
An Approach of Binary Neural Network Energy-Efficient Implementation


Abstract
:1. Introduction
- We propose an approach to accelerate BNN inference in an energy-efficient way. The excessive redundant operations in the binarized convolution processes of multi related kernels are safely skipped by adopting the kernel inclusion similarity scheme.
- In addition, an inclusion pruning strategy is exploited to further save the superfluous evaluations of neurons whose real output values can be determined early, resulting in pruning the whole operations of these neurons without any accuracy loss.
- To the best of our knowledge, our design can prune up to 51 percent of the operations while maintaining the original accuracies, leading to obtaining 118× and 3.6× energy efficiency improvement, respectively, when compared with the prior state-of-the-art works implemented on GPU/FPGA.
2. Preliminary and Related Works
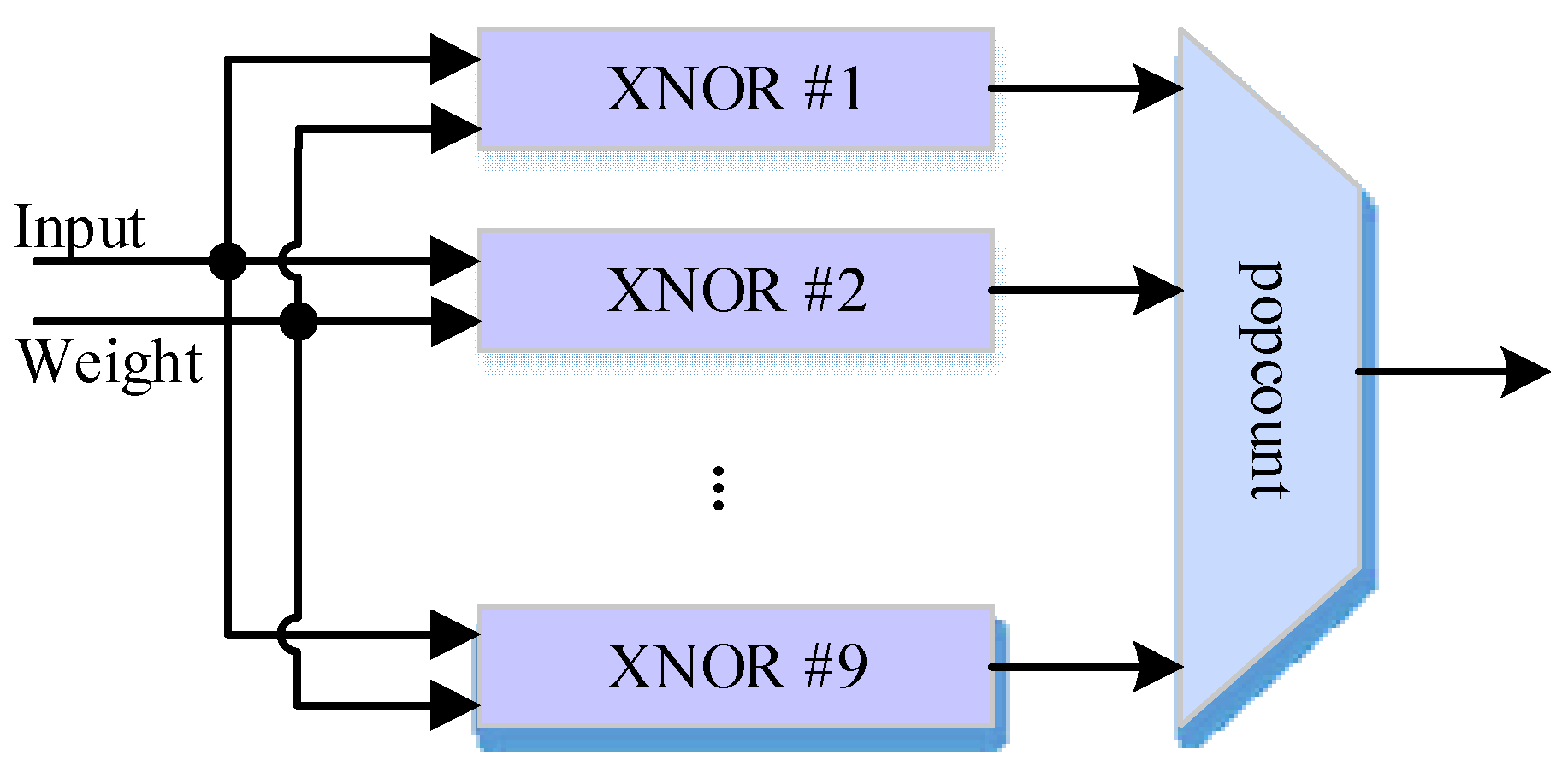
2.1. Preliminary of BNN
2.2. Related Works
3. Proposed Methods
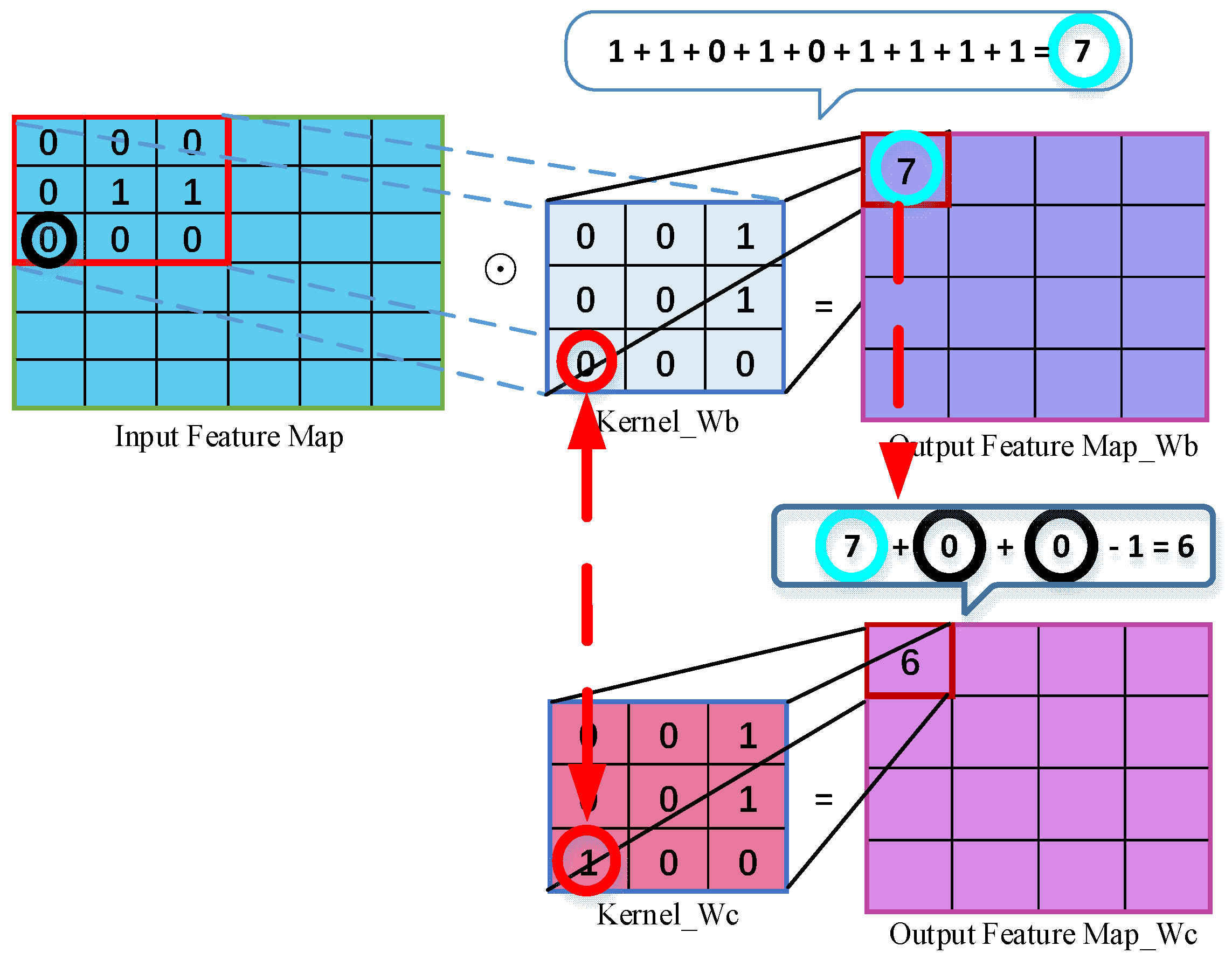
3.1. Kernel Inclusion Similarity
3.2. Reference Consistency Kernel Inclusion Similarity
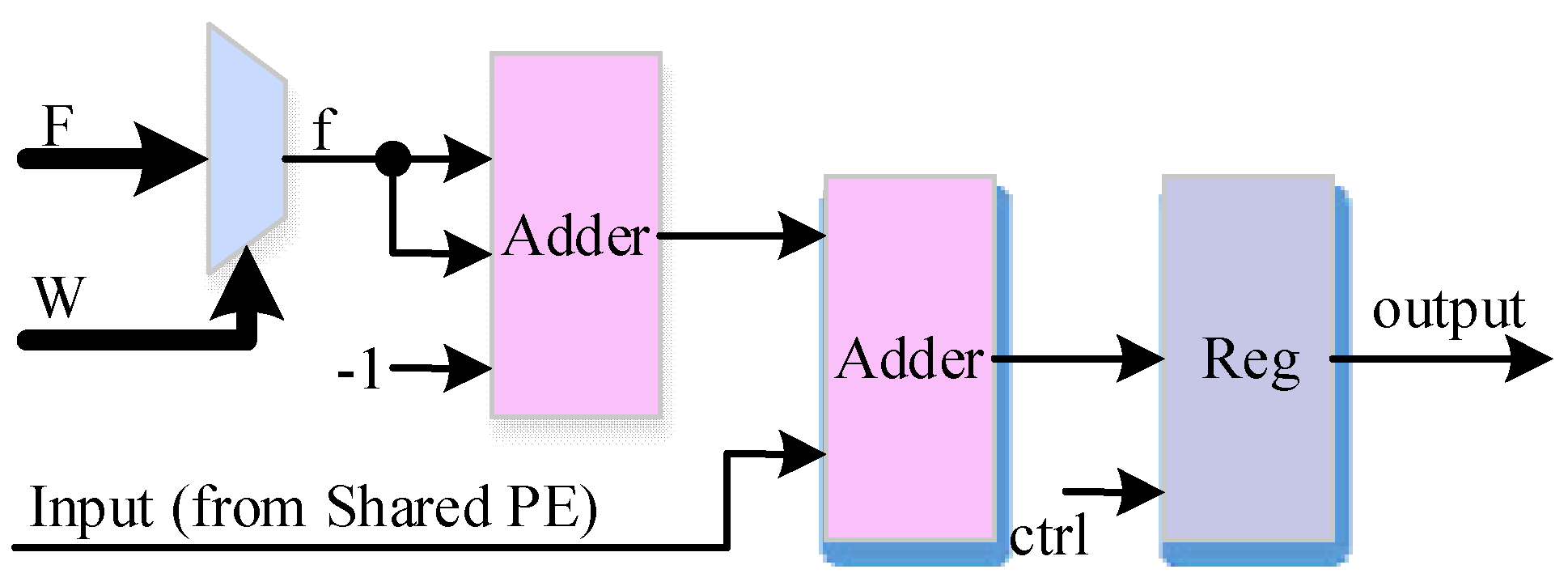
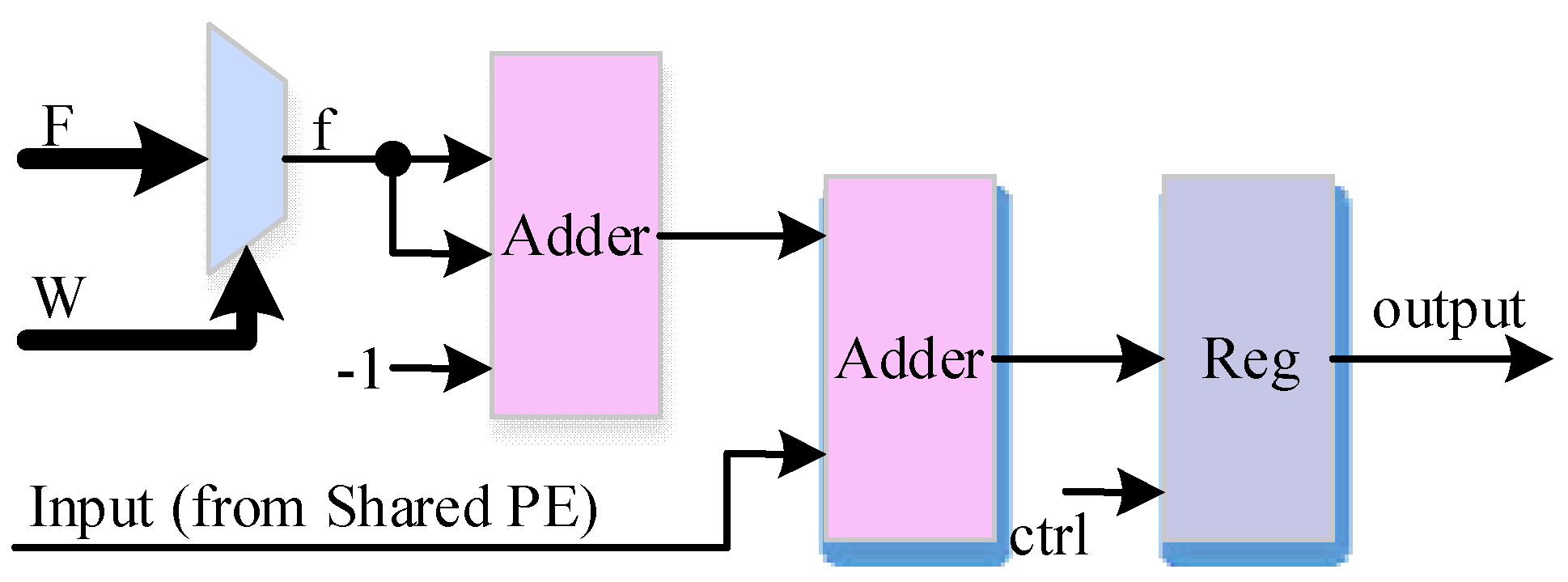
3.3. Inclusion Pruning Strategy
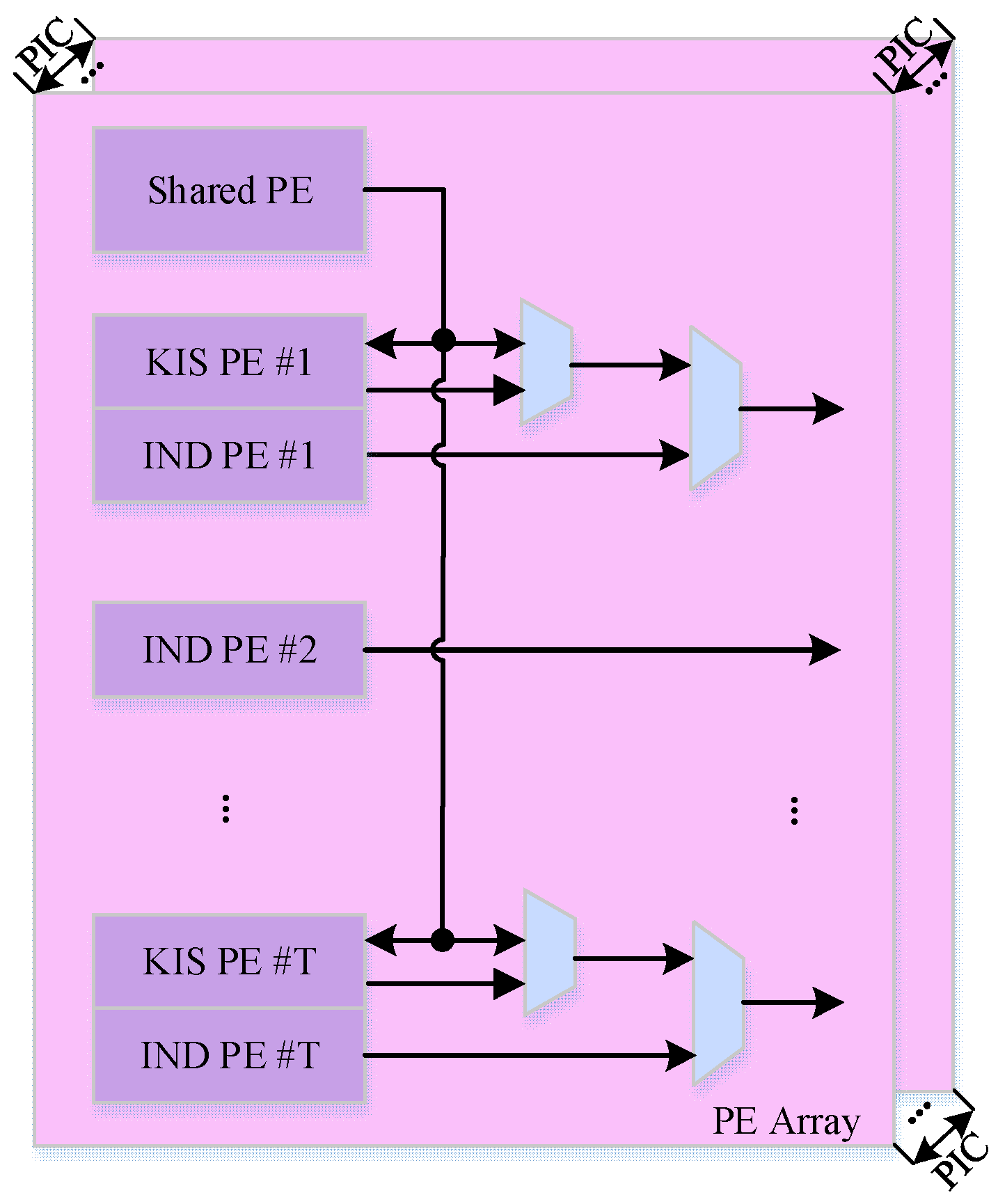
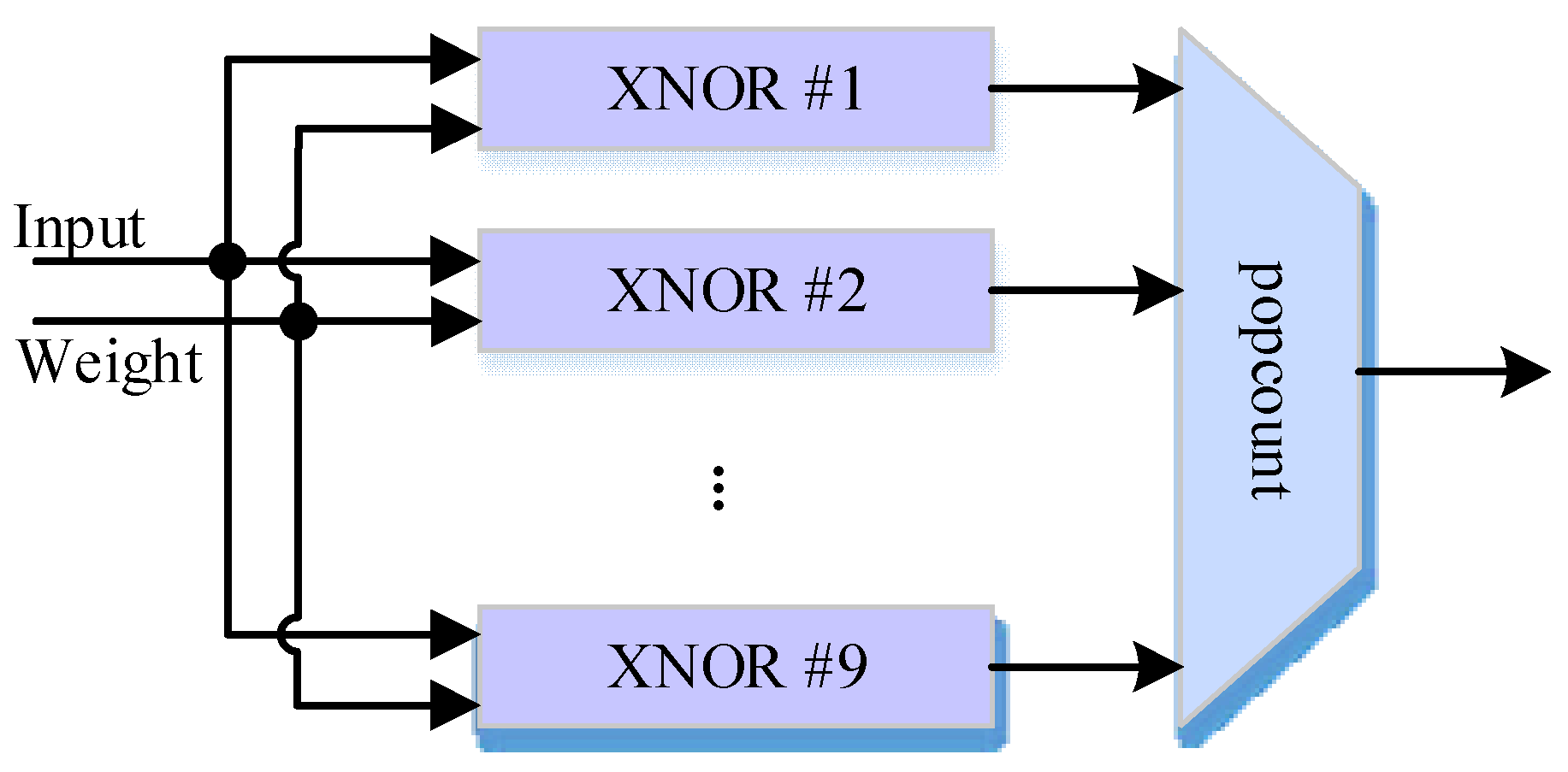
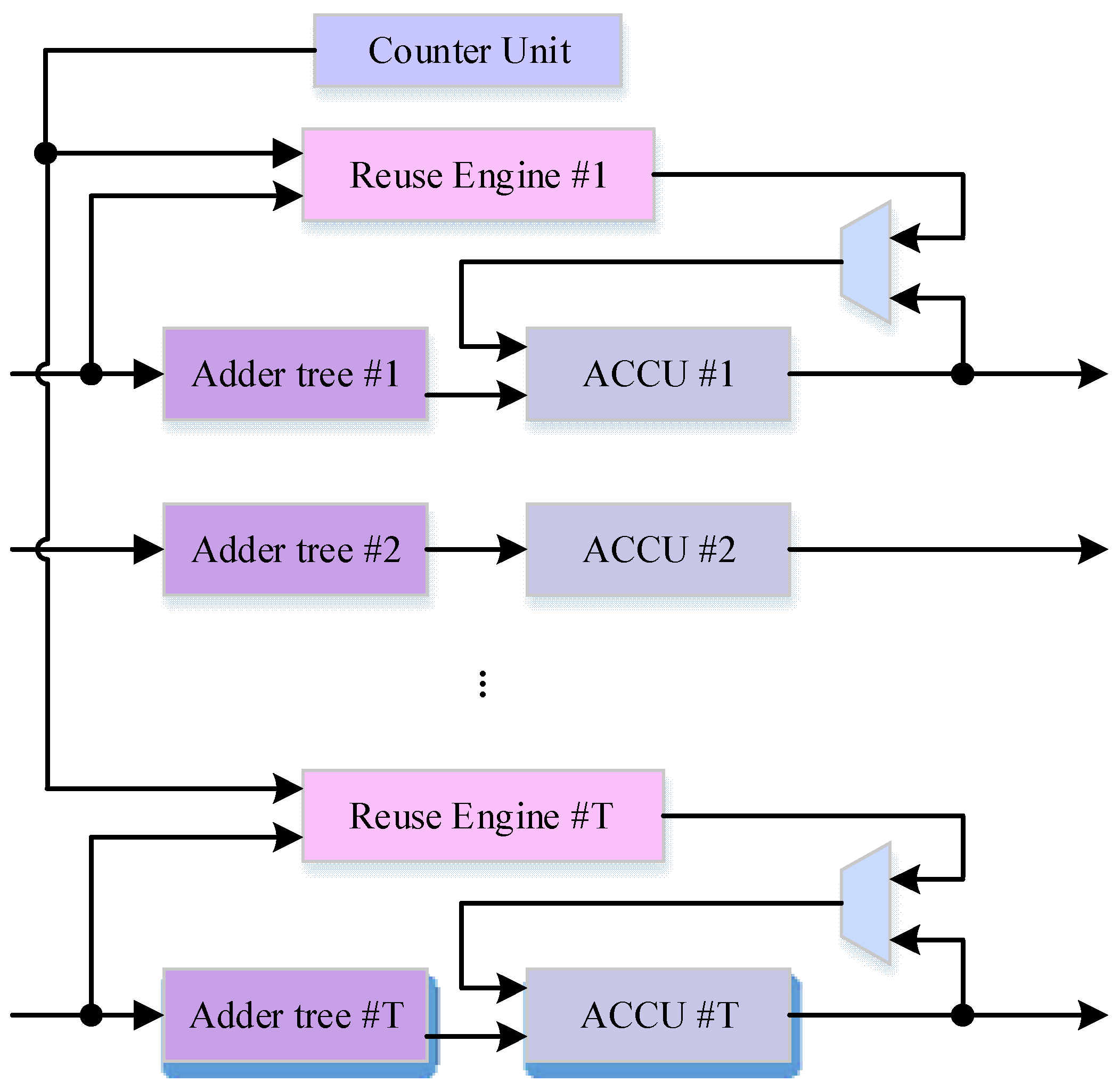
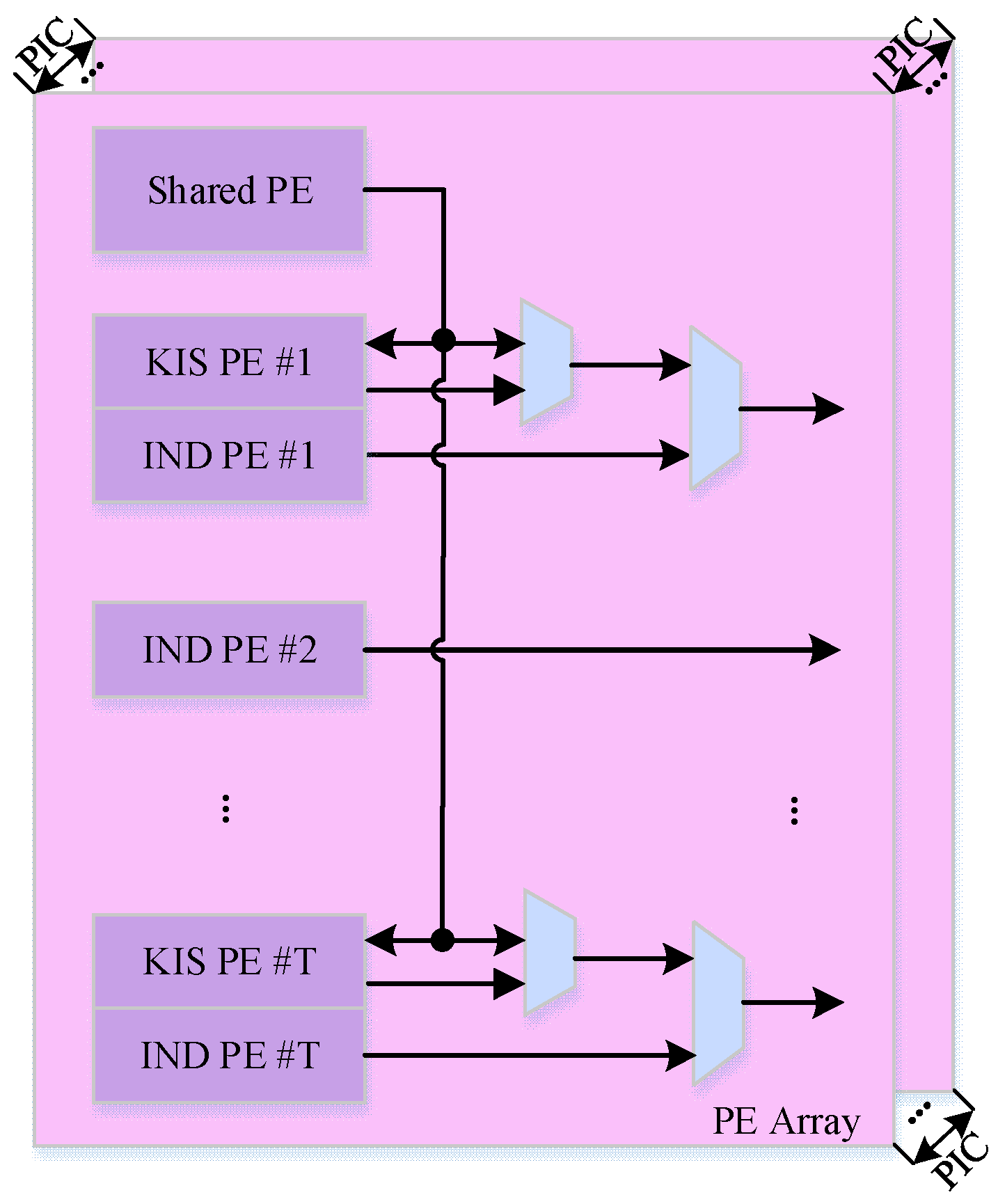
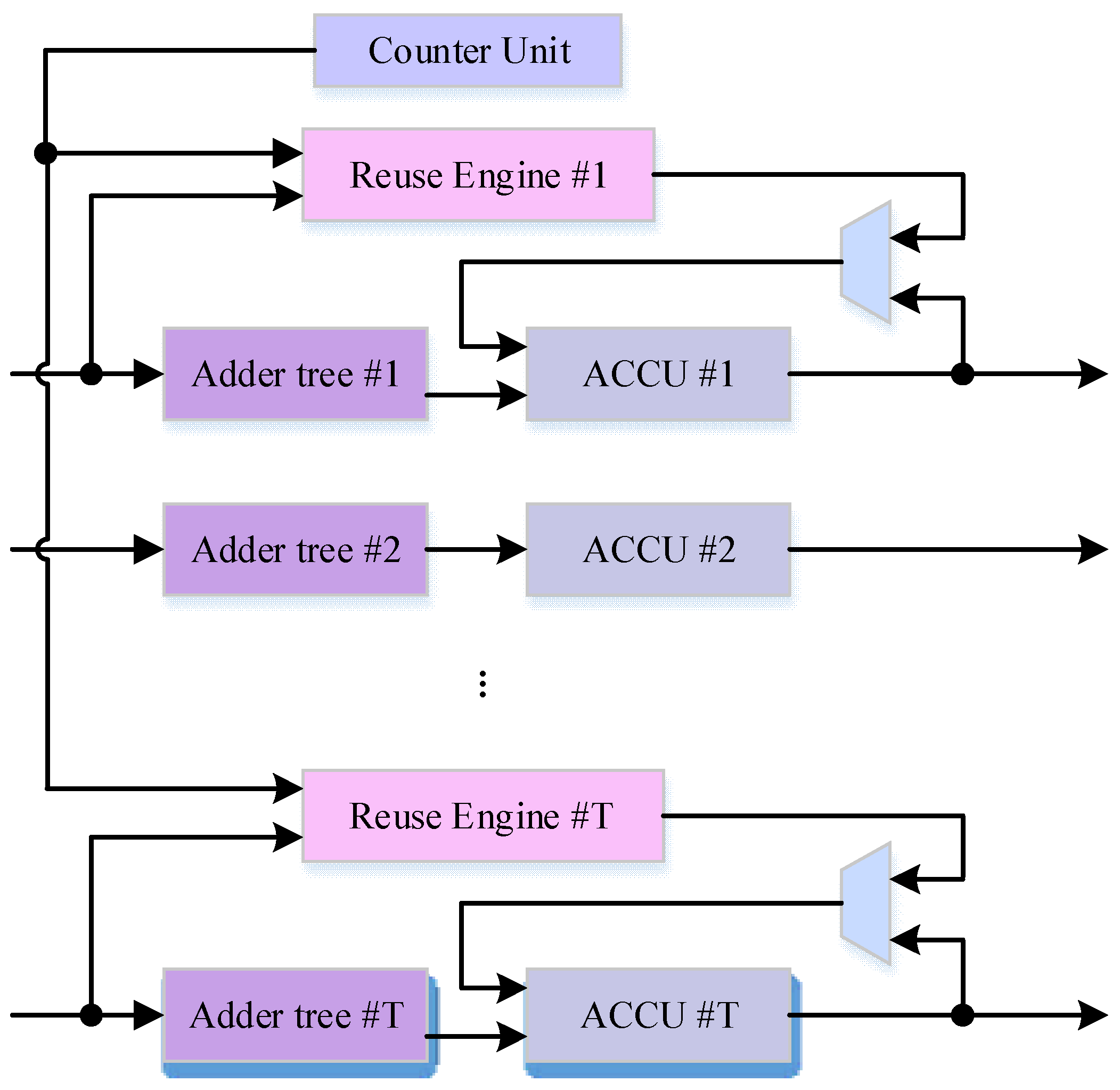
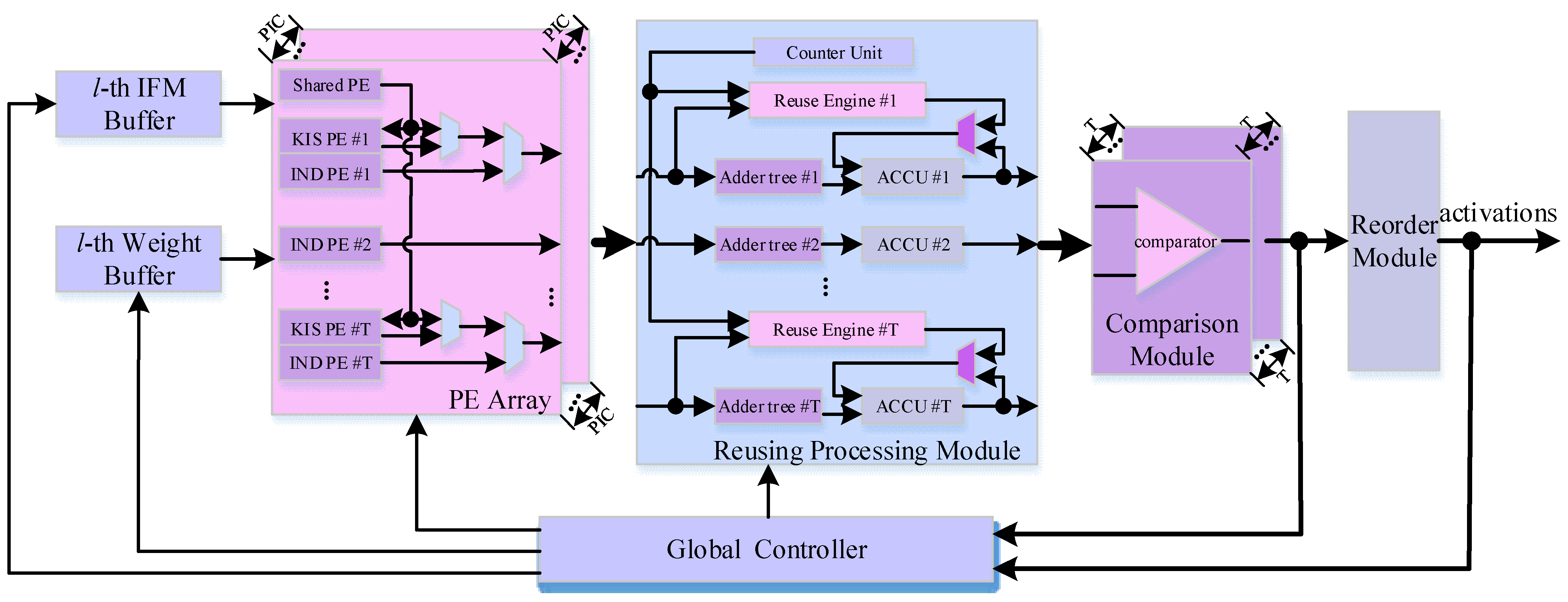
4. Design Architecture
5. Experimental Results
5.1. Operation Count Reduction
5.2. Comparisons to Other Designs
5.3. Cross-Platform Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, Q.; Zhang, W.; Yu, J.; Fan, J. Embedding Complementary Deep Networks for Image Classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9230–9239. [Google Scholar]
- Le Kernec, J.; Fioranelli, F.; Ding, C.; Zhao, H.; Sun, L.; Hong, H.; Lorandel, J.; Romain, O. Radar Signal Processing for Sensing in Assisted Living: The Challenges Associated with Real-Time Implementation of Emerging Algorithms. IEEE Signal Process. Mag. 2019, 36, 29–41. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Wu, Y.; Qin, H.; Liang, D.; Liu, X.; Yan, J. R³ Adversarial Network for Cross Model Face Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9860–9868. [Google Scholar]
- Lahoud, F.; Süsstrunk, S. Zero-Learning Fast Medical Image Fusion. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Wu, D.; Cao, W.; Wang, L. SpWMM: A High-Performance Sparse-Winograd Matrix-Matrix Multiplication Accelerator for CNNs. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 255–258. [Google Scholar]
- Bethge, J.; Bartz, C.; Yang, H.; Chen, Y.; Meinel, C. MeliusNet: Can binary neural networks achieve mobilenet-level accuracy? arXiv 2020, arXiv:2001.05936. [Google Scholar]
- Shimoda, M.; Sato, S.; Nakahara, H. All binarized convolutional neural network and its implementation on an FPGA. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 11–13 December 2017; pp. 291–294. [Google Scholar]
- Li, A.; Su, S.M. Accelerating Binarized Neural Networks via Bit-Tensor-Cores in Turing GPUs. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1. [Google Scholar] [CrossRef]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-net: ImageNet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Wang, E.; Davis, J.J.; Cheung, P.Y.K.; Constantinides, G.A. LUTNet: Learning FPGA Configurations for Highly Efficient Neural Network Inference. IEEE Trans. Comput. 2020, 69, 1795–1808. [Google Scholar] [CrossRef] [Green Version]
- Geng, T.; Li, A.; Wang, T.; Wu, C.; Li, Y.; Shi, R.; Wu, W.; Herbordt, M. O3BNN-R: An Out-of-Order Architecture for High-Performance and Regularized BNN Inference. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 199–213. [Google Scholar] [CrossRef]
- Kim, H.; Sim, J.; Choi, Y.; Kim, L.-S. NAND-Net: Minimizing Computational Complexity of In-Memory Processing for Binary Neural Networks. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 661–673. [Google Scholar] [CrossRef]
- Li, Y.; Ren, F. BNN Pruning: Pruning Binary Neural Network Guided by Weight Flipping Frequency. In Proceedings of the 2020 21st International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 25–26 March 2020; pp. 306–311. [Google Scholar]
- Guerra, L.; Zhuang, B.; Reid, I.; Drummond, T. Automatic pruning for quantized neural networks. arXiv 2020, arXiv:2002.00523. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. Available online: https://www.cs.toronto.edu/kriz/cifar.html (accessed on 30 April 2021).
- Wang, J.; Jin, X.; Wu, W. TB-DNN: A Thin Binarized Deep Neural Network with High Accuracy. In Proceedings of the 2020 22nd International Conference on Advanced Communication Technology (ICACT), Phoenix Park, Korea, 16–19 February 2020; pp. 419–424. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Xian, Z.; Li, H.; Li, Y. Weight Isolation-Based Binarized Neural Networks Accelerator. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–4. [Google Scholar]
- Liang, S.; Yin, S.; Liu, L.; Luk, W.; Wei, S. FP-BNN: Binarized neural network on FPGA. Neurocomputing 2018, 275, 1072–1086. [Google Scholar] [CrossRef]
- Zhao, R.; Song, W.; Zhang, W.; Xing, T.; Lin, J.-H.; Srivastava, M.; Gupta, R.; Zhang, Z. Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 15–24. [Google Scholar]
- Guo, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 51–513. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Baskin, C.; Liss, N.; Zheltonozhskii, E.; Bronstein, A.M.; Mendelson, A. Streaming Architecture for Large-Scale Quantized Neural Networks on an FPGA-Based Dataflow Platform. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 162–169. [Google Scholar]
- Fujii, T.; Sato, S.; Nakahara, H. A threshold neuron pruning for a binarized deep neural network on an FPGA. IEICE Trans. Inf. Syst. 2018, 101, 376–386. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.-C.; Lin, C.-C.; Lin, Y.-T.; Chen, Y.-C.; Wang, C.-Y. A Convolutional Result Sharing Approach for Binarized Neural Network Inference. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 780–785. [Google Scholar]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating Binarized Neural Networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar]
- Yonekawa, H.; Nakahara, H. On-Chip Memory Based Binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lake Buena Vista, FL, USA, 29 May–2 June 2017; pp. 98–105. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Li, A.; Geng, T.; Wang, T.; Herbordt, M.; Song, S.L.; Barker, K. BSTC: A novel binarized-soft-tensor-core design for accelerating bit-based approximated neural nets. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–22 November 2019; pp. 1–30. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [18] | This Work | |
|---|---|---|
| Platform | Virtex-7 | Zynq-7000 |
| (XC7VX690T) | (XC7Z100) | |
| Dataset | MNIST | MNIST |
| Network | LeNet | LeNet |
| Frequency (MHz) | 500 | 450 |
| Throughput (GOPS) | 3378 | 6921.97 |
| Power (W) | 2.08 | 1.72 |
| Efficiency (GOPS/W) | 1624 | 4019.73 |
| Accuracy | 98.2% | 98.4% |
| [20] | [19] | [21] | [23] | [11] | This Work | ||
|---|---|---|---|---|---|---|---|
| Platform | Zynq-7000 | Stratix-V | Zynq-7000 | Zynq-7000 | Zynq-7000 | Zynq-7000 | Zynq-7000 |
| (XC7Z020) | 5SGSD8 | (XC7Z020) | (XC7Z020) | (XC7Z045) | (XC7Z045) | (XC7Z100) | |
| Dataset | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 |
| Network | VGG-like | VGG-like | VGG-like | VGG-like | VGG-like | VGG-like | VGG-like |
| Frequency (MHz) | 143 | 150 | - | 143 | 200 | 200 | 200 |
| Throughput (GOPS) | 207.8 | 9396.41 | 722 | 502 | 2019.70 | 2953.56 | 9685.04 |
| Power (W) | 4.7 | 26.2 | 3.3 | 2.2 | - | - | 14.89 |
| Energy efficiency (Img/kJ) | 3.58 | - | 1.58 | 1.85 | 1.82 (lossless) | 2.65 (lossy) | 6.55 |
| Accuracy | 88.5% | 86.3% | 88.6% | 81.8% | 88.5% | 85.2% | 88.7% |
| [19] | [19] | [29] | This Work | |
|---|---|---|---|---|
| Platform | CPU | GPU | GPU | Zynq-7000 |
| Xeon E5-2640 | Tesla K40 | V100 | (XC7Z100) | |
| Dataset | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 |
| Network | VGG-like | VGG-like | VGG-like | VGG-like |
| Frequency (MHz) | 2500 | 745 | 1370 | 200 |
| Throughput (GOPS) | 181.29 | 1853.87 | 1237.42 | 9685.04 |
| Power (W) | 95 | 235 | - | 14.89 |
| Energy efficiency (Img/kJ) | 7.79 | 5830 | 5543 | 6.55 |
| Accuracy | 86.3% | 86.3% | 89.9% | 88.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Liu, Q.; Lai, J. An Approach of Binary Neural Network Energy-Efficient Implementation. Electronics 2021, 10, 1830. https://doi.org/10.3390/electronics10151830
Gao J, Liu Q, Lai J. An Approach of Binary Neural Network Energy-Efficient Implementation. Electronics. 2021; 10(15):1830. https://doi.org/10.3390/electronics10151830
Chicago/Turabian StyleGao, Jiabao, Qingliang Liu, and Jinmei Lai. 2021. "An Approach of Binary Neural Network Energy-Efficient Implementation" Electronics 10, no. 15: 1830. https://doi.org/10.3390/electronics10151830
APA StyleGao, J., Liu, Q., & Lai, J. (2021). An Approach of Binary Neural Network Energy-Efficient Implementation. Electronics, 10(15), 1830. https://doi.org/10.3390/electronics10151830