
Two-Stage Hybrid Network Clustering Using Multi-Agent Reinforcement Learning



Abstract
1. Introduction
- We propose a network clustering algorithm that consists of a preprocessing stage and learning stage to find the best combination of brokers in pub/sub-operated communication protocol.
- We design a custom deletion method to implement Delaunay triangulation prior to MARL.
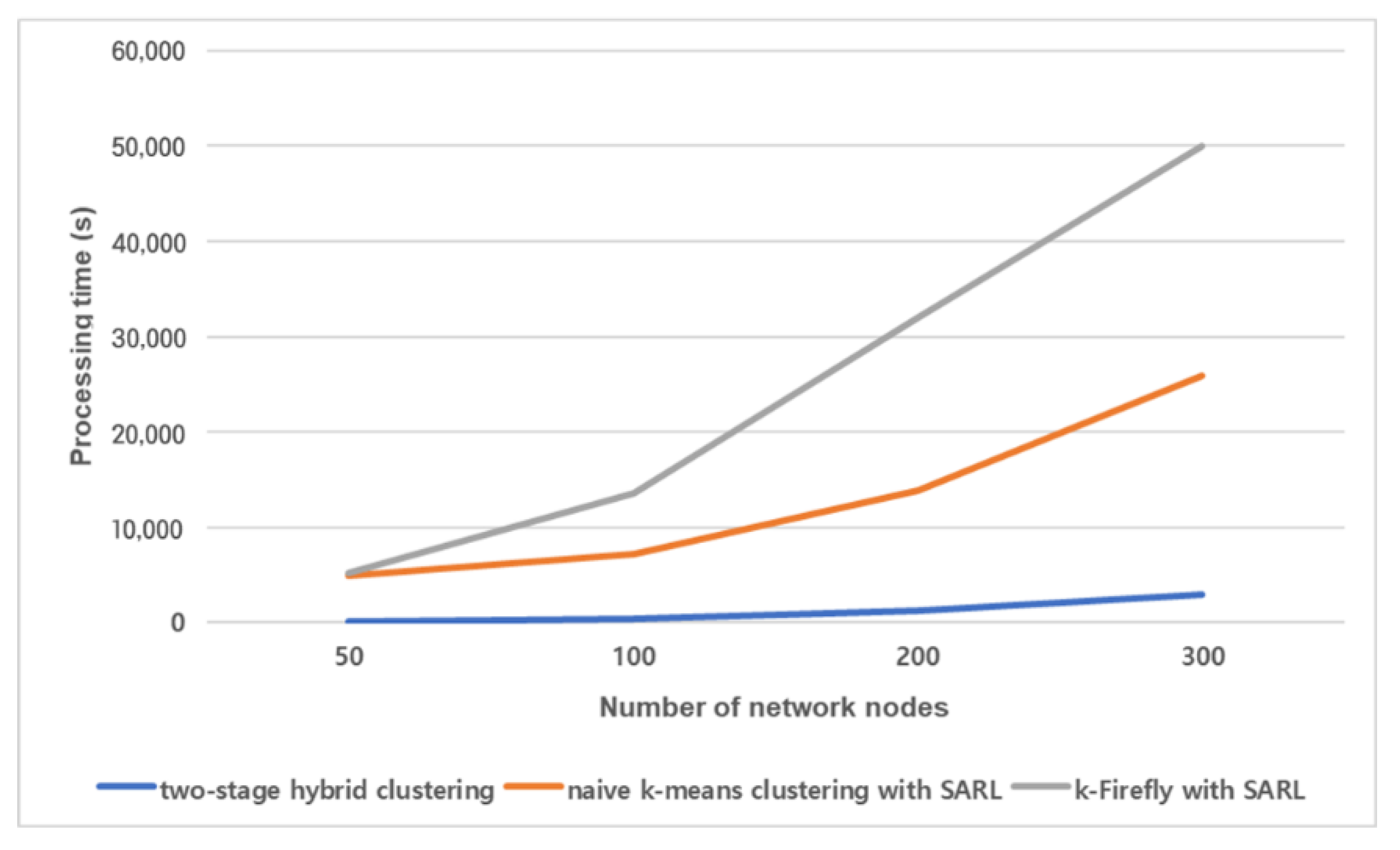
- We compare the proposed algorithm with three different algorithms: swarm intelligence-based algorithm, k-means clustering implemented SARL with and without preprocessing stage. The results show the superiority of the proposed two-stage hybrid network clustering algorithm compared with other algorithms.
2. Related Works
2.1. Delaunay Triangulation and Voronoi Diagram
2.2. Multi-Agent Reinforcement Learning (MARL)
2.3. Clustering Applications in Wireless Sensor Networks
2.4. Clustering Applications in Other Studies
2.5. Clustering with Swarm Intelligence-Based Algorithms
2.6. Broker Assignment
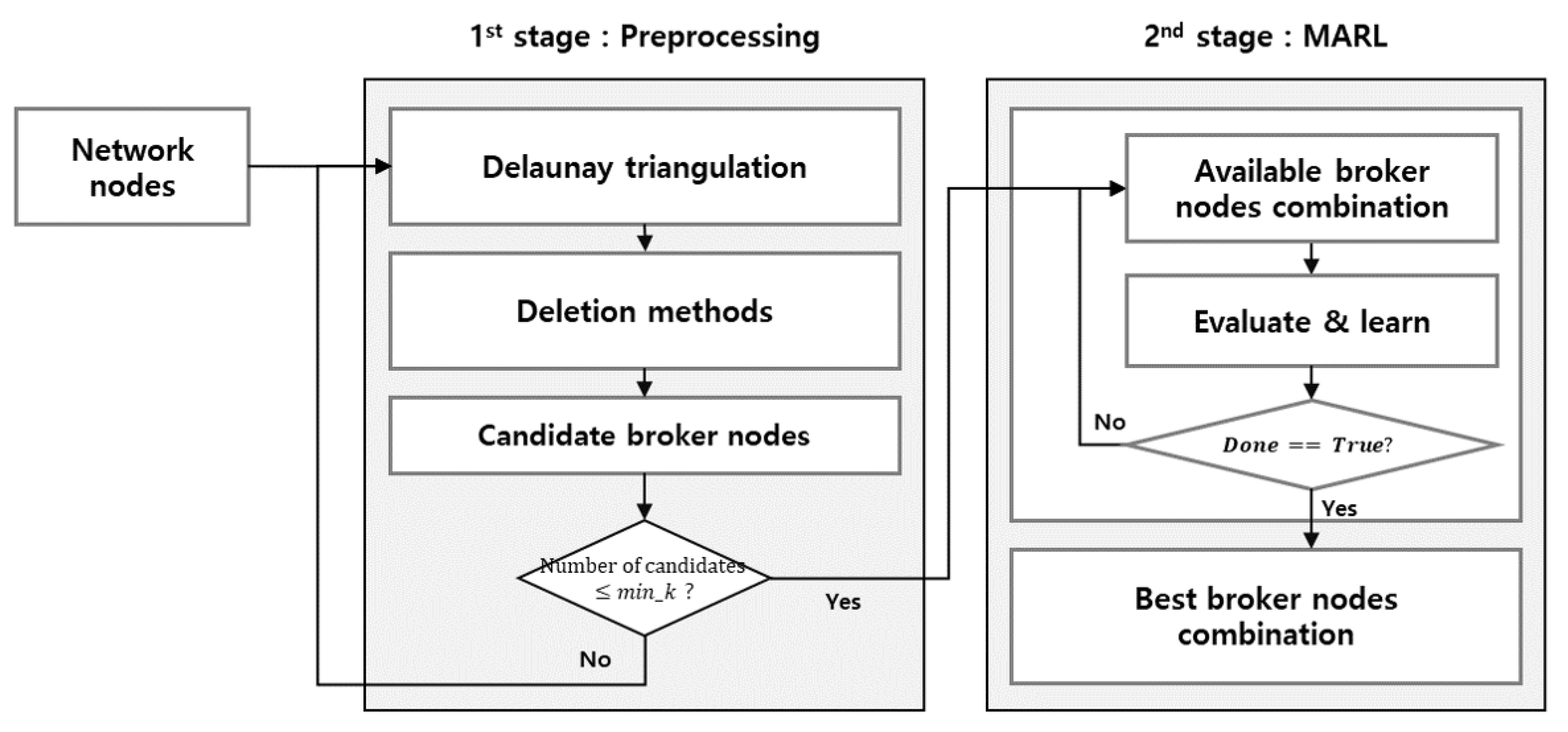
3. Design of the Two-Stage Hybrid Network Clustering Model
- First Stage: apply the Delaunay triangulation and deleting methods to fix the candidate broker nodes;
- Second Stage: employ the MARL to find the best combination of broker nodes.
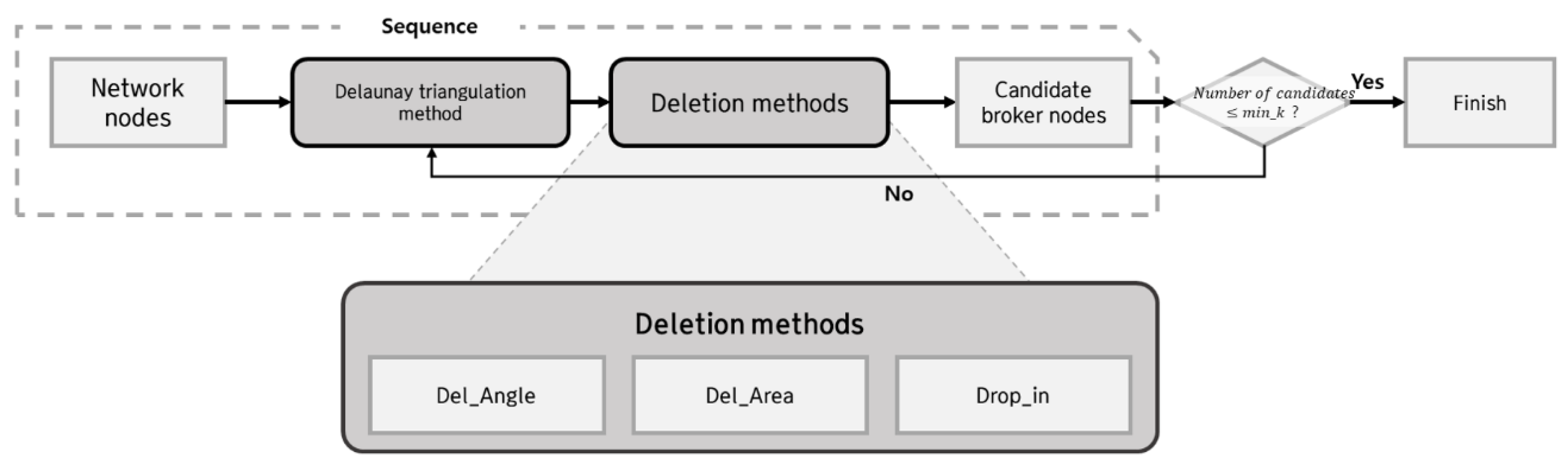
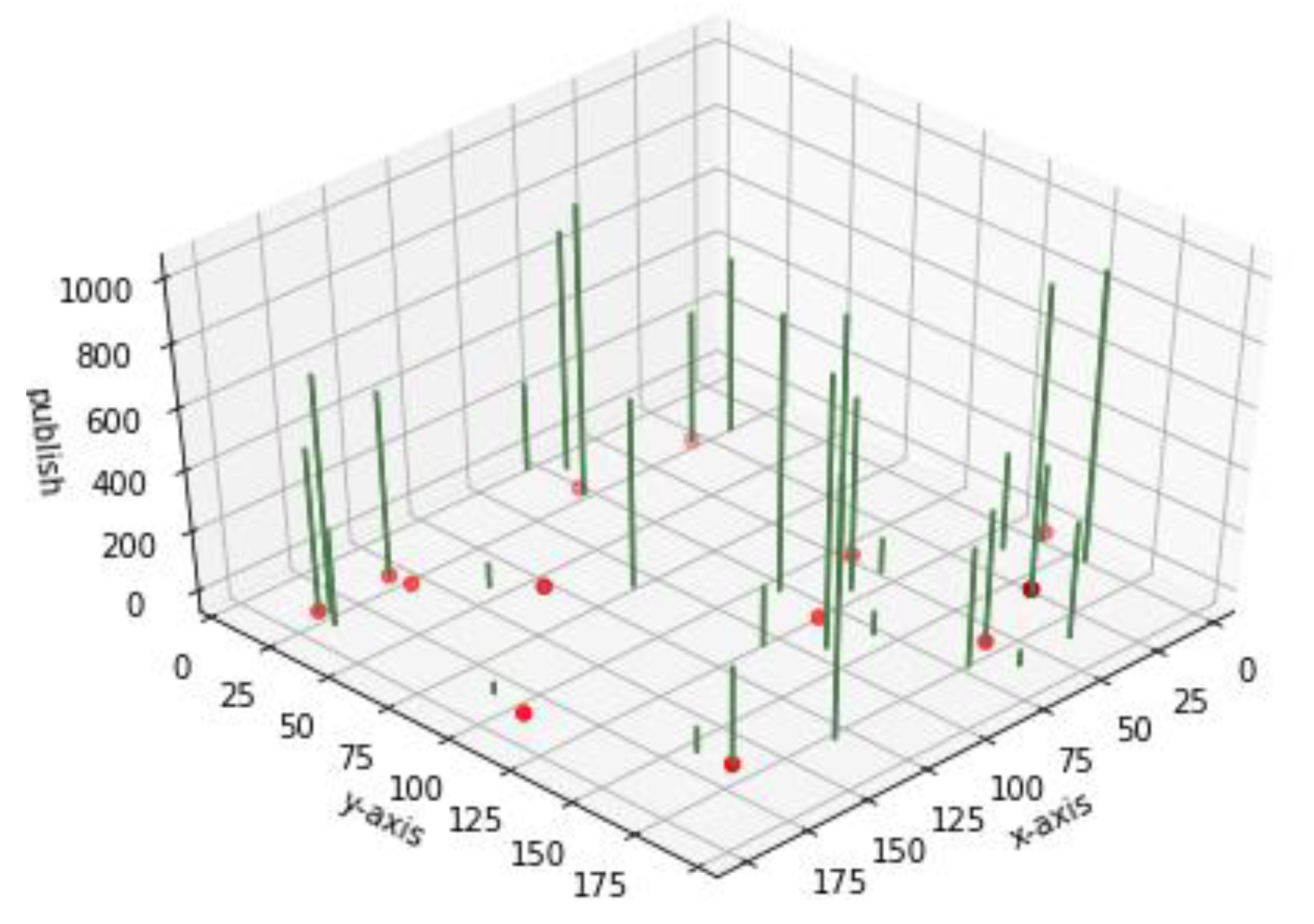
3.1. Delaunay Triangulation and Deletion Methods for Fixing Candidate Broker Nodes
- Del_Angle is the part where all obtuse triangles are discarded. The centers of these triangles are outside the triangles and cannot be used as candidate brokers.
- Del_Area is the part where p% of the largest triangles is discarded. After applying Del_Angle, all the remaining triangles are acute. However, when a candidate broker node is assigned near the center of a large triangle, the candidate broker node must have broad coverage, which is inefficient for network clustering. The network nodes must be included with the nearest broker node.
- Drop_in recovers the centers obtained from Delaunay triangulation. After applying Del_Angle and Del_Area, the triangles may have been reduced more than necessary. Drop_in also recovers some of the initial center points of Delaunay triangles and prevents excessive information loss in the repeated sequence of Delaunay triangulation and deleting methods.
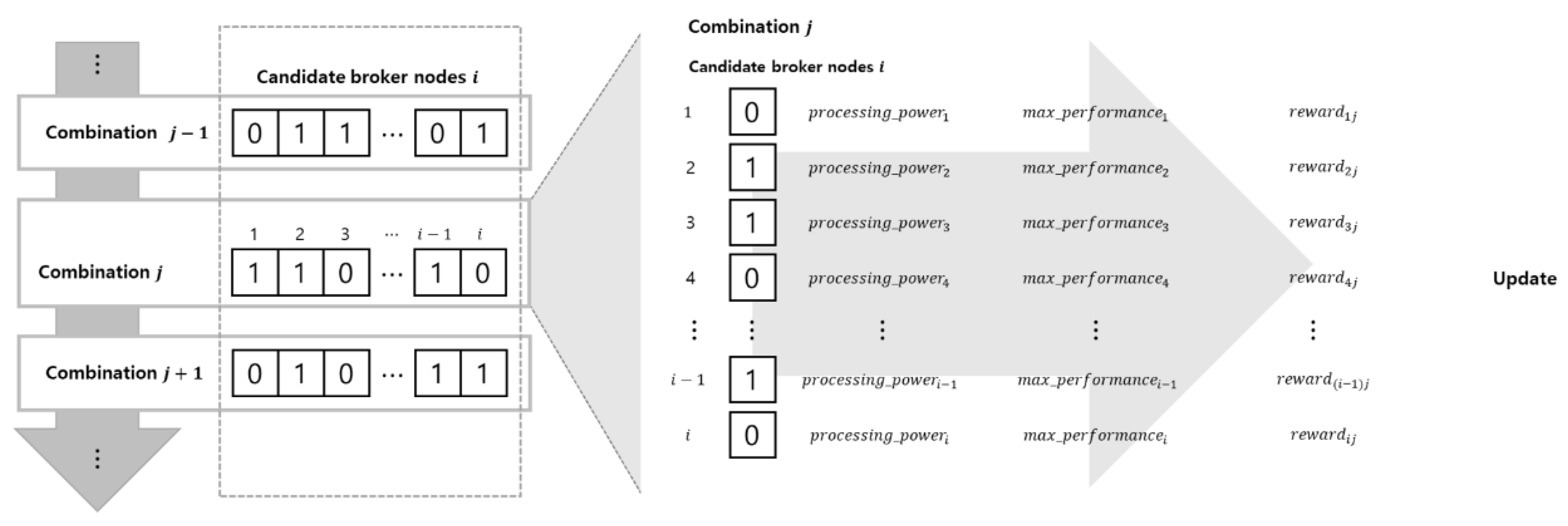
3.2. Best Broker Node Combination by MARL
4. Design of Experiments
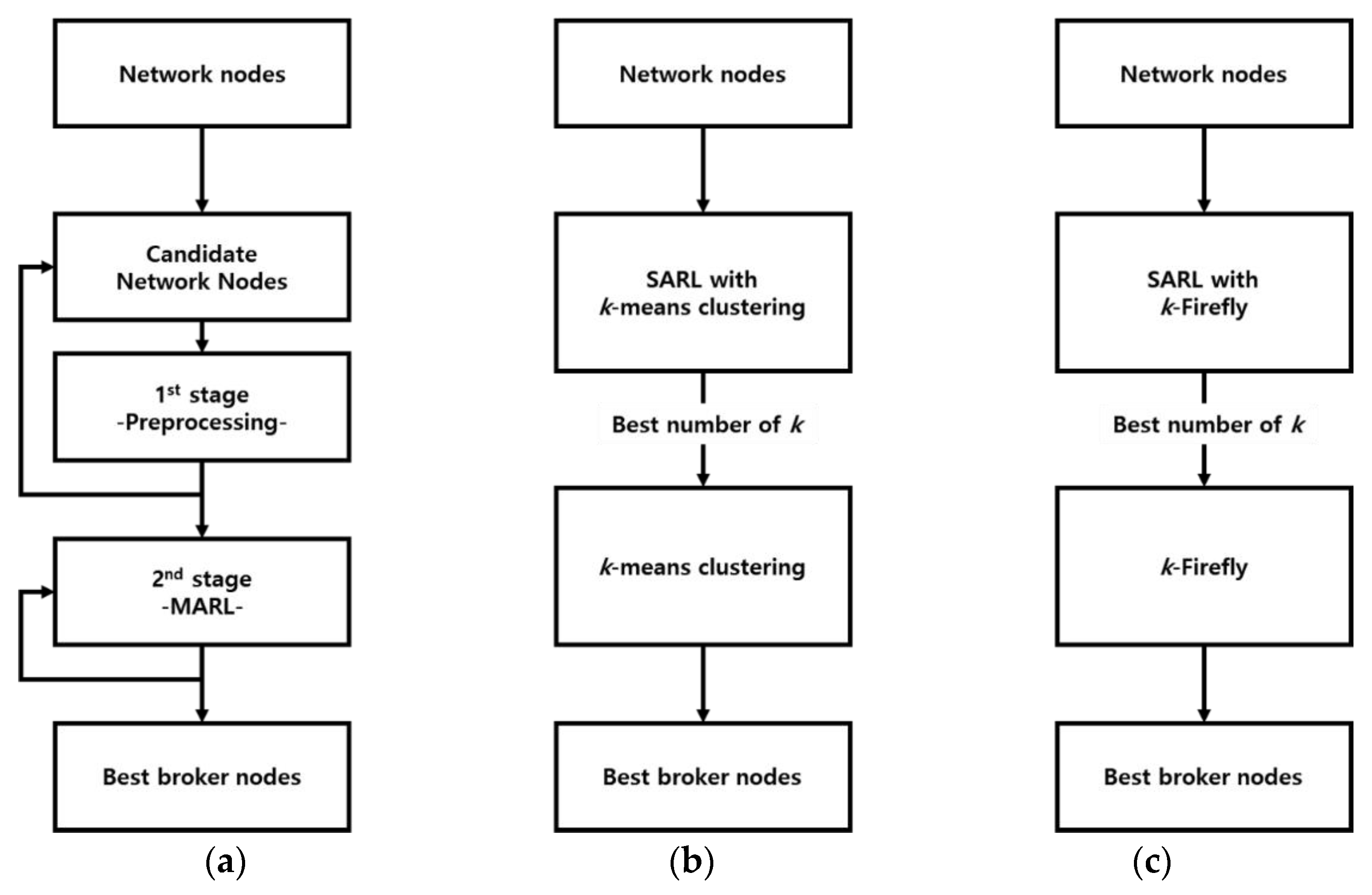
4.1. Algorithm 1: Two-Stage Hybrid Network Clustering Using MARL
- min_k: stopping threshold of the first stage. The introduction of Delaunay triangulation and deletion methods generates at least candidate broker nodes;
- area_ratio: discarding ratio of large triangles in Del_Area;
- dropin_ratio: reinstatement ratio of initial center points in Drop_in;
- angle_crit: determinant for obtuse triangles in Del_Angle. To control the discarding ratio of obtuse triangles, angle_crit can be increased or decreased.
| Algorithm 1 Two-Stage Hybrid Network Clustering using MARL |
| Input: initial network nodes, 01: initialize candidate broker nodes, 02: while 03: apply Delaunay triangulation to and obtain seed point (), vertices of Delaunay triangles 04: delete elements of that are centers of p% of the largest triangles made of 05: delete elements of that are centers of obtuse triangles made of 06: use with and to obtain 07: 08: end while 09: let each element of be agent i of MARL 10: initialize action—value function ), combination (), and for all agent 11: for all episodes do 12: for combination j = 1, M do 13: for all agent do 14: choose action with or randomly by exploration policy 15: execute action and obtain 16: obtain 17: 18: 19: end for 20: obtain 21: update with for all agent 22: end for 23: end for 24: obtain best broker node combination and its positions with for agent |
4.2. Algorithm 2: Naive k-Means Clustering Algorithm with SARL
| Algorithm 2k-means clustering with SARL to find k value |
| Input: initial network nodes, 01: initialize action-value function ) and state ( 02: 03: for all episodes do 04: for all steps do 05: choose action with or randomly by exploration policy 06: execute action and obtain 07: perform k-means clustering using value of as k 08: obtain reward 09: update with reward 10: end for 11: end for 12: obtain best k with 13: obtain best broker positions by performing k-means clustering with best k |
4.3. Algorithm 3: k-Firefly Algorithm with SARL
| Algorithm 3k-Firefly Algorithm with SARL to find k value |
| Input: initial network nodes, 01: initialize action-value function ) and state ( 02: 03: for all agent do 04: 05: for all episodes do 06: for all steps do 07: choose action with or randomly by exploration policy 08: execute action and obtain 09: perform k-Firefly using value of as k 10: obtain reward 11: update with reward 12: end for 13: end for 14: obtain best k with 15: obtain best broker positions by performing k-Firefly with best k |
5. Results
6. Conclusions
6.1. Contribution of the Proposed Work
6.2. Threats of Validity
Author Contributions
Funding
Conflicts of Interest
References
- Yassein, M.B.; Shatnawi, M.Q.; Aljwarneh, S.; Al-Hatmi, R. Internet of Things: Survey and open issues of MQTT protocol. In Proceedings of the 2017 International Conference on Engineering & MIS (ICEMIS), Monastir, Tunisia, 8–10 May 2017; pp. 1–6. [Google Scholar]
- Coates, A.; Ng, A.Y. Learning Feature Representations with K-Means. In Mining Data for Financial Applications; Springer Nature: Boston, MA, USA, 2012; Volume 7700, pp. 561–580. [Google Scholar]
- Yuan, C.; Yang, H. Research on K-Value Selection Method of K-Means Clustering Algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Learning the k in k-means. In Proceedings of the 16th International Conference on Neural Information Processing Systems (NIPS’03), Bangkok, Thailand, 1–5 December 2003. [Google Scholar]
- Klein, R. Voronoi Diagrams and Delaunay Triangulations. In Encyclopedia of Algorithms; Springer Nature: New York, NY, USA, 2016; pp. 2340–2344. [Google Scholar]
- Okabe, A.; Suzuki, A. Locational optimization problems solved through Voronoi diagrams. Eur. J. Oper. Res. 1997, 98, 445–456. [Google Scholar] [CrossRef]
- Jiang, N.; Deng, Y.; Nallanathan, A.; Chambers, J.A. Reinforcement Learning for Real-Time Optimization in NB-IoT Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1424–1440. [Google Scholar] [CrossRef]
- Chu, M.; Li, H.; Liao, X.; Cui, S. Reinforcement Learning-Based Multiaccess Control and Battery Prediction With Energy Harvesting in IoT Systems. IEEE Internet Things J. 2019, 6, 2009–2020. [Google Scholar] [CrossRef]
- Leong, P.; Lu, L. Multiagent Web for the Internet of Things. In Proceedings of the 2014 International Conference on Information Science & Applications (ICISA), Seoul, Korea, 6–9 May 2014; pp. 1–4. [Google Scholar]
- De Oliveira, T.B.F.; Bazzan, A.L.C.; Da Silva, B.C.; Grunitzki, R. Comparing Multi-Armed Bandit Algorithms and Q-learning for Multiagent Action Selection: A Case Study in Route Choice. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Sanyam, K. Multi-Agent Reinforcement Learning: A Report on Challenges and Approaches. Available online: https://arxiv.org/abs/1807.09427v1 (accessed on 25 July 2018).
- Shahrampour, S.; Rakhlin, A.; Jadbabaie, A. Multi-armed bandits in multi-agent networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2786–2790. [Google Scholar]
- Wang, J.; Cao, J.; Stojmenovic, M.; Zhao, M.; Chen, J.; Jiang, S. Pattern-RL: Multi-robot Cooperative Pattern Formation via Deep Reinforcement Learning. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 210–215. [Google Scholar]
- Liu, C.; Liu, F.; Liu, C.Y.; Wu, H. Multi-Agent Reinforcement Learning Based on K-Means Clustering in Multi-Robot Cooperative Systems. Adv. Mater. Res. 2011, 216, 75–80. [Google Scholar] [CrossRef]
- Longo, E.; Redondi, A.E.; Cesana, M.; Arcia-Moret, A.; Manzoni, P. MQTT-ST: A Spanning Tree Protocol for Distributed MQTT Brokers. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Jutadhamakorn, P.; Pillavas, T.; Visoottiviseth, V.; Takano, R.; Haga, J.; Kobayashi, D. A scalable and low-cost MQTT broker clustering system. In Proceedings of the 2017 2nd International Conference on Information Technology (INCIT), Nakhon Pathom, Thailand, 2–3 November 2017; pp. 1–5. [Google Scholar]
- Koziolek, H.; Grüner, S.; Rückert, J. A Comparison of MQTT Brokers for Distributed IoT Edge Computing. In Mining Data for Financial Applications; Springer: Cham, Switzerland, 2020; Volume 12292, pp. 352–368. [Google Scholar]
- Lin, K.; Xia, F.; Fortino, G. Data-driven clustering for multimedia communication in Internet of vehicles. Future Gener. Comput. Syst. 2019, 94, 610–619. [Google Scholar] [CrossRef]
- Ally, J.S.; Asif, M.; Ma, Q. Energy-Efficient MTC Data Offloading in Wireless Networks Based on K-Means Grouping Technique. J. Comput. Commun. 2019, 7, 47–61. [Google Scholar] [CrossRef]
- El Khrdiri, S.; Fakhet, W.; Moulahi, T.; Khan, R.; Thaljaoui, A.; Kachouri, A. Improved node localization using K-means clustering for Wireless Sensor Networks. Comput. Sci. Rev. 2020, 37, 100284. [Google Scholar] [CrossRef]
- Nasser, A.M.T.; Pawar, V.P. Machine learning approach for sensors validation and clustering. In Proceedings of the 2015 International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT), Mandya, India, 17–19 December 2015; pp. 370–375. [Google Scholar]
- Yang, Z.; Feng, L.; Chang, Z.; Lu, J.; Liu, R.; Kadoch, M.; Cheriet, M. Prioritized Uplink Resource Allocation in Smart Grid Backscatter Communication Networks via Deep Reinforcement Learning. Electron. 2020, 9, 622. [Google Scholar] [CrossRef]
- Narayanan, B.N.; Hardie, R.C.; Kebede, T.M.; Sprague, M.J. Optimized feature selection-based clustering approach for computer-aided detection of lung nodules in different modalities. Pattern Anal. Appl. 2017, 22, 559–571. [Google Scholar] [CrossRef]
- Messay-Kebede, T.; Narayanan, B.N.; Djaneye-Boundjou, O. Combination of Traditional and Deep Learning based Architectures to Overcome Class Imbalance and its Application to Malware Classification. In Proceedings of the NAECON 2018—IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 73–77. [Google Scholar]
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering Driven Deep Autoencoder for Video Anomaly Detection. Min. Data Financ. Appl. 2020, 329–345. [Google Scholar] [CrossRef]
- Zedadra, O.; Guerrieri, A.; Jouandeau, N.; Spezzano, G.; Seridi, H.; Fortino, G. Swarm intelligence-based algorithms within IoT-based systems: A review. J. Parallel Distrib. Comput. 2018, 122, 173–187. [Google Scholar] [CrossRef]
- Sun, W.; Tang, M.; Zhang, L.; Huo, Z.; Shu, L. A Survey of Using Swarm Intelligence Algorithms in IoT. Sensors 2020, 20, 1420. [Google Scholar] [CrossRef] [PubMed]
- Cheung, A.K.Y.; Jacobsen, H.-A. Publisher Placement Algorithms in Content-Based Publish/Subscribe. In Proceedings of the 2010 IEEE 30th International Conference on Distributed Computing Systems, Genova, Italy, 21–25 June 2010; pp. 653–664. [Google Scholar]
- Zhao, Y.; Kim, K.; Venkatasubramanian, N. DYNATOPS: A dynamic topic-based publish/subscribe architecture. In Proceedings of the 7th ACM International Conference on Distributed Event-Based Systems, Arlington, TX, USA, 29–30 June 2013; pp. 75–86. [Google Scholar]
- Jiang, S.; Cao, J.; Wu, H.; Yang, Y. Fairness-based Packing of Industrial IoT Data in Permissioned Blockchains. IEEE Trans. Ind. Inform. 2020, 1. [Google Scholar] [CrossRef]
- Bohler, C.; Cheilaris, P.; Klein, R.; Liu, C.-H.; Papadopoulou, E.; Zavershynskyi, M. On the Complexity of Higher Order Abstract Voronoi Diagrams. Available online: https://www.sciencedirect.com/science/article/pii/S0925772115000346 (accessed on 5 May 2015).
- Fortune, S. Voronoi diagrams and Delaunay triangulations. Computing in Euclidean Geometry; World Scientific: Singapore, 1995; pp. 225–265. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Network Nodes | 50 | 100 | 200 | 300 |
|---|---|---|---|---|
| min_k | 13 | 22 | 49 | 76 |
| Number of Network Nodes | 50 | 100 | 200 | 300 |
|---|---|---|---|---|
| Algorithm 1 | 3 | 10 | 23 | 35 |
| Algorithm 2 | 5 | 11 | 21 | 41 |
| Algorithm 3 | 9 | 24 | 43 | 53 |
| Number of Network Nodes | Number of Candidate Broker Nodes | min_k | Number of Selected Brokers | Processing Time (s) | |
|---|---|---|---|---|---|
| Two-stage hybrid clustering | 50 | 16 | 13 | 3 | 72 |
| 100 | 42 | 22 | 10 | 353 | |
| 200 | 70 | 49 | 23 | 1303 | |
| 300 | 121 | 76 | 35 | 2927 | |
| Two-stage hybrid clustering without first stage | 50 | - | 13 | 13 | 111 |
| 100 | - | 22 | 31 | 417 | |
| 200 | - | 49 | 56 | 1680 | |
| 300 | - | 76 | 73 | 3918 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Ryu, D.; Kim, J.; Kim, J.-H. Two-Stage Hybrid Network Clustering Using Multi-Agent Reinforcement Learning. Electronics 2021, 10, 232. https://doi.org/10.3390/electronics10030232
Kim J, Ryu D, Kim J, Kim J-H. Two-Stage Hybrid Network Clustering Using Multi-Agent Reinforcement Learning. Electronics. 2021; 10(3):232. https://doi.org/10.3390/electronics10030232
Chicago/Turabian StyleKim, Joohyun, Dongkwan Ryu, Juyeon Kim, and Jae-Hoon Kim. 2021. "Two-Stage Hybrid Network Clustering Using Multi-Agent Reinforcement Learning" Electronics 10, no. 3: 232. https://doi.org/10.3390/electronics10030232
APA StyleKim, J., Ryu, D., Kim, J., & Kim, J.-H. (2021). Two-Stage Hybrid Network Clustering Using Multi-Agent Reinforcement Learning. Electronics, 10(3), 232. https://doi.org/10.3390/electronics10030232