
Multi-Path Deep CNN with Residual Inception Network for Single Image Super-Resolution

 , ,
, ,  ,
,  ,
,
Abstract
:1. Introduction
- Inspired by the ResNet and Inception network architecture, we propose a multi-path deep CNN with Residual and inception network for the SISR method with two upsampling layers to reconstruct the desired HR output images;
- We introduce a new multipath schema to effectively boost the feature representation of the HR image. The multipath schema consists of two layers such as deconvolution layer and upsampling layer to reconstruct the high quality of HR image features;
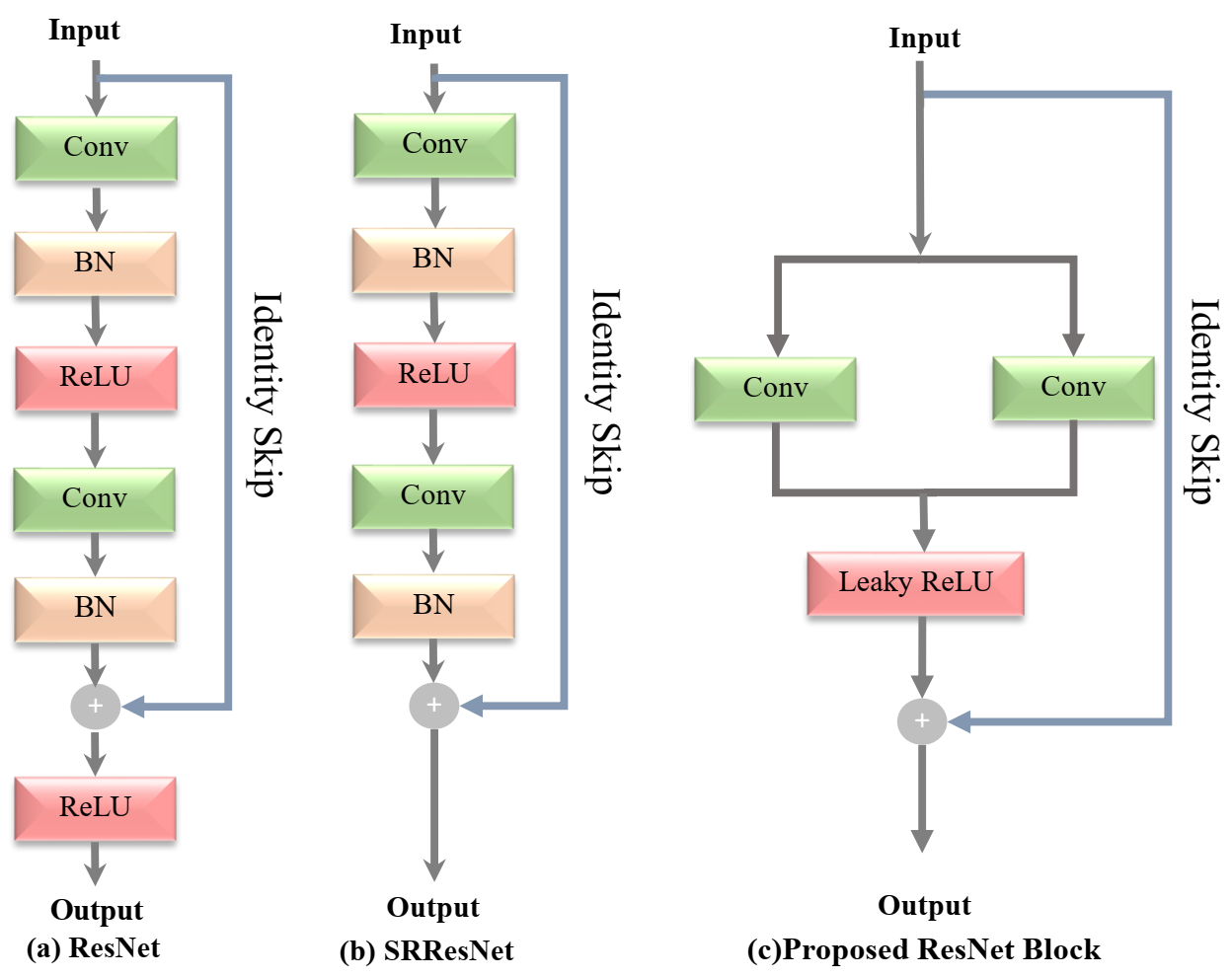
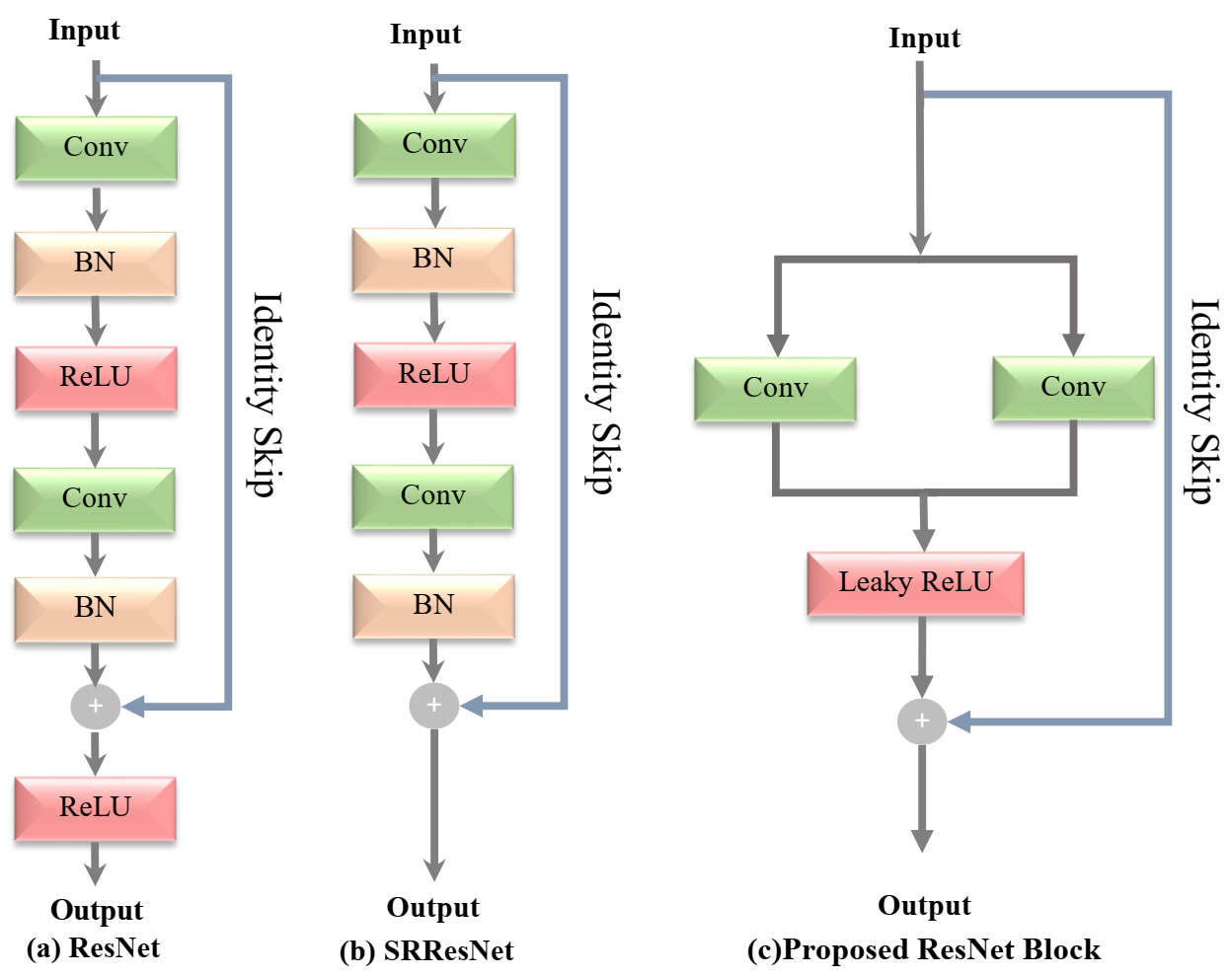
- Conventional deep CNN methods used the batch normalization Layer and max-pooling layer followed by the ReLU activation function, but our approach removes both batch normalization and max-pooling layer, to reduce the computational burden of the model and the conventional ReLU activation function is replaced with the leaky ReLU activation function to avoid the vanishing gradient problem during the training efficiently.
2. Related Work
2.1. Deep Learning-Based Image SR
2.2. Residual Skip Connection Based Image SR
2.3. Multi-Branch Based Image SR
3. Proposed Method
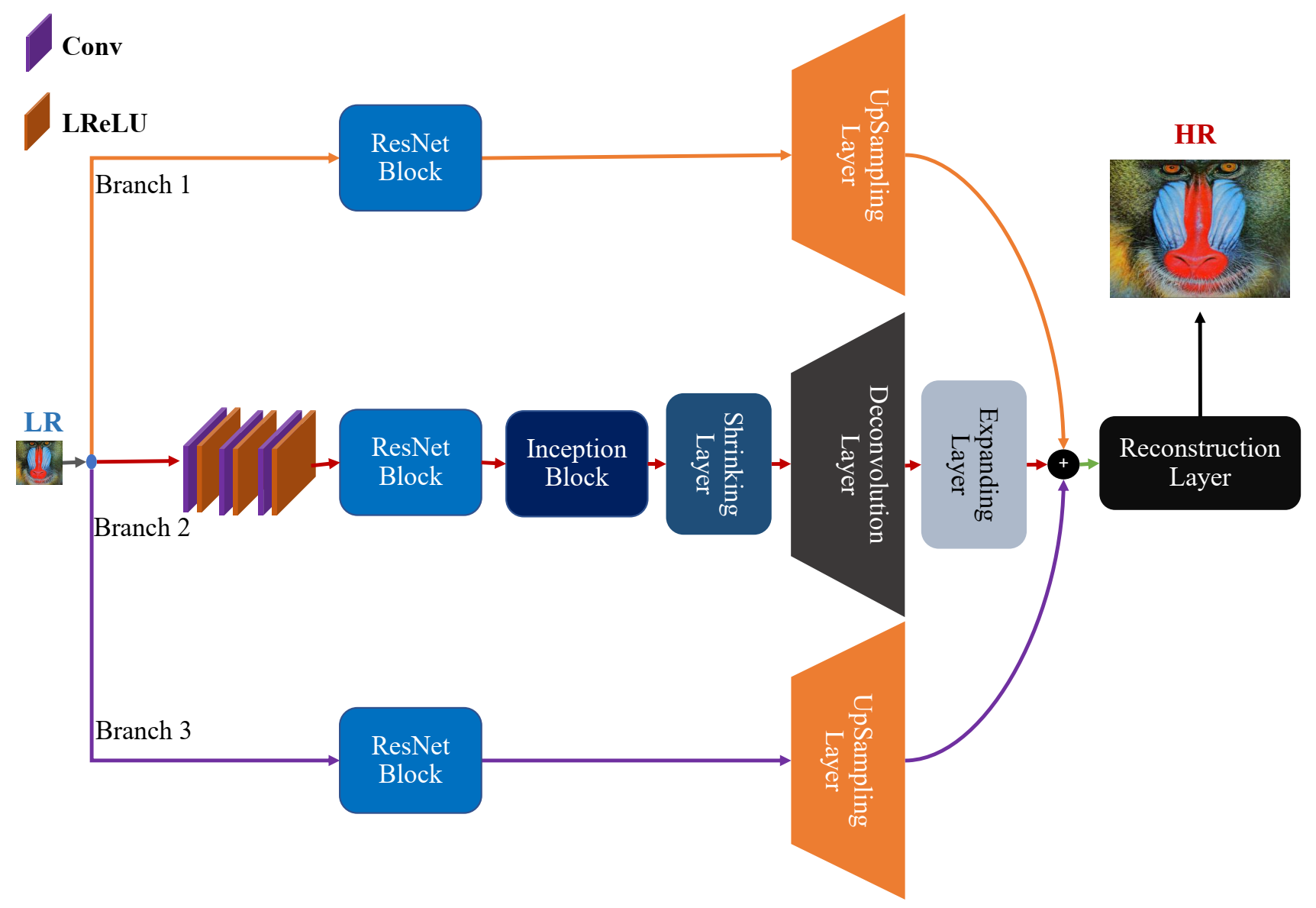
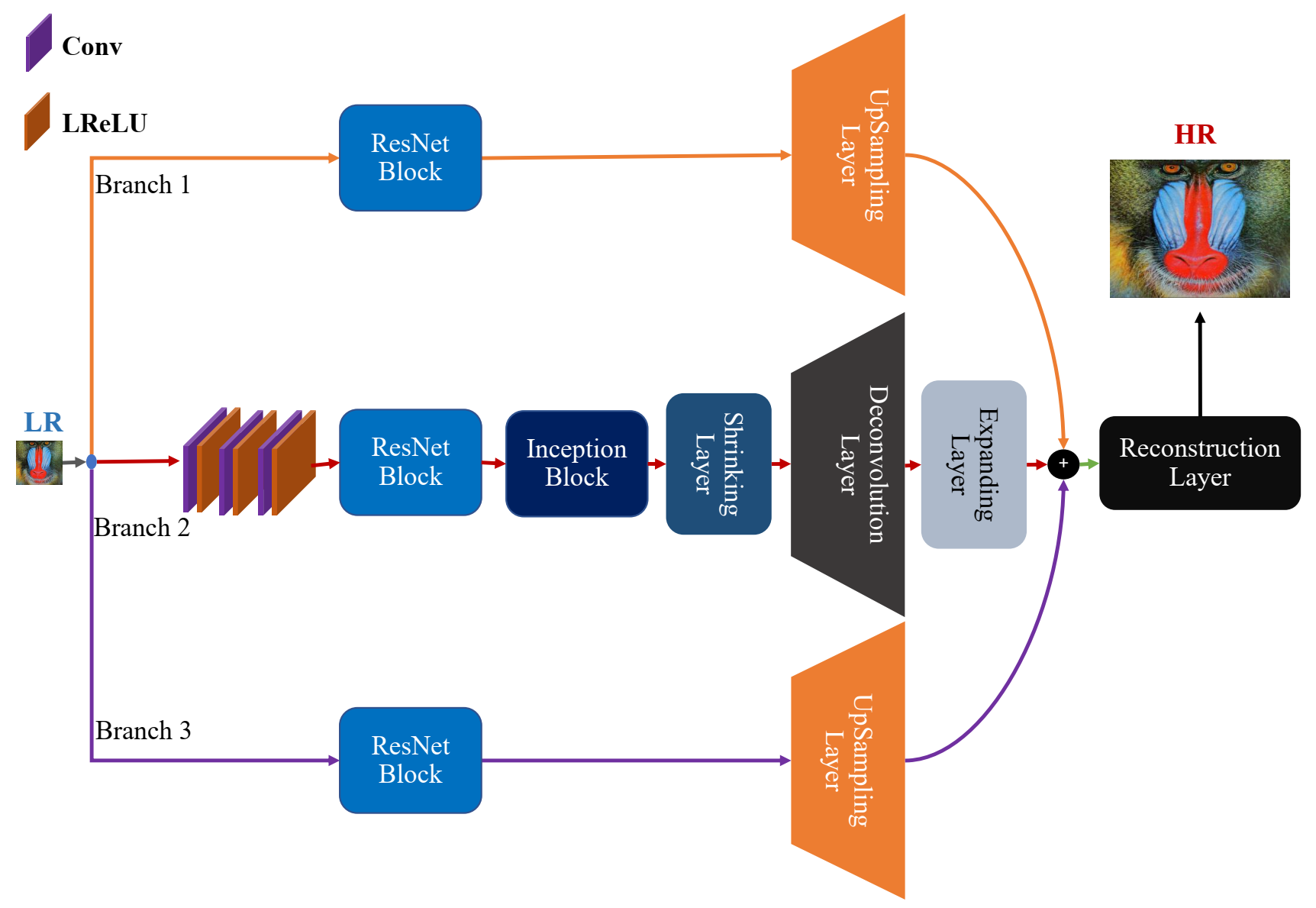
3.1. Architecture Overview
3.2. Feature Extraction
3.3. Residual Learning Paths
3.3.1. ResNet Block
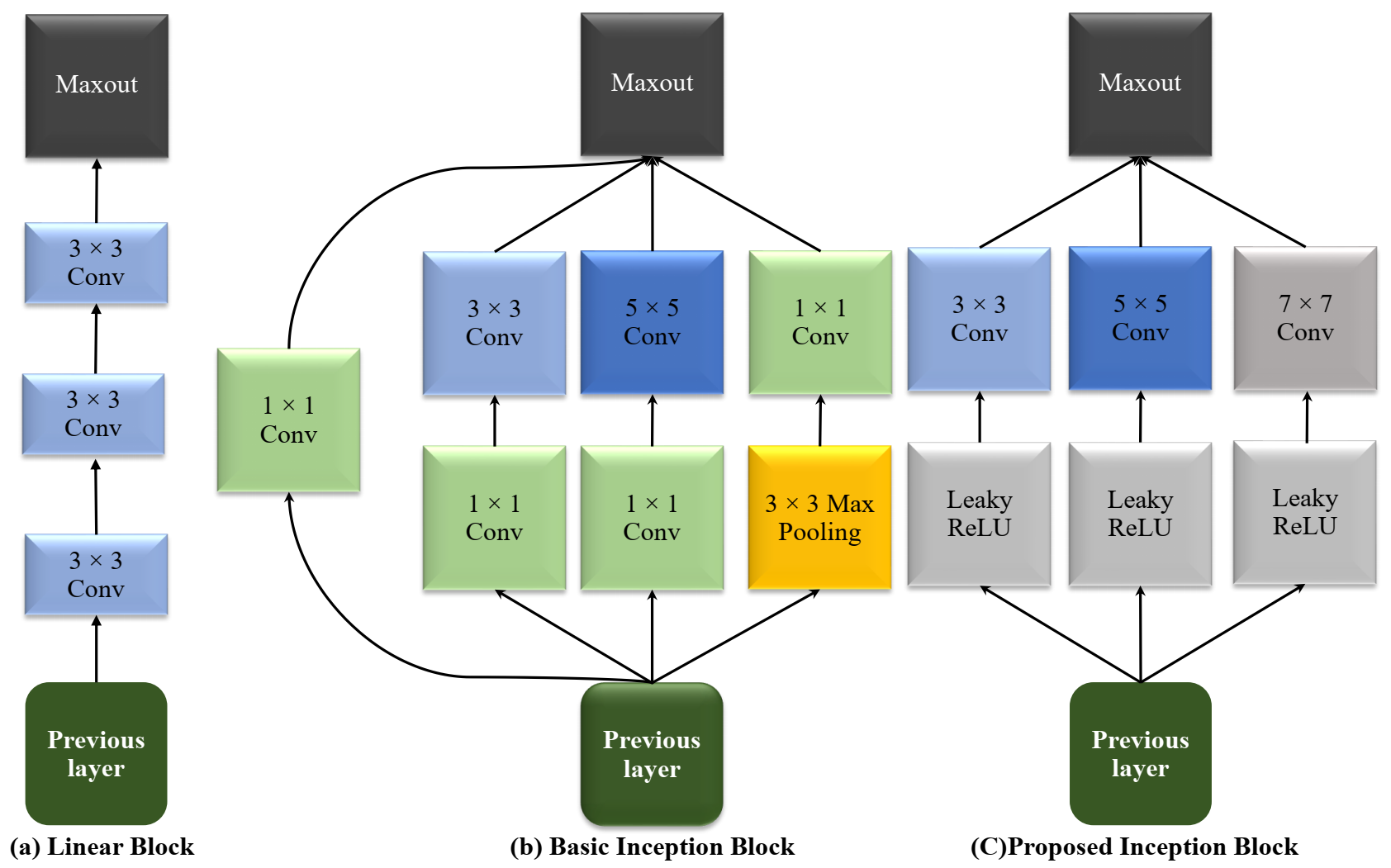
3.3.2. Inception Block
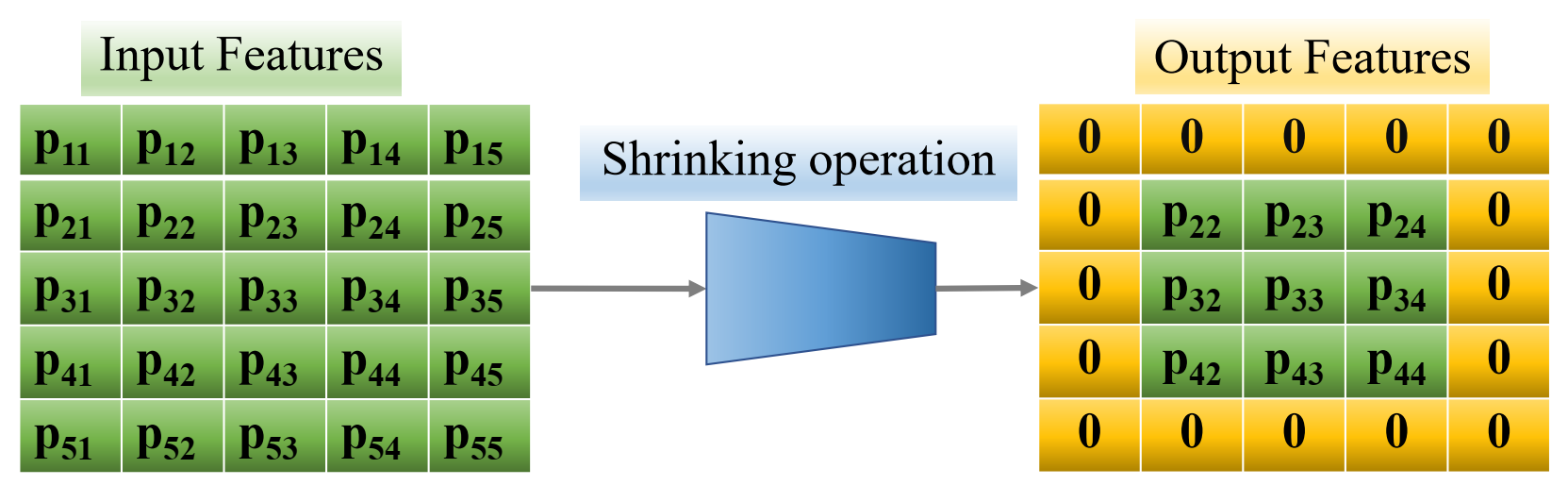
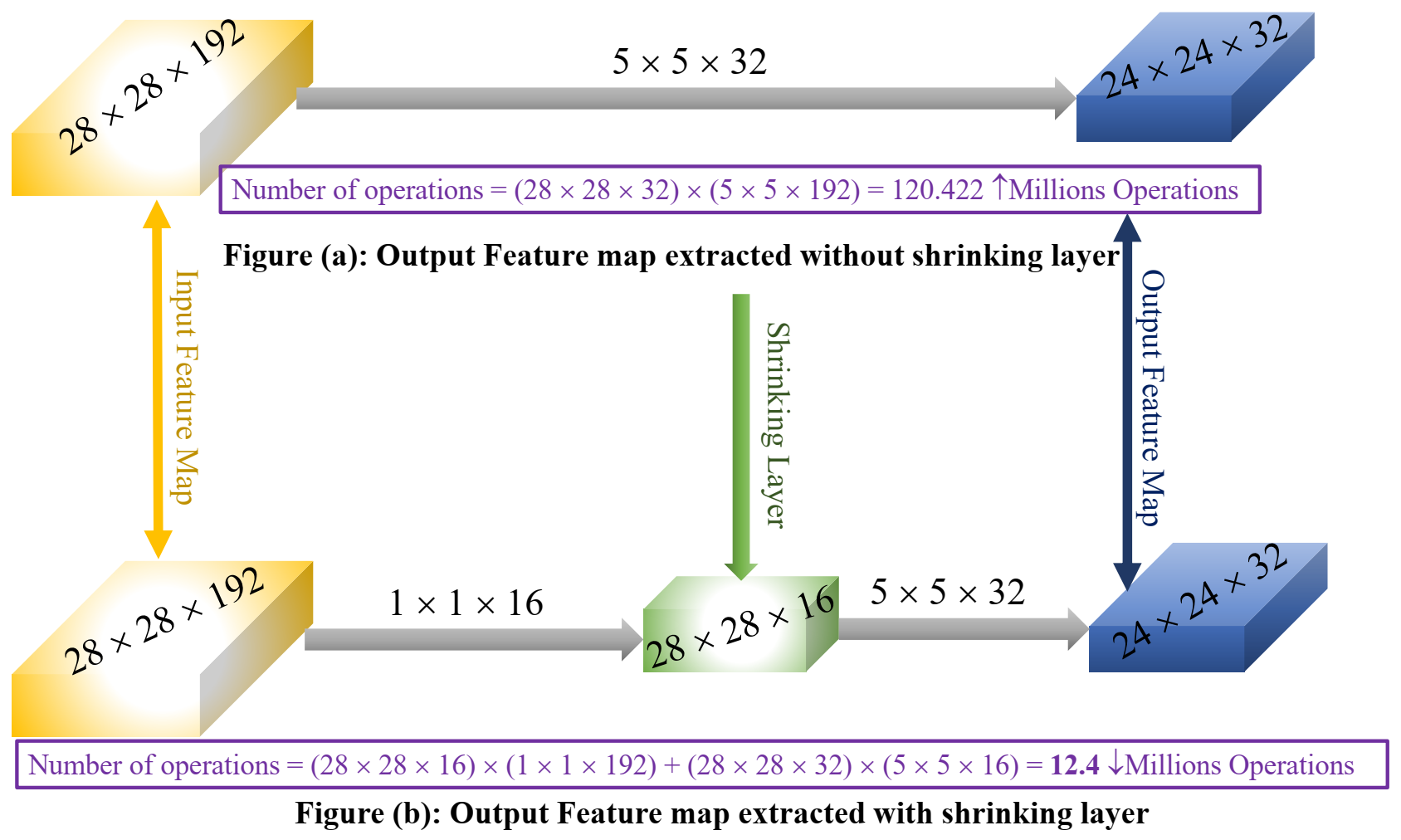
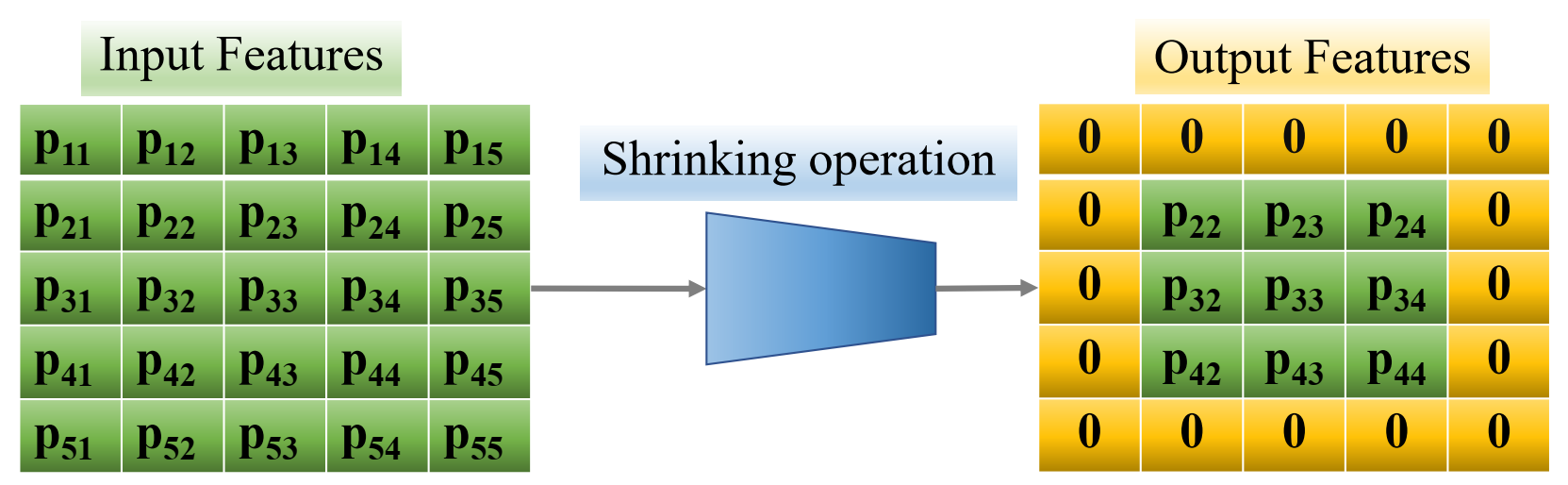
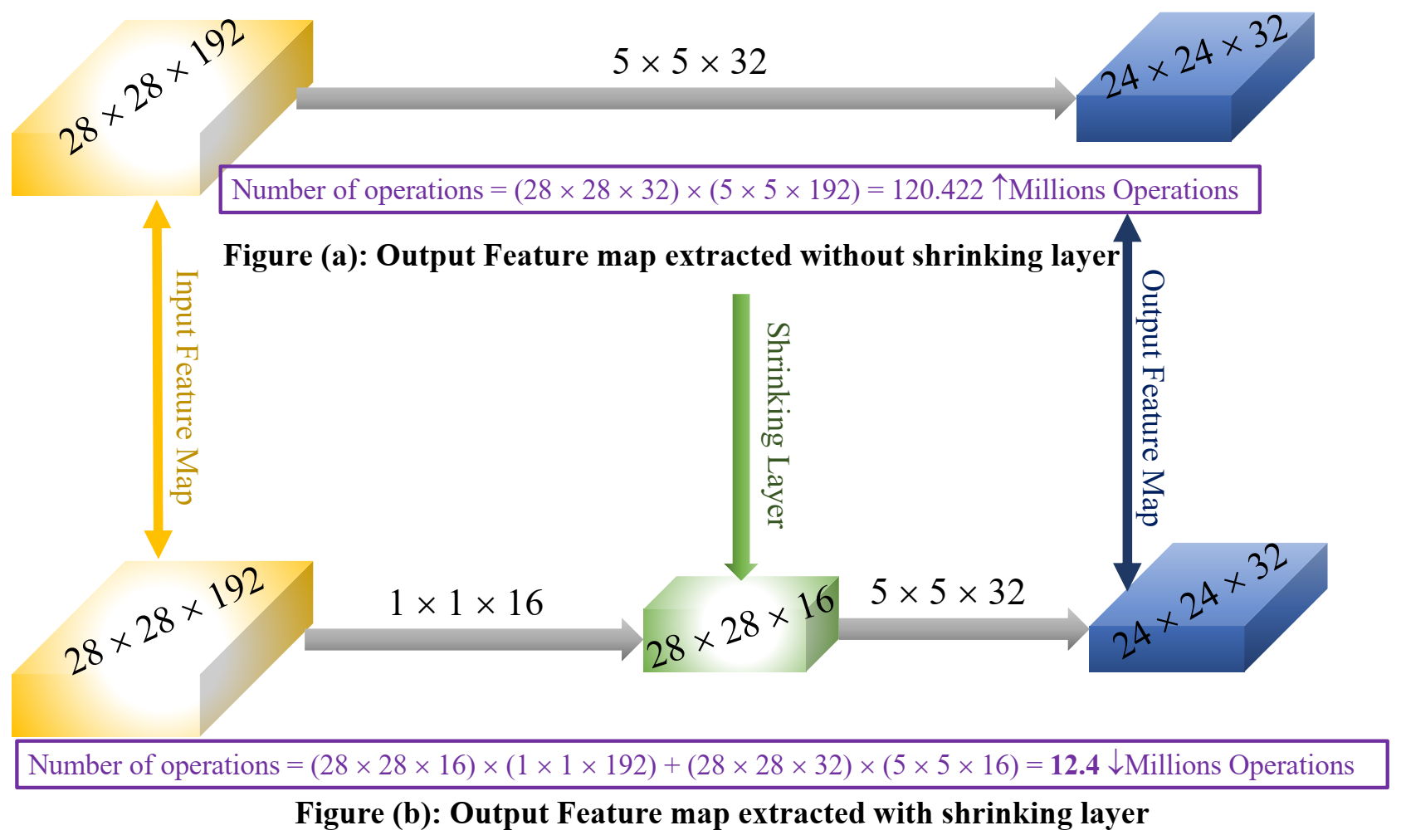
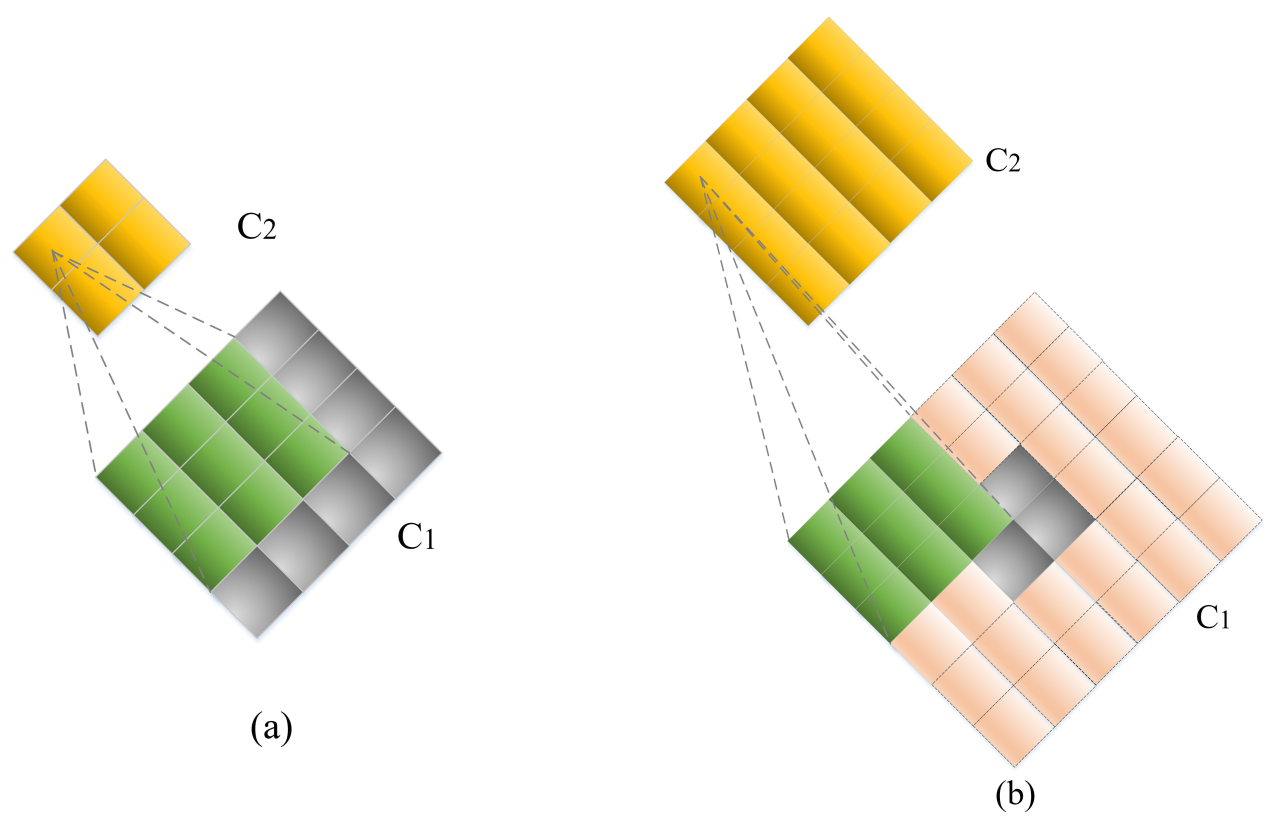
3.3.3. Shrinking Layer
3.3.4. Deconvolution Layer
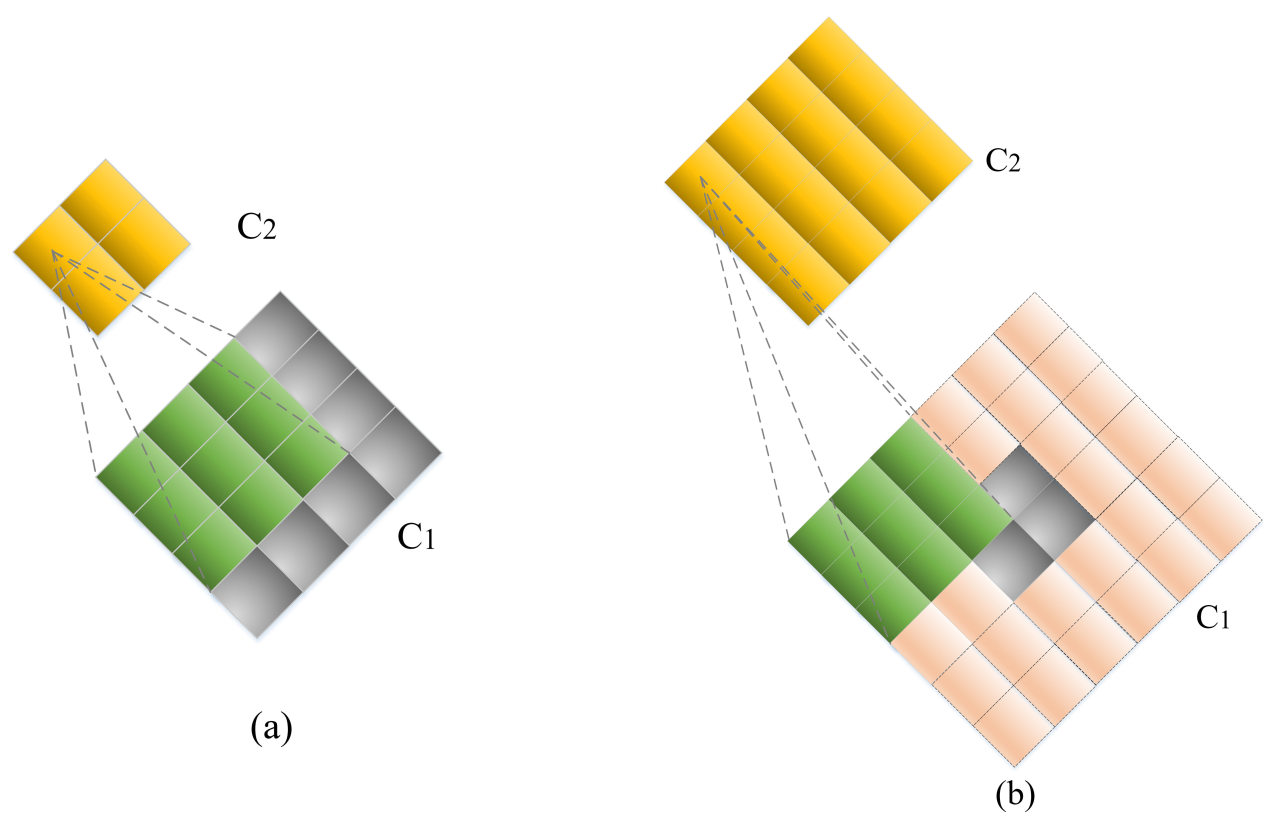
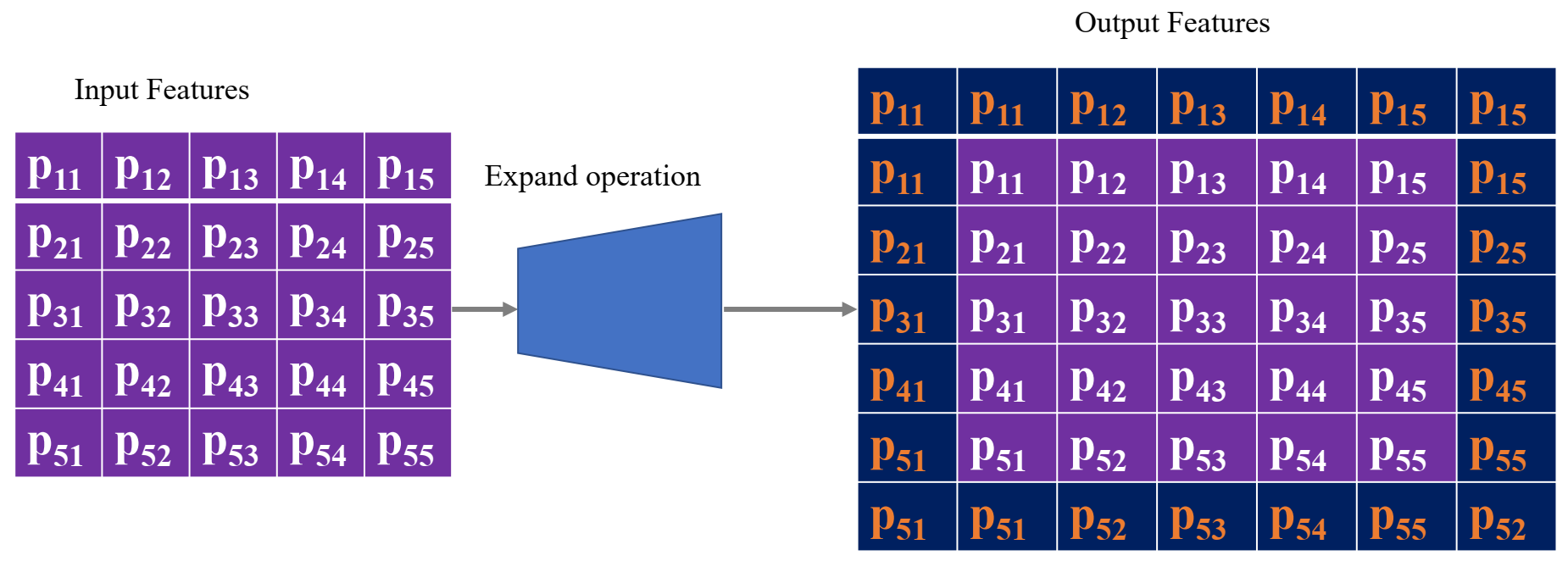
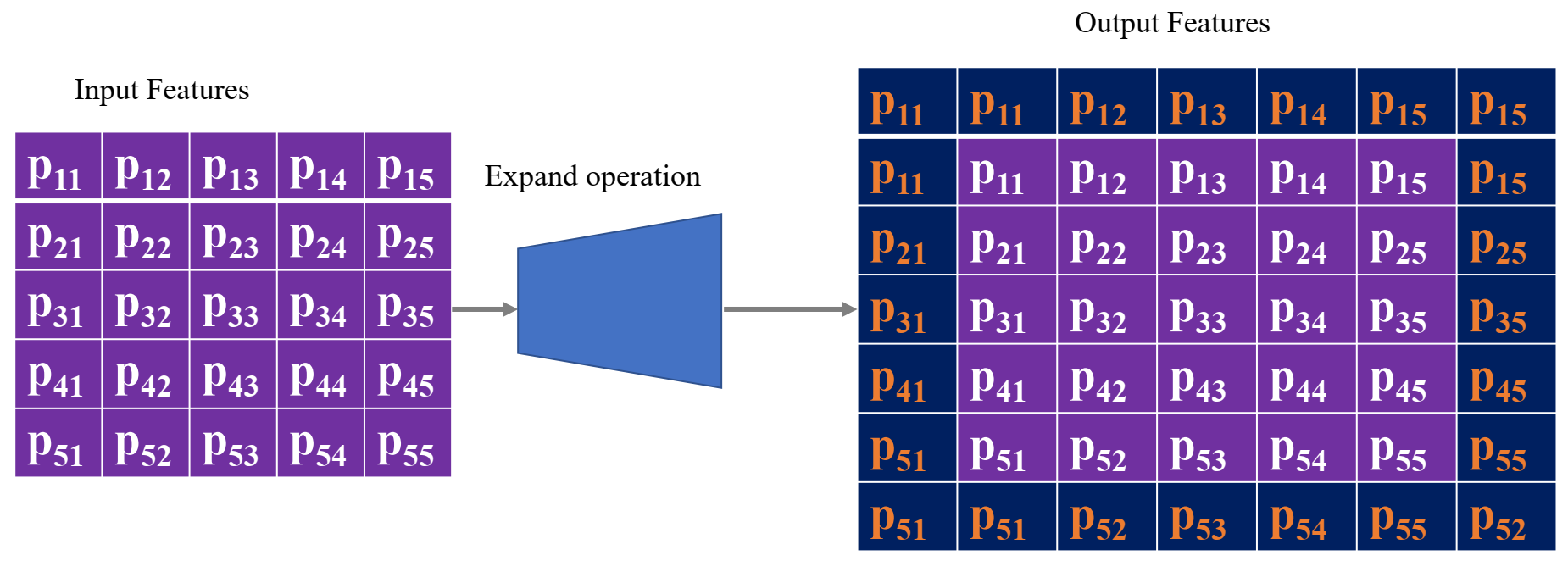
3.3.5. Expanding Layer
3.3.6. Upsampling Layer
3.4. Concatenation Layer
3.5. Reconstruction Layer
4. Experiments
4.1. Training and Testing Datasets
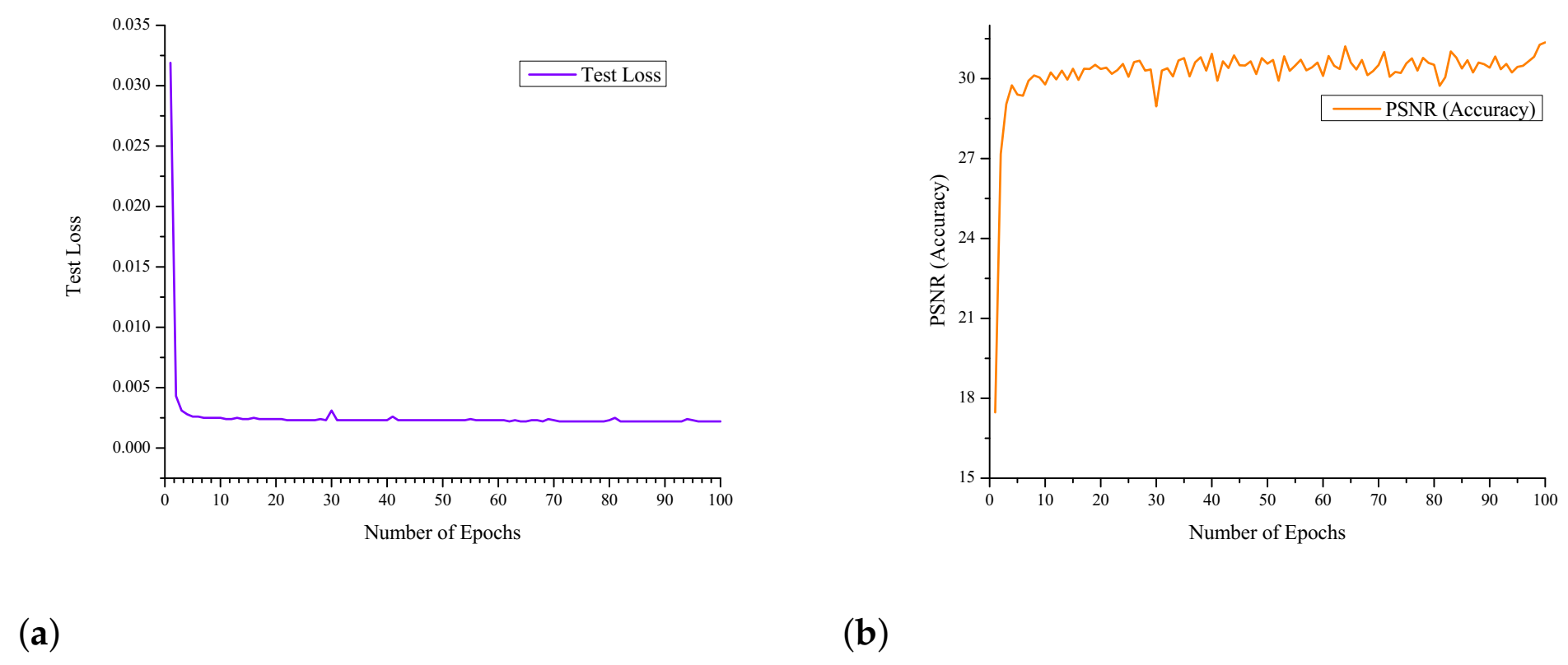
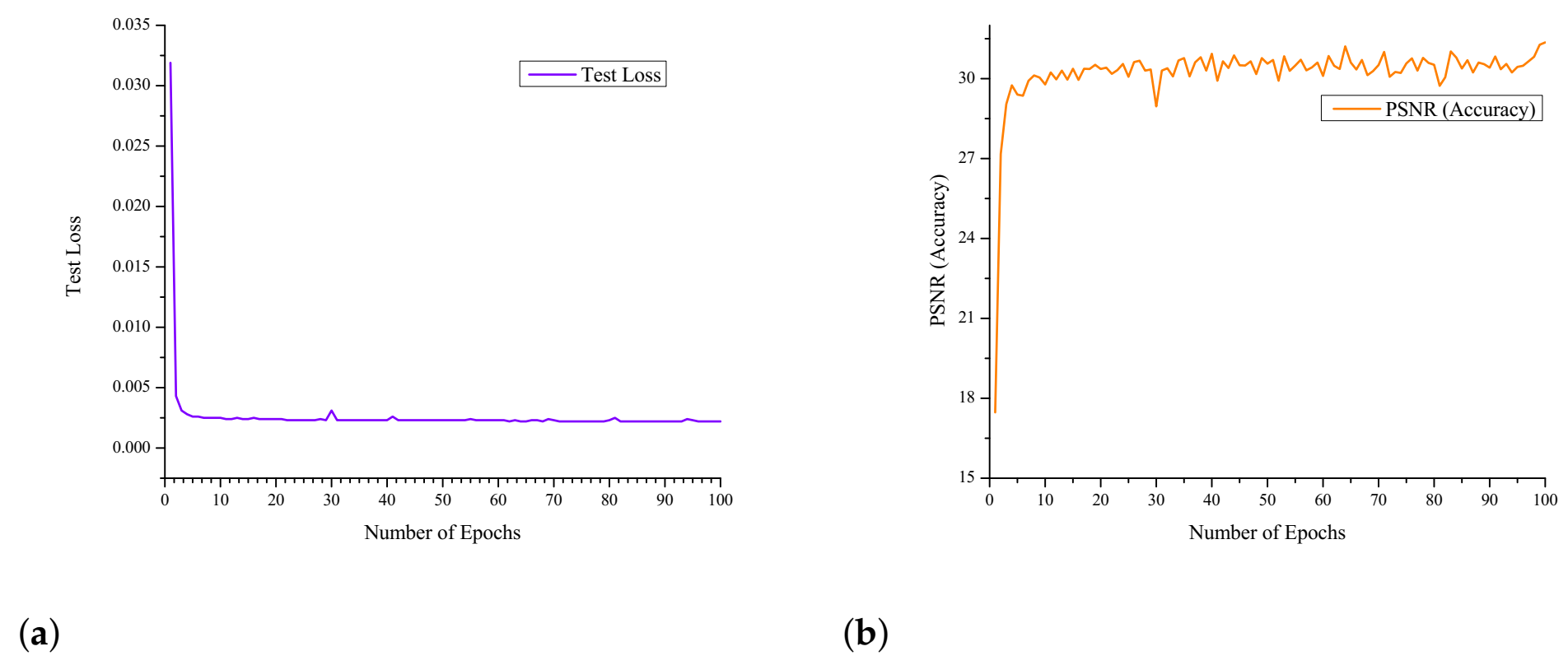
4.2. Implementation Details
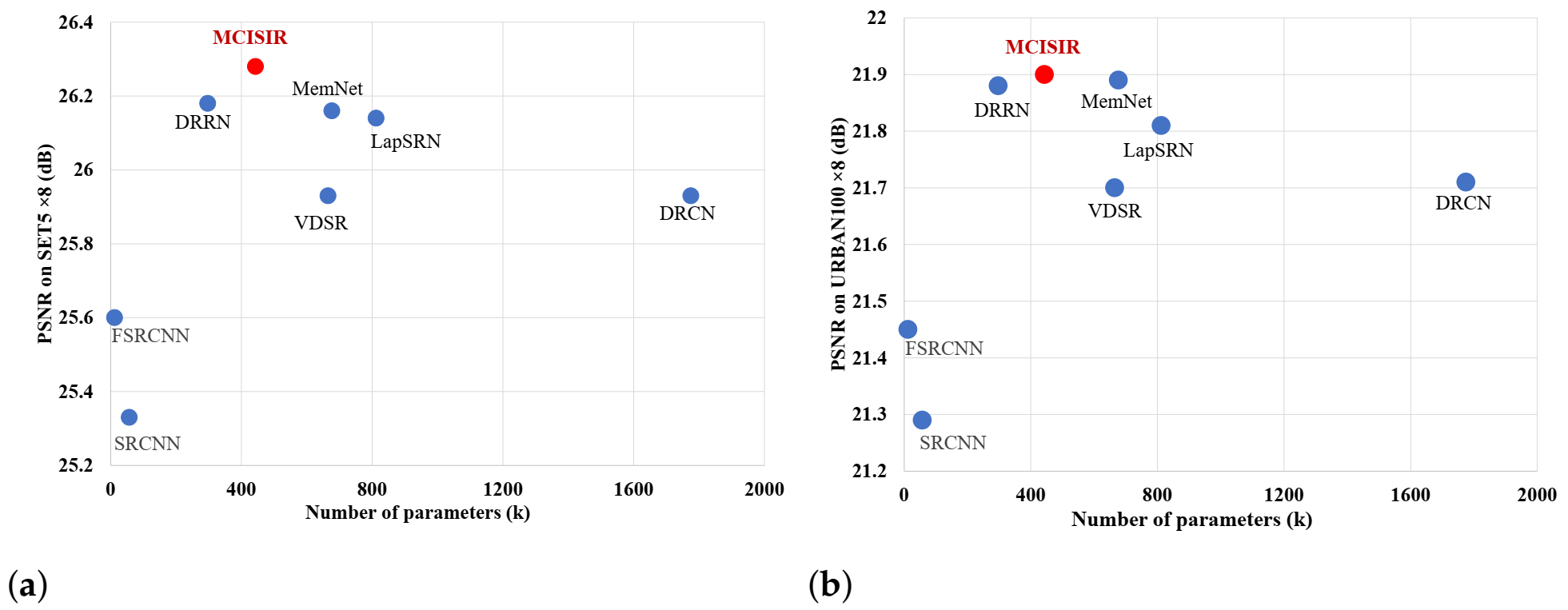
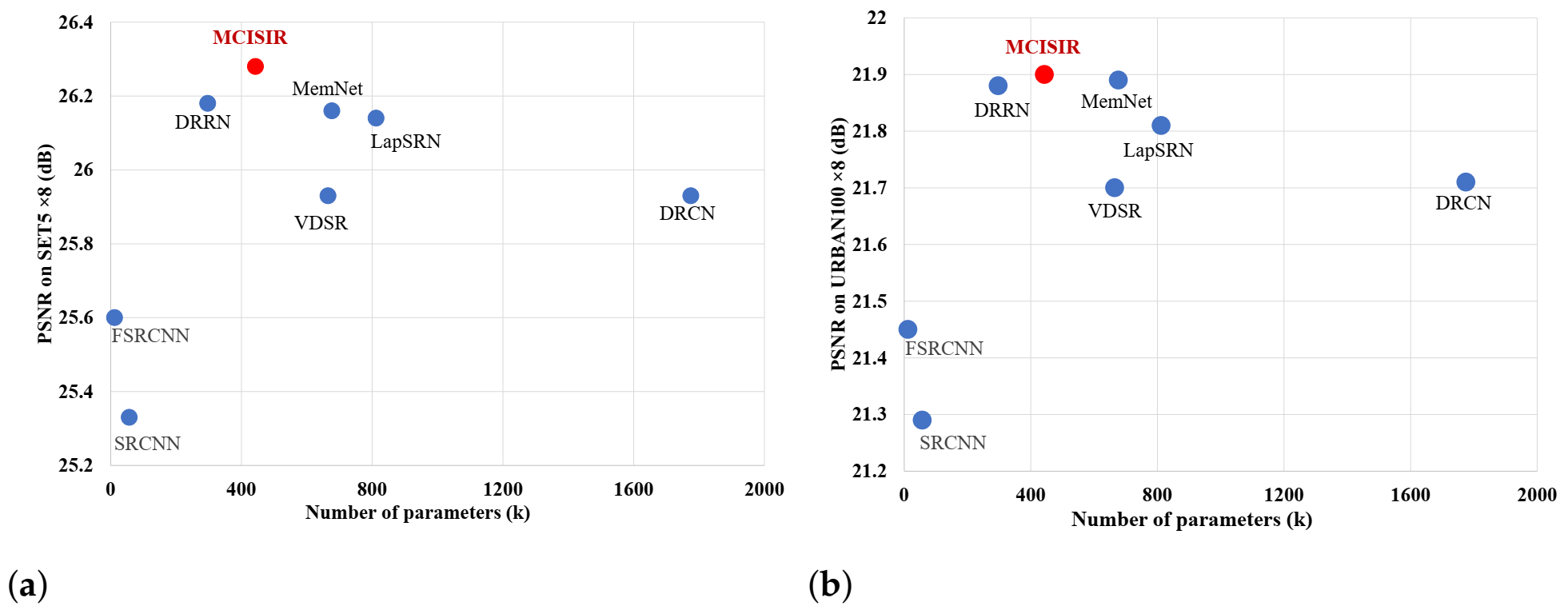
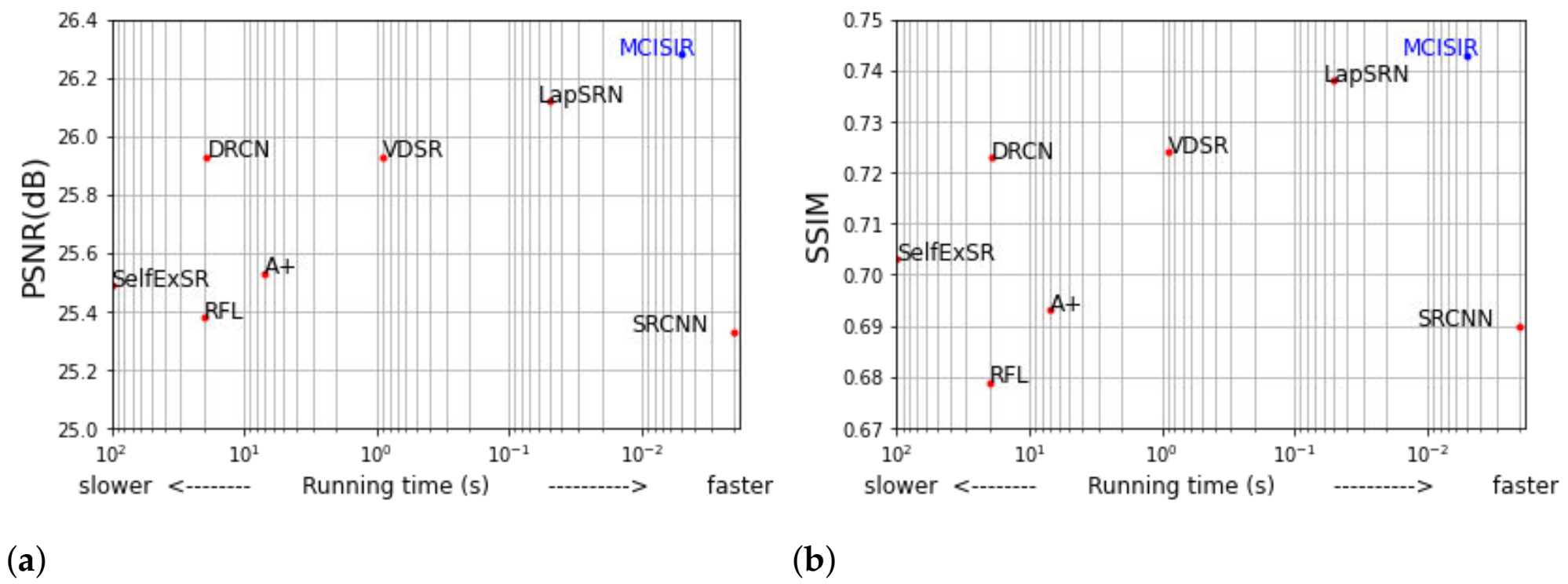
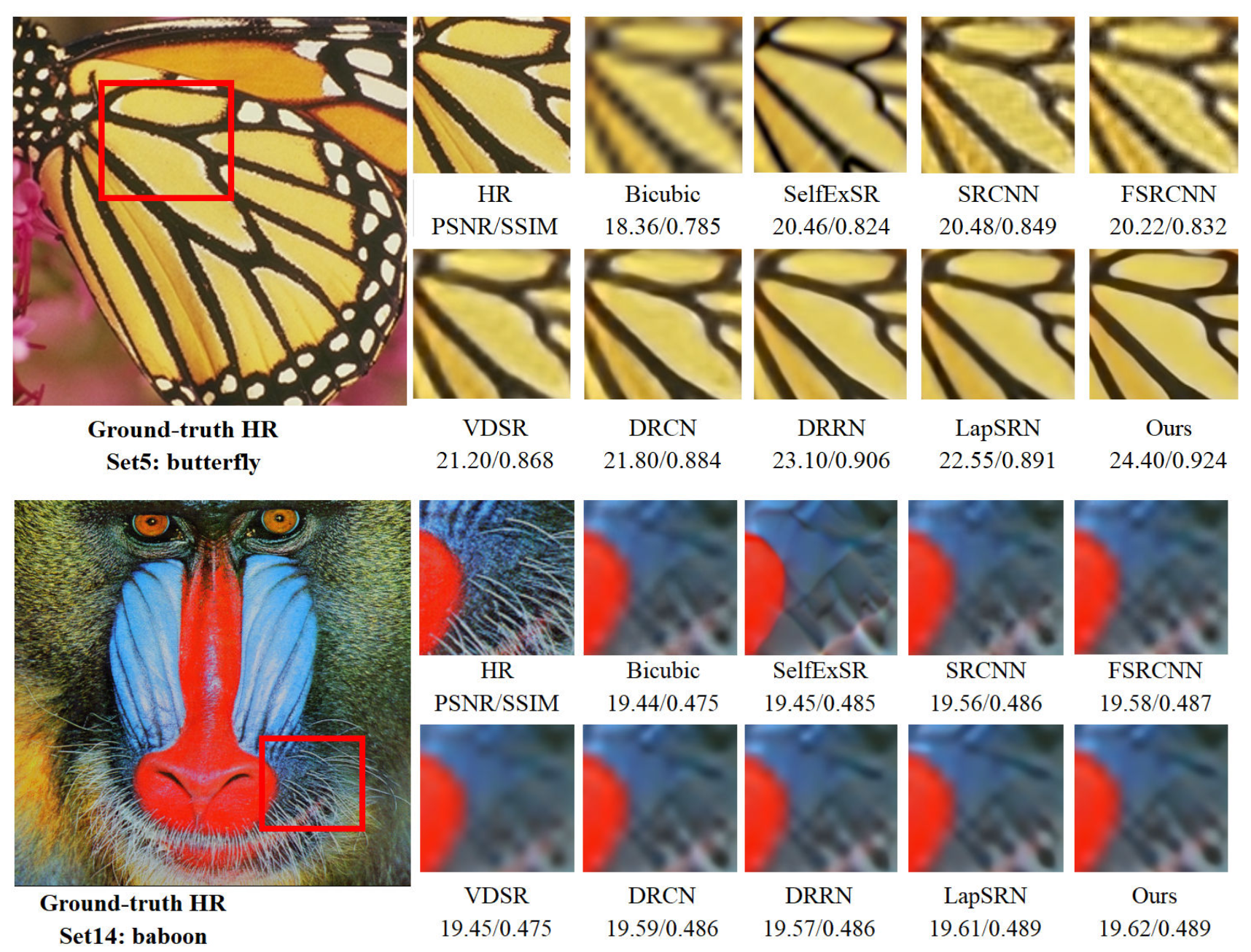
4.3. Comparisons with Current Existing State-of-the-Art Approaches
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BN | Batch normalization |
| CARN | Cascading residual network |
| CMSC | Cascading multi-scale cross network |
| CNN | Convolutional neural network |
| CUDA | Compute unified device architecture |
| dB | Decibels |
| DnCNN | Denoising convolutional neural network |
| DRCN | Deeply recursive convolutional network |
| DRDN | Deeply residual dense network |
| DRFN | Deep recurrent fusion network |
| DRLN | Densely residual Laplacian network |
| DRRN | Deep recursive residual network |
| EDSR | Enhanced deep super resolution |
| ESPCNN | Efficient sub-pixel convolutional neural network |
| FSRCNN | Fast super-resolution convolutional neural network |
| GPU | Graphics processing unit |
| HCNN | Hierarchical convolutional neural network |
| IDN | Information distillation network |
| IKC | Iterative kernel correction |
| ILSVRC | ImageNet large scale visual recognition challenge |
| LapSRN | Laplacian pyramid super-resolution network |
| LDCASR | Lightweight dense connected approach with attention to single image super-resolution |
| LR | Low-resolution |
| LReLU | Leaky ReLU |
| MDSR | Multi-scale deep SR |
| MemNet | Memory network |
| MFFRnet | Multi-level feature fusion recursive network |
| MIRN | Multiple improved residual networks |
| MSE | Mean squared error |
| PIQE | Perception-based image quality evaluation |
| PSNR | Peak signal-to-noise ratio |
| RCAN | Residual channel attention networks |
| RED-Net | Residual encoding–decoding convolutional neural network |
| ReLU | Rectified linear units |
| RIR | Residual in residual |
| SCRSR | Split-concate-residual super resolution |
| SGD | Stochastic gradient descent |
| SISR | Single image super-resolution |
| SRCNN | Super-resolution convolutional neural network |
| SRGAN | Super-resolution generative adversarial network |
| SRDenseNet | Super-resolution dense network |
| SSIM | Structural similarity index matrix |
| UIQI | Universal image quality index |
| VDSR | Very deep super resolution |
| VGG-Net | Visual geometry group net architecture |
| ZSSR | Zero-shot SR |
References
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 11–17 October 2021; pp. 14821–14831. [Google Scholar]
- Zhang, L.; Zhang, H.; Shen, H.; Li, P. A super-resolution reconstruction algorithm for surveillance images. Signal Process. 2010, 90, 619–626. [Google Scholar] [CrossRef]
- Onie, S.; Li, X.; Liang, M.; Sowmya, A.; Larsen, M.E. The use of closed-circuit television and video in suicide prevention: Narrative review and future directions. JMIR Ment. Health 2021, 8, e27663. [Google Scholar] [CrossRef]
- Hazra, D.; Byun, Y.-C. Upsampling real-time, low-resolution CCTV videos using generative adversarial networks. Electronics 2020, 9, 1312. [Google Scholar] [CrossRef]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Inception recurrent convolutional neural network for object recognition. Mach. Vis. Appl. 2021, 32, 1–14. [Google Scholar] [CrossRef]
- Hou, Q.; Cheng, M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Thornton, M.W.; Atkinson, P.M.; Holland, D.A. Sub-pixel mapping of rural land cover objects from fine spatial resolution satellite sensor imagery using super-resolution pixel-swapping. Int. J. Remote Sens. 2006, 27, 473–491. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J.; Xiao, J.; Yao, Y. Deep Distillation Recursive Network for Remote Sensing Imagery Super-Resolution. Remote Sens. 2018, 10, 1700. [Google Scholar] [CrossRef] [Green Version]
- Jiang, K.; Wang, Z.; Yi, P. A progressively enhanced network for video satellite imagery superresolution. IEEE Signal Process. Lett. 2018, 25, 1630–1634. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Guangcheng, W.; Lu, T.; Jiang, J. Edge-enhanced GAN for remote sensing image superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 8, 5799–5812. [Google Scholar] [CrossRef]
- Gallardo, N.; Gamez, N.; Rad, P.; Jamshidi, M. Autonomous decision making for a driver-less car. In Proceedings of the IEEE 12th System of Systems Engineering Conference (SoSE), Waikoloa, HI, USA, 18–21 June 2017; pp. 1–6. [Google Scholar]
- Luo, W.; Zhang, Y.; Feizi, A.; Göröcs, Z.; Ozcan, A. Pixel super-resolution using wavelength scanning. Light Sci. Appl. 2016, 5, e16060. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, F.; Yang, W.; Liao, Q. Interpolation-based image super-resolution using multisurface fitting. IEEE Trans. Image Process. 2012, 21, 3312–3318. [Google Scholar] [CrossRef]
- Hayit, G. Super-resolution in medical imaging. Comput. J. 2009, 52, 43–63. [Google Scholar]
- Dudczyk, J. A method of feature selection in the aspect of specific identification of radar signals. Bulletin of the Polish Academy of Sciences. Tech. Sci. 2017, 65, 113–119. [Google Scholar]
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [Green Version]
- Andiga, F. A nonlinear algorithm for monotone piecewise bicubic interpolation. Appl. Math. Comput. 2016, 272, 100–113. [Google Scholar]
- Fattal, R. Image upsampling via imposed edge statistics. ACM Trans. Graph. 2007, 26, 95-es. [Google Scholar] [CrossRef]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 2018, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Gao, X.; Tao, D.; Li, D. Single Image Super-Resolution With Non-Local Means and Steering Kernel Regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef] [PubMed]
- Stark, H.; Oskoui, P. High-resolution image recovery from image-plane arrays, using convex projections. JOSA A 1989, 11, 1715–1726. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Y.; Zhou, D.; Yang, R. An improved iterative back projection algorithm based on ringing artifacts suppression. Neurocomputing 2015, 162, 171–179. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video superresolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 294–310. [Google Scholar]
- Sun, S.; Xu, Z.; Shum, H.Y. Image super-resolution using gradient profile prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Wang, H.; Gao, X.; Zhang, K.; Li, J. Single image super-resolution using Gaussian process regression. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Timofte, R.; Smet, V.D.; Gool, L.V. Image super-resolution using gradient profile prior. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Timofte, R.; Smet, V.D.; Gool, L.V. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014; pp. 3791–3799. [Google Scholar]
- Karl, S.N.; Nguyen, T.Q. Image super-resolution using support vector regression. IEEE Trans. Image Process. 2007, 16, 1596–1610. [Google Scholar]
- Kim, I.M.; Kwon, Y. Single-image super-resolution using sparse regression and natural image prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1127–1133. [Google Scholar] [PubMed]
- Deng, C.; Xu, J.; Zhang, K.; Tao, D.; Li, X. Similarity constraints-based structured output regression machine: An approach to image super-resolution. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2472–2485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schulter, S.; Leistner, C.; Bischof, H. Fast and accurate image upscaling with super-resolution forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3791–3799. [Google Scholar]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Shi, W.; Caballero, J.; Theis, L.; Huszar, F.; Aitken, A.; Ledig, C.; Wang, Z. Is the deconvolution layer the same as a convolutional layer? arXiv 2016, arXiv:1609.07009. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Wright, J.; Thomas, S.H.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 11, 2861–2873. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Tian, Y.; Zhou, F.; Liao, Q.; Chen, H.; Zheng, C. Consistent coding scheme for single-image super-resolution via independent dictionaries. IEEE Trans. Multimed. 2016, 3, 313–325. [Google Scholar] [CrossRef]
- Li, J.; Gong, W.; Li, W. Dual-sparsity regularized sparse representation for single image super-resolution. Inf. Sci. 2015, 298, 257–273. [Google Scholar] [CrossRef]
- Gong, W.; Tang, Y.; Chen, X.; Qiane, Y.; Weigong, L. Combining edge difference with nonlocal self-similarity constraints for single image super-resolution. Neurocomputing 2017, 249, 157–170. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, L.; Chen, L.; Tang, Y.Y.; Zhou, Y. Weighted couple sparse representation with classified regularization for impulse noise removal. IEEE Trans. Image Process. 2015, 24, 4014–4026. [Google Scholar] [CrossRef]
- Liu, L.; Chen, L.; Chen, C.L.P.; Tang, Y.Y.; Pun, C.M. Weighted Joint Sparse Representation for Removing Mixed Noise in Image. IEEE Trans. Cybern. 2017, 47, 600–611. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, F.; Cheng, J.; Li, W.; Yap, P.T.; Shen, D. Longitudinally guided guper-resolution of neonatal brain magnetic resonance images. IEEE Trans. Cybern. 2019, 49, 662–674. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Yu, Y.; Tang, J.; Aizawa, M.A.; Aizawa, K. Context-patch face hallucination based on thresholding locality constrained representation and reproducing learning. IEEE Trans. Cybern. 2018, 50, 324–337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Mass, A.L.; Hannum, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Fan, Y.; Honghui, S.; Jiahui, Y.; Ding, L.; Wei, H.; Haichao, Y.; Zhangyang, W.; Xinchao, W.; Thomas, S.H. Balanced two-stage residual networks for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 161–168. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Mudunuri, S.P.; Biswas, S. Low resolution face recognition across variations in pose and illumination. IEEE Trans. Pattern Anal. Machine Intell. 2015, 38, 1034–1040. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Machine Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Lobanov, A.P. Resolution limits in astronomical images. arXiv 2005, arXiv:astro-ph/0503225. [Google Scholar]
- Swaminathan, A.; Wu, M.; Liu, K.R. Digital image forensics via intrinsic fingerprints. IEEE Trans. Inf. Forensics Secur. 2008, 1, 101–117. [Google Scholar] [CrossRef] [Green Version]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photorealistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Musunuri, Y.; Kwon, O.S. Deep Residual Dense Network for Single Image Super-Resolution. Electronics 2021, 10, 555. [Google Scholar] [CrossRef]
- Ren, H.; Mostafa, E.; Lee, J. Image super resolution based on fusing multiple convolution neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hui, Z.; Xiumei, W.; Xinbo, G. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Muhammad, W.; Aramvith, S. Multi-scale inception based super-resolution using deep learning approach. Electronics 2019, 8, 892. [Google Scholar] [CrossRef] [Green Version]
- Anwar, S.; Barnes, N. Densely residual laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Zha, L.; Yang, Y.; Lai, Z.; Zhang, Z.; Wen, J. A Lightweight Dense Connected Approach with Attention on Single Image Super-Resolution. Electronics 2021, 10, 1234. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Xin, Y.; Haiyang, M.; Jiqing, Z.; Ke, X.; Baocai, Y.; Qiang, Z.; Xiaopeng, W. DRFN: Deep recurrent fusion network for single-image super-resolution with large factors. IEEE Trans. Multimed. 2019, 21, 328–337. [Google Scholar]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1604–1613. [Google Scholar]
- Jin, X.; Xiong, Q.; Xiong, C.; Li, Z.; Gao, Z. Single image superresolution with multi-level feature fusion recursive network. Neurocomputing 2019, 370, 166–173. [Google Scholar] [CrossRef]
- Liu, B.; Boudaoud, D.A. Effective image super resolution via hierarchical convolutional neural network. Neurocomputing 2020, 374, 109–116. [Google Scholar] [CrossRef]
- Lin, D.; Xu, G.; Xu, W.; Wang, Y.; Sun, X.; Fu, K. Scrsr: An efficient recursive convolutional neural network for fast and accurate image super-resolution. Neurocomputing 2020, 398, 399–407. [Google Scholar] [CrossRef]
- Qiu, D.; Zheng, L.; Zhu, J.; Huang, D. Multiple improved residual networks for medical image super-resolution. Future Gener. Comput. Syst. 2021, 116, 200–208. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Adv. Neural Inf. Process. Syst. 2016, 29, 2802–2810. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the 8th IEEE International Conference on Computer Vision (ICCVs), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Adam, J.L.B. A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
Short Biography of Authors
 | Wazir Muhammad is a Lecturer Electrical Engineering Department, Balochistan University of Engineering and Technology Khuzdar. He was received his doctoral degree from the Department of Electrical Engineering Chulalongkorn University Bangkok, Thailand in 2019. Previously he was obtained ME degree in the field of Communication Systems and Networks from Mehran University of Engineering and Technology, Jamshoro, Sindh, Pakistan respectively. His research interests lie in the areas of Electrical Engineering, Communication Systems, Neural Networks, and Machine Learning, specifically in Deep Learning image super-resolution. |
 | Zuhaibuddin Bhutto received PhD in electronic engineering from Dong-A University South Korea in 2019, he also received B.E. degree in software engineering and M.E. degree in information technology from Mehran University of Engineering and Technology, Pakistan, in 2009 and 2011, respectively. Currently, he is pursuing a Ph.D. degree in electronics engineering from Dong-A University, South Korea. Since 2011, he has been an assistant professor at the Department of Computer System Engineering, Balochistan University of Engineering and Technology, Pakistan. His research interests include, image processing, MIMO technology; in particular, cooperative relaying, adaptive transmission techniques, energy optimization, machine learning, and deep learning. |
 | Arslan Ansari received the B.S. degree in Electrical Engineering from the Mehran University of Engineering and Technology, Jamshoro, Pakistan, in 2011 and PhD degree in Electronic System Engineering from Hanyang University, Ansan, South Korea back in 2016. He has worked as a Lecturer with the Mehran University of Engineering and Technology back in 2010 and currently working as assistant professor in the Department of Electronic Engineering at Dawood University of Engineering and Technology, Karachi. His current research interests include multilevel inverters and grid-connected renewable energy systems. Mr. Ansari was a recipient of the Scholarship for the Integrated Master and Ph.D. Program by the Government of Pakistan. |
 | Mudasar Latif Memon received a Ph.D. degree from Sungkyunkwan University, Korea, in 2019. He is currently working for Sukkur Institute of Business Administration University, Pakistan as Vice-Principal Technical, IBA Community College Naushahro Feroze. His research interests include artificial intelligence-based solutions to real-life engineering problems, emerging wireless networks, and healthcare systems. He has published 13 articles in international journals. |
 | Ramesh Kumar received the B.E. degree in Computer Systems Engineering from Mehran University of Engineering and Technology, Jamshoro, Pakistan, in 2005, the M.S. degree in Electronic, Electrical, Control and Instrumentation Engineering from Hanyang University, Ansan, South Korea, in 2009, and the Ph.D. degree in Electronics and Computer Engineering from Hanyang University, Seoul, South Korea back in 2016. He has worked as a Lecturer at the Electrical Engineering Department, The University of Faisalabad, Faisalabad back in 2010 and currently working as an Associate Professor in the Department of Computer System Engineering at Dawood University of Engineering and Technology, Karachi. His current research interests include 6G Communication Systems, Ultra-Massive MIMO, RF/FSO mixed Communication Channels, and Block-chain technology. Mr. Kumar was a recipient of the Scholarship for both master’s and Ph.D. Program by the Higher Education Commission, Pakistan. |
 | Ayaz Hussain received his Bachelor degree from Mehran University of Engineering and Technology, Jamshoro, in 2006, MS Engineering from Hanyang University, South Korea, in 2010, and PhD degree from Sungkyunkwan Univerisity, South Korea, in 2018. He is working as a professor in the Department of Electrical Engineering, Balochistan University of Engineering and Technology, Khuzdar, Pakistan. He is the author of many research articles. His research interests include a robust control system and wireless communication. |
 | Syed Ali Raza Shah is an Associate Professor and Dean, Faculty of Engineering in Balochistan University of Engineering and Technology Khuzdar, Pakistan. He earned his B.E in Mechanical Engineering from Balochistan University of Engineering and Technology Khuzdar, Pakistan and M.E in Mechanical Engineering from Eastern Mediterranean University North Cyprus, Turkey. His research interests include Quality Management, Energy Management, Operational Management, Sustainable manufacturing, Small and Medium- Sized Enterprises (SMEs) and sustainability. He is a Professional member of Pakistan Engineering Council (PEC). |
 | Imdadullah Thaheem received his B.E in Mechanical Engineering from Quaid-e-Awam University of Engineering Science and Technology Nawabshah in 2010. He achieved his M.E degree in Energy System Engineering from Mehran University of Engineering and Technology Jamshoro in 2015, and his Ph.D degree in Energy Science and Engineering from DGIST, South Korea in 2020. After his Ph.D, he joined as as a assistant professor in Energy systems Engineering Department of Balochistan University of Engineering Technology khuzdar, Pakistan since 2020. |
 | Shamshad Ali an Assistant Professor at Balochistan University of Engineering and Technology, Khuzdar, Pakistan. He received his Ph.D. from University of Electronic Science and Technology of China in 2019. He received his master’s degree from Mehran University of Engineering and Technology, Pakistan in 2013. He is currently working on highly efficient nitrogen doped carbon anodes for lithium- and sodium-ion batteries. His research interests include lithium-ion batteries, lithium–sulfur batteries, sodium-ion batteries, wireless sensors, and image processing |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | #Parameters | SET5 PSNR↑/SSIM↑ | SET14 PSNR↑/SSIM↑ | BSDS100 PSNR↑/SSIM↑ | URBAN100 PSNR↑/SSIM↑ | MANGA109 PSNR↑/SSIM↑ | Average PSNR↑/SSIM↑ |
|---|---|---|---|---|---|---|---|---|
| Bicubic | 4× | -/- | 28.43/0.811 | 26.01/0.704 | 25.97/0.670 | 23.15/0.660 | 24.93/0.790 | 25.70/0.727 |
| A+ | 4× | -/- | 30.32/0.860 | 27.34/0.751 | 26.83/0.711 | 24.34/0.721 | 27.03/0.851 | 27.17/0.779 |
| RFL | 4× | -/- | 30.17/0.855 | 27.24/0.747 | 26.76/0.708 | 24.20/0.712 | 26.80/0.841 | 27.03/0.773 |
| SelfExSR | 4× | -/- | 30.34/0.862 | 27.41/0.753 | 26.84/0.713 | 24.83/0.740 | 27.83/0.866 | 27.45/0.787 |
| SCN | 4× | 42 k | 30.41/0.863 | 27.39/0.751 | 26.88/0.711 | 24.52/0.726 | 27.39/0.857 | 27.32/0.782 |
| ESPCN | 4× | 20 k | 29.21/0.851 | 26.40/0.744 | 25.50/0.696 | 24.02/0.726 | 23.55/0.795 | 25.74/0.762 |
| SRCNN | 4× | 57 k | 30.50/0.863 | 27.52/0.753 | 26.91/0.712 | 24.53/0.725 | 27.66/0.859 | 27.42/0.782 |
| FSRCNN | 4× | 12 k | 30.72/0.866 | 27.61/0.755 | 26.98/0.715 | 24.62/0.728 | 27.90/0.861 | 27.57/0.785 |
| VDSR | 4× | 665 k | 31.35/0.883 | 28.02/0.768 | 27.29/0.726 | 25.18/0.754 | 28.83/0.887 | 28.13/0.804 |
| DRCN | 4× | 1775 k | 31.54/0.884 | 28.03/0.768 | 27.24/0.725 | 25.14/0.752 | 28.98/0.887 | 28.19/0.803 |
| LapSRN | 4× | 812 k | 31.54/0.885 | 28.19/0.772 | 27.32/0.727 | 25.21/0.756 | 29.09/0.890 | 28.27/0.806 |
| DRRN | 4× | 297 k | 31.68/0.888 | 28.21/0.772 | 27.38/0.728 | 25.44/0.764 | 29.46/0.896 | 28.43/0.810 |
| MemNet | 4× | 677 k | 31.74/0.889 | 28.26/0.772 | 27.40/0.728 | 25.50/0.763 | 29.42/0.894 | 28.46/0.809 |
| MCISIR [our] | 4× | 443 k | 31.77/0.889 | 28.29/0.772 | 27.43/0.729 | 25.54/0.764 | 29.48/0.896 | 28.50/0.810 |
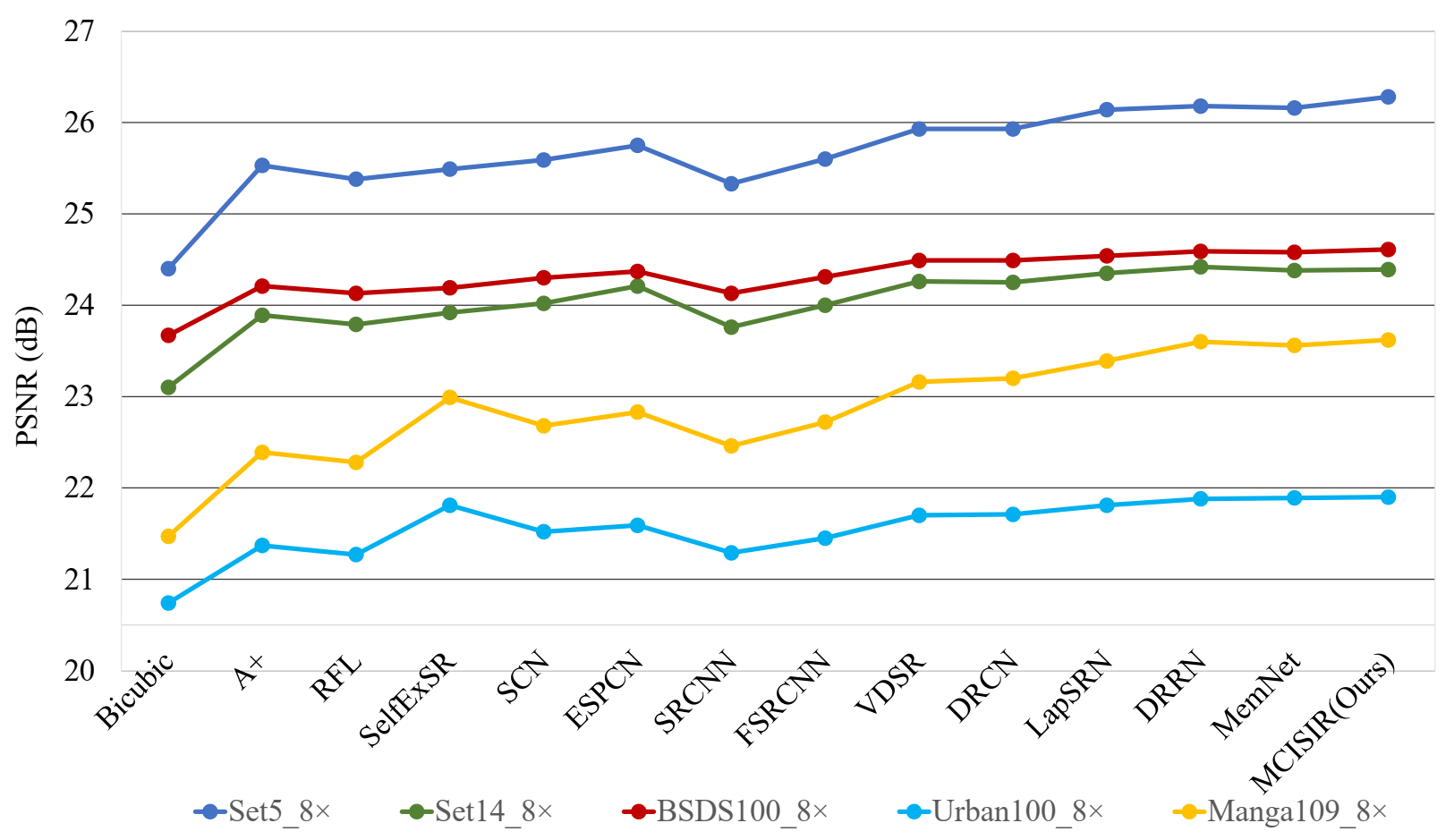
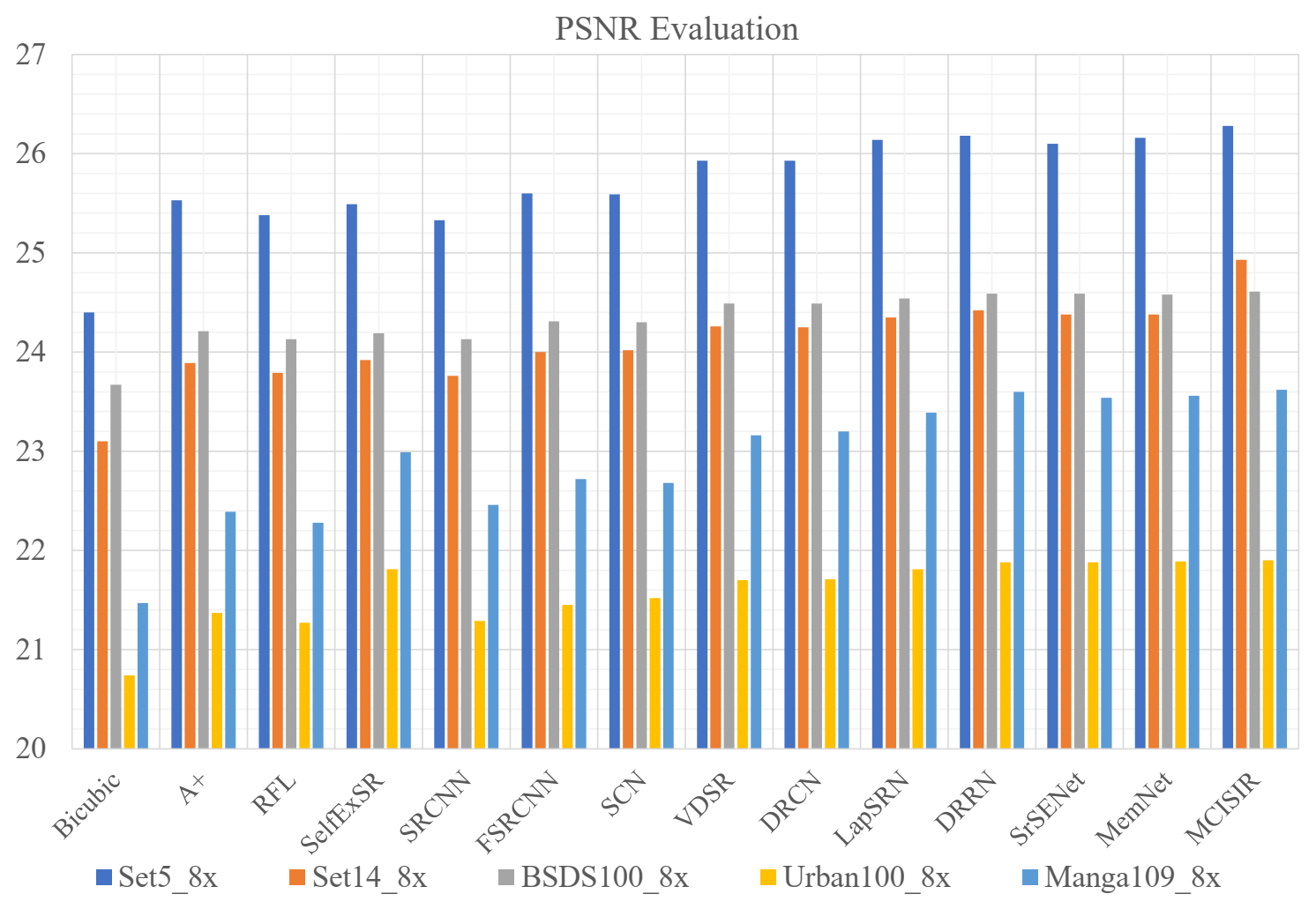
| Bicubic | 8× | -/- | 24.40/0.658 | 23.10/0.566 | 23.67/0.548 | 20.74/0.516 | 21.47/0.649 | 22.68/0.587 |
| A+ | 8× | -/- | 25.53/0.693 | 23.89/0.595 | 24.21/0.569 | 21.37/0.546 | 22.39/0.681 | 23.48/0.617 |
| RFL | 8× | -/- | 25.38/0.679 | 23.79/0.587 | 24.13/0.563 | 21.27/0.536 | 22.28/0.669 | 23.37/0.607 |
| SelfExSR | 8× | -/- | 25.49/0.703 | 23.92/0.601 | 24.19/0.568 | 21.81/0.577 | 22.99/0.719 | 23.68/0.634 |
| SCN | 8× | 42 k | 25.59/0.706 | 24.02/0.603 | 24.30/0.573 | 21.52/0.560 | 22.68/0.701 | 23.62/0.629 |
| ESPCN | 8× | 20 k | 25.75/0.673 | 24.21/0.510 | 24.37/ 0.527 | 21.59/0.542 | 22.83/0.671 | 23.75/0.585 |
| SRCNN | 8× | 57 k | 25.33/0.690 | 23.76/0.591 | 24.13/0.566 | 21.29/0.544 | 22.46/0.695 | 23.39/0.617 |
| FSRCNN | 8× | 12 k | 25.60/0.697 | 24.00/0.599 | 24.31/0.572 | 21.45/0.550 | 22.72/0.692 | 23.62/0.622 |
| VDSR | 8× | 665 k | 25.93/0.724 | 24.26/0.614 | 24.49/0.583 | 21.70/0.571 | 23.16/0.725 | 23.91/0.643 |
| DRCN | 8× | 1775 k | 25.93/0.723 | 24.25/0.614 | 24.49/0.582 | 21.71/0.571 | 23.20/0.724 | 23.92/0.643 |
| LapSRN | 8× | 812 k | 26.14/0.738 | 24.35/0.620 | 24.54/0.586 | 21.81/0.581 | 23.39/0.735 | 24.05/0.652 |
| DRRN | 8× | 297 k | 26.18/0.738 | 24.42/0.622 | 24.59/0.587 | 21.88/0.583 | 23.60/0.742 | 24.13/0.654 |
| MemNet | 8× | 677 k | 26.16/0.741 | 24.38/0.619 | 24.58/0.584 | 21.89/0.582 | 23.56/0.738 | 24.11/0.653 |
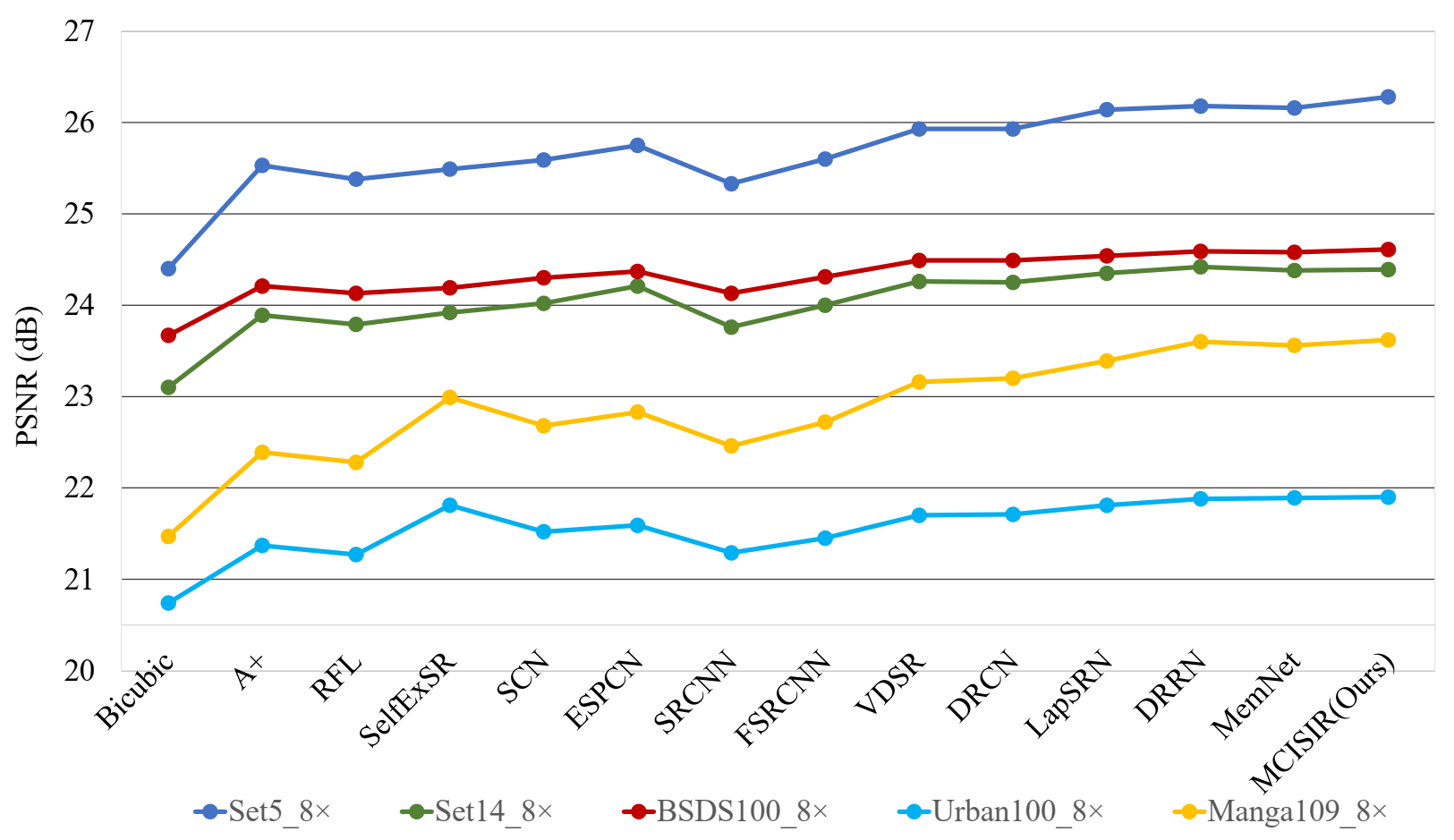
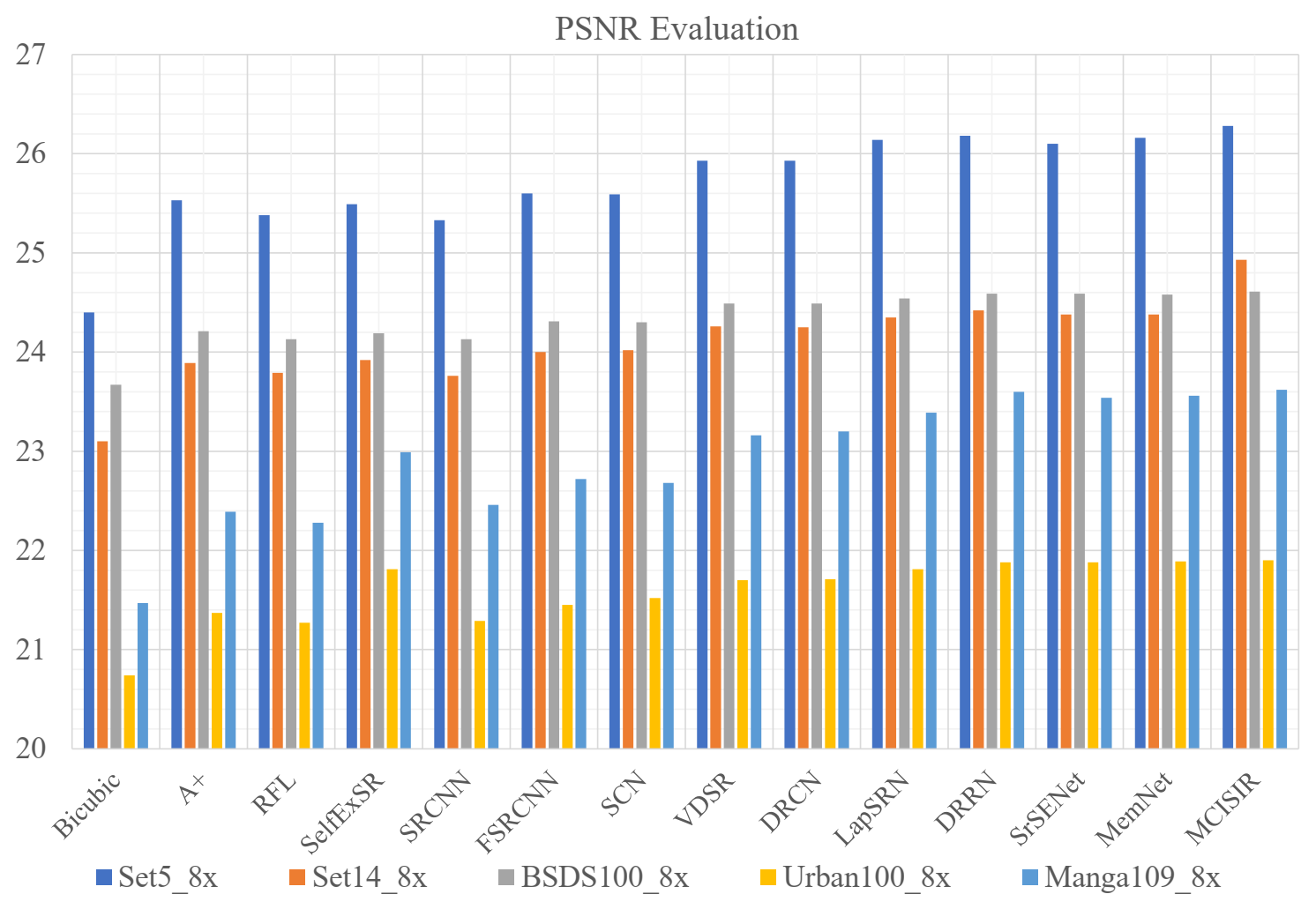
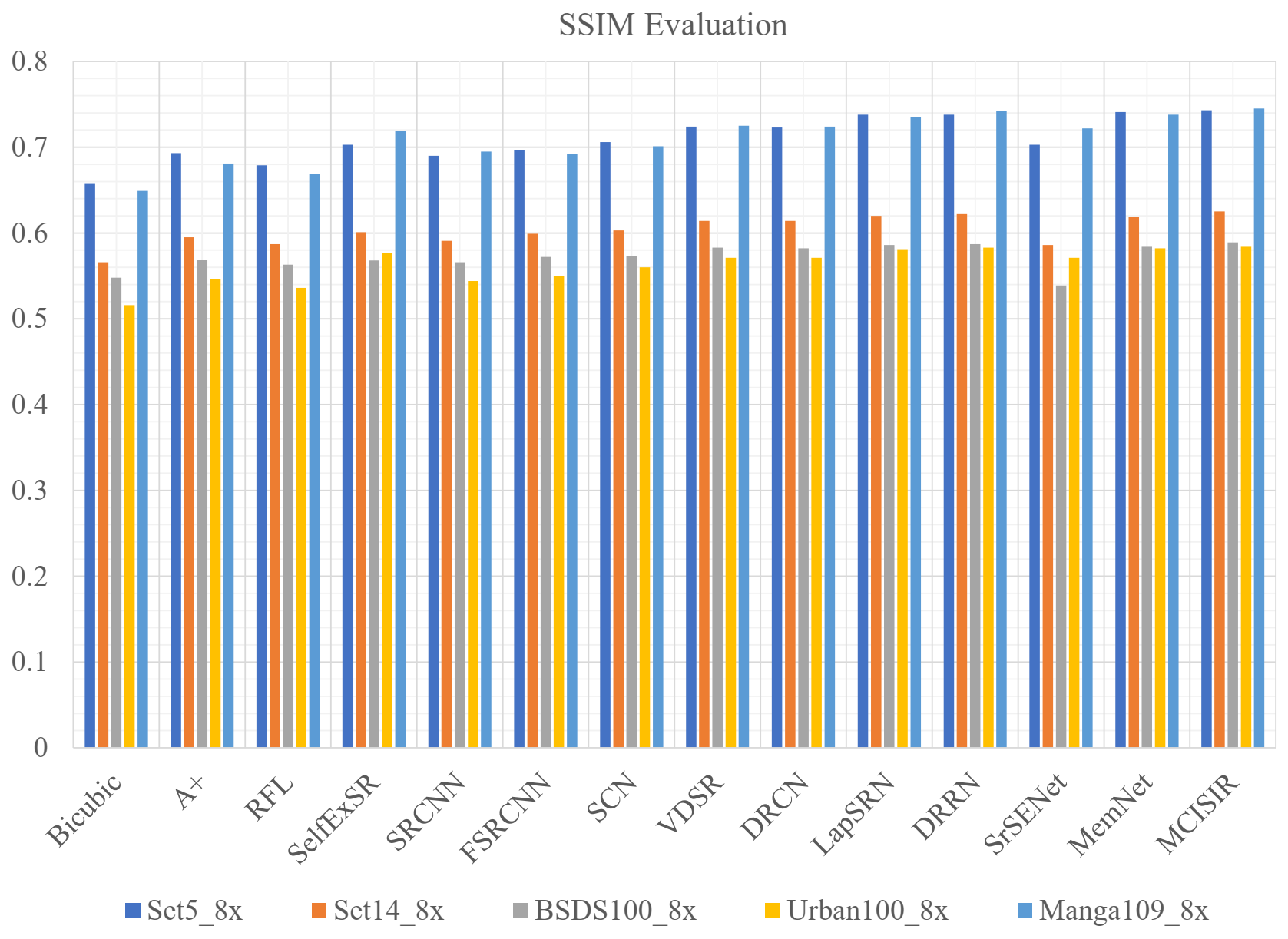
| MCISIR [our] | 8× | 443 k | 26.28/0.743 | 24.93/0.625 | 24.61/0.589 | 21.90/0.584 | 23.62/0.745 | 24.27/0.657 |
| Method | Input | No: of Filters | No: of Layers | #Network Parameters(k) | Reconstruction | Loss Function |
|---|---|---|---|---|---|---|
| SRCNN | LR + bicubic | 64 | 3 | 57 | Direct | |
| VDSR | LR + bicubic | 64 | 20 | 665 | Direct | |
| DRCN | LR + bicubic | 256 | 20 | 1,775 | Direct | |
| LapSRN | LR | 64 | 27 | 812 | Progressive | |
| MemNet | bicubic | 64 | 80 | 677 | Direct | |
| MCISIR (Our) | LR | 64 | 26 | 443 | Direct |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhammad, W.; Bhutto, Z.; Ansari, A.; Memon, M.L.; Kumar, R.; Hussain, A.; Shah, S.A.R.; Thaheem, I.; Ali, S. Multi-Path Deep CNN with Residual Inception Network for Single Image Super-Resolution. Electronics 2021, 10, 1979. https://doi.org/10.3390/electronics10161979
Muhammad W, Bhutto Z, Ansari A, Memon ML, Kumar R, Hussain A, Shah SAR, Thaheem I, Ali S. Multi-Path Deep CNN with Residual Inception Network for Single Image Super-Resolution. Electronics. 2021; 10(16):1979. https://doi.org/10.3390/electronics10161979
Chicago/Turabian StyleMuhammad, Wazir, Zuhaibuddin Bhutto, Arslan Ansari, Mudasar Latif Memon, Ramesh Kumar, Ayaz Hussain, Syed Ali Raza Shah, Imdadullah Thaheem, and Shamshad Ali. 2021. "Multi-Path Deep CNN with Residual Inception Network for Single Image Super-Resolution" Electronics 10, no. 16: 1979. https://doi.org/10.3390/electronics10161979
APA StyleMuhammad, W., Bhutto, Z., Ansari, A., Memon, M. L., Kumar, R., Hussain, A., Shah, S. A. R., Thaheem, I., & Ali, S. (2021). Multi-Path Deep CNN with Residual Inception Network for Single Image Super-Resolution. Electronics, 10(16), 1979. https://doi.org/10.3390/electronics10161979