
Pre-Processing Filter Reflecting Human Visual Perception to Improve Saliency Detection Performance


Abstract
1. Introduction
- According to the visual perception model, the rapid initial analysis of visual features in the natural scene recognition process starts at low spatial frequencies following a “coarse-to-fine” sequence [30,31,32,33]. In other words, when recognizing a scene, it first accepts the overall characteristics of the whole scene, and then recognizes the detailed characteristics. Saliency detection is a technology that detects an area or object that a person will pay attention to when facing a scene. Therefore, it is necessary to pay attention to the overall features rather than the details of the scene in consideration of the human scene recognition process. In addition, the performance of the superpixel method used as a segmentation method in saliency detection is judged by the similarity of pixels constituting each superpixel and whether the edge in the actual image is reflected. In order to satisfy both requirements, it is necessary to remove minute differences in pixel values while maintaining important edges. Therefore, if an edge-preserving filter is applied to the original image before performing superpixel segmentation, the segmentation result and saliency detection performance can be expected to improve.
- Simultaneous contrast effect is a visual illusion that perceives the same gray color differently depending on the brightness of the background. Studies that approach this visual illusion as a low-level process have analyzed that simple interactions between adjacent neurons are caused by simple filters implementing lateral inhibition in the early stages of the visual system, where they are performed [34,35,36,37,38]. In addition, various methods have been proposed to predict the brightness perceived by humans under the influence of visual illusions [39,40,41,42,43]. The ground truth image used to compare the performance of the saliency detection method is the result of the perception of brightness as the subject observes the image and creates it manually. Nevertheless, because the input image uses the original pixel-specific data as it is, it is used without considering human visual characteristics. Therefore, a pre-processing method that considers the brightness perception of the input image is required.
2. Proposed Methodology
- Bilateral filter: Both the foreground and the background in the image do not exist as a single pixel, and have meaning by clusters of pixels of similar color and brightness in a certain area. The superpixel-based saliency detection method focuses on this characteristic and divides the image into superpixels, which are clusters of similar pixels, and detects salient objects by considering the correlation of each cluster. The bilateral filter removes the detail within the clusters that degrades the correlation between superpixels. It also preserves prominent edges within the image so that the boundaries between superpixels better reflect real edges.
- Perceptual brightness prediction filter: In general, saliency detection methods use original data values of input images. However, since humans perceive relative brightness, stimulus distortion occurs in the scene recognition process. Since saliency detection is a technique for detecting areas or objects that humans judge to be salient, such stimulus distortion must be reflected in the detection process. The perceived brightness prediction filter calculates a relative brightness value that is actually perceived with respect to the light intensity obtained by the human eye.
2.1. Bilateral Filtering for Superpixel
2.2. Brightness Perception
3. Experimental Results and Analysis
3.1. Datasets
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Verification Framework
3.5. Subjective Quality Comparison
3.6. Objective Performance Comparison
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HVS | Human visual system |
| ODOG | Oriented difference-of-Gaussians |
| LODOG | Locally normalized oriented difference-of-Gaussians |
| ROI | Regions of interest |
| SLIC | Simple linear iterative clustering |
| V1 | Primary visual cortex |
| LGN | Lateral geniculate nucleus |
| DoG | Differece-of-Gaussians |
| RMS | Root mean square |
| PR | Precision–recall |
| ROC | Receiver operating characteristic |
| AUC | Area under the curve |
| FPR | False positive rate |
References
- Li, J.; Gao, W. Visual Saliency Computation: A Machine Learning Perspective; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Shepherd, G.M. The Synaptic Organization of the Brain; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Koch, C. Biophysics of Computation: Information Processing in Single Neurons; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Raichle, M.E. The brain’s dark energy. Sci. Am. 2010, 302, 44–49. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-Based Visual Saliency; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Liu, H.; Jiang, S.; Huang, Q.; Xu, C.; Gao, W. Region-based visual attention analysis with its application in image browsing on small displays. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 24–29 September 2007; pp. 305–308. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Tian, Y.; Duan, L.; Huang, T. Estimating visual saliency through single image optimization. IEEE Signal Process. Lett. 2013, 20, 845–848. [Google Scholar]
- Einhäuser, W.; Kruse, W.; Hoffmann, K.P.; König, P. Differences of monkey and human overt attention under natural conditions. Vis. Res. 2006, 46, 1194–1209. [Google Scholar] [CrossRef] [PubMed]
- Bruce, N.; Tsotsos, J. Saliency Based on Information Maximization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2005; pp. 155–162. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical image saliency detection on extended CSSD. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 717–729. [Google Scholar] [CrossRef]
- Cheng, M.M.; Warrell, J.; Lin, W.Y.; Zheng, S.; Vineet, V.; Crook, N. Efficient Salient Region Detection with Soft Image Abstraction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1529–1536. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient Object Detection: A Survey. arXiv 2014, arXiv:1411.5878. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE TIP 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Hu, S.M. Salientshape: Group saliency in image collections. Vis. Comput. 2014, 30, 443–453. [Google Scholar] [CrossRef]
- Adelson, E.H. Perceptual organization and the judgment of brightness. Science 1993, 262, 2042–2044. [Google Scholar] [CrossRef]
- Adelson, E.H. Checkershadow Illusion. 1995. Available online: http://persci.mit.edu/gallery/checkershadow (accessed on 1 November 2021).
- Adelson, E.H. 24 Lightness Perception and Lightness Illusions; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Schwartz, B.L.; Krantz, J.H. Sensation and Perception; Sage Publications: Los Angeles, CA, USA, 2017. [Google Scholar]
- Purves, D.; Shimpi, A.; Lotto, R.B. An empirical explanation of the Cornsweet effect. J. Neurosci. 1999, 19, 8542–8551. [Google Scholar] [CrossRef] [PubMed]
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; Henry Holt and Co., Inc.: New York, NY, USA, 1982. [Google Scholar]
- Craddock, M.; Martinovic, J.; Müller, M.M. Task and spatial frequency modulations of object processing: An EEG study. PLoS ONE 2013, 8, e70293. [Google Scholar]
- Kauffmann, L.; Ramanoël, S.; Guyader, N.; Chauvin, A.; Peyrin, C. Spatial frequency processing in scene-selective cortical regions. NeuroImage 2015, 112, 86–95. [Google Scholar] [CrossRef]
- Dima, D.C.; Perry, G.; Singh, K.D. Spatial frequency supports the emergence of categorical representations in visual cortex during natural scene perception. NeuroImage 2018, 179, 102–116. [Google Scholar] [CrossRef]
- Hering, E. Outlines of a Theory of the Light Sense; Harvard University Press: Cambridge, MA, USA, 1964. [Google Scholar]
- Wallach, H. Brightness constancy and the nature of achromatic colors. J. Exp. Psychol. Gen. 1948, 38. [Google Scholar] [CrossRef] [PubMed]
- Wallach, H. The perception of neutral colors. Sci. Am. 1963, 208, 107–117. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Dakin, S.C.; Bex, P.J. Natural image statistics mediate brightness ‘filling in’. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2003, 270, 2341–2348. [Google Scholar] [CrossRef] [PubMed]
- Blakeslee, B.; McCourt, M.E. Similar mechanisms underlie simultaneous brightness contrast and grating induction. Vis. Res. 1997, 37, 2849–2869. [Google Scholar] [CrossRef]
- Blakeslee, B.; McCourt, M.E. A multiscale spatial filtering account of the White effect, simultaneous brightness contrast and grating induction. Vis. Res. 1999, 39, 4361–4377. [Google Scholar] [CrossRef]
- Robinson, A.E.; Hammon, P.S.; de Sa, V.R. Explaining brightness illusions using spatial filtering and local response normalization. Vis. Res. 2007, 47, 1631–1644. [Google Scholar] [CrossRef] [PubMed]
- Blakeslee, B.; Cope, D.; McCourt, M.E. The Oriented Difference of Gaussians (ODOG) model of brightness perception: Overview and executable Mathematica notebooks. Behav. Res. Methods 2016, 48, 306–312. [Google Scholar] [CrossRef] [PubMed][Green Version]
- McCourt, M.E.; Blakeslee, B.; Cope, D. The oriented difference-of-Gaussians model of brightness perception. Electron. Imaging 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Xie, Y.; Lu, H.; Yang, M.H. Bayesian saliency via low and mid level cues. IEEE Trans. Image Process. 2012, 22, 1689–1698. [Google Scholar]
- Jiang, B.; Zhang, L.; Lu, H.; Yang, C.; Yang, M.H. Saliency detection via absorbing markov chain. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1665–1672. [Google Scholar]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M.H. Saliency detection via dense and sparse reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Liu, Z.; Meur, L.; Luo, S. Superpixel-based saliency detection. In Proceedings of the 2013 14th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Paris, France, 3–5 July 2013; pp. 1–4. [Google Scholar]
- Kim, J.; Han, D.; Tai, Y.W.; Kim, J. Salient region detection via high-dimensional color transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 883–890. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Yan, Y.; Ren, J.; Sun, G.; Zhao, H.; Han, J.; Li, X.; Marshall, S.; Zhan, J. Unsupervised image saliency detection with Gestalt-laws guided optimization and visual attention based refinement. Pattern Recognit. 2018, 79, 65–78. [Google Scholar] [CrossRef]
- Foolad, S.; Maleki, A. Graph-based Visual Saliency Model using Background Color. J. AI Data Min. 2018, 6, 145–156. [Google Scholar]
- Deng, C.; Yang, X.; Nie, F.; Tao, D. Saliency detection via a multiple self-weighted graph-based manifold ranking. IEEE Trans. Multimed. 2019, 22, 885–896. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic Superpixels; Technical Report; EPFL: Écublens, VD, Switzerland, 2010. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Durand, F.; Dorsey, J. Fast bilateral filtering for the display of high-dynamic-range images. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 23–26 July 2002; pp. 257–266. [Google Scholar]
- Weiss, B. Fast median and bilateral filtering. In ACM SIGGRAPH 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 519–526. [Google Scholar]
- Paris, S.; Durand, F. A fast approximation of the bilateral filter using a signal processing approach. Int. J. Comput. Vis. 2009, 81, 24–52. [Google Scholar] [CrossRef]
- Blasdel, G. Cortical Activity: Differential Optical Imaging; Elsevier: Amsterdam, The Netherlands, 2001; pp. 2830–2837. [Google Scholar]
- Bruce, N.D.; Shi, X.; Simine, E.; Tsotsos, J.K. Visual representation in the determination of saliency. In Proceedings of the 2011 Canadian Conference on Computer and Robot Vision, St. John’s, NL, Canada, 25–27 May 2011; pp. 242–249. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
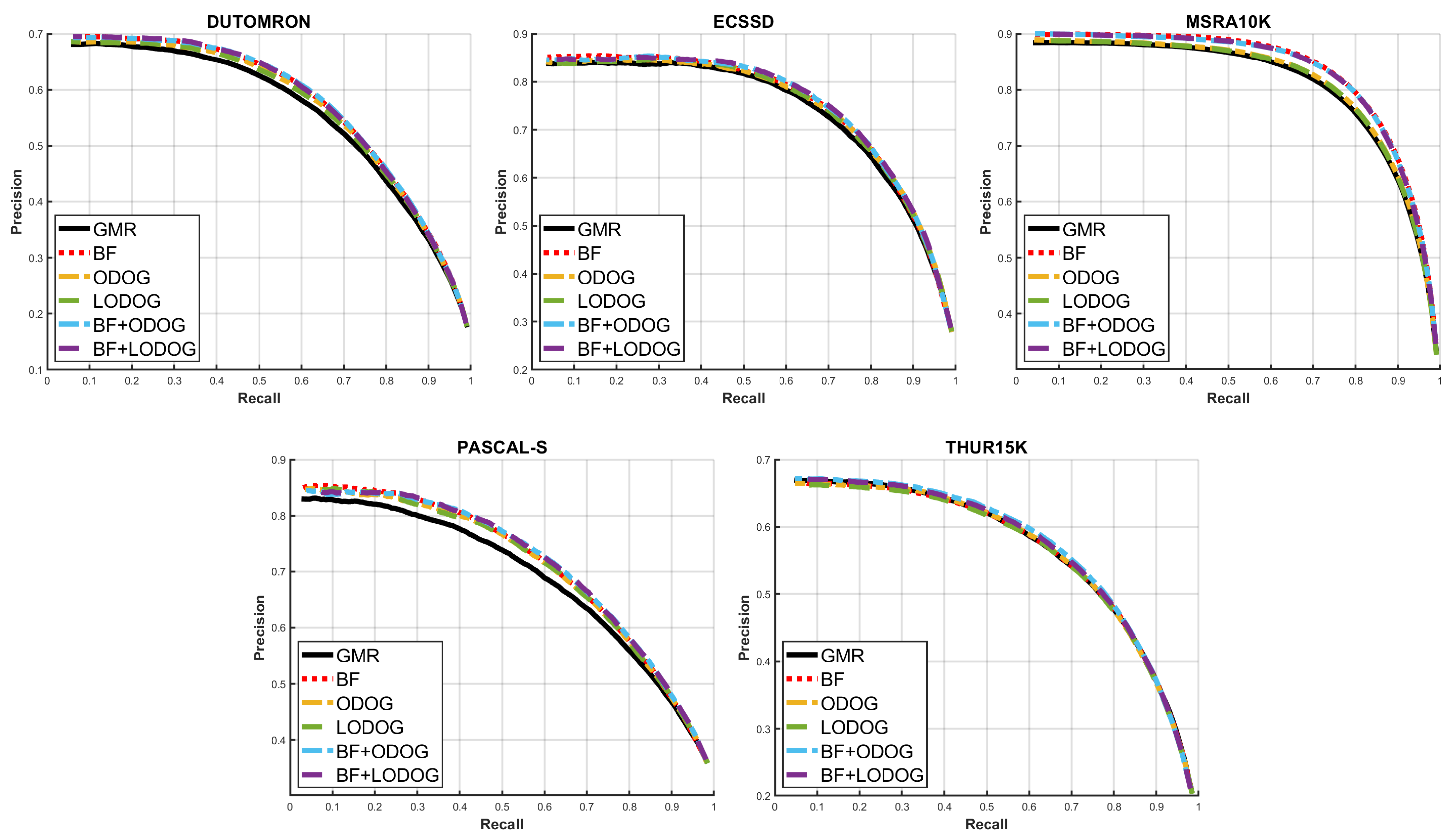{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Superpixels | Compactness |
|---|---|---|
| MC [45] | 250 | 20 |
| GMR [16] | 200 | 20 |
| DSR [46] | [50, 100, 150, 200, 250, 300, 350, 400] | [10, 10, 20, 20, 25, 25, 30, 30] |
| HDCT [48] | 500 pixels/superpixel | 20 |
| RBD [49] | 600 pixels/superpixel | 20 |
| GLGOV [50] | 200 pixels/superpixel | 20 |
| Name | Description |
|---|---|
| BF | Applying bilateral filter only |
| ODOG | Predicting perceived brightness using ODOG only |
| LODOG | Predicting perceived brightness using LODOG only |
| BF+ODOG | Applying a bilateral filter, and thereafter predicting by using ODOG |
| BF+LODOG | Applying a bilateral filter, and thereafter predicting by using LODOG |
| Method | Dataset | Original | BF | ODOG | LODOG | BF+ODOG | BF+LODOG |
|---|---|---|---|---|---|---|---|
| MC [45] | DUT-OMRON | 0.8876 | 0.8864 | 0.8886 | 0.8879 | 0.8876 | 0.8875 |
| ECSSD | 0.9247 | 0.9243 | 0.9252 | 0.9251 | 0.9269 | 0.9264 | |
| MSRA10K | 0.9552 | 0.9550 | 0.9550 | 0.9547 | 0.9551 | 0.9543 | |
| PASCAL-S | 0.8639 | 0.8622 | 0.8627 | 0.8641 | 0.8633 | 0.8630 | |
| THUR15K | 0.9138 | 0.9131 | 0.9137 | 0.9138 | 0.9136 | 0.9133 | |
| Avg. | 0.9090 | 0.9082 | 0.9091 | 0.9091 | 0.9093 | 0.9089 | |
| GMR [16] | DUT-OMRON | 0.8452 | 0.8506 | 0.8496 | 0.8480 | 0.8504 | 0.8507 |
| ECSSD | 0.9101 | 0.9139 | 0.9140 | 0.9143 | 0.9163 | 0.9168 | |
| MSRA10K | 0.9167 | 0.9268 | 0.9190 | 0.9185 | 0.9257 | 0.9260 | |
| PASCAL-S | 0.8237 | 0.8347 | 0.8329 | 0.8348 | 0.8370 | 0.8373 | |
| THUR15K | 0.8843 | 0.8835 | 0.8838 | 0.8836 | 0.8853 | 0.8854 | |
| Avg. | 0.8760 | 0.8819 | 0.8799 | 0.8799 | 0.8829 | 0.8832 | |
| DSR [46] | DUT-OMRON | 0.8907 | 0.8919 | 0.8932 | 0.8926 | 0.8904 | 0.8897 |
| ECSSD | 0.9120 | 0.9160 | 0.9118 | 0.9119 | 0.9128 | 0.9132 | |
| MSRA10K | 0.9526 | 0.9536 | 0.9533 | 0.9526 | 0.9515 | 0.9515 | |
| PASCAL-S | 0.8495 | 0.8527 | 0.8526 | 0.8527 | 0.8525 | 0.8520 | |
| THUR15K | 0.9006 | 0.9006 | 0.9009 | 0.8996 | 0.8991 | 0.8978 | |
| Avg. | 0.9011 | 0.9030 | 0.9024 | 0.9019 | 0.9013 | 0.9009 | |
| HDCT [48] | DUT-OMRON | 0.8996 | 0.8856 | 0.9005 | 0.9000 | 0.8900 | 0.8898 |
| ECSSD | 0.9150 | 0.8968 | 0.9167 | 0.9163 | 0.9028 | 0.9028 | |
| MSRA10K | 0.9641 | 0.9538 | 0.9640 | 0.9638 | 0.9567 | 0.9567 | |
| PASCAL-S | 0.8538 | 0.8404 | 0.8582 | 0.8582 | 0.8482 | 0.8475 | |
| THUR15K | 0.9049 | 0.8993 | 0.9052 | 0.9045 | 0.9014 | 0.9007 | |
| Avg. | 0.9075 | 0.8952 | 0.9089 | 0.9085 | 0.8998 | 0.8995 | |
| RBD [49] | DUT-OMRON | 0.8920 | 0.8921 | 0.8922 | 0.8921 | 0.8922 | 0.8924 |
| ECSSD | 0.9010 | 0.8992 | 0.8995 | 0.8999 | 0.8998 | 0.9011 | |
| MSRA10K | 0.9548 | 0.9545 | 0.9541 | 0.9542 | 0.9549 | 0.9549 | |
| PASCAL-S | 0.8526 | 0.8517 | 0.8543 | 0.8549 | 0.8535 | 0.8554 | |
| THUR15K | 0.8901 | 0.8895 | 0.8915 | 0.8914 | 0.8918 | 0.8920 | |
| Avg. | 0.8981 | 0.8974 | 0.8983 | 0.8985 | 0.8985 | 0.8992 | |
| GLGOV [50] | DUT-OMRON | 0.8932 | 0.8928 | 0.8934 | 0.8933 | 0.8934 | 0.8929 |
| ECSSD | 0.9145 | 0.9176 | 0.9150 | 0.9149 | 0.9181 | 0.9188 | |
| MSRA10K | 0.9665 | 0.9656 | 0.9659 | 0.9658 | 0.9658 | 0.9659 | |
| PASCAL-S | 0.8625 | 0.8643 | 0.8639 | 0.8641 | 0.8655 | 0.8661 | |
| THUR15K | 0.9063 | 0.9064 | 0.9064 | 0.9063 | 0.9073 | 0.9070 | |
| Avg. | 0.9086 | 0.9094 | 0.9089 | 0.9089 | 0.9100 | 0.9101 |
| Method | Dataset | Original | BF | ODOG | LODOG | BF+ODOG | BF+LODOG |
|---|---|---|---|---|---|---|---|
| MC [45] | DUT-OMRON | 0.5360 | 0.5381 | 0.5384 | 0.5382 | 0.5410 | 0.5413 |
| ECSSD | 0.6583 | 0.6583 | 0.6593 | 0.6595 | 0.6615 | 0.6617 | |
| MSRA10K | 0.7944 | 0.7938 | 0.7947 | 0.7952 | 0.7959 | 0.7953 | |
| PASCAL-S | 0.5540 | 0.5516 | 0.5567 | 0.5598 | 0.5538 | 0.5563 | |
| THUR15K | 0.5572 | 0.5583 | 0.5582 | 0.5578 | 0.5607 | 0.5598 | |
| Avg. | 0.6200 | 0.6201 | 0.6215 | 0.6221 | 0.6226 | 0.6229 | |
| GMR [16] | DUT-OMRON | 0.5042 | 0.5193 | 0.5145 | 0.5114 | 0.5204 | 0.5183 |
| ECSSD | 0.6389 | 0.6508 | 0.6494 | 0.6482 | 0.6514 | 0.6553 | |
| MSRA10K | 0.7082 | 0.7334 | 0.7136 | 0.7137 | 0.7309 | 0.7322 | |
| PASCAL-S | 0.5137 | 0.5305 | 0.5299 | 0.5306 | 0.5337 | 0.5353 | |
| THUR15K | 0.5312 | 0.5315 | 0.5296 | 0.5285 | 0.5355 | 0.5348 | |
| Avg. | 0.5792 | 0.5931 | 0.5874 | 0.5865 | 0.5944 | 0.5952 | |
| DSR [46] | DUT-OMRON | 0.5257 | 0.5331 | 0.5314 | 0.5299 | 0.5310 | 0.5299 |
| ECSSD | 0.6460 | 0.6559 | 0.6462 | 0.6457 | 0.6469 | 0.6479 | |
| MSRA10K | 0.7646 | 0.7758 | 0.7674 | 0.7668 | 0.7673 | 0.7681 | |
| PASCAL-S | 0.5497 | 0.5568 | 0.5519 | 0.5524 | 0.5541 | 0.5538 | |
| THUR15K | 0.5465 | 0.5482 | 0.5458 | 0.5443 | 0.5475 | 0.5459 | |
| Avg. | 0.6065 | 0.6140 | 0.6085 | 0.6078 | 0.6094 | 0.6091 | |
| HDCT [48] | DUT-OMRON | 0.5358 | 0.5172 | 0.5342 | 0.5340 | 0.5226 | 0.5223 |
| ECSSD | 0.6487 | 0.6162 | 0.6508 | 0.6507 | 0.6269 | 0.6256 | |
| MSRA10K | 0.7916 | 0.7689 | 0.7908 | 0.7900 | 0.7768 | 0.7761 | |
| PASCAL-S | 0.5418 | 0.5178 | 0.5510 | 0.5499 | 0.5296 | 0.5290 | |
| THUR15K | 0.5567 | 0.5505 | 0.5560 | 0.5552 | 0.5522 | 0.5515 | |
| Avg. | 0.6149 | 0.5941 | 0.6166 | 0.6160 | 0.6016 | 0.6009 | |
| RBD [49] | DUT-OMRON | 0.5411 | 0.5436 | 0.5425 | 0.5418 | 0.5448 | 0.5440 |
| ECSSD | 0.6503 | 0.6529 | 0.6493 | 0.6499 | 0.6546 | 0.6544 | |
| MSRA10K | 0.8073 | 0.8078 | 0.8069 | 0.8066 | 0.8081 | 0.8083 | |
| PASCAL-S | 0.5768 | 0.5761 | 0.5819 | 0.5808 | 0.5803 | 0.5809 | |
| THUR15K | 0.5424 | 0.5441 | 0.5454 | 0.5440 | 0.5489 | 0.5476 | |
| Avg. | 0.6236 | 0.6249 | 0.6252 | 0.6246 | 0.6273 | 0.6270 | |
| GLGOV [50] | DUT-OMRON | 0.5445 | 0.5470 | 0.5443 | 0.5432 | 0.5460 | 0.5460 |
| ECSSD | 0.6917 | 0.6935 | 0.6919 | 0.6910 | 0.6971 | 0.6961 | |
| MSRA10K | 0.8381 | 0.8369 | 0.8386 | 0.8379 | 0.8379 | 0.8380 | |
| PASCAL-S | 0.6031 | 0.6021 | 0.6057 | 0.6065 | 0.6061 | 0.6066 | |
| THUR15K | 0.5732 | 0.5786 | 0.5743 | 0.5730 | 0.5795 | 0.5785 | |
| Avg. | 0.6501 | 0.6516 | 0.6510 | 0.6503 | 0.6533 | 0.6530 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Wee, S.; Jeong, J. Pre-Processing Filter Reflecting Human Visual Perception to Improve Saliency Detection Performance. Electronics 2021, 10, 2892. https://doi.org/10.3390/electronics10232892
Lee K, Wee S, Jeong J. Pre-Processing Filter Reflecting Human Visual Perception to Improve Saliency Detection Performance. Electronics. 2021; 10(23):2892. https://doi.org/10.3390/electronics10232892
Chicago/Turabian StyleLee, Kyungjun, Seungwoo Wee, and Jechang Jeong. 2021. "Pre-Processing Filter Reflecting Human Visual Perception to Improve Saliency Detection Performance" Electronics 10, no. 23: 2892. https://doi.org/10.3390/electronics10232892
APA StyleLee, K., Wee, S., & Jeong, J. (2021). Pre-Processing Filter Reflecting Human Visual Perception to Improve Saliency Detection Performance. Electronics, 10(23), 2892. https://doi.org/10.3390/electronics10232892