
Can Deep Models Help a Robot to Tune Its Controller? A Step Closer to Self-Tuning Model Predictive Controllers



Abstract
1. Introduction
- Switching from the Gazebo model to the DNN model: previous work utilizes a Gazebo model of the robotic platform during weight set exploration. However, creating a Gazebo model requires expertise that may not be available for novice users. Hence, we opt for another simpler modeling approach in this work, i.e., deep neural networks (DNNs). Unlike the complicated process of obtaining a high-fidelity Gazebo model, in this case, novice users are only required to collect some data by manual flights and simply feed them to a DNN for modeling. Once trained, it will serve just like a Gazebo model to eliminate the need for risky trials on a real robot during weight set exploration.
- Fine-tuning of weight sets over real flights: to cater to several operational uncertainties, including decreasing battery voltage, communication delays, that may not be captured within the model, fine-tuning of the weight sets is also performed over the real robot. The real flight tuning feasibility of the proposed algorithm is demonstrated in this way.
- User study to evaluate the proposed tuning methodology: a comparison with the manual tuning procedure through a user-based study is performed, wherein users implicitly apply various strategies during the tuning process. Naively, they start by recognizing the dominating parameters and their effect on the performance, followed by the appropriate weight set selection. In essence, they optimize performance by exploring the selection space in a Bayesian way.
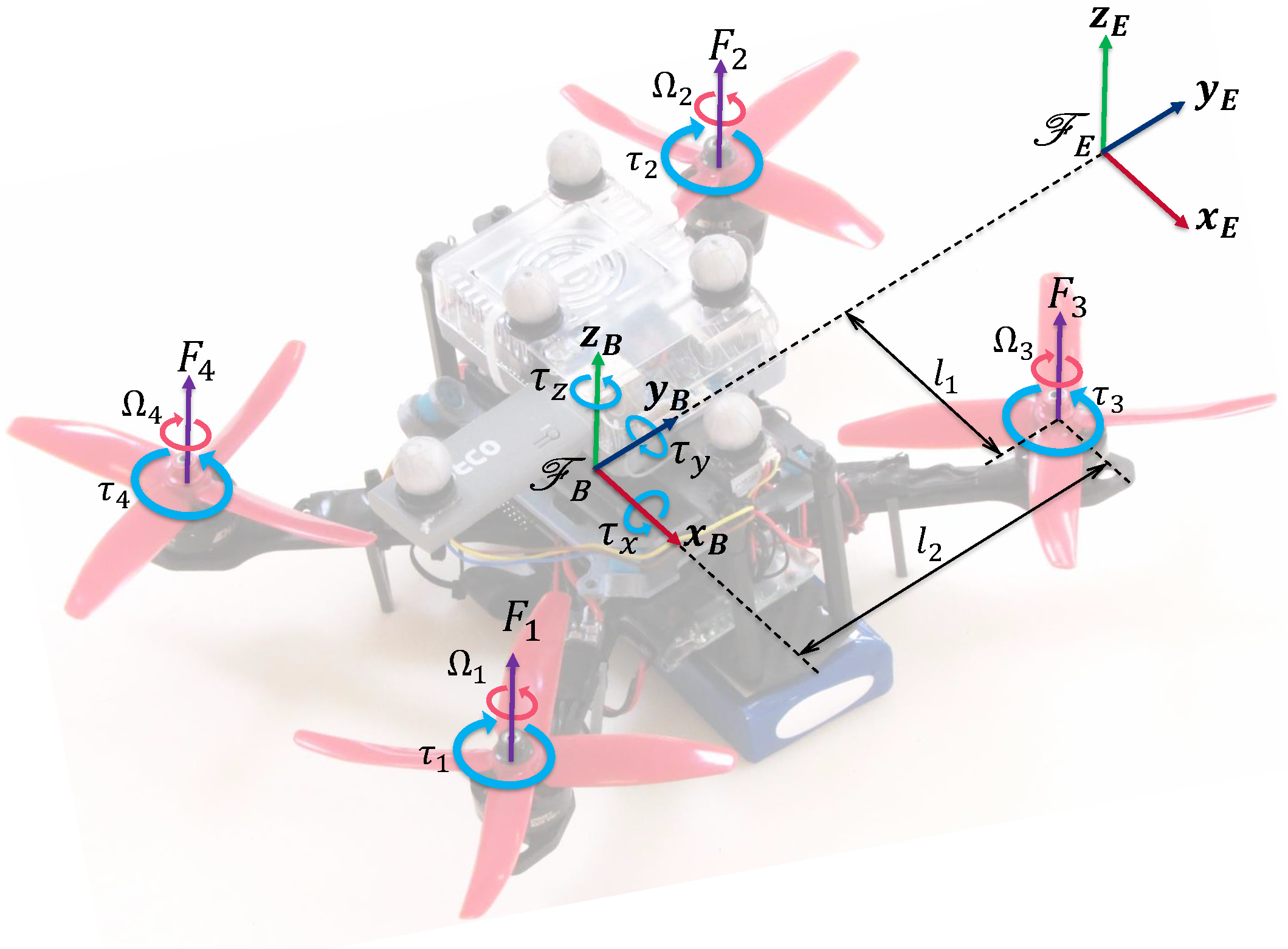
2. Quadrotor Aerial Robot
3. Position Tracking Nonlinear Model Predictive Controller
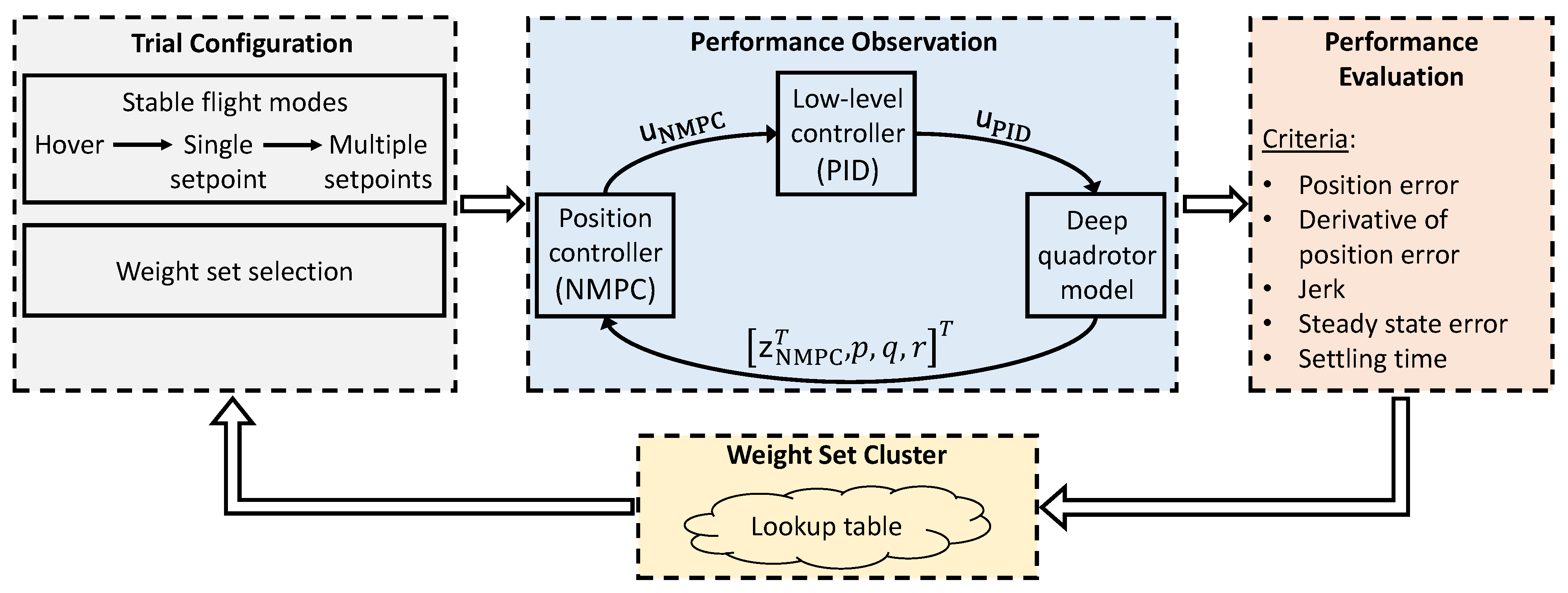
4. Proposed Auto-Tuning Approach
4.1. DNN-Based System Modeling
4.2. Active Exploration of Weight Sets
4.3. Overall Framework with Implementation Details
| Algorithm 1 Auto-tuning approach |
 |
5. Tuning Approach in Action
5.1. Benchmark Study for Simulation-Based Tuning
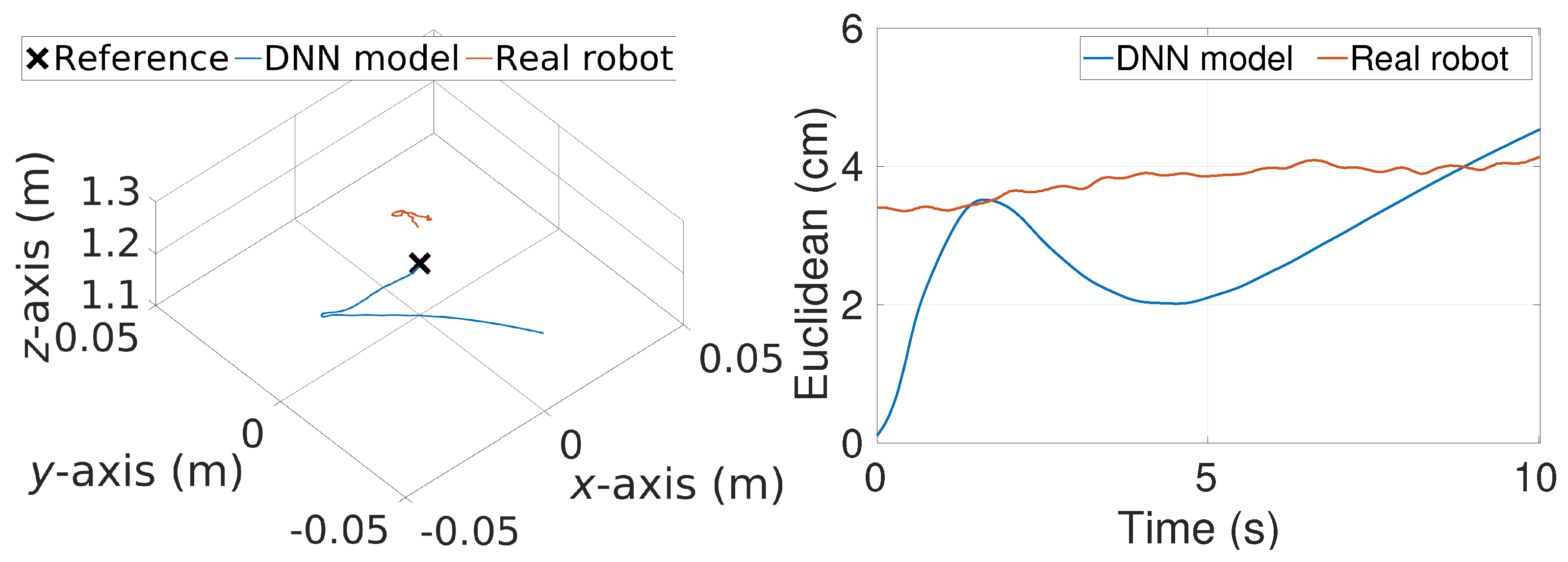
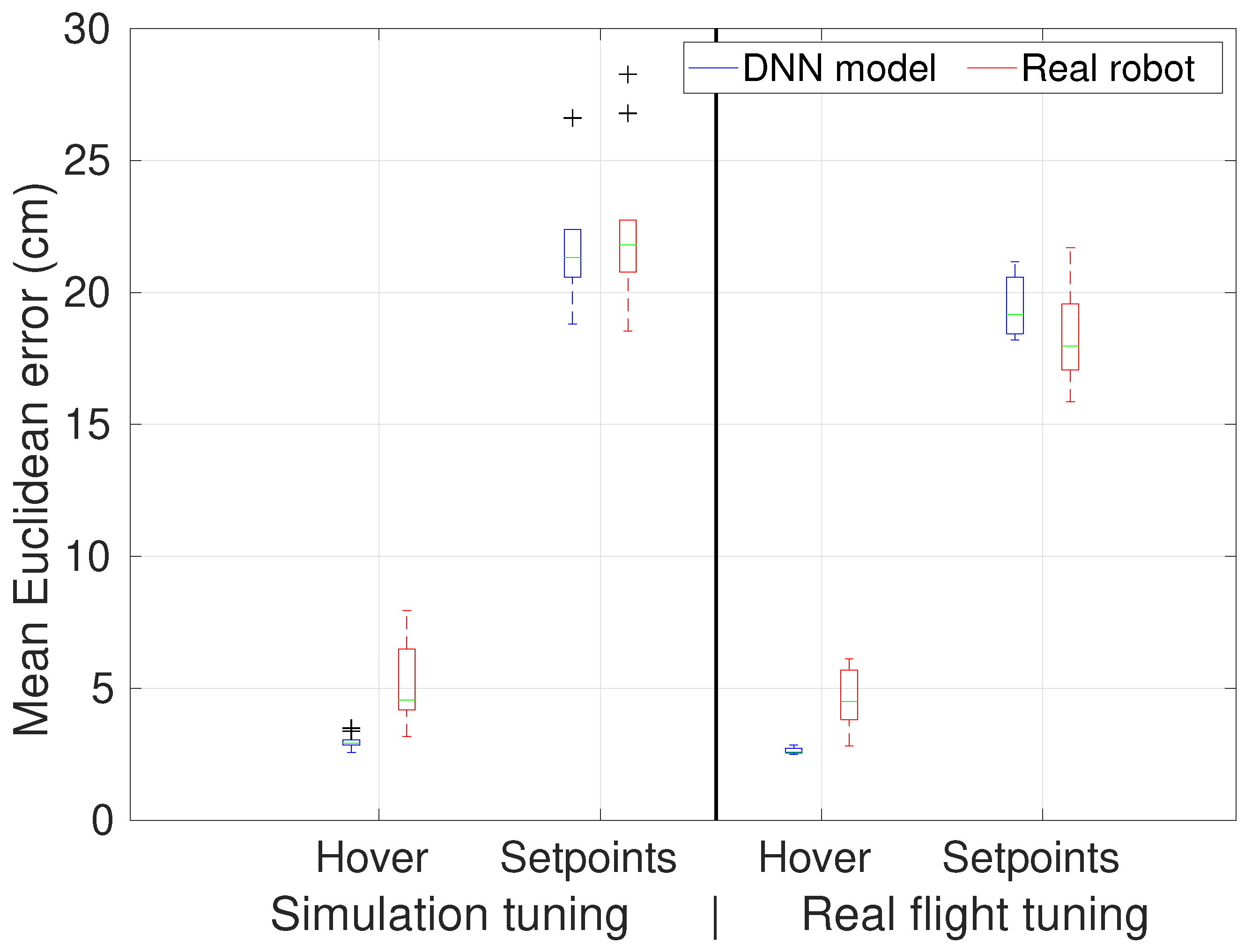
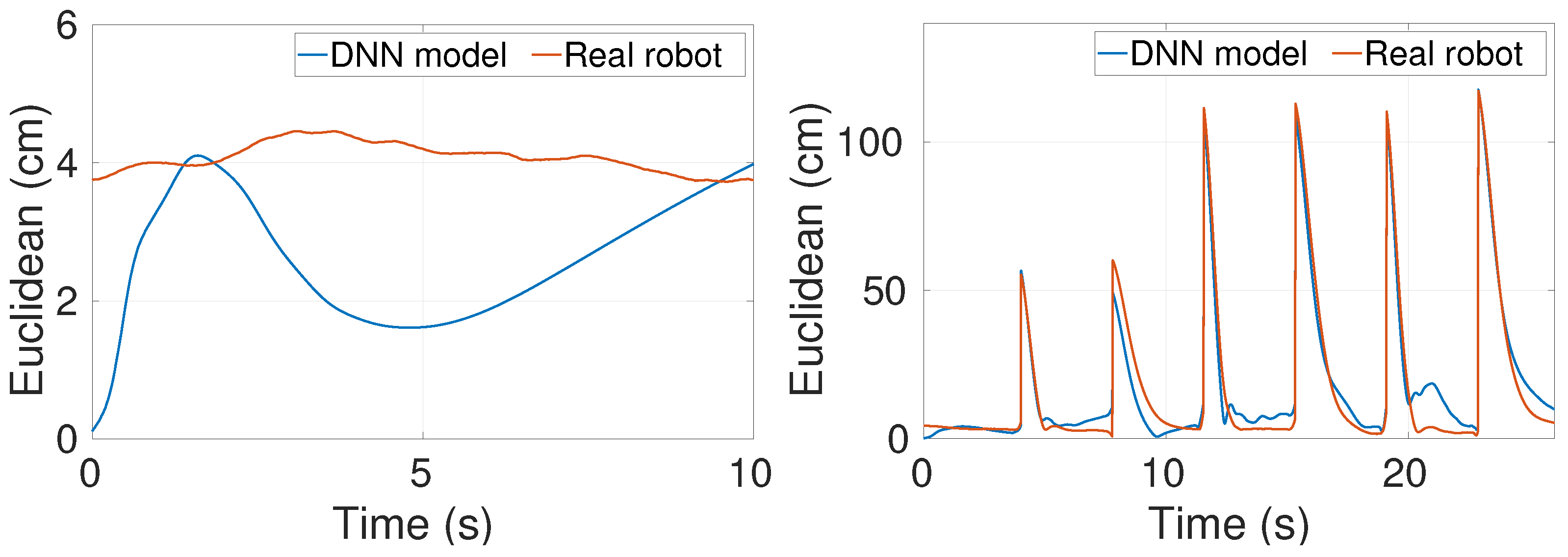
5.2. Further Tuning in Real Flights
6. Trajectory Tracking
6.1. Simulation-Based Tuning
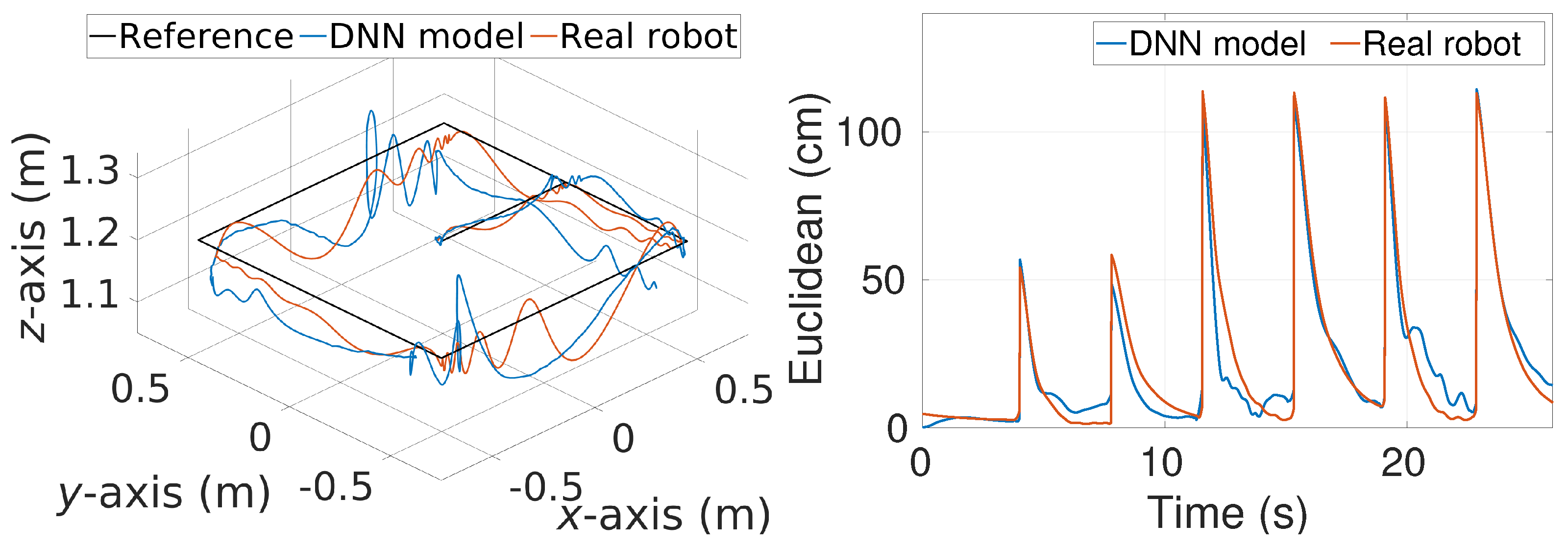
6.2. Real Flight Tuning
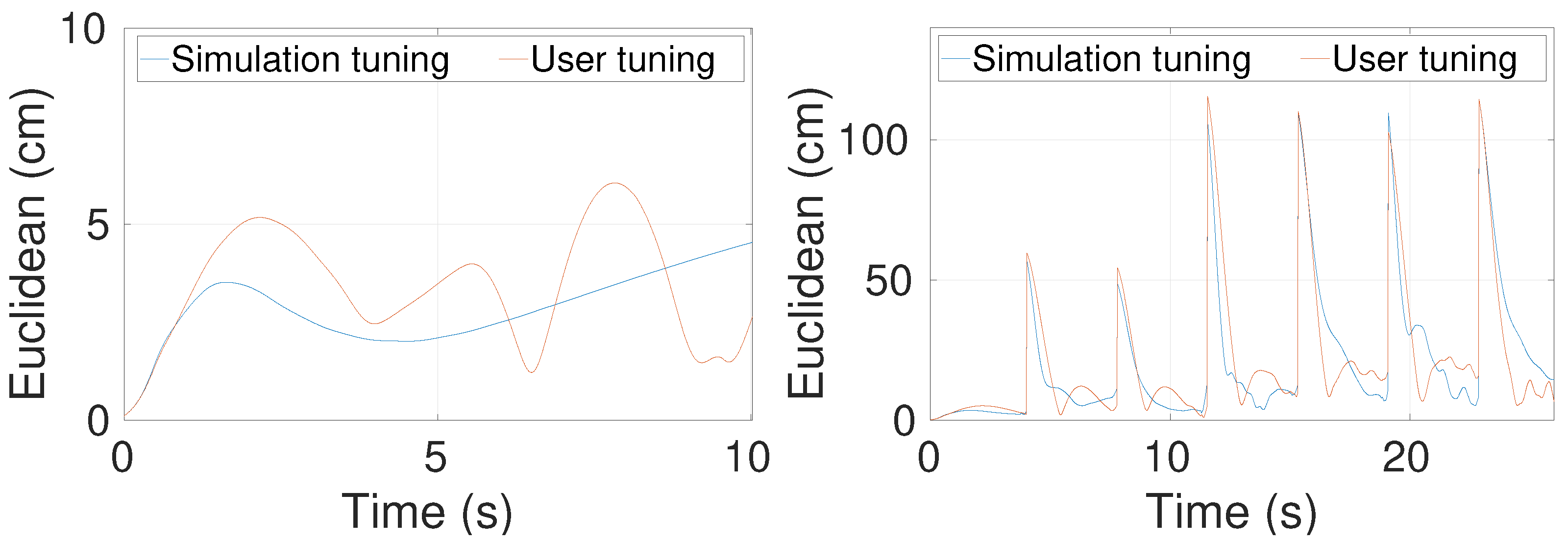
6.3. User-Based Tuning Study
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Ortiz, A.; Garcia-Nieto, S.; Simarro, R. Comparative Study of Optimal Multivariable LQR and MPC Controllers for Unmanned Combat Air Systems in Trajectory Tracking. Electronics 2021, 10, 331. [Google Scholar] [CrossRef]
- Ahn, T.; Lee, Y.; Park, K. Design of Integrated Autonomous Driving Control System That Incorporates Chassis Controllers for Improving Path Tracking Performance and Vehicle Stability. Electronics 2021, 10, 144. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Kayacan, E. Gaussian Process-based Learning Control of Aerial Robots for Precise Visualization of Geological Outcrops. In Proceedings of the 2020 European Control Conference (ECC), St. Petersburg, Russia, 12–15 May 2020; pp. 10–16. [Google Scholar]
- Imanberdiyev, N.; Kayacan, E. Redundancy Resolution based Trajectory Generation for Dual-Arm Aerial Manipulators via Online Model Predictive Control. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 674–681. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Kayacan, E.; Patel, S.; Kayacan, E.; Chowdhary, G. Learning-based Fast Nonlinear Model Predictive Control for Custom-made 3D Printed Ground and Aerial Robots. Control Eng. 2019. [Google Scholar] [CrossRef]
- Bai, G.; Meng, Y.; Liu, L.; Luo, W.; Gu, Q.; Liu, L. Review and Comparison of Path Tracking Based on Model Predictive Control. Electronics 2019, 8, 1077. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Kayacan, E. A constrained instantaneous learning approach for aerial package delivery robots: Onboard implementation and experimental results. Auton. Robots 2019, 43, 2209–2228. [Google Scholar] [CrossRef]
- Baca, T.; Hert, D.; Loianno, G.; Saska, M.; Kumar, V. Model Predictive Trajectory Tracking and Collision Avoidance for Reliable Outdoor Deployment of Unmanned Aerial Vehicles. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6753–6760. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Kayacan, E. Reconfigurable Fault-tolerant NMPC for Y6 Coaxial Tricopter with Complete Loss of One Rotor. In Proceedings of the 2018 IEEE Conference on Control Technology and Applications (CCTA), Copenhagen, Denmark, 21–24 August 2018; pp. 774–780. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Kayacan, E. Online Learning-based Receding Horizon Control of Tilt-rotor Tricopter: A Cascade Implementation. In Proceedings of the 2018 American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 1–6. [Google Scholar]
- Mehndiratta, M.; Kayacan, E. Receding horizon control of a 3 DOF helicopter using online estimation of aerodynamic parameters. Proc. Inst. Mech. Eng. Part J. Aerosp. Eng. 2017. [Google Scholar] [CrossRef]
- Eren, U.; Prach, A.; Koçer, B.B.; Raković, S.V.; Kayacan, E.; Açikmeşe, B. Model Predictive Control in Aerospace Systems: Current State and Opportunities. J. Guid. Control Dyn. 2017, 40, 1541–1566. [Google Scholar] [CrossRef]
- Lee, W.Y.J.; Mehndiratta, M.; Kayacan, E. Fly without borders with additive manufacturing: A microscale tilt-rotor tricopter design. In Proceedings of the 3rd International Conference on Progress in Additive Manufacturing (Pro-AM 2018), Singapore, 14–17 May 2018; pp. 256–261. [Google Scholar] [CrossRef]
- Kayacan, E.; Kayacan, E.; Ramon, H.; Saeys, W. Learning in Centralized Nonlinear Model Predictive Control: Application to an Autonomous Tractor-Trailer System. IEEE Trans. Control Syst. Technol. 2015, 23, 197–205. [Google Scholar] [CrossRef]
- Lee, J.; Yu, Z. Tuning of model predictive controllers for robust performance. Comput. Chem. Eng. 1994, 18, 15–37. [Google Scholar] [CrossRef]
- Shridhar, R.; Cooper, D.J. A Tuning Strategy for Unconstrained Multivariable Model Predictive Control. Ind. Eng. Chem. Res. 1998, 37, 4003–4016. [Google Scholar] [CrossRef]
- Di Cairano, S.; Bemporad, A. Model Predictive Control Tuning by Controller Matching. IEEE Trans. Autom. Control 2010, 55, 185–190. [Google Scholar] [CrossRef]
- Ali, E.; Zafiriou, E. Optimization-based tuning of nonlinear model predictive control with state estimation. J. Process Control 1993, 3, 97–107. [Google Scholar] [CrossRef][Green Version]
- Al-Ghazzawi, A.; Ali, E.; Nouh, A.; Zafiriou, E. On-line tuning strategy for model predictive controllers. J. Process Control 2001, 11, 265–284. [Google Scholar] [CrossRef]
- Ali, E. Heuristic on-line tuning for nonlinear model predictive controllers using fuzzy logic. J. Process Control 2003, 13, 383–396. [Google Scholar] [CrossRef]
- Shipman, W.J.; Coetzee, L.C. Reinforcement Learning and Deep Neural Networks for PI Controller Tuning. IFAC-PapersOnLine 2019, 52, 111–116. [Google Scholar] [CrossRef]
- Kofinas, P.; Dounis, A.I. Fuzzy Q-Learning Agent for Online Tuning of PID Controller for DC Motor Speed Control. Algorithms 2018, 11, 148. [Google Scholar] [CrossRef]
- Junell, J.; Mannucci, T.; Zhou, Y.; Van Kampen, E.J. Self-tuning gains of a quadrotor using a simple model for policy gradient reinforcement learning. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, San Diego, CA, USA, 4–8 January 2016; p. 1387. [Google Scholar]
- Howell, M.; Best, M. On-line PID tuning for engine idle-speed control using continuous action reinforcement learning automata. Control Eng. Pract. 2000, 8, 147–154. [Google Scholar] [CrossRef]
- Mehndiratta, M.; Camci, E.; Kayacan, E. Automated Tuning of Nonlinear Model Predictive Controller by Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Bouabdallah, S. Design and Control of Quadrotors with Application to Autonomous Flying. Ph.D. Thesis, EPFL, Swiss Federal Institute of Technology Lausanne, Lausanne, Switzerland, 2007. [Google Scholar]
- Kraus, T.; Ferreau, H.; Kayacan, E.; Ramon, H.; Baerdemaeker, J.D.; Diehl, M.; Saeys, W. Moving horizon estimation and nonlinear model predictive control for autonomous agricultural vehicles. Comput. Electron. Agric. 2013, 98, 25–33. [Google Scholar] [CrossRef]
- Du, X.; Htet, K.K.K.; Tan, K.K. Development of a Genetic-Algorithm-Based Nonlinear Model Predictive Control Scheme on Velocity and Steering of Autonomous Vehicles. IEEE Trans. Ind. Electron. 2016, 63, 6970–6977. [Google Scholar] [CrossRef]
- Diehl, M.; Bock, H.; Schlöder, J.P.; Findeisen, R.; Nagy, Z.; Allgöwer, F. Real-time optimization and nonlinear model predictive control of processes governed by differential-algebraic equations. J. Process Control 2002, 12, 577–585. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Camci, E.; Campolo, D.; Kayacan, E. Deep Reinforcement Learning for Motion Planning of Quadrotors Using Raw Depth Images. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 1998; Volume 1. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Tolerance Values for Each Configuration | |||
|---|---|---|---|---|
| Hover | Move-to-a-Setpoint | Follow-Sequential-Setpoints | ||
| Position error (m) | 0.15 | 0.3 | 0.35 | |
| 0.15 | 0.3 | 0.35 | ||
| 0.15 | 0.3 | 0.35 | ||
| Derivative of position error (m/s) | 0.025 | 0.4 | 0.5 | |
| 0.025 | 0.4 | 0.5 | ||
| 0.03 | 0.45 | 0.55 | ||
| Jerk (m/s) | 0.5 | 2 | 2 | |
| 0.5 | 2 | 2 | ||
| 1 | 3 | 3 | ||
| Steady state error (m) | 0.15 | 0.15 | 0.15 | |
| 0.15 | 0.15 | 0.15 | ||
| 0.15 | 0.15 | 0.15 | ||
| Settling time (s) | 1.5 | 4.5 | 4.5 | |
| Episodes | Without Heuristic | With Heuristic |
|---|---|---|
| 100 | 10 | 7 |
| 500 | 7 | 2 |
| 1000 | 7 | 1 |
| Episodes | Active () | Random () |
|---|---|---|
| 100 | 7 | 8 |
| 500 | 2 | 4 |
| 1000 | 1 | 1 |
| Active () | Random ) | |||
|---|---|---|---|---|
| Episodes | Average | Maximum | Average | Maximum |
| 100 | 6 | 1 | ||
| 500 | 24 | 1 | 2 | |
| 1000 | 23 | 3 | ||
| Mean | 2 | |||
| Active () | Random () | |||
|---|---|---|---|---|
| Episodes | Average | Maximum | Average | Maximum |
| 100 | ||||
| 500 | ||||
| 1000 | ||||
| Mean | ||||
| First Hour | Second Hour | |||||||
|---|---|---|---|---|---|---|---|---|
| Hover | Sequential-Setpoints | Hover | Sequential-Setpoints | |||||
| Mean Euc. Error (cm) | Number of Oscillations | Mean Euc. Error (cm) | Number of Oscillations | Mean Euc. Error (cm) | Number of Oscillations | Mean Euc. Error (cm) | Number of Oscillations | |
| User 1 | 31 | 176 | 1 | 204 | ||||
| User 2 | 20 | 220 | 20 | 34 | ||||
| User 3 | 34 | 138 | 29 | 232 | ||||
| User 4 | 20 | 50 | 18 | 47 | ||||
| User 5 | 36 | 146 | ||||||
| User 6 | 2 | 37 | 19 | 45 | ||||
| User 7 | 6 | 31 | ||||||
| User 8 | 0 | 44 | ||||||
| User 9 | 16 | 250 | 1 | 29 | ||||
| User 10 | 0 | 32 | 10 | 35 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehndiratta, M.; Camci, E.; Kayacan, E. Can Deep Models Help a Robot to Tune Its Controller? A Step Closer to Self-Tuning Model Predictive Controllers. Electronics 2021, 10, 2187. https://doi.org/10.3390/electronics10182187
Mehndiratta M, Camci E, Kayacan E. Can Deep Models Help a Robot to Tune Its Controller? A Step Closer to Self-Tuning Model Predictive Controllers. Electronics. 2021; 10(18):2187. https://doi.org/10.3390/electronics10182187
Chicago/Turabian StyleMehndiratta, Mohit, Efe Camci, and Erdal Kayacan. 2021. "Can Deep Models Help a Robot to Tune Its Controller? A Step Closer to Self-Tuning Model Predictive Controllers" Electronics 10, no. 18: 2187. https://doi.org/10.3390/electronics10182187
APA StyleMehndiratta, M., Camci, E., & Kayacan, E. (2021). Can Deep Models Help a Robot to Tune Its Controller? A Step Closer to Self-Tuning Model Predictive Controllers. Electronics, 10(18), 2187. https://doi.org/10.3390/electronics10182187