
Multiple Object Tracking in Deep Learning Approaches: A Survey





Abstract
:1. Introduction
- Describe the most basic techniques applied to the MOT.
- Categorize MOT methods and organize and explain the techniques used with deep learning methods.
- Include state-of-the-art papers and discuss MOT trends and challenges.
- Describe various benchmark datasets and evaluation metrics of the MOT.
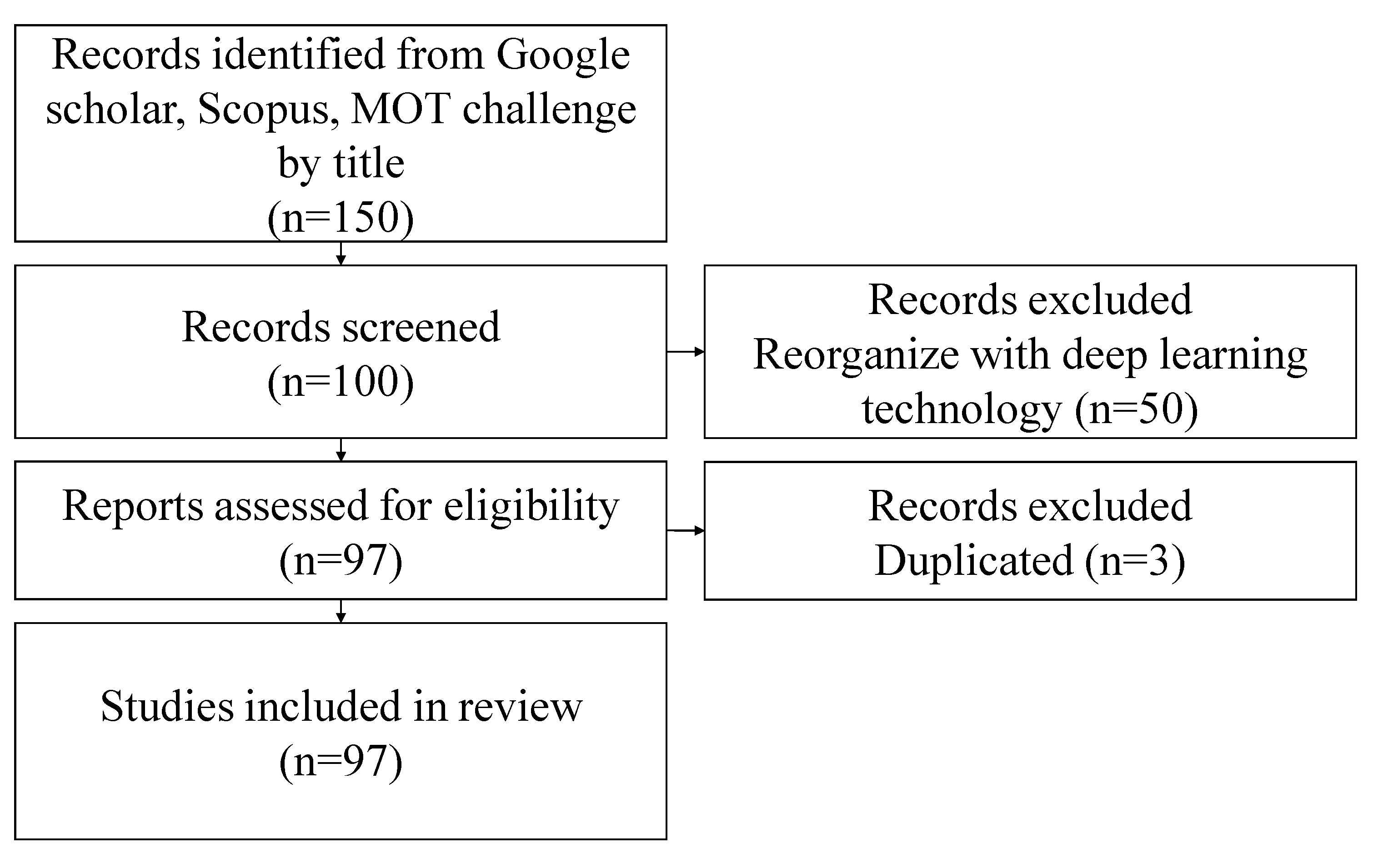
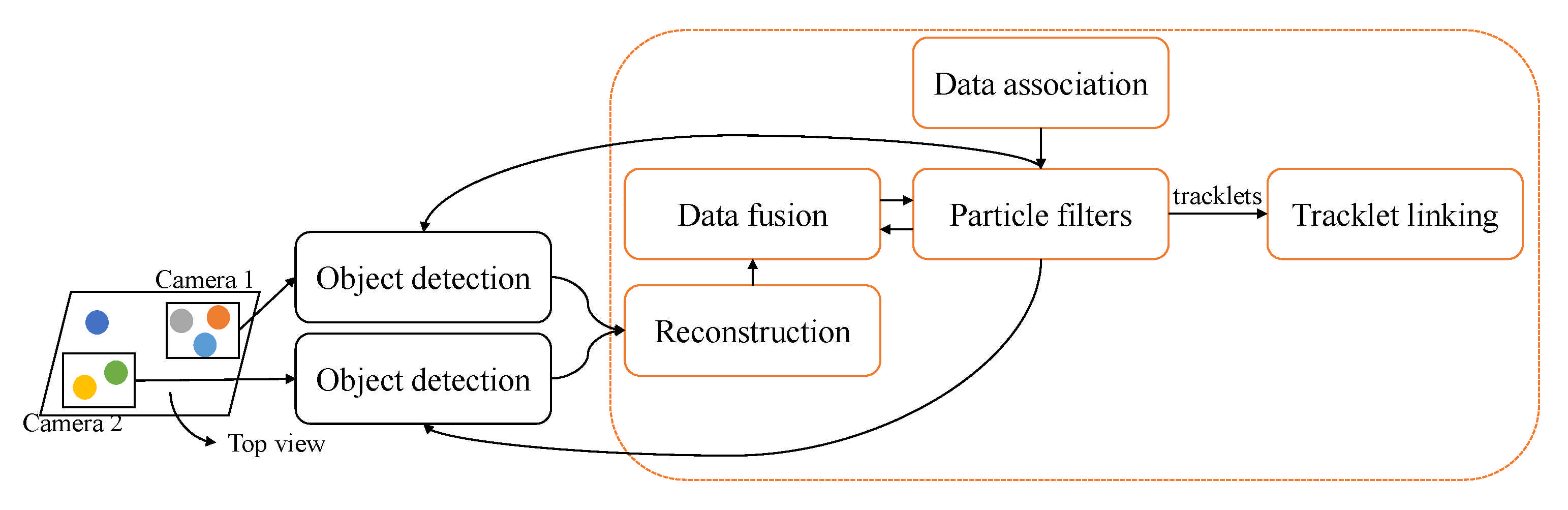
2. Methodology
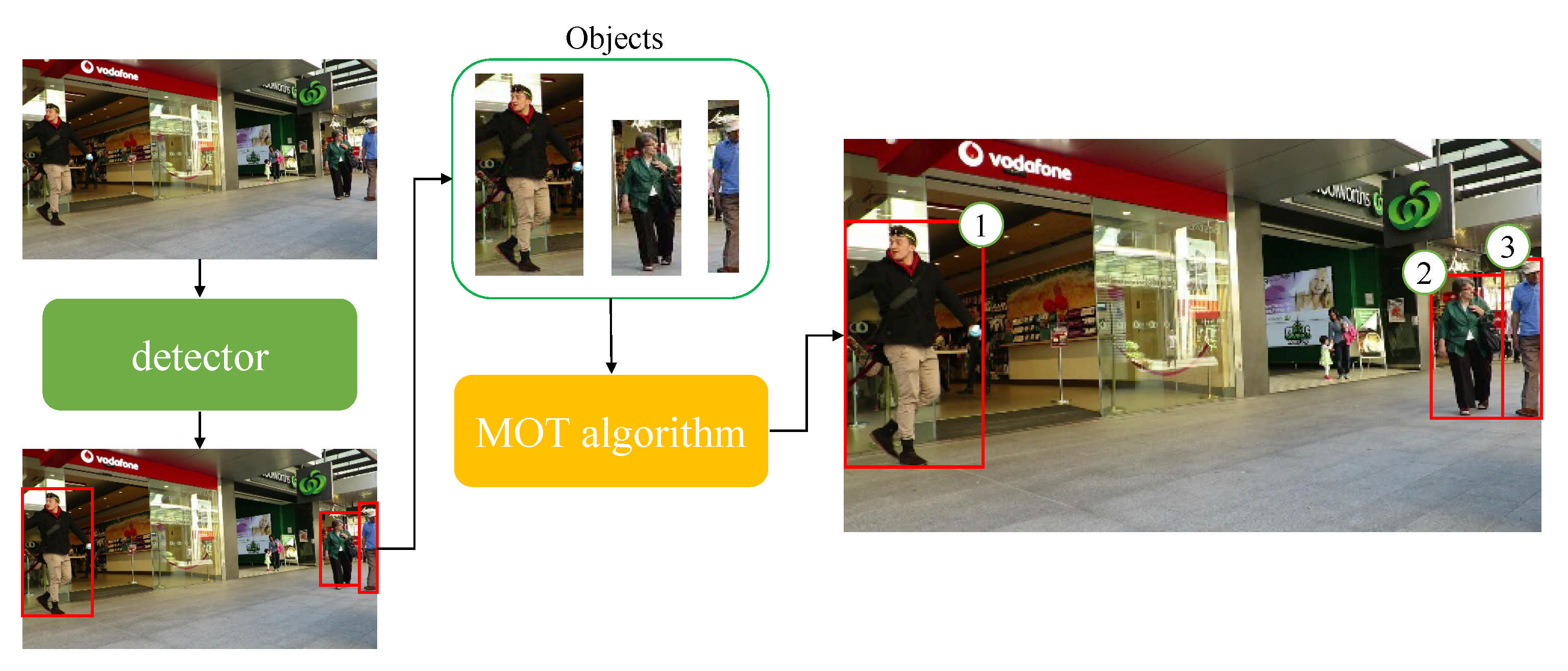
3. Multiple Object Tracking Analysis
3.1. Multiple Object Tracking Main Challenges
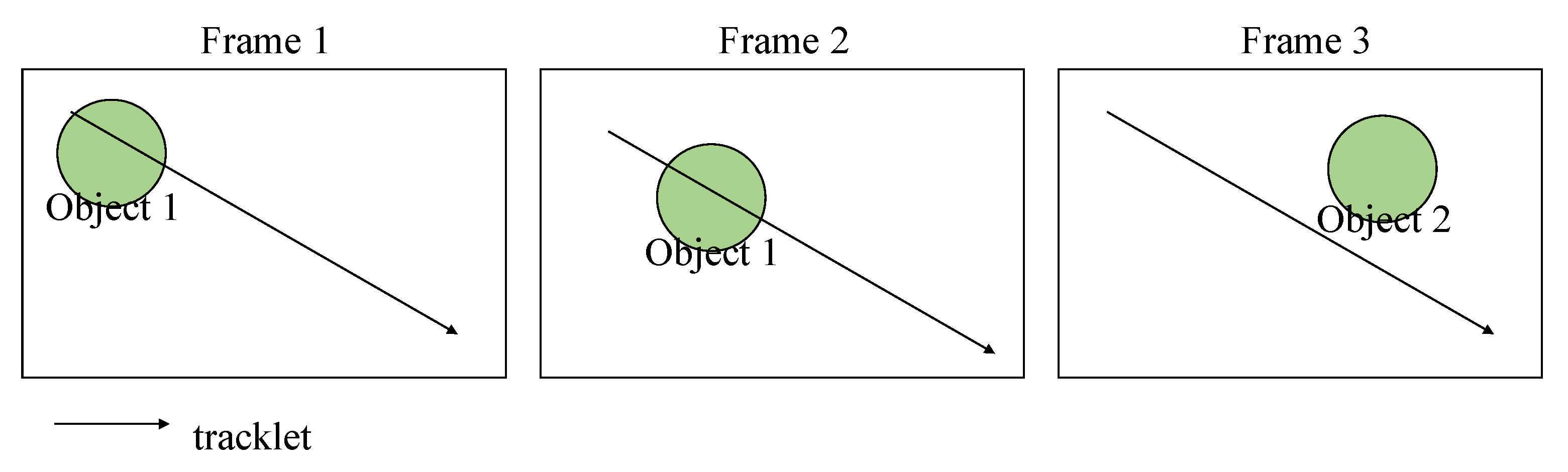
3.1.1. Occlusion
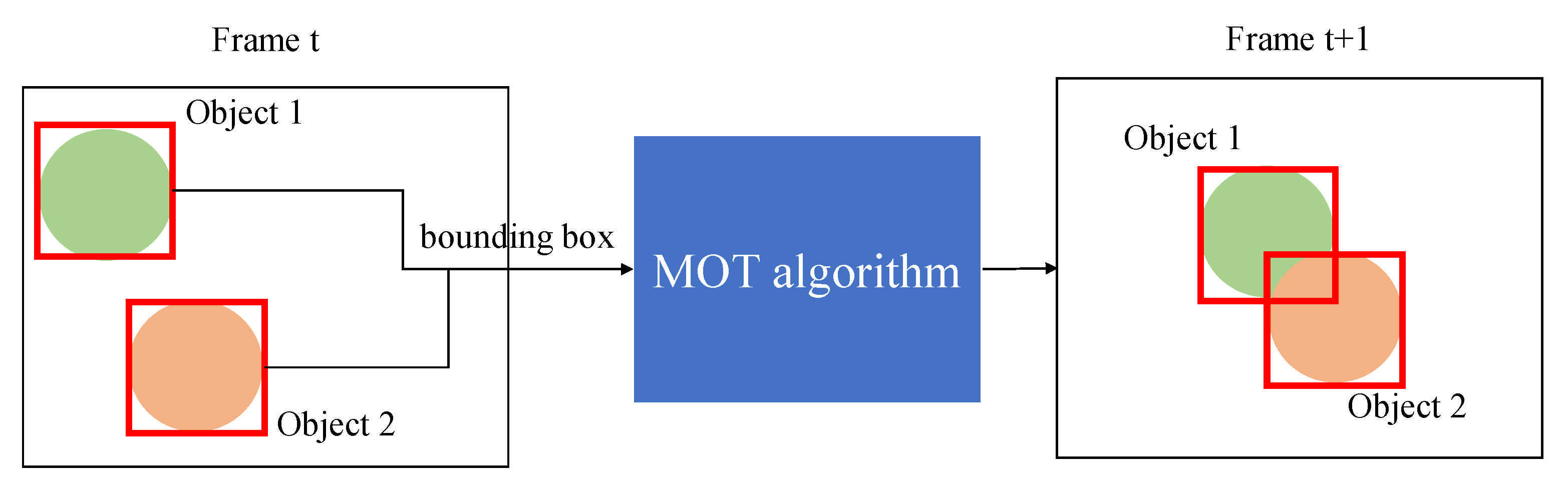
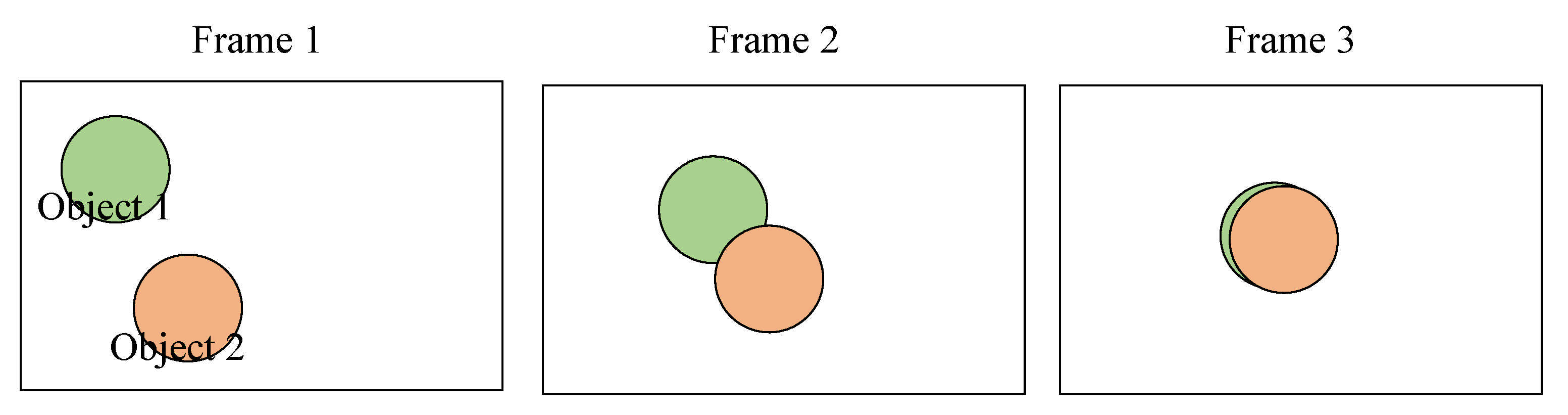
3.1.2. ID Switch
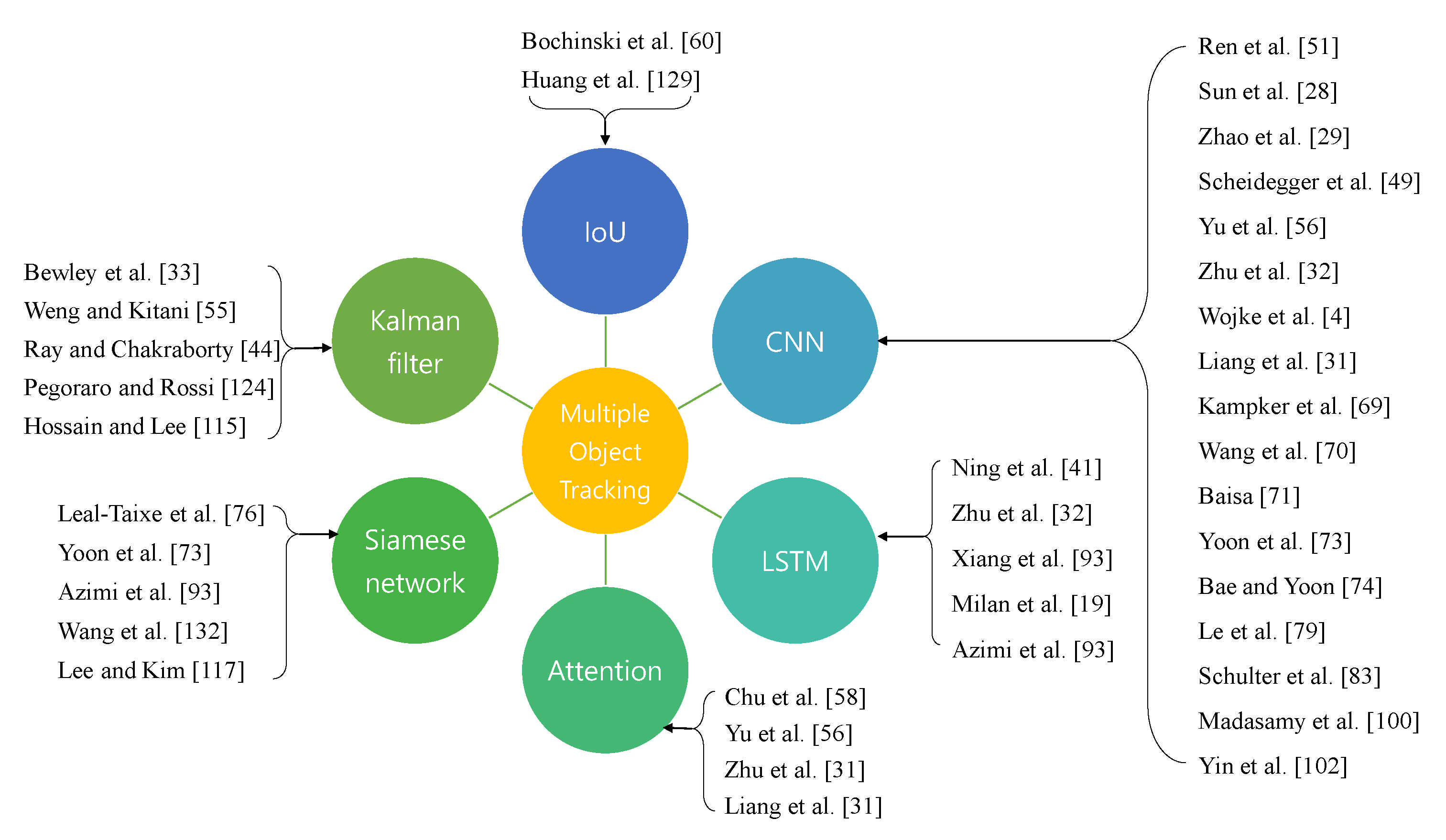
3.2. Multiple Object Tracking Main Concepts
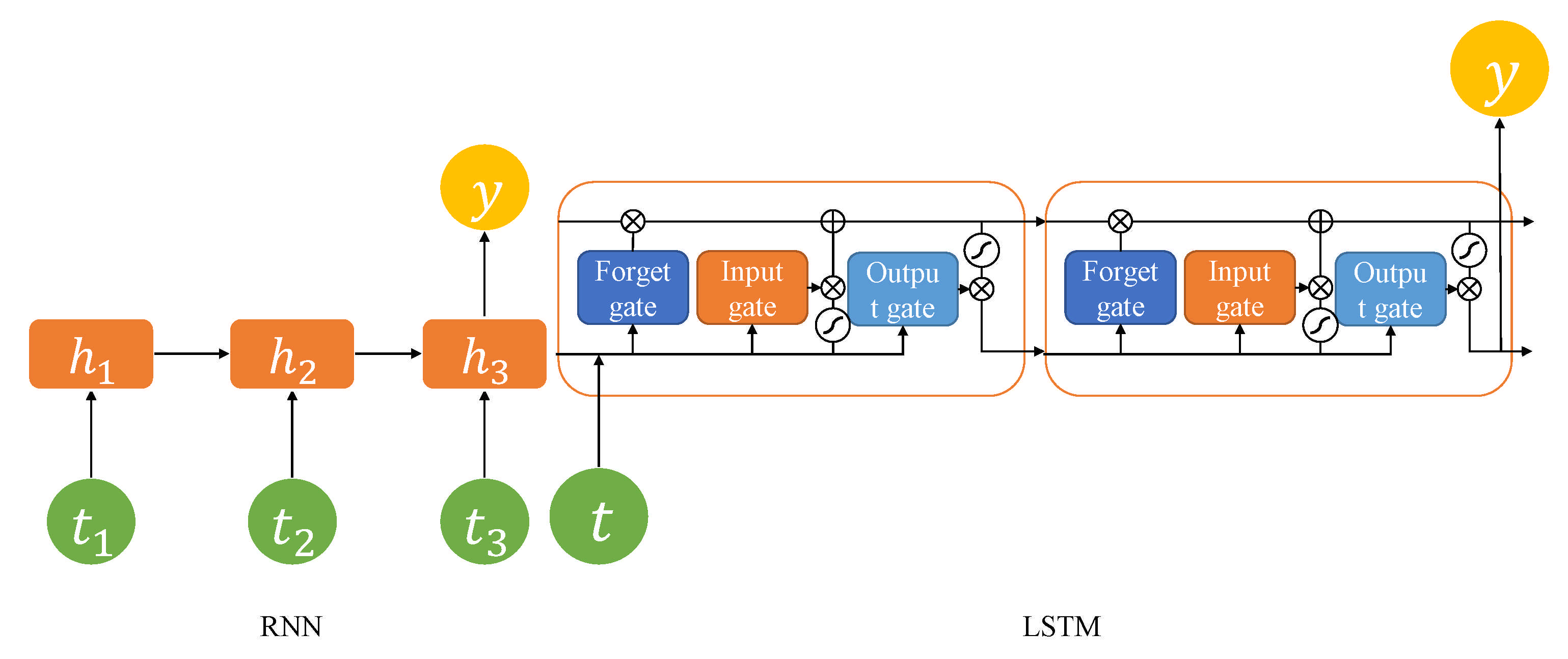
3.2.1. Recurrent Neural Network (RNN)
3.2.2. Long Short-Term Memory (LSTM)
3.2.3. Convolutional Neural Network (CNN)
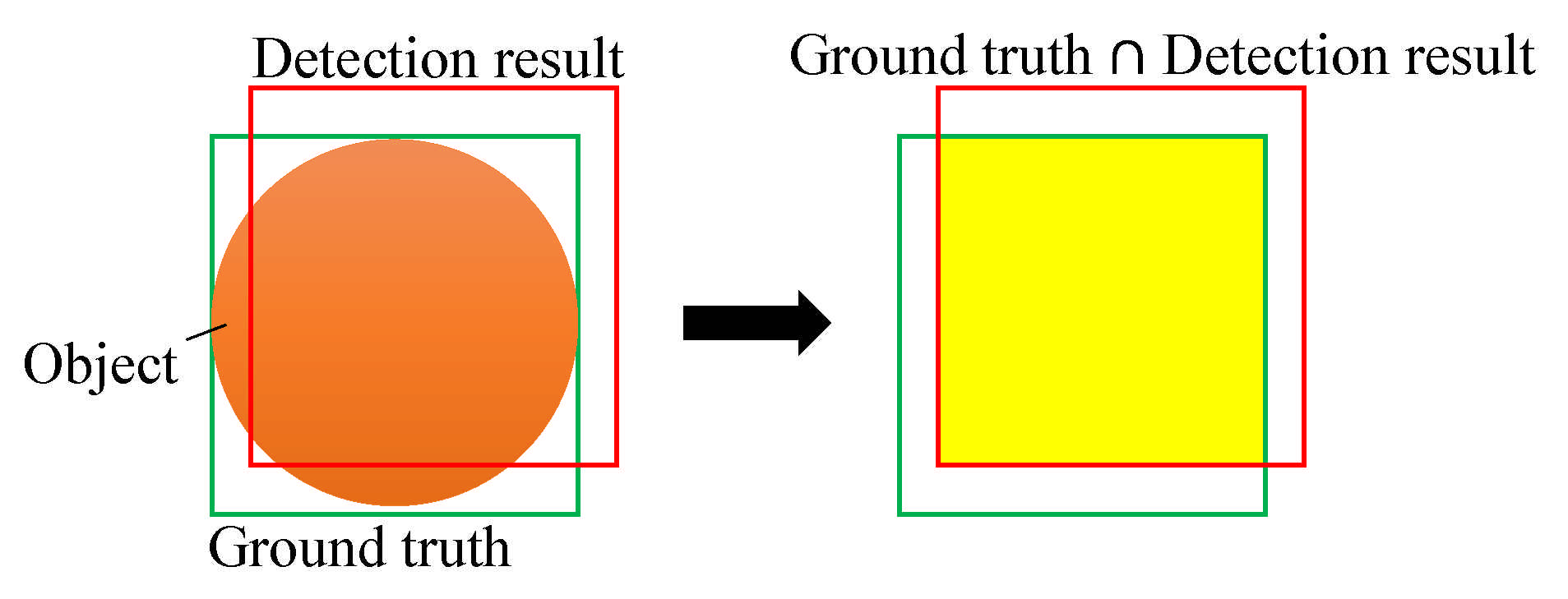
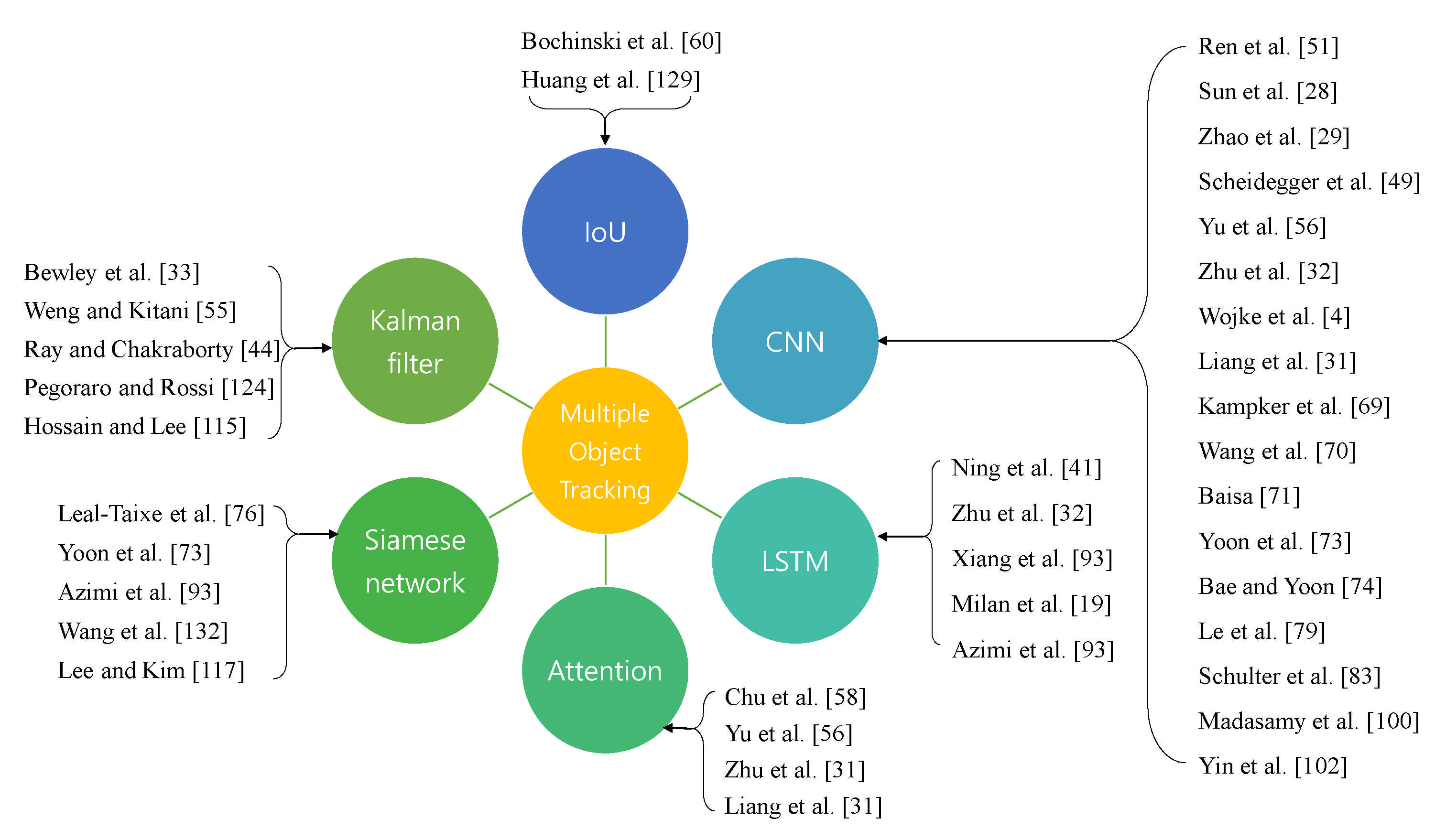
3.2.4. Intersection over Union (IoU)
3.2.5. Attention
3.3. Techniques Used in the Paper about Multiple Object Tracking
3.3.1. Appearance Learning
3.3.2. Occlusion Handling
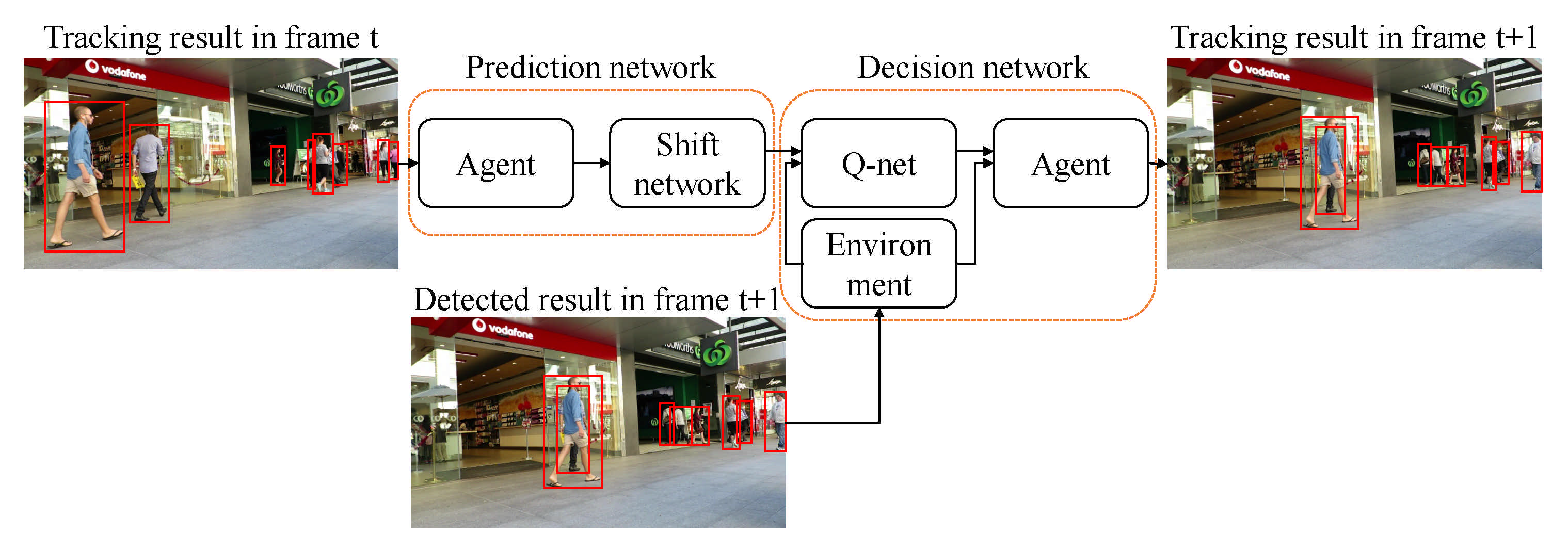
3.3.3. Detection and Prediction
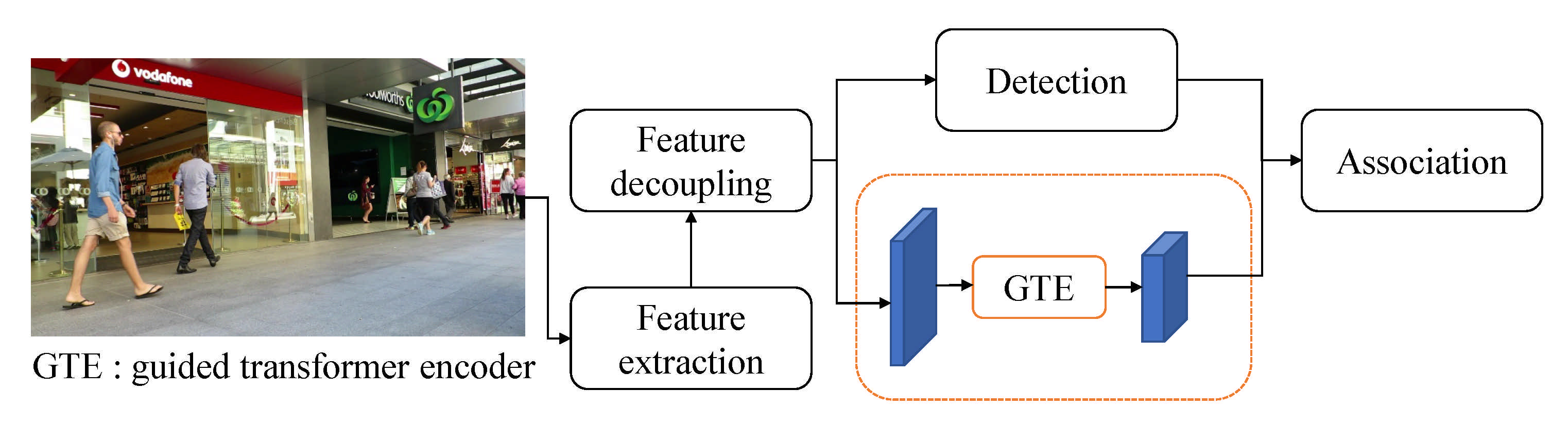
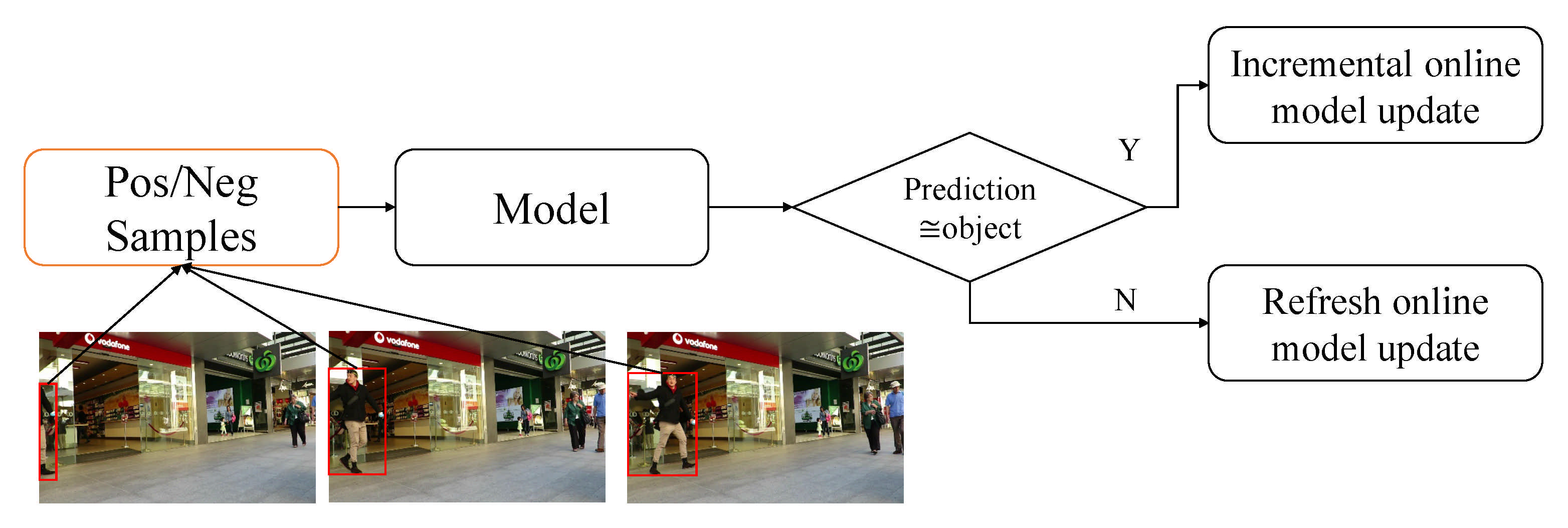
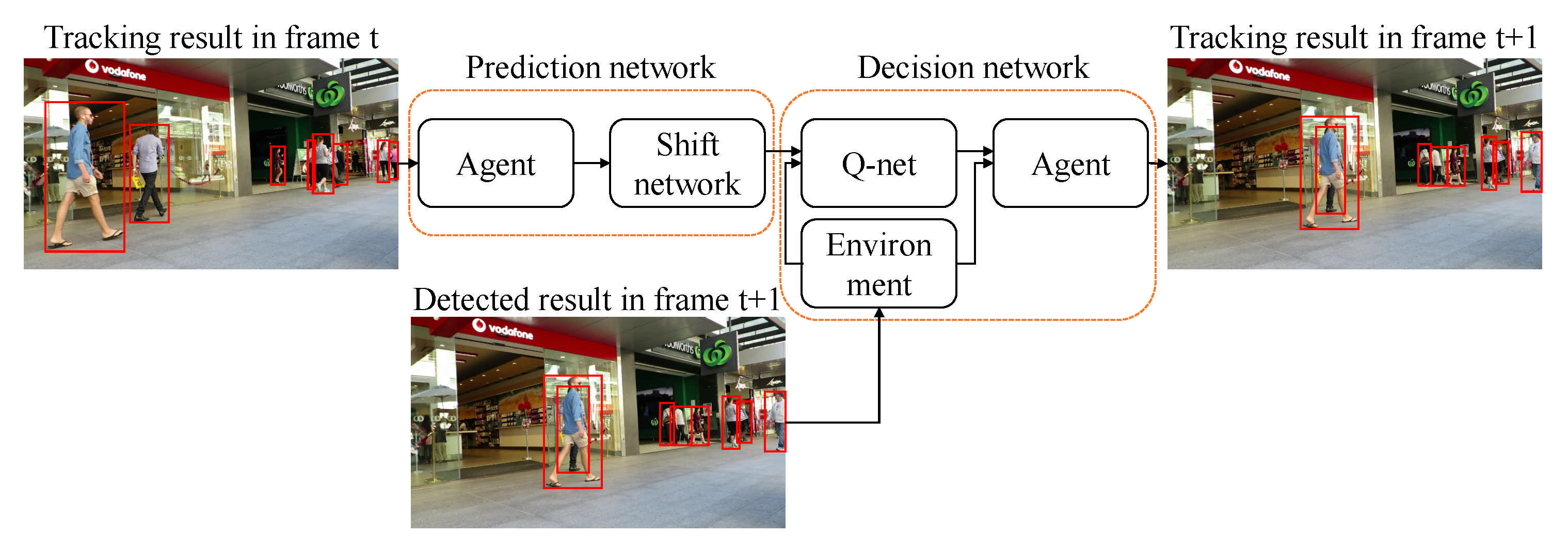
3.3.4. Computational Cost Minimization
3.3.5. Motion Variations
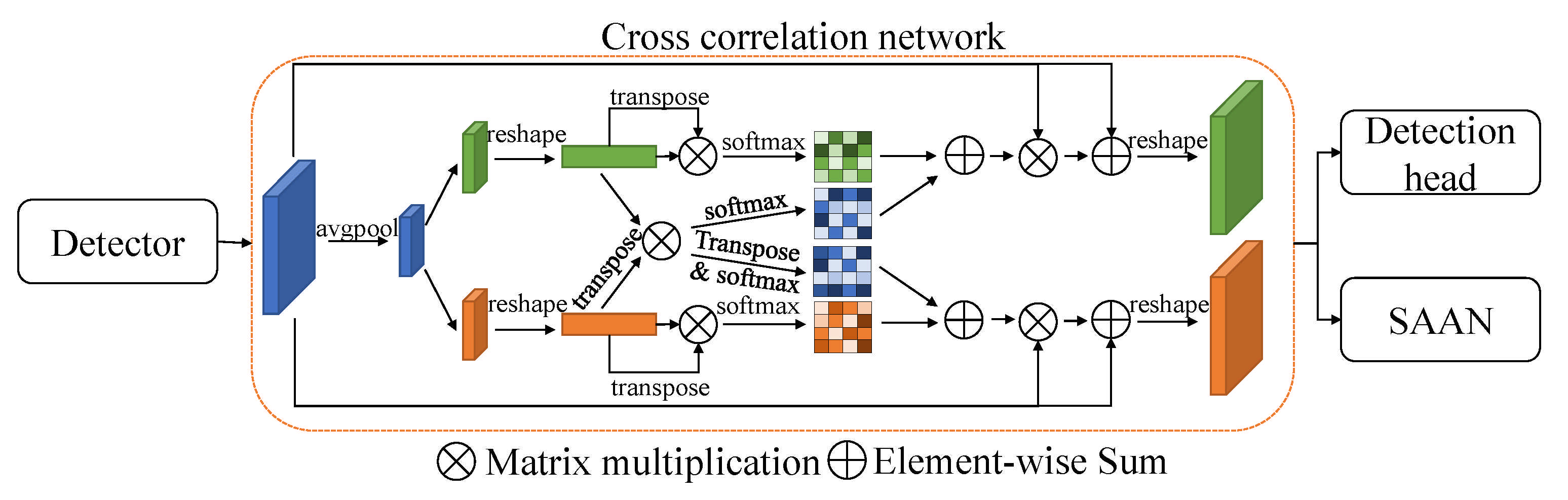
3.3.6. Appearance Variations, Drifting and Identity Switching
3.3.7. Distance and Long Occlusions Handling
3.3.8. Detection and Target Association
3.3.9. Affinity
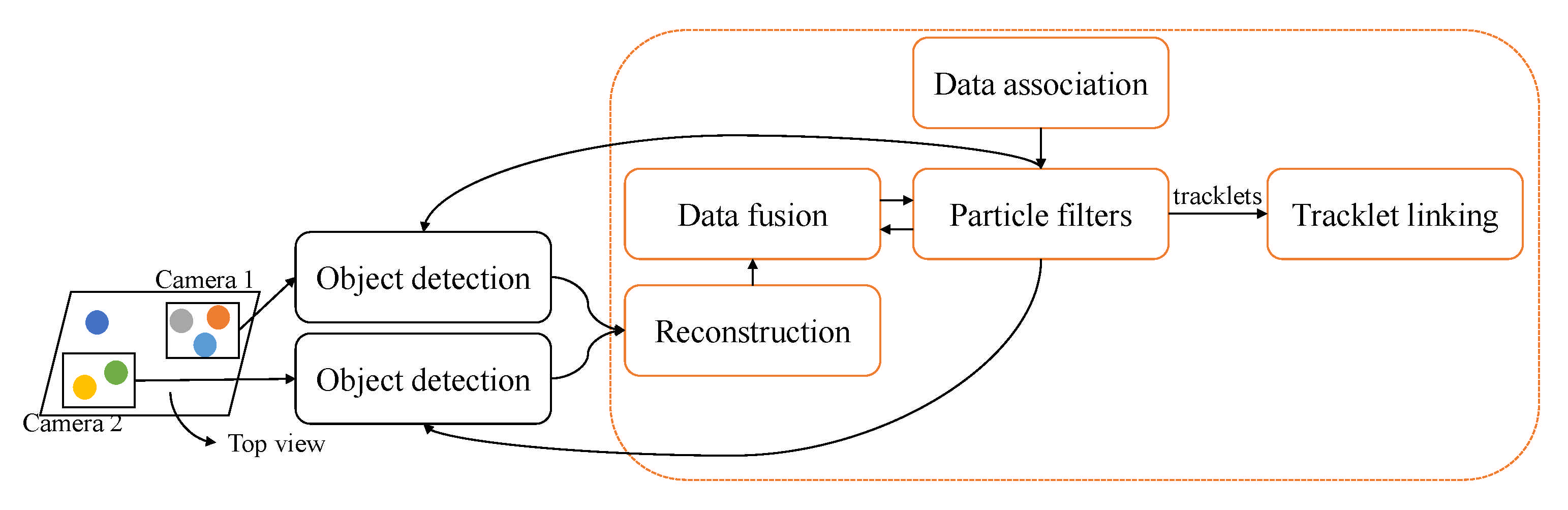
3.3.10. Tracklet Association
3.3.11. Automatic Detection Learning
3.3.12. Transformer
3.3.13. IoU
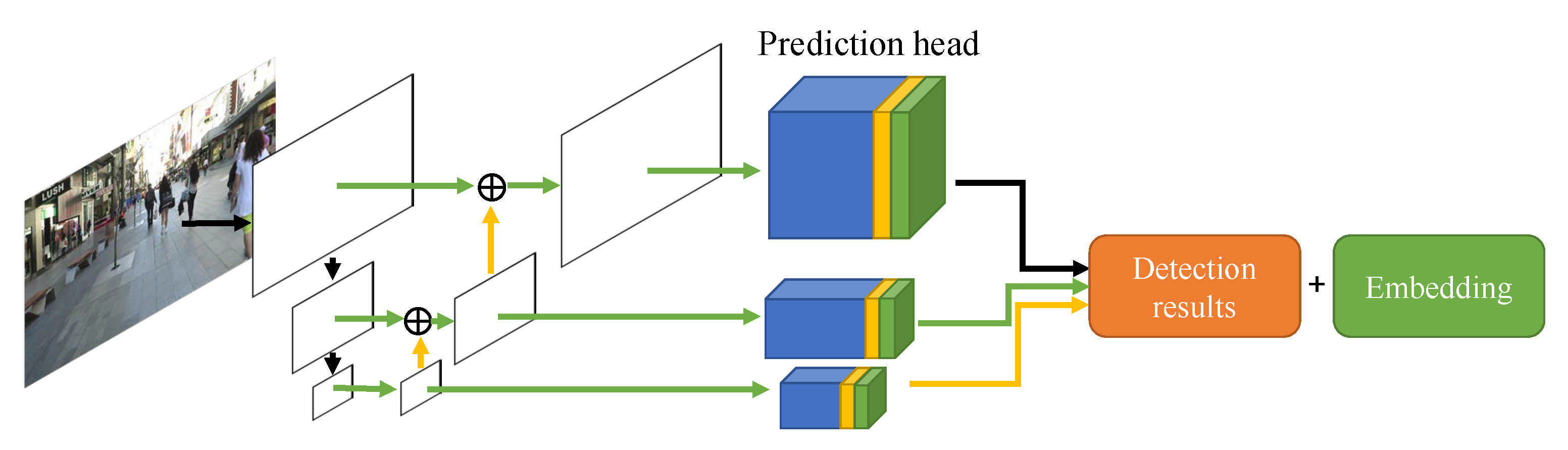
3.3.14. CNN
3.3.15. LSTM
3.3.16. Attention
3.3.17. Siamese Network
3.3.18. Kalman Filter
4. Multiple Object Tracking Benchmarks
4.1. KITTI Benchmark
4.2. MOT Benchmark
4.2.1. MOT15
4.2.2. MOT16
4.2.3. MOT17
5. Evaluation of Multiple Objects Tracking Benchmark Datasets
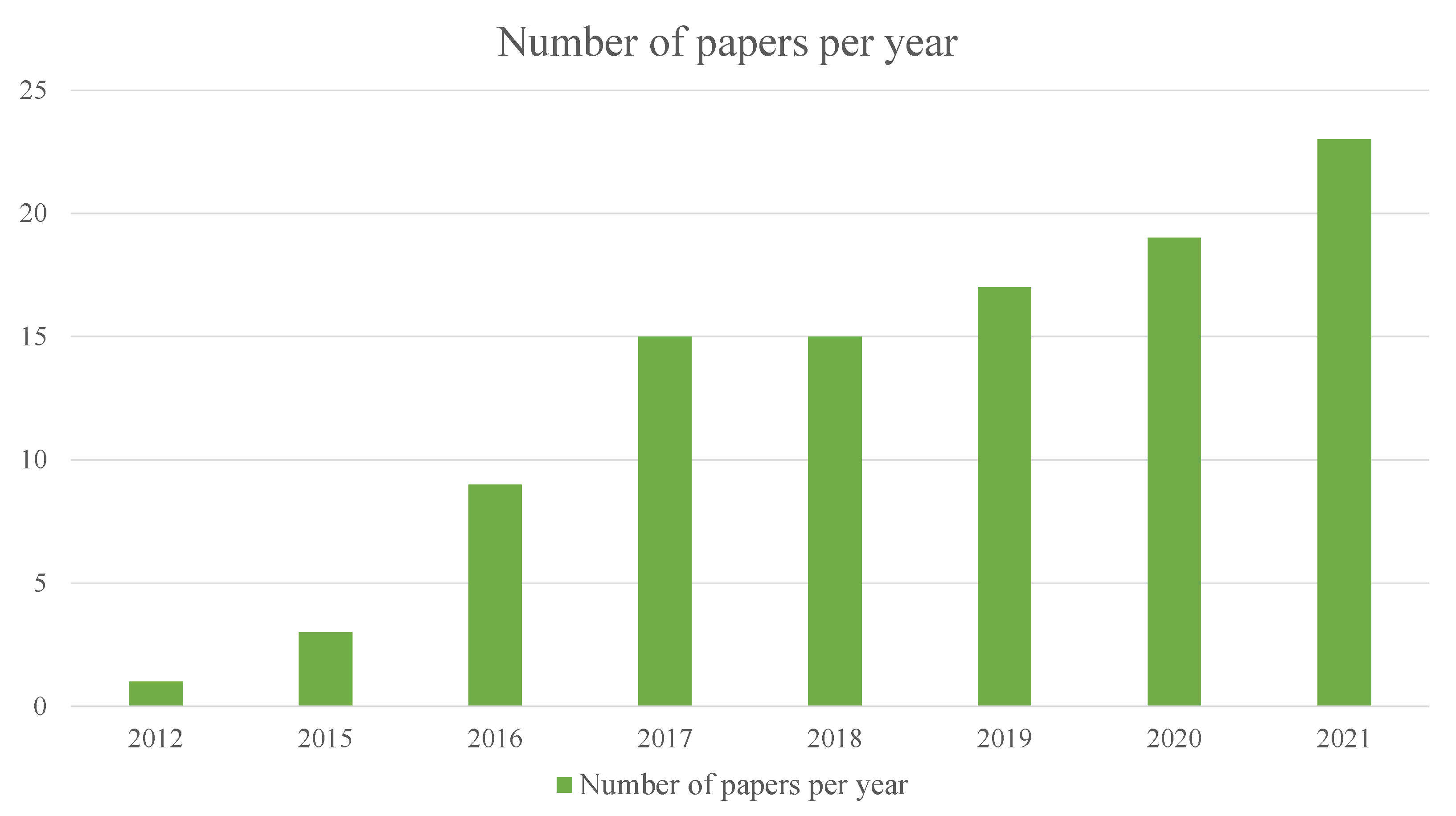
6. MOT Trends
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

| Benchmark | Name | Year | MOTA | MOTP | IDF1 | IDSw | IR | IS | FM | FAF | FP | FN | MT | ML | Frag | Hz | FPS | Ref. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MOT15 | LINF1 | 2016 | 40.5 | 74.9 | NA | 426 | 9.4 | NA | 953 | 1.4 | 8401 | 99,715 | 10.7 | 56.1 | NA | NA | NA | [42] |
| DAN | 2019 | 38.3 | 71.1 | 45.6 | 1648.08 | NA | NA | NA | NA | 1290.25 | 2700 | 17.6 | 41.2 | 1515.6 | 6.3 | NA | [28] | |
| MDP OFL | 2015 | 30.1 | 71.6 | NA | 690 | NA | NA | NA | NA | 8789 | 33,479 | 10.4 | 41.3 | 1301 | 0.8 | NA | [46] | |
| MDP REL | 2015 | 30.3 | 71.3 | NA | 680 | NA | NA | NA | NA | 9717 | 32422 | 13 | 38.4 | 1500 | 1.1 | NA | [46] | |
| 2018 | 32.7 | NA | 38.9 | NA | NA | NA | NA | NA | NA | NA | 26.2 | 19.6 | NA | NA | NA | [29] | ||
| EA-PHD-PF | 2016 | 53 | 75.3 | NA | 776 | NA | NA | NA | 1.3 | 7538 | 20,590 | 35.9 | 19.6 | 1269 | NA | NA | [53] | |
| C-DRL | 2018 | 37.1 | 71 | NA | NA | NA | NA | NA | 1.2 | 7036 | 30,440 | 14 | 31.3 | NA | NA | NA | [51] | |
| STAM | 2017 | 34.3 | 70.5 | NA | 348 | NA | NA | NA | NA | 5154 | 34,848 | 11.4 | 43.4 | 1463 | NA | NA | [58] | |
| CCC | 2018 | 35.6 | NA | 45.1 | 457 | NA | NA | 969 | NA | 10,580 | 28,508 | 23.2 | 39.3 | NA | NA | NA | [63] | |
| SORT | 2016 | 33.4 | 72.1 | NA | 1001 | NA | NA | NA | 1.3 | 7318 | 11.7 | 30.9 | NA | 1764 | 260 | NA | [33] | |
| FairMOT | 2020 | 59 | NA | 62.2 | 582 | NA | NA | NA | NA | NA | NA | 45.6 | 11.5 | NA | 30.5 | NA | [148] | |
| MOT16 | LINF1 | 2016 | 40.5 | 74.9 | NA | 426 | 9.4 | NA | 953 | 1.4 | 8401 | 99,715 | 10.7 | 56.1 | NA | NA | NA | [42] |
| EA-PHD-PF | 2016 | 52.5 | 78.8 | NA | 910 | NA | NA | NA | 0.7 | 4407 | 81,223 | 19 | 34.9 | 1321 | 12.2 | NA | [53] | |
| C-DRL | 2018 | 47.3 | 74.6 | NA | NA | NA | NA | NA | 1.1 | 6375 | 88,543 | 17.4 | 39.9 | NA | NA | NA | [51] | |
| STAM | 2018 | 46.0 | 74.9 | NA | 473 | NA | NA | NA | NA | 6895 | 91,117 | 14.6 | 43.6 | 1422 | NA | NA | [58] | |
| RelationTrack | 2021 | 75.6 | 80.9 | NA | 448 | NA | NA | NA | NA | 9786 | 34,214 | 43.1 | 21.5 | NA | NA | NA | [56] | |
| TNT | 2019 | 49.2 | NA | NA | 606 | NA | NA | NA | NA | 8400 | 83,702 | 17.3 | 40.3 | 882 | NA | NA | [40] | |
| DMAN | 2018 | 46.1 | 73.8 | NA | 532 | NA | NA | NA | NA | 7909 | 89,874 | 17.4 | 42.7 | 1616 | NA | NA | [32] | |
| Deep SORT | 2017 | 61.4 | 79.1 | NA | 781 | NA | NA | 2008 | NA | 12,852 | 56,668 | 32.8 | 18.2 | NA | 20 | NA | [4] | |
| Deep-TAMA | 2021 | 46.2 | NA | NA | 598 | NA | NA | 1127 | NA | 5126 | 92,367 | 14.1 | 44 | NA | NA | 2 | [66] | |
| CSTrack++ | 2020 | 70.7 | NA | NA | 1071 | NA | NA | NA | NA | NA | NA | 38.2 | 17.8 | NA | NA | 15.8 | [31] | |
| 2018 | 44 | 78.3 | NA | 560 | NA | NA | NA | NA | 7912 | 93,215 | 15.2 | 45.7 | 1212 | NA | NA | [68] | ||
| JDE | 2019 | 62.1 | NA | NA | 1608 | NA | NA | NA | NA | NA | NA | 34.4 | 16.7 | NA | NA | 30.3 | [70] | |
| oICF | 2016 | 42.8 | 74.3 | NA | 380 | NA | NA | NA | NA | NA | NA | 10.4 | 53.1 | 1397 | NA | NA | [81] | |
| MCMOT HDM | 2016 | 62.4 | 78.3 | NA | 1394 | NA | NA | NA | 1.7 | 9855 | 57,257 | 31.5 | 24.2 | 1318 | 34.9 | NA | [86] | |
| MOTDT | 2018 | 47.6 | NA | NA | 792 | NA | NA | NA | NA | 9253 | 85,431 | 15.2 | 38.3 | NA | NA | 20.6 | [84] | |
| FairMOT | 2020 | 68.7 | NA | 70.4 | 953 | NA | NA | NA | NA | NA | NA | 39.5 | 19 | NA | 25.9 | NA | [148] | |
| MOT17 | EB+DAN | 2019 | 53.5 | NA | 62.3 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | [28] |
| RelationTrack | 2021 | 75.6 | 80.9 | 75.8 | 448 | NA | 7.4 | NA | NA | 9786 | 34,214 | 43.1 | 21.5 | NA | NA | NA | [56] | |
| TNT | 2019 | 51.9 | NA | 58 | 2294 | NA | NA | NA | NA | 37,311 | 231,658 | 23.5 | 35.5 | 2917 | NA | NA | [40] | |
| DMAN | 2018 | 48.2 | 75.9 | NA | 2194 | NA | NA | NA | NA | 26,218 | 263,608 | 19.3 | 38.3 | 5378 | NA | NA | [32] | |
| 2021 | 50.3 | NA | 53.5 | 2192 | NA | NA | NA | NA | 25,479 | 252,996 | 19.2 | 37.5 | NA | NA | 1.5 | [66] | ||
| 2020 | 70.6 | NA | 71.6 | 3465 | NA | NA | NA | NA | NA | NA | 37.5 | 18.7 | NA | NA | 15.8 | [31] | ||
| 2018 | 44 | 78.3 | NA | 560 | NA | NA | NA | NA | 7912 | 93,215 | 15.2 | 45.7 | 1212 | NA | NA | [68] | ||
| FairMOT | 2020 | 67.5 | NA | 69.8 | 2868 | NA | NA | NA | NA | NA | NA | 37.7 | 20.8 | NA | 25.9 | NA | [148] |
References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016; pp. 770–778. [Google Scholar]
- Gui, Y.; Zhou, B.; Xiong, D.; Wei, W. Fast and robust interactive image segmentation in bilateral space with reliable color modeling and higher order potential. J. Electron. Imaging 2021, 30, 033018. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Wang, H.; Li, Y.; Dang, L.; Moon, H. Robust Korean License Plate Recognition Based on Deep Neural Networks. Sensors 2021, 21, 4140. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2020, 293, 103448. [Google Scholar] [CrossRef]
- Ellis, A.; Ferryman, J. PETS2010 and PETS2009 evaluation of results using individual ground truthed single views. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August 2010; pp. 135–142. [Google Scholar]
- Kalake, L.; Wan, W.; Hou, L. Analysis Based on Recent Deep Learning Approaches Applied in Real-Time Multi-Object Tracking: A Review. IEEE Access 2021, 9, 32650–32671. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Prisma Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Huo, W.; Ou, J.; Li, T. Multi-target tracking algorithm based on deep learning. J. Phys. Conf. Ser. IOP Publ. 2021, 1948, 012011. [Google Scholar] [CrossRef]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online multi-target tracking using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Tian, Y.; Dehghan, A.; Shah, M. On detection, data association and segmentation for multi-target tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2146–2160. [Google Scholar] [CrossRef]
- Ullah, M.; Alaya Cheikh, F. A directed sparse graphical model for multi-target tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18 June 2018; pp. 1816–1823. [Google Scholar]
- Mousavi, H.; Nabi, M.; Kiani, H.; Perina, A.; Murino, V. Crowd motion monitoring using tracklet-based commotion measure. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec City, QC, Canada, 27–30 September 2015; pp. 2354–2358. [Google Scholar]
- Butt, A.A.; Collins, R.T. Multiple target tracking using frame triplets. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Geramny, 2012; pp. 163–176. [Google Scholar]
- Wei, J.; Yang, M.; Liu, F. Learning spatio-temporal information for multi-object tracking. IEEE Access 2017, 5, 3869–3877. [Google Scholar] [CrossRef]
- Rodriguez, P.; Wiles, J.; Elman, J.L. A recurrent neural network that learns to count. Connect. Sci. 1999, 11, 5–40. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep affinity network for multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 104–119. [Google Scholar] [CrossRef] [Green Version]
- Zhao, D.; Fu, H.; Xiao, L.; Wu, T.; Dai, B. Multi-object tracking with correlation filter for autonomous vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef] [Green Version]
- Khan, G.; Tariq, Z.; Khan, M.U.G. Multi-person tracking based on faster R-CNN and deep appearance features. In Visual Object Tracking with Deep Neural Networks; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef] [Green Version]
- Liang, C.; Zhang, Z.; Lu, Y.; Zhou, X.; Li, B.; Ye, X.; Zou, J. Rethinking the competition between detection and ReID in Multi-Object Tracking. arXiv 2020, arXiv:2010.12138. [Google Scholar]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.H. Online multi-object tracking with dual matching attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 366–382. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Bochinski, E.; Senst, T.; Sikora, T. Extending IOU based multi-object tracking by visual information. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 8–16 October 2016; pp. 4651–4659. [Google Scholar]
- Wang, G.; Wang, Y.; Zhang, H.; Gu, R.; Hwang, J.N. Exploit the connectivity: Multi-object tracking with trackletnet. In Proceedings of the 27th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2019; pp. 482–490. [Google Scholar]
- Ning, G.; Zhang, Z.; Huang, C.; Ren, X.; Wang, H.; Cai, C.; He, Z. Spatially supervised recurrent convolutional neural networks for visual object tracking. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Fagot-Bouquet, L.; Audigier, R.; Dhome, Y.; Lerasle, F. Improving multi-frame data association with sparse representations for robust near-online multi-object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 774–790. [Google Scholar]
- Zamir, A.R.; Dehghan, A.; Shah, M. Gmcp-tracker: Global multi-object tracking using generalized minimum clique graphs. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Geramny, 2012; pp. 343–356. [Google Scholar]
- Ray, K.S.; Chakraborty, S. An efficient approach for object detection and tracking of objects in a video with variable background. arXiv 2017, arXiv:1706.02672. [Google Scholar]
- Kutschbach, T.; Bochinski, E.; Eiselein, V.; Sikora, T. Sequential sensor fusion combining probability hypothesis density and kernelized correlation filters for multi-object tracking in video data. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–5. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 4705–4713. [Google Scholar]
- Williams, J.L. Marginal multi-Bernoulli filters: RFS derivation of MHT, JIPDA, and association-based MeMBer. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1664–1687. [Google Scholar] [CrossRef] [Green Version]
- García-Fernández, Á.F.; Williams, J.L.; Granström, K.; Svensson, L. Poisson multi-Bernoulli mixture filter: Direct derivation and implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef] [Green Version]
- Scheidegger, S.; Benjaminsson, J.; Rosenberg, E.; Krishnan, A.; Granström, K. Mono-camera 3d multi-object tracking using deep learning detections and pmbm filtering. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, Suzhou, China, 26–30 June 2018; pp. 433–440. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of Siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- Ren, L.; Lu, J.; Wang, Z.; Tian, Q.; Zhou, J. Collaborative deep reinforcement learning for multi-object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 586–602. [Google Scholar]
- Zhang, Z.; Wu, J.; Zhang, X.; Zhang, C. Multi-target, multi-camera tracking by hierarchical clustering: Recent progress on dukemtmc project. arXiv 2017, arXiv:1712.09531. [Google Scholar]
- Sanchez-Matilla, R.; Poiesi, F.; Cavallaro, A. Online multi-target tracking with strong and weak detections. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 84–99. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Schindler, K.; Reid, I. Joint tracking and segmentation of multiple targets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; pp. 5397–5406. [Google Scholar]
- Weng, X.; Kitani, K. A baseline for 3d multi-object tracking. arXiv 2019, arXiv:1907.03961. [Google Scholar]
- Yu, E.; Li, Z.; Han, S.; Wang, H. RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation. arXiv 2021, arXiv:2105.04322. [Google Scholar]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A.; Leibe, B. Mots: Multi-object tracking and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20 June 2019; pp. 7942–7951. [Google Scholar]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017; pp. 4836–4845. [Google Scholar]
- Tang, S.; Andres, B.; Andriluka, M.; Schiele, B. Subgraph decomposition for multi-target tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; pp. 5033–5041. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Shin, J.; Kim, H.; Kim, D.; Paik, J. Fast and robust object tracking using tracking failure detection in kernelized correlation filter. Appl. Sci. 2020, 10, 713. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Ansari, J.A.; Murthy, J.K.; Krishna, K.M. Beyond pixels: Leveraging geometry and shape cues for online multi-object tracking. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3508–3515. [Google Scholar]
- Keuper, M.; Tang, S.; Andres, B.; Brox, T.; Schiele, B. Motion segmentation and multiple object tracking by correlation co-clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 140–153. [Google Scholar] [CrossRef]
- Chen, L.; Ren, M. Multi-appearance segmentation and extended 0–1 programming for dense small object tracking. PLoS ONE 2018, 13, e0206168. [Google Scholar] [CrossRef] [PubMed]
- Ruchay, A.; Kober, V.; Chernoskulov, I. Real-time tracking of multiple objects with locally adaptive correlation filters. In Proceedings of the Information Technology and Nanotechnology 2017, Samara, Russia, 25–27 April 2017; pp. 214–218. [Google Scholar]
- Yoon, Y.C.; Kim, D.Y.; Song, Y.M.; Yoon, K.; Jeon, M. Online multiple pedestrians tracking using deep temporal appearance matching association. Inf. Sci. 2021, 561, 326–351. [Google Scholar] [CrossRef]
- Xiang, J.; Zhang, G.; Hou, J. Online multi-object tracking based on feature representation and Bayesian filtering within a deep learning architecture. IEEE Access 2019, 7, 27923–27935. [Google Scholar] [CrossRef]
- Gan, W.; Wang, S.; Lei, X.; Lee, M.S.; Kuo, C.C.J. Online CNN-based multiple object tracking with enhanced model updates and identity association. Signal Process. Image Commun. 2018, 66, 95–102. [Google Scholar] [CrossRef]
- Kampker, A.; Sefati, M.; Rachman, A.S.A.; Kreisköther, K.; Campoy, P. Towards Multi-Object Detection and Tracking in Urban Scenario under Uncertainties. In Proceedings of the International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS), Funchal, Madeira, Portugal, 16–18 March 2018; pp. 156–167. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Wang, S. Towards real-time multi-object tracking. arXiv 2019, arXiv:1909.12605. [Google Scholar]
- Baisa, N.L. Online multi-object visual tracking using a GM-PHD filter with deep appearance learning. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Ju, J.; Kim, D.; Ku, B.; Han, D.K.; Ko, H. Online multi-object tracking with efficient track drift and fragmentation handling. JOSA A 2017, 34, 280–293. [Google Scholar] [CrossRef] [PubMed]
- Yoon, Y.C.; Song, Y.M.; Yoon, K.; Jeon, M. Online multi-object tracking using selective deep appearance matching. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Jeju, Korea, 24–26 June 2018; pp. 206–212. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef]
- KC, A.K.; Jacques, L.; De Vleeschouwer, C. Discriminative and efficient label propagation on complementary graphs for multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 61–74. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27 June 2016; pp. 33–40. [Google Scholar]
- Jiang, X.; Fang, Z.; Xiong, N.N.; Gao, Y.; Huang, B.; Zhang, J.; Yu, L.; Harrington, P. Data fusion-based multi-object tracking for unconstrained visual sensor networks. IEEE Access 2018, 6, 13716–13728. [Google Scholar] [CrossRef]
- Weng, X.; Yuan, Y.; Kitani, K. PTP: Parallelized Tracking and Prediction with Graph Neural Networks and Diversity Sampling. IEEE Robot. Autom. Lett. 2021, 6, 4640–4647. [Google Scholar] [CrossRef]
- Le, Q.C.; Conte, D.; Hidane, M. Online multiple view tracking: Targets association across cameras. In Proceedings of the 6th Workshop on Activity Monitoring by Multiple Distributed Sensing (AMMDS 2018), Newcastle upon Tyne, UK, 6 September 2018. [Google Scholar]
- Wu, C.W.; Zhong, M.T.; Tsao, Y.; Yang, S.W.; Chen, Y.K.; Chien, S.Y. Track-clustering error evaluation for track-based multi-camera tracking system employing human re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21 July 2017; pp. 1–9. [Google Scholar]
- Kieritz, H.; Becker, S.; Hübner, W.; Arens, M. Online multi-person tracking using integral channel features. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23 August 2016; pp. 122–130. [Google Scholar]
- Scheel, A.; Knill, C.; Reuter, S.; Dietmayer, K. Multi-sensor multi-object tracking of vehicles using high-resolution radars. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; pp. 558–565. [Google Scholar]
- Schulter, S.; Vernaza, P.; Choi, W.; Chandraker, M. Deep network flow for multi-object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 6951–6960. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Son, J.; Baek, M.; Cho, M.; Han, B. Multi-object tracking with quadruplet convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 5620–5629. [Google Scholar]
- Lee, B.; Erdenee, E.; Jin, S.; Nam, M.Y.; Jung, Y.G.; Rhee, P.K. Multi-class multi-object tracking using changing point detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 68–83. [Google Scholar]
- Xu, Y.; Ban, Y.; Delorme, G.; Gan, C.; Rus, D.; Alameda-Pineda, X. TransCenter: Transformers with Dense Queries for Multiple-Object Tracking. arXiv 2021, arXiv:2103.15145. [Google Scholar]
- Sun, P.; Jiang, Y.; Zhang, R.; Xie, E.; Cao, J.; Hu, X.; Kong, T.; Yuan, Z.; Wang, C.; Luo, P. Transtrack: Multiple-object tracking with transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Zeng, F.; Dong, B.; Wang, T.; Chen, C.; Zhang, X.; Wei, Y. MOTR: End-to-End Multiple-Object Tracking with TRansformer. arXiv 2021, arXiv:2105.03247. [Google Scholar]
- Zhang, J.; Sun, J.; Wang, J.; Yue, X.G. Visual object tracking based on residual network and cascaded correlation filters. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 8427–8440. [Google Scholar] [CrossRef]
- Dang, L.M.; Kyeong, S.; Li, Y.; Wang, H.; Nguyen, T.N.; Moon, H. Deep Learning-based Sewer Defect Classification for Highly Imbalanced Dataset. Comput. Ind. Eng. 2021, 161, 107630. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object tracking with neural gating using bilinear lstm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar]
- Azimi, S.M.; Kraus, M.; Bahmanyar, R.; Reinartz, P. Multiple Pedestrians and Vehicles Tracking in Aerial Imagery Using a Convolutional Neural Network. Remote Sens. 2021, 13, 1953. [Google Scholar] [CrossRef]
- Zhou, Y.F.; Xie, K.; Zhang, X.Y.; Wen, C.; He, J.B. Efficient Traffic Accident Warning Based on Unsupervised Prediction Framework. IEEE Access 2021, 9, 69100–69113. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, Z.; Wang, T.; He, Y. HROM: Learning High-Resolution Representation and Object-Aware Masks for Visual Object Tracking. Sensors 2020, 20, 4807. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Liu, Y.; Huang, H.; Liu, J.; Xie, W. A Scale-Adaptive Particle Filter Tracking Algorithm Based on Offline Trained Multi-Domain Deep Network. IEEE Access 2020, 8, 31970–31982. [Google Scholar] [CrossRef]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef] [Green Version]
- Hidayatullah, P.; Mengko, T.L.; Munir, R.; Barlian, A. Bull Sperm Tracking and Machine Learning-Based Motility Classification. IEEE Access 2021, 9, 61159–61170. [Google Scholar] [CrossRef]
- Xia, H.; Zhang, Y.; Yang, M.; Zhao, Y. Visual tracking via deep feature fusion and correlation filters. Sensors 2020, 20, 3370. [Google Scholar] [CrossRef] [PubMed]
- Madasamy, K.; Shanmuganathan, V.; Kandasamy, V.; Lee, M.Y.; Thangadurai, M. OSDDY: Embedded system-based object surveillance detection system with small drone using deep YOLO. EURASIP J. Image Video Process. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Dao, M.Q.; Frémont, V. A two-stage data association approach for 3D Multi-object Tracking. Sensors 2021, 21, 2894. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Feng, X.; Wu, H. Learning for Graph Matching based Multi-object Tracking in Auto Driving. J. Phys. Conf. Ser. IOP Publ. 2021, 1871, 012152. [Google Scholar] [CrossRef]
- Song, S.; Li, Y.; Huang, Q.; Li, G. A New Real-Time Detection and Tracking Method in Videos for Small Target Traffic Signs. Appl. Sci. 2021, 11, 3061. [Google Scholar] [CrossRef]
- Padmaja, B.; Myneni, M.B.; Patro, E.K.R. A comparison on visual prediction models for MAMO (multi activity-multi object) recognition using deep learning. J. Big Data 2020, 7, 1–15. [Google Scholar] [CrossRef]
- Chou, Y.S.; Wang, C.Y.; Lin, S.D.; Liao, H.Y.M. How Incompletely Segmented Information Affects Multi-Object Tracking and Segmentation (MOTS). In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2086–2090. [Google Scholar]
- Zhou, Y.; Cai, Z.; Zhu, Y.; Yan, J. Automatic ship detection in SAR Image based on Multi-scale Faster R-CNN. J. Phys. Conf. Ser. IOP Publ. 2020, 1550, 042006. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Li, Z.; Zhang, Y. Abnormal Behavior Recognition Based on Key Points of Human Skeleton. IFAC PapersOnLine 2020, 53, 441–445. [Google Scholar] [CrossRef]
- Xie, Y.; Shen, J.; Wu, C. Affine Geometrical Region CNN for Object Tracking. IEEE Access 2020, 8, 68638–68648. [Google Scholar] [CrossRef]
- Shao, Q.; Hu, J.; Wang, W.; Fang, Y.; Xue, T.; Qi, J. Location Instruction-Based Motion Generation for Sequential Robotic Manipulation. IEEE Access 2020, 8, 26094–26106. [Google Scholar] [CrossRef]
- Nobis, F.; Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A deep learning-based radar and camera sensor fusion architecture for object detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 15–17 October 2019; pp. 1–7. [Google Scholar]
- Wu, Q.; Yan, Y.; Liang, Y.; Liu, Y.; Wang, H. DSNet: Deep and shallow feature learning for efficient visual tracking. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 119–134. [Google Scholar]
- Zhu, W.; Yu, S.; Zheng, X.; Wu, Y. Fine-grained Vehicle Classification Technology Based on Fusion of Multi-convolutional Neural Networks. Sens. Mater. 2019, 31, 569–578. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images. Remote Sens. 2021, 13, 1670. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Yan, Z. Deep Learning Enhanced Multi-Target Detection for End-Edge-Cloud Surveillance in Smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Hossain, S.; Lee, D.j. Deep learning-based real-time multiple-object detection and tracking from aerial imagery via a flying robot with GPU-based embedded devices. Sensors 2019, 19, 3371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, Z.; Li, J.; Liu, D.; He, H.; Barber, D. Tracking by animation: Unsupervised learning of multi-object attentive trackers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15 June 2019; pp. 1318–1327. [Google Scholar]
- Lee, S.; Kim, E. Multiple object tracking via feature pyramid Siamese networks. IEEE Access 2018, 7, 8181–8194. [Google Scholar] [CrossRef]
- Dike, H.U.; Zhou, Y. A Robust Quadruplet and Faster Region-Based CNN for UAV Video-Based Multiple Object Tracking in Crowded Environment. Electronics 2021, 10, 795. [Google Scholar] [CrossRef]
- Gómez-Silva, M.J.; Escalera, A.D.L.; Armingol, J.M. Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View. Electronics 2020, 9, 1757. [Google Scholar] [CrossRef]
- Li, J.; Zhan, W.; Hu, Y.; Tomizuka, M. Generic tracking and probabilistic prediction framework and its application in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3634–3649. [Google Scholar] [CrossRef] [Green Version]
- Lv, X.; Dai, C.; Chen, L.; Lang, Y.; Tang, R.; Huang, Q.; He, J. A robust real-time detecting and tracking framework for multiple kinds of unmarked object. Sensors 2020, 20, 2. [Google Scholar] [CrossRef] [Green Version]
- Xu, T.; Feng, Z.H.; Wu, X.J.; Kittler, J. Joint group feature selection and discriminative filter learning for robust visual object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 7950–7960. [Google Scholar]
- Shahbazi, M.; Simeonova, S.; Lichti, D.; Wang, J. Vehicle Tracking and Speed Estimation from Unmanned Aerial Videos. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 623–630. [Google Scholar] [CrossRef]
- Pegoraro, J.; Rossi, M. Real-time People Tracking and Identification from Sparse mm-Wave Radar Point-clouds. IEEE Access 2021, 4, 78504–78520. [Google Scholar] [CrossRef]
- Liu, K. Deep Associated Elastic Tracker for Intelligent Traffic Intersections. In Proceedings of the 2nd International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things, Asia, Seoul, 16 November 2020; pp. 55–61. [Google Scholar]
- Wen, A. Real-Time Panoramic Multi-Target Detection Based on Mobile Machine Vision and Deep Learning. J. Phys. Conf. Ser. IOP Publ. 2020, 1650, 032113. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Xu, T.; Feng, Z.; Wu, X.J.; Kittler, J. Adaptive Channel Selection for Robust Visual Object Tracking with Discriminative Correlation Filters. Int. J. Comput. Vis. 2021, 129, 1359–1375. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, X.; Dong, M.; Xu, H. Multiple objects tracking in the UAV system based on hierarchical deep high-resolution network. Multimed. Tools Appl. 2021, 80, 13911–13929. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A deep learning-based hybrid framework for object detection and recognition in autonomous driving. IEEE Access 2020, 8, 194228–194239. [Google Scholar] [CrossRef]
- Chen, C.; Zanotti Fragonara, L.; Tsourdos, A. Relation3DMOT: Exploiting Deep Affinity for 3D Multi-Object Tracking from View Aggregation. Sensors 2021, 21, 2113. [Google Scholar] [CrossRef]
- Wang, N.; Zhou, W.; Song, Y.; Ma, C.; Liu, W.; Li, H. Unsupervised deep representation learning for real-time tracking. Int. J. Comput. Vis. 2021, 129, 400–418. [Google Scholar] [CrossRef]
- Wu, L.; Xu, T.; Zhang, Y.; Wu, F.; Xu, C.; Li, X.; Wang, J. Multi-Channel Feature Dimension Adaption for Correlation Tracking. IEEE Access 2021, 9, 63814–63824. [Google Scholar] [CrossRef]
- Yang, Y.; Xing, W.; Zhang, S.; Gao, L.; Yu, Q.; Che, X.; Lu, W. Visual tracking with long-short term based correlation filter. IEEE Access 2020, 8, 20257–20269. [Google Scholar] [CrossRef]
- Mauri, A.; Khemmar, R.; Decoux, B.; Ragot, N.; Rossi, R.; Trabelsi, R.; Boutteau, R.; Ertaud, J.Y.; Savatier, X. Deep Learning for Real-Time 3D Multi-Object Detection, Localisation, and Tracking: Application to Smart Mobility. Sensors 2020, 20, 532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akhloufi, M.A.; Arola, S.; Bonnet, A. Drones chasing drones: Reinforcement learning and deep search area proposal. Drones 2019, 3, 58. [Google Scholar] [CrossRef] [Green Version]
- Voeikov, R.; Falaleev, N.; Baikulov, R. TTNet: Real-time temporal and spatial video analysis of table tennis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–16 June 2020; pp. 884–885. [Google Scholar]
- Jiang, M.; Hai, T.; Pan, Z.; Wang, H.; Jia, Y.; Deng, C. Multi-agent deep reinforcement learning for multi-object tracker. IEEE Access 2019, 7, 32400–32407. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Belyaev, V.; Malysheva, A.; Shpilman, A. End-to-end Deep Object Tracking with Circular Loss Function for Rotated Bounding Box. In Proceedings of the 2019 IEEE XVI International Symposium “Problems of Redundancy in Information and Control Systems” (REDUNDANCY)m, Moscow, Russia, 21–25 October 2019; pp. 165–170. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16 June 2012; pp. 3354–3361. [Google Scholar]
- Stiefelhagen, R.; Bernardin, K.; Bowers, R.; Garofolo, J.; Mostefa, D.; Soundararajan, P. The CLEAR 2006 evaluation. In Proceedings of the International Evaluation Workshop on Classification of Events, Activities and Relationships, Southampton, UK, 6–7 April 2006; Springer: Berlin/Heidelberg, Geramny, 2006; pp. 1–44. [Google Scholar]
- Wu, H.; Han, W.; Wen, C.; Li, X.; Wang, C. 3D Multi-Object Tracking in Point Clouds Based on Prediction Confidence-Guided Data Association. IEEE Trans. Intell. Transp. Syst. 2021. early access. [Google Scholar] [CrossRef]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. 3d multi-object tracking: A baseline and new evaluation metrics. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10359–10366. [Google Scholar]
- Wang, S.; Cai, P.; Wang, L.; Liu, M. DiTNet: End-to-End 3D Object Detection and Track ID Assignment in Spatio-Temporal World. IEEE Robot. Autom. Lett. 2021, 6, 3397–3404. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 17–35. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. A simple baseline for multi-object tracking. arXiv 2020, arXiv:2004.01888. [Google Scholar]
- Dang, L.M.; Piran, M.; Han, D.; Min, K.; Moon, H. A survey on internet of things and cloud computing for healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Ref. | Year | Contributions |
|---|---|---|---|
| 1 | [9] | 2021 |
|
| 2 | [10] | 2020 |
|
| 3 | [11] | 2020 |
|
| 4 | [13] | 2020 |
|
| Methodology | Deep Learning Algorithms + Networks | Year |
|---|---|---|
| Appearance Learning | Spatial Temporal Information + Template Matching [24] | 2017 |
| CNN + Appearnce Model [40] | 2019 | |
| CNN + Compression Network [28] | 2019 | |
| LSTM [41] | 2017 | |
| Target appearance + Linear Subspace [42] | 2016 | |
| Generalized Minimum Clique Graphs (GMCP) [43] | 2012 | |
| Occlusion Handling | CNN + FDH [44] | 2017 |
| CNN + Semantic Information [29] | 2018 | |
| GMPHD [45] | 2017 | |
| CNN + Template Matching + Optical Flow [46] | 2015 | |
| Detection and Prediction | CNN + Poisson Multi-Bernoulli Mixture (PMBM) Filter [47,48,49] | 2018 |
| Box regression + Siamese Region Proposal (SiamRPN) [50] | 2019 | |
| CNN + Tracking-by-detection (TBD) + Reinforcement Learning [51] | 2018 | |
| F-RCNN + MTC [52] | 2017 | |
| Detector Confidence + PHDP [53] | 2016 | |
| Segmentation + CRF [54] | 2015 | |
| Computational Cost Minimization | 3D CNN + Kalman Filter [55] | 2019 |
| CNN + Global Context Distancing (GCD) + Guided Transformer Encoder (GTE) [56] | 2021 | |
| Segmentation + Single Convolutional Neural Network (SCNN) [57] | 2019 | |
| spatial- temporal attention mechanism (STAM) + CNN [58] | 2017 | |
| Subgraph Decomposition [59] | 2015 | |
| Motion Variations | TBD without Image information [60] | 2017 |
| CNN + kernelized filter [61] | 2020 | |
| Pairwise Cost [62] | 2018 | |
| CNN + Motion Segmentation [63,64] | 2018 | |
| LAC filters + CNN [65] | 2017 | |
| Appearance Variations, Drifting and Identity Switching | CNN + Data Association [30] | 2018 |
| Joint inference network [66] | 2021 | |
| cross correlation CNN + scale aware attention network [31] | 2020 | |
| LSTM + Bayesian filtering network [67] | 2019 | |
| CNN + LSTM + Attention network [32] | 2018 | |
| CNN [4] | 2017 | |
| Distance and Long Occlusions Handling | CNN [68] | 2018 |
| CNN [69] | 2018 | |
| Detection and Target Association | Kalman Filter + Hungarian Algorithm [33] | 2016 |
| CNN [70] | 2019 | |
| CNN + GMPHD [71] | 2019 | |
| Affinity | Appearance Learning [72] | 2017 |
| CNN [73] | 2018 | |
| R-CNN [19] | 2017 | |
| CNN + Online transfer learning [74] | 2017 | |
| Spatial Temporal and Appearance Modeling [75] | 2016 | |
| Siamese Network [76] | 2016 | |
| Tracklet Association | Visual Sensor Networks [77] | 2018 |
| GNN [78] | 2021 | |
| CNN + decision maiking algothm [79] | 2018 | |
| Single Camera Tracking + CNN [80] | 2017 | |
| Fast Constrained Domain Sets [81] | 2016 | |
| Sequential Monte Carlo (SMC) + Labeled Multi-Bernoulli (LMB) filter [82] | 2016 | |
| Automatic Detection Learning | CNN [83] | 2017 |
| Region-based Fully Convolutional Neural network (R-FCN) [84] | 2018 | |
| Quadruplet Convolutional Neural Networks (QCNN) [85] | 2017 | |
| CNN + Lucas-Kande Tracker (LKT) [86] | 2016 | |
| Transformer | CNN + Query Learning Networks (QLN) [87] | 2021 |
| CNN + GTE [56] | 2021 | |
| CNN + query key [88] | 2021 | |
| CNN + continuous query passing [89] | 2021 |
| Name | Year | Class | MOTA | MOTP | IDF1 | IDS | MT | ML | FR | Tracking Time(s) | fps | Ref. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018 | 32.7 | 38.9 | 26.2 | 19.6 | 0.09 | [29] | ||||||
| 2018 | car class | 80.4 | 81.3 | 121 | 62.8 | 6.2 | 613 | 73 | [49] | |||
| 2019 | car class | 83.34 | 85.23 | 10 | 65.85 | 11.54 | 222 | 214.7 | [55] | |||
| RRC-IIITH | 2018 | 84.24 | 85.73 | 468 | 73.23 | 2.77 | 944 | [62] | ||||
| 2017 | 67.36 | 78.79 | 65 | 53.81 | 9.45 | 574 | [83] | |||||
| PC3T | 2021 | 88.8 | 84.37 | 208 | 80 | 8.31 | 369 | 222 | [144] | |||
| DiTNet | 2021 | 84.62 | 84.18 | 19 | 74.15 | 12.92 | 196 | 0.01 | [146] | |||
| AB3DMOT | 2021 | car class | 86.24 | 78.43 | 0 | 15 | [145] |
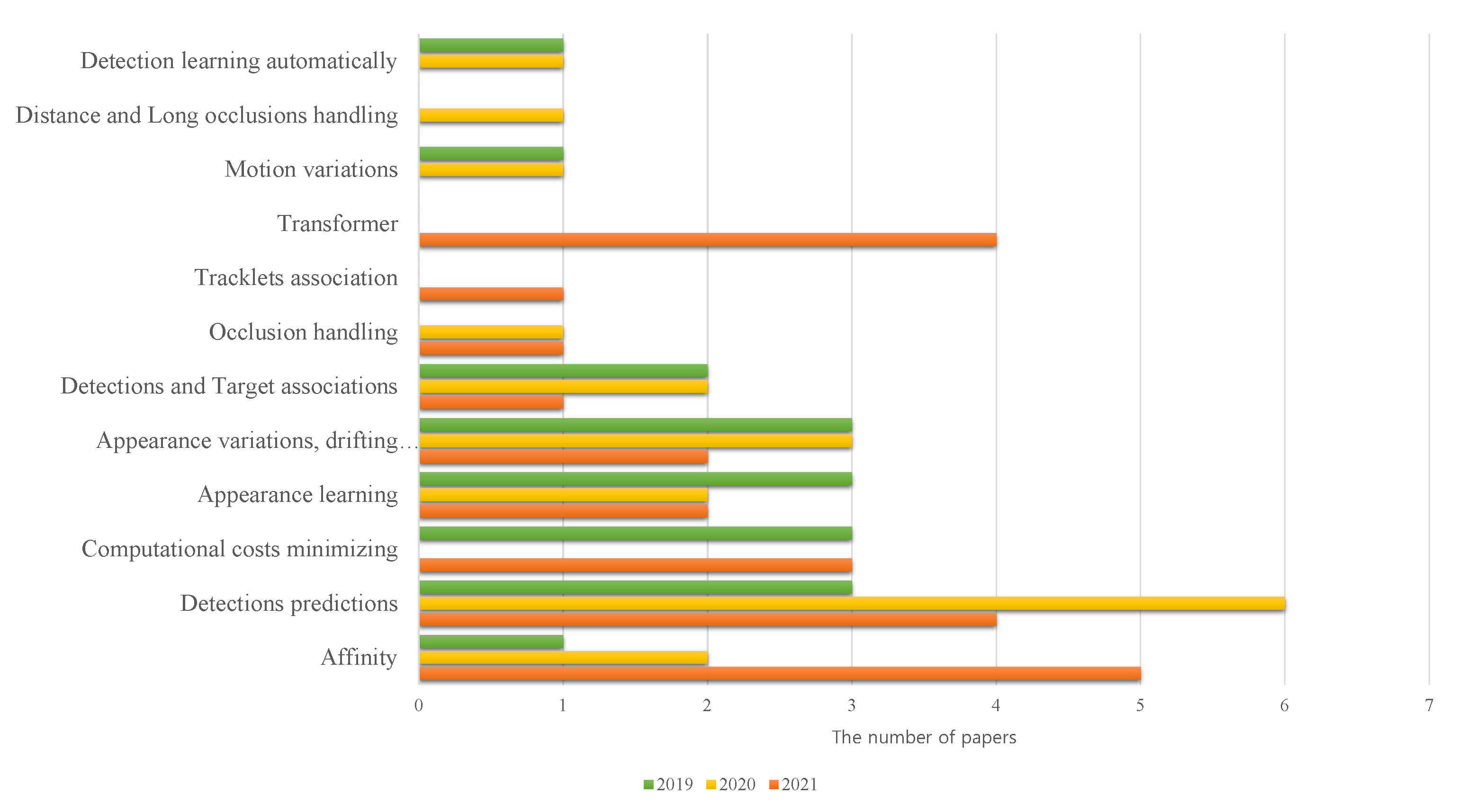
| Category | Issue | 2019 | 2020 | 2021 |
|---|---|---|---|---|
| Affinity | The number of papers is increasing | 6% | 10% | 22% |
| Appearance learning |
| 17% | 11% | 9% |
| Appearance Variations, Drifting, and Identity Switching | 17% | 16% | 9% | |
| Detection prediction |
| 18% | 32% | 18% |
| Detection and target associations | 12% | 11% | 4% | |
| Automatic Detection Learning | 6% | 5% | - | |
| Transformer | Models including deep learning and transformers have been published recently | - | - | 17% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Dang, L.M.; Lee, S.; Han, D.; Moon, H. Multiple Object Tracking in Deep Learning Approaches: A Survey. Electronics 2021, 10, 2406. https://doi.org/10.3390/electronics10192406
Park Y, Dang LM, Lee S, Han D, Moon H. Multiple Object Tracking in Deep Learning Approaches: A Survey. Electronics. 2021; 10(19):2406. https://doi.org/10.3390/electronics10192406
Chicago/Turabian StylePark, Yesul, L. Minh Dang, Sujin Lee, Dongil Han, and Hyeonjoon Moon. 2021. "Multiple Object Tracking in Deep Learning Approaches: A Survey" Electronics 10, no. 19: 2406. https://doi.org/10.3390/electronics10192406
APA StylePark, Y., Dang, L. M., Lee, S., Han, D., & Moon, H. (2021). Multiple Object Tracking in Deep Learning Approaches: A Survey. Electronics, 10(19), 2406. https://doi.org/10.3390/electronics10192406