
Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition?



Abstract
:1. Introduction
- develop machine learning models (RF and CNN) suitable for activity recognition on MCU;
- port these models to C code to enable their evaluation on MCU; and
- investigate and compare performance metrics of these models based on the settings, such as the model of the MCU, compilation options, quantization options, and input data window size.
2. Background and Related Work
2.1. Machine Learning
2.2. Microcontrollers
- Current consumption in the active mode. The MCU needs to be energy efficient to avoid rapidly running out of battery when machine learning is used.
- RAM size. Neural network models need to fit in the RAM of the microcontroller; this means that most state-of-the-art models cannot be directly used.
- Flash memory size. Other models, such as Random Forest classifiers, can be placed in the flash memory instead of RAM; the former usually is larger, meaning that larger models can be used.
- Instruction set. Cortex-M family microcontrollers use ARMv7-M and ARMv8-M instruction sets, which include instructions specifically optimized for neural networks. There are supporting libraries, such as CMSIS-NN, that allow the use of these instructions.
2.3. Machine Learning on Microcontrollers
2.4. Related Work
3. Experimental Design
3.1. Dataset
3.2. Dataset Preparation
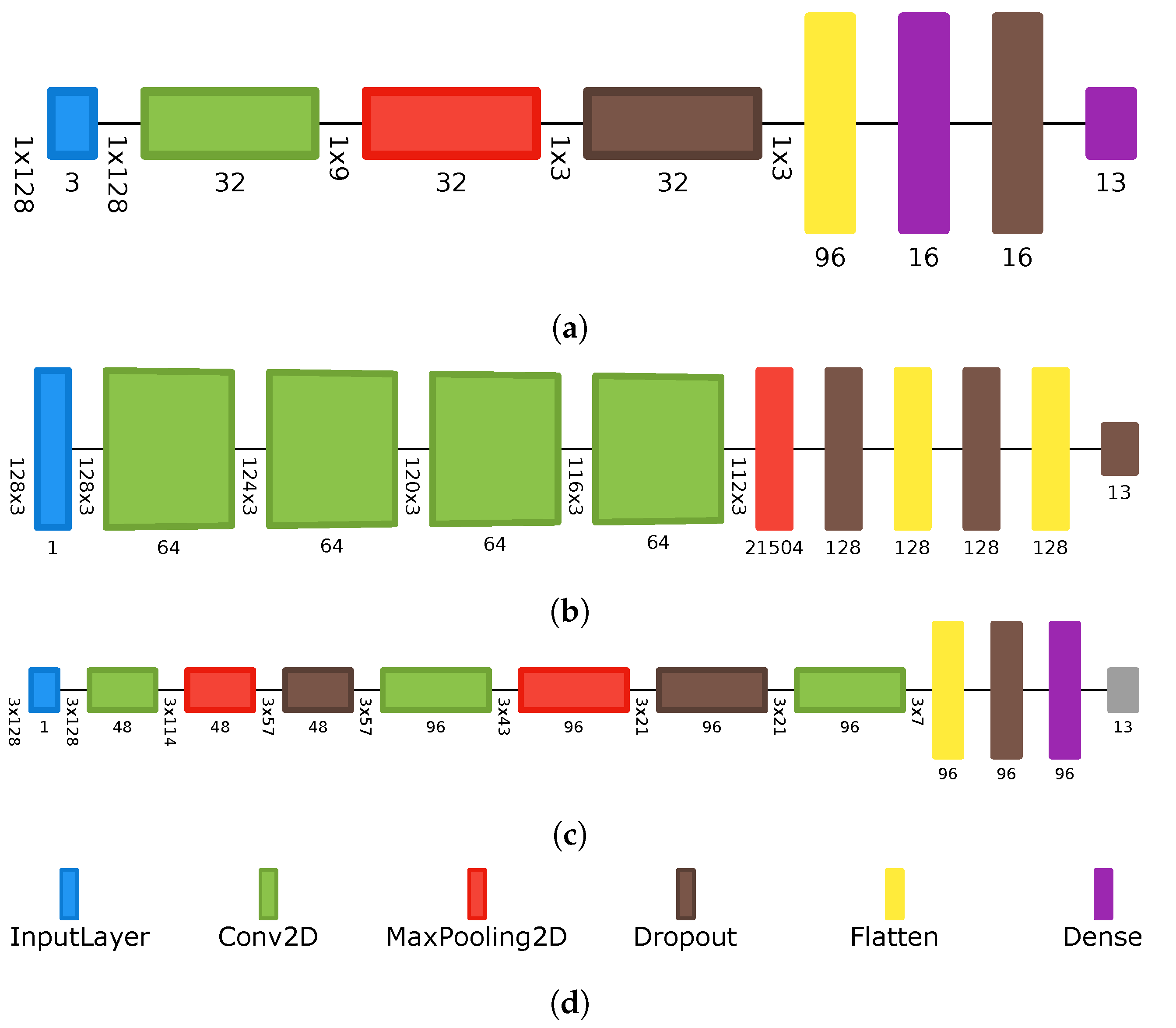
3.3. Classification with Neural Networks
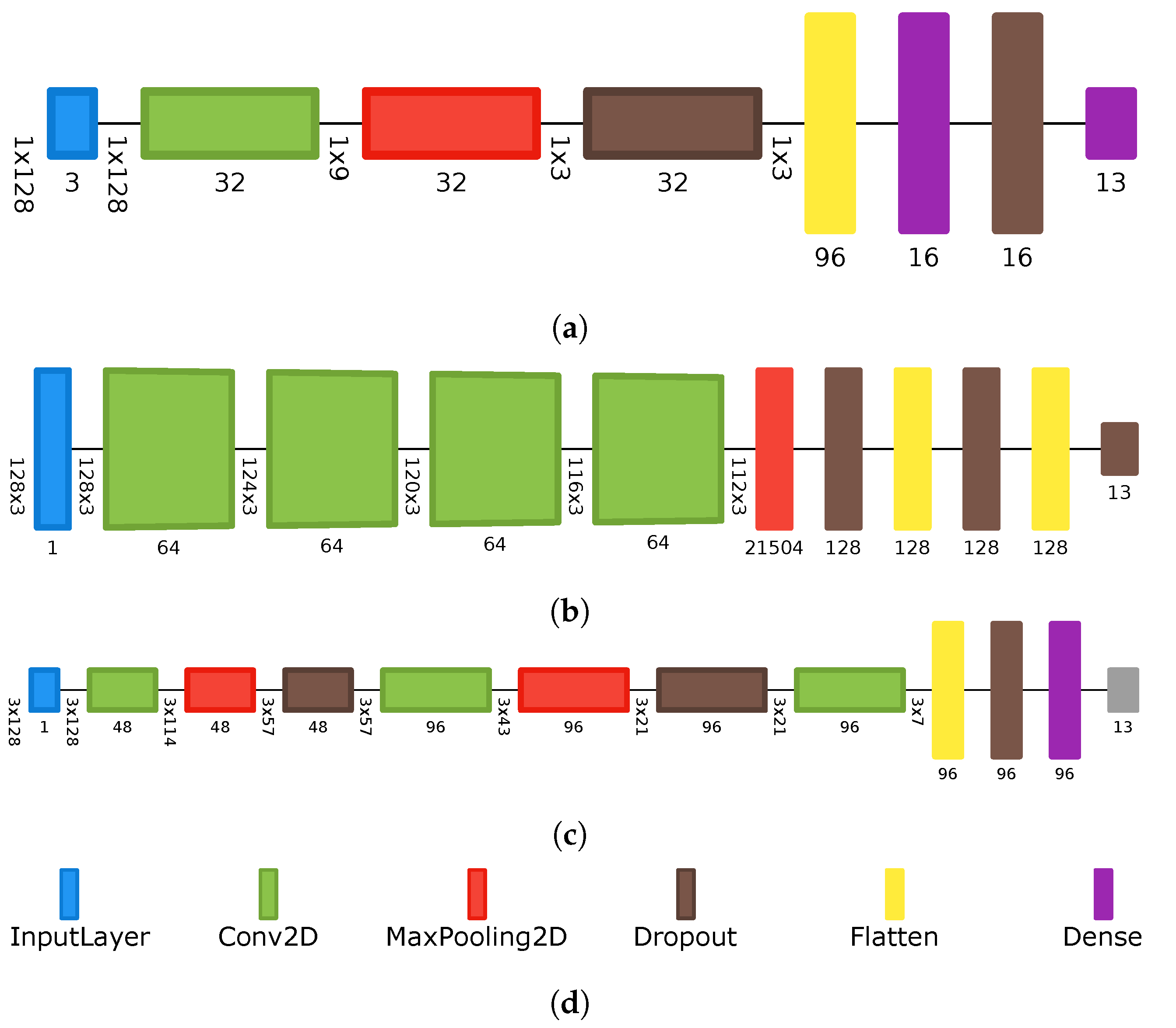
Architectures
3.4. Classification with Random Forests
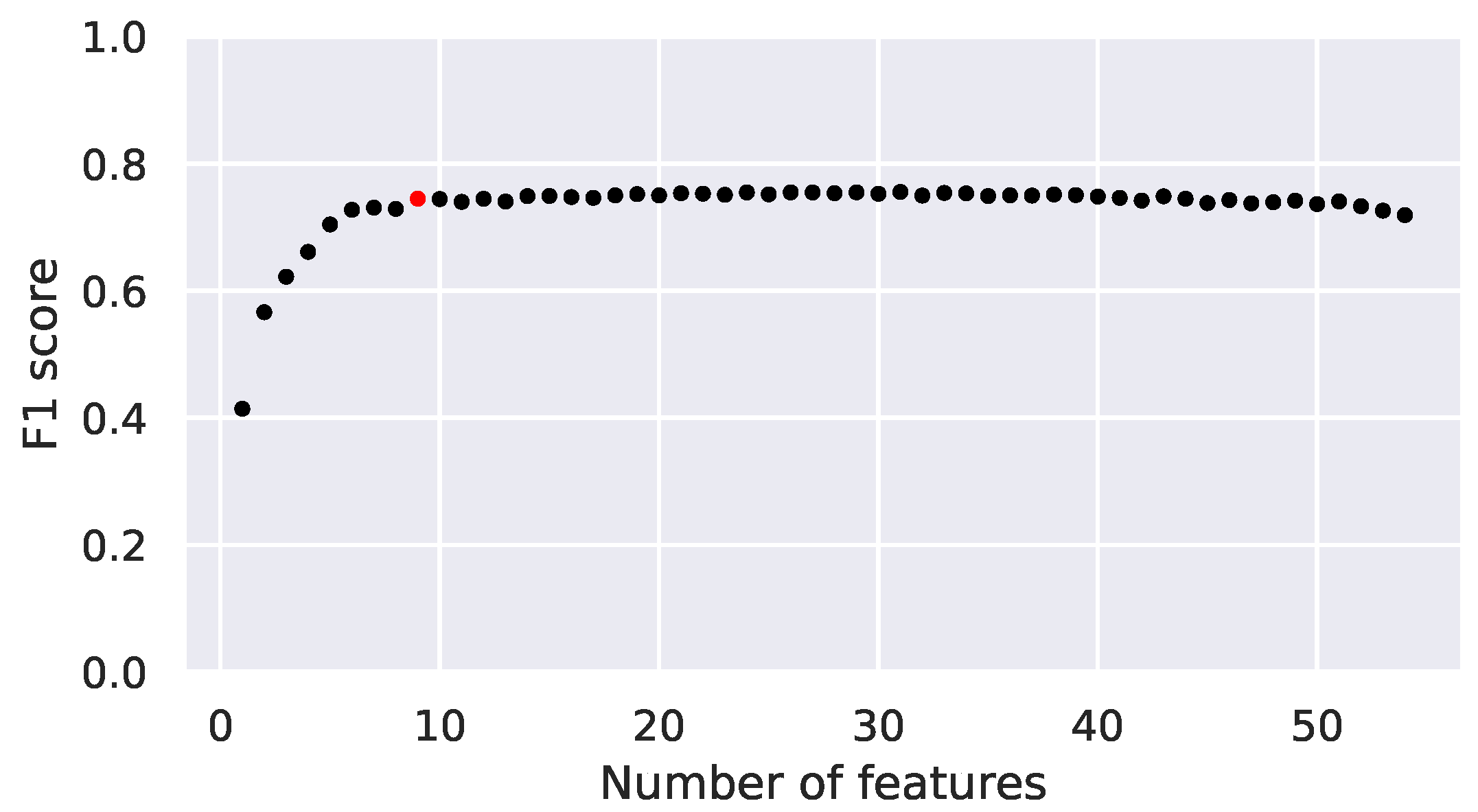
3.4.1. Features
3.4.2. Other Parameters
- number of trees;
- maximum depth of trees; and
- the splitting metric, and the minimum number of items per class.
4. Experimental Evaluation
4.1. Experimental Settings
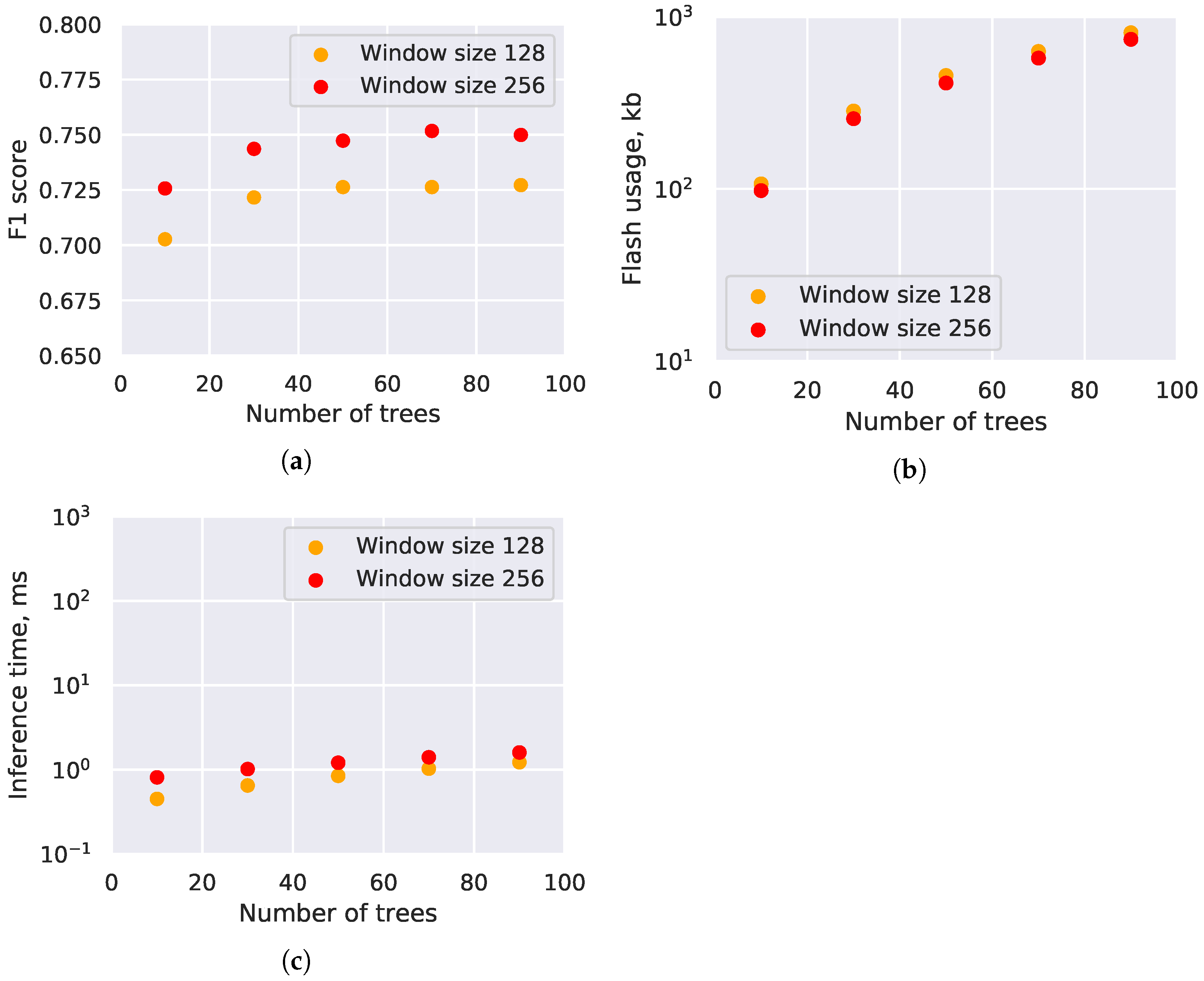
4.2. Random Forest Evaluation
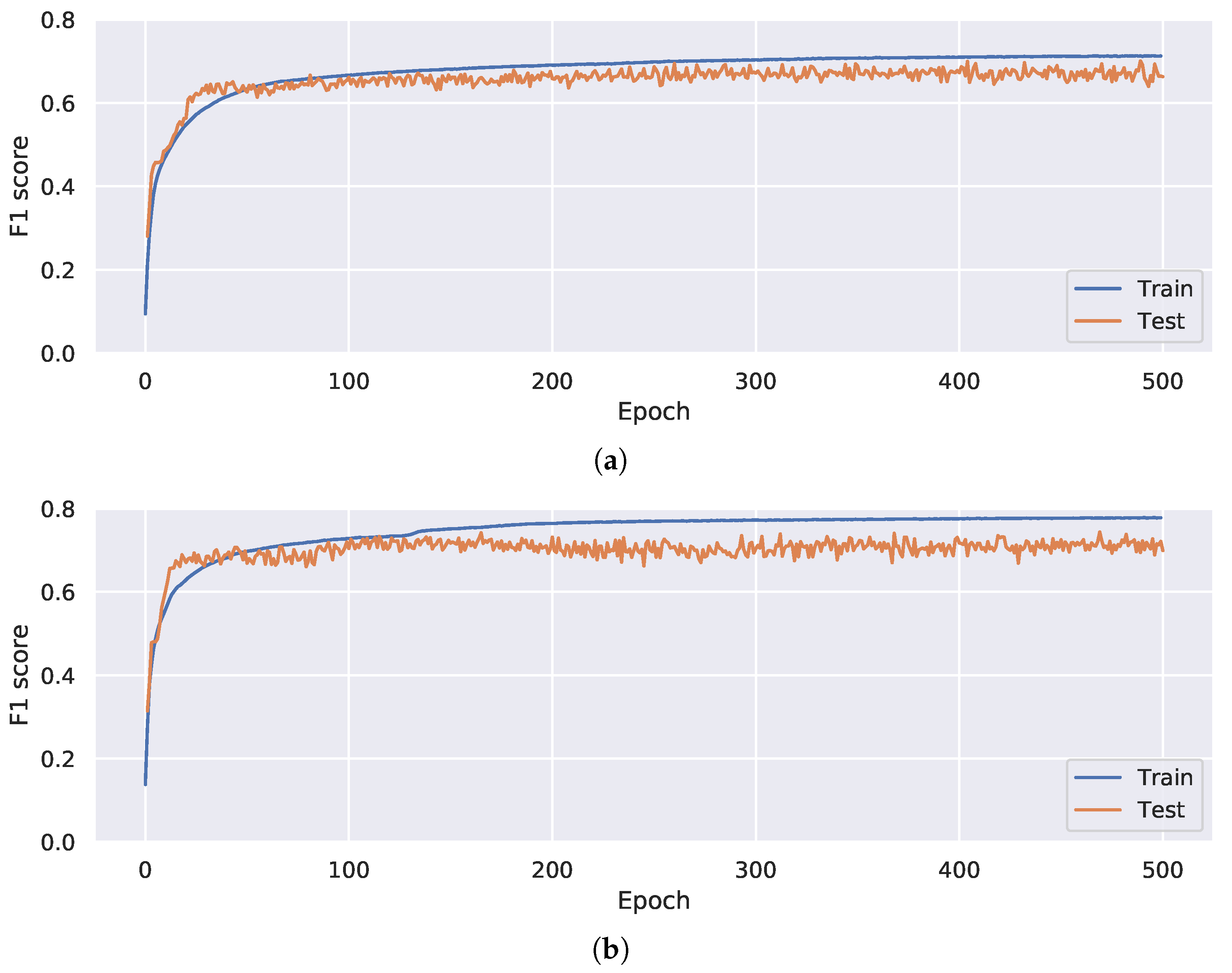
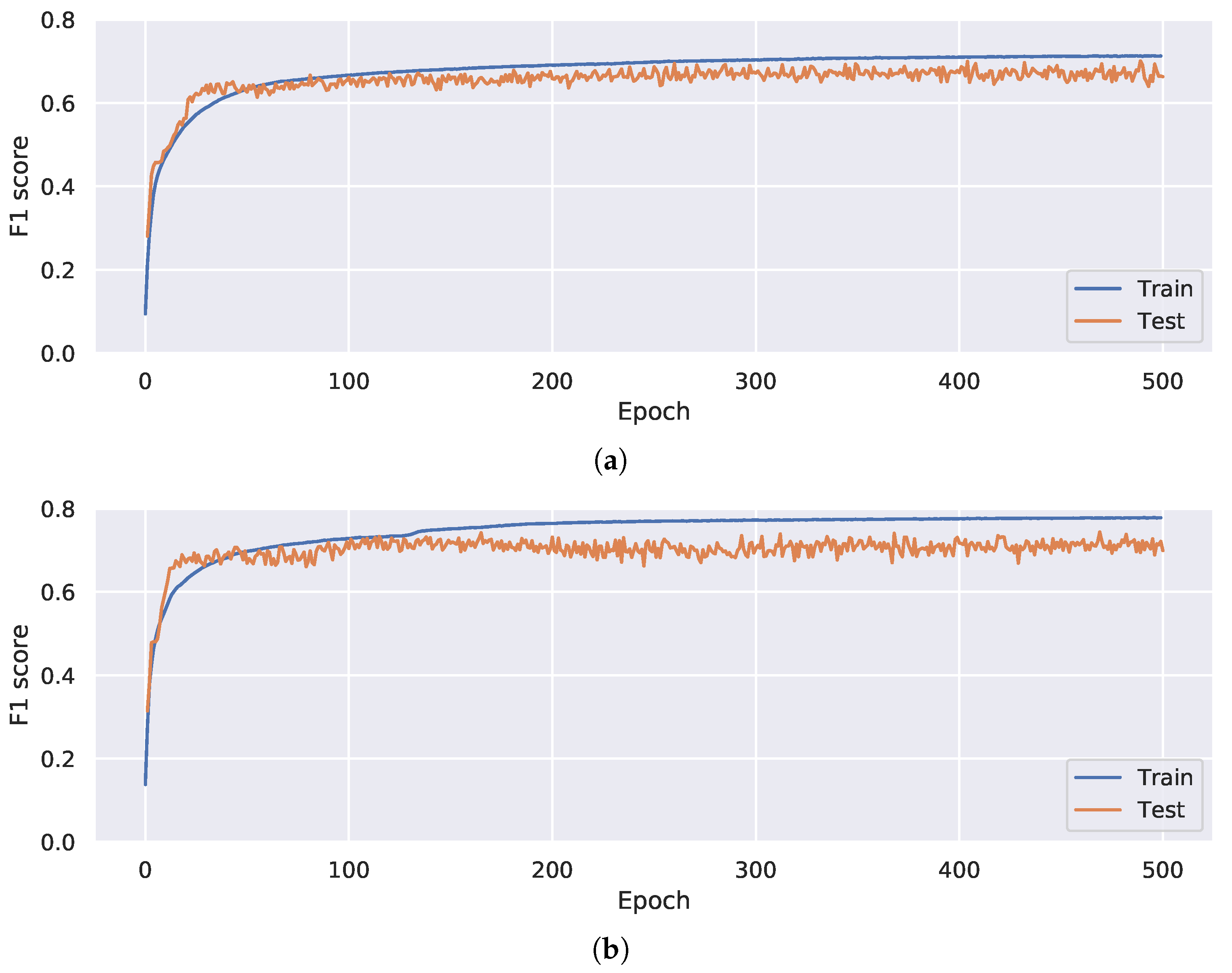
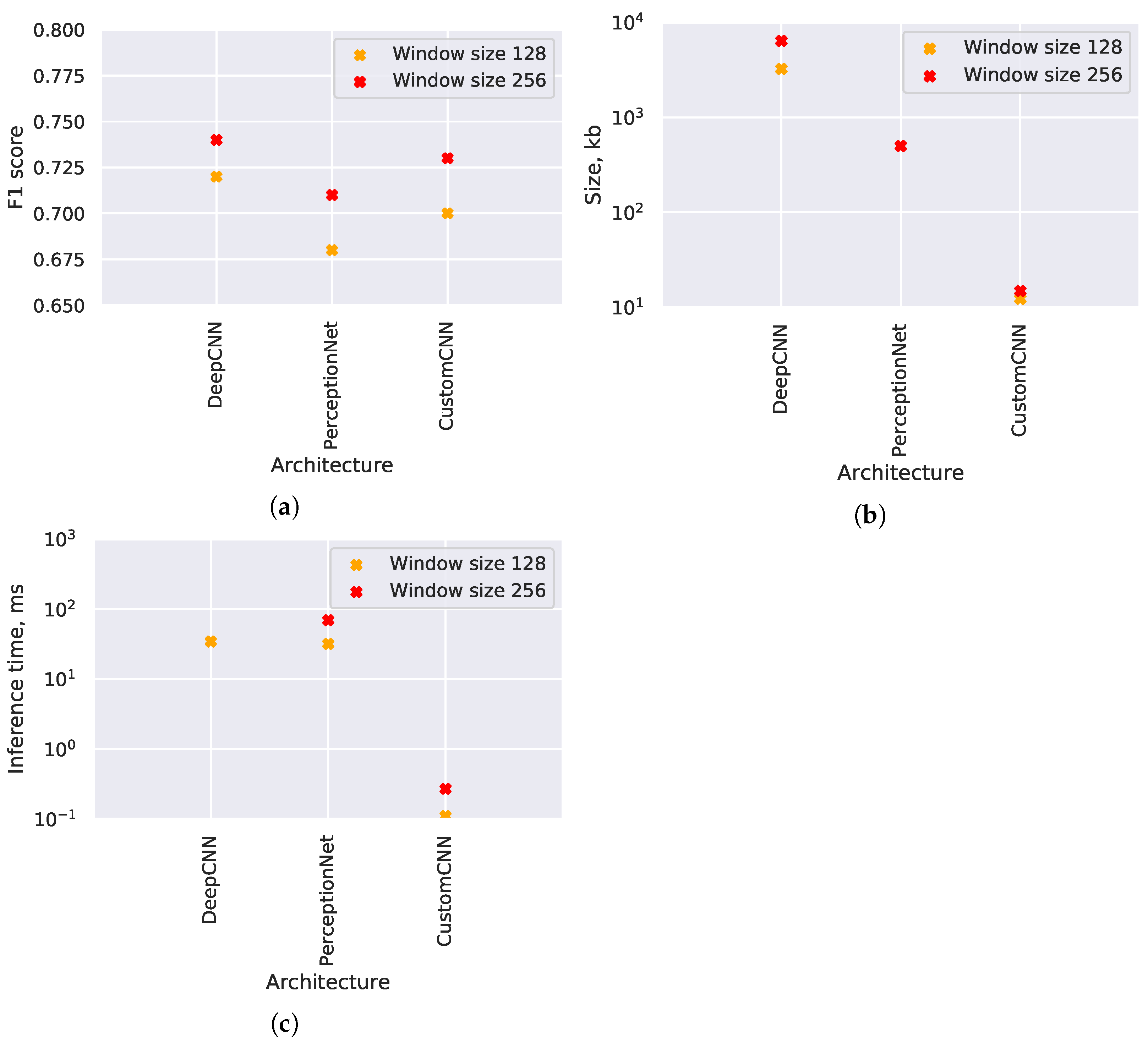
4.3. Neural Network Architecture Evaluation
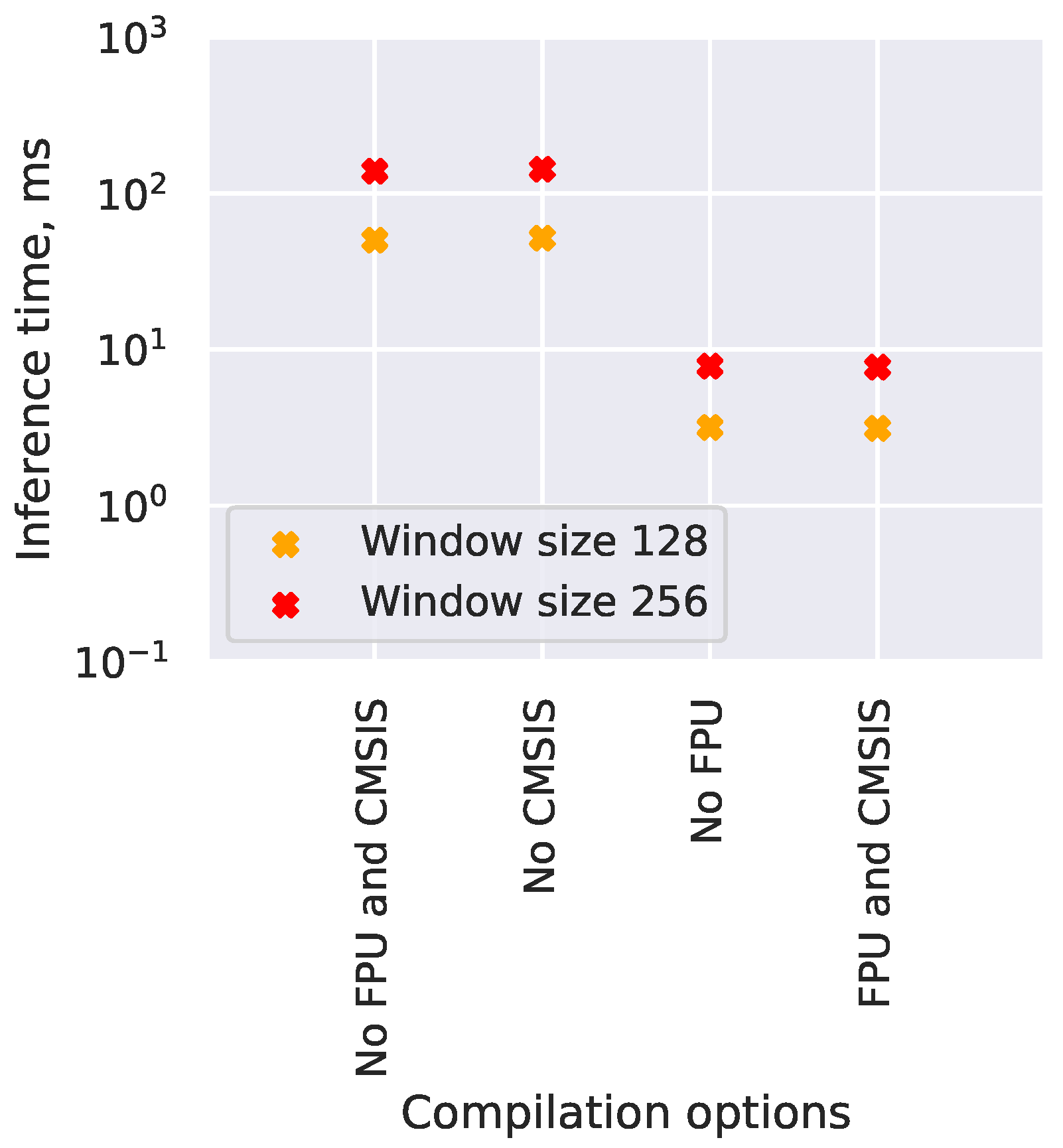
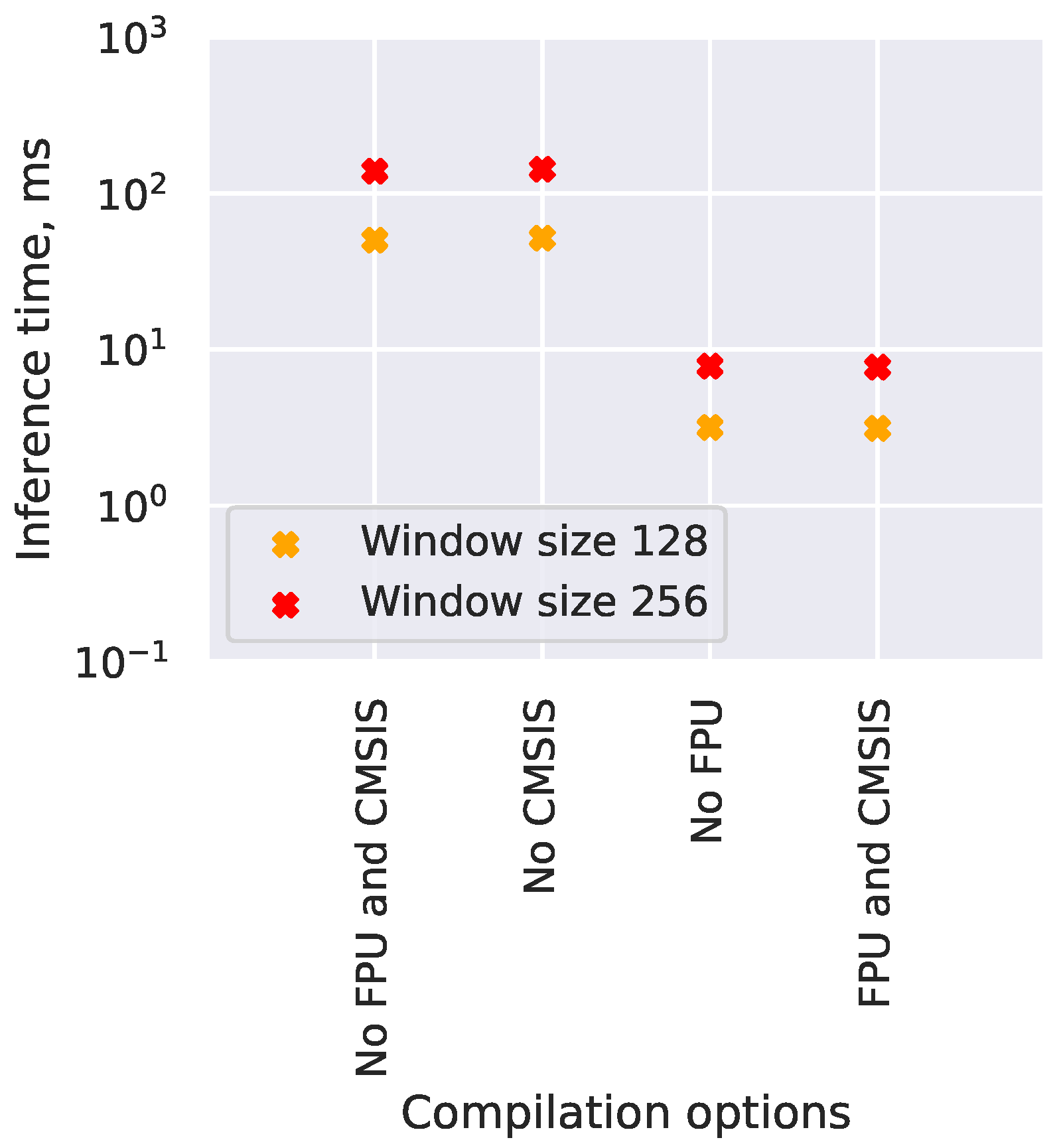
4.4. Neural Network Optimization Evaluation
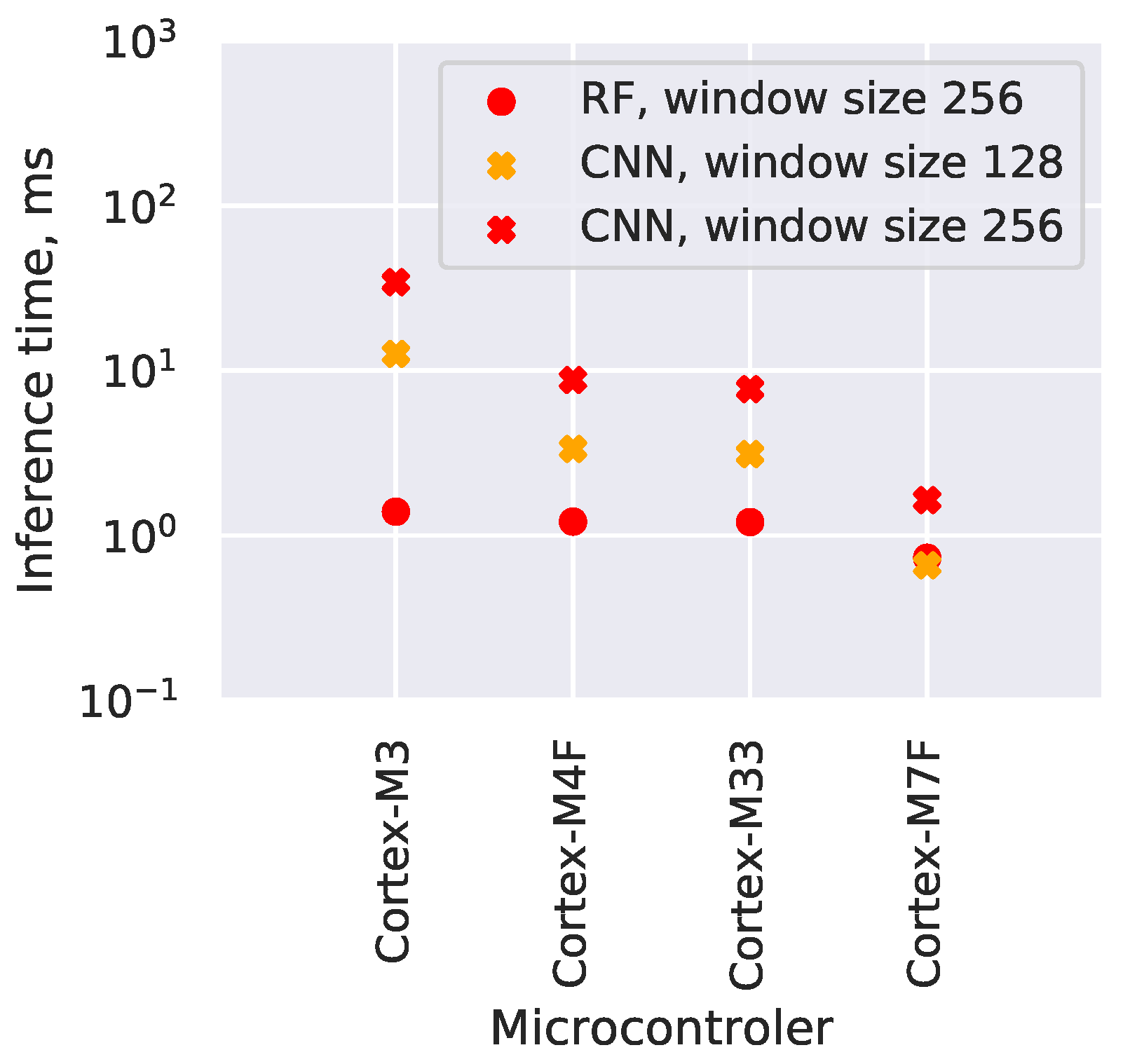
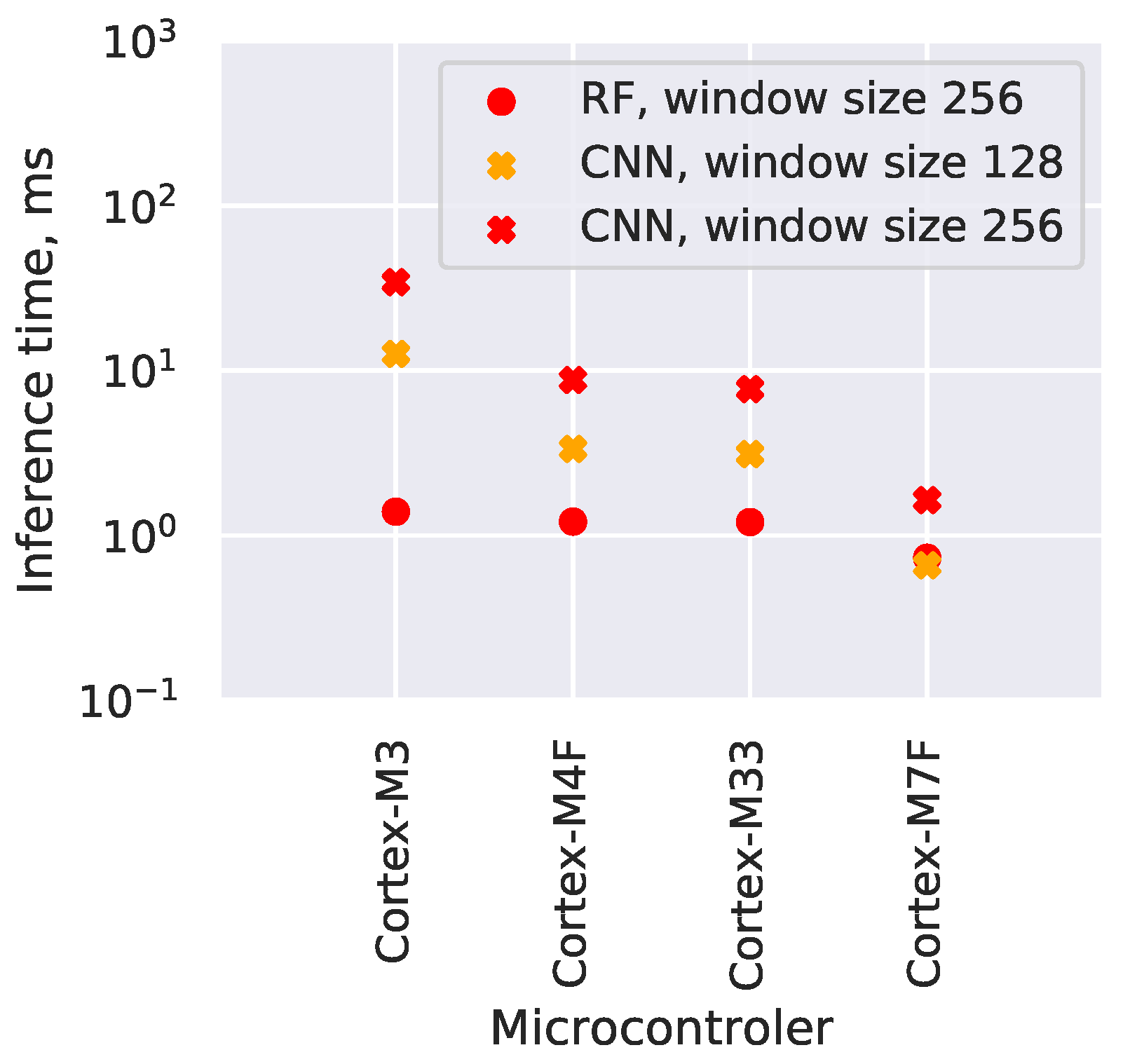
4.5. Neural Network and Random Forest Comparison
5. Discussion
5.1. Neural Network Performance Factors
5.2. Potential Criticisms of This Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Satyanarayanan, M. The Emergence of Edge Computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Microcontroller Unit (MCU) Shipments Worldwide from 2015 to 2023. Available online: https://www.statista.com/statistics/935382/worldwide-microcontroller-unit-shipments/ (accessed on 24 October 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- David, R.; Duke, J.; Jain, A.; Janapa Reddi, V.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Wang, T.; et al. TensorFlow Lite Micro: Embedded Machine Learning for TinyML Systems. In Proceedings of the 4th MLSys Conference, San Jose, CA, USA, 4–7 April 2021. [Google Scholar]
- Bormann, C.; Ersue, M.; Keranen, A. Terminology for Constrained-Node Networks; RFC 7228; IETF: Fremont, CA, USA, 2014; Available online: https://datatracker.ietf.org/doc/html/rfc7228 (accessed on 24 October 2021).
- Kasnesis, P.; Patrikakis, C.Z.; Venieris, I.S. PerceptionNet: A deep convolutional neural network for late sensor fusion. In Proceedings of SAI Intelligent Systems Conference; Springer: Berlin/Heidelberg, Germany, 2018; pp. 101–119. [Google Scholar]
- Twomey, N.; Diethe, T.; Fafoutis, X.; Elsts, A.; McConville, R.; Flach, P.; Craddock, I. A Comprehensive Study of Activity Recognition Using Accelerometers. Informatics 2018, 5, 27. [Google Scholar] [CrossRef] [Green Version]
- Elsts, A.; McConville, R.; Fafoutis, X.; Twomey, N.; Piechocki, R.; Santos-Rodriguez, R.; Craddock, I. On-Board Feature Extraction from Acceleration Data for Activity Recognition. In Proceedings of the International Conference on Embedded Wireless Systems and Networks (EWSN), Madrid, Spain, 14–16 February 2018. [Google Scholar]
- Elsts, A.; Twomey, N.; McConville, R.; Craddock, I. Energy-efficient activity recognition framework using wearable accelerometers. J. Netw. Comput. Appl. 2020, 168, 102770. [Google Scholar] [CrossRef]
- Ko, J.; Klues, K.; Richter, C.; Hofer, W.; Kusy, B.; Bruenig, M.; Schmid, T.; Wang, Q.; Dutta, P.; Terzis, A. Low power or high performance? A tradeoff whose time has come (and nearly gone). In European Conference on Wireless Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 98–114. [Google Scholar]
- SAM3X/SAM3A SeriesAtmel: SMART ARM-based MCU. Available online: https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-11057-32-bit-Cortex-M3-Microcontroller-SAM3X-SAM3A_Datasheet.pdf (accessed on 24 October 2021).
- nRF52840: Product Specification v1.2. Available online: https://infocenter.nordicsemi.com/pdf/nRF52840_PS_v1.2.pdf (accessed on 24 October 2021).
- nRF5340: Objective Product Specification v0.5. Available online: https://infocenter.nordicsemi.com/pdf/nRF5340_OPS_v0.5.pdf (accessed on 24 October 2021).
- Fafoutis, X.; Vafeas, A.; Janko, B.; Sherratt, R.S.; Pope, J.; Elsts, A.; Mellios, E.; Hilton, G.; Oikonomou, G.; Piechocki, R.; et al. Designing wearable sensing platforms for healthcare in a residential environment. EAI Endorsed Trans. Pervasive Health Technol. 2017, 12, e1. [Google Scholar]
- Vafeas, A.T.; Fafoutis, X.; Elsts, A.; Craddock, I.J.; Biswas, M.I.; Piechocki, R.J.; Oikonomou, G. Wearable Devices for Digital Health: The SPHERE Wearable 3. In Proceedings of the Embedded Wireless Systems and Networks (EWSN): On-Body Sensor Networks (OBSN 2020), Lyon, France, 17–19 February 2020. [Google Scholar]
- STM32F745xx STM32F746xx. Available online: https://www.st.com/resource/en/datasheet/stm32f746ng.pdf (accessed on 24 October 2021).
- Zheng, L.; Wu, D.; Ruan, X.; Weng, S.; Peng, A.; Tang, B.; Lu, H.; Shi, H.; Zheng, H. A novel energy-efficient approach for human activity recognition. Sensors 2017, 17, 2064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sudharsan, B.; Patel, P.; Breslin, J.G.; Ali, M.I. Ultra-fast machine learning classifier execution on iot devices without sram consumption. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Kassel, Germany, 22–26 March 2021; pp. 316–319. [Google Scholar]
- Boni, A.; Pianegiani, F.; Petri, D. Low-power and low-cost implementation of SVMs for smart sensors. IEEE Trans. Instrum. Meas. 2007, 56, 39–44. [Google Scholar] [CrossRef]
- Leech, C.; Raykov, Y.P.; Ozer, E.; Merrett, G.V. Real-time room occupancy estimation with Bayesian machine learning using a single PIR sensor and microcontroller. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; pp. 1–6. [Google Scholar]
- Banbury, C.; Zhou, C.; Fedorov, I.; Matas, R.; Thakker, U.; Gope, D.; Janapa Reddi, V.; Mattina, M.; Whatmough, P. Micronets: Neural network architectures for deploying tinyml applications on commodity microcontrollers. In Proceedings of the 4th MLSys Conference, San Jose, CA, USA, 4–7 April 2021. [Google Scholar]
- Heim, L.; Biri, A.; Qu, Z.; Thiele, L. Measuring what Really Matters: Optimizing Neural Networks for TinyML. arXiv 2021, arXiv:2104.10645. [Google Scholar]
- Crocioni, G.; Pau, D.; Delorme, J.M.; Gruosso, G. Li-Ion Batteries Parameter Estimation With Tiny Neural Networks Embedded on Intelligent IoT Microcontrollers. IEEE Access 2020, 8, 122135–122146. [Google Scholar] [CrossRef]
- Coffen, B.; Mahmud, M.S. TinyDL: Edge Computing and Deep Learning Based Real-time Hand Gesture Recognition Using Wearable Sensor. In Proceedings of the 2020 IEEE International Conference on E-health Networking, Application & Services (HEALTHCOM), Shenzhen, China, 1–2 March 2021; pp. 1–6. [Google Scholar]
- Banbury, C.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Kiraly, C.; Montino, P.; Kanter, D.; Ahmed, S.; Pau, D.; et al. MLPerf Tiny Benchmark. arXiv 2021, arXiv:2106.07597. [Google Scholar]
- Reiss, A.; Stricker, D. Creating and Benchmarking a New Dataset for Physical Activity Monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion, Greece, 6–8 June 2012; pp. 1–8. [Google Scholar] [CrossRef]
- ICM-20948: World’s Lowest Power 9-Axis MEMS MotionTracking™ Device. Available online: https://invensense.tdk.com/wp-content/uploads/2016/06/DS-000189-ICM-20948-v1.3.pdf (accessed on 24 October 2021).
- MC3635 3-Axis Accelerometer. Available online: https://mcubemems.com/wp-content/uploads/2017/09/MC3635-Datasheet-APS-048-0044v1.5.pdf (accessed on 24 October 2021).
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bäuerle, A.; Ropinski, T. Net2Vis: Transforming Deep Convolutional Networks into Publication-Ready Visualizations. arXiv 2019, arXiv:2106.07597. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Core | Clock | Active Mode | RAM | Flash | Price |
|---|---|---|---|---|---|---|
| Freq. MHz | Current, mA | kb | kb | EUR | ||
| ATSAM3X8E | Cortex-M3 | 84 | 70.9 | 96 | 512 | 8.38 |
| nRF52840 | Cortex-M4F | 64 | 3.3 | 256 | 1024 | 3.43 |
| nRF5340 | Cortex-M33 | 128 | 7.3 | 512 | 1024 | 7.20 |
| STM32F746NG | Cortex-M7F | 216 | 102.0 | 320 | 1024 | 13.34 |
| PerceptionNet | DeepCNN | Custom | |
|---|---|---|---|
| Input Shape | (3, 128, 1) | (128, 3, 1) | (1, 128, 3) |
| Convolutional Layers | 3 | 4 | 1 |
| Convolutional Filters | 48, 96, 96 | 64,64,64,64 | 32 |
| Convolutional Strides | 1, 1, 3 | 1 | (1, 8) |
| Convolutional Kernels | (1, 15), (1, 15), (3,15) | (5,1) | (1,64) |
| Pooling Layers | 3 | 0 | 2 |
| Dense Hidden Layers (Neurons) | 0 (0) | 2 (128, 128) | 1 (16) |
| Property | Value |
|---|---|
| Common Settings | |
| Window size | 128 or 256 |
| Dataset | PAMAP2 |
| Number of classes | 12 |
| Neural Network | |
| Framework | TensorFlow Lite Micro v2.4.0 |
| Training epochs | 200 |
| Batch size | 4096 |
| Quantization | int8 |
| Convolutional layers | 1 |
| Convolution filters | 32 |
| Random Forest | |
| Framework | scikit-learn |
| Number of trees | 50 |
| Max depth | 9 |
| Number of features | 9 |
| Window Overlap | DeepCNN | PerceptionNet | Custom |
|---|---|---|---|
| 99% | 0.73 (0.002) | 0.68 (0.008) | 0.69 (0.006) |
| 66% | 0.74 (0.005) | 0.66 (0.001) | 0.52 (0.010) |
| 50% | 0.74 (0.002) | 0.64 (0.011) | 0.42 (0.19) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elsts, A.; McConville, R. Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition? Electronics 2021, 10, 2640. https://doi.org/10.3390/electronics10212640
Elsts A, McConville R. Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition? Electronics. 2021; 10(21):2640. https://doi.org/10.3390/electronics10212640
Chicago/Turabian StyleElsts, Atis, and Ryan McConville. 2021. "Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition?" Electronics 10, no. 21: 2640. https://doi.org/10.3390/electronics10212640
APA StyleElsts, A., & McConville, R. (2021). Are Microcontrollers Ready for Deep Learning-Based Human Activity Recognition? Electronics, 10(21), 2640. https://doi.org/10.3390/electronics10212640