1. Introduction
As many emerging workloads—such as physics simulations and vision applications—have become more complex, vast, and diverse, they can no longer be handled efficiently by a simple, single central processing unit (CPU). Although a multitasking technique using multiple CPU cores has been proposed to achieve a high performance gain, it suffers from high parallelization overhead when creating multiple threads. To support single-thread performance efficiently, several accelerators such as vector processors, graphics processing units (GPUs), and neural processing units (NPUs) are often utilized. In particular, vector processors have become an essential part of modern computing because they can handle large workloads effectively through tight integration with existing CPUs.
Vector processing is a parallel computing technique that exploits data parallelism using a single-instruction multiple-data (SIMD) scheme, and it requires SIMD-purpose hardware and extensive software support to utilize the hardware. Most modern CPU cores for both general-purpose use and supercomputing generally contain vector processing units such as streaming SIMD extensions (SSE) [
1], advanced vector extensions (AVX) (for Intel CPUs) [
2], and Neon (for ARM CPUs) [
3]. To accelerate applications using vector processing units, programmers or compilers must generate special codes using these available vector instruction set architecture (ISA) extensions.
Although vector processing appears to be promising, the main challenge is programming. To accelerate applications efficiently using vector units, a compiler or programmer should find a substantial amount of underlying data parallelism and translate the parallelization potential into a real code to make sufficient use of the vector unit. Although many techniques for improving the quality of the vector code have been proposed [
4,
5,
6,
7], the resulting vector resource utilization is still low. Manual vector code optimization is a basic approach; however, it requires a deep understanding of the target vector architectures, and the optimized codes have limited reusability. Automatic compiler-level vectorization is a promising alternative to manual vector code generation, but it cannot provide sufficient coverage because it can vectorize only 45–71% of loops, even in synthetic benchmarks [
8]. Moreover, many vectorized applications do not show sufficient performance gains, as expected, owing to the high data alignment overhead [
4,
7]. Although many vectorization libraries also utilize vector units by providing more general interfaces, they are still limited in use.
To solve this problem, we propose a method of utilizing vector units as simple scalar processing units, similar to general arithmetic logic units (ALUs) inside CPU cores. With this scheme, normal instruction-level parallelism can be exploited more efficiently using both internal ALUs and vector units, whereas not all of the computational capabilities of the vector units are utilized. By utilizing only a subset of the computational resources to run scalar instructions on the vector units, two potential problems are identified. The first problem is resource waste, owing to the unnecessary computations of the remaining parallel resources. This can be prevented using several vector masking capabilities, such as the configurable vector length [
9,
10] or masked vector instruction features [
2,
11], which are widely supported by modern vector ISAs to prevent such side effects.
The second problem is the low performance of vector units when parallel resources are not fully utilized. To compensate for the low performance gain, the collaborative execution of the target application on both internal ALUs and vector units is a possibility. To maximize the collaboration performance, the optimal offloading ratio of the target workloads between the internal ALUs and the vector units should be determined based on the difference in the raw performance as well as the job offloading overhead from the CPUs to the vector units. Because a precise prediction of the ratio is almost impossible to achieve statically, a profile-guided optimization algorithm is a promising solution.
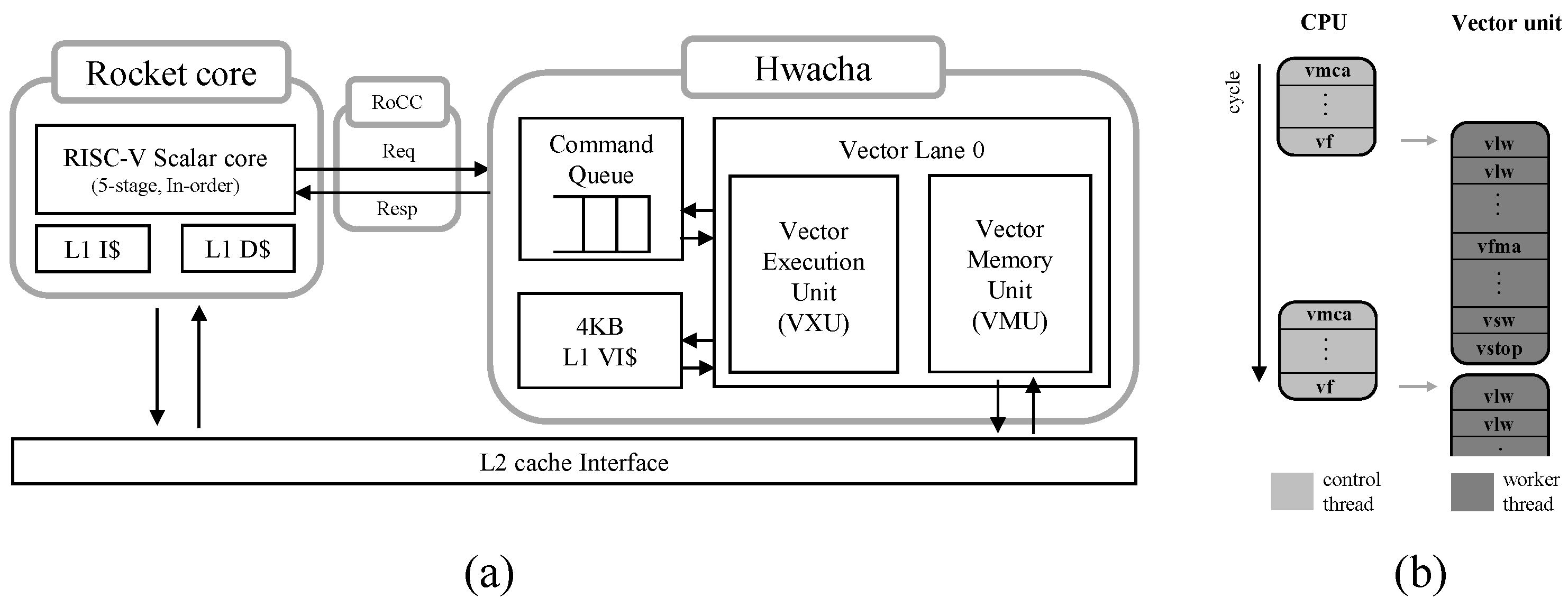
Based on these insights, a collaborative execution technique, referred to as Vector Offloader, was designed in this study to make the collaborative execution of scalar programs possible on internal ALUs and vector units without complex vectorization techniques. The technique splits the target loops into two scalar partitions to execute on internal ALUs and vector units by finding the optimal vector offloading ratios based on the profile information. The proposed technique was implemented on a RISC-V infrastructure (Rocket core) with a Hwacha vector processor extension [
12], and it was verified on a VCU118 FPGA board [
13]. Although the proposed technique has been implemented specifically on the vector accelerator, it is also applicable to other architectures that contain vector ALUs if dynamic out-of-order instruction scheduling is supported to make possible the parallel execution of main integer ALUs and vector units. The Vector Offloader achieved a 1.31× performance improvement on average for the Polybench benchmark suite [
14], with double, float, and integer data types for mini and small workload sizes, and it showed similar performance gains in all the test cases.
This paper provides the following contributions:
A method that utilizes vector units without considering data parallelism is introduced;
A profile-guided algorithm is introduced to determine the optimal offloading ratio based on an analysis of the importance of the work offloading size to the vector units;
The Vector Offloader is evaluated in depth in a field programmable gate array (FPGA)-based environment.
3. Motivation
3.1. Vectorization Challenges
Although most modern CPU designs include vector units, they are often underutilized or not efficiently used in many applications. The low utilization is primarily caused by the difficulty in generating efficient vector instruction streams; this is because a compiler or programmer must understand the target application characteristics. The first solution is to have experienced programmers understand the algorithm fully and then translate the full underlying data parallelism into a vectorized code. Clearly, this is difficult for average programmers and requires high development efforts from programmers whenever new applications are introduced. The second solution is to use an automatic compiler-level vectorization technique, which is a typical approach employed by various widely used compilers. However, this technique results in low coverage because only some predefined patterns are accepted, and the performance gain is insufficient even when a vectorized code can be generated.
Figure 2 shows the auto-vectorization coverage of widely used compilers: GCC [
20] and Clang [
21]. We vectorized 17 loops on 9 benchmarks from the Polybench [
14] suite by compiling them using the -O3 optimization level and -mavx2 microarchitecture options. As shown in
Figure 2, Clang and GCC can successfully vectorize only 29% and 59% of the loops, respectively. More specifically, Clang and GCC can apply innermost-loop-level vectorization on 29% of the target loops (same loops on both compilers), whereas GCC alone can apply vectorization onto 30% more loops, using advanced techniques to consider a scope wider than the innermost loop. Based on reports from the compilers, loop vectorization was not applied owing to the complicated access patterns, safety concerns regarding instruction reordering, and low expected performance gains.
3.2. Alternative: Parallel Execution of Scalar Workloads on CPUs and Vector Units
As discussed, it is difficult to fully utilize vector units using conventional approaches. Therefore, an advanced approach to efficiently utilize frequently idle or underutilized vector units without vectorization and to achieve significant performance improvement is required. To efficiently utilize the vector units, we decided to use them as additional scalar units through simple instruction translations. To improve the total performance, the task of the vector units can be offloaded partially. In this regard, the CPU and vector units should be able to execute in parallel, which is possible because most vector units are decoupled from the main CPUs. As a remaining issue, because CPUs must assign the tasks to the vector units, the task offloading cost on the CPU-side must be less than the corresponding execution cost such that offloading can be utilized.
To verify the execution latencies of each work on the CPU side, the offloading overhead, and the corresponding vector unit-side work, we measured the difference in execution time when executing a general matrix multiplication (GEMM) application from the Polybench suite [
14]. A cycle-accurate simulation was performed to achieve a more accurate measurement of the execution time.
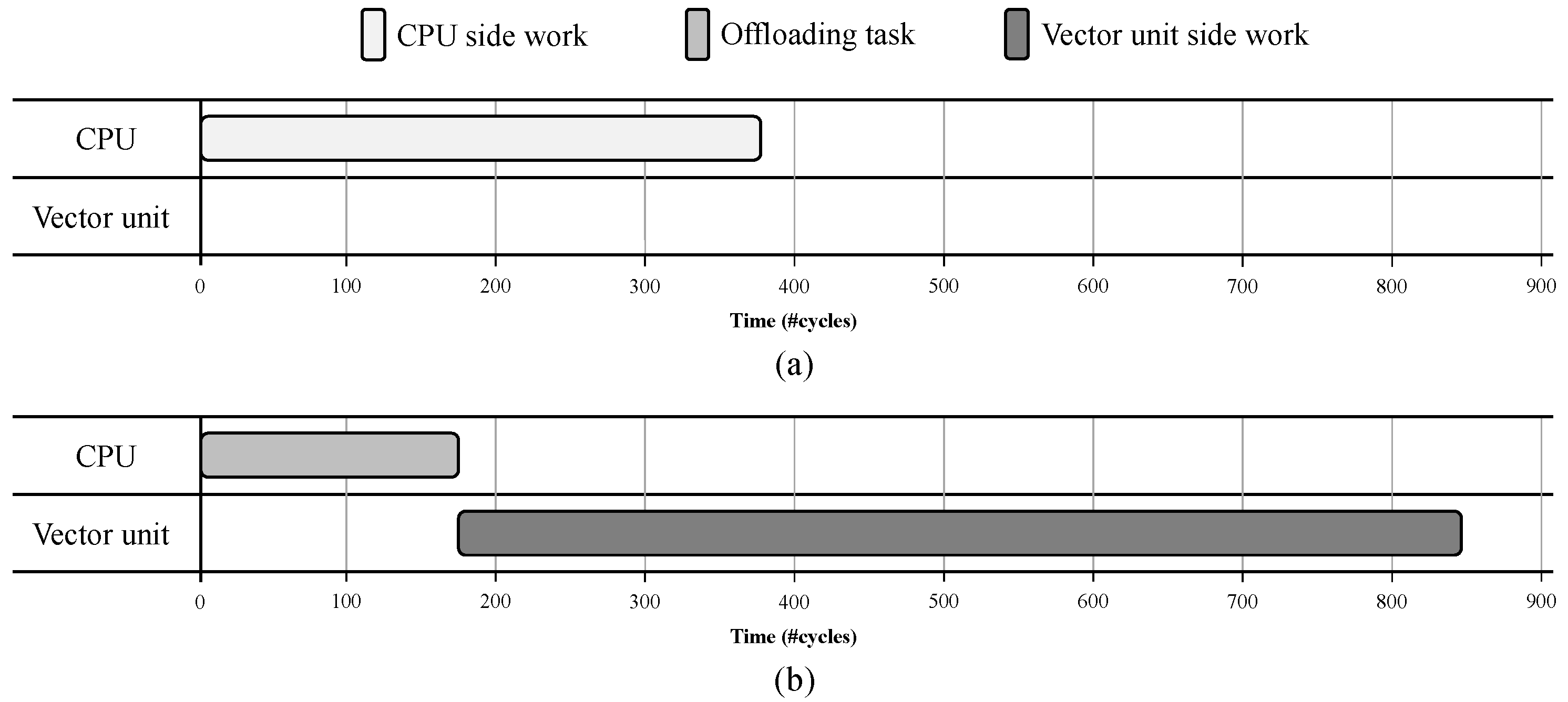
Figure 3 shows the hot code region execution time (number of cycles) for the CPU and vector unit-side work with the offloading overhead on the CPU.
Figure 3a shows the execution time of the CPU-side work when a CPU executes the hot code region in the CPU alone.
Figure 3b shows the execution time when the vector unit is utilized. The offloading overhead is the time when a CPU configures the vector unit’s registers and offloads the hot code region to the vector unit. The vector unit-side work is the time when the vector unit executes the hot code region allocated from the CPU side.
As shown in
Figure 3, the offloading overhead time is much shorter than the time required by the CPU-side work; therefore, it is proven that offloading can reduce the CPU overhead. However, as a key observation, the time required by the CPU-side work (as shown in
Figure 3a) differs from that for the vector unit-side work (as shown in
Figure 3b). The time required by the CPU-side work is less than the time required by the corresponding vector unit-side work, and the same trend was observed for all benchmarks in the Polybench suite [
14]. This result appears reasonable because each execution unit of the vector unit has a longer latency than the CPU, and the vector unit performs better than the CPU only when multiple execution units of the vector unit are executed in a lockstep. Therefore, because full offloading does not result in a sufficient performance gain, and the job offloading overhead on a CPU is much smaller than the native execution on the CPU, the parallel execution of the workload on both the CPUs and the vector units by segregating them into two partitions is a promising approach.
3.3. Maximizing Total Resource Utilization
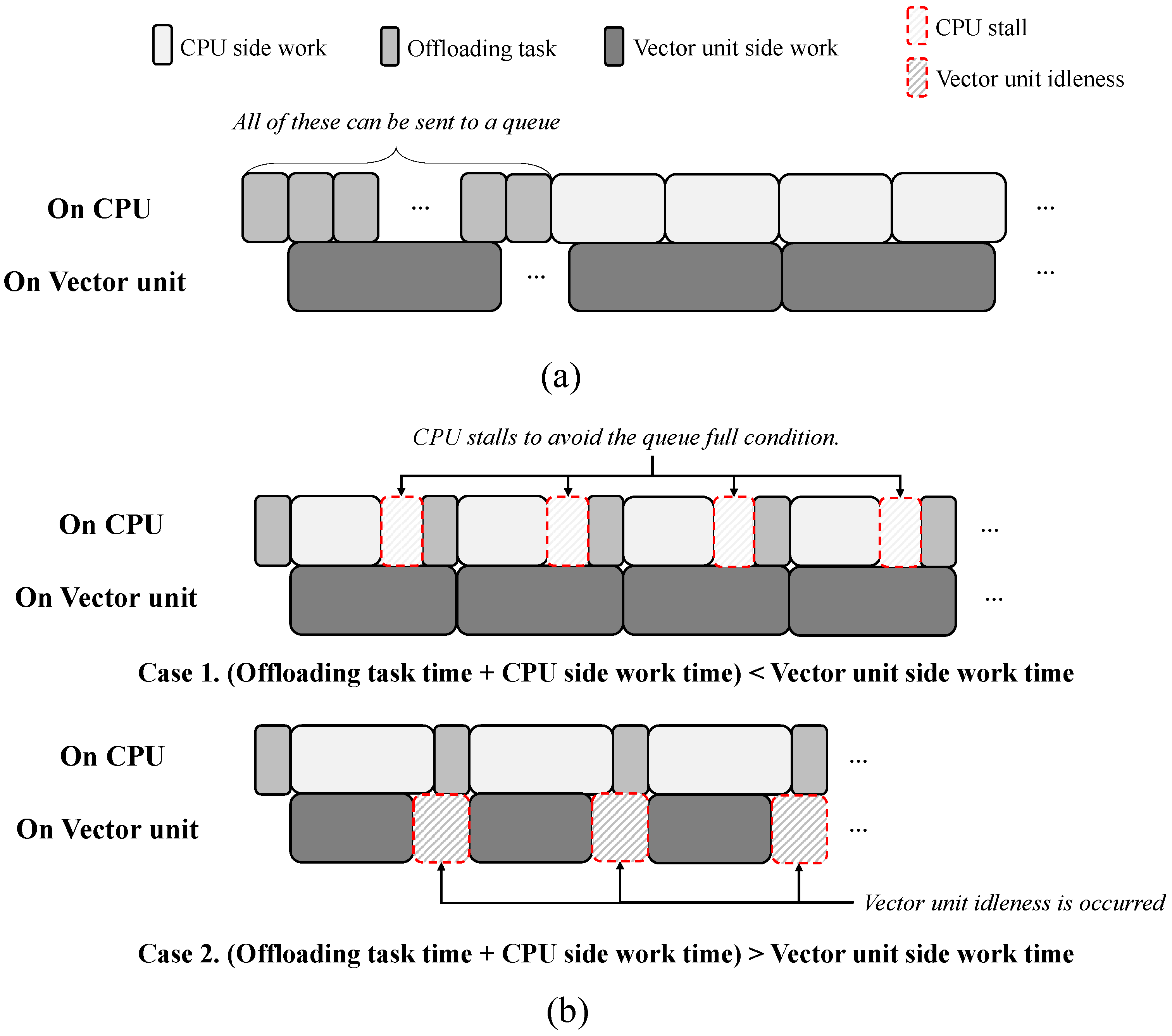
A command queue in the vector unit is a container in which a vector scalar unit fetches instructions offloaded from the CPU. If the command queue size is unlimited, the performance will be the best under a parallel execution.
Figure 4a shows that, based on this assumption, the CPU can initially offload all partitioned work on the vector unit in order to utilize the vector unit, and then execute the remaining tasks on the CPU-side. Because resource idleness does not occur at any time, the best performance is achieved. However, owing to the limited queue size, CPU stalls often occur when all tasks are assigned to the vector unit. Hence, the CPU should repeat the offloading of some of the tasks (bundle) and, as the vector unit is operating, execute the other tasks on the CPU side until the entire task is completed.
Figure 4b shows the inefficient offloading scenarios, including those on the bundled execution, to avoid the full command queue problem. As shown in
Figure 4b, case 1 indicates that the vector unit-side work required a longer time compared with the time required for both the CPU-side work and the offloading overhead combined. In this case, although both the CPU-side and offloading tasks for a bundle are completed, the corresponding offloaded task on the vector unit is not accomplished. Therefore, the total CPU resources cannot be fully utilized. By contrast,
Figure 4b shows an example for case 2, in which the time required for the vector unit-side work is less than that for the CPU-side task and offloading overhead combined. In this case, the vector unit will be in an idle state until the CPU completes the next offloading task. Therefore, the assigned workload should be segregated at an appropriate ratio to fully utilize the CPU and vector unit in parallel, thereby minimizing CPU or vector unit stalls.
3.4. Summary and Insight
To utilize the vector unit efficiently, we considered using the vector unit as an additional scalar computation unit to achieve performance improvements without vectorization, as well as distributing a target workload across the CPU and vector unit to simultaneously execute the partitioned workloads. However, because of problems such as pending communication or resource idleness, it is crucial to determine the amount of work that needs to be transferred to the vector unit. Hence, we proposed a profile-guided optimal offloading ratio search algorithm, which will be discussed in detail in the next section.
4. Vector Offloader
As discussed in
Section 3, programmers or compilers face difficulties in extracting the underlying data parallelism for the vectorization of various target applications. To solve this problem, we propose a code translation technique that offloads some portion of the workload to underutilized vector units without explicitly exploring data parallelism, but by retaining the original scalar code. Thus, we first generate instructions to be executed on the vector hardware from the original scalar code. We also insert additional codes to set up the vector hardware and prepare the data on the host-side code.
Section 4.1 describes the main concepts for offloading operations to vector units. Moreover, in
Section 4.2, we describe how to distribute the workloads on the CPU and vector units simultaneously. A profile-based algorithm for determining the optimal offloading ratio is proposed in
Section 4.3.
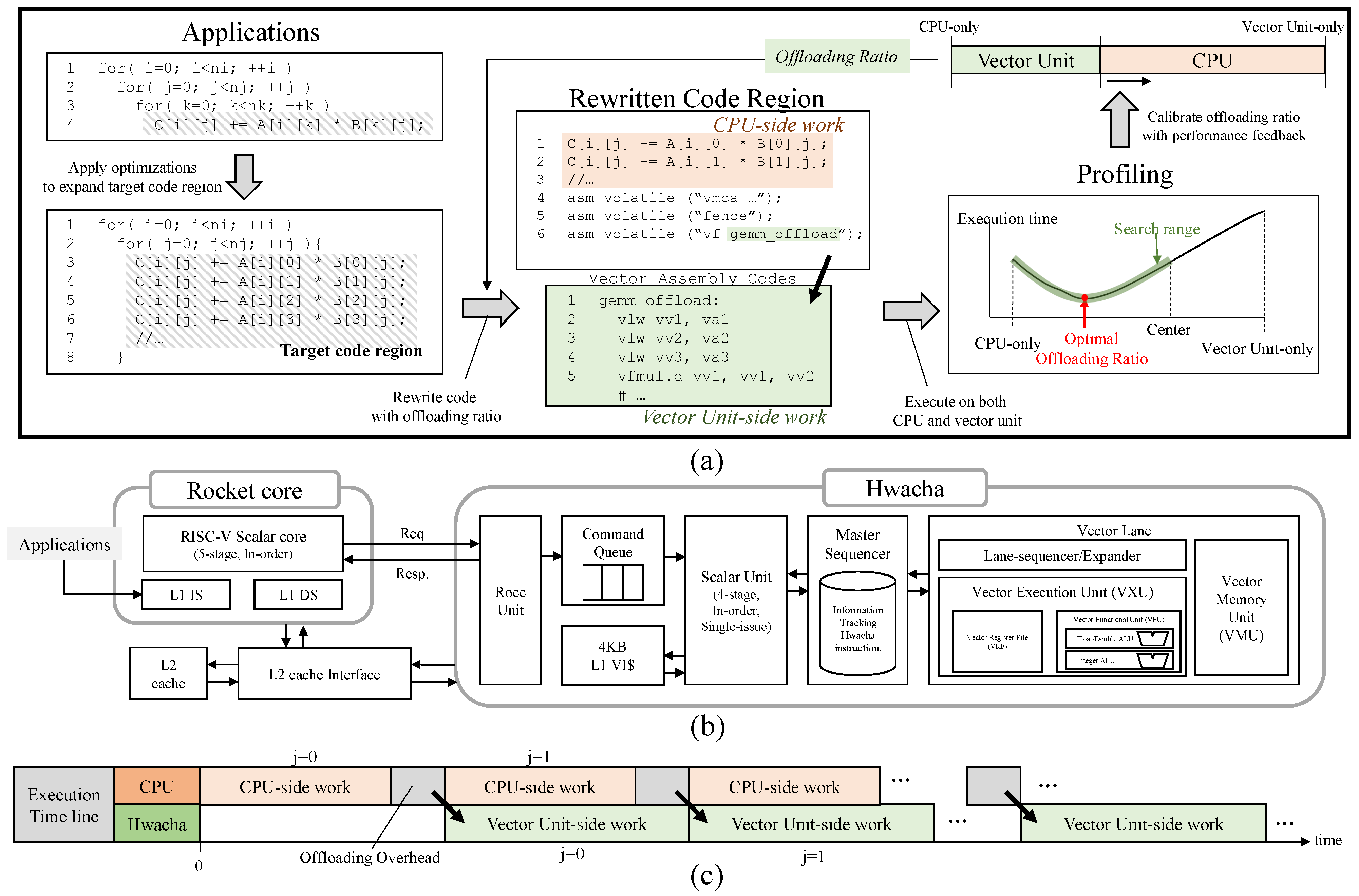
Figure 5 provides an overview of the workload distribution process for the CPU and vector units. As shown in the figure, we apply optimization techniques to expand the workload distribution area and rewrite the application based on the optimal offloading ratio of the vector unit. The application is initially executed only on the CPU. In sequence, the optimal offloading ratio is calibrated using a profile-guided search algorithm. Finally, the resulting execution binary generated based on the optimal offloading ratio is executed on both the Rocket core-based CPU and the Hwacha vector unit.
4.1. Workload Offloading to Vector Units without Considering Data Parallelism
As previously explained, we propose the Vector Offloader in order to make use of an underutilized vector unit as an additional unit for scalar computation. To conduct scalar operations on the vector unit without hardware modification, we rewrite the application code using the vector unit ISA.
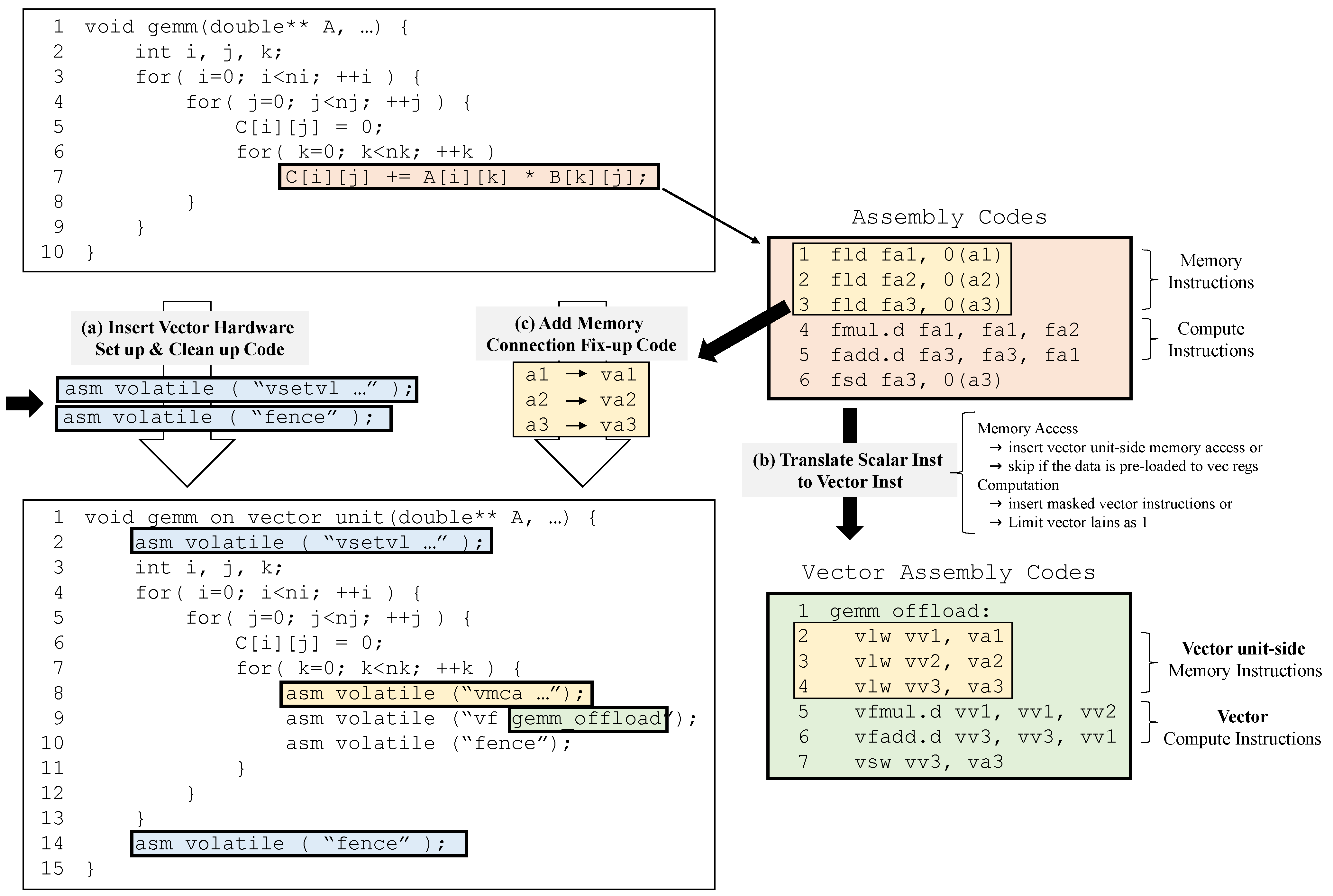
Figure 6 shows the code rewriting process for running a target application on a vector unit without exploiting data parallelism. As shown in the figure, the code rewriting process consists of three steps: (1) adding the setup and cleanup codes (host side), (2) translating the scalar instructions into vector instructions (vector unit side), and (3) adding a data preparation code for use in the vector hardware (host side).
As a key to the rewriting process, the vector code should behave like a scalar unit without causing other critical side effects, such as the storage of garbage data in unintended memory locations. Vector operations on a vector unit with multiple vector lanes, especially stores, can produce unintended results and update the data in the main memory. However, in modern vector architectures, masking instructions or a reconfigurable vector length support capability can solve this problem by allowing the instructions to be performed only in a single lane. As a result, by changing the scalar registers to the corresponding vector registers and converting scalar instructions to the corresponding vector instructions, an identical vector code can be created from the original scalar code while producing the same result. Unlike arithmetic operations, in memory access instructions such as load and store, a simple translation into vector instructions does not guarantee the same behavior because of the complexity of memory addressing. Therefore, the CPU thread may need to preload the data into vector registers or pass memory addresses to the vector units, depending on the structures of the specific target vector unit.
Based on these key considerations, we first insert the vector hardware setup and cleanup codes (
Figure 6a) at the start and end points of the host-side workload (an original program code executed on the CPUs). At this point, the vector hardware is set to use only a single lane. Vector instructions are then generated based on the original CPU-based assembly code by converting the scalar instructions into the equivalent vector instructions (
Figure 6b). If the vector hardware cannot be configured to use only a single lane in the setup code, masked vector instructions are used depending on the target vector hardware. The memory connection fix-up code is additionally generated in order for the vector unit-side memory operations to execute correctly; this is performed by preloading the memory data or by passing memory addresses from the CPU registers to the vector unit registers (
Figure 6c). Finally, as shown in
Figure 6, to perform the memory preparation and partial offloading workloads in the vector unit instead of the original computations on the CPU, we create modified codes by including the generated codes in the original application code.
4.2. Workload Distribution between CPUs and Vector Units
As discussed in
Section 3, offloading entire workloads often results in worse performance on the vector units than on the CPUs in case a highly optimized vector code is not generated by fully exploiting data parallelism. To solve this problem, we support a collaborative execution using the CPU and the vector unit simultaneously.
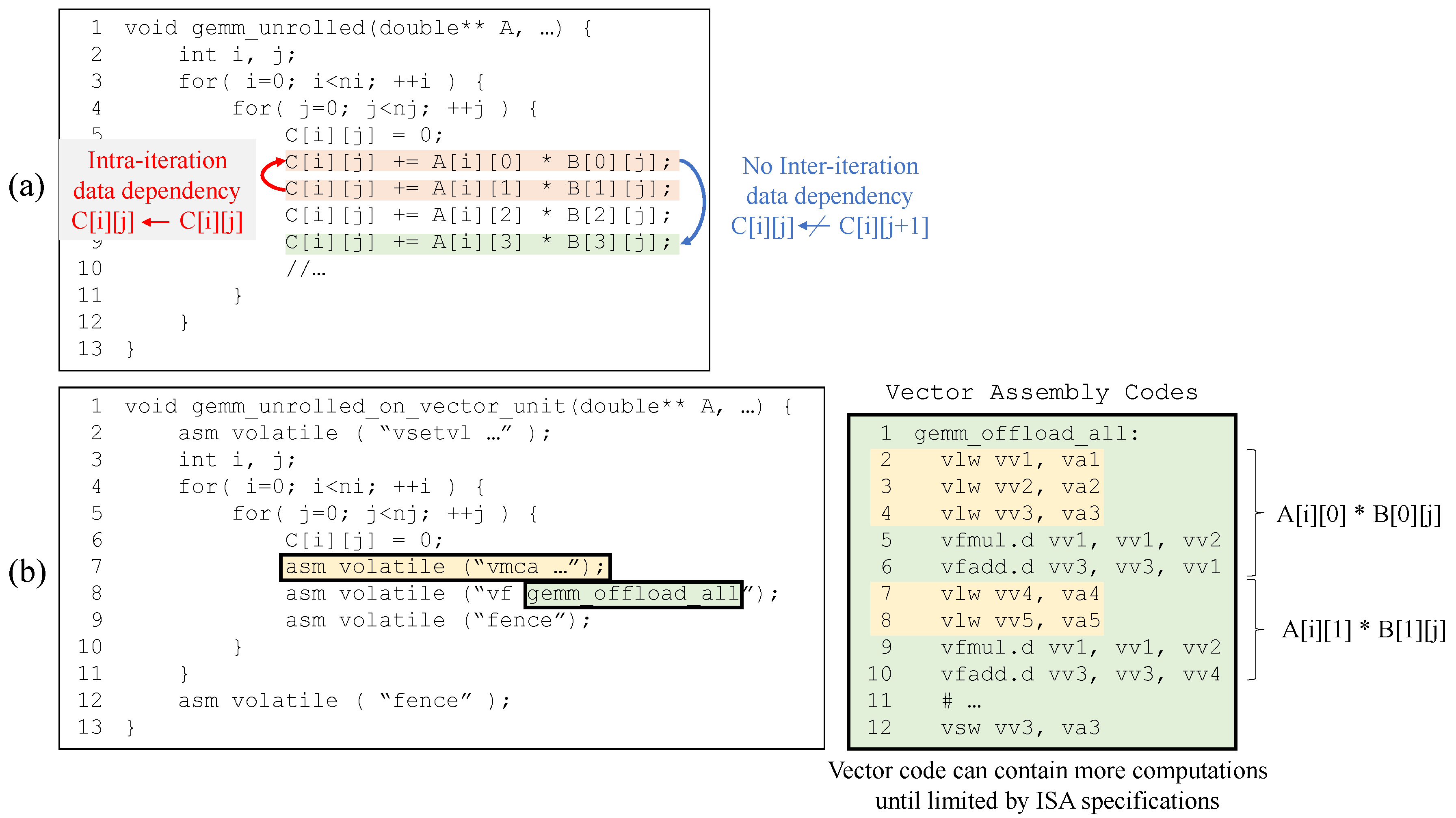
Figure 7 shows the potential opportunities in a general matrix multiplication application (GEMM) for distributing the workload to the CPU and vector units and concurrently performing the workload. We first apply several traditional compiler optimizations, such as the loop unrolling technique, to generate long and straight codes without branch divergence.
Figure 7a shows the result of applying loop unrolling to the GEMM. As shown in
Figure 7a, although the unrolled code is difficult to vectorize owing to the data dependencies within the loop body (intra-iteration data dependency), a parallel execution over different iterations is possible because there is no inter-iteration dependency. For more fine-grained workload balancing, we propose to split each iteration into CPU- and vector unit-side portions, and to concurrently execute the vector unit-side partition for the current (j) iteration and the CPU-side partition for the next (j + 1) iteration, similar to a two-stage pipeline execution. The concurrent execution of the CPU and vector units can be easily implemented by enforcing a partial order between the CPU and vector unit partitions within an iteration using fence instructions.
In addition, as more instructions are offloaded to the vector unit through loop unrolling, the vector code can be further optimized. For example, redundant instructions to access the same memory addresses within the vector code can be eliminated, as shown in
Figure 7b. This vector code optimization can increase the vector performance; therefore, more workloads can be offloaded to improve the total performance. However, because the exact degree of additional performance improvement cannot be statically predicted, profile-guided optimization is required to determine the optimal offloading ratio of the vector unit partition over the entire workload. When all vector registers are utilized, the offloading ratio cannot increase further; hence, another important factor for the offloading ratio is the target vector unit specification, such as the number of vector registers.
Figure 8 shows the modified code for concurrently executing the GEMM workload on the CPU and the vector unit. As shown in the figure, the CPU-side code is updated by adding vector hardware setup/cleanup codes, data preparation codes, and offloading control codes. A vector assembly code is also generated, and the code is fetched from the target vector unit directly when the host code executes the offloading control codes (vf gemm_offload_balanced). The fence instruction is added to guarantee the correctness of concurrent execution, and the ratio of the vector unit-side portion to the CPU-side portion can change depending on the offloading ratio.
4.3. Profile-Guided Optimal Offloading Ratio Search Algorithm
In this study, we propose a profile-guided search algorithm to determine the optimal offloading ratio. Algorithm 1 represents a simple search algorithm that gradually increases the ratio of offloading to the vector hardware until the total performance is saturated. It first initializes the variables for the search (lines 1–2) and iteratively searches for the optimal offloading ratio by executing the rewritten program based on the calibrated offloading ratio (lines 3–10). The offloading ratio continues to increase as the resulting performance improves (line 9). The algorithm increases the offloading ratio by two in order to reduce the search cost, while the unit ratio indicates the smallest instruction set that can be offloaded. The offloading ratio can increase to a given maximum limit value (line 3). To avoid problems caused by the illegal execution of vector fetch instructions such as branch misprediction, the maximum value is set to guarantee that the CPU performs the least amount of work in order to avoid exceptional cases. After determining the offloading ratio at the point of performance saturation (lines 3–10), the algorithm reduces the offloading ratio by 1 once, and then chooses the final optimal offloading ratio by comparing their performances (lines 11–17). The offloading ratio can increase up to the maximum offloading ratio (line 3) without a break (line 6), which means that vector-only execution is the best option.
| Algorithm 1 Find Optimal Offloading Ratio |
Require:Application, Maximum Offloading Ratio Ensure:Minimum Cycles and their Offloading Ratio - 1:
initialize OffloadingRatio ≔ 1 - 2:
initialize MinResultCycles, ResultCycles - 3:
whiledo - 4:
ResultCycles ≔ RunApp (OffloadingRatio) - 5:
if ResultCycles > MinResultCycles then - 6:
break - 7:
end if - 8:
MinResultCycles ≔ ResultCycles - 9:
OffloadingRatio += 2 - 10:
end while - 11:
ifthen - 12:
ResultCycles ≔ RunApp (OffloadingRatio - 1) - 13:
if ResultCycles < MinResultCycles then - 14:
MinResultCycles ≔ ResultCycles - 15:
OffloadingRatio -= 1 - 16:
end if - 17:
end if - 18:
return OffloadingRatio, MinResultCycles
|
6. Related Work
To efficiently utilize vector hardware, many studies have focused solely on the efficient scheduling of SIMD instructions, using improved auto-vectorization techniques or hardware modifications. However, these approaches could not fully utilize the vector unit. In this study, we proposed an alternate approach of utilizing the vector unit as an additional scalar unit rather than leaving it idle or underutilized.
Previous studies [
24,
25,
26] have focused on utilizing all available resources in parallel. SKMD [
24] presented a framework that manages the execution of a single kernel on available CPUs and GPUs by distributing the target workload. To maximize the performance in this framework, subsets of the data-parallel workload were assigned to multiple CPUs and GPUs by considering the performance differences and data transfer costs depending on the type of device. Paragon [
25] proposed a compiler platform to run possible data-parallel applications on CPUs and GPUs, which checks the dependency of speculatively running loops on the GPU. When a dependency is detected, it transfers the execution to the CPU, and after the dependency is resolved on the CPU, the execution is restarted on the GPU. Qilin [
26] is a heterogeneous programming system that generates code for both the CPU and GPU. It automatically partitions threads to the CPU and GPU by applying offline profiling and adaptive mapping of the computation to the target hardware. The key difference between our approach and these prior studies [
24,
25,
26] is that they considered the GPU as the target, whereas our method considers the vector unit as the target.
On the hardware side, SIMD-Morp [
27] introduced a flexible SIMD datapath to accelerate non-data-parallel applications by adding connectivity between the SIMD lanes. However, this method requires complex hardware configurations and good programming skills; moreover, efficient compiler support is necessary. Contrarily, our method does not change the baseline vector unit structure, and compiler support is much easier than vectorization.
7. Conclusions and Future Work
Most modern processors are equipped with vector units to exploit data-level parallelism. However, accelerating target applications using a vector unit is highly limited by the non-vectorizable (scalar) portions; therefore, the vector unit often remains underutilized. To overcome the underutilization of existing vector units, in this study, we proposed a technique for executing scalar programs by considering the vector unit as an additional scalar operation unit. We applied a code rewriting process and offloaded the split workloads based on the optimal offloading ratio into both the CPU and the vector unit. To identify the optimal offloading ratio, we presented a profile-based search algorithm that gradually increased the ratio of offloading to the vector unit until no additional improvement in performance was achieved. Our proposed method showed average speedups of 1.26×, 1.23×, and 1.21× with respect to double, float, and integer types on a mini dataset, and average speedups of 1.35×, 1.36×, and 1.27× for double, float, and integer types on a small dataset, respectively.
This study includes the following directions for future research: First, we believe that the Vector Offloader can be utilized in existing general parallelization infrastructures. Therefore, we will attempt to generalize our technique using existing parallel programming APIs such as OpenMP. Second, we will maximize the effectiveness of our technique using additional hardware modifications. Since our work can limit the vector width to support scalar codes on target vector units, fine-grained power control can substantially improve the power efficiency of our technique. To realize this, we have already applied the fine-grained clock gating logic to the baseline Hwacha architecture; to handle it, we will utilize the lane-wise clock gating for offloading with the use of customized instructions.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}