4.3. Experimental Results and Discussion
A total of 11,120 sensitive API call subgraphs are extracted from the experiment. On average, each subgraph has 159 nodes and 271 edges. The largest subgraph has 668 nodes and 1372 edges, and the smallest subgraph has 12 nodes and 10 edges. Each API called subgraph is labeled with 0 or 1, where 0 means benign application and 1 means malicious application. Through stratified sampling, 80% of benign apps and malicious apps are used for training, and 10-fold cross validation is used in training. The remaining 20% is used for testing. The adjacent matrix and node structure feature vectors of the labeled sensitive API call subgraph are trained as the input of DGCNDroid. During the training, function tanh is used as the activation function in the graph convolution layer, function ReLU is used as the activation function in other layers, and the back propagation is optimized by stochastic gradient descent algorithm. In order to evaluate the experimental effect, we propose the following three research questions:
(1) Question 1: In the training stage, when the best classification effect is obtained, what are the values of the number of graph convolutional layers, the nodes’ number of each graph convolutional layer and n of n-hop neighboring nodes?
In order to control the variables, the structural feature vector of nodes temporarily only retains the centrality measure, while the number of neighboring nodes within n hops is discussed in the next step. Experiments are carried out on the combination of different layers of the graph convolutional layer and the number of layer nodes, and the detection accuracy is utilized to evaluate the classification effect. The results are shown in
Table 5. It can be seen that when the number of convolutional layers is 4 and the number of nodes in each layer is 64, the best detection accuracy is achieved. Although similar accuracy is obtained when the number of convolutional layers is 5 and the number of layer nodes is 32, as the number of convolutional layers increases, the training overhead also increases. Therefore, the graph convolution structure determined by the method in this paper utilizes 4 graph convolutional layers, and the number of nodes in each layer is 64.
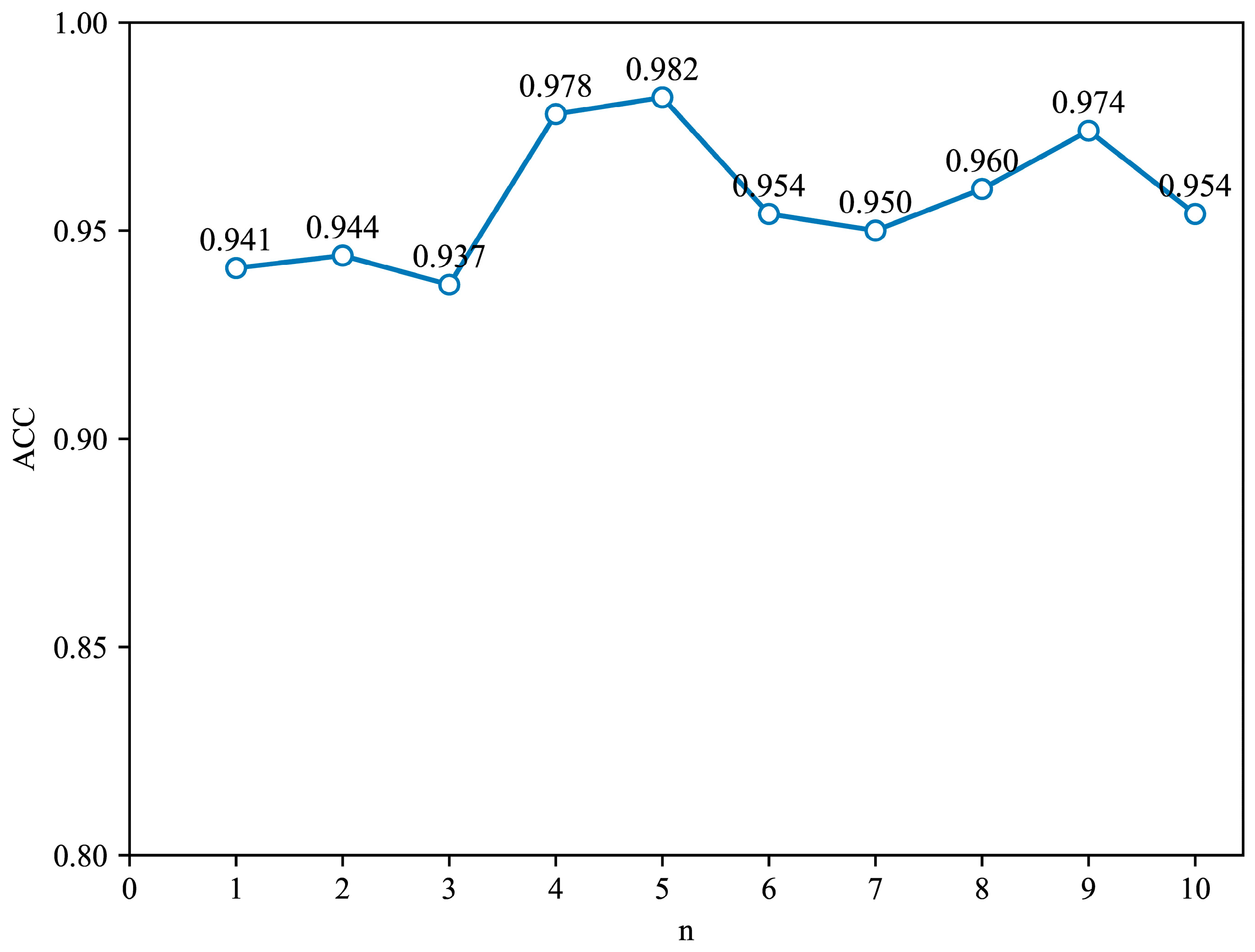
Furthermore, we choose the value of the number of hops n. At this time, the structural feature vector of the graph node is composed of the centrality measure and the number of neighboring nodes within n hops. Based on a graph convolutional network with 4 graph convolutional layers and 64 nodes in each layer, experiments were performed on the number of hops n in the range of 1 to 10, and the results are shown in
Figure 7. It can be seen that the best detection accuracy of 98.2% is obtained when the value of n is 5
In summary, the answer to question 1 is that the structure of the graph convolutional layer is determined to be 4 layers with 64 nodes for each, and the value of the hop number n is 5, so the graph node feature vector is composed of two centrality measures and the number of adjacent nodes within 5 hops.
(2) Question 2: Compared with the three existing approaches, namely the approach [
5] of using permission combinations as features, the approach [
17] of using API combinations as features and the approach [
15] of embedding graphs into vector space, how effective is the detection method proposed in this paper?
We compare DGCNDroid with the approach SigPID [
5], which uses permission combination as a feature, DeepFlow [
17], which uses API combination as a feature and AMDroid [
15], an approach to embed graphs into a vector space. As shown in
Table 6 and
Figure 8.
It can be seen from
Table 6 that DGCNDroid has a detection accuracy of up to 98% and a false positive rate of only 1.2%.
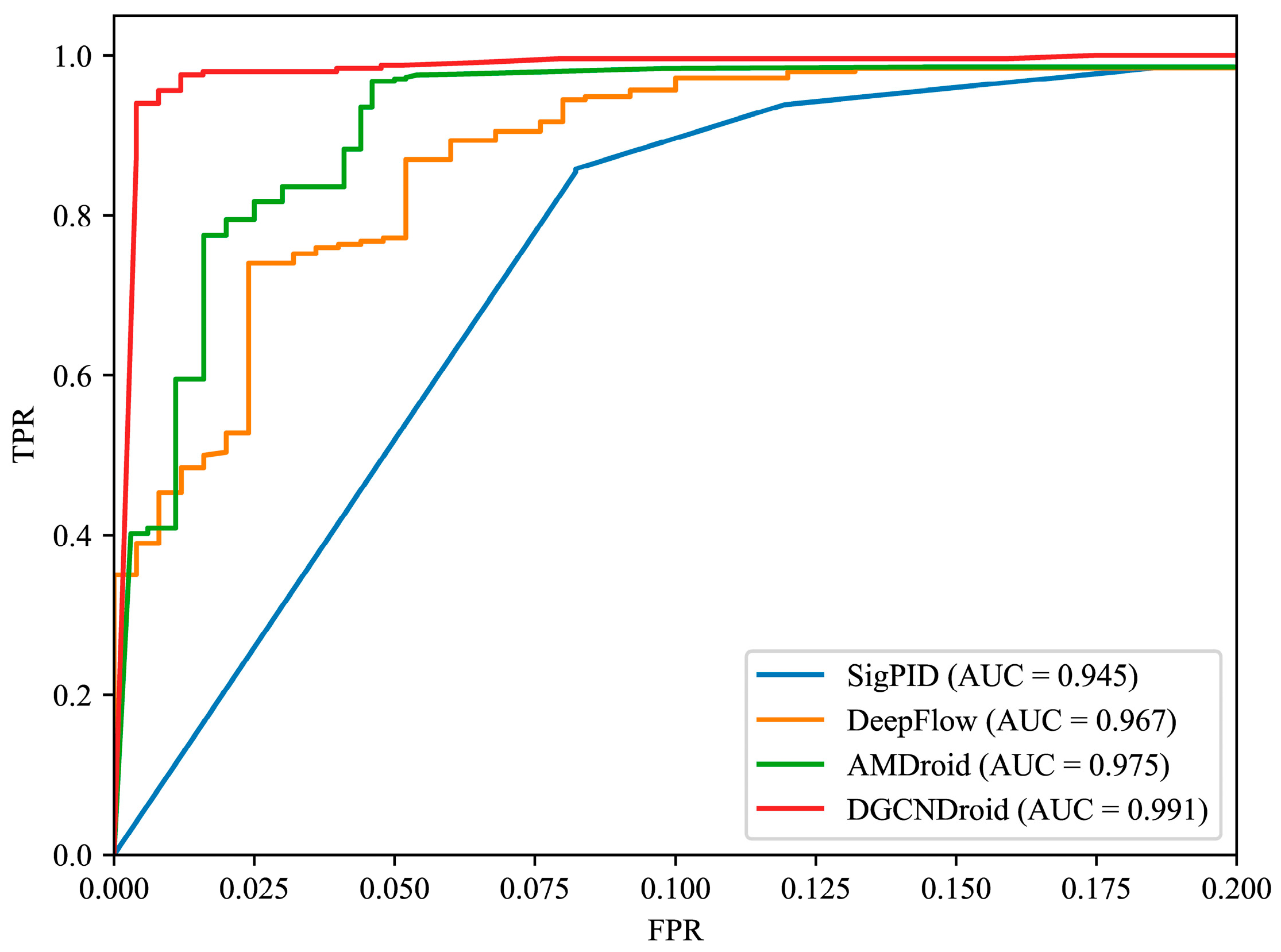
Figure 8 shows the comparison of ROC curves between DGCNDroid, SigPID [
5], DeepFlow [
17] and AMDroid [
15]. The ideal area under the ROC curve, in other words, AUC, is 1, so the closer the AUC area is to 1, the better the performance of the classifier. In the shape of the curve, the closer the inflection point of the curve is to the upper left corner, the higher the detection rate is and the lower the false positive rate is. It can be seen that compared with the ROC curves of the other three methods, the ROC curve of DGCNDroid is closer to the upper left corner, so it is more sensitive to malware detection and can better identify malware than other methods. At the same time, the curve of DGCNDroid is above the other three curves, so the area under the curve of DGCNDroid is significantly higher than that of the other three methods, which means that the DGCNDroid has a larger area under the curve.
In summary, the answer to Question 2 is that compared with the other three existing approaches, the approach in this paper has higher detection accuracy, recall rate and lower false positive rate, so the detection effect is better.
(3) Question 3: Can the approach of this paper be applied to multi-classification of malicious families, and how effective is the classification?
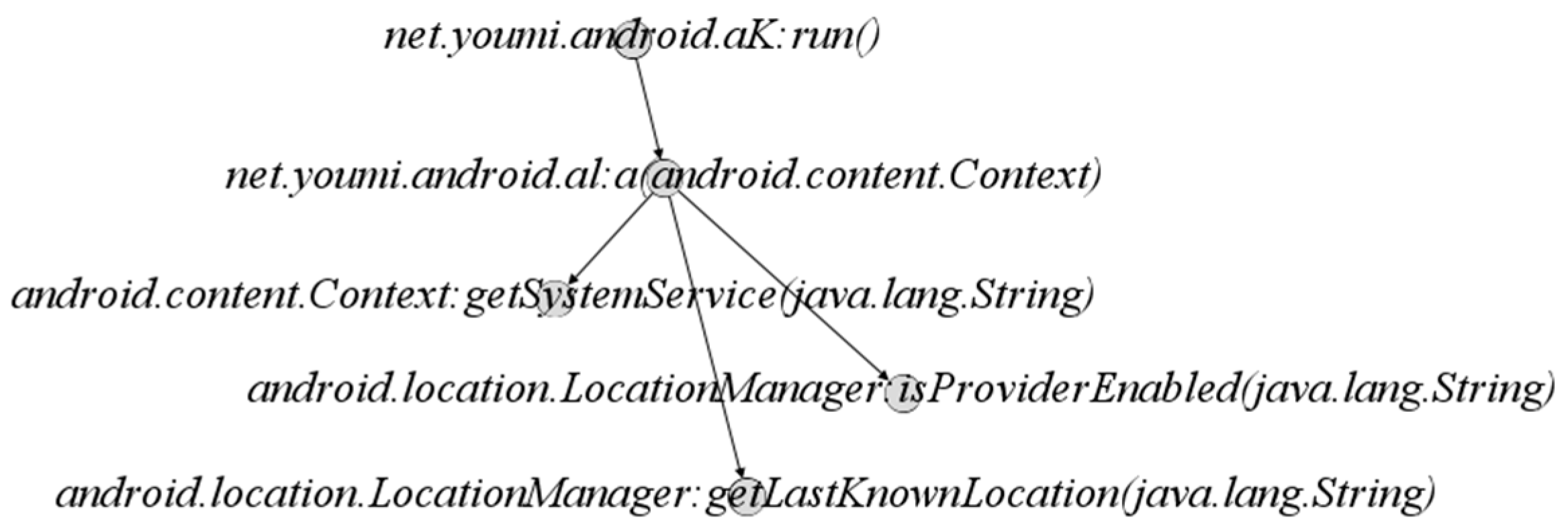
Although there are a large number of new malicious apps, most of them are variants of existing malicious applications. Malicious application developers usually use code reuse methods to modify or add new features based on the existing malicious application source code to achieve rapid release and cost reduction. Therefore, malicious applications will be aggregated in the form of families, and samples in the same family have similar malicious behaviors. As shown in
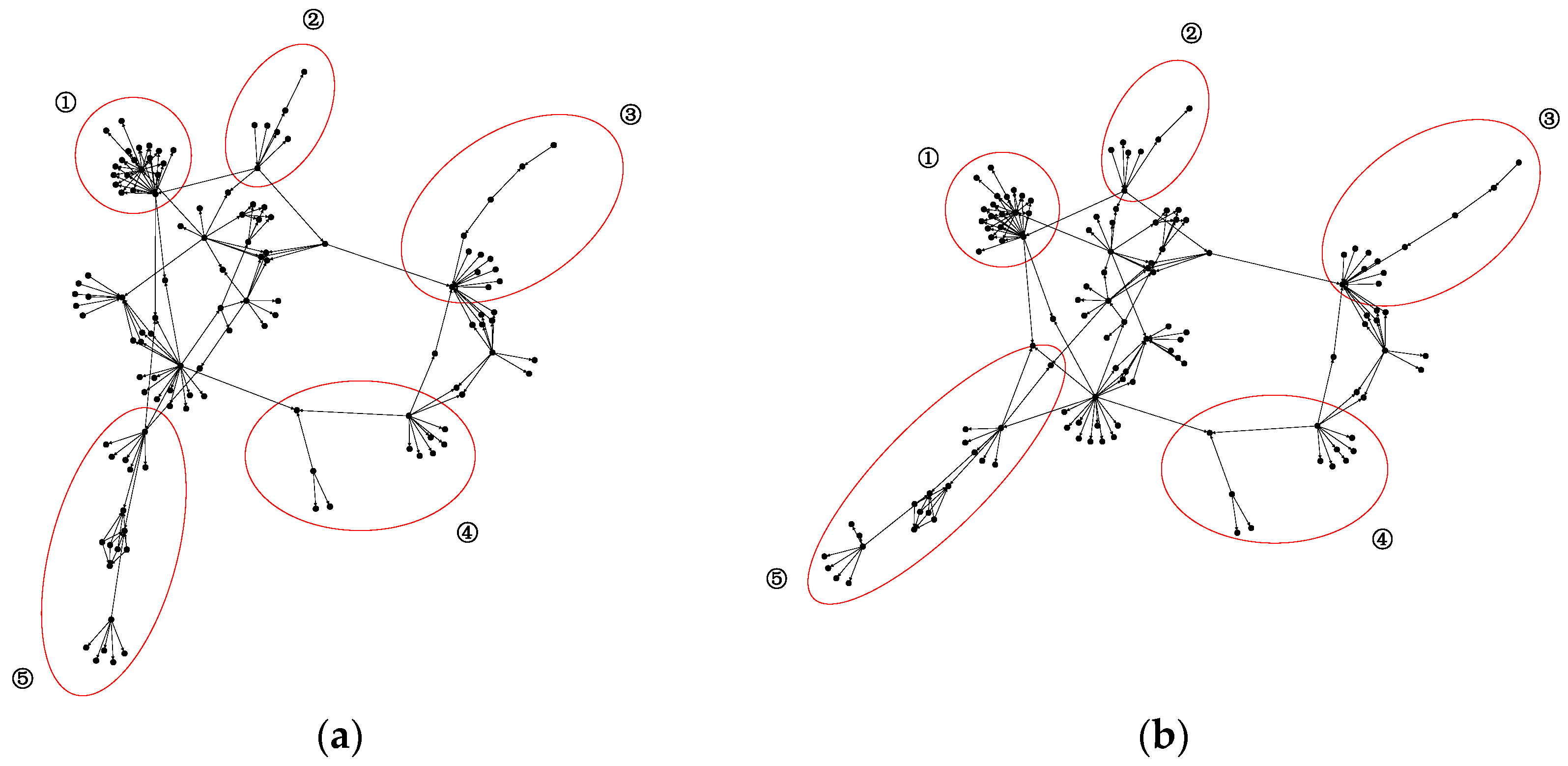
Figure 9, malicious application (a) and application (b) belong to the family SndApp. Their malicious behavior is to obtain information such as device ID, email address and phone number and upload it to a remote server. By observing and comparing their function call graphs in
Figure 9, it can be found that the two have a high similarity in the structure of the corresponding parts with the same number circled in red. Therefore, given that DGCNDroid can capture the structural features of the function call graph, we also conducted experiments on its multi-classification of malicious application families.
In order to compare with the results of the malicious family classification methods in literature [
14] and literature [
35], we utilize the same Android Malware Genome Project dataset [
36] that is part of Drebin dataset [
16] and contains 1260 applications from 49 families. For multi-classification, families containing only one sample need to be removed, and finally the dataset retains 1244 apps from 33 families. During training, the samples are sampled in a stratified manner at a ratio of 50%, and the remaining 50% of the samples are used for classification testing. When training the multi-classification model, the training samples are divided into 33 categories from 0 to 32. The structure of the deep graph convolutional network still follows the structure discussed in the binary classification, but the difference is that the final softmax output nodes are changed from 2 to 33. The macro accuracy is used to measure the classification effect on test set. The results are shown in
Table 7.
Compared with approach [
14] and approach [
35] using the same data set, DGCNDroid achieves higher classification accuracy than the approach Dendroid [
35] based on code structure mining. The classification effect of approach [
14] is slightly better than that of DGCNDroid, but FalDroid [
14] takes an average of 4.6 s to extract the graph features of an application [
14], and it takes an average of 3.9 s to extract the features of an application using the approach of this paper. Therefore, the approach in this paper is better in terms of time overhead than approach [
14].
In summary, the answer to question 3 is that the method in this article can also be applied to multi-classification of malicious families. The classification effect is close to the current advanced methods, but the time cost of feature extraction is better than the existing approaches.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}