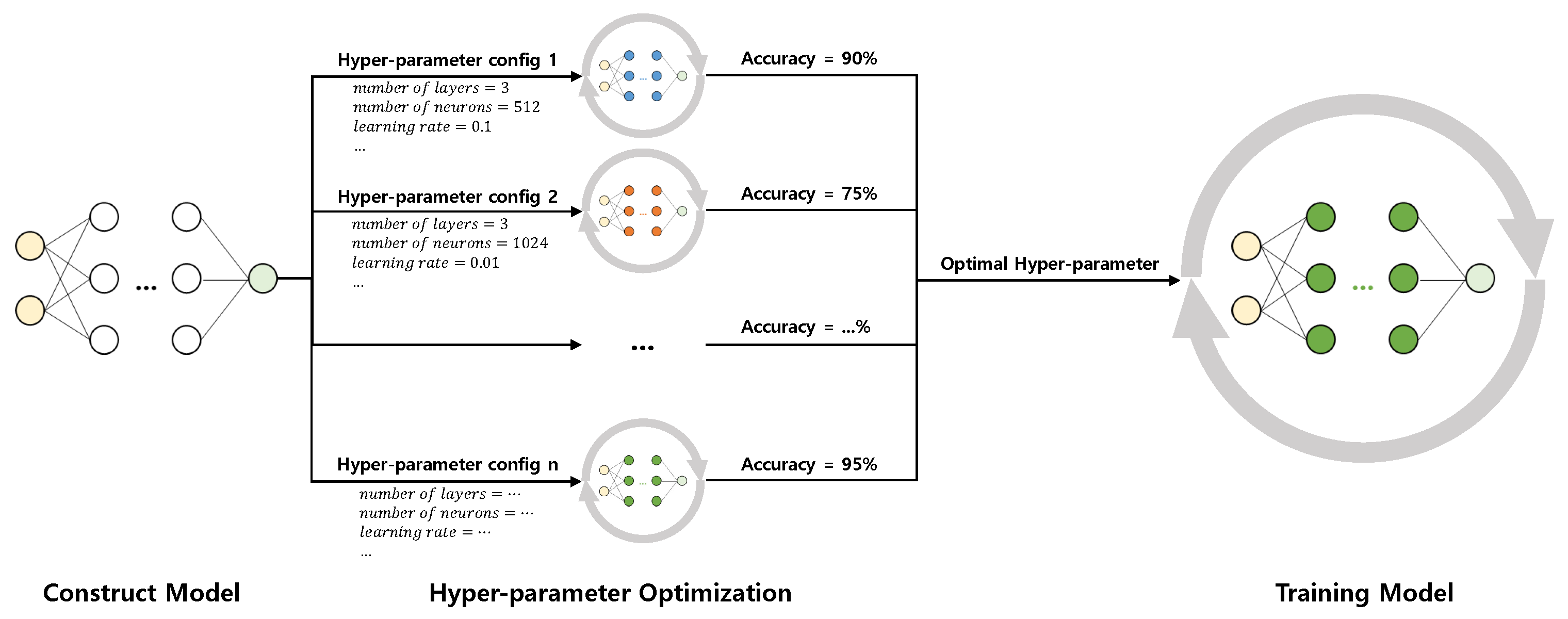
2.1.2. Hyper-Parameter Optimization
2.1.3. Grid Search
2.1.4. Random Search
2.1.5. Bayesian Optimization
2.2. Motivation
3. Design and Implementation
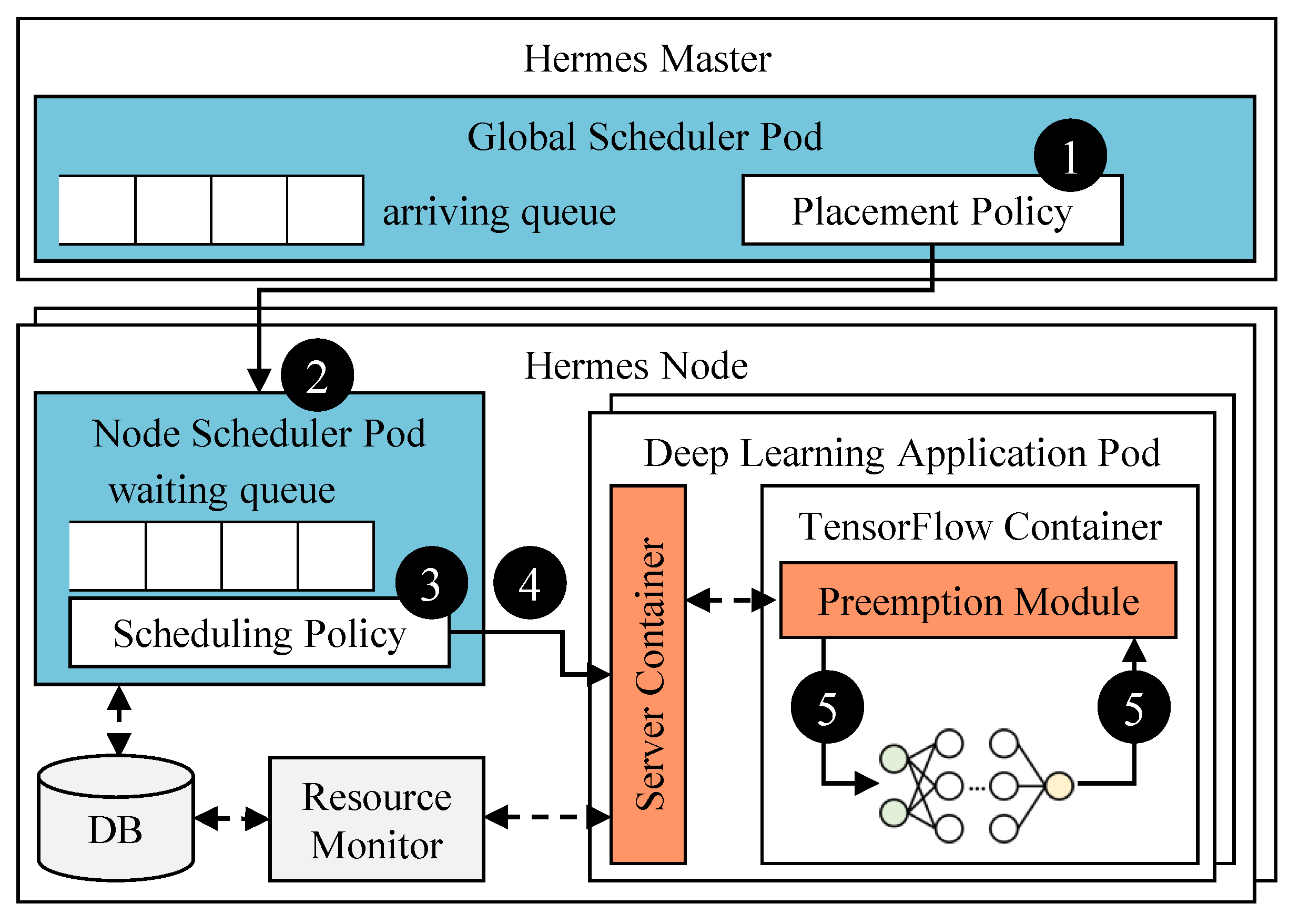
3.1. Overall Architecture of Hermes
3.2. Global Scheduler
| Algorithm 1 Placement Algorithm |
| Input: GPUs , Job |
| 1: for job do |
| 2: |
| 3: if then |
| 4: Initialize J |
| 5: Enqueue J to |
| 6: end if |
| 7: end for |
| Algorithm 2 Find_Available_GPU |
| Input: GPUs |
| Output: |
| 1: // : job count threshold in each GPU |
| 2: |
| 3: for GPU do |
| 4: if # of job in G is fewer than then |
| 5: if is null or # of job in G is fewer than then |
| 6: |
| 7: end if |
| 8: end if |
| 9: end for |
| 10: return |
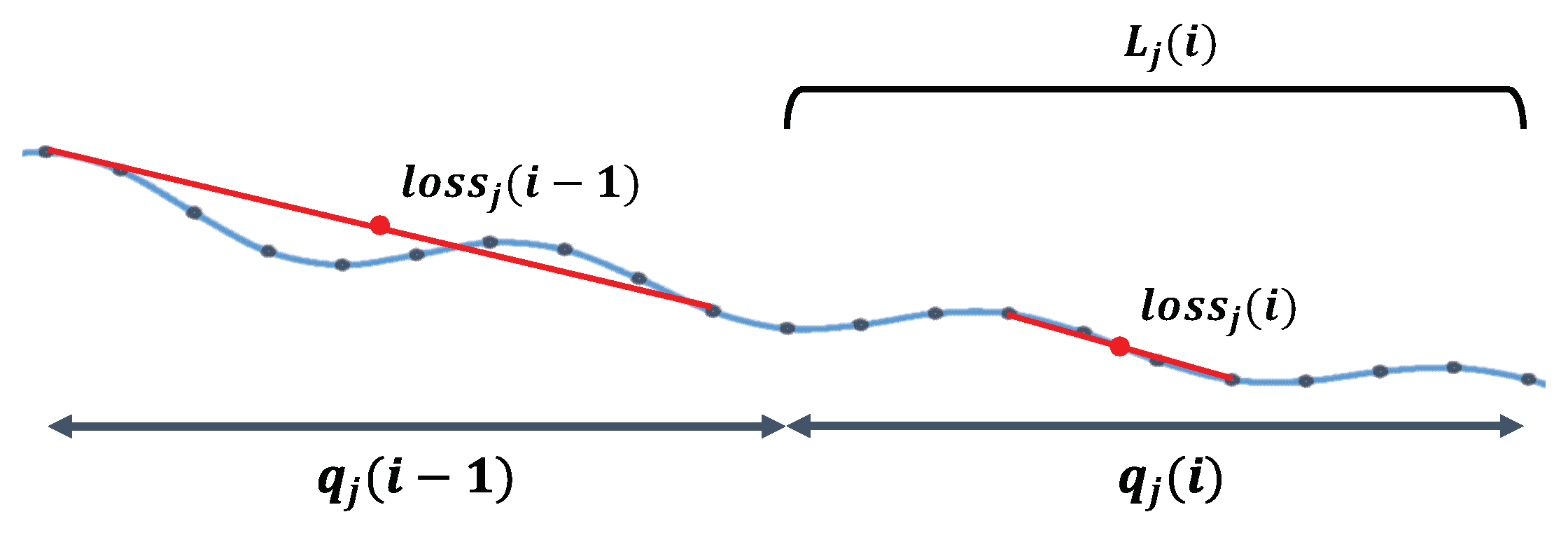
3.3. Node Scheduler
| Algorithm 3 Convergence-aware Scheduling Algorithm |
| Input: Iteration i, Convergences , GPUs |
| 1: for do |
| 2: |
| 3: |
| 4: |
| 5: if then |
| 6: continue |
| 7: end if |
| 8: for do |
| 9: if J is WAITING then |
| 10: Enqueue J to |
| 11: end if |
| 12: end for |
| 13: |
| 14: if needs preemption then |
| 15: if is PREEMPTIBLE then |
| 16: Preempt |
| 17: end if |
| 18: end if |
| 19: Schedule |
| 20: end for |
3.4. Preemption Module
4. Performance Evaluation
4.1. Experiment Setup
4.1.1. Testbed
4.1.2. Workloads
4.1.3. Baselines
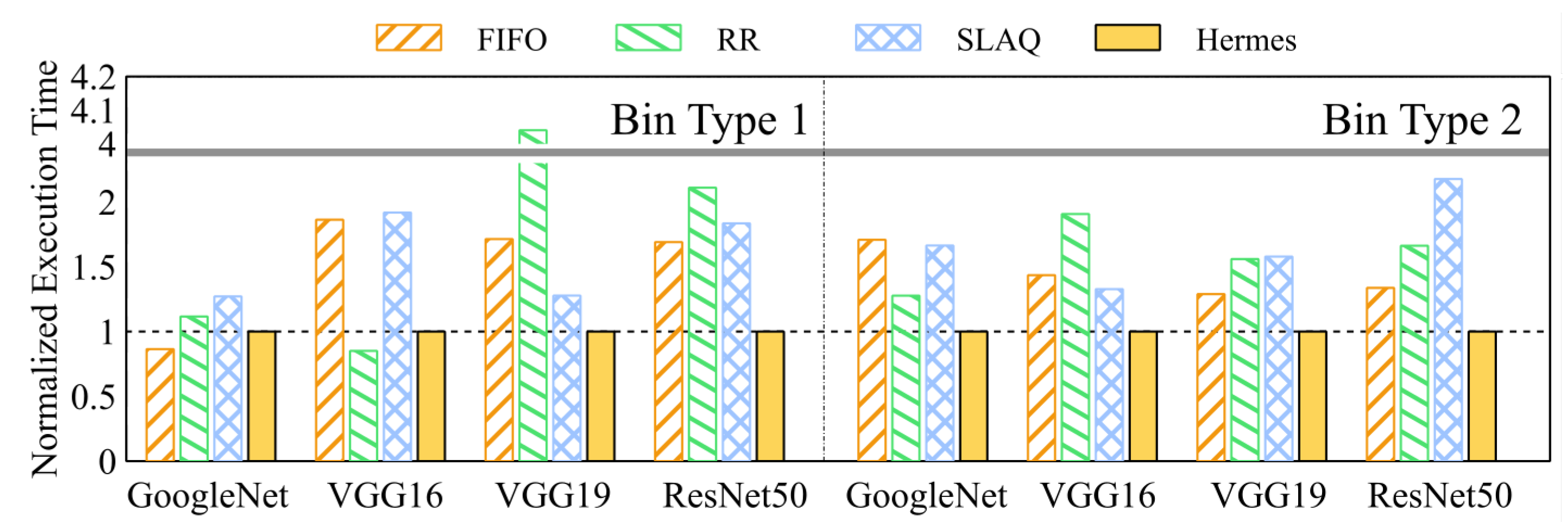
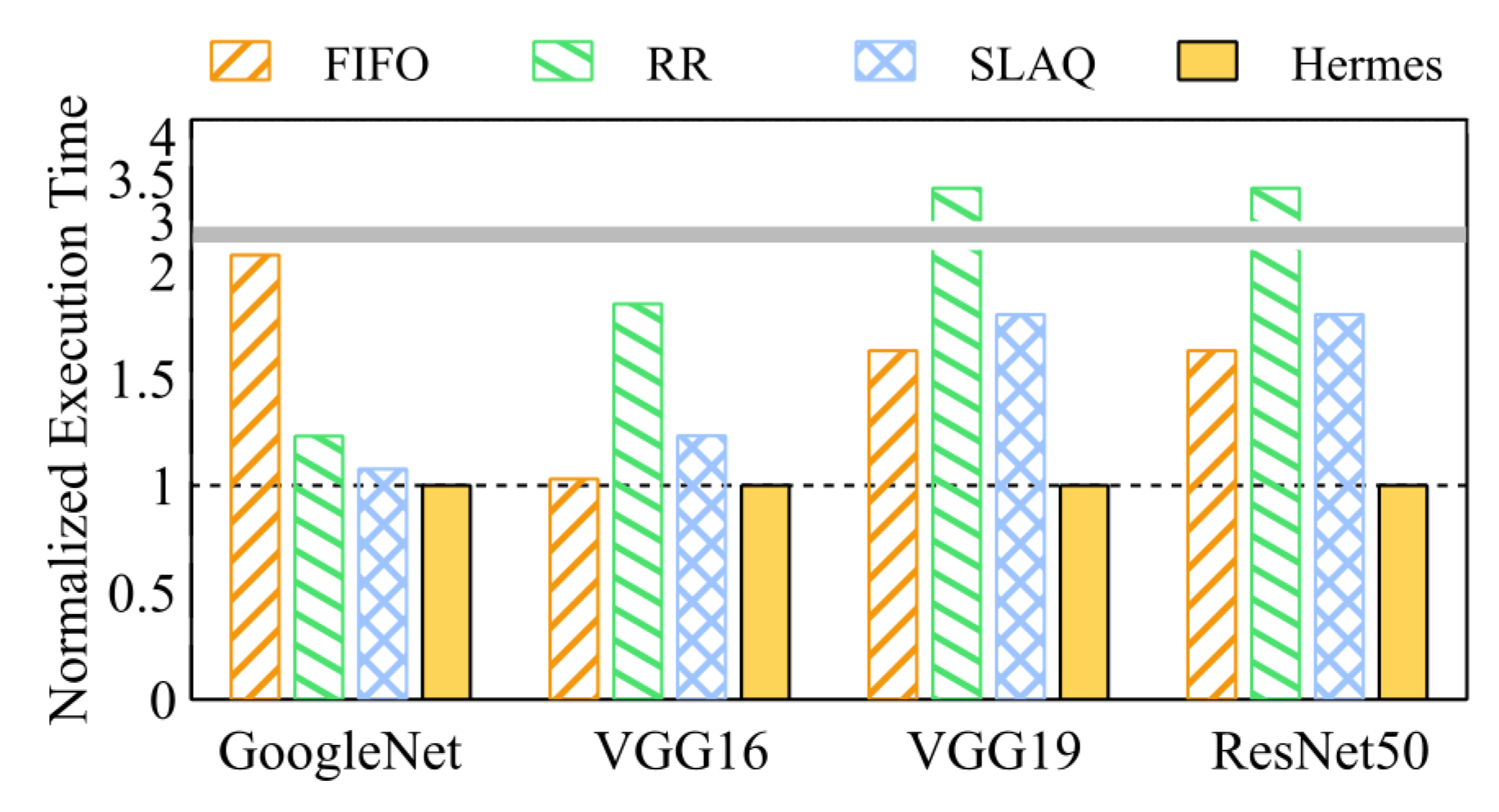
4.2. Hyper-Parameter Optimization Speed
4.3. Overhead Analysis
5. Related Work
5.1. Deep Learning Scheduling Frameworks
5.2. Hyper-Parameter Optimization Frameworks
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gu, J.; Chowdhury, M.; Shin, K.G.; Zhu, Y.; Jeon, M.; Qian, J.; Liu, H.; Guo, C. Tiresias: A GPU Cluster Manager for Distributed Deep Learning. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19); USENIX Association: Boston, MA, USA, 2019; pp. 485–500. [Google Scholar]
- Hertel, L.; Collado, J.; Sadowski, P.; Ott, J.; Baldi, P. Sherpa: Robust hyperparameter optimization for machine learning. SoftwareX 2020, 12, 100591. [Google Scholar] [CrossRef]
- Domhan, T.; Springenberg, J.T.; Hutter, F. Speeding up Automatic Hyperparameter Optimization of Deep Neural Networks by Extrapolation of Learning Curves. In Proceedings of the 24th International Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2015; pp. 3460–3468. [Google Scholar]
- Vavilapalli, V.K.; Seth, S.; Saha, B.; Curino, C.; O’Malley, O.; Radia, S.; Reed, B.; Baldeschwieler, E.; Murthy, A.C.; Douglas, C.; et al. Apache Hadoop YARN: Yet another resource negotiator. In Proceedings of the 4th annual Symposium on Cloud Computing-SOCC ’13; ACM Press: Santa Clara, CA, USA, 2013; pp. 1–16. [Google Scholar] [CrossRef]
- Hindman, B.; Konwinski, A.; Zaharia, M.; Ghodsi, A.; Joseph, A.D.; Katz, R.; Shenker, S.; Stoica, I. Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center. In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation; USENIX Association: Berkeley, CA, USA, 2011; pp. 295–308. [Google Scholar]
- Foundation, C.N.C. Kubernetes. Available online: https://kubernetes.io (accessed on 1 December 2020).
- Xiao, W.; Bhardwaj, R.; Ramjee, R.; Sivathanu, M.; Kwatra, N.; Han, Z.; Patel, P.; Peng, X.; Zhao, H.; Zhang, Q.; et al. Gandiva: Introspective Cluster Scheduling for Deep Learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18); USENIX Association: Carlsbad, CA, USA, 2018; pp. 595–610. [Google Scholar]
- Peng, Y.; Bao, Y.; Chen, Y.; Wu, C.; Guo, C. Optimus: An efficient dynamic resource scheduler for deep learning clusters. In Proceedings of the Thirteenth EuroSys Conference on-EuroSys ’18; ACM Press: Porto, Portugal, 2018; pp. 1–14. [Google Scholar] [CrossRef]
- Zheng, H.; Xu, F.; Chen, L.; Zhou, Z.; Liu, F. Cynthia: Cost-Efficient Cloud Resource Provisioning for Predictable Distributed Deep Neural Network Training. In Proceedings of the 48th International Conference on Parallel Processing-ICPP 2019; ACM Press: Kyoto, Japan, 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Zheng, W.; Tynes, M.; Gorelick, H.; Mao, Y.; Cheng, L.; Hou, Y. FlowCon: Elastic Flow Configuration for Containerized Deep Learning Applications. In Proceedings of the 48th International Conference on Parallel Processing-ICPP 2019; ACM Press: Kyoto, Japan, 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Mahajan, K.; Balasubramanian, A.; Singhvi, A.; Venkataraman, S.; Akella, A.; Phanishayee, A.; Chawla, S. Themis: Fair and Efficient GPU Cluster Scheduling. In Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20); USENIX Association: Santa Clara, CA, USA, 2020; pp. 289–304. [Google Scholar]
- Zhang, H.; Stafman, L.; Or, A.; Freedman, M.J. SLAQ: Quality-driven scheduling for distributed machine learning. In Proceedings of the 2017 Symposium on Cloud Computing-SoCC ’17; ACM Press: Santa Clara, CA, USA, 2017; pp. 390–404. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 29 January 2021).
- Tensorflow. TensorFlow Benchmark. Available online: https://github.com/tensorflow/benchmarks (accessed on 1 December 2020).
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Statist. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://openreview.net/forum?id=8gmWwjFyLj (accessed on 29 January 2021).
- Shallue, C.J.; Lee, J.; Antognini, J.; Sohl-Dickstein, J.; Frostig, R.; Dahl, G.E. Measuring the Effects of Data Parallelism on Neural Network Training. J. Mach. Learn. Res. 2019, 20, 1–49. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine Learning in Python. arXiv 2018, arXiv:1201.0490. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Sequential Model-Based Optimization for General Algorithm Configuration. In Learning and Intelligent Optimization; Coello, C.A.C., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 507–523. [Google Scholar]
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems 24; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, US, 2011; pp. 2546–2554. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. arXiV 2012, arXiv:1206.2944. Available online: https://arxiv.org/abs/1206.2944 (accessed on 29 January 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F.d., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, US, 2019; pp. 8024–8035. [Google Scholar]
- Liaw, R.; Bhardwaj, R.; Dunlap, L.; Zou, Y.; Gonzalez, J.E.; Stoica, I.; Tumanov, A. HyperSched: Dynamic Resource Reallocation for Model Development on a Deadline. In Proceedings of the ACM Symposium on Cloud Computing-SoCC ’19; ACM Press: Santa Cruz, CA, USA, 2019; pp. 61–73. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D.D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference, Austin, TX, USA, 24–29 June 2013; pp. 13–20. [Google Scholar]
- Rasley, J.; He, Y.; Yan, F.; Ruwase, O.; Fonseca, R. HyperDrive: Exploring hyperparameters with POP scheduling. In Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference on-Middleware ’17; ACM Press: Las Vegas, NV, USA, 2017; pp. 1–13. [Google Scholar] [CrossRef]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Values |
|---|---|
| Optimizer | |
| Batch size | |
| Learning rate | |
| Weight decay |
| Model | ||||
|---|---|---|---|---|
| GoogleNet | VGG16 | VGG19 | ResNet50 | |
| TensorFlow | 30.12 s | 94.26 s | 110.49 s | 66.88 s |
| Hermes | 32.73 s | 97.25 s | 112.73 s | 69.46 s |
| Frameworks | Scheduling Algorithm | Prior Knowledge | Objective | Consider DL Quality |
|---|---|---|---|---|
| Gandiva [7] | Time-sharing (RR) | None | Fairness | No |
| Tiresias [1] | Gittin index | JCT distribution | Minimize average JCT | No |
| Themis [11] | Semi-optimistic auction | None | Finish-time fairness | No |
| Optimus [8] | Remaining-time-driven | JCT estimation | Minimize average JCT | Yes |
| FlowCon [10] | Growth-efficiency-driven | None | Minimize average JCT | Yes |
| SLAQ [12] | Quality-driven | None | Average quality improvement | Yes |
| Hermes | Feedback-driven | None | Early feedback | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, J.; Yoo, Y.; Kim, K.-r.; Kim, Y.; Lee, K.; Park, S. A GPU Scheduling Framework to Accelerate Hyper-Parameter Optimization in Deep Learning Clusters. Electronics 2021, 10, 350. https://doi.org/10.3390/electronics10030350
Son J, Yoo Y, Kim K-r, Kim Y, Lee K, Park S. A GPU Scheduling Framework to Accelerate Hyper-Parameter Optimization in Deep Learning Clusters. Electronics. 2021; 10(3):350. https://doi.org/10.3390/electronics10030350
Chicago/Turabian StyleSon, Jaewon, Yonghyuk Yoo, Khu-rai Kim, Youngjae Kim, Kwonyong Lee, and Sungyong Park. 2021. "A GPU Scheduling Framework to Accelerate Hyper-Parameter Optimization in Deep Learning Clusters" Electronics 10, no. 3: 350. https://doi.org/10.3390/electronics10030350
APA StyleSon, J., Yoo, Y., Kim, K.-r., Kim, Y., Lee, K., & Park, S. (2021). A GPU Scheduling Framework to Accelerate Hyper-Parameter Optimization in Deep Learning Clusters. Electronics, 10(3), 350. https://doi.org/10.3390/electronics10030350