
COREA: Delay- and Energy-Efficient Approximate Adder Using Effective Carry Speculation


Abstract
:1. Introduction
- We propose a novel approximate adder that offers excellent energy-efficiency with high accuracy.
- We systematically analyze the proposed adder for error characteristics and hardware performance.
- We extensively compare the proposed adder with other adders using various aspects, including hardware-accuracy joint metrics.
- We present the efficacy of the proposed adder over existing approximate adders in a machine learning application.
2. Proposed Approximate Adder Design
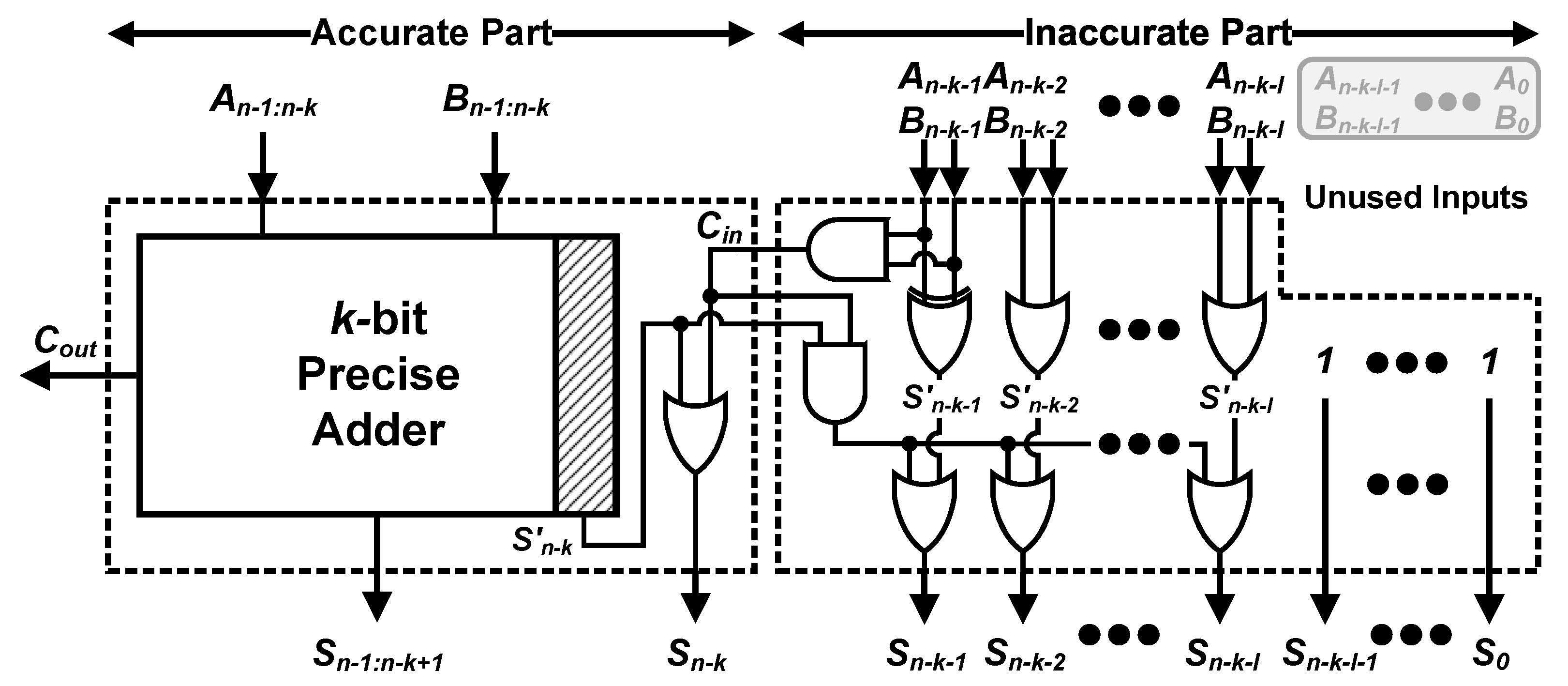
2.1. Proposed Adder Architecture
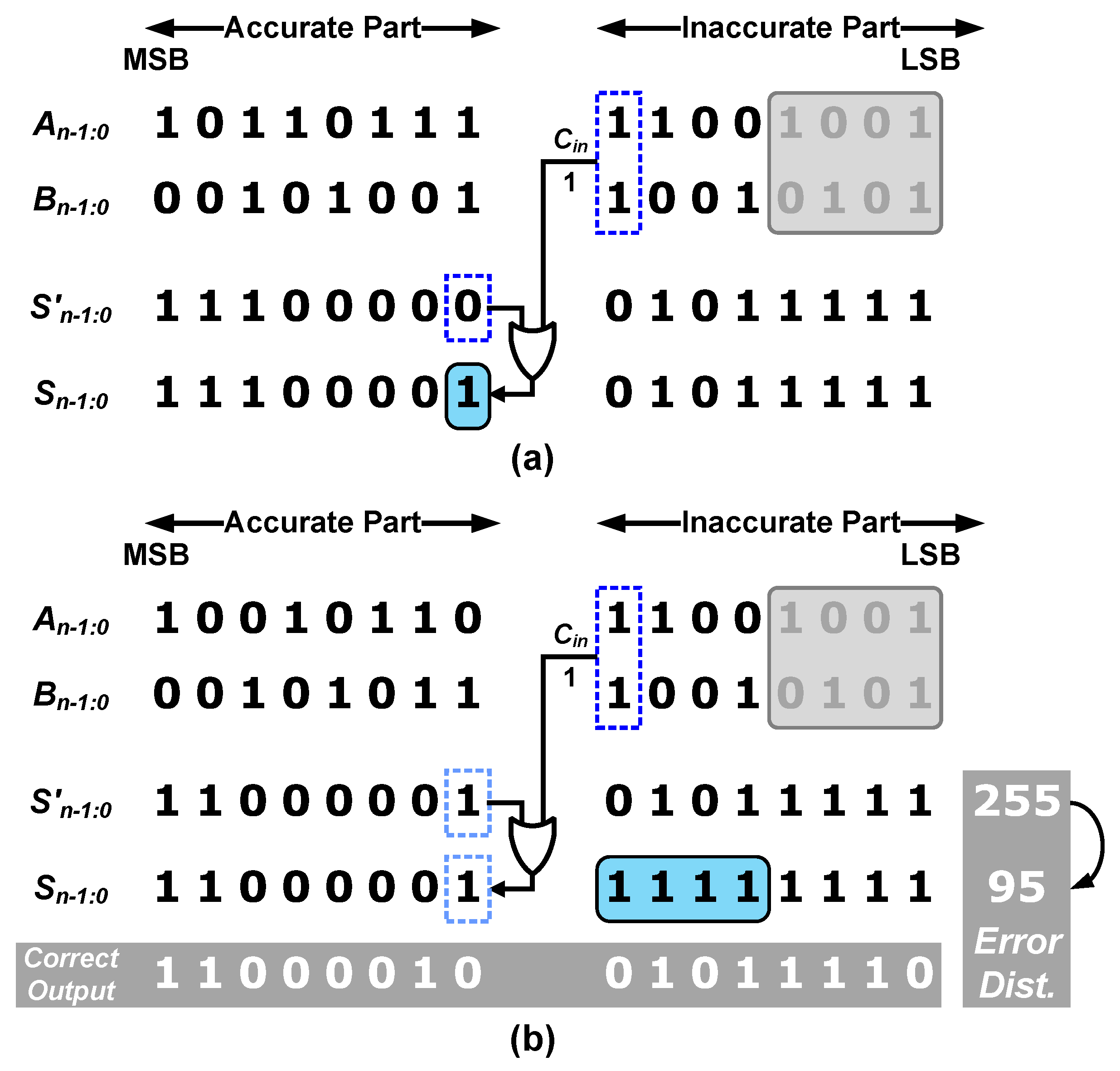
2.2. Operation of the Proposed Adder
2.3. Error Rate Analysis
3. Experimental Results
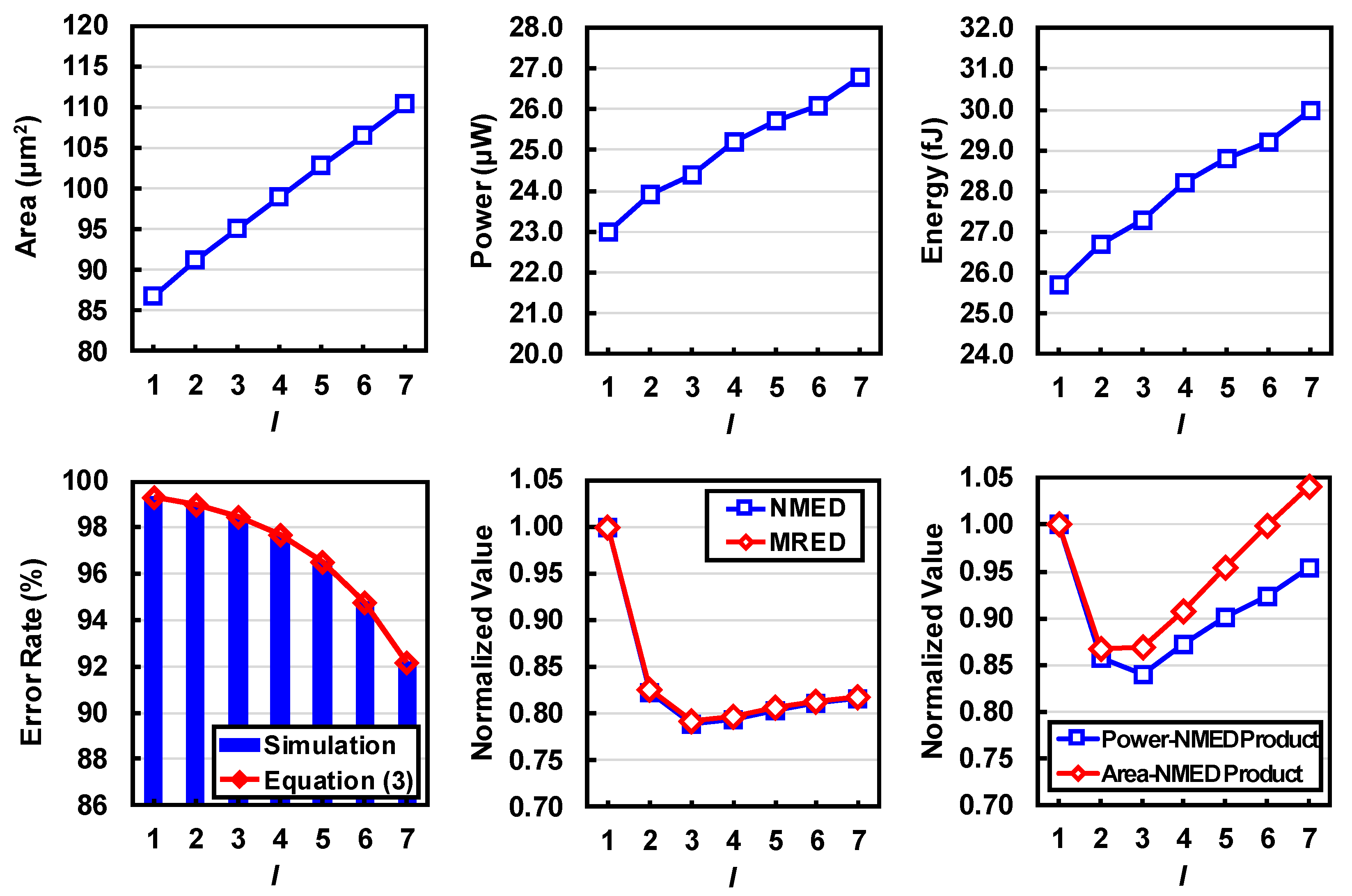
3.1. Performance Analysis
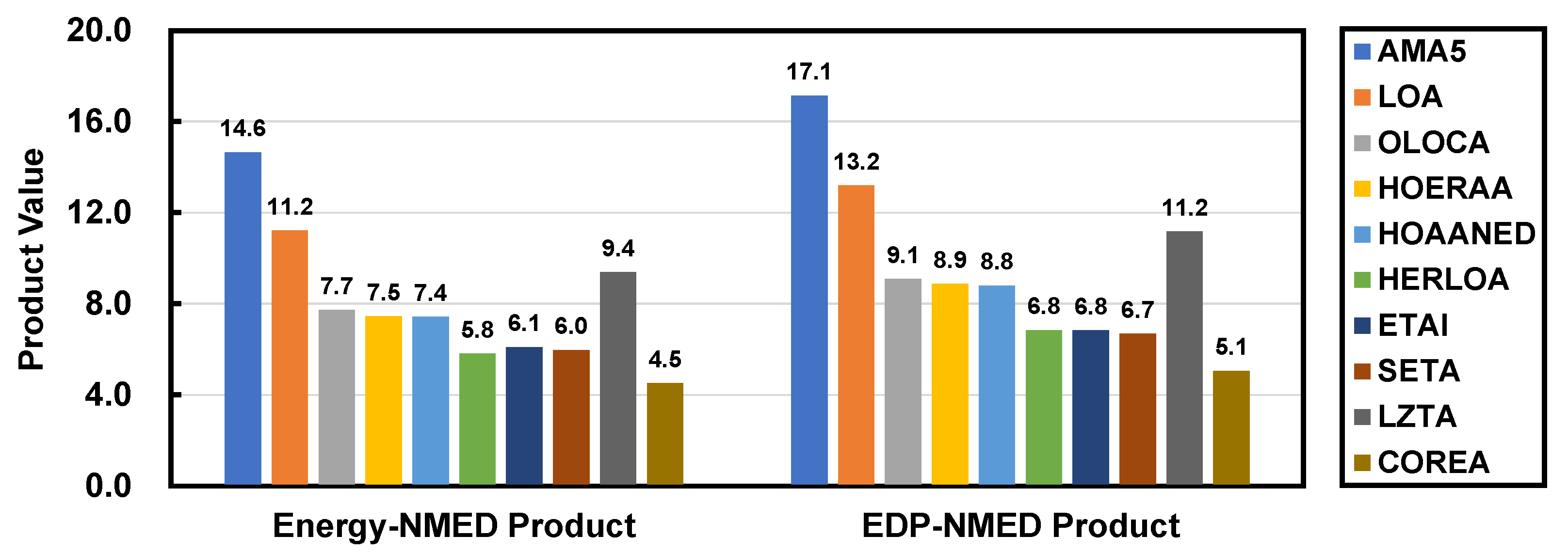
3.2. Performance Comparison with Other Approximate Adders
3.3. Tradeoff Analysis and Comparison
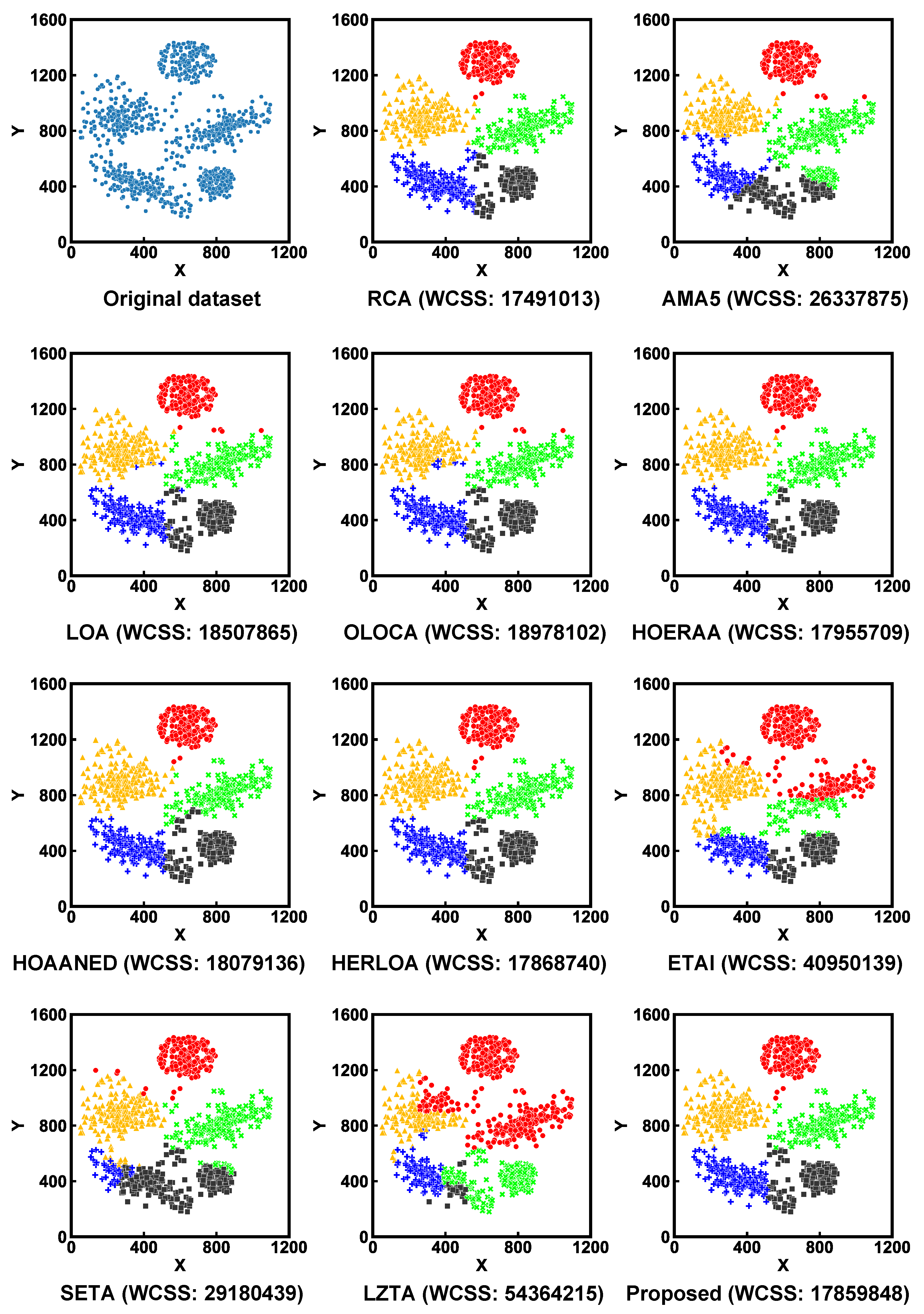
4. Case Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alom, A.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Hu, S.; Liu, S.; Fang, J.; Xu, S. Remote Sensing Image Fusion Based on Sparse Representation and Guided Filtering. Electronics 2019, 8, 303. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Li, P.; Kim, Y. A Parallel Digital VLSI Architecture for Integrated Support Vector Machine Training and Classification. IEEE Trans. Very Large Scale. Integr. (VLSI) Syst. 2015, 23, 1471–1484. [Google Scholar] [CrossRef]
- Khan, I.; Choi, S.; Kwon, Y.-W. Earthquake Detection in a Static and Dynamic Environment Using Supervised Machine Learning and a Novel Feature Extraction Method. Sensors 2020, 20, 800. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Khan, I.; Choi, S.; Kwon, Y.-W. A Smart IoT Device for Detecting and Responding to Earthquakes. Electronics 2019, 8, 1546. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S. A Survey of Techniques for Approximate Computing. ACM Comput. Survey 2016, 48, 62:1–62:33. [Google Scholar] [CrossRef] [Green Version]
- Pashaeifar, M.; Kamal, M.; Afzali-Kusha, A.; Pedram, M. Approximate Reverse Carry Propagation Adder for Energy-Efficient DSP Applications. IEEE Trans. Very Large Scale. Integr. (VLSI) Syst. 2018, 26, 2530–2541. [Google Scholar] [CrossRef]
- Mahdiani, H.; Ahmadi, A.; Fakhraie, S.M.; Lucas, C. Bio-Inspired Imprecise Computational Blocks for Efficient VLSI Implementation of Soft-Computing Applications. IEEE Trans. Circuits Syst. I Reg. Pap. 2010, 57, 850–862. [Google Scholar] [CrossRef]
- Zhu, N.; Goh, W.L.; Zhang, W.; Yeo, K.S.; Kong, Z.H. Design of Low-Power High-Speed Truncation-Error-Tolerant Adder and its Application in Digital Signal Processing. IEEE Trans. Very Large Scale. Integr. (VLSI) Syst. 2010, 18, 1225–1229. [Google Scholar]
- Gupta, V.; Mohapatra, D.; Raghunathan, A.; Roy, K. Low-Power Digital Signal Processing Using Approximate Adders. IEEE Trans. Comput.-Aided Design Integr. Circuits Syst. 2013, 32, 124–137. [Google Scholar] [CrossRef]
- Dalloo, A.; Najafi, A.; Garcia-Ortiz, A. Systematic Design of an Approximate Adder: The Optimized Lower Part Constant-OR Adder. IEEE Trans. Very Large Scale. Integr. (VLSI) Syst. 2018, 26, 1595–1599. [Google Scholar] [CrossRef]
- Seo, H.; Yang, Y.S.; Kim, Y. Design and Analysis of an Approximate Adder with Hybrid Error Reduction. Electronics 2020, 9, 471. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Seo, H.; Kim, Y.; Kim, Y. Approximate Adder Design with Simplified Lower-part Approximation. IEICE Electron. Express 2020, 17, 1–3. [Google Scholar] [CrossRef]
- Balasubramanian, P.; Maskell, D.L. Hardware Optimized and Error Reduced Approximate Adder. Electronics 2019, 8, 1212. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, P.; Nayar, R.; Maskell, D.L.; Mastorakis, N.E. An Approximate Adder With a Near-Normal Error Distribution: Design, Error Analysis and Practical Application. IEEE Access 2020, 9, 4518–4530. [Google Scholar] [CrossRef]
- Lee, J.; Seo, H.; Kim, Y.; Kim, Y. Design of a Low-Cost Approximate Adder with a Zero Truncation. In Proceedings of the International System-on-Chip (SOC) Design Conference, Yeosu, Korea, 21–24 October 2020; pp. 69–70. [Google Scholar]
- Kim, Y.; Zhang, Y.; Li, P. An Energy Efficient Approximate Adder with Carry Skip for Error Resilient Neuromorphic VLSI Systems. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 18–21 November 2013; pp. 130–137. [Google Scholar]
- Kim, Y.; Zhang, Y.; Li, P. Energy Efficient Approximate Arithmetic for Error Resilient Neuromorphic Computing. IEEE Trans. Very Large Scale. Integr. (VLSI) Syst. 2015, 23, 2733–2737. [Google Scholar] [CrossRef]
- Shafique, M.; Ahmad, W.; Hafiz, R.; Henkel, J. A Low Latency Generic Accuracy Configurable Adder. In Proceedings of the IEEE/ACM Design Automation Conference, San Francisco, CA, USA, 8–12 June 2015; pp. 81:1–81:6. [Google Scholar]
- Camus, V.; Cacciotti, M.; Schlachter, J.; Enz, C. Design of Approximate Circuits by Fabrication of False Timing Paths: The Carry Cut-Back Adder. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 746–757. [Google Scholar] [CrossRef] [Green Version]
- Ebrahimi-Azandaryani, F.; Akbari, O.; Kamal, M.; Afzali-Kusha, A.; Pedram, M. Block-Based Carry Speculative Approximate Adder for Energy-Efficient Applications. IEEE Trans. Circuits Syst. II Exp. Briefs 2020, 67, 137–141. [Google Scholar] [CrossRef]
- Kim, Y. An Accuracy Enhanced Error Tolerant Adder with Carry Prediction for Approximate Computing. IEIE Trans. Smart Process. Comput. 2019, 8, 324–330. [Google Scholar] [CrossRef]
- Kim, Y. A Novel Approximate Adder with Enhanced Low-cost Carry Prediction for Error Tolerant Computing. IEIE Trans. Smart Process. Comput. 2019, 8, 506–510. [Google Scholar] [CrossRef]
- Akbari, O.; Kamal, M.; Afzali-Kusha, A.; Pedram, M. RAP-CLA: A Reconfigurable Approximate Carry Look-Ahead Adder. IEEE Trans. Circuits Syst. II Exp. Briefs 2018, 65, 1089–1093. [Google Scholar] [CrossRef]
- Hu, J.; Li, Z.; Yang, M.; Huang, Z.; Qian, W. A High-Accuracy Approximate Adder with Correct Sign Calculation. Integration 2019, 65, 370–388. [Google Scholar] [CrossRef]
- Bhatnagar, H. Advanced ASIC Chip Synthesis: Using Synopsys Design Compiler Physical Compiler and Prime Time, 2nd ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002. [Google Scholar]
- Raha, A.; Jayakumar, H.; Raghunathan, V. Input-Based Dynamic Reconfiguration of Approximate Arithmetic Units for Video Encoding. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2016, 24, 846–857. [Google Scholar] [CrossRef]
- Soares, L.B.; da Rosa, M.M.A.; Diniz, C.M.; da Costa, E.A.C.; Bampi, S. Design Methodology to Explore Hybrid Approximate Adders for Energy-Efficient Image and Video Processing Accelerators. IEEE Trans. Circuits Syst. I Reg. Pap. 2019, 66, 2137–2150. [Google Scholar] [CrossRef]
- Liang, J.; Han, J.; Lombardi, F. New Metric for the Reliability of Approximate and Probabilistic Adders. IEEE Trans. Comput. 2013, 62, 1760–1771. [Google Scholar] [CrossRef]
- Clustering Benchmark. Available online: http://github.com/deric/clustering-benchmark (accessed on 25 July 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design | Area | Delay | Power | Energy | ADP | EDP |
|---|---|---|---|---|---|---|
| (ns) | (fJ) | |||||
| RCA | 162.6 | 2.27 | 46.2 | 104.9 | 3.69 | 2.38 |
| AMA5 | 94.7 | 1.17 | 25.0 | 29.3 | 1.11 | 3.43 |
| LOA | 101.8 | 1.18 | 25.5 | 30.0 | 1.20 | 3.55 |
| OLOCA | 90.2 | 1.18 | 24.1 | 28.4 | 1.06 | 3.35 |
| HOERAA | 94.1 | 1.19 | 24.9 | 29.6 | 1.12 | 3.52 |
| HOAANED | 93.1 | 1.18 | 24.9 | 29.5 | 1.10 | 3.47 |
| HERLOA | 113.0 | 1.18 | 28.8 | 33.9 | 1.33 | 4.01 |
| ETAI | 113.3 | 1.12 | 27.2 | 30.4 | 1.27 | 3.42 |
| SETA | 97.6 | 1.12 | 24.4 | 27.3 | 1.09 | 3.06 |
| LZTA | 86.4 | 1.19 | 23.6 | 28.1 | 1.03 | 3.34 |
| COREA | 95.0 | 1.12 | 24.4 | 27.3 | 1.06 | 3.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seok, H.; Seo, H.; Lee, J.; Kim, Y. COREA: Delay- and Energy-Efficient Approximate Adder Using Effective Carry Speculation. Electronics 2021, 10, 2234. https://doi.org/10.3390/electronics10182234
Seok H, Seo H, Lee J, Kim Y. COREA: Delay- and Energy-Efficient Approximate Adder Using Effective Carry Speculation. Electronics. 2021; 10(18):2234. https://doi.org/10.3390/electronics10182234
Chicago/Turabian StyleSeok, Hyelin, Hyoju Seo, Jungwon Lee, and Yongtae Kim. 2021. "COREA: Delay- and Energy-Efficient Approximate Adder Using Effective Carry Speculation" Electronics 10, no. 18: 2234. https://doi.org/10.3390/electronics10182234
APA StyleSeok, H., Seo, H., Lee, J., & Kim, Y. (2021). COREA: Delay- and Energy-Efficient Approximate Adder Using Effective Carry Speculation. Electronics, 10(18), 2234. https://doi.org/10.3390/electronics10182234