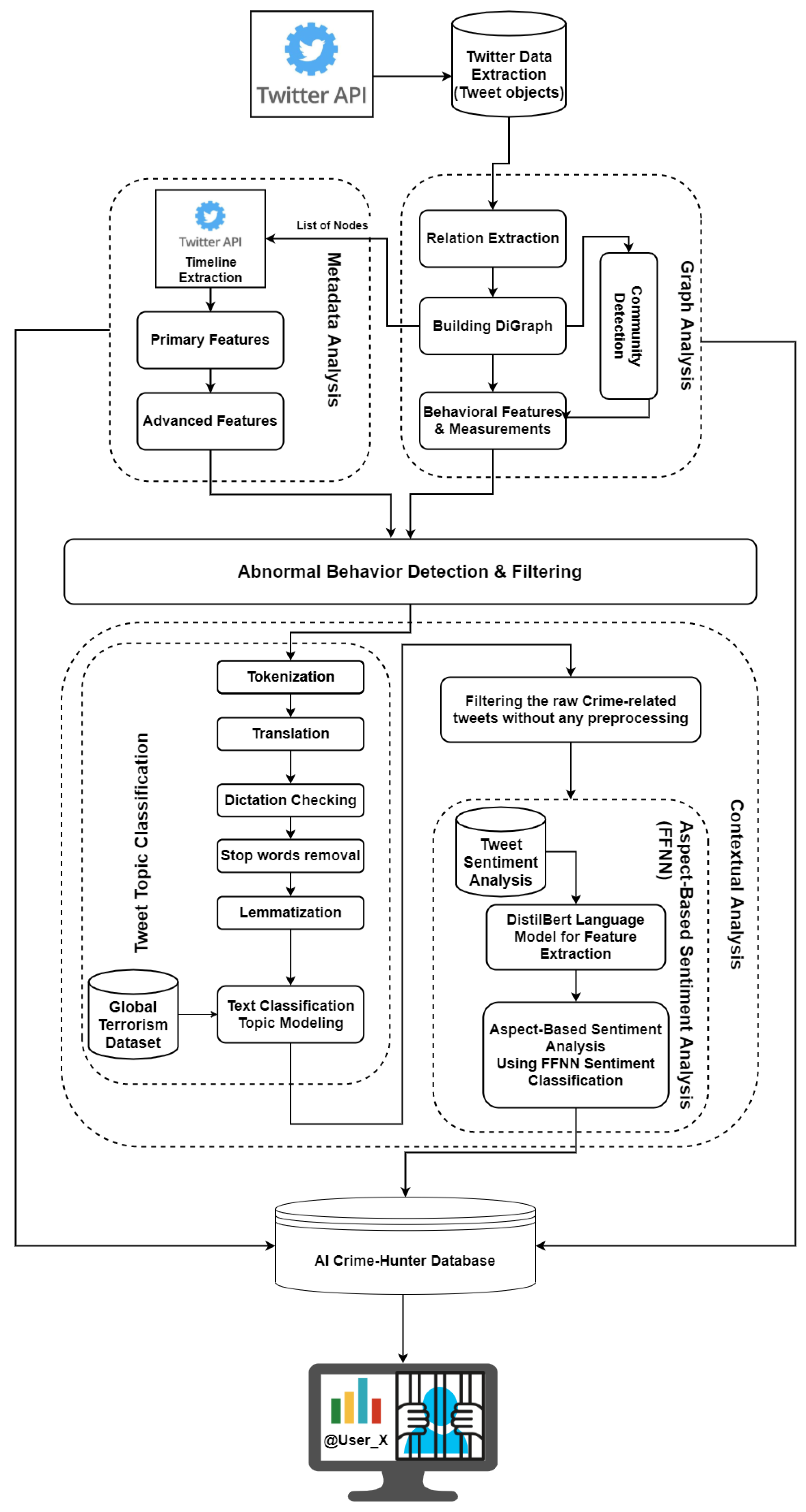
In the contextual analysis component, the aim is to investigate the content shared by each user to understand the agreement level of the user to crime-related topics. To do this, each tweet on the user’s timeline goes through different steps in two sub-components.
3.5.1. Topic Classification
Preprocessing was conducted in Python using NLTK [
32], Textblob [
33], re [
34], etc. Preprocessing consists of translation, tokenization, dictation checking, removing stop words, and lemmatization.
Tokenization is the technique used to break a sentence into smaller units; i.e., words. The translation aims to unify the language of the tweets to English as users are tweeting worldwide, and they do it in different languages. It is essential to translate tweets because the rest of the semantic analysis models extracting meanings from the input text are designed and implemented to work with English content; therefore, translation enables us not to lose some tweets and to understand different languages. In this research, the Google Translate API [
35] has been used because it contains a vast range of other languages; it is also easy and cheap to use.
Table 7 represents a comparison between some popular translation APIs.
Google Translate API has the highest user satisfaction, and it is easiest to implement and use; therefore, this API was chosen for the translation. Dictation checking is mandatory as, due to the character limitation of the tweets, users tend to shorten words; removing stop words is the process of removing the frequent words that are not carrying much information (such as “the”, “that”, “an”, “a”, etc.); finally, lemmatization is the process of restoring different versions of a word into their root. After the preprocessing is done, the cleaned text is ready to go through the analysis process.
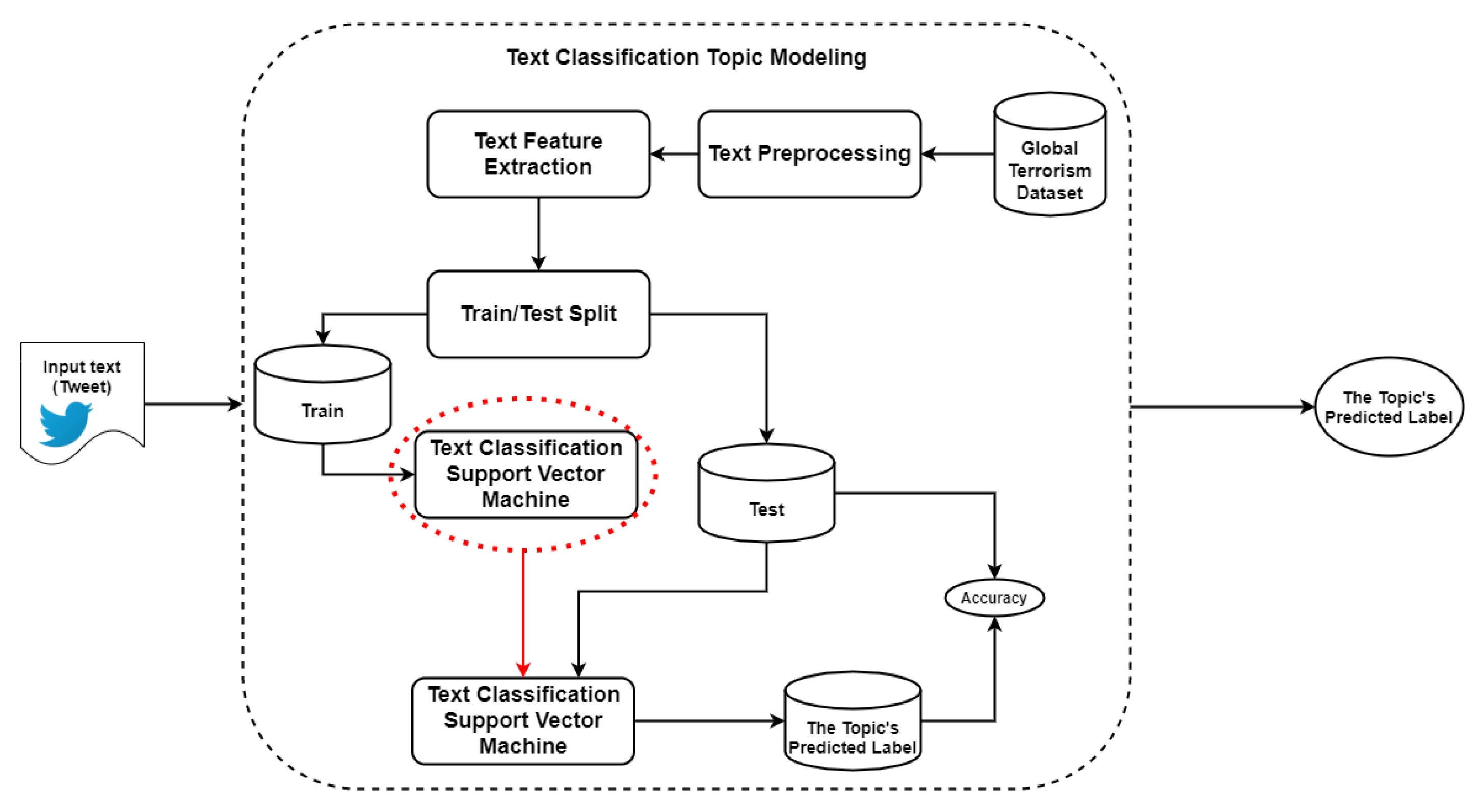
After all the tweets are preprocessed, the topic classification is performed. This step focuses on a specific user’s content and determines to what extent users are posting and spreading crime-related content. Later, we determine whether the user agrees or disagrees with the crime by applying sentiment analysis on the selected contents.
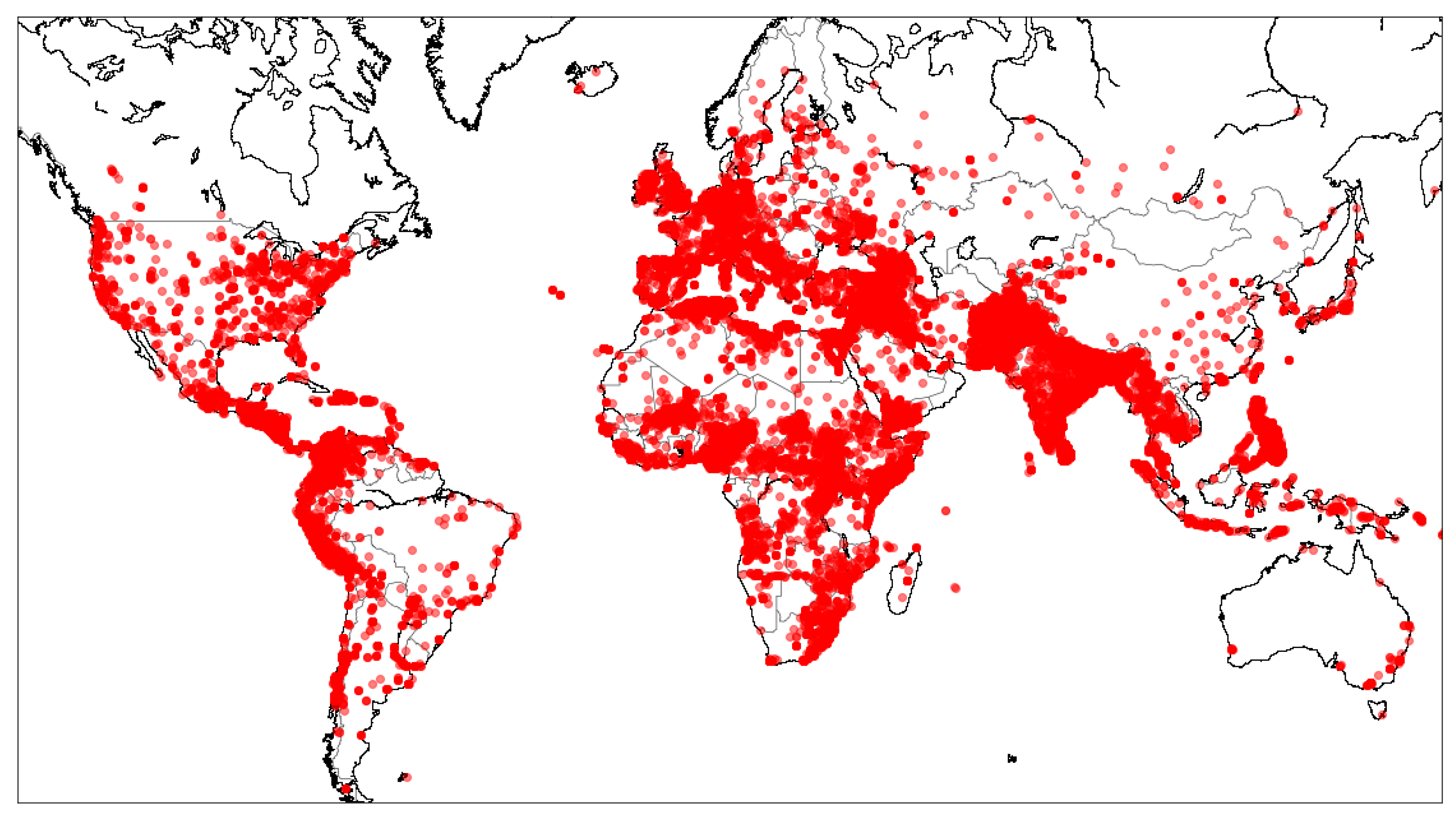
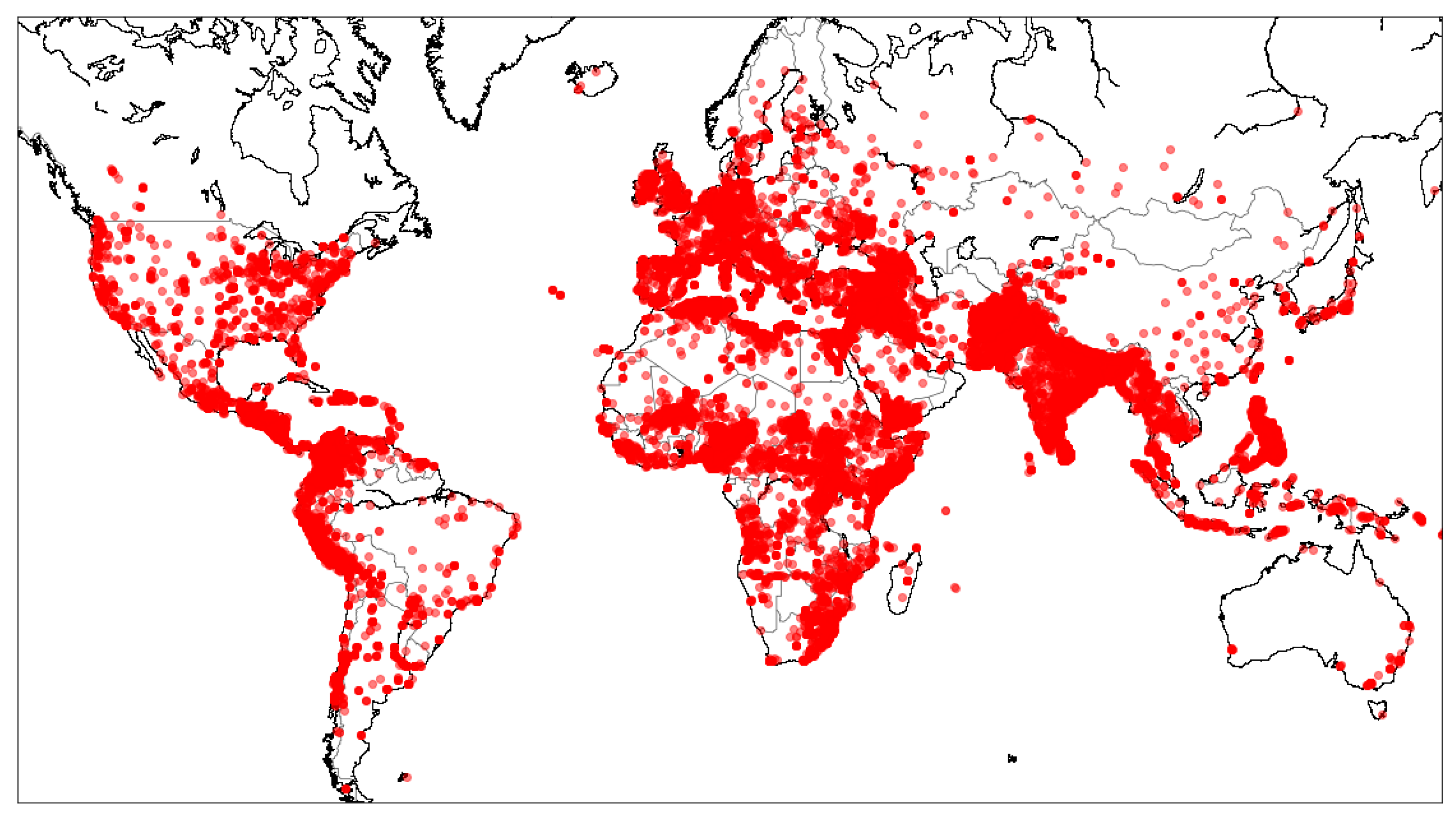
A text classification model was implemented and trained on the Global Terrorism Dataset (GTD) [
23] to apply topic modeling. This dataset is an open-source dataset containing information on 180,000 terrorist attacks worldwide from 1970 until 2017.
Figure 2 represents the locations of these terrorist attacks. This dataset mainly consists of violence, threats, and intimidation to pressure governments, international groups, or entire communities. It poses a severe threat to the international community. It includes significant threats to Westerners traveling or living abroad and indigenous peoples near or in areas of instability or terrorist activity.
Globally, all regions have seen an increase in the average impact of terrorism in recent years compared to the start of the 21st century. The rise in terrorism is most pronounced in the Middle East and North Africa, followed by Sub-Saharan Africa. The threat of terrorism is increasing in many parts of the world, especially the threat of terrorism against the interests and citizens of Western countries by groups and people triggered by recent oppositions.
The GTD dataset provides the text regarding the labels. This enables us to train a text classification model and, more importantly, evaluate it by comparing the actual values and the predicted labels. For the deployment of a text classification model, the text feature extraction needs to be performed before all other steps.
Figure 3 demonstrates the process of the text topic classification. In order to build a text classification model, it is essential to preprocess the text and extract features from it. After the preprocessing, two feature extraction approaches are applied; for this, six different classification models were selected.
Vectorization is a method to transfer text into numerical data, as required to apply any machine learning algorithm. The count vectorizer uses the number of the times that a word appears in the sentence; in this case, the dataset is transformed into a set in which the columns are the unique words and the rows indicate the values related to the number of times a word appears in each sentence [
38].
In contrast, the Term Frequency-Inverse Document Frequency (TF-IDF) vectorizer [
39] is a method that considers the significance of a word by calculating the term frequency, showing how frequently a word appears in the document. IDF, which is the weight of rare words, refers to words that rarely appear in the document. By multiplying these two values, the importance of the words is obtained. The equation below represents the TF-IDF formula.
where
t is a term (word),
d is the document (set of words),
is the document’s frequency of
t,
N is the count of the corpus, and
is the total document set.
To find the best result, two strategies of text feature extraction—the count vectorizer and the TF-IDF method—were applied, and the results are compared with each other.
Table 8 represents the results of the feature extraction and text classification models’ accuracy.
The results show that the SVM model with TF-IDF vectorizer performs better, with 88.89% accuracy. Therefore, after running the text classification models and detecting the topics of each tweet, the tweets related to crime were filtered and handed over to the next step—the aspect-based sentiment analysis—to discover the polarity and subjectivity of the users in general.
3.5.2. Aspect-Based Sentiment Analysis
Sentiment analysis is the process of interpreting a text and discovering its emotions. There are many different ways to perform sentiment analysis [
40], including three main solutions: rule-based [
41], feature-based [
42], and embedding-based methods [
43,
44]. The aspect-based sentiment analysis model is implemented using rule-based models to measure an input text’s subjectivity, indicating if a tweet is a fact or an opinion, and transformer-based sentiment analysis to understand if a tweet induces positive or negative emotions.
To measure the subjectivity of the tweets, the Textblob algorithm [
45], which is implemented as a library called TextBlob [
41], is used. It provides a simple interface for typical natural language processing (NLP) tasks such as part-of-speech tagging, noun extraction, sentiment analysis, classification, and translation. In Textblob, the emotion of the input text is defined by polarity and subjectivity. The polarity is a number between −1 and +1, which shows the text’s positivity or negativity; i.e., the closer the text is to −1, the more negative, a value closer to +1 shows greater positivity, and 0 represents neutral. However, the subjectivity shows if the input text is closer to an opinion or a fact. Subjectivity, as utilized in this proposed model, is between 0 and 1, where 0 designates facts and 1 indicates opinions; the closer the value to 1, the more likely the text is to be an opinion and vice versa. In addition, Textblob ignores unfamiliar words, considers words and phrases to assign polarity, and calculates the average of the resulting scores.
Q: How is it possible to create an aspect-based sentiment analysis model?
By considering the topic of the text and acknowledging the topic of the text before analyzing the sentiment of it, aspect-based sentiment analysis is made possible. As the goal of AI-Crime Hunter is to analyze and measure the agreement level to criminal topics, the tweets are passed through the topic text classification level, which is trained on the GTD Dataset to classify the input text (tweets) into two categories: crime-related and non-criminal. Consequently, the sentiment analysis is only performed on the crime-related tweets by filtering these tweets.
The sentiment analysis model was trained with a dataset of 1.6 million tweets, which is an open-source dataset [
46] gathered by the CS224N project of Stanford [
24]. It is a balanced dataset, with the tweets and their related labels indicating the polarity of each record.
Two different strategies for feature extraction were applied to the dataset, and the extracted features were used to train Long Short-Term Memory (LSTM) and Feed Forward Neural Network models.
For feature extraction using the Word2vec model, first, the tweet preprocessing is performed, and the dataset is subjected to tokenization, removing stop words, lemmatization, etc. Then, a Word2vec model is trained using the vocabularies existing in this dataset to save the syntactical information of the words by turning them into vectors in order not to lose the concept of the words and secret relationships between the words [
47].
Table 9 represents the similar words derived using the Word2vec model.
Next, a label encoder is applied to the target values: negative, neutral, and positive. Then, the dataset is split into train and test sets, and this way of using the word embedding model is considered as a method of text feature extraction.
After building the Word2vec model [
48], the embedding layer [
49] was created using the embedding matrix, using the words and the values of the vectors derived from the Word2vec model. The embedding matrix was defined as the weights of an embedding layer. Then, a Long-Term Short Memory (LSTM) network [
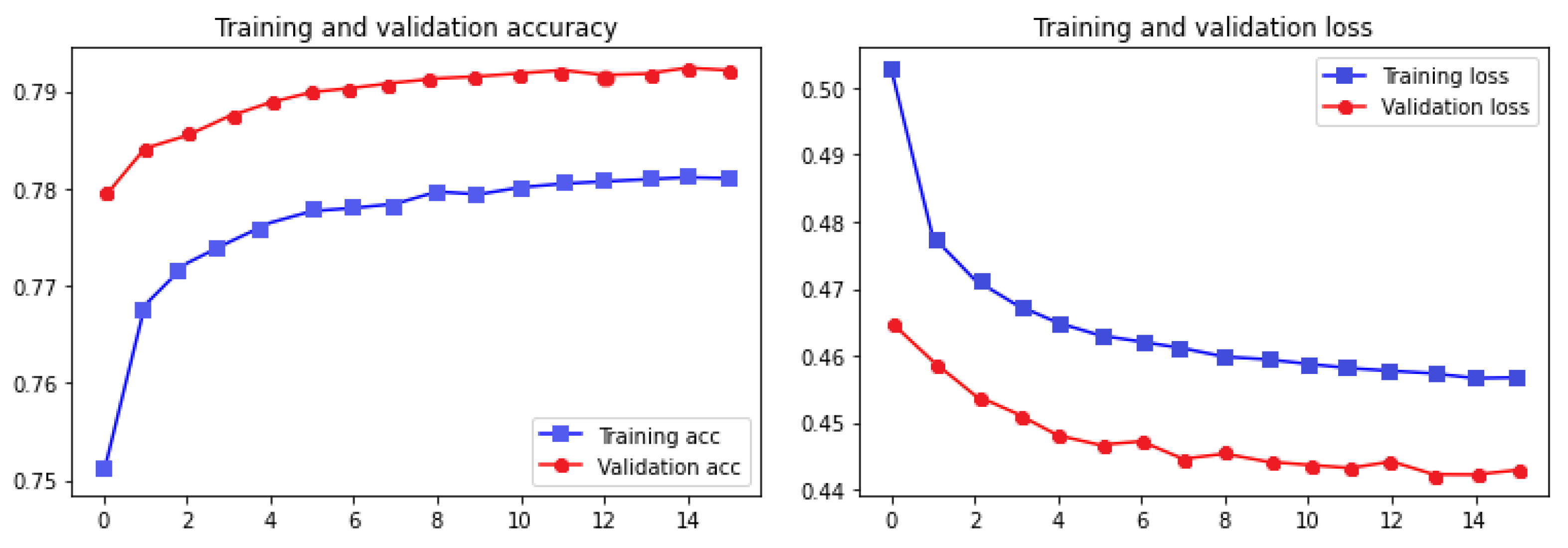
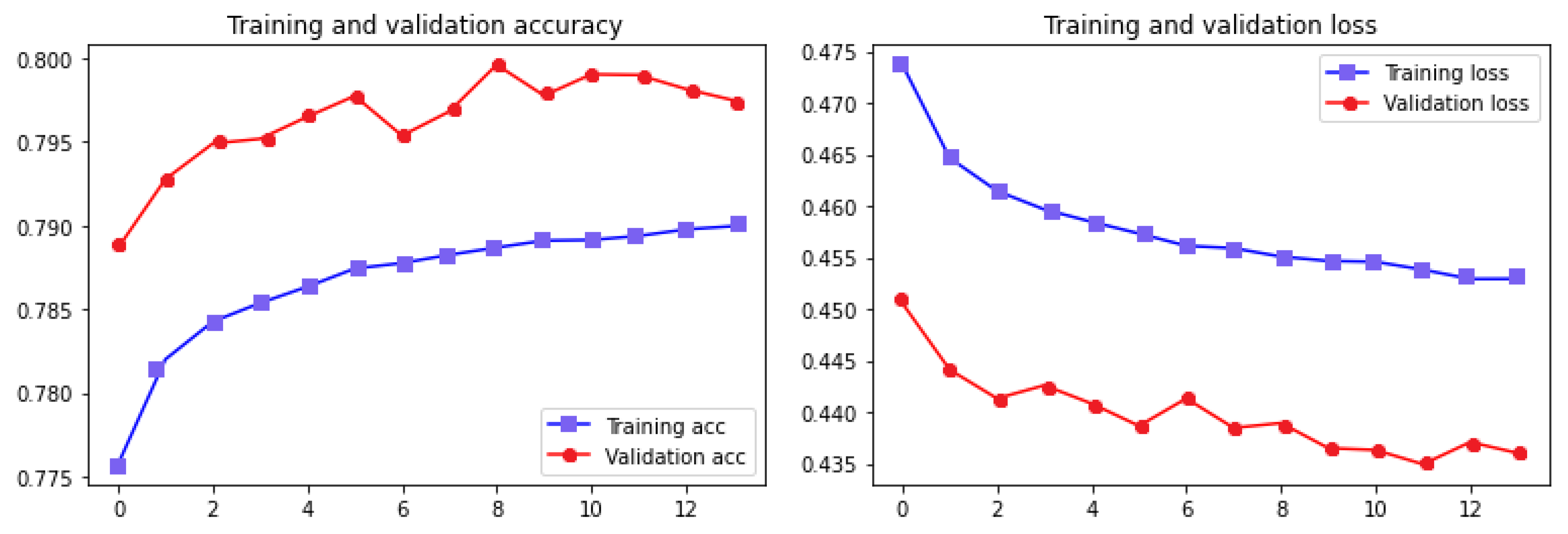
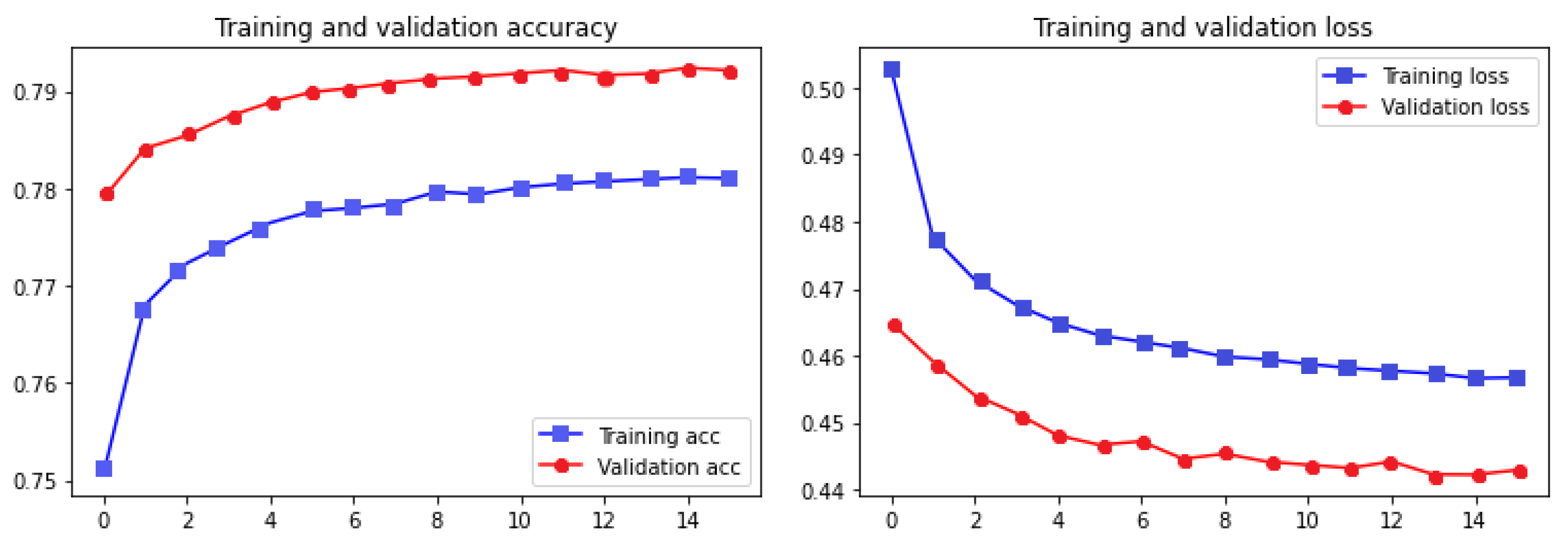
50] combined with dense layers and dropouts was trained with the training datasets. The accuracy and the loss of the model in the 15 epochs of training are presented in
Figure 4.
Table 10 represents more information about the quality of the classification.
- 2.
The Second Strategy: DistilBERT Language Model (Transformers) + FFNN
The big drawback o Recurrent Neural Networks and LSTMs are that the data need to go through the networks sequentially. When the text is long, this will lead to the vanishing gradient problem and forgetting the past; the LSTM network aims to improve RNNs by having a complex gating system to remember the past selectively. Still, the vanishing gradient problem exists, but these networks handle the text more effectively. Liu et al. propose a solution to the vanishing gradient problem in [
51]. However, both networks are very complex and need a long time for training and to become effective [
52].
Transformers work with a different mechanism. They are attention-based models, which means that they are able to work in parallel, so the text does not need to be input word by word sequentially—they can pass all the sentences at the same time [
53]. This ability allows them to perform much faster than RNNs, and they are deeply bidirectional.
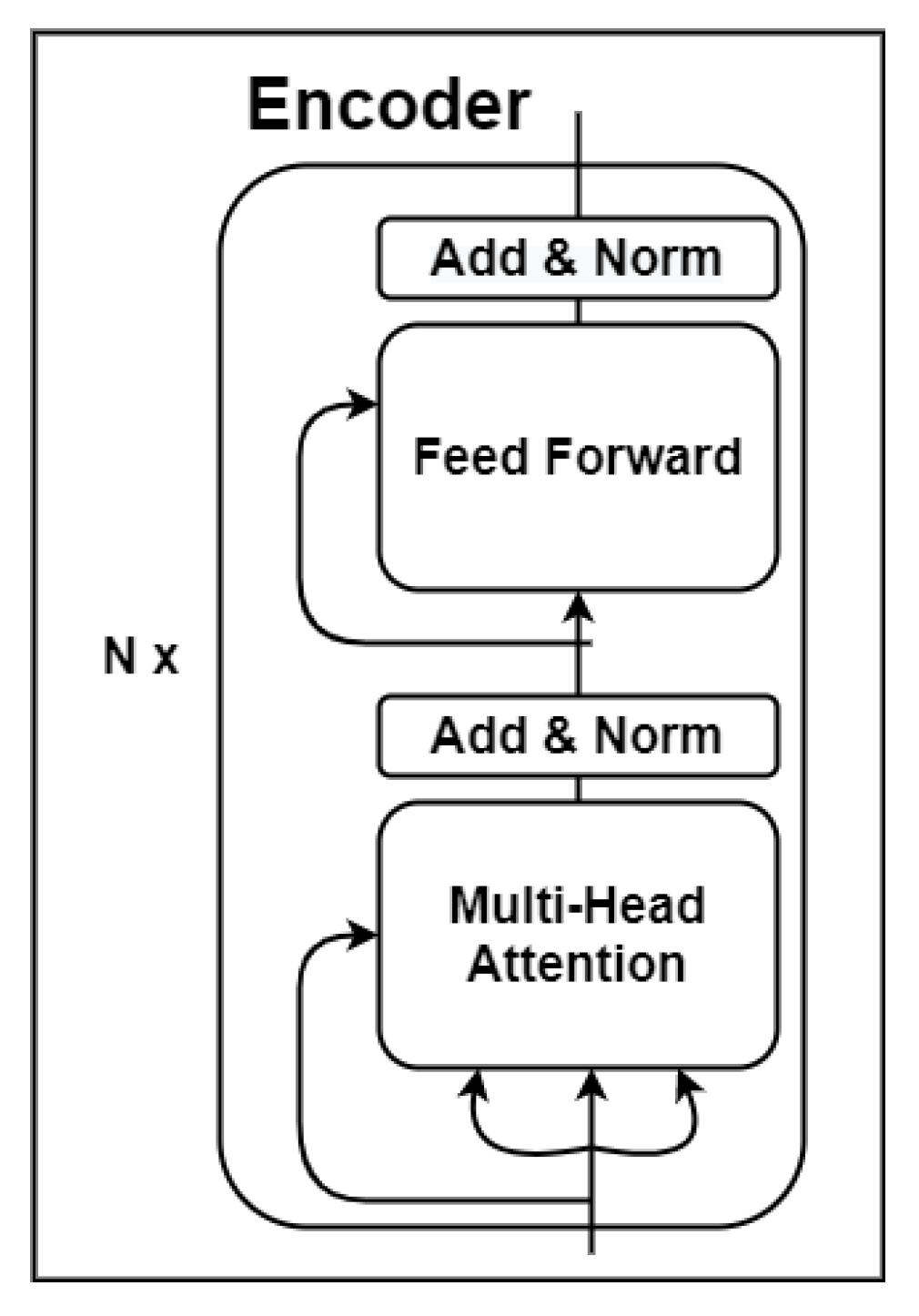
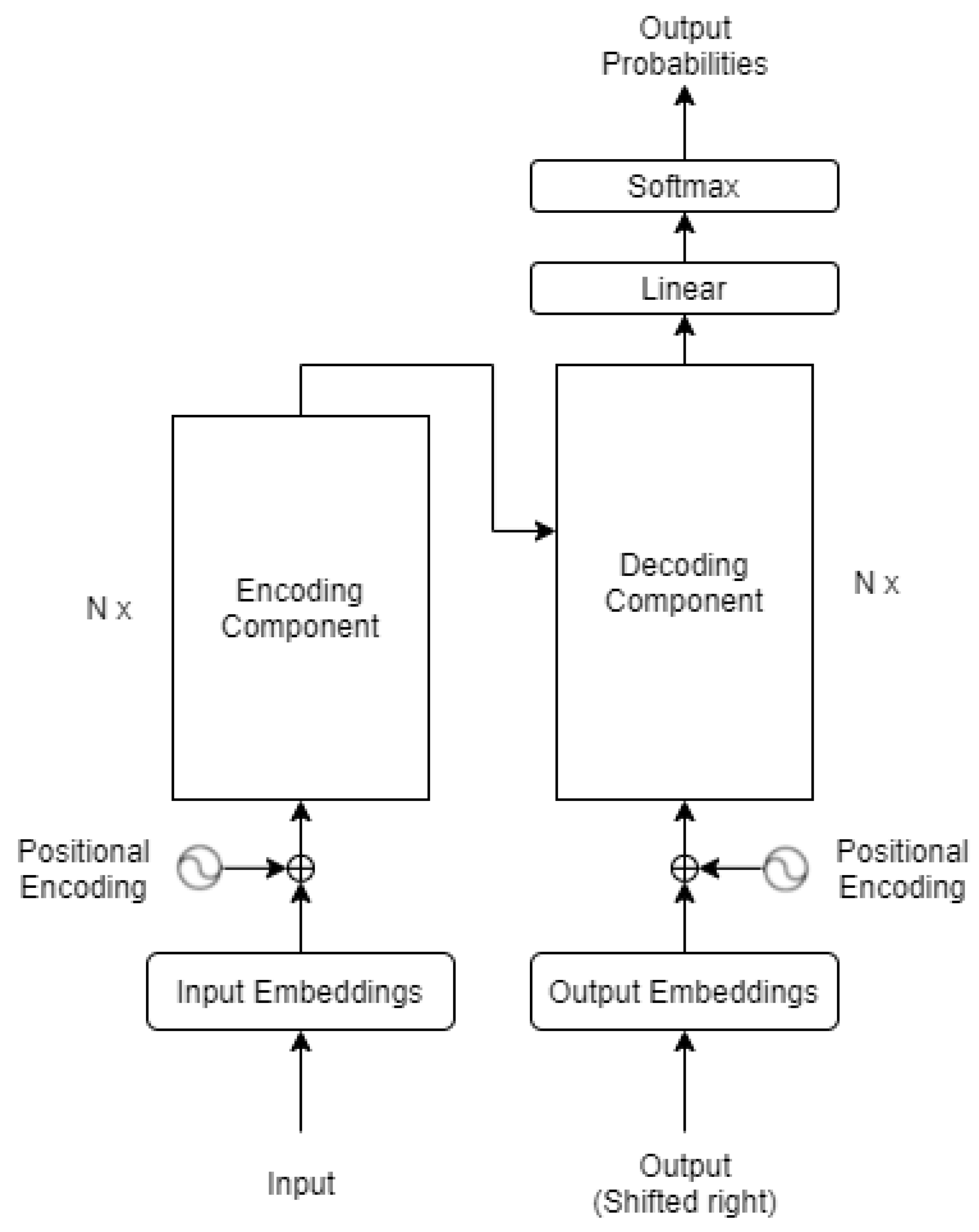
Figure 5 shows a mechanism of the transformers. In [
54], all the details of the architecture of transformers are presented. However, from a general point of view, the transformer consists of two components; the
encoder and the
decoder. The encoder takes all the words simultaneously and generates embeddings for each word simultaneously, encapsulating the meanings of the words, meaning that similar words have closer vector values. Depending on the task—i.e., getting an English sentence and predicting the next word in Spanish—the decoder takes these vectors and the previously generated words of the translated sentence and then uses them to generate the next word in Spanish. The encoder learns what the language is, the grammar, and the context [
55]. Moreover, the decoder learns how the English words are related to Spanish words.
Because both parts understand the language and perform independently, it is possible to use these two parts separately. By stacking encoders, Bidirectional Encoder Representation from Transformers (BERT) language models are created, and Generative Pre-trained Transformer (GPT) models are achieved by stacking decoders [
56].
In this study, the encoding part has been used for text feature extraction in order to turn the sentence into its respective vector [
57].
Figure 6 represents the architecture of the encoding part of the transformers. This can solve many different problems requiring an understanding of the language, such as neural machine translation, question answering, sentiment analysis, text summarization, etc.
A BERT model needs to be trained on a language and then fine-tuned to learn a specific task to solve the NLP problems. Training a language model is very computationally expensive, so instead, pre-trained BERT models are available to be utilized. The fine-tuning phase is done by adding a deep neural network designed to do a particular task to the output of the BERT component [
58]. For example, in the question and answering problem, the last layer of the deep network should be a dense layer with the number of nodes equal to the possible answers.
In this work, BERT is utilized for feature extraction. Moreover, a lighter, faster, and cheaper version of BERT, which is called DistilBERT [
59], is used. DistilBERT is 40% of the size of standard BERT, saving 97% of its language understanding capacity, but is 60% faster. The output vector size is 768, meaning that each sentence will have a fixed-size vector with 768 values.
It is essential to mention that the text preprocessing for BERT models is different from the traditional text preprocessing in terms of its details and implementations [
60,
61].
After applying the feature extraction using DistilBERT, the vectors representing each sentence, with their respective sentiment labels, are passed through a simple Feed-Forward Neural Network, with two dense layers and a dropout layer. Besides the great advantage of the BERT language model over Word2vec models, which is that it can vectorize sentences considering the position of the words in the whole sentence and the context instead of vectorizing the sentence word by word, the simplicity of the Feed-Forward Neural Network is another benefit against the LSTM model.
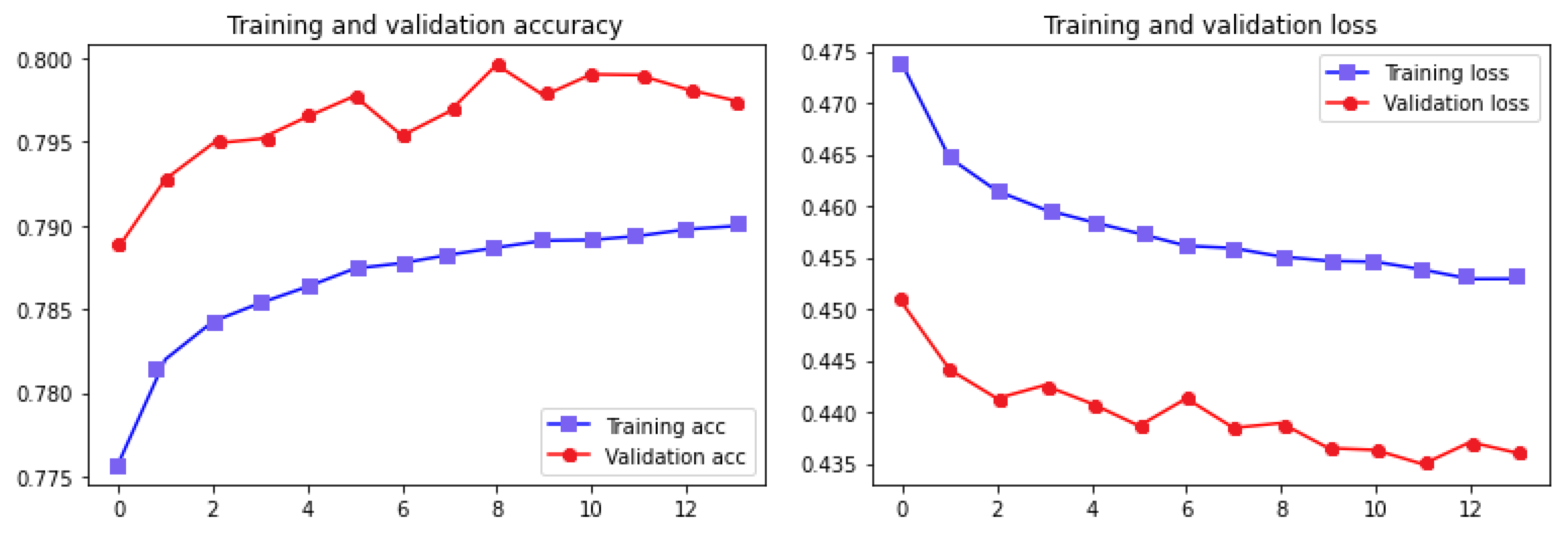
Figure 7 shows the accuracy and loss plot of the training and validation datasets.
Furthermore,
Table 11 represents the results of the aspect-based sentiment analysis using the DistilBERT method and Feed-Forward Neural Network.
By comparing the results of the two systems and considering the advantages of language models, the second proposed method performs much faster and is computationally less complex because, on the one hand, the language models process the whole sentence simultaneously, word by word in parallel, and have a higher contextual understanding of the language, and, on the other hand, the simplicity of Feed-Forward Neural Networks makes the second approach a better choice; thus, it was selected for further analysis.
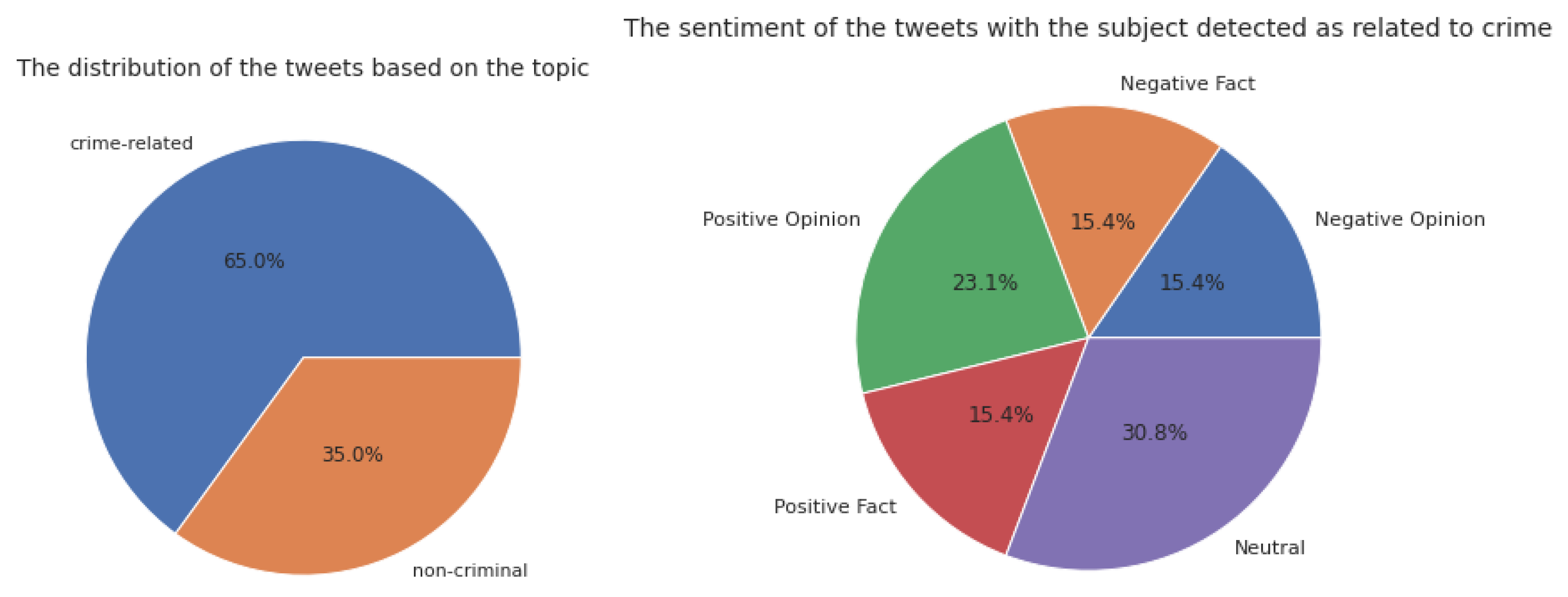
To present some of the outputs of the contextual analysis component of the system,
Table 12 presents some extracted tweets and the values of the corresponding results of the sentiment analysis algorithms. As is evident, the result will not be accurate if the tweet’s aspect is not considered. The tweet aspect is extracted by performing topic modeling to separate the crime-related tweets to improve the performance of sentiment analysis. This information is helpful because a positive opinion about a crime-related subject equals a high level of agreement with illegal content.
Applying the topic modeling and considering the topic to interpret a sentence’s sentiment enables us to understand the emotion of the input text more precisely; this procedure is aspect-based sentiment analysis. It is usually used when sentiment analysis is performed for a specific subject [
62]; for example, when a company wants to understand what customers think about its products. Alternatively, in general, ion this research, we are interested in what people think about crime-related topics.
In the next section, a successful case study and results are presented, respecting the policies of publishing Twitter data, which are restricted.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}