1. Introduction
Sentiment analysis (SA) [
1,
2,
3,
4] is one of the most critical tasks in the field of natural language processing (NLP). It is the process of analyzing and summarizing users’ opinions and emotions as expressed in a sentence. In simple words, in SA, we determine whether the underlying sentiment in a piece of text is positive, negative, or neutral. This has gained attention in academia and business, particularly when identifying customer satisfaction with products and services, offering valuable feedback on websites such as Flipkart, Amazon, etc., through online reviews.
In the last decade, the popularity of e-commerce websites among consumers has increased tremendously. Users are sharing their experiences online regarding the products and services that they have used. There is a steep increase in the number of online reviews that are being posted daily. These opinions and feedback act as a measure for the goodness of the products and services. Reading all these reviews is time-consuming and analyzing them is practically challenging. Therefore, there is a need for automation to effectively maintain and analyze these reviews. Reviews are used for decision-making by the organizations as well as the consumers. Consumers decide or confirm which products to buy based on the reviews, while organizations tend to improve or develop new products, plan marketing strategies and campaigns, etc.
Early studies in this field were centered only on detecting the overall polarity of a sentence, irrespective of the entities to which they referred (e.g., mobiles) and their aspects (camera, display, etc.). The basic assumption behind this task is that there is a single overall polarity for the whole review sentence. The sentence, however, can include various aspects, e.g., “This mobile comes with 6.53-inch AMOLED display which is pretty good but the 16MP camera disappoints”. The polarity of the aspect ‘display’ is Positive, while the polarity of the aspect ‘camera’ is Negative. The goal of Aspect-Based Sentiment Analysis (ABSA) is to consider fine-grained polarity against a particular aspect. This task is especially useful because a consumer may analyze the aggregated sentiment for each aspect of a given product and obtain a more in-depth understanding of its quality.
The ABSA task is analogous to learning the Aspect Category Detection subtask and the Aspect Category Polarity subtask at the same time.
Aspect Category Detection: This is a multi-label classification problem. In this task, we are provided a set of sentences and a pre-defined set of aspect categories, e.g., (FOOD, PRICE, etc.). The objective is to detect all the aspect categories that are discussed in each sentence. Typically, the aspect terms do not appear in the sentences as words. For instance, in the example, “Delicious but expensive”, the adjectives, ‘delicious’ and ‘expensive’ implies the presence of aspect categories FOOD and PRICE in the sentence.
Aspect Category Polarity: It is a multi-class classification problem. In this task, given the aspect categories for each review sentence, the objective is to decide the sentiment polarity (positive, negative, neutral, or conflict) of each aspect category present in the sentence. The ‘conflict’ polarity is assigned to an aspect when it has both the ‘positive’ and the ‘negative’ sentiments associated with it. For example, in the sentence, “The pizza was good but the burger was tasteless”, the aspect Food has the conflict polarity.
An example of the ABSA task is presented in
Table 1. There are two aspects present in the sentence: one is
Food, and the other is
Service. The polarity of aspect
Food is
negative, while the polarity of
Service is
positive.
Recently, pre-trained language models, such as ELMo [
5], OpenAI GPT [
6], and BERT [
7], have demonstrated their efficacy in solving many natural language-processing problems. BERT has performed exceptionally well on Question Answering (QA), and Natural Language Inference (NLI) tasks [
7], both of which are sentence-pair classification tasks. However, direct application of the BERT model does not result in significant improvements in the ABSA task. The authors in [
8] assumed that this was due to the unsuitable application of the BERT model.
Before the introduction of Transformers [
9] in 2017, language models mainly used RNNs and CNNs to perform NLP tasks. The Transformer is a significant improvement as it doesn’t need text to be processed in any predetermined order. Also, Transformers allow training on a massive amount of data in very little time. They are the basis for models like BERT.
Word embedding models like GloVe [
10], and word2vec [
11] map each word to a vector that tries to represent some aspects of the word’s meaning. Word embeddings are useful for many NLP tasks, but some limitations prevent them from being used. There is a limitation to what these word models can capture, as they are not trained on deep modeling tasks, so they cannot effectively represent the negation of words and word combinations. Another significant flaw is that these models ignore the context of the words. For example, the word
‘bank’ has different meanings in the sentences
“He opened a new account in the bank” and
“A dead body was found on the bank of the river”. However, embedding methods will assign the same vector for the word
‘bank’ in both sentences, so a single vector is forced to capture both meanings.
The above drawbacks were motivated by context-based language models that train a neural network to assign a vector to one word, based on either the surrounding context or the entire sentence. For example, the sentence, “He opened a new account in the bank”, represents ‘account’ based on the word’s context. A unidirectional model represents ‘account’ based on “He opened a new” but not “in the bank”. However, a bidirectional contextual model represents ‘account’ using the context—“He opened a new...in the bank”.
OpenAI GPT, ELMo, and BERT are examples of transfer-learning-based models. OpenAI GPT and ELMo were previous state-of-the-art contextual pre-training methods. OpenAI GPT is unidirectional, based on a unidirectional Transformer. ELMo is shallowly bidirectional. Two LSTMs are trained independently: one is left-to-right, and the other is right-to-left. Then, the learned embeddings are concatenated to generate the features that are used in downstream tasks. Only BERT is deeply bidirectional. In BERT, representations are learned based on both left and right contexts. ELMo is a feature-based approach, while the other two are fine-tuning approaches.
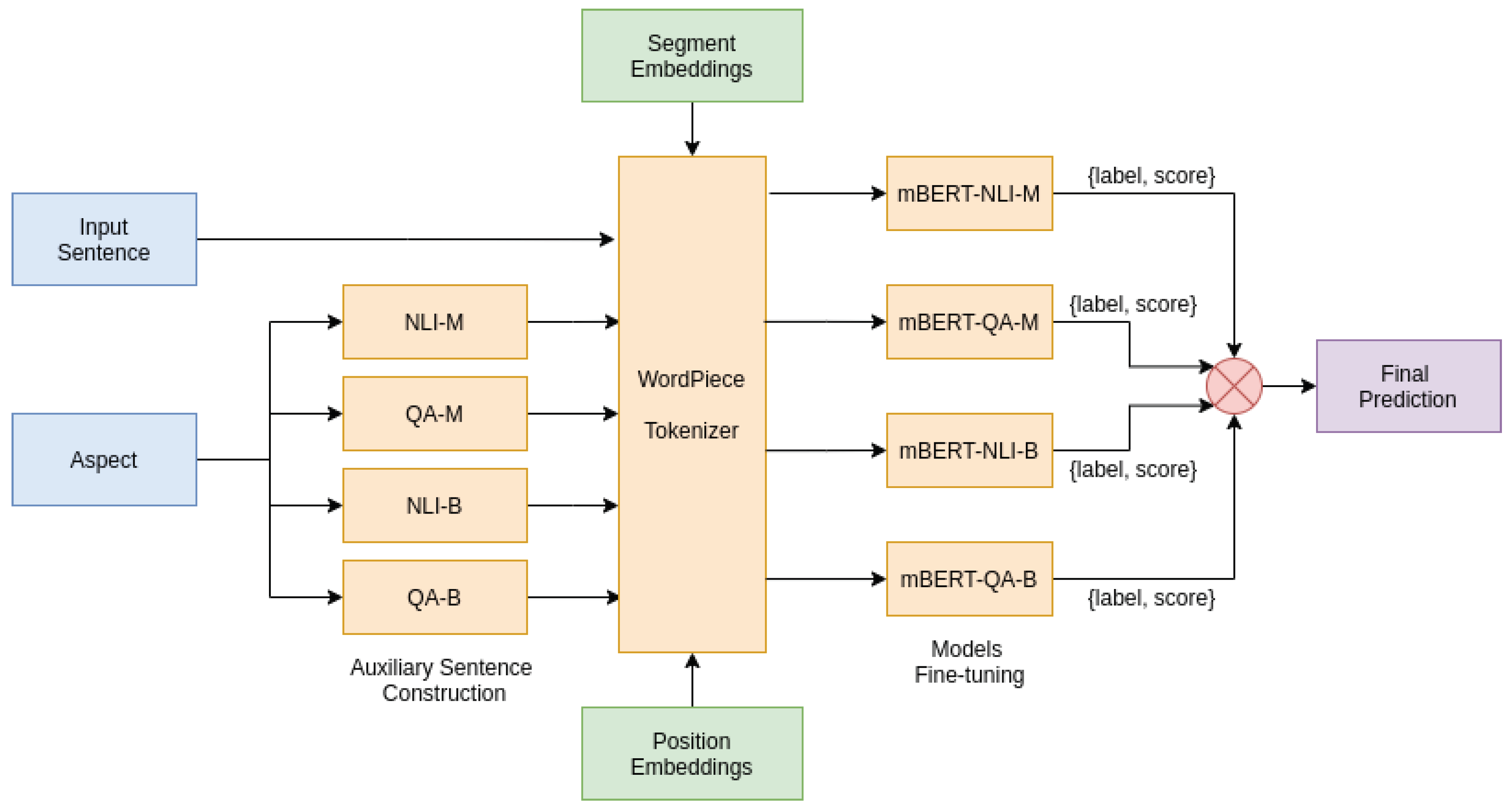
In this paper, we propose two ensemble models based on multilingual BERT, namely, mBERT-E-MV and mBERT-E-AS. As mBERT can take a single sentence or a pair of sentences as input, we transform ABSA task into a sentence-pair classification task by constructing an auxiliary sentence using aspect. Then, we fine-tune different pre-trained mBERT models for each auxiliary sentence construction method, based on the newly generated task. Finally, we ensemble the models using majority voting and average score for final prediction, and achieve state-of-the-art results on datasets belonging to different domains in the Hindi language.
The main contributions of the paper are as follows:
To the best of our knowledge, this is the first time the transfer-learning-based method has been used for aspect-based sentiment analysis in the Indian language;
The proposed methodology can be treated as a baseline for solving further problems involving Indian languages.
The rest of the paper is organised as follows.
Section 2 summarizes the relevant works in the field of aspect-based sentiment analysis.
Section 3 discusses the methodology of the proposed framework.
Section 4 presents the datasets used in the experiments and the experimental results. The paper concludes with the derived conclusions and the scope for the future presented in
Section 5.
2. Related Work
In prior works for ABSA, methods related to machine learning were dominant [
12,
13]. They were primarily concentrated on the extraction of hand-crafted lexical and semantic features [
14]. The authors [
15] proposed sentiment-specific word embedding. Such feature-engineering-based studies require professional-level knowledge in linguistics and have limitations regarding the achievement of the best possible performance. An SVM-based model was proposed in [
16], which used word-aspect-association lexicons for sentiment classification. The authors [
17] proposed a multi-kernel approach for aspect category detection. Previous aspect-based techniques did not appropriately adapt general lexicons in the context of aspect-based datasets, resulting in a reduced performance. The authors in [
18] presented extensions of two lexicon generation methods to handle this problem: one using a genetic algorithm and the other using statistical methods. They combined the generated lexicons with the well-known static lexicons to categorize these aspects into reviews.
Neural networks can dynamically extract features without feature engineering. They can transform the original features into continuous, low-dimensional vectors because of this ability; they have been gaining huge popularity in ABSA. The sentences and aspects were independently modeled using two separate LSTM models in [
19]. Then, pooling operation was performed to measure the attention given to the sentences and aspects. In recent years, with the increased use of attention mechanisms in deep learning models, many researchers have incorporated them into RNNs [
20,
21,
22], CNNs [
23], and memory networks [
22,
24]. This enables the model to learn various attention distribution levels for different aspects, as well as create attention-based embeddings. The authors [
22] proposed the use of delayed, context-aware updates with a memory network. Context-aware embeddings were generated using interaction-based embedding layers in [
25]. To handle the complications and increase the expressive power of LSTM, several attention layers were used with LSTM in [
20,
26]. In [
21], Attention-Based LSTM with Aspect Embedding (ATAE-LSTM) was proposed, which focused on identifying the sentiment-carrying words that were relatively correlated with the entity or target.
Most recently, the authors have used transfer-learning-based models. BERT has been used in various papers [
27,
28] to produce contextualized embeddings for input sentences, which were subsequently used to identify the sentiment for target-aspect pairs. The authors in [
29,
30] used BERT as the embedding layer, while the authors in [
31] used a fine-tuning approach for BERT, with an additional layer acting as the classification layer. BERT was fine-tuned for
Targeted Aspect-Based Sentiment Analysis (TABSA) in recent works [
32,
33] by altering the top-most classification layer to include the targets and aspects. Instead of utilizing the top-most classification layer of BERT, the authors in [
34] investigated the possibility of using the semantic knowledge present in BERT’s intermediate layers to improve BERTs fine-tuning performance. The authors [
8] proposed the construction of sentences from the target–aspect pairs, before feeding them to BERT to fully utilize the power of BERT models. However, BERT’s input format is limited to a sequence of words that cannot provide more contextual information. To overcome this issue, authors in [
35] introduced GBCN, a new method that enhances and controls the BERT representation for ABSA by combining a gating mechanism with context-aware aspect embeddings. The input texts are first fed into the BERT and context-aware embedding layers, resulting in independent BERT representations and refined context-aware embeddings. The most associated information chosen in this context is contained in these refined embeddings. The flow of sentiment information between these context-aware vectors and the output of the BERT encoding layer is then dynamically controlled by employing gating units.
However, these works are mainly carried out in the English language. For Indian languages, most of the existing works aim to classify the sentiments at either the sentence or at document level. ABSA in Indian languages is still an open challenge, as minimal resources are available, and hardly any significant work has been performed in this field in Indian languages. The authors [
36] used different models such as Decision Tree, Naive Bayes, and a sequential minimal optimization implementation of SVM (SMO) to solve the ABSA problem in the Hindi language. They used lexical features such as n-grams, non-contiguous n-grams, and character n-grams, together with a PoS tag and semantic orientation (SO) score [
37], for polarity classification.
The author [
38] showed the relationship between affective computing and sentiment analysis. The primary tasks of affective computing and sentiment analysis are emotion recognition and polarity detection. They can enhance the customer relationship management and recommendation system abilities, for example, to reveal which features customers enjoy or should be excluded from a recommendations system that received negative feedback. In [
39], the authors showed a range of the current approaches and tools for multilingual sentiment analysis. In addition to the challenge of understanding the formal textual content, it is also essential to consider the informal language, which is often coupled with localized slang, to express ‘true’ feelings.
The authors proposed BabelSenticNet [
40], the first multilingual concept-level knowledge base for sentiment analysis. The system was tested on 40 languages, proving the method’s robustness and its potential for utility in future research.
The authors [
41] proposed an attention-based bidirectional CNN-RNN deep model for sentiment analysis (ABCDM). The effectiveness of ABCDM is evaluated on five reviews and three Twitter datasets. It showed that ABCDM achieves state-of-the-art results for both long-review and short-tweet polarity classification.
In [
42], the authors proposed a multi-task ensemble [
43] framework of three deep learning models (i.e., CNN, LSTM, and GRU) and a hand-crafted feature representation for the predictions. The experimental results suggest that the proposed multi-task framework outperformed the single-task frameworks in all experiments.
5. Conclusions and Future Work
This paper proposes two ensemble models based on Multilingual BERT, namely mBERT-E-MV and mBERT-E-AS. Our proposed models outperformed the existing state-of-the-art models on Hindi datasets. On the III-Patna Hindi Reviews dataset, mBERT-E-MV reports F1-scores of 74.26%, 59.70%, 63.74% and 79.08% on the aspect category detection task in Electronics, Mobile Apps, Travel and Movies domains, respectively. It reports accuracies of 69.95%, 51.22%, 75.47% and 78.09% on the aspect polarity classification task for the four respective domains. Similarly, mBERT-E-AS reports F1-scores of 73.38%, 52.31%, 59.65% and 78.61% on the aspect category detection task for the respective domains. It reports accuracies of 70.49%, 48.78%, 75.47% and 79.77% on the aspect polarity classification task for the four respective domains.
Overall, BERT-based models performed much better than the other models. This is possible because of the construction of auxiliary sentences from the aspect information, which is analogous to exponentially increasing the dataset. A sentence
in the original dataset is transformed into (
,
), (
,
),... ,(
,
) in the sentence pair classification task. The BERT model has an additional advantage in handling sentence pair classification tasks, which is evident from its impressive improvement on the QA and NLI tasks. This improvement comes from both unsupervised Masked Language Modeling (MLM) and the Next Sentence Prediction (NSP) tasks, which are used to pre-train the BERT model [
7]. In MLM, a word in a sentence is masked, and then the model is trained to predict which word was masked based on the context of the word. In NSP, the model is trained to predict whether the two input sentences are connected logically/sequentially or whether they are unrelated to each other.
In future work, the proposed system can be applied to other NLP problems. As is evident from the obtained results, there is scope for augmenting the Hindi datasets for further improvements in performance. There is also scope for introducing a dataset for the TABSA task in Indian languages, as there is no dataset available for the same purpose.






{kind=link}