
Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing



Abstract
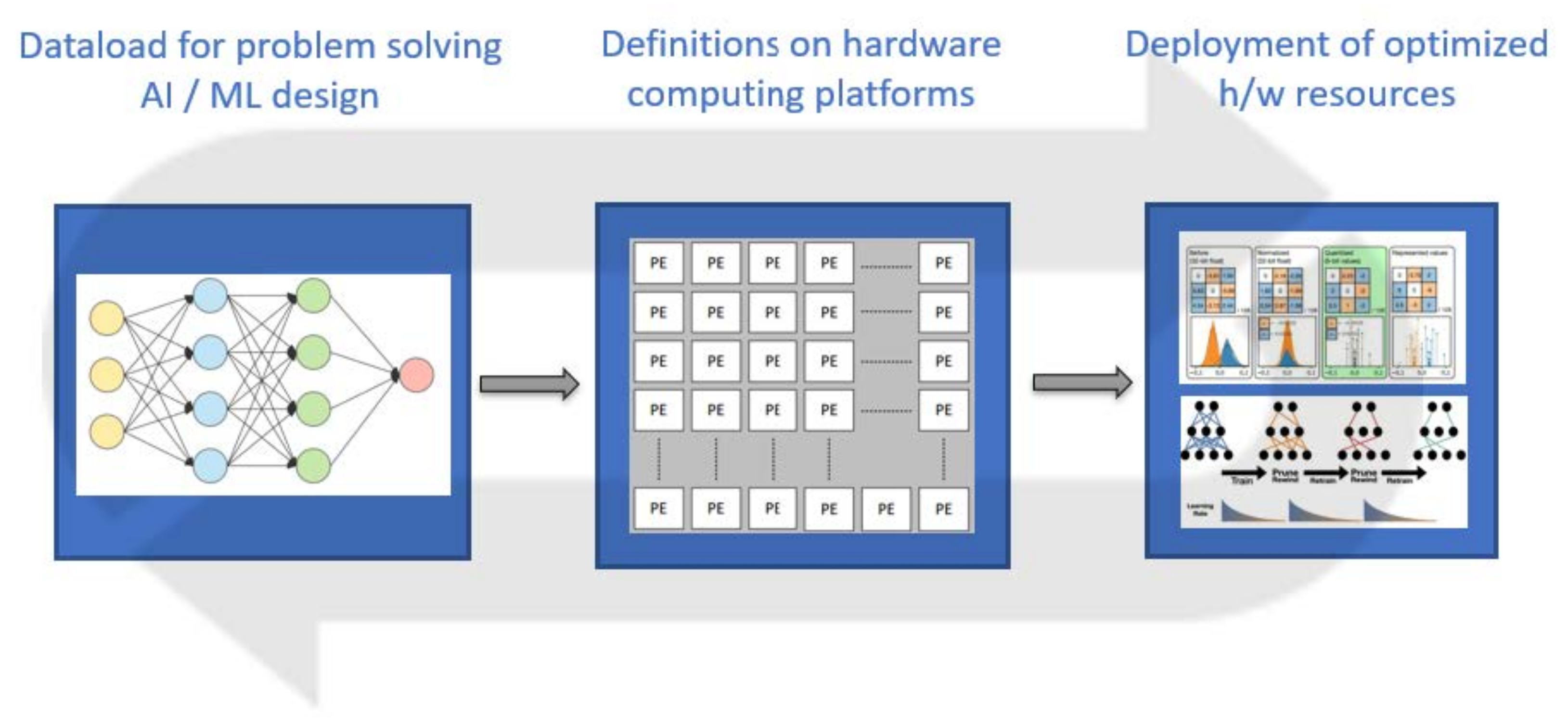
:1. Introduction
- First, the relationship to dataload that the AI/ML design will be processing is defined. The data are almost everything for deep learning and the best choices of the required resources are made when data have good quality. The selected dataload should be representing the data that the AI/ML design will confront when it is implemented, otherwise it will be flawed.
- Second comes the selection of the AI/ML design architecture as modeled in high level and the design constraints are defined. There are reasons to select between a very flexible FPGA implementation or an ASIC deployment for the purpose of the AI/ML design execution.
- Last but not least, the optimization and verification of the hardware design is discussed, with quantization, power consumption and area being the most important parts.
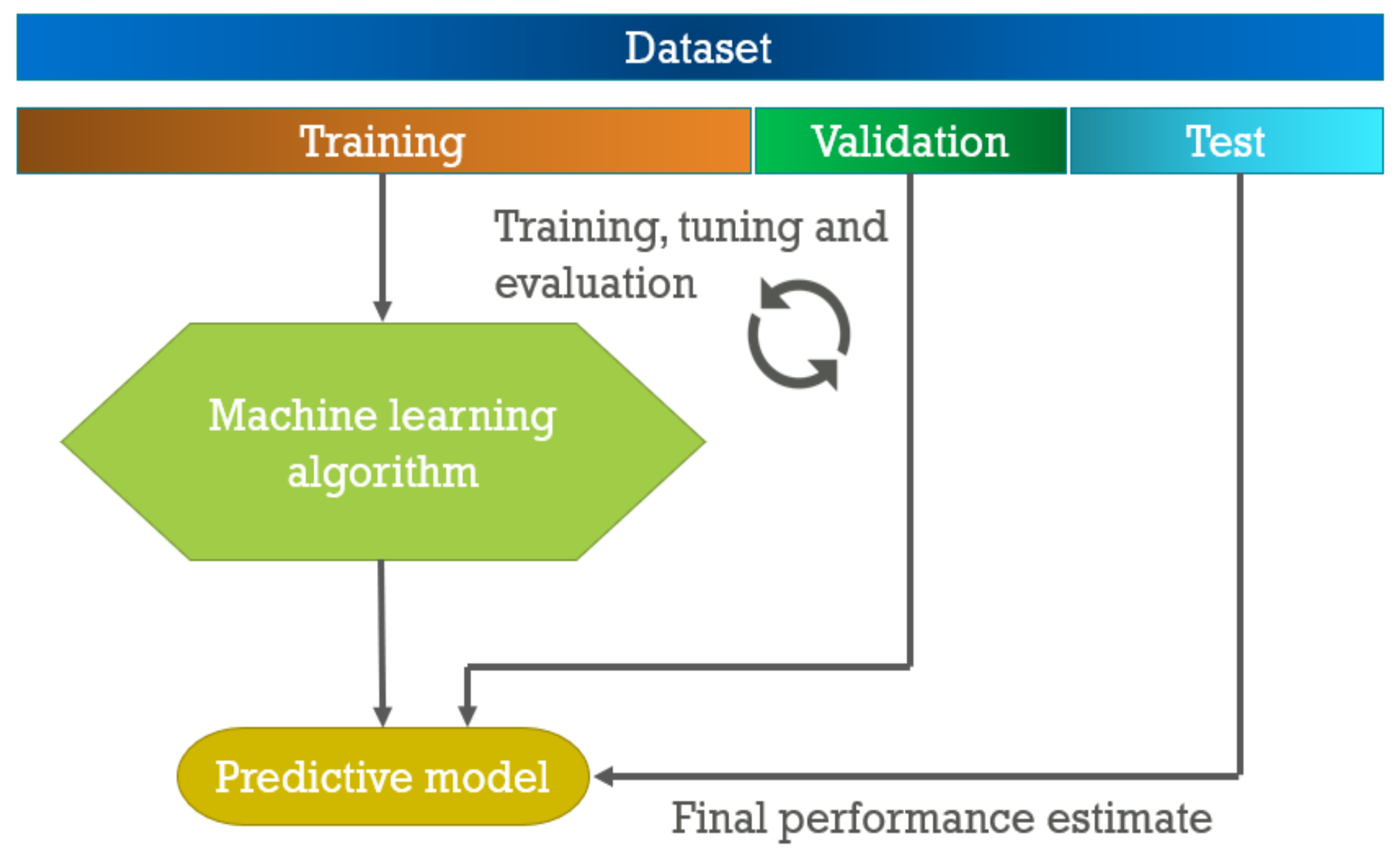
2. Dataload for Problem Solving
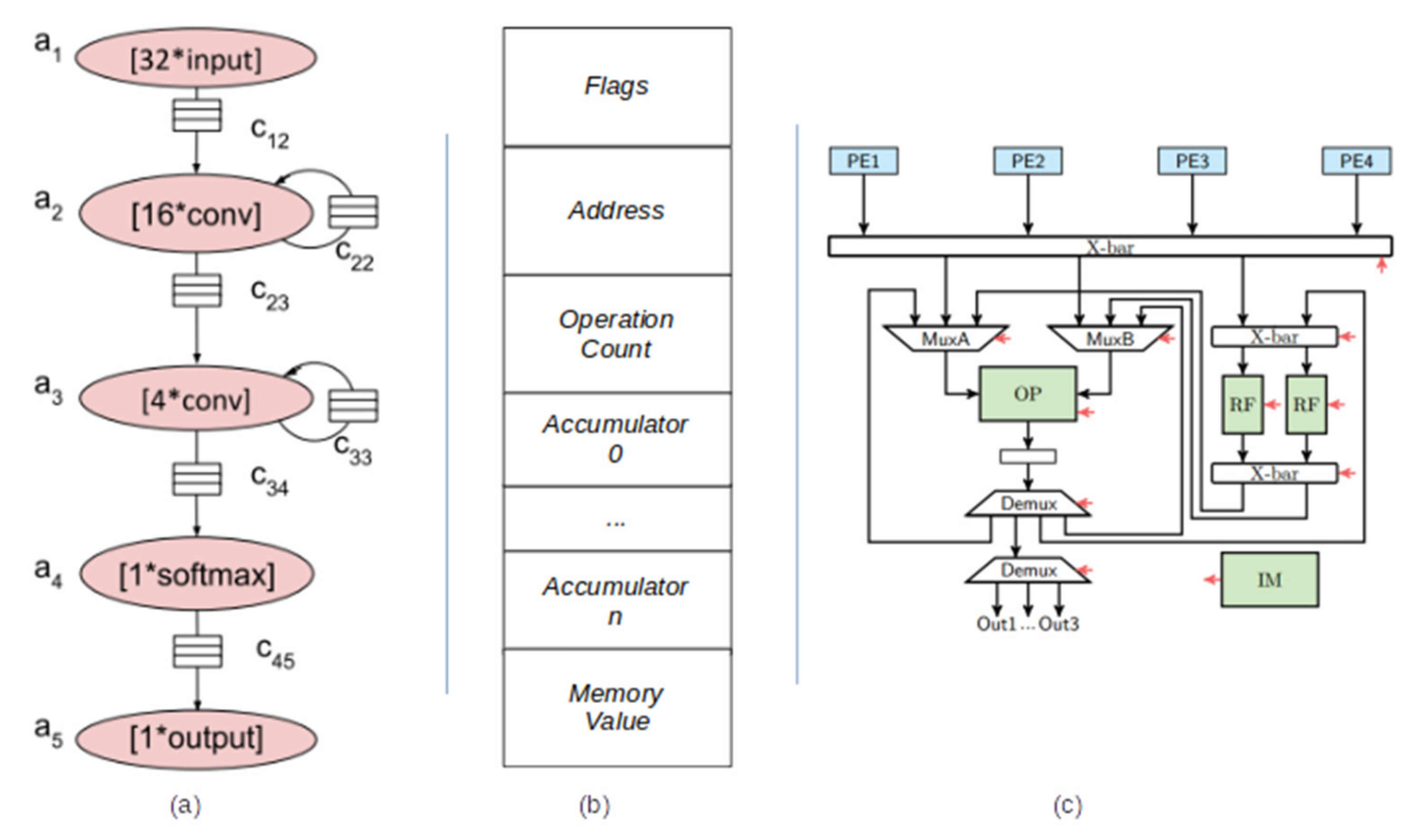
3. Definitions on Hardware Computing Platforms
3.1. FPGA-Based Accelerators
3.2. GPU-Based Accelerators
3.3. ASIC-Based Accelerators
4. Deployment of Optimized h/w Resources
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Farabet, C.; Poulet, C.; Han, J.Y.; LeCun, Y. CNP: An FPGA-based processor for Convolutional Networks. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 32–37. [Google Scholar]
- Sankaradas, M.; Jakkula, V.; Cadambi, S.; Chakradhar, S.; Durdanovic, I.; Cosatto, E.; Graf, H.P. A Massively Parallel Coprocessor for Convolutional Neural Networks. In Proceedings of the 2009 20th IEEE International Conference on Application-Specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009; pp. 53–60. [Google Scholar]
- Abu Talib, M.; Majzoub, S.; Nasir, Q.; Jamal, D. A systematic literature review on hardware implementation of artificial intelligence algorithms. J. Supercomput. 2021, 77, 1897–1938. [Google Scholar] [CrossRef]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. A Survey of FPGA Based Neural Network Accelerator. arXiv 2017, arXiv:1712.08934. [Google Scholar]
- Seng, K.; Lee, P.; Ang, L. Embedded Intelligence on FPGA: Survey, Applications and Challenges. Electronics 2021, 10, 895. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Y.; Wang, J.; Lai, J. A survey of FPGA design for AI era. J. Semicond. 2020, 41, 021402. [Google Scholar] [CrossRef]
- Capra, M.; Bussolino, B.; Marchisio, A.; Shafique, M.; Masera, G.; Martina, M. An Updated Survey of Efficient Hardware Architectures for Accelerating Deep Convolutional Neural Networks. Future Internet 2020, 12, 113. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Diniz, W.F.; Fremont, V.; Fantoni, I.; Nóbrega, E.G. An FPGA-based architecture for embedded systems performance acceleration applied to Optimum-Path Forest classifier. Microprocess. Microsyst. 2017, 52, 261–271. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; An, F.; Yu, H. A 307-fps 351.7-GOPs/W Deep Learning FPGA Accelerator for Real-Time Scene Text Recognition. In Proceedings of the 2019 International Conference on Field-Programmable Technology, Tianjin, China, 9–13 December 2019; pp. 263–266. [Google Scholar]
- Rankin, D.; Krupa, J.; Harris, P.; Flechas, M.A.; Holzman, B.; Klijnsma, T.; Pedro, K.; Tran, N.; Hauck, S.; Hsu, S.-C.; et al. FPGAs-as-a-Service Toolkit. In Proceedings of the 2020 IEEE/ACM International Workshop on Heterogeneous High-Performance Reconfigurable Computing (H2RC), Atlanta, GA, USA, 13 November 2020. [Google Scholar]
- Moolchandani, D.; Kumar, A.; Sarangi, S.R. Accelerating CNN Inference on ASICs: A Survey. J. Syst. Arch. 2021, 113, 101887. [Google Scholar] [CrossRef]
- Reuther, A.; Michaleas, P.; Jones, M.; Gadepally, V.; Samsi, S.; Kepner, J. Survey of Machine Learning Accelerators. In Proceedings of the 2020 IEEE High Performance Extreme Computing Conference (HPEC), Boston, MA, USA, 22–24 September 2020; pp. 1–12. [Google Scholar]
- Cavigelli, L.; Gschwend, D.; Mayer, C.; Willi, S.; Muheim, B.; Benini, L. Origami: A convolutional network accelerator. In Proceedings of the Great Lakes Symposium on VLSI, Pittsburgh, PA, USA, 20–22 May 2015; pp. 199–204. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. An energy-efficient reconfigurable accelerator for deep convolutional neural networks. In Proceedings of the 2016 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 31 January–4 February 2016; pp. 262–263. [Google Scholar]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 14–26. [Google Scholar]
- Andri, R.; Cavigelli, L.; Rossi, D.; Benini, L. YodaNN: An Ultra-Low Power Convolutional Neural Network Accelerator Based on Binary Weights. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburg, PA, USA, 11–13 July 2016; pp. 236–241. [Google Scholar]
- Gokmen, T.; Vlasov, Y. Acceleration of Deep Neural Network Training with Resistive Cross-Point Devices: Design Considerations. Front. Neurosci. 2016, 10, 333. [Google Scholar] [CrossRef] [Green Version]
- Ketkar, N. Introduction to PyTorch. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 195–208. [Google Scholar] [CrossRef]
- Goldsborough, P. A Tour of TensorFlow. arXiv 2016, arXiv:1610.01178. [Google Scholar]
- Abadi, M.; Isard, M.; Murray, D.G. A computational model for TensorFlow: An introduction. In Proceedings of the 1st ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, Barcelona, Spain, 18 June 2017; pp. 1–7. [Google Scholar]
- David, R.; Duke, J.; Jain, A.; Reddi, V.J.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Regev, S.; et al. Tensorflow lite micro: Embedded machine learning on tinyml systems. arXiv 2020, arXiv:2010.08678. [Google Scholar]
- Demosthenous, G.; Vassiliades, V. Continual Learning on the Edge with TensorFlow Lite. arXiv 2021, arXiv:2105.01946. [Google Scholar]
- Marchisio, A.; Hanif, M.A.; Khalid, F.; Plastiras, G.; Kyrkou, C.; Theocharides, T.; Shafique, M. Deep Learning for Edge Computing: Current Trends, Cross-Layer Optimizations, and Open Research Challenges. In Proceedings of the 2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Miami, FL, USA, 15–17 July 2019; pp. 553–559. [Google Scholar]
- Awan, A.A.; Subramoni, H.; Panda, D.K. An In-depth Performance Characterization of CPU- and GPU-based DNN Training on Modern Architectures. In Proceedings of the Machine Learning on HPC Environments, Denver, CO, USA, 13 November 2017; p. 8. [Google Scholar]
- Chen, X.; Chen, D.Z.; Hu, X.S. moDNN: Memory optimal DNN training on GPUs. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresded, Germany, 19–23 March 2018. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Jayalakshmi, T.; Santhakumaran, A. Statistical normalization and back propagation for classification. Int. J. Comput. Theory Eng. 2011, 3, 1793–8201. [Google Scholar]
- Bhanja, S.; Das, A. Impact of data normalization on deep neural network for time series forecasting. arXiv 2018, arXiv:1812.05519. [Google Scholar]
- Koval, S.I. Data Preparation for Neural Network Data Analysis. In Proceedings of the IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), St. Petersburg, Russia, 29 January–1 February 2018. [Google Scholar]
- Bernard, J. Python Data Analysis with Pandas. In Python Recipes Handbook; Apress: New York, NY, USA, 2016; pp. 37–48. [Google Scholar]
- Stancin, I.; Jovic, A. An overview and comparison of free Python libraries for data mining and big data analysis. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 977–982. [Google Scholar]
- Katsiapis, K.; Karmarkar, A.; Altay, A.; Zaks, A.; Polyzotis, N.; Ramesh, A.; Mathes, B.; Vasudevan, G.; Giannoumis, I.; Wilkiewicz, J.; et al. Towards ML Engineering: A Brief History of TensorFlow Extended (TFX). arXiv 2020, arXiv:2010.02013. [Google Scholar]
- Scheffer, T.; Joachims, T. Expected Error Analysis for Model Selection. In Proceedings of the International Conference on Machine Learning (ICML), Bled, Slovenia, 27–30 June 1999. [Google Scholar]
- Roelofs, R.; Fridovich-Keil, S.; Miller, J.; Shankar, V.; Hardt, M.; Recht, B.; Schmidt, L. A Meta-Analysis of Overfitting in Machine Learning. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Aderson, M.R.; Cafarella, M. Input selection for fast feature engineering. In Proceedings of the IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Kukačka, J.; Golkov, V.; Cremers, D. Regularization for Deep Learning: A Taxonomy. arXiv 2017, arXiv:1710.10686. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Benz, P.; Zhang, C.; Karjauv, A.; Kweon, I.S. Revisiting Batch Normalization for Improving Corruption Robustness. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Hawaii, HI, USA, 4–8 January 2021; pp. 494–503. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Zamir, A.R.; Sax, A.; Shen, W.; Guibas, L.J.; Malik, J.; Savarese, S. Taskonomy: Disentangling task transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 3712–3722. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5574–5584. [Google Scholar]
- Zhang, Z.; Xu, C.; Yang, J.; Tai, Y.; Chen, L. Deep hierarchical guidance and regularization learning for end-to-end depth estimation. Pattern Recognit. 2018, 83, 430–442. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yang, M.; Wang, H. Differential learning: A powerful tool for interactive content-based image retrieval. Eng. Lett. 2019, 27, 202–215. [Google Scholar]
- Kobayashi, T. Flip-invariant motion representation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5628–5637. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, H.; Wen, J. Dynamic feature selection method with minimum redundancy information for linear data. Appl. Intell. 2020, 50, 3660–3677. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Tian, X.; Jiang, N.; Wang, D. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discret. Dyn. Nat. Soc. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-Based Accelerators of Deep Learning Networks for Learning and Classification: A Review. IEEE Access 2019, 7, 7823–7859. [Google Scholar] [CrossRef]
- Hao, C.; Chen, Y.; Zhang, X.; Li, Y.; Xiong, J.; Hwu, W.; Chen, D. Effective Algorithm-Accelerator Co-design for AI Solutions on Edge Devices. In Proceedings of the 2020 on Great Lakes Symposium on VLSI (GLSVLSI ’20), Online, 7–9 September; pp. 283–290. [CrossRef]
- Putnam, A.; Caulfield, A.M.; Chung, E.S.; Chiou, D.; Constantinides, K.; Demme, J.; Esmaeilzadeh, H.; Fowers, J.; Gopal, G.P.; Gray, J.; et al. A reconfigurable fabric for accelerating large-scale datacenter services. Commun. ACM 2016, 59, 114–122. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’15), Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar] [CrossRef]
- Tridgell, S. Low Latency Machine Learning on FPGAs. Ph.D. Thesis, University of Sydney, Sydney, Australia, 2020. [Google Scholar]
- Kim, Y.; Kim, H.; Yadav, N.; Li, S.; Choi, K.K. Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics 2020, 9, 478. [Google Scholar] [CrossRef] [Green Version]
- Li, S. Towards Efficient Hardware Acceleration of Deep Neural Networks on FPGA. Ph.D. Thesis, University of Pittsburg, Pittsburg, PA, USA, 2018. [Google Scholar]
- Samal, K. FPGA Acceleration of CNN Training. Master’s Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2018. [Google Scholar]
- Pitsis, A. Design and Implementation of an FPGA-Based Convolutional Neural Network Accelerator. Diploma Thesis, Technical University of Crete, Crete, Greece, 2018. [Google Scholar]
- Su, C.; Zhou, S.; Feng, L.; Zhang, W. Towards high performance low bitwidth training for deep neural networks. J. Semicond. 2020, 41, 022404. [Google Scholar] [CrossRef]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 525–542. [Google Scholar]
- Minakova, S.; Stefanov, T. Buffer Sizes Reduction for Memory-efficient CNN Inference on Mobile and Embedded Devices. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Kranj, Slovenia, 26–28 August 2020; pp. 133–140. [Google Scholar]
- Bilsen, G.; Engels, M.; Lauwereins, R.; Peperstraete, J. Cyclo-static dataflow. IEEE Trans. Signal Process. 1996, 44, 397–408. [Google Scholar] [CrossRef]
- Benes, T.; Kekely, M.; Hynek, K.; Cejka, T. Pipelined ALU for effective external memory access in FPGA. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Portoroz, Slovenia, 26–28 August 2020; pp. 97–100. [Google Scholar]
- Stramondo, G.; Gomony, M.D.; Kozicki, B.; De Laat, C.; Varbanescu, A.L. μ-Genie: A Framework for Memory-Aware Spatial Processor Architecture Co-Design Exploration. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Portoroz, Slovenia, 26–28 August 2020; pp. 180–184. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Sérot, J.; Bourrasset, C.; Berry, F. Tactics to Directly Map CNN Graphs on Embedded FPGAs. IEEE Embed. Syst. Lett. 2017, 9, 113–116. [Google Scholar] [CrossRef] [Green Version]
- Duarte, J.M.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 2018, 13, P07027. [Google Scholar] [CrossRef]
- Fahim, F.; Hawks, B.; Herwig, C.; Hirschauer, J.; Jindariani, S.; Tran, N.; Carloni, L.P.; Di Guglielmo, G.; Harris, P.; Krupa, J.; et al. hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices. arXiv 2021, arXiv:2103.05579. [Google Scholar]
- Venieris, S.I.; Bouganis, C.S. fpgaConvNet: A framework for mapping convolutional neural networks on FPGAs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar]
- Ghaffari, A.; Savaria, Y. CNN2Gate: An Implementation of Convolutional Neural Networks Inference on FPGAs with Automated Design Space Exploration. Electronics 2020, 9, 2200. [Google Scholar] [CrossRef]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’17), Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar] [CrossRef] [Green Version]
- Vitis AI. Xilinx Viti AI. Available online: https://www.xilinx.com/products/design-tools/vitis/vitis-ai.html (accessed on 10 January 2021).
- Rupanetti, D.; Nepal, K.; Salamy, H.; Min, C. Cost-Effective, Re-Configurable Cluster Approach for Resource Constricted FPGA Based Machine Learning and AI Applications. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0228–0233. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kim, J.K.; Shao, C.; Mishra, A.; Esmaeilzadeh, H. From high-level deep neural models to FPGAs. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar]
- Che, S.; Li, J.; Sheaffer, J.W. Accelerating Compute-Intensive Applications with GPUs and FPGAs. In Proceedings of the Symposium on Application Specific Processors, Anaheim, CA, USA, 8–9 June 2008; pp. 101–107. [Google Scholar] [CrossRef]
- NVIDIA. Cuda-Zone. Available online: https://developer.nvidia.com/cuda-zone (accessed on 22 January 2021).
- Nvidia Corporation. TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 22 January 2021).
- Song, M.; Hu, Y.; Chen, H.; Li, T. Towards Pervasive and User Satisfactory CNN across GPU Microarchitectures. In Proceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Van Essen, B.; Macaraeg, C.; Gokhale, M.; Prenger, R. Accelerating a Random Forest Classifier: Multi-Core, GP-GPU, or FPGA? In Proceedings of the IEEE 20th International Symposium on Field-Programmable Custom Computing Machines, Toronto, ON, CA, 9–12 May 2012; pp. 232–239. [Google Scholar] [CrossRef] [Green Version]
- Czarnul, P.; Proficz, J.; Krzywaniak, A. Energy-Aware High-Performance Computing: Survey of State-of-the-Art Tools, Techniques, and Environments. Sci. Program. 2019, 2019, 8348791. [Google Scholar] [CrossRef] [Green Version]
- Price, D.C.; Clark, M.A.; Barsdell, B.R.; Babich, R.; Greenhill, L.J. Optimizing performance-per-watt on GPUs in high performance computing. Comput. Sci. Res. Dev. 2016, 31, 185–193. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhang, G.; Huang, H.H.; Wang, Z.; Zheng, W. Zheng Performance Analysis of GPU-Based Convolutional Neural Networks. In Proceedings of the 45th International Conference on Parallel Processing (ICPP), Philadelphia, PA, USA, 16–19 August 2016; pp. 67–76. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Becchi, M.; Zong, Z. Evaluating the Energy Efficiency of Deep Convolutional Neural Networks on CPUs and GPUs. In Proceedings of the IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom), Atlanta, GA, USA, 8–10 October 2016; pp. 477–484. [Google Scholar] [CrossRef]
- cuda-convnet2. Available online: https://github.com/akrizhevsky/cuda-convnet2 (accessed on 22 June 2021).
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cudnn: Efficient primitives for deep learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Deep Learning with OpenCV DNN Module. Available online: https://learnopencv.com/deep-learning-with-opencvs-dnn-module-a-definitive-guide/ (accessed on 22 June 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th (USENIX) Symposium on Operating Systems Design and Implementation (OSDI ‘16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Huynh, L.N.; Balan, R.K.; Lee, Y. DeepSense: A GPU-based Deep Convolutional Neural Network Framework on Commodity Mobile Devices. In Proceedings of the 2016 Workshop on Wearable Systems and Applications. Association for Computing Machinery, Singapore, 30 June 2016; pp. 25–30. [Google Scholar] [CrossRef]
- Wang, E.; Davis, J.J.; Zhao, R.; Ng, H.-C.; Niu, X.; Luk, W.; Cheung, P.Y.K.; Constantinides, G.A. Deep Neural Network Approximation for Custom Hardware. ACM Comput. Surv. 2019, 52, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Misra, J.; Saha, I. Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255. [Google Scholar] [CrossRef]
- Fischer, M.; Wassner, J. BinArray: A Scalable Hardware Accelerator for Binary Approximated CNNs. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Online, 27–30 January 2021; pp. 0197–0205. [Google Scholar]
- Mao, W.; Xiao, Z.; Xu, P.; Ren, H.; Liu, D.; Zhao, S.; An, F.; Yu, H. Energy-Efficient Machine Learning Accelerator for Binary Neural Networks. In Proceedings of the 2020 on Great Lakes Symposium on VLSI, New York, NY, USA, 8–11 September 2020. [Google Scholar]
- Véstias, M. Processing Systems for Deep Learning Inference on Edge Devices. In Smart Sensors, Measurement and Instrumentation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–240. [Google Scholar]
- Nascimento, D.V.; Xavier-de-Souza, S. An OpenMP translator for the GAP8 MPSoC. arXiv 2020, arXiv:2007.10219. [Google Scholar]
- Demler, M. Brainchip Akida Is a Fast Learne. In Microprocessor Report; The Linley Group: Mountain View, CA, USA, 2019. [Google Scholar]
- Pell, R. Maxim launches neural network accelerator chip. eeNewsEmbedded, 8 October 2020. [Google Scholar]
- DSPgroup DBM10 AI/ML SoC with DSP and Neural Network Accelerator. Available online: https://www.dspg.com/wp-content/uploads/2021/01/Power-Edge-AI-ML-SoC.pdf (accessed on 1 July 2021).
- Synaptics. Synaptics Expands into Low Power Edge AI Applications with New Katana Platform. Available online: https://www.synaptics.com/company/news/katana (accessed on 2 August 2021).
- SynSense. DynapSE2 a Low Power Scalable SNN Processor. Available online: https://www.synsense-neuromorphic.com/wp-content/uploads/2018/10/wp-dynapse2-opt-20181031.pdf (accessed on 2 August 2021).
- Fujii, T.; Toi, T.; Tanaka, T.; Togawa, K.; Kitaoka, T.; Nishino, K.; Nakamura, N.; Nakahara, H.; Motomura, M. New Generation Dynamically Reconfigurable Processor Technology for Accelerating Embedded AI Applications. In Proceedings of the 2018 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 41–42. [Google Scholar]
- Dalgaty, T.; Esmanhotto, E.; Castellani, N.; Querlioz, D.; Vianello, E. Ex Situ Transfer of Bayesian Neural Networks to Resistive Memory-Based Inference Hardware. Adv. Intell. Syst. 2021, 2000103. [Google Scholar] [CrossRef]
- Véstias, M. Efficient Design of Pruned Convolutional Neural Networks on FPGA. J. Signal Process. Syst. 2021, 93, 531–544. [Google Scholar] [CrossRef]
- Qi, X.; Liu, C. Enabling Deep Learning on IoT Edge: Approaches and Evaluation. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Bellevue, WA, USA, 25–27 October 2018; pp. 367–372. [Google Scholar]
- Reed, R. Pruning algorithms-a survey. IEEE Trans. Neural Netw. 1993, 4, 740–747. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Talathi, S.; Annapureddy, S. Fixed Point Quantization of Deep Convolutional Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Xu, D.; Li, T.; Li, Y.; Su, X.; Tarkoma, S.; Jiang, T.; Crowcroft, J.; Hui, P. Edge Intelligence: Architectures, Challenges, and Applications. arXiv 2020, arXiv:2003.12172. [Google Scholar]
- Manessi, F.; Rozza, A.; Bianco, S.; Napoletano, P.; Schettini, R. Automated Pruning for Deep Neural Network Compression. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 657–664. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Yu, J.; Lukefahr, A.; Palframan, D.; Dasika, G.; Das, R.; Mahlke, S. Scalpel: Customizing DNN pruning to the underlying hardware parallelism. ACM SIGARCH Comput. Arch. News 2017, 45, 548–560. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep Learning with Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Liu, W.; Jiang, Y.; Wang, Y.; Goh, W.L.; Yu, H.; Ren, F. A 34-FPS 698-GOP/s/W Binarized Deep Neural Network-Based Natural Scene Text Interpretation Accelerator for Mobile Edge Computing. IEEE Trans. Ind. Electron. 2019, 66, 7407–7416. [Google Scholar] [CrossRef]
- Gysel, P.; Motamedi, M.; Ghiasi, S. Hardware-oriented approximation of convolutional neural networks. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wang, J.; Lou, Q.; Zhang, X.; Zhu, C.; Lin, Y.; Chen, D. Design Flow of Accelerating Hybrid Extremely Low Bit-Width Neural Network in Embedded FPGA. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2018; pp. 163–1636. [Google Scholar]
- Vestias, M.P.; Duarte, R.P.; De Sousa, J.T.; Neto, H.C. A Configurable Architecture for Running Hybrid Convolutional Neural Networks in Low-Density FPGAs. IEEE Access 2020, 8, 107229–107243. [Google Scholar] [CrossRef]
- Albericio, J.; Judd, P.; Hetherington, T.H.; Aamodt, T.M.; Jerger, N.D.E.; Moshovos, A. Cnvlutin: Ineffectual-Neuron-Free Deep Neural Network Computing. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 1–13. [Google Scholar]
- Aimar, A.; Mostafa, H.; Calabrese, E.; Rios-Navarro, A.; Tapiador-Morales, R.; Lungu, I.-A.; Milde, M.B.; Corradi, F.; Linares-Barranco, A.; Liu, S.-C.; et al. NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 644–656. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient Inference Engine on Compressed Deep Neural Network. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 243–254. [Google Scholar]
- Hang, S.; Du, Z.; Zhang, L.; Lan, H.; Liu, S.; Li, L.; Guo, Q.; Chen, T.; Chen, Y. Cambricon-X: An accelerator for sparse neural networks. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar]
- Yao, S.; Zhao, Y.; Zhang, A.; Su, L.; Abdelzaher, T. Deepiot: Compressing deep neural network structures for sensing systems with a compressor-critic framework. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; pp. 1–14. [Google Scholar]
- Kantas, N.; Doucet, A.; Singh, S.S.; Maciejowski, J.; Chopin, N. On Particle Methods for Parameter Estimation in State-Space Models. Stat. Sci. 2015, 30, 328–351. [Google Scholar] [CrossRef] [Green Version]
- Imani, M.; Ghoreishi, S.F. Two-Stage Bayesian Optimization for Scalable Inference in State-Space Models. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J.S. How to Evaluate Deep Neural Network Processors: TOPS/W (Alone) Considered Harmful. IEEE Solid-State Circuits Mag. 2020, 12, 28–41. [Google Scholar] [CrossRef]
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An insightful visual performance model for multicore architectures. Commun. ACM 2009, 52, 65–76. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frameworks | Transformation Technique |
|---|---|
| HADDOC2 | Models CNN as a dataflow graph |
| hls4ml | Translating NN into FGPA firmware using Python and HLS |
| fpgaConvNet | Assign one processing stage per network layer |
| Dnnweaver2 | Use of dataflow graph |
| CNN2Gate | Automatic synthesis using OpenCL |
| FINN | Generate data streams based on Binary NN |
| Frameworks | Transformation Technique |
|---|---|
| Cuda-convnet2 [85] | CNN implementation using CUDA |
| cuDNN [86] | Nvidia’s CUDA SDK for CNN implementation |
| OpenCV DNN [87] | OpenCV library with DNN and optimized for GPU |
| Tensorflow [88] | CNN framework with GPU (CUDA) performance optimization |
| PyTorch [89] | Optimized tensor library for DL using GPU (CUDA) |
| DeepSense [90] | Mobile GPU-based CNN optimization using OpenCL |
| Vendor | Hardware Architecture |
|---|---|
| Greenwaves [96] | Composed of one Fabric Controller (FC)core and eight cores in a cluster as extended version of the RISC-V instruction set and separate data cache for each. |
| BrainChip [97] | It is based to spiking-neural-network (SNN) technology that connects 80 event-based neural processor units and it is optimized for low-power edge AI. |
| Maxim Integrated Products [98] | It is a hardware-based CNN accelerator that enables battery-powered applications to execute AI inferences. It is combined with a large on-chip system memory |
| DSP group [99] | It is a standalone hardware engine that is designed to accelerate the execution of NN inferences. It is optimized for efficiency to ensure ultra-low power consumption for small to medium size NNs |
| Synaptics [100] | proprietary power and energy optimized neural network and domain specific processing cores, significant on-chip memory |
| Synsense [101] | A scalable, fully-configurable digital event-driven neuromorphic processor with 1 M ReLU spiking neurons per chip for implementing Spiking Convolutional Neural Networks |
| Renesas [102] | Dynamically Reconfigurable Processor (DRP) technology is special purpose hardware that accelerates image processing algorithms by as much as 10×, or more |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flamis, G.; Kalapothas, S.; Kitsos, P. Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing. Electronics 2021, 10, 1912. https://doi.org/10.3390/electronics10161912
Flamis G, Kalapothas S, Kitsos P. Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing. Electronics. 2021; 10(16):1912. https://doi.org/10.3390/electronics10161912
Chicago/Turabian StyleFlamis, Georgios, Stavros Kalapothas, and Paris Kitsos. 2021. "Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing" Electronics 10, no. 16: 1912. https://doi.org/10.3390/electronics10161912
APA StyleFlamis, G., Kalapothas, S., & Kitsos, P. (2021). Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing. Electronics, 10(16), 1912. https://doi.org/10.3390/electronics10161912