
An Empirical Evaluation of NVM-Aware File Systems on Intel Optane DC Persistent Memory Modules †


Abstract
:1. Introduction
2. Background and Related Work
2.1. Intel Optane DC Persistent Memory Modules
2.2. NVM-Aware File Systems
2.3. Related Work
3. Evaluation Settings and Methodology
- Fileserver emulates the I/O activities of a file server. It is a write-intensive workloads that mixed operations of create, write, read, delete, and append.
- Varmail represents mail server workload that saves each email in a separate file. The workload consists of create, delete, append, and fsync operations.
- Webserver is a read-intensive workload that consists of open, read, close, and log append activities.
- Webproxy represents the I/O activities of a simple web proxy server. The workload consists of create, write, open, delete, and log append operations.
4. Evaluation
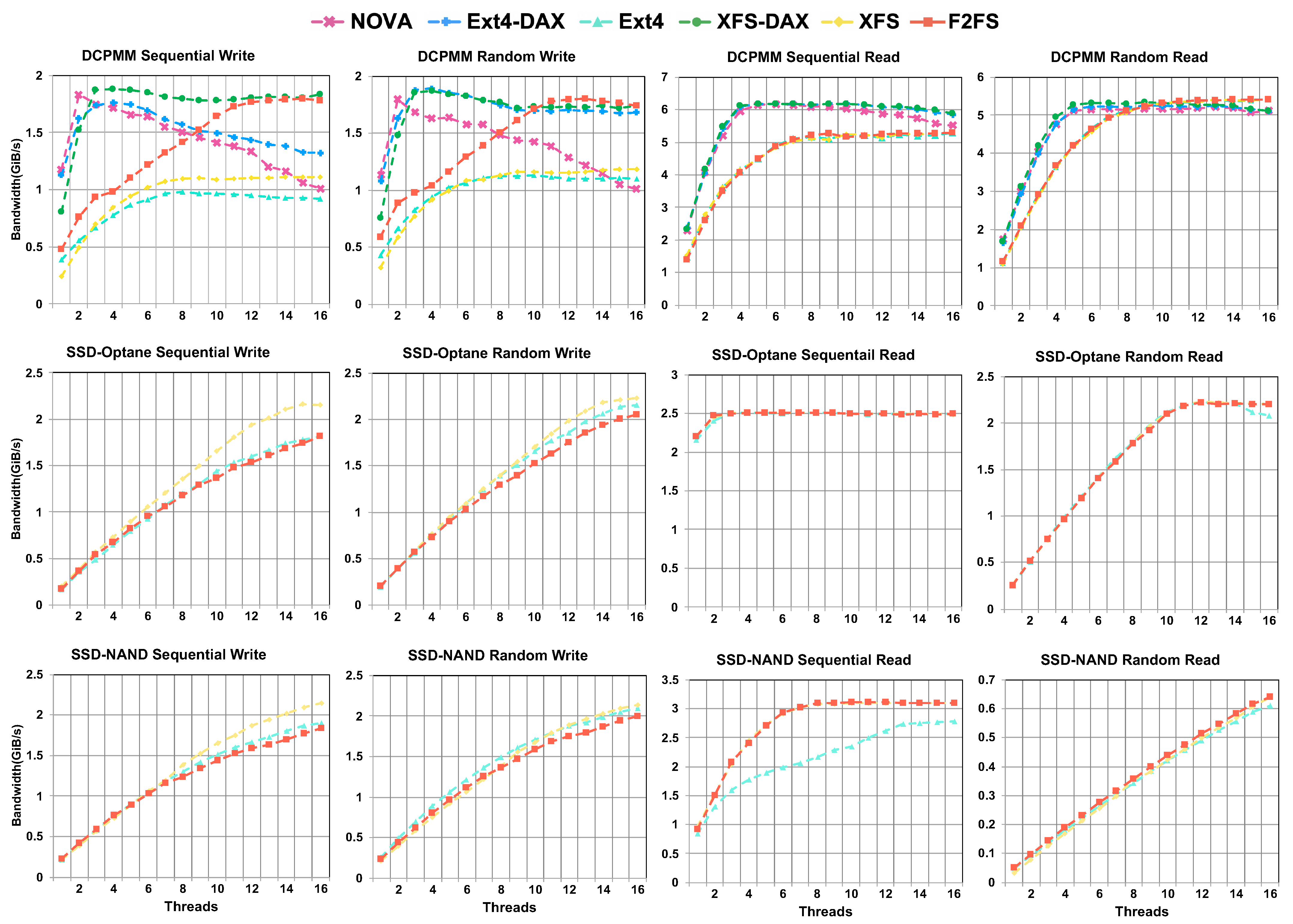
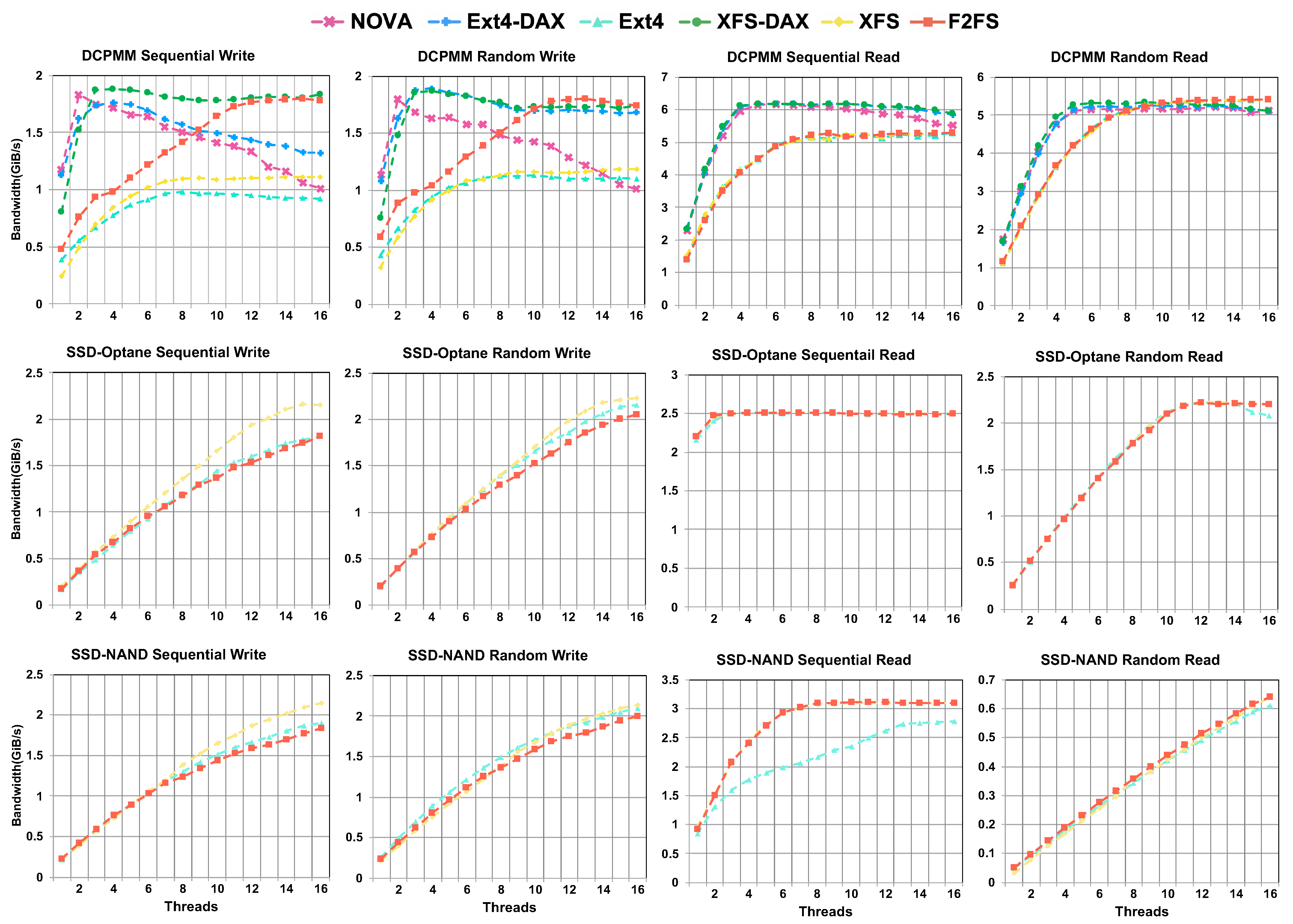
4.1. Micro-Benchmark Results
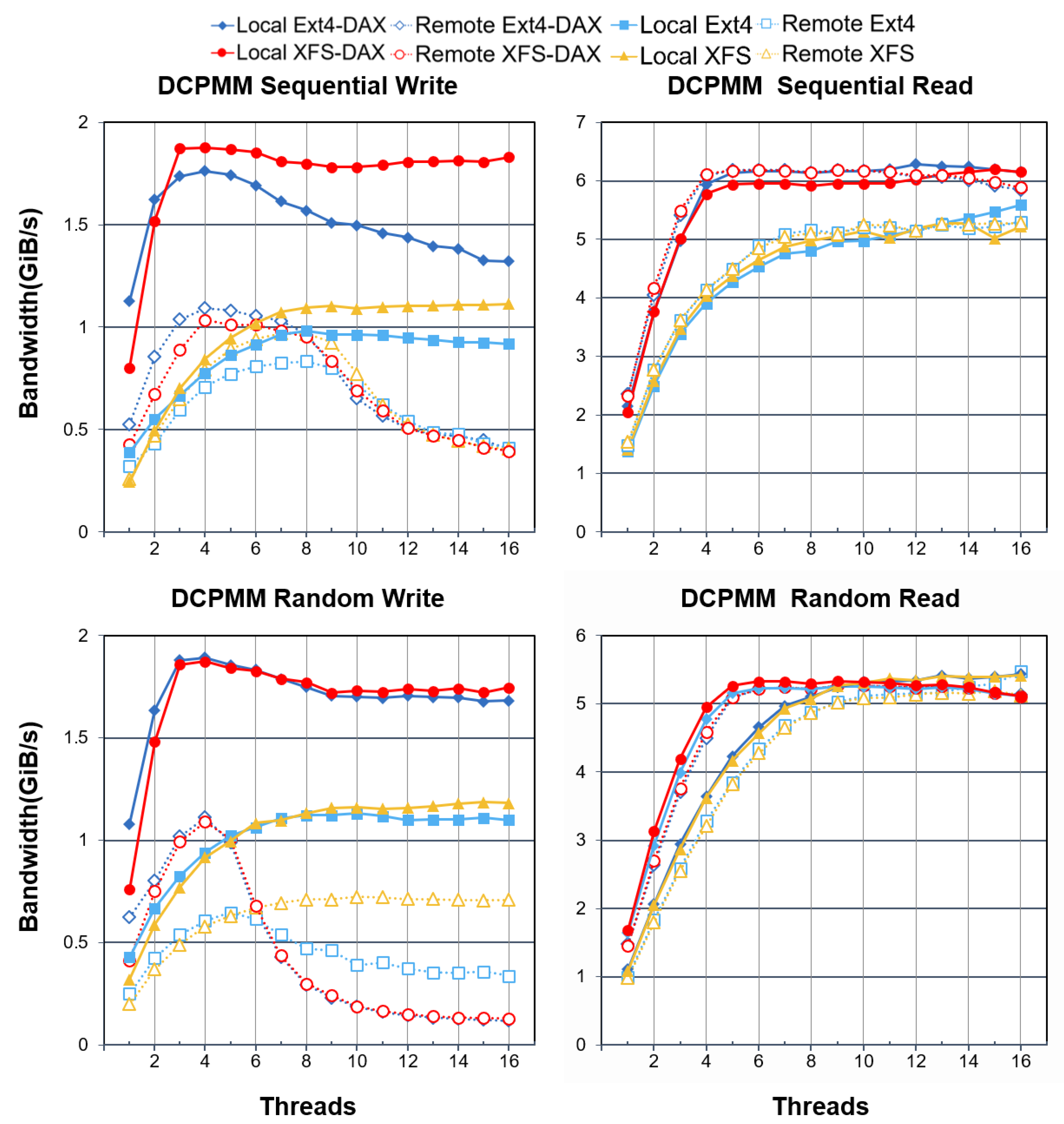
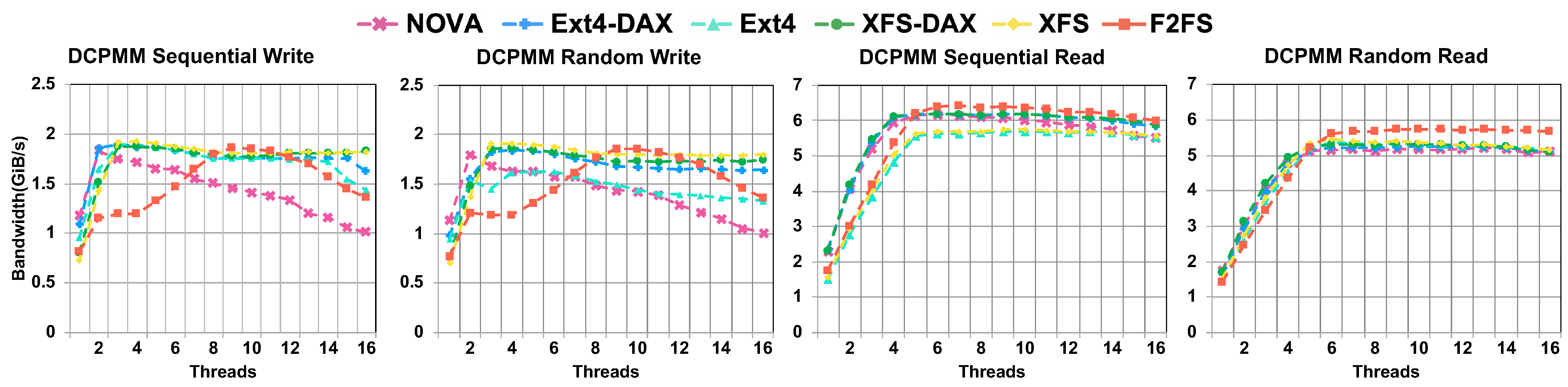
- A small number of threads is enough to saturate the write bandwidth of one DCPMM. In some situations, more threads may even degrade the performance.
- The read performance of DCPMMs is greatly superior to its write performance. Concurrent read access does not degrade the read performance significantly.
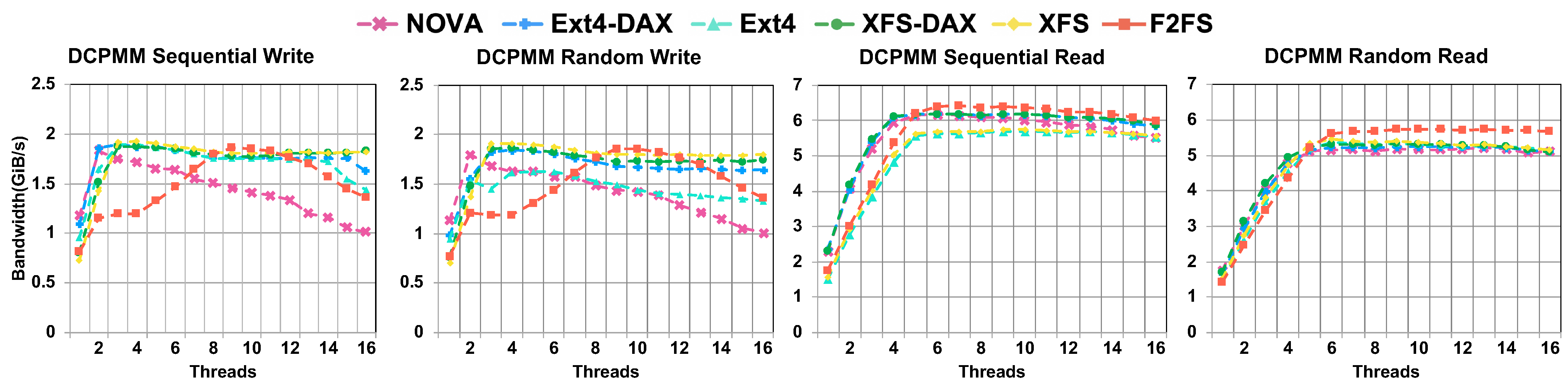
4.2. DAX vs. Direct I/O
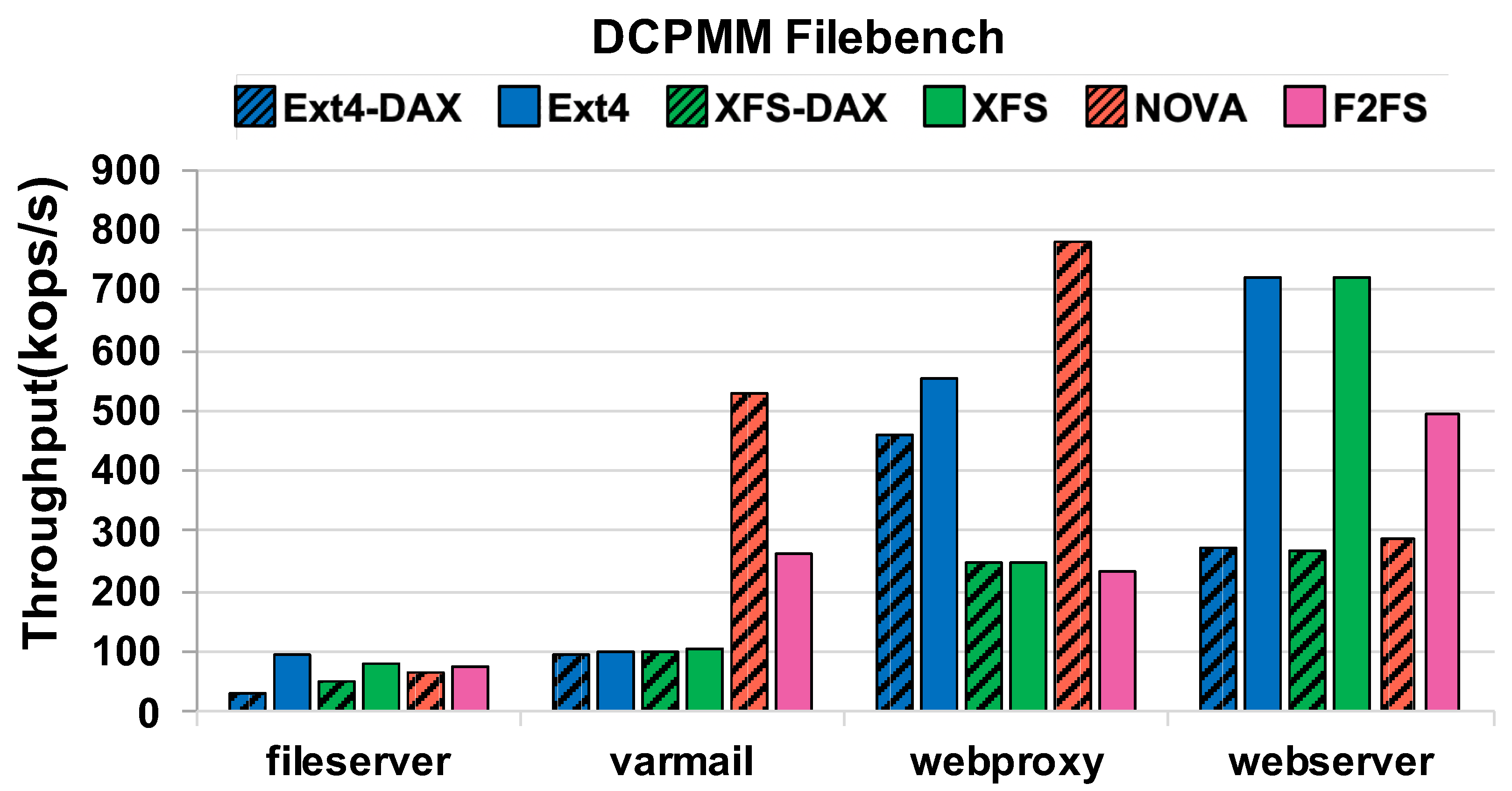
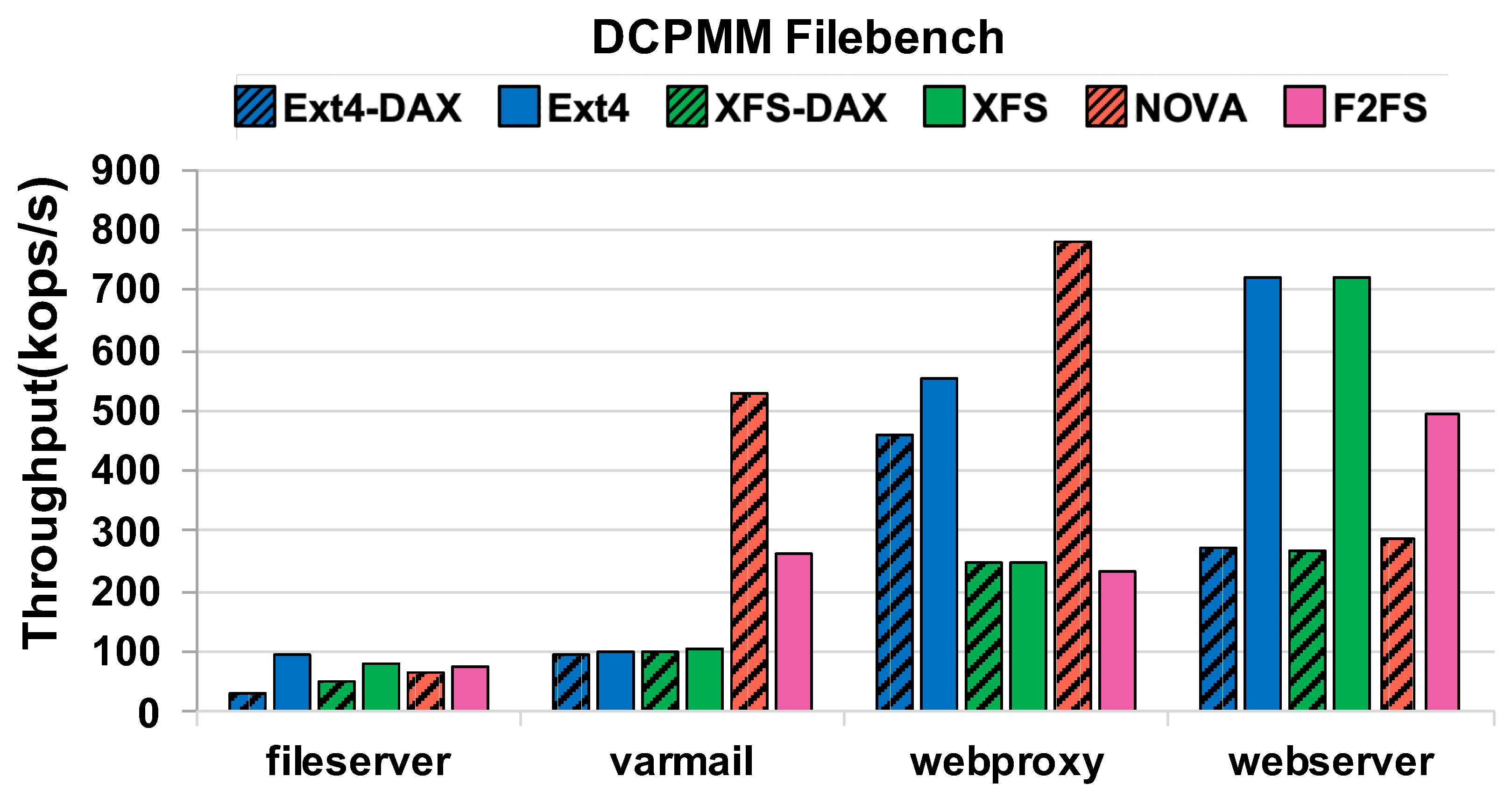
4.3. Macro-Benchmark Results
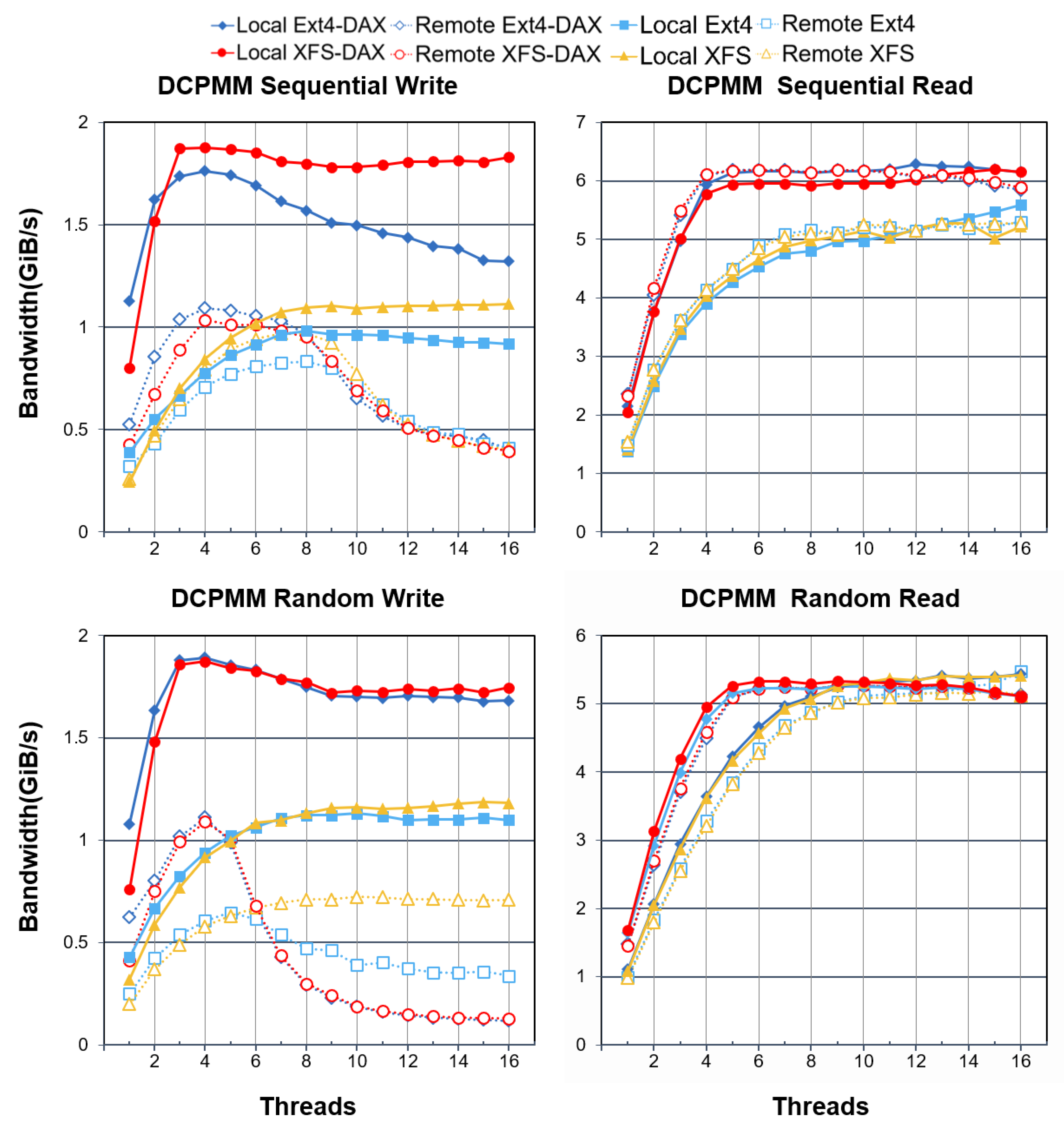
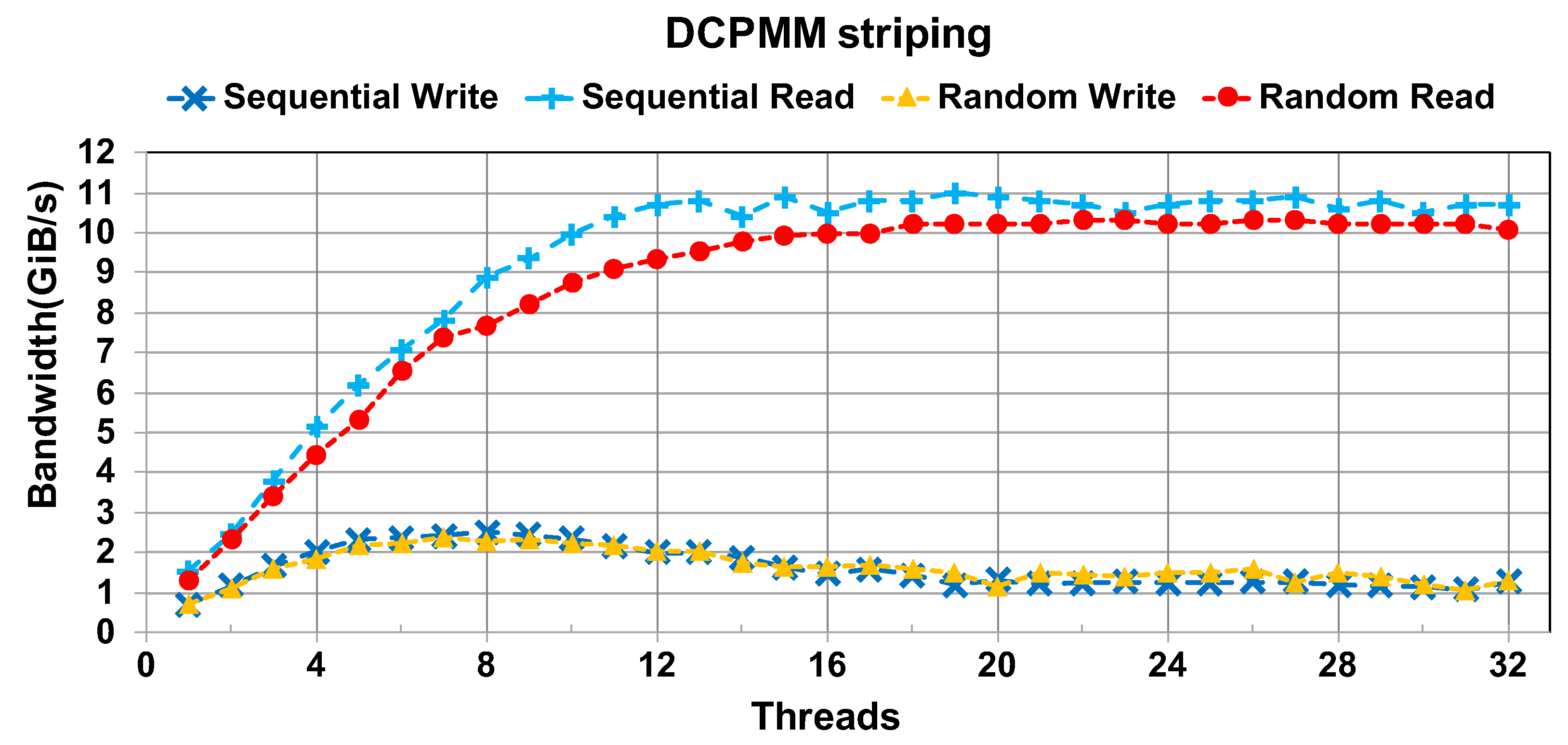
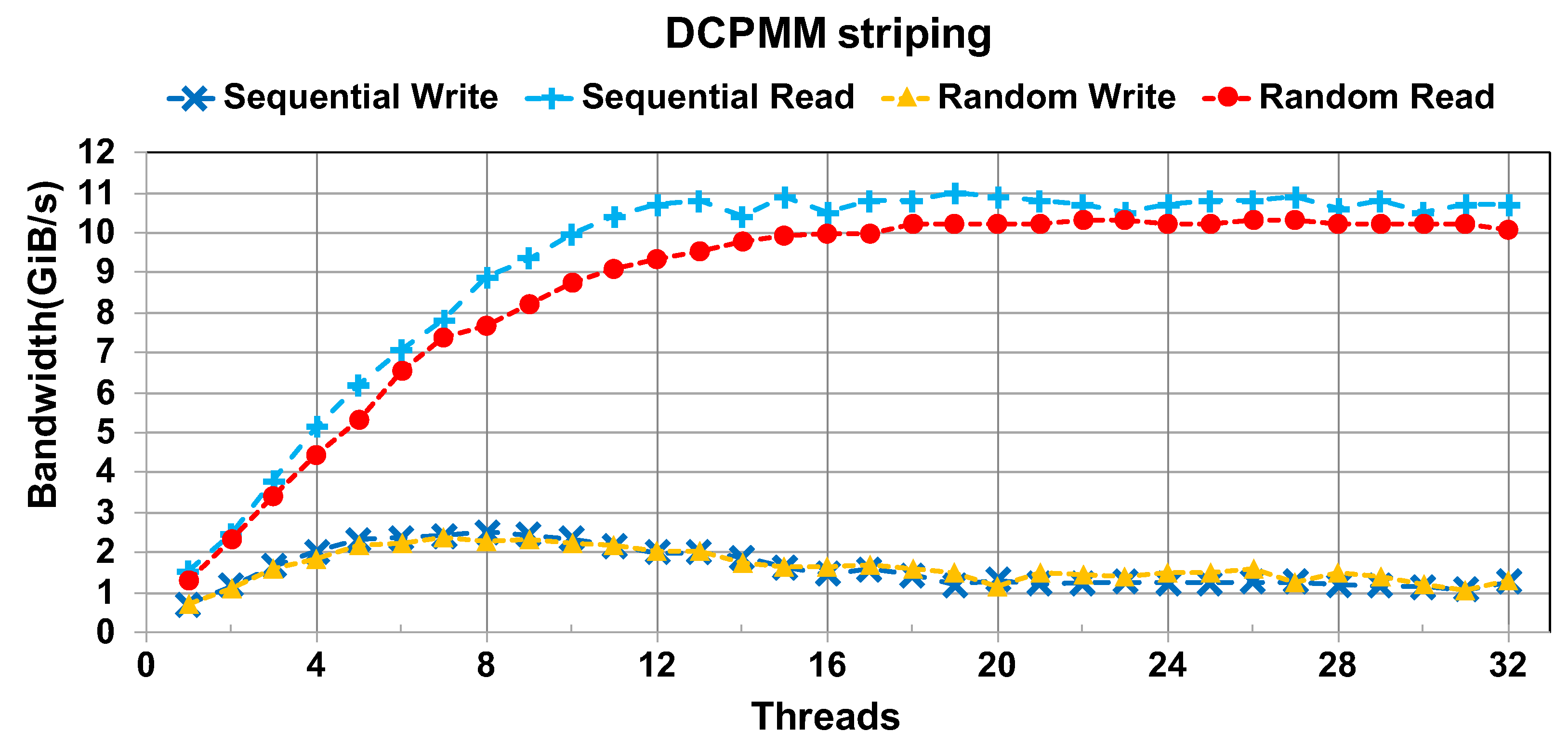
4.4. Remote Socket Stripping
4.5. Database on DCPMMs
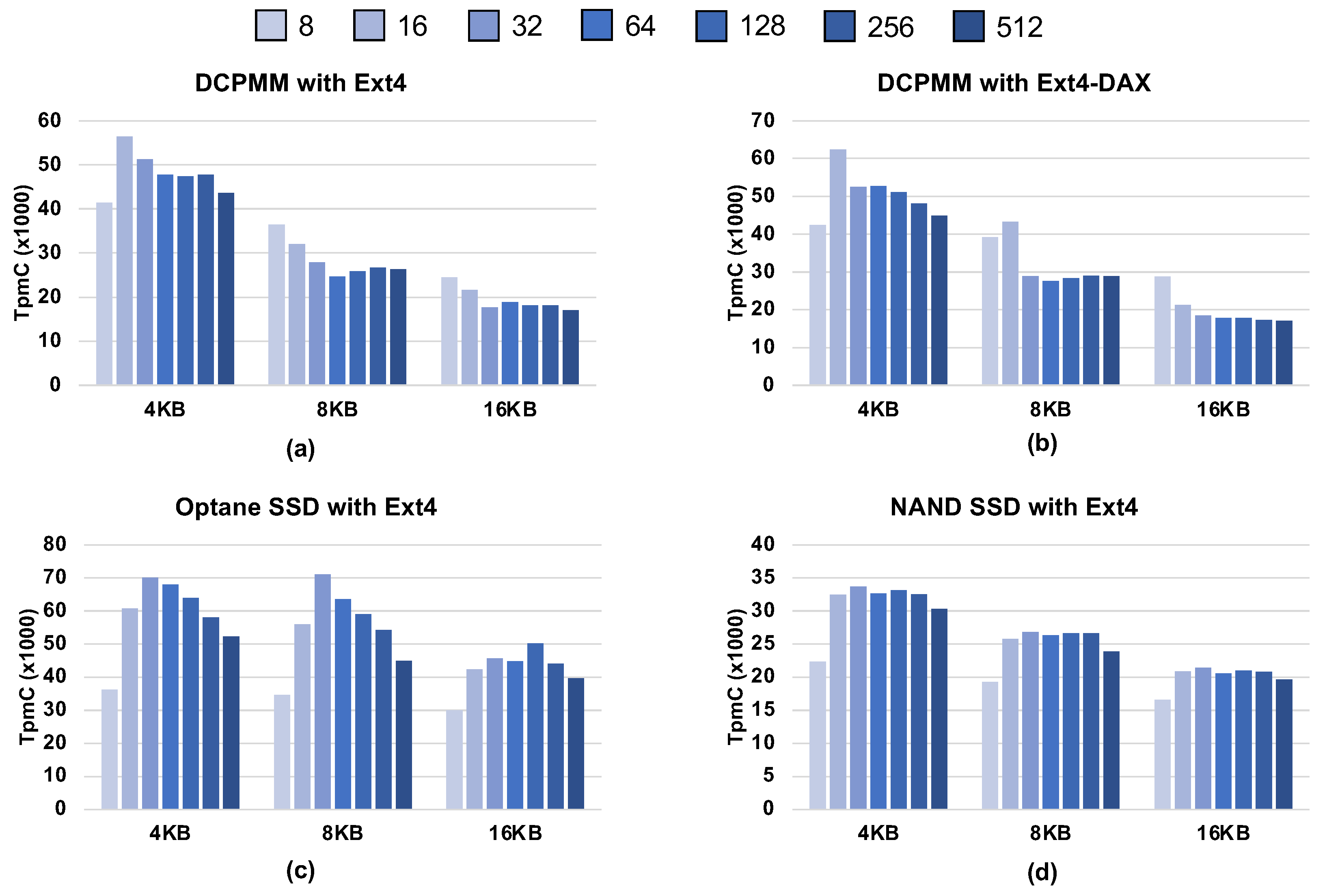
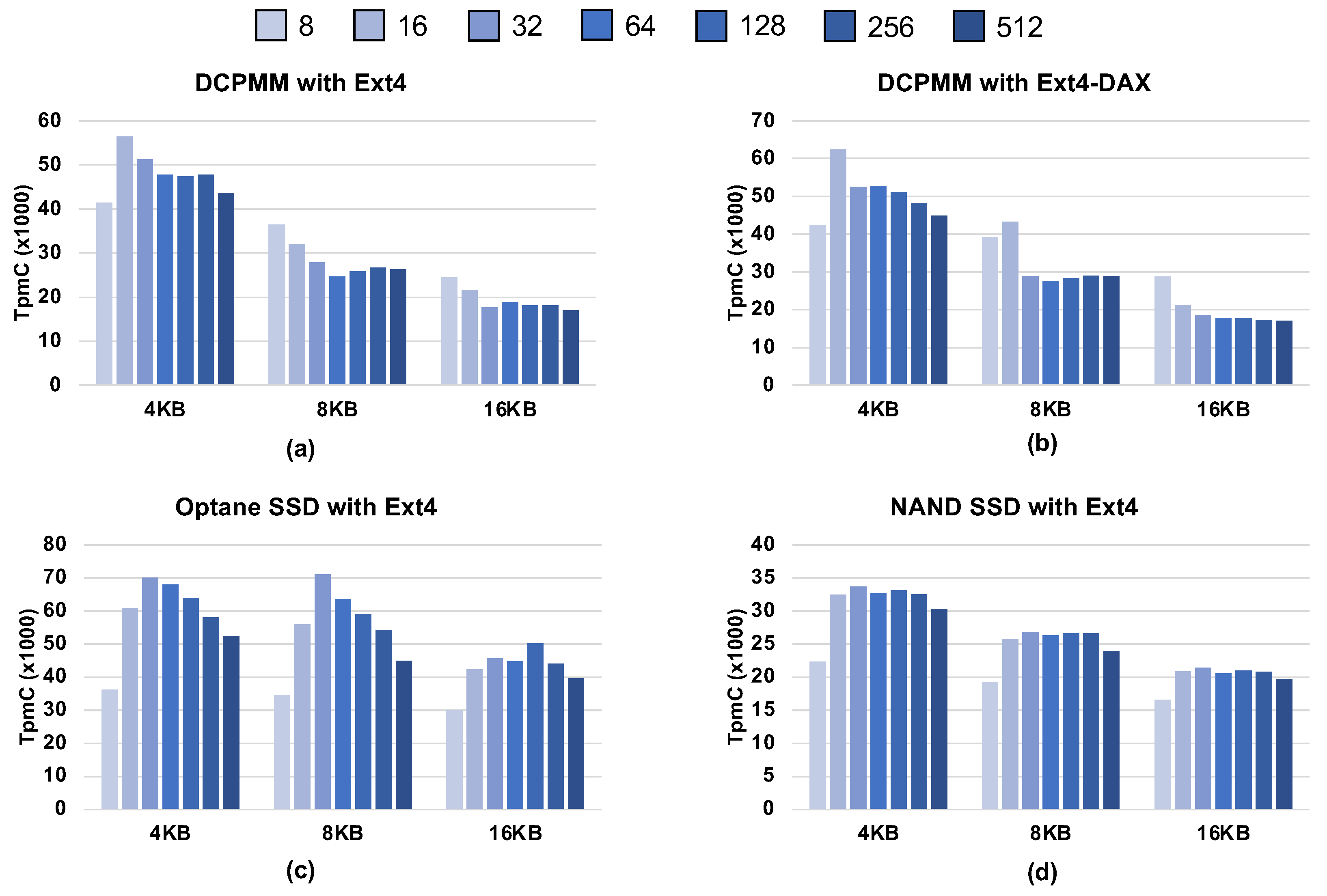
4.5.1. Effect of Page Sizes
4.5.2. Multiple Clients
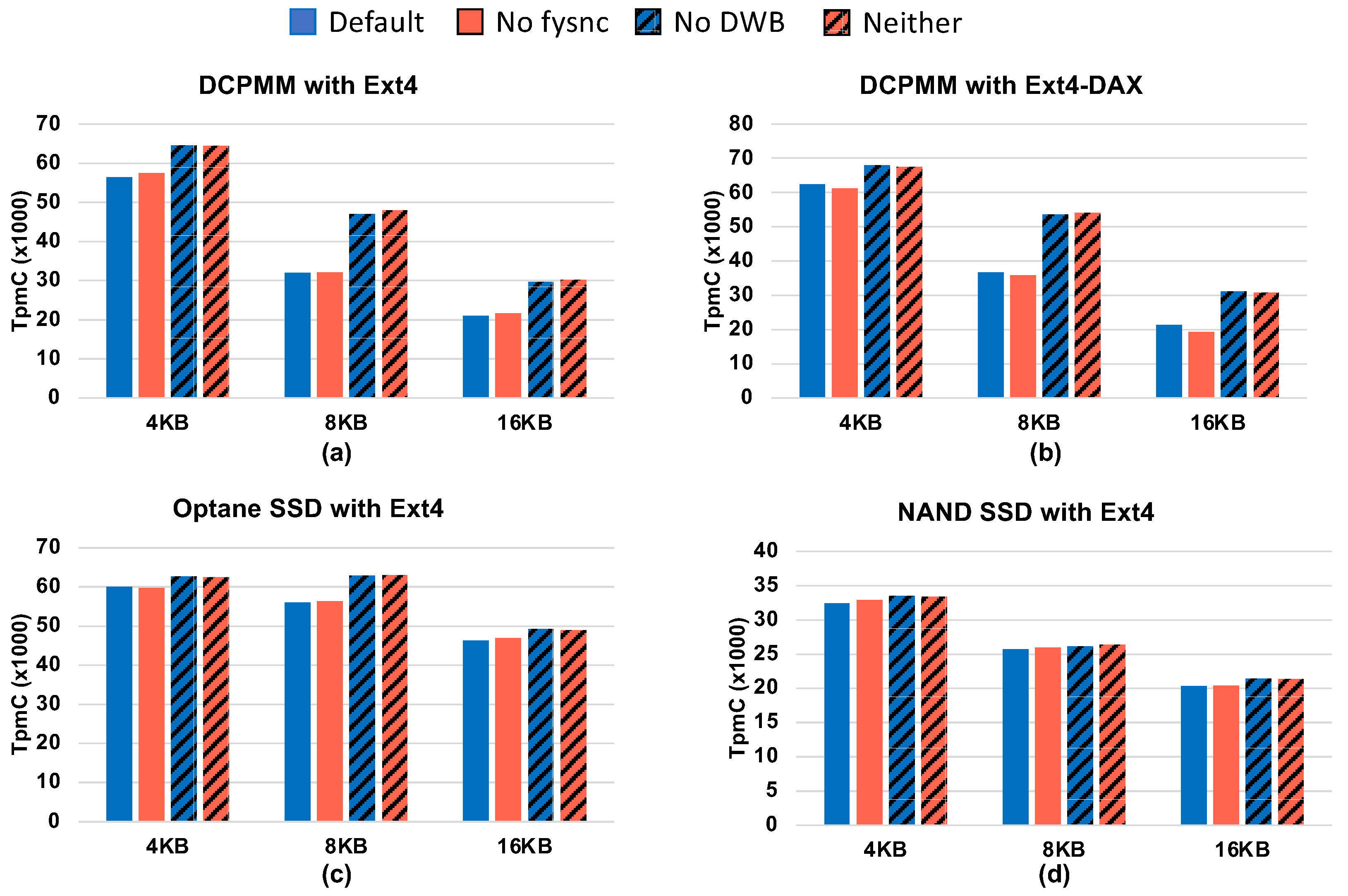
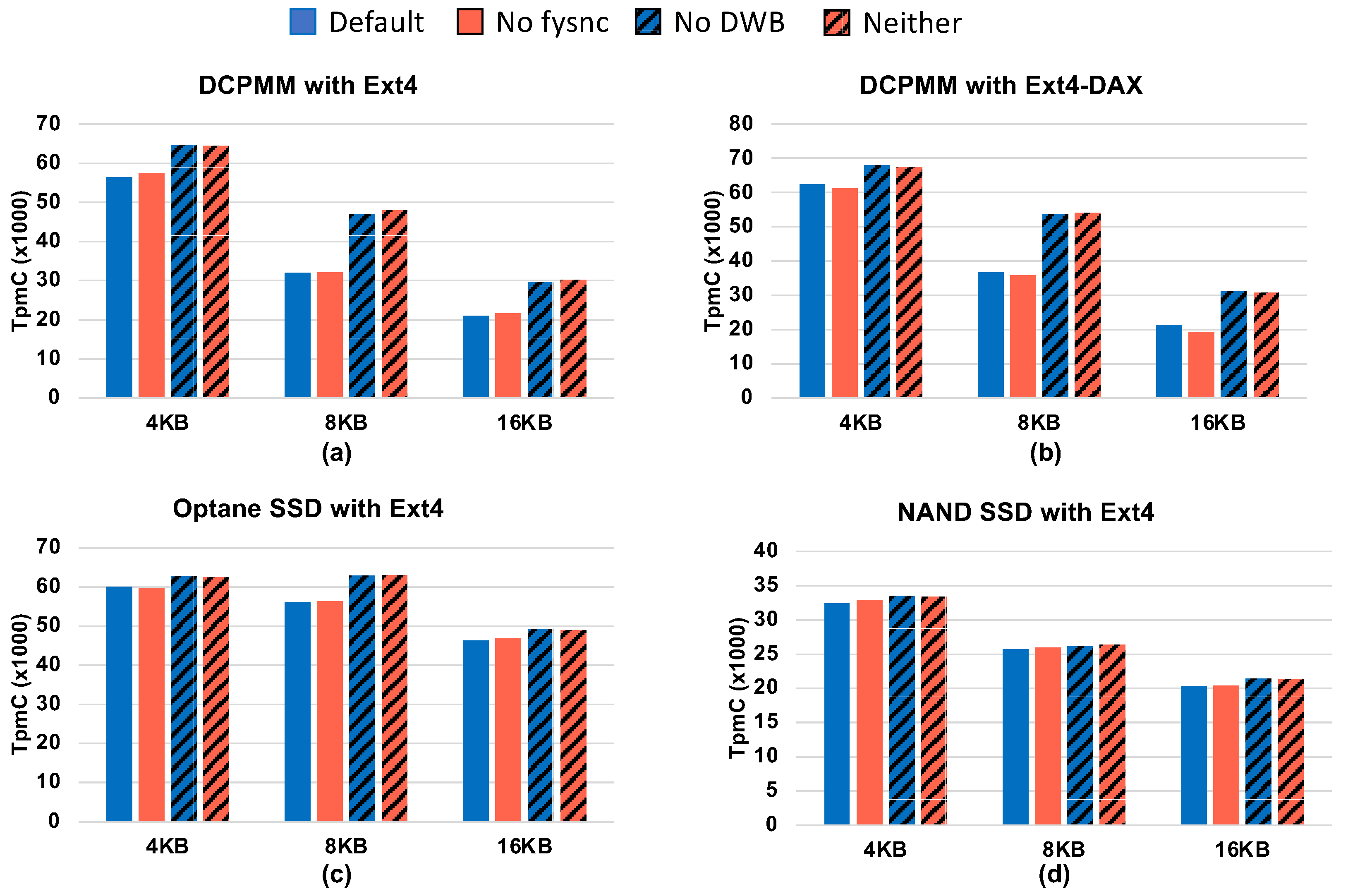
4.5.3. Consistency Techniques
4.5.4. Effect of Direct Access
5. Conclusions
- From the micro benchmark evaluation, we observed the following:
- Direct access has a significant improvement in the file system write performance but has a smaller impact on the read performance.
- A small number of threads is enough to saturate the write bandwidth of one DCPMM. In some situations, more threads may even degrade the performance.
- The read performance of DCPMMs is greatly superior to its write performance. Concurrent read access does not degrade the DCPMM read performance significantly.
- Accessing from remote sockets reduces the write performance of DCPMMs significantly, but has a small impact on the read performance.
- From the macro benchmark evaluation, we observed the following:
- 5.
- Page cache may provide better performance than DAX for read-intensive workloads.
- 6.
- A low overhead metadata management strategy is needed to fully utilize the potential of NVM devices.
- From the remote evaluation of socket stripping, we observed the following:
- 7.
- Under proper settings, organizing the DCPMMs distributed in different sockets can also bring out the full performance of the devices.
- From the evaluation of databases on DCPMMs, we observed the following:
- 8.
- DCPMM is better able to show its strengths from small size requests.
- 9.
- Even with the same APIs, we need to consider their different impact on normal block devices and NVM devices under different hardware platforms.
Author Contributions
Funding
Conflicts of Interest
References
- Kawahara, T. Scalable spin-transfer torque ram technology for normally-off computing. IEEE Des. Test Comput. 2010, 52–63. [Google Scholar] [CrossRef]
- Raoux, S.; Burr, G.W.; Breitwisch, M.J.; Rettner, C.T.; Chen, Y.C.; Shelby, R.M.; Salinga, M.; Krebs, D.; Chen, S.H.; Lung, H.L.; et al. Phase-change random access memory: A scalable technology. IBM J. Res. Dev. 2008, 52, 465–479. [Google Scholar] [CrossRef]
- Yang, Y.C.; Pan, F.; Liu, Q.; Liu, M.; Zeng, F. Fully room-temperature-fabricated nonvolatile resistive memory for ultrafast and high-density memory application. Nano Lett. 2009, 9, 1636–1643. [Google Scholar] [CrossRef] [PubMed]
- Handy, J. Understanding the intel/micron 3D XPoint memory. Proc. SDC 2015, 68. Available online: https://www.snia.org/sites/default/files/SDC15_presentations/persistant_mem/JimHandy_Understanding_the-Intel.pdf (accessed on 27 June 2021).
- Xue, C.J.; Zhang, Y.; Chen, Y.; Sun, G.; Yang, J.J.; Li, H. Emerging non-volatile memories: Opportunities and challenges. In Proceedings of the Seventh IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, Taipei, Taiwan, 9–14 October 2011; pp. 325–334. [Google Scholar]
- Chen, A. Emerging nonvolatile memory (NVM) technologies. In Proceedings of the 2015 45th European Solid State Device Research Conference (ESSDERC), Graz, Austria, 14–18 September 2015; pp. 109–113. [Google Scholar]
- Condit, J.; Nightingale, E.B.; Frost, C.; Ipek, E.; Lee, B.; Burger, D.; Coetzee, D. Better I/O through byte-addressable, persistent memory. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, Big Sky, Montana, 11–14 October 2009; pp. 133–146. [Google Scholar]
- Dulloor, S.R.; Kumar, S.; Keshavamurthy, A.; Lantz, P.; Reddy, D.; Sankaran, R.; Jackson, J. System software for persistent memory. In Proceedings of the Ninth European Conference on Computer Systems, Amsterdam, The Netherlands, 14–16 April 2014; pp. 1–15. [Google Scholar]
- Xu, J.; Swanson, S. {NOVA}: A log-structured file system for hybrid volatile/non-volatile main memories. In Proceedings of the 14th {USENIX} Conference on File and Storage Technologies ({FAST} 16), Santa Clara, CA, USA, 22–25 February 2016; pp. 323–338. [Google Scholar]
- Xu, J.; Zhang, L.; Memaripour, A.; Gangadharaiah, A.; Borase, A.; Da Silva, T.B.; Swanson, S.; Rudoff, A. NOVA-Fortis: A fault-tolerant non-volatile main memory file system. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 478–496. [Google Scholar]
- Intel. Intel® Optane™ DC Persistent Memory: A Major Advance in Memory and Storage Architecture. 2019. Available online: https://software.intel.com/content/www/us/en/develop/articles/intel-optane-dc-persistent-memory-a-major-advance-in-memory-and-storage-architecture.html (accessed on 13 August 2021).
- Intel® Optane™ SSD 900P Series. 2019. Available online: https://www.intel.com/content/www/us/en/products/details/memory-storage/consumer-ssds/optane-ssd-9-series.html (accessed on 15 August 2021).
- Zhu, G.; Han, J.; Lee, S.; Son, Y. An Empirical Evaluation of NVM-aware File Systems on Intel Optane DC Persistent Memory Modules. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Korea, 13–16 January 2021; pp. 559–564. [Google Scholar]
- Axboe, J. Fio-Flexible io Tester. 2014. Available online: http://freecode.com/projects/fio (accessed on 15 August 2021).
- Tarasov, V.; Zadok, E.; Shepler, S. Filebench: A flexible framework for file system benchmarking. USENIX Login 2016, 41, 6–12. [Google Scholar]
- Beeler, B. Intel Optane DC Persistent Memory Module (PMM). 2019. Available online: https://www.storagereview.com/news/intel-optane-dc-persistent-memory-module-pmm (accessed on 15 August 2021).
- Yang, J.; Kim, J.; Hoseinzadeh, M.; Izraelevitz, J.; Swanson, S. An empirical guide to the behavior and use of scalable persistent memory. In Proceedings of the 18th {USENIX} Conference on File and Storage Technologies ({FAST} 20), Santa Clara, CA, USA, 24–27 February 2020; pp. 169–182. [Google Scholar]
- Caulfield, A.M.; Mollov, T.I.; Eisner, L.A.; De, A.; Coburn, J.; Swanson, S. Providing safe, user space access to fast, solid state disks. ACM SIGPLAN Not. 2012, 47, 387–400. [Google Scholar] [CrossRef]
- Vučinić, D.; Wang, Q.; Guyot, C.; Mateescu, R.; Blagojević, F.; Franca-Neto, L.; Le Moal, D.; Bunker, T.; Xu, J.; Swanson, S.; et al. {DC} Express: Shortest Latency Protocol for Reading Phase Change Memory over {PCI} Express. In Proceedings of the 12th {USENIX} Conference on File and Storage Technologies ({FAST} 14), Santa Clara, CA, USA, 17–20 February 2014; pp. 309–315. [Google Scholar]
- Zhang, J.; Kwon, M.; Swift, M.; Jung, M. Scalable Parallel Flash Firmware for Many-core Architectures. In Proceedings of the 18th {USENIX} Conference on File and Storage Technologies ({FAST} 20), Santa Clara, CA, USA, 17–20 February 2020; pp. 121–136. [Google Scholar]
- Sweeney, A.; Doucette, D.; Hu, W.; Anderson, C.; Nishimoto, M.; Peck, G. Scalability in the XFS File System. In Proceedings of the USENIX Annual Technical Conference, San Diego, CA, USA, 22–26 January 1996; Volume 15. [Google Scholar]
- Wilcox, M. Add Support for NV-DIMMs to Ext4. 2014. Available online: https://lwn.net/Articles/613384 (accessed on 15 August 2021).
- Linux Kernel Documentation: Direct Access for Files. Available online: https://www.kernel.org/doc/Documentation/filesystems/dax.txt (accessed on 15 August 2021).
- Intel. Pmem.io: Using the Block Translation Table for Sector Atomicity. Available online: https://pmem.io/2014/09/23/btt.html (accessed on 15 August 2021).
- Yang, J.; Wei, Q.; Chen, C.; Wang, C.; Yong, K.L.; He, B. NV-Tree: Reducing consistency cost for NVM-based single level systems. In Proceedings of the 13th {USENIX} Conference on File and Storage Technologies ({FAST} 15), Santa Clara, CA, USA, 16–19 February 2015; pp. 167–181. [Google Scholar]
- Ma, T.; Zhang, M.; Chen, K.; Song, Z.; Wu, Y.; Qian, X. AsymNVM: An efficient framework for implementing persistent data structures on asymmetric NVM architecture. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 757–773. [Google Scholar]
- Peng, I.B.; Gioiosa, R.; Kestor, G.; Cicotti, P.; Laure, E.; Markidis, S. RTHMS: A tool for data placement on hybrid memory system. ACM SIGPLAN Not. 2017, 52, 82–91. [Google Scholar] [CrossRef]
- Dulloor, S.R.; Roy, A.; Zhao, Z.; Sundaram, N.; Satish, N.; Sankaran, R.; Jackson, J.; Schwan, K. Data tiering in heterogeneous memory systems. In Proceedings of the Eleventh European Conference on Computer Systems, London, UK, 18–21 April 2016; pp. 1–16. [Google Scholar]
- Weiland, M.; Brunst, H.; Quintino, T.; Johnson, N.; Iffrig, O.; Smart, S.; Herold, C.; Bonanni, A.; Jackson, A.; Parsons, M. An early evaluation of Intel’s optane DC persistent memory module and its impact on high-performance scientific applications. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, GA, USA, 17–19 November 2019; pp. 1–19. [Google Scholar]
- Götze, P.; Tharanatha, A.K.; Sattler, K.U. Data structure primitives on persistent memory: An evaluation. arXiv 2020, arXiv:2001.02172. [Google Scholar]
- Wu, K.; Arpaci-Dusseau, A.; Arpaci-Dusseau, R. Towards an Unwritten Contract of Intel Optane {SSD}. In Proceedings of the 11th {USENIX} Workshop on Hot Topics in Storage and File Systems (HotStorage 19), Renton, WA, USA, 8–9 July 2019. [Google Scholar]
- Son, Y.; Kang, H.; Han, H.; Yeom, H.Y. An empirical evaluation and analysis of the performance of NVM express solid state drive. Clust. Comput. 2016, 19, 1541–1553. [Google Scholar] [CrossRef]
- Xu, Q.; Siyamwala, H.; Ghosh, M.; Suri, T.; Awasthi, M.; Guz, Z.; Shayesteh, A.; Balakrishnan, V. Performance analysis of NVMe SSDs and their implication on real world databases. In Proceedings of the 8th ACM International Systems and Storage Conference, Haifa, Israel, 26–28 May 2015; pp. 1–11. [Google Scholar]
- Lee, C.; Sim, D.; Hwang, J.; Cho, S. F2FS: A new file system for flash storage. In Proceedings of the 13th {USENIX} Conference on File and Storage Technologies ({FAST} 15), Santa Clara, CA, USA, 16–19 February 2015; pp. 273–286. [Google Scholar]
- Percona-Lab. Tpcc-Mysql. Available online: https://github.com/Percona-Lab/tpcc-mysql (accessed on 15 June 2021).
- MySQL. Available online: https://www.mysql.com (accessed on 15 June 2021).
- Intel. Intel Optane Persistent Memory Product Brief. Available online: https://www.intel.com/content/www/us/en/products/docs/memory-storage/optane-persistent-memory/optane-dc-persistent-memory-brief.html (accessed on 15 August 2021).
- Chen, C.; Yang, J.; Wei, Q.; Wang, C.; Xue, M. Optimizing file systems with fine-grained metadata journaling on byte-addressable NVM. ACM Trans. Storage TOS 2017, 13, 1–25. [Google Scholar] [CrossRef]
- Intel. Pmem.io: Using Persistent Memory Devices with the Linux Device Mapper. Available online: https://pmem.io/2018/05/15/usingpersistentmemorydeviceswiththelinuxdevicemapper.html (accessed on 15 August 2021).
- Leutenegger, S.; Dias, D. A modeling study of the TPC-C benchmark. In Proceedings of the SIGMOD ’93, New York, NY, USA, 25–28 May 1993. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processor | Intel Xeon Gold 6242 Processor |
| Cores | 16 cores × 4 sockets (hyper-threading disabled) |
| Memory Controller | 2 iMCs × 3 channels × 2 sockets |
| NVM | 128 GB Optane DC Persistent Memory Module × 2 |
| Optane SSD | 480 GB Intel Optane SSD 900P |
| NAND-flash SSD | 3.2 TB Intel SSD DC P4610 |
| DRAM | 16 GB 2933 MHz DDR4 × per CPU socket |
| Operating System | Ubuntu 20.04 LTS with Linux kernel 5.1.0 |
| Database System | MySQL InnoDB 8.0.25 |
| Fileserver | Varmail | Webserver | Webproxy | |
|---|---|---|---|---|
| # of files | 500 K | 1 M | 500 K | 1 M |
| meandirwidth | 20 | 1 M | 20 | 1 M |
| average file size | 128 K | 32 K | 64 K | 32 K |
| # of thread | 16 | 16 | 16 | 16 |
| R/W Ratio | 1:2 | 1:1 | 10:1 | 5:1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, G.; Han, J.; Lee, S.; Son, Y. An Empirical Evaluation of NVM-Aware File Systems on Intel Optane DC Persistent Memory Modules. Electronics 2021, 10, 1977. https://doi.org/10.3390/electronics10161977
Zhu G, Han J, Lee S, Son Y. An Empirical Evaluation of NVM-Aware File Systems on Intel Optane DC Persistent Memory Modules. Electronics. 2021; 10(16):1977. https://doi.org/10.3390/electronics10161977
Chicago/Turabian StyleZhu, Guangyu, Jaehyun Han, Sangjin Lee, and Yongseok Son. 2021. "An Empirical Evaluation of NVM-Aware File Systems on Intel Optane DC Persistent Memory Modules" Electronics 10, no. 16: 1977. https://doi.org/10.3390/electronics10161977
APA StyleZhu, G., Han, J., Lee, S., & Son, Y. (2021). An Empirical Evaluation of NVM-Aware File Systems on Intel Optane DC Persistent Memory Modules. Electronics, 10(16), 1977. https://doi.org/10.3390/electronics10161977