
MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments

 ,
,  ,
,  and
and
Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contributions
- Develop an open-source (https://github.com/dimikout3/MarsExplorer (accessed on 4 November 2021)), openai-gym compatible environment tailored explicitly to the problem of exploration of unknown areas with an emphasis on generalization abilities.
- Translate the original robotics exploration problem to an RL setup, paving the way to apply off-the-shelf algorithms.
- Perform preliminary study on various state-of-the-art RL algorithms, including A3C, PPO, Rainbow, and SAC, utilizing the human-level performance as a baseline.
- Challenge the generalization abilities of the best performing PPO-based agent by evaluating multi-dimensional difficulty settings.
- Present side-by-side comparison with frontier-based exploration strategies.
1.4. Paper Outline
2. Environment
2.1. Setup
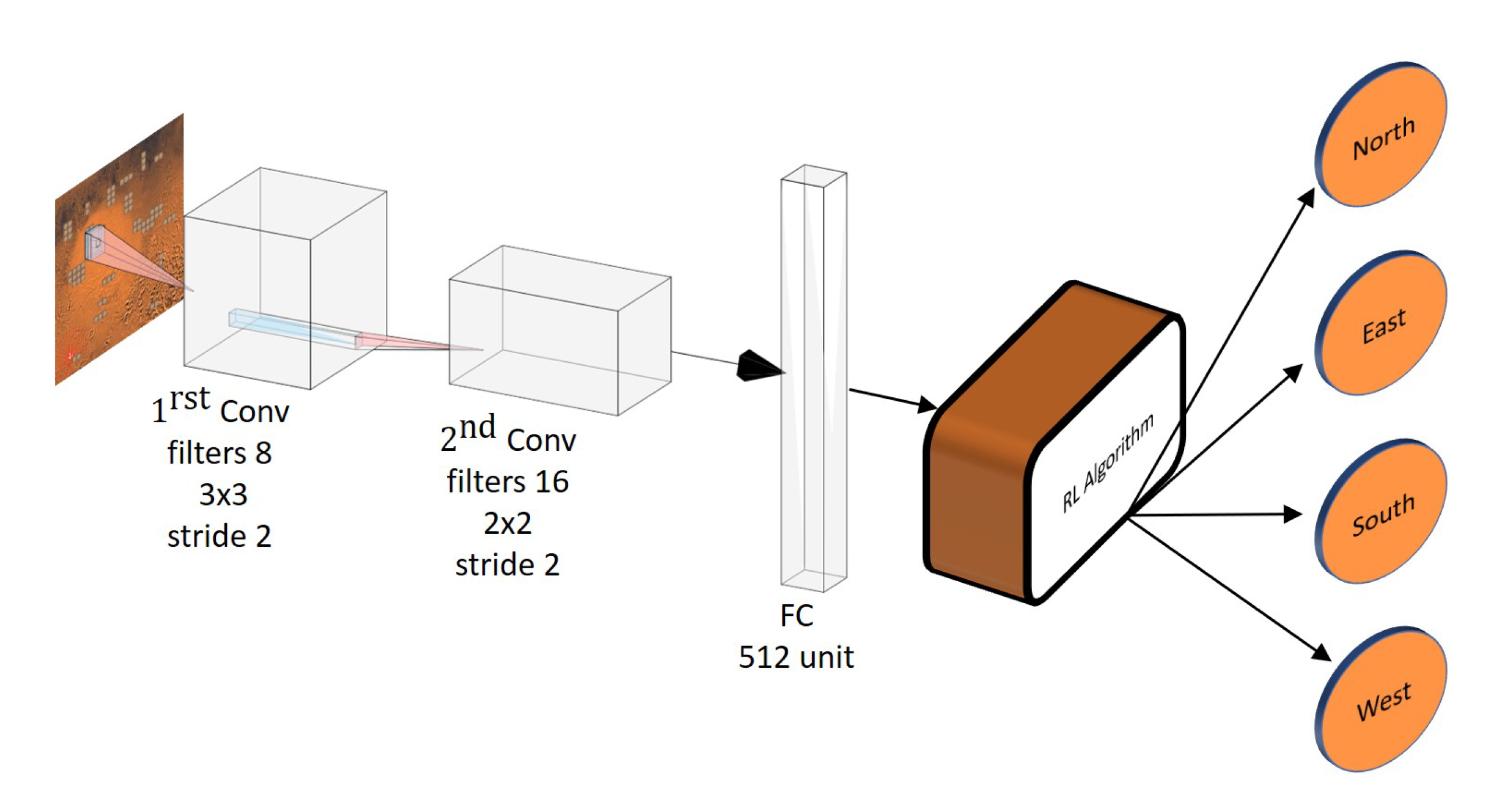
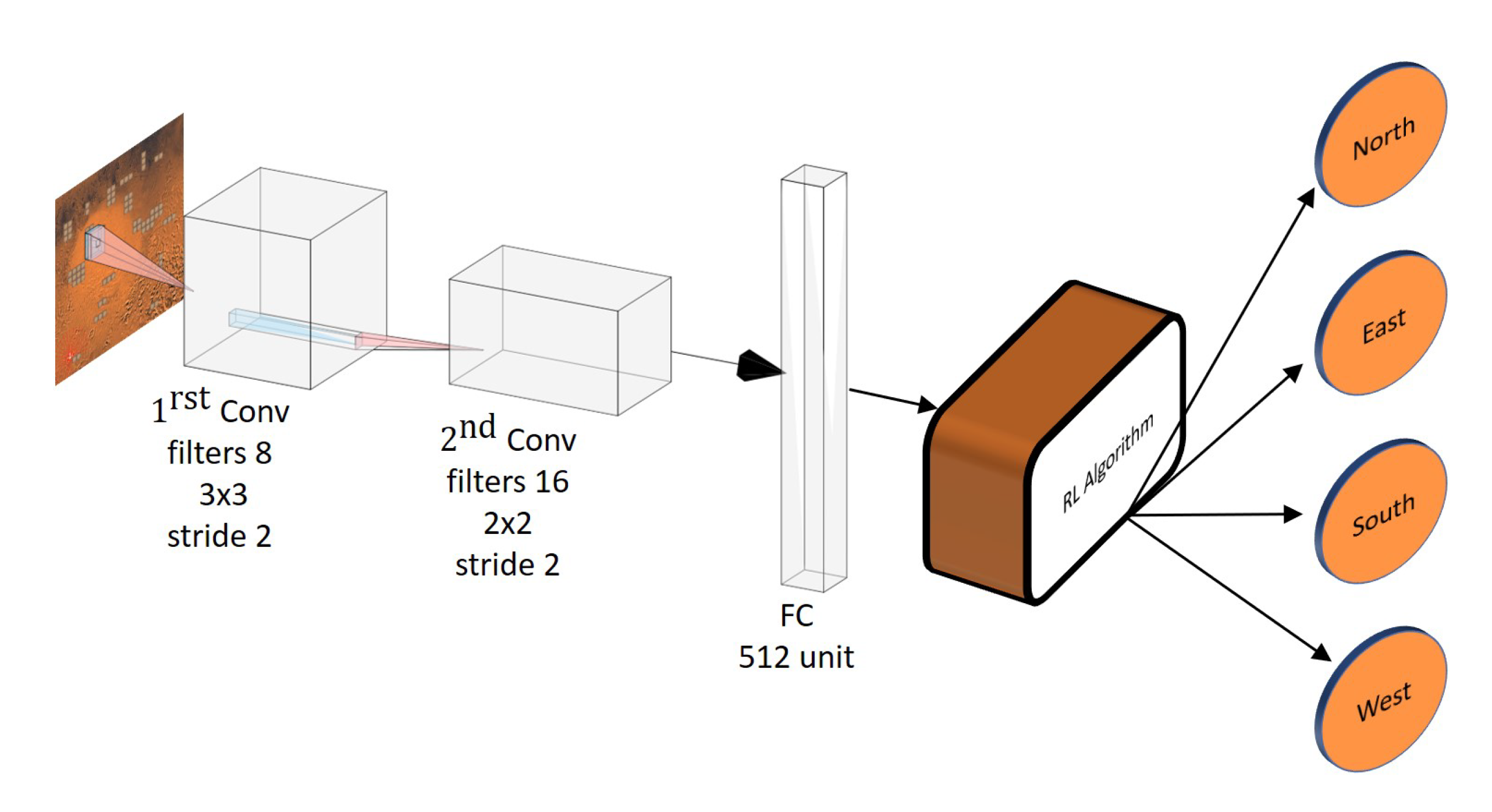
2.2. Action Space
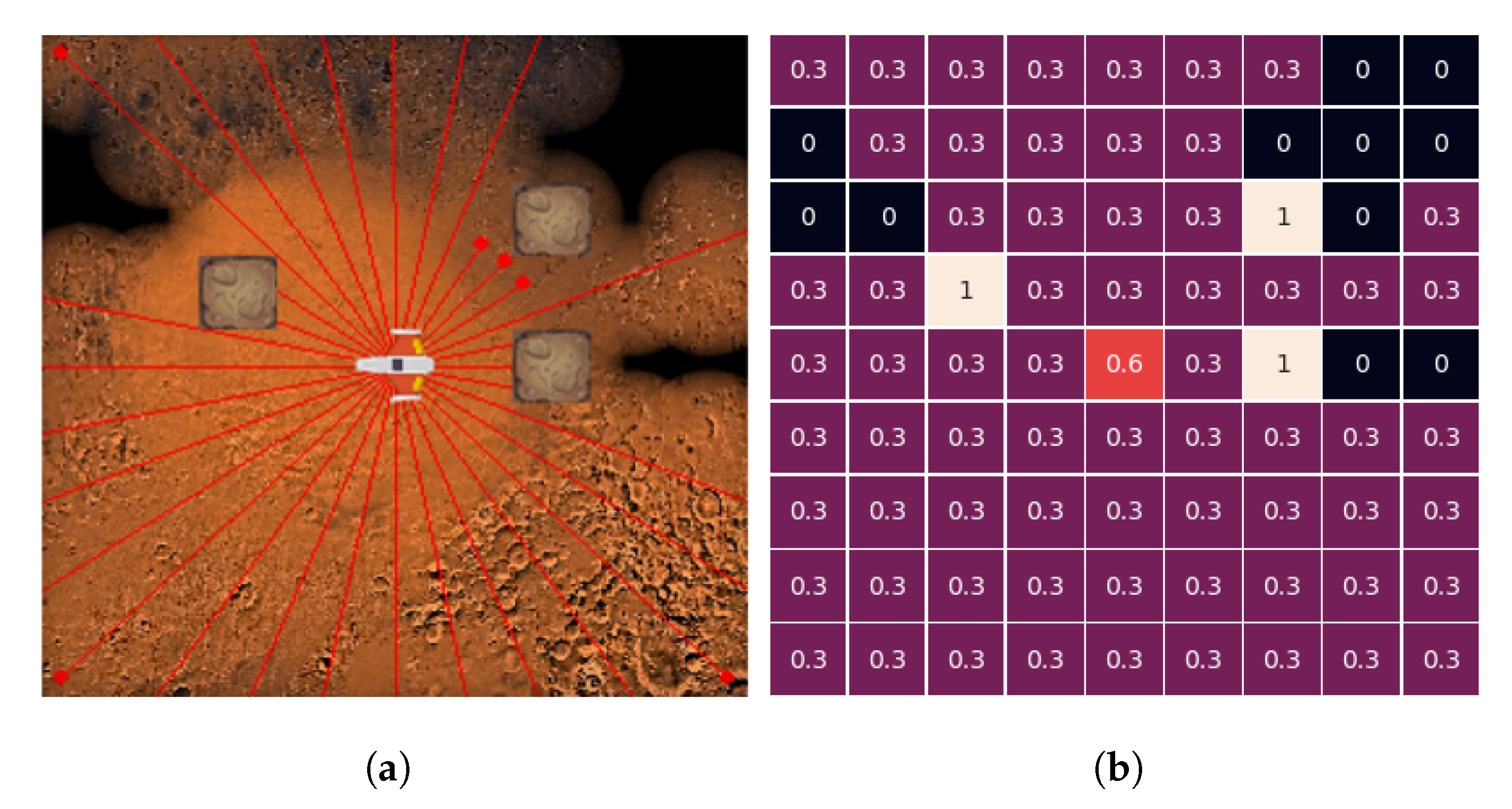
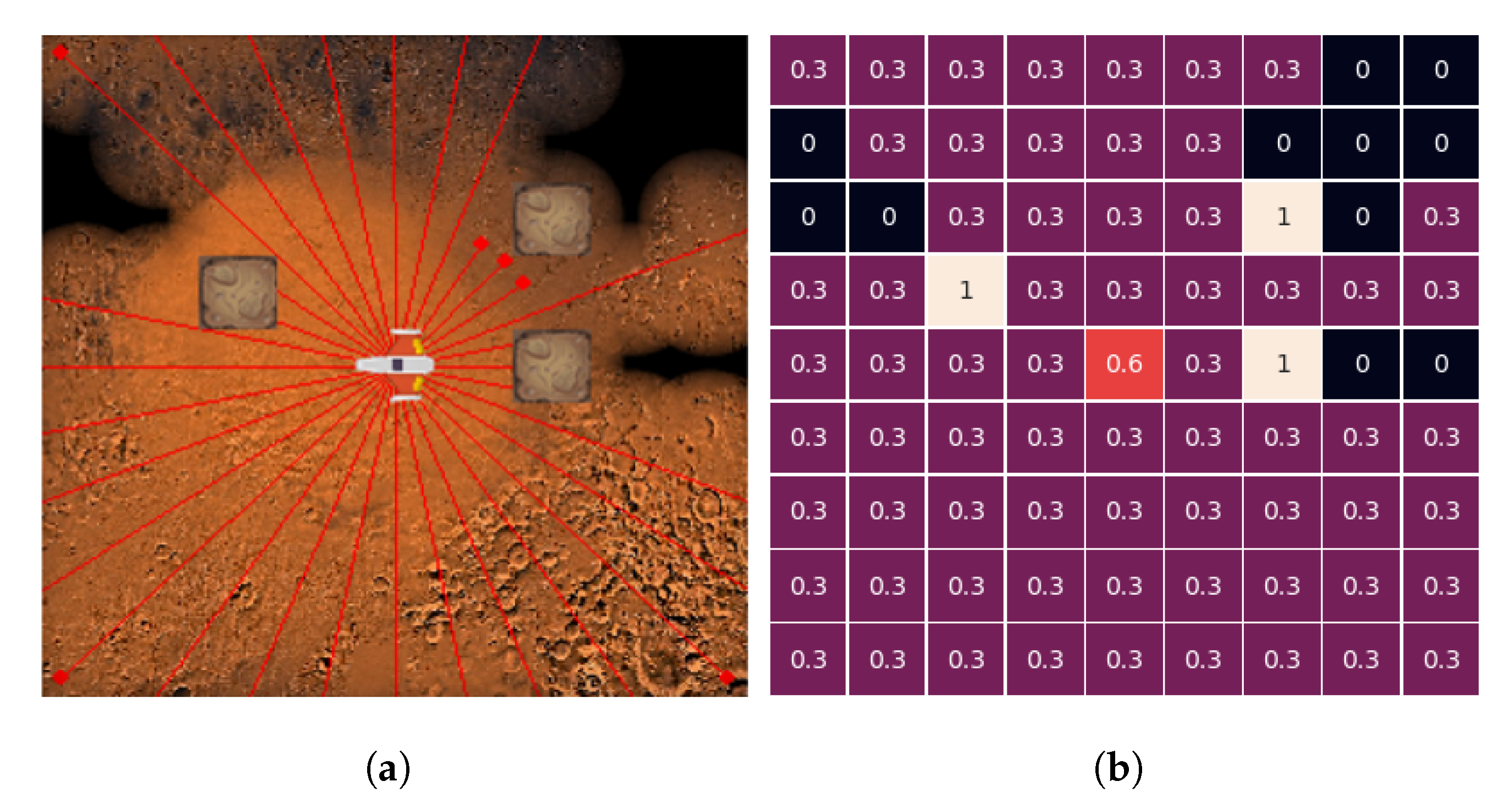
2.3. State Space
2.4. Reward Function
2.5. Key RL Attributes
3. Performance Evaluation
3.1. Implementation Details
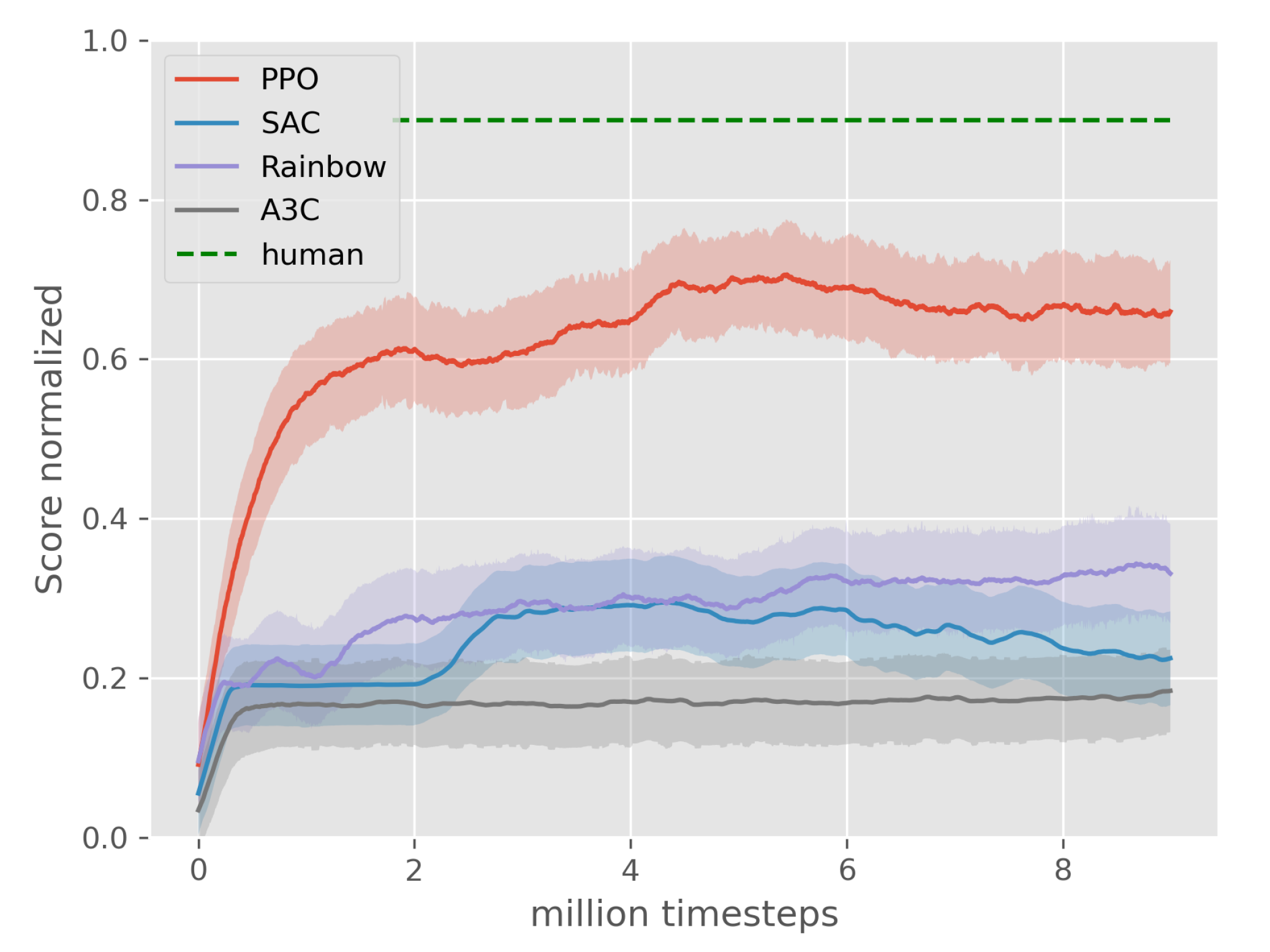
3.2. State-of-the-Art RL Algorithms Comparison
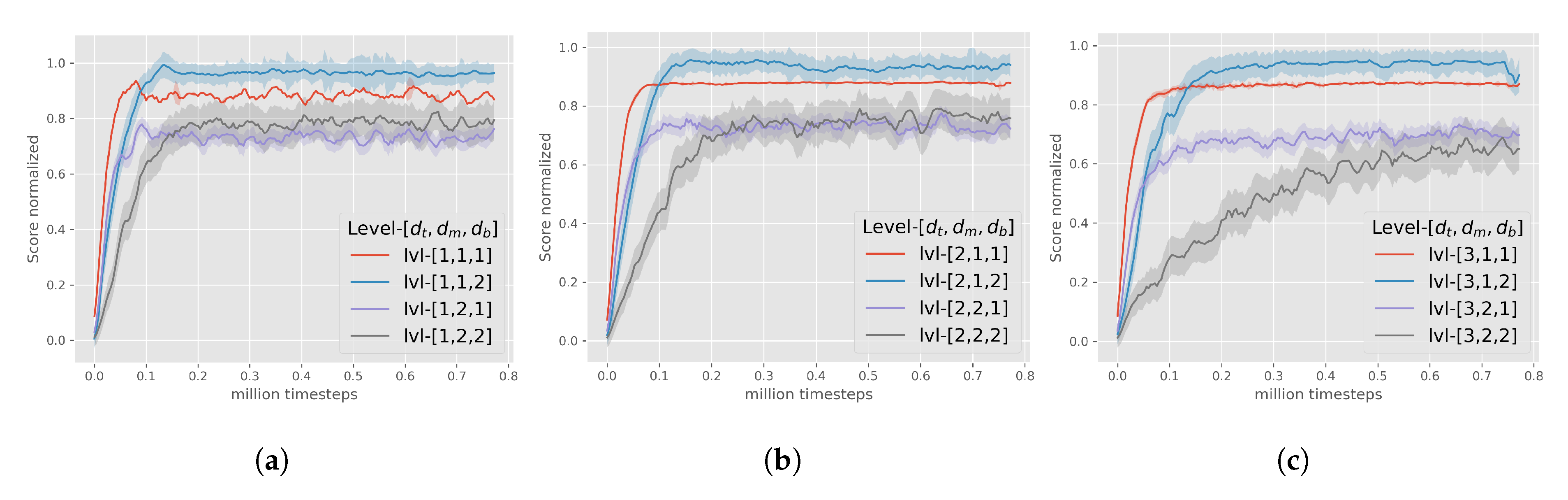
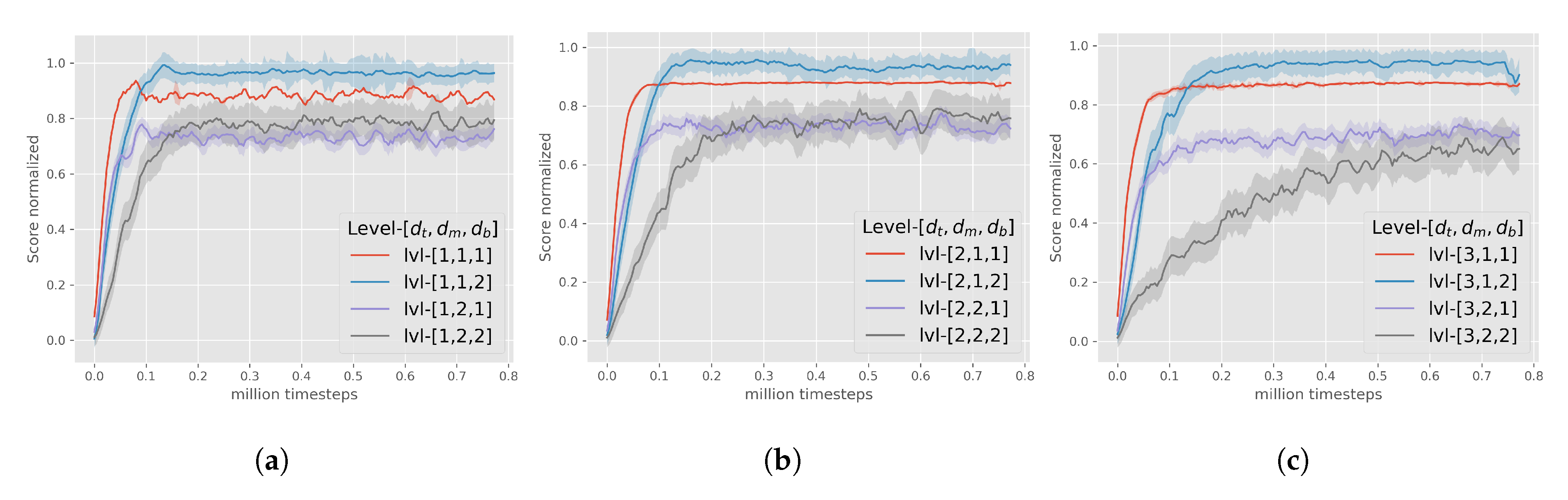
3.3. Multi-Dimensional Difficulty
- denotes the topology stochasticity, which defines the obstacles’ placement on the field. The fundamental positions of the obstacles are equally arranged in a 3 columns–3 rows format. The radius of deviation around these fundamental positions is controlled by . As the value of increases, the obstacles’ topology has a more unstructured formation. takes values from discrete set.
- denotes the morphology stochasticity, which defines the obstacles’ shape on the field. controls the area that might be occupied from each obstacle. The bigger the value of , the larger the compound areas of obstacles that might appear on the MarsExplorer terrain. takes values from discrete set.
- denotes the bonus rewards, that are assigned for the completion () and failure () of the mission (8). For this factor only two values are allowed , that correspond to cases of providing and not-providing the bonus rewards, respectively.
3.4. Learned Policy Evaluation
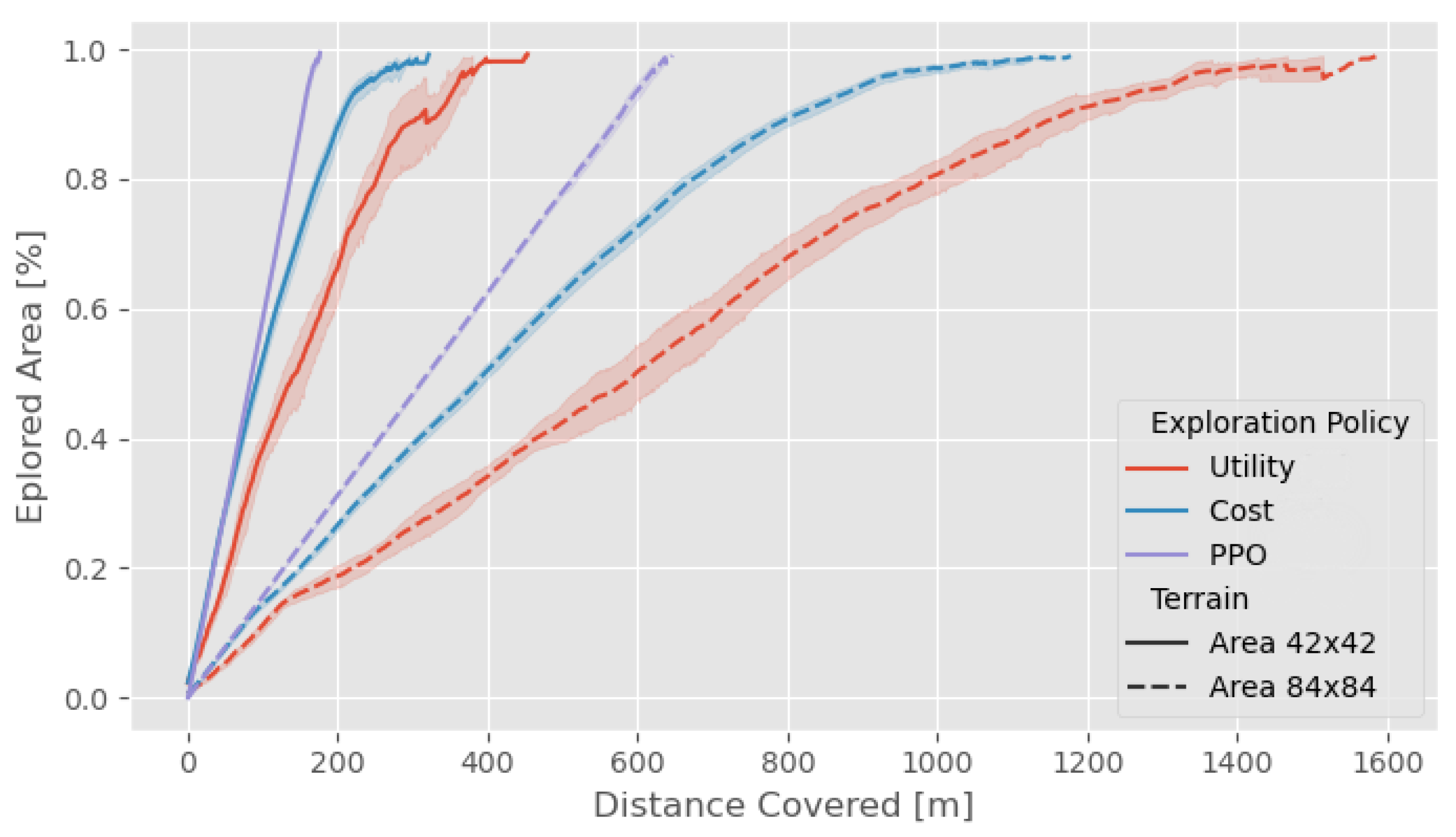
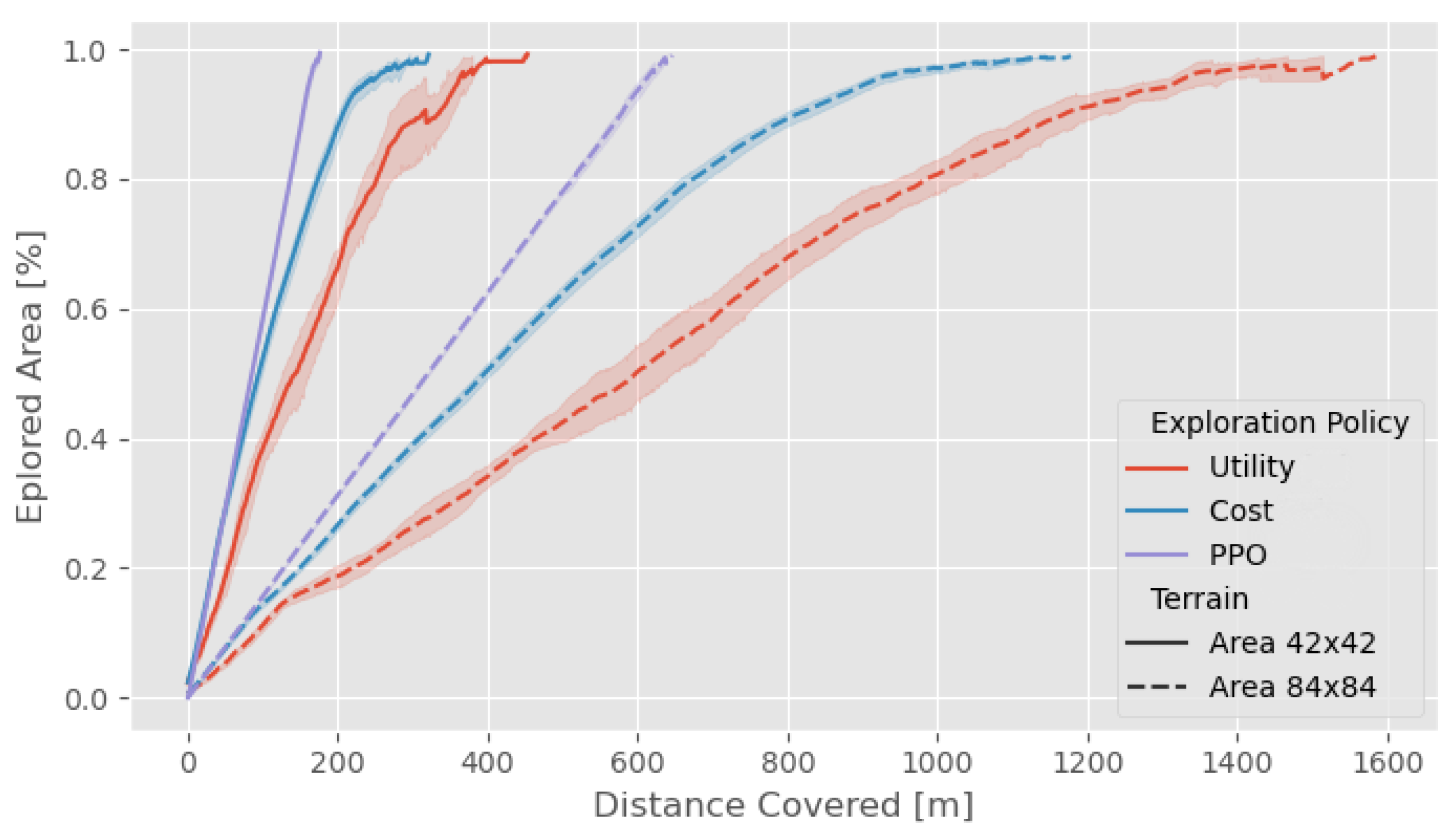
3.5. Comparison with Frontier-Based Methodologies for Varying Terrain Sizes
- Cost: the next action is chosen based on the distance from the nearest frontier cell.
- Utility: the decision-making is governed by frequently updated information potential field.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Comments |
|---|---|---|
| 0.95 | Discount factor of the MDP | |
| Learning rate | ||
| Critic | True | Used a critic as a baseline |
| GAE l | 0.95 | GAE (lambda) parameter |
| KL coeff | 0.2 | Initial coefficient for KL divergence |
| Clip | 0.3 | PPO clip parameter |
| Parameter | Value | Comments |
|---|---|---|
| 0.95 | Discount factor of the MDP | |
| Learning rate | ||
| Noisy Net | True | Used a noisy network |
| Noisy | 0.5 | initial value of noisy nets |
| Dueling Net | True | Used dueling DQN |
| Double dueling | True | Used double DQN |
| -greedy | [1.0, 0.02] | Epsilon greedy for exploration. |
| Buffer size | 50,000 | Size of the replay buffer |
| Priorited Replay | True | Prioritized replay buffer used |
| Parameter | Value | Comments |
|---|---|---|
| 0.95 | Discount factor of the MDP | |
| Learning rate | ||
| Twin Q | True | Use two Q-networks |
| Q hidden | [256, 256] | Hidden layer activation |
| Policy hidden | [256, 256] | Hidden layer activation |
| Buffer size | 1e6 | Size of the replay buffer |
| Priorited Replay | True | Prioritized replay buffer used |
| Parameter | Value | Comments |
|---|---|---|
| 0.95 | Discount factor of the MDP | |
| Learning rate | ||
| Critic | True | Used a critic as a baseline |
| GAE | True | General Advantage Estimation |
| GAE l | 0.99 | GAE(lambda) parameter |
| Value loss | 0.5 | Value Function Loss coefficient |
| Entropy coef | 0.01 | Entropy coefficient |
References
- Witze, A.; Mallapaty, S.; Gibney, E. All Aboard to Mars. 2020. Available online: https://www.nature.com/articles/d41586-020-01861-0 (accessed on 4 November 2021).
- Smith, M.; Craig, D.; Herrmann, N.; Mahoney, E.; Krezel, J.; McIntyre, N.; Goodliff, K. The Artemis Program: An Overview of NASA’s Activities to Return Humans to the Moon. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–10. [Google Scholar]
- Shrestha, R.; Tian, F.P.; Feng, W.; Tan, P.; Vaughan, R. Learned map prediction for enhanced mobile robot exploration. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1197–1204. [Google Scholar]
- Kapoutsis, A.C.; Chatzichristofis, S.A.; Doitsidis, L.; de Sousa, J.B.; Pinto, J.; Braga, J.; Kosmatopoulos, E.B. Real-time adaptive multi-robot exploration with application to underwater map construction. Auton. Robot. 2016, 40, 987–1015. [Google Scholar] [CrossRef]
- Batinovic, A.; Petrovic, T.; Ivanovic, A.; Petric, F.; Bogdan, S. A Multi-Resolution Frontier-Based Planner for Autonomous 3D Exploration. IEEE Robot. Autom. Lett. 2021, 6, 4528–4535. [Google Scholar] [CrossRef]
- Renzaglia, A.; Dibangoye, J.; Le Doze, V.; Simonin, O. Combining Stochastic Optimization and Frontiers for Aerial Multi-Robot Exploration of 3D Terrains. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4121–4126. [Google Scholar]
- Basilico, N.; Amigoni, F. Exploration strategies based on multi-criteria decision making for searching environments in rescue operations. Auton. Robot. 2011, 31, 401–417. [Google Scholar] [CrossRef]
- Palacios-Gasós, J.M.; Montijano, E.; Sagüés, C.; Llorente, S. Distributed coverage estimation and control for multirobot persistent tasks. IEEE Trans. Robot. 2016, 32, 1444–1460. [Google Scholar] [CrossRef]
- Koutras, D.I.; Kapoutsis, A.C.; Kosmatopoulos, E.B. Autonomous and cooperative design of the monitor positions for a team of UAVs to maximize the quantity and quality of detected objects. IEEE Robot. Autom. Lett. 2020, 5, 4986–4993. [Google Scholar] [CrossRef]
- Popov, I.; Heess, N.; Lillicrap, T.; Hafner, R.; Barth-Maron, G.; Vecerik, M.; Lampe, T.; Tassa, Y.; Erez, T.; Riedmiller, M. Data-efficient deep reinforcement learning for dexterous manipulation. arXiv 2017, arXiv:1704.03073. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Baker, B.; Kanitscheider, I.; Markov, T.; Wu, Y.; Powell, G.; McGrew, B.; Mordatch, I. Emergent tool use from multi-agent autocurricula. arXiv 2019, arXiv:1909.07528. [Google Scholar]
- Zhu, H.; Yu, J.; Gupta, A.; Shah, D.; Hartikainen, K.; Singh, A.; Kumar, V.; Levine, S. The Ingredients of Real World Robotic Reinforcement Learning. arXiv 2020, arXiv:2004.12570. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Dhariwal, P.; Hesse, C.; Klimov, O.; Nichol, A.; Plappert, M.; Radford, A.; Schulman, J.; Sidor, S.; Wu, Y.; Zhokhov, P. OpenAI Baselines. 2017. Available online: https://github.com/openai/baselines (accessed on 4 November 2021).
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Goldberg, K.; Gonzalez, J.; Jordan, M.; Stoica, I. RLlib: Abstractions for distributed reinforcement learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3053–3062. [Google Scholar]
- Lei, X.; Zhang, Z.; Dong, P. Dynamic path planning of unknown environment based on deep reinforcement learning. J. Robot. 2018, 2018, 5781591. [Google Scholar] [CrossRef]
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Zhang, D.; Manfredi, L. Path planning for active SLAM based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, 13, 263–272. [Google Scholar] [CrossRef]
- Zhang, K.; Niroui, F.; Ficocelli, M.; Nejat, G. Robot navigation of environments with unknown rough terrain using deep reinforcement learning. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–7. [Google Scholar]
- Niroui, F.; Zhang, K.; Kashino, Z.; Nejat, G. Deep reinforcement learning robot for search and rescue applications: Exploration in unknown cluttered environments. IEEE Robot. Autom. Lett. 2019, 4, 610–617. [Google Scholar] [CrossRef]
- Luis, S.Y.; Reina, D.G.; Marín, S.L.T. A Multiagent Deep Reinforcement Learning Approach for Path Planning in Autonomous Surface Vehicles: The YpacaraC-Lake Patrolling Case. IEEE Access 2021, 9, 17084–17099. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2018; Volume 32. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Zamora, I.; Lopez, N.G.; Vilches, V.M.; Cordero, A.H. Extending the OpenAI Gym for robotics: A toolkit for reinforcement learning using ROS and Gazebo. arXiv 2016, arXiv:1608.05742. [Google Scholar]
- Lopez, N.G.; Nuin, Y.L.E.; Moral, E.B.; Juan, L.U.S.; Rueda, A.S.; Vilches, V.M.; Kojcev, R. gym-gazebo2, a toolkit for reinforcement learning using ROS 2 and Gazebo. arXiv 2019, arXiv:1903.06278. [Google Scholar]
- Kapoutsis, A.C.; Chatzichristofis, S.A.; Kosmatopoulos, E.B. A distributed, plug-n-play algorithm for multi-robot applications with a priori non-computable objective functions. Int. J. Robot. Res. 2019, 38, 813–832. [Google Scholar] [CrossRef]
- Burgard, W.; Moors, M.; Fox, D.; Simmons, R.; Thrun, S. Collaborative multi-robot exploration. In Proceedings of the Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 476–481. [Google Scholar]
- Gray, L.; New, A. A mathematician looks at Wolfram’s new kind of science. Not. Am. Math. Soc. 2003, 50, 200–211. [Google Scholar]
- Cobbe, K.; Hesse, C.; Hilton, J.; Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2048–2056. [Google Scholar]
- Yin, H.; Chen, J.; Pan, S.J.; Tschiatschek, S. Sequential Generative Exploration Model for Partially Observable Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 10700–10708. [Google Scholar]
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Gonzalez, J.; Goldberg, K.; Stoica, I. Ray rllib: A composable and scalable reinforcement learning library. arXiv 2017, arXiv:1712.09381, 85. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Kapoutsis, A.C.; Chatzichristofis, S.A.; Kosmatopoulos, E.B. DARP: Divide areas algorithm for optimal multi-robot coverage path planning. J. Intell. Robot. Syst. 2017, 86, 663–680. [Google Scholar] [CrossRef] [Green Version]
- Sadat, S.A.; Wawerla, J.; Vaughan, R. Fractal trajectories for online non-uniform aerial coverage. In Proceedings of the 2015 IEEE international conference on robotics and automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2971–2976. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koutras, D.I.; Kapoutsis, A.C.; Amanatiadis, A.A.; Kosmatopoulos, E.B. MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments. Electronics 2021, 10, 2751. https://doi.org/10.3390/electronics10222751
Koutras DI, Kapoutsis AC, Amanatiadis AA, Kosmatopoulos EB. MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments. Electronics. 2021; 10(22):2751. https://doi.org/10.3390/electronics10222751
Chicago/Turabian StyleKoutras, Dimitrios I., Athanasios C. Kapoutsis, Angelos A. Amanatiadis, and Elias B. Kosmatopoulos. 2021. "MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments" Electronics 10, no. 22: 2751. https://doi.org/10.3390/electronics10222751
APA StyleKoutras, D. I., Kapoutsis, A. C., Amanatiadis, A. A., & Kosmatopoulos, E. B. (2021). MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments. Electronics, 10(22), 2751. https://doi.org/10.3390/electronics10222751