1. Introduction
With the increased spatial resolution of recently produced imaging sensors, a considerable amount of remote sensing satellite images, especially very high-resolution (VHR) images, are available. These images provide us with more information in greater detail about the land surface. The fine spatial optical sensors with metric or sub metric resolution, such as QuickBird, GeoEye, Pleiades, and World-View, allow detecting fine-scale objects, such as residential housing elements, commercial buildings, and transportation systems and utilities. However, the large-scale nature of these datasets introduces new challenges in image analysis.
Many applications, such as land resource management, urban planning, precise agriculture, and crisis management [
1,
2,
3,
4,
5,
6], rely on very high-resolution remote sensing imagery. One of the most crucial tasks for accurate information extraction from these images is classification, which classifies the scene’s objects into meaningful categories. Unfortunately, these categories are almost identical to each other in many cases, such as pastureland and agricultural farmland or trees and grass. So, we have difficulty distinguishing similar types, especially in a complex scene with many details. Accordingly, it is crucial to find a proper classification method that enables us to address this issue.
It is now proven that spatial information integration can improve accuracy, particularly with VHR images [
7]. The spatial information can determine the shape and size of the objects in the image, which is very helpful to reduce the noisy appearance of classified pixels in the final result. This happens a lot when the classifier uses only spectral information without considering spatial arrangements.
There are two common strategies to extract spatial information from VHR images: the crisp neighbourhood system [
8,
9,
10] and the adaptive neighbourhood system [
11,
12,
13]. The former considers a predefined neighbourhood system with a static shape, while the latter is based on modifying the neighbourhood system.
Markov random field (MRF)-based approaches and artificial neural networks (ANN) are examples of the first group [
9,
10,
13,
14]. Although these methodologies can lead to an increase in final accuracy, they suffer from some shortcomings. For example, a predefined neighbourhood system cannot characterize the specifications of objects with different sizes. The smaller items may disappear in the final map, or the larger ones may turn into pieces.
The other family of methods are based on sparse representation (SR) [
15,
16]. These methods are primarily pixel-wise sparse models but they usually incorporate the spatial context to the joint sparse model (JSM) [
17,
18,
19]. Using multiple-scale regions for each pixel and shaping a multiscale SR model is proposed in [
20] to contain complementary spatial information. However, optimal integration of spatial information is still a big challenge in this area of study.
To address the above issues, methodologies based on adaptive neighbourhood system are suggested, such as segmentation-based [
21,
22], morphological profiles (MPs) [
23,
24], attribute profiles (APs) [
13,
25], and extinction profiles (EPs) [
26,
27]. These approaches have their own limitations too. For example, segmentation algorithms extract image objects and generate relevant results according to specific criteria. Image objects in a scene, especially in urban areas, generally show multiscale or multilevel features. Therefore, they appear at different scales of analysis. So, the procedure for choosing the best scale is very complicated and time-consuming [
21].
The other contributions that use adaptive neighbourhood systems are based on morphological profiles (MPs). MPs are usually composed of applying opening or closing by reconstructions with a structuring element (SE) of different sizes. The introduction of the MP concept leads to creating the morphological spectrum for each pixel [
28,
29,
30,
31,
32]. Another study in this area is based on the derivative of MP introduced in [
33], which has more promising results. However, as an SE’s shape is fixed, different objects with different shapes cannot be accurately modelled. Besides, MPs are unable to extract information related to grey-level specifications of the objects in the image.
One can use the morphological attribute profile (AP) instead of morphological profile to address the shortcomings mentioned above. The concept of AP has been introduced first in [
25] to generalize MPs. This new concept uses sequential morphological attribute filters (AFs). So, it can provide a multilevel characterization of the image.
APs work based on connectivity rules. Thus, they only consider connected components in the image. Compared to the MPs, APs are more flexible because they can view different attributes to model the image’s structural information. Several studies are based on the APs, which can be found in [
25,
34] for classification and building extraction tasks. If multiple attributes have been taken into account, an extended AP (EAP) can be created.
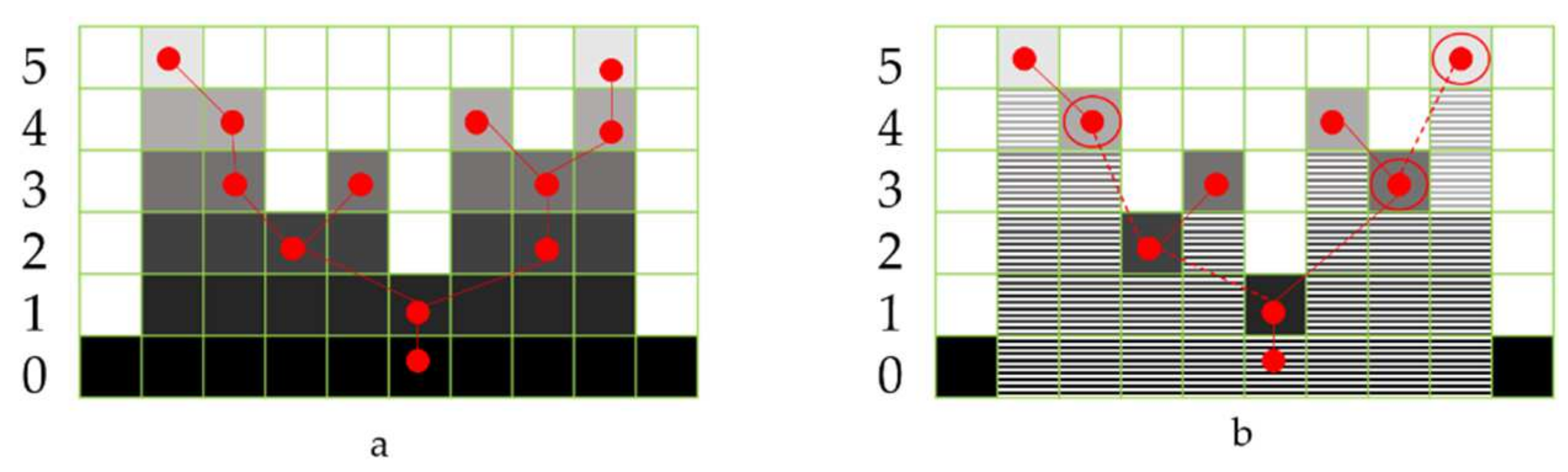
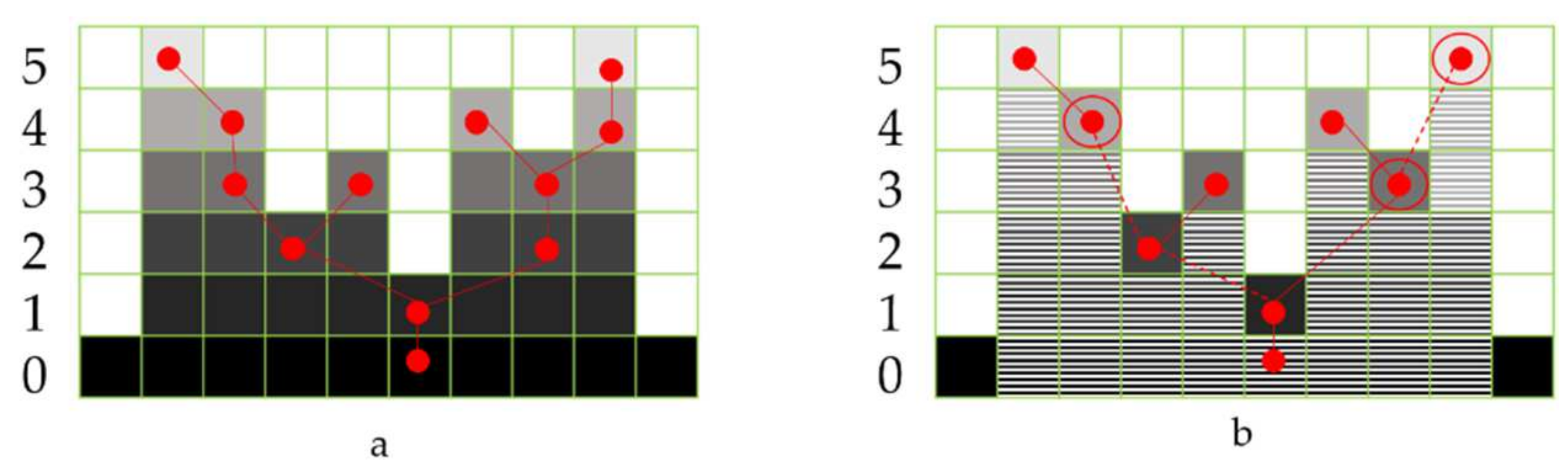
The other different variant of MPs, known as extinction profiles (EPs), is introduced in [
7], and they have shown promising results. EP’s implementation is based on the tree-representation (max-tree) [
35]. This concept will be thoroughly discussed in the next section.
The EP can create features for every pixel in the image with contextual information. Different methodologies have been tested to classify these features efficiently. Various studies, such as [
13,
36,
37], have been undertaken in this area. They mostly use support vector machine (SVM), random forest (RF), or artificial neural networks (ANNs) for spatial-spectral classification purposes, but they all have some limitations. For example, advanced SVMs with kernels like Gaussian or radial basis functions (RBFs) can handle the imbalance of the size of the image and the number of training samples. However, kernel SVMs cause overfitting in the case of sparse feature space [
38]. They also require several parameters to be set.
Random forest is another option for classification purposes that has been vastly used in different studies [
38,
39,
40,
41]. Although random forest-based methods are fast and yield stable results, their performance is easily influenced by the size of training samples [
42].
Another classification method that has been used more recently in the remote sensing community is artificial neural networks. ANNs are biologically inspired and multilayer classes of deep learning models that use a single neural network trained end to end from input vector obtained from image to classifier outputs [
43]. However, the standard ANNs are limited when dealing with multidimensional images because they need to adjust many parameters for neurons in the layer to reach satisfactory accuracy [
44]. Lately, deep networks have been demonstrated to achieve significant empirical improvements in most of the remote sensing fields like spatial-spectral classification [
22,
45,
46,
47,
48]. Many spatial-based techniques including semantic segmentation continuously advance. They have been employed to address remote sensing problems that are diverse and data-rich in nature [
49]. Examples of these researches include environmental monitoring [
50], crop cover and analysis [
51,
52], types of trees in forests [
53], and building detection [
54]. Deep learning methods automatically extract features that are tailored for the classification tasks, which makes such methods better choices for handling complicated approaches [
55]. The unique structure of the deep learning network may be able to learn features in different layers and adjust the parameters, at running time, based on accuracy, giving more importance to one layer than another depending on the problem [
47]. As the deep networks show great robustness and effectiveness in image classification, they have the potential to cope with the difficulties of non-linear spatial-spectral image analysis.
In this paper, a robust, precise approach is proposed to automatically extract spatial-spectral information from VHR images and classify them into thematic classes. In more detail, the main contributions of the paper are listed below:
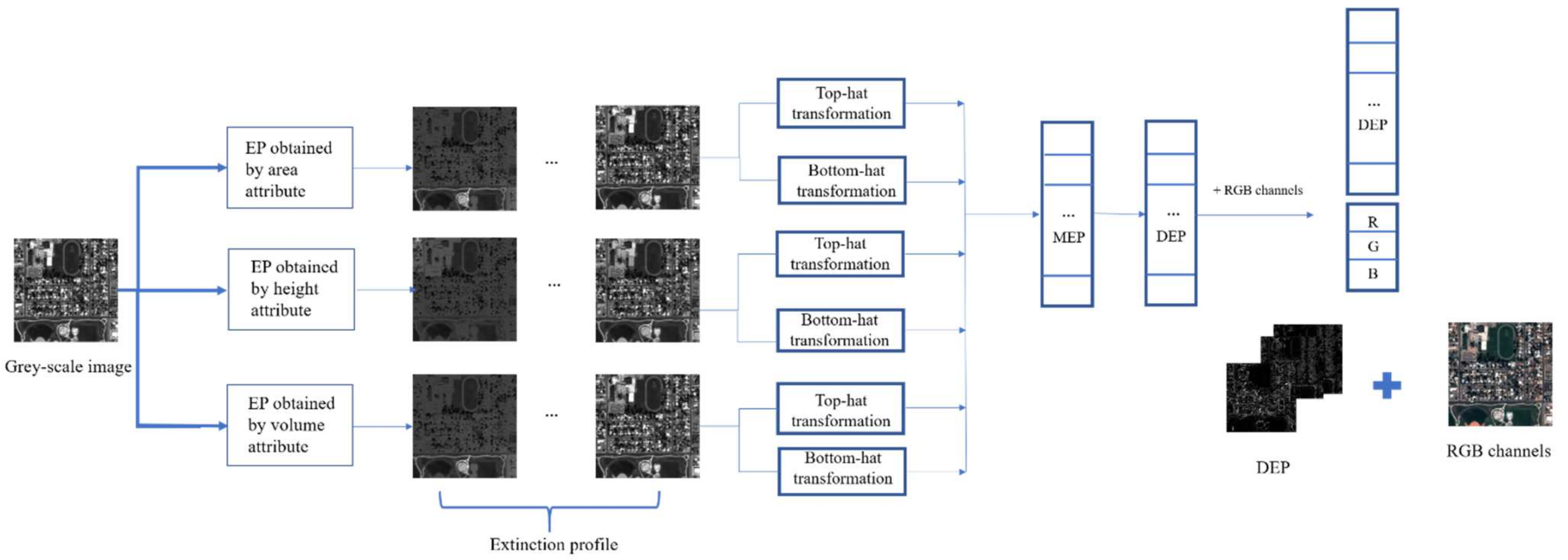
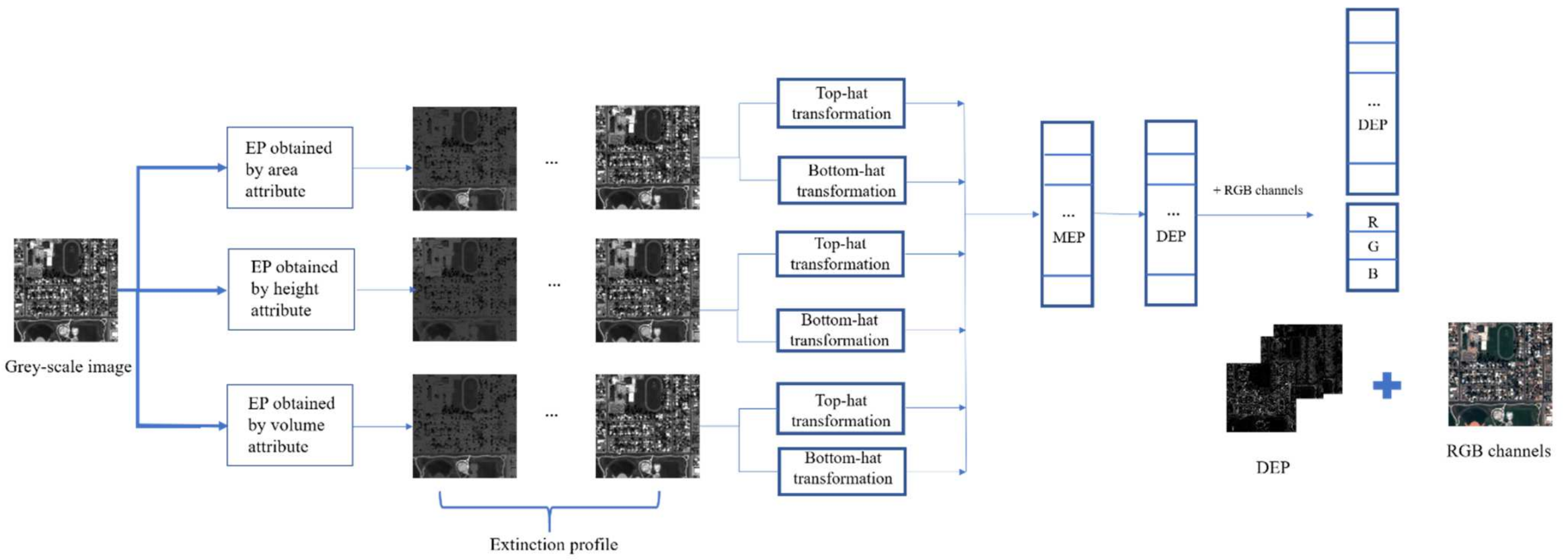
The paper applies a morphological spectrum, including differential extinction profile (DEF) and spectral information, to address the pixel specifications for further classification.
The differential extinction profile (DEF) used in the study is processed using morphology-based filters such as top-hat and bottom-hat filters. This leads to producing a concise, informative feature vector.
As the extinction profile automatically used a different number of extrema to make a complete profile, there is no need to set any parameters in the proposed approach. So, it can be used for different datasets with different characteristics.
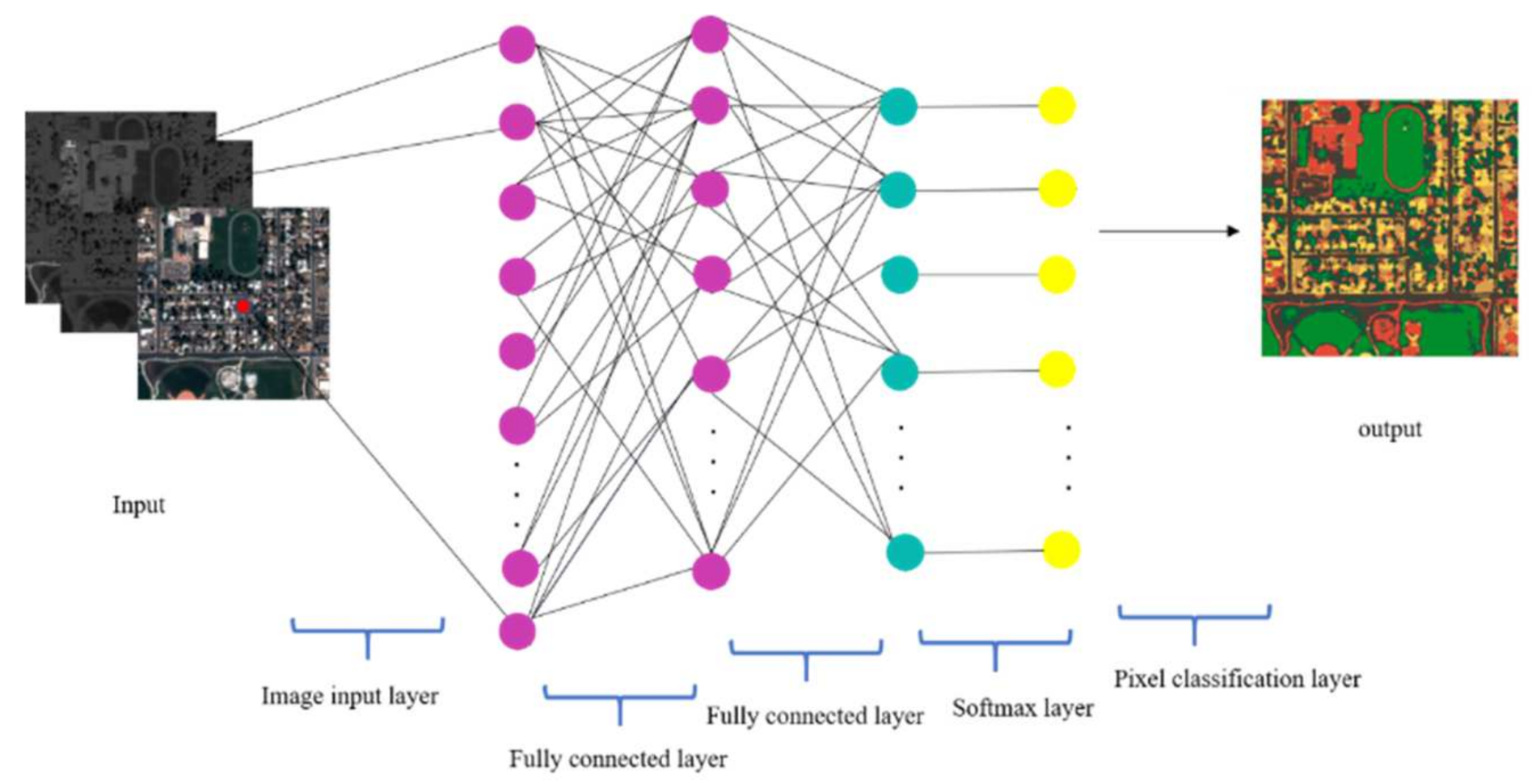
A simple, straightforward, yet accurate deep learning-based neural network has been developed for classification purposes.
The proposed approach is applied to different datasets. The entire process is fully automatic and speedy.
The remainder of this paper is organized as follows. The mathematical foundations of EP and deep-learning-based classifiers are addressed in the
Section 2. The proposed approach is explained in detail in the
Section 3. The experimental analyses, evaluations, and comparisons are presented in
Section 4, and the last section is attributed to the conclusion.
5. Conclusions
This paper proposes a novel approach for the spatial-spectral classification of very high-resolution remote sensing data. The proposed approach is based on the differential extinction profile (DEP) concept. The DEP is the derivative of extinction profile (EP) that can be made by applying top-hat and bottom-hat transformation on a grey-scale image. The DEP extracts geometrical information from an image with different kinds of attributes such as area, height, and volume. The spectral information, which is the RGB channels, have been added to DEP to build an input feature vector. This vector is incorporated in a straightforward deep learning classifier that does not contain complicated architecture with so many parameters.
The proposed approach has been performed on two VHR datasets: the Pleiades and the World-View 2 urban images. The obtained results have been compared with two of the most robust methods in the literature, i.e., support vector machine (SVM) and random forest (RF). We have also tested all mentioned classifiers through different types of the input vector, which are DMP + RGB and only RGB bands. To have a fair comparison, four types of criteria have been applied in this study, which are: overall accuracy (OA), Kappa coefficient (K), f-score (F), and total disagreement (T).
With respect to the experiments, it can be concluded that the newly proposed approach yields a more accurate final classification map than other methods. All four measures verified this claim. According to this research, the following points can be noted: (1) DEPs are capable of extracting contextual information so they can improve the classification accuracies due to their ability to preserve more correspondences in the image. (2) Our method includes different types of image attributes, like area, height, and volume, so it provides more promising results than other types of morphological profiles like MPs. (3) Incorporating spatial and spectral information in a robust, straightforward deep neural network makes the whole approach easy-to-use and implement. (4) The proposed approach is fully automatic and there is no need to set additional parameters.
In the future, it will be helpful to add an edge detection algorithm to the proposed approach to exclude edge pixels from the classification process. In this way, the final thematic map will be finer for practical use.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}