
Time Series Segmentation Using Neural Networks with Cross-Domain Transfer Learning




Abstract
1. Introduction
1.1. Motivation
1.2. Conceptual Background
1.3. Related Work
1.4. Structure Outline
2. Methodology
2.1. Baseline Model
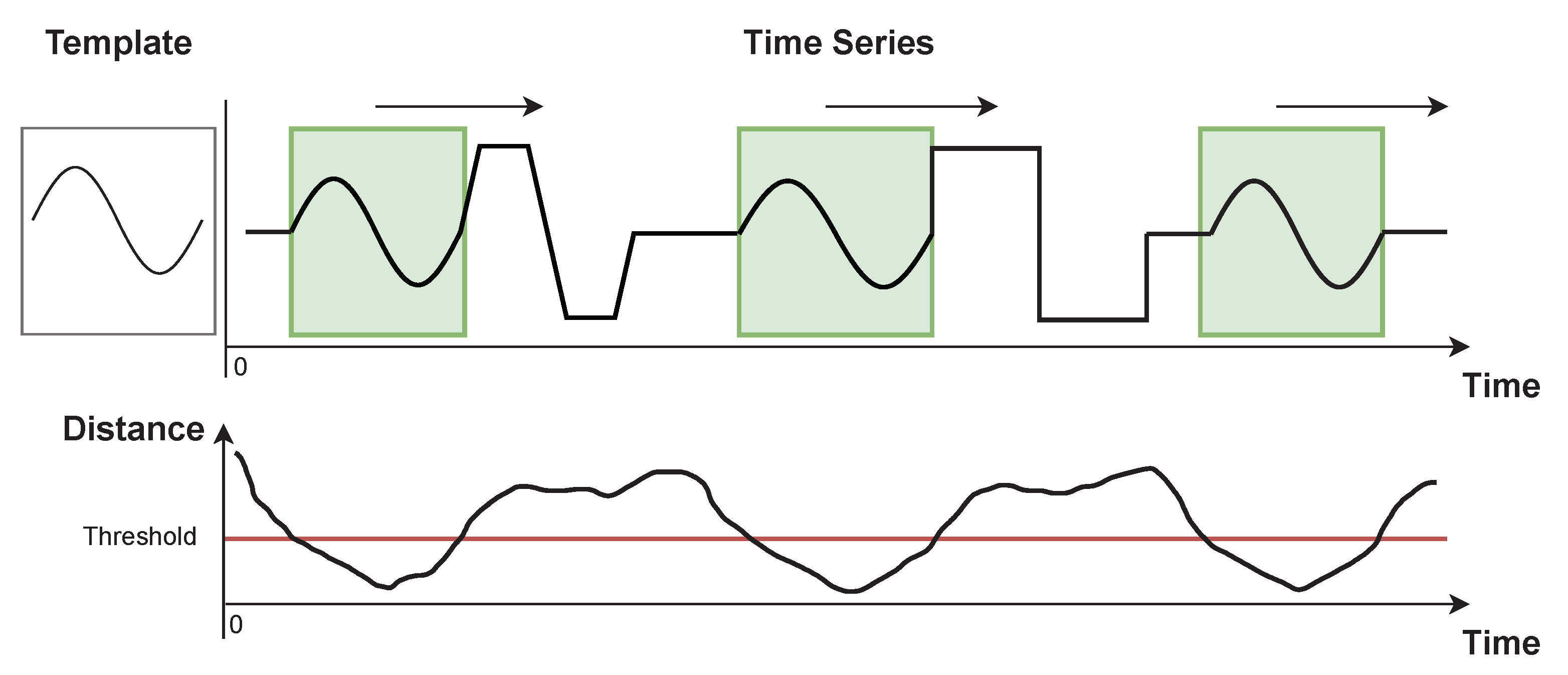
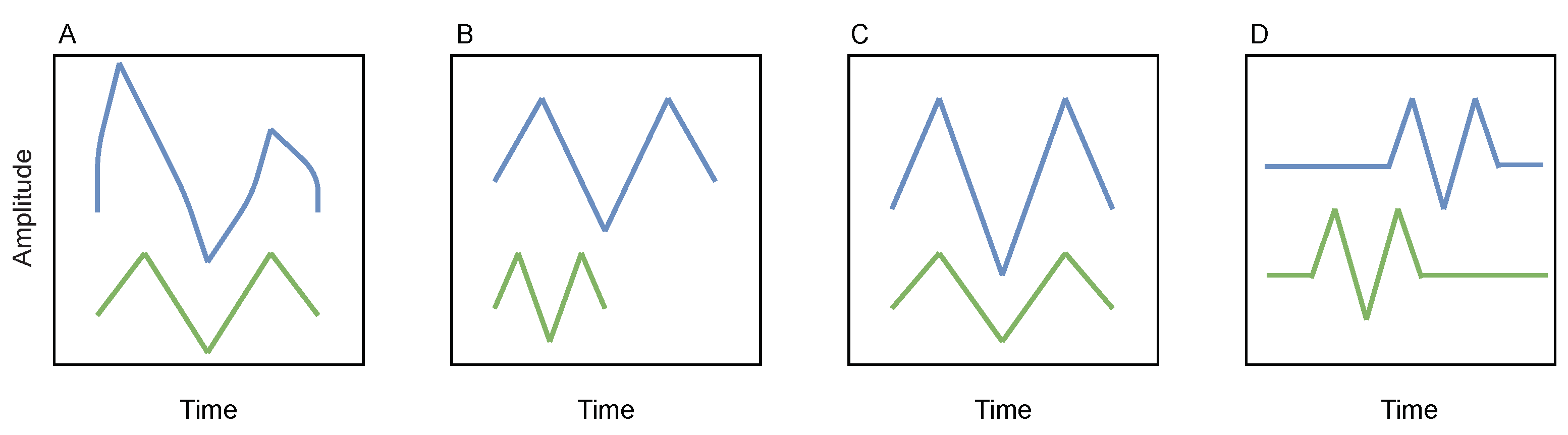
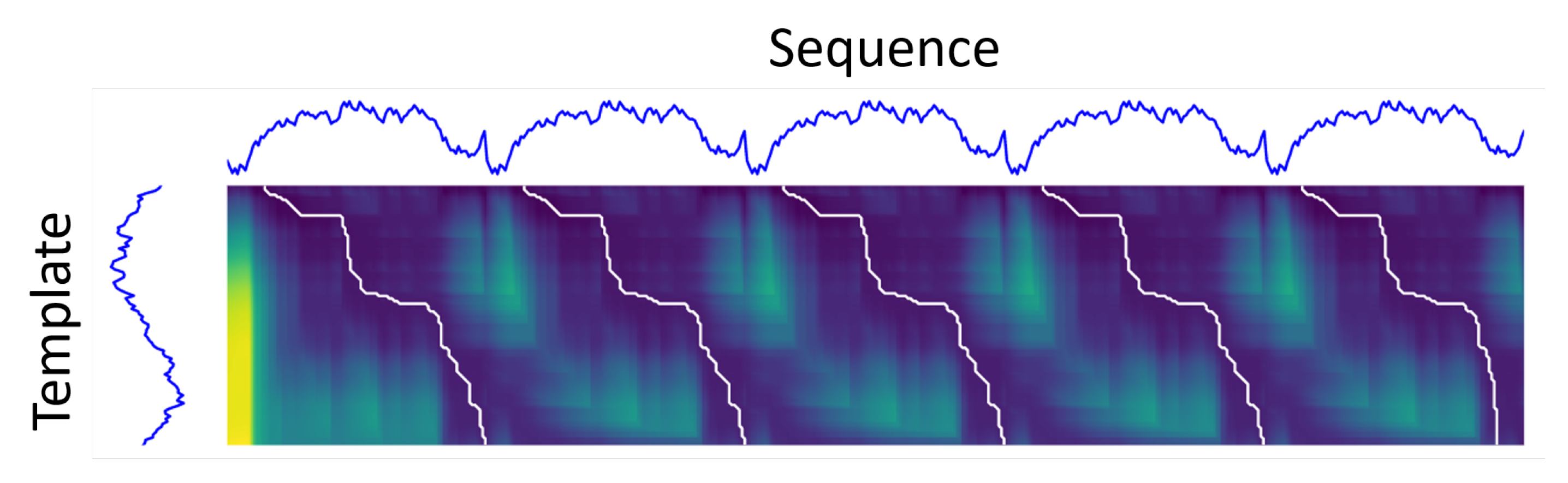
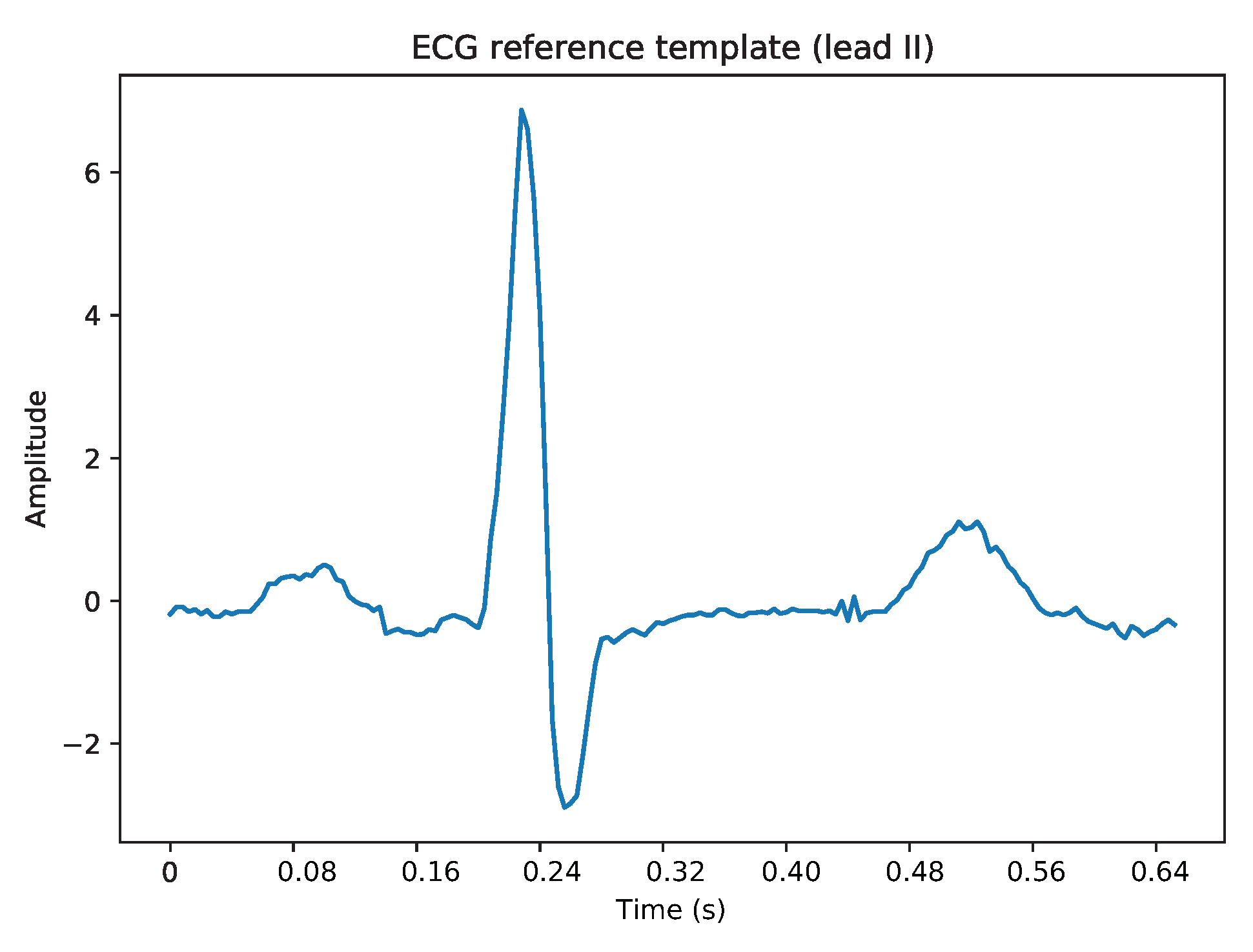
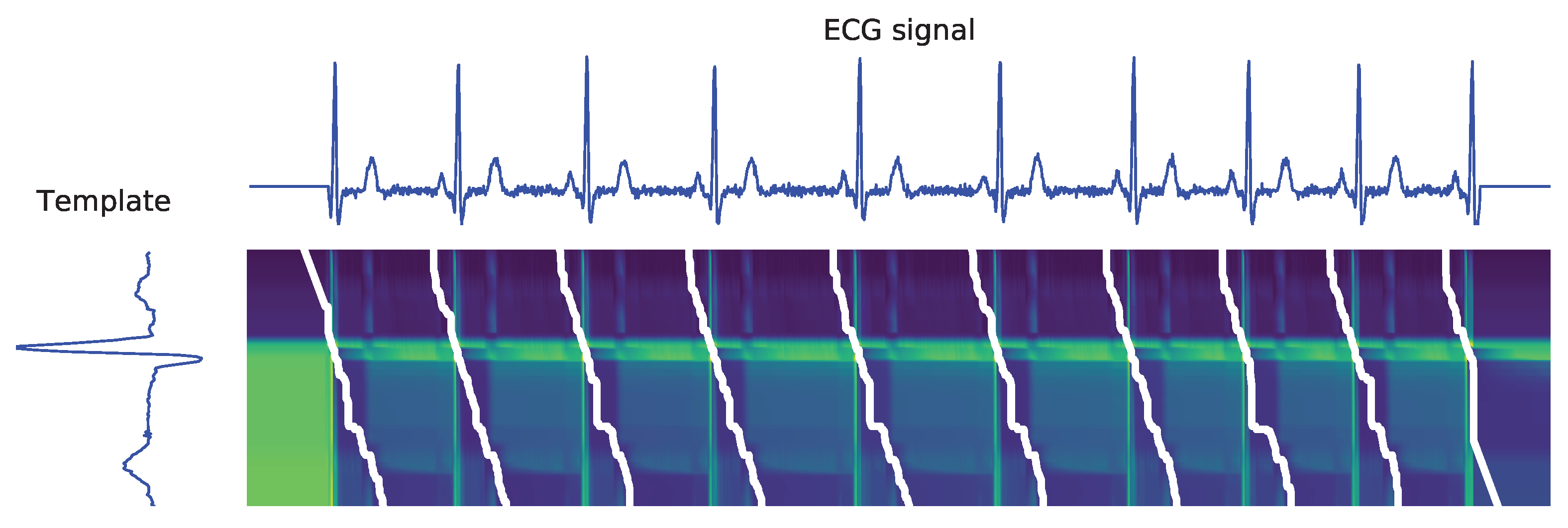
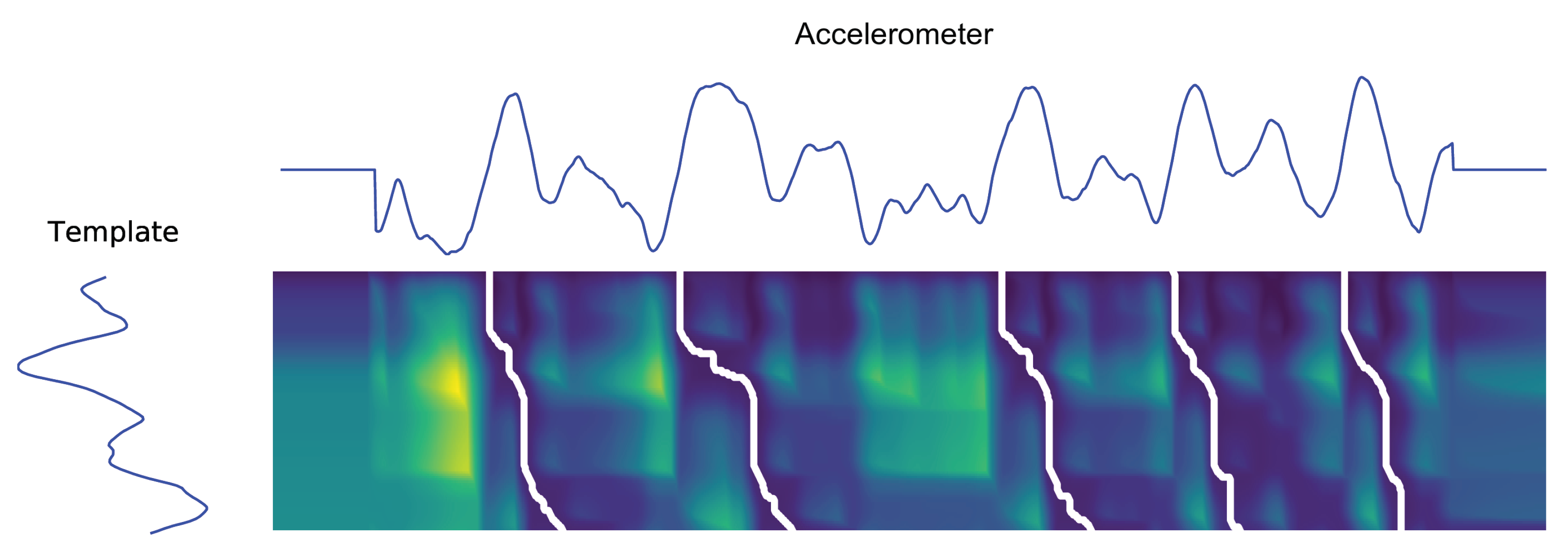
Subsequence Dynamic Time Warping (sDTW)
2.2. Univariate Analysis
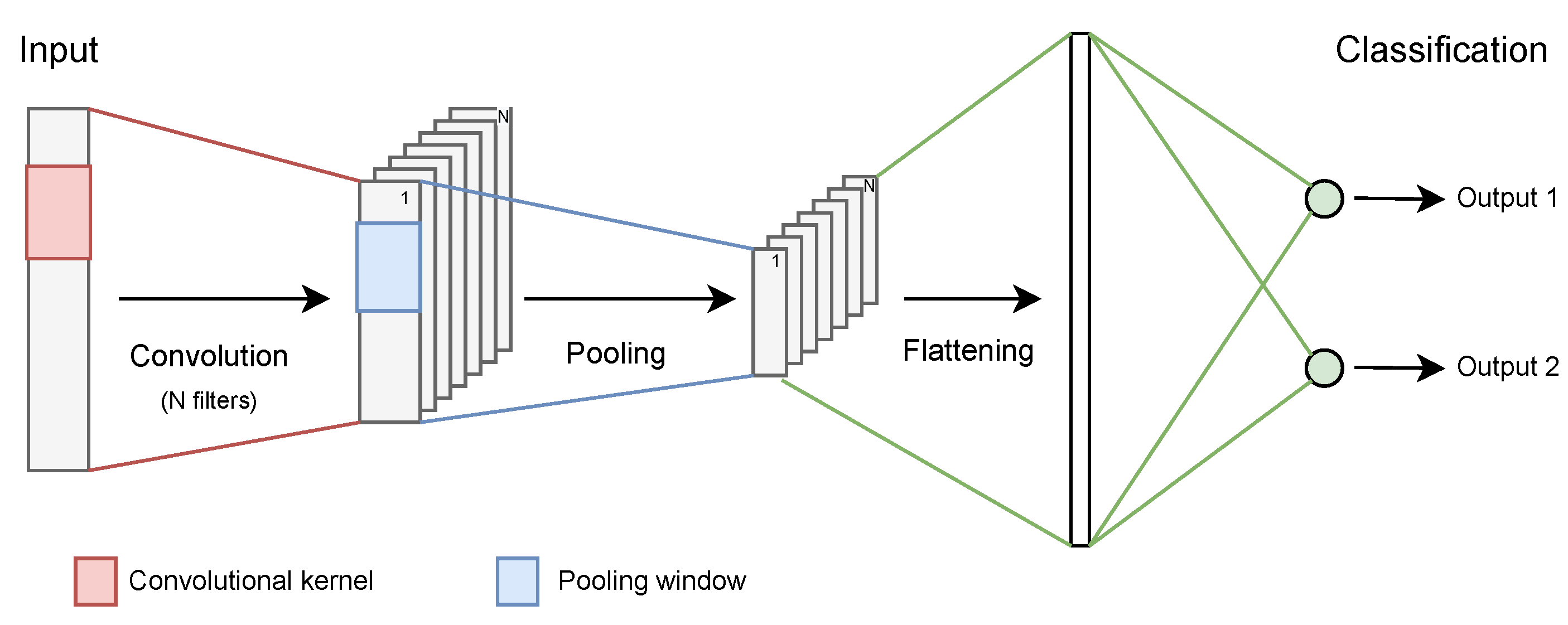
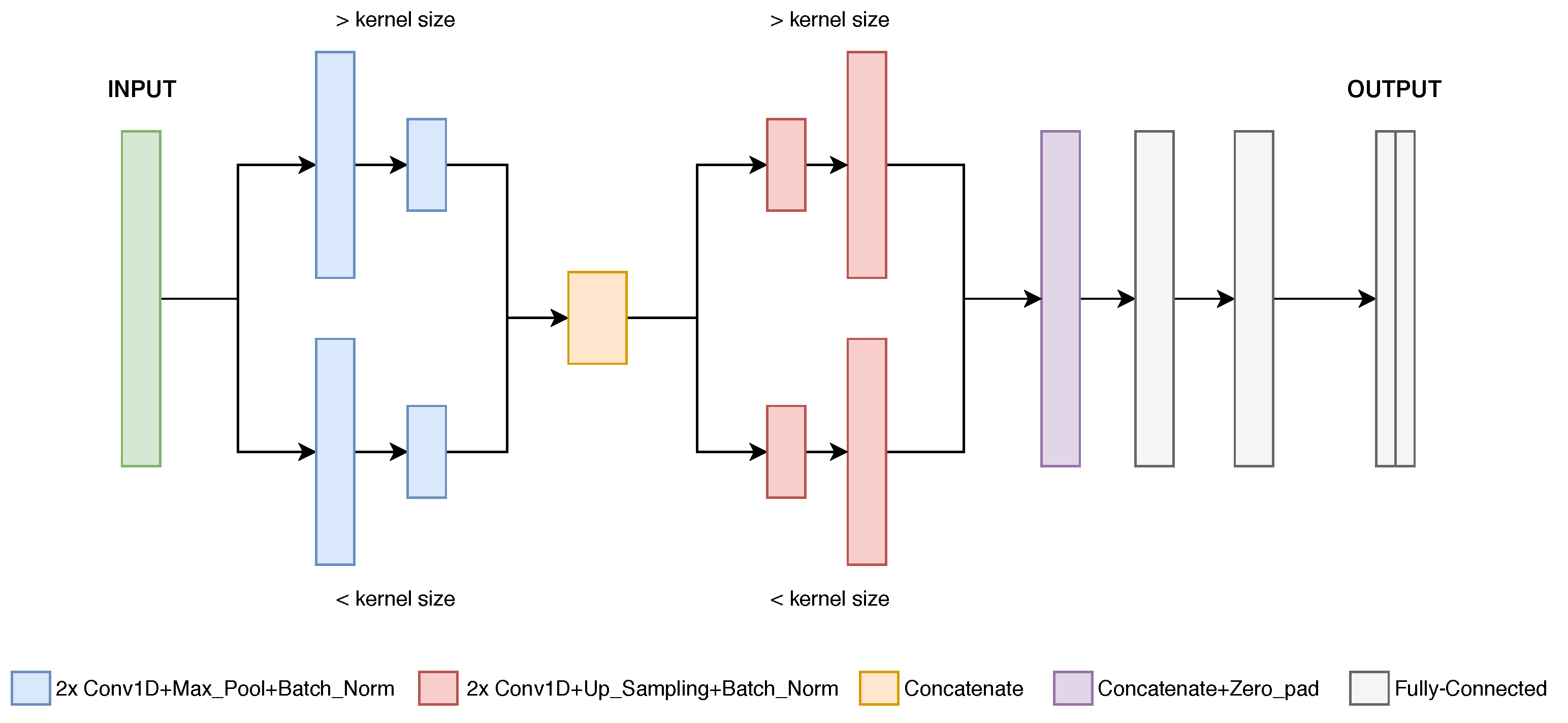
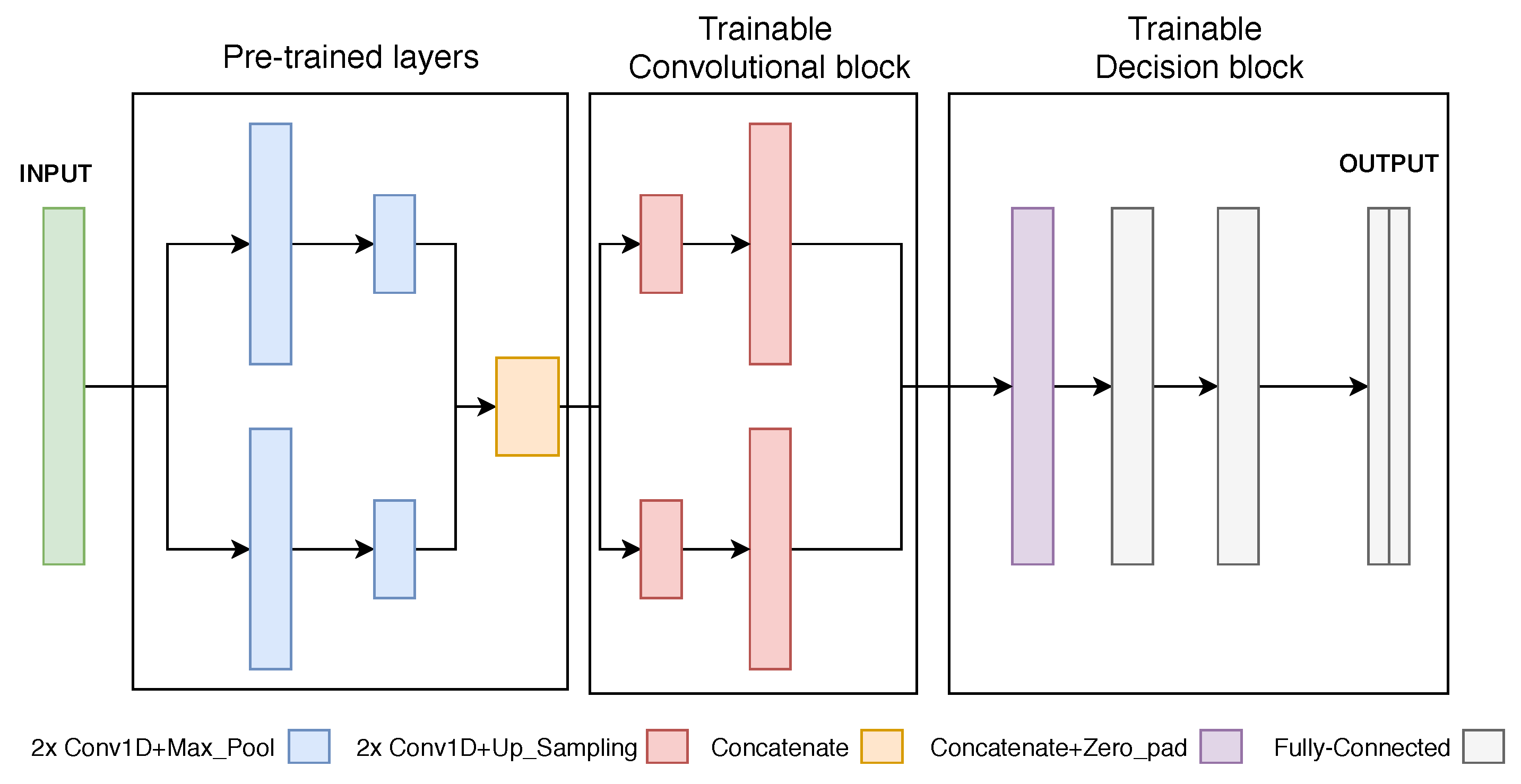
2.2.1. Proposed Model
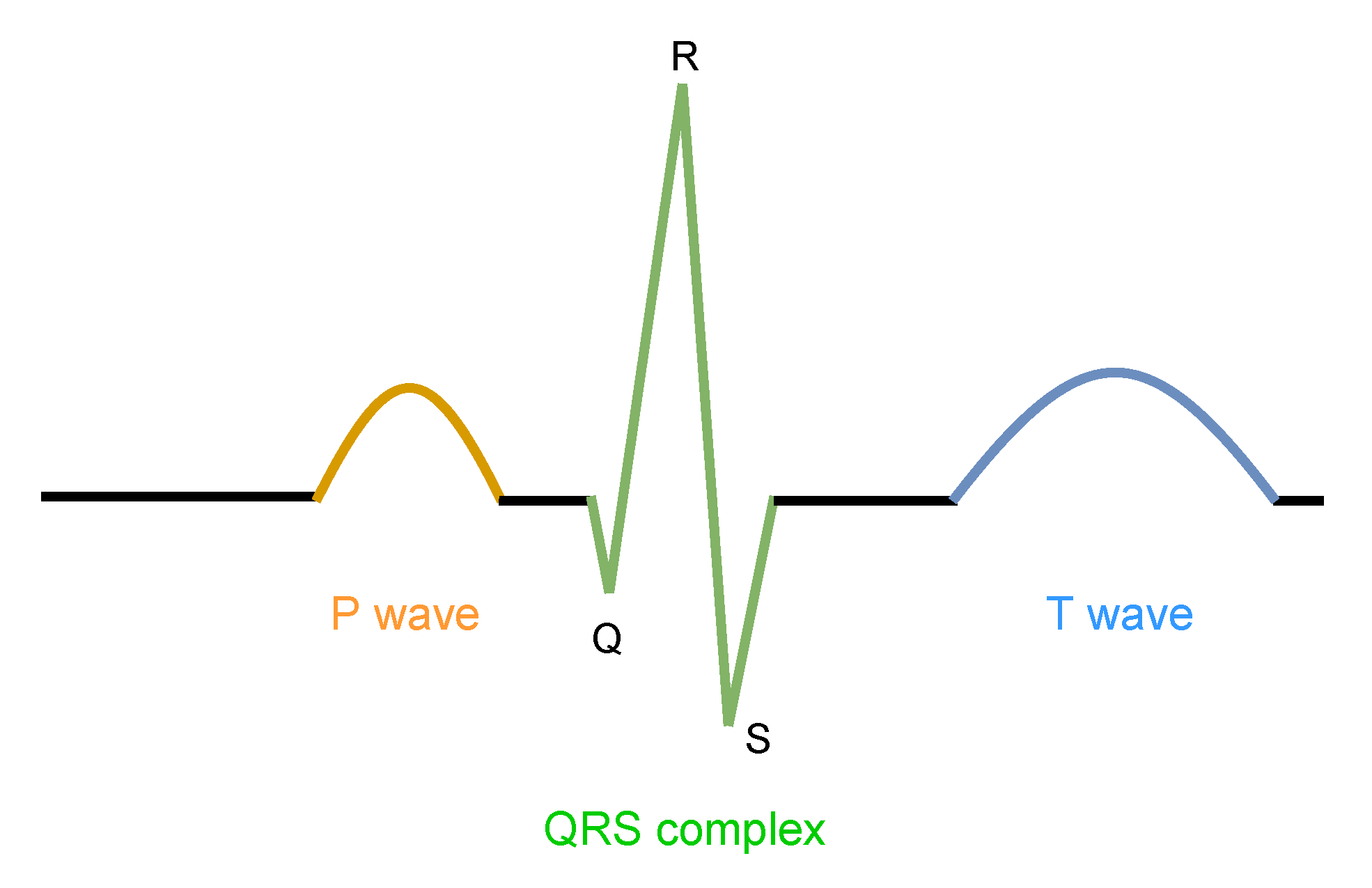
2.2.2. LUDB Dataset
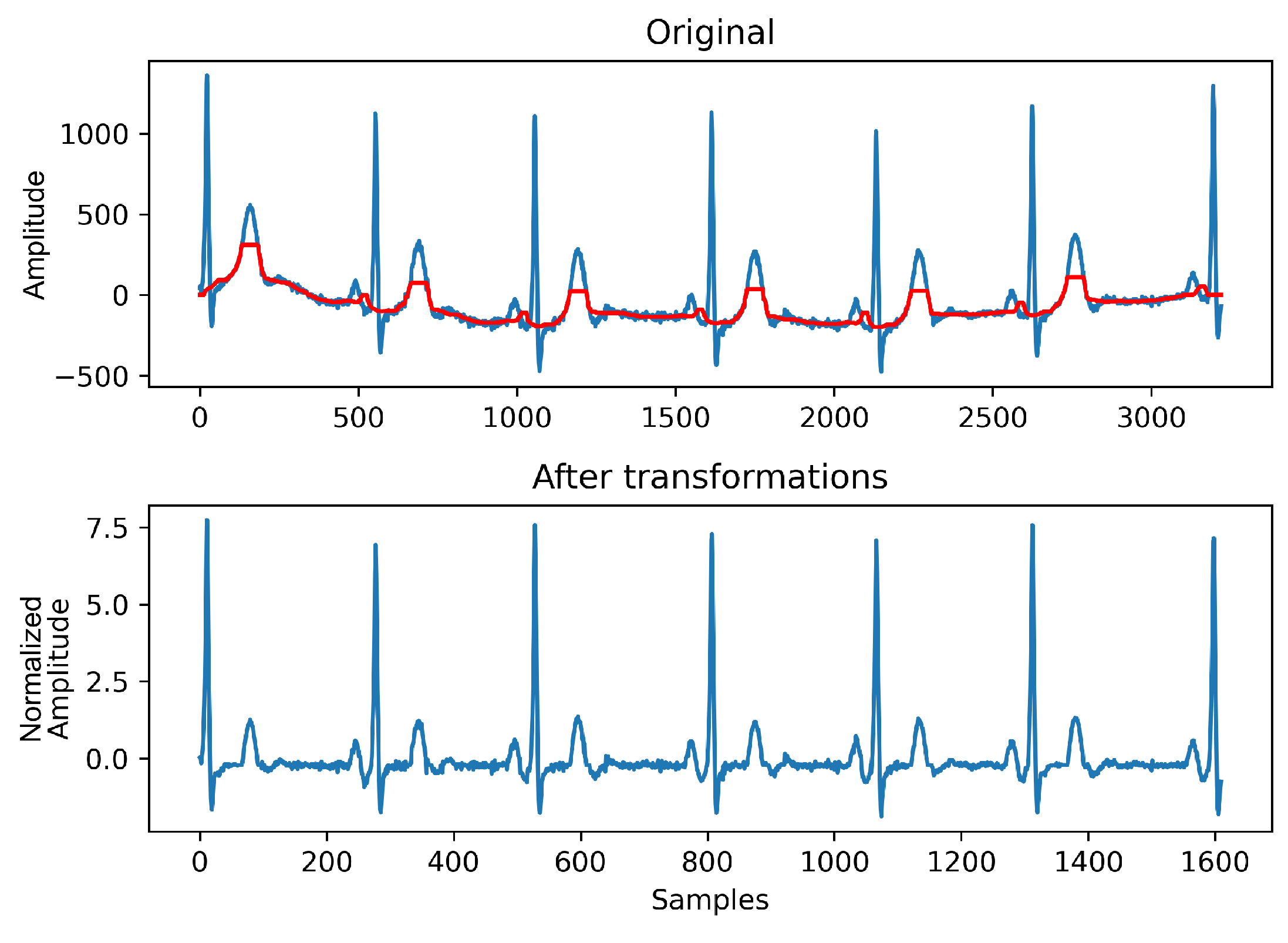
2.2.3. Pre-Processing
- Baseline wander removal: The application of two consecutive median filters (with 0.2 and 0.6-s sized kernels, in this order) [45], rectified ECG waves and baseline drift was partially removed;
- Downsampling: signals were downsampled by a factor of two, to reduce the computational cost of the associated segmentation algorithms. The sampling rate was reduced to 250 Hz;
- Standardization: The final step consisted of constraining the amplitude range of signals as follows:where and represent the signal mean and standard deviation, correspondingly.
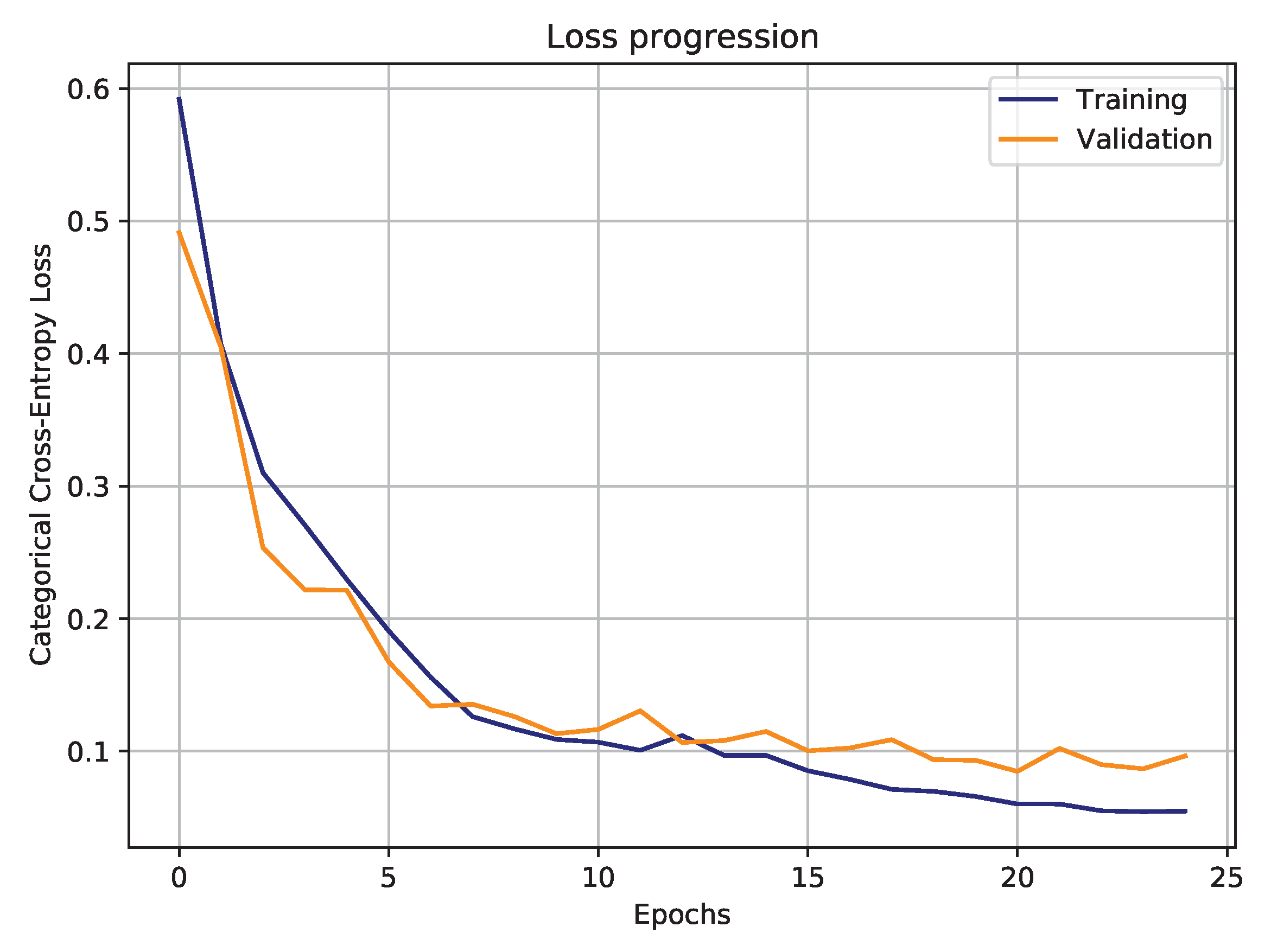
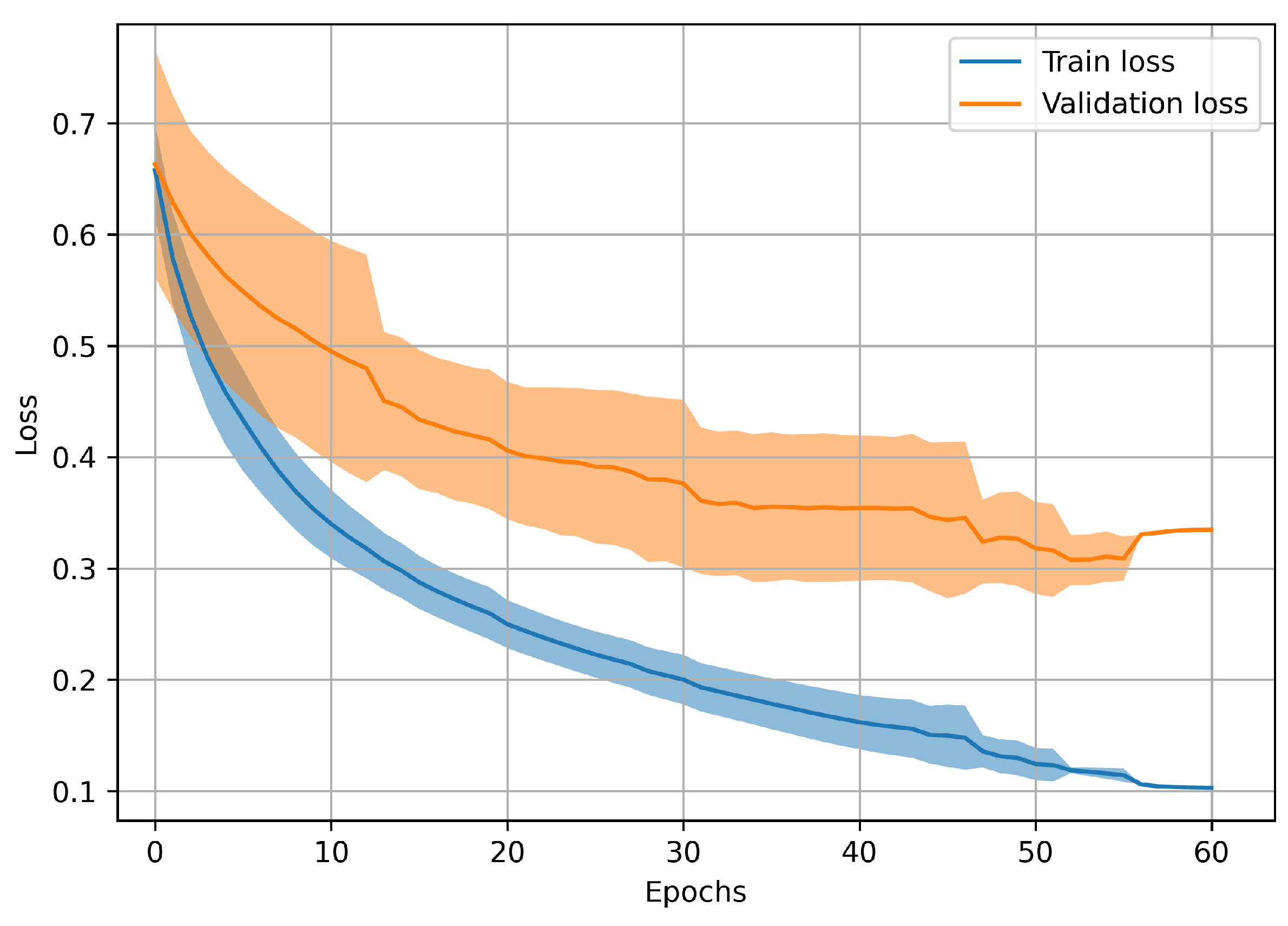
2.2.4. Training Stage
2.2.5. Baseline Model Parameters
2.3. Multivariate Analysis
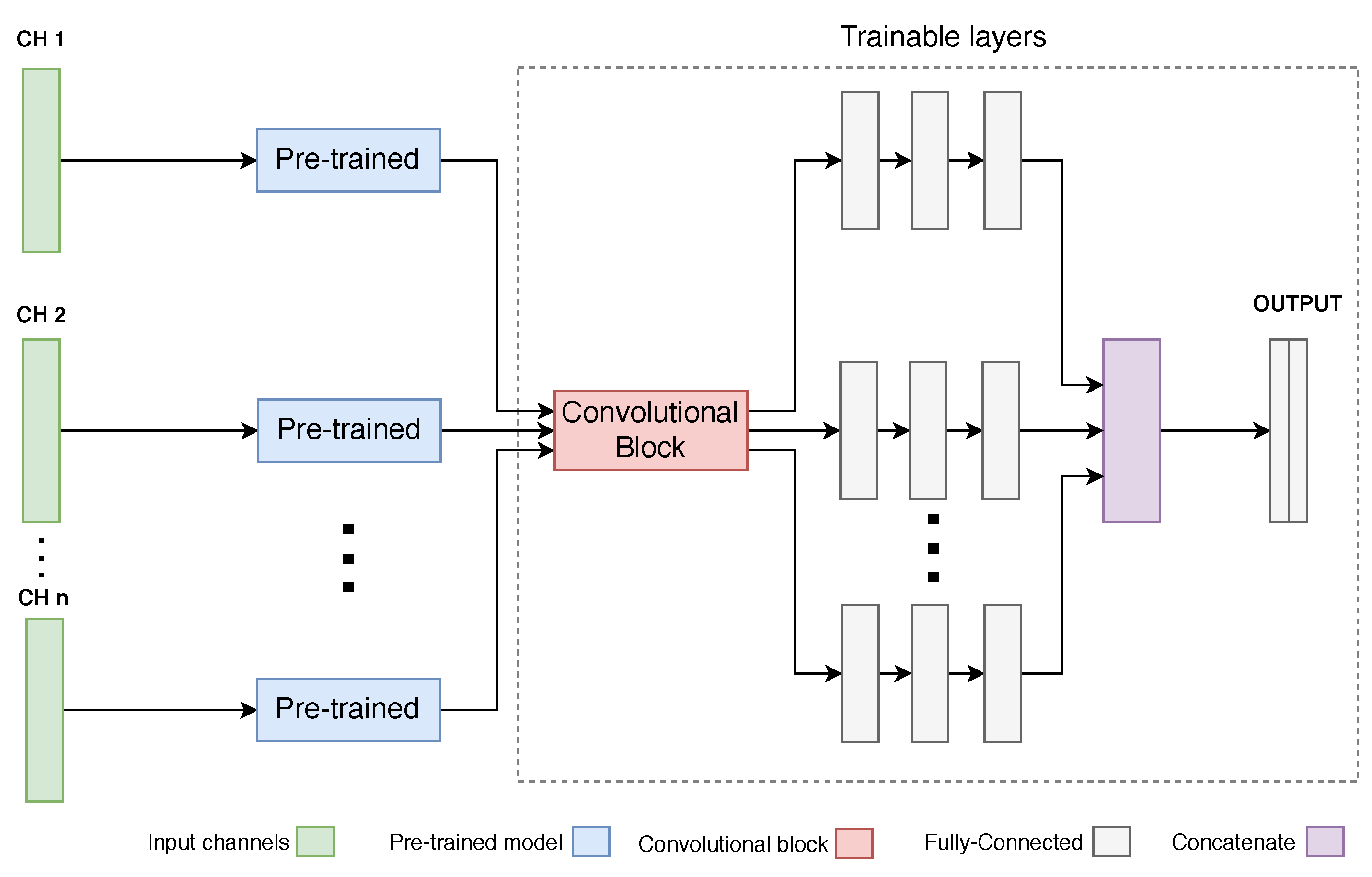
2.3.1. Proposed Model
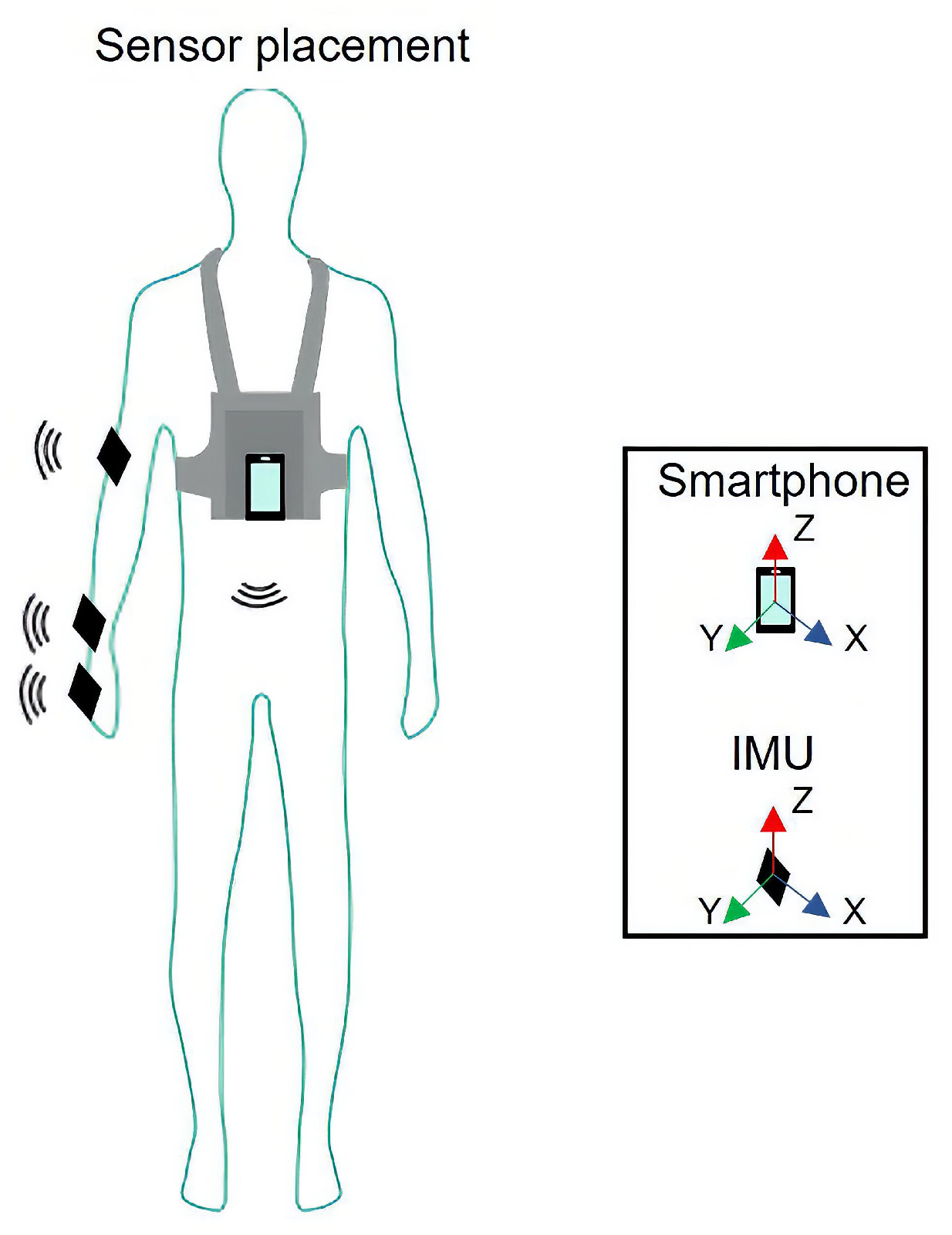
2.3.2. Human Activity Dataset
- Workers: A, B, C, D, E;
- Workstations: Fender, Liftgate;
- Sensors: Elbow, Wrist, Chest.
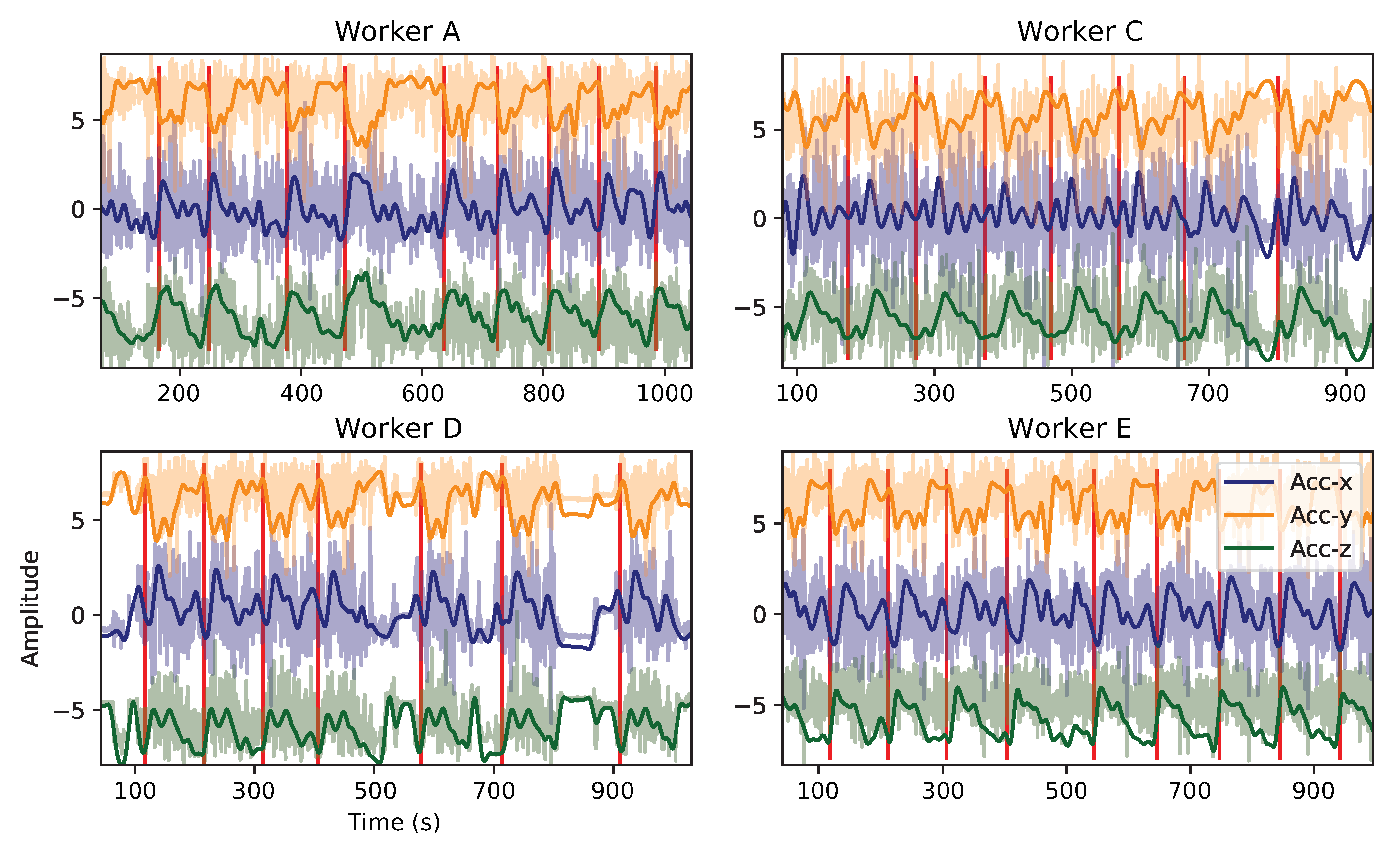
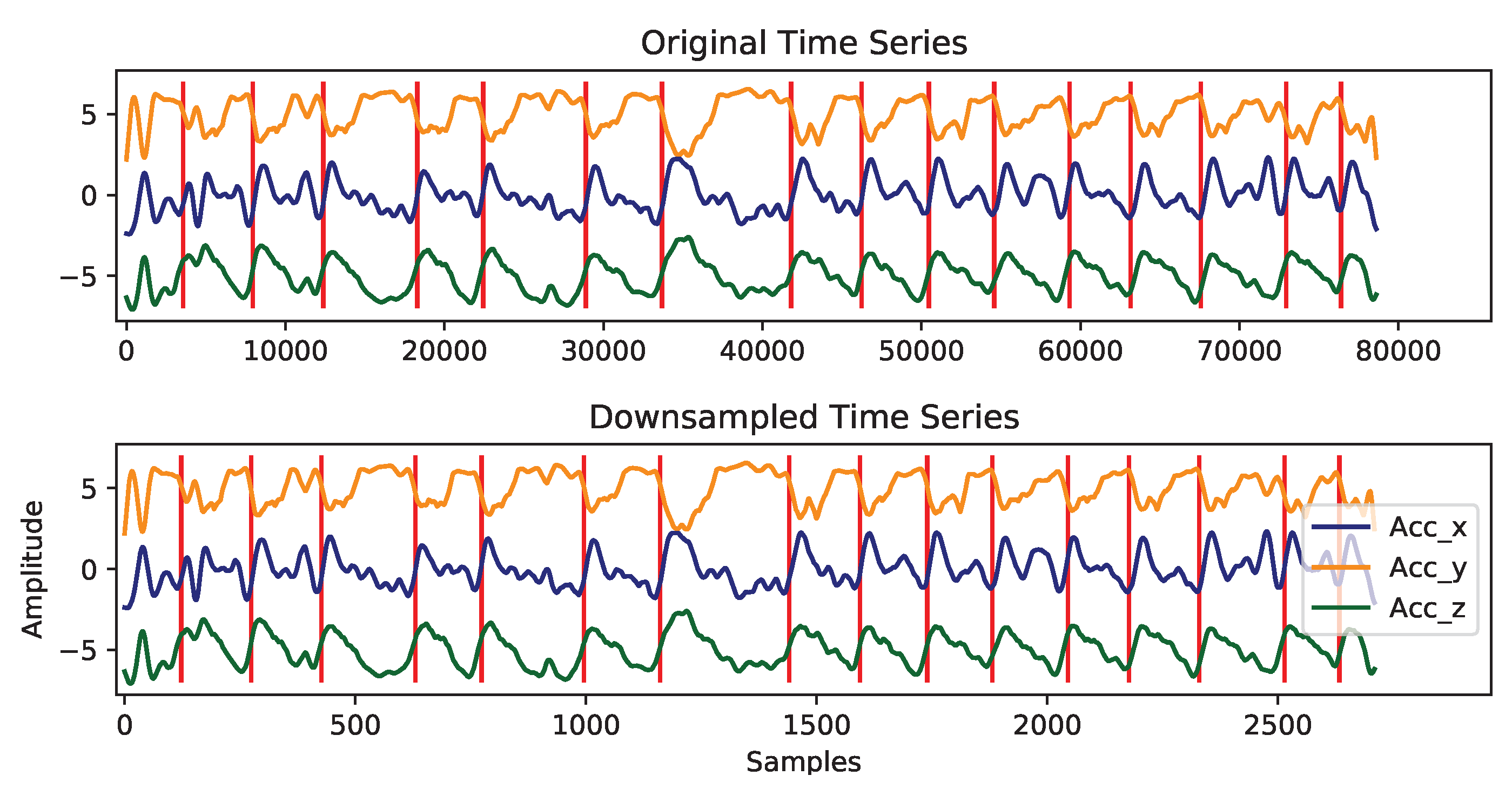
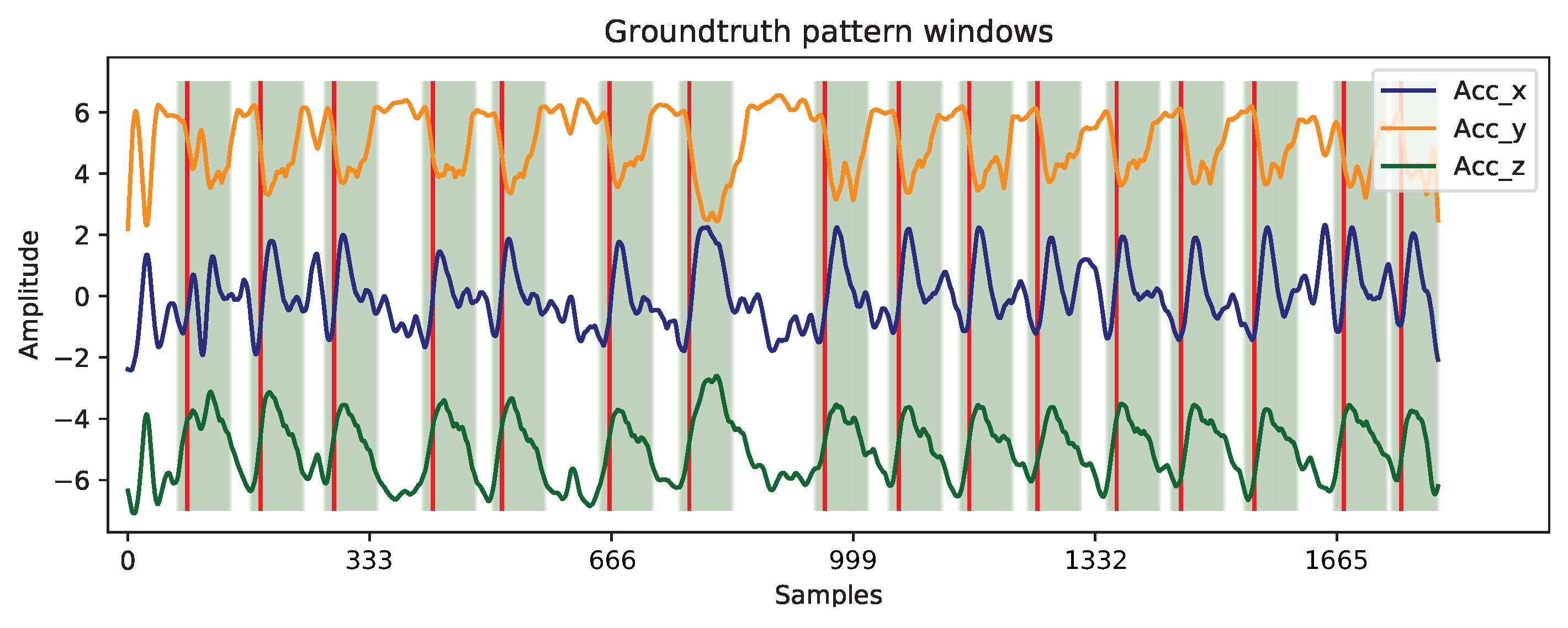
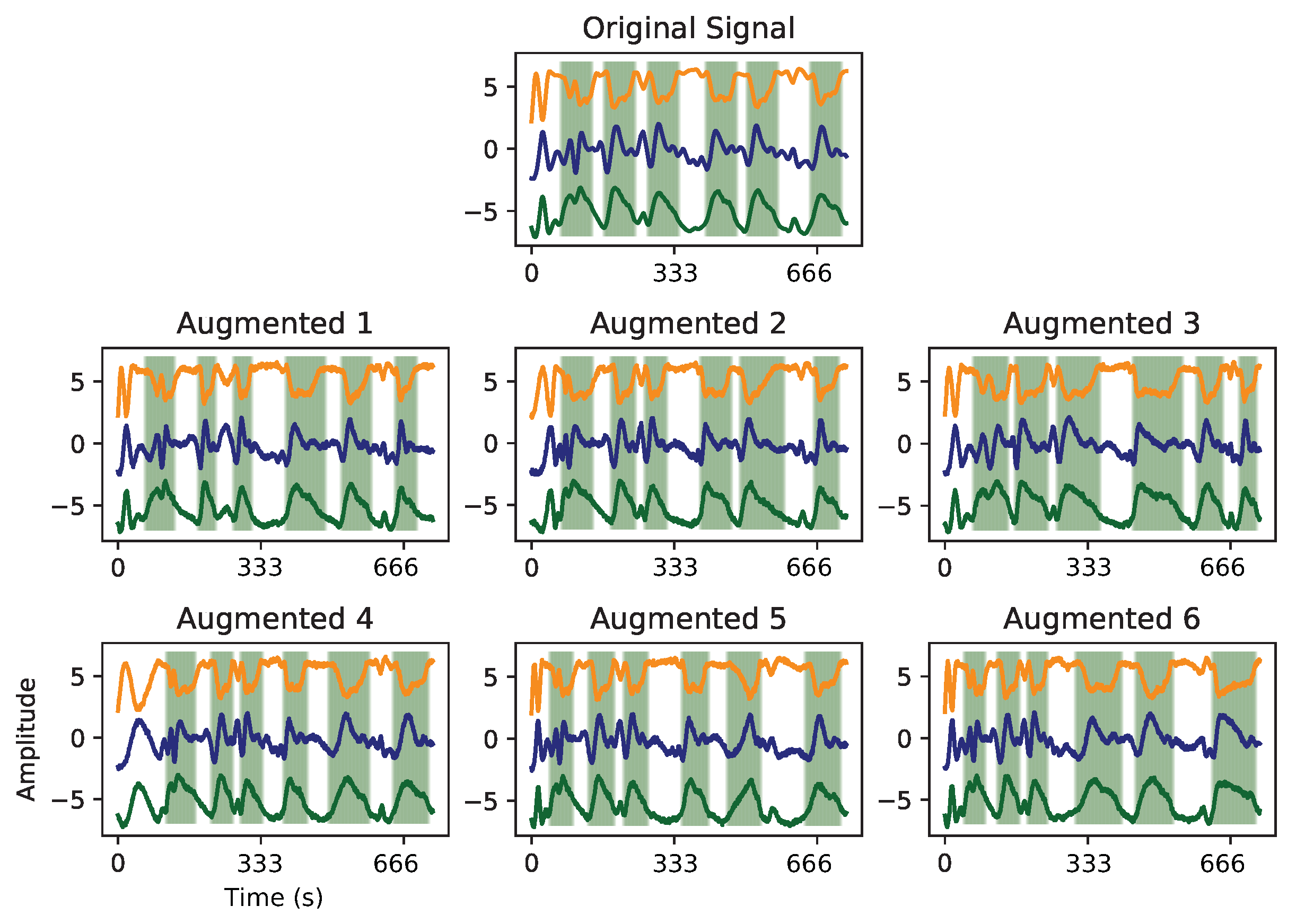
2.3.3. Pre-Processing
- Liftgatepattern: 72.85
- Fenderpattern: 46.36
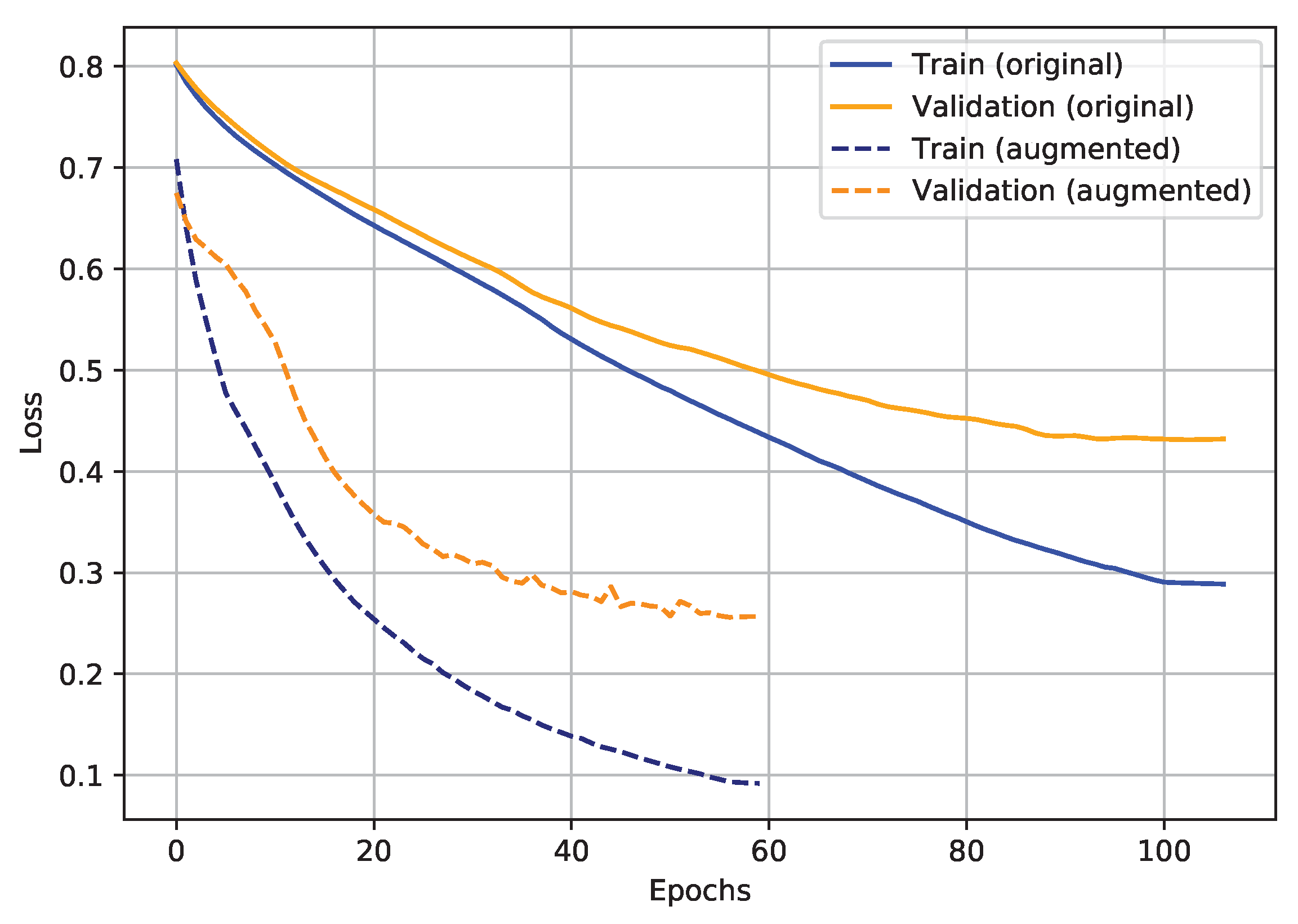
2.3.4. Training Stage
- Train the Hourglass-shape CNN with clinical signals (ECG): this step is similar to that presented in the previous experiment, where the same architecture was trained with ECG signals from LUDB dataset;
- Train the new architecture, adapted to multivariate data: in this step, the new network has been trained with the new target dataset (IMU data), with a frozen pre-trained block and both convolutional and decision-making trainable blocks;
- Fine-tuning: all the network weights were unfrozen and training was applied in the same set but with a much lower learning rate during a small number of epochs.
2.3.5. Baseline Model Parameters
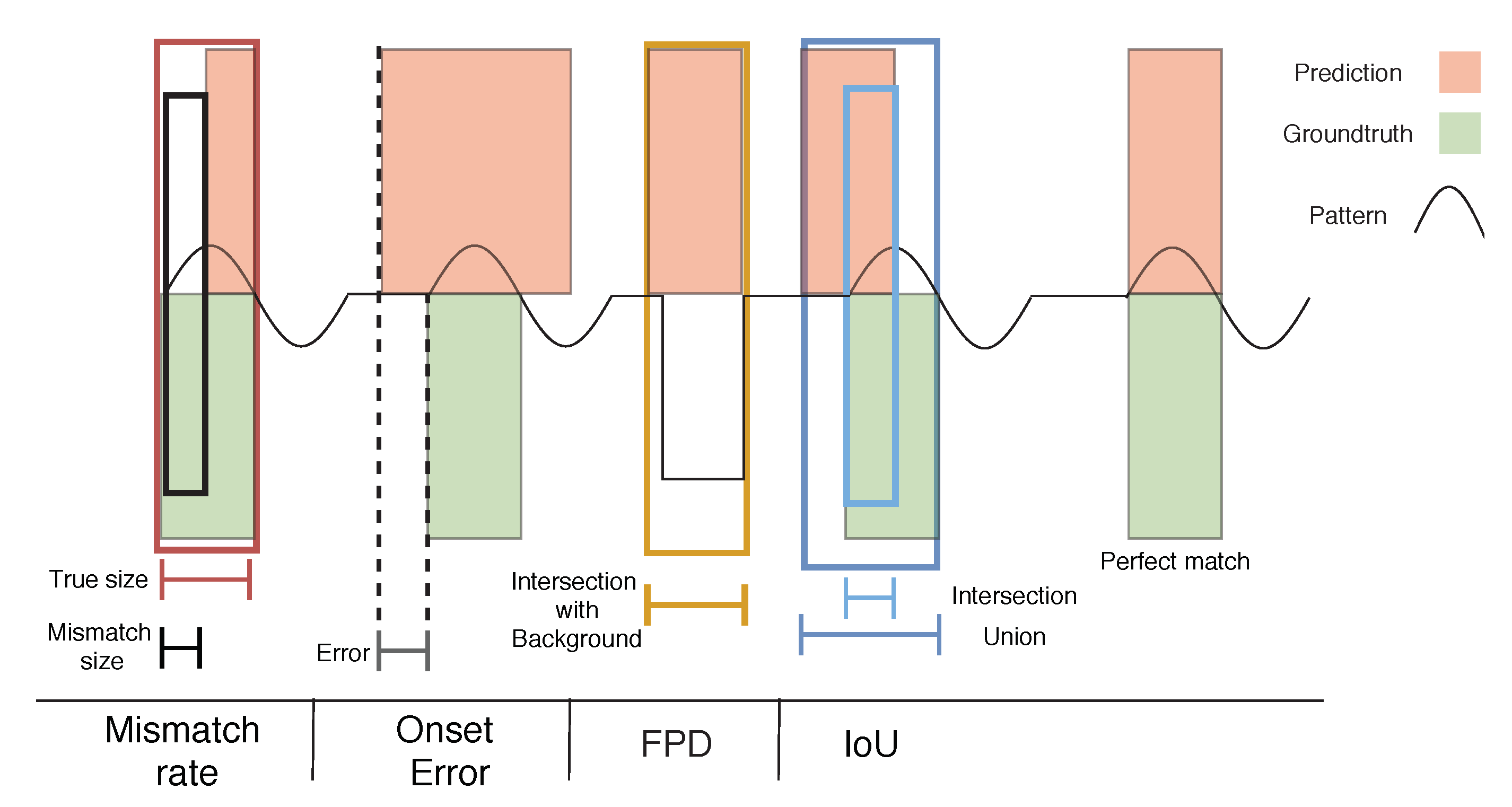
2.4. Evaluation
- Intersection-over-Union (IoU): also known as the Jaccard coefficient [51], it computes the ratio between the number of matching points of both true and predicted cycles (Intersection) and the number of points both cycles fill in the whole signal (Union). Cycle patterns achieving an IoU greater than 0.44 (chosen empirically in preliminary experiments) are classified as True Positives (TP);
- False Positive Detection (FPD): The intersection of each predicted cycle with the Background mask (normalized by the cycle length) is performed. Those having an FPD above 0.80 (chosen empirically in preliminary experiments) are labeled as False Positives (FP);
- Precision and Recall: from the two previous scores, Precision and Recall metrics are easily calculated. As IoU and FPD scores return the number of TP and FP cycles, respectively, these metrics are computed as follows:
- Mismatch Rate (MR): it represents the percentage of wrongly annotated points within each true cycle;
- Onset/Offset error: it measures the temporal distance between predicted and real cycles onset and offset points (error), a good indicator to confirm the quality of the alignment;
- Number of cycles: it compares the number of predicted and real cycles, being an additional high-level evaluation, as it is a metric of interest in such applications (e.g., for productivity measures).
3. Experimental Results
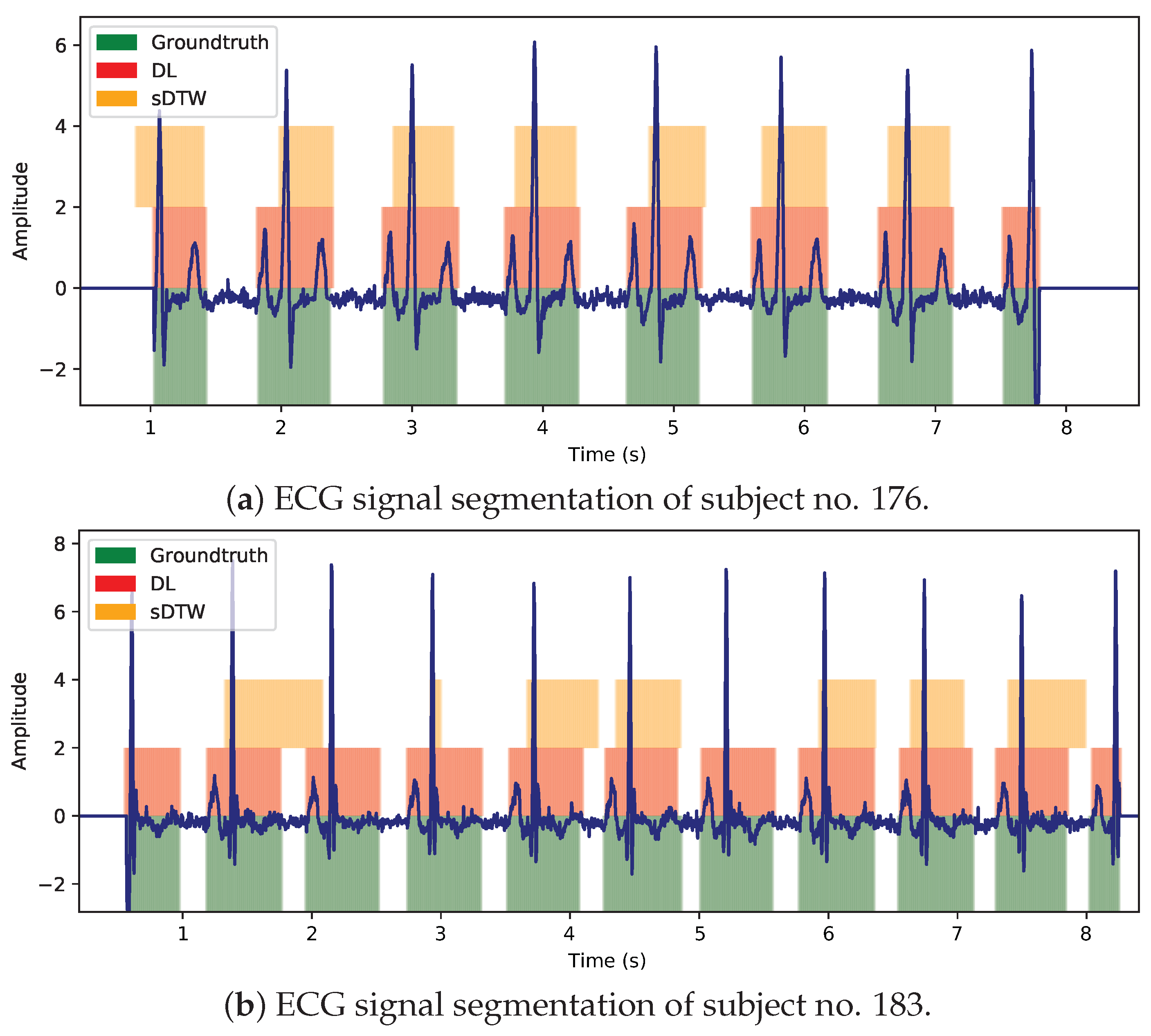
3.1. Univariate Analysis
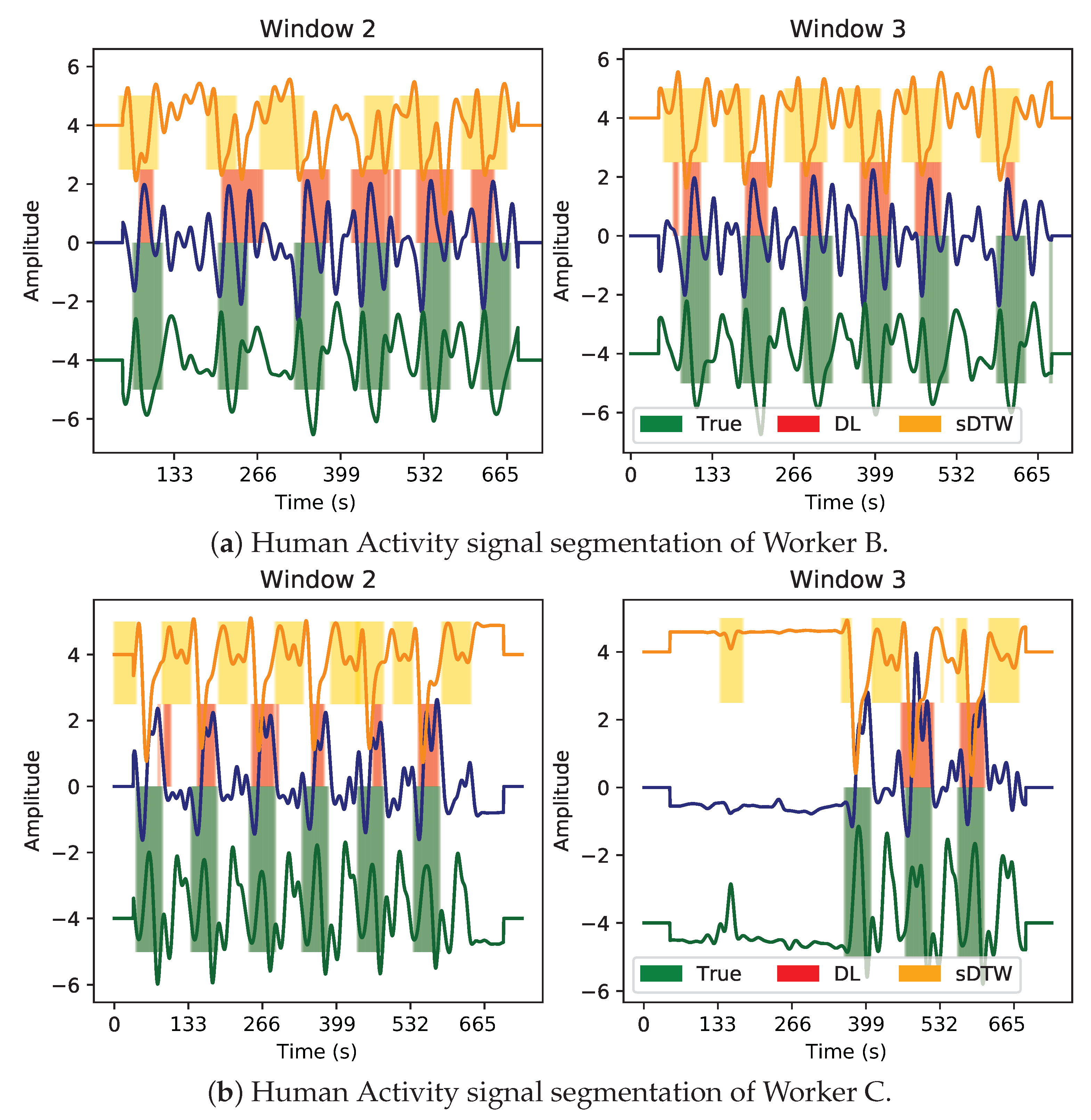
3.2. Multivariate Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
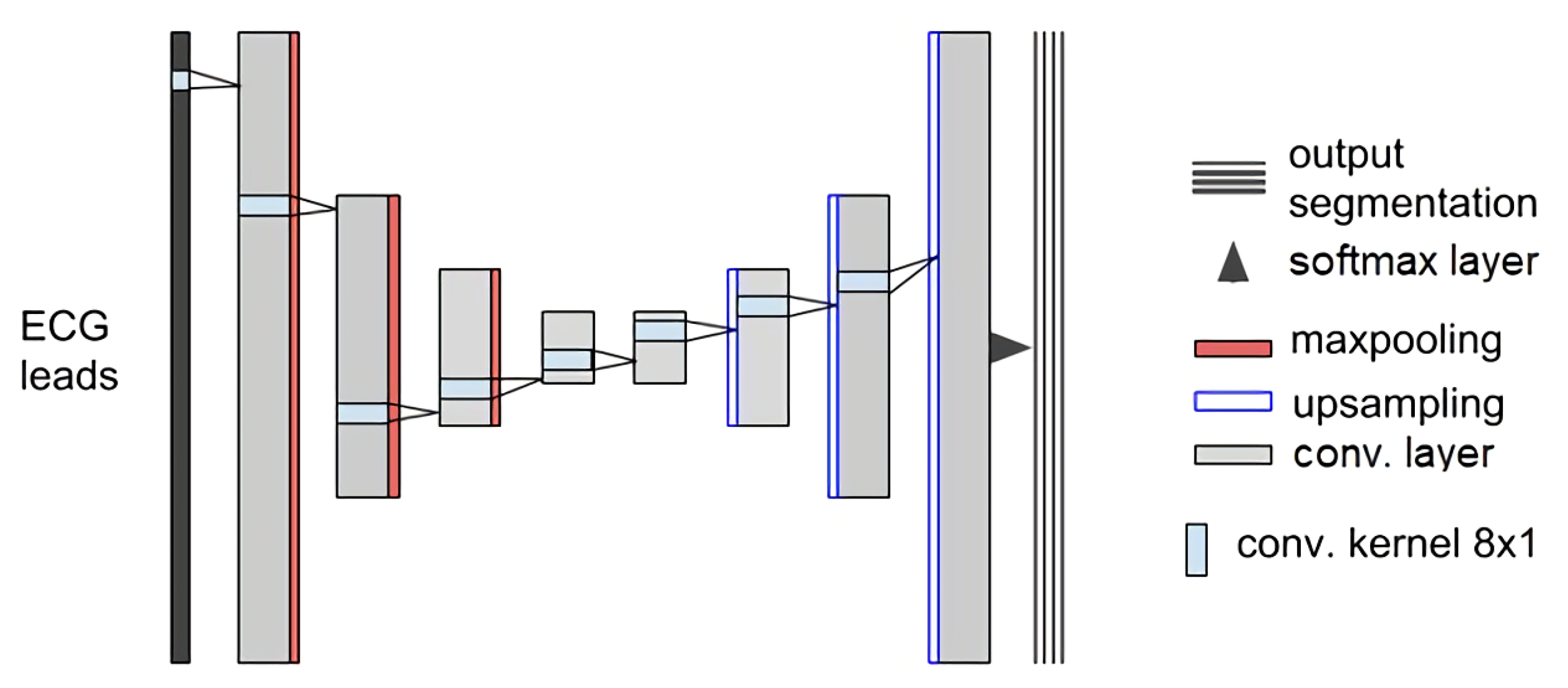
Appendix A. Supplementary Details about the Neural Network Architecture Choice

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Model | Evaluated Segment | |||||
|---|---|---|---|---|---|---|---|
| Sensitivity (%) | HG | 100.0 | 100.0 | 100.0 | 100.0 | 99.7 | 98.8 |
| C/D | 99.6 | 99.6 | 100.0 | 100.0 | 97.0 | 97.0 | |
| U-Net | 96.2 | 96.2 | 99.7 | 99.7 | 99.1 | 97.6 | |
| Precision (%) | HG | 90.7 | 90.7 | 98.4 | 88.1 | 91.9 | 90.8 |
| C/D | 89.7 | 89.7 | 98.2 | 87.8 | 93.3 | 93.0 | |
| U-Net | 92.3 | 92.3 | 99.7 | 99.4 | 95.9 | 94.2 | |
| Error distribution ( ) | HG | −1.8 ± 18.3 | −3.7 ± 15.6 | 1.3 ± 9.4 | −0.9 ± 11.3 | −5.1 ± 32.7 | −3.4 ± 28.3 |
| C/D | 1.2 ± 19.2 | −4.4 ± 17.6 | 1.3 ± 10.3 | 2.0 ± 11.3 | −2.9 ± 30.1 | 1.5 ± 29.8 | |
| U-Net | −1.0 ± 11.8 | −4.7 ± 14.7 | 0.1 ± 11.1 | 1.4 ± 10.6 | −10.0 ± 35.0 | −13.0 ± 33.0 | |
References
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human Activity Recognition using Inertial, Physiological and Environmental Sensors: A Comprehensive Survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef]
- Lin, J.; Williamson, S.; Borne, K.; DeBarr, D. Pattern Recognition in Time Series. 2011. Available online: https://cs.gmu.edu/~jessica/publications/astronomy11.pdf (accessed on 23 January 2021).
- Fong, S.; Lan, K.; Sun, P.; Mohammed, S.; Fiaidhi, J. A Time-Series Pre-Processing Methodology for Biosignal Classification using Statistical Feature Extraction. In Proceedings of the 10th IASTED International Conference on Biomedical Engineering (Biomed’13), Innsbruck, Austria, 11–13 February 2013. [Google Scholar] [CrossRef]
- Folgado, D.; Barandas, M.; Matias, R.; Martins, R.; Carvalho, M.; Gamboa, H. Time Alignment Measurement for Time Series. Pattern Recognit. 2018, 81, 268–279. [Google Scholar] [CrossRef]
- Rodpongpun, S.; Niennattrakul, V.; Ratanamahatana, C. Efficient Subsequence Search on Streaming Data Based on Time Warping Distance. ECTI Trans. Comput. Inf. Technol. 2011, 5, 2–8. [Google Scholar] [CrossRef]
- Osowski, S.; Tran, L. ECG Beat Recognition Using Fuzzy Hybrid Neural Network. Biomed. Eng. IEEE Trans. 2001, 48, 1265–1271. [Google Scholar] [CrossRef]
- Deppe, S.; Lohweg, V. Survey on time series motif discovery: Time series motif discovery. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1199. [Google Scholar] [CrossRef]
- Miao, S.; Vespier, U.; Cachucho, R.; Meeng, M.; Knobbe, A. Predefined pattern detection in large time series. Inf. Sci. 2016, 329, 950–964. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; San Tan, R. A Deep Convolutional Neural Network Model to Classify Heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef]
- Piacentino, E.; Guarner, A.; Angulo, C. Generating Synthetic ECGs Using GANs for Anonymizing Healthcare Data. Electronics 2021, 10, 389. [Google Scholar] [CrossRef]
- Deng, L.; Jaitly, N. Deep Discriminative and Generative Models for Speech Pattern Recognition. In Handbook of Pattern Recognition and Computer Vision (Ed. C.H. Chen); World Scientific: Singapore, 2016; pp. 27–52. [Google Scholar]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent Advances in Recurrent Neural Networks. arXiv 2018, arXiv:1801.01078. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef]
- Kasfi, K.T.; Hellicar, A.; Rahman, A. Convolutional Neural Network for Time Series Cattle Behaviour Classification. In Proceedings of the Workshop on Time Series Analytics and Applications; Association for Computing Machinery: New York, NY, USA, 2016; pp. 8–12. [Google Scholar] [CrossRef]
- Sereda, I.; Alekseev, S.; Koneva, A.; Kataev, R.; Osipov, G. ECG Segmentation by Neural Networks: Errors and Correction. arXiv 2018, arXiv:1812.10386. [Google Scholar]
- Cassisi, C.; Montalto, P.; Aliotta, M.; Cannata, A.; Pulvirenti, A. Similarity Measures and Dimensionality Reduction Techniques for Time Series Data Mining. In Advances in Data Mining Knowledge Discovery and Applications; Karahoca, A., Ed.; IntechOpen: Rijeka, Croatia, 2012; Chapter 3. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, J.; Liu, X.; Lau, R.; Wang, H.; Zhang, R. A Real Time Hybrid Pattern Matching Scheme for Stock Time Series. Conf. Res. Pract. Inf. Technol. Ser. 2010, 104, 161–170. [Google Scholar]
- Tsinaslanidis, P.E.; Zapranis, A.D. Dynamic Time Warping for Pattern Recognition. In Technical Analysis for Algorithmic Pattern Recognition; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 193–204. [Google Scholar] [CrossRef]
- Santos, A.; Rodrigues, J.; Folgado, D.; Santos, S.; Fujão, C.; Gamboa, H. Self-Similarity Matrix of Morphological Features for Motion Data Analysis in Manufacturing Scenarios. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies—BIOSIGNALS, INSTICC; SciTePress: Setubal, Portugal, 2021; pp. 80–90. [Google Scholar] [CrossRef]
- Nguyen-Dinh, L.V.; Roggen, D.; Calatroni, A.; Tröster, G. Improving Online Gesture Recognition with Template Matching Methods in Accelerometer Data. In Proceedings of the 12th International Conference on Intelligent Systems Design and Applications (ISDA), Kochi, India, 27–29 November 2012. [Google Scholar] [CrossRef]
- Barth, J.; Oberndorfer, C.; Kugler, P.; Schuldhaus, D.; Winkler, J.; Klucken, J.; Eskofier, B. Subsequence dynamic time warping as a method for robust step segmentation using gyroscope signals of daily life activities. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 6744–6747. [Google Scholar] [CrossRef]
- Gong, Z.; Chen, H. Dynamic State Warping. arXiv 2017, arXiv:1703.01141. [Google Scholar]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time Series Feature Extraction Library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Bota, P.; Silva, J.; Folgado, D.; Gamboa, H. A Semi-Automatic Annotation Approach for Human Activity Recognition. Sensors 2019, 19, 501. [Google Scholar] [CrossRef] [PubMed]
- Matias, P.; Folgado, D.; Gamboa, H.; Carreiro, A. Robust Anomaly Detection in Time Series through Variational AutoEncoders and a Local Similarity Score. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies—BIOSIGNALS, INSTICC; SciTePress: Setubal, Portugal, 2021; pp. 91–102. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Biometric User Identification Based on Human Activity Recognition Using Wearable Sensors: An Experiment Using Deep Learning Models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Avanzato, R.; Beritelli, F. Automatic ECG Diagnosis Using Convolutional Neural Network. Electronics 2020, 9, 951. [Google Scholar] [CrossRef]
- Kłosowski, G.; Rymarczyk, T.; Wójcik, D.; Skowron, S.; Cieplak, T.; Adamkiewicz, P. The Use of Time-Frequency Moments as Inputs of LSTM Network for ECG Signal Classification. Electronics 2020, 9, 1452. [Google Scholar] [CrossRef]
- Nurmaini, S.; Darmawahyuni, A.; Sakti Mukti, A.N.; Rachmatullah, M.N.; Firdaus, F.; Tutuko, B. Deep Learning-Based Stacked Denoising and Autoencoder for ECG Heartbeat Classification. Electronics 2020, 9, 135. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Gamboa, J.C.B. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. Non-Handcrafted Features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Perslev, M.; Jensen, M.H.; Darkner, S.; Jennum, P.J.; Igel, C. U-Time: A Fully Convolutional Network for Time Series Segmentation Applied to Sleep Staging. arXiv 2019, arXiv:1910.11162. [Google Scholar]
- Moskalenko, V.; Zolotykh, N.; Osipov, G. Deep Learning for ECG Segmentation. Adv. Neural Comput. Mach. Learn. Cogn. Res. III 2019, 856, 246–254. [Google Scholar] [CrossRef]
- Kuederle, A. sDTW Multi Path Matching. Available online: https://tslearn.readthedocs.io/en/stable/auto_examples/metrics/plot_sdtw.html (accessed on 28 July 2020).
- Müller, M. Dynamic time warping. Inf. Retr. Music. Motion 2007, 2, 69–84. [Google Scholar] [CrossRef]
- Hong, J.Y.; Park, S.H.; Baek, J.G. SSDTW: Shape segment dynamic time warping. Expert Syst. Appl. 2020, 150, 113291. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Jeong, M.K.; Omitaomu, O.A. Weighted dynamic time warping for time series classification. Pattern Recognit. 2011, 44, 2231–2240. [Google Scholar] [CrossRef]
- Munich, M.; Perona, P. Continuous Dynamic Time Warping for translation-invariant curve alignment with applications to signature verification. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456. Available online: http://proceedings.mlr.press/v37/ioffe15.html (accessed on 21 June 2020).
- Kalyakulina, A.I.; Yusipov, I.I.; Moskalenko, V.A.; Nikolskiy, A.V.; Kosonogov, K.A.; Osipov, G.V.; Zolotykh, N.Y.; Ivanchenko, M.V. LUDB: A New Open-Access Validation Tool for Electrocardiogram Delineation Algorithms. IEEE Access 2020, 8, 186181–186190. [Google Scholar] [CrossRef]
- Luz, E.J.; Schwartz, W.R.; Cámara-Chávez, G.; Menotti, D. ECG-based heartbeat classification for arrhythmia detection: A survey. Comput. Methods Programs Biomed. 2016, 127, 144–164. [Google Scholar] [CrossRef]
- De Chazal, P.; O’Dwyer, M.; Reilly, R.B. Automatic classification of heartbeats using ECG morphology and heartbeat interval features. IEEE Trans. Biomed. Eng. 2004, 51, 1196–1206. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar] [CrossRef]
- Santos, S.; Folgado, D.; Rodrigues, J.; Mollaei, N.; Fujão, C.; Gamboa, H. Explaining the Ergonomic Assessment of Human Movement in Industrial Contexts. In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies, Valletta, Malta, 24–26 February 2020; Volume 4, pp. 79–88. [Google Scholar] [CrossRef]
- Elisseeff, A.; Pontil, M. Leave-one-out error and stability of learning algorithms with applications Stability of Randomized Learning Algorithms Source. Int. J. Syst. Sci. IJSySc 2002, 6, 1–12. Available online: https://www.math.arizona.edu/~hzhang/math574m/Read/LOOtheory.pdf (accessed on 23 June 2020).
- Wen, T. tsaug. 2019. Available online: https://tsaug.readthedocs.io/en/stable/ (accessed on 20 July 2020).
- van Beers, F.; Lindström, A.; Okafor, E.; Wiering, M. Deep Neural Networks with Intersection over Union Loss for Binary Image Segmentation. ICPRAM 2019, 438–445. [Google Scholar] [CrossRef]
- Güneş, I.; Gunduz Oguducu, S.; Cataltepe, Z. Link prediction using time series of neighborhood-based node similarity scores. Data Min. Knowl. Discov. 2015, 30, 147–180. [Google Scholar] [CrossRef]
- Moody, G.; Mark, R. The impact of the MIT-BIH Arrhythmia Database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Iyengar, N.; Peng, C.K.; Morin, R.; Goldberger, A.L.; Lipsitz, L.A. Age-related alterations in the fractal scaling of cardiac interbeat interval dynamics. Am. J. Physiol. Regul. Integr. Comp. Physiol. 1996, 271, R1078–R1084. [Google Scholar] [CrossRef] [PubMed]
- Kemp, B.; Zwinderman, A.; Tuk, B.; Kamphuisen, H.; Oberye, J. Analysis of a sleep-dependent neuronal feedback loop: The slow-wave microcontinuity of the EEG. IEEE Trans. Biomed. Eng. 2000, 47, 1185–1194. [Google Scholar] [CrossRef]
- Maurice, P.; Malaisé, A.; Amiot, C.; Paris, N.; Richard, G.J.; Rochel, O.; Ivaldi, S. Human movement and ergonomics: An industry-oriented dataset for collaborative robotics. Int. J. Robot. Res. 2019, 38, 1529–1537. [Google Scholar] [CrossRef]
























| Number of Individuals | ||
|---|---|---|
| Training Set (64%) | Validation Set (16%) | Testing Set (20%) |
| 128 | 32 | 40 |
| Loss Function | Optimizer | Epochs | Activation Functions | Batch Size | |
|---|---|---|---|---|---|
| Type | LR a | ||||
| Categorical Cross-Entropy | Adam | 1 × 10−2 | 25 | tanH Softmax | 16 |
| Minimum Peak Height (H) | Minimum Inter-Peak Distance (D) |
|---|---|
| Activity | Sensor Location | Number of Samples | Total | ||||
|---|---|---|---|---|---|---|---|
| Worker A | Worker B | Worker C | Worker D | Worker E | |||
| Fender | Wrist | 3 | 3 | 3 | - | - | 9 |
| Chest | |||||||
| Liftgate | Elbow | 3 | - | 2 | 5 | 2 | 12 |
| Wrist | |||||||
| Step | Loss Function | Optimizer | Epochs | Early-Stopping Patience | Activation Function | Batch Size | |
|---|---|---|---|---|---|---|---|
| Type | LR a | ||||||
| 1 | Categorical Cross-Entropy | Adam | 1 × 10−2 | 25 | - | tanH Softmax | 16 |
| 2 | 1 × 10−4 | 100 | 5 epochs | 4 | |||
| 3 | 1 × 10−5 | 20 | 3 epochs | 8 | |||
| Minimum Peak Height (H) | Minimum Inter-Peak Distance (D) |
|---|---|
| Metric | Model | Optimal | |
|---|---|---|---|
| DL | sDTW | ||
| P/T ratio a | 1.01 ± 0.09 | 0.70 ± 0.15 | 1.00 |
| Precision (%) | 99.0 ± 6.7 | 94.3 ± 22.7 | 100.0 |
| Recall (%) | 97.5 ± 10.7 | 52.0 ± 24.7 | 100.0 |
| MR b (%) | 5.8 ± 12.0 | 42.4 ± 40.0 | 0.0 |
| Onset Error (s) | 0.03 ± 0.14 | 0.41 ± 0.50 | 0.00 |
| Offset Error (s) | 0.04 ± 0.15 | 0.40 ± 0.45 | 0.00 |
| Metric | Model | Activity (Sensor) | Optimal | |||
|---|---|---|---|---|---|---|
| Fender (Wrist) | Fender (Chest) | Liftgate (Elbow) | Liftgate (Wrist) | |||
| P/T ratio a | DL | 1.23 ± 0.30 | 1.27 ± 0.28 | 1.26 ± 0.51 | 1.26 ± 0.16 | 1.00 |
| sDTW | 1.41 ± 0.21 | 1.29 ± 0.24 | 1.18 ± 0.34 | 1.23 ± 0.17 | ||
| Precision (%) | DL | 76.9 ± 16.0 | 66.7 ± 2.6 | 83.1 ± 23.9 | 77.3 ± 15.1 | 100.0 |
| sDTW | 33.2 ± 35.6 | 67.5 ± 8.8 | 77.2 ± 23.5 | 56.6 ± 21.5 | ||
| Recall (%) | DL | 75.5 ± 13.2 | 64.8 ± 22.8 | 82.6 ± 8.7 | 62.5 ± 15.2 | 100.0 |
| sDTW | 26.2 ± 25.7 | 56.0 ± 21.0 | 72.0 ± 13.3 | 52.5 ± 26.1 | ||
| MR b (%) | DL | 33.0 ± 28.7 | 39.7 ± 32.6 | 30.6 ± 24.5 | 34.0 ± 33.8 | 0.0 |
| sDTW | 58.8 ± 35.1 | 45.0 ± 25.5 | 35.5 ± 33.9 | 53.1 ± 30.4 | ||
| Onset Error (s) | DL | 16.21 ± 21.35 | 22.29 ± 29.83 | 14.66 ± 15.67 | 38.70 ± 73.00 | 0.00 |
| sDTW | 29.59 ± 18.08 | 19.54 ± 12.86 | 14.26 ± 17.65 | 26.89 ± 22.13 | ||
| Offset Error (s) | DL | 15.77 ± 23.22 | 19.48 ± 31.77 | 17.70 ± 26.53 | 43.85 ± 77.83 | 0.00 |
| sDTW | 27.71 ± 18.13 | 13.15 ± 8.02 | 25.29 ± 27.36 | 20.90 ± 15.33 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matias, P.; Folgado, D.; Gamboa, H.; Carreiro, A. Time Series Segmentation Using Neural Networks with Cross-Domain Transfer Learning. Electronics 2021, 10, 1805. https://doi.org/10.3390/electronics10151805
Matias P, Folgado D, Gamboa H, Carreiro A. Time Series Segmentation Using Neural Networks with Cross-Domain Transfer Learning. Electronics. 2021; 10(15):1805. https://doi.org/10.3390/electronics10151805
Chicago/Turabian StyleMatias, Pedro, Duarte Folgado, Hugo Gamboa, and André Carreiro. 2021. "Time Series Segmentation Using Neural Networks with Cross-Domain Transfer Learning" Electronics 10, no. 15: 1805. https://doi.org/10.3390/electronics10151805
APA StyleMatias, P., Folgado, D., Gamboa, H., & Carreiro, A. (2021). Time Series Segmentation Using Neural Networks with Cross-Domain Transfer Learning. Electronics, 10(15), 1805. https://doi.org/10.3390/electronics10151805