
A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID


Abstract
:1. Introduction
2. Methodology
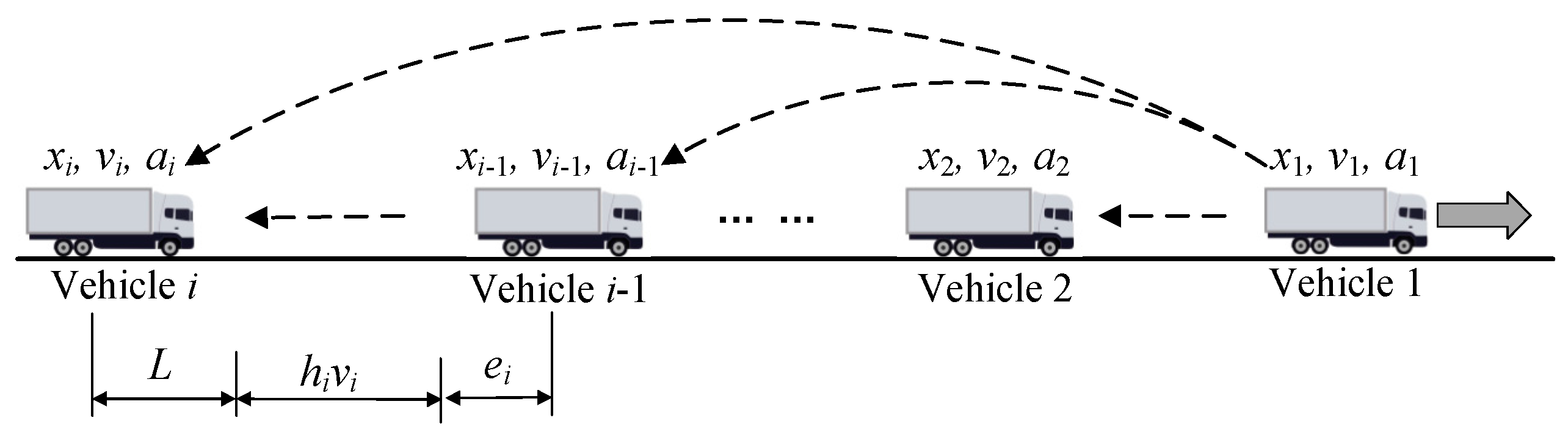
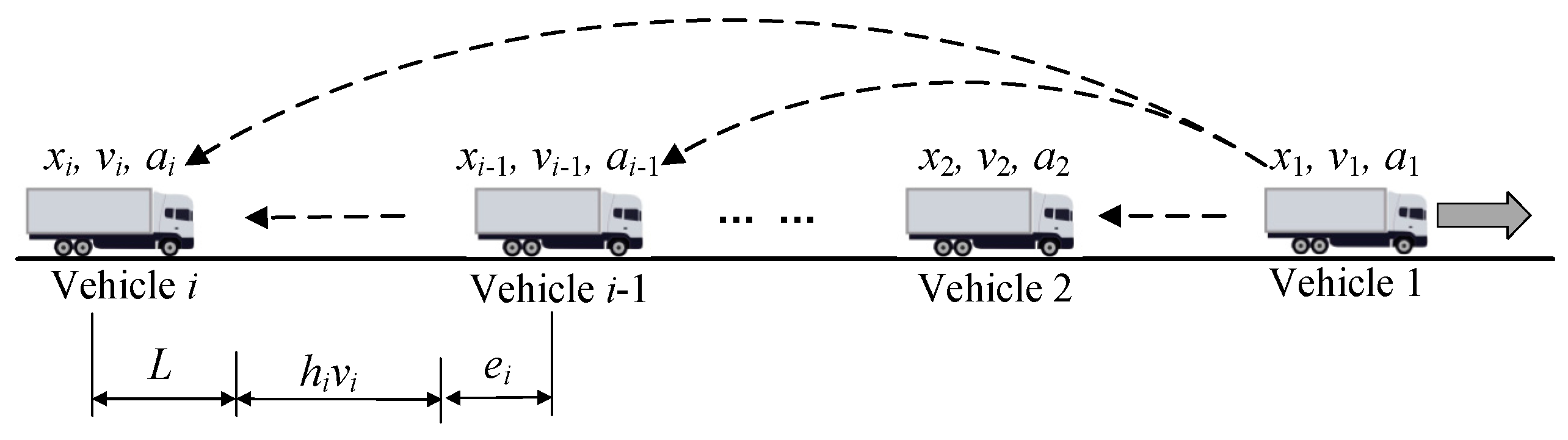
2.1. Vehicle Platoon Architecture
2.2. Vehicle Platoon Control
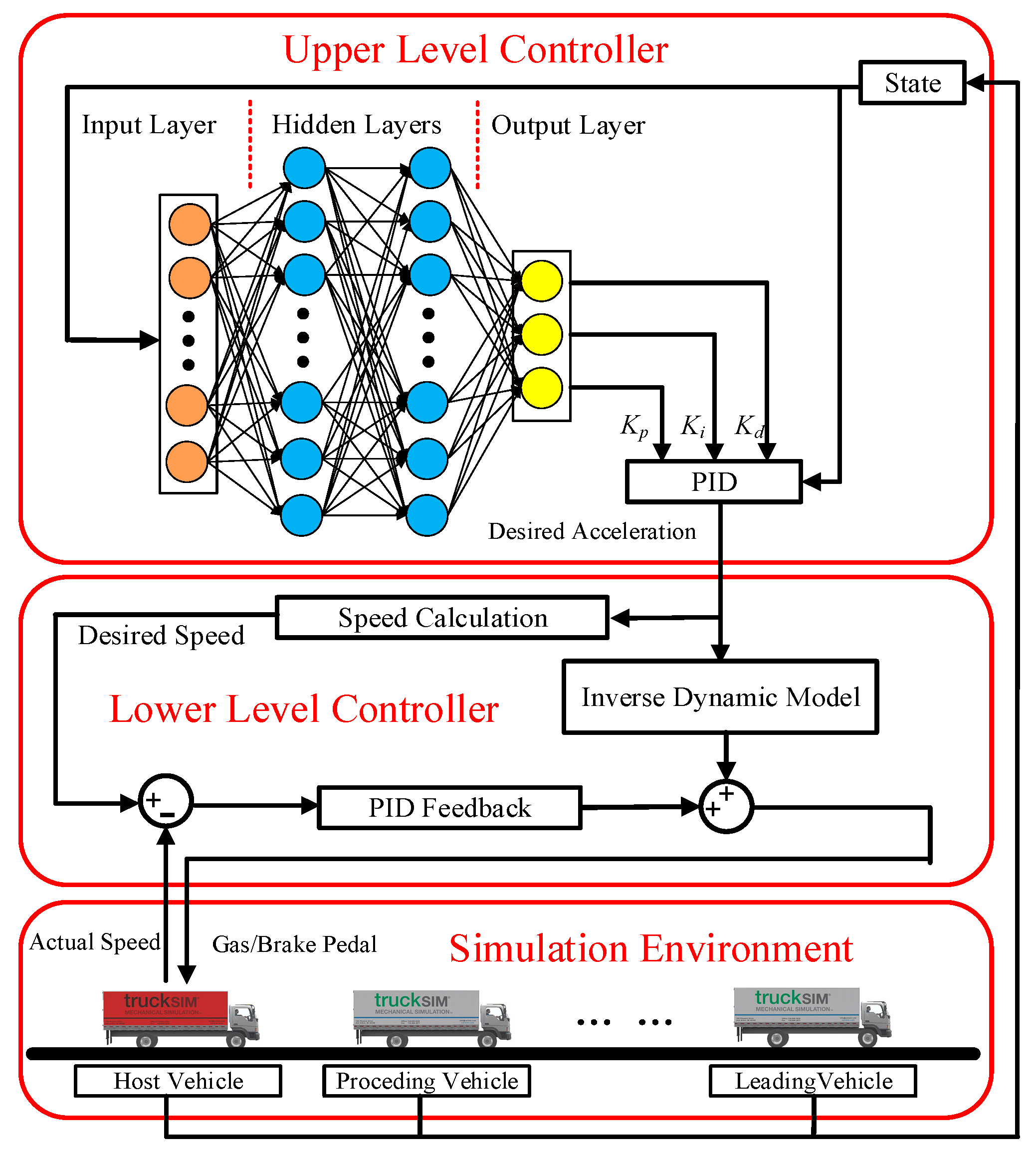
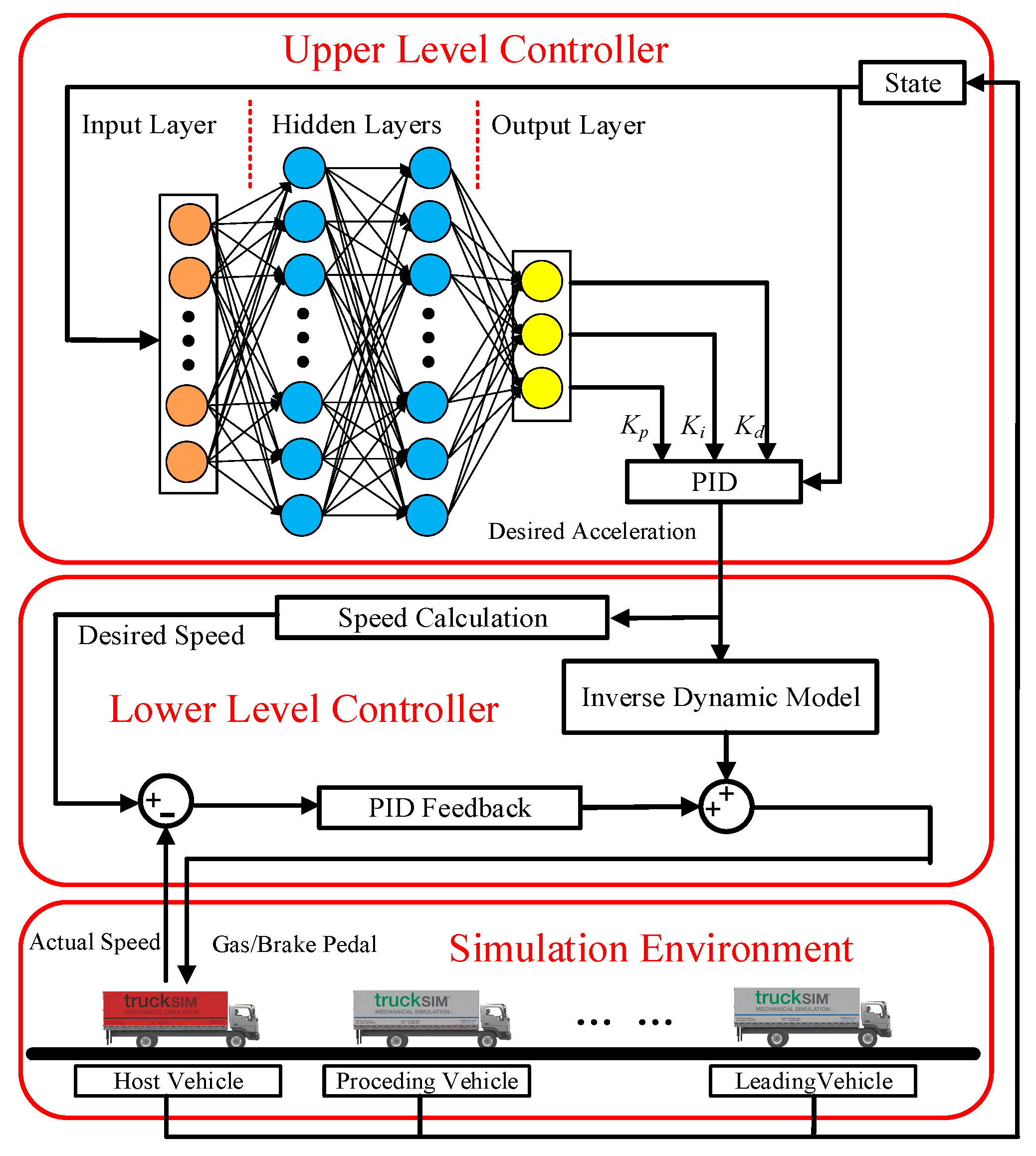
2.2.1. Upper-Level Controller
2.2.2. Lower-Level Controller
2.2.3. Transfer Function of Distance Error
2.3. String Stability
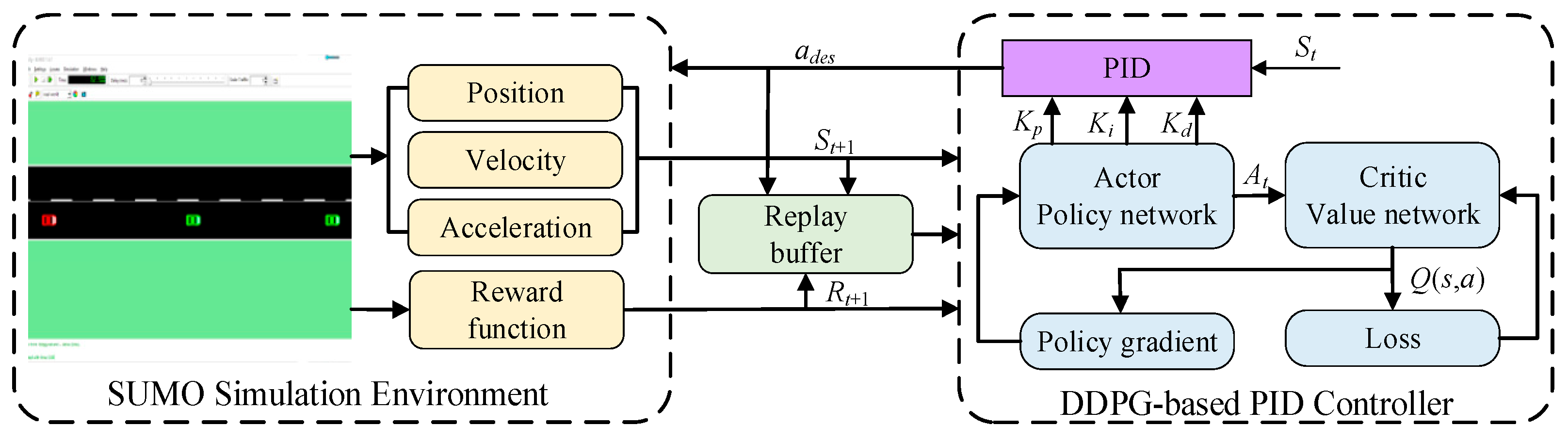
3. Design of DDPG-Based PID Vehicle Platoon Controller
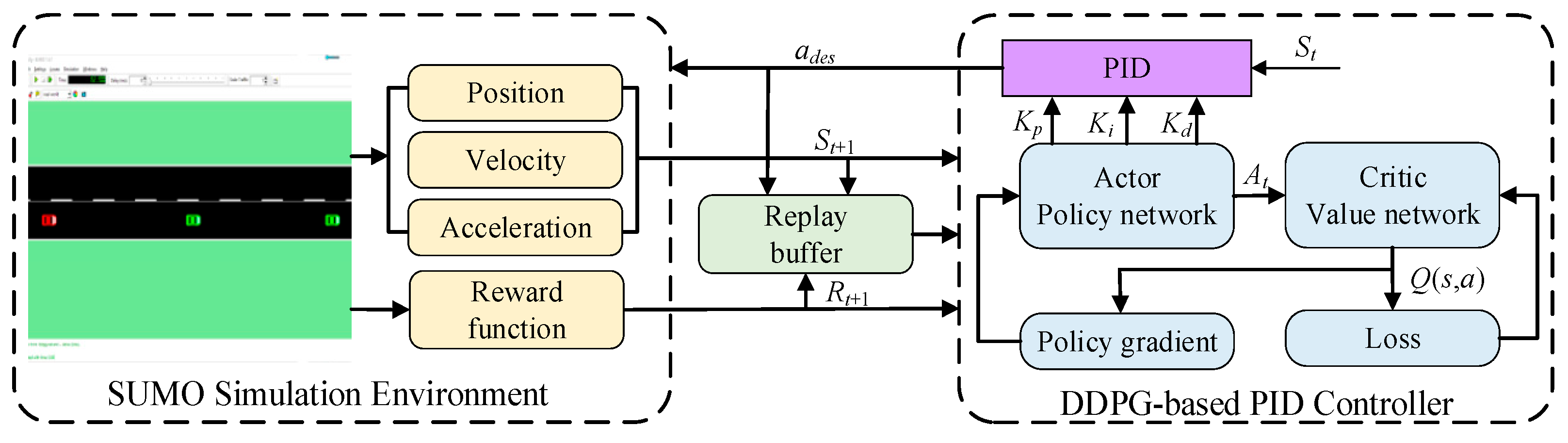
3.1. MDP Model for Vehicle Platoon Control
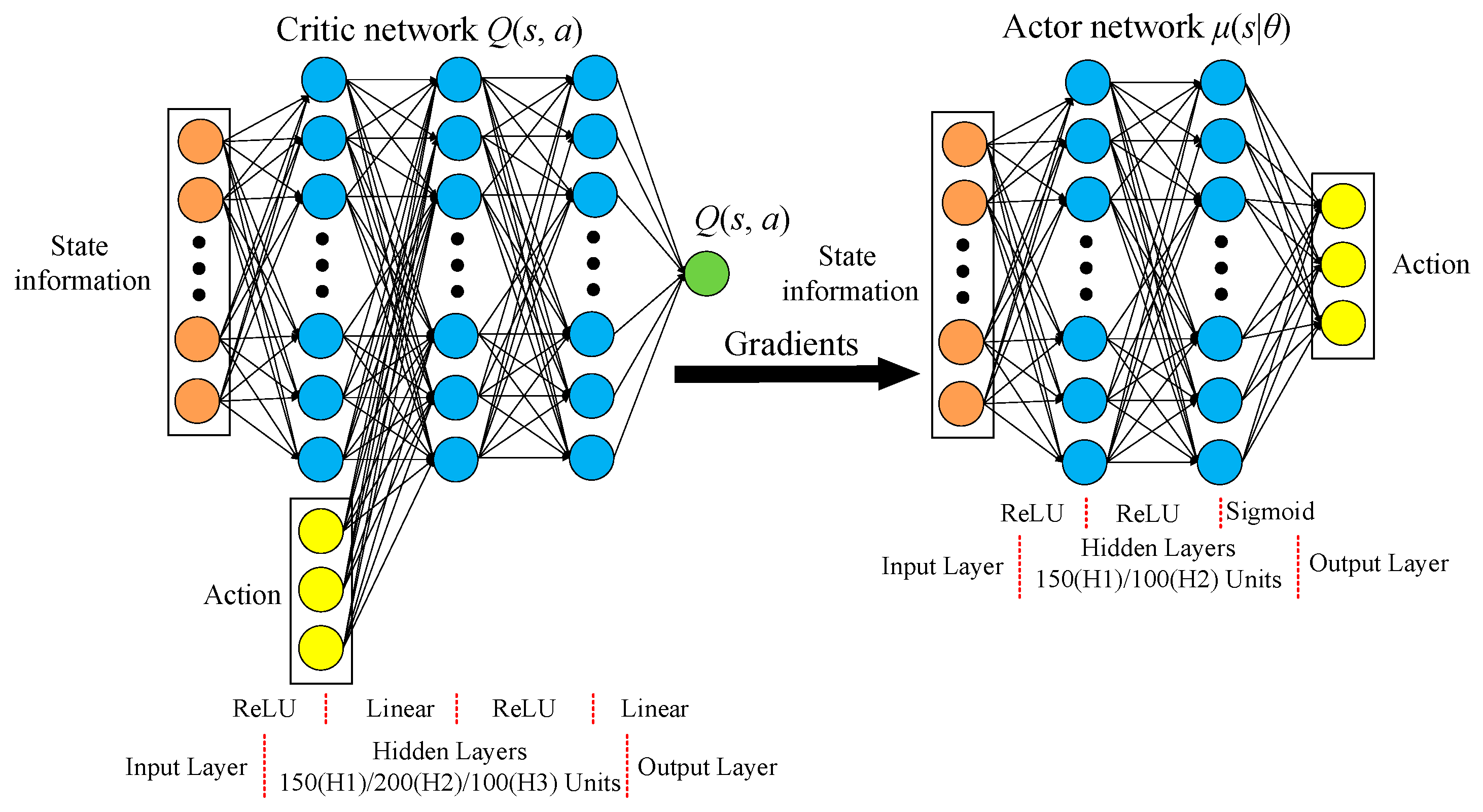
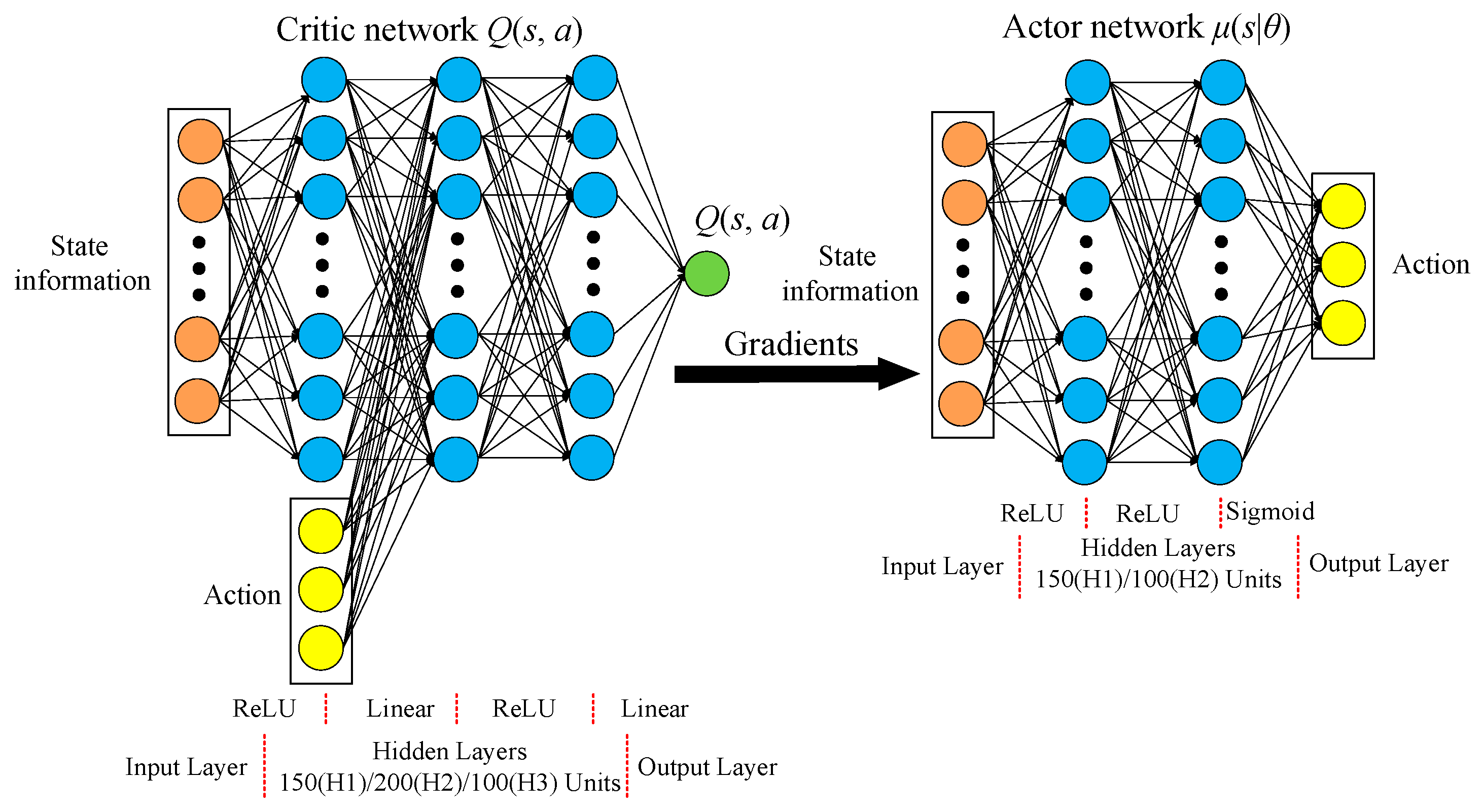
3.2. Structural Design of DDPG Algorithm
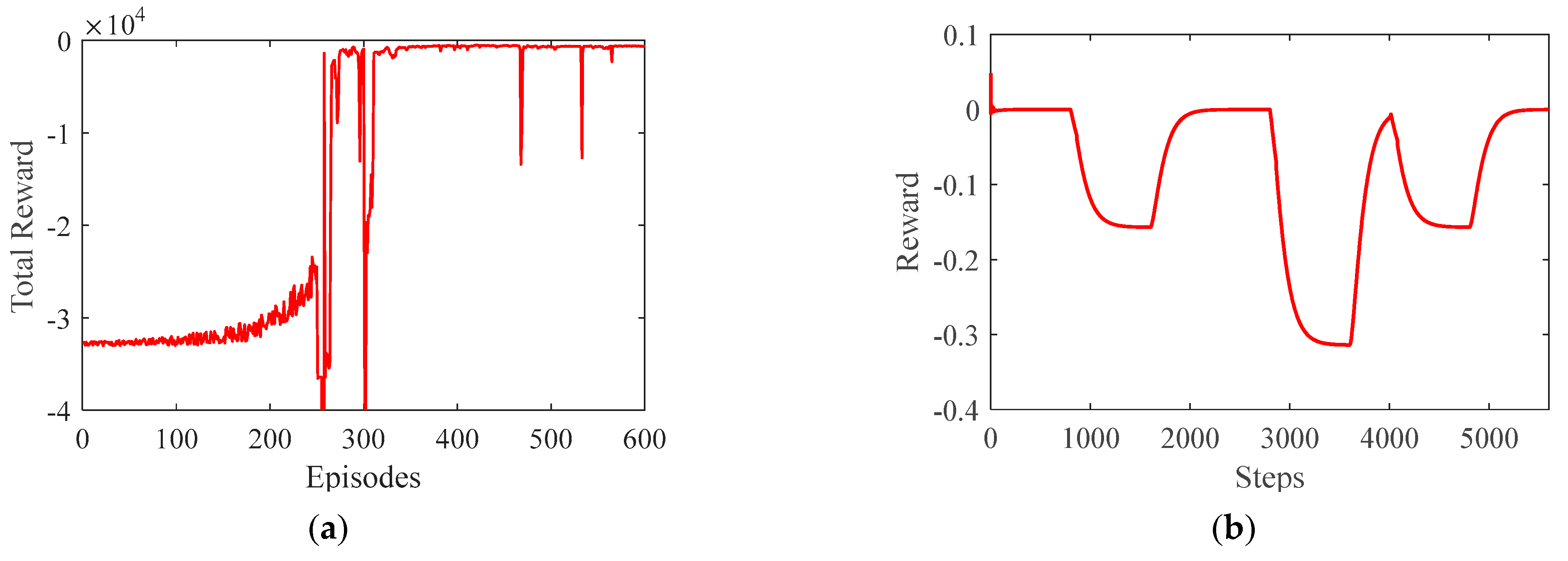
4. Training of DDPG-Based PID Control Algorithm
4.1. Training Environment-SUMO
4.2. Vehicle Platoon Control Policy Algorithm
| Algorithm 1. DDPG-based PID algorithm for vehicle platoon longitudinal control | |
| 1 | Randomly initialize critic network and actor network |
| 2 | Initialize target networks and replay buffer |
| 3 | for episode = 1, to M do |
| 4 | Initialize SUMO simulation environment; |
| 5 | Receive initial observation state s1; |
| 6 | for step = 1 to T do |
| 7 | Select action at based on current actor network and calculate the desired acceleration of host vehicle ades; |
| 8 | Execute desired acceleration ades in SUMO simulator and observe reward rt, new state st+1; |
| 9 | Save transition (st, at, rt, st+1) into replay buffer; |
| 10 | Sample a random batch size of N transitions from replay memory; |
| 11 | Update critic by minimizing the loss; |
| 12 | Update actor policy using the sampled gradient; |
| 13 | Update the target networks; |
| 14 | end for |
| 15 | end for |
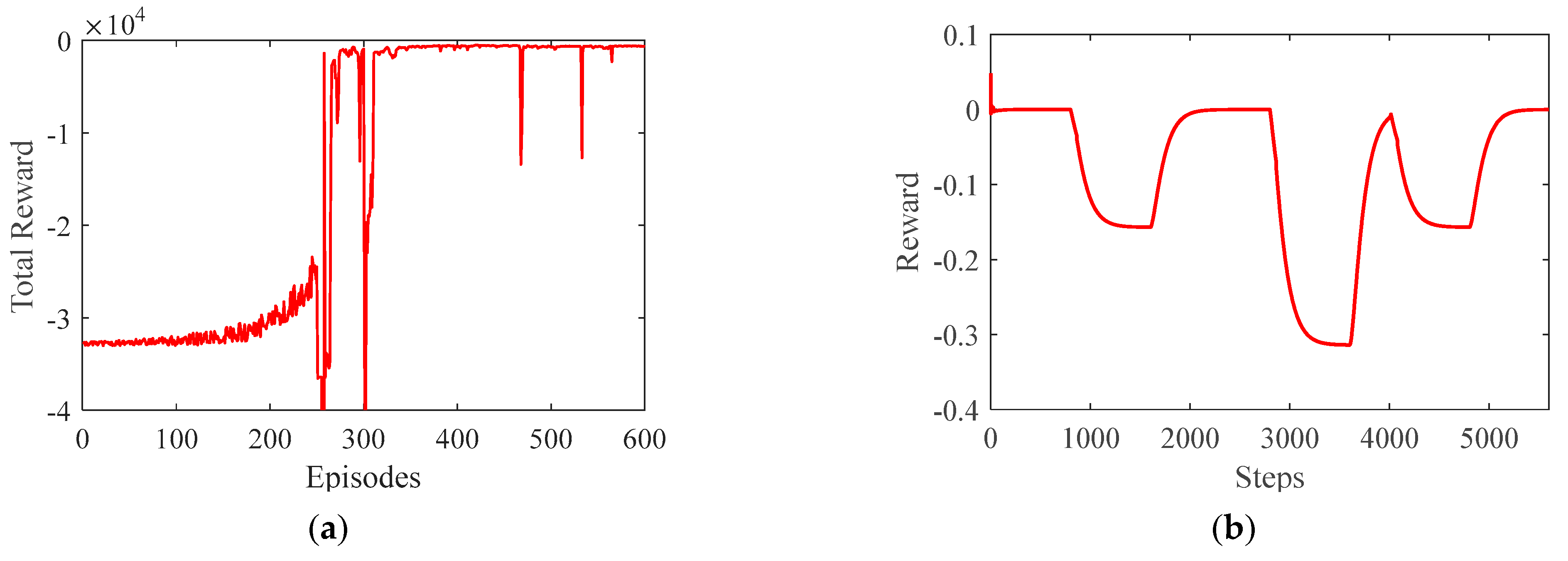
4.3. Algorithm Training Results
5. Experimental Results
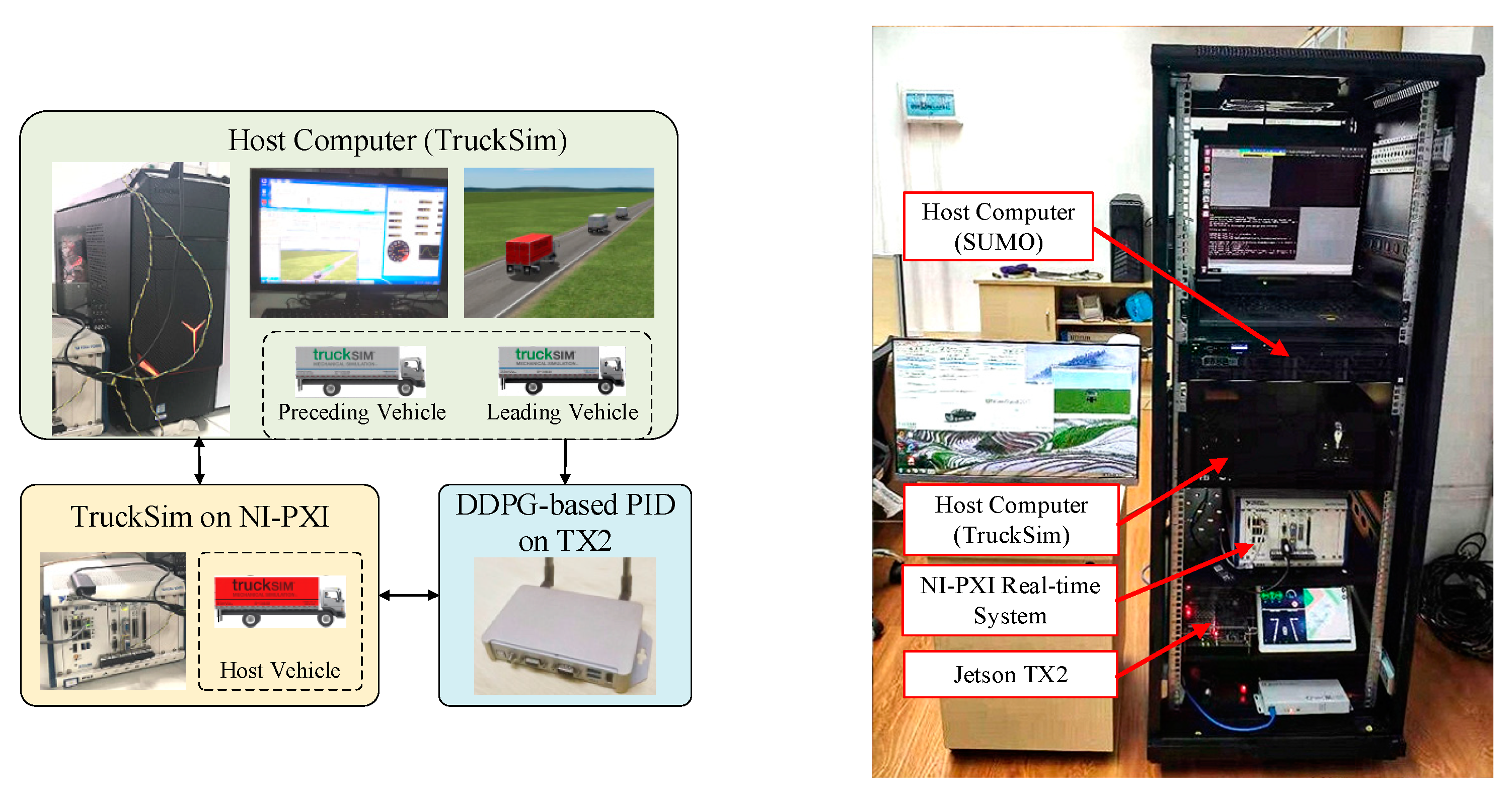
5.1. Design of Hardware-in-the-Loop (HIL) Platform
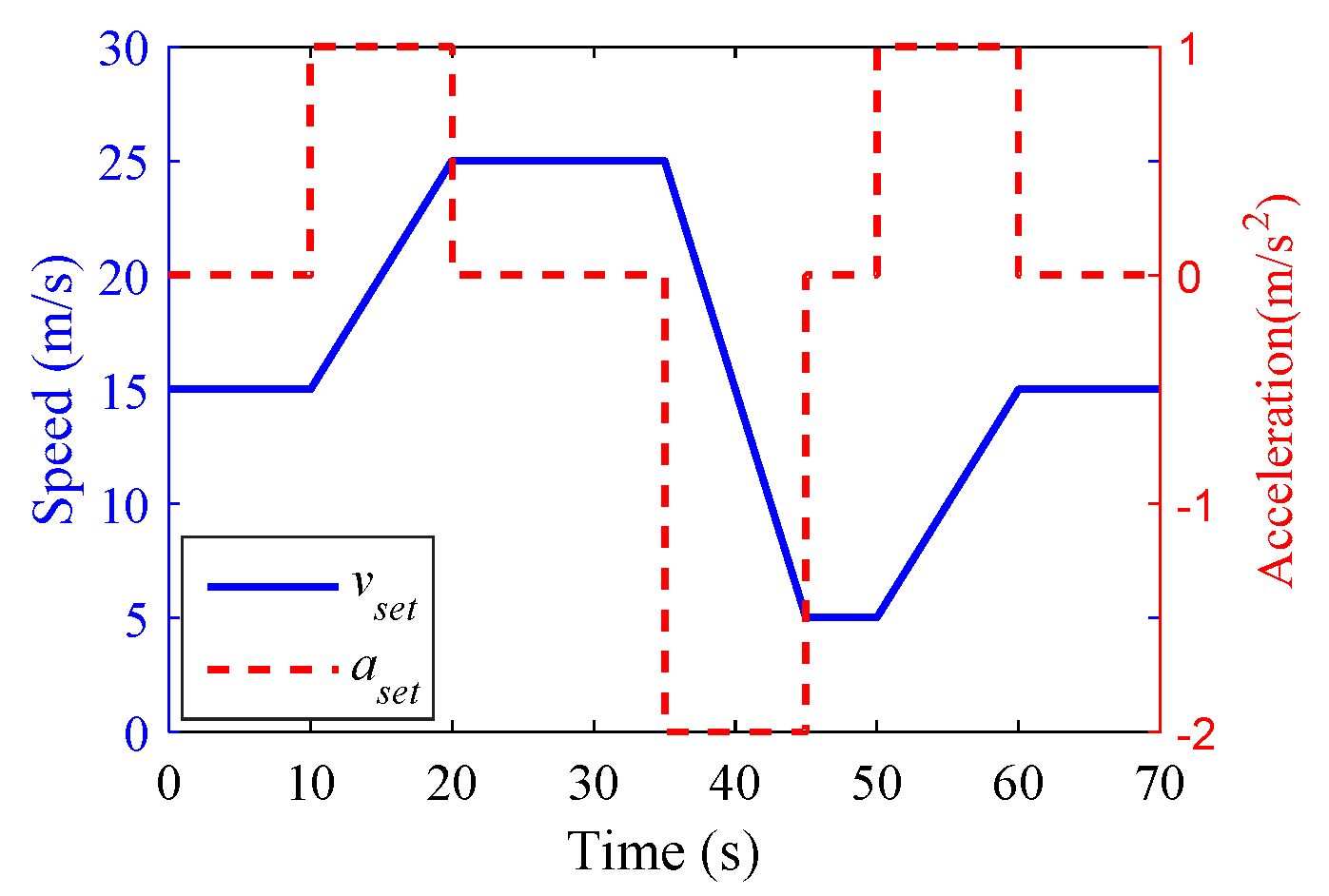
5.2. Experimental Setup and Parameter Settings
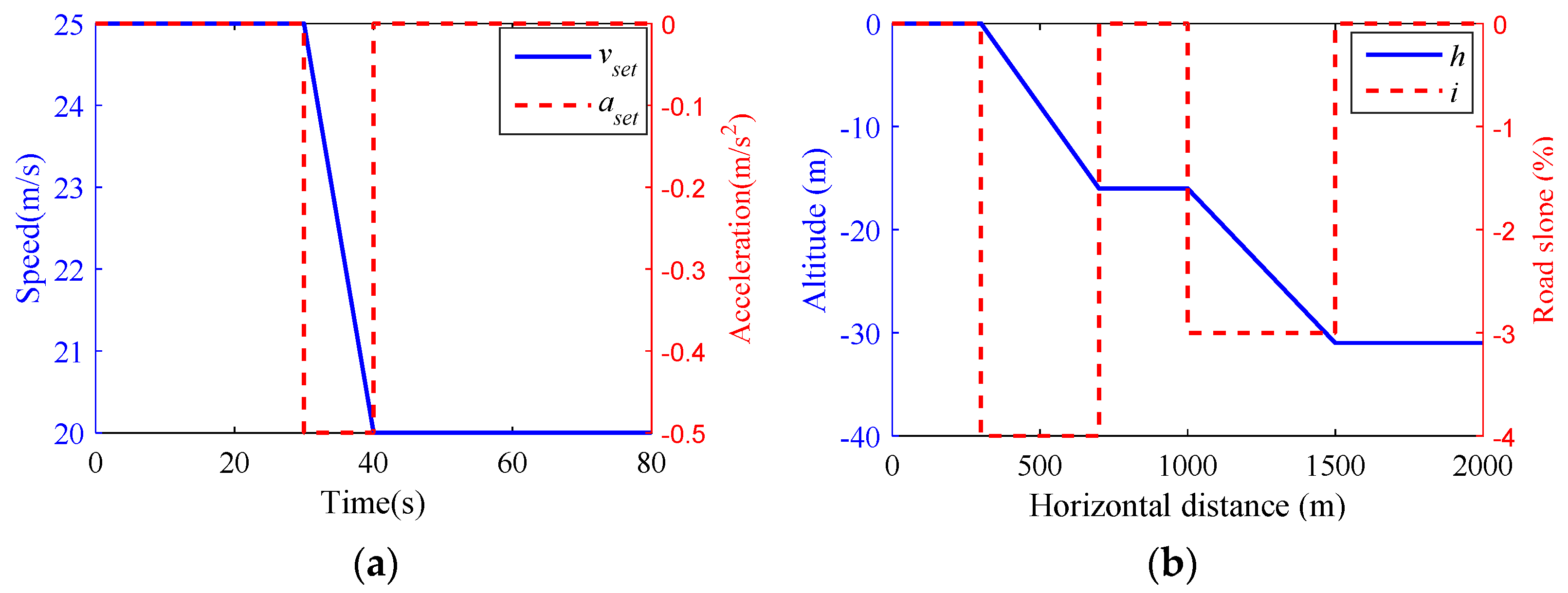
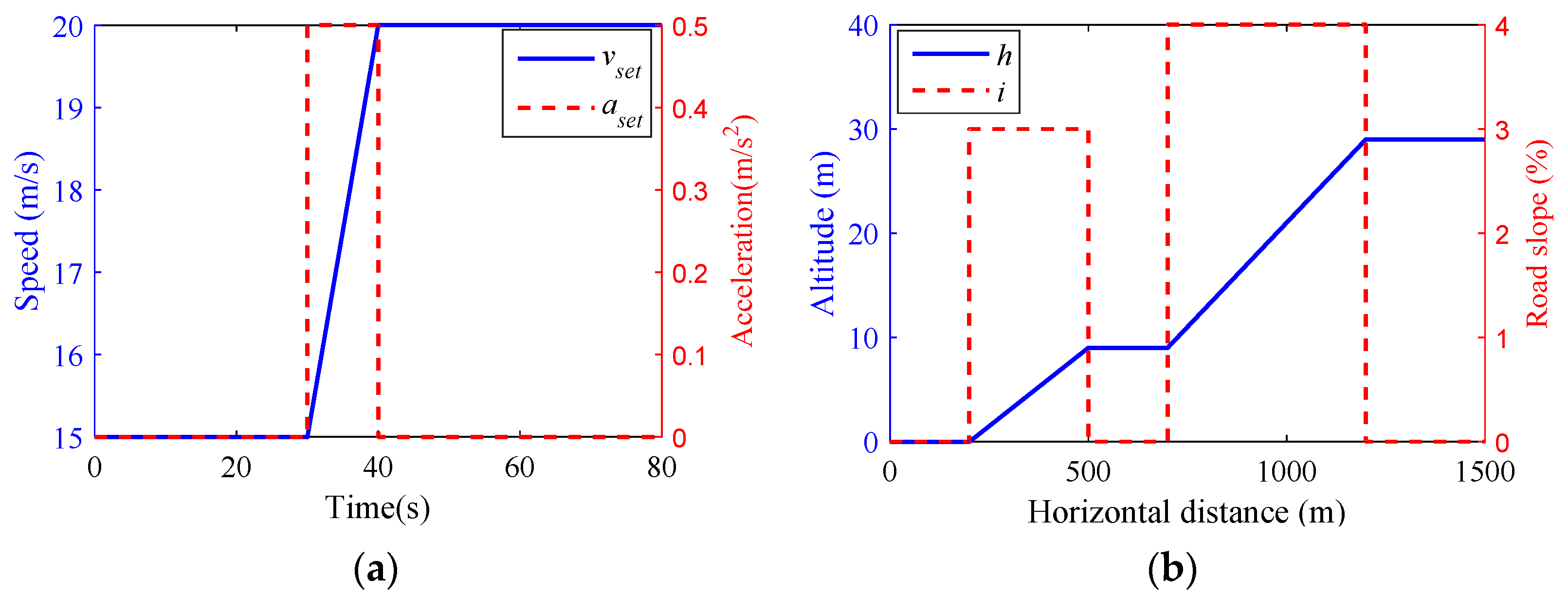
- Scenario 1
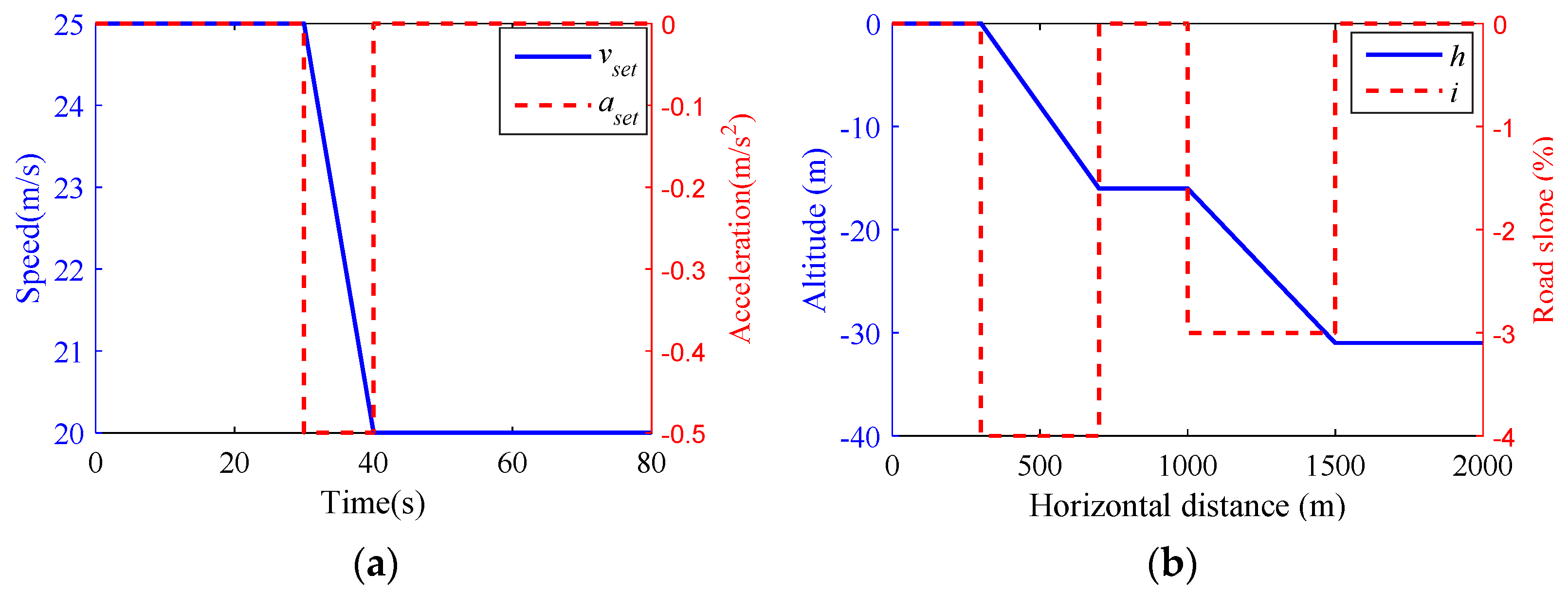
- Scenario 2
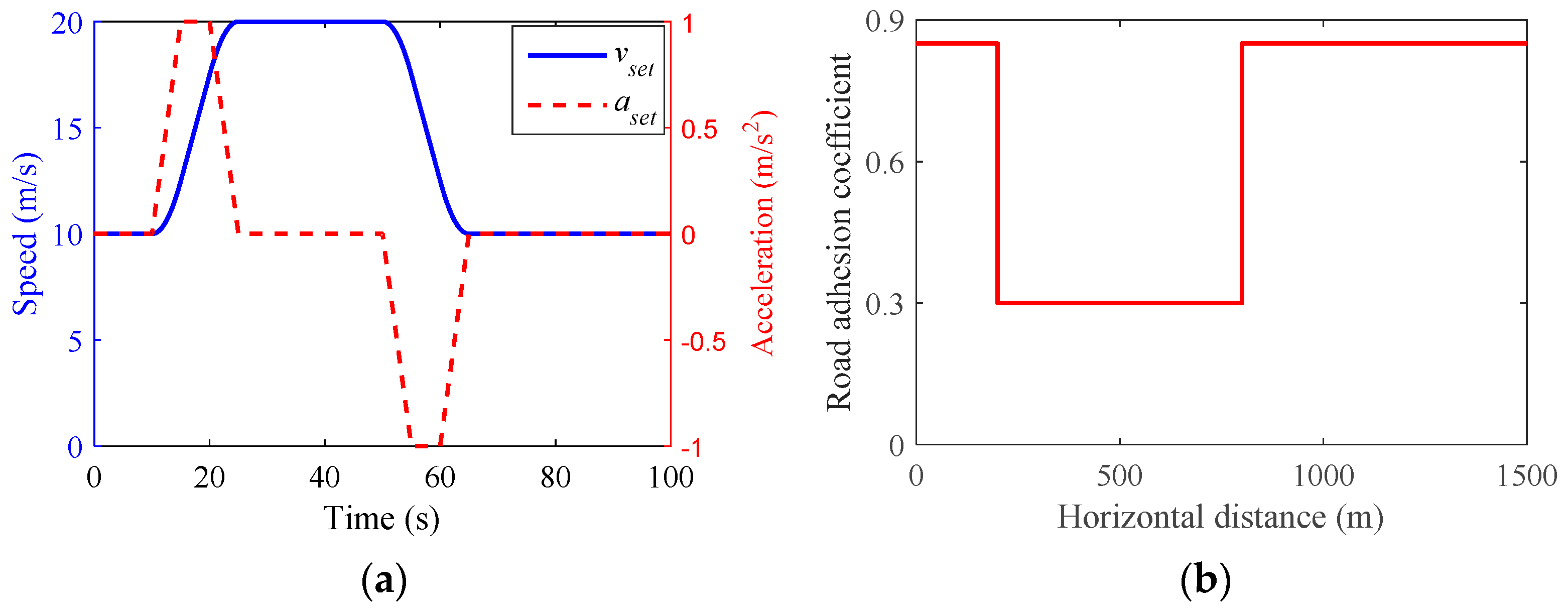
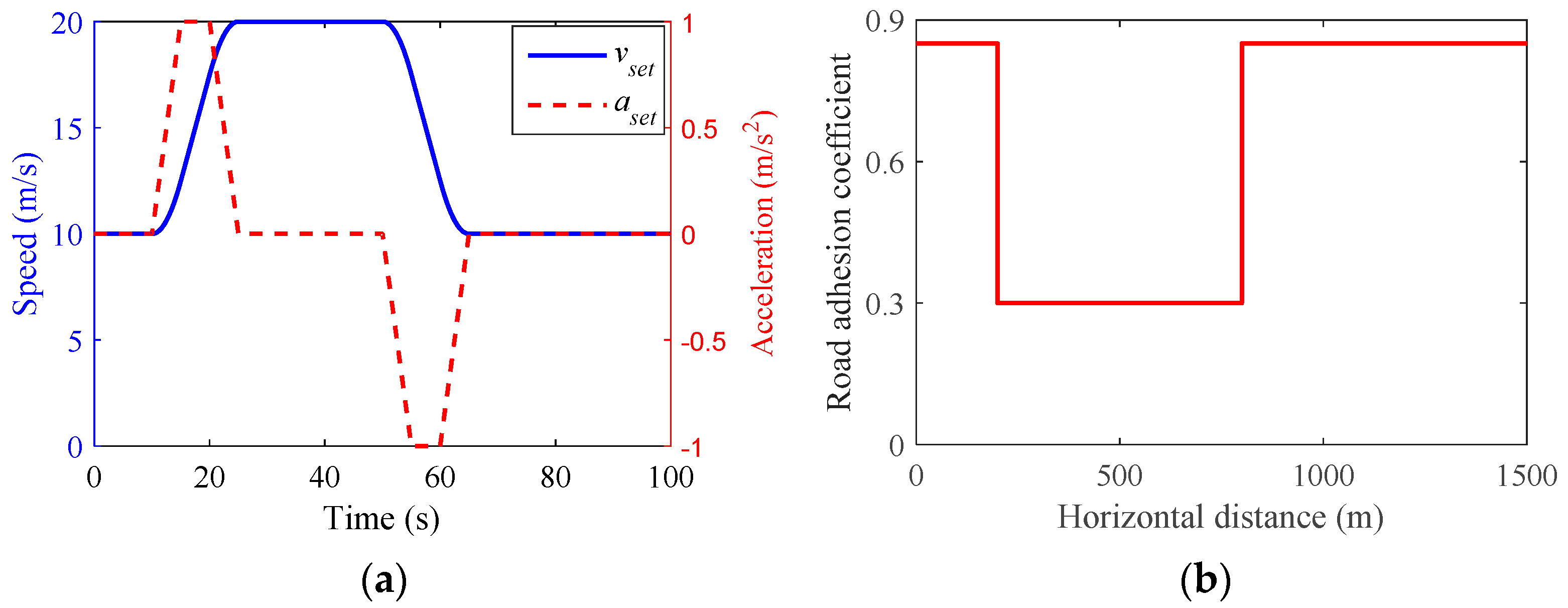
- Scenario 3
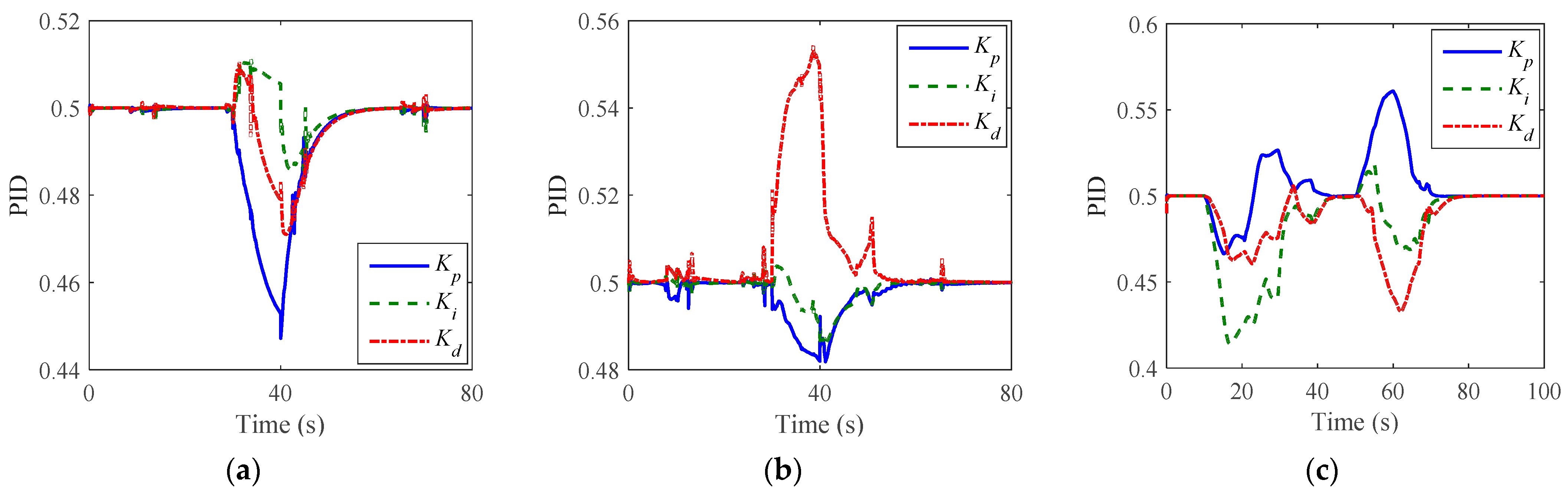
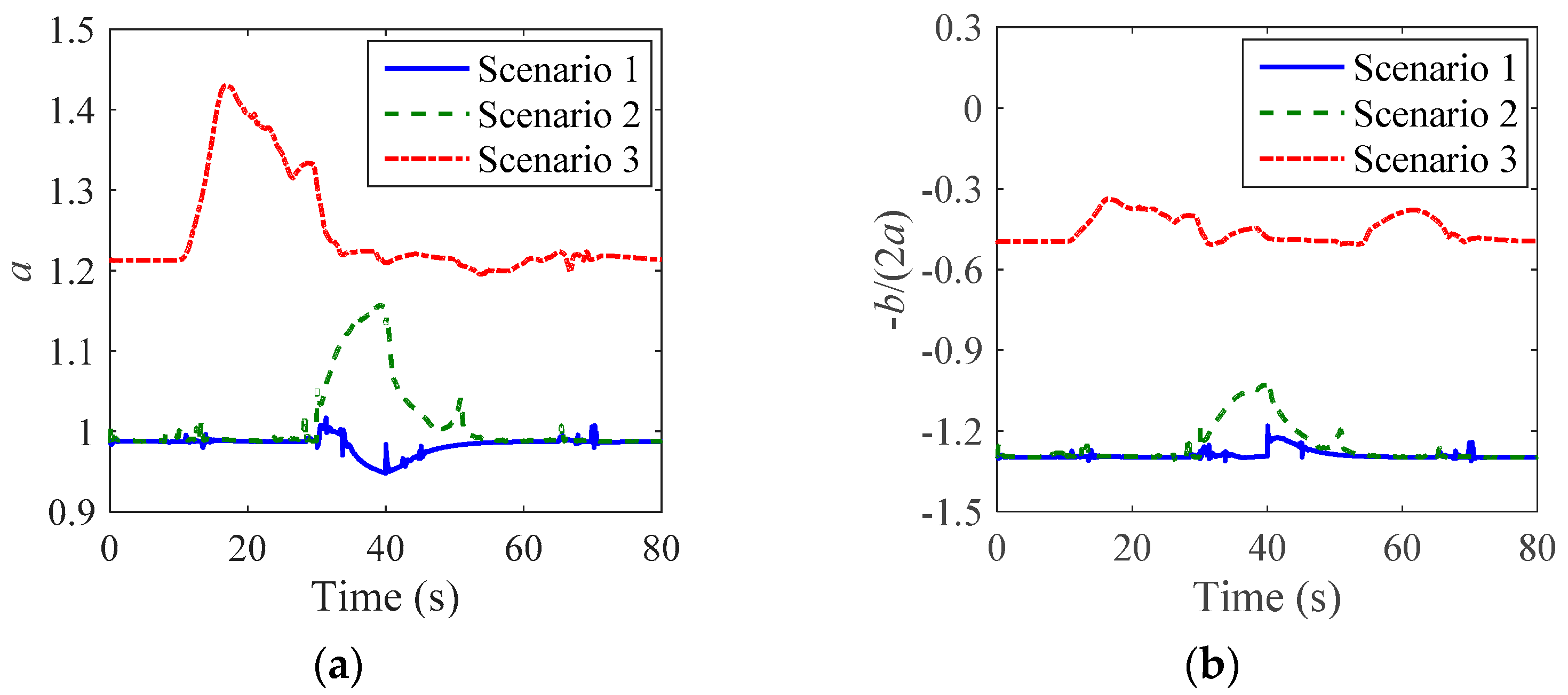
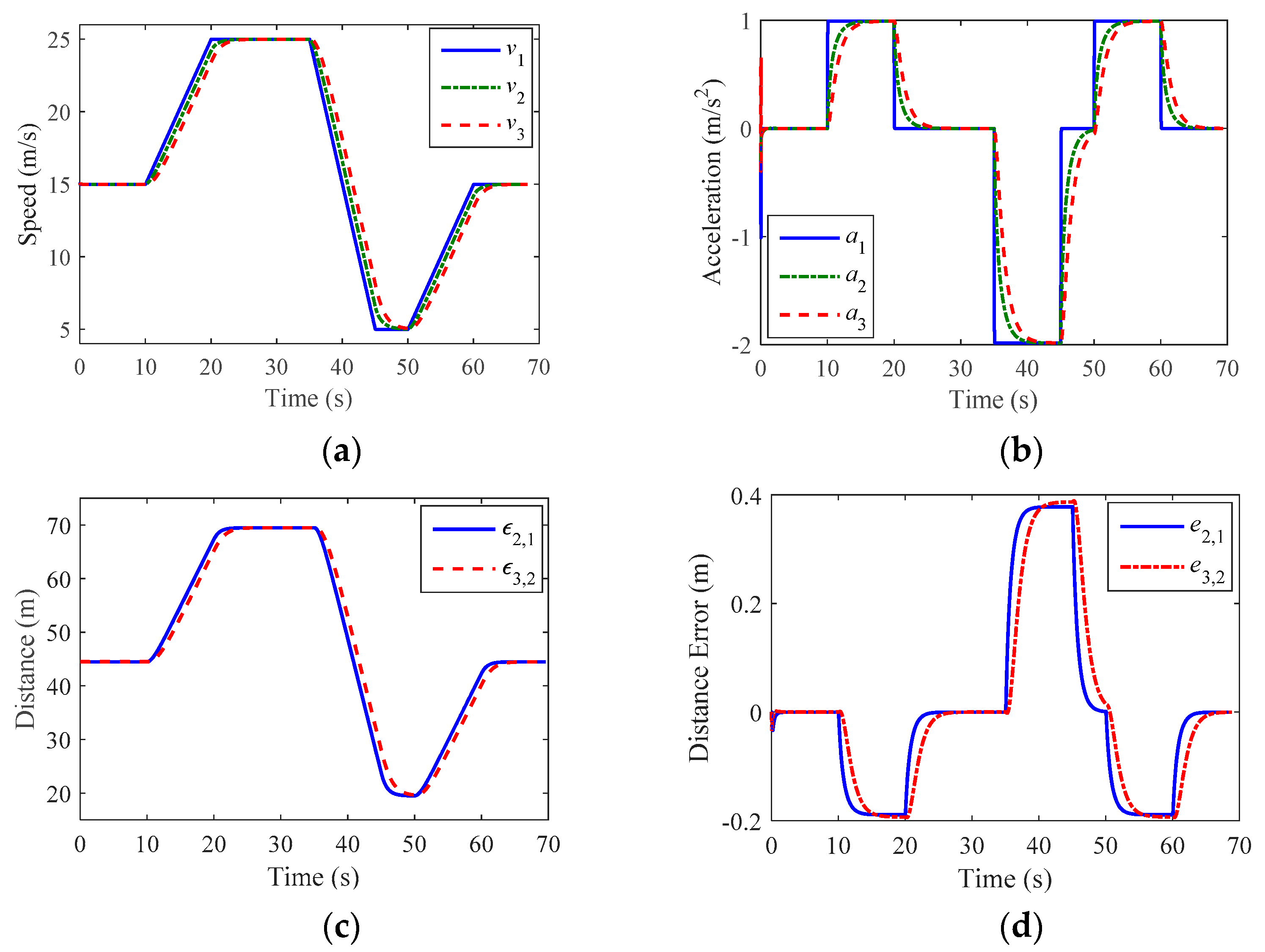
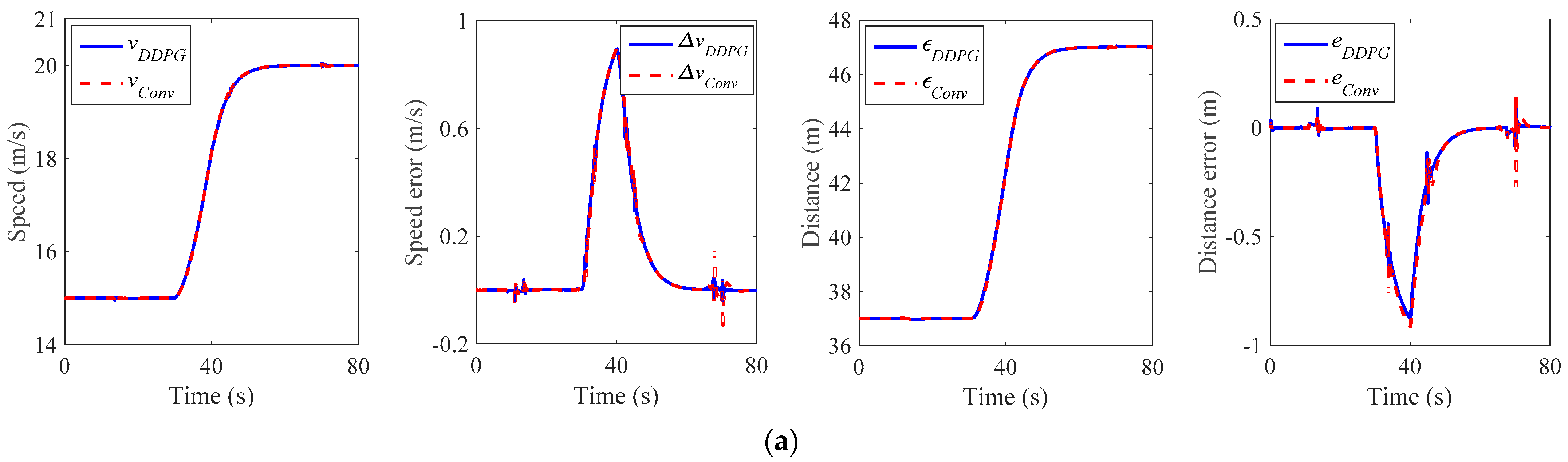
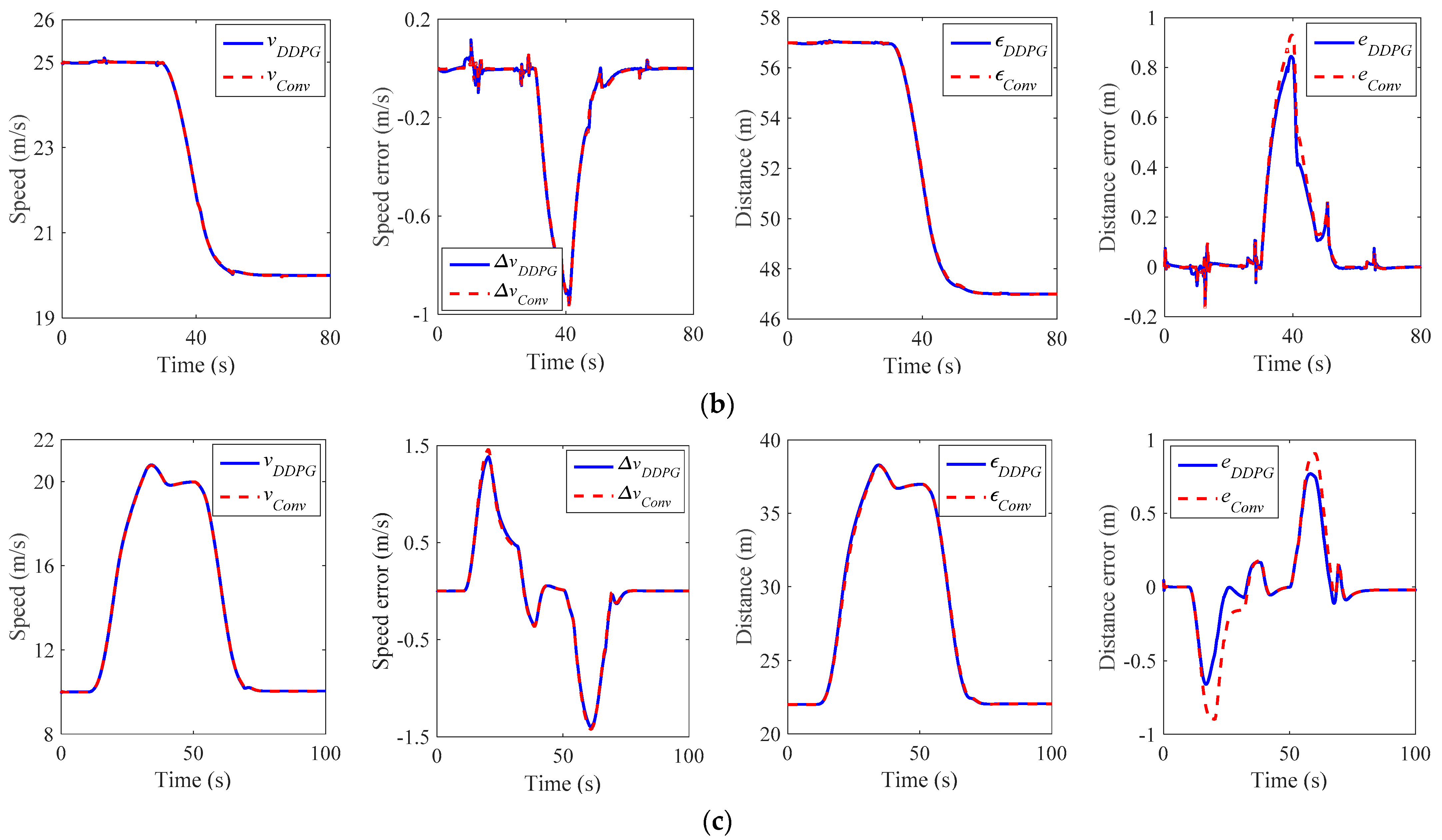
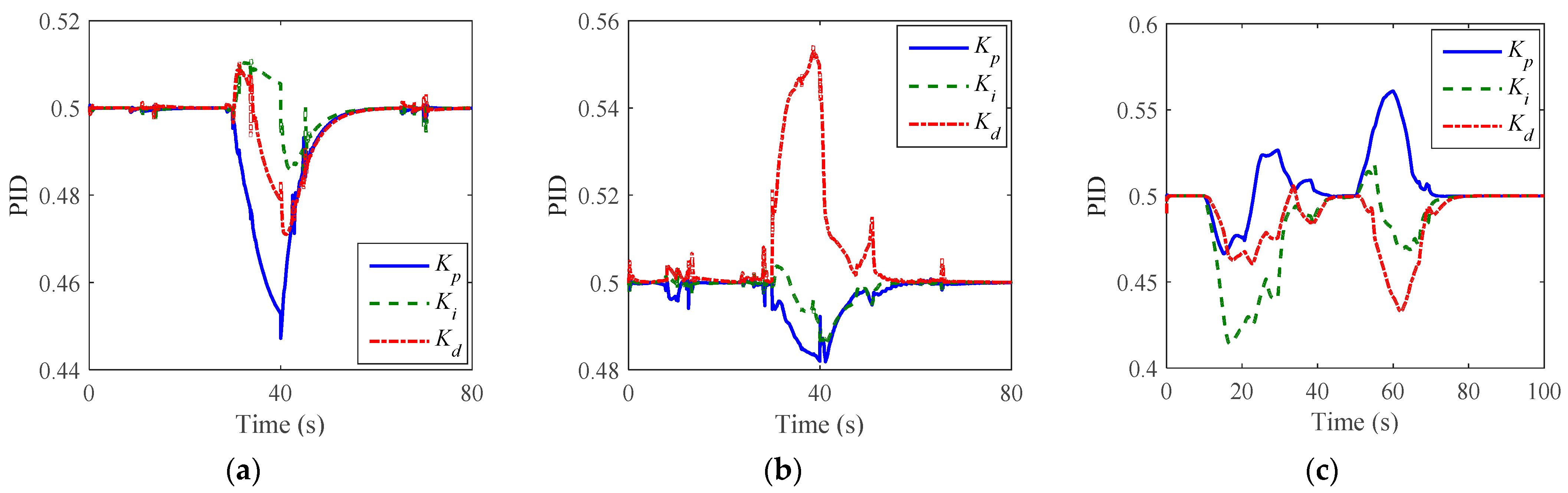
5.3. Validation Results
6. Discussion
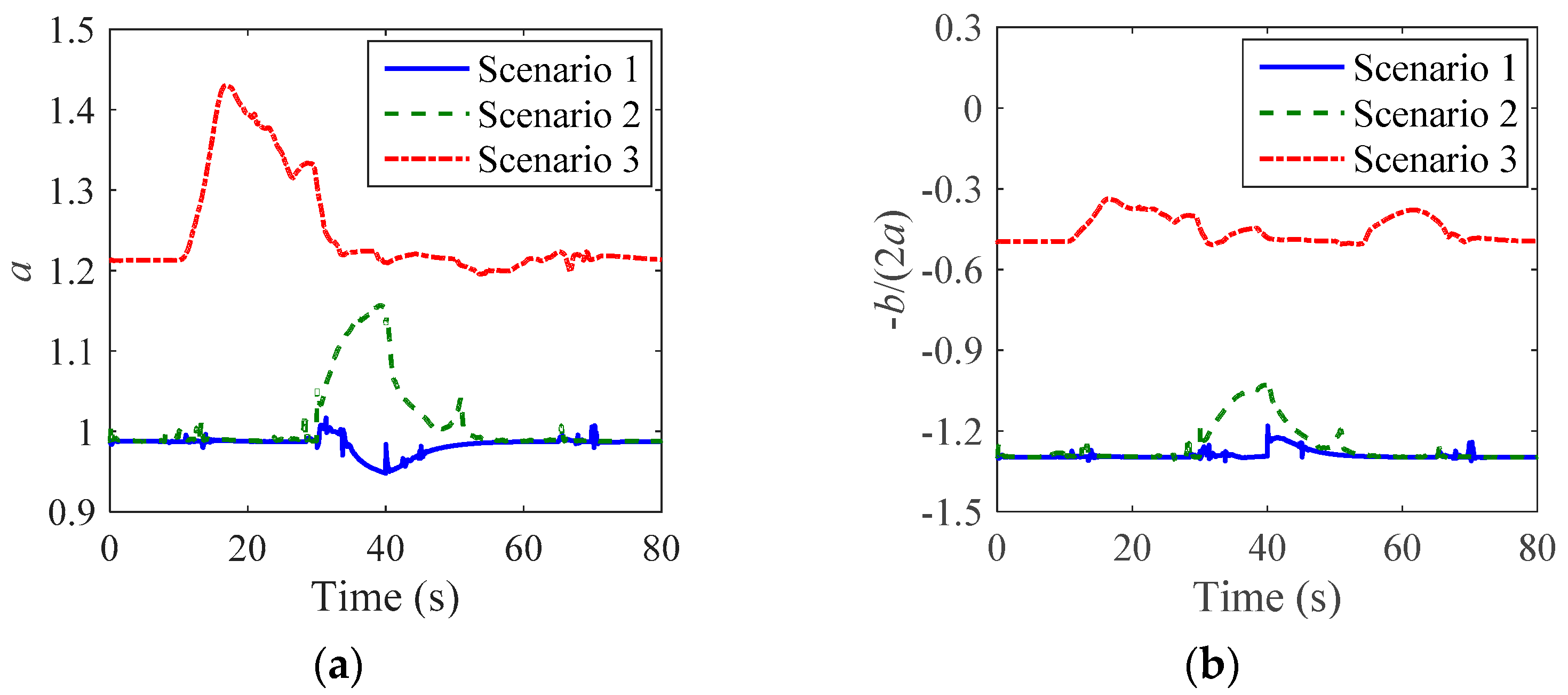
6.1. Stability Analysis
6.2. Control Effect Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, J.; Peng, W.; Sun, C. A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID. Electronics 2021, 10, 2580. [Google Scholar] [CrossRef]
- Talebpour, A.; Mahmassani, H.S. Influence of connected and autonomous vehicles on traffic flow stability and throughput. Transp. Res. Part C Emerg. Technol. 2016, 71, 143–163. [Google Scholar] [CrossRef]
- Wang, Z.; Bian, Y.; Shladover, S.E.; Wu, G.; Li, S.E.; Barth, M.J. A Survey on Cooperative Longitudinal Motion Control of Multiple Connected and Automated Vehicles. IEEE Intell. Transp. Syst. Mag. 2020, 12, 4–24. [Google Scholar] [CrossRef]
- Liu, B.; Gao, F.; He, Y.; Wang, C. Robust Control of Heterogeneous Vehicular Platoon with Non-Ideal Communication. Electronics 2019, 8, 207. [Google Scholar] [CrossRef] [Green Version]
- Na, G.; Park, G.; Turri, V.; Johansson, K.H.; Shim, H.; Eun, Y. Disturbance observer approach for fuel-efficient heavy-duty vehicle platooning. Veh. Syst. Dyn. 2020, 58, 748–767. [Google Scholar] [CrossRef]
- Chen, J.; Chen, H.; Gao, J.; Pattinson, J.-A.; Quaranta, R. A business model and cost analysis of automated platoon vehicles assisted by the Internet of things. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2020, 235, 721–731. [Google Scholar] [CrossRef]
- Hu, M.; Zhao, X.; Hui, F.; Tian, B.; Xu, Z.; Zhang, X. Modeling and Analysis on Minimum Safe Distance for Platooning Vehicles Based on Field Test of Communication Delay. J. Adv. Transp. 2021, 2021, 5543114. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, G.; Hao, P.; Boriboonsomsin, K.; Barth, M. Developing a platoon-wide Eco-Cooperative Adaptive Cruise Control (CACC) System. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1256–1261. [Google Scholar]
- Karoui, O.; Guerfala, E.; Koubaa, A.; Khalgui, M.; Tovard, E.; Wu, N.; Al-Ahmari, A.; Li, Z. Performance evaluation of vehicular platoons using Webots. IET Intell. Transp. Syst. 2017, 11, 441–449. [Google Scholar] [CrossRef]
- Fiengo, G.; Lui, D.G.; Petrillo, A.; Santini, S.; Tufo, M. Distributed Robust PID Control for Leader Tracking in Uncertain Connected Ground Vehicles with V2V Communication Delay. IEEE/ASME Trans. Mechatron. 2019, 24, 1153–1165. [Google Scholar] [CrossRef]
- Rajaram, V.; Subramanian, S.C. Design and hardware-in-loop implementation of collision avoidance algorithms for heavy commercial road vehicles. Veh. Syst. Dyn. 2016, 54, 871–901. [Google Scholar] [CrossRef]
- Guo, G.; Li, D. Adaptive Sliding Mode Control of Vehicular Platoons with Prescribed Tracking Performance. IEEE Trans. Veh. Technol. 2019, 68, 7511–7520. [Google Scholar] [CrossRef]
- Huang, Z.; Chu, D.; Wu, C.; He, Y. Path Planning and Cooperative Control for Automated Vehicle Platoon Using Hybrid Automata. IEEE Trans. Intell. Transp. Syst. 2019, 20, 959–974. [Google Scholar] [CrossRef]
- Liu, P.; Kurt, A.; Ozguner, U. Distributed Model Predictive Control for Cooperative and Flexible Vehicle Platooning. IEEE Trans. Control Syst. Technol. 2019, 27, 1115–1128. [Google Scholar] [CrossRef]
- Yan, M.; Ma, W.; Zuo, L.; Yang, P. Distributed Model Predictive Control for Platooning of Heterogeneous Vehicles with Multiple Constraints and Communication Delays. J. Adv. Transp. 2020, 2020, 4657584. [Google Scholar] [CrossRef]
- Li, S.E.; Gao, F.; Li, K.; Wang, L.; You, K.; Cao, D. Robust Longitudinal Control of Multi-Vehicle Systems—A Distributed H-Infinity Method. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2779–2788. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, S.E.; Li, K.; Ren, W. Platooning of Connected Vehicles with Undirected Topologies: Robustness Analysis and Distributed H-infinity Controller Synthesis. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1353–1364. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.0297. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Xu, X.; He, H.; Tan, J.; Sun, Z. Parameterized Batch Reinforcement Learning for Longitudinal Control of Autonomous Land Vehicles. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 730–741. [Google Scholar] [CrossRef]
- Wang, P.; Chan, C.; Fortelle, A.D.L. A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1379–1384. [Google Scholar]
- An, H.; Jung, J.-I. Decision-making system for lane change using deep reinforcement learning in connected and automated driving. Electronics 2019, 8, 543. [Google Scholar] [CrossRef] [Green Version]
- Chen, I.M.; Chan, C.-Y. Deep reinforcement learning based path tracking controller for autonomous vehicle. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2020, 235, 541–551. [Google Scholar] [CrossRef]
- Zhou, Y.; Fu, R.; Wang, C. Learning the Car-following Behavior of Drivers Using Maximum Entropy Deep Inverse Reinforcement Learning. J. Adv. Transp. 2020, 2020, 4752651. [Google Scholar] [CrossRef]
- Makantasis, K.; Kontorinaki, M.; Nikolos, I. Deep reinforcement-learning-based driving policy for autonomous road vehicles. IET Intell. Transp. Syst. 2019, 14, 13–24. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Zhang, X.; Sun, J. Automated vehicle’s behavior decision making using deep reinforcement learning and high-fidelity simulation environment. Transp. Res. Part C Emerg. Technol. 2019, 107, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Wang, Y.; Lin, P. A Feedback Force Controller Fusing Traditional Control and Reinforcement Learning Strategies. In Proceedings of the 2019 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hong Kong, China, 8–12 July 2019; pp. 259–265. [Google Scholar]
- Wang, J.; Xu, X.; Liu, D.; Sun, Z.; Chen, Q. Self-Learning Cruise Control Using Kernel-Based Least Squares Policy Iteration. IEEE Trans. Control Syst. Technol. 2014, 22, 1078–1087. [Google Scholar] [CrossRef]
- Dekker, L.G.; Marshall, J.A.; Larsson, J. Experiments in feedback linearized iterative learning-based path following for center-articulated industrial vehicles. J. Field Robot. 2019, 36, 955–972. [Google Scholar] [CrossRef]
- Zhao, Q.; Xu, H.; Jagannathan, S. Neural Network-Based Finite-Horizon Optimal Control of Uncertain Affine Nonlinear Discrete-Time Systems. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 486–499. [Google Scholar] [CrossRef]
- Sahoo, A.; Xu, H.; Jagannathan, S. Neural Network-Based Event-Triggered State Feedback Control of Nonlinear Continuous-Time Systems. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 497–509. [Google Scholar] [CrossRef]
- Choi, S.; Kim, S.; Jin Kim, H. Inverse reinforcement learning control for trajectory tracking of a multirotor UAV. Int. J. Control Autom. Syst. 2017, 15, 1826–1834. [Google Scholar] [CrossRef]
- Li, D.; Zhao, D.; Zhang, Q.; Chen, Y. Reinforcement Learning and Deep Learning Based Lateral Control for Autonomous Driving. IEEE Comput. Intell. Mag. 2019, 14, 83–98. [Google Scholar] [CrossRef]
- Lu, C.; Gong, J.; Lv, C.; Chen, X.; Cao, D.; Chen, Y. A Personalized Behavior Learning System for Human-Like Longitudinal Speed Control of Autonomous Vehicles. Sensors 2019, 19, 3672. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, X.; Chen, H.; Lian, C.; Li, D. Learning-Based Predictive Control for Discrete-Time Nonlinear Systems with Stochastic Disturbances. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6202–6213. [Google Scholar] [CrossRef]
- Ure, N.K.; Yavas, M.U.; Alizadeh, A.; Kurtulus, C. Enhancing Situational Awareness and Performance of Adaptive Cruise Control through Model Predictive Control and Deep Reinforcement Learning. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 626–631. [Google Scholar]
- Yang, J.; Liu, X.; Liu, S.; Chu, D.; Lu, L.; Wu, C. Longitudinal Tracking Control of Vehicle Platooning Using DDPG-based PID. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020; pp. 656–661. [Google Scholar]
- Zheng, Y.; Li, S.E.; Wang, J.; Cao, D.; Li, K. Stability and Scalability of Homogeneous Vehicular Platoon: Study on the Influence of Information Flow Topologies. IEEE Trans. Intell. Transp. Syst. 2016, 17, 14–26. [Google Scholar] [CrossRef] [Green Version]
- Swaroop, D.; Hedrick, J.K.; Chien, C.C.; Ioannou, P. A Comparision of Spacing and Headway Control Laws for Automatically Controlled Vehicles1. Veh. Syst. Dyn. 1994, 23, 597–625. [Google Scholar] [CrossRef]
- Lu, X.; Shladover, S. Integrated ACC and CACC development for Heavy-Duty Truck partial automation. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 4938–4945. [Google Scholar]
- Ploeg, J.; Shukla, D.P.; Wouw, N.V.D.; Nijmeijer, H. Controller Synthesis for String Stability of Vehicle Platoons. IEEE Trans. Intell. Transp. Syst. 2014, 15, 854–865. [Google Scholar] [CrossRef] [Green Version]
- Zhu, M.; Chen, H.; Xiong, G. A model predictive speed tracking control approach for autonomous ground vehicles. Mech. Syst. Signal Process. 2017, 87, 138–152. [Google Scholar] [CrossRef]
- Ntousakis, I.A.; Nikolos, I.K.; Papageorgiou, M. On Microscopic Modelling of Adaptive Cruise Control Systems. Transp. Res. Procedia 2015, 6, 111–127. [Google Scholar] [CrossRef] [Green Version]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 3. [Google Scholar]
- Wang, X.; Wang, R.; Jin, M.; Shu, G.; Tian, H.; Pan, J. Control of superheat of organic Rankine cycle under transient heat source based on deep reinforcement learning. Appl. Energy 2020, 278, 115637. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, W.; Shi, J.; Liu, J. Improve PID controller through reinforcement learning. In Proceedings of the 2018 IEEE CSAA Guidance, Navigation and Control Conference (CGNCC), Xiamen, China, 10–12 August 2018; pp. 1–6. [Google Scholar]
- Lee, D.; Lee, S.J.; Yim, S.C. Reinforcement learning-based adaptive PID controller for DPS. Ocean Eng. 2020, 216, 108053. [Google Scholar] [CrossRef]
- Wang, X.-S.; Cheng, Y.-H.; Sun, W. A Proposal of Adaptive PID Controller Based on Reinforcement Learning. J. China Univ. Min. Technol. 2007, 17, 40–44. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Meaning | Value |
|---|---|---|
| LRA | Learning rate for actor network | 0.0001 |
| LRC | Learning rate for critic network | 0.001 |
| Update rate | Update rate of target network tau | 0.001 |
| BUFFER_SIZE | Reply memory size | 100,000 |
| BATCH_SIZE | Batch size | 64 |
| ω1, ω2, ω3, ω4 | Reward function weight | 0.1, 5, 0.05, 1 |
| γ | Discount factor | 0.9 |
| Parameter | Meaning | Value |
|---|---|---|
| m | Mass (kg) | 5762 |
| hcg | Height of C.G (m) | 1.1 |
| L | Safe distance (m) | 5 |
| A | Frontal area (m2) | 6.8 |
| Lf/Lr | Front/rear track width (m) | 2.030/1.863 |
| Parameters | Scenario 1 | Scenario 2 | Scenario 3 |
|---|---|---|---|
| Initial speed (m/s) | 15 | 25 | 10 |
| Road slope (%) | 3 & 4 | −3 & −4 | 0 |
| Road adhesion coefficient | 0.85 | 0.85 | 0.3 & 0.85 |
| Desired time headway (s) | 2 | 2 | 1.5 |
| Maximum acceleration (m/s2) | 0.5 | −0.5 | 1 |
| Parameters | Upper Controller | Lower Controller | ||
|---|---|---|---|---|
| Preceding Vehicle | Host Vehicle | Driving Mode | Braking Mode | |
| Kp | 1 | 0.5 | 8000 | 5 |
| Ki | 0.5 | 0.5 | 3500 | 1 |
| Kd | 0.2 | 0.5 | 850 | 0.5 |
| Scenario | Maximum Speed Error (m/s) | Improvement (%) | Maximum Distance Error (m) | Improvement (%) | ||
|---|---|---|---|---|---|---|
| Conventional PID | DDPG-PID | Conventional PID | DDPG-PID | |||
| 1 | 0.91 | 0.88 | 3.30 | −0.92 | −0.87 | 5.43 |
| 2 | −0.97 | −0.95 | 2.06 | 0.93 | 0.85 | 8.60 |
| 3 | 1.46 | 1.38 | 5.48 | 0.90 | 0.77 | 14.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Peng, W.; Sun, C. A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID. Electronics 2021, 10, 2580. https://doi.org/10.3390/electronics10212580
Yang J, Peng W, Sun C. A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID. Electronics. 2021; 10(21):2580. https://doi.org/10.3390/electronics10212580
Chicago/Turabian StyleYang, Junru, Weifeng Peng, and Chuan Sun. 2021. "A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID" Electronics 10, no. 21: 2580. https://doi.org/10.3390/electronics10212580
APA StyleYang, J., Peng, W., & Sun, C. (2021). A Learning Control Method of Automated Vehicle Platoon at Straight Path with DDPG-Based PID. Electronics, 10(21), 2580. https://doi.org/10.3390/electronics10212580