
A Survey of Vision-Based Transfer Learning in Human Activity Recognition



Abstract
:1. Introduction
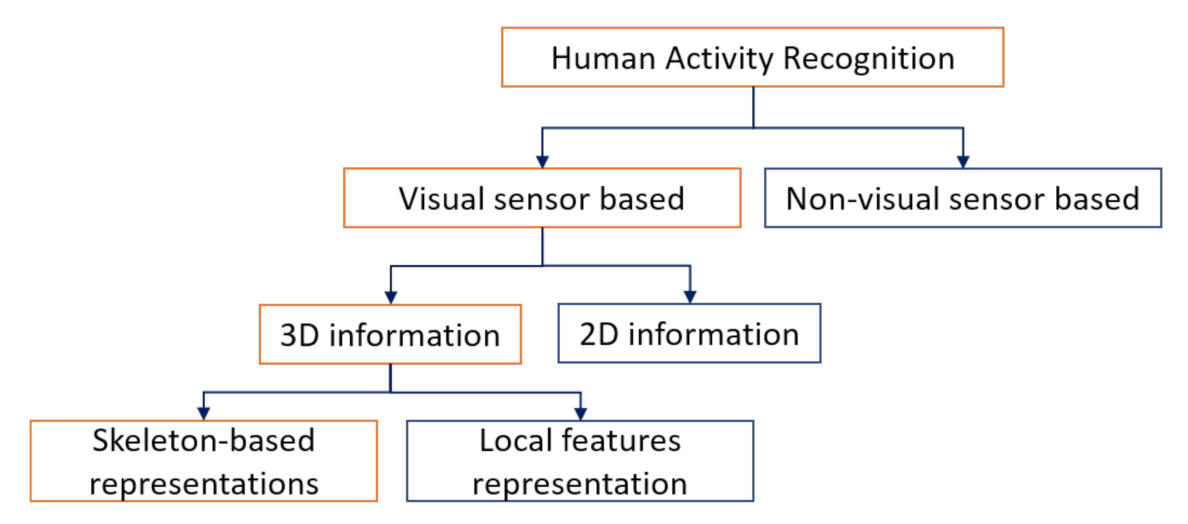
2. Human Activity Recognition with 3D Vision Sensors
2.1. Background and Challenge of 3D Vision-Based HAR
2.2. Data Collection of Human Activities in 3D Skeletal Data Space
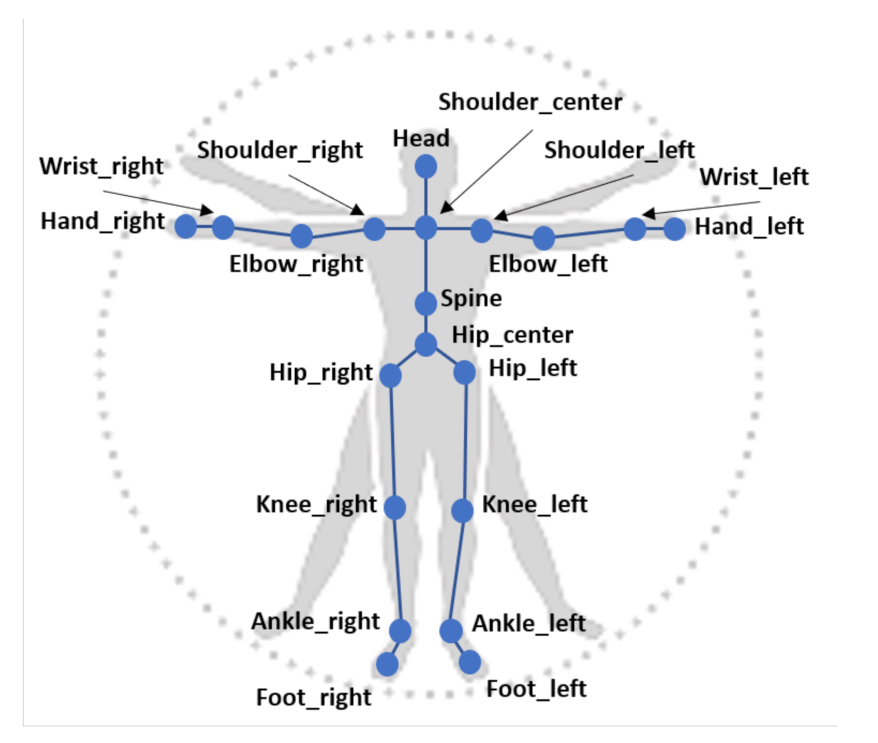
2.2.1. Direct Acquisition of 3D Human Skeletal Data from Sensors
2.2.2. 3D Skeleton Construction from Pose Estimation
2.2.3. Benchmark 3D Skeleton Human Activity Datasets
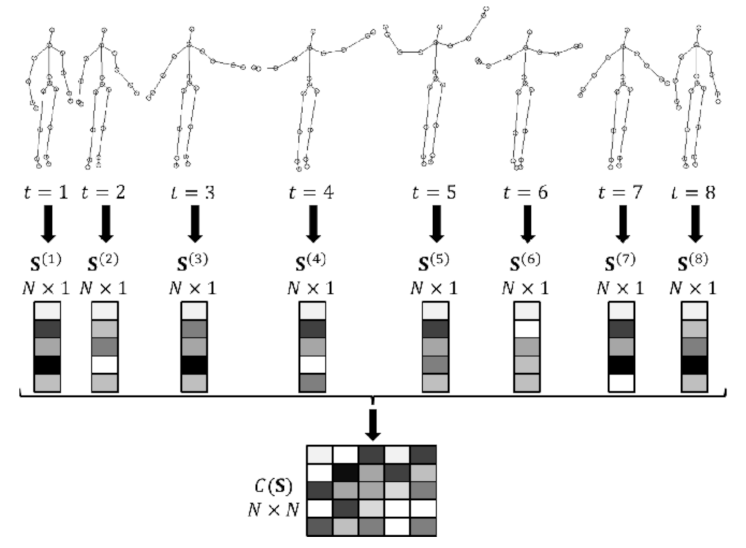
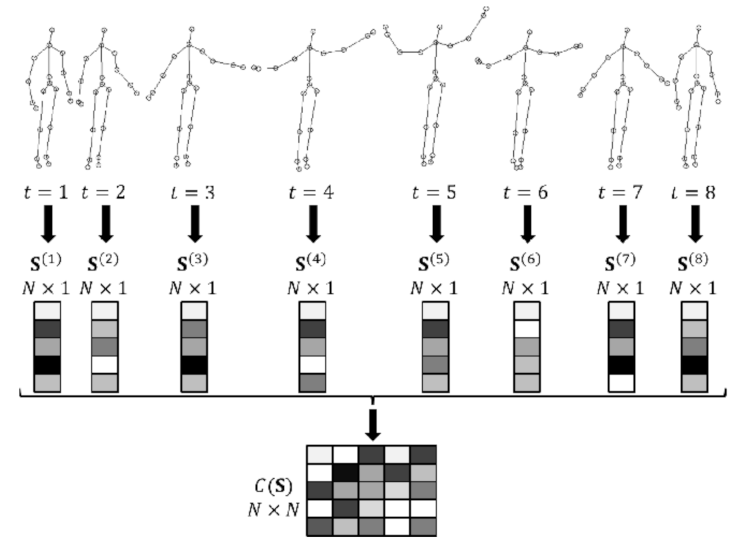
2.3. Feature Extraction in HAR from 3D Skeletal Human Activities Data
2.4. Recognition and Classification of 3D Skeletal Human Activity
2.4.1. Classification with Statistical and Classical Machine Learning Algorithms
2.4.2. Recognition of Human Activities Using Probabilistic Models
2.4.3. Recognition of Human Activities Using Fuzzy Systems
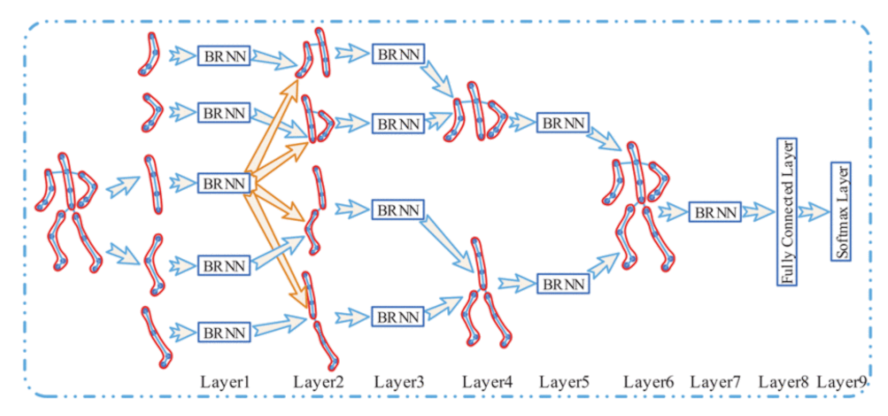
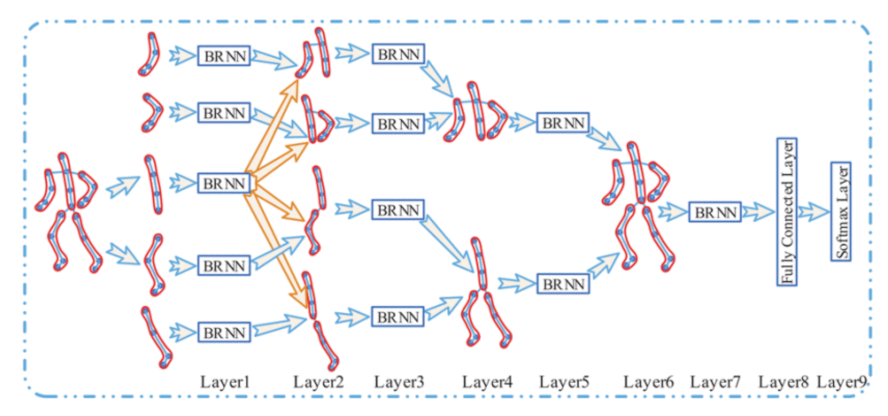
2.4.4. Recognition of Human Activities Using Artificial Neural Networks
2.4.5. Benchmark Performance of Different HAR Approaches
2.5. Limitations of Vision-Based HAR
- Suitable data for HAR systems must be obtained, as the data have a defining impact on any system. In addition, the algorithms used for recognition should be investigated and selected based on the performances obtained with the information modality and other relevant factors.
- Most research focuses on activity classification using one person; however, action detection and activity pattern discovery require more investigation to provide a better understanding of the nature of activities.
3. Human Activities and Transfer Learning
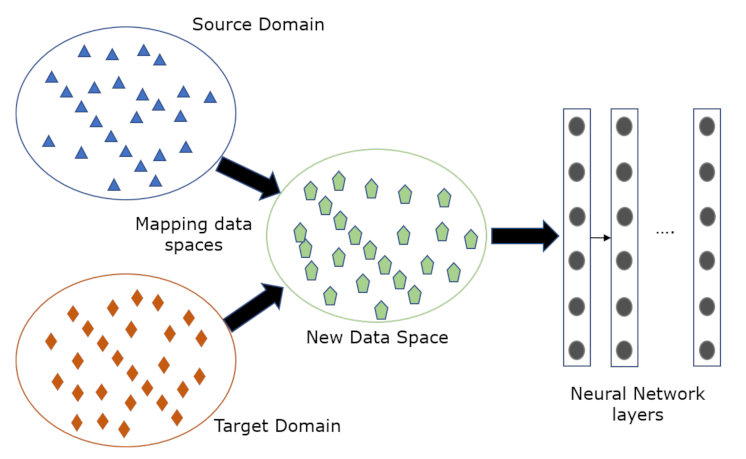
3.1. Ontology of the Transfer Learning of Human Activities
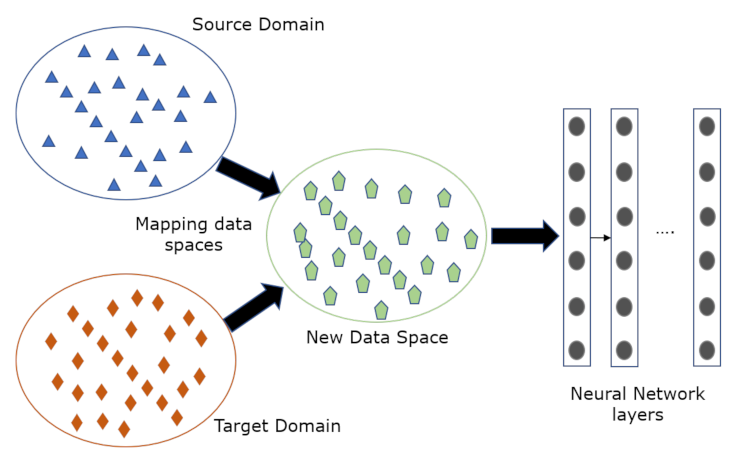
3.2. Neural Network Transfer Learning Methods
3.3. Genetic Algorithm Transfer Learning Methods
3.4. Fuzzy Logic Transfer Learning Methods
4. Research Opportunities
5. Challenges and Future Directions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data: A review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef] [Green Version]
- Faria, D.R.; Premebida, C.; Nunes, U. A Probabilistic Approach for Human Everyday Activities Recognition using Body Motion from RGB-D Images. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, RO-MAN, Edinburgh, England, 25–29 August 2014; pp. 732–737. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from RGBD images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MI, USA, 14–18 May 2012; pp. 842–849. [Google Scholar]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 2000, 90, 227–244. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Cao, Y.; Sun, J.; Yu, P.S. Deep Learning of Transferable Representation for Scalable Domain Adaptation. IEEE Trans. Knowl. Data Eng. 2016, 28, 2027–2040. [Google Scholar] [CrossRef]
- Tan, S.; Sim, K.C.; Gales, M. Improving the interpretability of deep neural networks with stimulated learning. In Proceedings of the Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–14 December 2015; pp. 617–623. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—NIPS’12, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning—ICANN 2018; Springer International Publishing: Rhodes, Greece, 2018; pp. 270–279. [Google Scholar]
- Wang, Y.; Han, X.; Liu, Z.; Luo, D.; Wu, X. Modelling inter-task relations to transfer robot skills with three-way RBMs. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015; pp. 1276–1282. [Google Scholar]
- Makondo, N.; Rosman, B.; Hasegawa, O. Knowledge transfer for learning robot models via Local Procrustes Analysis. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 1075–1082. [Google Scholar]
- Iglesias, J.A.; Angelov, P.; Ledezma, A.; Sanchis, A. Human activity recognition based on Evolving Fuzzy Systems. Int. J. Neural Syst. 2010, 20, 355–364. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S. Real-time life logging via a depth silhouette-based human activity recognition system for smart home services. In Proceedings of the 11th IEEE International Conference on Advanced Video and Signal-Based Surveillance, AVSS 2014, Seoul, Korea, 26–29 August 2014; pp. 74–80. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Human Activity Detection from RGBD Images. In Proceedings of the 16th AAAI Conference on Plan, Activity, and Intent Recognition; AAAIWS’11-16; AAAI Press: Palo Alto, CA, USA, 2011; pp. 47–55. [Google Scholar]
- Capela, N.A.; Lemaire, E.D.; Baddour, N. Feature Selection for Wearable Smartphone-Based Human Activity Recognition with Able bodied, Elderly, and Stroke Patients. PLoS ONE 2015, 10, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutorials 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Gupta, R.; Chia, A.Y.S.; Rajan, D. Human Activities Recognition Using Depth Images. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 283–292. [Google Scholar]
- Ni, B.; Pei, Y.; Moulin, P.; Yan, S. Multilevel Depth and Image Fusion for Human Activity Detection. IEEE Trans. Cybern. 2013, 43, 1383–1394. [Google Scholar]
- Manzi, A.; Fiorini, L.; Limosani, R.; Dario, P.; Cavallo, F. Two-person activity recognition using skeleton data. IET Comput. Vis. 2018, 12, 27–35. [Google Scholar] [CrossRef] [Green Version]
- Nunes, U.M.; Faria, D.R.; Peixoto, P. A human activity recognition framework using max-min features and key poses with differential evolution random forests classifier. Pattern Recognit. Lett. 2017, 99, 21–31. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, J.; Xia, L. Human activity recognition from 3D data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Belagiannis, V.; Amin, S.; Andriluka, M.; Schiele, B.; Navab, N.; Ilic, S. 3D Pictorial Structures for Multiple Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Burenius, M.; Sullivan, J.; Carlsson, S. 3D Pictorial Structures for Multiple View Articulated Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhang, H.; Parker, L.E. 4-dimensional local spatio-temporal features for human activity recognition. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, Francisco, CA, USA, 25–30 September 2011; pp. 2044–2049. [Google Scholar]
- Han, F.; Yang, X.; Reardon, C.; Zhang, Y.; Zhang, H. Simultaneous Feature and Body-Part Learning for real-time robot awareness of human behaviors. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2621–2628. [Google Scholar]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded Hand Pose Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Y.; Jiang, X.; Cao, R.; Wang, X. Robust Indoor Human Activity Recognition Using Wireless Signals. Sensors 2015, 15, 17195–17208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Hsieh, J.; Chuang, C.; Huang, C.; Chen, D.Y. Occluded human action analysis using dynamic manifold model. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1245–1248. [Google Scholar]
- Zhou, W.; Zhang, Z. Human Action Recognition With Multiple-Instance Markov Model. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1581–1591. [Google Scholar] [CrossRef]
- Chen, W.; Xiong, C.; Xu, R.; Corso, J.J. Actionness Ranking with Lattice Conditional Ordinal Random Fields. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–26 June 2014; pp. 748–755. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Belagiannis, V.; Amin, S.; Andriluka, M.; Schiele, B.; Navab, N.; Ilic, S. 3D Pictorial Structures Revisited: Multiple Human Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1929–1942. [Google Scholar] [CrossRef] [PubMed]
- Ijjina, E.P.; Chalavadi, K.M. Human action recognition in RGB-D videos using motion sequence information and deep learning. Pattern Recognit. 2017, 72, 504–516. [Google Scholar] [CrossRef]
- Poppe, R. A Survey on Vision-based Human Action Recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Zhao, M.; Tian, Y.; Zhao, H.; Alsheikh, M.A.; Li, T.; Hristov, R.; Kabelac, Z.; Katabi, D.; Torralba, A. RF-Based 3D Skeletons. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, SIGCOMM ’18, Budapest, Hungary, 20–25 August 2018. [Google Scholar]
- Microsoft. Developing with Kinect for Windows. 2017. Available online: https://developer.microsoft.com/en-us/windows/kinect/develop (accessed on 28 February 2017).
- Zhou, D.; Shi, M.; Chao, F.; Lin, C.M.; Yang, L.; Shang, C.; Zhou, C. Use of human gestures for controlling a mobile robot via adaptive CMAC network and fuzzy logic controller. Neurocomputing 2018, 282, 218–231. [Google Scholar] [CrossRef]
- Chao, F.; Huang, Y.; Zhang, X.; Shang, C.; Yang, L.; Zhou, C.; Hu, H.; Lin, C.M. A robot calligraphy system: From simple to complex writing by human gestures. Eng. Appl. Artif. Intell. 2017, 59, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Do, H.; Ou, Y.; Sheng, W. Human gesture recognition through a kinect sensor. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 1379–1384. [Google Scholar]
- Gaglio, S.; Re, G.L.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. -Hum. -Mach. Syst. 2015, 45, 586–597. [Google Scholar] [CrossRef]
- Parisi, G.; Weber, C.; S, W. Self-Organizing Neural Integration of Pose-Motion Features for Human Action Recognition. Front. Neurobotics 2015, 9, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Benedek, C.; Gálai, B.; Nagy, B.; Jankó, Z. Lidar-Based Gait Analysis and Activity Recognition in a 4D Surveillance System. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 101–113. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Chen, W.; Guo, G. Evaluating spatiotemporal interest point features for depth-based action recognition. Image Vis. Comput. 2014, 32, 453–464. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Depth silhouettes context: A new robust feature for human tracking and activity recognition based on embedded HMMs. In Proceedings of the 2015 12th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang City, Korea, 28–30 October 2015; pp. 294–299. [Google Scholar]
- Jalal, A.; Nadeem, A.; Bobasu, S. Human Body Parts Estimation and Detection for Physical Sports Movements. In Proceedings of the 2019 2nd International Conference on Communication, Computing and Digital systems (C-CODE), Islamabad, Pakistan, 6–7 March 2019; pp. 104–109. [Google Scholar]
- Anh, D.N. Detection of lesion region in skin images by moment of patch. In Proceedings of the 2016 IEEE RIVF International Conference on Computing Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), Hanoi, Vietnam, 7–9 November 2016; pp. 217–222. [Google Scholar]
- Wu, Q.; Xu, G.; Li, M.; Chen, L.; Zhang, X.; Xie, J. Human pose estimation method based on single depth image. Iet Comput. Vis. 2018, 12, 919–924. [Google Scholar] [CrossRef]
- Fan, X.; Zheng, K.; Lin, Y.; Wang, S. Combining local appearance and holistic view: Dual-Source Deep Neural Networks for human pose estimation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1347–1355. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Zhao, M.; Li, T.; Alsheikh, M.A.; Tian, Y.; Zhao, H.; Torralba, A.; Katabi, D. Through-Wall Human Pose Estimation Using Radio Signals. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7356–7365. [Google Scholar] [CrossRef]
- Li, Q.; He, F.; Wang, T.; Zhou, L.; Xi, S. Human Pose Estimation by Exploiting Spatial and Temporal Constraints in Body-Part Configurations. IEEE Access 2017, 5, 443–454. [Google Scholar] [CrossRef]
- Akhter, I.; Black, M.J. Pose-conditioned joint angle limits for 3D human pose reconstruction. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1446–1455. [Google Scholar]
- Li, T.; Liu, J.; Zhang, W.; Ni, Y.; Wang, W.; Li, Z. UAV-Human: A Large Benchmark for Human Behavior Understanding With Unmanned Aerial Vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 16266–16275. [Google Scholar]
- Dreher, C.R.G.; Wächter, M.; Asfour, T. Learning Object-Action Relations from Bimanual Human Demonstration Using Graph Networks. IEEE Robot. Autom. Lett. 2020, 5, 187–194. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of Motion Capture as Surface Shapes. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5442–5451. [Google Scholar]
- von Marcard, T.; Henschel, R.; Black, M.; Rosenhahn, B.; Pons-Moll, G. Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Sridhar, S.; Pons-Moll, G.; Theobalt, C. Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB. In Proceedings of the 3D Vision (3DV), 2018 Sixth International Conference, Verona, Italy, 5–8 September 2018. [Google Scholar]
- Trumble, M.; Gilbert, A.; Malleson, C.; Hilton, A.; Collomosse, J. Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors. In Proceedings of the 2017 British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. PKU-MMD: A Large Scale Benchmark for Skeleton-Based Human Action Understanding. In Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities, VSCC ’17, Mountain View, CA, USA, 23 October 2017; pp. 1–8. [Google Scholar]
- Tayyub, J.; Hawasly, M.; Hogg, D.C.; Cohn, A. CLAD: A Complex and Long Activities Dataset with Rich Crowdsourced Annotations. arXiv 2017, arXiv:1709.03456. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Shan, J.; Akella, S. 3D human action segmentation and recognition using pose kinetic energy. In Proceedings of the 2014 IEEE International Workshop on Advanced Robotics and its Social Impacts, Evanston, IL, USA, 11–13 September 2014; pp. 69–75. [Google Scholar]
- Subetha, T.; Chitrakala, S. A survey on human activity recognition from videos. In Proceedings of the 2016 International Conference on Information Communication and Embedded Systems (ICICES), Chennal, India, 25–26 February 2016; pp. 1–7. [Google Scholar]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3D Joint Locations. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence; AAAI Press: Beijing, China, 2013; pp. 2466–2472. [Google Scholar]
- Wei, P.; Zheng, N.; Zhao, Y.; Zhu, S.C. Concurrent action detection with structural prediction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3136–3143. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2009; pp. 242–264. [Google Scholar]
- Cippitelli, E.; Gasparrini, S.; Gambi, E.; Spinsante, S. A Human Activity Recognition System Using Skeleton Data from RGBD Sensors. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Tian, Y. Effective 3D action recognition using EigenJoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Yao, B.; Hagras, H.; Alhaddad, M.J.; Alghazzawi, D. A fuzzy logic-based system for the automation of human behavior recognition using machine vision in intelligent environments. Soft Comput. 2015, 19, 499–506. [Google Scholar] [CrossRef]
- Lim, C.H.; Chan, C.S. Fuzzy qualitative human model for viewpoint identification. Neural Comput. Appl. 2016, 27, 845–856. [Google Scholar] [CrossRef]
- Zhang, F.; Niu, K.; Xiong, J.; Jin, B.; Gu, T.; Jiang, Y.; Zhang, D. Towards a Diffraction-Based Sensing Approach on Human Activity Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–25. [Google Scholar] [CrossRef]
- Tang, C.I.; Perez-Pozuelo, I.; Spathis, D.; Brage, S.; Wareham, N.; Mascolo, C. SelfHAR: Improving Human Activity Recognition through Self-Training with Unlabeled Data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–30. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, H.; Brown, R. A sequence-to-sequence model-based deep learning approach for recognizing activity of daily living for senior care. J. Biomed. Informatics 2018, 84, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, Faster and More Explainable: A Graph Convolutional Baseline for Skeleton-Based Action Recognition. In Proceedings of the 28th ACM International Conference on Multimedia (ACMMM), Seattle, WA, USA, 12–16 October 2020; pp. 1625–1633. [Google Scholar]
- Li, T.; Fan, L.; Zhao, M.; Liu, Y.; Katabi, D. Making the Invisible Visible: Action Recognition Through Walls and Occlusions. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 872–881. [Google Scholar]
- Obinata, Y.; Yamamoto, T. Temporal Extension Module for Skeleton-Based Action Recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 534–540. [Google Scholar]
- Shell, J.; Coupland, S. Fuzzy Transfer Learning: Methodology and application. Inf. Sci. 2015, 293, 59–79. [Google Scholar] [CrossRef] [Green Version]
- Adama, D.A.; Lotfi, A.; Ranson, R.; Trindade, P. Transfer Learning in Assistive Robotics: From Human to Robot Domain. In Proceedings of the 2nd UK-RAS Conference on Embedded Intelligence (UK-RAS19), Loughborough, UK, 24 January 2019; pp. 60–63. [Google Scholar]
- MathWorks Inc. Transfer Learning Using AlexNet 2018. Available online: https://www.mathworks.com/help/deeplearning/examples/transfer-learning-using-alexnet.html (accessed on 30 December 2018).
- Helwa, M.K.; Schoellig, A.P. Multi-robot transfer learning: A dynamical system perspective. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS). IEEE/RSJ, Vancouver, BC, Canada, 24–28 September 2017; pp. 4702–4708. [Google Scholar]
- Feuz, K.D.; Cook, D.J. Transfer Learning Across Feature-Rich Heterogeneous Feature Spaces via Feature-Space Remapping (FSR). ACM Trans. Intell. Syst. Technol. 2015, 6, 3:1–3:27. [Google Scholar] [CrossRef] [Green Version]
- Bócsi, B.; Csató, L.; Peters, J. Alignment-based transfer learning for robot models. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar]
- Tommasi, T.; Orabona, F.; Caputo, B. Learning Categories From Few Examples With Multi Model Knowledge Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 928–941. [Google Scholar] [CrossRef] [Green Version]
- Zuo, H.; Lu, J.; Zhang, G.; Pedrycz, W. Fuzzy Rule-Based Domain Adaptation in Homogeneous and Heterogeneous Spaces. IEEE Trans. Fuzzy Syst. 2019, 27, 348–361. [Google Scholar] [CrossRef]
- Vatani Nezafat, R.; Sahin, O.; Cetin, M. Transfer Learning Using Deep Neural Networks for Classification of Truck Body Types Based on Side-Fire Lidar Data. J. Big Data Anal. Transp. 2019, 1, 71–82. [Google Scholar] [CrossRef] [Green Version]
- Kaya, A.; Keceli, A.S.; Catal, C.; Yalic, H.Y.; Temucin, H.; Tekinerdogan, B. Analysis of transfer learning for deep neural network based plant classification models. Comput. Electron. Agric. 2019, 158, 20–29. [Google Scholar] [CrossRef]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, C.; Herranz, L.; van de Weijer, J.; Gonzalez-Garcia, A.; Raducanu, B. Transferring GANs: Generating Images from Limited Data. Proocedings of the the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Saeedi, R.; Sasani, K.; Norgaard, S.; Gebremedhin, A.H. Personalized Human Activity Recognition using Wearables: A Manifold Learning-based Knowledge Transfer. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 1193–1196. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. roceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Koçer, B.; Arslan, A. Genetic Transfer Learning. Expert Syst. Appl. 2010, 37, 6997–7002. [Google Scholar] [CrossRef]
- Behbood, V. Fuzzy Transfer Learning for Financial Early Warning System. Ph.D. Thesis, University of Technology, Sydney, Australia, 2013. [Google Scholar]
- Shell, J. Fuzzy Transfer Learning. Ph.D. Thesis, De Montfort University, Leicester, UK, 2013. [Google Scholar]
- Zadeh, L. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Bellman, R.E.; Zadeh, L.A. Decision-Making in a Fuzzy Environment. Manag. Sci. 1970, 17, B141–B164. [Google Scholar] [CrossRef]
- Behbood, V.; Lu, J.; Zhang, G. Fuzzy bridged refinement domain adaptation: Long-term bank failure prediction. Int. J. Comput. Intell. Appl. 2013, 12, 1350003. [Google Scholar] [CrossRef]
- Behbood, V.; Lu, J.; Zhang, G. Fuzzy Refinement Domain Adaptation for Long Term Prediction in Banking Ecosystem. IEEE Trans. Ind. Informatics 2014, 10, 1637–1646. [Google Scholar] [CrossRef]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 29. [Google Scholar] [CrossRef]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ortega-Anderez, D.; Lotfi, A.; Langensiepen, C.; Appiah, K. A multi-level refinement approach towards the classification of quotidian activities using accelerometer data. J. Ambient. Intell. Humaniz. Comput. 2018, 10, 4319–4330. [Google Scholar] [CrossRef] [Green Version]
- Elbayoudi, A.; Lotfi, A.; Langensiepen, C. The human behaviour indicator: A measure of behavioural evolution. Expert Syst. Appl. 2019, 118, 493–505. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, F.; Zhang, G.; Lu, H.; Lu, J. Heterogeneous Unsupervised Cross-domain Transfer Learning. arXiv 2017, arXiv:1701.02511. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grouping | Summary | Benefits | Short-Comings | Example Sensors |
|---|---|---|---|---|
| 2D information | Infer human activities from 2D points extracted from images. | Processing does not require as much computational resources as 3D information |
| RGB cameras. E.g. Webcams. |
| 3D information | Identifies human activities from point clouds of changes in human movement or RF signals. |
|
| Motion Capture systems, RF devices [37], RGB-D sensors. E.g. Microsoft Kinect [38]. |
| Year | Dataset | Modality | Acquisition Device |
|---|---|---|---|
| 2021 | UAV-Human [55] | RGB + Depth + 3D joints | Azure DK |
| 2020 | Bimanual Actions Dataset [56] | RGB + Depth | PrimeSense |
| 2020 | NTU RGB+D 120 [57] | RGB + Depth + 3D joints | Kinect v2 |
| 2019 | AMASS [58] | Depth + 3D Mesh | MoCap |
| 2018 | 3DPW [59] | RGB | Camera + IMU |
| 2018 | MuPoTs-3D [60] | RGB + Depth | MoCap |
| 2017 | TotalCapture [61] | RGB + 3D joints | MoCap + IMU |
| 2017 | PKU-MMD [62] | RGB + Depth + 3D joints | Kinect v2 |
| 2017 | CLAD [63] | RGB + Depth + Point cloud | Kinect v1 |
| 2016 | NTU RGB+D [64] | RGB + Depth | Kinect v2 |
| Dataset | Approach | Modality | Prec. % | Rec. % | Acc. % |
|---|---|---|---|---|---|
| UAV-Human | Shift-GCN [55] | 3D joints | - | - | 37.98 |
| Bimanual Actions Dataset | Graph network [56] | RGB + Depth | 89.00 | 89.00 | - |
| NTU RGB+D 120 | Efficient-GCN [80] | 3D joints | - | - | 88.30 |
| PKU-MMD | RF-Action [81] | 3D joints | 94.4 | - | - |
| NTU RGB+D | Graph Convolution Network [82] | 3D joints | - | - | 96.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adama, D.A.; Lotfi, A.; Ranson, R. A Survey of Vision-Based Transfer Learning in Human Activity Recognition. Electronics 2021, 10, 2412. https://doi.org/10.3390/electronics10192412
Adama DA, Lotfi A, Ranson R. A Survey of Vision-Based Transfer Learning in Human Activity Recognition. Electronics. 2021; 10(19):2412. https://doi.org/10.3390/electronics10192412
Chicago/Turabian StyleAdama, David Ada, Ahmad Lotfi, and Robert Ranson. 2021. "A Survey of Vision-Based Transfer Learning in Human Activity Recognition" Electronics 10, no. 19: 2412. https://doi.org/10.3390/electronics10192412
APA StyleAdama, D. A., Lotfi, A., & Ranson, R. (2021). A Survey of Vision-Based Transfer Learning in Human Activity Recognition. Electronics, 10(19), 2412. https://doi.org/10.3390/electronics10192412