1. Introduction
Organizational development and adoption of artificial intelligence (AI) and machine learning (ML) technologies has exploded in popularity in recent years, with the total business value and total global spending on these technologies expected to reach USD 3.9 trillion and USD 77.6 billion by 2022, respectively [
1,
2]. One of the most significant drivers of the rapid rise of AI and ML has been cloud computing, through which the vast computational resources required to train and evaluate complex machine learning models have become widely available on an elastic, as-needed basis [
3]. Despite the widespread availability of cloud-based computational resources, both the execution time required to train today’s complex, state-of-the-art ML models and the cloud computing costs associated with training those models remain major obstacles in many real-world scientific, governmental, and commercial use cases [
4]. Furthermore, this problem is often made exponentially worse by the need to perform hyperparameter optimization, wherein a large number of candidate ML models with varying hyperparameter settings are trained and evaluated in an effort to find the best-performing model [
5,
6]. Tools and methods aimed at reducing the computational workload and associated monetary costs of arriving at a final, best-performing ML model are therefore highly desirable.
The scope of the model search problem may perhaps be best understood by considering a well-known case from the ML literature. In their highly cited paper, Krizhevsky et al. [
7] described the development and training of the AlexNet deep convolutional neural network (CNN), which achieved state-of-the-art computer vision performance in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Despite having just eight trainable layers and 60 million parameters in their CNN, and despite using multiple GPUs to accelerate the training process, these authors reported that five to six
days were required to train a single model. Just a few years later, it was not uncommon for CNNs competing in the ILSVRC to contain hundreds or even thousands of layers [
8,
9]. Training and evaluating many candidate models of this size and complexity would obviously require a great deal of time, even using today’s most advanced GPUs or tensor processing units.
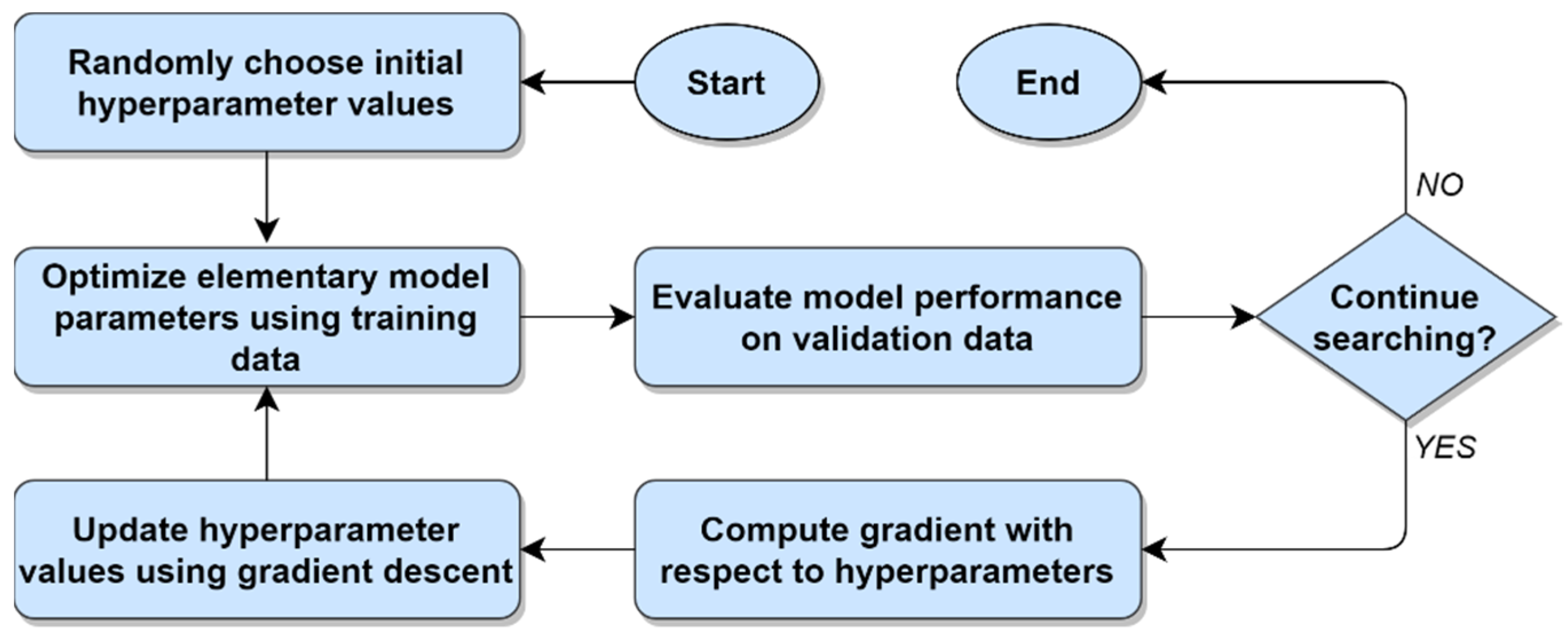
Since evaluating a large number of ML models can be very time-consuming and expensive, many researchers have considered the important problem of how to find an optimal or near-optimal ML model among the set of all possible models as quickly as possible. Unfortunately, many of the hyperparameters involved in ML model training are real-valued, which implies that there is often an infinite number of possible models that theoretically could be evaluated for a particular ML scenario. Recognizing that this situation clearly makes a brute-force model search infeasible, a considerable variety of approaches have been proposed for searching a finite subset of the possible model space. The simplest and most common of these methods involve performing a grid search or a random search, with the latter approach serving as a natural baseline for inter-method performance comparisons [
5]. Several more sophisticated guided search methods have also been proposed, including Bayesian methods [
10], population-based approaches such as evolutionary optimization [
11], early stopping methods [
12,
13], and hypergradient optimization [
14,
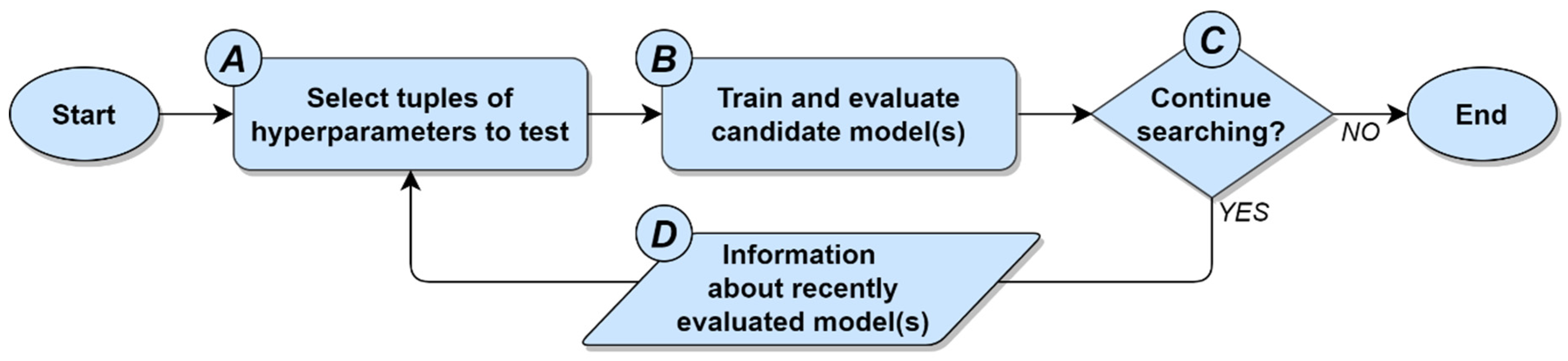
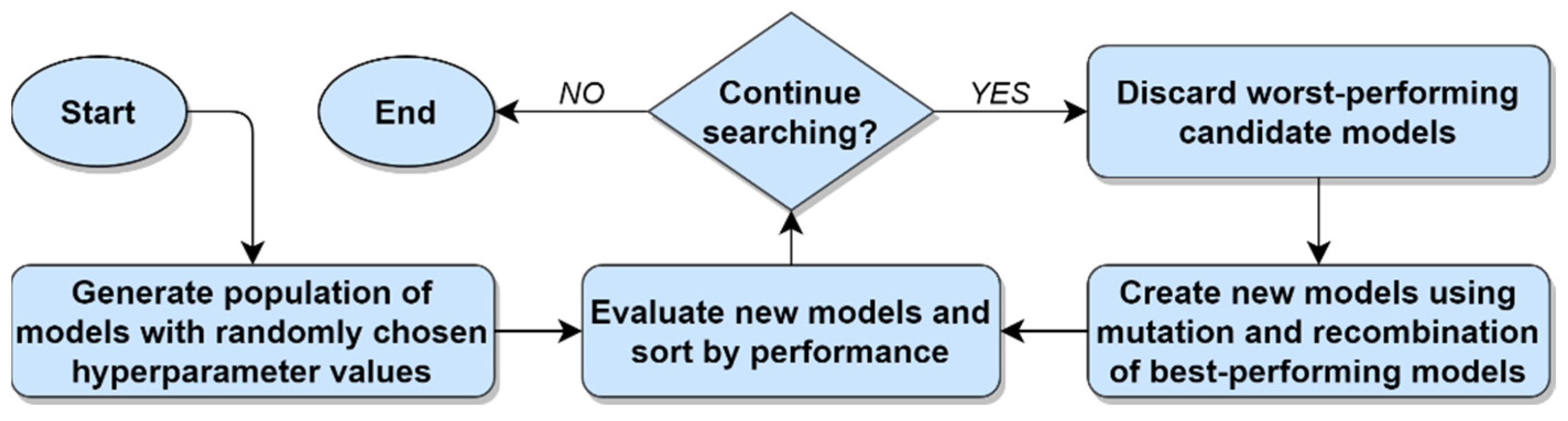
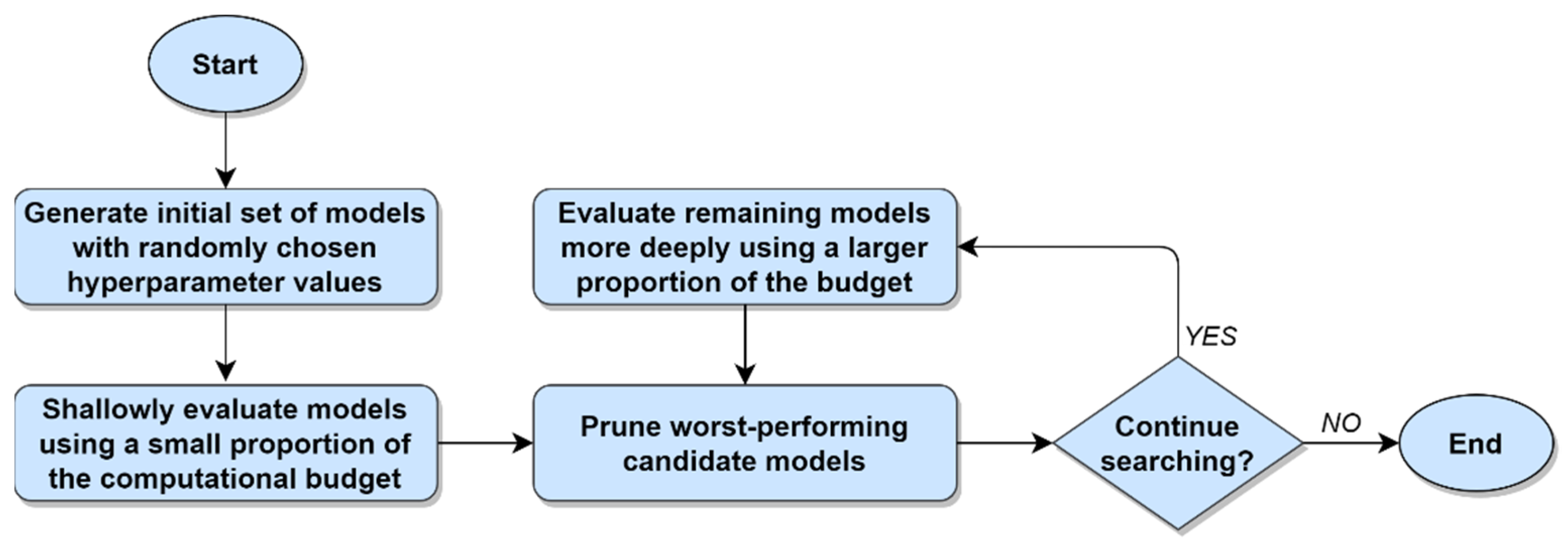
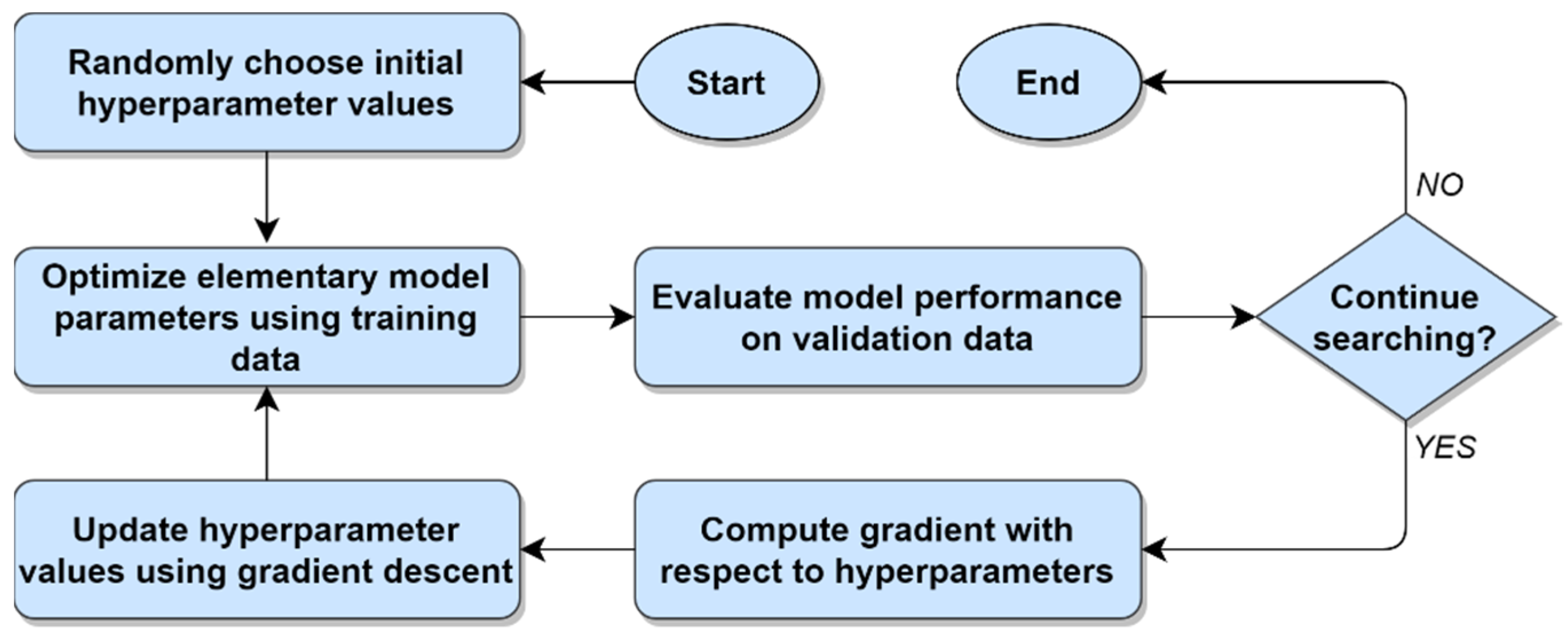
15], etc. Despite the different rules and theories upon which these guided search methods are based, all share a common general strategy: To identify relationships between hyperparameter values and a performance metric, and then use that knowledge to evaluate models located within promising regions of the search space. This general strategy for performing hyperparameter optimization is illustrated in
Figure 1 below.
With respect to the general approach to hyperparameter optimization depicted in
Figure 1, the factors that distinguish one guided search method from another are (1) variations in how tuples of hyperparameters are selected, (2) which stopping conditions are used, and (3) the information about the relationships between the hyperparameters and the performance metric that is used to guide the search process. Together, these three factors are respectively represented by items
A,
C, and
D in
Figure 1. What remains, then, is item
B, which represents the process of training and evaluating one or more candidate models, with each candidate model corresponding to a tuple of hyperparameter values from item
A. Evaluating the performance of each candidate model can be accomplished via any statistically defensible process, regardless of the specific guided search method being used. In practice, the task of evaluating an ML model’s performance is most commonly carried out using
k-fold cross validation [
16], wherein the data are randomly subdivided into
k folds, with each fold being iteratively used as a validation set for a model that has been trained using the remaining folds [
17].
In contrast to all extant guided search methods for hyperparameter optimization, the current study takes a completely different approach by considering the ML model training and evaluation process itself as a means of accelerating the search for the best-performing model. Put differently, rather than trying to find promising regions within the hyperparameter space, this study instead focuses on the process of measuring model performance as a way of reducing the time and costs associated with evaluating a large number of candidate ML models. Existing methods of hyperparameter optimization and ML model selection treat cross validation as a simple “black box” process in the sense that they are unconcerned with cross validation itself, and instead are interested only in the output of the cross-validation process. By contrast, the greedy
k-fold method proposed herein focuses directly and exclusively on what is happening inside this black box; i.e., the cross validation process itself. With respect to
Figure 1, the current study is thus primarily concerned with item
B, which, as noted in the discussion above, has been generally overlooked as a means of performing rapid hyperparameter optimization. Given that the ML model performance is most commonly carried out using
k-fold cross validation, this paper explicitly seeks to pioneer a new approach to hyperparameter optimization by inquiring into the following general research question:
Research Question: When performing hyperparameter optimization with k-fold cross validation, is it possible to improve the average time required to find the best-performing model by taking a greedy approach to the cross-validation process itself?
The balance of this paper is organized as follows:
Section 2 provides a review of the related literature by describing current methods of performing hyperparameter optimization, as well as the standard approach to
k-fold cross validation. The greedy
k-fold cross validation algorithm that forms the core of the current study is introduced in
Section 3, along with a discussion of the algorithm’s properties.
Section 3 also introduces an early stopping version of the greedy cross validation algorithm that can be used to quickly identify near-optimal ML models in scenarios that do not involve a computational budget constraint.
Section 4 describes two sets of experiments that were undertaken to evaluate the performance of the greedy
k-fold method. The first of these evaluates the greedy
k-fold method relative to the baseline standard
k-fold method, with the experiments comparing the ML model search performance of the greedy and standard methods across a variety of different ML algorithms and real-world datasets. The second set of experiments compares the performance of the early stopping version of the greedy cross validation algorithm against a competing, state-of-the-art early stopping algorithm in terms of both search time and the quality of the selected ML models. The outcomes of the evaluative experiments are presented and discussed in
Section 5, with the results indicating that (1) in comparison to the standard
k-fold method, greedy
k-fold cross validation can vastly reduce the average time required to identify the best-performing ML model among a set of candidate models, and (2) in comparison to the state-of-the-art successive halving algorithm, the early stopping version of the greedy cross validation algorithm generally identifies superior ML models in less time. The paper concludes with
Section 6, which provides a brief summary, describes the limitations of the work, and offers a few final remarks about future research directions.
3. Greedy k-Fold Cross Validation
The two versions of the greedy k-fold cross validation algorithm proposed in this section take a completely different approach to hyperparameter optimization than any of the guided search methods described previously. Specifically, whereas these existing methods seek to accelerate the ML model search process by identifying and searching promising areas within the hyperparameter space, the general approach of the greedy k-fold method is to focus on the k-fold cross-validation process itself as a means of achieving rapid hyperparameter optimization and model selection. At a fundamental level, the greedy k-fold cross validation method proposed here differs from the standard k-fold cross validation process in just one important way. In the standard approach, all of the folds for a given ML model are considered as validation sets in sequential order, one after another, thus allowing the overall performance of the model to be computed before the algorithm moves on to the next candidate model (i.e., within-model evaluation). By contrast, greedy k-fold cross validation considers a sequence of folds that originate from different ML models, with the specific model and validation fold to use next being greedily chosen at runtime. Put differently, the standard approach to k-fold cross validation can be thought of as relying on a sequence of within-model fold evaluations, while the greedy approach to k-fold cross validation can be thought of as relying on a sequence of between-model fold evaluations.
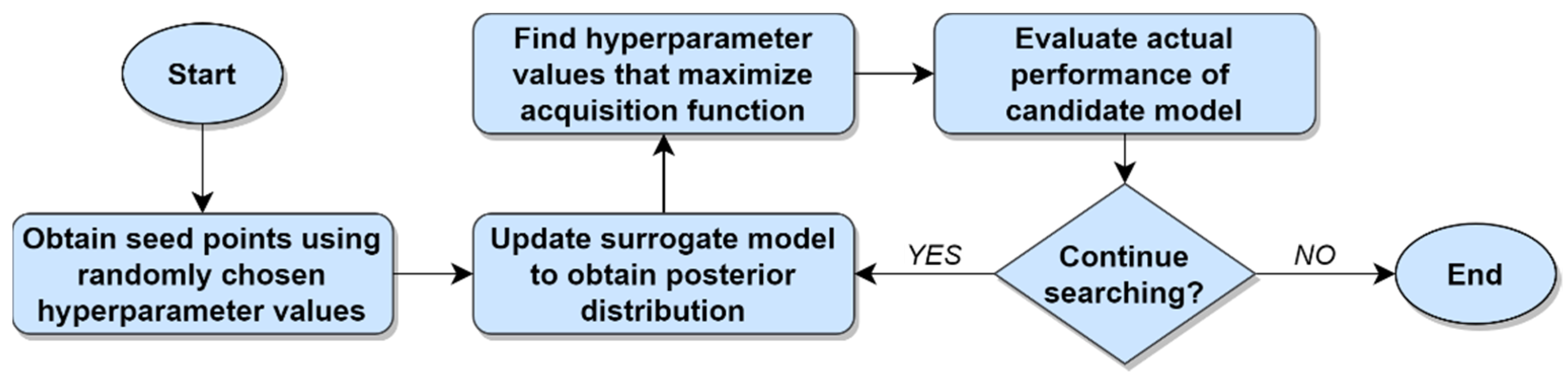
The greedy
k-fold cross validation algorithm begins by obtaining a partial performance estimate for each candidate model using just the first fold as a validation set, after having trained the model using the remaining folds. The model with the best initial performance is then identified, after which the second fold for that model is used as a validation set (with the remaining folds naturally being used as the training set). The performance estimate for the model is then updated to reflect the mean performance observed after having tested the model using the first two folds as validation sets. The model with the best mean performance at that moment is then identified, after which its next available fold is used as a validation set and the model’s mean performance is updated. This process repeats until either the computational budget has been exhausted or an early stopping criterion has been met, at which time the algorithm returns the best, fully evaluated model. The process of selecting an optimal ML model using greedy
k-fold cross validation when operating under the constraint of a computational budget is described in Algorithm 2 below.
| Algorithm 2. ML model selection using greedy k-fold cross validation with a computational budget. |
Input: M (set of candidate models), k (number of folds), D (dataset), b (computational budget)
Output: Best-performing, fully evaluated model
split D into k folds, s.t. D = {d1, d2, …, dk}
for each m ∈ M do
train m using folds {d2, …, dk}
Ρm ← performance of m evaluated using fold d1
Fm ← 1 (number of folds evaluated for m)
end for
η ← #M (set number of completed fold evaluations to cardinality of M)
while η < b do (while the computational budget is not exhausted)
m* = best incompletely evaluated m ∈ M (given the current mean performance for each m, per Ρ)
Fm* ← Fm* + 1
train m* using all folds di ∈ D where i ≠ Fm*
evaluate performance of m* using fold dFm*
Ρm* ← mean performance of m* for folds {d1, …, dFm*}
η ← η + 1
end while
return best, fully evaluated m ∈ M, per Ρ |
As indicated in the
while loop, the greedy
k-fold cross validation algorithm behaves greedily by always pursuing the most promising available option, with the extent to which an option is promising being determined by the current mean performance of its corresponding model. Put differently, the next fold that the greedy algorithm will evaluate will always originate from the best incompletely evaluated model, as determined by each candidate model’s current mean performance. In this way, the greedy
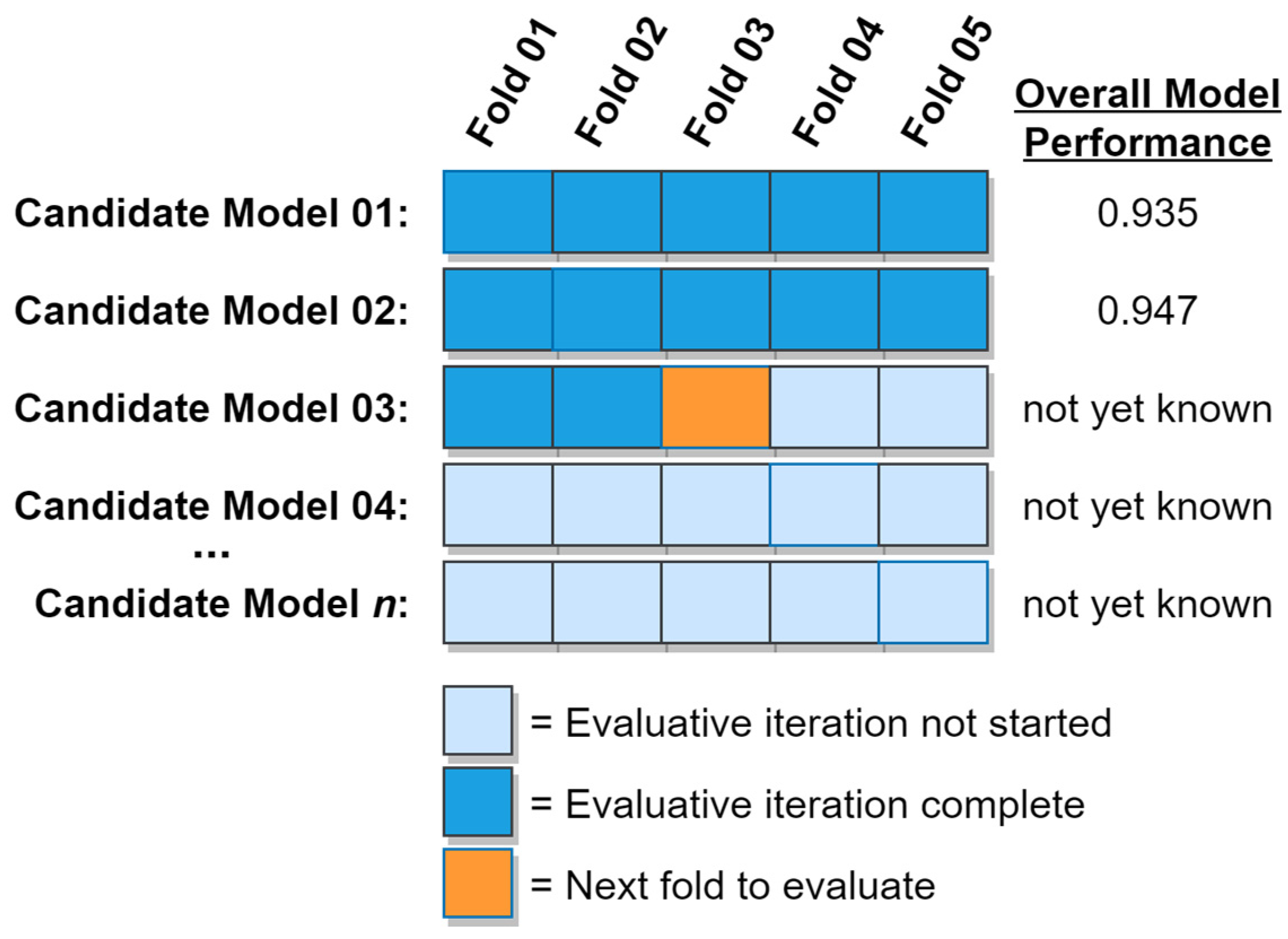
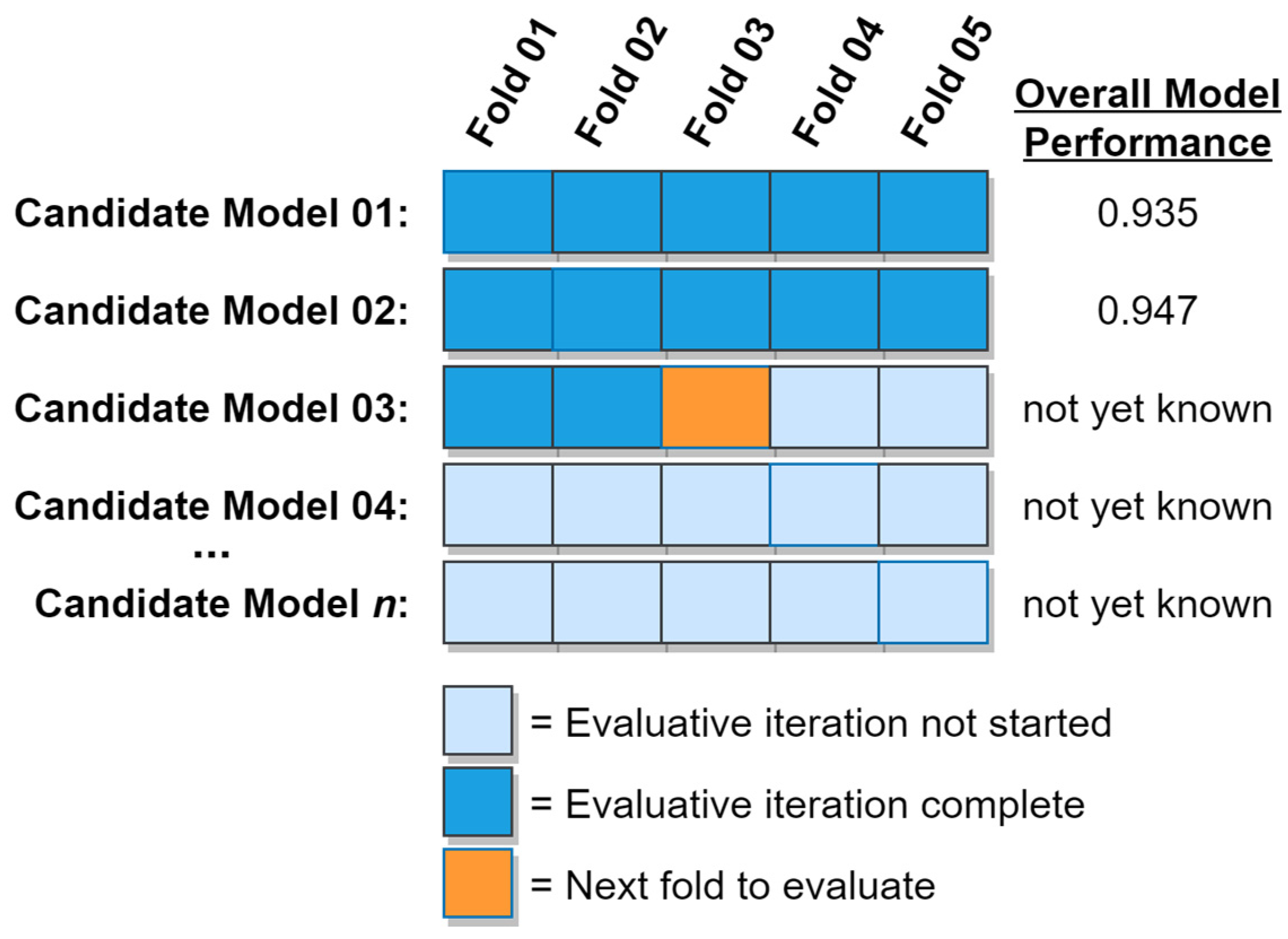
k-fold cross validation algorithm focuses its early efforts on the most promising candidate models. As time passes and the most promising models become fully evaluated, the algorithm will steadily evaluate folds from less and less promising models, but will never waver from the principle of greedily pursuing the most promising of its available options on each iteration. In the presence of a computational budget constraint, this behavior thus increases the probability of an optimal or near-optimal model being identified before the computational budget is exhausted. If instead an early stopping criterion based on model performance is being used, this behavior helps ensure that the early stopping criterion will be met as quickly as possible, thus accelerating the overall model search process. A graphical example of the greedy
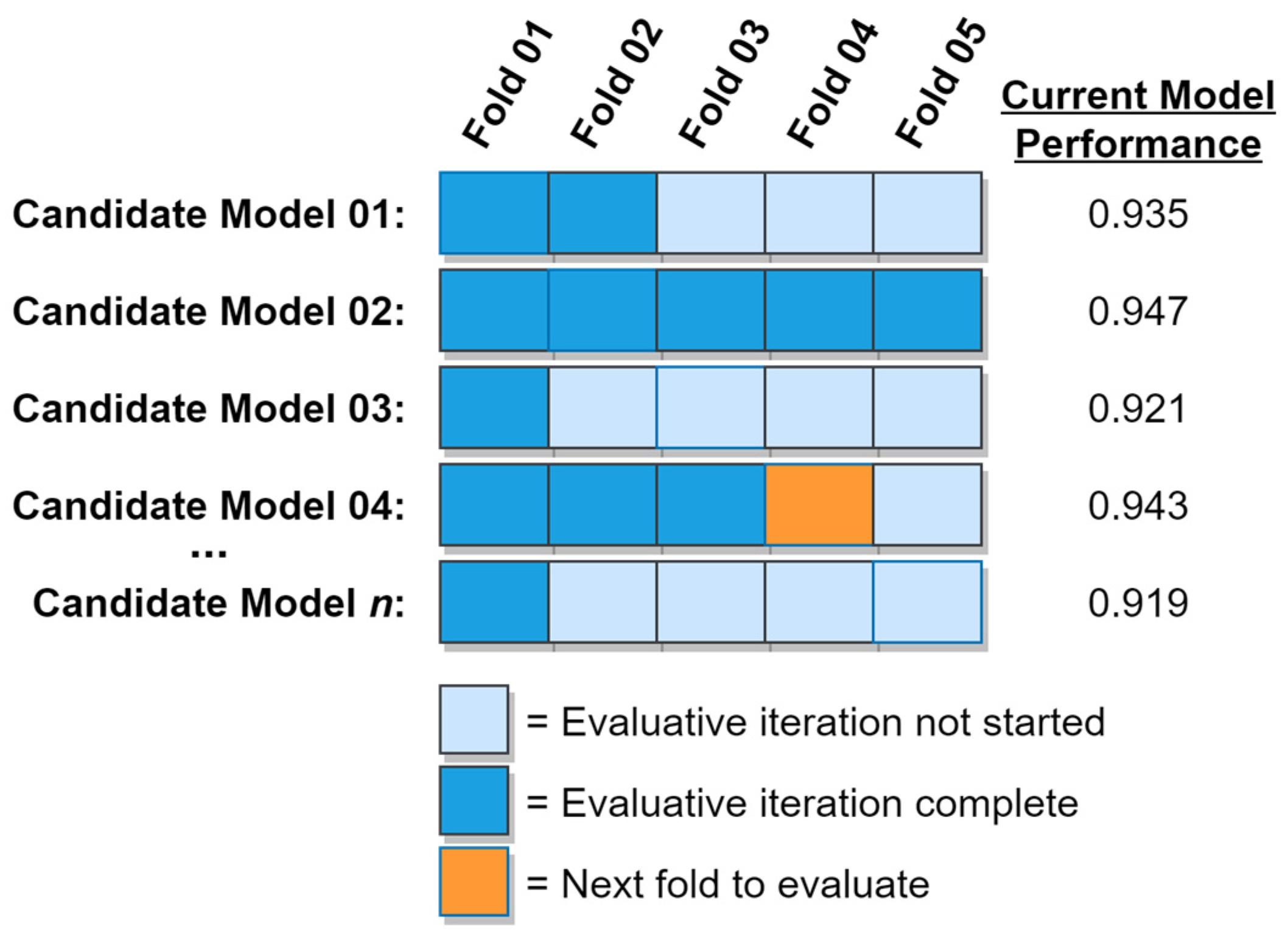
k-fold cross validation algorithm is shown in
Figure 10. In the figure, Candidate Model 02 has already been fully evaluated, while evaluation of the remaining models is still in progress.
Since hyperparameter optimization and ML model selection tasks do not always occur under the constraint of a computational budget, a variation of the greedy
k-fold cross validation method in which a simple early stopping criterion has been implemented is described in Algorithm 3 below. This criterion allows the greedy cross validation algorithm to decide whether to continue searching or to stop the search process early based on the data, rather than relying on a predefined computational budget constraint. In this variant of the greedy cross validation algorithm, an early stopping percentage (ε) is provided as an input parameter. The product of ε and the number of candidate models is run through a standard ceiling function to yield an early stopping threshold. Every time a candidate model becomes fully evaluated, that model’s overall performance is compared to the performance of the currently known, fully evaluated, best-performing model. If the newly completed model is found to be inferior to the currently known best model, then an inferior model counter is incremented. Whenever the value of the inferior model counter exceeds the early stopping threshold, the search is stopped immediately and the currently known, fully evaluated, best-performing model is returned. If, however, a newly completed candidate model is found to be superior to the currently known best model, then the newly completed model replaces the previous best-performing model, and the inferior model counter is reset to zero. In this way, the algorithm will continue searching as long as it continues to find better and better models. As soon as this steady improvement falters (as signaled by a sufficiently large succession of inferior models), the search process is terminated.
| Algorithm 3. ML model selection using greedy k-fold cross validation with early stopping. |
Input: M (set of candidate models), k (number of folds), D (dataset), ε (early stopping percentage)
Output: Best-performing, fully evaluated model
split D into k folds, s.t. D = {d1, d2, …, dk}
for each m ∈ M do
train m using folds {d2, …, dk}
Ρm ← performance of m evaluated using fold d1
Fm ← 1 (number of folds evaluated for m)
end for
η ← #M (set number of completed fold evaluations to cardinality of M)
ι ← 0 (initialize inferior model counter)
while η < #M∙k do (while there are more folds to be evaluated)
m* = best incompletely evaluated m ∈ M (given the current mean performance of each m, per Ρ)
Fm* ← Fm* + 1
train m* using all folds di ∈ D where i ≠ Fm*
evaluate performance of m* using fold dFm*
Ρm* ← mean performance of m* for folds {d1, …, dFm*}
η ← η + 1
if Fm* = k then (if all folds for m* have been evaluated)
if Pm* is the best performance thus far observed then
ι ← 0 (reset inferior model counter)
else (if m* is inferior to the currently known, fully evaluated, best-performing model)
ι ← ι + 1
if then (if the inferior model counter exceeds the early stopping threshold)
break (exit the loop immediately)
end if
end if
end if
end while
return best, fully evaluated m ∈ M, per Ρ |
4. Materials and Methods
Having presented two variants of the greedy
k-fold cross validation algorithm, this section describes two sets of evaluative experiments that were undertaken to assess the performance of each of those variants. The first group of experiments addressed scenarios involving a computational budget by comparing the performance of Algorithm 2 to that of the standard
k-fold method. The second group of experiments addressed scenarios without a computational budget by comparing the performance of Algorithm 3 to a leading early stopping method – the successive halving algorithm [
12,
13]. To rigorously evaluate each variant of the greedy
k-fold method, its performance was compared to its respective competing method (either standard
k-fold or successive halving) under many experimentally manipulated conditions, including using a variety of different ML algorithms, a variety of real-world datasets, and varying values of the number of folds (
k) and the number of candidate models (
n). Before describing these experiments, however, it is necessary to define the way in which the performance of the various methods was measured in the experiments.
4.1. Performance Metrics
Beginning with the first group of experiments—in which the greedy k-fold cross validation method was compared to the standard k-fold cross validation method—recall from the earlier discussion that for a hyperparameter space containing n models that are tested with cross validation using k folds, the total number of fold evaluations is nk. For a set of n candidate models, then, the performance of each method in the first group of experiments was measured by the average search time required to find the best-performing model in the set, with search time being calculated as the ratio of the total number of fold evaluations that were required to find the best-performing model relative to the total number of nk possible fold evaluations. This is a very convenient measure of search time since it naturally yields an interval that ranges from 0.0 to 1.0, thus allowing straightforward performance comparisons to be made across experimental conditions. Given the search time metric described above, it can be readily calculated that the time required to fully evaluate each candidate model is . The maximum theoretical time required to find the optimal model using the standard k-fold method is thus , while the minimum search time for the standard method is . Since the standard k-fold method essentially employs a linear search strategy, the average theoretical search time for the standard method is . On average, then, the standard k-fold cross validation method can be expected to find the optimal model after having fully evaluated 50% of the candidate models. While the maximum theoretical search time for the greedy k-fold method is also 1.0, the minimum time for the greedy method to find the optimal model is . The average theoretical search time for the greedy k-fold method will depend on the distributional properties of the training dataset and will hence vary from one ML scenario to the next.
For the second group of experiments—which compared the early stopping version of the greedy k-fold cross validation method to the successive halving method—a different set of performance metrics was required. The reason for this is that, by definition, early stopping algorithms stop the model search process early, and hence do not completely evaluate every model in the set of candidate models. As such, we can never be entirely certain that the final model chosen by an early stopping method is truly the best-performing model in the set of candidate models. Furthermore, it would be inequitable to quantify the search time for the greedy early stopping method and the successive halving method using the same metric from the first group of experiments, since the two algorithms evaluate neither the same number of folds nor folds consisting of the same number of cases. With these considerations in mind, two performance metrics were designed for the second set of experiments that compare each of the competing algorithms to a common baseline. Specifically, for each comparison of the greedy and successive halving early stopping methods, the common set of candidate models provided as input to each method was first fully evaluated using the standard k-fold method described in Algorithm 1. For any set of candidate models used in the second group of experiments, this approach thus provided a true performance ranking for each model in the set, as well as measurement of the total wall-clock time required by the standard k-fold method to conduct a complete search of every candidate model in the set. With this information available for each experiment, it was possible to compute two equitable metrics for comparing the greedy and successive halving early stopping methods, the first of which addressed the quality of the final model selected by each algorithm, and the second of which addressed the wall-clock time required by each algorithm to complete the model search process. In the case of the former, the quality of the final model selected by each algorithm was measured as the rank-based percentile of the chosen model relative to the true best-performing model in the set of candidate models. If, for example, an early stopping algorithm was given a set of n = 100 candidate models to consider and it ultimately selected the second-best model in the set, then the quality of the algorithm’s choice would be scored as (100−1)/100 = 0.99, indicating that only 1% of the other models in the set were superior to the chosen model. In the case of the latter, the speed of each early stopping algorithm was computed as the ratio of the wall-clock time required by the algorithm to complete the model search relative to the wall-clock time required by the standard k-fold method to perform an exhaustive search on the same set of candidate models. If, for example, an early stopping algorithm required 30 s to complete the search process while a comparable exhaustive search required 100 s, then the speed of the early stopping method for that experiment would be scored as 30/100 = 0.30, indicating that the early stopping method needed only 30% of the time required by the standard k-fold method to complete the model search.
4.2. ML Algorithms and Datasets
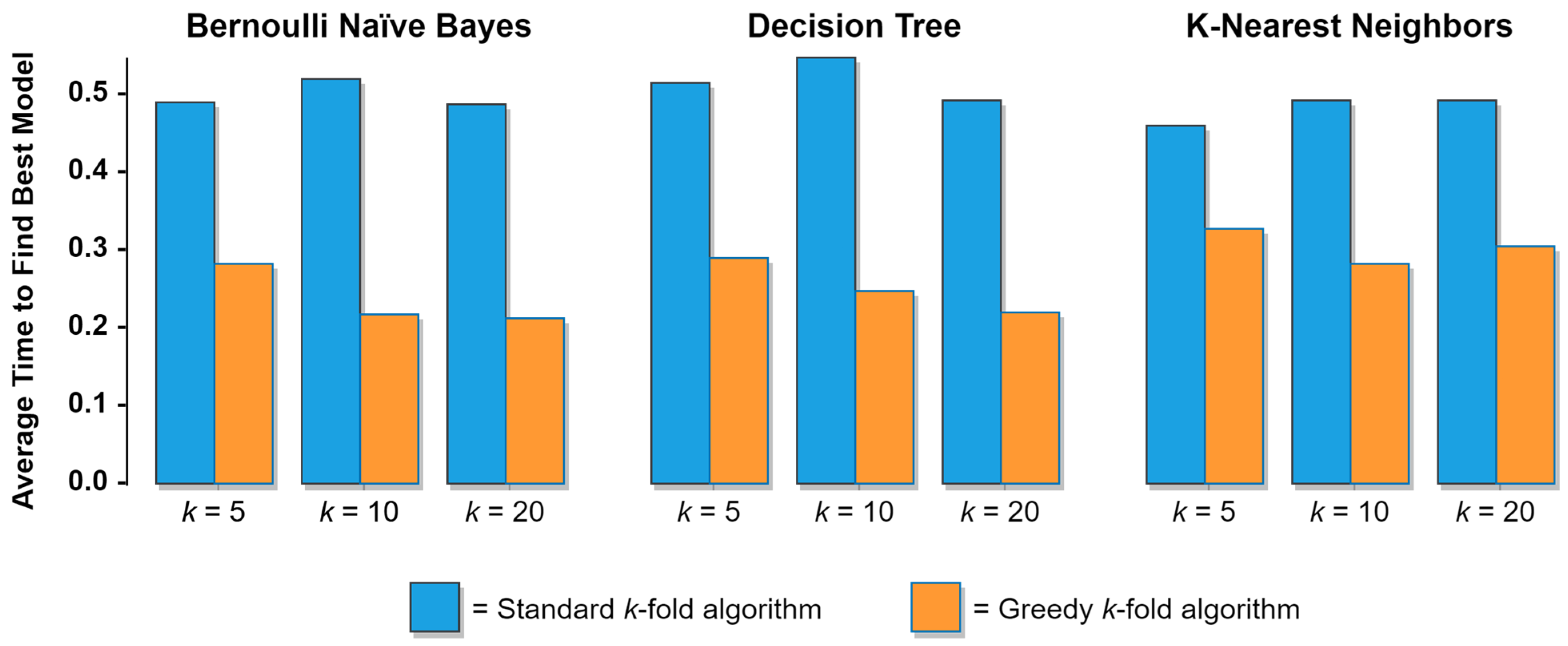
As noted previously, a variety of ML algorithms and real-world datasets were used in the experiments to compare the performance of the greedy
k-fold cross validation method to the standard (baseline)
k-fold cross validation and successive halving methods. These algorithms included the Bernoulli Naïve Bayes, Decision Tree, and K-Nearest Neighbors (KNN) classifiers, each of which was chosen due to its distinct approach to performing the classification task. All of the ML algorithms used in the experiments are open-source and freely available via the Python
scikit-learn library [
38]. The three datasets used in the experiments are all well-known among ML practitioners and included the Wisconsin Diagnostic Breast Cancer dataset (569 cases, 30 features, 2 classes), the Boston Home Prices dataset (506 cases, 13 features, 4 classes—discretized using a quartile split), and the Optical Recognition of Handwritten Digits dataset (1797 cases, 64 features, 10 classes). These three datasets were chosen since they varied widely in terms of their numbers of cases, features, and classes, and since they are all freely available as part of the
scikit-learn library [
38], thus helping ensure that the results of the experiments can be easily replicated.
4.3. ML Models and Folds
For each combination of ML classifier and dataset,
n different candidate models were evaluated in each experiment. The set of values used in the experiments for
n was derived from a geometric sequence with a common factor of two:
. For the first group of experiments (which extensively compared the greedy and standard
k-fold cross validation methods),
, yielding
. For the second group of experiments (which compared the greedy and successive halving early stopping methods),
, yielding a narrower
. A variety of values of
k were also used for the first group of experiments, with each cross-validation method being evaluated with
folds. These values of
k were chosen based on their common usage in applied ML projects. For the second group of experiments comparing the performance of the greedy and successive halving early stopping methods, each experiment relied on
k = 10 folds. The candidate models that were evaluated in the experiments varied according to the values of their hyperparameters, with the hyperparameter settings for each model being chosen randomly in accordance with Bergstra and Bengio [
21] using the same ranges of possible values for each hyperparameter that were used by Olsen et al. [
19].
4.4. Experiment Procedure
For each combination of ML classifier, dataset, and
n, the same set of candidate models was used to evaluate the competing methods in each experiment. This approach was adopted to ensure that any differences in inter-method performance could not be attributed to variation in hyperparameter settings among the
n available models. For the first group of experiments, all
n candidate models were fully evaluated using the standard and greedy cross validation methods during each experiment, with the completion time and value of the performance metric being recorded for each model and method. After all of the candidate models had been evaluated, the best-performing model and its corresponding evaluation completion times were identified for each cross-validation method. For the second group of experiments, all
n candidate models were first fully evaluated by the standard
k-fold cross validation method for each experiment in order to establish a baseline model search time and to identify the true performance rank for each model. The same candidate models were then provided to the greedy and successive halving early stopping methods, with the expectation that each method would partially evaluate the set of candidate models according to the tenets of its respective algorithm. For the current study, a value of 0.02 (or 2%) was used as the ε (early stopping percentage) parameter for the greedy early stopping algorithm. After completing the model search process, the elapsed wall-clock time and the true performance rank of each method’s chosen model were used to calculate the comparative search time and model quality metrics for that experiment, as described previously in
Section 4.1.
Finally, a total of 30 iterations of each experiment were carried out in the manner described immediately above in order to ensure that the resulting distributions of the performance metrics would be approximately Gaussian, per the central limit theorem [
39]. The performance of the greedy cross validation method could then be compared to the standard method (for the first set of experiments) and to the successive halving method (for the second set of experiments) in each of the experimental conditions by means of a Welch’s
t-test. Welch’s
t-tests were used in these comparisons since there was no reason to expect that the variances of the distributions of the performance metrics for the various methods would be equal, and Welch’s
t-tests allow for unequal variances [
40]. The results of the experiments are reported and discussed in the following section.
6. Conclusions
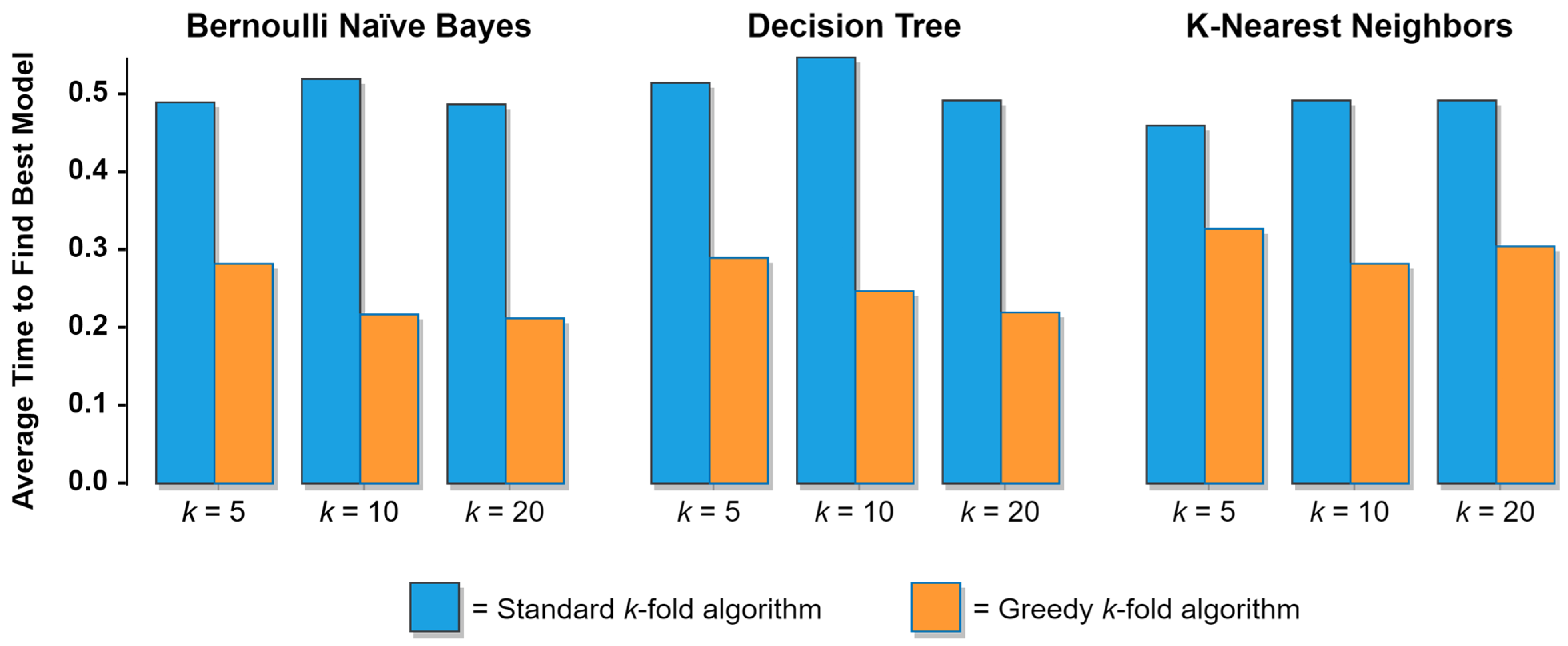
This paper developed and presented two variants of a greedy k-fold cross validation algorithm and subsequently evaluated their performance in a wide array of hyperparameter optimization and ML model selection tasks. By means of two large sets of experiments, it was shown (1) that the greedy method substantially outperforms the standard k-fold method in its ability to quickly identify optimal ML models in scenarios involving a computational budget, and (2) that the greedy method substantially outperforms the state-of-the-art successive halving method, in terms of both the wall-clock time required to complete the ML model search process and the quality of the final ML models selected by the competing methods. More specifically, given a set of candidate models, the first variant of the greedy k-fold method will, on average, identify the optimal ML model approximately twice as quickly as the standard method. This means that given a fixed computational budget, approximately twice as many candidate models could be considered using the greedy k-fold method than could otherwise be considered using the standard method. Alternatively, given a fixed number of candidate models, the greedy k-fold method would, on average, allow the best-performing model in the set to be identified using just half of the computational budget that would be required to achieve the same results using the standard method. For the second variant, the results indicate that given a set of candidate models, the greedy early stopping method consistently selects better-performing models than the successive halving method and that, on average, the greedy early stopping method completes the ML model search process approximately 70% faster than the successive halving method. From a practical perspective, these properties of the greedy k-fold method can translate to huge savings for companies by reducing the amount of time and money required to develop and train ML-based products and services, thereby yielding substantial gains in competitive advantage. The greedy k-fold method can also provide major benefits to AI and machine learning researchers who are developing and performing hyperparameter optimization on complex ML models.
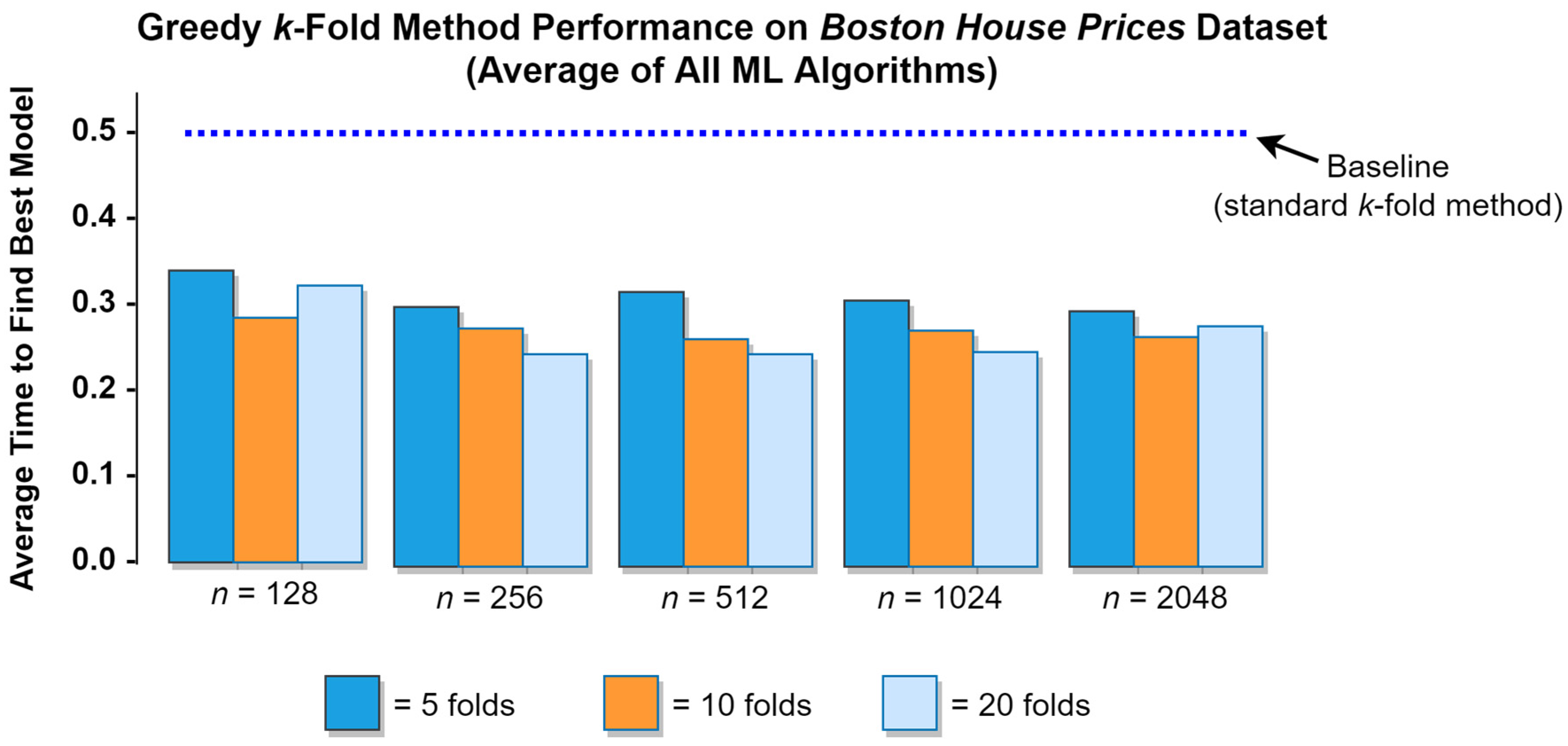
As with all research, this project has several limitations that merit acknowledgement. First, although efforts were taken to test the two variants of the greedy
k-fold algorithm on a variety of real-world datasets, those datasets were all relatively small, with the largest dataset containing just 1797 cases and 64 features. There is some indication among the results presented in
Table 1 that the performance of the greedy
k-fold method may improve on larger datasets (possibly due to less variation among the distributions of each fold), but this notion was not explicitly tested in the current study. Second, while the greedy method was subjected to three different ML algorithms in this project, all of those algorithms were classifiers. There is no obvious
a priori reason to expect that the greedy
k-fold method would perform differently for ML algorithms that produce ordinal or continuous predictions. Nevertheless, such algorithms were not used in the current study, which limits the generalizability of the results. Finally, the performance of the greedy
k-fold method described in the current paper was compared only against the standard
k-fold method and the successive halving method in terms of its ability to quickly identify an optimal model. While the greedy method is unique in terms of its focus on cross validation as a means of accelerating the hyperparameter optimization/ML model selection process, many other approaches to hyperparameter optimization have been proposed, and the greedy
k-fold method has not yet been compared to those methods.
Ultimately, this paper represents a small but important first step in investigating greedy
k-fold cross validation. Although this paper focused only on the potential of greedy cross validation as an accelerant for ML hyperparameter optimization and model selection, the greedy method may prove to be of great value in other situations, as well. There are, for example, many scenarios across a wide range of scientific disciplines in which cross validation is used as a basis for comparing competing models (e.g., [
41,
42,
43]), and the greedy method may be usefully applied to any of these scenarios. Outside of the realm of model selection, the greedy cross validation method developed in this paper may also be usefully applied to a wide variety of bandit problems. Clearly, much remains to be done. To be sure, the greedy
k-fold method described in this study is the simplest possible version of the algorithm, and more advanced and better performing algorithms based on the same principles may certainly be feasible. For example, could a more effective approach be developed to handle the exploration/exploitation dilemma? Could the distributional properties of a dataset’s folds be utilized as a basis for identifying when to abandon unpromising models? Can the greedy
k-fold method be combined with other approaches designed to accelerate hyperparameter optimization in order to identify optimal ML models even more quickly? All of these questions remain to be answered and hence represent fruitful opportunities for future research in this area. For now, we must content ourselves with the knowledge that the greedy
k-fold cross validation algorithm appears to be highly promising, and may open new doors for a vast array of optimization problems.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}